实验三多元线性回归模型和非线性回归模型
【实验目的】
掌握建立多元线性回归模型和非线性回归模型,以及比较、筛选模型的方法。【实验内容】
建立我国国有独立核算工业企业生产函数。
根据生产函数理论,生产函数的基本形式为:(,,,)
Y f t L Kε
=。其中,L、K 分别为生产过程中投入的劳动与资金,时间变量t反映技术进步的影响。表3.1列出了我国1978-1994年期间国有独立核算工业企业的有关统计资料;其中产出Y为工业总产值(可比价),L、K分别为年末职工人数和固定资产净值(可比价)。
表3.1 我国国有独立核算工业企业统计资料
年份时间t 工业总产值
Y(亿元)
职工人数
L(万人)
固定资产
K(亿元)
1978 1 3289.18 3139 2225.70 1979 2 3581.26 3208 2376.34 1980 3 3782.17 3334 2522.81 1981 4 3877.86 3488 2700.90 1982 5 4151.25 3582 2902.19 1983 6 4541.05 3632 3141.76 1984 7 4946.11 3669 3350.95 1985 8 5586.14 3815 3835.79 1986 9 5931.36 3955 4302.25 1987 10 6601.60 4086 4786.05 1988 11 7434.06 4229 5251.90 1989 12 7721.01 4273 5808.71 1990 13 7949.55 4364 6365.79 1991 14 8634.80 4472 7071.35 1992 15 9705.52 4521 7757.25 1993 16 10261.65 4498 8628.77 1994 17 10928.66 4545 9374.34
【实验步骤】
一、建立多元线性回归模型
(一)建立包括时间变量的三元线性回归模型;
在命令窗口依次键入以下命令即可:
⒈建立工作文件:CREATE A 1978 1994
⒉输入统计资料:DATA Y L K
⒊生成时间变量t:GENR T=@TREND(77)
⒋建立回归模型:LS Y C T L K
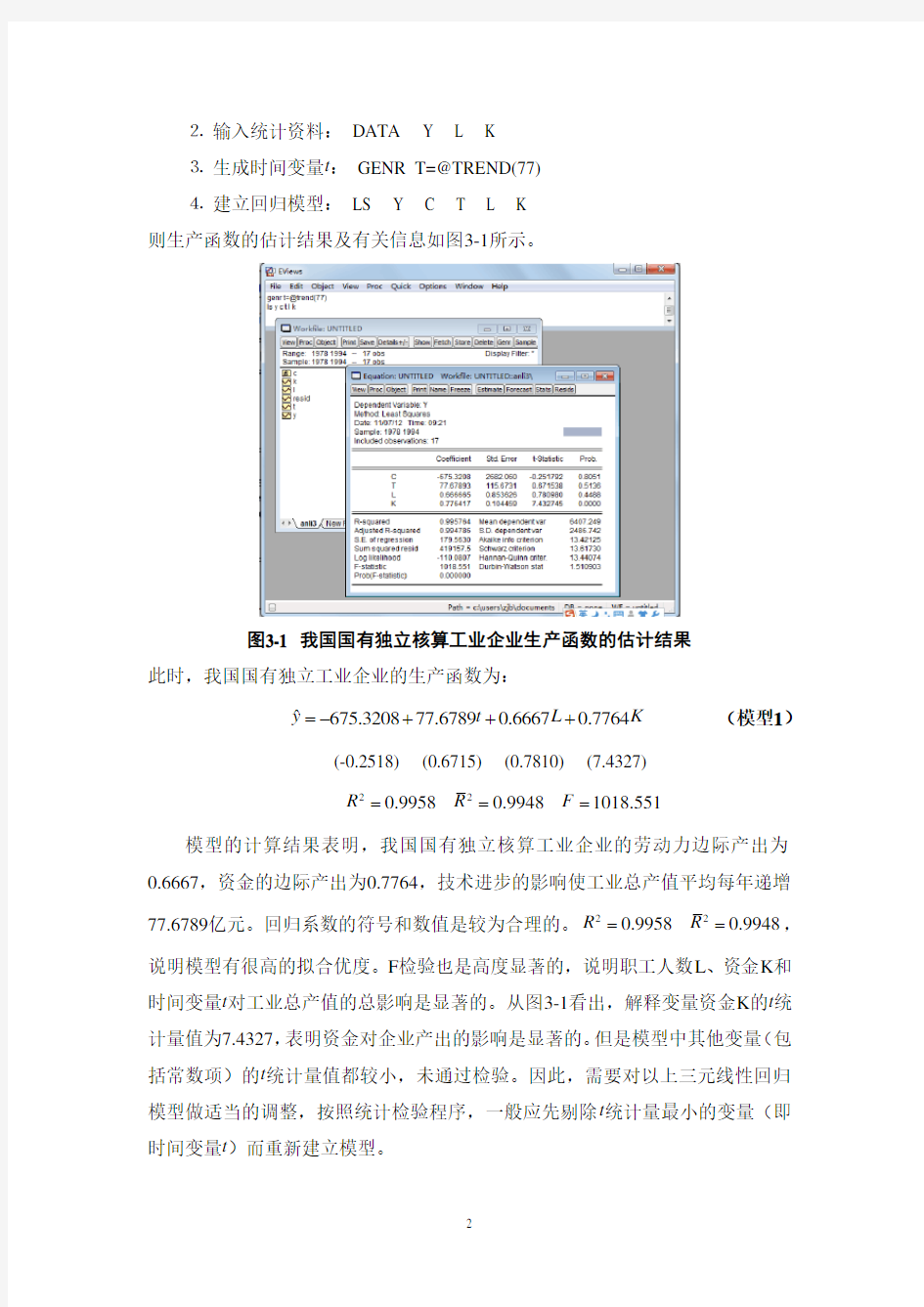
则生产函数的估计结果及有关信息如图3-1所示。
图3-1 我国国有独立核算工业企业生产函数的估计结果
此时,我国国有独立工业企业的生产函数为:
?675.320877.67890.66670.7764
=-+++(模型1)
y t L K
(-0.2518) (0.6715) (0.7810) (7.4327)
22
===
R R F
0.99580.99481018.551
模型的计算结果表明,我国国有独立核算工业企业的劳动力边际产出为0.6667,资金的边际产出为0.7764,技术进步的影响使工业总产值平均每年递增77.6789亿元。回归系数的符号和数值是较为合理的。22
R R
==,
0.99580.9948说明模型有很高的拟合优度。F检验也是高度显著的,说明职工人数L、资金K和时间变量t对工业总产值的总影响是显著的。从图3-1看出,解释变量资金K的t统计量值为7.4327,表明资金对企业产出的影响是显著的。但是模型中其他变量(包括常数项)的t统计量值都较小,未通过检验。因此,需要对以上三元线性回归模型做适当的调整,按照统计检验程序,一般应先剔除t统计量最小的变量(即时间变量t)而重新建立模型。
(二)建立剔除时间变量的二元线性回归模型; 命令:LS Y C L K
则生产函数的估计结果及有关信息如图3-2所示。
图3-2 剔除时间变量后的估计结果
此时,我国国有独立工业企业的生产函数为:
?2387.269 1.2085
0.8345y
L K =-++ (模型2)
(-2.9224) (4.4265) (14.5329) 220.99560.99501589.953R R F ===
从图3-2的结果看出,回归系数的符号和数值也是合理的。劳动力边际产出为1.2085,资金的边际产出为0.8345,表明这段时期劳动力投入的增加对我国国有独立核算工业企业产出的影响较为明显。模型2的拟合优度较模型1并无多大变化,F 检验也是高度显著的。但是,解释变量、常数项的t 检验值都比较大,显著性概率都小于0.05,因此模型2较模型1更为合理。
(三)建立非线性回归模型——C-D 生产函数。
C-D 生产函数为:Y AL K e αβε=,对于此类非线性函数,可以采用以下两种方式建立模型。
方式1:转化成线性模型进行估计; 在模型两端同时取对数,得:
ln ln ln ln y A L K αβε=+++
在EViews 软件的命令窗口中依次键入以下命令: GENR LNY=log (Y ) GENR LNL=log (L ) GENR LNK=log (K ) LS LNY C LNL LNK 则估计结果如图3-3所示。
图3-3线性变换后的C-D 生产函数估计结果
即可得到C-D 生产函数的估计式为:
?l n 1.95130.6045l n
0.6737l n y
L K =-++ (模型3)
(-1.1717) (2.2166) (9.3101)
220.99580.99511641.407R R F ===
即0.60450.6737?0.1424y
L K = 从模型3看出,资本与劳动的产出弹性都是在0到1之间,模型的经济意义合理,而且拟合优度较模型2还略有提高,解释变量都通过了显著性检验。
方式2:迭代估计非线性模型,迭代过程中可以作如下控制: ⑴在工作文件窗口中双击序列C ,输入参数的初始值; ⑵在方程描述框中点击Options ,输入精度控制值。 控制过程:
①参数初值:0,0,0;迭代精度:10-3
;
则生产函数的估计结果如图3-4所示。
图3-4 生产函数估计结果
此时,函数的表达式为:
1.0544
1.
5896.888y L K
-=?? (模型4)
(0.3048) (-2.0633) (8.6058)
220.98340.9811R R ==
