
相关分析方法
地理要素之间相互关系密切程度的测定,主要是通过对相关系数的计算与检验来完成的。
1. 两要素之间相关程度的测定
1) 相关系数的计算与检验
(1) 相关系数的计算
相关系数——表示两要素之间的相关程度的统计指标。
对于两个要素x与y,如果它们的样本值分别为xi与yi(i=1,2,...,n),它们之间的相关系数:
,
r xy>0,表示正相关,即同向相关;rxy<0,表示负相关,即异向相关。的绝对值越接近于1,两要素关系越密切;越接近于0,两要素关系越不密切。
■ 若记:
则:
■ 若问题涉及到x1,x2,…,xn等n个要素,多要素的相关系数矩阵:
[相关系数矩阵的性质]
[举例说明]
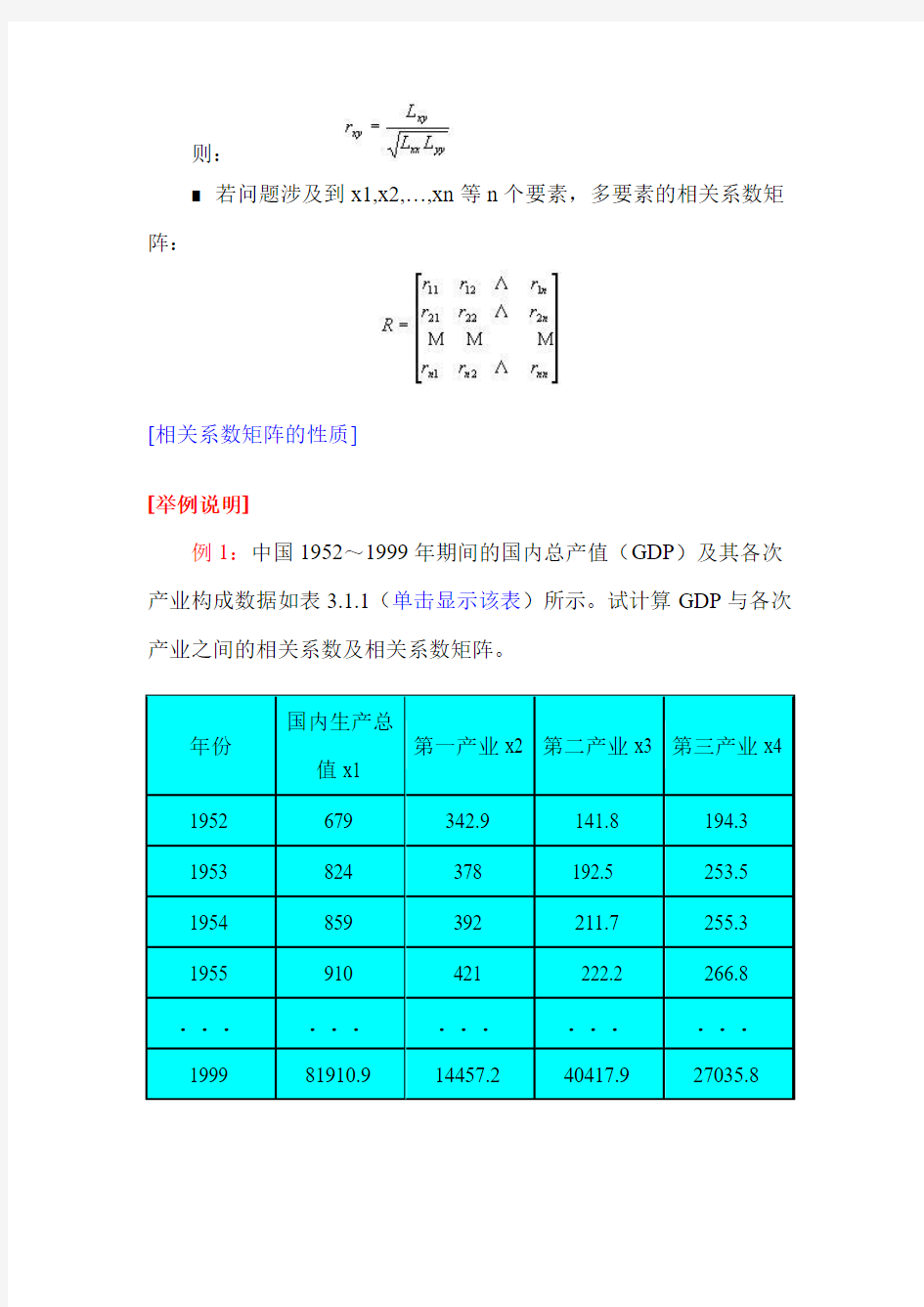
例1:中国1952~1999年期间的国内总产值(GDP)及其各次产业构成数据如表3.1.1(单击显示该表)所示。试计算GDP与各次产业之间的相关系数及相关系数矩阵。
解:
(1) 将表3.1.1中的数据代入相关系数计算公式计算,得到国内生产总值(GDP)与第一、二、三产业之间的相关系数分别为0.9954,0.9994,0.9989。
(2) 根据表3.1.1中的数据,进一步计算,得到国内生产总值及
一、二、三产业之间的相关系数矩阵:
(2) 相关系数的检验
一般情况下,相关系数的检验,是在给定的置信水平下,通过查相关系数检验的临界值表来完成。表3.1.2(点击显示该表)给出了相关系数真值(即两要素不相关)时样本相关系数的临界值
[临界值表说明]
2) 秩相关系数的计算与检验
(1) 秩相关系数的计算
秩相关系数——是描述两要素之间相关程度的一种统计指标,是将两要素的样本值按数据的大小顺序排列位次,以各要素样本值的位次代替实际数据而求得的一种统计量。实际上,它是位次分析方法的数量化。
设两个要素x和y有n对样本值,令R1代表要素x的序号(或
位次),R2代表要素y的序号(或位次),代表要素x和y的同一组样本位次差的平方,则要素x和y之间的秩相关系数被定义为
(2) 秩相关系数的检验
与相关系数一样,秩相关系数是否显著,也需要检验。表3.1.4(点击显示该表及表的说明)给出了秩相关系数检验的临界值。
[举例说明]
例2:全国1999年各省(市、区)的总人口(x)和社会总产值(y)及其位次列于表3.1.3(因为缺数据,香港、澳门、台湾三个地区未列入)(点击显示该表)。试计算总人口(x)与社会总产值(y)之间的秩相关系数并对其进行检验。
解:
(1) 计算秩相关系数。
