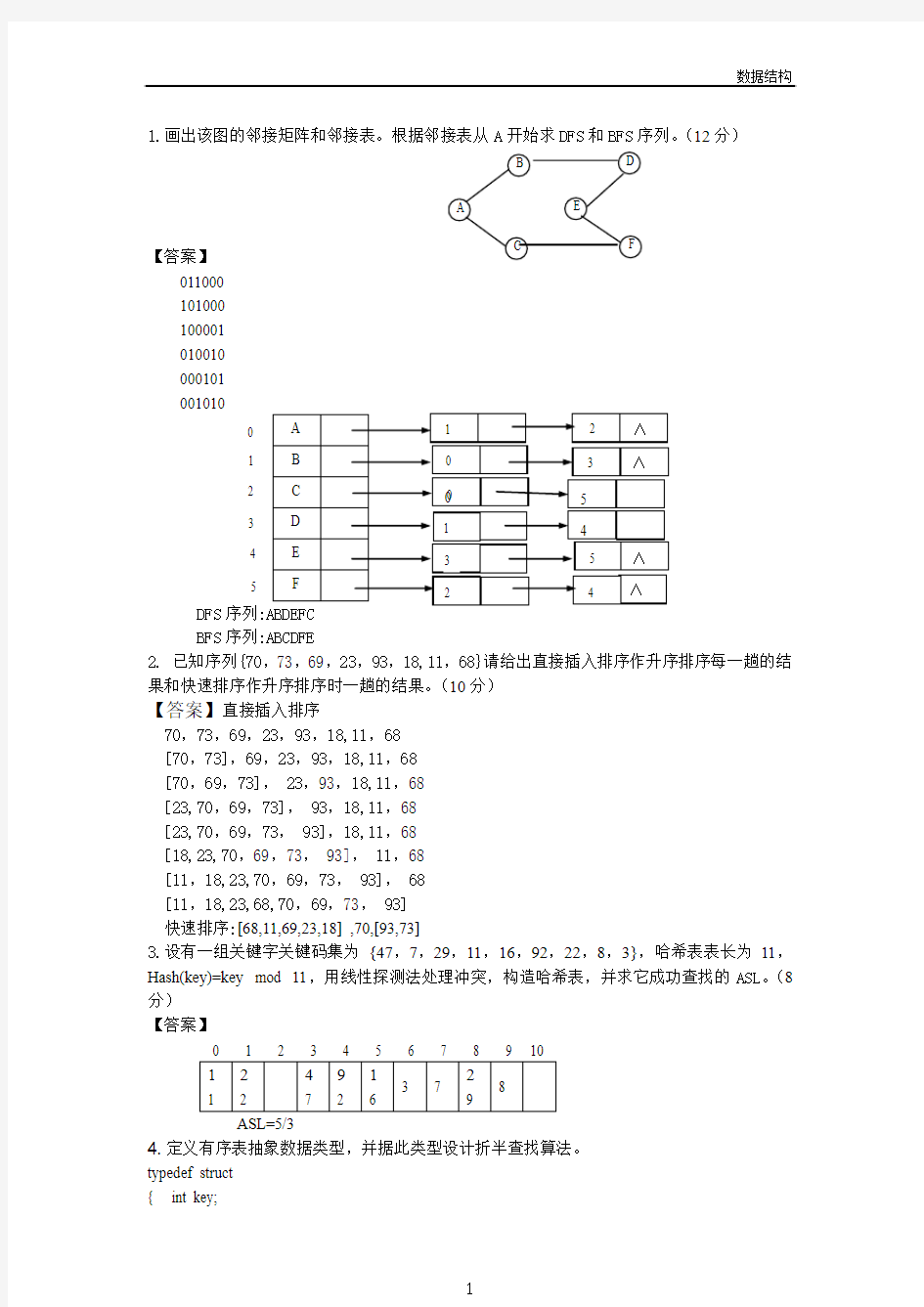

1.画出该图的邻接矩阵和邻接表。根据邻接表从A 开始求DFS 和BFS 序列。(12分)
【答案】
011000 101000 100001 010010 000101 001010
DFS 序列BFS 序列:ABCDFE
2. 已知序列{70,73,69,23,93,18,11,68}请给出直接插入排序作升序排序每一趟的结果和快速排序作升序排序时一趟的结果。(10分)
【答案】直接插入排序
70,73,69,23,93,18,11,68 [70,73],69,23,93,18,11,68 [70,69,73], 23,93,18,11,68 [23,70,69,73], 93,18,11,68 [23,70,69,73, 93],18,11,68 [18,23,70,69,73, 93], 11,68 [11,18,23,70,69,73, 93], 68 [11,18,23,68,70,69,73, 93] 快速排序:[68,11,69,23,18] ,70,[93,73]
3.设有一组关键字关键码集为 {47,7,29,11,16,92,22,8,3},哈希表表长为11, Hash(key)=key mod 11,用线性探测法处理冲突,构造哈希表,并求它成功查找的ASL 。(8分) 【答案】
ASL=5/3
4.定义有序表抽象数据类型,并据此类型设计折半查找算法。
typedef struct { int key;
float info; }JD;
int binsrch(JD r[],int n,int k) { int low,high,mid,found; low=1; high=n; found=0;
while((low<=high)&&(found==0)) { mid=(low+high)/2;
if(k>r[mid].key) low=mid+1; else if(k==r[mid].key) found=1; else high=mid-1; }
if(found==1) return(mid); else return(0); }
5. 用prim 算法求下图的最小生成树,写出最小生成树的生成过程。(5分)
6.设关键字的输入序列为{4,5,7,2,1,3,6}
(1)(8分)从空树开始构造平衡二叉树,画出每加入一个新结点时二叉树的形态,若发
生不平衡,指明需做的平衡旋转类型及平衡旋转的结果。
(2)(4分)上面的数据作为待排序的数据,写出用快速排序进行一趟划分后的数据序列
答案(1)
(2)一趟划分后的数据序列 3 1 2 4 7 5 6
7.画出无向图G的邻接表存储结构,根据邻接表存储结构写出深度优先和广度优先遍历序列。(7分)
【答案】
DFS遍历序列v1 v2 v4 v8 v5 v3 v6 v7(或1 2 4 8 5 3 6 7)
BFS遍历序列v1 v2 v3 v4 v5 v6 v7 v8(或1 2 3 4 5 6 7 8)
8.请在标号处填写合适的语句。完成下列程序。(每空1分,共5分)
int Binary_Search(S_TBL tbl,KEY kx)
{ /* 在表tbl中查找关键码为kx的数据元素,若找到返回该元素在表中的位置,否则,返回0 */ int mid,flag=0;
low=1;high=length;
while( ⑴&!flag )
{ /* 非空,进行比较测试*/
mid= ⑵;
if(kx else if(kx>tbl.elem[mid].key) ⑷; else { flag= ⑸;break;} } return flag; } 答案: (1)low<=high (2) (low+high)/2 (3) high=mid-1 (4) low=mid+1 (5) 1 9.下面是一个采用直接选择排序方法进行升序排序的函数,请在标号处填写合适的语句。(每空1分,共5分) 程序: Void seletesort(int A[n],int n) { int i,j,t,minval,minidx; for(i=1;i<=n-1;i++) { minval=A[i+1]; (1) for(j=i+2;j<=n;j++) if( (2) ) { (3) ; minidx=j;} if( (4) ) {t=A[i+1]; (5) A[minidx]=t; } } } 【答案】 (1)minidx=i+1 (2) minval>A[j] (3) minval=A[j] (4) i!=j (5) A[i+1]=A[minidx] 10. 试写出求有向无环图的关键路径算法的设计思路(10分) 【答案】 输入顶点和弧信息,建立其邻接表 计算每个顶点的入度 对其进行拓扑排序 排序过程中求顶点的Ve[i] 将得到的拓扑序列进栈 按逆拓扑序列求顶点的Vl[i] 计算每条弧的e[i]和l[i],找出e[i]=l[i]的关键活动 11、如下所示的连通图,请画出 (1) 以顶点①为根的深度优先生成树;(5分) (2) 如果有关节点,请找出所有的关节点。(5分) 【答案】(1) 该连通图从①出发做深度优先搜索,得到的深度优先生成树为: 结果不唯一 (2) 关节点为①、②、③、⑦、⑧ 12、设有13个初始归并段,其长度分别为28,16,37,42,5,9,13,14,20,17,30,12,18。试画出4路归并时的最佳归并树,并计算它的带权路径长度WPL。 【解答】因为(13 - 1) % (4 - 1) = 12 % 3 = 0,所以不需要添加空段。最佳归并树为 WPL = ( 5 + 9 + 13 + 12 + 16 + 14 + 17 + 18 + 28 + 37 + 20 + 30 ) * 2 + 42 = 480 13、设散列表为HT[0..12],即表的大小为m= 13。采用双散列法解决冲突。散列函数和再散列函数分别为: H0( key ) = key % 13; 注:%是求余数运算(= mod ) H i = ( H i-1 + REV ( key + 1) % 11 + 1) %13; i = 1, 2, 3, , m-1 其中,函数REV(x)表示颠倒10进制数x的各位,如REV(37) = 73,REV(7) = 7等。 若插入的关键码序列为{ 2, 8, 31, 20, 19, 18, 53, 27 }。试画出插入这8个关键码后的散列表。 【解答】 散列表HT[0..12],散列函数与再散列函数为 H0( key ) = key mod 13; H i= ( H i-1 + REV ( key + 1 ) mod 11 + 1 ) mod 13; 插入关键码序列为{ 2, 8, 31, 20, 19, 18, 53, 27 } H0( 2 ) = 2, 比较次数为1 H0( 8 ) = 8, 比较次数为1 H0( 31 ) = 5, 比较次数为1 H0( 20 ) = 7, 比较次数为1 H0( 19 ) = 6, 比较次数为1 H0( 18 ) = 5, 冲突,H1 = 9,比较次数为2 H0( 53 ) = 1,比较次数为1 H0( 27 ) = 1,冲突,H1 = 7,冲突,H2 = 0,比较次数为3 插入8个关键码后的散列表 14.有一种简单的排序算法,叫做计数排序(count Sorting)。这种排序算法对一个待排序的表(用数组表示)进行排序,并将排序结果存放到另一个新的表中。必须注意的是,表中所有待排序的关键码互不相同。计数排序算法针对表中的每个记录,扫描待排序的表一趟,统计表中有多少个记录的关键码比该记录的关键码小。假设针对某一个记录,统计出的计数值为c,那么,这个记录在新的有序表中的合适的存放位置即为c。 (1) 给出适用于计数排序的数据表定义;(4分) (2) 使用C++ 语言编写实现计数排序的算法;(10分) (3) 对于有n个记录的表,关键码比较次数是多少?