我的libsvm文档java 文档
- 格式:doc
- 大小:448.50 KB
- 文档页数:23

L i b S V M分类的实用指南LibSVM分类的实用指南摘要SVM(support vector machine)是一项流行的分类技术。
然而,初学者由于不熟悉SVM,常常得不到满意的结果,原因在于丢失了一些简单但是非常必要的步骤。
在这篇文档中,我们给出了一个简单的操作流程,得到合理的结果。
(译者注:本文中大部分SVM实际指的是LibSVM)1入门知识SVM是一项非常实用的数据分类技术。
虽然SVM比起神经网络(Neural Networks)要相对容易一些,但对于不熟悉该方法的用户而言,开始阶段通常很难得到满意的结果。
这里,我们给出了一份指南,根据它可以得到合理结果。
需要注意,此指南不适用SVM的研究者,并且也不保证一定能够获得最高精度结果。
同时,我们也没有打算要解决有挑战性的或者非常复杂的问题。
我们的目的,仅在于给初学者提供快速获得可接受结果的秘诀。
虽然用户不是一定要深入理解SVM背后的理论,但为了后文解释操作过程,我们还是先给出必要的基础的介绍。
一项分类任务通常将数据划分成训练集和测试集。
训练集的每个实例,包含一个"目标值(target value)"(例如,分类标注)和一些"属性(attribute)"(例如,特征或者观测变量)。
SVM的目标是基于训练数据产出一个模型(model),用来预测只给出属性的测试数据的目标值。
给定一个训练集,"实例-标注"对,,支持向量机需要解决如下的优化问题:在这里,训练向量xi通过函数Φ被映射到一个更高维(甚至有可能无穷维)空间。
SVM在这个高维空间里寻找一个线性的最大间隔的超平面。
C 0是分错项的惩罚因子(penalty parameter of the error term)。
被称之为核函数(kernel function)。
新的核函数还在研究中,初学者可以在SVM书中找到如下四个最基本的核函数:(线性、多项式、径向基函数、S型)1.1实例表1是一些现实生活中的实例。

Matlab下libsvm的配置使⽤【转】LIBSVM是⼀个由台湾⼤学林智仁(Lin Chih-Jen)教授等开发的SVM模式识别与回归的软件包,使⽤简单,功能强⼤,能够在matlab中使⽤。
⼀、安装1.下载在LIBSVM的主页上下载最新版本的软件包(libsvm-3.20),并解压到合适⽬录中。
2.编译如果你使⽤的是64位的操作的系统和Matlab,那么不需要进⾏编译步骤,因为⾃带软件包中已经包含有64位编译好的版本:libsvmread.mexw64、libsvmwrite.mexw64、svmtrain.mexw64、svmpredict.mexw64。
否则,需要⾃⼰编译⼆进制⽂件。
⾸先在matlab中进⼊LIBSVM根⽬录下的matlab⽬录(如C:\libsvm-3.20\matlab),在命令窗⼝输⼊>>mex -setup然后Matlab会提⽰你选择编译mex⽂件的C/C++编译器,就选择⼀个已安装的编译器。
之后Matlab会提⽰确认选择的编译器,输⼊y进⾏确认。
然后可以输⼊以下命令进⾏编译。
>>make注意,Matlab或VC版本过低可能会导致编译失败,建议使⽤最新的版本。
编译成功后,当前⽬录下会出现若⼲个后缀为mexw64(64位系统)或mexw32(32位系统)的⽂件。
3.重命名(可选,但建议执⾏)编译完成后,在当前⽬录下回出现svmtrain.mexw64、svmpredict.mexw64(64位系统)或者svmtrain.mexw32、svmpredict.mexw32(32位系统)这两个⽂件,把⽂件名svmtrain和svmpredict相应改成libsvmtrain和libsvmpredict。
这是因为Matlab中⾃带有SVM的⼯具箱,⽽且其函数名字就是svmtrain和svmpredict,和LIBSVM默认的名字⼀样,在实际使⽤的时候有时会产⽣⼀定的问题,⽐如想调⽤LIBSVM的变成了调⽤Matlab SVM。

libsvm参数说明【原创实用版】目录1.LIBSVM 简介2.LIBSVM 参数说明3.LIBSVM 的使用方法4.LIBSVM 的应用场景5.总结正文1.LIBSVM 简介LIBSVM(Library for Support Vector Machines)是一个开源的支持向量机(SVM)算法库,它提供了一系列用于解决分类和回归问题的高效算法。
LIBSVM 由 Chenning Peng 和 Tsung-Yuan Lee 开发,是 SVM 领域最为知名和广泛使用的工具之一。
2.LIBSVM 参数说明LIBSVM 包含了许多参数,这些参数可以影响模型的性能。
以下是一些重要的 LIBSVM 参数及其说明:- "kernel": 指定核函数类型,如"linear"(线性核)、"rbf"(高斯径向基函数核)等。
- "C": 指定惩罚参数 C,用于控制模型对训练数据的拟合程度。
较小的 C 值会导致更宽松的边界,可能允许一些误分类,但可以提高模型的泛化能力。
较大的 C 值则会强制模型在训练集上尽量减少误差,可能导致过拟合。
- "degree": 指定多项式核函数的阶数。
- "gamma": 指定高斯核函数的参数,用于控制核函数的形状。
- "coef0": 指定拉格朗日乘子 alpha 的初始值。
