Abaqus的Python后处理详解-kxh
- 格式:pdf
- 大小:4.71 MB
- 文档页数:24

基于PYTHON的ABAQUS后处理开发作者:李慧孙银茹来源:《中小企业管理与科技·上旬》2010年第06期摘要:ABAQUS的后处理功能不能完全提供我们在分析过程中所需的数据,为更好的扩展后处理功能,查看和分析结果数据,本文提出了使用Python语言对ABAQUS进行二次开发来达到这一目的的方法。
文中讨论了ABAQUS的脚本接口和对象模型在二次开发中的作用和调用流程,以及文件的读写与复制、数据读取与处理、结果输出与查看等关键技术。
以共轨管锥面密封性的分析为例,使用Python语言提取了分析结果数据并将结果作为初始条件加载于新的分析中,最终得到所需的分析数据。
关键词:ABAQUS Python 后处理有限元分析0 引言ABAQUS是目前国际上最为先进的通用非线性有限元分析软件之一,软件包括种类丰富的材料库和单元库,可以模拟绝大部分工程材料的线性和非线性行为,而且材料库和单元库分开,材料和单元之间的组合能力很强,可以胜任复杂结构的静态与动态分析[1]。
ABAQUS自带的CAE 模块是一个完整的ABAQUS环境,提供—个简单一致的接口,可以用于创建、提交、监视和评价模拟所得到的结果[2]。
Python是一种简单易学、功能强大的编程语言,它有高效率的高级数据结构,可以简单而有效地实现面向对象编程[2]。
ABAQUS有限元程序就通过集成脚本语言Python向二次开发者提供了很多库函数,通过Python语言调用这些库函数来增强ABAQUS的交互式操作能力。
本文通过Python脚本语言来提取ABAQUS的后处理结果,并对结果数据进行相应的计算和转换,并将处理结果作为初始条件应用于其后的开发过程中。
1 ABAQUS、PYTHON接口程序ABAQUS的二次开发可以通过Python脚本语言控制ABAQUS内核实现前处理建模和后处理的计算分析。
ABAQUS脚本接口是Python语言的一个扩展,可以使用Python语言编制脚本接口可以执行的程序,从而实现自动化重复性的工作、创建和修改模型数据库、访问数据库的功能。

・专题研究・ 收稿日期:2008205226基金项目:国家高技术研究发展计划(863计划)课题“深水钻井隔水管与井口技术”(2006AA09A10624)作者简介:赵焕卿(19632),男,河南偃师人,高级工程师,工程硕士,主要从事石油机械的研究与开发工作,E 2mail :zhaohq@ ;zhaohq2283@ 。
文章编号:100123482(2009)0120001205基于Python 的ABAQUS 后处理技术在隔水管静态分析中的应用赵焕卿a ,畅元江b(中国石油大学(华东)a.科技开发公司;b.机电工程学院,山东东营257061)摘要:为准确、高效地得到分析结果,研究了基于Pyt hon 语言的ABAQU S 后处理技术在隔水管静态分析中的应用。
采用ABAQU S 软件进行隔水管静态分析时,可调用自定义Pyt hon 程序访问数据库文件并直接提取相关分析结果,如隔水管最大等效应力、最大横向变形和最大弯曲应力等。
给出了基于Pyt hon 的ABAQU S 后处理技术在隔水管静态分析中的应用算例。
研究表明,自定义Pyt hon 程序提取隔水管分析结果准确、高效,扩展了ABAQU S 的应用,可为ABAQU S 在海洋工程中的应用和基于Pyt hon 的ABAQU S 后处理技术研究与应用提供参考。
关键词:Pyt hon ;ABAQU S 后处理技术;隔水管静态分析中图分类号:TE934.102 文献标识码:AApplication of Python 2based ABAQUS Post 2processingT echnique to Riser Static AnalysisZHAO Huan 2qing a ,C HAN G Yuan 2jiang b(a.Scienti f ic and Technological Com pany ;b.College of Mechanical and Elect ronic Engineering ,China Universit y of Pet roleum (H uadong ),Dong yi ng 257061,China )Abstract :In order to obtain t he interested calculation result s efficiently and accurately ,applica 2tion of pyt hon 2based ABAQU S po st 2p rocessing technique to riser static analysis was st udied in t his paper.When ABAQU S was employed to conduct riser static analysis ,customized Pyt hon program could be invoked to visit ABAQU S ODB files to ext ract directly such related calculation result s as max Mises st ress ,max lateral deflection and max bending st ress ,etc.An example was presented which illust rated t he application of pyt hon 2based ABAQU S post 2processing technique to riser static analysis.The research indicated t hat customized Pyt hon p rogram could be used to ext ract riser analysis result s efficiently and accurately ,which extended t he application of ABAQU S.It provided reference for application of ABAQU S to off shore engineering and for ap 2plication technique of Pyt hon 2based ABAQU S Post 2p rocessing technique.K ey w ords :Pyt hon ;ABAQU S post 2p rocessing technique ;riser static analysis 隔水管(立管)可用于钻井、采油和修井等作业,在海洋油气资源开发中具有举足轻重的作用[1]。
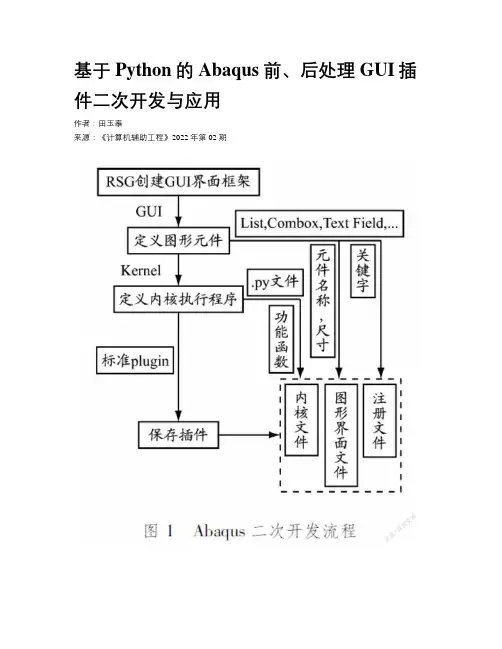
基于Python的Abaqus前、后处理GUI插件二次开发与应用作者:***来源:《计算机辅助工程》2022年第02期摘要:为提高Abaqus建模效率并进行可视化数据分析,利用Python语言对Abaqus前-后处理进行二次开发。
分析某柴油机机油-水冷却器模块组件,结果表明:前处理模块开发螺栓GUI插件,能够批量创建相同规格的螺栓载荷,提高前期建模效率,缩短分析周期;后处理模块开发Campbell制图插件,能根据工程实际需要将模态结果数据绘制成Campbell图,并将计算结果可视化输出。
关键词: Abaqus; Python; 二次开发; 前处理; 后处理; GUI界面中图分类号: TP391.99; TB115.1文献标志码: BGUI plugin redevelopment and application of Abaquspre-and post-processing based on PythonTIAN Yutai(Shanghai New Power Automotive Technology Co., Ltd., Shanghai 200438, China)Abstract: To improve the efficiency of Abaqus modeling and achieve visual data analysis,redevelopment of Abaqus pre-and post-processing is carried out with Python language. A diesel engine oil-water cooler module is analyzed. The results show that: a bolt GUI plug-in is developed for the pre-processing module, which can create bolt loads of the same specification in bulk,improving pre-modeling efficiency and shortening the analysis cycle; the Campbell mapping plug-in is investigated for the post-processing module, which can draw the modal result data into Campbell diagrams according to the actual needs of engineering and visualize the calculation results for output.Key words: Abaqus;Python; redevelopment; pre-processing;post-processing; GUI interface0引言作为国际通用计算分析软件,Abaqus具有丰富的单元类型与材料非线性模型,在各领域发挥至关重要的作用。