可以看出,模型4中劳动力弹性α=-1.0544,资金的产出弹性β=1.0429,很显然模型的经济意义不合理,因此,该模型不能用来描述经济变量间的关系。而且模型的拟合优度也有所下降,解释变量L 在5%的显著性水平下并不显著,所以应舍弃该模型。
②参数初值:0,0,0;迭代精度:10-5
; 则生产函数的估计结果如图3-5所示。
图3-5 生产函数估计结果
此时,生产函数的形式为:
0.61100.
=??(模型5)
0.1450
y L K
(0.5808) (2.2653) (10.4798)
22
==
R R
0.99570.9950
从模型5中看出,迭代414次收敛,资本与劳动的产出弹性都是在0到1之间,模型的经济意义合理,22
==,具有很高的拟合优度,解释变
R R
0.99570.9950
量都通过了显著性检验。将模型5与通过方式1所估计的模型3比较,可见两者是相当接近的。
③参数初值:1,1,1;迭代精度:10-5
图3-6 生产函数估计结果
此时,迭代129次后收敛,估计结果与模型5相同。
比较方式2的不同控制过程可见,迭代估计过程的收敛性及收敛速度与参数初始值的选取密切相关。若选取的初始值与参数真值比较接近,则收敛速度快;反之,则收敛速度慢甚至发散。因此,估计模型时最好依据参数的经济意义和有关先验信息,设定好参数的初始值。
二、比较、选择最佳模型
估计过程中,对每个模型检验以下内容,以便选择出一个最佳模型:
㈠回归系数的符号及数值是否合理;
㈡模型的更改是否提高了拟合优度;
㈢模型中各个解释变量是否显著;
㈣残差分布情况
以上比较模型的㈠、㈡、㈢步在步骤一中已有阐述,模型1中除了解释变量K之外,其余变量均未通过变量显著性检验,因此舍弃该模型。模型4的表达式说明了模型的经济意义不合理,不能用于描述我国国有工业企业的生产情况,也应舍弃此模型。
模型2、模型3、模型5都具有合理的经济意义,都通过了t检验和F检验,拟合优度非常接近,理论上讲都可以描述资本、劳动的投入与产出的关系。现分析这3个不同模型的残差分布情况。
分别在模型2、3、5的估计方程窗口中点击View/Actual, Fitted, Residual/ Actual, Fitted, Residual Table(图3-7),可以得到各个模型相应的残差分布表(图3-8至图3-10)。
从图3-8至图3-10看出,三个模型中,模型3的近期误差是最小的,并且拟合优度也是三个模型中最高的,故选择模型3作为我国国有工业企业生产函数。
图3-7
图3-8模型2的残差图
图3-9 模型3的残差图
图3-10 模型5的残差分析
SPSS—非线性回归(模型表达式)案例解析 2011-11-16 10:56 由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二! 非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型 还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢? 答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究: 第一步:非线性模型那么多,我们应该选择“哪一个模型呢?” 1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型 点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高! 点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S" 两个模型,点击确定,得到如下结果: 通过“二次”和“S “ 两个模型的对比,可以看出S 模型的拟合度明显高于
陕西科技大学实验报告 课 程: 数理金融 实验日期: 2014 年 5 月 22 日 班 级: 数学112 交报告日期: 2013 年 5 月 23 日 姓 名: 常海琴 报告退发: (订正、重做) 学 号: 201112010101 教 师: 刘利明 实验名称: 多元回归分析 一、实验预习: 1.多元回归模型。 2.多元回归模型参数的检验。 3.多元回归模型整体的检验。 二、实验的目的和要求: 通过案例分析掌握多元回归模型的建立方法和检验的标准;并掌握分析解决实际金融问题的能力。 三、实验过程:(实验步骤、原理和实验数据记录等) 软件:Eviews3.1 数据:给定美国机动车汽油消费量研究数据。 实验原理:最小二乘法拟合多元线性回归方程 数据记录: 实例中1950年到1987年机动汽车的消费量、汽车保有量、汽油价格、人口数、国民生产总值 图1各个量之间的关系
陕西科技大学理学院实验报告 - 2 - 1、录入数据 图2录入数据 2、回归分析 443322110X X X X Y βββββ++++= 图3运行结果 Y=24553723+1.418520x1-27995762x2-59.87480x3-30540.88x4 S (25079670) (0.266) (5027085) (198.5517) (9557.981) T (0.979) (5.314) (-5.568) (-0.301) (-3.195) 2R =0.966951 F=241.3764 - R =0.9629 dw=0.6265 四、实验总结:(实验数据处理和实验结果讨论等) 用残差和最小确定直线位置是一个途径。计算残差和有相互抵消的问题。用残差绝对值和最小确定直线位置也是一个途径绝对值计算起来比较麻烦。最小二乘法用绝对值平方和最小确定直线位置。0β、1β、2β、3β、4β具有线性特性,无偏特性,有效性。-R =0.9629基本上接近于1,拟合效果较好。
