用R语言做非参数和半参数回归笔记
- 格式:docx
- 大小:134.79 KB
- 文档页数:19

r语言回归参数摘要:1.R 语言与回归分析2.回归参数的概念与种类3.R 语言中回归参数的估计方法4.R 语言中回归参数的检验方法5.R 语言中回归参数的优化与选择6.总结正文:一、R 语言与回归分析R 语言是一种功能强大的数据处理与统计分析语言,被广泛应用于各个领域。
在统计学中,回归分析是一种重要的研究方法,用于分析自变量与因变量之间的关系。
R 语言为回归分析提供了丰富的函数和方法,使得回归分析在实际应用中更加高效和准确。
二、回归参数的概念与种类在回归分析中,回归参数是用于描述自变量与因变量之间关系的统计量。
回归参数通常包括两个部分:斜率(B)和截距(a)。
斜率表示自变量每变动一个单位时,因变量相应变动的数量;截距表示当自变量为0 时,因变量的取值。
在多元回归分析中,除了斜率和截距外,还可能有其他参数用于描述多个自变量与因变量之间的关系。
三、R 语言中回归参数的估计方法R 语言提供了多种回归函数用于估计回归参数,如线性回归的`lm()`函数、多项式回归的`poly()`函数、广义线性模型的`glm()`函数等。
这些函数可以方便地对数据进行回归分析,并输出回归参数的估计值。
例如,使用`lm()`函数对一组数据进行线性回归分析:```Rx <- c(1, 2, 3, 4, 5)y <- c(2, 4, 6, 8, 10)model <- lm(y ~ x, data = list(x = x, y = y))summary(model)```四、R 语言中回归参数的检验方法在得到回归参数的估计值后,需要对其进行检验以判断是否显著。
R 语言中提供了`t.test()`、`f.test()`等函数用于进行t 检验和F 检验。
例如,对上述线性回归模型的斜率进行t 检验:```Rt.test(model$coefficients[1], alternative = "two.sided", mu = 0)```五、R 语言中回归参数的优化与选择在实际应用中,回归参数的优化与选择至关重要。

r语言多组数据非参数检验主题:R语言中多组数据的非参数检验引言:在统计学中,我们经常需要对不同组别的数据进行比较和分析。
而非参数检验是一种常用的方法,可以用于比较不同组别的数据,而不需要对数据具有特定的分布形式。
R语言是一种强大的统计分析工具,提供了多种非参数检验方法,使得我们可以轻松地进行多组数据的比较。
本文将以R语言为工具,一步一步介绍多组数据的非参数检验方法。
一、读取数据:首先,我们需要从外部文件或者直接在R中定义数据,用于后续的分析。
在R中,可以使用read.csv()函数读取csv格式的文件,或者使用read.table()函数读取其他格式的文件。
在本文中,我们假设我们已经读取了两组数据,分别命名为group1和group2。
二、描述性统计分析:在进行非参数检验之前,我们需要先对数据进行一定的描述性统计分析,以了解数据的分布状况和基本特征。
在R语言中,可以使用summary()函数来计算数据的各种统计量,如均值、中位数、四分位数等。
此外,我们还可以使用hist()函数绘制直方图,来观察数据的分布情况。
三、非参数检验方法选择:在进行非参数检验之前,我们需要根据数据的特点选择合适的非参数检验方法。
常用的非参数检验方法包括Wilcoxon秩和检验、Mann-Whitney U检验、Kruskal-Wallis单因素方差分析等。
在R语言中,可以使用wilcox.test()函数进行Wilcoxon秩和检验,使用wilcox.test()或者kruskal.test()函数进行多组数据的比较。
四、Wilcoxon秩和检验:假设我们要比较group1和group2两组数据之间的差异。
我们可以使用wilcox.test()函数进行Wilcoxon秩和检验。
该检验假设两组数据的分布形状相同,只有位置参数不同。
在R语言中,我们可以使用如下代码进行Wilcoxon秩和检验:wilcox.test(group1, group2, paired = FALSE)其中,group1和group2分别表示两组数据的向量,paired = FALSE表示两组数据是不相关的。

用R语言做非参数和半参数回归笔记由詹鹏整理,仅供交流和学习根据南京财经大学统计系孙瑞博副教授的课件修改,在此感谢孙老师的辛勤付出!教材为:Luke Keele: Semiparametric Regression for the Social Sciences. John Wiley & Sons, Ltd. 2008.-------------------------------------------------------------------------第一章 introduction: Global versus Local Statistic一、主要参考书目及说明1、Hardle(1994). Applied Nonparametic Regresstion. 较早的经典书2、Hardle etc (2004). Nonparametric and semiparametric models: an introduction. Springer. 结构清晰3、Li and Racine(2007). Nonparametric econometrics: Theory and Practice. Princeton. 较全面和深入的介绍,偏难4、Pagan and Ullah (1999). Nonparametric Econometrics. 经典5、Yatchew(2003). Semiparametric Regression for the Applied Econometrician. 例子不错6、高铁梅(2009). 计量经济分析方法与建模:EVIEWS应用及实例(第二版). 清华大学出版社. (P127/143)7、李雪松(2008). 高级计量经济学. 中国社会科学出版社. (P45 ch3)8、陈强(2010). 高级计量经济学及Stata应用. 