机器学习_ISOLET Data Set(ISOLET数据集)
- 格式:pdf
- 大小:66.48 KB
- 文档页数:4

train validation test 划分
在机器学习和数据科学中,训练集(train)、验证集(validation)和测试集(test)的划分是非常重要的步骤。
这三种数据集在模型训练和评估中起着不同的作用。
1. 训练集(Train Set):用于训练机器学习模型的数据集。
它包含了用于构建模型的特征和标签,通过训练集,我们可以训练出具有一定预测能力的模型。
通常,训练集占总数据集的70%到80%。
2. 验证集(Validation Set):用于验证模型性能的数据集。
在模型训练过程中,我们需要不断地调整模型的参数和结构,以优化模型的性能。
验证集就是用来评估不同参数和结构下的模型性能,帮助我们选择最好的模型。
通常,验证集占总数据集的10%到20%。
3. 测试集(Test Set):用于最终评估模型性能的数据集。
在模型训练和参数调整完成后,我们需要使用测试集来评估模型的最终性能。
测试集的评估结果可以为我们提供对模型泛化能力的参考,即模型对新数据的预测能力。
通常,测试集占总数据集的10%左右。
通过合理地划分训练集、验证集和测试集,我们可以更好地评估模型的性能,并选择出最优的模型进行实际应用。
同时,这种划分也有助于防止过拟合和欠拟合问题,提高模型的泛化能力。

半监督数据集格式半监督学习是一种介于监督学习与无监督学习之间的机器学习方法,它结合了少量有标签数据和大量无标签数据的优势,旨在利用有限的标注数据来提高学习模型的性能。
在半监督学习中,数据集通常包含两部分:一部分是有标签数据(Labeled Data),另一部分是无标签数据(Unlabeled Data)。
这两种数据的格式对于训练有效的半监督学习模型至关重要。
一、有标签数据格式有标签数据是带有明确类别标签的数据集,这些数据集通常用于训练模型的初始阶段或用于调整模型的参数。
有标签数据的格式通常包括以下几个部分:1. 特征矩阵(Feature Matrix):这是一个二维数组,其中每一行代表一个样本,每一列代表一个特征。
特征可以是数值型、文本型、图像型等,具体取决于所处理的数据类型。
2. 标签向量(Label Vector):这是一个一维数组,与特征矩阵的行数相同,用于存储每个样本对应的类别标签。
标签通常是整数或字符串,表示样本所属的类别。
3. 元数据(Metadata):可选的部分,包括数据集的描述、特征的解释、标签的含义等。
元数据有助于理解数据集和标签的含义,对于模型训练和解释非常有帮助。
二、无标签数据格式无标签数据是没有明确类别标签的数据集,这些数据集通常用于模型的进一步训练或用于模型的自我学习。
无标签数据的格式与有标签数据类似,主要包括:1. 特征矩阵(Feature Matrix):与有标签数据相同,是一个二维数组,包含样本的特征信息。
2. 缺失的标签(Missing Labels):无标签数据的标签信息是缺失的,这部分数据用于模型的自我学习或用于生成伪标签(Pseudo-Labels)。
三、半监督数据集格式的挑战在半监督学习中,处理有标签和无标签数据的混合是一个挑战。
模型需要同时利用有标签数据的监督信息和无标签数据的非监督信息。
因此,数据集的组织和格式对于模型的训练效果至关重要。
1. 数据整合:将有标签数据和无标签数据整合到一个数据集中,并确保它们在模型训练过程中得到适当的处理。

UCI机器学习数据库使用说明收藏UCI机器学习数据库的网址: /ml/数据库不断更新至2010年,是所有学习人工智能都需要用到的数据库,是看文章、写论文、测试算法的必备工具。
数据库种类涉及生活、工程、科学各个领域,记录数也是从少到多,最多达几十万条。
UCI数据可以使用matlab的dlmread或textread读取,不过,需要先将不是数字的类别用数字,比如1/2/3等替换,否则读入不了数值,当字符了。
UCI数据库使用说明转自:/bbs/thread-37-1-1.html此目录包含数据集和相关领域知识(后面以简短的列表形式进行的注释),这些数据已经或能用于评价学习算法。
每个数据文件(*.data)包含以“属性-值”对形式描述的很多个体样本的记录。
对应的*.info 文件包含的大量的文档资料。
(有些文件_generate_ databases;他们不包含*.data文件。
)作为数据集和领域知识的补充,在utilities目录里包含了一些在使用这一数据集时的有用资料。
地址/~mlearn/MLRepository.html ,这里的UCI数据集可以看作是通过web的远程拷贝。
作为选择,这些数据同样可以通过ftp获得,ftp:// . 可是使用匿名登陆ftp。
可以在pub/machine-learning-databases目录中找到。
注意:UCI一直都在寻找可加入的新数据,这些数据将被写入incoming子目录中。
希望您能贡献您的数据,并提供相应的文档。
谢谢——贡献过程可以参考DOC-REQUIREMENTS文件。
