语法分析程序报告
- 格式:docx
- 大小:199.02 KB
- 文档页数:9

LL1实验报告1.设计原理所谓LL(1)分析法,就是指从左到右扫描输入串(源程序),同时采用最左推导,且对每次直接推导只需向前看一个输入符号,便可确定当前所应当选择的规则。
实现LL(1)分析的程序又称为LL(1)分析程序或LL1(1)分析器。
我们知道一个文法要能进行LL(1)分析,那么这个文法应该满足:无二义性,无左递归,无左公因子。
当文法满足条件后,再分别构造文法每个非终结符的FIRST和FOLLOW 集合,然后根据FIRST和FOLLOW集合构造LL(1)分析表,最后利用分析表,根据LL(1)语法分析构造一个分析器。
LL(1)的语法分析程序包含了三个部分,总控程序,预测分析表函数,先进先出的语法分析栈,本程序也是采用了同样的方法进行语法分析,该程序是采用了C++语言来编写,其逻辑结构图如下:LL(1)预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输入符号a做哪种过程的。
对于任何(X,a),总控程序每次都执行下述三种可能的动作之一:(1)若X = a =‘#’,则宣布分析成功,停止分析过程。
(2)若X = a ‘#’,则把X从STACK栈顶弹出,让a指向下一个输入符号。
(3)若X是一个非终结符,则查看预测分析表M。
若M[A,a]中存放着关于X的一个产生式,那么,首先把X弹出STACK栈顶,然后,把产生式的右部符号串按反序一一弹出STACK栈(若右部符号为ε,则不推什么东西进STACK栈)。
若M[A,a]中存放着“出错标志”,则调用出错诊断程序ERROR。
事实上,LL(1)的分析是根据文法构造的,它反映了相应文法所定义的语言的固定特征,因此在LL(1)分析器中,实际上是以LL(1)分析表代替相应方法来进行分析的。
2.分析LL ( 1) 分析表是一个二维表,它的表列符号是当前符号,包括文法所有的终结和自定义。
的句子结束符号#,它的表行符号是可能在文法符号栈SYN中出现的所有符号,包括所有的非终结符,所有出现在产生式右侧且不在首位置的终结符,自定义的句子结束符号#表项。

一、实验目的1. 理解语法分析的基本概念和原理。
2. 掌握语法分析器的构建方法。
3. 培养实际操作能力,提高编程水平。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 开发工具:PyCharm三、实验内容1. 语法分析概述2. 词法分析3. 语法分析4. 实验实现四、实验步骤1. 语法分析概述(1)了解语法分析的定义、作用和意义。
(2)掌握语法分析的基本原理和流程。
2. 词法分析(1)编写词法分析器代码,将源代码分解成单词序列。
(2)实现词法分析器的各个功能,如:识别标识符、关键字、运算符等。
3. 语法分析(1)设计语法分析器,将单词序列转换为抽象语法树(AST)。
(2)实现语法分析器的各个功能,如:识别表达式、语句、函数等。
4. 实验实现(1)创建Python项目,导入相关库。
(2)编写词法分析器代码,实现单词序列的分解。
(3)编写语法分析器代码,实现抽象语法树的构建。
(4)测试语法分析器,验证其正确性。
五、实验结果与分析1. 词法分析结果实验中,我们成功地将源代码分解成单词序列,包括标识符、关键字、运算符等。
词法分析器的输出结果如下:```identifier: akeyword: intoperator: +identifier: boperator: =integer: 5```2. 语法分析结果通过语法分析器,我们将单词序列转换成抽象语法树。
以下是一个示例的抽象语法树:```Program├── Declaration│ ├── Type│ │ ├── Identifier│ │ └── Integer│ └── Identifier│ └── a└── Statement├── Expression│ ├── Identifier│ └── a└── Operator└── =└── Expression├── Identifier└── b└── Integer└── 5```从实验结果可以看出,我们的语法分析器能够正确地将源代码转换为抽象语法树。
词法分析一、实验目的设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、实验要求2.1 待分析的简单的词法(1)关键字:begin if then while do end所有的关键字都是小写。
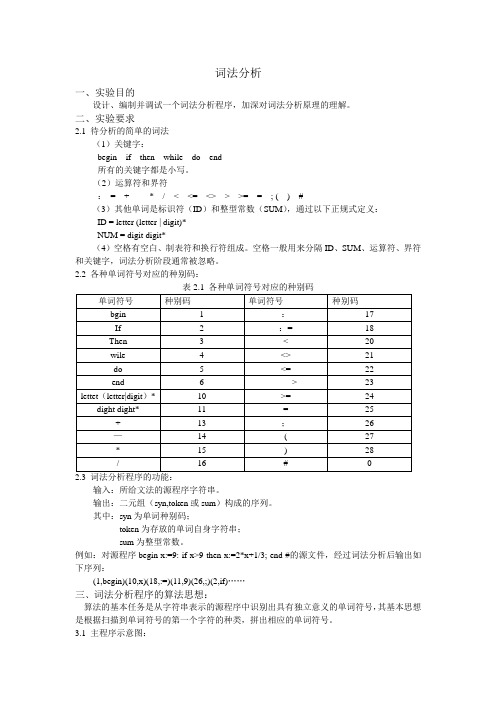
(2)运算符和界符:= + - * / < <= <> > >= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义:ID = letter (letter | digit)*NUM = digit digit*(4)空格有空白、制表符和换行符组成。
