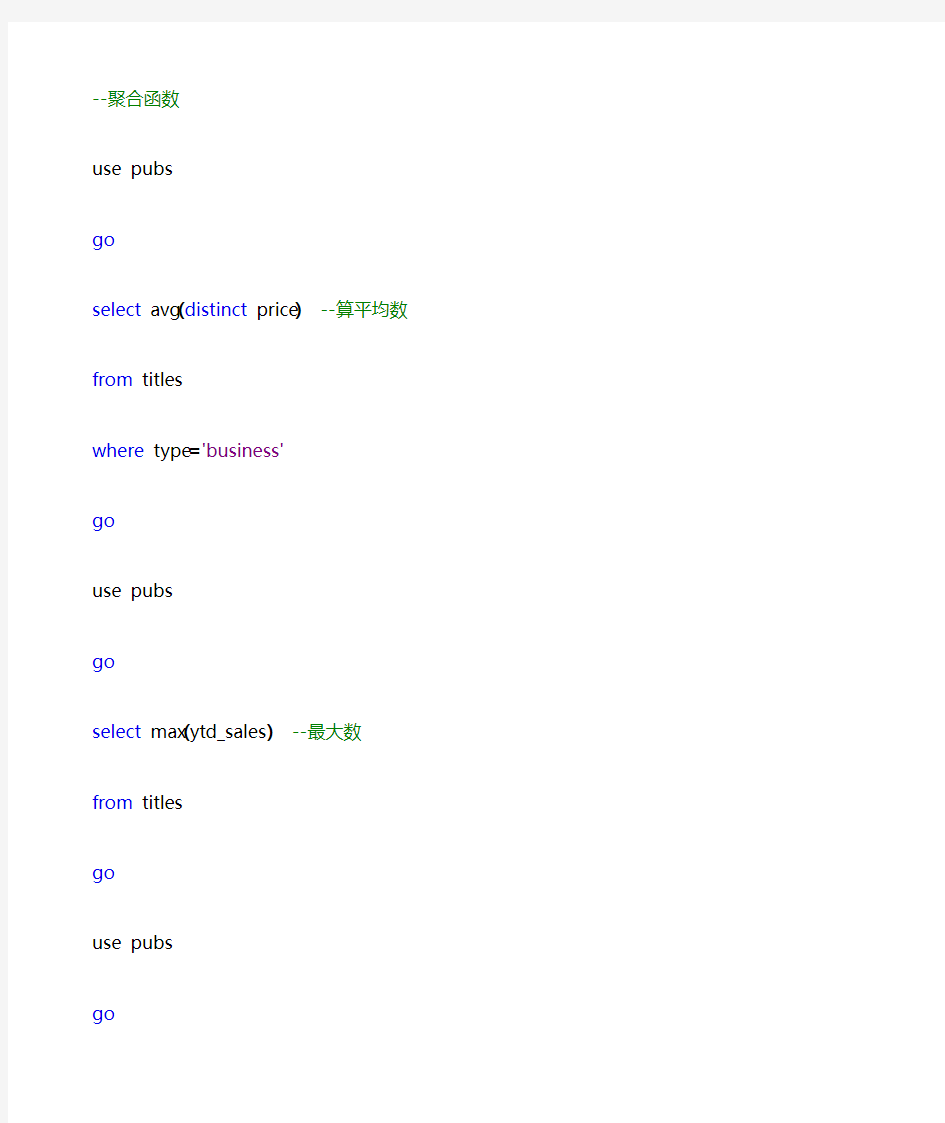

--聚合函数
use pubs
go
select avg(distinct price)--算平均数
from titles
where type='business'
go
use pubs
go
select max(ytd_sales)--最大数
from titles
go
use pubs
go
select min(ytd_sales)--最小数
from titles
go
use pubs
go
select type,sum(price),sum(advance)--求和
from titles
group by type
order by type
go
use pubs
go
select count(distinct city)--求个数
from authors
go
use pubs
go
select stdev(royalty)--返回给定表达式中所有值的统计标准偏差from titles
go
use pubs
go
select stdevp(royalty)--返回表达式中所有制的填充统计标准偏差from titles
go
use pubs
go
select var(royalty)--返回所有值的统计方差
from titles
go
use pubs
go
select varp(royalty)--返回所有值的填充的统计方差
from titles
go
--数学函数
select sin(23.45),atan(1.234),rand(),PI(),sign(-2.34)--其中rand是获得一个随机数
--配置函数
SELECT @@VERSION --获取当前数据库版本
SELECT @@LANGUAGE--当前语言
--时间函数
select getdate()as'wawa_getdate'--当前时间
select getutcdate()as'wawa_getutcdate'--获取utc时间
select day(getdate())as'wawa_day'--取出天
select month(getdate())as'wawa_month'--取出月
select year(getdate())as'wawa_year'--取出年
select dateadd(d,3,getdate())as wawa_dateadd --加三天,注意'd'表示天,'m'表示月,'yy'表示年,下面一样select datediff(d,'2004-07-01','2004-07-15')as wawa_datediff --计算两个时间的差
select datename(d,'2004-07-15')as wawa_datename --取出时间的某一部分
select datepart(d,getdate())as wawa_datepart --取出时间的某一部分,和上面的那个差不多
--字符串函数
select ascii(123)as'123',ascii('123')as'"123"',ascii('abc')as'"abc"'--转换成ascii码select char(123),char(321),char(-123)--根据ascii转换成字符
select lower('ABC'),lower('Abc'),upper('Abc'),upper('abc')--转换大小写
select str(123.45,6,1), str(123.45,2,2)--把数值转换成字符串
select ltrim(' "左边没有空格"')--去空格
select rtrim('"右边没有空格" ')--去空格
select ltrim(rtrim(' "左右都没有空格" '))--去空格
select left('sql server',3),right('sql server',6)--取左或者取右
use pubs
select au_lname,substring(au_fname,1,1)--取子串
from authors
order by au_lname
select charindex('123','abc123def',2)--返回字符串中指定表达式的起始位置
select patindex('123','abc123def'),patindex('%123%','abc123def')--返回表达式中某模式第一次出现的起始位置
select quotename('abc','{'),quotename('abc')--返回由指定字符扩住的字符串
select reverse('abc'),reverse('上海')--颠倒字符串顺序
select replace('abcdefghicde','cde','xxxx')--返回呗替换了指定子串的字符串
select space(5),space(-2)
--系统函数
select host_name()as'host_name',host_id()as'host_id',user_name()as'user_name',user_id()as 'user_id',db_name()as'db_name'
--变量的定义使用
--声明局部变量
declare @mycounter int
declare @last_name varchar(30),@fname varchar(20),@state varchar(2)--一下声明多个变量
--给变量赋值
use northwind
go
declare @firstnamevariable varchar(20),
@regionvariable varchar(30)
set@firstnamevariable='anne'--可以用set,也可以用select给变量赋值,微软推荐用set,但select在选择一个值直接赋值时很有用
set @regionvariable ='wa'
select lastname,firstname,title --用声明并赋值过的变量构建一个Select语句并查询
from employees
where firstname= @firstnamevariable or region=@regionvariable
go
--全局变量
select @@version --返回数据库版本
select @@error --返回最后的一次脚本错误
select @@identity--返回最后的一个自动增长列的id
--while,break,continue的使用
--首先计算所有数的平均价格,如果低于30的话进入循环让所有的price翻倍,
--里面又有个if来判断如果最大的单价还大于50的话,退出循环,否则继续循环,知道最大单价大于50就break出循环,呵呵,
--我分析的应该对吧.
