
多标签(multi-label)数据问题常用的分类器或者分类策略
多标记分类和传统的分类问题相比较,主要难点在于以下两个方面:
(1)类标数量不确定,有些样本可能只有一个类标,有些样本的类标可能高达几十甚至上百个。
(2)类标之间相互依赖,例如包含蓝天类标的样本很大概率上包含白云,如何解决类标之间的依赖性问题也是一大难点。
对于多标记学习领域的研究,国外起步较早,起源于2000年Schapire R E等人提出的基于boost方法的文本多分类,著名的学者有G Tsoumakas、Eyke Hüllermeier、Jesse Read,Saso Dzeroski等等。在国内,南京大学的周志华和张敏灵和哈工大的叶允明等等学者在这一领域较都有很好研究成果。
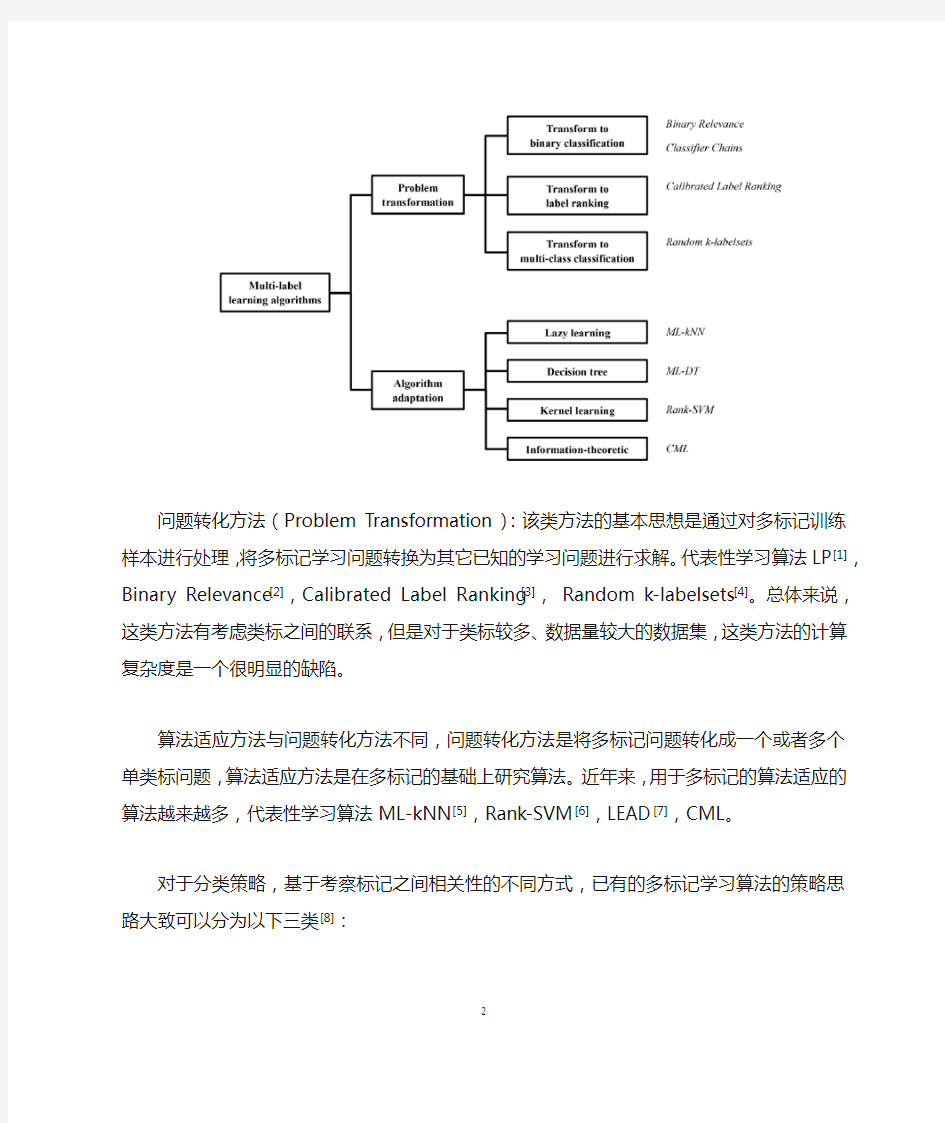
目前有很多关于多标签的学习算法,依据解决问题的角度,这些算法可以分为两大类:一是基于问题转化(Problem Transformation)的方法,二是基于算法适应的方法和算法适应方法(Algorithm Adaptation)。基于问题转化的多标记分类是转化问题数据,使之适用现有算法;基于算法适应的方法是指针对某一特定的算法进行扩展,从而能够直接处理多标记数据,改进算法,适应数据。基于这两种思想,目前已经有多种相对成熟的算法被提出,如下图所示:
问题转化方法(Problem Transformation):该类方法的基本思想是通过对多标记训练样本进行处理,将多标记学习问题转换为其它已知的学习问题进行求解。代表性学习算法LP[1],Binary Relevance[2],Calibrated Label Ranking[3],Random k-labelsets[4]。总体来说,这类方法有考虑类标之间的联系,但是对于类标较多、数据量较大的数据集,这类方法的计算复杂度是一个很明显的缺陷。
算法适应方法与问题转化方法不同,问题转化方法是将多标记问题转化成一个或者多个单类标问题,算法适应方法是在多标记的基础上研究算法。近年来,用于多标记的算法适应的算法越来越多,代表性学习算法ML-kNN[5],Rank-SVM[6],LEAD[7],CML。
对于分类策略,基于考察标记之间相关性的不同方式,已有的多标记学习算法的策略思路大致可以分为以下三类[8]:
a) “一阶(first-order)”策略:该类策略通过逐一考察单个标记而忽略标记之间的相关性,如将多标记学习问题分解为个独立的二类分类问题,从而构造多标记学习系统。该类方法效率较高且实现简单,但由于其完全忽略标记之间可能存在的相关性,其系统的泛化性能往往较低。
b) “二阶(second-order)”策略:该类策略通过考察两两标记之间的相关性,如相关标记与无关标记之间的排序关系,两两标记之间的交互关系等等,从而构造多标记学习系统。该类方法由于在一定程度上考察了标记之间的相关性,因此其系统泛化性能较优。
c) “高阶(high-order)”策略:该类策略通过考察高阶的标记相关性,如处理任一标记对其它所有标记的影响,处理一组随机标记集合的相关性等等,从而构造多标记学习系统。该类方法虽然可以较好地反映真实世界问题的标记相关性,但其模型复杂度往往过高,难以处理大规模学习问题。
[1] Madjarov G, Kocev D, Gjorgjevikj D, et al. An extensive experimental comparison
of methods for multi-label learning[J]. Pattern Recognition, 2012, 45(9): 3084-3104.
[2] Boutell M R, Luo J, Shen X, Brown C M. Learning multi-label scene classification.
Pattern Recognition, 2004, 37(9): 1757-1771.
[3] Fürnkranz J, Hüllermeier E, LozaMencía E, Brinker K. Multilabel classification via
calibrated label ranking. Machine Learning, 2008, 73(2): 133-153.
[4] Tsoumakas G, Vlahavas I. Random k-labelsets: An ensemble method for multilabel