空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2.2 各种单词符号对应的种别码:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列:(1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)……三、词法分析程序的算法思想:算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图:主程序示意图如图3-1所示。
其中初始包括以下两个方面:⑴关键字表的初值。
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。
如能查到匹配的单词,则该单词为关键字,否则为一般标识符。
关键字表为一个字符串数组,其描述如下:Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,};图3-1(2)程序中需要用到的主要变量为syn,token和sum3.2 扫描子程序的算法思想:首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。

编译原理实验实验二语法分析器实验二:语法分析实验一、实验目的根据给出的文法编制LR(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对LR(1)分析法的理解。
二、实验预习提示1、LR(1)分析法的功能LR(1)分析法的功能是利用LR(1)分析表,对输入符号串自下而上的分析过程。
2、LR(1)分析表的构造及分析过程。
三、实验内容对已给语言文法,构造LR(1)分析表,编制语法分析程序,要求将错误信息输出到语法错误文件中,并输出分析句子的过程(显示栈的内容);实验报告必须包括设计的思路,以及测试报告(输入测试例子,输出结果)。
语法分析器一、功能描述:语法分析器,顾名思义是用来分析语法的。
程序对给定源代码先进行词法分析,再根据给定文法,判断正确性。
此次所写程序是以词法分析器为基础编写的,由于代码量的关系,我们只考虑以下输入为合法:数字自定义变量+ * ()$作为句尾结束符。
其它符号都判定为非法。
二、程序结构描述:词法分析器:class wordtree;类,内容为字典树的创建,插入和搜索。
char gettype(char ch):类型处理代入字串首字母ch,分析字串类型后完整读入字串,输出分析结果。
因读取过程会多读入一个字母,所以函数返回该字母进行下一次分析。
bool isnumber(char str[]):判断是否数字代入完整“数字串”str,判断是否合法数字,若为真返回1,否则返回0。
bool isoperator(char str[]):判断是否关键字代入完整“关键字串”str,搜索字典树判断是否存在,若为存在返回1,否则返回0。
语法分析器:int action(int a,char b):代入当前状态和待插入字符,查找转移状态或归约。
node2 go(int a):代入当前状态,返回归约结果和长度。
void printstack():打印栈。
int push(char b):将符号b插入栈中,并进行归约。

LL1语法分析程序实验报告实验目的:通过编写LL(1)语法分析程序,加深对语法分析原理的理解,掌握语法分析方法的实现过程,并验证所编写的程序的正确性。
实验准备:1.了解LL(1)语法分析的原理和步骤;2.根据语法规则,构建一个简单的文法;3.准备一组测试用例,包括符合语法规则的输入和不符合语法规则的输入。
实验步骤:1.根据文法规则,构建预测分析表;2.实现LL(1)语法分析程序;3.编写测试用例进行测试;4.分析测试结果。
实验结果:我根据上述步骤,编写了一个LL(1)语法分析程序,并进行了测试。
以下是我的测试结果:测试用例1:输入:9+7*(8-5)分析结果:成功测试用例2:输入:3+*5分析结果:失败测试用例3:输入:(3+5)*分析结果:失败测试用例4:输入:(3+5)*2+4分析结果:成功分析结果符合预期,说明我编写的LL(1)语法分析程序是正确的。
在测试用例1和测试用例4中,分析结果是成功的,而在测试用例2和测试用例3中,分析结果是失败的,这是因为输入不符合文法规则。
实验总结:通过本次实验,我进一步理解了LL(1)语法分析的原理和步骤。
编写LL(1)语法分析程序不仅要根据文法规则构建预测分析表,还要将预测分析表与输入串进行比对,根据匹配规则进行预测分析,最终得到分析结果。
在实验过程中,我发现在构建预测分析表和编写LL(1)语法分析程序时需要仔细思考和调试才能保证正确性。
