分析报告(一)
实验项目:统计量描述实验日期:2012-3-16 实验地点:8教80680实验目的:熟悉描述性统计量的类型划分及作用;准确理解各种描述性统计量的构造原理;熟练掌握计算描述性统计量的SPSS 操作;培养运用描述统计方法解决身边实际问题的能力。
实验内容:(1):分析被调查者的户口和收入的基本情况
(2):分析储户存款金额的分布情况
(3):计算存款金额的基本描述统计量,并对城镇和农村户口进行比较分析
(4):分析储户存款数量是否存在不均衡现象
实验步骤:analysze—Descriptive statistics-- Frequencies
实验结果
:
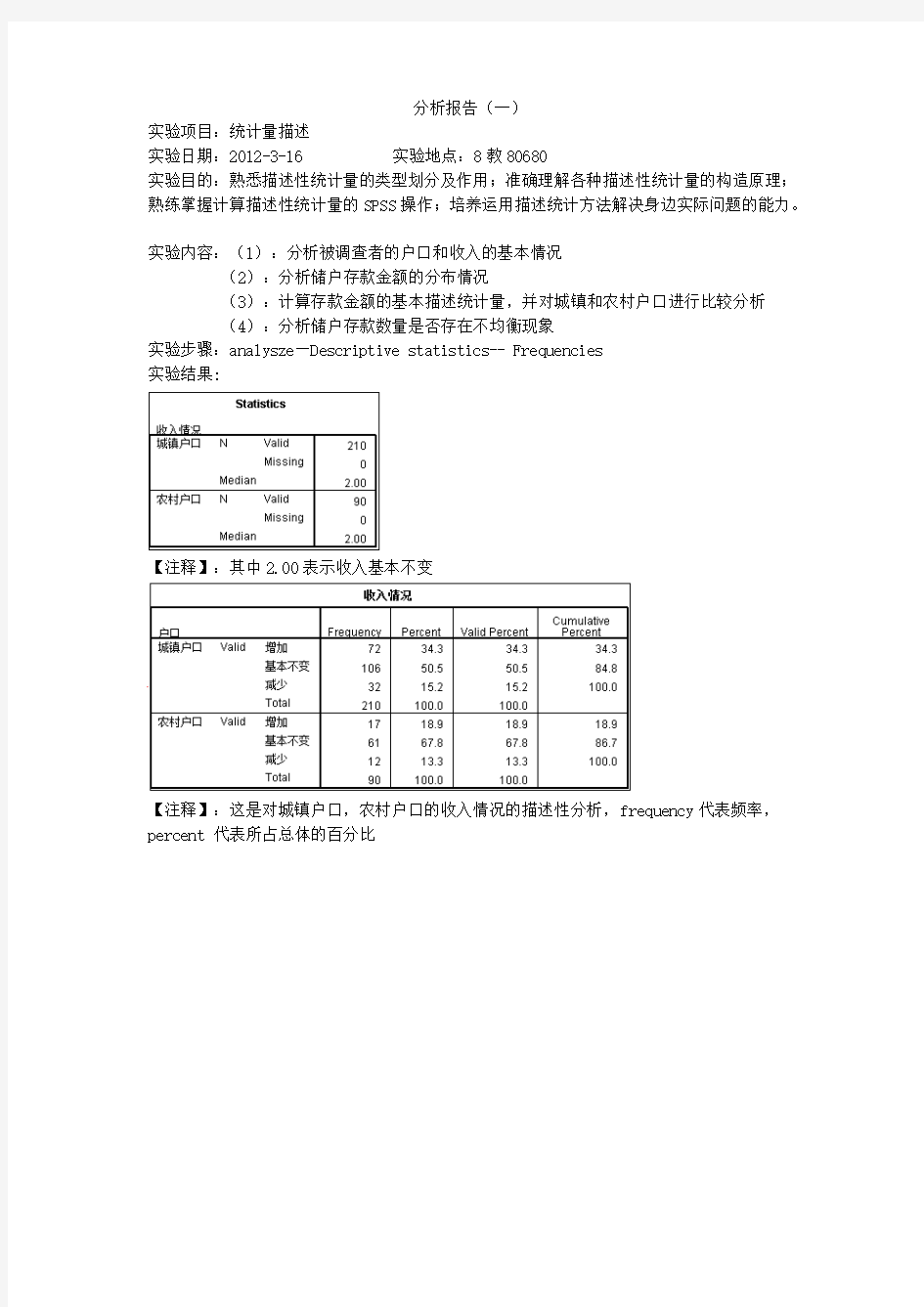
【注释】:其中2.00
表示收入基本不变
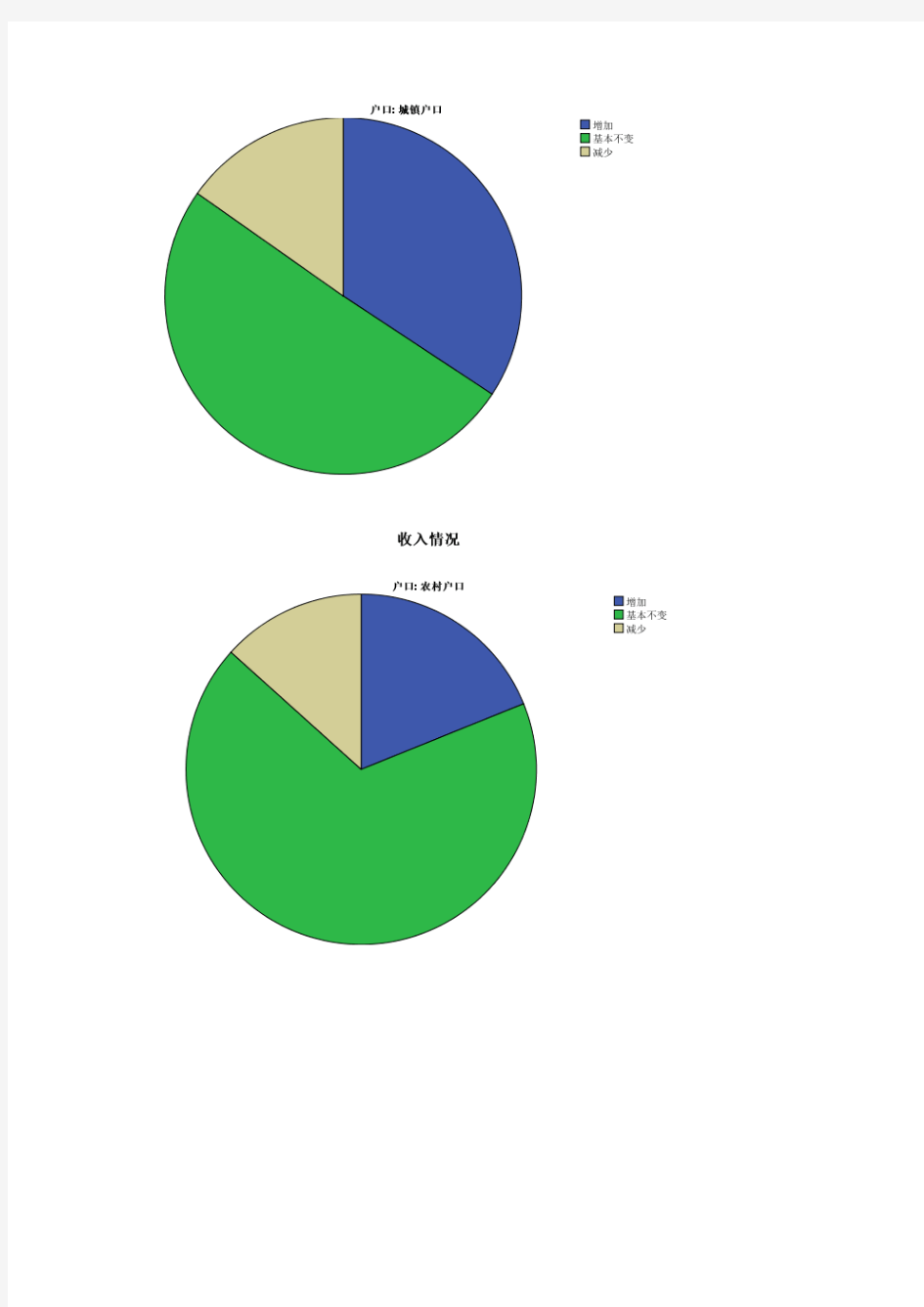
【注释】:这是对城镇户口,农村户口的收入情况的描述性分析,frequency 代表频率,percent 代表所占总体的百分比
【注释】:这是对存款金额的描述性分析,最小值是1,最大值是80502,均值是2454.27,标准差是6881.827,标准误是
0.141
【注释】:本表描述的是城镇户口和农村户口的最小值,最大值,均值,标准差,标准误。实验分析:(一)、总体看来,城镇户口和农村户口的收入情况:基本不变占据很大比例,说明经济发展较稳定(二)、城镇户口的收入增加所占的比例为34.3%,远超过农村户口的18.9%,说明农村的发展相较于城镇,还有很大的发展空间。(三)、存款金额最大值
(80502)和最小值(1)之间差距过大,说明贫富差距过大,从长远角度来看,不利于经济的发展,我们国家也有出台一些减小贫富差距的政策,加快城镇化建设之类的。实验小结:
备注:
分析报告(二)姓名:李懿帆 班级:统计2班 学号:2010101213实验项目:单样本t 检验实验日期:2012-3-23 实验地点:8教80680实验目的:准确掌握单样本t 检验的方法原理;熟练掌握单样本t 检验的SPSS 操作;学会利用单样本t 检验方法解决身边的实际问题实验内容:(1):某银行居民的平均存款与2500在95%的置信度下是否具有显著性差异 (2):求某银行居民的平均存款在95%的置信度下的置信区间实验步骤:analysze—Compare Means—One-Sample T Test 实验结果
:【注释】:这是该银行居民存款的描述性分析,包括有平均值=2454.27(千元),标准差=6881.827,均值的标准误差
=397.322
【注释】:单样本的检验结果是t 检验统计量:-.115,自由度df=299,双侧概率p 值大于显著性水平0.05,不应该拒绝原假设,即居民的平均存款与2500在95%的置信度下不存在显著性差异居民的平均存款在95%的置信度下的置信区间:为[2500-827.63,2500+736.17]实验分析:在95%的保证水平下,该银行居民的平均存款在2500元左右。实验小结:备注:分析报告(三)