classification. In: Kok J N, Koronacki J, de Mantaras R L, Matwin S, Mladeni? D, Skowron A, eds. Lecture Notes in Artificial Intelligence 4701, Berlin: Spr inger,
2007, 406-417.
[5] Zhang M-L, Zhou Z-H. ML-kNN: A lazy learning approach to multi-label learning.
Pattern Recognition, 2007, 40(7): 2038-2048.
[6] Elisseeff A, Weston J. A kernel method for multi-labelled classification. In: Dietterich
T G, Becker S, Ghahramani Z, eds. Advances in Neural Information Processing Systems 14 (NIPS’01), Cambridge, MA: MIT Press, 2002, 681-687.
[7] Zhang M-L, Zhang K. Multi-label learning by exploiting label dependency. In: Pro
ceedings of the 16th ACM SIGKDD International Conference on Knowledge Discov ery and Data Mining (KDD’10), Washington, D. C., 2010, 999-1007.
[8] Zhang M L, Zhang K. Multi-label learning by exploiting label dependency[C]// ACM
SIGKDD International Conference on Knowledge Discovery and Data Mining.
ACM, 2010:999-1008.
分类器的动态选择与循环集成方法 郝红卫;王志彬;殷绪成;陈志强 【期刊名称】《自动化学报》 【年(卷),期】2011(037)011 【摘要】In order to deal with the problems of low efficiency and inflexibility for selecting the optimal subset and combining classifiers in multiple classifier systems, a new method of dynamic selection and circulating combination (DSCC) is proposed. This method dynamically selects the optimal subset with high accuracy for combination based on the complementarity of different classification models. The number of classifiers in the selected subset can be adaptively changed according to the complexity of the objects. Circulating combination is realized according to the confidence of classifiers. The experimental results of handwritten digit recognition show that the proposed method is more flexible, efficient and accurate comparing to other classifier selection methods.%针对多分类器系统设计中最优子集选择效率低下、集成方法缺乏灵活性等问题,提出了分类器的动态选择与循环集成方法(Dynamic selection and circulating combination,DSCC).该方法利用不同分类器模型之间的互补性,动态选择出对目标有较高识别率的分类器组合,使参与集成的分类器数量能够随识别目标的复杂程度而自适应地变化,并根据可信度实现系统的循环集成.在手写体数字识别实验中,与其他常用的分类器选择方法相比,所提出的方法灵活高效,识别率更高.
