
第2章统计数据的描述——练习题
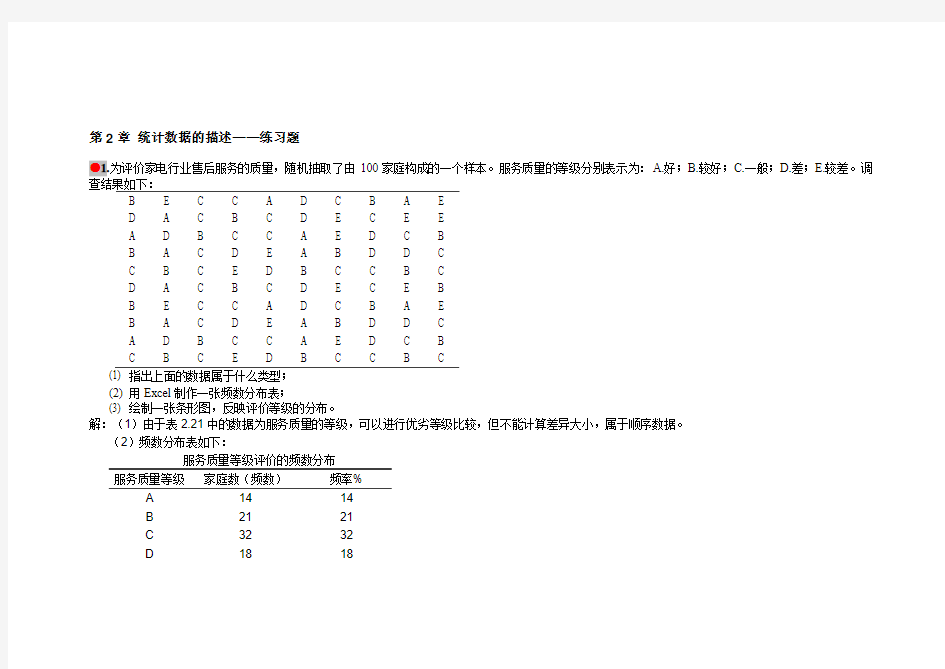
●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。调查结果如下:
B E
C C A
D C B A E
D A C B C D
E C E E
A D
B
C C A E
D C B
B A
C
D
E A B D D C
C B C E
D B C C B C
D A C B C D
E C E B
B E
C C A
D C B A E
B A
C
D
E A B D D C
A D
B
C C A E
D C B
C B C E
D B C C B C
(1) 指出上面的数据属于什么类型;
(2)用Excel制作一张频数分布表;
(3) 绘制一张条形图,反映评价等级的分布。
解:(1)由于表2.21中的数据为服务质量的等级,可以进行优劣等级比较,但不能计算差异大小,属于顺序数据。
(2)频数分布表如下:
服务质量等级评价的频数分布
服务质量等级家庭数(频数)频率%
A1414
B2121
C3232
D1818
E 15 15 合计
100
100
(3)条形图的制作:将上表(包含总标题,去掉合计栏)复制到Excel 表中,点击:图表向导→条形图→选择子图表类型→完成(见Excel 练习题2.1)。即得到如下的条形图:
20
40
A B C D E 服务质量等级评价的频数分布 频率%
服务质量等级评价的频数分布 家庭数(频数)
●2.为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下:
700 716 728 719 685 709 691 684 705 718
706 715 712 722 691 708 690 692 707 701 708 729 694 681 695 685 706 661 735 665 668 710 693 697 674 658 698 666 696 698 706 692 691 747 699 682 698 700 710 722 694 690 736 689 696 651 673 749 708 727 688 689 683 685 702 741 698 713 676 702 701 671 718 707 683 717 733 712 683 692 693
697
664
681
721
720 677 679 695 691 713 699 725 726 704 729
703
696
717
688
(1)利用计算机对上面的数据进行排序;
(2)以组距为10进行等距分组,整理成频数分布表,并绘制直方图;
(3)绘制茎叶图,并与直方图作比较。
解:(1)排序:将全部数据复制到Excel中,并移动到同一列,点击:数据→排序→确定,即完成数据排序的工作。(见Excel练习题2.4) (2)按题目要求,利用已排序的Excel表数据进行分组及统计,得到频数分布表如下:
(见Excel练习题2.4)
100只灯泡使用寿命非频数分布
按使用寿命分组(小时)灯泡个数(只)频率(%)
650~660 2 2
660~670 5 5
670~680 6 6
680~690 14 14
690~700 26 26
700~710 18 18
710~720 13 13
720~730 10 10
730~740 3 3
740~750 3 3
合计100 100
制作直方图:将上表(包含总标题,去掉合计栏)复制到Excel表中,选择全表后,点击:图表向导→柱形图→选择子图表类型→完成。即得到如下的直方图:
(见Excel练习题2.4)
5101520253065
0~
660670~680690~700710~720730~740
100只灯泡使用寿命非频数分布灯泡个数100只灯泡使用寿命非频数分布频率(%)
(3)制作茎叶图:以十位以上数作为茎,填入表格的首列,将百、十位数相同的数据的个位数按由小到大的顺序填入相应行中,即成为叶,
得到茎叶图如下:
65 1 8 66 1 4 5 6 8 67 1 3 4 6 7 9 68 1 1 2 3 3 3 4 5 5 5 8 8 9 9 69 0 0 1 1 1 1 2 2 2 3 3 4 4 5 5 6 6 6 7 7 8 8 8 8 9 9 70 0 0 1 1 2 2 3 4 5 6 6 6 7 7 8 8 8 9 71 0 0 2 2 3 3 5 6 7 7 8 8 9 72 0 1 2 2 5 6 7 8 9 9 73 3 5 6 74 1 4 7 将直方图与茎叶图对比,可见两图十分相似。
第5章 参数估计
●1.某快餐店想要估计每位顾客午餐的平均花费金额,在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1) 假定总体标准差为15元,求样本均值的抽样标准误差; (2) 在95%的置信水平下,求允许误差;
(3) 如果样本均值为120元,求总体均值95%的置信区间。 解:(1)已假定总体标准差为σ=15元, 则样本均值的抽样标准误差为 x σ=
n
σ=4915=2.1429
(2)已知置信水平1-α=95%,得 α/2Z =1.96,
于是,允许误差是E =n
α/2
σ
Z =1.96×2.1429=4.2000。 (3)已知样本均值为x =120元,置信水平1-α=95%,得 α/2Z =1.96, 这时总体均值的置信区间为 n
±α/2
σ
x Z =120±4.2=124.2115.8
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
x n
σ
σ=
15
49
=
=2.143 (2)在95%的置信水平下,求边际误差。
x x t σ?=?,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=2z α
因此,x x t σ?=?2x z ασ=?0.025x z σ=?=1.96×2.143=4.2 (3)如果样本均值为120元,求总体均值 的95%的置信区间。 置信区间为:
(),x x x x -?+?=()120 4.2,120 4.2-+=(115.8,124.2)
可知,如果样本均值为120元,总体均值95%的置信区间为(115.8,124.2)元。
5.2利用下面的信息,构建总体均值μ的置信区间:
1) 总体服从正态分布,且已知σ = 500,n = 15,
=8900,置信水平为95%。 解: N=15,为小样本正态分布,但σ已知。则1-α=95%,
。其置信区间公式为
∴置信区间为:8900±1.96×500÷√15=(8646.7 , 9153.2) 2) 总体不服从正态分布,且已知σ = 500,n = 35, =8900,置信水平为95%。
解:为大样本总体非正态分布,但σ已知。则1-α=95%,
。其置信区间公式为
∴置信区间为:8900±1.96×500÷√35=(8733.9 9066.1) 3) 总体不服从正态分布,σ未知,n = 35, =8900,s =500,置信水平为90%。
解:为大样本总体非正态分布,且σ未知,1-α=90%, 1.65。
2
α()
28.109,44.10192.336.10525
10
96.136.1052=±=?±=±n
z x σ
αx x x x 2
α()
28.109,44.10192.336.10525
