
第二讲相关分析与回归分析
第一节相关分析
1.1 变量的相关性
1.变量的相关性分两种,一种是研究两个变量X与Y的相关性。本节只研究前者,即两个变量之间的相关性;。
2.两个变量X与Y的相关性研究,是探讨这两个变量之间的关系密切到什么程度,能否给出一个定量的指标。这个问题的难处在于“关系”二字,从数学角度看,两个变量X、Y之间的关系具有无限的可能性,一个比较现实的想法是:确立一种“样板”关系,然后把X、Y的实际关系与“样板”关系比较,看它们“像”到了什么程度,给出一个定量指标。
3.取什么关系做“样板”关系?线性关系。这是一种单调递增或递减的关系,在现实生活中广为应用;另外,现实世界中大量的变量服从正态分布,对这些变量而言,可以用线性关系或准线性关系构建它们之间的联系。
1.2 相关性度量
1.概率论中用相关系数(correlation coefficient)度量两个变量的相关程度。
为区别以下出现的样本相关系数,有时也把这里定义的相关系数称为总体相关系数。可见相关系数是判断变量间线性关系的重要指标。
2.样本相关系数
我们也只能根据这个容量为n的样本来判断变量X和Y的相关性达到怎样的程度。
这个估计称为样本相关系数,或Pearson 相关系数。它能够根据样本观察值计算出两个变量相关系数的估计值。
和总体相关系数一样,如果0=XY ρ
,称X 和Y 不相关。这时它们没有线性关系。
多数情况下,样本相关系数取区间(-1, 1)中的一个值。相关系数的绝对值越大,表明X 和Y 之间存在的关系越接近线性关系。
1.3 相关性检验
两个变量X 和Y 之间的相关性检验是对原假设
H 0:Corr (X ,Y ) = 0
的显著性进行检验。检验类型为t 。如果H 0显著,则X 和Y 之间没有线性关系。
1.4 计算样本相关系数Correlate\Bivariate
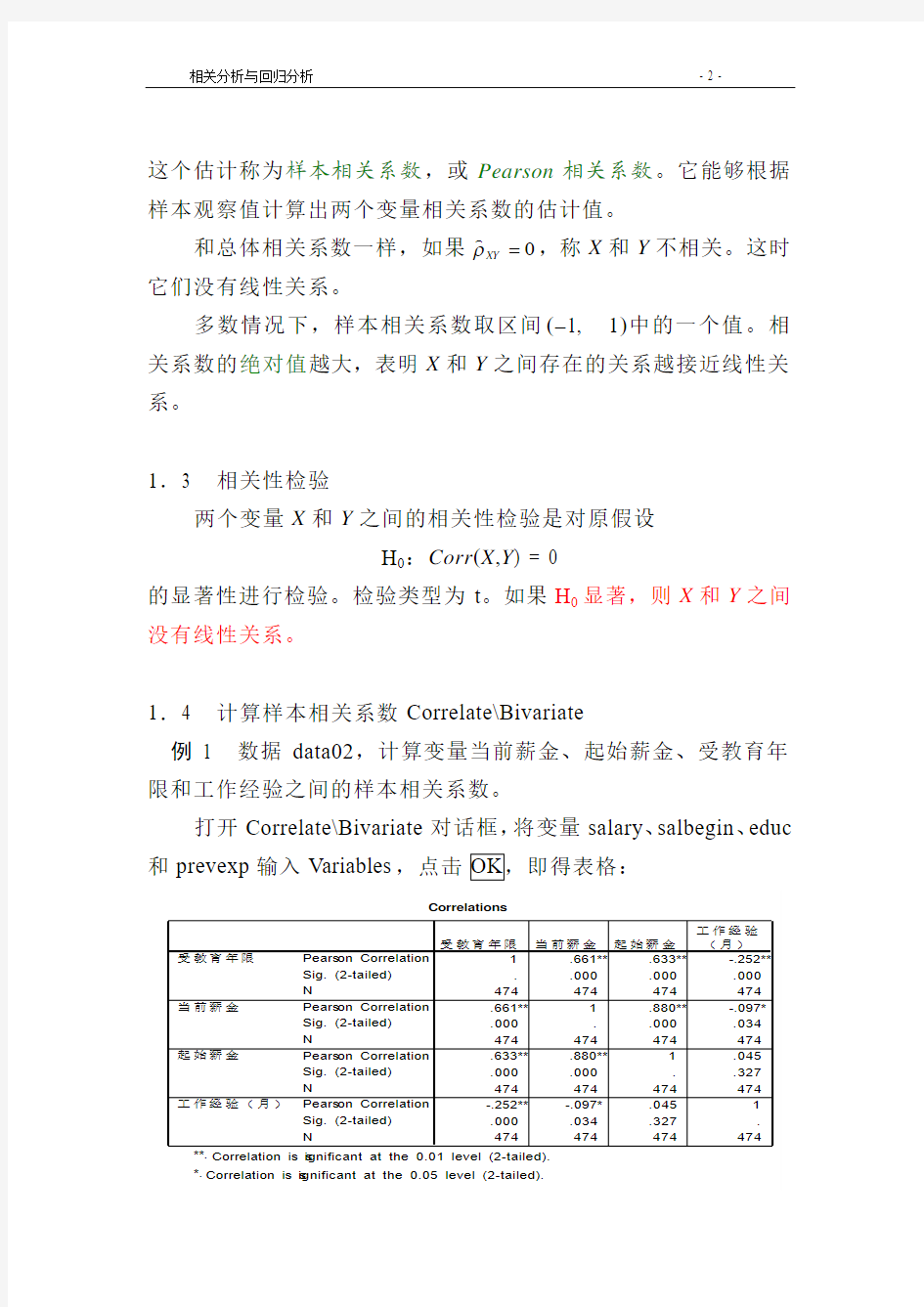
例1 数据data02,计算变量当前薪金、起始薪金、受教育年限和工作经验之间的样本相关系数。
打开Correlate\Bivariate 对话框,将变量salary 、salbegin 、educ 和prevexp 输入Variables ,点击OK ,即得表格:
Correlations
1.661**.633**-.252**..000.000.000474474474474.661**1.880**-.097*.000..000.034474474474474.633**.880**1.045.000.000..327474474474474-.252**-.097*.0451.000.034.327.474474474
474
Pears on Correlation Sig. (2-tailed)N
Pears on Correlation Sig. (2-tailed)N
Pears on Correlation Sig. (2-tailed)N
Pears on Correlation Sig. (2-tailed)N
受教育年限
当前薪金
起始薪金
工作经验(月)
受教育年限当前薪金起始薪金
工作经验
(月)
Correlation is s ignificant at the 0.01 level (2-tailed).**. Correlation is s ignificant at the 0.05 level (2-tailed).
*.
表格中的Pearson Correlation 指样本相关系数,例如起始薪金与受教育年限的相关系数为0.633;Sig .为相关性检验结果,起始薪金与受教育年限的相关性检验结果为Sig.=0.000,在0.05和0.01的水平下,都能否定它们不相关的假设。N 为观察值个数。
1.5 偏相关系数
1.控制变量 以上在计算变量X 和Y 的相关系数时,并没有考虑有其他变量的影响。例如:计算当前薪金(salary)与起始薪金(salbegin)的相关系数得0.890,但是当前薪金显然还受到受教育年限(educ)的影响,这个影响在计算相关系数时没有被扣除,因此0.890这个数字不完全真实。如扣除educ 的影响,在计算salary 和salbegin 的相关系数,就更接近真实了。这个被扣除的变量就叫控制变量,这里educ 便是控制变量。控制变量可以不止一个。 2.偏相关系数 扣除控制变量影响后得到的相关系数称为偏相关系数(partial correlation ),计算命令为:Correlate\Partial. 例2 数据data02,计算当前薪金与起始薪金在扣除受教育年限影响后的偏相关系数。
在Partial Correlations 对话框中,将变量salary 、salbegin 输入Variables ,将变量educ 输入Controlling for ,然后OK ,得:
Correlations
1.000.795..0000471.795 1.000
.000.471
Correlation Significance (2-tailed)df Correlation Significance (2-tailed)df 当前薪金
起始薪金
Control Variables
受教育年限当前薪金
起始薪金
其中Corrlation 指偏相关系数,df 自由度,Significance 是对原假设H 0:pCorr (X ,Y )=0检验结果得到的水平值。可见:偏相关系数值等于0.795;不能接受不相关的假设。
第二节 线性回归方程
2.1 一元线性回归方程
1.相关分析是以线性关系为“样板”,讨论变量X 和Y 的相关程度,这一程度用相关系数表示。我们不禁要问:这个“样板”是什么?也就是把这个做“样板”的线性表达式:
)1(10X
b b Y +=
给出来,这也就相当于把系数b 0和b 1估计出来。这样,变量X 和Y 的关系就可以表示成为:
)2(10ε
ε+=++=Y X b b Y
其中ε为误差,是一个随机变量。显然,相关系数绝对值越大,误
差ε在表达式中占的比重就越小,也就是线性部分Y
占的比重越大,这就有可能用线性表达式(1)近似表达变量X 和Y 的关系。称线性表达式(1)为变量Y 对于X 的(一元线性)回归方程。
回归分析的主要任务是回答:
1)回归方程(1)能否近似代表变量X 和Y 的关系。这实际是对线性部分与误差部分各占比重的估量;
2)怎样估计回归方程(1),也就是怎样估计参数b 0和b 1。 显然,在任务2)完成前,任务1)无从开始。 2.回归的基本假设
解决回归分析的主要任务还是要从样本:
)3(,...,2,1),
,(n
i Y X i i =
入手。套用(2),样本(3)可以写成:
)4(,...,2,1,
10n
i X b b Y i i i =++=ε
以下所有分析推导都从(4)出发。显然,需要用到一些数学方法。
为此提出以下基本假设: 假设1 E (εi ) = 0,i =1,2,…,n ;
假设2 Var (εi ) = σ2 = const ,i =1,2,…,n ; 假设3 Cov (εi , εj ) = 0,i ≠j ; 假设4 εi ~N (0, σ2),i =1,2,…,n 。 3.回归系数b 0、b 1的最小二乘估计
这一部分内容实际是估计回归方程。作为变量X 和Y 实际关系的近似,自然要求回归方程(1)计算出的Y 值与样本观察值具有最小误差。即把X 代入(1)计算出的Y 值:
)5(,...,2,1,
10n
i X b b Y i i =+=
与实际观察到的Y i 误差最小。回归系数的估计式。通过它,可以完全确定回归方程。 4.回归方程的评价
确定了回归方程后,一个重要问题浮出水面:这个回归方程有多大的代表性?能否投入使用?