(4分) (1) 数据表定义 【解答】 const int DefaultSize = 100; template template private: Type key;//关键码 field otherdata;//其它数据成员 public: Type getKey ( ) { return key; }//取当前结点的关键码 void setKey ( const Type x ) {key = x; }//将当前结点的关键码修改为x } template //用顺序表来存储待排序的元素,这些元素的类型是Type public: datalist ( int MaxSz = DefaultSize ) : MaxSize ( Maxsz ), CurrentSize (0) {Vector = new Element private: Element int MaxSize, CurrentSize;//最大元素个数与当前元素个数} (2) 计数排序的算法 【解答1】 template void countsort ( datalist int i, j, c; Type refer; for ( i = 0;i < initList.CurrentSize;i++ ) { c = 0; refer := initList.Vector[i].getKey ( ); for (j = 0;j < initList.CurrentSize;j++ ) if (initList.Vector[j].getKey ( ) < refer ) c++; resultList.Vector[c] = initList.Vector[i] } resultList.CurrentSize = initList.CurrentSize; } 【解答2】 template void countsort ( datalist int *c = new int[initList.CurrentSize]; for ( int i = 0;i < initList.CurrentSize;i++ ) c[i] = 0; for ( i = 0;i < initList.CurrentSize-1;i++ ) for ( int j = i+1;j < initList.CurrentSize;j++ ) if (initList.Vector[j].getKey ( ) < initList.Vector[i].getKey ( ) ) c[i]++; else c[j]++; for ( i = 0;i < initList.CurrentSize;i++ ) resultList.Vector[ c[i] ] = initList.Vector[i]; resultList.CurrentSize = initList.CurrentSize; } (3)对于n个记录的表,【解答1】关键码比较次数为n2,【解答2】关键码比较次数为n(n-1)/2。 15.下面给出的是一个在二叉树中查找值为x的结点,并打印该结点所有祖先结点的算法。在此算法中,假设值为x的结点不多于一个。此算法采用后序的非递归遍历形式。因退栈时需要区分其左、右子树是否已经遍历,故在结点进栈时附带有一个标志,=0,进入左子树,=1,进入右子树。用栈ST保存结点指针ptr及其标志tag。top是栈顶指针。 void print ( BinTreeNode * t;Type &x ) { stack ST;int i, top; top = 0; //置空栈 while ( t != NULL&&t→data != x || top != 0 ) { { //寻找值为x的结点ST [top].ptr = t; //进栈 } if ( t != NULL ) //找到值为x的结点 for ( i = 1;;i++ ) cout << ST[i].ptr→data << endl; else { while ( top > 0 &&ST [top].tag == 1 ) //未找到值为x的结点 top--; if ( top > 0 ) { 转向右子树 } } } }/*print*/ (1) 请将缺失的语句补上(8分) 【答案】 ①top++ ②t = t→leftChild ③i <= top ④t = ST[top].ptr→rightChild (2) 请给出对于右图所示的二叉树,使用上述算法搜索值为9的结点和值为10的结点的结果,以及在栈ST中的变化。(top是栈顶指针)(10分) 【答案】 → → ptr tag ptr tag 16. 一组记录的关键码为(10,8,6,3,4,8),写出利用冒泡排序算法进行升序排序的过程,并说明算法的稳定性。 【答案】 10 8 6 3 4 8 8 6 3 4 8 10 6 3 4 8 8 10 3 4 6 8 8 10 (2分) 稳定算法(1分) 17.已知一个图如图所示,请根据狄克斯特拉算法次求出从顶点V0到其余各顶点的最短路径。并指出求出最短路径的顶点次序依次是什么? 【答案】v2(10) v4(30) v3(50) v5(60) v1(无路径) 18.已知一组关键字(19,14,23,1,68,20,84,27,55,11,10,79) 哈希函数为:H(key)=key MOD 13, 哈希表长为m=16,设每个记录的查找概率相等。 用线性探测再散列处理冲突,即Hi=(H(key)+di) MOD m 。 1 请构造哈希表。(6分) 2 求平均查找长度ASL 。(2分) 3 求装填因子a 。(2分 ) a=0.75 19.已知以二维数组表示的图的临界矩阵如下图所示。(共12分) 1 判别此图为有向图还是无向图。(2分) 2 这个图有几个顶点。(2分) 3 求所有顶点的度数之和。(2分) 4 根据数组分别写出至序号为0的顶点开始进行遍历所得到的深度优先序列和广度优先序列。(6分) 【答案】 1. 有向图 2. 7个顶点 3. 18 4. 根据情况酌情扣分 DFS遍历序列0124356 BFS遍历序列0124536 20.定义有序表抽象数据类型,并据此类型设计折半查找算法。 typedef struct { int key; float info; }JD;(2分) int binsrch(JD r[],int n,int k) { int low,high,mid,found; low=1; high=n; found=0; while((low<=high)&&(found==0)) { mid=(low+high)/2; if(k>r[mid].key) low=mid+1; else if(k==r[mid].key) found=1; else high=mid-1; } if(found==1) return(mid); else return(0); }(8分) 21. 一组记录的关键码为(46,79,56,38,40,84)利用快速排序的方法,求以第一个记录为基准得到的一次划分结果。 【答案】40 38 46 56 79 22.已知一个图如图所示,请根据狄克斯特拉算法次求出从顶点1到其余各顶点的最短路径。并指出求出最短路径的顶点次序依次是什么? 【答案】2(3)5(9)4(13)3(15)6(17) 23.解释下列术语(2*5分) 线性表, 二叉树,二叉排序树,AVL 树,堆 线性表:n 个数据元素的有限序列。 二叉树:是一种树结构,它的每个结点至多只有二棵子树,分别称为左子树和右子树。 二叉排序树:或是一棵空树,或是具有下列性质的二叉树:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;它的左、右子树也分别为二叉排序树。 A VL 树:或是一棵空树,或是具有下列性质的二叉树:它的左、右子树都是二叉平衡树,且左子树和右子树的深度之差的绝对值不超过1。 堆:n 个元素的有限序列{k 1,k 2,……,k n }当且仅当满足下列关系时,称之为堆 : 24.有向图G 如下 : 1).(6分)将其看作AOE 网,请列出关键路径及关键路径长度(以 4).(6分)给出该图从顶点a 到顶点g 的最短路径(以 及最短路径长度 【答案】 1)关键路径为 ?????????? ???? ??? ?? ?? ?∞∞ ∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞109548612218 3) 4)a 到g 的最短路径为 25.一组记录的关键码为(10,8,6,3,4,8),写出利用冒泡排序算法进行升序排序的过程,并说明算法的稳定性。 【答案】 10 8 6 3 4 8 8 6 3 4 8 10 6 3 4 8 8 10 3 4 6 8 8 10 (2分) 稳定算法(1分) 26.已知一组关键字(19,14,23,1,68,20,84,27,55,11,10,79) 哈希函数为:H(key)=key MOD 13, 哈希表长为m=16,设每个记录的查找概率相等。用线性探测再散列处理冲突,即Hi=(H(key)+di) MOD m。 1.请构造哈希表。(6分) 2.求平均查找长度ASL。(2分) 3.求装填因子a。(2分) a=0.75 27.已知以二维数组表示的图的临界矩阵如下图所示。(共12分) 1.判别此图为有向图还是无向图。(2分) 2.这个图有几个顶点。(2分) 3.求所有顶点的度数之和。(2分) 4 根据数组分别写出至序号为0的顶点开始进行遍历所得到的深度优先序列和广度优先序列。(6分) 【答案】 1. 有向图 2. 7个顶点 3. 