
第四章:定量资料的参数估计与假设检验基础1抽样与抽样误差
抽样方法本身所引起的误差。当由总体中随机地抽取样本时,哪个样本被抽到是随机的,由所抽到的样本得到的样本指标x与总体指标μ之间偏差,称为实际抽样误差。当总体相当大时,可能被抽取的样本非常多,不可能列出所有的实际抽样误差,而用平均抽样误差来表征各样本实际抽样误差的平均水平。
σx=σ/
Sx=S/
2t分布
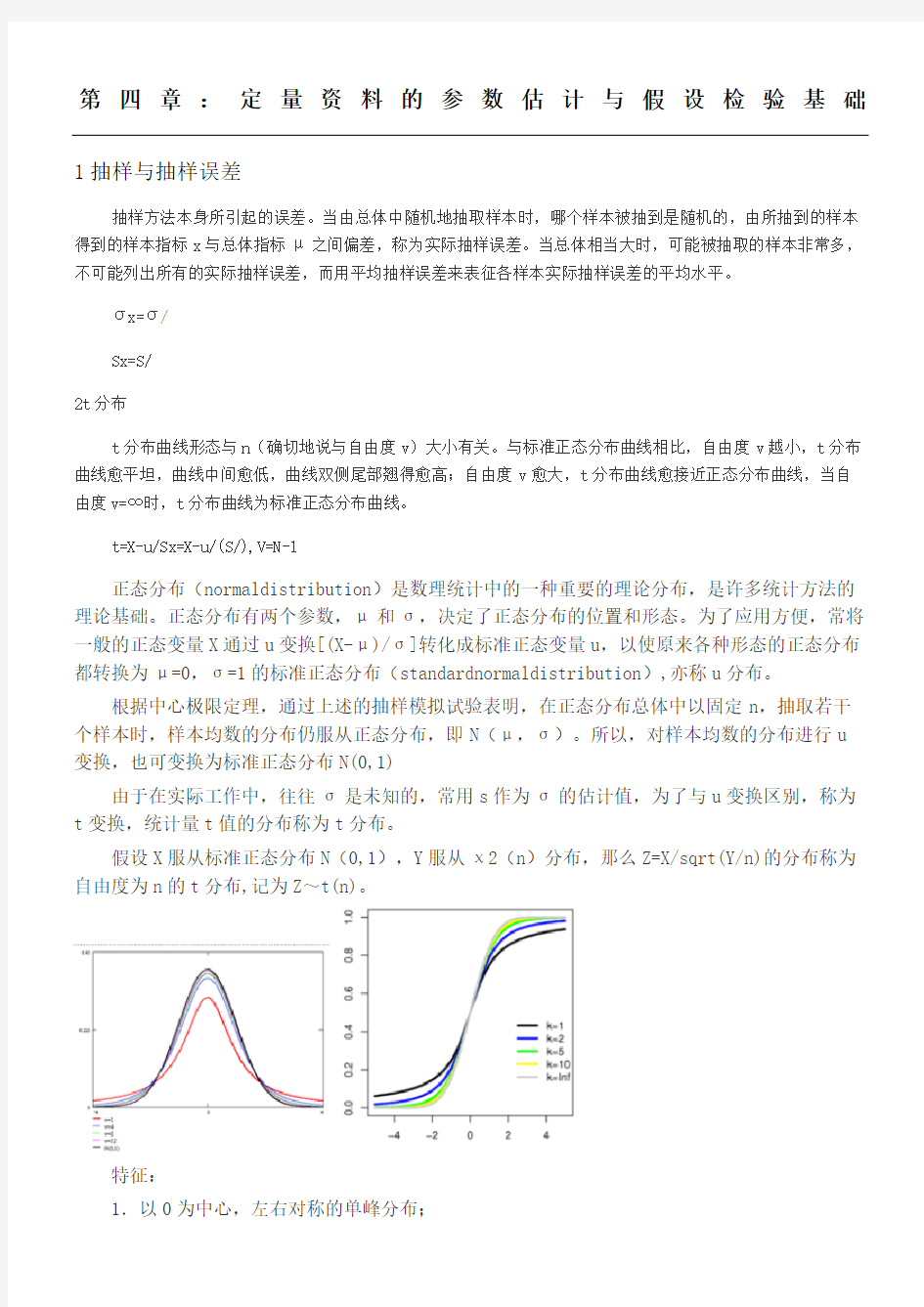
t分布曲线形态与n(确切地说与自由度v)大小有关。与标准正态分布曲线相比,自由度v越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度v愈大,t分布曲线愈接近正态分布曲线,当自由度v=∞时,t分布曲线为标准正态分布曲线。
t=X-u/Sx=X-u/(S/),V=N-1
正态分布(normaldistribution)是数理统计中的一种重要的理论分布,是许多统计方法的理论基础。正态分布有两个参数,μ和σ,决定了正态分布的位置和形态。为了应用方便,常将一般的正态变量X通过u变换[(X-μ)/σ]转化成标准正态变量u,以使原来各种形态的正态分布都转换为μ=0,σ=1的标准正态分布(standardnormaldistribution),亦称u分布。
根据中心极限定理,通过上述的抽样模拟试验表明,在正态分布总体中以固定n,抽取若干个样本时,样本均数的分布仍服从正态分布,即N(μ,σ)。所以,对样本均数的分布进行u 变换,也可变换为标准正态分布N(0,1)
由于在实际工作中,往往σ是未知的,常用s作为σ的估计值,为了与u变换区别,称为t变换,统计量t值的分布称为t分布。
假设X服从标准正态分布N(0,1),Y服从χ2(n)分布,那么Z=X/sqrt(Y/n)的分布称为自由度为n的t分布,记为Z~t(n)。
特征:
1.以0为中心,左右对称的单峰分布;
2.t分布是一簇曲线,其形态变化与n(确切地说与自由度ν)大小有关。自由度ν越小,t分布曲线越低平;自由度ν越大,t分布曲线越接近标准正态分布(u分布)曲线,如图.