- " CacheSize": 指定 LIBSVM 使用的内存缓存大小。
3.LIBSVM 的使用方法使用 LIBSVM 主要包括以下步骤:(1)数据预处理:将数据集分为特征矩阵 X 和目标向量 y。
(2)训练模型:调用 LIBSVM 的 train 函数,传入预处理后的数据和参数设置,训练 SVM 模型。
(3)预测:使用训练好的模型,调用 LIBSVM 的 predict 函数,对新的数据进行分类预测。

libsvm默认参数摘要:1.引言2.libsvm 的概述3.libsvm 的默认参数4.如何设置libsvm 的默认参数5.结论正文:1.引言支持向量机(Support Vector Machine,SVM)是一种非常强大和灵活的监督学习算法,可以应用于各种问题,包括分类和回归。
在SVM 中,libsvm 是一个非常受欢迎的开源软件库,提供了丰富的功能和良好的性能。
然而,对于初学者来说,libsvm 的默认参数可能会让人感到困惑。
在本文中,我们将介绍libsvm 的默认参数,以及如何设置它们。
2.libsvm 的概述libsvm 是一个开源的机器学习库,它提供了支持向量机(SVM)的实现。
libsvm 包含了许多功能,如分类、回归、多任务学习等。
它还有一个易于使用的命令行界面,用户可以通过命令行界面来训练模型、进行预测等。
3.libsvm 的默认参数libsvm 中的默认参数是在其内部算法中使用的参数。
这些参数对于初学者来说可能不太容易理解,但它们对于获得良好的性能非常重要。
libsvm 中的默认参数包括以下内容:- C:C 是一个超参数,用于控制模型的复杂度。
较小的C 值会导致更简单的模型,而较大的C 值会导致更复杂的模型。
- kernel:核函数是用于将输入数据投影到高维空间的函数。
libsvm 中的默认核函数是线性核。
- degree:度数是用于指定多项式核函数的阶数。
- gamma:gamma 是一个超参数,用于控制核函数的形状。
- coef0:coef0 是一个超参数,用于控制多项式核函数中的独立项。
4.如何设置libsvm 的默认参数用户可以通过修改libsvm 的配置文件或者在命令行中设置参数来修改默认参数。
以下是一些常见的参数设置方法:- 使用配置文件:用户可以在libsvm 的安装目录下找到config.txt 文件,该文件包含了所有可用的参数及其默认值。
用户可以编辑该文件,以设置所需的参数。

LIBSVM1 LIBSVM简介LIBSVM是台湾大学林智仁(Lin Chih-Jen)副教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows 系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件还有一个特点,就是对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数就可以解决很多问题;并且提供了交互检验(Cross -SVM回归等问题,包括基于一对一算法的多类模式识别问题。
SVM用于模式识别或回归时,SVM方法及其参数、核函数及其参数的选择,目前国际上还没有形成一个统一的模式,也就是说最优SVM算法参数选择还只能是凭借经验、实验对比、大范围的搜寻或者利用软件包提供的交互检验功能进行寻优。
ν-SVM回归和ε-SVM分类、νValidation)的功能。
该软件包可以在.tw/~cjlin/免费获得。
该软件可以解决C-SVM分类、-SVM回归等问题,包括基于一对一算法的多类模式识别问题。
SVM用于模式识别或回归时,SVM方法及其参数、核函数及其参数的选择,目前国际上还没有形成一个统一的模式,也就是说最优SVM算法参数选择还只能是凭借经验、实验对比、大范围的搜寻或者利用软件包提供的交互检验功能进行寻优。
2 LIBSVM使用方法LibSVM是以源代码和可执行文件两种方式给出的。
如果是Windows系列操作系统,可以直接使用软件包提供的程序,也可以进行修改编译;如果是Unix类系统,必须自己编译,软件包中提供了编译格式文件,我们在SGI工作站(操作系统IRIX6.5)上,使用免费编译器GNU C++3.3编译通过。
2.1 LIBSVM 使用的一般步骤:1) 按照LIBSVM软件包所要求的格式准备数据集;2) 对数据进行简单的缩放操作;3) 考虑选用RBF 核函数;4) 采用交叉验证选择最佳参数C与g;5) 采用最佳参数C与g 对整个训练集进行训练获取支持向量机模型;6) 利用获取的模型进行测试与预测。

LibSvm 使用说明学习心得(本页内容来自互联网,如果对您的利益造成侵害,请通知我,我会立即删除!)View this tutorial in: English Only TraditionalChinese Only Both (Default) (req. JavaScript if you want to switch languages)Core StyleSheets: Chocolate Midnight Modernist Oldstyle Steely Swiss Traditional Ultramarine* This document is written in multilingual format. We strongly suggest that you choose your language first to get a