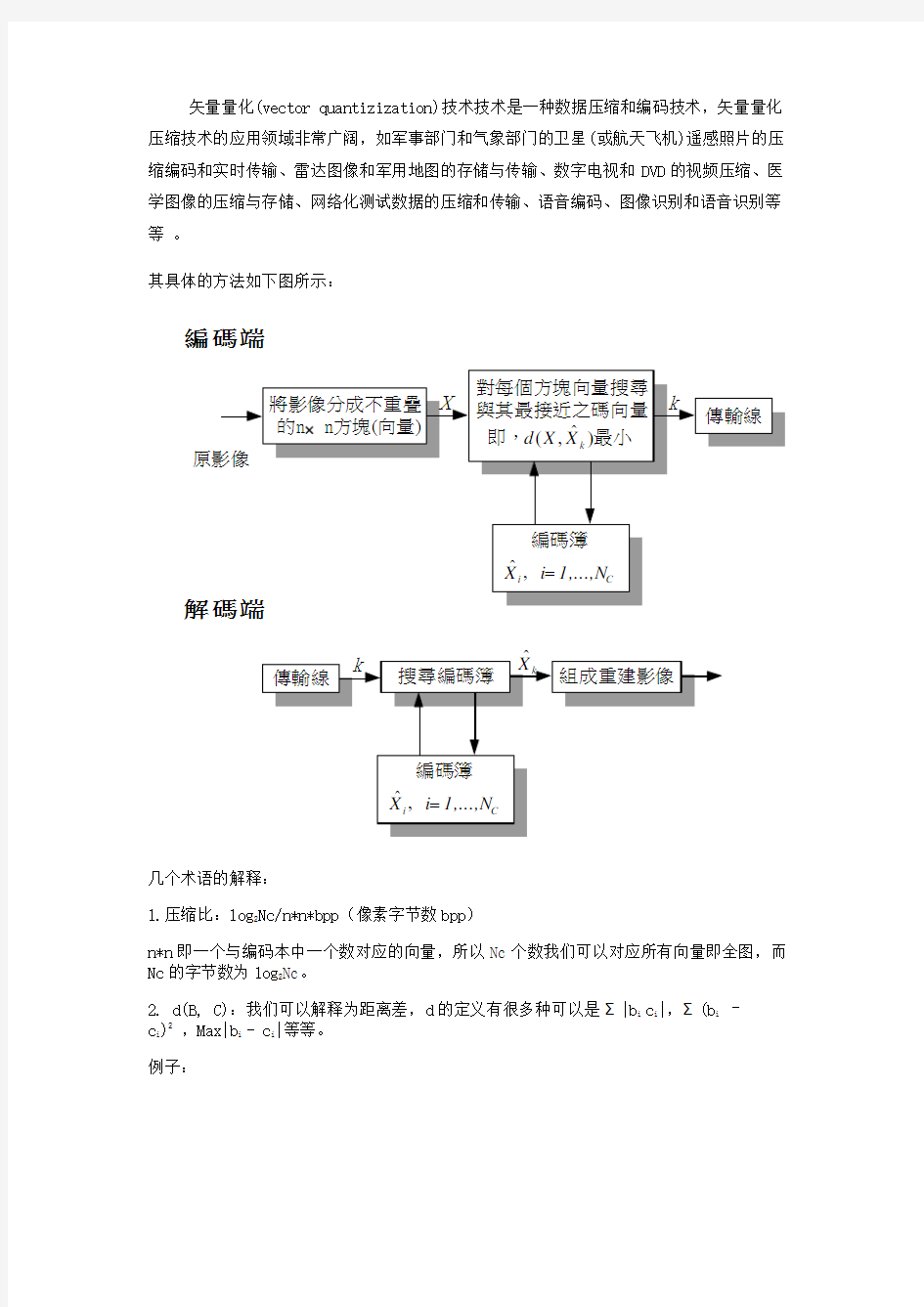

矢量量化(vector quantizization)技术技术是一种数据压缩和编码技术,矢量量化压缩技术的应用领域非常广阔,如军事部门和气象部门的卫星(或航天飞机)遥感照片的压缩编码和实时传输、雷达图像和军用地图的存储与传输、数字电视和DVD 的视频压缩、医学图像的压缩与存储、网络化测试数据的压缩和传输、语音编码、图像识别和语音识别等等 。
其具体的方法如下图所示:
几个术语的解释:
1.压缩比:log 2Nc/n*n*bpp (像素字节数bpp )
n*n 即一个与编码本中一个数对应的向量,所以Nc 个数我们可以对应所有向量即全图,而Nc 的字节数为log 2Nc 。
2. d(B, C):我们可以解释为距离差,d 的定义有很多种可以是Σ|b i c i |,Σ(b i – c i )2 ,Max|b i - c i |等等。
例子:
編碼端解
由上图我们可以看到左边为原图像,而右边为编码本。例如我们可以讲原图像以如图所示的方式分为若干个有四个量的向量如(100,100,80,80)其余编码本中的
(100,100,90,90)计算的d (X ,Xk )最小故我们可以用数字k 表示向量
(100,100,80,80)。其实我们可以理解为矢量量化就是讲图像中分割成若干的小块,然后再将小块分类,一类用一个码表示。
下面是一个我论文中看到的也是最常用的VQ 算法:LBG 算法也叫K 平均分类算法。 以下是步骤:
当然我们可以设置一个收敛的条件,这个可以根据自己需求设置ε大小,当到达某一步 时 收敛即迭代结束。 ε≤---)1()1(l l l D D
D
2012 年 第21卷 第 10 期 https://www.doczj.com/doc/5613331061.html, 计 算 机 系 统 应 用 Research and Development 研究开发 81 结合概率型神经网络(PNN )和学习矢量量化(LVQ )算法的文本分类方法① 李 敏, 余正涛 (昆明理工大学 信息工程与自动化学院, 昆明 650051) 摘 要: 针对文本自动分类问题, 提出一种基于概率型神经网络(PNN)和学习矢量量化(LVQ)相结合的文本分类算法, 该方法借助TFIDF 方法提取文本特征及特征值, 形成文本分类特征向量, 利用概率型神经网络构建分类模型, 并利用LVQ 学习算法对神经网络模型竞争层网络进行学习, 使相应模式向量相互靠拢, 远离其他模式, 从而实现文本分类. 实验结果表明, 提出的该方法在文本分类中表现了很好的效果, 不仅具有很好的分类准确率, 还表现出很好的学习效率. 关键词: 文本分类; 概率型神经网络; LVQ 学习算法; 特征提取; Text Classification Combined with Probabilistic Neural Network (PNN) and Learning Vector Quantization (LVQ) Algorithm LI Min,YU Zheng-Tao (School of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650051, China) Abstract : Aiming at the problem of text classification, one text classification method based on the probabilistic neural network ( PNN ) and learning vector quantization ( LVQ ) is proposed. The text features and feature values are extracted by use of TFIDF method, and text categorization feature vector are formed. In addition, classification model based on probabilistic neural network can be constructed and the learning of competitive layer network is completed by using LVQ algorithms, so the corresponding pattern vector to move closer to each other, away from the other modes, thereby