1)平方和分解公式公式中的三个平方和分别叫做: 总平方和(total) ∑=-=
n
i i
Y Y ST 12
)( 残差平方和(Residual) ∑=-=n
i i i Y Y SQ 12
)(
回归平方和(Regression) ∑=-=n i i
Y Y SR 12)?( 于是(9)式也可以写成: ST = SE + SR 。设就是平方和分解公式。 平方和分解公式指出一个事实:残差平方和SE 与回归平方和SR 之和是一个常量,而残差平方和SE 越大,表明回归方程跟样本观察值拟合得越差,反之则越好。但从回归平方和SR 看,则正好相反,即:SR 越大,回归方程跟样本观察值拟合得越好。 2)判决系数与复相关系数
定义 回归平方和SR 与平方总和ST 的比值称为回归方程的判决系数,用R 2表示判决系数,则有:
)10(2ST
SR R =
判决系数的算术平方根
2R 称为回归方程的复相关系数。
显然:102
≤≤R 。判决系数或复相关系数接近1则表示回归方程与样本观察值拟合得比较好。
判决系数也回答了(2)中线性部分Y
所占比重的问题。
3)回归方程的显著性检验
原假设 H 0:b 1 = 0 (回归方程不显著) 检验统计量:)
2/(-=
n SE SR
F
在给定检验的显著性水平α0(例如0.05)后,如果计算得统计量F 对应得水平值Sig.<α0,则拒绝接受H 0,这时称原假设H 0不显著,也就是回归方程显著,这就意味着:接受回归方程近似代表变量Y 和X 的关系。
5.回归分析命令Regression\Linear
例3 数据data04,计算身高(high)与体重(weight)的相关系数,并以身高为自变量,体重为因变量求线性回归方程,同时计算判决系数、检验回归方程的显著性(取检验水平α0=0.05)。
打开Linear Rgression 对话框,将因变量体重(weight)输入Dependent ,将变量身高(high)输入Independent ,点击OK ,得输出文件表格系列:
Variables Entered/Remov ed
b
high a .
Enter
Model 1
Variables Entered Variables Removed
Method All requested variables entered.a. Dependent Variable: weight
b.
该表格是变量进入或移出回归方程的记录,它指出:进入方程的变量是high ,没有变量移出方程,使用的方法为Enter (在回归方程的优化一节中会讨论)。两个注是:a.所有提供的自变量都进入方程。b.因变量是weight 。
Model Summary
.849a .721
.709
3.752
Model 1
R R Square
Adjusted
R Square
Std. Error of the Estimate
Predictors: (Constant), high
a.
模型概况表格。其中R Square 是判决系数,R 是复相关系数,Adjusted R Square 是校正的判决系数(容以后介绍)。注a.预测元素为:(常数),high 。即回归方程等号右端是这两部分组成。
ANOVA
b
907.6981907.69864.480.000a
351.9312514.077
1259.630
26
Regress ion Res idual Total
Model 1
Sum of Squares df Mean Square
F Sig.Predictors : (Constant), high a. Dependent Variable: weight
b.
方差分析表。这部分做回归方程的显著性检验,原假设H 0:回归方程不显著。表中Sum of Square 一列:Regression 是回归平方和,Residual 是残差平方和,Total 是总平方和。df 是相应的自由度,Mean Square 为对应均方和,它的定义是:
Mean Sqare = Sum of Square ÷ df
F 是统计量的值,
F = Regression Mean Square ÷ Residual Mean Square
最后的Sig.是F 值对应的显著性。由于Sig.=0.000<0.05,故原假设H 0为不显著,即回归方程显著。
最后一个表格是系数表:
Coefficients
a
-84.60516.193-5.225.00085.12910.601
.849
8.030.000
(Cons tant)high
Model 1
B Std. Error Uns tandardized Coefficients Beta
Standardized
Coefficients
t
Sig.Dependent Variable: weight
a.
其中Unstandard Coefficients (非标准化系数)给出回归方程的常数项(Constant)与变量high 的系数,它们在B 列中显示。因此,回归方程是:
high weight 129.85605.84+-=
2.2 多元线性回归方程
1.模型 在变量Y 和变量X 1,X 2,…,X p ,(p ≥2)之间建立关系:
)11(22110εε+=+++++=Y X b X b X b b Y p p
其中ε为随机变量,表示误差。线性部分 )12(22110p
p X b X b X b b Y ++++=
对于(X 1, X 2,…,X p ,Y )的一个容量为n 的观察值
)13(...,2,1,
),,,,(21n
i Y X X X i ip i i =
应有
)14(,...,2,1,22110n
i Y X b X b X b b Y I i ip p i i i =+=+++++=εε
对(14)中的随机误差εi 有与一元线性回归相同的假设。称(12)为变量Y 对于变量X 1,X 2,…,X p 的p 元线性回归方程。它的基本问题和一元线性回归方程相同,也是:回归方程如何估计;回归方程能否近似代表原变量的实际关系。 2.回归系数的估计 引入以下向量:
),...,,(,),...,,(2121'='=n n Y Y Y y εεεε
,),...,,,(210'=p b b b b b
,
??
???
?
?
?
?=np n n p p X X X X X X X X X X 21222
2111211111
则(14)可以表示为矩阵形式: )15(ε
+=b X y
残差平方和:
∑=-----=n
i ip p i i i X b X b X b b Y SE 1222110)(
)()(b X y b X y
-'-='=εε
b X X b y X b b X y y y
''+''--'=
将其对b
求导数:
022=b X X y X b
SE
'+'-=?? 如果矩阵X X '可逆,解得:
b
y X X X b ?)(1 ≡''=-
这就是参数b
的最小二乘估计。
3.回归方程的显著性检验
原假设:H 0:b 1 = b 2 =? = b p = 0(回归方程不显著) 检验统计量:)
1/(/--=
p n SE p
SR F
其中SR 、SE 定义同一元回归。 4.回归系数的显著性检验
多元线性回归分析也有有别于一元线性回归的特殊问题,回归系数的显著性即是其一。 1)偏回归平方和
2)回归系数的显著性检验
原假设 H 0:b j =0 (自变量X j 不显著) 备选假设 H 0:b j ≠0 (自变量X j 显著) 检验统计量
)
1/()
(--?=
p n SE j SR F j
它等价于统计量
jj j j c b t σ
??=
其中:
1
)?(?122
---∑=p n Y Y n
i i
i =σ。
5.关于校正的判决系数(Adjusted R Square)
由于判决系数R 2的值会随自变量个数增加而变大,因此它不能正确反映方程的拟合效果。校正判决系数旨在消除这种影响。它定义为:
)1(1
1
1122
R p n n MST MSE R adj -----=-
= 2.3 利用回归方程做预测
回归方程用途的主要部分是可以用它来做预测。
1.所谓回归方程的预测,就是在给定点),,,()
0()0(2
)0(1p X X X 利用回归方程对变量Y 作出估计。这是一个典型的点估计问题,估计量就是回归方程。
2.从估计的角度出发,回归方程的预测除点估计外,还有区间估计,即估计变量Y 的置信区间。
例4 数据data05,求变量Y 对于变量X 1, X 2, X 3, X 4的4元非标准化线性回归方程,并做显著性检验(水平取0.05),同时利用所得回归方程预测no=14的Y 值。
在Linear Regression 对话框中:将因变量Y 输入Dependent ,将自变量X 1, X 2, X 3, X 4输入Independent(s),将no 输入Selection Variable 并点击Rule ,在菜单中选择not equal to 并填入14。返回,点击Save ,在Save 对话框中选择Predicted Values 中的Unstandardized 和Prediction Intervals 中的Individual ,填入需要的置信度。返回,OK 。
Coefficients
a,b
62.40570.071.891.3991.551.745.607 2.083.071.510.724.528.705.501.102.755.043.135.896-.144.709
-.160
-.203.844
(Constant)x1x2x3x4
Model 1
B Std. Error Unstandardized Coefficients Beta
Standardized
Coefficients
t Sig.Dependent Variable: y
a. Selecting only cases for which no ~= 14
b.