美国各航空公司业绩的统计数据公布在《华尔街日报1998年鉴》(The Wall Street Journal Almanac 1998)上,有关航班正点到达的比率和每10万名乘客投诉的次数的数据如下: 航空公司名称航班正点率(%)投诉率(次/10万名乘客)西南(Southwest)航空公司81.8 0.21 大陆(Continental) 航空公司76.6 0.58 西北(Northwest)航空公司76.6 0.85 美国(US Airways)航空公司75.7 0.68 联合(United)航空公司73.8 0.74 美洲(American)航空公司72.2 0.93 德尔塔(Delta)航空公司71.2 0.72 70.8 1.22 美国西部(America West)航空公 司 环球(TWA)航空公司68.5 1.25 a. 画出这些数据的散点图 b. 根据再(a)中作出的散点图,表明二变量之间存在什么关系? c. 求出描述投诉率是如何依赖航班按时到达正点率的估计的回归方程 d. 对估计的回归方程的斜率作出解释 e. 如何航班按时到达的正点率是80%,估计每10万名乘客投诉的次数是多少?
1)作散点图: 2)根据散点图可知,航班正点率和投诉率成负直线相关关系。 3)作简单直线回归分析: SUMMARY OUTPUT 回归统计 Multiple R0.882607 R Square0.778996 Adjusted R Square0.747424 标准误差0.160818 观测值9 方差分析 df SS MS F Significance F 回归分析10.6381190.63811924.673610.001624残差70.1810370.025862 总计80.819156 Coefficient s标准误差t Stat P-value Lower 95%Upper 95%下限95.0%上限95.0% Intercept 6.017832 1.05226 5.7189610.000721 3.5296358.506029 3.5296358.506029 X Variable 1-0.070410.014176-4.967250.001624-0.10393-0.03689-0.10393-0.03689 4)y = -0.0704x + 6.0178
常见非线性回归模型 1.简非线性模型简介 非线性回归模型在经济学研究中有着广泛的应用。有一些非线性回归模型可以通 过直接代换或间接代换转化为线性回归模型,但也有一些非线性回归模型却无 法通过代换转化为线性回归模型。 柯布—道格拉斯生产函数模型 y AKL 其中L和K分别是劳力投入和资金投入, y是产出。由于误差项是可加的, 从而也不能通过代换转化为线性回归模型。 对于联立方程模型,只要其中有一个方程是不能通过代换转化为线性,那么这个联立方程模型就是非线性的。 单方程非线性回归模型的一般形式为 y f(x1,x2, ,xk; 1, 2, , p) 2.可化为线性回归的曲线回归 在实际问题当中,有许多回归模型的被解释变量y与解释变量x之间的关系都不是线性的,其中一些回归模型通过对自变量或因变量的函数变换可以转化为
线性关系,利用线性回归求解未知参数,并作回归诊断。如下列模型。 (1)y 0 1e x (2)y 0 1x2x2p x p (3)y ae bx (4)y=alnx+b 对于(1)式,只需令x e x即可化为y对x是线性的形式y01x,需要指出的是,新引进的自变量只能依赖于原始变量,而不能与未知参数有关。 对于(2)式,可以令x1=x,x2=x2,?,x p=x p,于是得到y关于x1,x2,?, x p 的线性表达式y 0 1x12x2 pxp 对与(3)式,对等式两边同时去自然数对数,得lnylnabx ,令 y lny, 0 lna, 1 b,于是得到y关于x的一元线性回归模型: y 0 1x。 乘性误差项模型和加性误差项模型所得的结果有一定差异,其中乘性误差项模型认为yt本身是异方差的,而lnyt是等方差的。加性误差项模型认为yt是等 方差的。从统计性质看两者的差异,前者淡化了y t值大的项(近期数据)的作用, 强化了y t值小的项(早期数据)的作用,对早起数据拟合得效果较好,而后者则 对近期数据拟合得效果较好。 影响模型拟合效果的统计性质主要是异方差、自相关和共线性这三个方面。 异方差可以同构选择乘性误差项模型和加性误差项模型解决,必要时还可以使用 加权最小二乘。
实验三 多元线性回归模型的估计和检验 一、实验目的:掌握多元线性回归模型的估计和检验方法 二、预备知识:普通最小二乘法(OLS) 三、实验内容:选择方程进行多元线性回归 四、实验步骤: (一)国内生产总值的增长模型 分析广东省国内生产总值的增长,根据广东数据(数据见“表:广东省宏观经济 数据-第三章.xls ”文件,各变量的表示按照试验指导课本上的来表示)选择不变价GDP (GDPB )、不变价资本存量(ZC )和从业人员(RY ),把GDPB 作为因变量,ZC 和RY 作为两个解释变量进行二元线性回归分析。 要求:按照试验指导课本100P ~102P ,分别作: 1、作散点图(GDPB 同ZC ,GDPB 同RY ) 2、进行因果关系检验(GDPB 同ZC ,GDPB 同RY ) 3、作GDPB 同ZC 和RY 的多元线性回归,写出模型估计的结果,并分析模型检验是均否通过?(三个检验) 4、将建立的二元回归模型(GDPB 同ZC 和RY )同一元回归模型(GDPB 同ZC 、GDPB 同RY )相比较,分析优点。 5、结合相关的经济理论,分析估计的二元回归模型的经济意义。
(二)宏观经济模型 根据广东数据,研究广东省居民消费行为、固定资产投资行为、货物和服务净出口行为和存货行为,分别建立居民消费模型、固定资产投资模型、货物和服务净出口模型和存货增加模型。 要求:按照试验指导课本510P ~211P ,分别作出以下模型,并对需要改进的 模型进行改进。写出最终估计的模型结果,并结合相关的经济理论,分析模型的经济意义。(数据见“表:广东省宏观经济数据-第三章.xls ”文件,各变量的表示按照试 验指导课本上的来表示。) 1、居民消费模型 2、固定资产投资模型 3、货物和服务净流出模型 4、存货增加模型
SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件: 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open;