realizing text classification. The experimental results show that the method in the text classification performance with very good results, and not only has good classification accuracy, but also shows a good learning efficiency. Key words : text classification; probabilistic neural network; LVQ learning method; feature extraction 1 引言 文本分类是文本信息处理的一个重要研究领域, 对提高文本检索、文本存储等应用的处理效率有着重要意义. 国内外在文本分类技术以及相关的信息检索、信息抽取等领域已经进行了比较深入的研究, 取得了不少研究成果. 常见的文本分类技术有神经网络方法、最小距离方法、朴素贝叶斯方法、KNN 方法、支持向量机方法(SVM)等. 在这些分类算法中, 神经网络的文本分类更具有优越的性能[1]. 目前国内对于 神经网络在文本分类中的应用研究也主要是在BP 神经网络、自组织特征映射神经网络、RBF 神经网络等几个应用比较广泛的神经网络方面, 对于概率型神经网络在文本分类中的应用研究涉及较少. 而概率神经网络是径向基网络的一种重要变形, 在模式识别问题上已经有比较多的应用, 取得较好的效果[2]. 本文利用概率型神经网络的特点, 结合LVQ 学习算法, 探讨该方法在文本分类的研究, 并取得了非常不错的效果. ① 基金项目:国家自然科学基金(61175068) 收稿时间:2012-02-06;收到修改稿时间:2012-03-05
CDMA的语音编码与信道编码 摘要:随着3G移动通信技术的逐步实现以及移动通信与互联网的融合,全球正迅速步 入移动信息时代。CDMA已被广泛接纳为第三代移动通信的核心技术之一,它具有优越的性能。本文主要介绍CDMA中常用的语音编码技术与信道技术。 关键词:语音编码信道编码受激励线性编码码激励线性预测编码编码器解码器一、CDMA中的语音编码技术 语音编码为信源编码,是将模拟信号转变为数字信号,然后在信道中传输。在数字移动通信中,语音编码技术具有相当关键的作用,高质量低速率的话音编码技术与高效率数字调制技术相结合,可以为数字移动网提供高于模拟移动网的系统容量。目前,国际上语音编码技术的研究方向有两个:降低话音编码速率和提高话音质。 语音编码技术的分类 语音编码技术有三种类型:波形编码、参量编码和混合编码。 波形编码:是在时域上对模拟话音的电压波形按一定的速率抽样,再将幅度量化,对每个量化点用代码表示。解码是相反过程,将接收的数字序列经解码和滤波后恢复成模拟信号。参量编码:又称声源编码,是以发音模型作基础,从模拟话音提取各个特征参量并进行量化编码,可实现低速率语音编码,达到2kbit/s-4.8kbit/s。但话音质量只能达到中等。 混合编码:是将波形编码和参量编码结合起来,既有波形编码的高质量优点又有参量编码的低速率优点。其压缩比达到4kbit/s-16kbit/s。泛欧GSM系统的规则脉冲激励――长期预测编码(RPE-LTP)就是混合编码方案。. CDMA的语音编码 CDMA系统如同其它数位式行动电话系统,它也采用语音编码技术来降低语音的资料速率。CDMA系统的语音编码主要有从线性预测编码技术发展而来的激励线性预测编码QCELP和增强型可变速率编码EVRC。 (1)QCELP 受激线性预测编码 QCELP,即QualComm Code Excited Linear Predictive(QualComm受激线性预测编码)。这种算法不仅可工作于4/4.8/8/9.6kbit/s等固定速率上,而且可变速率地工作于800bit/s~9600bit/s之间。Q4401、Q4413单片语音编码器就是基于这种编码算法。QCELP算法被认为是到目前为止效率效率最高的一种算法,它的主要特点之一,是使用适当的门限值来决定所需速率。I‘1限值懈景噪声电平变化而变化,这样就抑制了背景噪声,使得即使在喧闹的环境中,也能得到良好的话音质量,CDMA8Kbit/s的话音近似GSM 13Mbit/s的话音。CDMA采用QCELP编码等一系列技术,具有话音清晰、背景噪声小等优势,其性能明显优于其他无线移动通信系统,语音质量可以与有线电话媲美。 (2) CELP 码激励线性预测编码 CELP 码激励线性预测编码是Code Excited Linear Prediction的缩写。CELP是近10年来最成功的语音编码算法。CELP语音编码算法用线性预测提取声道参数,用一个包含许多典型的激励矢量的码本作为激励参数,每次编码时都在这个码本中搜索一个最佳的激励矢