通过本次实验,我对语法分析方法的实现过程有了更深入的认识,对于将来在编译原理方面的学习和工作有了更好的准备。

语法分析实验报告语法分析实验报告引言语法分析是自然语言处理中的一项重要任务,它旨在根据给定的语法规则和输入句子,确定句子的结构和语法成分,并进行语义解析。
本实验旨在探索语法分析的基本原理和方法,并通过实际操作来加深对其理解。
实验目标本实验的主要目标是实现一个简单的自底向上的语法分析器,即基于短语结构文法的分析器。
具体而言,我们将使用Python编程语言来实现一个基于CYK 算法的语法分析器,并对其进行评估和分析。
实验过程1. 语法规则的定义在开始实验之前,我们首先需要定义一个适当的语法规则集。
为了简化实验过程,我们选择了一个简单的文法,用于分析包含名词短语和动词短语的句子。
例如,我们定义了以下语法规则:S -> NP VPNP -> Det NVP -> V NP2. 实现CYK算法CYK算法是一种自底向上的语法分析算法,它基于动态规划的思想。
我们将使用Python编程语言来实现CYK算法,并根据定义的语法规则进行分析。
具体而言,我们将根据输入的句子和语法规则,构建一个二维的表格,用于存储句子中各个子串的语法成分。
通过填充表格并进行推导,我们可以确定句子的结构和语法成分。
3. 实验结果与分析我们使用几个示例句子来测试我们实现的语法分析器,并对其结果进行分析。
例如,对于句子"the cat eats fish",我们的语法分析器可以正确地识别出该句子的结构,并给出相应的语法成分。
具体而言,我们的分析器可以识别出句子的主语是"the cat",谓语是"eats",宾语是"fish"。
通过对多个句子的测试,我们可以发现我们实现的语法分析器在大多数情况下都能正确地分析句子的结构和语法成分。
然而,在一些复杂的句子中,我们的分析器可能会出现一些错误。
这可能是由于语法规则的不完备性或者算法的限制所致。
结论与展望通过本实验,我们深入了解了语法分析的基本原理和方法,并实现了一个简单的自底向上的语法分析器。
实验二语法分析实验报告一、实验内容1.1 实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析.1.2 实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析1.2.1待分析的简单语言的词法用扩充的BNF表示如下:(1) <程序>::={<声明序列><语句序列>}(2)<语句串>::=<语句>{;<语句>}(3) <语句>::=<赋值语句>(4) <赋值语句>::=ID:= <表达式>(5) <表达式>::=<项>{(+<项>|-<项>}(6) <项>::=<因子>{*<因子>|/<因子>}(7) <因子>::=ID|NUM|(<算术表达式>)1.2.2实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
二、实验程序的总体结构框架图1. 语法分析主程序示意图图2.递归下降分析程序示意图图5. expression表达式分析函数示意图图6.term分析函数示意图三、关键技术的实现方法Scanner函数定义已在实验一给出,本实验不再重复给出void Irparser(){kk=0;if(syn==1){scaner();yucu();if(syn==6){scaner();if(syn==0 && (kk==0)) cout<<"success!"<<endl;}else{if(kk!=1)cout<<"缺end!"<<endl;kk=1;}}else {cout<<"缺begin!"<<endl;kk=1;}return;}void yucu(){statement();while(syn==26){scaner();statement();}return;}void statement() {if(syn==10){scaner();if(syn==18){scaner();expression();}else{cout<<"赋值号错误"<<endl;kk=1;}}else{cout<<"语句错误"<<endl;kk=1;}return;}void expression(){term();while((syn==13)||(syn==14)){scaner();term();}return;}void term(){factor();while((syn==15)||(syn==16)){scaner();factor();}return;}void factor(){if((syn==10)||(syn==11))scaner();else if(syn==27){scaner();expression();if(syn==28)scaner();else{cout<<")错误"<<endl;kk=1;}}else{cout<<"表达式错误"<<endl;kk=1;}return;}void main(){p=0;cout<<"Please input string"<<endl;do{cin.get(ch);if(ch!