t(n)分布与标准正态N(0,1)的密度函数
对应于每一个自由度ν,就有一条t分布曲线,每条曲线都有其曲线下统计量t的分布规律,计算较复杂。
学生的t分布(或也t分布),在概率统计中,在置信区间估计、显着性检验等问题的计算中发挥重要作用。
t分布情况出现时(如在几乎所有实际的统计工作)的总体标准偏差是未知的,并要从数据估算。教科书问题的处理标准偏差,因为如果它被称为是两类:(1)那些在该样本规模是如此之大的一个可处理的数据为基础估计的差异,就好像它是一定的(2)这些说明数学推理,在其中的问题,估计标准偏差是暂时忽略的,因为这不是一点,这是作者或导师当时的解释。
3.均数的参数估计
可信区间
按一定的概率或可信度(1-α)用一个区间来估计总体参数所在的范围,该范围通常称为参数的可信区间或者置信区间,预先给定的概率(1-α)称为可信度或者置信度,常取95%或99%。
1.点估计用样本统计量直接作为总体参数的估计值。其方法简单,易于理解,但为考虑抽样误差的大小。
2.区间估计既按照预先给定的概率(1-a),确定的包含总体参数的可能范围。该范围被称为总体参数的可信
区间或置信区间。
假设检验基础
假设检验的基本思想是小概率反证法思想。小概率思想是指小概率事件(P<0.01或P<0.05)在一次试验中基本上不会发生。反证法思想是先提出假设(检验假设H0),再用适当的统计方法确定假设成立的可能性大小,如可能性小,则认为假设不成立,若可能性大,则还不能认为不假设成立。[2]
假设检验
假设是否正确,要用从总体中抽出的样本进行检验,与此有关的理论和方法,构成假设检验的内容。设A是关于总体分布的一项命题,所有使命题A成立的总体分布构成一个集合h0,称为原假设(常简称假设)。使命题A不成立的所有总体分布构成另一个集合h1,称为备择假设。如果h0可以通过有限个实参数来描述,则称为参数假设,否则称为非参数假设(见非参数结果)。如果
h0(或h1)只包含一个分布,则称原假设(或备择假设)为简单假设,否则为复合假设。对一个假设h0进行检验,就是要制定一个规则,使得有了样本以后,根据这规则可以决定是接受它(承认命题A正确),还是拒绝它(否认命题A正确)。这样,所有可能的样本所组成的空间(称样本空间)被划分为两部分HA和HR(HA的补集),当样本x∈HA时,接受假设h0;当x∈HR时,拒绝
h0。集合HR常称为检验的拒绝域,HA称为接受域。因此选定一个检验法,也就是选定一个拒绝域,故常把检验法本身与拒绝域HR
基本步骤
1、提出检验假设又称无效假设,符号是H0;备择假设的符号是H1。
H0:样本与总体或样本与样本间的差异是由抽样误差引起的;
H1:样本与总体或样本与样本间存在本质差异;
预先设定的检验水准为0.05;当检验假设为真,但被错误地拒绝的概率,记作α,通常取α=0.05或α=0.01。
2、选定统计方法,由样本观察值按相应的公式计算出统计量的大小,如X2值、t值等。根据资料的类型和特点,可分别选用Z检验,T检验,
3、根据统计量的大小及其分布确定检验假设成立的可能性P的大小并判断结果。若P>α,结论为按α所取水准不显着,不拒绝H0,即认为差别很可能是由于抽样误差造成的,在统计上不成立;如果P≤α,结论为按所取α水准显着,拒绝H0,接受H1,则认为此差别不大可能仅由抽样误差所致,很可能是实验因素不同造成的,故在统计上成立。P值的大小一般可通过查阅相应的界值表得到。
t检验若总体服从正态分布N(μ,σ),但σ未知,记,,则t=遵从自由度为n-1的t分布,可对μ有以下的水平为α的检验,其中tα为自由度为n-1的t分布的上α分位数。这些检验称为t检验。
第五章:定量资料的t检验
前言:T检验主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。
t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显着。
一、t检验分为单总体检验和双总体检验。
1.单总体t检验是检验一个样本平均数与一个已知的总体平均数的差异是否显着。当总体分布是正态分布,如总体标准差未知且样本容量小于30,那么样本平均数与总体平均数的离差统计量呈t分布。
单总体t检验统计量为:
t:为样本平均数与总体平均数的离差统计量
:为样本平均数
μ:为总体平均数
σx:为样本标准差
n:为样本容量
2.双总体t检验是检验两个样本平均数与其各自所代表的总体的差异是否显着。双总体t检验又分为两种情况,一是独立样本t检验,一是配对样本t检验。
独立样本t检验统计量为:
S 1和S
2
为两、样本方差;n
1
和n
2
为两样本容量。(上面的公式是1/n
1
+1/n
2
不是减!)
1/n
1-1/n
2的话无法计算相同的样本空间
配对样本t检验统计量为:
二、适用条件
(1)已知一个总体均数;
(2)可得到一个样本均数及该样本标准差;
(3)样本来自正态或近似正态总体。
三、t检验步骤
以单总体t检验为例说明:
问题:难产儿出生体重n=35,=3.42,S=0.40,一般婴儿出生体重μ
=3.30(大规模调查获得),问相同否?
解:1.建立假设、确定检验水准α
H
:μ=μ0(零假设,nullhypothesis)
H
1
:μ≠μ0(备择假设,alternativehypothesis,)
双侧检验,检验水准:α=0.05
2.计算检验统计量
3.查相应界值表,确定P值,下结论
查附表1,t
0.05/2.34=2.032,t 0.05/2.34 ,P>0.05,按α=0.05水准,不拒绝H0,两者的差别无统计 学意义 当总体呈正态分布,如果总体标准差未知,而且样本容量<30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t分布。 检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显着。检验分为单总体t检验和双总体t检验。 四、t检验注意事项 1、选用的检验方法必须符合其适用条件(注意:t检验的前提是资料服从正态分布)。理论上,即使样本量很小时,也可以进行t检验。(如样本量为10,一些学者声称甚至更小的样本也行),只要每组中变量呈正态分布,两组方差不会明显不同。如上所述,可以通过观察数据的分布或进行正态性检验估计数据的正态假设。方差齐性的假设可进行F检验,或进行更有效的Levene's检验。如果不满足这些条件,只好使用非参数检验代替t检验进行两组间均值的比较。 2、区分单侧检验和双侧检验。单侧检验的界值小于双侧检验的界值,因此更容易拒绝,犯第Ⅰ错误的可能性大。t检验中的p值是接受两均值存在差异这个假设可能犯错的概率。在统计学上上,当两组观察对象总体中的确不存在差别时,这个概率与我们拒绝了该假设有关。一些学者认为如果差异具有特定的方向性,我们只要考虑单侧概率分布,将所得到t-检验的P值分为两半。另一些学者则认为无论何种情况下都要报告标准的双侧t检验概率。 3、假设检验的结论不能绝对化。当一个统计量的值落在临界域内,这个统计量是统计上显着的,这时拒绝虚拟假设。当一个统计量的值落在接受域中,这个检验是统计上不显着的,这是不拒绝虚拟假设H0。因为,其不显着结果的原因有可能是样本数量不够拒绝H0,有可能犯第Ⅰ类错误。 4、正确理解P值与差别有无统计学意义。P越小,不是说明实际差别越大,而是说越有理由拒绝H0,越有理由说明两者有差异,差别有无统计学意义和有无专业上的实际意义并不完全相同。 5、假设检验和可信区间的关系结论具有一致性差异:提供的信息不同区间估计给出总体均值可能取值范围,但不给出确切的概率值,假设检验可以给出H0成立与否的概率。 6、涉及多组间比较时,慎用t检验。 科研实践中,经常需要进行两组以上比较,或含有多个自变量并控制各个自变量单独效应后的各组间的比较,(如性别、药物类型与剂量),此时,需要用方差分析进行数据分析,方差分析被认为是T检验的推广。在较为复杂的设计时,方差分析具有许多t-检验所不具备的优点。(进行多次的T检验进行比较设计中不同格子均值时)。 第六章定量资料的方差分析 6.1方差分析的基本思想和应用条件 1.总变异 各样本数值与总均数不同。总变异反映所有观察值的变异,量化值所有数据的均方MS总来表示。 SS总=Σ(X-?)2MS总=SS总/v总v总=N-1 2.组间变异 各组别间的均数不相同。包括了变量影响和随机误差。 SS组间=Σn i(?i-?)2MS组间=SS组间/v组间v组间=k-1 3.组内变异 组内的个数值不同。反映随机误差,又称误差变异。SS组内=SS总-SS组间 MS组内=SS组内/v组内 V组内=N-k F=MS组间/MS组内 1、各样本相互独立切随机,服从正态分布。 2、总体方差相等,即方差齐性。 6.2完全随机设计资料的方差分析 (1)建立假设检验,确定检验水准。 (2)计算检验统计量。 6.3随机区组设计资料的方差分析 SS总=SS处理+SS区组+SS误差 v总=v处理+v区组+v误差 又称q检验 q=(?A-?B)/(S[?A-?B])=(?A-?B)/√(MSe/2[1/n A+1/n B]) 分子为任意两个对比组A、B的样本均数之差,分母是差值的标准误,n是样本的例数,MSe为前述方差分析中算的MS组内或MS误差。 又称Dunnett-t检验 TD=(?T-?C)/(S[?T-?C])=(?T-?C)/√(MSe/2[1/n T+1/n C]) T代表多个处理组,C为对照组。 t检验练习题 一、单项选择题 1.两样本均数比较,检验结果05 P说明 .0 A.两总体均数的差别较小 B.两总体均数的差别较大 C.支持两总体无差别的结论 D.不支持两总体有差别的结论 E.可以确认两总体无差别 2.由两样本均数的差别推断两总体均数的差别,其差别有统计学意义是指 A.两样本均数的差别具有实际意义 B.两总体均数的差别具有实际意义 C.两样本和两总体均数的差别都具有实际意义 D.有理由认为两样本均数有差别 E.有理由认为两总体均数有差别 3.两样本均数比较,差别具有统计学意义时,P值越小说明 A.两样本均数差别越大 B.两总体均数差别越大 C.越有理由认为两样本均数不同 D.越有理由认为两总体均数不同 E.越有理由认为两样本均数相同 4.减少假设检验的Ⅱ类误差,应该使用的方法是 A.减少Ⅰ类错误B.减少测量的系统误差 C.减少测量的随机误差D.提高检验界值 E.增加样本含量 5.两样本均数比较的t 检验和u 检验的主要差别是 A.t 检验只能用于小样本资料 B.u 检验要求方差已知或大样本资料 C.t 检验要求数据方差相同 D.t 检验的检验效能更高 E.u 检验能用于两大样本均数比较 答案:DEDEB 二、计算与分析 1.已知正常成年男子血红蛋白均值为140g/L ,今随机调查某厂成年男子60人,测其血红蛋白均值为125g/L ,标准差15g/L 。问该厂成年男子血红蛋白均值与一般成年男子是否不同? [参考答案] 因样本含量n >50(n =60),故采用样本均数与总体均数比较的u 检验。 (1)建立检验假设,确定检验水平 00:μμ=H ,该厂成年男子血红蛋白均值与一般成年男子相同 11μμ≠:H ,该厂成年男子血红蛋白均值与一般成年男子不同 ??0.05 (2)计算检验统计量 X X X u μ σ-= = 60 15125 140-=7.75 (3)确定P 值,做出推断结论 7.75>1.96,故P <0.05,按α=0.05水准,拒绝0H ,接受1H ,可以认为该厂成年男子血红蛋白均值与一般成年男子不同,该厂成年男子血红蛋白均值低于一般成年男子。 2.某研究者为比较耳垂血和手指血的白细胞数,调查12名成年人,同时采取耳垂血和手指血见下表,试比较两者的白细胞数有无不同。 表成人耳垂血和手指血白细胞数(10g/L) 编号 耳垂血 手指血 1 9.7 6.7 2 6.2 5.4 3 7.0 5.7 4 5.3 5.0 5 8.1 7.5 6 9.9 8.3 7 4.7 4.6 8 5.8 4.2 9 7.8 7.5 10 8.6 7.0 11 6.1 5.3 12 9.9 10.3 [参考答案] 本题为配对设计资料,采用配对t 检验进行分析 (1)建立检验假设,确定检验水平 H 0:?d =0,成人耳垂血和手指血白细胞数差异为零 H 1:?d ?0,成人耳垂血和手指血白细胞数差异不为零 ??0.05 (2)计算检验统计量 ==∑∑2 ,6.11d d 20.36 0d d d d d d t S S μ--= ==672.312 912.0967 .0===n S d t d t =3.672>0.05/2,11t ,P <0.05,拒绝H 0,接受H 1,差别有统计学意义,可以认为两者的白细胞数不同。 3.分别测得15名健康人和13名Ⅲ度肺气肿病人痰中1α抗胰蛋白酶含量(g/L)如下表,问健康人与Ⅲ度肺气肿病人1α抗胰蛋白酶含量是否不同? 表健康人与Ⅲ度肺气肿患者α1抗胰蛋白酶含量(g/L) 健康人 Ⅲ度肺气肿患者 2.7 3.6 2.2 3.4 4.1 3.7 4.3 5.4 2.6 3.6 1.9 6.8 1.7 4.7 0.6 2.9 1.9 4.8 1.3 5.6 1.5 4.1 1.7 3.3 1.3 4.3 1.3 1.9 [参考答案] 由题意得,107.1,323.4015.1,067.22211====S X S X ; 本题是两个小样本均数比较,可用成组设计t 检验,首先检验两总体方差是否相等。 H 0:?12=?22,即两总体方差相等 H 1:?12≠?22,即两总体方差不等 ?=0.05 F =2122S S =2 2015 .1107.1=1.19 ()14,1205.0F =2.53>1.19,F <()14,1205.0F ,故P >0.05,按α=0.05水准,不拒绝H 0,差别无统计 学意义。故认为健康人与Ⅲ度肺气肿病人α1抗胰蛋白酶含量总体方差相等,可直接用两独立样本均数比较的t 检验。 (1)建立检验假设,确定检验水平 210:μμ=H ,健康人与Ⅲ度肺气肿病人1α抗胰蛋白酶含量相同 211μμ≠:H ,健康人与Ⅲ度肺气肿病人1α抗胰蛋白酶含量不同 ??0.05 (2)计算检验统计量 2)1()1(212 2 2211 2 -+-+-=n n S n S n S c =1.12 12121212()0|| X X X X X X X X t S S -----= = =5.63 (3)确定P 值,做出推断结论 t =5.63>0.001/2,26t ,P <0.001,拒绝H 0,接受H 1,差别有统计学意义,可认为健康人与Ⅲ度肺气肿病人α1抗胰蛋白酶含量不同。 4.某地对241例正常成年男性面部上颌间隙进行了测定,得其结果如下表,问不同身高正常男性其上颌间隙是否不同? 表某地241名正常男性上颌间隙(cm ) 身高(cm) 例数 均数 标准差 161~ 116 0.2189 0.2351 172~ 125 0.2280 0.2561 [参考答案] 本题属于大样本均数比较,采用两独立样本均数比较的u 检验。 由上表可知, 1n =116,1X =0.2189,1S =0.2351 2n =125,2X =0.2280,2S =0.2561 (1)建立检验假设,确定检验水平 210:μμ=H ,不同身高正常男性其上颌间隙均值相同 211μμ≠:H ,不同身高正常男性其上颌间隙均值不同 ??0.05 (2)计算检验统计量 1212X X X X X X u S --= = 0.91 (3)确定P 值,做出推断结论 u =0.91<1.96,故P >0.05,按α=0.05水准,不拒绝H 0,差别无统计学意义,尚不能认为不同身高正常男性其上颌间隙不同。 5.将钩端螺旋体病人的血清分别用标准株和水生株作凝溶试验,测得稀释倍数如下表,问两组的平均效价有无差别? 表钩端螺旋体病患者凝溶试验的稀释倍数 标准株 100 200 400 400 400 400 800 1600 1600 1600 3200 3200 3200 水生株 100 100 100 200 200 200 200 400 400 800 1600 [参考答案] 本题采用两独立样本几何均数比较的t 检验。 t =2.689>t 0.05/2,22,P <0.05,拒绝H 0,接受H 1,差别有统计学意义,可认为两组的平均效价有差别。 6.为比较男、女大学生的血清谷胱甘肽过氧化物酶(GSH-Px)的活力是否相同,某医生对某大学18~22岁大学生随机抽查男生48名,女生46名,测定其血清谷胱甘肽过氧化酶含量(活力单位),男、女性的均数分别为96.53和93.73,男、女性标准差分别为 7.66和14.97。问男女性的GSH-Px 是否相同? [参考答案] 由题意得1n =48,=1X 96.53,1S =7.66 2n =46,2X =93.73,2S =14.97 本题是两个小样本均数比较,可用成组设计t 检验或t ’检验,首先检验两总体方差是否相等。 H 0:?12=?22,即两总体方差相等 H 1:?12≠?22,即两总体方差不等 ?=0.05 F =2122S S =2 297 .147.66=3.82 F =3.82>()454705.0,F ,故P <0.05,差别有统计学意义,按?=0.05水准,拒绝H 0,接受H 1,故 认为男、女大学生的血清谷胱甘肽过氧化物酶的活力总体方差不等,不能直接用两独立样本均数比较的t 检验,而应用两独立样本均数比较的t ’检验。 2 2 212 121'n S n S X X t +-= =1.53,t ’0.05/2=2.009,t ’ H 0,差别无统计学意义,尚不能认为男性与女性的GSH-Px 有差别。 