高教出版社. (ch23/24)【其他参看原ppt第一章】二、内容简介方法:——移动平均(moving average)——核光滑(Kernel smoothing)——K近邻光滑(K-NN)——局部多项式回归(Local Polynormal)——Loesss and Lowess——样条光滑(Smoothing Spline)——B-spline——Friedman Supersmoother模型:——非参数密度估计——非参数回归模型——非参数回归模型——时间序列的半参数模型——Panel data 的半参数模型——Quantile Regression三、不同的模型形式1、线性模型linear models2、Nonlinear in variables3、Nonlinear in parameters四、数据转换 Power transformation(对参数方法)In the GLM framework, models are equally prone(倾向于) to some misspecification (不规范) from an incorrect functional form.It would be prudent(谨慎的) to test that the effect of any independent variable of a model does not have a nonlinear effect. If it does have a nonlinear effect, analysts in the social science usually rely on Power Transformations to address nonlinearity. [ADD: 检验方法见Sanford Weisberg. Applied Linear Regression (Third Edition). A John Wiley & Sons, Inc., Publication.(本科的应用回归分析课教材)]----------------------------------------------------------------------------第二章 Nonparametric Density Estimation非参数密度估计一、三种方法1、直方图 Hiatogram2、Kernel density estimate3、K nearest-neighbors estimate二、Histogram 对直方图的一个数值解释Suppose x1,…xN – f(x), the density function f(x) is unknown.One can use the following function to estimate f(x)【与x的距离小于h的所有点的个数】三、Kernel density estimateBandwidth: h; Window width: 2h.1、Kernel function的条件The kernel function K(.) is a continuous function, symmetric(对称的) around zero, that integrates(积分) to unity and satisfies additional bounded conditions:(1) K() is symmetric around 0 and is continuous;(2) ,,;(3) Either(a) K(z)=0 if |z|>=z0 for z0Or(b) |z|K(z) à0 as ;(4) , where is a constant.2、主要函数形式3、置信区间其中,4、窗宽的选择实际应用中,。
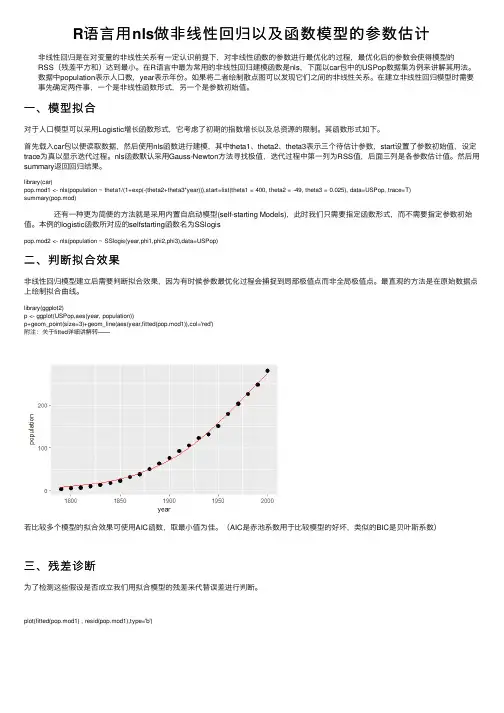
R语⾔⽤nls做⾮线性回归以及函数模型的参数估计⾮线性回归是在对变量的⾮线性关系有⼀定认识前提下,对⾮线性函数的参数进⾏最优化的过程,最优化后的参数会使得模型的RSS(残差平⽅和)达到最⼩。
在R语⾔中最为常⽤的⾮线性回归建模函数是nls,下⾯以car包中的USPop数据集为例来讲解其⽤法。
数据中population表⽰⼈⼝数,year表⽰年份。
如果将⼆者绘制散点图可以发现它们之间的⾮线性关系。
在建⽴⾮线性回归模型时需要事先确定两件事,⼀个是⾮线性函数形式,另⼀个是参数初始值。
⼀、模型拟合对于⼈⼝模型可以采⽤Logistic增长函数形式,它考虑了初期的指数增长以及总资源的限制。
其函数形式如下。
⾸先载⼊car包以便读取数据,然后使⽤nls函数进⾏建模,其中theta1、theta2、theta3表⽰三个待估计参数,start设置了参数初始值,设定trace为真以显⽰迭代过程。
nls函数默认采⽤Gauss-Newton⽅法寻找极值,迭代过程中第⼀列为RSS值,后⾯三列是各参数估计值。
然后⽤summary返回回归结果。
library(car)pop.mod1 <- nls(population ~ theta1/(1+exp(-(theta2+theta3*year))),start=list(theta1 = 400, theta2 = -49, theta3 = 0.025), data=USPop, trace=T)summary(pop.mod) 还有⼀种更为简便的⽅法就是采⽤内置⾃启动模型(self-starting Models),此时我们只需要指定函数形式,⽽不需要指定参数初始值。
本例的logistic函数所对应的selfstarting函数名为SSlogispop.mod2 <- nls(population ~ SSlogis(year,phi1,phi2,phi3),data=USPop)⼆、判断拟合效果⾮线性回归模型建⽴后需要判断拟合效果,因为有时候参数最优化过程会捕捉到局部极值点⽽⾮全局极值点。