姓名:李懿帆 班级:统计2班 学号:2010101213
实验项目:两个独立样本t 检验
实验日期:2012-3-30 实验地点:8教80680
实验目的:准确掌握两个独立样本t 检验的方法原理;熟练掌握两个独立样本t 检验的SPSS 操作;学会利用两个独立样本t 检验方法解决身边的实际问题
实验内容:(1):在95%的置信度下某银行城镇和农村户口的平均存款是否具有显著性差
异
(2):求某银行居民城镇和农村户口的平均存款差的置信度为95%的置信区间实验步骤:analysze—Compare Means—Independent-Samples T Test
实验结果:
【注释】:这是关于两独立样本T 检验的基本描述统计量,其中分别为样本量,均值,标
准差,均值的标准误
【注释】:这是关于两独立样本T 检验的检验结果。首先,利用F 检验对两总体方差是否相等的检验:Levene 检验的F 值=0.729,对应的P 值(sig )0.394,概率p 值大于显著性水平0.05,不应该拒绝原假设,即:两总体(城镇户口和农村户口)方差相等,通过了Levene 方差齐性检验。其次,利用t 检验对两总体均值差是否存在显著性差异的检验,t 统计量值为0.928,对应的双侧概率p 值为0.354,概率p 值大于显著性水平0.05,不应该拒绝原假设,即两总体(城镇户口和农村户口的平均存款)均值差不存在显著性差异。两个总体均值差的置信度为95%的置信区间为[-901.713,2511.627],该置信区间包含0,也说明两总体均值差不存在显著性差异。自由度为298,t 统计量的分子----两个总体均值差的均值,分母为两个总体均值差的标准误差实验分析:有一表可以得出,城镇户口和农村户口的平均存款存在较大的差异,而且农村户口的平均存款分布波动性很大,由其标准差可以看出。二表可以看出城镇户口和农村户口的平均存款均值差不存在显著性差异。实验小结:备注:分析报告(四)
姓名:李懿帆 班级:统计2班 学号:2010101213
实验项目:配对样本t 检验
实验日期:2012-3-30 实验地点:8教80680
实验目的:准确掌握配对样本t 检验的方法原理;熟练掌握配对样本t 检验的SPSS 操作;学会利用配对样本t 检验方法解决身边的实际问题
实验内容:(1):在95%的置信度下锻炼前后女性的平均体重是否具有显著性差异
(2):试求锻炼前后女性的平均体重差的置信度为95%的置信区间
实验步骤:analysze—Compare Means—Paired-Sample T Test
实验结果:
【注释】:这是35位女性锻炼前、后体重的描述性分析,包括有平均值分别为
89.2571,70.0286,标准差分别为5.33767,5.66457,均值的标准误差分别为
0.90223,
0.95749.