2. Opening excel data source——OK. 第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise.
进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.
3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.
第四节 非线形回归模型 一、 可线性化模型 在非线性回归模型中,有一些模型经过适当的变量变换或函数变换就可以转化成线性回归模型,从而将非线性回归模型的参数估计问题转化成线性回归模型的参数估计,称这类模型为可线性化模型。在计量经济分析中经常使用的可线性化模型有对数线性模型、半对数线性模型、倒数线性模型、多项式线性模型、成长曲线模型等。 1.倒数模型 我们把形如: u x b b y ++=110;u x b b y ++=1110 (3.4.1) 的模型称为倒数(又称为双曲线函数)模型。 设:x x 1*=,y y 1*=,即进行变量的倒数变换,就可以将其转化成线性回归模型。 倒数变换模型有一个明显的特征:随着x 的无限扩大,y 将趋于极限值0b (或0/1b ),即有一个渐进下限或上限。有些经济现象(如平均固定成本曲线、商品的成长曲线、恩格尔曲线、菲利普斯曲线等)恰好有类似的变动规律,因此可以由倒数变换模型进行描述。 2.对数模型 模型形式: u x b b y ++=ln ln 10 (3.4.2) (该模型是将u b e Ax y 1=两边取对数,做恒等变换的另一种形式,其中A b ln 0=)。 上式lny 对参数0b 和1b 是线性的,而且变量的对数形式也是线性的。因此,我们将以上模型称为双对数(double-log)模型或称为对数一线性(log-liner)模型。 令:x x y y ln ,ln **==代入模型将其转化为线性回归模型: u x b b y ++=*10* (3.4.3) 变换后的模型不仅参数是线性的,而且通过变换后的变量间也是线性的。 模型特点:斜率1b 度量了y 关于x 的弹性:
云南大学数学与统计学实验教学中心 实验报告 一、实验目的 1.熟悉MATLAB的运行环境. 2.学会初步建立数学模型的方法 3.运用回归分析方法来解决问题 二、实验内容 实验一:某公司出口换回成本分析 对经营同一类产品出口业务的公司进行抽样调查,被调查的13家公司,其出口换汇成本与商品流转费用率资料如下表。试分析两个变量之间的关系,并估计某家公司商品流转费用率是6.5%的出口换汇成本. 实验二:某建筑材料公司的销售量因素分析 下表数据是某建筑材料公司去年20个地区的销售量(Y,千方),推销开支、实际帐目数、同类商品
竞争数和地区销售潜力分别是影响建筑材料销售量的因素。1)试建立回归模型,且分析哪些是主要的影响因素。2)建立最优回归模型。 提示:建立一个多元线性回归模型。
三、实验环境 Windows 操作系统; MATLAB 7.0. 四、实验过程 实验一:运用回归分析在MATLAB 里实现 输入:x=[4.20 5.30 7.10 3.70 6.20 3.50 4.80 5.50 4.10 5.00 4.00 3.40 6.90]'; X=[ones(13,1) x]; Y=[1.40 1.20 1.00 1.90 1.30 2.40 1.40 1.60 2.00 1.00 1.60 1.80 1.40]'; plot(x,Y,'*'); [b,bint,r,rint,stats]=regress(Y,X,0.05); 输出: b = 2.6597 -0.2288 bint = 1.8873 3.4322 -0.3820 -0.0757 stats = 0.4958 10.8168 0.0072 0.0903 即==1,0?6597.2?ββ,-0.2288,0?β的置信区间为[1.8873 3.4322],1,?β的置信区间为[-0.3820 -0.0757]; 2r =0.4958, F=10.8168, p=0.0072 因P<0.05, 可知回归模型 y=2.6597-0.2288x 成立. 1 1.5 2 2.5 散点图 估计某家公司商品流转费用率是6.5%的出口换汇成本。将x=6.5代入回归模型中,得到 >> x=6.5; >> y=2.6597-0.2288*x y = 1.1725
非线性回归分析 回归分析中,当研究的因果关系只涉及因变量和一个自变量时,叫做一元回归分析;当研究的因果关系涉及因变量和两个或两个以上自变量时,叫做多元回归分析。此外,回归分析中,又依据描述自变量与因变量之间因果关系的函数表达式是线性的还是非线性的,分为线性回归分析和非线性回归分析。通常线性回归分析法是最基本的分析方法,遇到非线性回归问题可以借助数学手段化为线性回归问题处理 两个现象变量之间的相关关系并非线性关系,而呈现某种非线性的曲线关系,如:双曲线、二次曲线、三次曲线、幂函数曲线、指数函数曲线(Gompertz)、S型曲线(Logistic) 对数曲线、指数曲线等,以这些变量之间的曲线相关关系,拟合相应的回归曲线,建立非线性回归方程,进行回归分析称为非线性回归分析 常见非线性规划曲线 1.双曲线1b a y x =+ 2.二次曲线 3.三次曲线 4.幂函数曲线 5.指数函数曲线(Gompertz) 6.倒指数曲线y=a / e b x其中a>0, 7.S型曲线(Logistic) 1 e x y a b-= + 8.对数曲线y=a+b log x,x>0 9.指数曲线y=a e bx其中参数a>0 1.回归: (1)确定回归系数的命令 [beta,r,J]=nlinfit(x,y,’model’,beta0) (2)非线性回归命令:nlintool(x,y,’model’, beta0,alpha) 2.预测和预测误差估计: [Y,DELTA]=nlpredci(’model’, x,beta,r,J) 求nlinfit 或lintool所得的回归函数在x处的预测值Y及预测值的显著性水平为1-alpha的置信区间Y,DELTA. 例2 观测物体降落的距离s与时间t的关系,得到数据如下表,求s 2 解: 1. 对将要拟合的非线性模型y=a/ e b x,建立M文件volum.m如下:
实习报告书 学生姓名: 学号: 学院名称: 专业名称: 实习时间: 2014年 06 月 05 日 第六次实验报告要求 实验目的: 掌握多元线性回归模型的原理,多元线性回归模型的建立、估计、检验及解释变量的增减的方法,以及运用相应的Matlab软件的函数计算。 实验内容: 已知某市粮食年销售量、常住人口、人均收入、肉、蛋、鱼的销售数据,见表1。请选择恰当的解释变量和恰当的模型,建立粮食年销售量的回归模型,并对其进行估计和检验。 表1 某市粮食年销售量、常住人口、人均收入、肉、蛋、鱼的销售数据 年份粮食年销售 量Y/万吨 常住人口 X2/万人 人均收 入X3/ 元 肉销售 量X4/万 吨 蛋销售 量X5/ 万吨 鱼虾销 售量 X6/万吨 197498.45560.20153.20 6.53 1.23 1.89 1975100.70603.11190.009.12 1.30 2.03 1976102.80668.05240.308.10 1.80 2.71 1977133.95715.47301.1210.10 2.09 3.00 1978140.13724.27361.0010.93 2.39 3.29 1979143.11736.13420.0011.85 3.90 5.24 1980146.15748.91491.7612.28 5.13 6.83 1981144.60760.32501.0013.50 5.418.36 1982148.94774.92529.2015.29 6.0910.07 1983158.55785.30552.7218.107.9712.57 1984169.68795.50771.1619.6110.1815.12
某农场负责人认为早稻收获量(y:单位为kg/公顷)与春季降雨(x i:单位为mm)和春季温度(X2:单位为C )有一定的联系,通过7组试验获得了相关的数据。利用Excel得到下面的回归结果(a =0.1): 方差分析表 (1)将方差分析表中的所缺数值补齐。 (2 )写出早稻收获量与春季降雨量、春季温度的多元线性回归方程,并解释各回归系数的意义。 (3 )检验回归方程的线性关系是否显著? (4)检验各回归系数是否显著? 2 (5)计算判定系数R,并解释它的实际意义。 (6)计算估计标准误差Se,并解释它的实际意义。 (每个空格为0.5分) 2、设总体回归模型为Y= 口+ P 1X^^ 2X2+ & ?x^ ?x2,由EXCEL输出结果可知,?= -0.39 14.92x1估计回归方程为? = ? 218.45x2,回归系数 ?的意义指在温度不变的条件下,当降雨量每增加1mm早稻收获量平均增加 14.92 kg/公顷;回归系数:?的意义指在降雨量不变的条件下, 2 当温度增加1C,早稻收获量平均增加218.45 kg/公顷。---5 分 3、由于p值=0.000075 < a =0.05,则拒绝原假设,即表明回归方程的线性关系是显著的。
4、由于各回归系数的P值均小于a ( 0.05 ),所以各回归系数是显著的。 ---2 分5、2二§臾二1387849567二0.99,表示早稻收获量的总变异中有99%的部分可以由降 R SST 14000000 雨量、温度的联合变动来解释。---4 分 6、S =」SS E =V MST = J30376.08 =174.29(k为自变量个数),是总体回归模型 e n - k -1 中随机扰动项&的标准差的无偏估计量,用来衡量回归方程拟合程度的分析指标,S e越大,拟合程度越低;S e越小,拟合程度越高? —4 分
实验三多元回归模型 【实验目的】 掌握建立多元回归模型和比较、筛选模型的方法。 【实验内容】 建立我国国有独立核算工业企业生产函数。根据生产函数理论,生产函数的基本形式为:()ε, f t Y=。其中,L、K分别为生产过程中投入的劳动与资金, L , ,K 时间变量t反映技术进步的影响。表3-1列出了我国1978-1994年期间国有独立核算工业企业的有关统计资料;其中产出Y为工业总产值(可比价),L、K分别为年末职工人数和固定资产净值(可比价)。 资料来源:根据《中国统计年鉴-1995》和《中国工业经济年鉴-1995》计算整理 【实验步骤】 一、建立多元线性回归模型 ㈠建立包括时间变量的三元线性回归模型; 在命令窗口依次键入以下命令即可: ⒈建立工作文件: CREATE A 78 94 ⒉输入统计资料: DATA Y L K
⒊生成时间变量t : GENR T=@TREND(77) ⒋建立回归模型: LS Y C T L K 则生产函数的估计结果及有关信息如图3-1所示。 图3-1 我国国有独立核算工业企业生产函数的估计结果 因此,我国国有独立工业企业的生产函数为: K L t y 7764.06667.06789.7732.675?+++-= (模型1) t = 9958.02=R 9948.02=R 551.1018=F 模型的计算结果表明,我国国有独立核算工业企业的劳动力边际产出为,资金的边际产出为,技术进步的影响使工业总产值平均每年递增亿元。回归系数的符号和数值是较为合理的。9958.02=R ,说明模型有很高的拟合优度,F 检验也是高度显着的,说明职工人数L 、资金K 和时间变量t 对工业总产值的总影响是显着的。从图3-1看出,解释变量资金K 的t 统计量值为,表明资金对企业产出的影响是显着的。但是,模型中其他变量(包括常数项)的t 统计量值都较小,未通过检验。因此,需要对以上三元线性回归模型做适当的调整,按照统计检验程序,一般应先剔除t 统计量最小的变量(即时间变量)而重新建立模型。 ㈡建立剔除时间变量的二元线性回归模型; 命令:LS Y C L K 则生产函数的估计结果及有关信息如图3-2所示。
1. 总离差平方和可分解为回归平方和与残差平方和。( 对 ) 2. 整个多元回归模型在统计上是显着的意味着模型中任何一个单独的解释变量均是统计显着的。( 错 ) 3. 多重共线性只有在多元线性回归中才可能发生。( 对 ) 4. 通过作解释变量对时间的散点图可大致判断是否存在自相关。( 错 ) 5. 在计量回归中,如果估计量的方差有偏,则可推断模型应该存在异方差( 错 ) 6. 存在异方差时,可以用广义差分法来进行补救。( 错 ) 7. 当经典假设不满足时,普通最小二乘估计一定不是最优线性无偏估计量。( 错 ) 8. 判定系数检验中,回归平方和占的比重越大,判定系数也越大。( 对 ) 9. 可以作残差对某个解释变量的散点图来大致判断是否存在自相关。( 错 )做残差 ) n 5、经典线性回归模型(CLRM )中的干扰项不服从正态分布的,OLS 估计量将有偏的。错,,即使经典线性回归模型(CLRM )中的干扰项不服从正态分布的,OLS 估计量仍然是无偏的。 因为222)()?(βμββ=+=∑i i K E E ,该表达式成立与否与正态性无关。 1、在简单线性回归中可决系数2R 与斜率系数的t 检验的没有关系。错误,在简单线性回归 中,由于解释变量只有一个,当t 检验显示解释变量的影响显着时,必然会有该回归模型的可决系数大,拟合优度高。 2、异方差性、自相关性都是随机误差现象,但两者是有区别的。正确,异方差的出现总是与模型中某个解释变量的变化有关。自相关性是各回归模型的随机误差项之间具有相关关