better display.piaip's Using (lib)SVM Tutorial piaip 的 (lib)SVM 简易入门piaip at csie dot ntu dot edu dot tw,Hung-Te LinFri Apr 18 15:04:53 CST 2003$Id: svm_tutorial.html,v 1.12 2005/10/26 06:12:40 piaip Exp piaip $ 原作:林弘德,转载请保留原出处Why this tutorial is here我一直觉得 SVM 是个很有趣的东西,不过也一直没办法 (mostly 冲堂 ) 去听林智仁老师的 Data mining 跟 SVM 的课;后来看了一些网络上的文件跟听 kcwu 讲了一下libsvm的用法后,就想整理一下,算是对于并不需要知道完整 SVM 理论的人提供使用libsvm 的入门。
原始 libsvm 的 README 跟 FAQ 也是很好的文件,不过你可能要先对 svm 跟流程有点了解才看得懂 ( 我在看时有这样的感觉 ) ;这篇入门就是为了从零开始的人而写的。

SVM模式识别与回归软件包(LibSVM)详解SVM模式识别与回归软件包――LibSVMSVM用于模式识别或回归时,SVM方法及其参数、核函数及其参数的选择,目前国际上还没有形成一个统一的模式,也就是说最优SVM算法参数选择还只能是凭借经验、实验对比、大范围的搜寻或者利用软件包提供的交互检验功能进行寻优。
目前,LIBSVM拥有Java、Matlab、C#、Ruby、Python、R、Perl、Common LISP、LabView等数十种语言版本。
最常使用的是Matlab、Java和命令行的版本。
2:处理数据,把数据制作成LIBSVM的格式,其每行格式为: label index1:value1 index2:value2 ...其中我用了复旦的分类语料库,当然我先做了分词,去停用词,归一化等处理了 3:使用svm-train.exe训练,得到****.model文件。
里面有支持向量,gamma值等信息 4:使用svm-predict.exe做测试这里有几个问题现在必须说明:1:有关数据格式, index1:value1 index2:value2 ...这里面的index1,index2必须是有序的。
我测试了好多次才发现了这个问题,因为我原来做实验的数据室不必有序的。
2:有关python语言,python有些版本不同导致一些语法也是有差异的,建议使用低版本的,如2.6,比如2.6和3.*版本的有关print的规定是有差别的。
这几个.exe文件里面很多参数可以调的,我暂时是想学习下所以都只用了默认值了。
现在做好标记,以后要真做实验用他可以随时用上!2.准备好数据,首先要把数据转换成Libsvm软件包要求的数据格式为: labelindex1:value1 index2:value2 ...其中对于分类来说label为类标识,指定数据的种类;对于回归来说label为目标值。
(我主要要用到回归)Index是从1开始的自然数,value是每一维的特征值。

LIBSVM使用方法1libsvm简介2libsvm使用方法libsvm就是以源代码和可执行文件两种方式得出的。
如果就是windows系列操作系统,可以轻易采用软件包提供更多的程序,也可以展开修正编程;如果就是unix类系统,必须自己编程,软件包中提供更多了编程格式文件,我们在sgi工作站(操作系统irix6.5)上,采用免费编译器gnuc++3.3编程通过。
2.1libsvm使用的一般步骤:1)2)3)4)5)6)按照libsvm软件包所建议的格式准备工作数据集;对数据展开直观的翻转操作方式;考量采用rbf核函数;使用交叉检验挑选最佳参数c与g;使用最佳参数c与g对整个训练集展开训练以获取积极支持向量机模型;利用以获取的模型展开测试与预测。
2.2libsvm使用的数据格式该软件采用的训练数据和检验数据文件格式如下:::...其中就是训练数据集的目标值,对于分类,它就是标识某类的整数(积极支持多个类);对于重回,就是任一实数。
就是以1已经开始的整数,可以就是不已连续的;为实数,也就是我们常说道的自变量。
检验数据文件中的label只用作排序准确度或误差,如果它就是未明的,只需用一个数核对这一栏,也可以空着不填上。
在程序包中,还包括存有一个训练数据实例:heart_scale,便利参照数据文件格式以及练采用软件。
可以撰写大程序,将自己常用的数据格式转换成这种格式。
2.3svmtrain和svmpredict的用法svmtrain(训练建模)的用法:svmtrain[options]training_set_file[model_file]options:需用的选项即为则表示的涵义如下-ssvm类型:svm设置类型(默认0)0--c-svc1--v-svc2–一类svm3--e-svr4--v-svr-t核函数类型:核函数设置类型(默认2)0–线性:u'v1–多项式:(r*u'v+coef0)^degree2–rbf函数:exp(-r|u-v|^2)3–sigmoid:tanh(r*u'v+coef0)-ddegree:核函数中的degree设置(预设3)-gr(gama):核函数中的?函数设置(默认1/k)-rcoef0:核函数中的coef0设置(预设0)-ccost:设置c-svc,?-svr和?-svr的参数(默认1)-nnu:设置?-svc,一类svm和?-svr的参数(预设0.5)-pe:设置?-svr中损失函数?的值(默认0.1)-mcachesize:设置cache内存大小,以mb为单位(预设40)-eε:设置允许的终止判据(默认0.001)-hshrinking:与否采用启发式,0或1(预设1)-wiweight:设置第几类的参数c为weight?c(c-svc中的c)(默认1)-vn:n-fold可视化检验模式其中-g选项中的k是指输入数据中的属性数。