18 4. DFS遍历序列0124356 BFS遍历序列0124536 28.定义有序表抽象数据类型,并据此类型设计折半查找算法。 typedef struct { int key; float info; }JD;(2分) int binsrch(JD r[],int n,int k) { int low,high,mid,found; low=1; high=n; found=0; while((low<=high)&&(found==0)) { mid=(low+high)/2; if(k>r[mid].key) low=mid+1; else if(k==r[mid].key) found=1; else high=mid-1; } if(found==1) return(mid); else return(0); }(8分) 29、设关键字的输入序列为{55,31,11,37,46,73,63,2,7} 1.(10分)从空树开始构造平衡二叉树,画出每加入一个新结点时二叉树的形态,若发生不平衡,指明需做的平衡旋转类型及平衡旋转的结果。 2.(2分)计算该平衡二叉树在等概率下,查找成功的平均查找长度。 3.(3分)上面的数据作为待排序的数据,写出用快速排序进行一趟划分后的数据序列 30.(10分)有一哈希表 HT, 表长 m=16, 哈希函数 H(key)=key mod 13 试用: (1)开放定址, 线性再散列解决冲突. (2)链地址解决冲突方法. 将一 组关键字序列 {19, 14, 33, 01, 68, 20, 84, 27} 登入 HT 中. (只需画出 空间分配, 不需要写出算法). 31.(5分)3阶B树如下,画出删除24 后的B树 32、简要回答下列问题(2*5分) 1、写出二叉树中序遍历的递归算法。 2、简述拓扑排序算法步骤。 3 3、(15分)对下图的AOE 网,回答下列问题: 1. 每个事件的最早开始时间Ve[i]和最迟开始时间Vl[i]。 2. 关键路径和关键路径长度。 3. 指出哪些活动加速可使整个工程提前完成。 34(15分)写出下列算法: 1.有序线性表,用单链表存储,结点结构为(data,next ),删除值介于s 和t 之间的结点。2. 请写出顺序查找算法。 35、简答题 (每小题12分,共36分) 1、设已有12个不等长的初始归并段,各归并段的长度(包含记录数)分别为 RUN1 (25), RUN2 (13), RUN3 (04), RUN4 (55), RUN5 (30), RUN6 (47), RUN7 (19), RUN8 (80), RUN9 (76), RUN10 (92), RUN11 (55), RUN12 (89) 若采用的是4路平衡归并排序,试画出其最佳归并树,并计算每趟归并时的读记录数。(括号内即为该归并段包含的记录数) 【解答】构造最佳归并树 因为 (12 - 1) % ( 4 - 1 ) = 2,所以需要补充 4 - 2 - 1 = 1个空归并段,命名为RUN0 (0)。依此构造4叉霍夫曼树: R0 (00) R3 (04) R2 (13) R7 (19) R1 (25) R5 (30) R0237 (36) R6 (47) R4 (55) R11 (55) R9 (76) R8 (80) R12 (89) R10 (92) R0123567 (138) R48911(266) R0-12 (585) 此即最佳归并树。第一趟读记录数为36,第二趟读记录数为138 + 266 = 404,第三趟读记录数为89 + 92 +138 + 266 = 585。 36、设散列表的长度m = 13;散列函数为H (K)=K mod m,给定的关键码序列为19, 14, 23, 01, 68, 20, 84, 27, 55, 11,试画出用线性探查法解决冲突时所构造的散列表。并求出在等概率的情况下,这种方法的搜索成功时的平均搜索长度和搜索不成功时的平均搜索长度。 【解答】 设散列表的长度m = 13;散列函数为H (K)=K mod m,给定的关键码序列为19, 14, 23, 01, 68, 20, 84, 27, 55, 11,则有 H(19) = 6,成功;H(14) = 1,成功;H(23) = 10,成功; H(01) = 1,冲突,= 2,成功;H(68) = 3,成功;H(20) = 7,成功; H(84) = 6,冲突,= 7,冲突,= 8,成功; H(27) = 1,冲突,= 2,冲突,= 3,冲突,= 4,成功; H(55) = 3,冲突,= 4,冲突,= 5,成功;h(11) = 11,成功。 (1) (2) (1) (4) (3) (1) (1) (3) (1) (1) 在等概率的情况下,搜索成功时的平均搜索长度 ASL succ= ( 1 + 2 + 1 + 4 + 3 + 1 + 1 + 3 + 1 + 1 ) / 10 = 18 / 10, 搜索不成功时的平均搜索长度 ASL unsucc= ( 1 + 9 + 8 + 7 + 6 + 5 + 4 + 3 + 2 + 1 + 3 + 2 + 1 ) / 13 = 52 / 13 = 4。 37、画出在一个初始为空的A VL树中依次插入3, 1, 4, 6, 9, 8, 5, 7 时每一步插入后A VL树的形态。若做了某种旋转,说明旋转的类型。然后,给出在这棵插入后得到的A VL树中删去根结点后的结果。 【解答】 在这个AVL树中删除根结点时有两种方案: 【方案1】在根的左子树中沿右链走到底,用5递补根结点中原来的6,再删除5所在的结点。 【方案2】在根的右子树中沿左链走到底,用7递补根结点中原来的6,再删除7所在的结点。 38下面给出的算法是建立AOV网络并对其进行拓扑排序的算法,其中有多个语句缺失。 void Graph::TopologicalSort ( ) { Edge * p, q; int i, j, k; for ( i = 0; i < n;i++ ) { ; } cin >> j >> k;//输入有向边 while ( j &&k ) { p = new Edge (k);//建立边结点, dest域赋为k //链入顶点j的边链表的前端 ; count[k]++;//顶点k入度加一 cin >> j >> k; } int top = -1; for ( i = 0;i < n;i++ ) //建立入度为零顶点的链栈 if ( count[i] == 0 ) { ; } for ( i = 0; i < n; i++ ) if ( top == -1 ) {cout << "Network has a cycle" << endl;return;} else { j = top;; cout<< NodeTable[j].data << endl; q = NodeTable[j].adj; while ( q ) { k = q→dest; if ( -- count[k] == 0 ) { count[k] = top; top = k; ; }}} (1) 请将缺失的语句补上:(10分) (2) 请给出对于下面AOV网络,使用上述算法进行拓扑排序的结果,以及在count数组中建立的链式栈的变化。(top是栈顶指针)(10分) top→ A B C D E F 初始 (1) 请将缺失的语句补上 ①count[i] = 0 ②NodeTable[j].adj = p ③top = i ④top = count[top] ⑤q = q→link (2) 对于下面AOV网络,使用上述算法进行拓扑排序的结果,以及在count数组中建立的链式栈的变化。(top是栈顶指针) 排序结果是A B C D E F,链式栈count的变化如下: tp tp→A B tp→ C tp→ D tp→ E tp→ F tp→ 初始输出A 输出B 输出C 输出D 输出E 输出F B进栈C进栈D进栈E进栈F进栈栈空 39.下面的排序算法的思想是:第一趟比较将最小的元素放在r[1]中, 最大的元素放在r[n]中;第二趟比较将次小的放在r[2]中,将次 大的放在r[n-1]中, . . . .依次下去,直到待排序列为递增序。 (注:←→代表两个变量的数据交换) void sort(SqList&r,int n){ i=1; while( (7) ){ min=max=1; for (j=i+1; (8) ;++j){ if ( (9) ) min=j; else if (r[j].key>r[max].key) max=j; } if ( (10) ) r[min]←→r[j]; if (max!=n-i+1){ if ( (11) ) r[min] ←→r[n-i+1]; else (12) ; } i++; }//sort 【答案】 (7) i 40.