从表中可知,回归方程是:
4321144.0102.0510.0551.1405.62X X X X Y -+++=
在0.05的显著性水平下,自变量都不显著。
ANOVA
b,c
2667.8994666.975111.479.000a
47.8648 5.983
2715.763
12
Regression Residual Total
Model 1
Sum of Squares df Mean Square
F Sig.Predictors: (Constant), x4, x3, x1, x2a. Dependent Variable: y
b. Selecting only cases for which no ~= 14
c.
此表显示,在0.05的显著性水平下,回归方程显著。
Model Summary
b,c
.991a .982
.974 2.4460
Model 1
no ~= 14
(Selected)R R Square
Adjusted
R Square
Std. Error of the Estimate
Predictors: (Constant), x4, x3, x1, x2
a. Unless noted otherwise, statistics are based only on cases for which no ~= 14 .
b. Dependent Variable: y
c.
进一步还能得到判决系数为0.982,校正判决系数为0.974,复相关系数为0.991。
关于no=14观察值的Y 预测值在原始数据文件中生成的新变量PRE ?1中,为94.19281,95%置信区间的左、右端点分别由新变量LICI ?1和UICI ?1给出,由是知为(69.87367, 118.51195)。 例5 数据data05,求变量X 1的偏回归平方和。
在例4中,ANOVA 表给出回归平方和是2667.899,按照偏回归平方和的定义,求Y 对于X 2,X 3,X 4的回归方程,此时ANOVA 表格
ANOVA
b,c
2641.9493880.650107.375.000a
73.81598.202
2715.763
12
Regression Residual Total
Model 1
Sum of Squares df Mean Square
F Sig.Predictors: (Constant), x4, x3, x2a. Dependent Variable: y
b. Selecting only cases for which no ~= 14
c.
显示回归平方和为2641.949,故变量X 1的偏回归平方和等于
?SR (X 1) = 2667.899 - 2641.949 = 25.95
也就是方程中少了自变量X 1,回归平方和就要损失25.95。 2.4 回归方程的优化
本节讨论在给定的显著性水平下,建立一个所有自变量都显著的回归方程的不同方法。为区别以下的方法,称上一节讨论的
建立回归方程的方法为强制进入法(Enter 方法)。 1.前进法(Forward)
第一步 建立p 个一元线性回归方程:
p j X b b Y j
j j ,...,2,1,???)1(1)1(0=+= 在通过显著性检验的回归方程中,选择F 值最大者留下,不妨设这个方程就是:
1)1(11)1(01???X b b Y +=
第二步 用入选的自变量X 1与其余p -1个自变量生成p -1个搭配:X 1, X j , j=2,…,p ,求出p -1个回归方程:
p j X b X b b Y j j j ,...,3,2,????2
)2(21)2(1)2(0=++=
再从显著的方程中,选择X 2最显著的方程留下。
以下的步骤与以上相同,直到剩下的自变量中没有一个显著为止,最后的方程即所求。
例6 数据data05,用前进法求回归方程。
做法同例2,只是在Linear Regression 对话框的Mathod 一栏将Enter 改变为Forward 。
Variables Entered/Remov ed
a,b x4.
Forward (Criterion:Probabilit y-of-F-to-enter <= .050)x1
.
Forward (Criterion:Probabilit y-of-F-to-enter <= .050)
Model 1
2
Variables Entered Variables Removed
Method Dependent Variable: y
a. Models are based only on cases for which no ~= 14
b.
此表显示:进入变量检验的临界概率为0.05,即显著水平大于此
值的变量都要出局。在此标准下,X 4首选入方程,X 1次选入方程,其他变量落选。
Model Summary
.821a .675.6458.9639.986b .972
.967 2.7343
Model
12
no ~= 14
(Selected)R R Square
Adjusted R Square
Std. Error of the Estimate
Predictors: (Constant), x4a. Predictors: (Constant), x4, x1
b.
此表显示:第一个方程(自变量只有X 4)的判决系数为0.645,而第二个方程(自变量为X 4和X 1)的判决系数为0.967,有了很大的提升。
ANOVA
c,d
1831.89611831.89622.799.001a
883.8671180.352
2715.763122641.00121320.500
176.627
.000b
74.762107.476
2715.763
12
Regression Residual Total
Regression Residual Total
Model 1
2
Sum of Squares df Mean Square
F Sig.Predictors: (Constant), x4a. Predictors: (Constant), x4, x1b. Dependent Variable: y
c. Selecting only cases for which no ~= 14
d.
此表显示:第一、第二两个回归方程都显著。
Coefficients
a,b
117.568 5.262
22.342.000-.738.155-.821-4.775.001103.097 2.124
48.540.000-.614.049-.683-12.621.0001.440.138
.563
10.403.000
(Constant)x4
(Constant)x4x1
Model 12
B Std. Error Unstandardized Coefficients Beta
Standardized
Coefficients
t
Sig.Dependent Variable: y
a. Selecting only cases for which no ~= 14
b.
此表显示:第一个方程是4738.0568.117X Y -=,方程中没有不显著变量;第二个方程是14440.1614.0097.103X X Y +-=,方程中也没有不显著变量。
Excluded Variables
c
.563a 10.403.000.957.940.322a .415.687.130.053-.511a -6.348.000-.895.999.430b 2.242.052.599.053-.175b -2.058.070
-.566
.289
x1x2x3x2x3
Model 1
2
Beta In
t
Sig.Partial Correlation
Tolerance
Collinearity Statistics Predictors in the Model: (Constant), x4a. Predictors in the Model: (Constant), x4, x1b. Dependent Variable: y
c.
此表显示每次筛选中未进入方程的变量。注意未进入第二个方程的变量X2和X3,它们的Sig.值分别是0.052和0.070,均大于临界概率0.05,这就是它们被淘汰的原因。 2.退后法(Backward)
做法与前进法相反。即第一步将所有的p 个自变量都进入方程,从第二步开始,每一步都将方程中最不显著的自变量剔除,直到方程中没有不显著的自变量为止。 例7 数据data05,用后退法求回归方程。
打开Linear Regression 对话框,Method 一栏改为Backward ,其他一切做法照旧。点击OK ,得输出:
Variables Entered/Remov ed
b,c
x4, x3, x1,x2
a .
Enter .x3
Backward (criterion:Probabilit y of
F-to-remo ve >= .100)..x4
Backward (criterion:Probabilit y of
F-to-remo ve >= .100).
Model 12
3
Variables Entered Variables Removed
Method All requested variables entered.a. Dependent Variable: y
b. Models are based only on cases for which no ~= 14
c.
此表显示:剔除变量的临界概率为0.100,第一个方程按照后退法应该把所有自变量都进入方程,所以Model 1显示X 4,X 3,X 1,X 2全都进入方程,注意这时Method 显示的是Enter 而非Backward ,想一想这是为什么。第二个方程也就是Model 2把X 3剔除出去,这时Method 显示Backward 。第三个方程即Model 3又把X 4剔除出去,以后没有剔除动作,这Model 3就是最终结果。
Model Summary
.991a .982
.974 2.4460.991b .982
.976 2.3087.989c .979
.974 2.4063
Model
123
no ~= 14
(Selected)R R Square
Adjusted R Square
Std. Error of the Estimate
Predictors: (Constant), x4, x3, x1, x2a. Predictors: (Constant), x4, x1, x2b. Predictors: (Constant), x1, x2
c.
这张表格无需多做解释。提醒读者,从中可以看到随自变量个数增加,判决系数确有增大的趋势。
ANOVA
d,e
2667.8994666.975111.479.000a
47.8648 5.983
2715.763122667.7903889.263166.832
.000b
47.9739 5.3302715.763122657.85921328.929
229.504
.000c
57.90410 5.790
2715.763
12
Regression Residual Total
Regression Residual Total
Regression Residual Total
Model 1
2
3
Sum of Squares df Mean Square
F Sig.Predictors: (Constant), x4, x3, x1, x2a. Predictors: (Constant), x4, x1, x2b. Predictors: (Constant), x1, x2c. Dependent Variable: y
d. Selecting only cases for which no ~= 14
e.
这张表也无需多做解释,它指出三个模型都显著。
Excluded Variables
c
.043a .135.896.048.021.106b 1.354.209.411.318-.263b
-1.365.205
-.414
.053
x3x3x4
Model 23
Beta In
t Sig.Partial Correlation
Tolerance
Collinearity Statistics Predictors in the Model: (Constant), x4, x1, x2a. Predictors in the Model: (Constant), x1, x2b. Dependent Variable: y
c.