use pubs
go
while (select avg(price)from titles)<$30
begin
update titles
set price=price*2
select max(price)from titles
if(select max(price)from titles)>$50
break
else
continue
end
print 'too much for the marker to bear'
--事务编程经典例子
--begin transaction是开始事务,commit transaction是提交事务,rollback transaction是回滚事务
--这个例子是先插入一条记录,如果出现错误的话就回滚事务,也就是取消,并直接return(返回),如果没错的话就commit 提交这个事务了哦
--上面的那个return返回可以返回一个整数值,如果这个值是0的话就是执行的时候没出错,如果出错了就是一个负数, --这个return也可以用在存储过程中,可用用 exec @return_status= pro_name来获取这个值
use pubs
go
begin tran mytran
insert into stores(stor_id,stor_name)
values('333','my books')
go
insert into discounts(discounttype,stor_id,discount)
values('清仓甩卖','9999',50.00)
if @@error<>0
begin
rollback tran mytran
print '插入打折记录出错'
return
end
commit tran mytran
--事务处理的保存点示例
--做了事务保存点后可以rollback(回滚)到指定的保存点,不至于所有的操作都不能用
use pubs
go
select*from stores
begin transaction testsavetran
insert into stores(stor_id,stor_name)
values('1234','W.Z.D Book')
save transaction before_insert_data2
go
insert into stores(stor_id,stor_name)
values('5678','foreat Books')
go
rollback transaction before_insert_data2
select*from stores
--存储存储过程
use pubs
if exists(select name from sysobjects where name='proc_calculate_taxes'and type='P') drop procedure proc_calculate_taxes
go
create procedure proc_calculate_taxes (@p1 smallint=42,@p2 char(1),@p3 varchar(8)='char') as
select*
from titles
--执行过程
EXECUTE PROC_CALCULATE_TAXES @P2='A'
excel常用函数及使用方法 一、数字处理 (一)取绝对值:=ABS(数字) (二)数字取整:=INT(数字) (三)数字四舍五入:=ROUND(数字,小数位数) 二、判断公式 (一)把公式返回的错误值显示为空: 1、公式:C2=IFERROR(A2/B2,"") 2、说明:如果是错误值则显示为空,否则正常显示。 (二)IF的多条件判断 1、公式:C2=IF(AND(A2<500,B2="未到期"),"补款","") 2、说明:两个条件同时成立用AND,任一个成立用OR函数。 三、统计公式 (一)统计两表重复 1、公式:B2=COUNTIF(Sheet15!A:A,A2) 2、说明:如果返回值大于0说明在另一个表中存在,0则不存在。 (二)统计年龄在30~40之间的员工个数 公式=FREQUENCY(D2:D8,{40,29} (三)统计不重复的总人数 1、公式:C2=SUMPRODUCT(1/COUNTIF(A2:A8,A2:A8)) 2、说明:用COUNTIF统计出每人的出现次数,用1除的方式把出现次数变成分母,然后相加。
(四)按多条件统计平均值 =AVERAGEIFS(D:D,B:B,"财务",C:C,"大专") (五)中国式排名公式 =SUMPRODUCT(($D$4:$D$9>=D4)*(1/COUNTIF(D$4:D$9,D$4:D$9))) 四、求和公式 (一)隔列求和 1、公式:H3=SUMIF($A$2:$G$2,H$2,A3:G3) 或=SUMPRODUCT((MOD(COLUMN(B3:G3),2)=0)*B3:G3) 2、说明:如果标题行没有规则用第2个公式 (二)单条件求和 1、公式:F2=SUMIF(A:A,E2,C:C) 2、说明:SUMIF函数的基本用法 (三)单条件模糊求和 说明:如果需要进行模糊求和,就需要掌握通配符的使用,其中星号是表示任意多个字符,如"*A*"就表示a前和后有任意多个字符,即包含A。 (四)多条求模糊求和 1、公式:=SUMIFS(C2:C7,A2:A7,A11&"*",B2:B7,B11) 2、说明:在sumifs中可以使用通配符* (五)多表相同位置求和 1、公式:=SUM(Sheet1:Sheet19!B2) 2、说明:在表中间删除或添加表后,公式结果会自动更新。
15 个常用的Excel函数公式,拿来即用1、查找重复内容 =IF(COUNTIF(A:A,A2)>1," 重复","") 2、重复内容首次出现时不提示 =IF(COUNTIF(A$2:A2,A2)>1," 重复","") 3、重复内容首次出现时提示重复 =IF(COUNTIF(A2:A99,A2)>1," 重复","")
4、根据出生年月计算年龄 =DATEDIF(A2,TODAY(),"y") 5、根据身份证号码提取出生年月 =--TEXT(MID(A2,7,8),"0-00- 00") 6、根据身份证号码提取性别 =IF(MOD(MID(A2,15,3),2)," 男"," 女") 7、几个常用的汇总公式 A列求和:=SUM(A:A)