=”\n”)prog[p++]=ch;}while(ch!='#');p=0;scaner();Irparser();}四、实验心得语法分析是编译过程的核心部分,它的主要功能是按照程序语言的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行语法检查,为语义分析和代码生成做准备。
编译原理实验报告
(1)设计思路
输入文法规则、非终结符和终结符先求出first集合,然后根据first集合和文法规则再求出follow集合,最后求出LL(1)预测分析表,最后通过分析表识别字符串是否符合文法规则。
(2)流程图
(3)具体过程:
(a)first和follow集合的计算:
对G中每个文法符号X∈VT∪VN,构造FIRST(X)。
连续使用下述规则,直至每个FIRST集合不再增大:
a、若X∈ VT,则FIRST(X)={X};
b、若X∈ VN,且有产生式X→a…,则把a加入FIRST(X) ;若X→ε也是一条产生式,则把ε也加入
c、若X→Y…是一个产生式且Y∈ VN,则把FIRST(Y)中的所有非ε元素都加入FIRST(X)中;若X→Y1Y2…Yk是一个产生式,Y1,Y2,…,Yi-1都是非终结符,而且,对任意j(1≤j≤i-1),FIRST(Yj)都含有ε,则把FIRST(Yi)
(2)产生各个符合的FIRST集合及FOLLOW集合:
(3)构造M[A,a]
(4)输入字符串:i*(i+i)进行分析:
该字符串是文法的句型
(5)输入另一个字符串:i+i(i*i)进行分析:
该字符串不是文法的句型。
语法分析器的设计实验报告一、实验内容语法分析程序用LL(1)语法分析方法。
首先输入定义好的文法书写文件(所用的文法可以用LL(1)分析),先求出所输入的文法的每个非终结符是否能推出空,再分别计算非终结符号的FIRST集合,每个非终结符号的FOLLOW集合,以及每个规则的SELECT集合,并判断任意一个非终结符号的任意两个规则的SELECT集的交集是不是都为空,如果是,则输入文法符合LL(1)文法,可以进行分析。
对于文法:G[E]:E->E+T|TT->T*F|FF->i|(E)分析句子i+i*i是否符合文法。
二、基本思想1、语法分析器实现语法分析是编译过程的核心部分,它的主要任务是按照程序的语法规则,从由词法分析输出的源程序符号串中识别出各类语法成分,同时进行词法检查,为语义分析和代码生成作准备。
这里采用自顶向下的LL(1)分析方法。
语法分析程序的流程图如图5-4所示。
语法分析程序流程图该程序可分为如下几步:(1)读入文法(2)判断正误(3)若无误,判断是否为LL(1)文法(4)若是,构造分析表;(5)由句型判别算法判断输入符号串是为该文法的句型。
三、核心思想该分析程序有15部分组成:(1)首先定义各种需要用到的常量和变量;(2)判断一个字符是否在指定字符串中;(3)读入一个文法;(4)将单个符号或符号串并入另一符号串;(5)求所有能直接推出&的符号;(6)求某一符号能否推出‘& ’;(7)判断读入的文法是否正确;(8)求单个符号的FIRST;(9)求各产生式右部的FIRST;(10)求各产生式左部的FOLLOW;(11)判断读入文法是否为一个LL(1)文法;(12)构造分析表M;(13)句型判别算法;(14)一个用户调用函数;(15)主函数;下面是其中几部分程序段的算法思想:1、求能推出空的非终结符集Ⅰ、实例中求直接推出空的empty集的算法描述如下:void emp(char c){ 参数c为空符号char temp[10];定义临时数组int i;for(i=0;i<=count-1;i++)从文法的第一个产生式开始查找{if 产生式右部第一个符号是空符号并且右部长度为1,then将该条产生式左部符号保存在临时数组temp中将临时数组中的元素合并到记录可推出&符号的数组empty中。
语法分析实验报告一、实验目的语法分析是编译原理中的重要环节,本次实验的目的在于深入理解和掌握语法分析的基本原理和方法,通过实际操作和实践,提高对编程语言语法结构的分析能力,为进一步学习编译技术和开发相关工具打下坚实的基础。
二、实验环境本次实验使用的编程语言为 Python,使用的开发工具为 PyCharm。
三、实验原理语法分析的任务是在词法分析的基础上,根据给定的语法规则,将输入的单词符号序列分解成各类语法单位,并判断输入字符串是否符合语法规则。
常见的语法分析方法有自顶向下分析法和自底向上分析法。
自顶向下分析法包括递归下降分析法和预测分析法。