10
96.136.1052=±=?±=±n
z x σ
αx x
其置信区间为: 8900±1.65×500÷√35=(8761 9039)
4) 总体不服从正态分布,σ未知,n = 35
,
=8900,s =500,置信水平为99%。 解:为大样本总体非正态分布,且σ未知,1- =99%,
2.58。
其置信区间为:8900±2.58×500÷√35=(8681.9 9118.1)
●3.某大学为了解学生每天上网的时间,在全校7500名学生中采取不重复抽样方法随机抽取36人,调查他们每天上网的时间,得到下面的数据(单位:小时):
3.3 3.1 6.2 5.8 2.3
4.1
5.4 4.5 3.2 4.4 2.0 5.4 2.6
6.4 1.8 3.5 5.7 2.3 2.1 1.9 1.2 5.1 4.3 4.2 3.6 0.8 1.5 4.7 1.4 1.2 2.9 3.5 2.4 0.5 3.6 2.5
求该校大学生平均上网时间的置信区间,置信水平分别为90%、95%和99%。
解:⑴计算样本均值x :将上表数据复制到Excel 表中,并整理成一列,点击最后数据下面空格,选择自动求平均值,回车,得到x =3.316667, ⑵计算样本方差s :删除Excel 表中的平均值,点击自动求值→其它函数→STDEV →选定计算数据列→确定→确定,得到s=1.6093
也可以利用Excel 进行列表计算:选定整理成一列的第一行数据的邻列的单元格,输入“=(a7-3.316667)^2”,回车,即得到各数据的离差平方,在最下行求总和,得到:
x x
∑2
i (x -x )=90.65
再对总和除以n-1=35后,求平方根,即为样本方差的值
s=
1
n -∑2i
(x -x )=
90.65
35
=1.6093。 ⑶计算样本均值的抽样标准误差: 已知样本容量 n =36,为大样本, 得样本均值的抽样标准误差为 x σ=
n
s =361.6093=0.2682
⑷分别按三个置信水平计算总体均值的置信区间:
① 置信水平为90%时:
由双侧正态分布的置信水平1-α=90%,通过2β-1=0.9换算为单侧正态分布的置信水平β=0.95,查单侧正态分布表得 α/2Z =1.64,
计算得此时总体均值的置信区间为
n
±α/2
s
x Z =3.3167±1.64×0.2682= 3.75652.8769
可知,当置信水平为90%时,该校大学生平均上网时间的置信区间为(2.87,3.76)小时;
② 置信水平为95%时:
由双侧正态分布的置信水平1-α=95%,得 α/2Z =1.96,
计算得此时总体均值的置信区间为
n
±α/2
s
x Z =3.3167±1.96×0.2682= 3.84232.7910
可知,当置信水平为95%时,该校大学生平均上网时间的置信区间为(2.79,3.84)小时;
③ 置信水平为99%时:
若双侧正态分布的置信水平1-α=99%,通过2β-1=0.99换算为单侧正态分布的置信水平β=0.995,查单侧正态分布表得 α/2Z =2.58,
计算得此时总体均值的置信区间为
n
±α/2
s
x Z =3.3167±2.58×0.2682= 4.00872.6247
可知,当置信水平为99%时,该校大学生平均上网时间的置信区间为(2.62,4.01)小时。
●4.某居民小区共有居民500户,小区管理者准备采取一项新的供水设施,想了解居民是否赞成。采取重复抽样方法随机抽取了50户,其中有32户赞成,18户反对。
(1)求总体中赞成该项改革的户数比率的置信区间,置信水平为95%; (2)如果小区管理者预计赞成的比率能达到80%,应抽取多少户进行调查? 解: 已知总体单位数N =500,重复抽样,样本容量n =50,为大样本,
样本中,赞成的人数为n 1=32,得到赞成的比率为 p =
n 1n =3250
=64% (1)赞成比率的抽样标准误差为
(1)p p n -=0.640.36
50
?=6.788% 由双侧正态分布的置信水平1-α=95%,得 α/2Z =1.96,
计算得此时总体户数中赞成该项改革的户数比率的置信区间为
(1)
p p p n
-±α/2
Z = 64%±1.96×6.788%=77.304%50.696%
可知,置信水平为95%时,总体中赞成该项改革的户数比率的置信区间为(50.70%,77.30%)。
(2)如预计赞成的比率能达到80%,即 p =80%, 由
(1)p p n -=6.788%,即0.80.2
n
?=6.788% 得样本容量为 n =
2
0.80.2
(6.788%)?= 34.72 取整为35,
即可得,如果小区管理者预计赞成的比率能达到80%,应抽取35户进行调查。
5.顾客到银行办理业务时往往需要等待一段时间,而等待时间的长短与许多因素有关,比如,银行业务员办理业务的速度,顾客等待排队的方式等。为此,某银行准备采取两种排队方式进行试验,第一种排队方式是:所有顾客都进入一个等待队列;第二种排队方式是:顾客在三个业务窗口处列队等待。为比较哪种排队方式使顾客等待的时间更短,银行各随机抽取10名顾客,他们在业务办理时所等待的时间(单位:分钟)如下:
方式1 6.5 6.6 6.7 6.8 7.1 7.3 7.4 7.7 7.7 7.7 方式2
4.2
5.4
5.8
6.2
6.7
7.7
7.7
8.5
9.3
10.0
要求:
(1) 构建第一种排队方式等待时间标准差的95%的置信区间 (2) 构建第二种排队方式等待时间标准差的95%的知心区间 (3) 根据(1)和(2)的结果,你认为哪种排队方式更好? 卷面解答过程: 解:已知n=10
(1) 根据抽样结果计算得
x =7.150
s=0.477
又∵α=0.05,由单方差得总体标准差σ的95%的置信区间为(6.809, 7.491);
(2) 根据抽样结果计算得
x =7.150
s=1.822
又∵α=0.05,由单方差得总体标准差σ的95%的置信区间为(5.847, 8.453)。
(3) 根据上面两道题目的答案可知,第一种排队方式所需等待的时间较为稳定,更为可取。 MINITAB 操作步骤:
(1) 输入数据→统计→基本统计量→单样本t →选择数据→选项:95%
MINITAB 显示: 单样本 T: C1
平均值
变量 N 平均值 标准差 标准误 95% 置信区间 C1 10 7.150 0.477 0.151 (6.809, 7.491)
(2) 同上
6.从两个正态总体中分别抽取两个独立的随机样本,它们的均值和标准差如下表:
来自总体1的样本 来自总体2的样本
141=n 72=n 2.531=x 4.432=x
8.9621=s
0.1022
2=s
(1) 求21μμ-90%的置信区间;
(2) 求21μμ-95%的置信区间。 解:(1.86,17.74);(0.19,19.41)。
7.一家人才测评机构对随机抽取的10名小企业的经理人采用两种方法进行自信心测试,得到的自信心测试分数如下:
人员编号 方法1
方法2
1 78 71 7
2 66 46 20
3 73 63 10
4 89 84
5 5 91 74 17
6 49 51 -2
7 6
8 55 13 8 76 60 16
9 85 77 8 10
55
39
16
试构建两种分方法自信心平均得分之差95%的置信区间。
解:11)
(x d 21i
=-=
∑n
x i
68.61
)(S 2
d =--=n d d i
因此,均值之差的0.95的置信区间为:
n
s d ?