【注释】:两配对样本T 检验的相关分析,这是35位女性锻炼前、后体重的描述性分析,其中两者的相关系数为0.052,P 值(sig )0.768,概率p 值大于显著性水平0.05,不应该拒绝原假设,即锻炼前后体重不存在显著性差异
包括:相关系数和检验的概率P 值。这两个变量的相关系数=0.520,根据直观的分析,说明二者具的线性相关;对相关系数进行显著性检验,其概率P 值
=0.768
【注释】:两配对样本T 检验的主要结果,分别是:
两配对样本的平均差值;锻炼前体重和锻炼后体重平均差19.2286;
差值的标准差为7.98191;
差值的均值标准误差为1.34919;
置信度为95%的差值的置信区间为[16.4867,21.9705];
T 统计量14.252;自由度为34;
双侧概率P 值=0
实验分析:
实验小结:
备注:
分析报告(五)
姓名:李懿帆 班级:统计2班 学号:2010101213
实验项目:单因素方差分析
实验日期:2012-4-6 实验地点:8教80680
实验目的:1、掌握单因素方差分析的基本理论和基本步骤
2、熟练掌握单因素方差分析的SPSS 操作
3、能够利用单因素方差分析工具解决身边的实际问题
实验内容:某企业为了制定某商品的广告策略,对18个地区和4种不同广告形式的商品销售额分别进行单因素的方差分析
(1):不同地区的销售额是否有显著性差异
(2):不同广告形式的销售额是否有显著性差异
实验步骤:analysze—Compare Means----One-way ANOVA
实验结果:
(1
):不同地区的销售额是否有显著性差异
方差齐性检验【注释】:方差齐性检验结果, Levene 统计量值为1.459,对应的p 值为0.121,大于显著性水平0.05,不应该拒绝原假设,即认为不同地区的销售额的总体方差无显著性差异,
满足方差分析的前提条件。
【注释】:不同地区对销售额单因素方差分析结果:
观测变量销售额的总离差平方和为26169.306;其中,不同地区对销售额产生的(组间)离差平方和为9265.306,对应的方差为545.018;抽样误差所引起的(组内)离差平方和为16904,对应的方差为134.159,F 统计量为组间离差平方和对应的方差/组内离差平方和对应的方差=4.062,F 统计量对应的概率p 值为0.00,小于显著性水平0.05,则应拒绝原假设,认为不同地区对销售额产生了显著性影响,或不同地区对销售额的影响效应不全为0。
【注释】:18个不同地区的销售额均值的折线图;
根据上面的单因素方差分析的基本分析得出,控制变量(地区)对因变量(销售额)产生
了显著性影响。
【注释】:上图是多重比较,第一、二列分别是不同地区销售额的均值差和标准误,相除得检验统计量的观测值。第四、五列是不同地区销售额均值差的95%的置信区间上、下限,第三列为检验统计量的p值
城市1和城市2的概率p值为0.451,大于显著性水平0.05,说明城市1和城市2的销售额均值不具有显著性差异。(城市1和城市3,4…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市2和城市3的概率p值为0.005,小于显著性水平0.05,说明城市2和城市3的销售额均值具有显著性差异。(城市2和城市4…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市3和城市4的概率p值为0.763,大于显著性水平0.05,说明城市3和城市4的销售额均值不具有显著性差异。(城市3和城市5…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市4和城市5的概率p值为0.255,小于显著性水平0.05,说明城市4和城市5的销售额均值具有显著性差异。(城市4和城市6…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市5和城市6的概率p值为0.283,大于显著性水平0.05,说明城市5和城市6的销售额均值不具有显著性差异。(城市5和城市7…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市6和城市7的概率p值为0.19,大于显著性水平0.05,说明城市6和城市7的销售额均值不具有显著性差异。(城市6和城市8…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市7和城市8的概率p值为0.013,小于显著性水平0.05,说明城市7和城市8的销售额均值具有显著性差异。(城市7和城市9…18,如果p值大于0.05,则说明这两个城市
销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市8和城市9的概率p值为0.007,小于显著性水平0.05,说明城市8和城市9的销售额均值具有显著性差异。(城市8和城市10…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市9和城市10的概率p值为0.001,小于显著性水平0.05,说明城市9和城市10的销售额均值具有显著性差异。(城市9和城市11…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市10和城市11的概率p值为0.000,小于显著性水平0.05,说明城市10和城市11的销售额均值具有显著性差异。(城市10和城市12…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市11和城市12的概率p值为0.003,小于显著性水平0.05,说明城市11和城市12的销售额均值具有显著性差异。(城市11和城市13…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市12和城市13的概率p值为0.636,大于显著性水平0.05,说明城市1和城市2的销售额均值不具有显著性差异。(城市12和城市14…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市13和城市14的概率p值为0.620,大于显著性水平0.05,说明城市1和城市2的销售额均值不具有显著性差异。(城市13和城市15…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市14和城市15的概率p值为0.620,大于显著性水平0.05,说明城市1和城市2的销售额均值不具有显著性差异。(城市14和城市16…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市15和城市16的概率p值为0.698,大于显著性水平0.05,说明城市1和城市2的销售额均值不具有显著性差异。(城市15和城市17…18,如果p值大于0.05,则说明这两个城市销售额均值不具有显著性差异,如果小于0.05,则说明这两个城市销售额均值具有显著性差异。)
城市16和城市17的概率p值为0.009,小于显著性水平0.05,说明城市16和城市17的销售额均值具有显著性差异。
城市16和城市18概率p值为0.88,大于显著性水平0.05,说明这两个城市销售额均值不具有显著性差异。
城市17和城市18概率p值为0.014,小于显著性水平0.05,说明这两个城市销售额均值具有显著性差异。
将显示同类子集中的组均值,将使用调和均值样本大小为8,
【注释】:多重比较的相似性子集划分,形成了5个相似性子集,说明了5组的均值有显著性差异,而组内的相似性概率分别为0.129,0.058,0.066,0.058,0.167,若从销售额的角度来选择城市,则城市11是销售额最低的。
(2
):不同广告形式的销售额是否有显著性差异
方差齐性检验
【注释】:方差齐性检验结果, Levene 统计量值为0.765,对应的p 值为0.515,大于显著性水平0.05,不应该拒绝原假设,即认为不同广告形式的销售额的总体方差无显著性差异,满足方差分析的前提条件。卷弯扁,审某些异
【注释】:不同广告形式对销售额单因素方差分析结果:
观测变量销售额的总离差平方和为26169.306;其中,不同广告形式对销售额产生的(组间)离差平方和为5866.083,对应的方差(均方)为1955.361;抽样误差所引起的(组内)离差平方和为20303.222,对应的方差为145.023,F 统计量为组间离差平方和对应的方差/组内离差平方和对应的方差=13.483,F 统计量对应的概率p 值为0.00,小于显著性水平0.05,则应拒绝原假设,认为不同广告形式对销售额产生了显著性影响,或不同地区对销售额的影响效应不全为0
。
【注释】:4个不同广告的销售额均值的折线图;
根据上面的单因素方差分析的基本分析得出,控制变量(地区)对因变量(销售额)产生了显著性影响。
本科生实验报告 实验课程统计学 学院名称商学院 专业名称会计学 学生姓名苑蕊 学生学号0113 指导教师刘后平 实验地点成都理工大学南校区 实验成绩 二〇一五年十月二〇一五年十月
依据上述资料编制组距变量数列,并用次数分布表列出各组的频数和频率,以及向上、向下累计的频数和频率, 并绘制直方图、折线图。 学生 实验 心得
2.已知2001-2012年我国的国内生产总值数据如表2-16所示。 学生 实验 心得 要求:(1)依据2001-2012年的国内生产总值数据,利用Excel软件绘制线图和条形图。
(2)依据2012年的国内生产总值及其构成数据,绘制环形图和圆形图。 学生 实验 心得 3.计算以下数据的指标数据 1100 1200 1200 1400 1500 1500 1700 1700 1700 1800 1800 1900 1900 2100 2100 2200 2200 2200 2300 2300 2300 2300 2400 2400 2500 2500 2500 2500 2600 2600 2600 2700 2700 2800 2800 2800 2900 2900 2900 3100 3100 3100 3100 3200 3200 3300 3300 3400 3400 3400 3500 3500 3500 3600 3600 3600 3800 3800 3800 4200
4.一家食品公司,每天大约生产袋装食品若干,按规定每袋的重量应为100g。为对产品质量进行检测,该企业质检部门采用抽样技术,每天抽取一定数量的食品,以分析每袋重量是否符合质量要求。现从某一天生产的一批食品8000袋中随机抽取了25袋(不重复抽样),测得它们的重量分别为: 学生实验心得 101 103 102 95 100 102 105 已知产品重量服从正态分布,且总体方差为100g。试估计该批产品平均重量的置信区间,置信水平为95%.