从SVM的那几张图可以看出来,SVM是一种典型的两类分类器,即它只回答属于正类还是负类的问题。而现实中要解决的问题,往往是多类的问题(少部分例外,例如垃圾邮件过滤,就只需要确定“是”还是“不是”垃圾邮件),比如文本分类,比如数字识别。如何由两类分类器得到多类分类器,就是一个值得研究的问题。 还以文本分类为例,现成的方法有很多,其中一种一劳永逸的方法,就是真的一次性考虑所有样本,并求解一个多目标函数的优化问题,一次性得到多个分类面,就像下图这样: 多个超平面把空间划分为多个区域,每个区域对应一个类别,给一篇文章,看它落在哪个区域就知道了它的分类。 看起来很美对不对?只可惜这种算法还基本停留在纸面上,因为一次性求解的方法计算量实在太大,大到无法实用的地步。 稍稍退一步,我们就会想到所谓“一类对其余”的方法,就是每次仍然解一个两类分类的问题。比如我们有5个类别,第一次就把类别1的样本定为正样本,其余2,3,4,5的样本合起来定为负样本,这样得到一个两类分类器,它能够指出一篇文章是还是不是第1类的;第二次我们把类别2 的样本定为正样本,把1,3,4,5的样本合起来定为负样本,得到一个分类器,如此下去,我们可以得到5个这样的两类分类器(总是和类别的数目一致)。到了有文章需要分类的时候,我们就拿着这篇文章挨个分类器的问:是属于你的么?是属于你的
么?哪个分类器点头说是了,文章的类别就确定了。这种方法的好处是每个优化问题的规模比较小,而且分类的时候速度很快(只需要调用5个分类器就知道了结果)。但有时也会出现两种很尴尬的情况,例如拿一篇文章问了一圈,每一个分类器都说它是属于它那一类的,或者每一个分类器都说它不是它那一类的,前者叫分类重叠现象,后者叫不可分类现象。分类重叠倒还好办,随便选一个结果都不至于太离谱,或者看看这篇文章到各个超平面的距离,哪个远就判给哪个。不可分类现象就着实难办了,只能把它分给第6个类别了……更要命的是,本来各个类别的样本数目是差不多的,但“其余”的那一类样本数总是要数倍于正类(因为它是除正类以外其他类别的样本之和嘛),这就人为的造成了上一节所说的“数据集偏斜”问题。 因此我们还得再退一步,还是解两类分类问题,还是每次选一个类的样本作正类样本,而负类样本则变成只选一个类(称为“一对一单挑”的方法,哦,不对,没有单挑,就是“一对一”的方法,呵呵),这就避免了偏斜。因此过程就是算出这样一些分类器,第一个只回答“是第1类还是第2类”,第二个只回答“是第1类还是第3类”,第三个只回答“是第1类还是第4类”,如此下去,你也可以马上得出,这样的分类器应该有5 X 4/2=10个(通式是,如果有k个类别,则总的两类分类器数目为k(k-1)/2)。虽然分类器的数目多了,但是在训练阶段(也就是算出这些分类器的分类平面时)所用的总时间却比“一类对其余”方法少很多,在真正用来分类的时候,把一篇文章扔给所有分类器,第一个分类器会投票说它是“1”或者“2”,第二个会说它是“1”或者“3”,让每一个都投上自己的一票,最后统计票数,如果类别“1”得票最多,就判这篇文章属于第1类。这种方法显然也会有分类重叠的现象,但不会有不可分类现象,因为总不可能所有类别的票数都是0。看起来够好么?其实不然,想想分类一篇文章,我们调用了多少个分类器?10个,这还是类别数为5的时候,类别数如果是1000,要调用的分类器数目会上升至约500,000个(类别数的平方量级)。这如何是好? 看来我们必须再退一步,在分类的时候下功夫,我们还是像一对一方法那样来训练,只是在对一篇文章进行分类之前,我们先按照下面图的样子来组织分类器(如你所见,这是一个有向无环图,因此这种方法也叫做DAG SVM)
2008年12月 December 2008 计 算 机 工 程Computer Engineering 第34 第24期 Vol 卷.34 No.24 ·人工智能及识别技术·文章编号:1000—3428(2008)24—0218—03 文献标识码:A 中图分类号:TP391.4 集成学习的多分类器动态组合方法 陈 冰,张化祥 (山东师范大学信息科学与工程学院,济南 250014) 摘 要:为了提高数据的分类性能,提出一种集成学习的多分类器动态组合方法(DEA)。该方法在多个UCI 标准数据集上进行测试,并与文中使用的基于Adaboost 算法训练出的各个成员分类器的分类效果进行比较,证明了DEA 的有效性。 关键词:多分类器;聚类;动态分类器组合;Adaboost 算法 Dynamic Combinatorial Method of Multiple Classifiers on Ensemble Learning CHEN Bing, ZHANG Hua-xiang (College of Information Science and Engineering, Shandong Normal University, Jinan 250014) 【Abstract 】In order to improve the classification performance of dataset, a dynamic combinatorial method of multiple classifiers on ensemble learning DEA is proposed in the paper. DEA is tested on the UCI benchmark data sets, and is compared with several member classifiers trained based on the algorithm of Adaboost. In this way, the utility of DEA can be proved. 