分工: 第四章的资料:段磊 第五章的资料:张天翼 第六章的资料:陈菲 t 检验练习题:杨吉程 整理资料与查缺补漏:董永涛 例题7.5一家食品生产企业以生产袋装食品为主,每天的产量大约为8000袋左右。按规定每袋的重量应为100g。为对产品质量进行检测,企业质检部门经常要进行抽检,以分析 每袋重量是否符合要求。现从某天生产的一批食品中随机抽取25袋,测得每袋重量如表7—2所示。 表7—2 25袋食品的重量 112.5 101.0 103.0 102.0 110.5 102.6 107.5 95.0 108.8 115.6 100.0 123.5 102.0 101.6 102.2 116.6 95.4 97.8 108.6 105.0 136.8 102.8 101.5 98.4 93.3 已知产品重量的分布,且总体标准差为10g,试估计该天产品平均质量的置信区间,以为95%建立该种食品重量方差的置信区间。 解:已知δ=10,n=25,置信水平1-α=95%,Z x/2=1.96 案例处理摘要 案例 有效缺失合计 N 百分比N 百分比N 百分比 重量25 100.0% 0 .0% 25 100.0% 描述 统计量标准误 重量均值105.7600 1.93038 均值的95% 置信区间下限101.7759 上限109.7441 5% 修整均值104.8567 中值102.6000 方差93.159 标准差9.65190 极小值93.30 极大值136.80 范围43.50 四分位距9.15 偏度 1.627 .464 峰度 3.445 .902 重量 重量 Stem-and-Leaf Plot Frequency Stem & Leaf 1.00 9 . 3 4.00 9 . 5578 10.00 10 . 0111222223 4.00 10 . 5788 2.00 11 . 02 从正态总体N (μ1,σ)和N (μ2,σ)中分别抽取含量为n 1和n 2的样本,两样本均数差值X 1 -X 2 服从正态分布N (μ1-μ2,σ12 -),其中 σ12X X - ① 其中①式中σX 1 -X 2 为两样本均数差值的标准误,其估计值为 12X X S - ② 其中②式中2C S 为两样本合并的方差,其计算公式为: 22 2111222 212()/()/2 X X n X X n S c n n -+-=+-∑∑∑ ③ 如已计算出S 1 和 S 2 ,则可用公式 ③ 计算出 12X X S - 在0H :μ1=μ2=0的条件下,t 的计算公式为: 1212|| X X X X t S --=,ν=122n n +-⑤ 例3-3 测得14名慢性支气管炎病人与11名健康人的尿中17酮类固醇(u mol/24h )排出量如下,试比较两组人的尿中17酮类固醇的排出量有无不同。 病人X1:10.05 18.75 18.99 15.94 13.96 17.22 14.69 15.10 9.42 8.21 7.24 24.60 健康人X2:17.95 30.46 10.88 22.38 12.89 23.01 13.89 19.40 15.83 26.72 17.29 (1)建立假设检验,确定检验水准 102=H μμ:,即病人与健康人的尿中17酮类固醇的排出量相同 102H μμ≠:,即病人与健康人的尿中17酮类固醇的排出量不相同 α=0.05 (2)计算t 值 本例114n =,1212.35X =∑ ,213549.0919X =∑ 211n = , 2210.70X =∑ ,224397.6486X =∑ 11/2212.35/1415.17 22/2210.70/1119.15X X n X X n ======∑∑① 按公式③2221112222 12()/()/2X X n X X n S c n n -+-=+-∑∑∑ 229.9993S c ==223549.0919-(212.35)/14+4397.6486-(210.70)/1114+11-2 按公式② 12X X S - 12X X S - 按公式 ⑤1212|| X X t S --=,ν=122n n +- |15.17-19.15|=1.80352.2068 t = (3)确定P 值,作出推断结论 ν=14112=2+- ,查附表2,t 界值表 ,得 0.01/2,23 1.714t =0.05/2,23 2.069t = 现<0.10/2,230.05/2,23t t t <<,故0.01>P >0.05 。 按α=0.05水准,不拒绝0H ,差异无统计学意义,尚不能认为慢性支气管炎病人与健康人的尿中17酮类固醇的排出量不同。 T检验 习题1.按规定苗木平均高达1.60m以上可以出圃,今在苗圃中随机抽取10株苗木,测定的苗木高度如下: 1.75 1.58 1.71 1.64 1.55 1.72 1.62 1.83 1.63 1.65 假设苗高服从正态分布,试问苗木平均高是否达到出圃要求?(要求α=0.05) 解:1)根据题意,提出:无效假设为:苗木的平均苗高为H0=1.6m; 备择假设为:苗木的平均苗高H A>1.6m; 2)定义变量:在spss软件中的“变量视图”中定义苗木苗高, 之后在“数据视图”中输入苗高数据; 3)分析过程 在spss软件上操作分析过程如下:分析——比较均值——单样本T检验——将定义苗高导入检验变量——检验值定义为1.6——单击选项将置信区间设为95%——确定输出如下: 表1.1:单个样本统计量 表1.2:单个样本检验 4)输出结果分析 由表1.1数据分析可知,变量苗木苗高的平均值为1.6680m,标 准差为0.0843,说明样本的离散程度较小,标准误为0.0267,说明抽样误差较小。 由表1.3数据分析可知,T检验值为2.55,样本自由度为9,t检验的双尾检验值为0.031<0.05,说明差异性显著,因此,否定无效假设H0,取备择假设H A。 根据题意,苗木的苗高服从正态分布,由以上分析知:在显著水平为0.05的水平上检验,苗木的平均苗高大于1.6m,符合出圃的要求。 习题2.从两个不同抚育措施育苗的苗圃中各以重复抽样的方式抽得样本如下: 样本1苗高(CM):52 58 71 48 57 62 73 68 65 56 样本2苗高(CM):56 75 69 82 74 63 58 64 78 77 66 73 设苗高服从正态分布且两个总体苗高方差相等(齐性),试以显著水平α=0.05检验两种抚育措施对苗高生长有无显著性影响。 解:1)根据题意提出:无效假设为H0:两种抚育措施对苗木生长没有显著的影响;备择假设H A:两种抚育措施对苗高生长影响显著; 2)在spss中的“变量视图”中定义变量“苗高1”,“抚育措施”,之后在“数据视图”中输入题中的苗高数据,及抚育措施,其中措施一定义为“1”措施二定义为“2”; 3)分析过程 在spss软件上操作分析过程如下:分析——比较变量——独立 教育统计学t检验练习集团文件版本号:(M928-T898-M248-WU2669-I2896-DQ586-M1988) 实验报告实验名称:t 检验成绩: 实验日期: 2011年10月31日实验报告日期:2011年11 月日 林虹 一、实验目的 (1)掌握单一样本t检验。 (2)掌握相关样本t检验 (3)掌握独立样本t检验 二、实验设备 (1)微机 (2)SPSS for Windows V17.0统计软件包 三、实验内容: 1.某市统一考试的数学平均成绩为75分,某校一个班的成绩见表4-1。 问该班的成绩与全市平均成绩的差异显着吗? 表4-1 学生的数学成绩 12345678910111213141516编 号 96977560926483769097829887568960成 绩 17181920212223242526272829303132编 号 成 68747055858656716577566092548780绩 2.某物理教师在教学中发现,在课堂物理教学中采用“先讲规则(物理 的定理或法则),再举例题讲解规则的具体应用”与采用“先讲例 题,再概括出解题规则”这两种教学方法的教学效果似乎不同。为了验证他的这个经验性发现是否属实,他选择了两个近似相等的班级进行教学实验。进行教学实验时的教学内容、教学时间和教学地点等无关变量他都做了严格的控制,分别采用“例-规”法与“规-例”法对两个班的学生进行物理教学,然后,两个班的被试都进行同样的物理知识测验。测验成绩按“5分制”进行评定。两组被试的测验成绩见数据文件data4-02。请用SPSS,通过适当的统计分析方法,检验这两种教学方法的教学效果是否存在实质性差别。 3.某幼儿园分别在儿童入园时和入园一年后对他们进行了“比奈智力测 验”,测验结果见数据文件data4-03。请问,儿童入园一年后的智商有明显的变化吗? (例题) 4.