系。3、通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与模型有无截距项无关。错误,模型有截距项时,如果被考察的定性因素有m个相互排斥属性,则模型中引入m-1个虚拟变量,否则会陷入“虚拟变量陷阱”;模型无截距项时,若被考察的定性因素有m个相互排斥属性,可以引入m个虚拟变量,这时不会出现多重共线性。 4、满足阶条件的方程一定可以识别。错误,阶条件只是一个必要条件,即满足阶条件的的方程也可能是不可识别的。 5、库依克模型、自适应预期模型与局部调整模型的最终形式是不同的。错误,库依克模型、自适应预期模型与局部调整模型的最终形式是相同的,其最终形式都是一阶自回归模型。2、多重共线性问题是随机扰动项违背古典假定引起的。错误,应该是解释变量之间高度相关引起的. (3) 线性回归模型意味着因变量是自变量的线性函数。(错) (4) 在线性回归模型中,解释变量是原因,被解释变量是结果。(对) 1、虚拟变量的取值只能取0或1(对) 2、通过引入虚拟变量,可以对模型的参数变化进行检验(对) 1、简单线性回归模型与多元线性回归模型的基本假定是相同的。错 在多元线性回归模型里除了对随机误差项提出假定外,还对解释变量之间提 出无多重共线性的假定。 2、在模型中引入解释变量的多个滞后项容易产生多重共线性。对 在分布滞后模型里多引进解释变量的滞后项,由于变量的经济意义一样,只
《统计学》案例——相关回归分析 案例一质量控制中的简单线性回归分析 1、问题的提出 某石油炼厂的催化装置通过高温及催化剂对原料的作用进行反应,生成各种产品,其中液化气用途广泛、易于储存运输,所以,提高液化气收率,降低不凝气体产量,成为提高经济效益的关键问题。 通过因果分析图和排列图的观察,发现回流温度是影响液化气收率的主要原因,因此,只有确定二者之间的相关关系,寻找适当的回流温度,才能达到提高液化气收率的目的。经认真分析仔细研究,确定了在保持原有轻油收率的前提下,液化气收率比去年同期增长1个百分点的目标,即达到12.24%的液化气收率。 2、数据的收集
目标值确定之后,我们收集了某年某季度的回流温度与液化气收率的30组数据(如上表),进行简单直线回归分析。 3.方法的确立 设线性回归模型为εββ++=x y 10,估计回归方程为x b b y 10?+= 将数据输入计算机,输出散点图可见,液化气收率y 具有随着回流温度x 的提高而降低的趋势。因此,建立描述y 与x 之间关系的模型时,首选直线型是
合理的。 从线性回归的计算结果,可以知道回归系数的最小二乘估计值 b 0=21.263和b 1=-0.229,于是最小二乘直线为 x y 229.0263.21?-= 这就表明,回流温度每增加1℃,估计液化气收率将减少0.229%。 (3)残差分析 为了判别简单线性模型的假定是否有效,作出残差图,进行残差分析。
从图中可以看到,残差基本在-0.5—+0.5左右,说明建立回归模型所依赖的假定是恰当的。误差项的估计值s=0.388。 (4)回归模型检验 a.显著性检验 在90%的显著水平下,进行t 检验,拒绝域为︱t ︱=︱b 1/ s b1︱>t α/2=1.7011。 由输出数据可以找到b 1和s b1,t=b 1/ s b1=-0.229/0.022=-10.313,于是拒绝原假设,说明液化气收率与回流温度之间存在线性关系。 b.拟合度检验 判定系数r 2=0.792。这意味着液化气收率的样本变差大约有80%可以由它与回流温度的线性关系来解释。 2r r ==-0.89 这样,r 值为y 与x 之间存在中高度的负线性关系提供了进一步的证据。 由于n ≥30,我们近似确定y 的90%置信区间为: s z y )(?2 α±=21.263-0.229x ±1.282×0.388 = 21.263-0.229x ± 0.497
1.3非线性回归问题, 知识目标:通过典型案例的探究,进一步学习非线性回归模型的回归分析。 能力目标:会将非线性回归模型通过降次和换元的方法转化成线性化回归模型。 情感目标:体会数学知识变化无穷的魅力。 教学要求:通过典型案例的探究,进一步了解回归分析的基本思想、方法及初步应用. 教学重点:通过探究使学生体会有些非线性模型通过变换可以转化为线性回归模型,了解在解决实际问题的 过程中寻找更好的模型的方法. 教学难点:了解常用函数的图象特点,选择不同的模型建模,并通过比较相关指数对不同的模型进行比较. 教学方式:合作探究 教学过程: 一、复习准备: 对于非线性回归问题,并且没有给出经验公式,这时我们可以画出已知数据的散点图,把它与必修模块《数学1》中学过的各种函数(幂函数、指数函数、对数函数等)的图象作比较,挑选一种跟这些散点拟合得最好的函数,然后采用适当的变量代换,把问题转化为线性回归问题,使其得到解决. 二、讲授新课: 1. 探究非线性回归方程的确定: 1. 给出例1:一只红铃虫的产卵数y 和温度x 有关,现收集了7组观测数据列于下表中,试建立y 与x 之间的/y 个 2. 讨论:观察右图中的散点图,发现样本点并没有分布在某个带状区域内,即两个变量不呈线性相关关系,所以不能直接用线性回归方程来建立两个变量之间的关系. ① 如果散点图中的点分布在一个直线状带形区域,可以选线性回归模型来建模;如果散点图中的点分布在一个曲线状带形区域,就需选择非线性回归模型来建模. ② 根据已有的函数知识,可以发现样本点分布在某一条指数函数曲线y =2C 1e x C 的周围(其中12,c c 是待定的参数),故可用指数函数模型来拟合这两个变量. ③ 在上式两边取对数,得21ln ln y c x c =+,再令ln z y =,则21ln z c x c =+,可以用线性回归方程来拟合. ④ 利用计算器算得 3.843,0.272a b =-=,z 与x 间的线性回归方程为 0.272 3.843z x =-,因此红铃虫的产卵数对温度的非线性回归方程为0.272 3.843x y e -=. ⑤ 利用回归方程探究非线性回归问题,可按“作散点图→建模→确定方程”这三个步骤进行. 其关键在于如何通过适当的变换,将非线性回归问题转化成线性回归问题. 三、合作探究 例 2.:炼钢厂出钢时所用的盛钢水的钢包,在使用过程中,由于钢液及炉渣对包衬耐火材料的侵蚀,使其容积不断增大,请根据表格中的数据找出使用次数 x 与增大的容积y 之间的关系.