这是被剔除变量的清单。Model 2中变量X 3被剔除理由是它的Sig.值为0.896,远大于临界值0.100,并且是所有Sig.值大于临界值的变量中最大的一个。类似解释Model 2。
Coefficients
a,b
62.40570.071.891.3991.551.745.607 2.083.071.510.724.528.705.501.102.755.043.135.896-.144.709-.160-.203.84471.64814.142 5.066.0011.452.117.56812.410.000.416.186.430 2.242.052-.237.173-.263-1.365.20552.577 2.28622.998.0001.468.121.57412.105.000.662.046
.685
14.442.000
(Constant)x1x2x3x4
(Constant)x1x2x4
(Constant)x1x2
Model 1
2
3
B Std. Error Unstandardized Coefficients Beta
Standardized
Coefficients
t Sig.Dependent Variable: y
a. Selecting only cases for which no ~= 14
b.
这是三个回归方程的清单:模型1方程为
4321144.0102.0510.0551.1405.62X X X X Y -+++=
按系统给的0.100的检验水平,除X 1显著外,其余自变量均不显著,而且Sig.最大者为X 3达到0.896,故剔除X 3,重新回归,得模型2,方程为
421237.0416.0452.1648.71X X X Y -++=
自变量X4不显著,剔除之,重新回归,得模型3,方程为
21662.0468.1577.52X X Y ++=
此方程中已经没有不显著自变量。 3.逐步回归法(Stepwise)
前进法中,每一步向方程内引入一个最显著的自变量。由于新变量的引入,回归方程中原有的自变量的显著水平会发生相应的变化,有的变量原来是显著的,现在成为不显著。对于每一步可能产生的新的不显著变量,前进法没有提出如何处理,而是让它们继续留在回归方程内。换句话说,变量一旦进入方程,就不会被剔除出方程。逐步回归法就是针对这一缺点,在每一步,不仅引入一个最显著的变量,还把已经存在于方程内的变得不显著的
自变量,剔除掉最不显著的那个。如此直到方程中没有不显著的自变量为止。
2.5 回归方程的诊断 1.共线性(Collinearity)诊断
1)共线性的含义 p (≥2)元线性回归方程
p
p X b X b X b b Y ?????22110++++= 中,如果自变量X 1,X 2,…,X p 也构成一个显著的线性模型。换言之:存在一个自变量,不妨设它是X 1,如果用X 1作因变量,对于剩下的自变量X 2,…,X p 构成一个显著的p -1元线性回归方程:
p
p X c X c c X +++= 2201? (2)变量X j 的容限(Tolerance)
设2j R 是以自变量X j 为因变量,与其他 p -1个自变量构成的p -1元线性回归方程的判决系数,称
21)(j j R X Tol -=
为变量X j 的容限。它是判断回归方程共线性的重要指标。显然有:
1)(0≤≤j X Tol ,并且:Tol (X j ) 的值越小,自变量X j 的共线性越显
著。
2.残差独立性判断 1)残差
残差(Residual)指实际观察值与预测值之差:
n i Y Y e i
i i ,...,2,1,?=-=
残差向量:
Y X X X X I Y Y e n ])([?1
''-=-=-
(1)残差的均值为零,即有:
0)(=e E
。 (2)残差的协方差矩阵
])([)(12X X X X I e D n ''-=-σ
2)Durbin-Watson 统计量
∑
∑
==--=
n
t t
n
t t t e
e e d 1
2
2
2
1)(
当n 充分大时,)?1(2ρ
-≈d ,其中的ρ
?是残差序列的一阶自
相关系数的估计。可见此时的d 值约在区间[0, 4]之内,而当d =2时,可判定残差序列独立。
附录:二阶段最小二乘法(Two-stage Least-squares)
一.自变量与因变量互为影响
最小二乘估计适用于自变量单向影响因变量。但在许多经济学问题中,出现自变量和因变量双向影响的现象。例如:
价格与需求;
工资水平与工作表现; 收入水平与受教育程度。
以下是一个实例:研究收入(LW)与受教育水平(Educ)、种族(Black ,是否黑人)、年龄(Age)的线性回归方程。有:
Age b Black b Educ b b LW 3210+++=
此外,一个不争的事实是:受教育水平(Educ)也受收入(LW)的影响。解决的办法是另外寻找一些与受教育水平(Educ)和收入(LW)只有单向影响的自变量,用以预测受教育水平,这个预测模型是:
Age c Black c Med c Fed c c Educ 43210++++=
用Educ 的预测值代入原回归模型,进行估计。 二.二阶段最小二乘法
Regression\2-Stage Least Squares
第七章 相关与回归分析 一、本章学习要点 (一)相关分析就是研究两个或两个以上变量之间相关程度大小以及用一定函数来表达现象相互关系的方法。现象之间的相互关系可以分为两种,一种是函数关系,一种是相关关系。函数关系是一种完全确定性的依存关系,相关关系是一种不完全确定的依存关系。相关关系是相关分析的研究对象,而函数关系则是相关分析的工具。 相关按其程度不同,可分为完全相关、不完全相关和不相关。其中不完全相关关系是相关分析的主要对象;相关按方向不同,可分为正相关和负相关;相关按其形式不同,可分为线性相关和非线性相关;相关按影响因素多少不同,可分为单相关和复相关。 (二)判断现象之间是否存在相关关系及其程度,可以根据对客观现象的定性认识作出,也可以通过编制相关表、绘制相关图的方式来作出,而最精确的方式是计算相关系数。 相关系数是测定变量之间相关密切程度和相关方向的代表性指标。相关系数用符号“γ”表示,其特点表现在:参与相关分析的两个变量是对等的,不分自变量和因变量,因此相关系数只有一个;相关系数有正负号反映相关系数的方向,正号反映正相关,负号反映负相关;计算相关系数的两个变量都是随机变量。 相关系数的取值区间是[-1,+1],不同取值有不同的含义。当1||=γ时,x 与y 的变量为完全相关,即函数关系;当1||0<<γ时,表示x 与y 存在一定的线性相关,||γ的数值越大,越接近于1,表示相关程度越高;反之,越接近于0,相关程度越低,通常判别标准是:3.0||<γ称为微弱相关,5.0||3.0<<γ称为低度相关,8.0||5.0<<γ称为显著相关,1||8.0<<γ称为高度相关;当0||=γ时,表示y 的变化与x 无关,即不相关;当0>γ时,表示x 与y 为线性正相关,当0<γ时,表示x 与y 为线性负相关。 皮尔逊积距相关系数计算的基本公式是: ∑∑∑∑∑∑∑---= =] )(][)([22222y y n x x n y x xy n y x xy σσσγ 斯皮尔曼等级相关系数和肯特尔等级相关系数是测量两个等级变量(定序测度)之间相 关密切程度的常用指标。 (三)回归分析是对具有相关关系的两个或两个以上变量之间数量变化的一般关系进行测定,确定一个相应的数学表达式,以便从一个已知量来推测另一个未知量,为估计预测提供一个重要的方法。回归分析按自变量的个数分,有一元回归和多元回归,按回归线的形状分,有线性回归和非线性回归。与相关分析相比,回归分析的特点是:两个变量是不对等的,必须区分自变量和因变量;因变量是随机的,自变量是可以控制的量;对于一个没有因果关系的两变量,可以求得两个回归方程,一个是y 倚x 的回归方程,一个是x 倚y 的回归方程。 简单线性回归方程式为:bx a y c +=,式中c y 是y 的估计值,a 代表直线在y 轴上的截距,b 表示直线的斜率,又称为回归系数。回归系数的涵义是,当自变量x 每增加一个单位时,因变量y 的平均增加值。当b 的符号为正时,表示两个变量是正相关,当b 的符号为负时,表示两个变量是负相关。a 、b 都是待定参数,可以用最小平方法求得。求解a 、b 的公式为: ∑∑∑∑∑--= 2 2)(x x n y x xy n b ; n x b n y a ∑∑-= 回归估计标准误差是衡量因变量的估计值与观测值之间的平均误差大小的指标。利用此 指标可以说明回归方程的代表性。其计算公式为: 2 ) (2 --= ∑n y y S c yx 或2 2 ---= ∑∑∑n xy b y a y S yx 回归估计标准误和相关系数之间具有以下关系:
(一) 填空题 1、 现象之间的相关关系按相关的程度分有________相关、________相关和_______ 相关;按相关的方向分有________相关和________相关;按相关的形式分有-________相关和________相关;按影响因素的多少分有________相关和-________相关。 2、 对现象之间变量关系的研究中,对于变量之间相互关系密切程度的研究,称为 _______;研究变量之间关系的方程式,根据给定的变量数值以推断另一变量的可能值,则称为_______。 3、 完全相关即是________关系,其相关系数为________。 4、 在相关分析中,要求两个变量都是_______;在回归分析中,要求自变量是 _______,因变量是_______。 5、 person 相关系数是在________相关条件下用来说明两个变量相关________的统 计分析指标。 6、 相关系数的变动范围介于_______与_______之间,其绝对值愈接近于_______, 两个变量之间线性相关程度愈高;愈接近于_______,两个变量之间线性相关程度愈低。当_______时表示两变量正相关;_______时表示两变量负相关。 7、 当变量x 值增加,变量y 值也增加,这是________相关关系;当变量x 值减少, 变量y 值也减少,这是________相关关系。 8、 在判断现象之间的相关关系紧密程度时,主要用_______进行一般性判断,用_______进行数量上的说明。 9、 在回归分析中,两变量不是对等的关系,其中因变量是_______变量,自变量是 _______量。 10、 已知13600))((=----∑y y x x ,14400)(2=--∑x x ,14900)(2=-∑-y y ,那么,x 和y 的相关系数r 是_______。 11、 用来说明回归方程代表性大小的统计分析指标是________指标。 12、 已知1502=xy σ,18=x σ,11=y σ,那么变量x 和y 的相关系数r 是_______。 13、 回归方程bx a y c +=中的参数b 是________,估计特定参数常用的方法是 _________。 14、 若商品销售额和零售价格的相关系数为-0.95,商品销售额和居民人均收入的相关系数为0.85,据此可以认为,销售额对零售价格具有_______相关关系,销售额与人均收入具有_______相关关系,且前者的相关程度_______后者的相关程度。 15、 当变量x 按一定数额变动时,变量y 也按一定数额变动,这时变量x 与y 之间存在着_________关系。 16、 在直线回归分析中,因变量y 的总变差可以分解为_______和_______,用公式表示,即_____________________。 17、 一个回归方程只能作一种推算,即给出_________的数值,估计_________的可能值。 18、 如估计标准误差愈小,则根据回归直线方程计算的估计值就_______ 19、 已知直线回归方程bx a y c +=中,5.17=b ;又知30=n ,∑=13500y ,
统计学基础第八章相关与回归分析 【教学目的】 1.掌握相关系数的测定和性质 2.明确相关分析与回归分析的特点 3.建立回归直线方程,掌握估计标准误差的计算 【教学重点】 1.相关关系、相关分析和回归分析的概念 2.相关系数计算 3.回归方程的建立和依此进行估计和预测 【教学难点】 1.相关分析和回归分析的区别 2.相关系数的计算 3.回归系数的计算 4.估计标准误的计算 【教学时数】 教学学时为8课时 【教学内容参考】 第一节相关关系 一、相关关系的含义 宇宙中任何现象都不是孤立地存在的,而是普遍联系和相互制约的。这种现象间的相互联系、相互制约的关系即为相关关系。 相关关系因其依存程度的不同而表现出相关程度的差别。有些现象间存在着严格的数据依存关系,比如,在价格不变的条件下销售额量之间的关系,圆的面积与半径之间的关系等等,均具有显著的一一对应关系。这些关系可由数学中的函数关系来确切的描述,因而也可以认为是一种完全相关关系。有些现象间的依存关系则没有那么严格。当一种现象的数量发生变化时,另一种现象的数量却在一定的范围内发生变化,比如身高与体重的关系就是如此。一般来说,身高越高,
体重越重,但二者之间的关系并非严格意义上的对应关系,身高1.75米的人,对应的体重会有多个数值,因为影响体重的因素不只身高而已,它还会受遗传、饮食习惯等因素的制约和影响。社会经济现象中大多存在这种非确定的相关关系。 在统计学中,这些在社会经济现象之间普遍存在的数量依存关系,都成为相关关系。在本章,我们主要介绍那些能用函数关系来描述的具有经济统计意义的相关关系。 二、相关关系的特点 1.现象之间确实存在数量上的依存关系 如果一个现象发生数量上的变化,则另一个现象也会发生数量上的变化。在相互依存的两个变量中,可以根据研究目的,把其中的一个变量确定为自变量,把另一个对应变量确定为因变量。例如,把身高作为自变量,则体重就是因变量。 2.现象之间数量上的关系是不确定的 相关关系的全称是统计相关关系,它属于变量之间的一种不完全确定的关系。这意味着一个变量虽然受另一个(或一组)变量的影响,却并不由这一个(或一组)变量完全确定。例如,前面提到的身高和体重之间的关系就是这样一种关系。 三、相关关系的种类 现象之间的相互关系很复杂,它们涉及的变动因素多少不同,作用方向不同,表现出来的形态也不同。相关关系大体有以下几种分类: (一)正相关与负相关 按相关关系的方向分,可分为正相关和负相关。当两个因素(或变量)的变动方向相同时,即自变量x值增加(或减少),因变量y值也相应地增加(或减少),这样的关系就是正相关。如家庭消费支出随收入增加而增加就属于正相关。如果两个因素(或变量)变动的方向相反,即自变量x值增大(或减小),因变量y值随之减小(或增大),则称为负相关。如商品流通费用率随商品经营的规模增大而逐渐降低就属于负相关。 (二)单相关与复相关 按自变量的多少分,可分为单相关和复相关。单相关是指两个变量之间的相关关系,即所研究的问题只涉及到一个自变量和一个因变量,如职工的生活水平与工资之间的关系就是单相关。复相关是指三个或三个以上变量之间的相关关系,即所研究的问题涉及到若干个自变量与一个因
第九章 线性回归和相关分析 9.1 什么叫做回归分析?直线回归方程和回归截距、回归系数的统计意义是什么,如何计算?如何对直线回归进行假设测验和区间估计? 9.2 a s 、b s 、x y s /、y s 、y s ?各具什么意义?如何计算(思考各计算式的异同)? 9.3 什么叫做相关分析?相关系数、决定系数各有什么具体意义?如何计算?如何对相关系数作假设测验? 9.4 什么叫做协方差分析?为什么要进行协方差分析?如何进行协方差分析(分几个步骤)?为什么有时要将i y 矫正到x 相同时的值?如何矫正? 9.5 测得不同浓度的葡萄糖溶液(x ,mg /l )在某光电比色计上的消光度(y )如下表,试计算: (1)直线回归方程y ?=a +bx ,并作图;(2)对该回归方程作假设测验;(3)测得某样品的消光度为0.60,试估算该样品的葡萄糖浓度。 x 0 5 10 15 20 25 30 y 0.00 0.11 0.23 0.34 0.46 0.57 0.71 [答案:(1)y ? =-0.005727+0.023429x ,(2)H0被否定,(3)25.85mg/l] 9.6 测得广东阳江≤25oC 的始日(x)与粘虫幼虫暴食高峰期(y)的关系如下表(x 和y 皆以8月31日为0)。试分析:(1)≤25oC 的始日可否用于预测粘虫幼虫的暴食期;(2)回归方程及其估计标准误;(3)若某年9月5日是≤25oC 的始日,则有95%可靠度的粘虫暴食期在何期间? 年份 54 55 56 57 58 59 60 x 13 25 27 23 26 1 15 y 50 55 50 47 51 29 48 [答案:(1)r=0.8424;(2)y ? =33.2960+0.7456x , x y s /=4.96;(3)9月22日~10月23日] 9.7 研究水稻每一单茎蘖的饱粒重(y ,g)和单茎蘖重(包括谷粒)(x ,g)的关系,测定52个早熟桂花黄单茎蘖,得:SSx=234.4183,SSy=65.8386,SP=123.1724,b=0.5254,r=0.99;测定49个金林引单茎蘖,得SSx=65.7950,SSy=18.6334,SP=33.5905,b=0.5105,r=0.96。试对两回归系数和相关系数的差异作假设测验,并解释所得结果的意义。 [答案: 2 1b b s -=0.0229,t <1; 2 1z z s -=0.2053,t=3.413] 9.8 下表为1963、1964、1965三年越冬代棉红铃虫在江苏东台的化蛹进度的部分资料,试作协方差分析。 x 日 期 (以6月10日为0) y 化 蛹 进 度(%) 1963年 1964年 1965年
第七章 相关分析与回归分析 例1、有10个同类企业的固定资产和总产值资料如下: 根据以上资料计算(1)协方差和相关系数;(2)建立以总产值为因变量的一元线性回归方程;(3)当固定资产改变200万元时,总产值平均改变多少?(4)当固定资产为1300万元时,总产值为多少? 解:计算表如下: (1)协方差——用以说明两指标之间的相关方向。 2 2) )((n y x xy n n y y x x xy ∑∑∑∑- = - -= σ
35.126400100 9801 6525765915610>=?-?= 计算得到的协方差为正数,说明固定资产和总产值之间存在正相关关系。 (2)相关系数用以说明两指标之间的相关方向和相关的密切程度。 ∑∑∑ ∑∑∑∑--- = ] )(][) ([2 2 2 2 y y n x x n y x xy n r 95 .0) 980110866577 10()6525566853910(9801 65257659156102 2 =-??-??-?= 计算得到的相关系数为0.95,表示两指标为高度正相关。 (3) 2 2 26525 56685391098016525765915610) (-??-?= --= ∑∑∑∑∑x x n y x xy n b 90 .014109765 126400354257562556685390 6395152576591560== --= 85 .39210 65259.010 9801=? -= -=x b y a 回归直线方程为: x y 9.085.392?+= (4)当固定资产改变200万元时,总产值平均改变多少? x y ?=?9.0,180 2009.0|200=?=?=?x y 万元 当固定资产改变200万元时,总产值平均增加180万元。 (5)当固定资产为1300万元时,总产值为多少? 85 .156213009.085.392|1300=?+==x y 万元 当固定资产为1300万元时,总产值为1562.85万元。 例2、试根据下列资产总值和平均每昼夜原料加工量资料计算相关系数。