(1.5*12分)下表中 m, n 分别是一棵二叉树中的二个结点, 表中行号 i=1, 2, 3, 4 分别表示四种 m, n 的相对关系, 列号 j=1, 2, 3 分别表示在前序, 中序, 后序遍历中 m, n 之间的先后次序关系. 要求在 i, j 所表示的关系能够 发生的方格内打上 √. 例如: 如果你认为 n 是 m 的祖先, 并且在中序遍 历中 n 能比 m 先被访问, 则在 (3, 2) 格内打上 √. 答案: 41.(14分)对给定的有7个顶点的有向图的邻接矩阵如下: 1).(3分)画出该有向图; 2).(3分)画出邻接表; 3).(3分)从V 1 出发到其余个顶点的最短路径长度(顶点号从1计); 4).(5分)若将图看成AOE-网,列出其关键活动及相应的有向边,关键路径长度是多 少? ??? ? ?? ? ??? ??????? ???? ?∞∞∞∞ ∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞∞ ∞∞∞∞∞∞∞∞∞∞∞∞∞5735531723 52 【答案】 1.有向图: 3.(3 分)从V1 出发到其余个顶点的最短路径长度 V1->V2:2 V1->V3:4 V1->V4: 3 V1->V5:7 V1->V6:9 V1->V7:14 4.(5分)关键活动及相应的有向边:<1,3>,<3,4>,<4,5>,<5,6>,<6,7> 关键路径长度:19 42、阅读算法,回答问题(每小题8分,共16分) 2.void AG(BtreeNode * BT)//BT为指向一棵二叉树根结点的指针 { BTreeNode * s[10]; int top=—1; BTreeNode * p=BT; while(top!=—1|| p!=NULL) {//当栈非空或p指针非空时执行循环 while(p!=NULL){ top++; s[top]=p; p=p—>left } if(top !=—1){ p=s[top]; top——; cout<<p—>data<<”; p=p—>right; } } } 该算法的功能为:。 43. 3阶B树如下,画出删除37后的B树 44、算法填空,在画有横线的地方填写合适的内容(10分) 从一维数组A[n]中二分查找关键字为K的元素的递归算法,若查找成功则返回对应元素的下标,否则返回—1。 int Binsch(ElemType A[],intlow,int high,KeyType K) { if(low<high) { int mid=(low+high)/2; if(K==A[mid].key) ; else if(K<A[mid].key ; else ; } else return —1 } 45.阅读下列函数arrange() int arrange(int a&#;,int 1,int h,int x) {//1和h分别为数据区的下界和上界 int i,j,t; i=1;j=h; while(i while(i while(i if(i { t=a[j];a[j]=a[i];a[i]=t;} } if(a[i] else return i-1; } (1)写出该函数的功能; (2)写一个调用上述函数实现下列功能的算法:对一整型数组b[n]中的元素进行重新排列,将所有负数均调整到数组的低下标端,将所有正数均调整到数组的高下标端,若有零值,则置于两者之间,并返回数组中零元素的个数。 【答案】(1)该函数的功能是:调整整数数组a&#;中的元素并返回分界值i,使所有 (2)int f(int b&#;,int n) 或int f(int b&#;,int n) { { int p,q;int p,q; p=arrange(b,0,n-1,0);p=arrange(b,0,n-1,1); q= arrange(b,p+1,n-1,1);q= arrange(b,0,p,0); return q-p;return p-q; } } 46.画出图G的邻接链表,根据此邻接链表写出从1结点出发的DFS序列和BFS序列,并用Prim算法求下列图G的最小生成树。在算法执行到某一时刻,已选取的顶点集U={1,2,3},边集TE={(1,2),(2,3)},要选取下一条权值最小的边,应从哪一边集中选取?并画出最小生成树。(10分) 第三章排序 一、选择题 1.某内排序方法的稳定性是指( D )。 A.该排序算法不允许有相同的关键字记录、 B.该排序算法允许有相同的关键字记录 C.平均时间为0(n log n)的排序方法 D.以上都不对 2.下面给出的四种排序法中( )排序法是不稳定性排序法。 A. 插入 B. 冒泡 C. 二路归并 D. 快速排序3.下列排序算法中,其中( CD )是稳定的。 A. 堆排序,冒泡排序 B. 快速排序,堆排序 C. 直接选择排序,归并排序 D. 归并排序,冒泡排序 6.若要求尽可能快地对序列进行稳定的排序,则应选( B )。 A.快速排序 B.归并排序 C.冒泡排序 12.排序趟数与序列的原始状态有关的排序方法是( D )排序法。 A.插入 B. 选择 C. 冒泡 D. 快速 17.数据序列(8,9,10,4,5,6,20,1,2)只能是下列排序算法中的( C )的两趟排序后的结果。 A.选择排序 B.冒泡排序 C.插入排序 18.数据序列(2,1,4,9,8,10,6,20)只能是下列排序算法中的( A )的两趟排序后的结果。 A. 快速排序 B. 冒泡排序 C. 选择排序 D. 插入排序19.对一组数据(84,47,25,15,21)排序,数据的排列次序在排序的过程中的变化为(1) 84 47 25 15 21 (2) 15 47 25 84 21 (3) 15 21 25 84 47 (4) 15 21 25 47 84,则采用的排序是 ( A )。 A. 选择 B. 冒泡 C. 快速 D. 插入24.下列序列中,( D )是执行第一趟快速排序后所得的序列。 A. [68,11,18,69] [23,93,73] B. [68,11,69,23] [18,93,73] C. [93,73] [68,11,69,23,18] 实验七查找、排序的应用 一、实验目的 1、本实验可以使学生更进一步巩固各种查找和排序的基本知识。 2、学会比较各种排序与查找算法的优劣。 3、学会针对所给问题选用最适合的算法。 4、掌握利用常用的排序与选择算法的思想来解决一般问题的方法和技巧。 二、实验内容 [问题描述] 对学生的基本信息进行管理。 [基本要求] 设计一个学生信息管理系统,学生对象至少要包含:学号、姓名、性别、成绩1、成绩2、总成绩等信息。要求实现以下功能:1.总成绩要求自动计算; 2.查询:分别给定学生学号、姓名、性别,能够查找到学生的基本信息(要求至少用两种查找算法实现); 3.排序:分别按学生的学号、成绩1、成绩2、总成绩进行排序(要求至少用两种排序算法实现)。 [测试数据] 由学生依据软件工程的测试技术自己确定。 三、实验前的准备工作 1、掌握哈希表的定义,哈希函数的构造方法。 2、掌握一些常用的查找方法。 1、掌握几种常用的排序方法。 2、掌握直接排序方法。 四、实验报告要求 1、实验报告要按照实验报告格式规范书写。 2、实验上要写出多批测试数据的运行结果。 3、结合运行结果,对程序进行分析。 五、算法设计 a、折半查找 设表长为n,low、high和mid分别指向待查元素所在区间的下界、上界和中点,key为给定值。初始时,令low=1,high=n,mid=(low+high)/2,让key与mid指向的记录比较, 若key==r[mid].key,查找成功 若key 实验四:查找与排序 【实验目的】 1.掌握顺序查找算法的实现。 2.掌握折半查找算法的实现。 【实验内容】 1.编写顺序查找程序,对以下数据查找37所在的位置。 5,13,19,21,37,56,64,75,80,88,92 2.编写折半查找程序,对以下数据查找37所在的位置。 5,13,19,21,37,56,64,75,80,88,92 【实验步骤】 1.打开VC++。 2.建立工程:点File->New,选Project标签,在列表中选Win32 Console Application,再在右边的框里为工程起好名字,选好路径,点OK->finish。 至此工程建立完毕。 3.创建源文件或头文件:点File->New,选File标签,在列表里选C++ Source File。给文件起好名字,选好路径,点OK。至此一个源文件就被添加到了你刚创建的工程之中。 4.写好代码 5.