1 如何显示最大、最小应力在Visualization>Options>contour >Limits中选中Min/Max:Show Location2 后处理有些字符(图例啊,版本号啊,坐标系啊)不想显示view-view annotation option ,选择打勾3 后处理中显示边界条件Viewport--ODB Display Options 边界条件处打勾4 在模型上只显示云图,不显示网格option菜单-common-visible edges--free edges顺便窜一下,在前处理mesn之后不想显示网格,只显示模型的话,更简单:工具栏有显示mesh、显示线框、显示实体连续的三个按钮。
5 你想调大变形放大系数(Deformation Scal Factor)让变形显示更明显一点?注意:非线性问题,这个默认为是1(也就是不放大),只有线性的才能改。
option菜单-common-visible edges--Deformation Scale factor6 如何在后处理中移动图例选Gneral--legend 可以隐藏选Legent--Upper left corner 可以移动7 对ODB结果处理以后,如何保存结果從visualization模塊開啟odb檔(不要直接從job manager開啟),並取消勾選read only,對已有的XY-data作copy to odb。
8 job步提交运算后警告信息出现setwarning 或者nodewarning,(类似这样的语句:....have been identified in element setErrElemVolSmallNegZero.... identified in element setErrElemDistortedWarnNodeUnconstrainedWarnNodeMissMasterIntersectWarnElemDistorted.这里的Warn打头的代表相应的警告信息,Err代表相应的错误信息)我怎么知道这些set或者node到底在哪儿?在job步job manager点result,tool--- display group---在item 选node或者element,右边就出现相应的警告几何部分,勾选“Highlight item inviewport”就能在模型中高亮这些警告部分。

基于 PYTHON 的 ABAQUS 后处理开发
李慧;孙银茹
【期刊名称】《中小企业管理与科技》
【年(卷),期】2010(000)016
【摘要】ABAQUS的后处理功能不能完全提供我们在分析过程中所需的数据,为更好的扩展后处理功能,查看和分析结果数据,本文提出了使用Python语言对ABAQUS进行二次开发来达到这一目的的方法.文中讨论了ABAQUS的脚本接口和对象模型在二次开发中的作用和调用流程,以及文件的读写与复制、数据读取与处理、结果输出与查看等关键技术.以共轨管锥面密封性的分析为例,使用Python 语言提取了分析结果数据并将结果作为初始条件加载于新的分析中,最终得到所需的分析数据.
【总页数】2页(P268-269)
【作者】李慧;孙银茹
【作者单位】
【正文语种】中文
【相关文献】
1.基于Python的ABAQUS后处理技术在隔水管静态分析中的应用 [J], 赵焕卿;畅元江
2.基于Python-Matlab的Abaqus后处理技术在柴油机有限元分析中的应用 [J], 高喆;禹朝帅;刘钊宾;刘世谦;林好利
3.基于ABAQUS/Python的数控弯管专用后处理模块的拓展 [J], 冯颖;杨合;陈德
正;李恒;詹梅
4.基于Python的ABAQUS数控弯管数值模拟后处理 [J], 岳永保;杨合;詹梅;许旭东;李光俊
5.基于Python的ABAQUS后处理研究开发及其在薄壁管数控弯曲中的应用 [J], 郭玲;杨合;邱晞;李恒;詹梅;郭良刚
因版权原因,仅展示原文概要,查看原文内容请购买。

Abaqus中Python后处理详解By NUAAPh.D Kong Xianghong2013/04/23下图是Abaqus ODB文件的数据结构,后处理操作主要对以下两步分进行操作:1) 对场变量的读取路径:odb.setps[].frames[].fieldOutputs[]2) 对历史变量的读取路径:odb.setps[].historyRegions[].historyOutputs[]1 Abaqus ODB 文件数据结构2.1 创建3D实体Part创建截面为10×10mm,长度为20mm的拉伸体部件。
2.2 对3D实体Part划分单元模型建得比较小,划分单元也比较少,这样得到的odb文件也比较小,有助于更方便地了解odb文件的数据结构。
2.3 创建材料及截面2.4 给Part赋材料属性及创建装配实例2.5 创建分析步为了输出HistoryOutput,所以分析步的增了步设置了多步(10步)。
2.6 编辑场输出变量2.7 为历史输出变量创建Node Set2.8 编辑历史输出变量2.9 创建边界条件施加边界条件的Region为Set-1。
2.10 施加载荷2.11 创建Job在Job编辑对话框的Parallelization标签页中也可定义并行计算的核数。
2.12 在Abaqus/CAE中查看分析结果3.1 打开关闭odb文件的方法方法一:from odbAccess import *myodb=openOdb('D:/.../Job-1.odb')myodb.close()方法二:import odbAccessmyodb=session.openOdb('D:/.../Job-1.odb')myodb.close()方法三:import visualizationmyodb=visualization.openOdb('D:/.../Job-1.odb')myodb.close()3.2 使用prettyPrint()方法查看odb 数据结构(1)在Abaqus 命令行借口中输入如下四行Python 程序:>>> from odbAccess import *>>> from textRepr import *>>> myodb=openOdb('Job-1.odb')>>> prettyPrint(myodb,1) 程序运行结果如右图所示,prettyPrint()的第2个参数表示打印odb文件数据的级数,可以逐渐调大该参数,观察打印结果。

利用Python对Abaqus进行后处理结果输出-----中大_戚超_2016.10.31 概述在Abaqus的二次开发过程中,通常需要采用Python脚本语言将Abaqus的计算结果进行输出,然后再进行处理。
Python使Abaqus的内核语言,使用较为方便,Abaqus运行Python语言的方式有多种,可以直接命令窗口,也可以读入脚本,还可以采用类似批处理的方式。
本次以一个例子细说Python语言在Abaqus后处理中的应用,模型的计算结果云图如图1所示。
图1 计算结果2 输出所有积分点上的Mises应力直接上Python代码:import osfrom odbAccess import*from textRepr import*myodb=openOdb(path='Job-1.odb')cpFile=open('artlcF1.txt','w')RF=myodb.steps['Step-1'].frames[1].fieldOutputs['S'].valuesfor i in range(len(RF)) :cpFile.write('%.3F\n' %(RF[i].mises))else:cpFile.close()#引入模块,因为需要打开结果文件#打开结果文件,并复制给变量myodb#打开一个txt文件#将输出场赋值给RF#循环语句,向txt文件逐行写入mises应力Abaqus的结构层次分的很细,比如结果文件下分如下:使用过Abaqus的都知道step表示载荷步,frame表示载荷子步,因而在读取Mises应力时需要详细地指定输出哪一步的应力,而应力结果是输出场数据(fieldOutput)的中一种,需要指定是何种应力,程序才知道怎么读取并写入。
由于Abaqus里面涉及的变量特别多,通常很难记清楚那一项下面都有哪些量可以调用,此时比较好的方式是采用print 函数查看,例如查看myodb.steps['Step-1'].frames[1].fieldOutputs 下面有哪些变量可以调用,在窗口输入:print myodb.steps['Step-1'].frames[1].fieldOutputs显示:{'AC YIELD': 'FieldOutput object', 'CF': 'FieldOutput object', 'E': 'FieldOutput object', 'PE': 'Fiel dOutput object', 'PEEQ': 'FieldOutput object', 'PEMAG': 'FieldOutput object', 'RF': 'FieldOutput object', 'S': 'FieldOutput object', 'U': 'FieldOutput object'}各种不同的结果,包括位移、应力和支反力等等,因此可以知道通过如下的方式读取应力:myodb.steps['Step-1'].frames[1].fieldOutputs ['S']此时读取的信息特别多,我们想要的是其中的数值信息,因此可以:myodb.steps['Step-1'].frames[1].fieldOutputs ['S'].values通过此句能够读取所有节点的应力数据,输出其中一个:print myodb.steps['Step-1'].frames[1].fieldOutputs ['S'].values[0]显示:({'baseElementType': 'C3D8R', 'conjugateData': None, 'conjugateDataDouble': 'unknown', 'da ta': array([-855397.25, 58.817497253418, 358.723419189453, -139.652938842773, -456.986175537109, 4.29301929473877], 'f'), 'dataDouble': 'unknown', 'elementLabel': 1, 'fac e': None, 'instance': 'OdbInstance object', 'integrationPoint': 1, 'inv3': -855606.3125, 'localCoordSystem': None, 'localCoordSystemDouble': 'unknown', 'magnitude': None, 'maxInPlanePrincipal': 0.0, 'maxPrincipal': 359.0310********, 'midPrincipal': 58.7767 486572266, 'minInPlanePrincipal': 0.0, 'minPrincipal': -855397.5, 'mises': 855606.375, 'nodeLabel': None, 'outOfPlanePrincipal': 0.0, 'position': INTE GRATION_POINT, 'precision': SINGLE_PRECISION, 'press': 284993.25, 'sectionPoint': None, 'tr esca': 855756.5, 'type': TENSOR_3D_FULL})输出的信息特别多,但是可以看到有mises这一项。