A列最小值: =MIN(A:A) A列最大值: =MAX (A:A) A列平均值: =AVERAGE(A:A) A列数值个数: =COUNT(A:A) 8、成绩排名 =RANK.EQ(A2,A$2:A$7) 9、中国式排名(相同成绩不占用名次) =SUMPRODUCT((B$2:B$7>B2)/COUNTIF(B$2:B$7,B$2:B$7))+1 10、90 分以上的人数
=COUNTIF(B1:B7,">90") 11、各分数段的人数 同时选中 E2:E5,输入以下公式,按 Shift+Ctrl+Enter =FREQUENCY(B2:B7,{70;80;90}) 12、按条件统计平均值 =AVERAGEIF(B2:B7,"男",C2:C7) 13、多条件统计平均值 =AVERAGEIFS(D2:D7,C2:C7,男"",B2:B7," 销售")
18个Excel最常用的公式运算技巧总结 大家经常用Excel处理表格和数据,在处理表格和数据过程中,会用到公式和函数,下面我们就为大家整理一些Excel常用公式及使用方法,希望对大家有所帮助。 一、查找重复内容公式:=IF(COUNTIF(A:AA2)>1”重复””")。 二、用出生年月来计算年龄公式: =TRUNC((DAYS360(H6”2009/8/30″FALSE))/3600)。 三、从输入的18位身份证号的出生年月计算公式: =CONCATENATE(MID(E274)”/”MID(E2112)”/”MID(E2132))。 四、从输入的身份证号码内让系统自动提取性别,可以输入以下公式:=IF(LEN(C2)=15IF(MOD(MID(C2151)2)=1”男””女”)IF(MOD(MID(C2171)2)=1”男””女”))公式内的“C2”代表的是输入身份证号码的单元格。 五、求和:=SUM(K2:K56) ——对K2到K56这一区域进行求和;
六、平均数:=AVERAGE(K2:K56) ——对K2 K56这一区域求平均数; 七、排名:=RANK(K2,K$2:K$56) ——对55名学生的成绩进行排名; 八、等级:=IF(K2>=85”优”IF(K2>=74”良”IF(K2>=60”及格””不及格”))) 九、学期总评:=K2*0.3+M2*0.3+N2*0.4 ——假设K列、M列和N列分别存放着学生的“平时总评”、“期中”、“期末”三项成绩; 十、最高分:=MAX(K2:K56) ——求K2到K56区域(55名学生)的最高分; 十一、最低分:=MIN(K2:K56) ——求K2到K56区域(55名学生)的最低分; 十二、分数段人数统计:
Excel函数公式大全工作中最常用Excel函数公式大全 一、数字处理 1、取绝对值 =ABS(数字) 2、取整 =INT(数字) 3、四舍五入 =ROUND(数字,小数位数) 二、判断公式 1、把公式产生的错误值显示为空 公式:C2 =IFERROR(A2/B2,"") 说明:如果是错误值则显示为空,否则正常显示。 ? 2、IF多条件判断返回值 公式:C2 =IF(AND(A2<500,B2="未到期"),"补款","") 说明:两个条件同时成立用AND,任一个成立用OR函数.
? 三、统计公式 1、统计两个表格重复的内容 公式:B2 =COUNTIF(Sheet15!A:A,A2) 说明:如果返回值大于0说明在另一个表中存在,0则不存在。 ? 2、统计不重复的总人数 公式:C2 =SUMPRODUCT(1/COUNTIF(A2:A8,A2:A8)) 说明:用COUNTIF统计出每人的出现次数,用1除的方式把出现次数变成分母,然后相加。
? 四、求和公式 1、隔列求和 公式:H3 =SUMIF($A$2:$G$2,H$2,A3:G3) 或 =SUMPRODUCT((MOD(COLUMN(B3:G3),2)=0)*B3:G3) 说明:如果标题行没有规则用第2个公式 ? 2、单条件求和 公式:F2 =SUMIF(A:A,E2,C:C) 说明:SUMIF函数的基本用法
? 3、单条件模糊求和 公式:详见下图 说明:如果需要进行模糊求和,就需要掌握通配符的使用,其中星号是表示任意多个字符,如"*A*"就表示a前和后有任意多个字符,即包含A。 ? 4、多条件模糊求和 公式:C11 =SUMIFS(C2:C7,A2:A7,A11&"*",B2:B7,B11) 说明:在sumifs中可以使用通配符*
高可用MS SQL Server数据库解决方案 建设目标 减少硬件或软件故障造成的影响,保持业务连续性,从而将用户可以察觉到的停机时间减至最小,确保数据库服务7*24小时(RTO为99.9%)运转,建设一套完整的高可用性MS SQL Server数据库系统。 需求分析 服务器宕机造成的影响 服务器宕机时间使得丢失客户收益并降低员工生产效率,为了避免对业务造成影响,从两个方面采取预防措施: 一、计划宕机时的可用性: ●补丁或补丁包安装 ●软硬件升级 ●更改系统配置 ●数据库维护 ●应用程序升级 二、防止非计划性宕机: ●人为错误导致的失败 ●站点灾难 ●硬件故障
●数据损毁 ●软件故障 现有状况 ●服务器存在单点故障; ●数据库未做高可用性配置; ●数据库版本为MS SQL Server2008; ●服务器配置为CPU E7540 2.0,24G存; ●数据库容量约800G 技术解决方案 解决思路 考虑到本项目的需求和最佳性能,为了达到最佳可用性,方案采用两台数据库服务器做故障转移集群,连接同一台存储做数据库的共享存储,实现故障自动转移。同时,将旧服务器作为镜像数据库,采用SQL Server 2012的alwayson 功能来再次完成自动故障转移,并可以分担查询的负载。
架构拓扑 新数据库:承担数据库主体计算功能,用于生产数据,采用双机集群,实现自动故障转移。 旧数据库:通过镜像功能,存储数据库副本,用于发生故障时的转移。也可配置为只读,承担备份的负载。 存储:存储采用双控制器,双FC连接两台服务器,避免单点故障。 主/辅域控制器:采用双机模式,SQL Server 2012 实现高可用的必备基础设施。 高可靠性技术方案 SQL Server的企业版支持所有的高可用性功能,这些功能包括:
电脑办公常用的Excel函数 公式及设计方法与技巧 一、数字处理 1、取绝对值 =ABS(数字) 2、取整 =INT(数字) 3、四舍五入 =ROUND(数字,小数位数) 二、判断公式 1、把公式产生的错误值显示为空 公式:C2 =IFERROR(A2/B2,"") 说明:如果是错误值则显示为空,否则正常显示。 2、IF多条件判断返回值 公式:C2
=IF(AND(A2<500,B2="未到期"),"补款","") 说明:两个条件同时成立用AND,任一个成立用OR函数。 三、统计公式 1、统计两个表格重复的内容 公式:B2 =COUNTIF(Sheet15!A:A,A2) 说明:如果返回值大于0说明在另一个表中存在,0则不存在。 2、统计不重复的总人数 公式:C2
=SUMPRODUCT(1/COUNTIF(A2:A8,A2:A8)) 说明:用COUNTIF统计出每人的出现次数,用1除的方式把出现次数变成分母,然后相加。 四、求和公式 1、隔列求和 公式:H3 =SUMIF($A$2:$G$2,H$2,A3:G3) 或 =SUMPRODUCT((MOD(COLUMN(B3:G3),2)=0)*B3:G3) 说明:如果标题行没有规则用第2个公式。 2、单条件求和 公式:F2
=SUMIF(A:A,E2,C:C) 说明:SUMIF函数的基本用法。 3、单条件模糊求和 公式:详见下图 说明:如果需要进行模糊求和,就需要掌握通配符的使用,其中星号是表示任意多个字符,如"*A*"就表示a前和后有任意多个字符,即包含A。 4、多条件模糊求和 公式:C11
§1、4 常用得分布及其分位数 1、 卡平方分布 卡平方分布、t 分布及F 分布都就是由正态分布所导出得分布,它们与正态分布一起,就是试验统计中常用得分布。 当X 1、X 2、… 、Xn 相互独立且都服从N(0,1)时,Z=∑i i X 2 得分布称为自由度等于n 得2χ分布,记作Z ~2χ(n),它得分布 密度 p(z )=??? ????>??? ??Γ--,,00,2212122其他z e x n z n n 式中得??? ??Γ2n =u d e u u n ?∞+--012,称为Gamma 函数,且()1Γ=1, ?? ? ??Γ21=π。2χ分布就是非对称分布,具有可加性,即当Y 与Z 相互独立,且Y ~2χ(n ),Z ~2χ(m ),则Y+Z ~2χ(n+m )。 证明: 先令X 1、X 2、…、X n 、X n+1、X n+2、…、 X n+m 相互独立且都服从N(0,1),再根据2χ分布得定义以及上述随机变量得相互独立性,令 Y=X 21+X 22+…+X 2n ,Z=X 21+n +X 22+n +…+X 2m n +, Y+Z= X 21+X 22+…+X 2n + X 21+n +X 22+n +…+X 2m n +, 即可得到Y+Z ~2χ(n +m )。 2、 t 分布 若X 与Y 相互独立,且 X ~N(0,1),Y ~2χ(n ),则Z =n Y X 得分布称为自由度等于n 得t 分布,记作Z ~ t (n ),它得分布密度 P(z)=)()(221n n n ΓΓ+2121+-???? ??+n n z 。 请注意:t 分布得分布密度也就是偶函数,且当n>30时,t
15个常用的Excel函数公式,拿来即用 1、查找重复内容 =IF(COUNTIF(A:A,A2)>1,"重复","") 2、重复内容首次出现时不提示 =IF(COUNTIF(A$2:A2,A2)>1,"重复","") 3、重复内容首次出现时提示重复 =IF(COUNTIF(A2:A99,A2)>1,"重复","")
4、根据出生年月计算年龄 =DATEDIF(A2,TODAY(),"y") 5、根据身份证号码提取出生年月 =--TEXT(MID(A2,7,8),"0-00-00") 6、根据身份证号码提取性别 =IF(MOD(MID(A2,15,3),2),"男","女") 7、几个常用的汇总公式 A列求和:=SUM(A:A)
A列最小值:=MIN(A:A) A列最大值:=MAX (A:A) A列平均值:=AVERAGE(A:A) A列数值个数:=COUNT(A:A) 8、成绩排名 =RANK.EQ(A2,A$2:A$7) 9、中国式排名(相同成绩不占用名次) =SUMPRODUCT((B$2:B$7>B2)/COUNTIF(B$2:B$7,B$2:B$7))+1 10、90分以上的人数
=COUNTIF(B1:B7,">90") 11、各分数段的人数 同时选中E2:E5,输入以下公式,按Shift+Ctrl+Enter =FREQUENCY(B2:B7,{70;80;90}) 12、按条件统计平均值 =AVERAGEIF(B2:B7,"男",C2:C7) 13、多条件统计平均值 =AVERAGEIFS(D2:D7,C2:C7,"男",B2:B7,"销售")
三角函数公式及其记忆方法 一、同角三角函数的基本关系式 (一)基本关系 1、倒数关系 1cot tan =?αα 1csc sin =?αα 1sec cos =?αα 2、商的关系 αααtan cos sin = ααα tan csc sec = αααcot sin cos = αα α cot sec csc = 3、平方关系 1cos sin 22=+αα αα22sec tan 1=+ αα22csc cot 1=+ (二)同角三角函数关系六角形记忆法 构造以"上弦、中切、下割;左正、右余、中间1"的正六边形为模型。 1、倒数关系 对角线上两个函数互为倒数; 2、商数关系 六边形任意一顶点上的函数值等于与它相邻的两个顶点上函数值的乘积。 (主要是两条虚线两端的三角函数值的乘积,下面4个也存在这种关系。)。由此,可得商数关系式。 3、平方关系 在带有阴影线的三角形中,上面两个顶点上的三角函数值的平方和等于下面 顶点上的三角函数值的平方。 二、诱导公式的本质 所谓三角函数诱导公式,就是将角n·(π/2)±α的三角函数转化为角α的三角函数。 (一)常用的诱导公式 1、公式一: 设α为任意角,终边相同的角的同一三角函数的值相等: z k k ∈=+,sin )2sin(ααπ z k k ∈=+,cos )2cos(ααπ z k k ∈=+,tan )2tan(ααπ z k k ∈=+,cot )2cot(ααπ z k k ∈=+,sec )2sec(ααπ z k k ∈=+,csc )2csc(ααπ 2、公式二:α为任意角,π+α的三角函数值与α的三角函数值之间的关系: ααπsin )sin(-=+ ααπcos )cos(-=+ ααπtan )tan(=+ ααπcot )cot(=+ ααπsec )sec(-=+ ααπcsc )csc(-=+ 3、公式三:任意角α与 -α的三角函数值之间的关系: ααsin )sin(-=- ααcos )cos(=- ααtan )tan(-=- ααcot )cot(-=- ααsec )sec(=- ααcsc )csc(-=-