某心理学工作者以大学生为被试,以“正性”和“负性”两种面部表 情模式的照片为实验材料,测量被试对“正性”和“负性”面部表情识别的时间,测验结果见数据文件data4-04。请用SPSS中适当的统计分析方法检验两种面部表情模式对大学生识别面部表情的时间是否存在明显的影响。 5.某小学教师分别采用“集中学习”与“分散学习”两种方式教两个小 学二年级班级的学生学习相同的汉字,两个班学生的学习成绩见 data4-05。请问哪种学习方式效果更好? 6.某省语文高考平均成绩为78分,某学校的成绩见data4-06。请问该 校考生的平均成绩与全省平均成绩之间的差异显着吗? 两独立样本T检验 目的:利用来自两个总体的独立样本,推断两个总体的均值是否存在显著差异。 检验前提: 样本来自的总体应服从或近似服从正态分布; 两样本相互独立,样本数可以不等。 两独立样本T检验的基本步骤: 提出假设 原假设H_0:μ_1-μ_2=0 备择假设H_1:μ_1-μ_2≠0 建立检验统计量 如果两样本来自的总体分别服从N(μ_1,σ_1^2 )和N(μ_2,σ_2^2 ),则两样本均值差(x_1 ) ?-x ?_2应服从均值为μ_1-μ_2、方差为σ_12^2的正态分布。 第一种情况:当两总体方差未知且相等时,采用合并的方差作为两个总体方差的估计,为:s^2=((n_1-1) s_1^2+(n_2-1) s_2^2)/(n_1+n_2-2) 则两样本均值差的估计方差为: σ_12^2=s^2 (1/n_1 +1/n_2 ) 构建的两独立样本T检验的统计量为: t= ((x_1 ) ?-x ?_2)/√(s^2 (1/n_1 +1/n_2 ) ) 此时,T统计量服从自由度为n_1+n_2-2个自由度的t分布。 第二种情况:当两总体方差未知且不相等时,两样本均值差的估计方差为: σ_12^2=(s_1^2)/n_1 +(s_2^2)/n_2 构建的两独立样本T检验的统计量为: t= ((x_1 ) ?-x ?_2)/√((s_1^2)/n_1 +(s_2^2)/n_2 ) 此时,T统计量服从修正自由度的t分布,自由度为: f= ((s_1^2)/n_1 +(s_2^2)/n_2 )^2/(((s_1^2)/n_1 )^2/n_1 +((s_2^2)/n_2 )^2/n_2 ) 可见,两总体方差是否相等是决定t统计量的关键。所以在进行T检验之前,要先检验两总体方差是否相等。SPSS中使用方差齐性检验(Levene F检验)判断两样本方差是否相等近而间接推断两总体方差是否有显著差异。 三、计算检验统计量的观测值和p值 将样本数据代入,计算出t统计量的观测值和对应的概率p值。 四、在给定显著性水平上,做出决策 首先,利用F统计量判断两总体方差是否相等,Levene F检验的原假设为两独立总体方差相等。概率p<0.05时,有充分理由拒绝原假设,说明方差不齐;否则,两样本方差无显著性差异。 其次,将设定的显著性水平α与检验统计量的p值比较,如果t统计量的p值小于α,落入拒绝域内,则我们有充分理由拒绝原假设,认为两总体均值有显著差异。 SPSS实现过程: 菜单:Analyze -> Compare Means-> Independent Samples T test Test Variable(s):待检验的变量(一般是定距或定序变量) Grouping Variable :分组变量(只能比较两个样本) 第四章抽样误差与假设检验 练习题 一、单项选择题 1. 样本均数的标准误越小说明 A. 观察个体的变异越小 B. 观察个体的变异越大 C. 抽样误差越大 D. 由样本均数估计总体均数的可靠性越小 E. 由样本均数估计总体均数的可靠性越大 2. 抽样误差产生的原因是 A. 样本不是随机抽取 B. 测量不准确 C. 资料不是正态分布 D. 个体差异 E. 统计指标选择不当 3. 对于正偏态分布的的总体, 当样本含量足够大时, 样本均数的分布近似为 A. 正偏态分布 B. 负偏态分布 C. 正态分布 D. t分布 E. 标准正态分布 4. 假设检验的目的是 A. 检验参数估计的准确度 B. 检验样本统计量是否不同 C. 检验样本统计量与总体参数是否不同 D. 检验总体参数是否不同 E. 检验样本的P值是否为小概率 5. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109/L~ 9.1×109/L,其含义是 A. 估计总体中有95%的观察值在此范围内 B. 总体均数在该区间的概率为95% C. 样本中有95%的观察值在此范围内 D. 该区间包含样本均数的可能性为95% E. 该区间包含总体均数的可能性为95% 答案:E D C D E 二、计算与分析 1.为了解某地区小学生血红蛋白含量的平均水平,现随机抽取该地小学生450人,算得其血红蛋白平均数为101.4g/L,标准差为1.5g/L,试计算该地小学生血红蛋白平均数的95%可信区间。 [参考答案] 样本含量为450,属于大样本,可采用正态近似的方法计算可信区间。 101.4 X=, 1.5 S=,450 n=,0.07 X S=== 95%可信区间为 下限: /2.101.4 1.960.07101.26 X X u S α=-?= -(g/L) 上限: /2.101.4 1.960.07101.54 X X u S α +=+?=(g/L) 即该地成年男子红细胞总体均数的95%可信区间为101.26g/L~101.54g/L。 2.研究高胆固醇是否有家庭聚集性,已知正常儿童的总胆固醇平均水平是175mg/dl,现测得100名曾患心脏病且胆固醇高的子代儿童的胆固醇平均水平为207.5mg/dl,标准差为30mg/dl。问题: ①如何衡量这100名儿童总胆固醇样本平均数的抽样误差? ②估计100名儿童的胆固醇平均水平的95%可信区间; ③根据可信区间判断高胆固醇是否有家庭聚集性,并说明理由。 [参考答案] ①均数的标准误可以用来衡量样本均数的抽样误差大小,即 30 S=mg/dl,100 n= 3.0 X S=== ②样本含量为100,属于大样本,可采用正态近似的方法计算可信区间。 207.5 X=,30 S=,100 n=,3 X S=,则95%可信区间为 下限: /2.207.5 1.963201.62 X X u S α=-?= -(mg/dl) t 检验计算公式: 当总体呈正态分布,如果总体标准差未知,而且样本容量n <30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t 分布。 t 检验是用t 分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。t 检验分为单总体t 检验和双总体t 检验。 1.单总体t 检验 单总体t 检验是检验一个样本平均数与一已知的总体平均数的差异是否显 著。当总体分布是正态分布,如总体标准差σ未知且样本容量n <30,那么样本平均数与总体平均数的离差统计量呈t 分布。检验统计量为: X t μ -= 。 如果样本是属于大样本(n >30)也可写成: X t μ -= 。 在这里,t 为样本平均数与总体平均数的离差统计量; X 为样本平均数; μ为总体平均数; X σ为样本标准差; n 为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为79.2分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步 建立原假设0H ∶μ=73 第二步 计算t 值 79.273 1.63X t μ --= = = 第三步 判断 因为,以0.05为显著性水平,119df n =-=,查t 值表,临界值 0.05(19)2.093t = ,而样本离差的t = 1.63小与临界值 2.093。所以,接受原假设, 即进步不显著。 2.双总体t 检验 双总体t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。双总体t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验完全类似,只不过0r =。 相关样本的t 检验公式为: t = 在这里,1X ,2X 分别为两样本平均数; 1 2 X σ,2 2X σ分别为两样本方差; γ为相关样本的相关系数。 例:在小学三年级学生中随机抽取10名学生,在学期初和学期末分别进行了两次推理能力测验,成绩分别为79.5和72分,标准差分别为9.124,9.940。问两次测验成绩是否有显著地差异? 检验步骤为: 第一步 建立原假设0H ∶1μ=2μ 第二步 计算t 值 X X t -= =3.459。 