通信学报981001通信学报 JOURNAL OF CHINA INSTITUTE OF COMMUNICATIONS 1998年 第19卷 第10期 No.10 Vol.19 1998科技期刊 张基宏 (深圳大学信息工程学院 深圳 518060) 何振亚(东南大学无线电工程系 南京 210018) 摘 要 本文分析了模糊矢量量化(FVQ)图像编码的原理,提出了一种指数型模糊学习矢量量化算法 (EFLVQ)。实验结果表明,该算法具有快速收敛性能,设计的图像码书峰值信噪比与FVQ算法相比也略有改善。 关键词 图像编码 模糊矢量量化 An Exponential Fuzzy Learning Vector Quantization Algorithm for Image Coding Zhang Jihong (Information Engineering Faculty of Shenzhen Univ., Shenzhen 518060) He Zhenya (Dept. of Radio Engineering of Southeast Univ., Nanjing 210018) Abstract The principle of fuzzy vector quantization (FVQ) for image coding is discussed in this paper, and an exponential fuzzy learning vector quantization algorithm (EFLVQ) is proposed. Simulation results show that the proposed method has a better convergence rate than FVQ , and the PSNR is also improved a little. Key words Image coding, Fuzzy vector quantization 1 引言 在矢量量化码书设计算法中,LBG算法[1]是较成功的算法。它是最优标量量化M-L算法在多维空间中的推广。因其理论上的严密性和实施过程中的简便性以及较好的设计效果得到了广泛的应用,并成为各种改进算法的基础。但LBG算法是轮流满足最佳多维量化器的两个必要条件:分割条件和质心条件,仅为局部最佳并且强烈依赖于初始码书的选取[2]。Kohonen自组织特征映射技术[3]设计的码书性能与LBG算法相当。随机松驰算法[4]能得到全局最佳码书,但运算量很大。上述算法均是基于硬判决的,即每个训练矢量是根据一些准则分配给单个聚类,而忽略了该训练矢量属于其它聚类的可能性。 模糊C-均值(FCM)聚类算法为训练集的每个元素分配一个介于0和1之间的隶属值,表示训练矢量隶属于一个确定聚类的程度[5]。尽管FCM算法性能比LBG好,但很少用来设计码书,因为计算量很大。1995年Nicolas. B.K等人首次将模糊逻辑引进矢量量化的码书设计,提出了模糊矢量量化(FVQ)算法[6]。FVQ用隶属函数来定量表示训练矢量分配的不确定度,并给出了训练过程中从软判决向硬判决转变的一种有效策略,和保证算法不会局部最优的门限值选取条件。FVQ设计的码书对初始码书依赖性小,而且不会局部最小;性能与FCM相当; 运算量也小于FCM,但仍然较大。作者在文献[7]中提出了指数型FVQ(EFVQ)算法,旨在进一步提高收敛速度,尽管略有改善,但效果不甚明显。 本文提出了一种指数型模糊学习矢量量化算法(EFLVQ)。该算法保持了FVQ对初始码书的依赖性小,不会陷入局部最小的优点,收敛速度比FVQ明显提高,而且设计的图像码书性能也比FVQ算法略好。 2 FVQ原理 设训练矢量集为X={x 1,x 2,…,x M },x i ∈R n i=1,2,…,M;码书矢量集为Y={y 1,y 2,…,y K },y j ∈R n j=1,2,…,K。FVQ将每一聚类作为一个模糊集,用隶属函数μj (x i )来表示训练矢量隶属于一个确定聚类的程度。这样每个训练矢量依隶属函数的测度分配给多个聚类。若被考虑的训练矢量是一超球体的中心,对存在重叠的超球体的中心保证了所有训练矢量参与其中。有效的降低了设计结果对初始码书的依赖性。FVQ通过迭代,即逐步收敛重叠的超球体来实现训练矢量逐步从软判决向硬判决的转变。转变速度可利用聚类过程中超球体的收缩方案来调整。具体策略如下:令I (v)i 是在v次迭代中,属于中心位于训练矢量x i ∈X超球体的码书矢量集合。在v次迭代后,中心位于训练矢量x i 超球体所包含的码书矢量y j ∈I (v)i 须满足对x i 的距离小于或等于x i 和y j ∈I (v)i 的平均距离file:///E|/qk/txxb/981001.htm(第 1/6 页)2010-3-23 9:25:31