目前,多数数据使用下面的格式:一个实例一行,没有空格,属性值之间使用逗号“,”隔开,并且缺少的值使用问号“?”表示。
并请在做出您的贡献后提醒一下站点管理员:ml-repository@下面以UCI中IRIS为例介绍一下数据集:ucidata\iris中有三个文件:Indexiris.datasindex为文件夹目录,列出了本文件夹里的所有文件,如iris中index的内容如下:Index of iris18 Mar 1996 105 Index08 Mar 1993 4551 iris.data30 May 1989 2604 siris.data为iris数据文件,内容如下:5.1,3.5,1.4,0.2,Iris-setosa4.9,3.0,1.4,0.2,Iris-setosa4.7,3.2,1.3,0.2,Iris-setosa……7.0,3.2,4.7,1.4,Iris-versicolor6.4,3.2,4.5,1.5,Iris-versicolor6.9,3.1,4.9,1.5,Iris-versicolor……6.3,3.3,6.0,2.5,Iris-virginica5.8,2.7,5.1,1.9,Iris-virginica7.1,3.0,5.9,2.1,Iris-virginica……如上,属性直接以逗号隔开,中间没有空格(5.1,3.5,1.4,0.2,),最后一列为本行属性对应的值,即决策属性Iris-setosa。
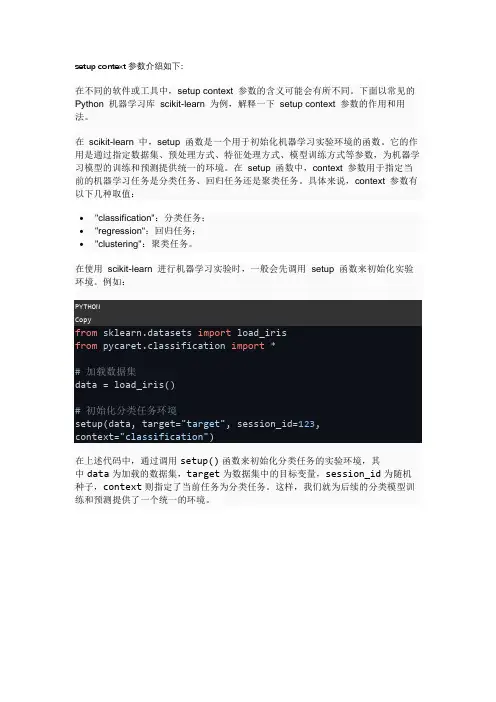
setup context参数介绍如下:在不同的软件或工具中,setup context 参数的含义可能会有所不同。
下面以常见的Python 机器学习库scikit-learn 为例,解释一下setup context 参数的作用和用法。
在scikit-learn 中,setup 函数是一个用于初始化机器学习实验环境的函数。
它的作用是通过指定数据集、预处理方式、特征处理方式、模型训练方式等参数,为机器学习模型的训练和预测提供统一的环境。
在setup 函数中,context 参数用于指定当前的机器学习任务是分类任务、回归任务还是聚类任务。
具体来说,context 参数有以下几种取值:•"classification":分类任务;•"regression":回归任务;•"clustering":聚类任务。
在使用scikit-learn 进行机器学习实验时,一般会先调用setup 函数来初始化实验环境。
例如:from sklearn.datasets import load_irisfrom pycaret.classification import *# 加载数据集data = load_iris()# 初始化分类任务环境setup(data, target="target", session_id=123,context="classification")在上述代码中,通过调用setup()函数来初始化分类任务的实验环境,其中data为加载的数据集,target为数据集中的目标变量,session_id为随机种子,context则指定了当前任务为分类任务。
这样,我们就为后续的分类模型训练和预测提供了一个统一的环境。

在进⾏机器学习建模时,为什么需要验证集(validationset)?在进⾏机器学习建模时,为什么需要评估集(validation set)? 笔者最近有⼀篇⽂章被拒了,其中有⼀位审稿⼈提到论⽂中的⼀个问题:”应该在验证集上⾯调整参数,⽽不是在测试集“。
笔者有些不明⽩为什么除了训练集、测试集之外,还需要额外划分⼀个验证集。
经过查找资料,在《Deep Learning with Python》这本书上⾯我发现了⽐较好的解释,于是将这部分内容摘录在本博⽂中,并且翻译为中⽂。
下⽂摘⾃《Deep Learning with Python》4.2⼩节,翻译如下: 不在同样的数据上⾯验证模型的原因显然在于:在⼏轮训练之后,模型就会过拟合。
即,相较于模型在训练数据上⼀直在变好的表现,模型在新样本上的表现会在某⼀时刻开始变差。
机器学习的⽬的是构造有很强泛化能⼒—在新样本上有着良好的表现—的模型,⽽过拟合是我们需要重点解决的问题。
这⼀⼩节,我们将会聚焦于如何去衡量模型的泛化能⼒:如何去评估模型。
训练集、验证集和测试集 评估模型的重点在于将可⽤数据还分为三个部分:训练集(training set)、验证集(validation set)和测试集(test set)。
在训练集上⾯训练模型,并且在验证集上⾯评估模型。
⼀旦模型被准备好,最后就在测试集上⾯测试模型。
为什么不直接使⽤两个数据集:⼀个训练集和⼀个测试集?直接在训练集上⾯训练模型,在测试集上⾯评估模型,这样不是更简单⼀些吗? 不这样做的原因在于,开发⼀个模型通常需要我们去调整模型的配置:例如,选择最佳的全连接层数或者每⼀层的节点数(这些被称之为模型的超参数,以区分于模型⾃⾝的参数,如:模型的权重和偏置)。
我们通过模型在验证集上⾯的表现来做这种调整。
本质上,这种调整也是⼀种学习的过程:在某种参数空间中寻找最佳的模型配置。