±)9(t d 0.025
即:9
68.62.262211?
±
8.从两个总体中各抽取一个25021==n n 的独立随机样本,来自总体1的样本比率为%401=p ,来自总体2的样本比率为%302=p 。
(1)构造21ππ-90%的置信区间; (2)构造21ππ-95%的置信区间。
解:(1)10%±6.98%;(2)10%±8.32%。
7.25 从两个总体中各抽取一个12n n ==250的独立随机样本,来自总体1的样本比例为1p =40%,来自总体2的样本比例为2p =30%。要求:
(1)构造12ππ-的90%的置信区间。 (2)构造12ππ-的95%的置信区间。 解:总体比率差的估计
大样本,总体方差未知,用z 统计量
()()()
1212112212
11p p z p p p p n n ππ---=
--+()0,1N
样本比率p1=0.4,p2=0.3 置信区间:
()()()()1122112212212212121111,p p p p p p p p p p z p p z n n n n αα??---- ?--?+-+?+ ???
1α-=0.90,2z α=0.025z =1.645
()()()()1122112212212212121111,p p p p p p p p p p z p p z n n n n αα??---- ?--?+-+?+ ???
=()()()()0.410.40.310.30.410.40.310.30.1 1.645,0.1 1.645250250250250??
---- ?-?++?+
???
=(3.02%,16.98%)
1α-=0.95,2z α=0.025z =1.96
()()()()1122112212212212121111,p p p p p p p p p p z p p z n n n n αα??---- ?--?+-+?+ ??? =()()()()0.410.40.310.30.410.40.310.30.1 1.96,0.1 1.96250250250250??
---- ?-?++?+
???
=(1.68%,18.32%)
9、生产工序的方差是工序质量的一个重要度量。当方差较大时,需要对工序进行改进以减小方差。两部机器生产的袋茶重量(单位:g )的数据如下:
机器3.3.3.3.2.3.3.3.2.3.3.3.3.3.3.3.3.3.3.3.3.
1 4
5 20 22 50 95 1
6 20 22 98 75 38 45 48 18 90 70 28 35 20 12 25 机器2 3.2
2
3.38 3.30 3.30 3.34 3.28 3.30 3.28 3.19 3.20 3.29 3.35 3.16 3.34 3.35 3.30 3.05 3.33 3.27 3.28 3.25
。构造两个总体方差比2
2
21σσ的95%的置信区间。 答案:已知,
1x =3.33,21s =0.06,2x =3.27,2
2
s =0.006, 根据自由度n 1 =21-1=20和n 2=21-1=20,当置信区间为95%时,查F 分布表得:F α/2(20)= F 0.025(20)=2.12,根据公式),(1
),(1222121n n F n n F αα=-得,F 1-α/2(20)=1/2.12=0.47。再根据公式212
2
2122
2122221αασσ-≤
≤F s s F s s 得:4.7221.28,即两部机器生产的袋茶重量的总体方差比2
2
2
1
σσ的95%的置信区间为(4.72,21.28)。
●10.某超市想要估计每个顾客平均每次购物花费的金额。根据过去的经验,标准差大约为120元,现要求以95%的置信水平估计每个购物金额的置信区间,并要求允许误差不超过20元,应抽取多少个顾客作为样本?
解:已知总体标准差x σ=120,由置信水平1-α=95%,得置信度α/2Z =1.96,允许误差E ≤ 20
即由允许误差公式 E=/2
Z n
x ασ整理得到样本容量n 的计算公式:
n=2(
)E
α/2x
Z σ≥2
(
)20
?1.96120=138.2976 由于计算结果大于47,故为保证使“≥”成立,至少应取139个顾客作为样本。 解:222
2x
z n ασ?=
?,1α-=0.95,2z α=0.025z =1.96,
2222x
z n ασ
?=
?22
2
1.9612020
?==138.3,取n=139或者140,或者150。
11.假定两个总体的标准差分别为:121=σ,152=σ,若要求误差范围不超过5,相应的置信水平为95%,假定21n n =,估计两个总体均值之差21μμ-时所需的样本容量为多大? 解: 57。 n1=n2=()
12
2222122
x x z n ασσ-?+=
?
,1α-=0.95,2z α=0.025z =1.96,
n1=n2=()
12
2222122x x z n ασσ-?+=?=
()
2222
1.9612155?+=56.7,取n=57
12.假定21n n =,允许误差05.0=E ,相应的置信水平为95%,估计两个总体比率之差21ππ-时所需的样本容量为多大?
解:n1=n2=()()12
221122211p p z p p p p n α-?-+-????=?,1α-=0.95,2
z α=0.025z =1.96,取p1=p2=0.5,
n1=n2=()()12
2
211222
11p p z p p p p n α-?-+-????=?= ()22221.960.50.50.05?+=768.3,取n=769,或者780或800。
解: 769。
第六章 假设检验
1.依题意提出的假设 Ho :μ≤6.07,H1:μ>6.07
检验统计量Ζ=(7.25-6.70)/[2.5÷(200)?] Ζ=2.5
p 值=1-0.994=0.006 p<α,拒绝原假设
所以,这个调查能证明“如今每个家庭每天收看电视的平均时间增加了”。
第6章 假设检验
6.1 一项包括了200个家庭的调查显示,每个家庭每天看电视的平均时间为
7.25小时,标准差为2.5小时。据报道,10年前每天每个家庭看电视的平均时间是6.70小时。取显著性水平,这个调查能否证明“如今每个家庭每天收看电视的平均时间增加了”?
详细答案:
,=3.11,,拒绝,如今每个家庭每天收看电视的平均时间显著地增加了。
6.2 为监测空气质量,某城市环保部门每隔几周对空气烟尘质量进行一次随机测试。已知该城市过去每立方米空气中悬浮颗粒的平均值是82微克。在最近一段时间的检测中,每立方米空气中悬浮颗粒的数值如下(单位:微克):
81.6 86.6 80.0 85.8 78.6 58.3 68.7 73.2
96.6 74.9 83.0 66.6 68.6 70.9 71.7 71.6
77.3 76.1 92.2 72.4 61.7 75.6 85.5 72.5
74.0 82.5 87.0 73.2 88.5 86.9 94.9 83.0
根据最近的测量数据,当显著性水平时,能否认为该城市空气中悬浮颗粒的平均值显著低于过去的平均值?