libSVM的使用文档11. 程序介绍和环境设置windows下的libsvm是在命令行运行的Console Program。
所以其运行都是在windows的命令行提示符窗口运行(运行,输入cmd)。
运行主要用到的程序,由如下内容组成:libsvm-2.9/windows/文件夹中的:svm-train.exesvm-predict.exesvm-scale.exelibsvm-2.9/windows/文件夹中的:checkdata.pysubset.pyeasy.pygrid.py另外有:svm-toy.exe,我暂时知道的是用于演示svm分类。
其中的load按钮的功能,是否能直接载入数据并进行分类还不清楚,尝试没有成功;python文件夹及其中的svmc.pyd,暂时不清楚功能。
因为程序运行要用到python脚本用来寻找参数,使用gnuplot来绘制图形。
所以,需要安装python和Gnuplot。
(Python v3.1 Final可从此下载:/detail/33/320958.shtml)(gnuplot可从其官网下载:)为了方便,将gnuplot的bin、libsvm-2.9/windows/加入到系统的path中,如下:gnuplot.JPGlibsvm.JPG这样,可以方便的从命令行的任何位置调用gnuplot和libsvm的可执行程序,如下调用svm-train.exe:pathtest.JPG出现svm-train程序中的帮助提示,说明path配置成功。
至此,libsvm运行的环境配置完成。
下面将通过实例讲解如何使用libsvm进行分类。
2. 使用libsvm进行分类预测我们所使用的数据为UCI的iris数据集,将其类别标识换为1、2、3。
然后,取3/5作为训练样本,2/5作为测试样本。
使用论坛中“将UCI数据转变为LIBSVM使用数据格式的程序”一文将其转换为libsvm所用格式,如下:训练文件tra_iris.txt1 1:5.4 2:3.4 3:1.7 4:0.21 1:5.1 2:3.7 3:1.5 4:0.41 1:4.6 2:3.6 3:1 4:0.21 1:5.1 2:3.3 3:1.7 4:0.51 1:4.8 2:3.4 3:1.9 4:0.2……2 1:5.9 2:3.2 3:4.8 4:1.82 1:6.1 2:2.8 3:4 4:1.32 1:6.3 2:2.5 3:4.9 4:1.52 1:6.1 2:2.8 3:4.7 4:1.22 1:6.4 2:2.9 3:4.3 4:1.3……3 1:6.9 2:3.2 3:5.7 4:2.33 1:5.6 2:2.8 3:4.9 4:23 1:7.7 2:2.8 3:6.7 4:23 1:6.3 2:2.7 3:4.9 4:1.83 1:6.7 2:3.3 3:5.7 4:2.13 1:7.2 2:3.2 3:6 4:1.8……测试文件tes_iris.txt1 1:5.1 2:3.5 3:1.4 4:0.21 1:4.9 2:3 3:1.4 4:0.21 1:4.7 2:3.2 3:1.3 4:0.21 1:4.6 2:3.1 3:1.5 4:0.21 1:5 2:3.6 3:1.4 4:0.21 1:5.4 2:3.9 3:1.7 4:0.4……2 1:7 2:3.2 3:4.7 4:1.42 1:6.4 2:3.2 3:4.5 4:1.52 1:6.9 2:3.1 3:4.9 4:1.52 1:5.5 2:2.3 3:4 4:1.32 1:6.5 2:2.8 3:4.6 4:1.5……3 1:6.3 2:3.3 3:6 4:2.53 1:5.8 2:2.7 3:5.1 4:1.93 1:7.1 2:3 3:5.9 4:2.13 1:6.3 2:2.9 3:5.6 4:1.83 1:6.5 2:3 3:5.8 4:2.2……libsvm的参数选择一直是令人头痛的问题。

(1)第一次玩博客,导致费了不少时间,尤其是贴图片时候,老是显示不出来,好几遍,才能完整显示图片,而且色彩失真,实在是out了!下面直接进入主题了,请看第一篇。
申明一点,libsvm涉及到的数据格式以及处理,本人认为太简单,且google一下,到处都是,故在本人博客中略,实在需要的话,说一声,我详细写上,并附上数据转化格式。
系统是xp win32位的;如何知道自己的系统是32还是64位,不要再说吧,相信大家都会,略吧1.准备阶段:Python26;libsvm2.9;gp44rc1win32;以上三个软件均安装或者解压缩在c:\目录下,即c:\Python;c:libsvm\;c:\gnuplot。
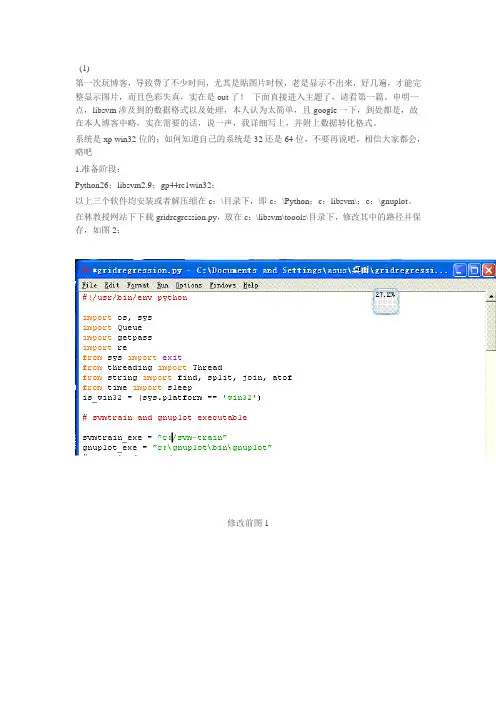