实验二用EXCEL计算描述统计量 一. 实验目的: 1.掌握Excel中基本的数据处理方法; 2.学会使用Excel进行统计分组,能以此方式独立完成相关作业。 二.实验要求: 1.已学习教材相关内容,理解数据整理中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2.准备好一个统计分组问题及相应数据(可用本实验导引所提供问题和数据)。三.实验内容: 1.熟练运用进行统计分组。 2.了解Excel的图表功能:创建图表、增强图表; 四. 实验步骤 1. 按照题目把数据输入excel中,如下图所示。 2.制作频数(率)分布表,如下面两个图所示。
3.根据频数(率)分布表在分别制作直方图,折线图和曲线图,如下三个图所示。
实验五用EXCEL进行假设检验 一.实验目的:用EXCEL进行参数估计和假设检验 二.实验步骤: 在EXCEL中,进行参数估计只能使用公式和函数的方法,而假设检验除以上两种方法外,还可以使用假设检验工具。 1、假设检验公式 ⑴构造工作表。如图所示,首先在各个单元格输入以下内容,其中左边是变量名,右边是相应的计算公式。
数据可使用实验三的样本数据 ⑵将A列的名称定义成为B列各个公式计算结果的变量名。选定A3:B4,A6:B8, A10:B11,A13:B15和A17:B19单元格,选择“公式”菜单的“定义的名称”子菜单的“根据所选内容创建”选项,用鼠标点击“最左列”,点击“确定”按钮即可。如下图所示: ⑶输入样本数据,以及总体标准差、总体均值假设、置信水平数据。 ⑷为样本数据指定名称。选定C1:C11单元格,选择“公式”菜单的“定义的名
华东理工大学2016–2017学年第二学期 《多元统计学》实验报告 实验名 称实验1数据整理与描述统计分析
教师批阅:实验成绩: 教师签名: 日期: 实验报告正文: 实验数据整理 (一)对“employee”进行数据整理 1.观察量排序 ( based on current salary) 2.变量值排序(based on current salary : rsalary) 3.计算新的变量(incremental salary=current salary - beginning salary)
4.拆分数据文件(based on gender) 结论:There are 215 female employees and 259 male employees. 5.分类汇总 (break variable: gender ; function: mean ) 结论:The average current salary of female is . The average current salary of male is . (二)分别给出三种工作类别的薪水的描述统计量 实验描述统计分析 1)样本均值矩阵 结论:总共分析六组变量,每组含有十个样本。 每股收益(X1)的均值为;净资产收益率(X2)的均值为;总资产报酬率(X3)的均值为;销售净
利率(X4)的均值为;主营业务增长率(X5)的均值为;净利润增长率(X6)的均值为. 2)协方差阵 结论:矩阵共六行六列,显示了每股收益(X1)、净资产收益率(X2)、总资产报酬率(X3)、销售净利率(X4)、主营业务增长率(X5)和净利润增长率(X6)的协方差。 3)相关系数 结论:矩阵共六行六列,显示了每股收益 (X1)、净资产收益率(X2)、总资产报酬 率(X3)、销售净利率(X4)、主营业务增 长率(X5)和净利润增长率(X6)之间的 相关系数。 每格中三行分别显示了相关系数、显著性 检验与样本个数。 4)矩阵散点图
软件工程实验报告 姓名:冯巧 学号 实验题目:实验室设备管理系统 1、系统简介: 每天对实验室设备使用情况进行统计,对于已彻底损坏的作报废处理,同时详细记录有关信息。对于有严重问题(故障)的要即时修理,并记录修理日期、设备名、修理厂家、修理费用、责任人等。对于急需但又缺少的设备需以“申请表”的形式送交上级领导请求批准购买。新设备购入后立即对新设备登记(包括类别、设备名、型号、规格、单价、数量、购置日期、生产厂家、购买人等),同时更新申请表的内容。 2、技术要求及限定条件: 采用C#语言设计桌面应用程序,同时与数据库MySql进行交互。系统对硬件的要求低,不需要网络支持,在单机环境下也能运行,在局域网环境下也能使用。方案实施相对容易,成本低,工期短。 一:可行性分析 1、技术可行性分析 计算机硬件设备,数据库,实验室设备管理软件与实验室设备管理系统的操作人员组成,能够实现实验室设备管理的信息化,提高工作效率,实现现代化的实验室设备管理。系统需要满足实验室设备管理(包括对实验设备的报废、维修和新设备的购买)、实验室设备信息查询(包括按类别进行查询和按时间进行查询)、实验室设备信息统计报表(包括对已报废设备的统计、申请新设备购买的统计和现有设备的统计)。这些功能框图如下图所示: 2、经济可行性分析 依据用户的现实需求、技术现状、经济条件、工期以及其他局限性因素等等因素,考虑到工期的长短、技术的成熟可靠、操作方便等因素,本方案具备经济可行性。
3、系统可选择的开发方案 ①方案A用C#开发系统的特点是:开发工具与数据库集成一体,可视化,开发速度较快,但数据库能够管理的数据规模相对较小。系统对硬件的要求低,不需要网络支持,在单机环境下也能运行,在局域网环境下也能使用。方案的实施相对容易,成本低,工期短。 ②方案B:以小型数据库管理系统为后台数据库,该前台操作与数据库分离,也能够实现多层应用系统。系统对硬件的要求居中,特别适合在网络环境下使用,操作方便。但系统得实现最复杂,成本最高,工期也较长。 二:软件需求分析 1.软件系统需求基本描述: 实验室设备管理系统是现代企业资源管理中的一个重要内容,也是资源开发利用的基础性工作。实验室设备在信息化之前,在用户系统管理、设备维修管理、设备的增删改查管理等方面存在诸多不利于管理的地方,不适应现代的企业管理形势和资源的开发利用。 2.软件系统数据流图(由加工、数据流、文件、源点和终点四种元素组成): 1)顶层数据流图 2)二层流程图 3)总数据流图
信息与电气工程学院HIS信息系统详细分析报告(2016/2017学年第一学期) 题目: HIS信息系统详细分析 __ 专业班级:信息1401 姓名:谭玉龙 指导教师:崔东 设计周数: 设计成绩: 2016年12月8日
一、实验目的 1.详细分析个系统的详细内容,具体功能和相应流程图 二、具体内容 一、门诊管理系统 挂号系统 1、系统特点 ●提高医院工作效率,减轻工作人员的劳动强度,缩短患者 排队挂号的等候时间 ●支持多种挂号方式(随时挂号、电话预约挂号、磁卡/IC 卡自动挂号、网上预约挂号) ●支持各种身份的患者挂号(自费、公费、合同单位、医保) ●患者初诊的门诊号自动保存,方便患者复诊时基本信息及 上次就诊信息的快速查询调用 ●支持患者选择医生 ●可以对所有就诊患者的地域来源进行统计分析,服务于医 院的经营决策 ●实时快速准确的工作量统计 2、功能简介 ●日常挂号业务 ●预约挂号业务 ●专家门诊时间安排及专家限号功能
●患者挂号、退号、修改、转科业务 ●各种数据维护功能 ●挂号工作人员财务交款 3、查询统计 ●门诊患者挂号明细查询 ●门诊挂号科室工作量统计 ●门诊挂号费用收入统计 ●全院门诊量分科室统计 ●全院门诊量分类别统计 ●医生(专家)挂号量统计 ●就诊患者区域来源分布统计分析 4、业务流程图 图一:挂号业务流程路
收费系统 1、系统特点 ●支持划价、收费于一体和划价、收费分开两种业务工作模 式 ●各种费用同一窗口录入(西药处方,中药处方,检查化验 单等),根据价表自动划价 ●支持套餐和协定处方录入 ●支持病人信息IC卡存储及读取 ●支持多种结算方式,结算比例,同时提供结算比例的自定 义功能 ●与门诊药房库存关联,实现实时无药报警 ●支持与医生工作站,医技科室工作站联网,实现医生处方 的接收和信息传递 ●支持门诊患者费用明细清单的打印 ●具有前屏显示功能,通过语音和屏幕显示患者应收,实收, 找零及问候语等信息 ●提供严密的发票管理功能 ●强大的统计报表功能 ●快捷方便的录入方式,全键盘操作,简单易学 2、功能简介 ●划价收费 ●退费功能(处方退费,红方退费,检查单退费),退费权