编译->链接->调试 #include "stdio.h" #include "malloc.h" #define OVERFLOW -1 #define OK 1 #define MAXNUM 100 typedef int Elemtype; typedef int Status; typedef struct { Elemtype *elem; int length; }SSTable; Status InitList(SSTable &ST ) { int i,n; ST.elem = (Elemtype*) malloc (MAXNUM*sizeof (Elemtype)); if (!ST.elem) return(OVERFLOW); printf("输入元素个数和各元素的值:"); scanf("%d\n",&n); for(i=1;i<=n;i++) { scanf("%d",&ST.elem[i]); } ST.length = n; return OK; } int Seq_Search(SSTable ST,Elemtype key) { int i; ST.elem[0]=key; for(i=ST.length;ST.elem[i]!=key;--i); return i; } int BinarySearch(SSTable ST,Elemtype key) { int low,high,mid; low=1; high=ST.length; 人教版小学四年级下册语文排序专项练习题及答案(一) ()田野的尽头,连绵的山峰像海里起伏的波涛。()溪水是那么清澈、明净;水里的小鱼儿自由自在地游来游去。 ()小溪的另一边是田野,如今黄澄澄的,正报告着丰收的喜讯。 ()一条小溪从我们村子旁静静地流过。 ()山腰上的公路,像一条银灰色的绸带飘向远方。()小溪的一边是果园,春天,花香弥漫;秋天,硕果累累。 参考答案:5、2、4、1、6、3 (二) ()人们都说这个山村像一幅风景画。 ()村前有一口大水塘,塘水清如明镜。 ()山脚下有一个村子,村子景色秀丽。 ()塘里荷花点点,偶尔有小鱼跳出水面。 ()村后有一片青翠的竹林,林中鸟声清脆悦耳。()水里倒映着蓝天白云。答案:6、2、1、4、5、3 (三) ()一听到这熟悉的叫声,我就猜准它一定生蛋了。()我高兴地把蛋捡在手里,还热乎乎的呢。 ()跨进屋门,果然,一个鹅蛋似的双黄蛋躺在鸡窝里。 ()一天下午,我参加学习小组后回家,老远就听到我家的那只老母鸡“咯咯哒”、“咯咯哒”地在房子里叫个不停。 答案:2、4、3、1。 (四) ()当太阳一落山,黄昏的薄霭像轻纱一样笼罩山野的时候,青蛙便逐渐热闹起来。 ()蛙们纷纷跳入稻田去了,蛙声也暂时停息。 ()这时候,人要是从田埂上经过,就听见路两旁扑通扑通的声音。 ()但是人刚一走过,他们又扯开嗓子,放肆地叫起来。 ()乡村的夏夜,便是蛙的世界。 答案:2、4、3、5、1 (五) ()一大滴松脂从树上滴下来,把苍蝇和蜘蛛包在了里面。 ()松脂球埋在泥沙里成了化石。 ()地壳变动了,森林被海水淹没了。 ()松脂不断往下滴,盖住了原来的地方,积成了一个松脂球。 ()一个夏天的晌午,热辣辣的太阳照射着松树林。 数据结构查找排序经典试题 一、填空 1、针对有n条记录的顺序表做顺序查找,假定各记录的查找机会均等,则平均查找长度 ASL=_______。 2、在二叉平衡树中,平衡因子hl-hr的所有可能取值有____________。 3、在排序操作中,待排序的记录有n条,若采用直接插入排序法,则需进行 _________趟的 插入才能完成排序。 4、在排序操作中,待排序的记录有n条,若采用冒泡排序法,则至多需进行_________趟的 排序。 5、直接插入排序算法的时间复杂度为________________。 6、按()遍历二叉排序树,可以得到按值递增的关键字序列,在下图 所示的二叉排序树中,查找关键字85的过程中,需和85进行比较的关键字序列为()。 50 95 20 55 70 10 30 85 二、判断 1、平衡二叉树中子树的深度不能大于1。() 2、快速排序法是稳定的排序方法。() 3、任何一种排序方法都必须根据关键字值比较的结果来将记录从一个地方移动到另一个地 方。() 4、冒泡排序法是稳定的排序方法。() 5、折半插入排序法是稳定的排序方法。() 三、选择 1、在排序操作中,待排序的记录有n条,若采用直接插入排序法,则需进行_________趟的 插入才能完成排序。 A、n B、(n-1)/2 C、n+1 D、n-1 2、采用顺序查找法查找长度为n的线性表时,平均查找长度为() A、n B、(n-1)/2 C、n/2 D、(n+1)/2 3、用折半查找法在{11,33,55,77,99,110,155,166,233}中查找155需要进行()次比较。 A、1 B、2 C、3 D、4 4、请指出在顺序表(2,5,7,10,14,15,18,23,35,41,52)中,用折半查找法查找12需做()次比较。 A、5 B、4 C、3 D、2 5、如果待排序序列中两个数据元素具有相同的值,在排序前后它们的相互位置发生颠倒, (三) 1单选(2分) 关于问题与问题求解,下列说法正确的是()。 A.在问题求解中,提出假设就是对问题求解结果的一种假设。 B.问题求解是人们为寻求问题答案而进行的一系列思维活动。 C.问题是客观存的,提出问题与发现问题与人对事情的好奇心和求知欲无关。 D.所有问题都是有科学研究价值的。 E.人类进行问题求解的一般思维过程可分为问题分析、提出假设和检验假设。 F.问题的发现与人的好奇心和求知欲有关,与人的知识和经验无关。 正确答案:B、E 2单选(2分) 关于贪心算法,下列叙述中正确的是()。 A.贪心算法所做出的选择只是在某种意义上的局部最优选择。 B.贪心算法并不从整体最优考虑。 C.贪心算法无法求得问题的最优解。 D.贪心算法的时间效率最高。 E.选择能产生问题最优解的最优量度标准是使用贪婪算法的核心。 正确答案:A、E 3单选(2分) 关于数学模型(Mathematical Model)和数学建模(Mathematical Modeling),下列说法正确的是()。 A.数学建模包括模型准备、模型假设和模型建立三个基本步骤。 B.数学模型是问题求解的逻辑模型,与时间变量无关。 C.数学模型是研究和掌握系统运动规律的有力工具,可以对实际问题进行分析、预测和求解。 D.数学建模是对实际问题进行抽象、提炼出数学模型的过程。 E.数学模型是对实际问题的数学抽象,是用数学符号、数学式子等对实际问题本质属性的抽象而又简洁的刻画。正确答案:D、E 4单选(2分) 关于问题的算法复杂性,下列叙述正确的是()。 A.NP问题就是时间复杂性为O(2n)的问题。 B.NP问题都是不可解的。 C.问题求解算法的时间复杂度是该问题实例规模n的多项式函数,则这种可以在多项式时间内解决的问题称为P类问题。 D.NP问题虽然不能在多项式时间内求解,但对于所有解,都可以在多项式时间内验证它是否为问题的解。 E.NP问题就是时间复杂性为O(n!)的问题。 F.不能在多项式时间内求解的问题为NP问题。 正确答案:C、F 5单选(2分) 设数据表共有n=10个元素,其关键值为{2,5,6,10,15,21,26,30,56,78},要查找的关键字为K=30,则查找成功时,所做的比较操作的次数是()。 A.8次 B.3次 C.2次 D.1次 E.4次 正确答案:C 6单选(2分) 关于算法(Algorithm),下列叙述正确的是()。 A.在算法设计中,设计师和程序员之间采用流程图工具。 B.在算法描述中,自然语言、流程图和伪代码不能混合使用。 C.算法是问题求解方法及求解过程的描述。 D.自然语言描述常用于细节的描述。 E.在算法设计中,用户和分析师常采用伪代码描述算法,沟通思想。 正确答案:C 7单选(2分) 河南工业大学实验报告 课程名称数据结构实验项目实验三查找和排序(二)——排序院系信息学院计科系专业班级计科1203 姓名张伟龙学号 201216010313 指导老师范艳峰日期 2013.6.5 批改日期成绩 一实验目的 掌握希尔排序、快速排序、堆排序的算法实现。 二实验内容及要求 实验内容:1.实现希尔排序。 2.实现快速排序。 3. 实现堆排序。 (三选一) 实验要求:1. 根据所选题目,用C语言编写程序源代码。 2. 源程序必须编译调试成功,独立完成。 三实验过程及运行结果 选择第三题: Source Code: #include int rchild=2*i+1; //i的右孩子节点序号 int max=i; //临时变量 if(i<=size/2) //如果i是叶节点就不用进行调整 { if(lchild<=size&&a[lchild]>a[max]) { max=lchild; } if(rchild<=size&&a[rchild]>a[max]) { max=rchild; } if(max!