一、非对称分析(回归)做回归分析的前提条件:方差齐次性、独立、数据满足正态分布如果数据不正态,导致的后果平均值95%置信区间,两边不对称如果方差不等,某一边的标准差、置信区间大,有重叠回归Y定性时,整个式子叫做“分类排序”;X定性又定量时,整个方程叫“协方差分析”二、单因素方差分析(1)验证数据的正态性,零假设:均值相等,一组一组地验证:tapply(df$yield,df$Treat,shapiro.test),正态分析函数(shapiro.test),当结果P>0.05,则是一种自然分布(2)合并检验正态性:shapiro.test(resid(lm(yield~Treat,df)))(3)方差齐性检验,零假设:方差相等:bartlett.test(yield~Treat,df)(4)方差分析:fit <- aov(yield ~ Treat, df) 【“~”表示回归,aov是单因素方差分析ANOVA函数】(5)小知识:范函数:[summary.] /[plot.](6)P=1-pf(value组间方差-即组间变异幅度,Df-treat, Df-Residuals)Treat-Meansq/Treat-Value=Residuals-MeansqDf Sum Sq Mean Sq F value Pr(>F)Treat 4 301.2 75.30 11.18 0.000209 ***Residuals 15 101.0 6.73---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘’ 1(7)多重比较:安装赖老师的写的包(NEwR2),library(NEwR2),LSD多重比较:Least Significance Difference;多个t检验Install.package(‘agricolae’)(8)(9)结果P值,犯“1类错误,拒接真的原假设”的概率,正常我们说的P=0.05,就是:我们可以接受犯这个错误的概率。


由詹鹏整理 ,仅供交流和学习根据南京财经大学统计系孙瑞博副教授的课件修改 ,在此感谢孙老师的辛勤付出!教材为:Luke Keele: Semiparametric Regression for the Social Sciences. John Wiley & Sons, Ltd. 2008.-------------------------------------------------------------------------第一章 introduction: Global versus Local Statistic一、主要参考书目及说明1、Hardle(1994). Applied Nonparametic Regresstion. 较早的经典书2、Hardle etc (2004). Nonparametric and semiparametric models: an introduction. Springer. 结构清晰3、Li and Racine(2007). Nonparametric econometrics: Theory and Practice. Princeton. 较全面和深入的介绍 ,偏难4、Pagan and Ullah (1999). Nonparametric Econometrics. 经典5、Yatchew(2003). Semiparametric Regression for the Applied Econometrician. 例子不错6、高铁梅(2009). 计量经济分析方法与建模:EVIEWS应用及实例(第二版). 清华大学出版社. (P127/143)7、李雪松(2008). 高级计量经济学. 中国社会科学出版社. (P45 ch3)8、陈强(2010). 高级计量经济学及Stata应用. 高教出版社. (ch23/24)【其他参看原ppt第一章】二、内容简介方法:——移动平均(moving average)——核光滑(Kernel smoothing)——K近邻光滑(K-NN)——局部多项式回归(Local Polynormal)——Loesss and Lowess——样条光滑(Smoothing Spline)——B-spline——Friedman Supersmoother模型:——非参数密度估计——非参数回归模型——非参数回归模型——时间序列的半参数模型——Panel data 的半参数模型——Quantile Regression三、不同的模型形式1、线性模型linear models2、Nonlinear in variables3、Nonlinear in parameters四、数据转换 Power transformation(对参数方法)In the GLM framework, models are equally prone(倾向于) to some misspecification (不规范) from an incorrect functional form.It would be prudent(谨慎的) to test that the effect of any independent variable of a model does not have a nonlinear effect. If it does have a nonlinear effect, analysts in the social science usually rely on Power Transformations to address nonlinearity.[ADD: 检验方法见Sanford Weisberg. Applied Linear Regression (Third Edition). A John Wiley & Sons, Inc., Publication.