重庆大学 学生实验报告 实验课程名称统计学课程实验 开课实验室 DS1421 学院建管年级 2011级专业班财管02班学生姓名熊俸英学号 开课时间 2012 至 2013 学年第 2 学期 建设管理及房地产学院制
《统计学》实验报告 开课实验室:年月日
陈谦87769277 刘文55845182 周克66628579 程前75507288 徐非64859193 1)选中以上数据后,复制到excel表格中,点击工具栏中”数据”下“自动筛选”,点击统计学成绩栏分数等于“90”; 结果为: 2)继上一小题,点击“经济学成绩”下“前10个”,会出现对话框,把数字“10”改为“3”,点击确定;
结果为: 3)选中数据,前面留出两栏空白,并复制数据表头(选中数据第一排),到空白处第一排,在第二排各科成绩下面输入“>60”,如图:选中数据,点击“数据”—“高级筛选”,点击条件区 域(选中表格前2行),点击确定: 2.B 组题第5题 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。服务质量的等级分别表示为: A.好;B .较好;C.一般;D.较差;E .差。调查结果如下所示; B C A C B E C B A B D A D B C C E D E B A D B A C B E C B A B A C C D A B D D A C D C E B B C D C C A A C A C C D C E D A E C C A C D A A E B A D E C A B C E B A D A B C B E D B C A B C D C B A B A D 要求编制品质数列,列出频率、频数,并选用适当的统计图如:圆形图、条形图等形象地显示资料整理的结果。(要求展现整理过程) 留出两栏空白,条件区域时输入筛选条件 为查询结
机械制造技术基础实验指导书 同济大学机械工程学院 二00九年十一月
实验一 加工误差统计分析 一、实验目的 1、学会用点图法研究被加工零件尺寸的变化规律和控制被加工零件 尺寸 2、在已调整好的机床上加工一批零件,鉴定该机床的工艺能力。 3、掌握绘制R x -点图的方法,能根据R x -点图分析工艺过程的稳定性,计算工序能力系数等。 二、实验使用的设备和工具 1、机床:斯来福临精密数控平面磨床K-P36 Compact 2、量具:螺旋测微仪、千分仪 三、实验内容 在数控磨床上加工一批零件,依次测量出其高度尺寸,然后绘制被加 工零件尺寸的R x -图,分析被加工零件尺寸的变化规律,从中找出误差的性质和原因,并计算机床的工艺能力系数、确定机床的工艺能力等级。 四、实验原理和方法 在磨床上用磨削45HRC59~62工件一批,做出R x -控制图。 应用数理统计方法对加工误差(或其他质量指标)进行分析,是进行过程控制的一种有效方法,也是实施全面质量管理的一个重要方面。其基本原理是利用加工误差的统计特性,对测量数据进行处理,作出R x -点图,据此对加工误差的性质、工序能力及工艺稳定性等进行识别和判断,进而对加工误差作出综合分析。详见教材相关章节。 1、 R x -图绘制: 1)确定样组容量,对样本进行分组 样组容量一般取m=2~10件,通常取4或5。 按样组容量和加工时间顺序,将样本划分成若干个样组。 2)计算各样组的平均值和极差 对于第i 个样组,其平均值和极差计算公式为: 1 1 n i i j m j x x == ∑,a x i n i i i 式中 i x ——第i 个样组的平均值;
统计学实验报告1 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
实验报告
二、打开文件“数据 3.XLS”中“城市住房状况评价”工作表,完成以下操作。 1)通过函数,计算出各频率以及向上累计次数和向下累计次数;2)根据两城市频数分布数据,绘制出两城市满意度评价的环形图三、打开文件“数据 3.XLS”中“期末统计成绩”工作表,完成以下操作。 1)要求根据数据绘制出雷达图,比较两个班考试成绩的相似情况。 实验过程: 实验任务一: 1)利用函数frequency制作一张频数分布表 步骤1:打开文件“数据 3. XLS”中“某公司4个月电脑销售情况”工作表 步骤 2.在“频率(%)”的右侧加入一列“分组上限”,因统计分组采用“上限不在内”,故每组数据的上限都比真正的上限值小0.1,例如:“140-150”该组的上限实际值应为“150”,但我们为了计算接下来的频数取“149.9”. 步骤3.选定C20:C29,再选择“插入函数”按钮 3 步骤 4.选择类别“统计”—选择函数“FREQUENCY”
步骤5.在“data_array”对话框中输入“A2:I13”,在“bins_array”对话框中输入“E20:E29 该函数的第一个参数指定用于编制分布数列的原始数据,第二个参数指定每一组的上限. 步骤6.选定C20:C30区域,再按“自动求和” 按钮,即可得到频数的合计
步骤7.在D20中输入“=(C20/$C$30)*1OO” 步骤8:再将该公式复制到D21:D29中,并按“自动求和”按钮计算得出所有频率的合计。
统计分析综合实验报告 学院: 专业: 姓名: 学号:
统计分析综合实验考题 一.样本数据特征分析: 要求收集国家统计局2011年全国人口普查与2000年全国人口普查相关数据,进行二者的比较,然后写出有说明解释的数据统计分析报告,具体要求如下: 1.报告必须包含所收集的公开数据表,至少包括总人口,流动人口,城乡、性别、年龄、民族构成,教育程度,家庭户人口八大指标; 2.报告中必须有针对某些指标的条形图,饼图,直方图,茎叶图以及累计频率条形图;(注:不同图形针对不同的指标)3.采用适当方式检验二次调查得到的人口年龄比例以及教育程度这两个指标是否有显著不同,写明检验过程及结论。 4.报告文字通顺,通过数据说明问题,重点突出。 二.线性回归模型分析: 自选某个实际问题通过建立线性回归模型进行研究,要求: 1.自行搜集问题所需的相关数据并且建立线性回归模型; 2.通过SPSS软件进行回归系数的计算和模型检验; 3.如果回归模型通过检验,对回归系数以及模型的意义进行 解释并且作出散点图
一、样本数据特征分析 2010年全国人口普查与2000年全国人口普查相关数据分析报告 2011年第六次全国人口普查数据显示,总人口数为1370536875,比2000年的第五次人口普查的1265825048人次,总人口数增加73899804人,增长5.84%,平均年增长率为0.57%。
做茎叶图分析: 描述 年份统计量标准误 人口数量2000年均值40084265.35 4698126.750 均值的 95% 置信区间 下限30489410.50 上限49679120.21 5% 修整均值39305445.50 中值35365072.00 方差 68424424372574 4.400 标准差26158062.691 极小值2616329
概率统计实验报告 班级16030 学号16030 姓名 2018 年1 月3 日