【Key words 】multiple classifiers; clustering; dynamic classifier ensemble; Adaboost algorithm 1 概述 近年来,多分类器组合(DEA)技术在各个领域已经得到了广泛的应用,如模式识别中的人脸识别、网络安全、语言学中的词义消歧[1]等。 关于多分类器系统的研究越来越多,大量的理论和实验结果表明,通过多分类器组合不但可以提高分类的正确率,而且能够提高模式识别系统的效率和鲁棒性。尽管在各个方面提出了不同的分类器组合方法,但这些方法都或多或少地存在某些缺陷,它们或者先利用聚类对数据集进行处理,再直接用同种类型的分类器来分类[2];或者采用不同类型的分类器,而不对数据集做任何处理[1];更多的是利用不同的融合算法来训练生成同种类型的分类器,再利用它们对数据分类。另外,通常所使用的分类方法如决策树、K-近邻、Bayes 等都是有导师信息的机器学习过程。但实际中存在着大量的数据没有标记样本类别,如果再运用这些分类方法,其操作性就比较差了。而聚类等非监督学习能自适应地处理大量的未知类别的样本。基于监督学习与非监督学习的优势互补,将两者结合起来各取所长,一定能够收到很好的效果。另外值得注意的一点:目标识别中利用不同的分类器可以得到不同的分类识别结果,而且结果之间具备相当的互补性,从而可以提高分类的效果,克服单分类器存在的问题。 2 多分类器动态组合流程 图1是DEA 方法一次随机取样的流程。这里,小样本集 1,2,…,k 是对训练数据集按照类别标号得到的k 个小集合;分类器组合1,2,…,k 表示的是由训练数据集训练出的分类器对每个小样本集合分类根据分类错误率得到的k 组性能较好(错误率较低)的分类器组合。其中,总的分类器是在Adaboost 基础上每次随机地生成以决策树、贝叶斯、k-近邻中的一个作为基分类器,直到生成50个为止。接下来利用这k 组分类器去分类类别标号相对应的测试数据中的聚类集合(为了表示的方便,图中假设小样本集与聚类集合是一一对应的)。最后用每个聚类集中被错误分类的样本数之和除以测试数据总数,即得一次采样的错误率。 图1 多分类器动态组合流程 3 多分类器动态组合 3.1 集成学习 集成学习[3]方法是根据样本训练多分类器来完成分类任务的方法,这些分类器具有一定的互补功能,在减少分类误 基金项目:山东省科技攻关计划基金资助项目(2005GG4210002);山东省青年科学家科研奖励基金资助项目(2006BS01020);山东省教育厅科技计划基金资助项目(J07YJ04);山东省自然科学基金资助项目(Y2007G16) 作者简介:陈 冰(1981-),女,硕士研究生,主研方向:数据挖掘,机器学习;张化祥,教授、博士 收稿日期:2008-04-14 E-mail :zyxcscb@https://www.doczj.com/doc/59662827.html, —218 —万方数据
————————————————————————————————————————————————多类型分类器融合的文本分类方法研究 作者李惠富,陆光 机构东北林业大学信息与计算机工程学院 基金项目黑龙江省自然科学基金资助项目(F201201) 预排期卷《计算机应用研究》2019年第36卷第3期 摘要传统的文本分类方法大多数使用单一的分类器,而不同的分类器对分类任务的侧重点不同,就使得单一的分类方法有一定的局限性,同时每个特征提取方法对特征词的考虑角度不同。 针对以上问题,提出了多类型分类器融合的文本分类方法。该模型使用了word2vec、主成分 分析、潜在语义索引以及TFIDF特征提取方法作为多类型分类器融合的特征提取方法。并在 多类型分类器加权投票方法中忽略了类别信息的问题,提出了类别加权的分类器权重计算方 法。通过实验结果表明,多类型分类器融合方法在二元语料库、多元语料库以及特定语料库 上都取得了很好的性能,类别加权的分类器权重计算方法比多类型分类器融合方法在分类性 能方面提高了1.19%。 关键词文本分类;分类器融合;主成分分析;潜在语义索引 作者简介李惠富(1992-),男,黑龙江讷河人,硕士研究生,主要研究方向为文本挖掘;陆光(1963年-),男(通信作者),副教授,博士,主要研究方向为电子商务与系统开发(lg603@https://www.doczj.com/doc/59662827.html,). 中图分类号TP391 访问地址https://www.doczj.com/doc/59662827.html,/article/02-2019-03-005.html 发布日期2018年4月17日 引用格式李惠富, 陆光. 多类型分类器融合的文本分类方法研究[J/OL]. 2019, 36(3). [2018-04-17]. https://www.doczj.com/doc/59662827.html,/article/02-2019-03-005.html.