在林教授网站下下载gridregression.py,放在c:\libsvm\toools\目录下,修改其中的路径并保存,如图2:修改前图1修改后图2同样修改c:\libsvm\toools\中的grid和easy文件,并保存,修改后的结果如图3、4,此二个文件为分类时用。
图3图4图52.应用部分如果是想在分类方面应用,则,在c:\python目录下,运行图5中命令,结果如图6、7 下图为gnuplot结果。
图6图7如果采用grid命令,按图8操作,结果如图9,10;图8图9图10(2)从图9中,可知,c和g值分别为:0.03125,0.0078125,将这两个参数代入到svm-train中进行训练和预测,如图11-12所示图11图12 最后文件夹中多了一个model文件,图13所示:图13最后进行预测,如图14-16所示:图14图15图16从图15结果可知,预测精度为0,说明结果相当差,这是因为我胡乱应用几个不相关的数据进行的结果,实际上纯粹是搞的玩的,但是我的心情还是非常高兴的,因为我已经搞定了如何应用libsvm,这里只是给各位朋友介绍如何应用libsvm,呵呵。
到此,分类应用操作完毕,接下来介绍如何回归。
LIBSVM常见问题最后编辑时间:周日,2011年3月13日十三时30分52秒GMTOriginal Text:Q: How to handle the name conflict between svmtrain in the libsvm matlab interface and thatin MATLAB bioinformatics toolbox?显示其他翻译∙所有的问题(74)∙∙∙∙∙∙∙∙∙o有些课程已作为一种工具libsvm的o使用libsvm的一些应用程序/工具o libsvm的文件在哪里可以找到?o更改日志和早期版本在哪里?o如何举LIBSVM?o我想用我的软件libsvm的。
没有任何许可证的问题吗?o是否有一个额外的工具库libsvm的基础吗?o UNIX机器上,我得到了“共享库加载错误”或“无法打开共享对象文件。
”发生了什么事?o我已经修改了源和想建立的图形界面“SVM玩具”MSWindows上。
我应该怎样做呢?o我是一个MS Windows用户,但为什么只有这些预编译的。
exe(SVM玩具),实际运行?o有什么区别“。
”和“*”outputed在训练吗?o为什么偶尔崩溃的程序(包括MATLAB或其他接口),并给出一个分割故障?o如何建立一个动态库(。
dll文件)MS Windows上吗?o在某些系统上(例如,Ubuntu的),编译LIBSVM提供了很多的警告信息。
这是一个问题,如何禁用警告消息?o为什么有时不是所有的数据的属性出现在训练/模型文件?o如果我的数据都是非数值?o你为什么考虑稀疏的格式?将培训密集的数据要慢得多?o为什么有时我的数据的最后一行不读SVM的火车?o有一个程序来检查,如果我的数据是正确的格式吗?o我可以把数据文件的意见?o如何转换其他数据格式LIBSVM格式?o培训的C-SVM的输出类似于以下。
他们是什么意思?o你能解释模型文件?o我应该使用float或double存储在缓存中的数字?o我该如何选择内核呢?o libsvm的线性SVM的特殊待遇吗?o免费支持向量的数量很大。
Libsvm-2.5程序代码注释[1]Chih-Chung Chang and Chih-Jen Lin, LIBSVM : a library for support vector machines, 2001. Software available at .tw/~cjlin/libsvm[2]J. Platt. Fast training of support vector machines using sequential minimaloptimization. In B. Scholkopf, C. Burges, and A. Smola, editors, Advances inkernel methods: support vector learning. MIT Press, 1998.[3] Sequential Minimal Optimization for SVM/people/xge/svm/smo.pdf[4]Chang, C.-C. and C.-J. Lin (2001). Training ν_-support vector classifiers: Theory and algorithms. Neural Computation 13 (9), 2119–2147.[5]Chang, C.-C. and C.-J. Lin (2002). Training ν_support vector regression: Theory and algorithms. Neural Computation 14 (8), 1959–1977.第一节: SVM.h 文件struct svm_node { int index ; double value ;};struct svm_node 用来存储单一向量中的单个特征,例如: 向量 x1={ 0.002, 0.345, 4, 5.677};那么用struct svm_node 来存储时就使用一个包含5个svm_node 的数组来存储此4维向量,内存映象如下:1 2 3 4 -1 0.002 0.345 4.0005.677空其中如果value 为0.00,该特征将不会被存储,其中(特征3)被跳过:1 2 4 5 -1 0.002 0.345 4.0005.677空0.00不保留的好处在于,做点乘的时候,可以加快计算速度,对于稀疏矩阵,更能充分体现这种数据结构的优势。