=i) { swap(a[i],a[max]); HeapAdjust(a,max,size); //避免调整之后以max为父节点的子树不是堆 } } } void BuildHeap(int *a,int size) //建立堆 { int i; for(i=size/2;i>=1;i--) //非叶节点最大序号值为size/2 { HeapAdjust(a,i,size); } } 第二轮排序和查找算法综合1 行政班:教学班:姓名:学号: 根据课本上的排序算法和查找算法回答1-6题: 1.【加试题】有一个数组,采用冒泡排序,第一遍排序后的结果为:4,10,5,32,6,7,9,17,24那么该数组的原始顺序不可能 ...的是() A.10,5,32,6,7,9,17,24,4 B.10,5,32,6,7,9,4,17,24 C.10,5,32,4,6,7,9,17,24 D.4,10,5,32,17,9,24,6,7 2.【加试题】对下列数据序列进行冒泡升序排序,排序效率最低的序列() A.31,29,24,20,15,10 B.10,15,20,24,29,31 C.29,10,31,15,20,24 D.24,29,31,20,15,10 3.【加试题2】数组变量d(1)到d(8)的值依次为87、76、69、66、56、45、37、23,用“对分查找”找到“69”的过程中,依次被访问到的数据是() A.69 B.66、69 C.66、76、69 D.56、66、76、69 4.【加试题2】用对分查找法和顺序查找法在数字序列“1,2,3,5,8,13,21,34,55”中查找数字13,两种方法都能访问到的数字是() A.3 B.5 C.8 D.34 5.【加试题2】在有序单词序列“bike,cake,data,easy,feel,great,hive,mark,sweet”中,用对分查找算法找到“easy”过程中,依次被访问到的数据为() A.feel, data, easy B.great, data, easy C.bike, cake, dada,easy D.feel,cake,data,easy 6.【加试题2】下列有关查找的说法,正确的是() A.进行对分查找时,被查找的数据必须已按升序排列 B.进行对分查找时,如果查找的数据不存在,则无需输出结果 C.在新华字典中查找某个汉字,最适合使用顺序查找 D.对规模为n的数据进行顺序查找,平均查找次数是21 n 7. 【加试题】实现某排序算法的部分VB程序如下:数组元素a(1)到a(5)的数据依次为“38,70,53,57,30”。经过下列程序“加工”后数组元素a(1)到a(5)的数据应该是() For i = 1 To 1 For j = 5 To i + 1 Step -1 If a(j) > a(j - 1) Then t = a(j) a(j) = a(j - 1) a(j - 1) = t End If Next j Next i 命题:杜宗飞 A.70,57,38,53,30 B.30, 38,70,53,57 C.70,38,57,53,30 D.30, 38,57,53,70 8.【加试题】有如下程序段: For i = 1 To 2 排序练习题 1() ()碧溪河从村前流过。 ()村后是一望无际的桑园。 ()我家住在碧溪河边,这是江南水乡的小村庄。 ()河里一群小鱼在水中游来游去,水面上不时溅起朵朵水花。 ()春天,桑树抽出新芽,整个桑园就像绿色的海洋。 2() ()一些不知名的小花,长在绿草中,像蓝天上缀着的星星。 ()小花园在教室的左边,长八米,宽四米。 ()花园里四周的道路上都长满了青草,好象铺了一层绿毯。 ()它紧靠短墙,由一排横、两排竖的篱笆和这面短墙围起来。 ()花是老师精心栽培的,有的长在地上,有的长在盆里,构成了一个个图案。()到了夏天,大的、小的、圆的、长的、各种形状的绿叶,托着红的、黄的、蓝的、白的各色各样的花儿,美丽极了! 3() ()地上的水越来越多。 ()雨落在对面的屋顶的瓦片上。 ()像一层薄烟罩在屋顶上。 ()渐渐地连成了一条线。 ()溅起一朵朵水花。 ()雨水顺着房檐流下来。 ()汇合成一条条小溪。 ()开始像断了线的珠子。 4() ()王红同学真值得我们学习。 ()今天,老天爷一直紧绷着脸,阴沉沉的,好象跟谁生气似的。 ()就在这个时候,我看见一个女同学飞快地朝操场奔去。 ()天突然下起雨来。 ()啊!那是三年级(4)班的王红。 ()下午放学的时候,同学们背起书包正准备回家。 ()原来,她是冒雨去降国旗的。 ()红领巾在她胸前飘动,就像一束跳动的火苗。 5() ()我们坐在河边柳树下,放下了鱼钩。 ()忽然,浮标一沉,我急忙把鱼竿往上一提,一条银白色的小鱼钓上来了。()星期天早晨,我和小明扛着鱼竿到郊外去钓鱼。 ()浅红色的浮标漂在水面上。 ()我们高兴地把鱼竿举在空中,摇晃着,喊着:“我们钓着鱼了!” 6() ()他正想坐下时,管理员对他说:“先生,请你不要坐在这里,这里是马克思的座位。” ()管理员笑着说:“是的,很多年来,他每天都到这里来读书。” ()那个读者问:“他每天都来吗?你是说他今天一定会来?” ()话刚说完,马克思果然跨进门来了。 ()一天清早,伦敦大英博物馆里,有位读者看见有个座位空着,便走了过来。 7() ()我连忙站起来让老爷爷坐。 ()我刚坐下,一位老爷爷提着篮子上了车。 ()星期日,我坐汽车去奶奶家。 ()老爷爷微笑着说:“谢谢,你真是个好孩子。” ()上车后,我找到一个座位。 ()我说:“不用谢,这是我应该做的。” 8() ()我说了声:“谢谢奶奶。”就把压岁钱交给爸爸,留着给我交学费。 ()奶奶说:“这孩子到底长了一岁,懂事多了。” ()奶奶乐呵呵地从怀里掏出一个红包,说是给我的压岁钱。 ()屋子里充满了欢声笑语。 ()我奔到奶奶身边,祝奶奶健康长寿。 9() ()小脸蛋鼓鼓的,像嘴里含着里两个核桃。 ()身上穿着大翻领西装和蓝色直筒裤。 ()我的“小顽童”真逗人喜爱。 ()脚穿一双特大号皮鞋。 ()眉毛下两只眼睛,仿佛在转动。 ()他头上戴着一顶红白相间的西瓜帽。 10() 《编程实训》 实验报告书 专业:计算机科学与技术 班级:151班 学号: 姓名: 指导教师: 日期:2016年6月30日 目录 一、需求分析 (3) 1.任务要求 (3) 2.软件功能分析 (3) 3.数据准备 (3) 二、概要设计 (3) 1.功能模块图 (4) 2.模块间调用关系 (4) 3.主程序模块 (5) 4.抽象数据类型描述 (5) 三、详细设计 (6) 1.存储结构定义 (6) 2.各功能模块的详细设计 (7) 四、实现和调试 (7) 1.主要的算法 (7) 2.主要问题及解决 (8) 3.测试执行及结果 (8) 五、改进 (9) 六、附录 (9) 1.查找源程序 (9) 2.排序源程序 (9) 目录 1 需求分析 1.1 任务要求 对于从键盘随机输入的一个序列的数据,存入计算机内,给出各种查找算法的实现; 以及各种排序算法的实现。 1.2 软件功能分析 任意输入n个正整数,该程序可以实现各类查找及排序的功能并将结果输出。 1.3 数据准备 任意输入了5个正整数如下: 12 23 45 56 78 2 概要设计(如果2,3合并可以省略2.4) 2.1 功能模块图(注:含功能说明) 2.2 模块间调用关系 2.3 主程序模块 2.4 抽象数据类型描述 存储结构:数据结构在计算机中的表示(也称映像)叫做物理结构。又称为存储结构。数据类型(data type)是一个“值”的集合和定义在此集合上的一组操作的总称。 3 详细设计 3.1 存储结构定义 查找: typedef int ElemType ; //顺序存储结构 typedef struct { ElemType *elem; //数据元素存储空间基址,建表时按实际长度分配,号单元留空 int length; //表的长度 第九章查找 单项选择题 1.顺序查找法适合于存储结构为的线性表。 A. 散列存储 B. 顺序存储或链接存储 C. 压缩存储 D. 索引存储 2.对线性表进行二分查找时,要求线性表必须。 A. 以顺序方式存储 B. 以顺序方式存储,且结点按关键字有序排列 C. 以链接方式存储 D. 以链接方式存储,且结点按关键字有序排列 3.采用顺序查找方法查找长度为n的线性表时,每个元素的平均查找长度为。 A. n B. n/2 C. (n+1)/2 D. (n-1)/2 4.采用二分查找方法查找长度为n的线性表时,每个元素的平均查找长度为。 A. O(n2) B. O(nlog2n) C. O(n) D. O (logn) 5.二分查找和二叉排序树的时间性能。 A. 相同 B. 不相同 6.