结果,根据模型在验证集上⾯的表现来调整其配置会很快地导致模型在验证集上⾯过拟合,即便模型从来没有直接在验证集上进⾏训练。

机器学习中的数据预处理步骤介绍在机器学习中,数据预处理是一个至关重要的步骤,它涉及到对原始数据进行清洗、转换和整理,以便让数据更适合用于机器学习模型的训练和预测。
本文将介绍机器学习中常见的数据预处理步骤,包括数据清洗、数据缺失处理、数据变换和特征缩放。
数据清洗是数据预处理的第一步,它的目的是处理数据中的异常值、噪声和重复项。
异常值指的是与其他数据明显不同的数值,可能是由于测量误差或数据录入错误导致的。
噪声是指数据中的无用信息,可能干扰了模型的学习能力。
重复项是指数据集中存在完全相同的数据,它们对模型的训练过程没有任何帮助。
常见的数据清洗操作包括删除异常值、降噪和去重。
数据缺失是指数据集中某些属性的值缺失的情况。
数据缺失可能会导致模型训练的不准确和偏差。
因此,数据处理中需要考虑如何处理缺失值。
常见的处理方法包括删除缺失值的样本、对缺失值进行替代(如使用平均值、中位数或众数填充缺失值)、使用插值方法进行填充(如线性插值或K近邻插值)或使用机器学习算法预测缺失值。
数据变换是将原始数据转换为更适合机器学习模型的形式。
常见的数据变换方法包括特征选择、特征构建和特征转换。
特征选择是从原始数据中选择最相关的特征子集,以减少特征维度和降低模型复杂度。
特征构建是根据原始数据生成新的特征,以帮助模型更好地捕捉数据中的模式和特征。
特征转换是将原始数据转换为其他表示形式,如对数转换、归一化、标准化等。
特征缩放是一种常见的数据预处理步骤,它的目的是将不同范围的特征值调整到相同的尺度上,以便模型能够更好地进行学习。
常见的特征缩放方法包括最小-最大缩放(将特征值缩放到指定的最小值和最大值之间)、标准化缩放(将特征值缩放为均值为0、标准差为1的正态分布)和归一化缩放(将特征值缩放到0到1的范围内)。
除了以上介绍的数据预处理步骤,数据预处理还涉及到其他一些技术,如数据集划分、数据采样、特征编码等。
数据集划分是将原始数据集划分为训练集和测试集,以便对模型进行评估和验证。
机器学习如何智能化数据处理随着互联网技术的发展,数据已经成为当今最为重要的资源之一,它们无时不刻地被各种设备、应用程序、系统收集、储存、传输和处理。
这无疑给数据处理带来了前所未有的挑战,也催生了机器学习这一强有力的技术手段。
机器学习能够智能化地处理数据,提升数据的价值和意义,使得数据成为人们研究和决策的有力支持。
机器学习的基本定义是,通过分析和识别数据的特征和规律,让计算机自动建立模型,并利用这些模型进行预测和决策。
要实现这个目标,需要多方面知识和技能的综合应用,包括数学、统计学、数据结构、算法和编程等方面。
不同的机器学习方法和模型适用于不同的数据类型和处理任务,在实际应用中需要选择和组合合适的方法来实现数据分析和处理的目标。
一般来说,机器学习可以分为监督学习、无监督学习和半监督学习三大类。
监督学习利用带标签的训练数据,训练模型来预测新的数据的标签或类别,如分类、回归等;无监督学习则不需要标签,通过探索数据本身的结构和规律,进行聚类、降维、异常检测等操作;半监督学习则同时利用有标签和无标签的数据,适用于少量标签而大量无标签的情况,如图像识别、语音识别等。
在数据处理中,机器学习有很多应用场景,如图像识别、语音识别、自然语言处理、预测和决策等。
其中,特别值得一提的是,机器学习在数据挖掘和大数据分析中扮演着核心和重要的角色。
这些数据通常来自于各种来源,包括结构化数据(如数据库、电子表格等)、语义数据(如知识库、网页信息等)和半结构化数据(如XML文件、JSON数据等),通常需要进行分类、聚类、关联规则挖掘、异常检测和预测等操作。
机器学习的数据处理过程可以简要概述如下:首先,需要对数据进行预处理,包括数据清洗、数据集成、数据变换和数据规约等步骤。
数据清洗是指删除与数据处理无关的数据,或者对缺失、噪声或异常数据进行修复,保证数据的完整性和准确性;数据集成则是指将不同来源的数据合并为一个整体,消除冗余数据和不一致性;数据变换则是对数据进行转换,以便更好地进行分析和处理,如对数变换、标准化、正则化等;数据规约则是将数据简化或抽取关键信息,以便更快地进行分析和处理,如采样、降维等。
Spambase Data Set(spambase数据集)数据摘要:Classifying Email as Spam or Non-Spam中文关键词:机器学习,Spambase,回归,多变量,UCI,英文关键词:Machine Learning,Spambase,Regression,MultiVarite,UCI,数据格式:TEXT数据用途:This data is used for classification.