1、 问题概述和分析 (1) 实验内容说明: 题目12、(综合性实验)分析验证中心极限定理的基本结论: “大量独立同分布随机变量的和的分布近似服从正态分布”。 (2) 本门课程与实验的相关内容 大数定理及中心极限定理; 二项分布。 (3) 实验目的 分析验证中心极限定理的基本结论。 2、实验设计总体思路 2.1、引论 在很多实际问题中,我们会常遇到这样的随机变量,它是由大量的相互独立的随机 因素的综合影响而形成的,而其中每一个个别因素在总的影响中所起的作用是微小的,这种随机变量往往近似的服从正态分布。 2.2、 实验主题部分 2.2.1、实验设计思路 1、 理论分析 设随机变量X1,X2,......Xn ,......独立同分布,并且具有有限的数学期望和方差:E(Xi)=μ,D(Xi)=σ2(k=1,2....),则对任意x ,分布函数 满足 该定理说明,当n 很大时,随机变量 近似地服从标准正 态分布N(0,1)。因此,当n 很大时, 近似地服从正 态分布N(n μ,n σ2). 2、实现方法(写清具体实施步骤及其依据) (1) 产生服从二项分布),10(p b 的n 个随机数, 取2.0=p , 50=n , 计算n 个随 机数之和y 以及 ) 1(1010p np np y --; 依据:n 足够大,且该二项分布具有有限的数学期望和方差。 (2) 将(1)重复1000=m 组, 并用这m 组 ) 1(1010p np np y --的数据作频率直方图进 行观察. 依据:通过大量数据验证随机变量的分布,且符合极限中心定理。
实验报告 课程名称统计学学号 11学生姓名辅导教师 系别经济与管理系实验室名称实验时间 1.实验名称 统计指数分析 2.实验目的 掌握各项指数的计算及因素分析法的运用。 在 Excel 中完成各项指数及有关数值的计算,主要用到的是公式和公式复制 3.实验内容 甲乙丙三种商品基期和报告期各项数据如下: 价格(元) P销量 q 商品计量单位 基期 p0报告期 p1基期 q0报告期 q1 甲个302810001200 乙双202120001600 丙公斤232515001500 合计 1)计算三种商品的个体销售量指数和个体价格指数。 2)三种商品的销售额总指数。 3)三种商品的销售量总指数和价格总指数。 4)分析销售量变动和价格变动对销售额影响的绝对额。(这一问分析要手写完成) 4.实验原理 在 Excel 中实现综合指数及其相关数值的计算,主要用到的是公式和公式的复制功 能 5.实验过程及步骤 (1)在工作表中输入已知数据的名称和数值(包括商品名称,计量单位,基期价格,报告 期价格,基期销售量和报告期销售量) (2)计算综合指标的各个综合总量在单元格G4中输入公式“ =C4*E4”,在H4中输入“=D4*F4”, 在 I4 中输入“ =C4*F4”, 在 J4 中输入“ =D4*E4”, 公式复制 在 A7 中输入合计,在单元格中输入“=SuM(G4:G6),再将单元格 G7的公式向右复制到 J7 (3)分别计算各个综合指标及其分子分母之差额 在单元格 A10 中输入“销售额总额指数” ,在单元格 F10 中输入公式“ =H7/G7*100” , 在单元格 H10 中输入公式” =H7-G7”
统计学实验报告 一.实验步骤总结数据的搜集与整理 一.数据的搜集 ●间接数据的搜集 方法一:直接通过进入专业的数据库网站查询数据 方法二:使用搜索引擎进行数据的搜索 ●直接数据的搜集 抽样调查: 1.调查方案设计 2.调查问卷设计 3.问卷发放 4.问卷回收 二.数据的整理 ●数据编码 1.在Excel中选择三列,将三列分别命名,后两列为:编码符号、代表含义 2.数据搜集好后,按照他们的特征进行分类,并依次放入第一列 3.在“编码符号”列为每一个列别编码,并在“代表含义”列说明编码的含义 ●数据的录入 转置(行与列换位): 1.激活数据所在单元格 2.单击鼠标右键,选中“复制” 3.在空白处激活另一单元格,点击鼠标右键,选中“选择性粘贴”项。 4.在弹出的“选择性粘贴”对话框中,粘贴项选中“全部”,运算选中“无”,选中“转置” 复选框,点击确定按钮既得转置的结果。 单元格内部换行:“Alt+Enter”组合键 ●数据的导入 方法一:1.单击菜单栏“文件—打开”,在弹出的的“打开”对话框中找到要导入的文件。 2.双击鼠标左键或者单击打开按钮,所需要的文件就被导入了。 方法二:1.单击菜单栏“数据—导入外部数据—导入数据”,在弹出的“选取数据源”的对话框中找到要导入的文件。 2.双击鼠标左键或者单击打开按钮,所需要的文件就被导入了。 ●数据的筛选 自动筛选: 1.选中要筛选的数据区域 2.使用菜单栏中的“数据—筛选—自动筛选”,这时每列的第一个单元格的右边都会出现 一个下拉箭头,我们就可以通过下拉菜单中的选择实现筛选。 3.如果选择了下拉菜单中的“自定义”,就会弹出一个“自定义自动筛选方式”对话框, 在对话框中可自己选择筛选条件,然后点击确定按钮。 高级筛选: 1. 将要筛选数据区域的列标题复制粘贴在空白区域,并在他们对应下的单元格中输入所要
《应用统计学》实验报告 实验一用Excell抽样 一、实验题目 某车间现有同型号的车床120部,检察员从中随机抽取由12部车床构成一个样本。请拟定抽样方式,确定样本单位。 二、实验步骤 第一步:给车床编号 从1到120依次给每部车床编号。 第二步:选定抽样方式 采用简单随机抽样。 第三步:使用Excell抽样 具体步骤如下: 1、打开Excell; 2、依次将车床编号输入到单元格区域$A$1:$L$12的不同单元格中; 3、单击“工具”菜单; 4、选择“数据分析”选项,然后从“数据分析”对话框中选择“抽样”; 5、单击“确定”,弹出抽样对话框; 6、在“输入区域”框中输入产品编号所在的单元格区域; 7、在“抽样方法”项下选择“随机”,在“样本数”框中输入12; 8、在“输出选项”下选择“输出区域”,在“输出区域”框中输入$A$14; 9、单击“确定”,得到抽样结果。 三、实验结果 用Excell从该120部车床中随机抽出的一个样本中各单位的编号依次为: 79 71 13 41 72 81 21 54 73 88 16
84 实验二用Excell画直方图 一、实验题目 某工厂的劳资部门为了研究该厂工人工人的收入情况,首先收集了30名工人的工作资料, 下面为工资数值。 530 535 490 420 480 475 420 495 485 620 525 530 550 470 515 530 535 555 455 595 530 505 600 505 550 435 425 530 525 610 二、实验步骤 第一步:在工具菜单中单击数据分析选项,从其对话框的分析工具列表中选择直方图,打开直方图对话框; 第二步:在输入区域输入$A$2:$F$6,在接收区域输入$D$9:$D$15; 第三步:选择输出选项,可选择输入区域、新工作表组或新工作薄; 第四步:选择图表输出,可以得到直方图;选择累计百分率,系统将在直方图上添加累积频率折线;选择柏拉图,可得到按降序排列的直方图; 第五步:按确定按钮,可得输出结果。 三、实验结果 本实验所画直方图如下图所示:
1. 正态性检验 Kolmogorov-Smirnov a Shapir o-Wilk 统计量df Sig. 统计量df Sig. 净资产收益率.113 35 .200*.978 35 .677 总资产报酬率.121 35 .200*.964 35 .298 资产负债率.086 35 .200*.962 35 .265 总资产周转率.180 35 .006 .864 35 .000 流动资产周转率.164 35 .018 .885 35 .002 已获利息倍数.281 35 .000 .551 35 .000 销售增长率.103 35 .200*.949 35 .104 资本积累率.251 35 .000 .655 35 .000 *. 这是真实显著水平的下限。 a. Lilliefors 显著水平修正 此表给出了对每一个变量进行正态性检验的结果,因为该例中样本中n=35<2000,所以此处选用Shapiro-Wilk统计量。由Sig.值可以看到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面的分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成的向量遵从正态分布(尽管事实上并非如此)。这四个指标涉及公司的获利能力、资本结构及成长能力,我们认为这四个指标可以对公司运营能力做出近似的度量。 2. 主体间因子 N 行业电力、煤气及水的生产和供应 业 11 房地行业15 信息技术业9 多变量检验a 效应值 F 假设df 误差df Sig. 截距Pillai 的跟踪.967 209.405b 4.000 29.000 .000 Wilks 的Lambda .033 209.405b 4.000 29.000 .000 Hotelling 的跟踪28.883 209.405b 4.000 29.000 .000 Roy 的最大根28.883 209.405b 4.000 29.000 .000 行业Pillai 的跟踪.481 2.373 8.000 60.000 .027 Wilks 的Lambda .563 2.411b8.000 58.000 .025 Hotelling 的跟踪.698 2.443 8.000 56.000 .024