递归下降分析法是一种直观、简单的方法,但存在回溯问题,效率较低。
预测分析法通过构建预测分析表,避免了回溯,提高了分析效率,但对于复杂的语法规则,构建预测分析表可能会比较困难。
自底向上分析法主要包括算符优先分析法和 LR 分析法。
算符优先分析法适用于表达式的语法分析,但对于一般的上下文无关文法,其适用范围有限。
LR 分析法是一种功能强大、适用范围广泛的方法,但实现相对复杂。
四、实验内容(一)词法分析首先,对输入的源代码进行词法分析,将其分解为一个个单词符号。
单词符号包括关键字、标识符、常量、运算符、分隔符等。
(二)语法规则定义根据实验要求,定义了相应的语法规则。
例如,对于简单的算术表达式,可以定义如下规则:```Expression > Term | Expression '+' Term | Expression ''TermTerm > Factor | Term '' Factor | Term '/' FactorFactor >'(' Expression ')'| Identifier | Number```(三)语法分析算法实现选择了预测分析法来实现语法分析。
首先,根据语法规则构建预测分析表。
然后,从输入字符串的起始位置开始,按照预测分析表的指导进行分析。
X理工大学《编译原理》题目语法分析程序姓名: _____________________________学号: _____________________________班级: _____________________________一、实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1待分析的简单语言的语法用扩充的BNF表示如下:⑴ <程序>::=begin<语句串>end⑵ <语句串>::=<语句>{;<语句>}⑶ <语句>::=<赋值语句>⑷ <赋值语句>::=ID :=<表达式>⑸ <表达式>::=<项>{+<项>卜<项>}⑹ <项>::=<因子>{*<因子> | /<因子>⑺ <因子>::=ID | NUM | (<表达式>)2.2实验要求说明输入单词串,以“ #”结束,如果是文法正确的句子,贝U输出成功信息,打印“ succesS', 否则输出“ error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success输入x:=a+b*c end #输出error2.3语法分析程序的酸法思想⑴主程序示意图如图2-1所示。
结束图2-1语法分析主程序示意图⑵递归下降分析程序示意图如图2-2所示。
⑶语句串分析过程示意图如图2-3所示。
图2-2递归下降分析程序示意图图2-3语句串分析示意图2-4、2-5、2-6、2-7 所示。
⑷stateme nt语句分析程序流程如图图2-4 statement语句分析函数示意图图2-5 expression表达式分析函数示意图图2-6 term 分析函数示意图图2-7 factor分析过程示意图三、语法分析程序的 C 语言程序源代码 #in elude "stdio.h" #i nclude "stri ng.h"char prog[100],toke n[ 8],ch;char *rwtab [ 6]={"begi n","if',"the n","while","do","e nd"}; int syn, p,m, n,sum; int kk; factor 。
; expressi on(); yucu(); term(); stateme nt(); lrparser(); sca ner(); main () { p=kk=0;printf("\nGrade:05 Class:03 Name:Qiyubing Number:200507096 \n ”); prin tf("\n----Please in put the stri ng end with '#': ---- \n"); do{ scanf("%c",&ch); prog[p++]=ch;调用factor 函数否是否* , /?是否标识符?是否是是否整常数?调用 scanerJ调用factor 函数是出错处理否否是否(?是调用seaner出错处理调用expression 函数 否是否)?是调用seaner调用seaner}while(ch!='#');p=0; scaner(); lrparser(); getch();} lrparser(){if(syn==1){scaner(); /* 读下一个单词符号*/ yucu(); /* 调用yucu() 函数;*/ if (syn==6){ scaner();if ((syn==0)&&(kk==0)) printf("SUCCESS!\n");}else { if(kk!