实验实训报告 课程名称:计量经济学实验 开课学期: 2011-2012学年第一学期开课系(部):经济系 开课实验(训)室:数量经济分析实验室学生姓名: 专业班级: 学号: 重庆工商大学融智学院教务处制
实验题目 实验(训)项目名称多元线性回归模型的估计和统 指导教师 计检验 实验(训)日期所在分组 实验概述 【实验(训)目的及要求】 目的:掌握多元线性回归模型的估计、检验。 要求:在老师指导下完成多元线性回归模型的建立、估计、统计检验,并得到正确的分析结果。 【实验(训)原理】 当多元线性回归模型在满足线性模型古典假设的前提下,最小二乘估计结果具有无偏性、有效性等性质,在此基础上进一步对估计所得的模型进行经济意义检验及统计检验。 实验内容 【实验(训)方案设计】 1、创建工作文件和导入数据; 2、完成变量的描述性统计; 3、进行多元线性回归估计; 4、统计检验:可决系数分析(R2);(2)参数显著性分析(t检验);(3)方程显著性分析(F检验); 5、进行变量非线性模型的线性化处理,并比较不同模型的拟合优度(因变量相同时)。 实验背景 选择包括中央和地方税收的“国家财政收入”中的“各项税收”(简称“TAX”)作为被解释变量,以反映国家税收的增长。选择“国内生产总值(GDP)”作为经济整体增长水平的代表;选择中央和地方“财政支出”作为公共财政需求的代表(FIN);选择“商品零售物价指数”作为物价水平的代表(PRIC),并将它们设为影响税收收入的解释变量。建立中国税收的增长模型,并对已建立的模型进行检验。
【实验(训)过程】(实验(训)步骤、记录、数据、分析 ) 1、根据实验数据的相关信息建立Workfile ; 在菜单中依次点击File\New\Workfile,在出现的对话框“Workfile range ”中选择数据频率。因为本例分析中国1978-2002年度的税收(Tax )与GDP 、财政支出(FIN )、商品零售物价指数(PRIC )之间关系,因此,在数据频率选项中选择“Annual ”选项。在“start data ”输入“1978”,在“end data ”输入“2002”。 2、导入数据; 在菜单栏中选择“Quick\Empty Group ”,将TAX 、GDP 、FIN 、PRIC 的年度数据从Excel 导入,并将这四个序列的名称分别改为“TAX ” 、“TAX ” 、“GDP ” 、“FIN ” 、“PRIC ” 。 或者在EViews 命令窗口中直接输入“data TAX GDP FIN PRIC ” ,在弹出的编辑框中将这四个个变量的时间数列数据从Excel 中复制过来。 3、给出自变量和因变量的描述性统计结果,并判断数据序列是否服从正态分布 (5%α=) 变量名 Mean Median Std J-B 值 J.B p 值 是否服从正态分布 GDP 35977 18548 34445 3.308 0.191 是 FIN 5855 3084 5968 9.390 0.009 否 PRIC 105 103 7 4.125 0.127 是 TAX 4848 2822 4871 6.908 0.032 否 4、给出自变量和因变量之间的相关系数矩阵: GDP FIN PRIC TAX GDP 1.000 0.957 -0.290 0.969 FIN 0.957 1.000 -0.375 0.997 PRIC -0.290 -0.375 1.000 -0.334 TAX 0.969 0.997 -0.334 1.000 5、假设总体回归模型1为0123TAX GDP FIN PRIC u ββββ=++++,进行多元回归估计 并报告估计结果:
某农场负责人认为早稻收获量(y :单位为kg/公顷)与春季降雨(x 1:单位为mm )和春季温度(x 2:单位为℃)有一定的联系,通过7组试验获得了相关的数据。利用Excel 得到下面的回归结果(α=0.1): 方差分析表 (2)写出早稻收获量与春季降雨量、春季温度的多元线性回归方程,并解释各回归系数的意义。 (3)检验回归方程的线性关系是否显著? (4)检验各回归系数是否显著? (5)计算判定系数2 R ,并解释它的实际意义。 (6)计算估计标准误差Se ,并解释它的实际意义。 (每个空格为0.5分) -----3分 2、设总体回归模型为Y =1 2 1 2 x x αεββ+ ++ 估计回归方程为y ?=1 2 1 2 ???x x αββ++,由EXCEL 输出结果可知,y ?=120.3914.92218.45-++x x ,回归系数1 ?β 的意义指在温度不变的条件下,当降雨量每增加1mm ,早稻收获量平均增加14.92kg/公顷;回归系数 2 ?β 的意义指在降雨量不变的条件下, 当温度增加1℃,早稻收获量平均增加218.45kg/公顷。 ---5分
3、由于p 值=0.000075<α=0.05,则拒绝原假设,即表明回归方程的线性关系是显著的。 ---2分 4、由于各回归系数的P 值均小于α(0.05),所以各回归系数是显著的。 ---2分 5、 2 13878495.67 0.9914000000 = ==SSR SST R ,表示早稻收获量的总变异中有99%的部分可以由降雨量、温度的联合变动来解释。 ---4分 6、 174.29= ===e S (k 为自变量个数) ,是总体回归模型中随机扰动项ε的标准差的无偏估计量,用来衡量回归方程拟合程度的分析指标,e S 越大, 拟合程度越低;e S 越小,拟合程度越高. ---4分