详细答案:
,=-2.39,,拒绝,该城市空气中悬浮颗粒的平均值显著低于过去的平均值。
6.3 安装在一种联合收割机的金属板的平均重量为25公斤。对某企业生产的20块金属板进行测量,得到的重量数据如下:
22.6 26.6 23.1 23.5
27.0 25.3 28.6 24.5
26.2 30.4 27.4 24.9
25.8 23.2 26.9 26.1
22.2 28.1 24.2 23.6
假设金属板的重量服从正态分布,在显著性水平下,检验该企业生产的金属板是否符合要求?
详细答案:
,,,不拒绝,没有证据表明该企业生产的金属板不符合要求。
6.4 在对消费者的一项调查表明,17%的人早餐饮料是牛奶。某城市的牛奶生产商认为,该城市的人早餐饮用牛奶的比例更高。为验证这一说法,生产商随机抽取
550人的一个随机样本,其中115人早餐饮用牛奶。在显著性水平下,检验该生产商的说法是否属实?详细答案:
,,,拒绝,该生产商的说法属实。
6.5 某生产线是按照两种操作平均装配时间之差为5分钟而设计的,两种装配操作的独立样本产生如下结果:
第2章统计数据的描述——练习题 ●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C D E A B D D C A D B C C A E D C B C B C E D B C C B C (1) 指出上面的数据属于什么类型; (2)用Excel制作一张频数分布表; (3) 绘制一张条形图,反映评价等级的分布。 解:(1)由于表中的数据为服务质量的等级,可以进行优劣等级比较,但不能计算差异大小,属于顺序数据。 (2)频数分布表如下: 服务质量等级评价的频数分布 服务质量等级家庭数(频数)频率% A1414 B2121 C3232 D1818
E1515 合计100100 (3)条形图的制作:将上表(包含总标题,去掉合计栏)复制到Excel表中,点击:图表向导→条形图→选择子图表类型→完成(见Excel练习题。即得到如下的条形图: 700716728719685709691684705718 706715712722691708690692707701 708729694681695685706661735665 668710693697674658698666696698 706692691747699682698700710722 694690736689696651673749708727 688689683685702741698713676702 701671718707683717733712683692 693697664681721720677679695691 713699725726704729703696717688 (1)利用计算机对上面的数据进行排序;
第二章定量变量的描述性统计(中大.公卫学院.医学统计与流行病学系.骆福添.020-********) 第一节频数分布 ·收集到的数据必须给读者介绍一下,例2-1数据 怎么讲,读出来? 介绍特征,有何特征? ·例:肿瘤什么年龄多发?对发病年龄分组整理 ·脉搏:不妨对脉搏进行分组整理 一、频数分布表 例2-1测得130健康成年男子脉搏资料(次/分)如下,试编制频数表和观察频数分布情况。 66 77 64 67 76 75 75 71 65 62 76 72 71 60 67 75 75 73 79 66 69 79 78 70 72 70 72 78 72 67 72 80 68 70 61 70 73 72 71 81 70 66 75 71 63 77 74 76 68 65 77 69 77 75 79 64 79 73 76 61 80 64 69 70 73 68 65 70 69 66 81 63 64 80 74 78 76 66 70 73 60 76 82 73 64 65 73 73 63 80 68 76 70 79 77 64 70 66 69 73 78 76 制作频数表的步骤为: 1.计算极差极差R=84 -57=27 (次/分)。 2.决定组数、组距和组段 (1)组数:10组左右 (2)组距:等组距(取方便数) (3)组段:下限(最小值)、上限(最大值.空穴)、组中值(代表值.正中)注意:组段应包含全部数据(上下封顶、取方便数) 3.列表划记特别简单、特难全对 表2-1 130名健康成年男子脉搏(次/分)的频数分布表 组段划记频数相对频数(%) 频数频数(%) (1) (2) (3) (4)=(3)/N(5)=(3) (6)=(5)/N 56~ 2 1.54 2 1.54 59~正 5 3.85 7 5.38 62~正正12 9.23 19 14.62 65~正正正15 11.54 34 26.15 68~正正正正正25 19.23 59 45.38 71~正正正正正一26 20.00 85 65.38 74~正正正19 14.62 104 80.00 77~正正正15 11.54 119 91.54 80~正正10 7.69 129 99.23 83~85 一 1 0.77 130 100.00 合计130 ·频数表有2个重要特征: (1)集中趋势划记的杠杠(数据)多数向中间集中 (2)离散趋势划记的杠杠(数据)少数向两头分散
第2章统计数据的描述 练习: 2.1为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。服务质量的 等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C D E A B D D C A D B C C A E D C B C B C E D B C C B C (1) 指出上面的数据属于什么类型; (2)用Excel制作一张频数分布表; (3) 绘制一张条形图,反映评价等级的分布。 2.2某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元): 152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 97 88 123 115 119 138 112 146 113 126 (1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率; (2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业, 105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。 2.3某百货公司连续40天的商品销售额如下(单位:万元): 41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42 36 37 37 49 39 42 32 36 35 根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。 2.4为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果 如下: 700 716 728 719 685 709 691 684 705 718 706 715 712 722 691 708 690 692 707 701