(本科的应用回归分析课教材)]----------------------------------------------------------------------------第二章Nonparametric Density Estimation非参数密度估计一、三种方法1、直方图 Hiatogram2、Kernel density estimate3、K nearest-neighbors estimate二、Histogram 对直方图的一个数值解释Suppose x1,…xN – f(x), the density function f(x) is unknown.One can use the following function to estimate f(x)【与x的距离小于h的所有点的个数】三、Kernel density estimateBandwidth: h; Window width: 2h.1、Kernel function的条件The kernel function K(.) is a continuous function, symmetric(对称的) around zero, that integrates(积分) to unity and satisfies additional bounded conditions:(1) K() is symmetric around 0 and is continuous;(2) ,,;(3) Either(a) K(z)=0 if |z|>=z0 for z0Or(b) |z|K(z) à0 as;(4) , where is a constant.2、主要函数形式3、置信区间其中 ,4、窗宽的选择实际应用中 ,。

非参数回归r语言-概述说明以及解释1.引言1.1 概述非参数回归是一种不依赖于特定函数形式的回归分析方法,它不需要对数据的分布做出假设。
相比于传统的参数回归方法,非参数回归更加灵活,能够更好地拟合复杂的数据模式。
在实际应用中,非参数回归可以有效地处理非线性关系、异常值和数据噪音等问题,因此受到越来越多研究者和数据分析师的青睐。
本文将重点介绍在R语言中如何进行非参数回归分析,包括常用的非参数回归方法、分析步骤以及如何利用R语言中的工具进行非参数回归分析。
同时,我们将讨论非参数回归的优缺点,以及对R语言在非参数回归中的意义和展望非参数回归的发展。
希望本文能够帮助读者更加深入地了解非参数回归方法,并在实践中灵活运用。
1.2 文章结构本文分为引言、正文和结论三部分。
在引言部分,将包括概述、文章结构和目的等内容,为读者提供对非参数回归和R语言的整体了解。
在正文部分,将介绍什么是非参数回归、在R语言中如何进行非参数回归分析以及非参数回归的优缺点。
最后,在结论部分将对非参数回归的应用进行总结,探讨R语言在非参数回归中的意义,以及展望非参数回归的发展前景。
通过以上结构,读者将逐步深入了解非参数回归和R语言在该领域的应用和发展。
1.3 目的本文旨在探讨非参数回归在数据分析中的应用,特别是在R语言环境下的实现方法。
通过深入了解非参数回归的概念、原理和优缺点,读者可以更全面地了解这一方法在处理不确定性较大、数据分布不规律的情况下的优势和局限性。
此外,本文还旨在介绍R语言中如何进行非参数回归分析,帮助读者学习如何利用这一工具进行数据建模和预测分析。
最终,通过对非参数回归的应用和发展的展望,希望能够激发更多的研究者和数据分析师对于这一领域的兴趣,推动非参数回归方法在实际应用中的进一步发展和创新。
2.正文2.1 什么是非参数回归非参数回归是一种用于建立数据之间关系的统计方法,它不对数据的分布做出任何假设。
在传统的参数回归中,我们通常会假设数据服从某种特定的分布,比如正态分布,然后通过参数估计来拟合模型。

用R语言做非参数非参数统计是一种统计学方法,不依赖于数据的分布假设。
相比于参数统计,非参数统计更加灵活,可以处理各种类型的数据。
在R语言中,有很多函数和包可以用来进行非参数统计分析。
首先,我们可以使用Wilcoxon秩和检验(Mann-Whitney U检验)来比较两组独立样本的中位数差异。
Wilcoxon秩和检验是一种非参数的假设检验方法,适用于两组样本的中位数比较。
在R语言中,使用wilcox.test(函数可以进行Wilcoxon秩和检验。
例如,假设我们有两组样本x和y,我们可以使用以下代码进行Wilcoxon秩和检验:```Rx<-c(1,2,3,4,5)y<-c(6,7,8,9,10)result <- wilcox.test(x, y)print(result)```这段代码将计算两组样本的Wilcoxon秩和检验结果,并打印输出。
除了Wilcoxon秩和检验,我们还可以使用Kruskal-Wallis检验来比较多组样本的中位数差异。
Kruskal-Wallis检验是一种非参数的方差分析方法,适用于多组样本的中位数比较。
在R语言中,使用kruskal.test(函数可以进行Kruskal-Wallis检验。
例如,假设我们有三组样本x、y和z,我们可以使用以下代码进行Kruskal-Wallis检验:```Rx<-c(1,2,3,4,5)y<-c(6,7,8,9,10)z<-c(11,12,13,14,15)result <- kruskal.test(list(x, y, z))print(result)```这段代码将计算三组样本的Kruskal-Wallis检验结果,并打印输出。
另外,对于变量间的相关性检验,我们可以使用Spearman秩相关系数。
Spearman秩相关系数是一种非参数的相关性分析方法,适用于非线性关系的变量间的相关性分析。

⽤R语⾔做回归分析使⽤R做回归分析整体上是⽐较常规的⼀类数据分析内容,下⾯我们具体的了解⽤R语⾔做回归分析的过程。
⾸先,我们先构造⼀个分析的数据集x<-data.frame(y=c(102,115,124,135,148,156,162,176,183,195),var1=runif(10,min=1,max=50),var2=runif(10,min=100,max=200),var3=c(235,321,412,511,654,745,821,932,1020,1123))接下来,我们进⾏简单的⼀元回归分析,选择y作为因变量,var1作为⾃变量。
⼀元线性回归的简单原理:假设有关系y=c+bx+e,其中c+bx 是y随x变化的部分,e是随机误差。
可以很容易的⽤函数lm()求出回归参数b,c并作相应的假设检验。