概率论中几种常用的重要的分布 摘要:本文主要探讨了概率论中的几种常用分布,的来源和他们中间的关系。其在实际中的应用。 关键词 1 一维随机变量分布 随机变量的分布是概率论的主要内容之一,一维随机变量部分要介绍六中常 用分布,即( 0 -1) 分布、二项分布、泊松分布、均匀分布、指数分布和正态分布. 下面我们将对这六种分布逐一地进行讨论. 随机事件是按试验结果而定出现与否的事件。它是一种“定性”类型的概念。为了进一步研究有关随机试验的问题,还需引进一种“定量”类型的概念,即,根据试验结果而定取什么值(实值或向量值)的变数。称这种变数为随机变数。本章内将讨论取实值的这种变数—— 一维随机变数。 定义1.1 设X 为一个随机变数,令 ()([(,)])([]),()F x P X x P X x x =∈-∞=-∞ +∞. 这样规定的函数()F x 的定义域是整个实轴、函数值在区间[0,1]上。它是一个普通的函数。成这个函数为随机函数X 的分布函数。 有的随机函数X 可能取的值只有有限多个或可数多个。更确切地说:存在着有限多个值或可数多个值12,,...,a a 使得 12([{,,...}])1P X a a ∈= 称这样的随机变数为离散型随机变数。称它的分布为离散型分布。 【例1】下列诸随机变数都是离散型随机变数。 (1)X 可能取的值只有一个,确切地说,存在着一个常数a ,使([])1P X a ==。称这种随机变数的分布为退化分布。一个退化分布可以用一个常数a 来确定。 (2)X 可能取的值只有两个。确切地说,存在着两个常数a ,b ,使 ([{,}])1P X a b ∈=.称这种随机变数的分布为两点分布。如果([])P X b p ==,那 么,([])1P X a p ===-。因此,一个两点分布可以用两个不同的常数,a b 及一个在区间(0,1)内的值p 来确定。 特殊地,当,a b 依次为0,1时,称这两点分布为零-壹分布。从而,一个零-壹分布可以用一个在区间(0,1)内的值p 来确定。 (3)X 可能取的值只有n 个:12,...,a a (这些值互不相同),且,取每个i a 值
工作中最常用的excel函数公式大全 一、数字处理 1、取绝对值=ABS(数字) 2、取整=INT(数字) 3、四舍五入=ROUND(数字,小数位数) 二、判断公式 1、把公式产生的错误值显示为空 公式:C2=IFERROR(A2/B2,"") 说明:如果是错误值则显示为空,否则正常显示。 2、IF多条件判断返回值公式: C2=IF(AND(A2<500,B2="未到期"),"补款","") 说明:两个条件同时成立用AND,任一个成立用OR函数。
1、统计两个表格重复的内容 公式:B2=COUNTIF(Sheet15!A:A,A2) 说明:如果返回值大于0说明在另一个表中存在,0则不存在。 2、统计不重复的总人数 公式:C2=SUMPRODUCT(1/COUNTIF(A2:A8,A2:A8)) 说明:用COUNTIF统计出每人的出现次数,用1除的方式把出现次数变成分母,然后相加。
1、隔列求和 公式:H3=SUMIF($A$2:$G$2,H$2,A3:G3) 或=SUMPRODUCT((MOD(COLUMN(B3:G3),2)=0)*B3:G3) 说明:如果标题行没有规则用第2个公式 2、单条件求和 公式:F2=SUMIF(A:A,E2,C:C) 说明:SUMIF函数的基本用法
3、单条件模糊求和 公式:详见下图 说明:如果需要进行模糊求和,就需要掌握通配符的使用,其中星号是表示任意多个字符,如"*A*"就表示a前和后有任意多个字符,即包含A。 4、多条件模糊求和 公式:C11=SUMIFS(C2:C7,A2:A7,A11&"*",B2:B7,B11) 说明:在sumifs中可以使用通配符*
MSSQL2008导入数据教程 一、导入数据的前提条件: 1、必需安装SQL SERVER2008 企业管理器——(SQL SERVER 一般会简称成MSSQL) 2、网络必需稳定,如果网络太慢客户端的MSSQL管理器会出现假死状态 二、需要了解的知识: 1、一个数据库可以包含多个数据表、多个存储过程、多个视图、函数等; 2、一个数据表肯定包含了多条数据行,比如文章内容就存在数据表里;
3、视图可以理解为虚拟的数据表,这个表的数据来自物理数据表,比如可以把三个表合成一个视图以便查询; 4、存储过程和函数是一段SQL脚本,它们大大增强了SQL语言的功能和灵活性;
通过以上的内容已经大概了解了SQL数据库需要的一些知识,下面开始来导数据。 三、数据导入的总体步骤: 1、在本机连接到远程服务器。 2、在本机生成SQL脚本,并把本机生成的脚本放到远程执行(这一步会建好表结构存储过程之类的,但没有把表里的数据行导进去)。 3、导入数据表里的数据(这一步就是把本机数据表里的数据行导入到远程的数据表)。 注意:以下演示涉及到的地址、用户名密码等信息为举例说明,实际操作请按自己所取得的主机信息填写。
例如:本地电脑上有个数据库,这个数据库包含"数据表"、"视图"、"自定义函数"、"存储过程",要把这些都导到远程服务器。 例如:购买的主机MSSQL数据库的远程服务器信息是这样的: 数据库地址: https://www.doczj.com/doc/5115303975.html, 数据库用户名:hds100005678 数据库密码:****** 第一步:在本机连接到远程服务器;