2007 年 6 月 JOURNAL OF CIRCUITS AND SYSTEMS June 2007 文章编号:1007-0249 (2007) 03-0117-04 一种改进的2.4kb/s 混合激励线性预测声码器方案* 马欣, 刘常澍, 李文元, 张毓忠 (天津大学 电子信息工程学院,天津 300072 ) 摘要:本文针对标准的2.4kb/s MELP 声码器的不足之处提出了两项改进措施,一是提出了一种新的参数“能量—微分过零率比”,用来对语音的过渡段和弱能量浊音段的清浊音判决进行调整;二是对线谱对的多级矢量量化(MSVQ )提出了一种多径搜索算法。实验和主观听觉测试表明,在同样2.4kb/s 的码率下,改进MELP 声码器的合成语音在可懂度和自然度方面都有一定的提高。 关键词:清浊音判决;MELP ;声码器;多级矢量量化(MSVQ ) 中图分类号:TN912.3 文献标识码:A 1 引言 在美国联邦政府选择新一代 2.4kb/s 语音编码标准以代替原来的LPC-10e 模型的过程中,A.V. MaCree 等提出了一种混合激励线性预测(MELP ,Mixed Exitation Linear Prediction )声码器方案[1]。该方案以传统的LPC 线性预测声码器为内核,加入了混合激励、准周期脉冲、自适应频谱增强技术、脉冲波形发散和表示残差基音谐波的傅立叶幅度等五项改进技术。这些改进使得MELP 在2.4kb/s 的低码率下保证了良好的合成语音质量。 但是,经过大量的听觉测试,发现用MELP 方案合成的语音还是存在一些问题。特别是在语音的过渡区段,人工合成音的迹象比较明显,语音听起来显得有些生硬。为了使合成语音听起来更加自然,本文对MELP 算法模型提出了以下两项改进措施:(1)提出了一种新的表征语音特征的参数——短时能量—微分过零率比,以解决语音过渡期和弱能量浊音帧的清浊音误判问题;(2)提出了一种线谱频率多级矢量量化的多径搜索算法,解决了有些情况下编码矢量与输入矢量之间总体失真度偏大的问题。 实验和主观听觉测试结果表明,这两项措施是有效的。改进后的MELP 模型在同样的2.4kb/s 码率下,合成语音在可懂度和自然度上都有一定的提高。 2 改进的模型 2.1 能量—微分过零率比(edzc R )参数 实验表明,不自然合成音多发生在元音语音段的开始、结束或 两个元音发音之间的结合部分,也就是人的发音状态处于过渡态的 时期。在元音段的开始或结束时期,语音能量通常比较低。两个元 音之间,有一段基音周期不是很规则的时期。不规则的基音成分或 弱能量段使得基音相关性弱,难以准确判定其清浊音性质。标准 MELP 模型对这个问题的解决方法,是采用自相关系数检测法对5 个子带进行清浊音初判后,再计算残差信号的峰度(peakiness ),对 相应子带的清浊音判决进行调整。因为峰度是和语音段的能量相关的,通常浊音段的能量要比清音段或无声段高,所以通过残差信号峰度可以减少部分情况下的清浊音误判。但是峰度调整对于有些情况处理得还是不够理想。这是因为元音(浊音)开始段和结束段的能量水平通常也比较低,与清音段的能量水平差别并不显著。所以有时候能量较弱的浊音段还是会被误 * 收稿日期:2004-09-22 修订日期:2004-11-24 图 1 原始声音信号、采用标准MELP 算法的合成语音和采用能量—微分过零率比R edzc 改进的MELP 合成语音
第一章计算机基础知识 1.1计算机概述 一、计算机的四特点:1.有信息处理的特性2.有程序控制的特性3.有灵活选择的特性4.有正确应用的特性 二、计算机发展经历5个重要阶段,它们是并行关系:1.大型机阶段40-50年代2.小型机阶段60-70年代3.微型机阶段70-80年代4.客户机/服务器阶段5.Internet阶段(Arpanet 是在1983年第一个使用TCP/IP协议的;在1991年6月我国第一条与国际互联网连接的专线建成,它从中国科学院高能物理研究所接到美国斯坦福大学的直线加速器中心;在1994年实现4大主干网互连(中国公用计算机互联网Chinanet、中国科学技术网Cstnet、中国教育和科研计算机网Cernet、中国金桥信息网ChinaGBN),即全功能连接或正式连接) 三、计算机应用领域:1.科学计算2.事务处理3.过程控制4.辅助工程(CAE,CAI,CA T) 5.