分析报告(一) 实验项目:统计量描述实验日期:2012-3-16 实验地点:8教80680实验目的:熟悉描述性统计量的类型划分及作用;准确理解各种描述性统计量的构造原理;熟练掌握计算描述性统计量的SPSS 操作;培养运用描述统计方法解决身边实际问题的能力。 实验内容:(1):分析被调查者的户口和收入的基本情况 (2):分析储户存款金额的分布情况 (3):计算存款金额的基本描述统计量,并对城镇和农村户口进行比较分析 (4):分析储户存款数量是否存在不均衡现象 实验步骤:analysze—Descriptive statistics-- Frequencies 实验结果 : 【注释】:其中2.00 表示收入基本不变 【注释】:这是对城镇户口,农村户口的收入情况的描述性分析,frequency 代表频率,percent 代表所占总体的百分比
【注释】:这是对存款金额的描述性分析,最小值是1,最大值是80502,均值是2454.27,标准差是6881.827,标准误是 0.141 【注释】:本表描述的是城镇户口和农村户口的最小值,最大值,均值,标准差,标准误。实验分析:(一)、总体看来,城镇户口和农村户口的收入情况:基本不变占据很大比例,说明经济发展较稳定(二)、城镇户口的收入增加所占的比例为34.3%,远超过农村户口的18.9%,说明农村的发展相较于城镇,还有很大的发展空间。(三)、存款金额最大值 (80502)和最小值(1)之间差距过大,说明贫富差距过大,从长远角度来看,不利于经济的发展,我们国家也有出台一些减小贫富差距的政策,加快城镇化建设之类的。实验小结: 备注:
本科生实验报告 实验课程统计学原理 学院名称管理科学学院 专业名称工商管理 学生姓名雷** 学生学号3201407040** 指导教师王** 实验地点6C402 实验成绩 二〇一六年五月——二〇一六年六月
填写说明 1、适用于本科生所有的实验报告(印制实验报告册除外); 2、专业填写为专业全称,有专业方向的用小括号标明; 3、格式要求: ①用A4纸双面打印(封面双面打印)或在A4大小纸上用蓝黑色水笔书写。 ②打印排版:正文用宋体小四号,1.5倍行距,页边距采取默认形式(上下 2.54cm,左右2.54cm,页眉1.5cm,页脚1.75cm)。字符间距为默认值(缩 放100%,间距:标准);页码用小五号字底端居中。 ③具体要求: 题目(二号黑体居中); 摘要(“摘要”二字用小二号黑体居中,隔行书写摘要的文字部分,小4 号宋体); 关键词(隔行顶格书写“关键词”三字,提炼3-5个关键词,用分号隔开,小4号黑体); 正文部分采用三级标题; 第1章××(小二号黑体居中,段前0.5行) 1.1 ×××××小三号黑体×××××(段前、段后0.5行) 1.1.1小四号黑体(段前、段后0.5行) 参考文献(黑体小二号居中,段前0.5行),参考文献用五号宋体,参照《参考文献著录规则(GB/T 7714-2005)》。
目录 实验一统计数据的整理 (1) 1.1. 图表呈现 (1) 1.2. 图表具体分析 (6) 实验二用SPSS软件进行描述性统计分析 (7) 2.1. Q5变量统计分析 (7) 2.2. Q6变量统计分析 (9) 2.3. Q7数值型统计分析 (13) 2.4. Q8数值型统计分析 (15) 2.5. Q9分类统计分析 (23) 2.6. Q10分类统计分析(条形统计图) (25) 2.7. Q11分类统计分析(圆饼统计图) (27) 2.8. Q13分类统计分析(条形统计图) (29) 实验三参数估计 (30) 3.1. Q7数值型统计分析 (30) 3.2. Q8数值型统计分布 (31) 实验四假设检验 (34) 4.1. 对Q7进行单样本假设检验 (34) 4.2. 对Q8独立样本的T检验 (34) 实验五相关回归 (36) 5.1. 风险态度指标 (36) 5.2. 观念认同指标 (39) 5.3. 不确定性的担忧指标 (41) 5.4. 综合指标 (44)
成都工业学院 实验报告 专业国际商务 实验课程统计实务 实验项目统计数据整理与分析指导教师王晓燕 班级1403022 姓名学号赵澜豫18
一、实验目的项目一:《统计数据整理》实验通过上机实验,使每个学生掌握利用Excel 对 原始资料进行统计分组并编制分配数列的方法;掌握利用Excel 进行图表制作的方法。项目二:《数据分布 特征的描述及抽样推断》实验通过上机实验,使学生掌握Excel 在数据分布特征的描述及抽样推断中的应 用方法,并能对实验结果进行解释、分析,得出明确实验结论。项目三: 《回归分析》实验 通过上机实验,使学生掌握利用Excel 进行回归分析的方法,并能对实验结果进行解释、得出明确实验结论。 分析,二、实验内容 项目一:某灯泡厂准备采用一种新工艺,为检查新工艺是否使灯泡的寿命有所延长,对采用新工艺生产的100 只灯泡进行测试,结果如下:(单位:小时) 716 728 719 685 709 691 684 705 718 700 715 712 722 691 708 690 692 707 701 706 729 694 681 695 685 706 661 735 665 708 710 693 697 674 658 698 666 696 698 668 692 691 747 699 682 698 700 710 722 706 690 736 689 696 651 673 749 708 727 694 689 683 685 702 741 698 713 676 702 688 671 718 707 683 717 733 712 683 692 701 697 664 681 721 720 677 697 695 691 693 699 725 726 704 729 703 696 717 688 713
电子科技大学通信与信息工程学院 标准实验报告 实验名称:随机数的产生及统计特性分析 电子科技大学教务处制表
电子科技大学 实验报告 学生姓名:吴子文学号:2902111011 指导教师:周宁 实验室名称:通信系统实验室 实验项目名称:随机数的产生及统计特性分析 实验学时:6(课外) 【实验目的】 随机数的产生与测量:分别产生正态分布、均匀分布、二项分布和泊松分布或感兴趣分布的随机数,测量它们的均值、方差、相关函数,分析其直方图、概率密度函数及分布函数。通过本实验进一步理解随机信号的一、二阶矩特性及概率特性。 编写MATLAB程序,产生服从N(m, sigma2)的正态分布随机数,完成以下工作: (1)、测量该序列的均值,方差,并与理论值进行比较,测量其误差大小,改变序列长度观察结果变化; (2)、分析其直方图、概率密度函数及分布函数; (3)、计算其相关函数,检验是否满足Rx(0)=mu^2+sigma2,观察均值mu 为0和不为0时的图形变化; (4)、用变换法产生正态分布随机数,重新观察图形变化,与matlab函数产生的正态分布随机数的结果进行比较。 【实验原理】 1、产生服从N(m, sigma2)的正态分布随机数,在本实验中用matlab中的函数normrnd()产生服从正态分布的随机数。 (1)R = normrnd(mu,sigma) 产生服从均值为mu,标准差为sigma的随机数,mu和sigma可以为向量、矩阵、或多维数组。 (2)R = normrnd(mu,sigma,v) 产生服从均值为mu 标准差为sigma的随机数,v是一个行向量。如果v是一个1×2的向量,则R为一个1行2列的矩阵。