在abaqus中使用python实现的功能(一、二)By lxm9977(lxm200501@)功能一:实行提交多个job的功能。
对象:Job object使用:在源文件开始写上import job,源程序用mdb.jobs[name] 使用名字为name的job对象。
建立一个job对象的方法:z利用已有的inp文件中建立job:mdb.JobFromInputFile()z利用已有的cae中建立job: Job(...)建议用第一种方法。
设定参数的方法:9利用第一种方法建立job的时候,可以设定很多的参数,比如type,queue,userSubroutine等。
格式:mdb.JobFromInputFile(name=,inputFile=,type=,queue =,userSubroutine=,…….)。
9也可以先建立一个job,然后利用job对象的setValues来设定参数,格式:job.setValues(type=,queue=,userSubroutine=,…….)。
一个简单的例子:文件:job.pyfrom abaqusConstants import *import jobmdb.JobFromInputFile(name='job-1-1',inputFileName='Job-1.inp')#基于inp文件Job-1.inp建立名称为job-1-1的jobmdb.jobs['job-1-1'].setValues(waitMinutes=1)#设定参数mdb.jobs['job-1-1'].submit()#提交任务mdb.jobs['job-1-1'].waitForCompletion()运行:在cmd下面运行:Abaqus cae nogui=job.py如果是多个job,同样道理了,不多说了。


Python语言和ABAQUS后处理二次开发1易桂莲杜家政隋允康2(北京工业大学机械工程与应用电子技术学院,100124北京)摘要:采用Python脚本语言二次开发ABAQUS的后处理模块,讨论了ABAQUS的脚本接口和对象模型在二次开发中的作用和调用流程。
通过开发Python脚本程序提取ABAQUS进行数值模拟后的计算结果,有效地解决了提取大量结果进行重复操作的问题,提高了后处理的效率。
关键词:ABAQUS后处理二次开发;Python;动力响应分析;振动特性0 引言ABAQUS是国际上最先进的大型通用有限元计算分析软件之一,可以模拟绝大部分工程材料的线性和非线性行为。
ABAQUS自带的CAE是进行有限元分析的前后处理模块,也是建模、分析和后处理的人机交互平台,它具有良好的人机对话界面,因此ABAQUS软件在工程中得到了广泛的应用。
Python是一种面向对象的脚本语言,它功能强大,既可以独立运行,也可以用作脚本语言。
特别适用于快速的应用程序开发[1]。
通过开发Python脚本程序提取ABAQUS进行数值模拟后的计算结果,有效地解决了提取大量结果进行重复操作的问题1 二次开发接口介绍ABAQUS 脚本接口是一个基于对象的程序库,脚本接口中的每个对象都拥有相应的数据成员和函数。
对象的函数专门用于处理对象中的数据成员,被称为相应对象的方法,用于生成对象的方法被称为构造函数。
在对象创建后,可以使用该对象提供的方法来处理对象中的数据成员[2]。
ABAQUS提供了一套应用程序编程接口(API,Application Program Interface)来操作ABAQUS/CAE实现建模/后处理等功能。
接口编程采用Python的语法编写脚本,但扩展了Python脚本语言,额外提供了大约500个对象模型。
对象模型之间关系复杂,图1展示了这些对象模型之间的层次结构和相互关系。
其中,Container表示容器,里面包含有其他的对象;Singular object表示单个对象。
ABAQUS后处理简明教程1.结果文件导入在 ABAQUS 后处理模块中,首先需要将结果文件导入到后处理环境中。
选择 "File -> Import" 菜单,然后选择相应的结果文件。
通常的结果文件后缀名为 .odb。
2.查看模型几何形状在后处理环境中,可以通过选择 "Viewport" 菜单下的 "Model" 选项来查看模型的几何形状。
可以选择不同的视角查看模型,并通过放大和缩小功能来调整视图。
3.查看节点和单元信息在后处理环境中,可以选择 "Viewport" 菜单下的 "Node Labels"或 "Element Labels" 选项来显示节点和单元的信息。
这些信息可以帮助理解模拟结果的分布情况。
4.查看结果云图在后处理环境中,可以选择 "Viewport" 菜单下的 "Contours" 选项来查看云图。
云图是结果变量在模型中的分布情况,可以帮助理解模型中的应力、应变等物理量的分布情况。
可以选择不同的结果变量、显示颜色、调整显示范围等。
5.创建剖面图在后处理环境中,可以选择 "Viewport" 菜单下的 "Section Cuts"选项来创建剖面图。
剖面图可以帮助理解模型的截面上的物理量分布情况,比如剪力、弯矩等。
可以选择不同的剖面方向、显示不同的物理量、调整显示范围等。
6.创建动画在后处理环境中,可以选择 "Viewport" 菜单下的 "Animations" 选项来创建动画。
动画可以显示时间步的变化情况,可以帮助理解模拟结果的随时间的变化情况。
可以选择不同的时间范围、时间步长、显示的物理量等。
7.创建图表在后处理环境中,可以选择 "Graphs" 菜单下的 "XY Data" 选项来创建图表。
基于Python的Abaqus二次开发实例讲解(asian58 2013.6.26)基于Python的Abaqus的二次开发便捷之处在于:1、所有的代码均可以先在Abaqus\CAE中操作一遍后再通过rp文件读取,然后再在此基础上进行相应的修改;2、Python是一种解释性语言,读起来非常清晰,因此在修改程序的过程中,不存在程序难以理解的问题;3、Python是一种通用性的、功能非常强大的面向对象编程语言,有许多成熟的类似于Matlab函数的程序在网络上流传,为后期进一步的数据处理提供了方便。
为了更加方便地完成Abaqus的二次开发,需进行一些相关约定:1、所有参数化直接通过点的坐标值进行,直接对几何尺寸的参数化反而更加繁琐;2、程序参数化已不允许在模型中添加太多的Tie,因此不同零部件的绑定直接通过共节点来进行,这就要求建模方法与常规的建模方法有所区别。
思路如下:将一个整机拆成几个大的Part来建立,一个Part中包含许多零件,这样在划分网格式时就可以自动实现共节点的绑定。
不同的零件可通过建立不同的Set来进行区分,不同Part 的绑定可以通过Tie来实现。
将一个复杂的结构拆成几个恰当的Part来建立,一方面可以将复杂的模型简单化,使建立复杂模型成为可能;另一方面,不同的Part可单独调用,从而又可实现程序的模块化,增加程序的适应范围,延长程序的使用寿命,也方便后期程序的维护和修改。
3、通过py文件建立起的模型要进行参数优化,已不适合采用Isight中Abaqus模块,需要用到Isight的Simcode模块。
下面详细解释一个臂架的py文件。
#此程序用来绘制臂架前段#导入相关模块# -*- coding: mbcs -*-from abaqus import *from abaqusConstants import *#定义整个臂架的长、宽、高L0=14300W0=1650H0=800#创建零件P01_12 L1=H0+200 W1=200 T1=12s = mdb.models['Model-1'].ConstrainedSketch(name='__profile__', sheetSize=2000.0)g, v, d, c = s.geometry, s.vertices, s.dimensions, s.constraints s.setPrimaryObject(option=STANDALONE)s.rectangle(point1=(W0/2, L1/2), point2=(W0/2+W1, -L1/2))s.rectangle(point1=(-W0/2, L1/2), point2=(-W0/2-W1, -L1/2))p = mdb.models['Model-1'].Part(name='Part-1', dimensionality=THREE_D, type=DEFORMABLE_BODY)p = mdb.models['Model-1'].parts['Part-1'] p.BaseShell(sketch=s)session.viewports['Viewport: 1'].setValues(displayedObject=p) del