人工智能6.网络应用7.多媒体应用 1.2计算机硬件系统 1.一个完整的计算机系统由软件和硬件两部分组成。 2.硬件具有原子的特性,成本低速度快;软件具有比特的特性,成本高速度慢。二者在功能上具有等价性、且具有同步性。 3.计算机硬件组成四个层次:①芯片②板卡③整机④网络 一、计算机硬件的种类:计算机传统分类:巨型机、大型计算机,中型计算机,小型计算机、微型计算机。 IEEE1989年分类:大型主机、小型计算机、个人计算机、工作站、巨型计算机、小巨型计算机。 计算机现实分类:服务器(按处理器体系结构分CISC\RISC\VLIW三种,按结构分刀片式),工作站(基于RISC和UNIX操作系统的份额专业工作站和基于Interl和Windows的PC工作站),台式机,笔记本,手持设备。 二、计算机指标: 1.字长(位数)。8位是一个字节,16位是一个字,32位是一个双字长,64位是两个双字长。指CPU一次能处理寄、存器能储存32位数据 2.速度。MIPS是表示单字长定点指令的平均执行速度,MFLOPS是考察单字长浮点指令的平均执行速度。3.容量。Byte用B表示。4.数据传输率(带宽)。Bps用b。5.可靠性。平均无故障时间MTBF和平均故障修复时间MTTR来表示。6.产品名称和版本。越高越好。 3. 微处理器简史:Intel8080(8位)→Intel8088(16位)→奔腾(32位)→安腾(64位)三.奔腾芯片的技术特点:奔腾32位芯片,主要用于台式机和笔记本,奔腾采用了精简指令RISC技术。 ⑴超标量技术。通过内置2条U、V(仅精简指令)整数指令流水线和1条浮点指令流水线,同时执行多个处理,其实质是用空间换取时间。 ⑵超流水线技术。通过细化流水,提高主频,使得机器在一个周期内完成一个甚至多个操作,其实质是用时间换取空间。经典奔腾每条整数流水线分为四级流水:指令预取,译码,执行和写回结果。浮点流水线分8级流水,前4点同,后4点:二级浮点操作、一级4舍5入及写回浮点运算、一级为出错报告 ⑶分支预测。为提高流水线吞吐率,内置分支目标缓存器,动态的预测程序分支的转移情况。 ⑷双CACHE哈佛结构:指令与数据分开。⑸固化常用指令。⑹增强的64位数据总线。内部总线是32位,外部总线增为64位。
最佳矢量量化器码本设计 指导教师姓名: ××× 报告提交日期: 20××年×月×日
摘要 矢量量化技术作为一种有损压缩编码技术在语音信号的存储和低码率传输过程中起到了巨大的推动作用。本文主要介绍了适量量化的一些基本概念,以及矢量编码器的码本设计方法。 关键词 适量量化矢量量化器 矢量量化 矢量量化介绍 矢量量化是70年代后期发展起来的一种数据压缩技术基本思想:将若干个标量数据组构成一个矢量,然后在矢量空间给以整体量化,从而压缩了数据而不损失多少信息。矢量量化技术是七十年代后期发展起来的一种数据压缩和编码技术,广泛应用于语音编码、语音合成、语音识别和说话人识别、图像压缩等领域。矢量量化的基本原理是:将若干个标量数据组成一个矢量(或者是从一帧语音数据中提取的特征矢量)在多维空间给予整体量化,从而可以在信息量损失较少的情况下压缩数据量。矢量量化有效地应用了矢量中各元素间的相关性,因此可以有比标量量更好的压缩效果。一般来说矢量维数越大量化越优越。
矢量量化原理概述 标量量化 将抽样值的整个动态范围被分成若干个小区间,每个小区间有一个代表值,量化时落入小区间的信号值就用这个代表值代替,或者叫被量化为这个代表值。这时的信号量是一维的,所以称为标量量化。 矢量量化 若干个标量数据组成一个矢量,矢量量化是对矢量进行量化,和标量量化一样,它把矢量空间分成若干个小区域,每个小区域寻找一个代表矢量,量化时落入小区域的矢量就用这个代表矢量代替,或者叫被量化为这个代表矢量。 矢量量化的要点 首先设计一个好码本。关键在于如何划分J个区域边界。这需要大量的输入信号矢量,经过统计实验才能确定,这个过程称为“训练”或“学习”。 应用聚类算法,按照一定的失真度准则(失真测度),对训练的数据进行分类,从而把训练数据在多维空间中划分成一个以码字为中心的胞腔,常用的是LBG算法来实现。 未知矢量的量化。按照选定的失真度准则(失真测度),把未知矢量,量化为失真度最小的码字。
矢量量化(vector quantizization)技术技术是一种数据压缩和编码技术,矢量量化压缩技术的应用领域非常广阔,如军事部门和气象部门的卫星(或航天飞机)遥感照片的压缩编码和实时传输、雷达图像和军用地图的存储与传输、数字电视和DVD 的视频压缩、医学图像的压缩与存储、网络化测试数据的压缩和传输、语音编码、图像识别和语音识别等等 。 其具体的方法如下图所示: 几个术语的解释: 1.压缩比:log 2Nc/n*n*bpp (像素字节数bpp ) n*n 即一个与编码本中一个数对应的向量,所以Nc 个数我们可以对应所有向量即全图,而Nc 的字节数为log 2Nc 。 2. d(B, C):我们可以解释为距离差,d 的定义有很多种可以是Σ|b i c i |,Σ(b i – c i )2 ,Max|b i - c i |等等。 例子: 編碼端解