第八章相关与回归分析 一、本章重点 1.相关系数的概念及相关系数的种类。事物之间的依存关系,可以分为函数关系和相关关系。相关关系又有单向因果关系和互为因果关系;单相关和复相关;线性相关和非线性相关;不相关、不完全相关和完全相关;正相关和负相关等类型。 2.相关分析,着重掌握如何画相关表、相关图,如何测定相关系数、测定系数以及进行相关系数的推断。相关表和相关图是变量间相关关系的生动表示,对于未分组资料和分组资料计算相关系数的方法是不同的,一元线性回归中相关系数和测定系数有着密切的关系,得到样本相关系数后还要对总体相关系数进行科学推断。 3.回归分析,着重掌握一元回归的基本原理方法,一元回归是线性回归的基础,多元线性回归和非线性回归都是以此为基础的。用最小平方法估计回归参数,回归参数的性质和显著性检验,随机项方差的估计,回归方程的显著性检验,利用回归方程进行预测是回归分析的主要内容。 4.应用相关与回归分析应注意的问题。相关与回归分析都有它们的应用范围,必须知道在什么情况下能用,什么情况下不能用。相关分析和回归分析必须以定性分析为前提,否则可能会闹出笑话,在进行预测时选取的样本要尽量分散,以减少预测误差,在进行预测时只有在现有条件不变的情况下才能进行,如果条件发生了变化,原来的方程也就失去了效用。 二、难点释疑 本章难点在于计算公式多,不容易记忆,所以更要注重计算的练习。为了掌握基本计算的内容,起码应认真理解书上的例题,做完本指导书上的全部计算题。初学者可能会感到本章公式多且复杂,难于记忆,其实只要抓住Lxx、Lxy、Lyy 这三个记号,记住它们的展开式,几个主要的公式就不难记忆了。如果能自己把这些公式推证一下,搞清其关系,那就更容易记住了。 三、练习题 (一)填空题 1事物之间的依存关系,根据其相互依存和制约的程度不同,可以分为(函数关系)和(相关关系)两种。 2.相关关系按相关关系的情况可分为()和();按自变量的多少分(单相关)和(复相关);按相关的表现形式分(线性相关)和(非线性相关);按相关关系的密切程度分(完全相关)、(不完全相关)和(不相关);按相关关系的方向分(正相关)和(负相关)。 3.回归方程只能用于由(自变量)推算(因变量)。 4.一个自变量与一个因变量的线性回归,称为(一元线性回归) 5.估计变量间的关系的紧密程度用(相关系数) 6.在相关分析中,要求两个变量都是随机的,而在回归分析中要求自变量是(不是随机的),因变量是(随机的)。 7.已知剩余变差为250,具有12对变量值资料,那么这时的估计标准误差是()。 8.将现象之间的相关关系,用表格来反映,这种表称为(相关表),将现象之间的相关关系用图表示称(相关图)。
回归分析与相关分析联系、区别?? 简单线性回归分析是对两个具有线性关系的变量,研究其相关性,配合线性回归方程,并根据自变量的变动来推算和预测因变量平均发展趋势的方法。 回归分析(Regression analysis)通过一个变量或一些变量的变化解释另一变量的变化。 主要内容和步骤:首先依据经济学理论并且通过对问题的分析判断,将变量分为自变量和因变量,一般情况下,自变量表示原因,因变量表示结果;其次,设法找出合适的数学方程式(即回归模型)描述变量间的关系;接着要估计模型的参数,得出样本回归方程;由于涉及到的变量具有不确定性,接着还要对回归模型进行统计检验,计量经济学检验、预测检验;当所有检验通过后,就可以应用回归模型了。 回归的种类 回归按照自变量的个数划分为一元回归和多元回归。只有一个自变量的回归叫一元回归,有两个或两个以上自变量的回归叫多元回归。 按照回归曲线的形态划分,有线性(直线)回归和非线性(曲线)回归。 相关分析与回归分析的关系 (一)相关分析与回归分析的联系 相关分析是回归分析的基础和前提,回归分析则是相关分析的深入和继续。相关分析需要依靠回归分析来表现变量之间数量相关的具体形式,而回归分析则需要依靠相关分析来表现变量之间数量变化的相关程度。只有当变量之间存在高度相关时,进行回归分析寻求其相关的具体形式才有意义。如果在没有对变量之间是否相关以及相关方向和程度做出正确判断之前,就进行回归分析,很容易造成“虚假回归”。与此同时,相关分析只研究变量之间相关的方向和程度,不能推断变量之间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况,因此,在具体应用过程中,只有把相关分析和回归分析结合起来,才能达到研究和分析的目的。 (二)相关分析与回归分析的区别 1.相关分析中涉及的变量不存在自变量和因变量的划分问题,变量之间的关系是对等的;而在回归分析中,则必须根据研究对象的性质和研究分析的目的,对变量进行自变量和因变量的划分。因此,在回归分析中,变量之间的关系是不对等的。 2.在相关分析中所有的变量都必须是随机变量;而在回归分析中,自变量是确定的,因变量才是随机的,即将自变量的给定值代入回归方程后,所得到的因变量的估计值不是唯一确定的,而会表现出一定的随机波动性。 3.相关分析主要是通过一个指标即相关系数来反映变量之间相关程度的大小,由于变量之间是对等的,因此相关系数是唯一确定的。而在回归分析中,对于互为因果的两个变量(如人的身高与体重,商品的价格与需求量),则有可能存在多个回归方程。 需要指出的是,变量之间是否存在“真实相关”,是由变量之间的内在联系所决定的。相关分析和回归分析只是定量分析的手段,通过相关分析和回归分析,虽然可以从数量上反映变量之间的联系形式及其密切程度,但是无法准确判断变量之间内在联系的存在与否,也无法判断变量之间的因果关系。因此,在具体应用过程中,一定要注意把定性分析和定量分析结合起来,在定性分析的基础上展开定量分析。
问:请详细说明相关分析与回归分析的相同与不同之处 相关分析与回归分析都是研究变量相互关系的分析方法,相关分析是回归分析的基础,而回归分析则是认识变量之间相关程度的具体形式。 下面分为三个部分详细描述两种分析方法的异同: 第一部分:相关分析 一、相关的含义与种类 (一)相关的含义 相关是指自然与社会现象等客观现象数量关系的一种表现。 相关关系是指现象之间确实存在的一定的联系,但数量关系表现为不严格相互依存关系。即对一个变量或几个变量定一定值时,另一变量值表现为在一定范围内随机波动,具有非确定性。如:产品销售收入与广告费用之间的关系。 (二)相关的种类 1. 根据自变量的多少划分,可分为单相关和复相关 2. 根据相关关系的方向划分,可分为正相关和负相关 3. 根据变量间相互关系的表现形式划分,线性相关和非线性相关 4.根据相关关系的程度划分,可分为不相关、完全相关和不完全相关 二、相关分析的意义与内容 (一)相关分析的意义 相关分析是研究变量之间关系的紧密程度,并用相关系数或指数来表示。其目的是揭示现象之间是否存在相关关系,确定相关关系的表现形式以及确定现象变量间相关关系的密切程度和方向。 (二)相关分析的内容 1. 明确客观事物之间是否存在相关关系 2. 确定相关关系的性质、方向与密切程度 三、直线相关的测定 (一)相关表与相关图 1. 相关表 在定性判断的基础上,把具有相关关系的两个量的具体数值按照一定顺序平行排列在一张表上,以观察它们之间的相互关系,这种表就称为相关表。 2. 相关图
把相关表上一一对应的具体数值在直角坐标系中用点标出来而形成的散点图则称为相关图。利用相关图和相关表,可以更直观、更形象地表现变量之间的相互关系。 (二)相关系数 1. 相关系数的含义与计算 相关系数是直线相关条件下说明两个变量之间相关关系密切程度的统计分析指标。相关系数的理论公式为: y x xy r δδδ2= (1)xy 2δ 协方差 x δ x 的标准差 y δ y 的标准差 (2)xy 2δ 协方差对相关系数r 的影响,决定:???<>数值的大小正、负)或r r r (00 简化式 ()()2222∑∑∑∑∑∑∑-?--= y y n x x n y x xy n r 变形:分子分母同时除以2 n 得 r =???????????? ??-???????????? ??-?-∑∑∑∑∑∑∑2222n y n y n x n x n y n x n xy =()[]()[]2222y y x x y x xy -*-?-=y x y x xy δδ-?- n x x x ∑-=2)(δ=()[]n x x x x ∑+?-222=()222x n x x n x +??-∑∑ = () 22x x - 2. 相关系数的性质
高中数学:第八章 方差分析与回归分析 §1 单因素试验的方差分析 试验指标:研究对象的某种特征。 例 各人的收入。 因素:与试验指标相关的条件。 例 各人的学历,专业,工作经历等与工资有关的特征。 因素水平:因素所在的状态 例 学历是因素,而高中,大学,研究生等,就是学历因素水平;数学,物理等就是专业的水平。 问题:各因素水平对试验指标有无显著的差异? 单因素试验方差分析模型 假设 1) 影响试验指标的因素只有一个,为A ,其水平有r 个:1,,r A A L ; 2) 每个水平i A 下,试验指标是一个总体i X 。各个总体的抽样过程 是独立的。 3)2~(,)i i i X N μσ,且22i j σσ=。 问题:分析水平对指标的影响是否相同 1)对每个总体抽样得到样本{,1}ij i X j n ≤≤,由其检验假设: 原假设0:i j H μμ=,,i j ?;备选假设:1:i j H μμ≠,,i j ?; 2)如果拒绝原假设,则对未知参数21,,,r μμσL 进行参数估计。 注 1)接受假设即认为:各个水平之间没有显著差异,反之则有显著差异。
