
大作业
汽车市场研究
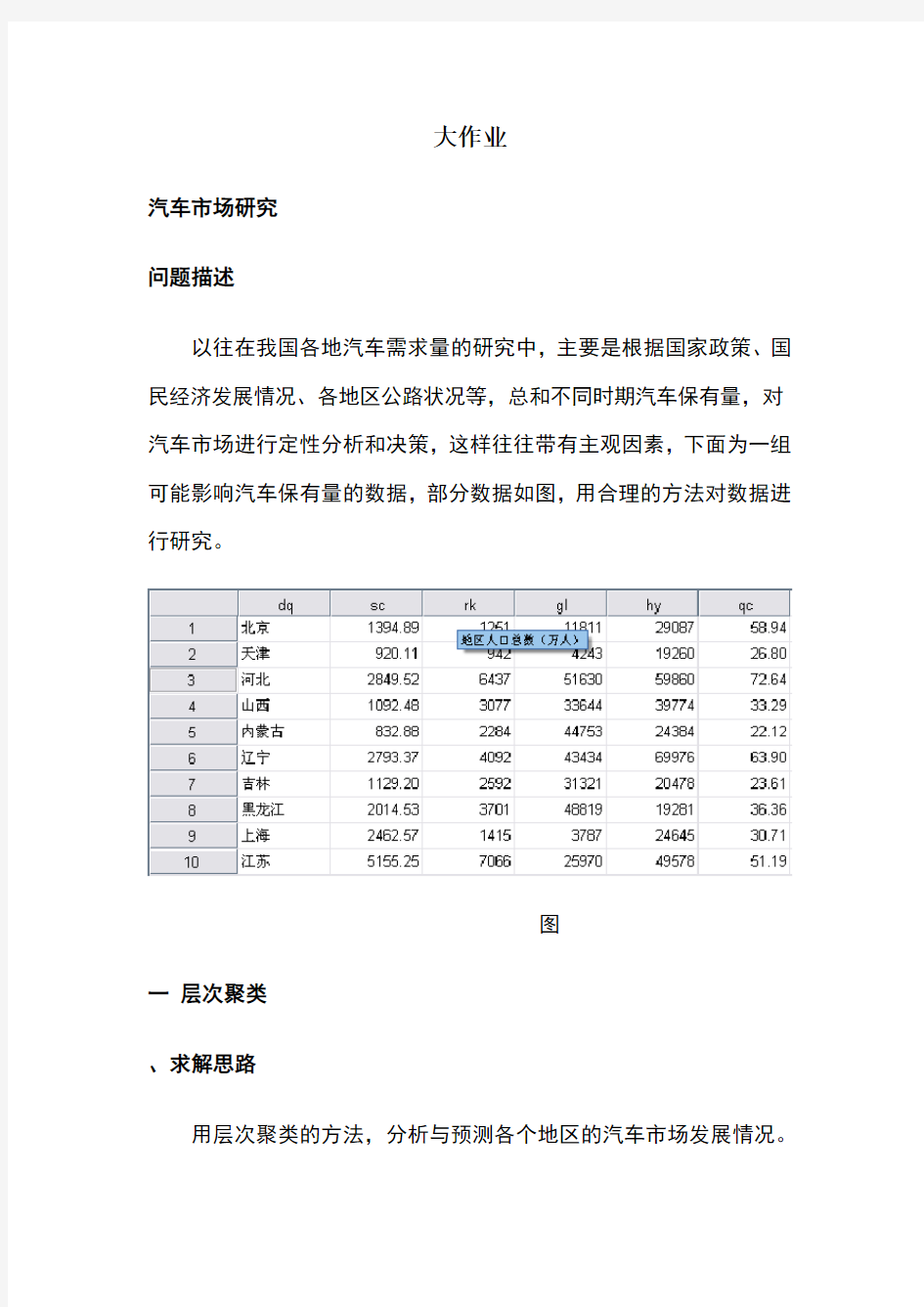
问题描述
以往在我国各地汽车需求量的研究中,主要是根据国家政策、国民经济发展情况、各地区公路状况等,总和不同时期汽车保有量,对汽车市场进行定性分析和决策,这样往往带有主观因素,下面为一组可能影响汽车保有量的数据,部分数据如图,用合理的方法对数据进行研究。
图
一层次聚类
、求解思路
用层次聚类的方法,分析与预测各个地区的汽车市场发展情况。
首先对原始数据进行标准化变换处理,经过运算使得每列数据的平均值为0,方差为1,这样原始数据中5列具有不同比较标准的数据就能放在一起比较;然后用标准化后的30个不同地区数据求出欧式距离;最后采用Wald离差平方和法。
、问题求解与分析
通过SPSS软件求解的结果与分析:
结果分析:图为层次分析的凝聚状态表,第一列为聚类步骤,表示共进行了29个步骤的分析;第二列和第三列表示某部聚类分析中,哪两个样本或聚类成了一类;第四列表示两个样本或类间距,从图看出,距离小的样本之间先聚类;第五列和第六列表示某步聚类分析中,参与聚类的是样本还是类,0表示样本;第七列表示本步聚类分析结果在下面聚类的第几步中用到。
图
结果分析:图将30个样本分为三类,第一类包括1、2、6、9、10、11,第二类包括3、4、7、12、15、16、18、19、22、26,第三类包括5、8、13、14、17、20、21、23、24、25、27、28、29、30 。
Case
3 Cluster
s
1:北京1
2:天津1 3:河北2 4:山西2
5:内蒙
古
3 6:辽宁1 7:吉林2
8:黑龙
江
3
9:上海1 10:江
1苏
11:浙
1江
12:安
2徽
13:福
3建
14:江
3西
15:山
2东
16:河
2南
17:湖
3北
18:湖
2南
19:广
2东
20:广
3西
21:海
3南
22:四
2川
23:贵
3州
24:云
3南
25:西
3藏
26:陕
2西
27:甘
3肃
28:青
3海
29:宁
3夏
30:新
3
疆
图
结果分析:图是层次聚类分析的树形图,由于部分样本或小类之间的距离较小,因此光从该图很难清晰看出哪几个样本先聚类,这时应借助于图进行判别。
* * * * * * * * * * * * * * * * * * * H I E R A R C H I C A L C L U S T E R
A N A L Y S I S * * * * * * * * * * * * * * * * * * *
Dendrogram using Ward Method
Rescaled Distance Cluster Combine
C A S E 0 5
10 15 20
25
Label Num +---------+---------+---------+--
-------+---------+