libsvm参数说明摘要:一、libsvm 简介1.libsvm 的作用2.libsvm 的安装和使用二、libsvm 参数说明1.核函数选择2.C 参数调整3.罚参数选择4.迭代次数选择5.其他参数三、libsvm 参数调整策略1.交叉验证2.网格搜索3.启发式方法四、libsvm 在实际应用中的案例分析1.情感分析2.文本分类3.图像分类正文:一、libsvm 简介libsvm 是一款常用的支持向量机(SVM)开源实现库,它提供了C、Python、Java 等语言的接口,方便用户在不同平台上进行使用。
libsvm 具有较高的效率和准确性,被广泛应用于数据挖掘、机器学习、模式识别等领域。
1.libsvm 的作用libsvm 主要作用是实现支持向量机算法,它可以解决分类和回归问题,包括线性分类和非线性分类。
此外,libsvm 还提供了核函数,使得它可以处理高维数据和复杂数据的分类问题。
2.libsvm 的安装和使用libsvm 的安装过程比较简单,只需要按照官方文档的指导进行操作即可。
安装完成后,可以通过调用libsvm 提供的API 进行模型的训练和预测。
二、libsvm 参数说明libsvm 提供了丰富的参数供用户调整,以达到最佳的效果。
1.核函数选择核函数是libsvm 的重要组成部分,它决定了libsvm 如何处理输入数据。
libsvm 提供了多种核函数,如线性核、多项式核、径向基函数核等。
用户可以根据问题的特点选择合适的核函数。
2.C 参数调整C 参数是libsvm 中的一个重要参数,它控制了模型的软约束程度。
较小的C 值会使得模型更加灵活,可能导致过拟合;较大的C 值会使得模型更加严格,可能导致欠拟合。
因此,合理调整C 参数对于模型的性能至关重要。
3.罚参数选择罚参数是libsvm 中的另一个重要参数,它控制了模型对训练数据的惩罚程度。
较小的罚参数会导致模型对训练数据的拟合程度过高,可能会导致过拟合;较大的罚参数会使得模型对训练数据的拟合程度降低,可能会导致欠拟合。
libsvm参数说明摘要:1.LIBSVM 简介2.LIBSVM 参数说明3.LIBSVM 的使用方法4.LIBSVM 的应用场景5.总结正文:1.LIBSVM 简介LIBSVM 是一个开源的支持向量机(Support Vector Machine,简称SVM)算法库,它可以在各种平台上运行,包括Windows、Linux 和MacOS 等。
LIBSVM 提供了一系列的机器学习算法,如线性SVM、多项式SVM、径向基函数SVM 等,这些算法可以广泛应用于各种数据挖掘和机器学习任务中,如分类、回归和排序等。
2.LIBSVM 参数说明在使用LIBSVM 时,需要对数据进行预处理,主要包括数据格式转换、特征选择和样本划分等。
此外,还需要对SVM 算法的参数进行设置,以优化模型的性能。
LIBSVM 中常用的参数包括:(1)核函数(Kernel):LIBSVM 支持多种核函数,如线性核、多项式核、径向基函数核和Sigmoid 核等。
核函数的选择会影响到模型的复杂度和分类性能。
(2)惩罚参数(C):惩罚参数用于控制模型对训练数据的拟合程度。
较小的C 值会导致模型过于复杂,容易出现过拟合现象;较大的C 值则会使模型过于简单,容易出现欠拟合现象。
(3)度量函数(Metric):LIBSVM 支持多种度量函数,如欧氏距离、汉明距离和马氏距离等。
度量函数的选择会影响到模型的性能。
(4)迭代次数(Max_iter):迭代次数用于控制模型的训练过程,较小的迭代次数会导致模型训练不充分,较大的迭代次数则会使模型训练时间过长。
(5)终止条件(Epsilon):终止条件用于控制模型的训练过程,当模型的误差小于指定的Epsilon 时,训练过程将终止。
3.LIBSVM 的使用方法使用LIBSVM 时,需要先下载并安装LIBSVM 库,然后按照以下步骤进行操作:(1)准备数据集:将数据集转换为LIBSVM 所支持的格式,通常为文本格式或ARFF 格式。
LibSVM(JAVA)二次开发接口调用及源码更改的文档浙江大学协调服务研究所文档整理:陈伟chenweishaoxing#下载libsvm方法:google libsvm找到官网下载:.tw/~cjlin/libsvm/,其中图片中椭圆的解压文档下载下来libsvm工具包有几个版本的,其中python的最经典,用的人比较多,还支持matlab,C++等等。
我们用的java版的,就到解压开的java文件夹中!java文件夹导入到eclipse工程中创建一个java工程,把上图的源码复制到eclipse中,如同所示在工程下创建一个文件夹,里面存放训练测试用的数据首次调用的Demo举例在java的工程中创建一个属于自己的包,然后写一个mian类。