连接成功后可以看到在本机的MSSQL管理器上多了个服务器节点; 第二步:在本机生成SQL脚本,并把本机生成的脚本放到远程执行;
常用的excel函数公式大全 一、数字处理 1、取绝对值 =ABS(数字) 2、取整 =INT(数字) 3、四舍五入 =ROUND(数字,小数位数) 二、判断公式 1、把公式产生的错误值显示为空 公式:C2 =IFERROR(A2/B2,"") 说明:如果是错误值则显示为空,否则正常显示。
2、IF多条件判断返回值 公式:C2 =IF(AND(A2<500,B2="未到期"),"补款","") 说明:两个条件同时成立用AND,任一个成立用OR函数。 三、统计公式 1、统计两个表格重复的内容 公式:B2 =COUNTIF(Sheet15!A:A,A2) 说明:如果返回值大于0说明在另一个表中存在,0则不存在。
2、统计不重复的总人数 公式:C2 =SUMPRODUCT(1/COUNTIF(A2:A8,A2:A8)) 说明:用COUNTIF统计出每人的出现次数,用1除的方式把出现次数变成分母,然后相加。 四、求和公式
1、隔列求和 公式:H3 =SUMIF($A$2:$G$2,H$2,A3:G3) 或 =SUMPRODUCT((MOD(COLUMN(B3:G3),2)=0)*B3:G3)说明:如果标题行没有规则用第2个公式 2、单条件求和 公式:F2 =SUMIF(A:A,E2,C:C) 说明:SUMIF函数的基本用法
3、单条件模糊求和 公式:详见下图 说明:如果需要进行模糊求和,就需要掌握通配符的使用,其中星号是表示任意多个字符,如"*A*"就表示a前和后有任意多个字符,即包含A。
4、多条件模糊求和 公式:C11 =SUMIFS(C2:C7,A2:A7,A11&"*",B2:B7,B11) 说明:在sumifs中可以使用通配符* 5、多表相同位置求和 公式:b2 =SUM(Sheet1:Sheet19!B2) 说明:在表中间删除或添加表后,公式结果会自动更新。 6、按日期和产品求和
目录 1. 均匀分布 (1) 2. 正态分布(高斯分布) (2) 3. 指数分布 (2) 4. Beta分布(:分布) (2) 5. Gamm 分布 (3) 6. 倒Gamm分布 (4) 7. 威布尔分布(Weibull分布、韦伯分布、韦布尔分布) (5) 8. Pareto 分布 (6) 9. Cauchy分布(柯西分布、柯西-洛伦兹分布) (7) 2 10. 分布(卡方分布) (7) 8 11. t分布................................................ 9 12. F分布 ............................................... 10 13. 二项分布............................................ 10 14. 泊松分布(Poisson 分布)............................. 11 15. 对数正态分布........................................
1. 均匀分布 均匀分布X ~U(a,b)是无信息的,可作为无信息变量的先验分布。
2. 正态分布(高斯分布) 当影响一个变量的因素众多,且影响微弱、都不占据主导地位时,这个变量 很可能服从正态分布,记作 X~N (」f 2)。正态分布为方差已知的正态分布 N (*2)的参数」的共轭先验分布。 1 空 f (x ): —— e 2- J2 兀 o' E(X), Var(X) _ c 2 3. 指数分布 指数分布X ~Exp ( )是指要等到一个随机事件发生,需要经历多久时间。其 中,.0为尺度参数。指数分布的无记忆性: Plx s t|X = P{X t}。 f (X )二 y o i E(X) 一 4. Beta 分布(一:分布) f (X )二 E(X) Var(X)= (b-a)2 12 Var(X)二 1 ~2
EXCEL的常用函数计算公式速记使用技巧-(举例)一、单组数据加减乘除运算指令: ①单组数据求乘法公式:=(A1/B1) 举例:在C1中输入 =A1/B1 即求10与5的商值2,电脑操作方法同上; ②单组数据求乘法公式:=(A1*B1) 举例:在C1中输入 =A1*B1 即求10与5的积值50,电脑操作方法同上; ③单组数据求减差公式:=(A1-B1) 举例:在C1中输入 =A1-B1 即求10与5的差值5,电脑操作方法同上; ④单组数据求加和公式:=(A1+B1) 举例:单元格A1:B1区域依次输入了数据10和5,计算:在C1中输入 =A1+B1 后点击键盘“Enter(确定)”键后,该单元格就自动显示10与5的和15。 ⑤其它应用: 在D1中输入 =A1^3 即求5的立方(三次方); 在E1中输入 =B1^(1/3)即求10的立方根 小结:在单元格输入的含等号的运算指令式,Excel中称之为公式,都是数学里面的基本运算指令,只不过在计算机上有的运算指令符号发生了改变——“×”与“*”同、“÷”与“/”同、“^”与“乘方”相同,开方作为乘方的逆运算指令,把乘方中和指数使用成分数就成了数的开方运算指令。这些符号是按住电脑键盘“Shift”键同时按住键盘第二排相对应的数字符号即可显示。如果同一列的其它单元格都需利用刚才的公式计算,只需要先用鼠标左键点击一下刚才已做好公式的单元格,将鼠标