安徽12 ─┐
河南16 ─┼─┐
广东19 ─┤│
四川22 ─┘├─────┐
吉林7 ─┐││
陕
西26 ─┼─┘├─────────────┐
湖
南18 ─┘│
│
河
北 3 ─┐│
│
山
西 4 ─┼───────┘
│
山
东15 ─┘
├─────────────────────────┐
贵
州23 ─┐
│
│
青
海28 ─┼─────────┐
│
│
西
藏25 ─┘│
│
│
黑龙
江8 ─┬─┐├───────────┘
│
宁
夏29 ─┘│││
内蒙
古 5 ─┐├───────┘
│
新
疆30 ─┤│
│
湖
北17 ─┤│
│
江
西14 ─┼─┘
广
西20 ─┤│
云
南24 ─┤│
甘
肃27 ─┤│
福
建13 ─┤│
海
南21 ─┘
天
津 2 ─┐
│
浙
江11 ─┼───┐
│
上
海9 ─┘├───────────────────────────────────────────┘
北京 1 ─┐│
江苏10 ─┼───┘
辽宁 6 ─┘
图
总分析:第一类反应的是我国经济发展较发达地区与相对欠发达地区。1、2、9代表为北京、天津、上海三个直辖市,在全国具有举足轻重的地位,它们的汽车市场发展仍将处于全国领先水平;6、10、11代表辽宁、江苏、浙江,由于地理、人口、气候及交通等原因,汽车市场的发展将作为今后发展的重要因素,带动这些地区经济的腾飞。第二类中10个元素,分别代表陕西、山东、陕西等,这些地区从经济发展看处于中等水平,将是今后汽车发展的大市场。第三类为内蒙古、宁夏、新疆等,这些地区相对来说经济发展较慢,汽车发展空间不大。
二多元线性回归分析
求解思路
用多远线性回归的方法,分析国内生产总值、地区人口总数、地区公路长度、全社会货运量对汽车保有量是否有影响。
首先自变量强制进入,不用管个因素质量如何,对回归方程是否有影响;然后选择输出默认输出项,输出回归系数的标准误差、标准回归系数等;最后选择Model fit和Descriptives,输出判定系数、自变量与因变量的均值、标准差等。
问题求解与分析
通过SPSS软件求解的结果与分析:
图
结果分析:图为四个自变量和一个因变量的平均值、方差和个案数为30。
Variables Entered/Removed b
Model Variables
Entered
Variables
Removed Method
1全社会货运量
(万吨), 地
区公路长度
(km), 国内
生产总值(亿
元), 地区人
口总数(万人)
a
.Enter
a. All requested variables
entered.
图
结果分析:图2. 2中第二列为被引入的变量,第三列为从回归方程中被剔除的各个变量,第四列为进入方式。
图
结果分析:图输出常用统计量关系数R为,调整的判定系数为,回归估计的标准误差S=。