model<-lm(y~var1,data=x)summary(model)Call:lm(formula = x$y ~ x$var1 + 1)Residuals:Min 1Q Median 3Q Max-47.630 -18.654 -3.089 21.889 52.326Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) 168.4453 15.2812 11.023 1.96e-09 ***x$var1 -0.4947 0.4747 -1.042 0.311Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 30.98 on 18 degrees of freedomMultiple R-squared: 0.05692, Adjusted R-squared: 0.004525F-statistic: 1.086 on 1 and 18 DF, p-value: 0.3111从回归的结果来看,p值为0.311,变量var1不不显著,正常情况下p值⼩于0.05则认为有⾼的显著性⽔平。

R语⾔线性回归知识点总结回归分析是⼀种⾮常⼴泛使⽤的统计⼯具,⽤于建⽴两个变量之间的关系模型。
这些变量之⼀称为预测变量,其值通过实验收集。
另⼀个变量称为响应变量,其值从预测变量派⽣。
在线性回归中,这两个变量通过⽅程相关,其中这两个变量的指数(幂)为1.数学上,线性关系表⽰当绘制为曲线图时的直线。
任何变量的指数不等于1的⾮线性关系将创建⼀条曲线。
线性回归的⼀般数学⽅程为y = ax + b以下是所使⽤的参数的描述y是响应变量。
x是预测变量。
a和b被称为系数常数。
建⽴回归的步骤回归的简单例⼦是当⼈的⾝⾼已知时预测⼈的体重。
为了做到这⼀点,我们需要有⼀个⼈的⾝⾼和体重之间的关系。
创建关系的步骤是进⾏收集⾼度和相应重量的观测值的样本的实验。
使⽤R语⾔中的lm()函数创建关系模型。
从创建的模型中找到系数,并使⽤这些创建数学⽅程获得关系模型的摘要以了解预测中的平均误差。
也称为残差。
为了预测新⼈的体重,使⽤R中的predict()函数。
输⼊数据下⾯是代表观察的样本数据# Values of height151, 174, 138, 186, 128, 136, 179, 163, 152, 131# Values of weight.63, 81, 56, 91, 47, 57, 76, 72, 62, 48LM()函数此函数创建预测变量和响应变量之间的关系模型。
语法线性回归中lm()函数的基本语法是lm(formula,data)以下是所使⽤的参数的说明公式是表⽰x和y之间的关系的符号。
数据是应⽤公式的向量。
创建关系模型并获取系数x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)# Apply the lm() function.relation <- lm(y~x)print(relation)当我们执⾏上⾯的代码,它产⽣以下结果Call:lm(formula = y ~ x)Coefficients:(Intercept) x38.4551 0.6746获取相关的摘要x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)# Apply the lm() function.relation <- lm(y~x)print(summary(relation))当我们执⾏上⾯的代码,它产⽣以下结果Call:lm(formula = y ~ x)Residuals:Min 1Q Median 3Q Max-6.3002 1.6629 0.0412 1.8944 3.9775 Coefficients:Estimate Std. Error t value Pr(>|t|) (Intercept)38.45509 8.04901 4.778 0.00139 **x 0.67461 0.05191 12.997 1.16e-06 ***---Signif. codes: 0 ‘***' 0.001 ‘**' 0.01 ‘*' 0.05 ‘.' 0.1 ‘ ' 1 Residual standard error: 3.253 on 8 degrees of freedom Multiple R-squared: 0.9548, Adjusted R-squared: 0.9491 F-statistic: 168.9 on 1 and 8 DF, p-value: 1.164e-06predict()函数语法线性回归中的predict()的基本语法是predict(object, newdata)以下是所使⽤的参数的描述object是已使⽤lm()函数创建的公式。
非参数统计r语言非参数统计是一种统计学方法,它不依赖于数据的具体分布形式,而是通过对数据的排序、排列、秩次等进行分析来得出结论。
在统计学中,非参数统计方法常常用于处理那些不满足正态分布假设的数据,或者对数据分布形式不确定的情况下进行分析。
R语言是一种广泛应用于数据分析和统计学领域的编程语言,它提供了丰富的数据处理、统计分析和可视化工具,使得非参数统计方法的应用变得更加方便和高效。
下面将介绍一些常见的非参数统计方法在R语言中的实现。
首先是Wilcoxon秩和检验,也称为Mann-Whitney U检验,用于比较两组独立样本的中位数是否有显著差异。
在R语言中,可以使用wilcox.test()函数进行计算,通过设置参数来指定要进行的检验类型,例如单侧检验、双侧检验等。
其次是Kruskal-Wallis检验,用于比较多组独立样本的中位数是否有显著差异。
在R语言中,可以使用kruskal.test()函数进行计算,通过将多组数据传入函数中进行比较,得出检验的结果和统计量。
另外,对于非参数统计中的秩相关检验,如Spearman秩相关系数检验和Kendall秩相关系数检验,也可以在R语言中进行计算。
通过使用cor.test()函数,可以计算两组数据的秩相关系数并进行假设检验,得出相关性的显著性。
除此之外,R语言中还提供了一些其他非参数统计方法的实现,如符号检验、秩和检验、秩秩相关检验等。
这些方法的应用可以帮助研究人员在数据分析中更全面地考虑数据的性质和假设,从而得出更可靠的统计结论。
总的来说,非参数统计方法在R语言中的应用丰富多样,可以满足不同数据分析的需求,帮助研究人员更好地理解数据的特征和结构,为科学研究和决策提供支持。
通过掌握R语言中的非参数统计方法,可以更好地应对实际数据分析中的挑战,为数据科学的发展和应用做出贡献。