第三步 判断 根据自由度19df n =-=,查t 值表0.05(9) 2.262t =,0.01(9) 3.250t =。由于实际计算出来的t =3.495>3.250=0.01(9)t ,则0.01P <,故拒绝原假设。 结论为:两次测验成绩有及其显著地差异。 由以上可以看出,对平均数差异显著性检验比较复杂,究竟使用Z 检验还是使用t 检验必须根据具体情况而定,为了便于掌握各种情况下的Z 检验或t 检验, 独立样本的T检验 (independent-samples T T est) 对于相互独立的两个来自正态总体的样本,利用独立样本的T 检验来检验这两个样本的均值和方差是否来源于同一总体。在SPSS 中,独立样本的T检验由“Independent-Sample T Test”过程来完成。 例:双语教师的英语水平有高低之分,他们(她们)所教的学生对双语教学的态度是否有显著差异? 例题分析: ——研究目的:寻找差异 ——自变量:双语教师的英语水平(ordinal data等级变量),有两个水平:;level1低水平,level2 高水平 ——因变量:学生的双语教学态度(interval data等距变量) SPSS操作步骤 ·Analyze→Compare Means→Independent Samples T Test ·Click the 双语教学态度to the column of “Test V ariable(s)” and the 教师英语水平分组to the column of “Grouping variable” ·Click the button of “Define Groups…” and put the group numbers “1” and “3” into Group 1 and Group 2, and “Continue” back, then “OK”. 结果在论文中的呈现方式 独立样本T检验结果显示,双语教师的英语水平不同,其所教学生对双语教学的态度有显著差异(t=-3,249, df=72, p<0.05)。双语教师英语水平较低所教的学生,他们对双语教学态度的得分也显著低于英语水平较高的双语教师所教的学生(MD=-0.65)。这可能是因为…… 练习:文科生和理科生对双语教学的态度是否有显著差异? 配对样本T检验(Paired-samples T Test) 配对样本T检验,用于检验两个相关的样本(配对资料)是否来自具有相同均值的总体。 例:本次调查中,学生对自己英语能力水平和英语知识水平的评价之间是否有显著差异? 例题分析: ——研究目的:寻找差异 ——自变量:学生的评价对象(norminal data定类数据),有两个水平:level1对自身英语能力水平的评价,level2对自身英语知识水平的评价。 ——因变量:学生自身英语能力和知识的评价分数 1、两配对样本T检验 2、单因素方差分析 3、多因素方差分析 一、两配对样本T检验 定义:两配对样本T检验是根据样本数据对样本来自的两配对总体的均值是否有显著性差异进行推断。 一般用于同一研究对象(或两配对对象)分别给予两种不同处理的效果比较,以及同一研究对象(或两配对对象)处理前后的效果比较。 两配对样本T检验的前提要求如下: 两个样本应是配对的。在应用领域中,主要的配对资料包括:具有年龄、性别、体重、病况等非处理因素相同或相似者。首先两个样本的观察数目相同,其次两样本的观察值顺序不能随意改变。 样本来自的两个总体应服从正态分布 二、配对样本t检验的基本实现思路 设总体X1服从正太分布N(u1,σ12),总体X2服从正太分布 N(u2,σ22),分别从这两个总体中抽取样(X11,X12,?,X1N)和X21,X22,?,X2N),且两样本相互配对。要求检验μ1和μ2是否有显著差异。 第一步,引进一个新的随机变量Y=X1?X2对应的样本值为(y1,y2,?,y n),其中,y i=x1i?x2i(i=1,2,?,n) 这样,检验的问题就转化为单样本t检验问题。即转化为检验Y 的均值是否与0有显著差异。 第二步,建立零假设H0:μY=0 第三步,构造t统计量 t= y? S y √n?1 ? ~t(n?1) 第四步,SPSS自动计算t值和对应的P值 第五步,作出推断: 若P值<显著水平α,则拒绝零假设 即认为两总体均值存在显著差异 若P值>显著水平α,则不能拒绝零假设, 即认为两总体均值不存在显著差异 三、SPSS配对样本t检验的操作步骤 例题:研究一个班同学在参加了暑期数学、化学培训班后,学习成绩是否有显著变化。数据如表3所示。 1.操作步骤: 首先打开SPSS软件 1.1输入数据 点击:文件-----打开文本数据(D)-----选择需要编辑的数据-----打开 第四章 抽样误差与假设检验 练习题 一、单项选择题 1. 样本均数的标准误越小说明 A. 观察个体的变异越小 B. 观察个体的变异越大 C. 抽样误差越大 D. 由样本均数估计总体均数的可靠性越小 E. 由样本均数估计总体均数的可靠性越大 2. 抽样误差产生的原因是 A. 样本不是随机抽取 B. 测量不准确 C. 资料不是正态分布 D. 个体差异 E. 统计指标选择不当 3. 对于正偏态分布的的总体, 当样本含量足够大时, 样本均数的分布近似 为 A. 正偏态分布 C. 正态分布 E. 标准正态分布 4. 假设检验的目的是 A. 检验参数估计的准确度 C. 检验样本统计量与总体参数是否不同 D. 检验总体参数是否不同 E. 检验样本的P 值是否为小概率 5. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109 /L ~ 9.1×109 /L ,其含义是 A. 估计总体中有95%的观察值在此范围内 B. 总体均数在该区间的概率为95% C. 样本中有95%的观察值在此范围内 D. 该区间包含样本均数的可能性为95% B. 负偏态分布 D. t 分布 B. 检验样本统计量是否不同 E.该区间包含总体均数的可能性为95% 答案:E D C D E 、计算与分析 1. 为了解某地区小学生血红蛋白含量的平均水平,现随机抽取该地小学生 450 人,算得其血红蛋白平均数为 101.4g/L ,标准差为 1.5g/L ,试计算该地小 学生血红蛋白平均数的 95%可信区间。 [参考答案] 样本含量为 450,属于大样本,可采用正态近似的方法计算可信区间。 95%可信区间为 下限: X -u .S =101.4- 1.960.07=101.26(g/L) 上限:X +u .S =101.4+ 1.960.07=101.54(g/L) 即该地成年男子红细胞总体均数的 95%可信区间为 101.26g/L ~101.54g/L 。 2. 研究高胆固醇是否有家庭聚集性,已知正常儿童的总胆固醇平均水平是 175mg/dl ,现测得100 名曾患心脏病且胆固醇高的子代儿童的胆固醇平均水平为 207.5mg/dl ,标准差为 30mg/dl 。问题: ① 如何衡量这100 名儿童总胆固醇样本平均数的抽样误差? ② 估计100 名儿童的胆固醇平均水平的95%可信区间; ③ 根据可信区间判断高胆固醇是否有家庭聚集性,并说明理由。 [参考答案] ① 均数的标准误可以用来衡量样本均数的抽样误差大小,即 S = 30 mg/dl, n = 100 ② 样本含量为 100 ,属于大样本,可采用正态近似的方法计算可信区间。 X = 207.5 , S =30,n =100,S = 3,则95%可信区间为 下限: X -u .S = 207.5 - 1.96 3 = 201.62 (mg/dl) 上限:X +u .S = 207.5 + 1.96 3 = 213.38 (mg/dl ) X =101.4 , S =1.5,n =450, S 1.5 n = 450 = 0.07 S 30 n 100 = 3.0 教育统计学t检验练习内部编号:(YUUT-TBBY-MMUT-URRUY-UOOY-DBUYI-0128) 实验报告实验名称:t 检验成绩: 实验日期: 2011年10月31日实验报告日期:2011年11 月日 林虹 一、实验目的 (1)掌握单一样本t检验。 (2)掌握相关样本t检验 (3)掌握独立样本t检验 二、实验设备 (1)微机 (2)SPSS for Windows 统计软件包 三、实验内容: 1.某市统一考试的数学平均成绩为75分,某校一个班的成绩见表4-1。问该班的 成绩与全市平均成绩的差异显着吗 表4-1 学生的数学成绩 12345678910111213141516 编 号 成96977560926483769097829887568960 号 68747055858656716577566092548780 成 绩 2.