第二章统计数据的描述 一、填空题: 1.统计分组有等距分组与异距分组两大类。 2. 频率是每组数据出现的次数与全部次数之和的比值。 3. 统计分组的关键在于确定组数和组距。 4. 统计表从形式上看,主要由表头(总标题)、横行标题、纵栏标题和数字资料(指标数值)四部分组成。 5. 均值是测度集中趋势最主要的测度指标,标准差是测度离散趋势最主要的测度指标。 6.当平均水平和计量单位不同时,需要用变异系数(离散系数)来测度数据之间的离散程度。 7.众数是一组数据中出现次数最多的变量值。 8.对于一组数据来说,四分位数有 3 个。 二、单项选择题: 1. 次数是分配数列组成的基本要素之一,它是指( B )。 A、各组单位占总体单位的比重 B、分布在各组的个体单位数 C、数量标志在各组的划分 D、以上都不对 2. 某连续变量数列,其末组为600以上。又如其邻近组的组中值为560,则末组的组中值为 ( D )。 A、620 B、610 C、630 D、640 3. 变量数列中各组频率的总和应该是( B )。 A、小于1 B、等于1 C、大于1 D、不等于1 4. 某连续变量数列,其首组为500以下。又如其邻近组的组中值为520,则首组的组中值为 ( C )。 A、460 B、470 C、480 D、490 5. 在下列两两组合的指标中,哪一组的两个指标完全不受极端数值的影响(D ) A、算术平均数和调和平均数 B、几何平均数和众数 C、调和平均数和众数 D、众数和中位数 6. 在编制等距数列时,如果全距等于56,组数为6,为统计运算方便,组距应取(D )
A、9.3 B、9 C、6 D、10 7. 一项关于大学生体重的调查显示,男生的平均体重是60公斤,标准差为5公斤;女生的平均体重是50公斤,标准差为5公斤.据此数据可以推断( B) 用变异系数算 A、男生体重的差异较大 B、女生体重的差异较大 C、男生和女生的体重差异相同 D、无法确定 8. 某生产小组有9名工人,日产零件数分别为10,11,14,12,13,12,9,15,12.据此数据计算的结果是( A ) 众数12 中位数12 平均数12 A、均值=中位数=众数 B、众数>中位数>均值 C、中位数>均值>众数 D、均值>中位数>众数 9. 按连续型变量分组,最后一组为开口组,下限值为2000。已知相邻组的组距为500,则最后一组组中值为(B ) A、2500 B、2250 C、2100 D、2200 10. 下列数据是某班所有学生的统计学考试成绩:72,90,91,84,85,57,90,84,77,84,69,77,66,87,85,95,86,78,86,45,87,92,73,82。这些成绩的极差是(B) A、78 B、50 C、45 D、40 11. 下列关于众数的叙述中,不正确的是( C ) A、一组数据可能存在多个众数 B、一组数据可能没有众数 C、一组数据的众数是唯一的 D、众数不受极端数值的影响 三、多项选择题: 1. 下列分组哪些是按品质标志分组?(BCDE ) A、职工按工龄分组 B、科技人员按职称分组 C、人口按民族分组 D、企业按所有制分组 E、人口按地区分组 F、职工按收入水平分组 2. 下列分组哪些是按数量标志分组(AF )。 A、职工按工龄分组 B、科技人员按职称分组 C、人口按民族分组 D、企业按所有志分组 E、人口按地区分组 F、职工按收入水平分组 3. 下列哪些属于离散程度的测度指标(BDE )。 A、几何平均数 B、极差 C、中位数 D、方差 E、离散系数 4. 下列哪些属于集中趋势的测度指标(AC )。
第2章 定量资料的统计描述 案例2-1(P27) 答:该资料为一正常人群发汞值的检测结果,已整理成频率分布表(P27)。统计描述时应首先考察资料的分布规律,通过频率(频数)分布表(表2-9 P27)和直方图(图2-3 P14)可以看出,此238人发汞值的频数分布呈正偏态分布,即观察值绝大多数集中在发汞值较小的组段。 对偏态分布,选用算术均数和标准差进行统计描述是不恰当的。应选用中位数描述该市居民发汞平均水平,选用四分位间距描述居民发汞值变异度,计算如下: 25507523.5(23825%20) 4.7(mol/kg) 6625.5(23850%86) 6.6(mol/kg) 602 7.5(23875%146)8.9(mol/kg) 48(%) x x L x i P L n x f f P u P u P u =+?==+?==+?==+?S
离散程度指标: 四分位间距=P75-P25=8.9-4.7=4.2umol/kg。 故该市居民发汞平均水平为6.6 umol/kg,离散度为4.2umol/kg,
思考与练习(P31) 1. 答: (1) 某年某地120例6-7岁正常男童胸围测量结果(cm)的频数分布 Group Frequency Percent Cumulative Percent 49.0- 1 .8 .8 50.0- 4 3.3 4.2 51.0- 8 6.7 10.8 52.0- 6 5.0 15.8 53.0- 19 15.8 31.7 54.0- 18 15.0 46.7 55.0- 14 11.7 58.3 56.0- 26 21.7 80.0 57.0- 10 8.3 88.3 58.0- 9 7.5 95.8 59.0- 4 3.3 99.2 61.0-62.0 1 .8 100.0 Total 120 100.0
第2章统计描述 思考与练习参考答案 一、最佳选择题 1. 编制频数表时错误的作法是( E )。 A. 用最大值减去最小值求全距 B. 组距常取等组距,一般分为10~15组 C. 第一个组段须包括最小值 D. 最后一个组段须包括最大值 E. 写组段,如“~3,3~5, 5~,…” 2. 描述一组负偏峰分布资料的平均水平时,适宜的统计量是(A)。 A. 中位数 B. 几何均数 C. 调和均数 D. 算术均数 E. 众数 3. 比较5年级小学生瞳距和他们坐高的变异程度,宜采用(A)。 A. 变异系数 B. 全距 C. 标准差 D. 四分位数间距 E. 百分位数与的间距 4. 均数X和标准差S的关系是(A)。 A. S越小,X对样本中其他个体的代表性越好 B. S越大,X对样本中其他个体的代表性越好 C. X越小,S越大 D. X越大,S越小 E. S必小于X 5. 计算乙肝疫苗接种后血清抗-HBs的阳转率,分母为(B)。 A. 阳转人数 B. 疫苗接种人数 C. 乙肝患者数 D. 乙肝病毒携带者数 E. 易感人数 6. 某医院的院内感染率为人/千人日,则这个相对数指标属于(C)。 A. 频率 B. 频率分布 C. 强度 D. 相对比 E. 算术均数 7. 纵坐标可以不从0开始的图形为(D)。
A. 直方图 B. 单式条图 C. 复式条图 D. 箱式图 E. 以上均不可 二、简答题 1. 对定量资料进行统计描述时,如何选择适宜的指标 答:详见教材表2-18。 教材表2-18 定量资料统计描述常用的统计指标及其适用场合 描述内容指标意义适用场合 平均水平均数个体的平均值对称分布 几何均数平均倍数取对数后对称分布 中位数位次居中的观察值 ①非对称分布;②半定量资料;③末端开 口资料;④分布不明 众数频数最多的观察值不拘分布形式,概略分析 调和均数基于倒数变换的平均值正偏峰分布资料 变异度全距观察值取值范围不拘分布形式,概略分析 标准差(方差)观察值平均离开均数的 程度 对称分布,特别是正态分布资料 四分位数 间距居中半数观察值的全距 ①非对称分布;②半定量资料;③末端开 口资料;④分布不明 变异系数标准差与均数的相对比 ①不同量纲的变量间比较;②量纲相同但 数量级相差悬殊的变量间比较 2. 举例说明频率和频率分布的区别和联系。 答:2005年某医院为了调查肺癌患者接受姑息手术治疗1年后的情况,被调查者150人,分别有30人病情稳定,66人处于进展状态,54人死亡。 当研究兴趣只是了解死亡发生的情况,则只需计算死亡率54/150=36%,属于频率指标。当研究者关心患者所有可能的结局时,则可以算出反映3种结局的频率分别为20%、44%、36%,它们共同构成所有可能结局的频率分布,是若干阳性率的组合。
第二章统计数据的描述 一、单项选择题 1.当数据呈对称分布或接近对称分布时,应选择( )作为集中趋势的代表值。 A .众数 B .均值 C .中位数 D .几何平均数 2.( )是用来对两组数据的差异程度进行相对比较的。 A .标准差 B .离散系数 C .平均差 D .全距 3.由组距数列确定众数时,如果众数相邻两组的次数相等时,则( )。 A .众数为零 B .众数就是那个最大的变量值 C .众数组的组中值就是众数 D .众数就是当中那一组的变量值 4.某连续变量数列,其首组为50以下。又知其邻近组的组中值为75,则首组的组中值为( ) A 24 B 25 C 26 D 27 5.两组数据相比较( )。 A.标准差大的离散程度也就大 B.标准差大的离散程度就小 C .离散系数大的离散程度也就大 D.离散系数大的离散程度就小 6.某连续变量分为5组:第一组为40—50,第二组为50—60,第三组为60—70,第四组为70—80,第五组为80以上,则( ) A.50在第一组,70在第四组 B.60在第三组,80在第五组 C.70在第三组,80在第五组 D.80在第四组,50在第二组 7.若某总体次数分布呈左偏分布,则成立的有()。 A.x >e M >o M B.x