mdb.models['Model-1'].sketches['__profile__']#定义零件的厚度p = mdb.models['Model-1'].parts['Part-1'] f = p.faces pickedFaces01 = f.findAt (((W0/2, L1/2, 0),),((-W0/2, L1/2, 0),), ) p.assignThickness(faces=pickedFaces01, thickness=T1) p.Set(faces=pickedFaces01, name='P01_12')#创建辅助平面和辅助坐标系p = mdb.models['Model-1'].parts['Part-1']p.DatumCsysByThreePoints(name='Datum csys-1', coordSysType=CARTESIAN, origin=( 0.0, 0.0, 0.0), line1=(1.0, 0.0, 0.0), line2=(0.0, 1.0, 0.0))p = mdb.models['Model-1'].parts['Part-1']p.DatumPlaneByPrincipalPlane(principalPlane=XYPLANE, offset=L0)#创建零件P02_12 L2=L1 W2=W1 T2=12p = mdb.models['Model-1'].parts['Part-1'] d = p.datums#将草图原点参数化t = p.MakeSketchTransform(sketchPlane=d[5], sketchUpEdge=d[4].axis2, sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, origin=(0.0, 0.0, L0)) s = mdb.models['Model-1'].ConstrainedSketch(name='__profile__', sheetSize=29006.85, gridSpacing=725.17, transform=t) g, v, d1, c = s.geometry, s.vertices, s.dimensions, s.constraints s.setPrimaryObject(option=SUPERIMPOSE)p = mdb.models['Model-1'].parts['Part-1']s.rectangle(point1=(W0/2, L2/2), point2=(W0/2+W2, -L2/2))s.rectangle(point1=(-W0/2, L2/2), point2=(-W0/2-W2, -L2/2))p = mdb.models['Model-1'].parts['Part-1']d2 = p.datumsp.Shell(sketchPlane=d2[5], sketchUpEdge=d2[4].axis2, sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, sketch=s)s.unsetPrimaryObject()del mdb.models['Model-1'].sketches['__profile__']#定义零件的厚度p = mdb.models['Model-1'].parts['Part-1'] Array f = p.facespickedFaces02 = f.findAt(((W0/2, L1/2, L0),),((-W0/2, L1/2, L0),), )p.assignThickness(faces=pickedFaces02, thickness=T2)p.Set(faces=pickedFaces02, name='P02_12')#创建零件P03_12和零件P04_08T3=12T4=8p = mdb.models['Model-1'].parts['Part-1']d = p.datumst = p.MakeSketchTransform(sketchPlane=d[5], sketchUpEdge=d[4].axis2, sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, origin=(0.0, 0.0, L0)) s = mdb.models['Model-1'].ConstrainedSketch(name='__profile__', sheetSize=29006.85, gridSpacing=725.17, transform=t)g, v, d1, c = s.geometry, s.vertices, s.dimensions, s.constraintss.setPrimaryObject(option=SUPERIMPOSE)#创建草图p = mdb.models['Model-1'].parts['Part-1']s.Line(point1=(-W0/2-W1, H0/2), point2=(-W0/2, H0/2))s.Line(point1=(W0/2, H0/2), point2=(W0/2+W1, H0/2))s.Line(point1=(-W0/2-W1, -H0/2), point2=(-W0/2, -H0/2))s.Line(point1=(W0/2, -H0/2), point2=(W0/2+W1, -H0/2))p = mdb.models['Model-1'].parts['Part-1']d2 = p.datumsp.ShellExtrude(sketchPlane=d2[5], sketchUpEdge=d2[4].axis2,sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, sketch=s, depth=L0, flipExtrudeDirection=ON)s.unsetPrimaryObject()del mdb.models['Model-1'].sketches['__profile__']#定义零件P03_12的厚度p = mdb.models['Model-1'].parts['Part-1']f = p.facespickedFaces03 = f.findAt(((-W0/2, H0/2, L0/2),),((W0/2, H0/2, L0/2),),)p.assignThickness(faces=pickedFaces03, thickness=T3)p.Set(faces=pickedFaces03, name='P03_12')#定义零件P04_12的厚度p = mdb.models['Model-1'].parts['Part-1']f = p.facespickedFaces04 = f.findAt(((-W0/2, -H0/2, L0/2),),((W0/2, -H0/2, L0/2),),)p.assignThickness(faces=pickedFaces04, thickness=T4)p.Set(faces=pickedFaces04, name='P04_12')#创建零件P05_08T5=8p = mdb.models['Model-1'].parts['Part-1']d = p.datumst = p.MakeSketchTransform(sketchPlane=d[5], sketchUpEdge=d[4].axis2, sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, origin=(0.0, 0.0, L0))s = mdb.models['Model-1'].ConstrainedSketch(name='__profile__',sheetSize=29006.85, gridSpacing=725.17, transform=t)g, v, d1, c = s.geometry, s.vertices, s.dimensions, s.constraintss.setPrimaryObject(option=SUPERIMPOSE)p = mdb.models['Model-1'].parts['Part-1']s.Line(point1=(-W0/2-W1/2, H0/2), point2=(-W0/2-W1/2, -H0/2))s.Line(point1=(W0/2+W1/2, H0/2), point2=(W0/2+W1/2, -H0/2))p = mdb.models['Model-1'].parts['Part-1']d2 = p.datumsp.ShellExtrude(sketchPlane=d2[5], sketchUpEdge=d2[4].axis2,sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, sketch=s, depth=L0,flipExtrudeDirection=ON)s.unsetPrimaryObject()del mdb.models['Model-1'].sketches['__profile__']#定义零件P05_8的厚度p = mdb.models['Model-1'].parts['Part-1']f = p.facespickedFaces05 = f.findAt(((-W0/2-W1/2, 0, L0/2),),((W0/2+W1/2, 0, L0/2),),)p.assignThickness(faces=pickedFaces05, thickness=T5)p.Set(faces=pickedFaces05, name='P05_08')#创建零件P06_08L6=W0+W1n=L0//2520+1T6=8p = mdb.models['Model-1'].parts['Part-1']f, d = p.faces, p.datumst = p.MakeSketchTransform(sketchPlane=f[0], sketchUpEdge=d[4].axis2, sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, origin=(W0/2+W1/2, -H0/2,0))s = mdb.models['Model-1'].ConstrainedSketch(name='__profile__',sheetSize=28684, gridSpacing=717, transform=t)g, v, d1, c = s.geometry, s.vertices, s.dimensions, s.constraintss.setPrimaryObject(option=SUPERIMPOSE)p = mdb.models['Model-1'].parts['Part-1']#循环命令绘制平行隔板for i in range(0,n): Array s.Line(point1=(-500-(i*2520), H0), point2=(-500-(i*2520), 0.0))p = mdb.models['Model-1'].parts['Part-1']f1, d2 = p.faces, p.datumsp.ShellExtrude(sketchPlane=f1[0], sketchUpEdge=d2[4].axis2,sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, sketch=s, depth=L6,flipExtrudeDirection=ON)s.unsetPrimaryObject()del mdb.models['Model-1'].sketches['__profile__']#定义零件P06_08的厚度p = mdb.models['Model-1'].parts['Part-1']f = p.facesfor i in range(0,n): Array pickedFaces = f.findAt(((0, H0/4, 500+i*2520),))p.assignThickness(faces=pickedFaces, thickness=T6)p.Set(faces=pickedFaces, name='P06_08_'+str(1+i))#创建零件P07_12,P08_12W7=200L7=W0+W1T7=12T8=12p = mdb.models['Model-1'].parts['Part-1']f, e = p.faces, p.edgest = p.MakeSketchTransform(sketchPlane=f.findAt(coordinates=(W0/2+W1/2, 0.0, 100.0)),sketchUpEdge=e.findAt(coordinates=(W0/2+W1/2, 0.0, 0.0)),sketchOrientation=RIGHT,sketchPlaneSide=SIDE1,origin=(W0/2+W1/2, -H0/2, 0.0))s = mdb.models['Model-1'].ConstrainedSketch(name='__profile__',sheetSize=53678, gridSpacing=1341, transform=t)g, v, d, c = s.geometry, s.vertices, s.dimensions, s.constraintss.setPrimaryObject(option=SUPERIMPOSE)p = mdb.models['Model-1'].parts['Part-1']#循环命令绘制平行隔板for i in range(0,n):s.Line(point1=(400+i*2520, -H0), point2=(600+i*2520, -H0))s.Line(point1=(400+i*2520, 0), point2=(600+i*2520, 0))p = mdb.models['Model-1'].parts['Part-1']f1, e1 = p.faces, p.edgesp.ShellExtrude(sketchPlane=f.findAt(coordinates=(W0/2+W1/2, 0.0, 100.0)),sketchUpEdge=e.findAt(coordinates=(W0/2+W1/2, 0.0, 0.0)),sketchPlaneSide=SIDE1,sketchOrientation=RIGHT, sketch=s, depth=W0+W1, flipExtrudeDirection=ON, keepInternalBoundaries=ON)s.unsetPrimaryObject()del mdb.models['Model-1'].sketches['__profile__']#定义零件P07_12的厚度p = mdb.models['Model-1'].parts['Part-1']f = p.facesfor i in range(0,n):pickedFaces07 = f.findAt(((0, H0/2, 400+i*2520),),((0, H0/2, 600+i*2520),),) p.assignThickness(faces=pickedFaces07, thickness=T7)p.Set(faces=pickedFaces07, name='P07_12_'+str(1+i))fp=[]for i in range(0,2):fp.append(f.findAt(((0, H0/2, 400+i*2520),),((0, H0/2, 600+i*2520),),))p.Set(faces=fp, name='P07_fp')#定义零件P08_12的厚度p = mdb.models['Model-1'].parts['Part-1']f = p.facesfor i in range(0,n):pickedFaces08 = f.findAt(((0, -H0/2, 400+i*2520),),((0, -H0/2, 600+i*2520),),) p.assignThickness(faces=pickedFaces08, thickness=T7)p.Set(faces=pickedFaces08, name='P08_12_'+str(1+i))#为中间隔板创建空腔#定义相关参数边界距离、圆角d0=100r0=100p = mdb.models['Model-1'].parts['Part-1']f1, e1 = p.faces, p.edgest = p.MakeSketchTransform(f.findAt(coordinates=(0, 0.0, 500.0)),sketchUpEdge=e.findAt(coordinates=(W0/2+W1/2, 0.0, 500.0)),sketchPlaneSide=SIDE1, sketchOrientation=RIGHT,origin=(0.0, 0.0, 500.0))s = mdb.models['Model-1'].ConstrainedSketch(name='__profile__',sheetSize=5910.0, gridSpacing=147.0, transform=t)g, v, d1, c = s.geometry, s.vertices, s.dimensions, s.constraintss.setPrimaryObject(option=SUPERIMPOSE)p = mdb.models['Model-1'].parts['Part-1']p.projectReferencesOntoSketch(sketch=s, filter=COPLANAR_EDGES)#创建矩形s.rectangle(point1=(-W0/2-W1/2+d0, H0/2-d0), point2=(W0/2+W1/2-d0, -H0/2+d0)) #创建圆角s.FilletByRadius(radius=r0,curve1=g[29], nearPoint1=(-W0/2-W1/2+d0, H0/2-d0), curve2=g[26], nearPoint2=(-W0/2-W1/2+d0, H0/2-d0))s.FilletByRadius(radius=r0, curve1=g[26], nearPoint1=(-W0/2-W1/2+d0, -H0/2+d0), curve2=g[27], nearPoint2=(-W0/2-W1/2+d0, -H0/2+d0)) s.FilletByRadius(radius=r0, curve1=g[27], nearPoint1=(W0/2+W1/2-d0, -H0/2+d0), curve2=g[28], nearPoint2=(W0/2+W1/2-d0, -H0/2+d0)) s.FilletByRadius(radius=r0, curve1=g[28], nearPoint1=(W0/2+W1/2-d0, H0/2-d0), curve2=g[29], nearPoint2=(W0/2+W1/2-d0, H0/2-d0))p = mdb.models['Model-1'].parts['Part-1']f1, d2 = p.faces, p.datumsp.CutExtrude(f.findAt(coordinates=(0, 0.0, 500.0)),sketchUpEdge=e.findAt(coordinates=(W0/2+W1/2, 0.0, 500.0)),sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, sketch=s, depth=L0, flipExtrudeDirection=OFF)s.unsetPrimaryObject()del mdb.models['Model-1'].sketches['__profile__']#开始建立梁Beam_1p = mdb.models['Model-1'].parts['Part-1']f, d = p.faces, p.datums#绘制参考面p.DatumPlaneByOffset(plane=f.findAt(coordinates=(W0/2, -H0/2, 100.0)),flip=SIDE2, offset=8.0)dp1 = d.keys()[-1]p = mdb.models['Model-1'].parts['Part-1']d = p.datumst = p.MakeSketchTransform(sketchPlane=d[dp1], sketchUpEdge=d[4].axis1,sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, origin=(0.0, 0.0,0.0))s = mdb.models['Model-1'].ConstrainedSketch(name='__profile__', sheetSize=31857.0, gridSpacing=796.0, transform=t)g, v, d1, c = s.geometry, s.vertices, s.dimensions, s.constraintss.setPrimaryObject(option=SUPERIMPOSE)p = mdb.models['Model-1'].parts['Part-1']#计算中间加强梁的数量if n%2==1:n1=n//2 n2=n//2 else:n1=n//2 n2=n//2-1 for i in range(0,n1):s.Line(point1=(-500-i*2520*2, W0/2+W1/2), point2=(-500-2520-i*2520*2,-W0/2-W1/2 )) for i in range(0,n2):s.Line(point1=(-500-2520-i*2520*2,-W0/2-W1/2), point2=(-500-2*2520-i*2520*2,W0/2+W1/2 ))#在基准平面dp1上面绘制梁p = mdb.models['Model-1'].parts['Part-1'] d2 = p.datums e = p.edgesp.Wire(sketchPlane=d2[dp1], sketchUpEdge=d2[4].axis1, sketchPlaneSide=SIDE1, sketchOrientation=RIGHT, sketch=s) s.unsetPrimaryObject()del mdb.models['Model-1'].sketches['__profile__'] edges1=[] for i in range(0,n-1): edges1.append (e.findAt(((0, -H0/2-8, 500+2520/2+i*2520),),)) p.Set(edges=edges1, name='Beam_1') ############################开始定义有限元分析的相关参数 #定义材料mdb.models['Model-1'].Material(name='steel')mdb.models['Model-1'].materials['steel'].Elastic(table=((210000.0, 0.3), )) mdb.models['Model-1'].materials['steel'].Density(table=((7.8e-06, ), ))#定义壳单元属性mdb.models['Model-1'].HomogeneousShellSection(name='shell', preIntegrate=OFF, material='steel', thicknessType=UNIFORM, thickness=10.0, thicknessField='', idealization=NO_IDEALIZATION, poissonDefinition=DEFAULT,thicknessModulus=None, temperature=GRADIENT, useDensity=OFF, integrationRule=SIMPSON, numIntPts=5) #赋所有壳单元属性p = mdb.models['Model-1'].parts['Part-1']for i in range(1,5):region1 = p.sets['P0'+str(i)+'_12']p.SectionAssignment(region=region1, sectionName='shell', offset=0.0,offsetType=FROM_GEOMETRY , offsetField='',thicknessAssignment=FROM_GEOMETRY )region2 = p.sets['P05_08']p.SectionAssignment(region=region2, sectionName='shell', offset=0.0, offsetType=FROM_GEOMETRY, offsetField='',thicknessAssignment=FROM_GEOMETRY)for i in range(1,n+1): Array region3 = p.sets['P06_08_'+str(i)]p.SectionAssignment(region=region3, sectionName='shell', offset=0.0,offsetType=FROM_GEOMETRY, offsetField='',thicknessAssignment=FROM_GEOMETRY)for i in range(1,n+1):region4 = p.sets['P07_12_'+str(i)]p.SectionAssignment(region=region4, sectionName='shell', offset=0.0,offsetType=FROM_GEOMETRY, offsetField='',thicknessAssignment=FROM_GEOMETRY)for i in range(1,n+1):region5 = p.sets['P08_12_'+str(i)]p.SectionAssignment(region=region5, sectionName='shell', offset=0.0,offsetType=FROM_GEOMETRY, offsetField='',thicknessAssignment=FROM_GEOMETRY)#定义梁单元属性mdb.models['Model-1'].LProfile(name='L_65', a=65.0, b=65.0, t1=7.0, t2=7.0)mdb.models['Model-1'].BeamSection(name='B_65', integration=DURING_ANALYSIS,poissonRatio=0.0, profile='L_65', material='steel', temperatureVar=LINEAR,consistentMassMatrix=False)#赋所有梁单元属性p = mdb.models['Model-1'].parts['Part-1']region = p.sets['Beam_1']p.SectionAssignment(region=region, sectionName='B_65', offset=0.0,offsetType=MIDDLE_SURFACE, offsetField='',thicknessAssignment=FROM_SECTION)p.assignBeamSectionOrientation(region=region, method=N1_COSINES, n1=(0.0, 0.0,-1.0))#定义装配体import assemblya = mdb.models['Model-1'].rootAssemblya.DatumCsysByDefault(CARTESIAN)p = mdb.models['Model-1'].parts['Part-1']a.Instance(name='Part-1-1', part=p, dependent=ON)#定义分析步import stepmdb.models['Model-1'].StaticStep(name='Step-1', previous='Initial')#定义底面与梁的tiedimport interactiona = mdb.models['Model-1'].rootAssemblyregion1=a.instances['Part-1-1'].sets['P04_12']region2=a.instances['Part-1-1'].sets['Beam_1']mdb.models['Model-1'].Tie(name='Constraint-1', master=region1, slave=region2, positionToleranceMethod=COMPUTED, adjust=OFF, tieRotations=ON, thickness=ON)#开始定义耦合#导入相关模块import regionToolseta = mdb.models['Model-1'].rootAssemblyd, r = a.datums, a.referencePoints#定义参考点a.ReferencePoint(point=(0.0, H0/2, 500+2520/2))rp1 = r.keys()[-1]refPoints1=(r1[rp1], )region1=regionToolset.Region(referencePoints=refPoints1)s1 = a.instances['Part-1-1'].facesregion2 = a.instances['Part-1-1'].sets['P07_fp']mdb.models['Model-1'].Coupling(name='Constraint-2', controlPoint=region1, surface=region2, influenceRadius=WHOLE_SURFACE, couplingType=DISTRIBUTING, localCsys=None, u1=ON, u2=ON, u3=ON, ur1=ON, ur2=ON, ur3=ON)#########################定义边界条件import loada = mdb.models['Model-1'].rootAssemblyd, r = a.datums, a.referencePointsregion = a.instances['Part-1-1'].sets['P02_12']mdb.models['Model-1'].DisplacementBC(name='SPC', createStepName='Initial', region=region, u1=SET, u2=SET, u3=SET, ur1=SET, ur2=SET, ur3=SET,amplitude=UNSET, distributionType=UNIFORM, fieldName='', localCsys=None)a = mdb.models['Model-1'].rootAssemblyregion = a.instances['Part-1-1'].sets['P08_12_'+str(n-1)]mdb.models['Model-1'].DisplacementBC(name='SPC2', createStepName='Initial', region=region, u1=SET, u2=SET, u3=SET, ur1=SET, ur2=SET, ur3=SET,amplitude=UNSET, distributionType=UNIFORM, fieldName='', localCsys=None)r1 = a.referencePointsrefPoints1=(r1[rp1], )region = regionToolset.Region(referencePoints=refPoints1)mdb.models['Model-1'].ConcentratedForce(name='force', createStepName='Step-1',region=region, cf2=-10000.0, distributionType=UNIFORM, field='',localCsys=None)mdb.models['Model-1'].Gravity(name='G', createStepName='Step-1', comp2=-9.8, distributionType=UNIFORM, field='')#################划分网格import meshp = mdb.models['Model-1'].parts['Part-1']p.seedPart(size=20.0, deviationFactor=0.1, minSizeFactor=0.1)p.generateMesh()a = mdb.models['Model-1'].rootAssembly###############创建作业并提交分析import jobmdb.Job(name='006', model='Model-1', description='', type=ANALYSIS, atTime=None, waitMinutes=0, waitHours=0, queue=None, memory=90,memoryUnits=PERCENTAGE, getMemoryFromAnalysis=True,explicitPrecision=SINGLE, nodalOutputPrecision=SINGLE, echoPrint=OFF,modelPrint=OFF, contactPrint=OFF, historyPrint=OFF, userSubroutine='',scratch='', multiprocessingMode=DEFAULT, numCpus=4, numDomains=4) mdb.jobs['006'].submit(consistencyChecking=ON)mdb.jobs['006'].waitForCompletion()###############进入后处理模块import visualizationo3 = session.openOdb(name='F:/ABAQUS/006.odb')session.viewports['Viewport: 1'].setValues(displayedObject=o3)session.viewports['Viewport: 1'].odbDisplay.display.setValues(plotState=( CONTOURS_ON_DEF, ))session.viewports['Viewport: 1'].view.setValues(session.views['Iso'])mdb.saveAs(pathName='F:/ABAQUS/006.cae')第11 页共11 页。
abaqus后处理22 后处理22.1 显示局部坐标系上的结果问:我前处理用的是直角坐标系,但是我想在后处理中输出关于柱坐标的位移分量是不是要设计局部的坐标系?怎样设计?答:后处理时点菜单tools / coordinates system / create, 创建柱坐标系(例如使用默认的名称csys-1). 菜单result / options, 点tranformation, 点user-specified, 选中csys-1, 点OK. 窗口左上角显示的变量如果原来是U, U1,现在就变为U,U1(CSYS-1).22.1 显示局部坐标系上的结果问:我前处理用的是直角坐标系,但是我想在后处理中输出关于柱坐标的位移分量是不是要设计局部的坐标系?怎样设计?答:后处理时点菜单tools / coordinates system / create, 创建柱坐标系(例如使用默认的名称csys-1). 菜单result / options, 点tranformation, 点user-specified, 选中csys-1, 点OK. 窗口左上角显示的变量如果原来是U, U1,现在就变为U,U1(CSYS-1).22.2 绘制曲线(X–Y data)问:例如我想用odb文件建立这样一个曲线:x y(自行指定)currentmax("my-xy01") 1.0currentmax("my-xy02") 3.3………………搜索了半天也找不到,在此向用过的前辈请教,或者有第三方软件也请指点。
(虽然我手工excel也能做,但是那个时间就……-_-b)答:后处理菜单 tools / XY Data / Create, 先创建你的"my-xy01",再选择Operate on XY Data,来建立公式。
详见 Getting Started with ABAQUS 附录D.11 Operating on X–Y data问:我在学习forming a channel例子的时候,发现帮助是将冲头力和位移画在一张图里了(图13-17,见getting started with abaqus),并且将explicit 和standard的结果也都画在一张图中了,可是我只能将field output的结果,也就是随时间变化的结果画出来,怎么修改x轴的输出量呢?答:后处理菜单tools / xy-data / manager,点create, 选odb field output,为每条曲线定义这样一个xy-data (两个不同的odb文件也没关系),选中多个xy-data, 点plot,就可以把它们画在一起。
abaqus中结果后处理⼩⽅法今天主要跟⼤家讲三个abaqus结果后处理的实⽤⼩⽅法。
后处理也是很重要的,毕竟好不容易把结果计算出来了,如果能通过⼀些⼩技巧使结果更清楚、漂亮的展⽰给⼤家,何乐⽽不为呢?下⾯是我经常⽤到的但是abaqus参考书很少提到的⼩技巧。
(1)合理调整图例⼤⼩Abaqus中odb⽂件默认的图例都⽐较⼩,如下图所⽰。
如果直接这样放在报告或⽂章⾥别⼈很难看清楚具体数值。
这时你需要调整图例⼤⼩,甚⾄是调整字体、颜⾊等,使图例更清楚直观。
点击上侧⼯具栏viewport下拉菜单,选择viewport annotation options,将会弹出下⾯的选项卡,在这⾥你可以设置compass、triad等等是否显⽰,点击legend选项卡,可以设置legend的⼤⼩、字体等。
(2)合理设置⽹格的存在与否在结果⽂件中,⽹格的存在往往会影响图⽚的美观性,⼤家可以对⽐下⾯这两张图,其他条件完全⼀致,前者有⽹格的存在,后者把⽹格去掉了。
由于设置的⽹格太密了,导致云纹图都看不清了,影响别⼈对结果最直观的观察。
这样整体的图⽚还是把⽹格去掉⽐较好,能更好的向⼤家展⽰结果。
那么怎样将⽹格去掉呢?具体操作步骤如下:点击上侧⼯具栏options,选择common选项卡,弹出下⾯的对话框在visible edges⼀项选择no edges就达到这样的效果啦。
(3)三维图像输出特定的⾯对于像下图中的三维图像,如果你只想输出某⼀个⾯的结果,你可能会想到⽤旋转、平移模型等⽅法,使你想要的那个⾯朝上。
但是这种⼿动⽅法很难将模型的⾓度调整好,多多少少会有⼀点偏移。
来源:谦谦有限元,版权归作者所有,旨在分享。
abaqus的python手册全文共四篇示例,供读者参考第一篇示例:一、Abaqus中Python的应用1. 调用Abaqus APIAbaqus提供了一个丰富的API,通过Python可以轻松地调用这些API来完成各种任务。
比如创建模型、定义边界条件、设置分析参数等。
用户可以通过编写Python脚本来实现自定义的分析过程。
2. 扩展Abaqus功能通过编写Python脚本,用户可以扩展Abaqus的功能,实现一些Abaqus原生功能不支持的功能。