某物理教师在教学中发现,在课堂物理教学中采用“先讲规则(物理的定理或 法则),再举例题讲解规则的具体应用”与采用“先讲例题,再概括出解题规则”这两种教学方法的教学效果似乎不同。为了验证他的这个经验性发现是否属实,他选择了两个近似相等的班级进行教学实验。进行教学实验时的教学内容、教学时间和教学地点等无关变量他都做了严格的控制,分别采用“例-规” 法与“规-例”法对两个班的学生进行物理教学,然后,两个班的被试都进行同样的物理知识测验。测验成绩按“5分制”进行评定。两组被试的测验成绩见数据文件data4-02。请用SPSS,通过适当的统计分析方法,检验这两种教学方法的教学效果是否存在实质性差别。 3.某幼儿园分别在儿童入园时和入园一年后对他们进行了“比奈智力测验”,测 验结果见数据文件data4-03。请问,儿童入园一年后的智商有明显的变化吗(例题) 4.某心理学工作者以大学生为被试,以“正性”和“负性”两种面部表情模式的 照片为实验材料,测量被试对“正性”和“负性”面部表情识别的时间,测验结果见数据文件data4-04。请用SPSS中适当的统计分析方法检验两种面部表情模式对大学生识别面部表情的时间是否存在明显的影响。 5.某小学教师分别采用“集中学习”与“分散学习”两种方式教两个小学二年级 班级的学生学习相同的汉字,两个班学生的学习成绩见data4-05。请问哪种学习方式效果更好 6.某省语文高考平均成绩为78分,某学校的成绩见data4-06。请问该校考生的 平均成绩与全省平均成绩之间的差异显着吗 ** 第四章:定量资料的参数估计与假设检验基础1抽样与抽样误差 抽样方法本身所引起的误差。当由总体中随机地抽取样本时,哪个样本被抽到是随机的,由所抽到的样本得到的样本指标x与总体指标μ之间偏差,称为实际抽样误差。当总体相当大时,可能被抽取的样本非常多,不可能列出所有的实际抽样误差,而用平均抽样误差来表征各样本实际抽样误差的平均水平。 σx=σ/ Sx=S/ 2t分布 t分布曲线形态与n(确切地说与自由度v)大小有关。与标准正态分布曲线相比,自由度v越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度v愈大,t分布曲线愈接近正态分布曲线,当自由度v=∞时,t分布曲线为标准正态分布曲线。 t=X-u/Sx=X-u/(S/),V=N-1 正态分布(normaldistribution)是数理统计中的一种重要的理论分布,是许多统计方法的理论基础。正态分布有两个参数,μ和σ,决定了正态分布的位置和形态。为了应用方便,常将一般的正态变量X通过u变换[(X-μ)/σ]转化成标准正态变量u,以使原来各种形态的正态分布都转换为μ=0,σ=1的标准正态分布(standardnormaldistribution),亦称u分布。 根据中心极限定理,通过上述的抽样模拟试验表明,在正态分布总体中以固定n,抽取若干个样本时,样本均数的分布仍服从正态分布,即N(μ,σ)。所以,对样本均数的分布进行u 变换,也可变换为标准正态分布N(0,1) 由于在实际工作中,往往σ是未知的,常用s作为σ的估计值,为了与u变换区别,称为t变换,统计量t值的分布称为t分布。 假设X服从标准正态分布N(0,1),Y服从χ2(n)分布,那么Z=X/sqrt(Y/n)的分布称为自由度为n的t分布,记为Z~t(n)。 特征: 1.以0为中心,左右对称的单峰分布; 实验报告实验名称:t 检验成绩: 实验日期: 2011年10月31日实验报告日期:2011年11 月日 林虹 一、实验目的 (1)掌握单一样本t检验。 (2)掌握相关样本t检验 (3)掌握独立样本t检验 二、实验设备 (1)微机 (2)SPSS for Windows V17.0统计软件包 三、实验内容: 1.某市统一考试的数学平均成绩为75分,某校一个班的成绩见表4-1。 问该班的成绩与全市平均成绩的差异显着吗? 表4-1 学生的数学成绩 12345678910111213141516编 号 成 96977560926483769097829887568960绩 编 17181920212223242526272829303132号 成 68747055858656716577566092548780绩 2.某物理教师在教学中发现,在课堂物理教学中采用“先讲规则(物理的 定理或法则),再举例题讲解规则的具体应用”与采用“先讲例题,再概括出解题规则”这两种教学方法的教学效果似乎不同。为了验证他的这个经验性发现是否属实,他选择了两个近似相等的班级进行教学实验。进行教学实验时的教学内容、教学时间和教学地点等无关变量他都做了严格的控制,分别采用“例-规”法与“规-例”法对两个班的学生进行物理教学,然后,两个班的被试都进行同样的物理知识测验。测验成绩按“5分制”进行评定。两组被试的测验成绩见数据文件data4-02。 请用SPSS,通过适当的统计分析方法,检验这两种教学方法的教学效果是否存在实质性差别。 3.某幼儿园分别在儿童入园时和入园一年后对他们进行了“比奈智力测 验”,测验结果见数据文件data4-03。请问,儿童入园一年后的智商有明显的变化吗? (例题) 4.某心理学工作者以大学生为被试,以“正性”和“负性”两种面部表情 模式的照片为实验材料,测量被试对“正性”和“负性”面部表情识别的时间,测验结果见数据文件data4-04。请用SPSS中适当的统计分析方法检验两种面部表情模式对大学生识别面部表情的时间是否存在明显的影响。 5.某小学教师分别采用“集中学习”与“分散学习”两种方式教两个小学 采用SPSS统计软件进行操作。 1、某研究者检测了某山区16名健康成年男性的血红蛋白含量(g/L),检测结果见下表。问:该山区健康成年男性的血红蛋白含量与一般健康成年男性血红蛋白含量的总体均数132 g/L 是否有差别。 编号血红蛋白含量(g/L) 1 145 2 150 3 138 4 126 5 140 6 145 7 135 8 115 9 135 10 130 11 120 12 133 13 147 14 125 15 114 16 165 2、为研究老年慢性支气管炎病人与健康人的尿中17酮类固醇排出量是否相等,现随机抽取老年慢性支气管炎病人14例和健康人11例,分别测定尿中17酮类固醇排出量,结果见下表。老年慢性支气管炎病人与健康人的尿中17酮类固醇排出量是否相等? 表老年慢性支气管炎病人与健康人的尿中17酮类固醇排出量(mg/24h) 病人组健康人组 2.90 4.97 5.41 4.24 5.48 4.36 4.60 2.72 4.03 2.37 5.10 2.09 5.92 7.10 5.18 5.60 8.79 4.57 3.14 7.71 6.46 4.99 3.72 6.64 4.01 3、将20名某病患者随机分为两组,分别用甲、乙两药治疗,测得治疗前与治疗后一个月的血沉(mm/小时)如下表。 试问:(1)甲、乙两药是否均有效? (2)甲、乙两药的疗效有无差别? 表甲、乙两药治疗前后的血沉(mm/小时) 甲药病人号 1 2 3 4 5 6 7 8 9 10 治疗前20 23 16 21 20 17 18 18 15 19 治疗后16 19 13 20 20 14 12 15 13 13 乙药病人号 1 2 3 4 5 6 7 8 9 10 治疗前19 20 19 23 18 16 20 21 20 20 治疗后16 13 15 13 13 15 18 12 17 14 4、对10例肺癌病人和12例矽肺0期工人用X光片测量肺门横径右侧距RD值(cm),结果见下表。问:肺癌病人的RD值是否高于矽肺0期工人的RD值。 3.23 2.78 3.50 3.23 4.04 4.20 4.15 4.87 4.28 5.12 4.34 6.21 4.47 7.18 4.64 8.05 4.75 8.56 4.82 9.60 4.95 5.10 5、为研究女性服用某避孕新药后是否影响其血清总胆固醇含量,将20名女性按年龄配成10对,每对中随机抽取一人服用新药,另一人服用安慰剂,经过一定时间后,测得血清总胆固醇含量(mmol/L),结果如下表。以此研究解答以下问题: t检验有单样本t检验,配对t检验和两样本t检验。 单样本t检验:是用样本均数代表的未知总体均数和已知总体均数进行比较,来观察此组样本与总体的差异性。 配对t检验:是采用配对设计方法观察以下几种情形,1,两个同质受试对象分别接受两种不同的处理;2,同一受试对象接受两种不同的处理;3,同一受试对象处理前后。 u检验:t检验和就是统计量为t,u的假设检验,两者均是常见的假设检验方法。当样本含量n较大时,样本均数符合正态分布,故可用u检验进行分析。当样本含量n小时,若观察值x符合正态分布,则用t检验(因此时样本均数符合t分布),当x为未知分布时应采用秩和检验。 F检验又叫方差齐性检验。在两样本t检验中要用到F检验。 