r语言多组数据非参数检验-回复标题:使用R语言进行多组数据的非参数检验在统计分析中,非参数检验是一种重要的工具,它不需要对数据分布做出任何假设。
在R语言中,我们可以方便地进行多组数据的非参数检验。
以下是一步一步的详细指导。
一、理解非参数检验非参数检验主要用于比较两组或多组数据的分布是否存在显著差异,而无需对数据的总体分布做出特定的假设。
这使得非参数检验在处理异常值、偏态分布或者样本量较小的数据时具有优势。
二、准备数据在进行非参数检验之前,我们需要先准备好数据。
假设我们有三组数据,分别存储在变量group1, group2, group3中。
Rset.seed(123)group1 <- rnorm(20, mean = 50, sd = 10)group2 <- rnorm(20, mean = 60, sd = 10)group3 <- rnorm(20, mean = 70, sd = 10)这里我们使用了R的随机数生成函数rnorm生成了三组正态分布的数据。
三、Kruskal-Wallis H检验Kruskal-Wallis H检验是一种常用的非参数检验方法,用于比较两组或多组数据的分布是否相同。
在R中,我们可以使用kruskal.test函数来进行Kruskal-Wallis H检验。
Rdata <- c(group1, group2, group3)group <- factor(rep(c("group1", "group2", "group3"), each = length(group1)))kruskal.test(data ~ group)在这个例子中,我们首先将三组数据合并到一个向量data中,然后创建了一个因子group来表示每个数据点所属的组别。
最后,我们使用kruskal.test函数进行了Kruskal-Wallis H检验。
r语言多组数据非参数检验-回复R语言多组数据非参数检验是一种常用的统计分析方法,适用于未满足正态分布假设的情况。
本文将以此为主题,从介绍非参数检验的背景和原理,到详细讲解R语言中多组数据非参数检验的步骤,一步一步回答读者的疑问。
一、非参数检验的背景和原理非参数检验是一种不基于总体分布假设的统计方法,主要用于比较两个或多个组之间的差异。
相比于参数检验,非参数检验更为灵活,适用范围更广。
非参数检验的原理是通过对数据进行排序和秩次变换,来忽略数据分布的形状和特征,只关注于数据的顺序关系,从而进行统计推断。
二、R语言中多组数据非参数检验的步骤在R语言中,进行多组数据的非参数检验可以使用多种函数,下面将一步一步介绍具体的操作步骤。
1. 导入数据首先,需要将数据导入R语言中,并将其存储为矩阵或数据框的形式。
可以使用`read.csv()`或`read.table()`函数将数据从外部文件导入,也可以直接使用`data.frame()`函数手动创建数据框。
2. 定义分组变量根据研究设计,将数据分组。
通常可以使用向量或因子变量的形式定义分组变量,例如:group <- c("A", "A", "A", "B", "B", "B")。
3. 进行非参数检验R语言中有多个函数可以进行非参数检验,根据研究目的和数据类型的不同,选择合适的函数。
常用的函数有:- wilcox.test(): 用于比较两个独立样本之间的差异,返回Wilcoxon秩和检验的结果。
- kruskal.test(): 用于比较多个独立样本之间的差异,返回Kruskal-Wallis 检验的结果。
- friedman.test(): 用于比较多个相关样本之间的差异,返回Friedman 秩和检验的结果。
这些函数都有相似的参数,包括x(数据向量或因子)、y(分组变量)和alternative(备择假设),可以根据需要进行设置。
r语言非参数检验R语言是数据分析领域中最流行的语言之一,它强大的分析能力和开放的社区使其成为许多研究人员的首选。
其中,非参数检验是进行数据分析的一种方法,它在数据不服从正态分布的情况下也可以进行假设检验。
本文将围绕R语言中的非参数检验展开,在介绍什么是非参数检验以及怎样在R语言中使用非参数检验进行假设检验等方面展开阐述。
一、什么是非参数检验?在进行假设检验时,我们通常会利用正态分布等假设情况,但是当数据不服从正态分布时,我们则需要通过非参数方法进行假设检验。
非参数检验是一种没有假设总体分布的统计方法,它允许我们在数据不服从特定分布的情况下进行假设检验,这使得它更加灵活和适应不同分布的数据集。
二、在R语言中使用非参数检验在R语言中,我们经常使用t.test函数进行假设检验。
但是当数据不服从正态分布时,我们就需要使用不同的函数进行假设检验。
R语言中的非参数检验函数包括:1、Wilcox.test()Wilcox.test()函数用于对两组数据进行Wilcox秩和检验,它是检验两个独立样本的中位数是否相等的一种方法。
比如,我们可以使用Wilcox.test()函数来检验两个不同班级的学生在一次考试中的排名。
2、Kruskal.test()Kruskal.test()函数用于对三组及三组以上的数据进行Kruskal–Wallis检验,它适用于比较多组样本的差异。
比如,我们可以使用Kruskal.test()函数来检验不同班级在一次考试中的平均分是否有显著差异。
3、Mann-Whitney.test()Mann-Whitney.test()函数用于对两组数据中的位置数据进行Mann-Whitney检验。
它是非参数的Wilcox等级和检验的简化,比Wilcox.test()函数更加高效。
我们可以使用Mann-Whitney.test()函数来检验两个不同班级的学生在一次考试中的及格率是否有显著差异。
4、Krsmirnov.test()Krsmirnov.test()函数用于对一个或两组数据进行Kolmogorov-Smirnov检验,它是用于检验一个样本是否与一个理论分布一致的一种方法。
用R语言做回归分析标题:利用R语言进行回归分析,从数据准备到模型评估引言:回归分析是统计学中常用的一种方法,用于探索多个自变量与一个因变量之间的关系。
R语言是一种强大的统计分析工具,其中的回归分析函数可以帮助我们进行数据探索和建模。