n=31,n(n2-1)=29760,将表3.1.3中最后一列数据代入上面的秩相关系数公式计算得:
即:总人口(x)与国内生产总值(y)之间的等级相关系数为0.806。
(2) 秩相关系数的检验。
n=31,表中没有给出相应的样本数下的临界值,但同一显著水平下,随着样本数的增大,临界值r a减少。在n=30时,查表得:
r0.05=0.306,r0.01=0.432,由于r`xy=0.806>r0.01=0.432,故r`xy在α=0.01的置信水平上是显著的。
2. 多要素间相关程度的测定
1) 偏相关系数的计算与检验
(1) 偏相关系数的计算
偏相关系数矩阵:
①一级偏相关系数的计算:
②二级偏相关系数的计算:
(2) 偏相关系数的性质
(3) 偏相关系数的显著性检验
偏相关系数的显著性检验,一般采用t检验法。
计算公式为
[举例说明]
例3:对于某四个地理要素x1,x2,x3,x4的23个样本数据,经过计算得到了如下的单相关系数矩阵:
试计算各个一级和二级偏相关系数并对其进行显著性检验。
解:
(1) 求一级偏相关系数;
把数值代入一级偏相关系数公式计算得:
同理,依次可以计算出其它各一级偏相关系数,见表3.1.5。
(2) 求二级偏相关系数;
求出一级偏相关系数后,可代入公式计算二级偏相关系数:
同理,依次可计算出其它各二级偏相关系数,见表3.1.6。
(3) 显著性检验。
对于r24·13=0.821,
在自由度为23-3-1=19时,查表得t0.001=3.883,t>t a,这表明在置信度水平=0.001上,偏相关系数r24·13是显著的。
2) 复相关系数的计算与检验
复相关分析法能够反映各要素的综合影响。几个要素与某一个要素之间的复相关程度,用复相关系数来测定。
(1) 复相关系数的计算
复相关系数,可以利用单相关系数和偏相关系数求得。
设y为因变量,x1,x2,…,x k为自变量,则将y与x1,x2,…,x k之间的复相关系数记为R y·12…k。则其计算公式如下。
当有k个自变量时,
(2) 复相关系数的性质
(3) 复相关系数的显著性检验
一般采用F检验法。
计算公式:
n为样本数,k为自变量个数。查F检验的临界值表,可以得到不同显著性水平上的临界值Fα,若F>F0.01,则表示复相关在置信度水平a=0.01上显著,称为极显著;若,则表示复相关在