由上图我们可以看到左边为原图像,而右边为编码本。例如我们可以讲原图像以如图所示的方式分为若干个有四个量的向量如(100,100,80,80)其余编码本中的 (100,100,90,90)计算的d (X ,Xk )最小故我们可以用数字k 表示向量 (100,100,80,80)。其实我们可以理解为矢量量化就是讲图像中分割成若干的小块,然后再将小块分类,一类用一个码表示。 下面是一个我论文中看到的也是最常用的VQ 算法:LBG 算法也叫K 平均分类算法。 以下是步骤: 当然我们可以设置一个收敛的条件,这个可以根据自己需求设置ε大小,当到达某一步 时 收敛即迭代结束。 ε≤---)1()1(l l l D D D
文献综述 题目关于信源信道联合编码的研究学生姓名 gyp 专业班级通信工程07-1班 学号 2007******* 院(系)计算机与通信工程学院 指导教师(职称) **(讲师) 完成时间 2009年 3 月 12 日
1 前言 “信息论”又称“通信中的数学理论”,是研究信息的传输、存储和处理的科学。通信的根本目的是将消息有效而可靠地从信源传到信宿。 信源编码的目的在于提高系统的有效性(传信率越高失真越小)。中心问题是:对一给定的信源,在失真度确定的条件下,使得失真满足要求所需的最低传信率;在传信率确定的情况下,系统所能达到的最小失真。 信道编码理论核心是提高系统的可靠性。中心问题:寻求一种适当的编码手段,在一定的传信率条件下,通过有规律地增加冗余度保证消息以尽可能小的差错概率从信源传到信宿[1]。 长期以来,在香农的信源信道分离理论的指导下,信源编码理论和信道编码理论都取得可喜成果。但是当前的分离理论仅适用与点对点通信系统,并假定系统可容忍无限长的传输时延和预先掌握信道统计特性。在当前,图像/视频实时业务,无线和IP网络信道的时变性,原分离的信源信道理论已经无法满足实际的通信需求。而建立在香农的全局率失真理论之上的信源-信道联合编码理论应运而生。如图1信源信道联合编码框图[2]。
1979年—— 提出信源信道联合编码[3]。 近年来—— K.Sayood等人,研究利用压缩编码后信息的先验后验信息向译码器传递信息。 F.R.K schischang和B.J.Frey等人,提出因子图形并提出一种针对全局函数边 界计算的一般性算法。 I.Kozintsev等人,提出一种基于因子图形框架,同时包含信源与信道编码的全 局图形模型(还用到冗余信息存在准则和和积准则)。 J.Hagenauer等人,提出一种基于变长译码的变长软译码算法。 Banister等人,提出针对JPEG2000信源编码和Turbo信道编码的联合方法。Hamzaoui等人,提出互联网和无线信道下传输内嵌图像的联合编码方法; 且采用局部搜索算法对信源信道进行最优化不等差错保护。Rabiner等人,提出结合隐性马尔科夫信源和低密度奇偶校验码的联合方法。Lisimachos等人,提出基于DCT和运动补偿分级视频编码和传输的联合方法。Kiewer等人,提出变长编码信源和信道编码并行级联的鲁棒性传输算法。
基于小波变换和分类矢量量化的图像压缩算法修改版
————————————————————————————————作者:————————————————————————————————日期:
基于小波变换和分类矢量量化的图像压缩算法 学号20082334024姓名 岳东 专业 通信工程 摘 要:提出一种用于图像压缩的分类矢量量化算法,该算法在对图像进行多级小波变换后,利用3个方向上各自小波系数之间的相关性,构造符合图像特征的跨频带矢量,依据矢量能量和零树矢量综合判定进行矢量分类,并采用了基于人眼视觉特性的加权均方误差准则和基于成对最近邻算法(PNN)的L BG算法进行矢量量化,提高了图像的编码效率和重构质量。仿真结果表明,该算法实现简单,在较低的编码率下,可达到较好的压缩效果。 关 键 词:小波变换,跨频带矢量构造,矢量分类,矢量量化 1 算法原理 1.1 图像小波分解的特点和跨频带矢量的构造 小波变换是一种非平稳信号的分析方法,其基本思想是用一族函数)(,t ψb a 来表示或逼近一个函数)t (f ,这族函数称为小波函数。实际小波变换中,为了方便,多采用二进小波变换。