本文将介绍如何使用R语言进行回归分析,从数据准备到模型评估,帮助读者更好地理解和应用回归分析方法。
一、数据准备回归分析的第一步是准备数据。
我们假设有一个数据集包含了多个自变量(如年龄、性别、教育水平等)和一个连续的因变量(如收入)。
在R语言中,我们可以使用read.csv(函数导入数据集,并使用head(函数查看数据的前几行,以了解数据的结构。
代码示例:data <- read.csv("data.csv")head(data)二、数据探索在进行回归分析之前,我们需要对数据进行探索,了解自变量与因变量之间的关系以及数据的分布情况。
在R语言中,可以使用summary(函数查看数据的统计摘要信息,使用cor(函数计算变量之间的相关系数矩阵,并使用scatterplotMatrix(函数绘制散点图矩阵。
代码示例:summary(data)cor(data)scatterplotMatrix(data)三、模型建立在完成数据的探索后,我们可以开始建立回归模型。
R语言中有多个函数可以进行回归分析,例如lm(函数用于建立线性回归模型,glm(函数用于建立广义线性模型等。
我们需要选择合适的模型,并根据自变量与因变量之间的关系来建立模型。
代码示例:summary(model)四、模型评估模型建立后,我们需要对模型进行评估,以确定其拟合效果和预测能力。
在R语言中,可以使用summary(函数查看模型的统计指标,例如R-squared、F-statistic和p-value等。
我们还可以使用plot(函数绘制模型的残差图,以判断模型是否满足回归分析的假设。
代码示例:summary(model)plot(model, which=1)五、模型改进在评估模型后,如果发现模型的拟合效果不理想,我们可以尝试改进模型。
由詹鹏整理,仅供交流和学习根据南京财经大学统计系孙瑞博副教授的课件修改,在此感谢孙老师的辛勤付出!教材为:Luke Keele: Semiparametric Regression for the Social Sciences. John Wiley & Sons, Ltd. 2008.-------------------------------------------------------------------------第一章introduction: Global versus Local Statistic一、主要参考书目及说明1、Hardle(1994). Applied Nonparametic Regresstion. 较早的经典书2、Hardle etc (2004). Nonparametric and semiparametric models: an introduction. Springer. 结构清晰3、Li and Racine(2007). Nonparametric econometrics: Theory and Practice. Princeton. 较全面和深入的介绍,偏难4、Pagan and Ullah (1999). Nonparametric Econometrics. 经典5、Yatchew(2003). Semiparametric Regression for the Applied Econometrician. 例子不错6、高铁梅(2009). 计量经济分析方法与建模:EVIEWS应用及实例(第二版). 清华大学出版社. (P127/143)7、李雪松(2008). 高级计量经济学. 中国社会科学出版社. (P45 ch3)8、陈强(2010). 高级计量经济学及Stata应用. 高教出版社. (ch23/24)【其他参看原ppt第一章】二、内容简介方法:——移动平均(moving average)——核光滑(Kernel smoothing)——K近邻光滑(K-NN)——局部多项式回归(Local Polynormal)——Loesss and Lowess——样条光滑(Smoothing Spline)——B-spline——Friedman Supersmoother模型:——非参数密度估计——非参数回归模型——非参数回归模型——时间序列的半参数模型——Panel data 的半参数模型——Quantile Regression三、不同的模型形式1、线性模型linear models2、Nonlinear in variables3、Nonlinear in parameters四、数据转换Power transformation(对参数方法)In the GLM framework, models are equally prone(倾向于) to some misspecification(不规范)from an incorrect functional form.It would be prudent(谨慎的)to test that the effect of any independent variable of a model does not have a nonlinear effect. If it does have a nonlinear effect, analysts in the social science usually rely on Power Transformations to address nonlinearity.[ADD: 检验方法见Sanford Weisberg. Applied Linear Regression (Third Edition). A John Wiley & Sons, Inc., Publication.