比如可以编写一个脚本来实现特定的后处理功能,或者实现一些自定义的材料模型等。
3. 批量处理任务在实际工程中,通常需要进行大量的有限元分析任务。
通过编写Python脚本,可以实现批量处理任务,提高工作效率。
比如可以编写一个循环来处理多个模型,或者实现并行计算等。
4. 与其他软件集成Python是一种通用的编程语言,可以方便地与其他软件集成。
比如可以通过Python脚本实现Abaqus和CAD软件(比如SolidWorks)的数据交互,或者实现Abaqus和MATLAB的联合分析等。
1. 环境搭建首先需要在电脑上安装Abaqus和Python环境。
Abaqus支持Python2.7和Python3.6及以上版本。
安装完Abaqus后,需要在Abaqus命令窗口中输入“abaqus cae nogui=python”命令进入Python环境。
2. Python基础知识在使用Abaqus的Python API之前,需要掌握一些基本的Python知识。
比如变量、循环、条件语句等。
可以通过在线教程或书籍学习Python的基础知识。
下面我们来看一个简单的Python脚本示例,实现一个简单的有限元分析任务:```pythonfrom abaqus import *from abaqusConstants import *# 创建一个模型myModel = mdb.Model(name='ExampleModel')myAssembly = myModel.rootAssemblymyPart = myModel.Part(name='Part-1',dimensionality=THREE_D, type=DEFORMABLE_BODY)# 创建一个立方体myPart.Cube(center=(0, 0, 0), size=10.0)# 后处理odb = session.odbs['ExampleJob.odb']session.viewports['Viewport:1'].setValues(displayedObject=odb)```以上示例演示了如何使用Python脚本创建一个简单的有限元模型,并进行力学分析。
Abaqus中Python后处理详解By NUAAPh.D Kong Xianghong2013/04/23下图是Abaqus ODB文件的数据结构,后处理操作主要对以下两步分进行操作:1) 对场变量的读取路径:odb.setps[].frames[].fieldOutputs[]2) 对历史变量的读取路径:odb.setps[].historyRegions[].historyOutputs[]1 Abaqus ODB 文件数据结构2.1 创建3D实体Part创建截面为10×10mm,长度为20mm的拉伸体部件。
2.2 对3D实体Part划分单元模型建得比较小,划分单元也比较少,这样得到的odb文件也比较小,有助于更方便地了解odb文件的数据结构。
2.3 创建材料及截面2.4 给Part赋材料属性及创建装配实例2.5 创建分析步为了输出HistoryOutput,所以分析步的增了步设置了多步(10步)。
2.6 编辑场输出变量2.7 为历史输出变量创建Node Set2.8 编辑历史输出变量2.9 创建边界条件施加边界条件的Region为Set-1。
2.10 施加载荷2.11 创建Job在Job编辑对话框的Parallelization标签页中也可定义并行计算的核数。
2.12 在Abaqus/CAE中查看分析结果3.1 打开关闭odb文件的方法方法一:from odbAccess import *myodb=openOdb('D:/.../Job-1.odb')myodb.close()方法二:import odbAccessmyodb=session.openOdb('D:/.../Job-1.odb')myodb.close()方法三:import visualizationmyodb=visualization.openOdb('D:/.../Job-1.odb')myodb.close()3.2 使用prettyPrint()方法查看odb 数据结构(1)在Abaqus 命令行借口中输入如下四行Python 程序:>>> from odbAccess import *>>> from textRepr import *>>> myodb=openOdb('Job-1.odb')>>> prettyPrint(myodb,1) 程序运行结果如右图所示,prettyPrint()的第2个参数表示打印odb文件数据的级数,可以逐渐调大该参数,观察打印结果。
注:当odb 文件在Abaqus的工作路径下时,使用openOdb()打开odb 文件时可以不用写路径。
3.2 使用prettyPrint()方法查看odb数据结构(1)prettyPrint()的第2个参数设为2时的打印结果,可以只关注steps下的数据。
3.3 使用getIndentedRepr()方法查看odb数据结构(1)在Abaqus/CAE命令行中输入以下Python程序,可以将odb文件数据打印到指定的文本文件中。
>>>from odbAccess import *>>>from textRepr import *>>>f1=open('D:/Report2.txt','w')>>>myodb=openOdb('Job-1.odb')>>>r=getIndentedRepr(myodb,2)>>>f1.write(r)>>>f1.close()>>>myodb.close()右图是将getIndentedRepr()方法第二个参数设为4时,打印到Report4.txt 文件中是odb 文件数据。
仔细观察文本文件中的数据结构,有助于更好的理解odb 文件的数据结构。
3.3 使用getIndentedRepr()方法查看odb 数据结构(2)3.4 在命令行接口中查看odb文件数据(1) >>> from odbAccess import * # 导入odbAccess模块>>> myodb=openOdb('Job-1.odb') # 打开odb文件>>> mystep=myodb.steps # odb.steps>>> mystep.keys() # 查看steps['Step-1']>>> step1=mystep['Step-1'] # 读取Step-1>>> step1.__members__ # 查看Step-1中的数据['acousticMass', 'acousticMassCenter', 'description', 'domain', 'eliminatedNodalDofs', 'frames', 'historyRegions','inertiaAboutCenter', 'inertiaAboutOrigin', 'loadCases', 'mass', 'massCenter', 'name', 'nlgeom', 'number', 'previousStepName', 'procedure', 'retainedEigenModes', 'retainedNodalDofs','timePeriod', 'totalTime']3.4 在命令行接口中查看odb文件数据(2)>>> frm=step1.frames # 读取odb.steps['Step-1'].frames >>> len(frm) # frams的长度11>>> frm10=frm[10] # 取frames[10],即frames[-1]>>> frm10.__members__ # 查看frames[10]['associatedFrame', 'cyclicModeNumber', 'description','domain', 'fieldOutputs', 'frameId', 'frameValue', 'frequency', 'incrementNumber', 'isImaginary', 'loadCase', 'mode']>>> fld=frm10.fieldOutputs # 取fieldOutputs>>> fld.keys() # 查看fieldOutputs中的键['E', 'S', 'U']3.4 在命令行接口中查看odb文件数据(3)>>> fldS=fld['S'] # 取应力S>>> fldS.__members__ # 查看S包含的数据['baseElementTypes', 'componentLabels', 'description','isComplex', 'locations', 'name', 'type', 'validInvariants','values']>>> val=fldS.values # 所有单元的应力数据>>> len(val)16>>> v1=val[0] # 取第一个单元的应力数据>>> v1.__members__ # 查看第一个单元包含的应力['baseElementType', ..., 'data', 'dataDouble', 'elementLabel', ..., 'inv3', ..., 'magnitude', ..., 'mises', 'nodeLabel','outOfPlanePrincipal', 'position', 'precision', 'press','sectionPoint', 'tresca', 'type']3.4 在命令行接口中查看odb文件数据(4)>>> dt=v1.data # 取单元应力S11,S22,....,S23 >>> dtarray([0.383725494146347, 0.383725494146347, -100.0,6.84141999931516e-16, -0.345002353191376, -0.345002353191376], 'f')>>> dt[0] # S110.38372549>>> dt[5] # S23-0.34500235>>> v1.mises # mises应力100.387283325195>>> v1.elementLabel #单元编号1Thanks!/kxh86/kxh86。