2)在水平只有两个时,问题就是双正态总体的均值假设检验问题和参数估计问题。 检验方法 数据结构式:ij i ij i ij X μεμδε=+=++,偏差2~(0,)ij N εσ是相互独立的, 11r i i i n n μμ==∑。不难验证,1 0r i k δ==∑。 各类样本均值 水平i A 的样本均值:1 1i n i ij j i X X n == ∑g ; 水平总样本均值:11111i n r r ij i i i j i X X n X n n =====∑∑∑,1 r i i n n ==∑; 偏差平方和与效应 组间偏差平方和: 2 221 1 ()r r A i i i i i i S n X X n X nX ===-=-∑∑g g ;(衡量由不同水平产生的差异) 组内偏差平方和: 2 2 211 1 1 ()()i i n n r r E ij i ij i i i j i j S X X X n X =====-=-∑∑∑∑g g ; (衡量由随机因素在同一水平上产生的差异) 总偏差平方和: 2 2 211 1 ()i n r r T ij i ij i j i S X X n X nX ====-=-∑∑∑; (综合衡量因素,水平之间,随机因素的差异) 定理1(总偏差平方和分解定理) T A E S S S =+。 即2 2 211 11 11 ()()()i i i n n n r r r ij ij i i i j i j i j X X X X X X ======-=-+-∑∑∑∑∑∑g g ,或直接证明。 注:利用11 ()()0i n r ij i i i j X X X X ==--=∑∑即可证明。 定理2(统计特性) 2 ()E ES n r σ=-,2 21(1)r A i i i ES r n σδ==-+∑,2 21 (1)r T i i i ES n n σδ==-+∑。
相关分析与回归分析 一、试验目标与要求 本试验项目的目的是学习并使用SPSS软件进行相关分析与回归分析,具体包括: (1)皮尔逊pearson简单相关系数的计算与分析 (2)学会在SPSS上实现一元及多元回归模型的计算与检验。 (3)学会回归模型的散点图与样本方程图形。 (4)学会对所计算结果进行统计分析说明。 (5)要求试验前,了解回归分析的如下内容。 参数α、β的估计 回归模型的检验方法:回归系数β的显著性检验(t-检验);回归 方程显著性检验(F-检验)。 二、试验原理 1.相关分析的统计学原理 相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson简单相关系数。 2.回归分析的统计学原理 相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数与模型进行检验与判断,并进行预测等。 线性回归数学模型如下: y i 01x i12x i2k x i k i 在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数: ???? y i 0 1x i12x i2k x i k e i 回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释
第十一章线性相关分析与线性回归分析 11.1 两个变量之间的线性相关分析 相关分析是在分析两个变量之间关系的密切程度时常用的统计分析方法。最简单的相关分析是线性相关分析,即两个变量之间是一种直线相关的关系。相关分析的方法有很多,根据变量的测量层次不同,可以选择不同的相关分析方法。总的来说,变量之间的线性相关关系分为三种。一是正相关,即两个变量的变化方向一致。二是负相关,即两个变量的变化方向相反。三是无相关,即两个变量的变化趋势没有明显的依存关系。两个变量之间的相关程度一般用相关系数r 来表示。r 的取值范围是:-1≤r≤1。∣r∣越接近1,说明两个变量之间的相关性越强。∣r∣越接近0,说明两个变量之间的相关性越弱。相关分析可以通过下述过程来实现: 11.1.1 两个变量之间的线性相关分析过程 1.打开双变量相关分析对话框 执行下述操作: Analyze→Correlate(相关)→Bivariate(双变量)打开双变量相关分析对话框,如图11-1 所示。 图11-1 双变量相关分析对话框 2.选择进行相关分析的变量 从左侧的源变量窗口中选择两个要进行相关分析的变量进入Variable 窗口。 3.选择相关系数。 Correlation Coefficient 是相关系数的选项栏。栏中提供了三个相关系数的选项:(1)Pearson:皮尔逊相关,即积差相关系数。适用于两个变量都为定距以上变量,且两个
变量都服从正态分布的情况。这是系统默认的选项。 (2)Kendall:肯德尔相关系数。它表示的是等级相关,适用于两个变量都为定序变量的情况。 (3)Spearman:斯皮尔曼等级相关。它表示的也是等级相关,也适用于两个变量都为定序变量的情况。 4.确定显著性检验的类型。 Test of Significance 是显著性检验类型的选项栏,栏中包括两个选项: (1)Two-tailed:双尾检验。这是系统默认的选项。 (2)One-tailed:单尾检验。 5.确定是否输出相关系数的显著性水平 Flag significant Correlations:是标出相关系数的显著性选项。如果选中此项,系统在输出结果时,在相关系数的右上方使用“*”表示显著性水平为0.05;用“**”表示显著性水平为0.01。 6. 选择输出的统计量 单击Options 打开对话框,如图11-2 所示。 图11-2 相关分析选项对话框 (1)Statistics 是输出统计量的选项栏。 1)Means and standard deviations 是均值与标准差选项。选择此项,系统将在输出文件中输出均值与标准差。 2)Cross- product deviations and covariances 是叉积离差与协方差选项。选择此项,系统将在输出文件中输出每个变量的离差平方和与两个变量的协方差。 上述两项选择只有在主对话框中选择了Pearson:皮尔逊相关后,计算结果才有价值。 (2)缺失值的处理办法 Missing Valuess 是处理缺失值的选项栏。 1)Exclude cases pairwise 是成对剔除参与相关系数计算的两个变量中有缺失值的个案。2)Exclude cases listwise 是剔除带有缺失值的所有个案。 上述选项做完以后,单击Continue 按钮,返回双变量相关分析对话框。 8.单击OK 按钮,提交运行。系统在输出文件窗口中输出相关分析的结果。 11.1.2 两个变量之间的线性相关分析实例分析
第七章 相关回归分析 皮尔逊线性相关系数计算的基本公式: (简捷法) ])(][)([(积差法)22222∑∑∑∑∑∑∑--- ==y y n x x n y x xy n s s s y x xy γ 简单线性回归方程式为:bx a y c +=, 式中c y 是y 的估计值,a 代表直线在y 轴上的截距,b 表示直线的斜率,又称为回归系数。回归系数的涵义是,当自变量x 每增加一个单位时,因变量y 的平均增加值。 当b 的符号为正时,表示两个变量是正相关,当b 的符号为负时,表示两个变量是负相关。a 、b 都是待定参数,可以用最小平方法求得。 求解a 、b 的公式为: ∑∑∑∑∑--=22) (x x n y x xy n b ; n x b n y a ∑∑-= 相关系数与回归系数之间具有以下的关系: x y s s r b = (一) 填空题 1.在相关关系中,把具有因果关系相互联系的两个变量中起影响作用的变量称为_______,把另一个说明观察结果的变量称为________。 2.现象之间的相关关系按相关的程度分有________相关、________相关、________相关和_______相关;按相关的方向分有________相关和______ _相关;按影响因素的多少分有________相关和________相关。 3.对现象之间变量关系的研究中,对于变量之间相互关系密切程度的研究,称为_______;研究变量之间关系的方程式,根据给定的变量数值以推断另一变量的可能值,则称为_______。 4.完全相关即是________关系,其相关系数为________。 5.相关系数的变动范围介于_______与_______之间,其绝对值愈接近于_______,两个变量之间线性相关程度愈高;愈接近于_______,两个变量之间线性相关程度愈低。当_______时表示两变量正相关;_______时表示两变量负相关。 6.当变量x 值增加,变量y 值也增加,这是________相关关系;当变量x 值减少,变量y 值也减少,这是________相关关系。 7.已知13600))((=----∑y y x x ,14400)(2=--∑x x ,14900)(2 =-∑-y y ,那么,x 和y 的相关系数r 是_______。 8.已知1502=xy s ,18=x s ,11=y s ,那么变量x 和y 的相关系数r 是_______。 9.已知直线回归方程bx a y c +=中,5.17=b ;又知30=n , ∑=13500y ,12=- x , 则可知_______=a 。