第2章 统计数据的描述 练习: 2 比较哪个企业的总平均成本高?并分析其原因。 2. 11在某地区抽取的120家企业按利润额进行分组,结果如下: 按利润额分组(万元) 企业数(个) 200~300 19 300~400 30 400~500 42 500~600 18 600以上 11 合计 120 计算120家企业利润额的均值和标准差。 2. 12对10名成年人和10名幼儿的身高(厘米)进行抽样调查,结果如下: 成年组 166 169 172 177 180 170 172 174 168 173 幼儿组 68 69 68 70 71 73 72 73 74 75 (1)要比较成年组和幼儿组的身高差异,你会采用什么样的指标测度值?为什么? (2)比较分析哪一组的身高差异大? 答案 2.10 (1)甲企业平均成本=19.41(元),乙企业平均成本=18.29(元);原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。 2.11 x =426.67(万元);48.116=s (万元)。 2.12 (1)离散系数,因为它消除了不同组数据水平高地的影响。 (2)成年组身高的离散系数: 024.01.1722 .4== s v ; 幼儿组身高的离散系数: 032.03.713 .2== s v ; 由于幼儿组身高的离散系数大于成年组身高的离散系数,说明幼儿组身高的离散程度 相对较大。
第5章参数估计 练习: 5.1从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25。 (1)样本均值的抽样标准差x σ等于多少? (2)在95%的置信水平下,允许误差是多少? 5.2某快餐店想要估计每位顾客午餐的平均花费金额,在为期3周的时间里选取49名顾客 组成了一个简单随机样本。 (1)假定总体标准差为15元,求样本均值的抽样标准误差; (2)在95%的置信水平下,求允许误差; (3)如果样本均值为120元,求总体均值95%的置信区间。 5.3某大学为了解学生每天上网的时间,在全校7500名学生中采取不重复抽样方法随机抽 取36人,调查他们每天上网的时间,得到下面的数据(单位:小时): 3.3 3.1 6.2 5.8 2.3 4.1 5.4 4.5 3.2 4.4 2.0 5.4 2.6 6.4 1.8 3.5 5.7 2.3 2.1 1.9 1.2 5.1 4.3 4.2 3.6 0.8 1.5 4.7 1.4 1.2 2.9 3.5 2.4 0.5 3.6 2.5 求该校大学生平均上网时间的置信区间,置信水平分别为90%、95%和99%。 5.4从一个正态总体中随机抽取容量为8 的样本,各样本值分别为:10,8,12,15,6,13,5,11。 求总体均值95%的置信区间。 5.5某居民小区为研究职工上班从家里到单位的距离,抽取了由16个人组成的一个随机样 本,他们到单位的距离(公里)分别是: 10 3 14 8 6 9 12 11 7 5 10 15 9 16 13 2 求职工上班从家里到单位平均距离95%的置信区间。 5.6在一项家电市场调查中,随机抽取了200个居民户,调查他们是否拥有某一品牌的电视 机。其中拥有该品牌电视机的家庭占23%。求总体比率的置信区间,置信水平分别为90%和95%。 5.7某居民小区共有居民500户,小区管理者准备采取一向新的供水设施,想了解居民是否 赞成。采取重复抽样方法随机抽取了50户,其中有32户赞成,18户反对。 (1)求总体中赞成该项改革的户数比率的置信区间,置信水平为95%; (2)如果小区管理者预计赞成的比率能达到80%,应抽取多少户进行调查? 答案 5.1 (1) 79 .0 = x σ;(2)E=1.55。 5.2 (1) 14 .2 = x σ;(2)E=4.2;(3)(115.8,124.2)。 5.3 (2.88,3.76);(2.80,3.84);(2.63,4.01)。 5.4 (7.1,12.9)。 5.5 (7.18,11.57)。 5.6 (18.11%,27.89%);(17.17%,22.835)。
第一章统计数据的描述习题及答案 1.简述众数、中位数和均值的特点和应用场合。 答:众数、中位数和均值是分布集中趋势的三个主要测度,众数和中位数是从数据分布形状及位置角度来考虑的,而均值是对所有数据计算后得到的。众数容易计算,但不是总是存在,应用场合较少;中位数直观,不受极端数据的影响,但数据信息利用不够充分;均值数据提取的信息最充分,但受极端数据的影响。 2.为什么要计算离散系数? 答:在比较二组数据的差异程度时,由于方差和标准差受变量值水平和计量单位的影响不能直接比较,由此需计算离散系数作为比较的指标。 3.某百货公司6月份各天的销售额数据如下(单位:万元): 257 276 297 252 238 310 240 236 265 278 271 292 261 281 301 274 267 280 291 258 272 284 268 303 273 263 322 249 269 295 (1)计算该百货公司日销售额的均值、中位数和四分位数;(2)计算日销售额的标准差。 解:(1)将全部30个数据输入Excel表中同列,点击列标,得到30个数据的总和为8223,于是得该百货公司日销售额的均值: 或点选单元格后,点击“自动求和”→“平均值”,在函数EVERAGE()的空格中输入“A1:A30”,回车,得到均值也为274.1。在Excel表中将30个数据重新排序,则中位数位于30个数据的中间位置,即靠中的第15、第16两个数272和273的平均数: 由于中位数位于第15个数靠上半位的位置上,所以前四分位数位于第1~第15个数据的中间位置(第8位)靠上四分之一的位置上,由重新排序后的Excel表中第8位是261,第15位是272,从而: 同理,后四分位数位于第16~第30个数据的中间位置(第23位)靠下四分之一的位置上,由重新排序后的Excel表中第23位是291,第16位是273,从而: (2)未分组数据的标准差计算公式为:
C语言程序设计详解 第二章数据描述与基本操作 一、主要知识点 (一)C的基本类型节 (二)常量和符号常量 1、常量定义:在程序运行过程中,其值不能被改变的量称为常量。常量常区分不同的类型,如1 2、0、-3为整型常量,‘a’、‘D’为字符常量。 2、符号常量:用一个标示符代表一个常量的,称为符号常量,即标示符形式的常量。常量不同于变量,它的值在作用域不能改变,也不能再被赋值。 (三)变量 1、变量定义:其值可以改变的量称为变量。 2、标识符的命名规范和其它高级语言一样,用来标识变量名、符号常量名、函数名、数组名、类型名、文件名的有效字符序列称为标识符,C语言中的标识符命名规范为:○1变量名只能由字母、数字和下划线三种字符组成,且第一个字符必须是字母或者下划线。 ○2C语言中标识符的长度(字符个数)无统一规定,随系统而不同。许多系统取前7个字符。 ○3C语言有32个关键字它们已有专门含义,不应该采用与它们同名的变量名。 ○4C语言将大小写字母认为是两个不同字。习惯上符号常量名用大写,变量名用小写来示区别,但大写字母作变量名并无错误。 (四)整型数据 1、整型常量 整型常量即整常数。C语言整常数可用以下三种表示形式。 ○1十进制表示。如321,-234,34.324 ○2八进制表示。以0开头的数是八进制数。如0123