SVM入门(十)将SVM用于多类分类 从SVM的那几张图可以看出来,SVM是一种典型的两类分类器,即它只回答属于正类还是负类的问题。而现实中要解决的问题,往往是多类的问题(少部分例外,例如垃圾邮件过滤,就只需要确定“是”还是“不是”垃圾邮件),比如文本分类,比如数字识别。如何由两类分类器得到多类分类器,就是一个值得研究的问题。 还以文本分类为例,现成的方法有很多,其中一种一劳永逸的方法,就是真的一次性考虑所有样本,并求解一个多目标函数的优化问题,一次性得到多个分类面,就像下图这样: 多个超平面把空间划分为多个区域,每个区域对应一个类别,给一篇文章,看它落在哪个区域就知道了它的分类。 看起来很美对不对?只可惜这种算法还基本停留在纸面上,因为一次性求解的方法计算量实在太大,大到无法实用的地步。 稍稍退一步,我们就会想到所谓“一类对其余”的方法,就是每次仍然解一个两类分类的问题。比如我们有5个类别,第一次就把类别1的样本定为正样本,其余2,3,4,5的样本合起来定为负样本,这样得到一个两类分类器,它能够指出一篇文章是还是不是第1类的;第二次我们把类别2 的样本定为正样本,把1,3,4,5的样本合起来定为负样本,得到一个分类器,如此下去,我们可以得到5个这样的两类分类器(总是和类别的数目一致)。到了有文章需要分类的时候,我们就拿着这篇文章挨个分类器的问:是属于你的么?是属于你的么?哪个分类器点头说是了,文章的类别就确定了。这种方法的好处是每个优化问题的
规模比较小,而且分类的时候速度很快(只需要调用5个分类器就知道了结果)。但有时也会出现两种很尴尬的情况,例如拿一篇文章问了一圈,每一个分类器都说它是属于它那一类的,或者每一个分类器都说它不是它那一类的,前者叫分类重叠现象,后者叫不可分类现象。分类重叠倒还好办,随便选一个结果都不至于太离谱,或者看看这篇文章到各个超平面的距离,哪个远就判给哪个。不可分类现象就着实难办了,只能把它分给第6个类别了……更要命的是,本来各个类别的样本数目是差不多的,但“其余”的那一类样本数总是要数倍于正类(因为它是除正类以外其他类别的样本之和嘛),这就人为的造成了上一节所说的“数据集偏斜”问题。 因此我们还得再退一步,还是解两类分类问题,还是每次选一个类的样本作正类样本,而负类样本则变成只选一个类(称为“一对一单挑”的方法,哦,不对,没有单挑,就是“一对一”的方法,呵呵),这就避免了偏斜。因此过程就是算出这样一些分类器,第一个只回答“是第1类还是第2类”,第二个只回答“是第1类还是第3类”,第三个只回答“是第1类还是第4类”,如此下去,你也可以马上得出,这样的分类器应该有5 X 4/2=10个(通式是,如果有k个类别,则总的两类分类器数目为k(k-1)/2)。虽然分类器的数目多了,但是在训练阶段(也就是算出这些分类器的分类平面时)所用的总时间却比“一类对其余”方法少很多,在真正用来分类的时候,把一篇文章扔给所有分类器,第一个分类器会投票说它是“1”或者“2”,第二个会说它是“1”或者“3”,让每一个都投上自己的一票,最后统计票数,如果类别“1”得票最多,就判这篇文章属于第1类。这种方法显然也会有分类重叠的现象,但不会有不可分类现象,因为总不可能所有类别的票数都是0。看起来够好么?其实不然,想想分类一篇文章,我们调用了多少个分类器?10个,这还是类别数为5的时候,类别数如果是1000,要调用的分类器数目会上升至约500,000个(类别数的平方量级)。这如何是好? 看来我们必须再退一步,在分类的时候下功夫,我们还是像一对一方法那样来训练,只是在对一篇文章进行分类之前,我们先按照下面图的样子来组织分类器(如你所见,这是一个有向无环图,因此这种方法也叫做DAG SVM)
综合 1、统计的含义包括()。ACD A.统计资料 B.统计指标 C.统计工作 D.统计学 E.统计调查 2、统计研究运用各种专门的方法,包括()。ABCDE A.大量观察法 B.统计分组法 C.综合指标法 D.统计模型法 E.统计推断法 3、全国第5次人口普查中()。BCE A.全国人口数是统计总体? B.总体单位是每一个人 C.全部男性人口数是统计指标 D.人口性别比是总体的品质标志 E.人的年龄是变量 4、下列各项中,属于连续变量的有()。ACD A.基本建设投资额 B.岛屿个数 C.国民生产总值中3次产业比例 D.居民生活费用价格指数 E.就业人口数 5、下列指标中,属于数量指标的有()。AC A.国民生产总值 B.人口密度 C.全国人口数 D.投资效果系数 E.工程成本降低率 6、下列标志中,属于品质标志的有()。BE A.工资 B. 所有制 C.旷课次数 D.耕地面积 E.产品质量 7、下列各项中,哪些属于统计指标?()ACDE A.我国2005年国民生产总值 B.某同学该学期平均成绩 C.某地区出生人口总数 D.某企业全部工人生产某种产品的人均产量 E.某市工业劳动生产率 8、统计指标的表现形式有()。BCE A.比重指标 B.总量指标 C.相对指标 D.人均指标 E.平均指标 9、总体、总体单位、标志、指标间的相互关系表现为()。ABCD A.没有总体单位也就没有总体,总体单位也不能离开总体而存在 B.总体单位是标志的承担者 C.统计指标的数值来源于标志