移至该单元格的右下角,带出现十字符号提示时,开始按住鼠标左键不动一直沿着该单元格依次往下拉到你需要的某行同一列的单元格下即可,即可完成公司自动复制,自动计算。 二、多组数据加减乘除运算指令: ①多组数据求加和公式:(常用) 举例说明:=SUM(A1:A10),表示同一列纵向从A1到A10的所有数据相加; =SUM(A1:J1),表示不同列横向从A1到J1的所有第一行数据相加; ②多组数据求乘积公式:(较常用) 举例说明:=PRODUCT(A1:J1)表示不同列从A1到J1的所有第一行数据相乘; =PRODUCT(A1:A10)表示同列从A1到A10的所有的该列数据相乘; ③多组数据求相减公式:(很少用) 举例说明:=A1-SUM(A2:A10)表示同一列纵向从A1到A10的所有该列数据相减; =A1-SUM(B1:J1)表示不同列横向从A1到J1的所有第一行数据相减; ④多组数据求除商公式:(极少用) 举例说明:=A1/PRODUCT(B1:J1)表示不同列从A1到J1的所有第一行数据相除; =A1/PRODUCT(A2:A10)表示同列从A1到A10的所有的该列数据相除; 三、其它应用函数代表指令: ①平均函数 =AVERAGE(:);②最大值函数 =MAX (:);③最小值函数 =MIN (:); ④统计函数 =COUNTIF(:):举例:Countif ( A1:B5,”>60”) 说明:统计分数大于60分的人数,注意,条件要加双引号,在英文状态下输入。 1、请教excel中同列重复出现的货款号应怎样使其合为一列,并使款号后的数 值自动求和?
首先,简要介绍基础语句: 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only 5、说明:删除新表drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键:Alter table tabname add primary key(col) 说明:删除主键:Alter table tabname drop primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:drop view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ?%value1%? ---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count(*) as totalcount from table1 求和:select sum(field1) as sumvalue from table1 平均:select avg(field1) as avgvalue from table1 最大:select max(field1) as maxvalue from table1 最小:select min(field1) as minvalue from table1 11、说明:几个高级查询运算词 A:UNION 运算符 UNION 运算符通过组合其他两个结果表(例如TABLE1 和TABLE2)并消去表中任何重复行而派生出一个结果表。当ALL 随UNION 一起使用时(即UNION ALL),不消除重
(Excel)常用函数公式及操作技巧之六: 条件自定义格式(二) ——通过知识共享树立个人品牌。常用的自定义格式 单元格属性自定义中的“G/通用格式“和”@”作用有什么不同? 设定成“G/通用格式“的储存格,你输入数字1..9它自动认定为数字,你输入文字a..z它自动认定为文字,你输入数字1/2它会自动转成日期。 设定成“@“的储存格,不管你输入数字1..9、文字a..z、1/2,它一律认定为文字。 文字与数字的不同在於数字会呈现在储存格的右边,文字会呈现在储存格的左边。 常用的自定义格式拿出来大家分享 我最常用的有: 1. 0”文本”、0.0”文本”、0.00”文本”等(输入带单位符号的数值); 2. #”文本”、#.#”文本”、###,###.##”文本”等(同上); 3. [DBNum1][$-804]G/通用格式、[DBNum2][$-804]G/通用格式等(数值的大小写格式); 4.@”文本”(在原有的文本上加上新文本或数字); 5.0000000 (发票号码等号码输入); 6. yyyy/mm 7. yyyy/m/d aaaa -->ex. 2003/12/20 星期六 8. m"月"d"日" (ddd) -->ex. 12月20日(Sat) 9. "Subject (Total: "0")" -->单纯加上文字 10. "Balance"* #,##0_ -->对齐功能 11. [蓝色]+* #,##0_ ;-* #,##0_ -->正负数的颜色变化 12. **;**;**;** -->仿真密码保护(搭配sheet保护) 13. [红色][<0];[绿色][>0] (小于0时显示红色,大于0时绿色,都以绝对值显示) 14 [>0]#,##0.00;[<0]#,##0.00;0.00 (会计格式,以绝对值形式显示) 自定义格式 Excel中预设了很多有用的数据格式,基本能够满足使用的要求,但对一些特殊的要求,如强调显示某些重要数据或信息、设置显示条件等,就要使用自定义格式功能来完成。Excel的自定义格式使用下面的通用模型:正数格式,负
1、查找重复内容公式:=IF(COUNTIF(A:A,A2)>1,"重复","")。 2、用出生年月来计算年龄公式: =TRUNC((DAYS360(H6,"2009/8/30",FALSE))/360,0)。 3、从输入的18位身份证号的出生年月计算公式: =CONCATENATE(MID(E2,7,4),"/",MID(E2,11,2),"/",MID(E2,13,2))。 4、从输入的身份证号码内让系统自动提取性别,可以输入以下公式: =IF(LEN(C2)=15,IF(MOD(MID(C2,15,1),2)=1,"男","女"),IF(MOD(MID(C2,17,1),2)=1,"男","女"))公式内的“C2”代表的是输入身份证号码的单元格。 1、求和:=SUM(K2:K56) ——对K2到K56这一区域进行求和; 2、平均数:=AVERAGE(K2:K56) ——对K2 K56这一区域求平均数; 3、排名:=RANK(K2,K$2:K$56) ——对55名学生的成绩进行排名; 4、等级:=IF(K2>=85,"优",IF(K2>=74,"良",IF(K2>=60,"及格","不及格"))) 5、学期总评:=K2*0.3+M2*0.3+N2*0.4 ——假设K列、M列和N列分别存放着学生的“平时总评”、“期中”、“期末”三项成绩; 6、最高分:=MAX(K2:K56) ——求K2到K56区域(55名学生)的最高分;