○3十六进制表示。以Ox开头的数是16进制。如Ox123 2、整型变量 整型变量分为:基本型、短整型、长整型和无符号型4种。 ○1基本型,以int表示 ○2短整型,以short int表示或short表示 ○3长整型,以long int表示或long表示 ○4无符号型,存储单元中全部二进制位(bit)用作存数本身,而不包括符号。 3、整型数据的取值范围 4、整型常量的分类 ○1一个整常量,如果其值在-32768~32767范围内,认为他是int型,他可以赋值给int 型和long int型变量。 ○2一个整常量,如果其值超过了上述范围,而在-2147483648~2147483647范围内,则认为它是long int型,可以将它赋值给一个ling int型变量。 ○3在一个整常量后面加一个字母l或L,则认为是ling int型常量。 (五)实型数据 1、实型常量 实数在C语言中又称为浮点数。实数有两种表示形式: ○1十进制形式。它由数字和小数点组成(注意必须有小数点)。例:0.123、.123、123.0、0.0都是hi十进制数形式。 ○2指数形式。如123.56e4或123.56E4都代表123.56 *10^4。但字母e(或E)之前必须有数字,e后面指数必须为整数。例如:e3、1.2e3.5、.e3、e都是不合法的指数形式。 例:下面四个选项中,均是不合法的浮点数的选项是 B 。 A、160. 0.12 e3 B、123 2e4.2 .e5 C、-.18 123e4 0.0 D、-.e3 .234 1e3 2、实型变量 C实型变量分为单精度(float型)和双精度(double型)两类。 在一般系统中,一个单精度型数据在内存中占4个字节(32位),一个double型数据占8个字节。一个单精度型变量能接收7位有效数字,一个double型变量能接收17位有效数字,数值的范围随机器系统而异。
第二章单变量和双变量统计描述分析 第一节单变量统计描述基本技术 一、变量的计量尺度/层次 1、定类变量——最低层次的变量类型。只有类别属性之分,无大小程度之分。根据变量值,只能知道研究对象的异同。从数学运算特性来看,定类变量只有等于或不等于的性质。 2、定序变量——层次高于定类变量。取值除类别属性外,还有等级、次序之分。数学运算特性除等于或不等于外,还有大于或小于。 3、定距变量——层次高于定序变量。取值除类别属性、次序之外,取值之间的距离可以用标准化的举例度量。数学运算特性除等于不等于,大于小于之外,还可以加减。如收入,以1元为标准化距离,则2000元比1500元多了500元。 4、定比变量——最高层次变量。除了上述三种属性外,可以进行乘除运算。 1、社会学研究中,能够满足定距而不能同时满足定比要求的变量不多。如智商,因为智商0分只有相对的意义,0分不等于没有智商,且0值不固定。当前社会统计方法很少要求达到定比层测,所以只介绍前三种层次变量。 2、在社会学研究当中,有些变量的层次是不统一可变的,可用定序层次也可用定距层次,根据研究需要。高层次变量可以降低层次来使用。一般来说,测量层次越高越好,数学特性就越多,统计分析就越方便,能了解资料的程度就越深入。 二、基本技术 1、次数分布(定类)——针对定类变量 最基本的统计分析方法。面对大量的数据资料,首先要组织整理,第一步就是要采用次数分布来简化资料,看某变量的每一个值出现的次数是多少。 定类变量的取值要求:变量取值必须完备,使得每个各观察值都有所归类;必须互斥,一个观察值只能归入一类,对于分组数据遵循上限不包括在内原则。 次数分布可简化资料,但不能比较样本,因为样本量不同。 2、比、比例和比率(通常保留一位或两位小数) 比:某两类的次数相除,如性别比=男性/女性 比例:某类次数除以总数,老年人口比例=老年人口数/总人口数×100% 比率:某一确定变量相对应的某些事件发生的频率。分子和分母不存在隶属关系,有时是不同的变量,如人均GDP,患病率。 3、累加次数和累加百分比(定序和定距)
第二章描述性统计命令与输出结果说明 上述数据也可以用变量x表示血磷测定值,分组变量group=0表示患者组和group=1表示健康组(如:患者组中第一个数据为2.6,则x=2.6,group=0;又如:健康组中第三个数据为1.98,则x为1.98以及group为1),并假定这些数据已以STATA格式存入ex2a.dta文件中。 计算资料均数,标准差命令summarize,以述资料为例: . summarize Variable Obs Mean Std. Dev. Min Max x1 11 4.710909 1.302977 2.6 6.53 x2 13 3.354615 1.304368 1.67 5.78 Mean 均值;Std.Dev.标准差 即:本例中急性克山病患者组的样本数为11,血磷测定值均数为4.711(mg%),相应的标准差为1.303,最小值为2.6以及最大值为6.53;健康组的样本量为13,血磷测定值均数为3.3546,相应的标准差为1.3044,最小值为1.67以及最大值为5.78。 计算资料均数,标准差,中位数,低四分位数和高四分位数的命令summarize 以及子命令detail,仍以述资料为例:
. summarize x1 x2,detail x1 Percentiles Smallest 1% 2.6 2.6 5% 2.6 3.24 10% 3.24 3.73 Obs 11 25% 3.73 3.73 Sum of Wgt. 11 50% 4.73 Mean 4.710909 Largest Std. Dev. 1.302977 75% 5.78 5.58 90% 6.4 5.78 Variance 1.697749 95% 6.53 6.4 Skewness -.0813446 99% 6.53 6.53 Kurtosis 1.809951 x2 Percentiles Smallest 1% 1.67 1.67 5% 1.67 1.98 10% 1.98 1.98 Obs 13 25% 2.33 2.33 Sum of Wgt. 13 50% 3.6 Mean 3.354615 Largest Std. Dev. 1.304368 75% 4.17 4.17 90% 4.82 4.57 Variance 1.701377 95% 5.78 4.82 Skewness .2963943 99% 5.78 5.78 Kurtosis 1.875392 . 结果: Percentiles 显示了从1%到99%的分位数的取值。第二列是最小和最大的5个数。第三列从上到下:obs观测值数目、mean平均数、std.dev标准差、variance 方差。 skewness偏度:偏度的绝对值越小,表明该数据的正态对称性越好。 kurtosis峰度:峰度值越大表明该数据的正态峰越明显。 95%可信限计算: 正态数据:ci 变量名 0-1 数据:ci 变量名,binomial poisson分布数据:ci变量名,poisson 90%可信限计算(其它可信限类推) 正态数据:ci 变量名,level(90) 0-1数据:ci 变量名,level(90) binomial poisson分布数据:ci 变量名,level(90) poisson ci x1 x2 . ci x1 x2 Variable Obs Mean Std. Err. [95% Conf. Interval] x1 11 4.710909 .3928624 3.835557 5.586261 x2 13 3.354615 .3617667 2.566393 4.142837 [95%Conf.Interval]为95%的可信限,因此x1的95%可信限为[3.8356,5.5863],x2的95%可信限为[2.5664,4.1428]。 根据样本数,样本均数和标准差计算可信限。