对)(2 R L 空间中的任意函数)t (f ,它的二进小波变换为 ∫∞ +∞ ,,d )()(=t t ψt f C n m n m (1) 其中,2 ,2 =)(m n m t ψ)2(n t ψm ,而)(t 满足 0=d )(∫ ∞ +∞ t t ψ。 将小波变换一维推广到二维就可用于图像处理。通过水平和垂直滤波,可分离二维小波变换将原始图像分解为水平﹑垂直﹑对角和低频4个子带,其中低频部分可继续进一步分解。图像经小波变换后所得到的系数有特殊性质。在不同尺度的高频子带图像之间存在同构特性,而且3个方向上不同尺度下的小波系数能量大小不同,各方向的侧重不同。在同一方向上,有更强的同构性和相似性,事实上,各方向不同尺度下对应频带的相关性是最强的。为提高矢量量化的编码效率,在构造矢量时,必须充分利用这些相关性。此外,图像的能量主要集中在低频子带,高频子带所占能量较少,且不同分辨率不同高频子带中的分布非常相似,接近G amma 分布或Laplac e分布。各高频子带系数大部分分布在零值附近,概率密度分布曲线的中心点和最大值为零。这样,对带内及带间相关性的充分利用和对零值附近小波系数的有效处理,就成为提高图像压缩效率的关键。 高性能的矢量量化器必须依照图像小波系数的特性来构造矢量。使用不同子带的系数构成矢量来压缩小波系数,就可以利用不同尺度同方向小波系数的相关性。根据以上分析,本文
矢量量化(Vector Quantization) 一.矢量量化初步 1.基本原理 2.设计码本(LBG) 3.量化 二.矢量量化进一步 1.分裂矢量量化(Splitted VQ) 2.多极矢量量化(Cascaded VQ) 3.树形矢量量化器 4.其它各种类型矢量量化器 三. 几个矢量量化的工程实现问题 1.分级矢量量化中的多路径搜索问题 2.用模拟退火(Simulated Annealing) 算法训练最佳码本[2] 四. 矢量量化的应用
一.矢量量化初步 1. 基本原理 结论:在信息论中已证明,矢量量化优于标量量化。 ? 矢量量化是先将K 个(2≥K )个采样值形成K 维空间K R 中的一个矢量,然后将这个矢量一次进行量化。它可以大大降低数码率。 ? 基础是信息论的分支: 率失真(畸变)理论 对于一定的量化速率R(以每个采样信号平均所用的量化比特数来衡量,bit/采样),量化失真D(以量化信号与原信号之间的误差均方值和原信号均方值之比来衡量)是一定的。 矢量量化总是优于标量量化的。这是因为矢量量化有效地应用了矢量中各分量间的四种相互关联的性质:线性依赖性,非线性依赖性,概率密度函数的形状以及矢量维数。 定义: 1) 源:若将K M ?个信号采样组成的信源序列{} j x 中每K 个为一组分为M 个随机矢量,构成信 源空间{}M X X X X ,,,21 =(X 在K 维欧氏空间K R 中),其中第j 个矢量可记为 {}12,,,j k X x x x = ,M j ,,2,1 =。 2) 子空间:把K R 无遗漏地划分成n N 2=个互不相交的子空间N R R R ,,,21 ,满足: ?????≠===j i R R R R j i N i K i ,01 3) 码本:在每个子空间i R 中找一个代表矢量i Y ,令恢复矢量集为:{}N Y Y Y Y ,,,21 =。Y 也叫输 出空间、码本或码书(Code Book),i Y 称为码矢(Code V ector)或码字(Code Word),Y 内矢量的数目 N ,则叫做码本长度。
第一章绪论 1.语音信号处理是以语音语言学和数字信号处理为基础而形成的一门涉及面很广的综合性的学科。p1d3 2.语音信号处理的应用技术列举:语音编码、语音识别、语音合成、说话人识别和语种辨识、语音转换和语音隐藏(语音信息伪装、语音数字水印技术)、语音增强等p4d3 3.当前语音信号处理应用的3个主流技术:矢量量化技术、隐马尔可夫模型技术、人工神经网络技术。p4d3 第二章语音信号处理基础知识 1.语音是组成语言的声音,是声音(Acoustic)和语言(Language)的组合体。p5d2 2.语音的基本声学特性包括音色,音调,音强、音长。p7d2 音色:也叫音质,是一种声音区别于另一种声音的基本特征。 音调:是指声音的高低,它取决于声波的频率。 音强:声音的强弱,它由声波的振动幅度决定。 音长:声音的长短,它取决于发音时间的长短。 3. 说话时一次发出的,具有一个响亮的中心,并被明显感觉到的语音片段叫音节(Syllable)。一个音节可以由一个音素(Phoneme)构成,也可以由几个音素构成。音素是语音发音的最小单位。p7d3 4.任何语言都有语音的元音(V owel)和辅音(Consonant)两种音素。p7d3 8.