第七章 相关分析与回归分析 (3)当固定资产改变200万元时,总产值平均改变多少?(4)当固定资产为1300万元时,总产值为多少? (1)协方差——用以说明两指标之间的相关方向。 2 2))((n y x xy n n y y x x xy ∑∑∑∑-= --=σ 035.126400100 9801 6525765915610>=?-?= 计算得到的协方差为正数,说明固定资产和总产值之间存在正相关关系。 (2)相关系数用以说明两指标之间的相关方向和相关的密切程度。 ∑∑∑∑∑∑∑---= ] )(][)([2222y y n x x n y x xy n r
95.0) 98011086657710()6525566853910(9801 65257659156102 2 =-??-??-?= 计算得到的相关系数为0.95,表示两指标为高度正相关。 (3) 2 226525 5668539109801 6525765915610)(-??-?=--= ∑∑∑∑∑x x n y x xy n b 90.014109765 12640035 42575625566853906395152576591560==--= 85.39210 6525 9.0109801=?-= -=x b y a 回归直线方程为: x y 9.085.392?+= (4)当固定资产改变200万元时,总产值平均改变多少? x y ?=?9.0,1802009.0|200=?=?=?x y 万元 当固定资产改变200万元时,总产值平均增加180万元。 (5)当固定资产为1300万元时,总产值为多少? 85.156213009.085.392|1300=?+==x y 万元 当固定资产为1300万元时,总产值为1562.85万元。 例2、试根据下列资产总值和平均每昼夜原料加工量资料计算相关系数。 解:【分析】本题中“企业数”应看成资产总值和平均每昼夜原料加工量两变量的次数,在计算相关系数的过程,要进行“加权”。
第三节 多元线性相关与回归分析 一、标准的多元线性回归模型 上一节介绍的一元线性回归分析所反映的是1个因变量与1个自变量之间的关系。但是,在现实中,某一现象的变动常受多种现象变动的影响。例如,消费除了受本期收入水平的影响外,还会受以往消费和收入水平的影响;一个工业企业利润额的大小除了与总产值多少有关外,还与成本、价格等有关。这就是说,影响因变量的自变量通常不是一个,而是多个。在许多场合,仅仅考虑单个变量是不够的,还需要就一个因变量与多个自变量的联系来进行考察,才能获得比较满意的结果。这就产生了测定与分析多因素之间相关关系的问题。 研究在线性相关条件下,两个和两个以上自变量对一个因变量的数量变化关系,称为多元线性回归分析,表现这一数量关系的数学公式,称为多元线性回归模型。多元线性回归模型是一元线性回归模型的扩展,其基本原理与一元线性回归模型相类似,只是在计算上比较麻烦一些而已。限于本书的篇幅和程度,本节对于多元回归分析中与一元回归分析相类似的内容,仅给出必要的结论,不作进一步的论证。只对某些多元回归分析所特有的问题作比较详细的说明。 多元线性回归模型总体回归函数的一般形式如下: t kt k t t u X X Y ++?++=βββ221 (7.51) 上式假定因变量Y 与(k-1)个自变量之间的回归关系可以用线性函数来近似反映.式中,Y t 是变量Y 的第t个观测值;X jt 是第j 个自变量X j 的第t个观测值(j=1,2,……,k);u t 是随机误差项;β1,β2,… ,βk 是总体回归系数。βj 表示在其他自变量保持不变的情况下,自变量X j 变动一个单位所引起的因变量Y 平均变动的数额,因而又叫做偏回归系数。该式中,总体回归系数是未知的,必须利用有关的样本观测值来进行估计。 假设已给出了n个观测值,同时1?β,2?β…,k β?为总体回归系数的估计,则多元线性回 归模型的样本回归函数如下: t kt k t t e X X Y ++?++=βββ???221 (7.52) (t =1,2,…,n) 式中,e t 是Y t 与其估计t Y ?之间的离差,即残差。与一元线性回归分析相类似,为了进 行多元线性回归分析也需要提出一些必要的假定。多元线性回归分析的标准假定除了包括上一节中已经提出的关于随机误差项的假定外,还要追加一条假定。这就是回归模型所包含的自变量之间不能具有较强的线性关系,同时样本容量必须大于所要估计的回归系数的个数即n >k 。我们称这条假定为标准假定6。 二、多元线性回归模型的估计 (一)回归系数的估计 多元线性回归模型中回归系数的估计同样采用最小二乘法。设 ∑-=∑=22)?(t t t Y Y e Q 2221)???(kt k t t X X Y βββ-?--∑= (7.53) 根据微积分中求极小值的原理,可知残差平方和Q存在极小值,欲使Q达到最小,Q对1?β、2?β…,k β?的偏导数必须等于零。将Q对1?β、2?β…,k β?求偏导数,并令其等于零,加以整理后可得到以下k个方程式: ∑=∑+?+∑+t kt k t Y X X n βββ???221 ∑=∑+?+∑+∑t t kt t k t t Y X X X X X 2222221???βββ (7.54)
第七章相关与回归分析习题 一、填空题 1、客观现象之间的数量联系有两种不同的类型:一种函数关系;另一种是相关关系。 2、现象之间是否存在相关关系是进行相关与回归分析的基础,其主要测定方法是计算相关系数。 3、若估计标准误差愈小,则根据直线回归方程计算的估计值就越能代表实际值。 4、对某实验结果做线性回归分析,得到形如y=a+bx的方程,现对回归系数b做显著性检验,该假设检验中原假设为 H0:b=0 ,备择假设为 H1:b≠0 ,若拒绝原假设,则认为 x 对y有显著的影响。 二、选择题 单选题: 1、相关分析对资料的要求是((1)) (1)两变量均为随机的(2)两变量都不是随机的 (3)自变量是随机的,因变量不是随机的 (4)因变量是随机的,自变量不是随机的 2、回归方程Y=a+bx中的回归系数b说明自变量变动一个单位时,因变量((4)) (1)变动a+b个单位(2)变动1/b个单位 (3)变动b个单位(4)平均变动b个单位 3、相关系数r的取值范围((2)) (1)-∞ 用下面的数据做相关分析和一元线性回归分析: 选用普通高等学校毕业生数和高等学校发表科技论文数量做相关分析和一元线性回归分析。 一、相关分析 1.作散点图 普通高等学校毕业生数和高等学校发表科技论文数量的相关图 从散点图可以看出:普通高等学校毕业生数和高等学校发表科技论文数量的相关性很大。 2.求普通高等学校毕业生数和高等学校发表科技论文数量的相关系数 把要求的两个相关变量移至变量中,因为都是定距数据,选择相关系数中的Pearson,点击确定,可以得到下面的结果: Correlations 普通高等学校毕业生数(万人) 高等学校发表科技论文数量(篇) 普通高等学校毕业生数(万人) Pearson Correlation 1 .998** Sig. (2-tailed) .000 N 14 14 高等学校发表科技论文数量(篇) Pearson Correlation .998** 1 Sig. (2-tailed) .000 N 14 14 **. Correlation is significant at the level (2-tailed). 两相关变量的Pearson相关系数=,表示呈高度正相关;相关系数检验对应的概率P值=,小于显着性水平,应拒绝原假设(两变量之间不具有相关性),即毕业生人数好发表科技论文数之间的相关性显着。 3.求两变量之间的相关性 选择相关系数中的全部,点击确定: Correlations (万人) (篇) Kendall's tau_b (万人) Correlation Coefficient ** Sig. (2-tailed) . . N 14 14 (篇) Correlation Coefficient ** Sig. (2-tailed) . . N 14 14 Spearman's rho (万人) Correlation Coefficient ** Sig. (2-tailed) . . N 14 14 (篇) Correlation Coefficient ** Sig. (2-tailed) . . N 14 14 **. Correlation is significant at the level (2-tailed). 注解:两相关变量(毕业生数和发表论文数)的Kendall相关系数=,呈正相关;无相关系数检验对应的概率P值,应接受原假设(两变量之间不具有相关性),即毕业生数与发表论文数之间相关性不显着。 两相关变量(毕业生数和发表论文数)的Spearman相关系数=,呈正相关;无相关系数检验对应的概率P值,应接受原假设(两变量之间不具有相关性),即毕业生数与发表论文数之间相关性不显着。 4.普通高等学校毕业生数和高等学校发表科技论文数量的相关系数 将所求变量移至变量,将控制变量移至控制中,选中显示实际显着性水平,点击确定: Correlations 普通高等学校毕业生数(万人) 高等学校发表科技论文数量(篇) 普通高等学校毕业生数(万人) Pearson Correlation 1 .998** Sig. (2-tailed) .000 N 14 14相关分析和一元线性回归分析SPSS报告
相关主题
文本预览