从两研究总体中随机抽取样本,要对这两个样本进行比较的时候,首先要判断两总体方差是否相同,即方差齐性。若两总体方差相等,则直接用t检验,若不等,可采用t'检验或变量变换或秩和检验等方法。 其中要判断两总体方差是否相等,就可以用F检验。 简单的说就是检验两个样本的方差是否有显著性差异这是选择何种T检验(等方差双样本检验,异方差双样本检验)的前提条件。 在t检验中,如果是比较大于小于之类的就用单侧检验,等于之类的问题就用双侧检验。 卡方检验 是对两个或两个以上率(构成比)进行比较的统计方法,在临床和医学实验中应用十分广泛,特别是临床科研中许多资料是记数资料,就需要用到卡方检验。 方差分析 用方差分析比较多个样本均数,可有效地控制第一类错误。方差分析(analysis of variance,ANOV A)由英国统计学家,以F命名其统计量,故方差分析又称F检验。 其目的是推断两组或多组资料的总体均数是否相同,检验两个或多个样本均数的差异是否有统计学意义。我们要学习的主要内容包括 单因素方差分析即完全随机设计或成组设计的方差分析(one-way ANOV A): 用途:用于完全随机设计的多个样本均数间的比较,其统计推断是推断各样本所代表的各总体均数是否相等。完全随机设计(completely random design)不考虑个体差异的影响,仅涉及一个处理因素,但可以有两个或多个水平,所以亦称单因素实验设计。在实验研究中按随机化原则将受试对象随机分配到一个处理因素的多个水平中去,然后观察各组的试验效应;在观察研究(调查)中按某个研究因素的不同水平分组,比较该因素的效应。 两因素方差分析即配伍组设计的方差分析(two-way ANOV A): 用途:用于随机区组设计的多个样本均数比较,其统计推断是推断各样本所代表的各总体均数是否相等。随机区组设计考虑了个体差异的影响,可分析处理因素和个体差异对实验效应的影响,所以又称两因素实验设计,比完全随机设计的检验效率高。该设计是将受试对象先按配比条件配成配伍组(如动物实验时,可按同窝别、同性别、体重相近进行配伍),每个配伍组有三个或三个以上受试对象,再按随机化原则分别将各配伍组中的受试对象分配到各个处理组。值得注意的是,同一受试对象不同时间(或部位)重复多次测量所得到的资料称为重复测量数据(repeated measurement data),对该类资料不能应用随机区组设计的两因素方差分析进行处理,需用重复测量数据的方差分析。 方差分析的条件之一为方差齐,即各总体方差相等。因此在方差分析之前,应首先检验各样本的方差是否具有齐性。常用方差齐性检验(test for homogeneity of variance)推断 【案例1】有12名接种卡介苗的儿童,八周后用两批不同的结核菌素,一批是标准结核菌素,一批是新制结核菌素,分别注射在儿童的前臂,两种结核菌素的皮肤浸润平均直径(mm)如表5-1所示。某医生计算标准品与新制品的差值,均数3.25cm,故认为新制结核菌素的皮肤浸润直径比标准结核菌素的小。 【问题】 (1)该医生的结论是否正确?为什么? (2)问两种结核菌素的反应性有无差别? 表112名儿童分别接种结核菌素的皮肤浸润结果(m m) 编号标准品新制品差值d 112.010.02.0 214.510.04.5 315.512.53.0 412.013.0-1.0 513.010.03.0 612.05.56.5 710.58.52.0 87.56.51.0 99.05.53.5 1015.08.07.0 1113.06.56.5 1210.59.51.0 【案例2】为比较两种方法对乳酸饮料中脂肪含量测定结果是否不同,随机抽取了10份乳酸饮料制品,分别用脂肪酸水解法和哥特里-罗紫法测定其结果如表3-5第(1)~(3)栏。问两法测定结果是否不同? 表2 两种方法对乳酸饮料中脂肪含量的测定结果(%) 编号(1) 哥特里-罗紫法 (2) 脂肪酸水解法 (3) 差值d (4)=(2) (3) 1 0.840 0.580 0.260 2 0.591 0.509 0.082 3 0.67 4 0.500 0.174 4 0.632 0.316 0.316 5 0.687 0.337 0.350 6 0.978 0.51 7 0.461 7 0.750 0.454 0.296 8 0.730 0.512 0.218 9 1.200 0.997 0.203 10 0.870 0.506 0.364 2.724 【案例3】某研究者为比较耳垂血和手指血的白细胞数,调查12名成年人,同时采取耳垂血和手指血见下表,试比较两者的白细胞数有无不同。 表成人耳垂血和手指血白细胞数(10g/L) 编号耳垂血手指血 第三章习题 安庆师范学院 胡云峰 3.1对某地区的6名2周岁男婴的身高、胸围、上半臂进行测量。得样本数据如表3.1所示。 假设男婴的测量数据X (a )(a=1,…,6)来自正态总体N 3(μ,∑)的随机样本。根据以往的资料,该地区城市2周岁男婴的这三项的均值向量μ0=(90,58,16)’,试检验该地区农村男婴与城市男婴是否有相同的均值向量。 表3.1某地区农村2周岁男婴的体格测量数据 男婴身高(X 1)cm 胸围身高(X 2)cm 上半臂围身高(X 3)cm 17860.616.527658.112.539263.2 14.54815914581 60.815.568459.5 14 解 1.预备知识∑未知时均值向量的检验:H 0:μ=μ0H 1:μ≠μ0 H 0成立时 122 )(0,) (1)(1,) ()'((1)))()'()(,1) (1)1(,) (1)P P X N n S W n n X n S X n X S X T p n n p T F P n p n p μμμμμ---∑--∑??∴----=-----+∴ -- 当 2 (,)(1) n p T F p n p p n α-≥--或者22T T α≥拒绝0 H 当 2 (,)(1) n p T F p n p p n α-<--或者22T T α<接受0 H 这里2 (1) (, )p n T F p n p n p αα-= --2.根据预备知识用matlab 实现本例题算样本协方差和均值 程序x=[7860.616.5;7658.112.5;9263.214.5;8159.014.0;8160.815.5;8459.514.0];[n,p]=size(x);i=1:1:n; xjunzhi=(1/n)*sum(x(i,:));y=rand(p,n);for j=1:1:n 独立样本T检验要求被比较的两个样本彼此独立,既没有配对关系,要求两个样本均来自正态分布,要求均值是对于检验有意义的描述统计量。 例如:男性和女性的工资均值比较 分析——比较均值——独立样本T检验。 分析身高大于等于155厘米与身高小于155的两组男生的体重和肺活量均值之间是否有显着性差异。 基本信息的描述 方差齐次性检验(详见下面第二个例题)和T检验的计算结果。从sig(双侧)栏数据可以看出,无论两组体重还是肺活量,方差均是齐的,均选择假设方差相等一行数据进行分析得出结论。 体重T检验结果,sig(双侧)=,小于,拒绝原假设。两组均值之差的99%上、下限均为正值,也说明两组体重均值之差与0的差异显着。由此可以得出结论,按身高分组的两组体重均值差异,在统计学上高度显着。 肺活量T检验的结果,sig(双侧)=,大于,。两组均值之差的上下限为一个正值,一个负值,也说明差值的99%上下限与0的差异不显着。由此可以得出结论,按身高分组烦人两组肺活量均值差异在99%水平上不显着,均值差异是由抽样误差引起的。 以性别作为分组变量,比较当前工资salary变量的均值 方差齐性检验(levene检验)结果,F值为,显着性概率为p<,因此结论是 两组方差差异显着,及方差不齐。在下面的T 检验结果中应该选择假设方差不相等一行的数据作为本例的T检验的结果数据,另一航是假设方差相等的T检验的据算数据,不取这个结果。 T的值 sig 两组均值差异为.平均现工资女的低于男的. 差值的标准误为 差分的95%的置信区间在-18003~-12816之间,不包括0,也说明两组均值之差与0有显着差异。 结论:从T 检验的P的值为<,和均值之差值的95%置信区间不包括0都能得出,女雇员现工资明显低于男雇员,茶差异有统计学意义。t检验习题及答案
T检验公式推导过程附例题
T检验例题
教育统计学t检验练习
两独立样本和配对样本T检验
医药数理统计第六章习题(检验假设和t检验)
t检验计算公式
三种常用的T检验
两配对样本T检验整理
医药数理统计第六章习题(检验假设和t检验)
教育统计学t检验练习
t检验的与习题
教育统计学t检验练习
t检验及方差分析练习题
t检验有单样本t检验
42配对样本t检验例题
matlab与单样本t检验
独立样本T检验
相关主题
文本预览