当声带振动发出的声音气流从喉腔、咽腔进入口腔从唇腔出去时,这些声腔完全开放,气流顺利通过,这种音称为元音。p7d3 9.呼出的声流,由于通路的某一部分封闭起来或受到阻碍,气流被阻不能畅通,而克服发音器官的这种阻碍而产生的音素称为辅音。p7d3 7.发辅音时由声带是否振动引起浊音和清音的区别,声带振动的是浊音,声带不振动的是清音。p7d3 8.元音构成音节的主干(因为无论从长度还是能量看,元音在音节中都占主要部分。)p7d3 9.元音的一个重要声学特性是共振峰(Formant)。共振峰参数是区别不同元音的重要参数,它一般包括共振峰频率(Formant Frequency)的位置和频带宽度(Formant Bandwidth)。p7d5 16.人类的声道和鼻道可以看作是非均匀截面的声道管,声道管的谐振频率称为共振峰频率(共振峰)。p7d5 10.汉语音节一般由声母、韵母和声调三部分组成。汉语普通话中有6000多个常用字,每个汉字是一个音节。p10d6 10. 发浊音时,气流通过声门时使声带发生振动,产生准周期激励脉冲串,这个脉冲串的周期就称为基音周期(pitch),其倒数成为基音频率。 11.汉语是一种声调语言,声调的变化就是浊音基音周期(或基音频率)的变化。p14d5 13. 无论是单音节语音还是连续语音,其中浊音段的基因频率是随时间而变化的,基因频率的不同轨迹成为声调。p9d11 14. 当两个响度不同的声音作用于人耳时,响度较高的频率成分的存在会影响到对响度较低的频率成分的感受,使其变得不易察觉,这种现象成为掩蔽效应。 15.语音信号的生成模型可由激励模型、声道模型和辐射模型三个子模型构成,三者是串联(串联/并联)的关系。p21-26 16.语音信号激励模型一般分为浊音激励和清音激励,发浊音时激励模型为脉冲波。p21d6 17.语音信号激励模型一般分为浊音激励和清音激励,发清音时激励信号通常被模拟为随机白噪声。p22d2
111()1q j j j p i i i b z H z G a z -=-=+=-∑∑ 1 1()1p i i i H z G a z -==-∑ )n 原始 )???≠±±±====0,...,3,2,1,0)(0,1)0(k k kT h k h 第一章 1.1 什么是通信?通信系统是如何分类的? 答:通信是指有一地向另一地进行消息的有效传递。 分类:按传输媒质分:有线通信和无线通信。 按信道中所传信号不同:数字通信、模拟通信 按调制方式分:基带传输、频带传输 按业务不同:电报、电话、传真、数据传输、可视电话、无线寻呼等 按收发者是否运动:移动通信、固定通信 按工作频段:长波通信、短波通信、微波通信等 1.2 何为数字通信?数字通信的优缺点是什么? 答:利用数字信号传输信息的系统称为数字通信系统。 优点:抗干扰、抗噪声性能好,差错可控,易加密,易于与现代技术相结合。 缺点:数字几代信号占用的频带宽,要求收端和发端保持严格同步,故设备较复杂。 第二章 2.1 矢量量化的概念 答:矢量量化是一种高效的数据压缩技术。它将若干个时间里三幅度连续的抽样值分为一组,组成多为空间的一个矢量,再对该矢量进行量化处理,从而提高量化效率。 2.2 线性预测的基本概念 答:一个语音的抽样能够用过去若干个语音抽样的线性组合来毕竟,通过使实际语音抽样和线性预测抽样值见插值达到最小值,即进行最小军方误差的进行逼近,能够决定唯一的一组预测系数。 2.3 描述语音信号的三种模型 答:零极点模型:同时含有极点和零点,称做自回归—滑动 平均模型,简称为ARMA 模型,这是一般模型。 全极点模型:当分子多项式为常数,即b =0时。这时模型的 输出只取决于过去的信号值,称为自回归模型(AR 模型)。 全零点模型:如果分母多项式为1,为全零点模型, 称为滑动平均模型,简称MA 模型。 2.4 线性预测合成分析(LPAS-LPC )声码器的基本思想是什么?他的基本构成。激励信号的三种形式。编码过程。 答:基本思想:合成来指导分析。将合成器引入发送端,是指与分析器想结合,在编码器中产生译码器端完全一致的合成语音。比较原始语音信号与合成信号。根据一定的误差准则调正计算相关参数,使得两者之间的误差达到最小。 基本构成: 编码器 译码器 第三章 5.4 基带码应满足什么条件?[特点] 答:无直流分量,低频和高频分量小;有利于时钟提取;具有透明性,即与信源的统计特性无关;具有一定的误码检测能力;误码增殖要小;设备的经济性。 5.17 时域均衡的原理是什么? 答:要力求包括它本身在内的传输系统特性所形成的接收波形接近奈奎斯特波形,或满足下式: h(t)是形成滤波器的时间响应;T 是码元间隔 第四张 1()[1]q j j j H z G b z -==+∑