D.指标是说明总体特征的,标志是说明总体单位特征的 E.指标和标志都能用数值表示 10、国家统计系统的功能或统计的职能有()。ABCD A.收集信息职能 B.提供咨询职能 C.实施监督职能 D.支持决策职能 E.组织协调职能 11、当人们谈及什么是统计时,通常可以理解为()ACD A.统计工作 B.统计整理 C.统计资料 D.统计学 E.统计学科 12、调查得到的经过整理具有信息价值的统计资料包括()ABDE A.统计数据 B.统计图标 C.统计软件 D.统计年鉴 E.统计报告 13、以下关于统计学的描述,正确的有()ACD A.统计学是一门收集、整理和分析统计数据的方法论科学 B.统计学是一门收集、整理和分析统计数据的实质性科学 C.统计学的研究目的是探索数据的内在数量规律性 D.统计学提供了探索数据内在规律的一套方法 E.统计学提供了探索数据内在规律的一套软件 14、统计数据按其采用的计量尺度不同可以分为()ABC A.分类数据 B.顺序数据 C.数值型数据 D.截面数据 E.扇面数据 15、统计数据按其收集方法不同,可以分为()AB A.观测数据 B.实验数据 C.时序数据 D.混合数据 E.顺序数据 16、统计数据按被描述的对象和时间的关系不同分为()ABD A.截面数据 B.时间序列数据 C.观测数据 D.混合数据 E.扇面数据 17、从统计方法的构成看,统计学可以分为()AD A.描述统计学 B.理论统计学 C.应用统计学 D.推断统计学 E.管理统计学 18、如果要研究某市987家外资企业的基本情况,下列属于统计指标的有()ABD A.所有外资企业的职工平均工资 B.所有外资企业的平均利润 C.甲企业的固定资产原值 D.所有外资企业平均职工人数 E.部分外资企业平均职工人数 统计数据的收集 1、普查是一种()。BCD A.非全面调查 B.专门调查 C.全面调查 D.一次性调查 E.经常性调查 2、某地对集市贸易个体户的偷漏税情况进行调查,1月5日抽选5%样本检查,5月1日抽选10%样本检查,这种调查是()。ABC
SVM的常用多分类算法概述 摘要:SVM方法是建立在统计学习理论基础上的机器学习方法,具有相对优良的分类性能,是一种非线性分类器。最初SVM是用以解决两类分类问题,不能直接用于多类分类,当前已经有许多算法将SVM推广到多类分类问题,其中最常用两类:OAA和OAO算法,本文主要介绍这两类常用的多分类算法。 关键词:SVM;多分类;最优化 自从90年代初V. Vapnik提出经典的支持向量机理论(SVM),由于其完整的理论框架和在实际应用中取得的很多好的效果,在模式识别、函数逼近和概率密度估计领域受到了广泛的重视。SVM方法是建立在统计学习理论基础上的机器学习方法,具有相对优良的分类性能。SVM是一种非线性分类器。它的基本思想是将输入空间中的样本通过某种非线性函数关系映射到一个特征空间中,使两类样本在此特征空间中线性可分,并寻找样本在此特征空间中的最优线性区分平面。它的几个主要优点是可以解决小样本情况下的机器学习问题,提高泛化性能,解决高维问题、非线性问题,可以避免神经网络结构选择和局部极小点问题。 1. SVM方法 若样本集Q={(x i,y i)|i=1,……,L}∈R d*{-1,+1}是线性可分的。则存在分类超平面w T x+b=0,x∈R d对样本集Q中任一(x i,y i)都满足: 在空间R d中样本x=(x1,…, x d)r到分类超平面的距离d=|w T*x+b|/||w||,其中 ||w||= . 当存在x 使得w T x i+b=±1, 则图1中超平面的分类间隔 margin = 2/ ‖w ‖。 使分类间隔margin 最大的超平面即为最优分类超平面。寻找最优分类超平面的问题将转化为求如下一个二次规划问题: minΦ( w) =1/2‖w ‖ 满足约束条件: y i ( w T x i + b) ≥1 , i = 1 ,2 , ?, L 采用Lagrange 乘子转换为一个对偶问题,形式如下: 满足约束条件:
第一部分统计分析流程 一.资料分类: (1)定量(数量性状)资料 (2)定性(质量性状)资料 (3)等级资料 二.数据录入SPSS: (1) 建立变量名 (2) 录入数据: A. 定量资料的原始数据 B. 定性或等级资料的次数数据(也可是原始数据) 三.数据分布的检测 (1)定量资料:正态性或其它连续分布检测 (2)定性资料:一般可不做,若题目要求则进行离散分布检测 四.基本统计分析 (1)选择合适的统计指标对数据进行统计描述 (2)用SPSS进行基本统计分析,获取该统计指标 (3)用三线表或统计图进行归纳 五.进行统计推断,置信区间计算和其它分析(如相关分析)(1)选择合适的统计推断方法(注意方法的前提条件) (2)用SPSS进行统计推断分析,获得P值 (3)根据小概率事件不可能性原理进行统计推断 六.根据统计分析结果,结合专业知识,给出生物学解释。
第二部分 数据分布的检测 一. 定量资料总体分布:单样本K-S 检验 可检验:正态分布(Normal ),均匀分布(uniform ),泊松分布(Poisson),指数分布(Exponential)]等 连续型数据 分布。 【1】 通过探索分析explore 中调用Normality plots with tests, 检测正态分布; 【2】 通过非参数检验调用单样本K-S 检验,检测各种分布。 二. 定性资料和等级资料分布:卡方检验 通过非参数检验调用卡方检验 离散变量总体 分布。 第三部分 统计指标的选择 一. 数量性状资料(包括计量和计数资料) 1.正态分布: (2) 大样本(n>30): (集中趋势)± S (样本间的变异) (3) 小样本(n ≤30): (集中趋势)± (抽样误差) 2. 偏态分布: 中位数(median ,集中趋势) ,四分位间距(IQR ,变异程度) 二. 质量性状资料和等级资料(次数资料) 1.样本含量n 足够多时: 统计次数―>率或比 (相对值) 2..样本含量n 少时: 统计次数―> 用绝对数表示 x x x S
统计方法的选择 一、两组或多组计量资料的比较 1.两组资料: 1)大样本资料或服从正态分布的小样本资料 (1)若方差齐性,则作成组t检验 (2)若方差不齐,则作t’检验或用成组的Wilcoxon秩和检验 2)小样本偏态分布资料,则用成组的Wilcoxon秩和检验2.多组资料: 1)若大样本资料或服从正态分布,并且方差齐性,则作 完全随机的方差分析。如果方差分析的统计检验为有统 计学意义,则进一步作统计分析:选择合适的方法 (如:LSD检验,Bonferroni检验等)进行两两比较。 2)如果小样本的偏态分布资料或方差不齐,则作 Kruskal Wallis的统计检验。如果Kruskal Wallis的统计检验为有统计学意义,则进一步作统计分析:选择合适 的方法(如:用成组的Wilcoxon秩和检验,但用Bonferroni方法校正P值等)进行两两比较。 二、分类资料的统计分析 1.单样本资料与总体比较 1)二分类资料: (1)小样本时:用二项分布进行确切概率法检验;
(2)大样本时:用U检验。 2)多分类资料:用Pearson c2检验(又称拟合优度检验)。 2. 四格表资料 1)n>40并且所以理论数大于5,则用Pearson c2 2)n>40并且所以理论数大于1并且至少存在一个理论数<5,则用校正 c2或用Fisher’s 确切概率法检验 3)n£40或存在理论数<1,则用Fisher’s 检验 3. 2×C表资料的统计分析 1)列变量为效应指标,并且为有序多分类变量,行变量为分组变量,则行评分的CMH c2或成组的Wilcoxon秩和检验 2)列变量为效应指标并且为二分类,列变量为有序多分类变量,则用趋势c2检验 3)行变量和列变量均为无序分类变量 (1)n>40并且理论数小于5的格子数<行列表中格子总数的25%,则用Pearson c2 (2)n£40或理论数小于5的格子数>行列表中格子总数的25%,则用Fisher’s 确切概率法检验 4. R×C表资料的统计分析 1)列变量为效应指标,并且为有序多分类变量,行变量为分组变量,则CMH c2或Kruskal Wallis的秩和检验