数据详细介绍:Spambase Data SetAbstract: Classifying Email as Spam or Non-Spam.Source:Creators:Mark Hopkins, Erik Reeber, George Forman, Jaap SuermondtHewlett-Packard Labs, 1501 Page Mill Rd., Palo Alto, CA 94304Donor:George Forman (gforman at nospam ) 650-857-7835Data Set Information:The "spam" concept is diverse: advertisements for products/web sites, make money fast schemes, chain letters, pornography...Our collection of spam e-mails came from our postmaster and individuals who had filed spam. Our collection of non-spam e-mails came from filed work and personal e-mails, and hence the word 'george' and the area code '650' are indicators of non-spam. These are useful when constructing a personalized spam filter. One would either have to blind such non-spam indicators or get a very wide collection of non-spam to generate a general purpose spam filter.For background on spam:Cranor, Lorrie F., LaMacchia, Brian A. Spam!Communications of the ACM, 41(8):74-83, 1998.(a) Hewlett-Packard Internal-only Technical Report. External forthcoming.(b) Determine whether a given email is spam or not.(c) ~7% misclassification error. False positives (marking good mail as spam) are very undesirable.If we insist on zero false positives in the training/testing set, 20-25% of the spam passed through the filter.Attribute Information:The last column of 'spambase.data' denotes whether the e-mail was considered spam (1) or not (0), i.e. unsolicited commercial e-mail. Most of the attributes indicate whether a particular word or character was frequently occuring in the e-mail. The run-length attributes (55-57) measure the length of sequences of consecutive capital letters. For the statistical measures of each attribute, see the end of this file. Here are the definitions of the attributes:48 continuous real [0,100] attributes of type word_freq_WORD= percentage of words in the e-mail that match WORD, i.e. 100 * (number of times the WORD appears in the e-mail) / total number of words in e-mail. A "word" in this case is any string of alphanumeric characters bounded by non-alphanumeric characters or end-of-string.6 continuous real [0,100] attributes of type char_freq_CHAR]= percentage of characters in the e-mail that match CHAR, i.e. 100 * (number of CHAR occurences) / total characters in e-mail1 continuous real [1,...] attribute of type