(本科的应用回归分析课教材)]----------------------------------------------------------------------------第二章 Nonparametric Density Estimation非参数密度估计一、三种方法1、直方图Hiatogram2、Kernel density estimate3、K nearest-neighbors estimate二、Histogram 对直方图的一个数值解释Suppose x1,…xN – f(x), the density function f(x) is unknown.One can use the following function to estimate f(x)【与x的距离小于h的所有点的个数】三、Kernel density estimateBandwidth: h; Window width: 2h.1、Kernel function的条件The kernel function K(.) is a continuous function, symmetric(对称的) around zero, that integrates(积分) to unity and satisfies additional bounded conditions:(1) K() is symmetric around 0 and is continuous;(2) ,,;(3) Either(a) K(z)=0 if |z|>=z0 for z0Or(b) |z|K(z) à0 as ;(4) , where is a constant.2、主要函数形式3、置信区间其中,4、窗宽的选择实际应用中,。
其中,s是样本标准差,iqr是样本分位数级差(interquartile range)四、K nearest-neighbors estimate五、R语言部分lines(den5,lty=1,col="blue")----------------------------------------------------------------------------第三章 smoothing and local regression一、简单光滑估计法 Simple Smoothing1、Local Averaging 局部均值按照x排序,将样本分成若干部分(intervals or “bins”);将每部分x对应的y值的均值作为f(x)的估计。
三种不同方法:(1)相同的宽度(equal width bins):uniformly distributed.(2)相同的观察值个数(equal no. of observations bins):k-nearest neighbor.(3)移动平均(moving average)K-NN:等窗宽:2、kernel smoothing 核光滑其中,二、局部多项式估计Local Polynomial Regression1、主要结构局部多项式估计是核光滑的扩展,也是基于局部加权均值构造。
——local constant regression——local linear regression——lowess (Cleveland, 1979)——loess (Cleveland, 1988)【本部分可参考:Takezana(2006). Introduction to Nonparametric Regression.(P185 3.7 and P195 3.9) Chambers and Hastie(1993). Statistical models in S. (P312 ch8)】2、方法思路(1)对于每个xi,以该点为中心,按照预定宽度构造一个区间;(2)在每个结点区域内,采用加权最小二乘法(WLS)估计其参数,并用得到的模型估计该结点对应的x值对应y值,作为y|xi的估计值(只要这一个点的估计值);(3)估计下一个点xj;(4)将每个y|xi的估计值连接起来。
【R操作library(KernSmooth) #函数locpoly()library(locpol) #locpol(); locCteSmootherC()library(locfit) #locfit()#weight funciton: kernel=”tcub”. And “rect”, “trwt”, “tria”, “epan”, “bisq”, “gauss”】3、每个方法对应的估计形式(1)变量个数p=0, local constant regression (kernel smoothing)min(2)变量个数p=1, local linear regressionmin(3)Lowess (Local Weighted scatterplot smoothing)p=1:min【还有个加权修正的过程,这里略,详见原书或者PPT】(4)Loess (Local regression)p=1,2:min【还有个加权修正的过程,这里略,详见原书或者PPT】(5)Friedman supersmoothersymmetric k-NN, using local linear fit,varying span, which is determined by local CV,not robust to outliers, fast to computesupsmu( ) in R三、模型选择需要选择的内容:(1)窗宽the span;(2)多项式的度the degree of polynomial for the local regression models;(3)权重函数the weight functions。
【其他略】四、R语言部分----------------------------------------------------------------------------第四章样条估计spline一、基本思想按照x将样本分成多个区间,对每个区间分别进行估计。
不同于核估计,这里不用移动计算,从而减小了计算量。
二、最简单的形式Linear Spline with k knots:其中,,三、其他样条模型1、p次样条估计——二次样条Quadratic Spline (basis functions with k knots)——三次样条Cubic Spline (with k knots, use quadratic basis functions)——p-order spline (with k knots)2、B-splines (with k knots cubic B-spline basis)其中,3、Natural Splines以上估计方法对结点(knots)之间的估计比较准确,但对边界的拟合效果较差。