如图ComMain.javapackage com.endual.paper.main;import java.io.IOException;import service.svm_predict;import service.svm_train;public class ComMain {public static void main(String[] args) throws IOException {String []arg ={ "trainfile\\train1.txt", //存放SVM训练模型用的数据的路径"trainfile\\model_r.txt"}; //存放SVM通过训练数据训/ //练出来的模型的路径String []parg={"trainfile\\train2.txt", //这个是存放测试数据"trainfile\\model_r.txt", //调用的是训练以后的模型"trainfile\\out_r.txt"}; //生成的结果的文件的路径System.out.println("........SVM运行开始..........");//创建一个训练对象svm_train t = new svm_train();//创建一个预测或者分类的对象svm_predict p= new svm_predict();t.main(arg); //调用p.main(parg); //调用}}6.运行工程就可以看到了结果了Libsvm二次开发的首先要熟悉调用接口的源码你一定会有疑问:SVM的参数怎么设置,cross-validation怎么用。
那么我们首先来说明一个问题,交叉验证在一般情况下要自己开发自己写。
Libsvm内置了交叉验证,但是如果我希望用同交叉验证的数据用决策树来做,怎么办,显然Libsvm并没有保存交叉验证的数据。
============================================================ 我已经将注释写在了源码中。
Svm_train类的文档说明package service;import libsvm.*;import java.io.*;import java.util.*;public class svm_train {private svm_parameter param; // set by parse_command_lineprivate svm_problem prob; // set by read_problemprivate svm_model model;private String input_file_name; // set by parse_command_lineprivate String model_file_name; // set by parse_command_lineprivate String error_msg;private int cross_validation;private int nr_fold;private static svm_print_interface svm_print_null = new svm_print_interface(){public void print(String s) {}};private static void exit_with_help(){System.out.print("Usage: svm_train [options] training_set_file [model_file]\n"+"options:\n"+"-s svm_type : set type of SVM (default 0)\n"+" 0 -- C-SVC\n"+" 1 -- nu-SVC\n"+" 2 -- one-class SVM\n"+" 3 -- epsilon-SVR\n"+" 4 -- nu-SVR\n"+"-t kernel_type : set type of kernel function (default 2)\n"+" 0 -- linear: u'*v\n"+" 1 -- polynomial: (gamma*u'*v + coef0)^degree\n"+" 2 -- radial basis function: exp(-gamma*|u-v|^2)\n"+" 3 -- sigmoid: tanh(gamma*u'*v + coef0)\n"+" 4 -- precomputed kernel (kernel values in training_set_file)\n"+"-d degree : set degree in kernel function (default 3)\n"+"-g gamma : set gamma in kernel function (default 1/num_features)\n"+"-r coef0 : set coef0 in kernel function (default 0)\n"+"-c cost : set the parameter C of C-SVC, epsilon-SVR, and nu-SVR (default 1)\n"+"-n nu : set the parameter nu of nu-SVC, one-class SVM, and nu-SVR (default 0.5)\n"+"-p epsilon : set the epsilon in loss function of epsilon-SVR (default 0.1)\n"+"-m cachesize : set cache memory size in MB (default 100)\n"+"-e epsilon : set tolerance of termination criterion (default 0.001)\n"+"-h shrinking : whether to use the shrinking heuristics, 0 or 1 (default 1)\n"+"-b probability_estimates : whether to train a SVC or SVR model for probability estimates, 0 or 1 (default 0)\n"+"-wi weight : set the parameter C of class i to weight*C, for C-SVC (default 1)\n"+"-v n : n-fold cross validation mode\n"+"-q : quiet mode (no outputs)\n");System.exit(1);}private void do_cross_validation(){int i;int total_correct = 0;double total_error = 0;double sumv = 0, sumy = 0, sumvv = 0, sumyy = 0, sumvy = 0;double[] target = new double[prob.l];svm.svm_cross_validation(prob,param,nr_fold,target);if(param.svm_type == svm_parameter.EPSILON_SVR ||param.svm_type == svm_parameter.NU_SVR){for(i=0;i<prob.l;i++){double y = prob.y[i];double v = target[i];total_error += (v-y)*(v-y);sumv += v;sumy += y;sumvv += v*v;sumyy += y*y;sumvy += v*y;}System.out.print("Cross Validation Mean squared error = "+total_error/prob.l+"\n");System.out.print("Cross Validation Squared correlation coefficient = "+((prob.l*sumvy-sumv*sumy)*(prob.l*sumvy-sumv*sumy))/((prob.l*sumvv-sumv*sumv)*(prob.l*sumyy-sumy*sumy))+"\n");}else{for(i=0;i<prob.l;i++)if(target[i] == prob.y[i])++total_correct;System.out.print("Cross Validation Accuracy = "+100.0*total_correct/prob.l+"%\n");}}private void run(String argv[]) throws IOException{System.out.println("我的数组的长度是:" + argv.length) ;parse_command_line(argv); //解析svm参数的配置,我们去这个方法看看,你可以按住crlt,然后鼠标点击这个方法read_problem();error_msg = svm.svm_check_parameter(prob,param);if(error_msg != null){System.err.print("ERROR: "+error_msg+"\n");System.exit(1);}if(cross_validation != 0){do_cross_validation();}else{model = svm.svm_train(prob,param);svm.svm_save_model(model_file_name,model);}}public static void main(String argv[]) throws IOException{svm_train t = new svm_train();t.run(argv);}private static double atof(String s){double d = Double.valueOf(s).doubleValue();if (Double.isNaN(d) || Double.isInfinite(d)){System.err.print("NaN or Infinity in input\n");System.exit(1);}return(d);}//解析控制台输入的string类型的值,因为svm的参数是由整数来代表的,//那么通过这个方法将控制台输入的字符串解析成为整数的private static int atoi(String s){return Integer.parseInt(s);}//欢迎来到解析svm参数的方法private void parse_command_line(String argv[]){int i; //设置了一个方法域的一个i变量,用于遍历argv这个字符串数组的的哦svm_print_interface print_func = null; // default printing to stdout,这个是一个接口//创建一个SVM的参数对象,SVM的参数都在这个对象中。