有一个有序表为{1,3,9,12,32,41,45,62,75,77,82,95,100},当二分查找值为82的结点时,次比较后查找成功。 A. 1 B. 2 C. 4 D. 8 7.设哈希表长m=14,哈希函数H(key)=key%11。表中有4个结点: addr(15)=4 addr(38)=5 addr(61)=6 addr(84)=7 其余地址为空,如用二次探测再散列处理冲突,关键字为49的结点的地址是。 A. 8 B. 3 C. 5 D. 9 8.有一个长度为12的有序表,按二分查找法对该表进行查找,在表内各元素等概率情况下查找成功所需的平均比较次数为。 A. 35/12 B. 37/12 C. 39/12 D. 43/12 9.采用分块查找时,若线性表中共有625个元素,查找每个元素的概率相同,假设采用顺序查找来确定结点所在的块时,每块应分个结点最佳地。 A. 10 B. 25 C. 6 D. 625 10.如果要求一个线性表既能较快地查找,又能适应动态变化的要求,可以采用查找方法。 A. 分块 B. 顺序 C. 二分 D. 散列 填空题 1.顺序查找法的平均查找长度为;二分查找法的平均查找长度为;分块查找法(以顺序查找确定块)的平均查找长度为;分块查找法(以二分查找确定块)的平均查找长度为;哈希表查找法采用链接法处理冲突时的平均查找长度为。 2.在各种查找方法中,平均查找长度与结点个数n无关的查找方法是。 3.二分查找的存储结构仅限于,且是。 4.在分块查找方法中,首先查找,然后再查找相应的。 5.长度为255的表,采用分块查找法,每块的最佳长度是。 6.在散列函数H(key)=key%p中,p应取。 7.假设在有序线性表A[1..20]上进行二分查找,则比较一次查找成功的结点数为,则 1.画出该图的邻接矩阵和邻接表。根据邻接表从A 开始求DFS 和BFS 序列。(12分) 【答案】 011000 101000 100001 010010 000101 001010 DFS 序列BFS 序列:ABCDFE 2. 已知序列{70,73,69,23,93,18,11,68}请给出直接插入排序作升序排序每一趟的结果和快速排序作升序排序时一趟的结果。(10分) 【答案】直接插入排序 70,73,69,23,93,18,11,68 [70,73],69,23,93,18,11,68 [70,69,73], 23,93,18,11,68 [23,70,69,73], 93,18,11,68 [23,70,69,73, 93],18,11,68 [18,23,70,69,73, 93], 11,68 [11,18,23,70,69,73, 93], 68 [11,18,23,68,70,69,73, 93] 快速排序:[68,11,69,23,18] ,70,[93,73] 3.设有一组关键字关键码集为 {47,7,29,11,16,92,22,8,3},哈希表表长为11, Hash(key)=key mod 11,用线性探测法处理冲突,构造哈希表,并求它成功查找的ASL 。(8分) 【答案】 ASL=5/3 4.定义有序表抽象数据类型,并据此类型设计折半查找算法。 typedef struct { int key; float info; }JD; int binsrch(JD r[],int n,int k) { int low,high,mid,found; low=1; high=n; found=0; while((low<=high)&&(found==0)) { mid=(low+high)/2; if(k>r[mid].key) low=mid+1; else if(k==r[mid].key) found=1; else high=mid-1; } if(found==1) return(mid); else return(0); } 5. 用prim 算法求下图的最小生成树,写出最小生成树的生成过程。(5分) 6.设关键字的输入序列为{4,5,7,2,1,3,6} (1)(8分)从空树开始构造平衡二叉树,画出每加入一个新结点时二叉树的形态,若发 生不平衡,指明需做的平衡旋转类型及平衡旋转的结果。 (2)(4分)上面的数据作为待排序的数据,写出用快速排序进行一趟划分后的数据序列 【一】需求分析 课程题目是排序算法的实现,课程设计一共要设计八种排序算法。这八种算法共包括:堆排序,归并排序,希尔排序,冒泡排序,快速排序,基数排序,折半插入排序,直接插入排序。 为了运行时的方便,将八种排序方法进行编号,其中1为堆排序,2为归并排序,3为希尔排序,4为冒泡排序,5为快速排序,6为基数排序,7为折半插入排序8为直接插入排序。 【二】概要设计 1.堆排序 ⑴算法思想:堆排序只需要一个记录大小的辅助空间,每个待排序的记录仅占有一个存储空间。将序列所存储的元素A[N]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的元素均不大于(或不小于)其左右孩子(若存在)结点的元素。算法的平均时间复杂度为O(N log N)。 ⑵程序实现及核心代码的注释: for(j=2*i+1; j<=m; j=j*2+1) { if(j temp=su[i]; su[i]=su[0]; su[0]=temp; head(0,i-1); } cout<<"排序之后的数组为:"< 部编三年级语文句子排序实用技巧(附练习题及答案) 排序题三字经 排序题,并不难;通读题,前后看; 有代词,往前串;同话题,连一连; 找顺序,时空间;标志词,抓关键; 内容上,要映现;排完了,先浏览; 不通顺,再换换;对答案,笑开颜。 句子排序的技巧 将排列错乱的句子整理成一段通顺连贯的话,这是一项综合训练能力,可以训练我们对句子的理解能力、表达能力,及写作能力。其实这类题型并不难,很多题目都有十分明朗的线索或表明顺序的提示,只要我们找到其中的规律,就一定能化难为易。 看到题目,首先要反复阅读,不要急于求成。只有在读懂的情况下才可以弄明白句子之间的内在联系。我们可以先考虑一下几个句子重点写了什么事,有哪些步骤等,只有这样仔细阅读才可以找到句子排列的顺序,找到句与句之间的内在联系,把握句子的排列顺序。 1时间的顺序 在有的题中,几个句子虽然被打乱了,但是可以明显找到关于时间的词语:如早上、中午、下午;几天前、昨天、今天、到了晚上等,这些词语就是明显告诉了我们句子排列的顺序,只要结合这几个时间词语便可以正确排列句子。 2方位顺序 如果是介绍一个地方、一个空间或者一个物件时,有时会出现上面、下面、左边、右边、中间等方位的词语,那么这些方位词就是我们排列句子的依据,我们可以根据先上后下,先左后右,先中间后两边,从里到外等顺序排列句子。 3事情发展的顺序 如果是写事的,就会有描写事情起因的词语,如开始、后来、最后等提示,也许会先介绍事情的起因,然后是事情是怎么发展的,最后的结果等,自然我们就可以按照事情发展的顺利来排列了。 4参观的顺序或地点转换的顺序 如果是游记、参观之类的文章,就会有一个参观的顺序,先看到了什么,接着是什么,有时是过渡句中有意暗示我们,诸如“看完了某处,我们又来到了某处”之类的话语,这就是排列顺序的方法。 句子排序练习题 1 ()碧溪河从村前流过。 ()村后是一望无际的桑园。 ()我家住在碧溪河边,这是江南水乡的小村庄。 ()河里一群小鱼在水中游来游去,水面上不时溅起朵朵水花。 ()春天,桑树抽出新芽,整个桑园就像绿色的海洋。 2 ()一些不知名的小花,长在绿草中,像蓝天上缀着的星星。 ()小花园在教室的左边,长八米,宽四米。 ()花园里四周的道路上都长满了青草,好象铺了一层绿毯。 ()它紧靠短墙,由一排横、两排竖的篱笆和这面短墙围起来。 ()花是老师精心栽培的,有的长在地上,有的长在盆里,构成了一个个图案。 ()到了夏天,大的、小的、圆的、长的、各种形状的绿叶,托着红的、黄的、蓝的、白的各色各样的花儿,美丽极了! 3 ()地上的水越来越多。 ()雨落在对面的屋顶的瓦片上。 ()像一层薄烟罩在屋顶上。 ()渐渐地连成了一条线。 ()溅起一朵朵水花。 ()雨水顺着房檐流下来。 ()汇合成一条条小溪。 ()开始像断了线的珠子。 4 ()王红同学真值得我们学习。 ()今天,老天爷一直紧绷着脸,阴沉沉的,好象跟谁生气似的。 ()就在这个时候,我看见一个女同学飞快地朝操场奔去。 ()天突然下起雨来。 第7章查找 【例7-1】有序表按关键字排列如下:7,14,18,21,23,29,31,35,38,42,46,49,52,在表中查找关键字为14和22的数据元素,并画出折半查找过程的判定树。 解:折半查找的过程描述如下: ①low=1;high=length;//设置初始区间 ②当low>high时,返回查找失败信息//表空,查找失败 ③low≤high,mid=(low+high)/2; //取中点 a. 