01如何选择合适的统计学方法? 1连续性资料 1.1 两组独立样本比较 1.1.1 资料符合正态分布,且两组方差齐性,直接采用t检验。 1.1.2 资料不符合正态分布,(1)可进行数据转换,如对数转换等,使之服从正态分布,然后对转换后的数据采用t检验;(2)采用非参数检验,如Wilcoxon检验。 1.1.3 资料方差不齐,(1)采用Satterthwate 的t’检验;(2)采用非参数检验,如Wilcoxon检验。 1.2 两组配对样本的比较 1.2.1 两组差值服从正态分布,采用配对t检验。 1.2.2 两组差值不服从正态分布,采用wilcoxon的符号配对秩和检验。 1.3 多组完全随机样本比较 1.3.1资料符合正态分布,且各组方差齐性,直接采用完全随机的方差分析。如果检验结果为有统计学意义,则进一步作两两比较,两两比较的方法有LSD检验,Bonferroni法,tukey 法,Scheffe法,SNK法等。 1.3.2资料不符合正态分布,或各组方差不齐,则采用非参数检验的Kruscal-Wallis法。如果检验结果为有统计学意义,则进一步作两两比较,一般采用Bonferroni法校正P值,然后用成组的Wilcoxon检验。 1.4 多组随机区组样本比较 1.4.1资料符合正态分布,且各组方差齐性,直接采用随机区组的方差分析。如果检验结果为有统计学意义,则进一步作两两比较,两两比较的方法有LSD检验,Bonferroni法,tukey 法,Scheffe法,SNK法等。 1.4.2资料不符合正态分布,或各组方差不齐,则采用非参数检验的Fridman检验法。如果检验结果为有统计学意义,则进一步作两两比较,一般采用Bonferroni法校正P值,然后用符号配对的Wilcoxon检验。 ****需要注意的问题: (1)一般来说,如果是大样本,比如各组例数大于50,可以不作正态性检验,直接采用t 检验或方差分析。因为统计学上有中心极限定理,假定大样本是服从正态分布的。 (2)当进行多组比较时,最容易犯的错误是仅比较其中的两组,而不顾其他组,这样作容易增大犯假阳性错误的概率。正确的做法应该是,先作总的各组间的比较,如果总的来说差别有统计学意义,然后才能作其中任意两组的比较,这些两两比较有特定的统计方法,如上面提到的LSD检验,Bonferroni法,tukey法,Scheffe法,SNK法等。**绝不能对其中的两组直接采用t检验,这样即使得出结果也未必正确** (3)关于常用的设计方法:多组资料尽管最终分析都是采用方差分析,但不同设计会有差
统计学方法的正确抉择 一.统计方法抉择的条件 在临床科研工作中,正确地抉择统计分析方法,应充分考虑科研工作者的分析目的、临床科研设计方法、搜集到的数据资料类型、数据资料的分布特征与所涉及的数理统计条件等。其中任何一个问题没考虑到或考虑有误,都有可能导致统计分析方法的抉择失误。 此外,统计分析方法的抉择应在科研的设计阶段来完成,而不应该在临床试验结束或在数据的收集工作已完成之后。 对临床科研数据进行统计分析和进行统计方法抉择时,应考虑下列因素: 1.分析目的 对于临床医生及临床流行病医生来说,在进行统计分析前,一定要明确利用统计方法达到研究者的什么目的。一般来说,统计方法可分为描述与推断两类方法。一是统计描述(descriptive statistics),二是统计推断(inferential statistics)。 统计描述,即利用统计指标、统计图或统计表,对数据资料所进行的最基本的统计分析,使其能反映数据资料的基本特征,有利于研究者能准确、全面地了解数据资料所包涵的信息,以便做出科学的推断。统计表,如频数表、四格表、列联表等;统计图,如直方图、饼图,散点图等;统计指标,如均数、标准差、率及构成比等。 统计推断,即利用样本所提供的信息对总体进行推断(估计或比较),其中包括参数估计和假设检验,如可信区间、t检验、方差分析、 2检验等,如要分析甲药治疗与乙药治疗两组的疗效是否不相同、不同地区某病的患病率有无差异等。 还有些统计方法,既包含了统计描述也包含了统计推断的内容,如不同变量间的关系分析。相关分析,可用于研究某些因素间的相互联系,以相关系数来衡量各因素间相关的密切程度和方向,如高血脂与冠心病、慢性宫颈炎与宫颈癌等的相关分析;回归分析,可用于研究某个因素与另一因素(变量)的依存关系,即以一个变量去推测另一变量,如利用回归分析建立起来的回归方程,可由儿童的年龄推算其体重。 2.资料类型 资料类型的划分现多采用国际通用的分类方法,将其分为两类:数值变量(numerical variable)资料和分类变量(categorical variable)资料。数值变量是指其值是可以定量或准确测量的变量,其表现为数值大小的不同;而分类变量是指其值是无法定量或不能测量的变量,其表现没有数值的大小而只有互不相容的类别或属性。分类变量又可分为无序分类变量和有序分类变量两小类,无序分类变量表现为没有大小之分的属性或类别,如:性别是两类无序分类变量,血型是四类无序分类变量;有序分类变量表现为各属性或类别间有程度之分,如:临床上某种疾病的“轻、中、重”,治疗结果的“无效、显效、好转、治愈”。由此可见,数值变量资料、无序分类变量资料和有序分类变量资料又可叫做计量资料、计数资料和等级资料。