统计学实验报告
实验一:数据特征的描述 实验内容包括:众数、中位数、均值、方差、标准差、峰度、偏态等实验资料:某月随机抽取的50户家庭用电度数数据如下: 88 65 67 454 65 34 34 9 77 34 345 456 40 23 23 434 34 45 34 23 23 45 56 5 66 33 33 21 12 23 3 345 45 56 57 58 56 45 5 4 43 87 76 78 56 65 56 98 76 55 44 实验步骤: (一)众数 第一步:将50个户的用电数据输入A1:A50单元格。 第二步:然后单击任一空单元格,输入“=MODE(A1:A50)”,回车后即可得众数。 (二)中位数 仍采用上面的例子,单击任一空单元格,输入“=MEDIAN(A1:A50)”,回车后得中位数。 (三)算术平均数 单击任一单元格,输入“=AVERAGE(A1:A50)”,回车后得算术平均数。 (四)标准差 单击任一单元格,输入“=STDEV(A1:A50)”,回车后得标准差。 故实验结果如下图所示:
上面的结果中,平均指样本均值;标准误差指样本平均数的标准差;中值即中位数;模式指众数;标准偏差指样本标准差,自由度为n-1;峰值即峰度系数;偏斜度即偏度系数;区域实际上是极差,或全距。 实验二:制作统计图 实验内容包括: 1.直方图:用实验一资料 2.折线图、柱状图(条形图)、散点图:自编一时间序列数据, 不少于10个。 3.圆形图:自编有关反映现象结构的数据,不少于3个。 实验资料:1.直方图所用数据:某月随机抽取的50户家庭用电度数数据如下: 88 65 67 454 65 34 34 9 77 34 345 456 40 23 23 434 34 45 34 23 23 45 56 5 66 33 33 21 12 23 3 345 45 56 57 58 56 45 5 4 43 87 76 78 56 65 56 98 76 55 44 2.折线图、柱状图(条形图)、散点图、圆形图所用数据: 2005年至2014年各年GDP总量统计如下: 年份 GDP (亿元) 2005 184575.8 2006 217246.6 2007 268631 2008 318736.1 2009 345046.4 2010 407137.8 2011 479576.1 2012 532872.1 2013 583196.7 2014 634043.4 实验步骤:
数理统计学实验报告院: 专业:班级:学号: 学生姓名: 指导教师姓名: 实验日期: 实验1 1950~1983年我国三类产品出口总额及其构成 年份出口总额其中
用表中的资料,按以下要求绘制图表: (一)用表中1950、1960、1970、1980四年三类产品的出口金额绘制分组柱形图,然后将图复制到Word文档。 (二)用表中1950和1980两年三类产品的出口金额占总金额的百分比,分别绘制两幅饼图, 然后将图复制到Word文档; (三)用1950、1960、1970、1980四年三类产品出口金额绘制折线图, 然后将图复制到Word文档。 (四)将以上一张表、三幅图联系起来,结合我国当时的历史背景写一篇300字左右的统计分析报告。 (一)
(二)1950:
1980: (三) (四) 总结
建国初期,我国对外贸易仅限于原苏联和东欧等前社会主义国家,对外贸易规模极其有限,基本上处于封闭半封闭状态。1950年,出口额极少,以农副产品为主的出口占我国出口总额的百分之五十八,而工矿产品的出口极少只占百分之九。随着经济发展,出口额增长,工矿产品的出口额增长迅速,而出口产品以农副产品加工品为主。改革开放以来,我国走上了对外开放之路,从大规模“引进来”到大踏步“走出去”,一跃而成为世界对外贸易大国。工矿产品的出口量急剧增长,以工矿产品为主的出口额占总出口额的百分之五十,而农副产品的出口持续减少。 通过office软件制图分析可以清楚明确的看出我国出口经济的发展情况,通过对比可以发现,我国在改革开放之后出口经济大力发展,并以农副产品向工矿产品转变,并以工矿产品为主的出口经济产生。
机械加工误差统计分析实验 一、实验目的: 了解机械加工过程中工件的尺寸分布状态和变化规律,学习、掌握加工误差的统计分析方法。 二、实验原理: 机械加工过程中存在系统性和随机性误差的综合影响,造成工件的加工尺寸不断变化。统计分析方法就是以生产现场对一定数量的工件测量所得的结果为基础,运用数理统计方法进行处理,评定其加工情况,进而研究误差的性质及影响因素。 机械加工中采用的统计分析有两种方法:即分布图法和点图法。 1、分布图法 理论研究与生产实践证明,在调整好的机床上连续加工一批工件,如果没有系统性误差存在,只在随机性误差因素的作用下,加工工件的尺寸将服从正态分布,(见图4-1),它的方程为: ( )()2 2σ?Χ?Χ? Χ= 式中:X--工件的尺寸; Χ--工件的平均尺寸; σ--均方根偏差(标准差)。 根据概率论与数理统计原理: 工件的尺寸可近似的认为分布在X ±3σ的范围内,那么该工序的工艺能力系数: 6C δσ Ρ= 式中:δ—图纸上规定的工件的公差值。 在实验过程中,根据加工情况所做实验分布曲线符合正态分布,则说明工艺过程是稳定的。若出现明显差异,说明工艺过程不稳定,工艺系统中存在系统误差因素。因此,根据分布曲线可以很方便的推测、判断工序的加工情况。 2、点图法 在生产实践中常用点图法来观察尺寸变化趋势,控制加工过程。在调整好的机床上连续加工一批工件,依次进行分组,计算小组平均值 X 和极差R ,以加工组序或时间为横坐标,则平均值Χ为纵坐标,做出X 图;极差R 为纵坐标,作出R 图(见图 4-2)
Χ能够反映变值系统性误差的变化规律,R 图则反映随机性误差的大小。 对于稳定工艺过程,若样组数为m ,则点图的中心线及上、下控制线按表4-1 各式计算: 上表4-2式中:A 、D 1、D 2--系数,可根据工件分组情况查表得出;若点子超出R 图控制线,则说明随机误差过大,工艺系统出现了异常情况,都应对机床重新调整或停机检查。 对于不稳定工艺过程,由于系统存在变值系统误差因素的影响,被加工工件尺寸将按一定规律变化,其控制图就不能按上述办法来做了,具体做法可以参考教材。 三、实验所用设备、仪器、试件 机床:M1020A 无心外圆磨床 量具:千分尺一把 试件:(8~20)mm 的轴 四、 实验方法与步骤 五、本实验的试件在M1020A 无心外圆磨床上加工。磨床调整好以后,连续磨削100个轴, 按加工顺序排列,然后用千分尺进行测量,然后数据处理。 表-2 m 2 3 4 5 6 7 8 9 10 c 1.128 1.693 2.059 2.326 2.534 2.704 2.847 2.970 3.078 d 0.8528 0.8884 0.87980.86410.84800.83300.8200 0.808 0.797 A 1.8806 1.0231 0.72850.57680.48330.41930.3726 0.3367 0.3082D 1 3.2681 2.5742 2.2819 2.1145 2.0039 1.9242 1.8641 1.8162 1.7768D 2 0 0 0 0 0 0.0758 0.1359 0.1838 0.2232