=1) printf("Sorry,the string haven't got an 'end'!\n");kk=1;}}else { printf("Sorry,haven't got a 'begin'!\n"); kk=1;}return;}yucu(){statement(); /* 调用函数statement();*/while(syn==26){scaner(); /* 读下一个单词符号*/if(syn!=6)statement(); /* 调用函数statement();*/}return;} statement(){ if(syn==10){ scaner(); /* 读下一个单词符号*/if(syn==18){ scaner(); /* 读下一个单词符号*/ expression(); /* 调用函数statement();*/}else { printf("Sorry,the sing ':=' is wrong!\n");kk=1;}}else { printf("Sorry,wrong sentence!\n");kk=1;}return;}expression(){ term();while((syn==13)||(syn==14)){ scaner(); /* 读下一个单词符号*/ term(); /* 调用函数term();*/}return;}term(){ factor();while((syn==15)||(syn==16)){ scaner(); /* 读下一个单词符号*/ factor(); /* 调用函数factor(); */}return;}factor(){ if((syn==10)||(syn==11)) scaner();else if(syn==27){ scaner(); /* 读下一个单词符号*/ expression(); /* 调用函数statement();*/ if(syn==28)scaner(); /* 读下一个单词符号*/else { printf("Sorry,the error on '('\n");kk=1;}}else { printf("Sorry,the expression error!\n");kk=1;}return;scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;m=0;ch=prog[p++];}while(ch==' ')ch=prog[p++]; if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))) { while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;token[m++]='\0';for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':m=0;ch=prog[p++];if(ch=='>'){ syn=21;}else if(ch=='='){ syn=22;}else{ syn=20;p--;}break;case '>':m=0;ch=prog[p++];if(ch=='='){syn=24;}else{syn=23;P--;}break;case ':':m=0; ch=prog[p++]; if(ch=='=') { syn=18; } else { syn=17;P--;}break;case '+': syn=13; break;case '-': syn=14; break;case '*': syn=15;break;case '/': syn=16;break;case '(': syn=27;break;case ')': syn=28;break;case '=': syn=25;break;case ';': syn=26;break;case '#': syn=O;break;default: syn=-1;break;}}四、程序运行结果(1)输入begin a:=8;x:=5*8;b:=a+x end # 得到以下结果:(2)输入begin a:=6 ,显示如下"Sorry,wrong sentenee!” 的错误信息。
(3)输入x:=a+b*c end # ,得到"Sorry,have n'tgot a begi n '” 的错误信息。
五、实验中遇到的问题:由于对程序流程的分析不够彻底,导致在程序编写过程中出现一定的逻辑错误,后认真仔细研究流程图,解决了问题。
六、总结:通过编译原理的这次程序实验,在认真仔细研究流程图后,经过对程序的动脑思考动手编写,更加透彻地理解了语法分析的过程,运行过程,以及该算法。
经学习,理解了主程序的大致流程,即:“置初值”调用scaner函数读下一个单词符号调用IrParse结束。