实验三 多元线性回归模型及非线性回归 一、多元线性回归模型 例题3.2.2 建立2006年中国城镇居民人均消费支出的多元线性回归模型。 数据: 地区 2006年消费支出Y 2006年可支配收入X1 2005年消费支出X2 北京 14825.41 19977.52 13244.2 天津 10548.05 14283.09 9653.3 河北 7343.49 10304.56 6699.7 山西 7170.94 10027.70 6342.6 内蒙古 7666.61 10357.99 6928.6 辽宁 7987.49 10369.61 7369.3 吉林 7352.64 9775.07 6794.7 黑龙江 6655.43 9182.31 6178.0 上海 14761.75 20667.91 13773.4 江苏 9628.59 14084.26 8621.8 浙江 13348.51 18265.10 12253.7 安徽 7294.73 9771.05 6367.7 福建 9807.71 13753.28 8794.4 江西 6645.54 9551.12 6109.4 山东 8468.40 12192.24 7457.3 河南 6685.18 9810.26 6038.0 湖北 7397.32 9802.65 6736.6 湖南 8169.30 10504.67 7505.0 广东 12432.22 16105.58 11809.9 广西 6791.95 9898.75 7032.8 海南 7126.78 9395.13 5928.8 重庆 9398.69 11569.74 8623.3 四川 7524.81 9350.11 6891.3 贵州 6848.39 9116.61 6159.3 云南 7379.81 10069.89 6996.9 西藏 6192.57 8941.08 8617.1 陕西 7553.28 9267.70 6656.5 甘肃 6974.21 8920.59 6529.2 青海 6530.11 9000.35 6245.3 宁夏 7205.57 9177.26 6404.3 新疆 6730.01 8871.27 6207.5 1、 建立模型 01122Y X X βββμ=+++ 2、估计模型 (1)录入数据 打开EViews6,点“File ” “New ”“Workfile ”
多元线性回归模型 一.概述 当今农村农民人均纯收入与多个因素存在着紧密的联系,例如人均工资收入,人均农林牧渔产值人均生产费用支出,人均转移性和财产性收入等。本次将以安徽1995-2009年农村居民纯收入与人均工资收入,人均生产费用支出,人均转移性和财产性收入等因素的数据,通过建立计量经济模型来分析上述变量之间的关系,强调农村居民生活的重要性,从而促进全国经济的发展。 二、模型构建过程 ⒈变量的定义 被解释变量:农民人均纯收入y 解释变量:人均工资收入x1, 人均农林牧渔产值x2 人均生产费用支出x3 人均转移性和财产性收入x4。 建立计量经济模型:解释农民人均纯收入与人均工资收入,人均生产费用支出,人均转移性和财产性收入的关系 ⒉模型的数学形式 设定农民人均纯收入与五个解释变量相关关系模型,样本回归模型为: ∧Y i=∧ β + ∧ β 1 X i1+∧β 2 X i2+∧β 3 X i3+∧β 4 X i4+e i ⒊数据的收集 该模型的构建过程中共有四个变量,分别是中国从1995-2009年人均工资收入,人均农林牧渔产值人均生产费用支出,人均转移性和财产性收入,因此为时间序列数据,最后一个即2009年的数据作为预测对比数据,收集的数据如下所示: ⒋用OLS法估计模型 回归结果,散点图分别如下:
Y?=33.632+0.659X1+0.59X2-0.274X3+0.152X4 i d.f.=10 ,R2=0.997116 , Se=(186.261) (0.1815 (0.1245) (0.2037) (0.5699) t=(0.1805) (3.632) (4.741) (-1.347) (2.674) 三、模型的检验及结果的解释、评价
2020年高中数学选修2-3《回归分析的初步应用--探究非线性回归模型》教案精编 版
回归分析的初步应用(教案) ——探究非线性回归模型 佛山市第三中学张云雁 一、教材分析 1. 教材的地位与作用: “回归分析的初步应用”是人民教育出版社A版《数学选修2-3》统计案例一章的内容,是《必修3》“线性回归分析”的延伸。根据高中课程标准,这里准备安排4个课时,本次说课的内容为第3课时。 虽然线性回归分析具有广泛的应用,但是大量实际问题的两个变量不一定都呈线性相关关系,所以有必要探究如何建立非线性回归模型,进行更有效的数据处理。 2. 教学重点、难点: 教学重点:探究用线性回归模型研究非线性回归模型。 教学难点:如何选择不同的模型建模,以及如何将非线性回归模型转化为线性回归模型。 二、学情分析 教学对象是高二的学生,通过前面的学习,具有一定的线性回归分析、相关指数和残差分析的知识,这为探究非线性模型奠定了良好的基础,但由于学生较少接触数学建模的思想,思路不够开阔,为模型间的转化带来了一定的困难。 三、教学目标 知识与技能目标:能根据散点图的特点选择回归模型,通过函数变换,借助线性回归模型研究非线性回归模型。 过程与方法目标:经历非线性回归模型的探索过程,掌握建立非线性模型的基本步骤,体会统计方法的特点。
情感、态度与价值观:以探究问题为中心,感受研究非线性回归模型的必要意义,体验数学的文化内涵,形成学习数学的积极态度。 四、教学方法 1. 教法分析 主要采用“引导发现,合作探究”的教学方法,通过组织学生观察、分析、计算、交流、归纳,让学生在探究学习的过程中经历知识形成的全过程。 利用多媒体辅助教学,优化了教学过程,大大提高了课堂教学效率。 2.学法分析 重点指导学生通过观察思考、类比联想,形成“自主探究、合作交流”的学习形式,培养学生从“学会知识”到“会学知识”。 五、教学过程 (一)知识回顾 首先以07年广东的一道高考题引入新课: 下表提供了某厂节能降耗技术改造后生产甲产品过程中记录的产量(吨)与相应的生产能耗(吨标准煤)的几组对照数据: (1)请画出上表数据的散点图; (2)请根据上表提供的数据,用最小二乘法求出y关于x的线性回归方程?y bx a =+; (3)已知该厂技改前100吨甲产品的生产能耗为90吨标准煤.试根据(2)求出的线性回归方程,预测生产100吨甲产品的生产能耗比技改前降低多少吨标准煤? 师:回忆并叙述建立线性回归模型的基本步骤? 生:选取变量、画散点图、选择模型、估计参数、分析与预测。 [设计意图]:为建立非线性回归模型作准备。