第二章数据分布特征的测度 对数据分布特征主要从三个方面进行测度和描述:一是分布的集中趋势,反映数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏斜程度和峰度。本章主要介绍如何使用函数以及“数据分析”工具对数据分布特征进行测度和描述。 第一节函数的介绍 本节主要介绍在统计分析中需要用到的一些函数,其中包括我们本章(描述统计)中以及在概率分布、参数估计与假设检验、方差分析、相关与回归等分析中涉及到的函数,读者在后面章节的学习中可以参阅本节的内容。 一、统计计算中经常用到的函数(函数列表)★ Excel为用户提供了数学、三角函数、统计函数、数据库函数、财务函数、工程函数、逻辑函数、文本函数、时间和日期函数、信息函数、查找和引用函数等10类300多种,可以满足多方面的需要。其中,统计函数最多达78种;此外还有14种数据库函数,以及在统计中经常使用的数学函数20种,合计112种。下面将这些函数名称及功能列表显示。 ★本小节摘自: 安维默主编,《统计电算化》第34~37页,中国统计出版社,2000
表2-1 可用于统计分析的函数(续2)
1、函数的语法 工作表函数包括两个部分:函数名和紧跟的一个或多个参数。函数名,例如SUM和A VERAGE,表明函数要执行的操作;参数则指定函数所使用的值或单元格。例如,在公式“=SUM(C3:C5)”中,SUM为函数名,C3:C5为参数。此函数计算单元格C3、C4和C5中值的总和。函数的参数可以为数值类型。例如,公式“=SUM(327,209,176)”中的SUM 函数将数字327、209和176求和。不过通常的做法是,先在工作表的单元格中输入使用的数字,然后将这些单元格作为函数的参数使用。请注意函数参数两端的括号:开括号表示参数的开始,必须紧跟在函数名后。如果在函数名和括号之间输入了空格或其他字符,那么Excel会显示错误信息“Microsoft Excel 在公式中发现了错误。建议更正如下:是否接受建议的修改?”如果单击【是】按钮,则Excel会自动更新公式;如果单击【否】按钮,则单元格中将显示错误值﹟NAME?。 如果在函数中使用多个参数,则要用逗号将参数隔开。例如,公式“=PRODUCT (C1,C2,C5)”告诉Excel将单元格C1,C2,和C5的数值相乘。函数中可使用的参数多达30个,但公式的长度不能超过1024个字符。参数可以是工作表中包括任意数目单元格的区域。例如,函数“=SUM(A1:A5,C2:C10,D3:D7)”只有3个参数,但对29个单元格的数据进行求和运算(第一个参数A1:A5,指从A1到A5的所有单元格,依此类推)。反过来,引用的单元格中也可以包括公式,这些公式引用更多的单元格或单元格区域。使用这些参数,就可以轻松地创建复杂的公式来执行功能强大的各种操作。 2、函数的输入 对一些单变量和比较简单的函数,可用键盘直接输入。其方法与在单元格中输入公式相
第2章统计数据的描述 练习题部分: 2.1为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。服务质量的 等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C D E A B D D C A D B C C A E D C B C B C E D B C C B C (2)用Excel制作一张频数分布表; (3)绘制一张条形图,反映评价等级的分布。 2.2某行业管理局所属40个企业2008年的产品销售收入数据如下(单位:万元): 152 124 129 116 100 103 92 95 127 104 105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 97 88 123 115 119 138 112 146 113 126 (1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率; (2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业, 105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。 2.3某百货公司连续40天的商品销售额如下(单位:万元): 41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42 36 37 37 49 39 42 32 36 35 根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。 2.4为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果 如下: 700 716 728 719 685 709 691 684 705 718 706 715 712 722 691 708 690 692 707 701 708 729 694 681 695 685 706 661 735 665 668 710 693 697 674 658 698 666 696 698 706 692 691 747 699 682 698 700 710 722 694 690 736 689 696 651 673 749 708 727
第2章 描述性统计分析实例 当进行数据分析时,如果研究者得到的数据量很小,那么就可以通过直接观察原始数据来获得所有的信息;如果得到的数据量很大,那么就必须借助各种描述指标来完成对数据的描述工作。用少量的描述指标来概括大量的原始数据,对数据展开描述的统计分析方法被称为描述性统计分析。常用的描述性统计分析有频数分析、描述性分析、探索分析、列联表分析。下面我们将一一介绍这几种方法在实例中的应用。 2.1 实例1——频数分析 2.1.1 频数分析的功能与意义 SPSS的频数分析(Frequencies)是描述性统计分析中比较常用的方法之一。通过频数分析,我们可以得到详细的频数表以及平均值、最大值、最小值、方差、标准差、极差、平均数标准误、偏度系数和峰度系数等重要的描述统计量,还可以通过分析得到合适的统计图。所以进行频数分析不仅可以方便地对数据按组进行归类整理,还可以对数据的分布特征形成初步的认识。 2.1.2 相关数据来源 下载资源\video\chap02\... 下载资源\sample\2\正文\原始数据文件\案例2.1.sav 【例2.1】表2.1给出了山东省某学校50名高二学生的身高。试分析这50名学生的身高分布特征,计算平均值、最大值、最小值、标准差等统计量,并绘制频数表、直方图。 表2.1 山东省某学校50名高二学生的身高 编号身高(cm) 001 175 002 163 003 156 004 174 005 167 … … 048 158 049 164 050 163
15 第2章 描述性统计分析实例 2.1.3 SPSS分析过程 在用SPSS 进行分析之前,我们要把数据录入到SPSS 中。本例中有两个变量,分别是编 号和身高。我们把编号定义为字符型变量,把身高定义为数值型变量,然后录入相关数据。录入完 成后,数据如图2.1所示。 图2.1 案例2.1数据 先做一下数据保存,然后开始 展开分析,步骤如下: 进入SPSS 24.0,打开相关数据文件,选 择“分析”|“描述统计”| “频率”命令,弹出如图2.2所示的对话框。 选择进行频数分析的变量。在“频率”对 话框的左侧列表框中选择“身高”选项,单击中间 的按钮使之进入“变量”列表框。 选择是否输出频数表格。选中“频率”对 话框左下角的“显示频率表”复选框,要求输出频数表格。 选择输出相关描述统计量。单击“频率”对话框右上角的“统计”按钮,弹出如图 2.3所示的对话框,在该对话框中可以设置相关描述统计量。我们在“百分位值”选项组中选中“四分位数”“分割点”复选框;在“集中趋势”选项组中选中“平均值”“中位数”“众数”“总和”复选框;在“离散”选项组中选中“标准差”“方差”“范围”“最小值”“最大值”“标 准误差平均值”复选框;在“分布”选项组中选中“偏度”“峰度”复选框。设置完毕后,单击“继续”按钮返回“频率”对话框。 设置图表的输出。单击“频率”对话框中的“图表”按钮,弹出如图 2.4所示的对话 框,选择有关的图形输出。在此我们选择直方图,并且带正态曲线。 图2.2 “频率”对话框