capital_run_length_average= average length of uninterrupted sequences of capital letters1 continuous integer [1,...] attribute of type capital_run_length_longest= length of longest uninterrupted sequence of capital letters1 continuous integer [1,...] attribute of type capital_run_length_total= sum of length of uninterrupted sequences of capital letters= total number of capital letters in the e-mail1 nominal {0,1} class attribute of type spam= denotes whether the e-mail was considered spam (1) or not (0), i.e. unsolicited commercial e-mail.数据预览:点此下载完整数据集。
信息集名词解释
信息集(Data set)是指在某一领域或主题中收集到的大量数据的集合。
这些数据可以是数值、文字、图片或其他形式的信息。
信息集通
常被用于进行数据分析、研究或制定决策。
信息集的特点包括数据的数量庞大、来源多样化、包含全面和详细的
信息等。
通过对信息集的分析和挖掘,我们可以获得关于某一领域或
主题的深入洞察,并且可以从中发现规律、趋势或模式。
为了确保信息集的质量和可靠性,收集数据时需要注意数据的准确性、完整性和一致性。
同时,也需要遵守相关的法律法规,保护数据的隐
私和安全。
信息集的使用范围广泛,在各个领域都有应用。
例如,在市场调研中,通过收集消费者的购买习惯和嗜好,可以帮助企业了解市场需求,做
出更好的营销决策。
在医学领域,通过分析医疗信息集,可以提供医
学研究和临床决策的依据。
同时,信息集也为数据科学、人工智能等
领域的发展提供了基础和支持。
机器学习的数据准备与预处理方法机器学习是一种基于数据的人工智能方法,其目标是通过训练模型从数据中获取知识并做出准确的预测。
然而,在进行机器学习之前,我们需要对数据进行准备和预处理,以确保数据的质量和合理性。
本文将介绍机器学习的数据准备和预处理方法,帮助读者更好地理解这一关键步骤。
1. 数据清洗数据清洗是数据准备中的第一步,目的是处理数据集中的错误、缺失或无效的数据。
常见的数据清洗方法包括:- 删除重复的数据:若数据集中存在多个完全相同的数据点,则只需保留一个。
- 处理缺失数据:根据情况,可以采取删除含有缺失数据的样本或填充缺失值的方法。
- 处理异常值:通过统计方法或可视化手段,识别并处理异常值,以避免其对模型的影响。
2. 特征选择特征选择是指从原始数据中选择出对于问题有意义的特征。
一个好的特征选择方法可以提高模型的准确性,并减少模型的计算成本。
常见的特征选择方法包括:- 过滤法(Filter method):根据统计指标或启发式规则对特征进行排序,选择与目标变量最相关的特征。
- 包裹法(Wrapper method):通过训练模型评估特征的重要性,逐步选择特征。
- 嵌入法(Embedded method):在模型训练过程中,通过正则化等方法选择特征。
3. 特征缩放特征缩放是指将不同尺度的特征转化为相似的尺度。
这是因为在机器学习中,特征的尺度不同可能会导致模型的偏好不均衡。
常见的特征缩放方法包括:- 标准化(Standardization):将特征缩放到均值为0,标准差为1的正态分布上。
- 归一化(Normalization):将特征缩放到0和1之间,保留特征的原始分布。
- 缩放到固定范围:将特征缩放到指定的范围,例如[-1, 1]或[0, 1]。
4. 特征转换特征转换是指将原始数据转换为适合机器学习算法的形式。
常见的特征转换方法包括:- 独热编码(One-Hot Encoding):将离散型特征转换为二进制的向量表示形式。
ISOLET Data Set(ISOLET数据集)
数据摘要:
Goal: Predict which letter-name was spoken--a simple classification task.
中文关键词:
机器学习,ISOLET,分类,多变量,UCI,
英文关键词:
Machine Learning,ISOLET,Classification,MultiVarite,UCI,
数据格式:
TEXT
数据用途:
This data is used for classification.
数据详细介绍:
ISOLET Data Set
Abstract: Goal: Predict which letter-name was spoken--a simple classification task.
Source:
Creators:
Ron Cole and Mark Fanty
Department of Computer Science and Engineering,
Oregon Graduate Institute, Beaverton, OR 97006.
cole '@' , fanty '@'
Donor:
Tom Dietterich
Department of Computer Science
Oregon State University, Corvallis, OR 97331
tgd '@'
Data Set Information:
This data set was generated as follows. 150 subjects spoke the name of each letter of the alphabet twice. Hence, we have 52 training examples from each speaker. The speakers are grouped into sets of 30 speakers each, and are referred to as isolet1, isolet2, isolet3, isolet4, and isolet5. The data appears in isolet1+2+3+4.data in sequential order, first the speakers from isolet1, then isolet2, and so on. The test set, isolet5, is a separate file.
You will note that 3 examples are missing. I believe they were dropped due to difficulties in recording.
I believe this is a good domain for a noisy, perceptual task. It is also a very good domain for testing the scaling abilities of algorithms. For example, C4.5 on this domain is slower than backpropagation!
I have formatted the data for C4.5 and provided a C4.5-style names file as well.
Attribute Information:
The features are described in the paper by Cole and Fanty cited above. The features include spectral coefficients; contour features, sonorant features, pre-sonorant features, and
post-sonorant features. Exact order of appearance of the features is not known.
Relevant Papers:
Fanty, M., Cole, R. (1991). Spoken letter recognition. In Lippman, R. P., Moody, J., and Touretzky, D. S. (Eds). Advances in Neural Information Processing Systems 3. San Mateo, CA: Morgan Kaufmann.
[Web Link]
Dietterich, T. G., Bakiri, G. (1991) Error-correcting output codes: A general method for improving multiclass inductive learning programs. Proceedings of the Ninth National Conference on Artificial Intelligence (AAAI-91), Anaheim, CA: AAAI Press.
[Web Link]
Dietterich, T. G., Bakiri, G. (1994) Solving Multiclass Learning Problems via Error-Correcting Output Codes. Available as URL: [Web Link]
[Web Link]
Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions on Information Theory, May 1972, 431-433.
[Web Link]
See also: 1988 MLC Proceedings, 54-64.
数据预览:
点此下载完整数据集。