7、最低分:=MIN(K2:K56) ——求K2到K56区域(55名学生)的最低分; 8、分数段人数统计: (1)=COUNTIF(K2:K56,"100") ——求K2到K56区域100分的人数;假设把结果存放于K57单元格; (2)=COUNTIF(K2:K56,">=95")-K57 ——求K2到K56区域95~99.5分的人数;假设把结果存放于K58单元格; (3)=COUNTIF(K2:K56,">=90")-SUM(K57:K58) ——求K2到K56区域90~94.5分的人数;假设把结果存放于K59单元格; (4)=COUNTIF(K2:K56,">=85")-SUM(K57:K59) ——求K2到K56区域85~89.5分的人数;假设把结果存放于K60单元格; (5)=COUNTIF(K2:K56,">=70")-SUM(K57:K60) ——求K2到K56区域70~84.5分的人数;假设把结果存放于K61单元格; (6)=COUNTIF(K2:K56,">=60")-SUM(K57:K61) ——求K2到K56区域60~69.5分的人数;假设把结果存放于K62单元格; (7)=COUNTIF(K2:K56,"<60") ——求K2到K56区域60分以下的人数;假设把结果存放于K63单元格;
excel常用函数公式及技巧搜集5 博客分类: ExcelVBA及公式应用 对带有单位的数据如何进行求和 在数据后必须加入单位,到最后还要统计总和,请问该如何自动求和?(例如:A1:2KG,A2:6KG.....,在最后一行自动计算出总KG数)。 =SUMPRODUCT(--LEFT(A1:A5,(LEN(A1:A5)-2)))&”KG” 对a列动态求和 可以随着a列数据的增加,在“b1”单元格=sum(x)对a列动态求和。 =SUM(OFFSET(A1,0,0,COUNTA(A:A),1)) 动态求和公式 自A列A1单元格到当前行前面一行的单元格求和。 =SUM(INDIRECT("A1:A"&ROW()-1)) 列的跳跃求和 若有20列(只有一行),需没间隔3列求和,该公式如何做? 假设a1至t1为数据(共有20列),在任意单元格中输入公式: =SUM(IF(MOD(TRANSPOSE(ROW(1:20)),3)=0,(a1:t1)) 按ctrl+shift+enter结束即可求出每隔三行之和。 跳行设置:如有12行,需每隔3行求和 =SUM(IF(MOD((ROW(1:12)),3)=0,(A1:A12))) 有规律的隔行求和 要求就是在计划、实际、差异三项中对后面的12个月求和。 =SUMPRODUCT(--(MOD(COLUMN(F3:AO3)-CELL("Col",F3)+0,3)=0),F3:AO3) =SUMIF($F$2:$AO$2,C$2,$F3:$AO3)
=SUMPRODUCT((MOD(COLUMN($F3:$AO3),3)=MOD(COLUMN(F3),3))*$F3:$AO3) 也可以拖动填充,插入行、列也不影响计算结果。 如何实现奇数行或偶数行求和 假设数据在A1:A100 奇数行:=SUMPRODUCT(MOD(ROW($A$1:$A$100),2)*$A$1:$A$100) 偶数行:=SUMPRODUCT((MOD(ROW($A$1:$A$100),2)=0)*($A$1:$A$100)) 奇数行求和=SUMPRODUCT((A1:A100)*MOD(ROW(A1:A100),2)) 偶数行求和=SUMPRODUCT((A1:A100)*NOT(MOD(ROW(A1:A100),2))) 单数行求和 隔行求和用什么函数,即:A1+A3+A5+A7+A9…公式如何用。 {=SUM(N(OFFSET(A1,ROW(1:50)*2-2,)))} {=SUM(IF(MOD(ROW(A1:A100),2)=1,A1:A100,0))} 统计偶数单元格合计数值 统计F4到F62的偶数单元格合计数值。 {=SUM(IF(MOD(ROW(F4:F62),2)=0,F4:F62))} 隔行求和公式设置 均为数组公式: =SUM(IF(MOD(ROW(A1:A110),2),A1:A110,0)) =SUM(N(OFFSET($A$1,ROW(1:55)*2-2,,,))) =SUM((MOD(ROW(A1:A100),2)=1)*(A1:A100)) =SUM((MOD(ROW(A1:A100),2)=0)*(A1:A100)) =SUMPRODUCT((MOD(ROW(A1:A100),2)=0)*A1:A100) 隔列将相同项目进行求和 隔列将出勤日和工资分别进行求和
§1.4 常用的分布及其分位数 1. 卡平方分布 卡平方分布、t 分布及F 分布都是由正态分布所导出的分布,它们与正态分布一起,是试验统计中常用的分布。 当X 1、X 2、…、Xn 相互独立且都服从N(0,1)时,Z=∑i i X 2 的 分布称为自由度等于n 的2χ分布,记作Z ~2χ(n),它的分 布密度 p(z )=???????>??? ??Γ--,,00,2212122其他z e x n z n n 式中的??? ??Γ2n =u d e u u n ?∞+--012,称为Gamma 函数,且()1Γ=1, ?? ? ??Γ21=π。2χ分布是非对称分布,具有可加性,即当Y 与Z 相互独立,且Y ~2χ(n ),Z ~2χ(m ),则Y+Z ~2χ(n+m )。 证明: 先令X 1、X 2、…、X n 、X n+1、X n+2、…、 X n+m 相互独立且都服从N(0,1),再根据2χ分布的定义以及上述随机变量的相互独立性,令 Y=X 21+X 22+…+X 2n ,Z=X 21+n +X 22+n +…+X 2m n +, Y+Z= X 21+X 22+…+X 2n + X 21+n +X 22+n +…+X 2m n +, 即可得到Y+Z ~2χ(n +m )。 2. t 分布 若X 与Y 相互独立,且 X ~N(0,1),Y ~2χ(n ),则Z =n Y X 的分布称为自由度等于n 的t 分布,记作Z ~ t (n ),它的分布密度 P(z)=)()(221n n n ΓΓ+2121+-???? ??+n n z 。 请注意:t 分布的分布密度也是偶函数,且当n>30时,t