若kx xxx大学实验报告 课程名称数据结构实验项目实验三查找和排序(一)——查找 院系信息学院计类系专业班级计类1501 姓名学号 指导老师日期 批改日期成绩 一实验目的 1.掌握哈希函数——除留余数法的应用; 2. 掌握哈希表的建立; 3. 掌握冲突的解决方法; 4. 掌握哈希查找算法的实现。 二实验内容及要求 实验内容:已知一组关键字(19,14,23,1,68,20,84,27,55,11,10,79),哈希 函数定义为:H(key)=key MOD 13, 哈希表长为m=16。实现该哈希表的散列,并 计算平均查找长度(设每个记录的查找概率相等)。 实验要求:1. 哈希表定义为定长的数组结构;2. 使用线性探测再散列或链 地址法解决冲突;3. 散列完成后在屏幕上输出数组内容或链表;4. 输出等概率 查找下的平均查找长度;5. 完成散列后,输入关键字完成查找操作,要分别测 试查找成功与不成功两种情况。 注意:不同解决冲突的方法会使得平均查找长度不同,可尝试使用不同解决 冲突的办法,比较平均查找长度。(根据完成情况自选,但至少能使用一种方法 解决冲突) 三实验过程及运行结果 #include #define q 13 int sign=2; typedef struct Hash { int date; //值域 int sign; //标记 }HashNode; void compare(HashNode H[],int p,int i,int key[]) //线性冲突处理{ p++; if(H[p].sign!=0) { sign++; compare(H,p,i,key); } else { H[p].date=key[i]; H[p].sign=sign; sign=2; } } void Hashlist(HashNode H[],int key[]) { int p; for(int i=0;i<12;i++) { p=key[i]%q; if(H[p].sign==0) { H[p].date=key[i]; H[p].sign=1; } else compare(H,p,i,key); } } int judge(HashNode H[],int num,int n) //查找冲突处理 { 数据结构查找与排序练习题 一、选择题 1.对N个元素的表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为( ) A.(N+1)/2 B. N/2 C. N D. [(1+N)*N ]/2 2.适用于折半查找的表的存储方式及元素排列要求为( ) A.链接方式存储,元素无序 B.链接方式存储,元素有序 C.顺序方式存储,元素无序 D.顺序方式存储,元素有序 3.当在一个有序的顺序存储表上查找一个数据时,即可用折半查找,也可用顺序查找,但前者比后者的查找速度( ) A.必定快 B.不一定 C. 在大部分情况下要快 D. 取决于表递增还是递减4.有一个长度为12的有序表,按二分查找法对该表进行查找,在表内各元素等概率情况下查找成功所需的平均比较次数为()。 A.35/12 B.37/12 C.39/12 D.43/12 5.折半查找的时间复杂性为() A. O(n2) B. O(n) C. O(nlogn) D. O(logn) 6.对有18个元素的有序表作折半查找,则查找A[3]的比较序列的下标为() A.1,2,3 B.9,5,2,3 C.9,5,3 D.9,4,2,3 7.设有序表的关键字序列为{1,4,6,10,18,35,42,53,67,71,78,84,92,99},当用二分查找法查找健值为84的结点时,经()次比较后查找成功。 A.2 B. 3 C. 4 D.12 8.用n个键值构造一棵二叉排序树,最低高度为() A.n/2 B.、n C.logn D.logn+1 9.分别以下列序列构造二叉排序树,与用其它三个序列所构造的结果不同的是( ) A.(100,80, 90, 60, 120,110,130) B.(100,120,110,130,80, 60, 90) C.(100,60, 80, 90, 120,110,130) D.(100,80, 60, 90, 120,130,110) 10.设有一组记录的关键字为{19,14,23,1,68,20,84,27,55,11,10,79},用链地址法构造散列表,散列函数为H(key)=key% 13,散列地址为1的链中有()个记录。A.1 B. 2 C. 3 D. 4 11.已知一采用开放地址法解决Hash表冲突,要从此Hash表中删除出一个记录,正确的做法是() A.将该元素所在的存储单元清空。 B.将该元素用一个特殊的元素代替 C.将与该元素有相同Hash地址的后继元素顺次前移一个位置。 D.用与该元素有相同Hash地址的最后插入表中的元素替代。 12.假定有k个关键字互为同义词,若用线性探测法把这k个关键字存入散列表中,至少要进行多少次探测?( ) A.k-1次 B. k次C. k+1次D. k(k+1)/2次 13.散列表的地址区间为0-17,散列函数为H(K)=K mod 17。采用线性探测法处理冲突,并将关键字序列26,25,72,38,8,18,59依次存储到散列表中。 (1)元素59存放在散列表中的地址是()。 A. 8 B. 9 C. 10 D. 11 (2)存放元素59需要搜索的次数是()。 A. 2 B. 3 C. 4 D. 5 14.将10个元素散列到100000个单元的哈希表中,则()产生冲突。 A. 一定会 B. 一定不会 C. 仍可能会 第3章排序自测卷答案姓名班级 一、填空题(每空1分,共24分) 1. 大多数排序算法都有两个基本的操作:比较(两个关键字的大小)和移动(记录或改变指向记录的指 针)。 2. 在对一组记录(54,38,96,23,15,72,60,45,83)进行直接插入排序时,当把第7个记录60插入到有 序表时,为寻找插入位置至少需比较3次。(可约定为,从后向前比较) 3. 在插入和选择排序中,若初始数据基本正序,则选用插入排序(到尾部);若初始数据基本反序,则选 用选择排序。 4. 在堆排序和快速排序中,若初始记录接近正序或反序,则选用堆排序;若初始记录基本无序,则最好选 用快速排序。 5. 对于n个记录的集合进行冒泡排序,在最坏的情况下所需要的时间是O(n2) 。若对其进行快速排序,在 最坏的情况下所需要的时间是O(n2) 。 6. 对于n个记录的集合进行归并排序,所需要的平均时间是O(nlog2n) ,所需要的附加空间是O(n) 。 7.【计研题2000】对于n个记录的表进行2路归并排序,整个归并排序需进行log2n 趟(遍),共计移 动n log2n次记录。 (即移动到新表中的总次数!共log2n趟,每趟都要移动n个元素) 8.设要将序列(Q, H, C, Y, P, A, M, S, R, D, F, X)中的关键码按字母序的升序重新排列,则: 冒泡排序一趟扫描的结果是H, C, Q, P, A, M, S, R, D, F, X ,Y; 初始步长为4的希尔(shell)排序一趟的结果是P, A, C, S, Q, D, F, X , R, H,M, Y; 二路归并排序一趟扫描的结果是H, Q, C, Y,A, P, M, S, D, R, F, X ; 快速排序一趟扫描的结果是F, H, C, D, P, A, M, Q, R, S, Y,X; 堆排序初始建堆的结果是A, D, C, R, F, Q, M, S, Y,P, H, X。 9. 在堆排序、快速排序和归并排序中, 若只从存储空间考虑,则应首先选取堆排序方法,其次选取快速排序方法,最后选取归并排序方法; 若只从排序结果的稳定性考虑,则应选取归并排序方法; 若只从平均情况下最快考虑,则应选取快速排序方法; 若只从最坏情况下最快并且要节省内存考虑,则应选取堆排序方法。 二、单项选择题(每小题1分,共18分) (C)1.将5个不同的数据进行排序,至多需要比较次。数据结构及应用算法教程习题第三章 排序
(完整word版)查找、排序的应用 实验报告
查找与排序实验报告
人教版小学四年级下册语文排序专项练习题及答案69730
数据结构查找排序经典试题
第三章整理
河南工业大学实验报告——查找和排序(排序)——张伟龙
2018年浙江省选考信息技术查找与排序强化习题一答案
二年级语文下册 排序练习题
查找排序实验报告
第9章 查找练习题及答案
图+查找+排序解答题,程序题
各种排序实验报告
部编版三年级下册句子排序实用技巧及练习题(附答案)【2020春】
查找排序习题讲解
河南工业大学实验报告_实验三 查找和排序(一)——查找
大二数据结构复习-查找排序练习题
第3章 排序答案
相关主题
文本预览