置信度水平a=0.05上显著;若,则表示复相关在置信度水平a=0.10上显著;若F [举例说明] 例4:对于某四个地理要素x1,x2,x3,x4的23个样本数据,经过计算得到了如下的单相关系数矩阵: 若以x4为因变量,x1,x2,x3为自变量,试计算x4与x1,x2,x3之间的复相关系数并对其进行显著性检验。 解: (1) 计算复相关系数 按照公式计算: (2) 显著性检验 ,复相关达到了极显著水平。 二、常用相关分析方法及其计算 在教育与心理研究实践中,常用的相关分析方法有积差相关法、等级相关法、质量相关法,分述如下。 (一)积差相关系数 1. 积差相关系数又称积矩相关系数,是英国统计学家皮尔逊(Pearson )提出的一种计算相关系数的方法,故也称皮尔逊相关。这是一种求直线相关的基本方法。 积差相关系数记作XY r ,其计算公式为 ∑∑∑===----= n i i n i i n i i i XY Y y X x Y y X x r 1 2 1 2 1 ) ()() )(( (2-20) 式中i x 、i y 、X 、Y 、n 的意义均同前所述。 若记X x x i -=,Y y y i -=,则(2-20)式成为 Y X XY S nS xy r ∑= (2-21) 式中n xy ∑称为协方差,n xy ∑的绝对值大小直观地反映了两列变量的一致性程 度。然而,由于X 变量与Y 变量具有不同测量单位,不能直接用它们的协方差 n xy ∑来表示两列变量的一致性,所以将各变量的离均差分别用各自的标准差 除,使之成为没有实际单位的标准分数,然后再求其协方差。即: ∑∑?= = )()(1Y X Y X XY S y S x n S nS xy r Y X Z Z n ∑?= 1 (2-22) 这样,两列具有不同测两单位的变量的一致性就可以测量计算。 计算积差相关系数要求变量符合以下条件:(1)两列变量都是等距的或等比的测量数据;(2)两列变量所来自的总体必须是正态的或近似正态的对称单峰分布;(3)两列变量必须具备一一对应关系。 2. 积差相关系数的计算 利用公式 (2-20)计算相关系数,应先求两列变量各自的平均数与标准差,再求离中差的乘积之和。在统计实践中,为方便使用数据库的数据格式,并利于计算机计算,一般会将(2-20)式改写为利用原始数据直接计算XY r 的公式。即: ∑∑∑∑∑∑∑---= 2 22 2 ) () (i i i i i i i i XY y y n x x n y x y x n r (2-23) (二)等级相关 在教育与心理研究实践中,只要条件许可,人们都乐于使用积差相关系数来度量两列变量之间的相关程度,但有时我们得到的数据不能满足积差相关系数的计算条件,此时就应使用其他相关系数。 等级相关也是一种相关分析方法。当测量得到的数据不是等距或等比数据,而是具有等级顺序的测量数据,或者得到的数据是等距或等比的测量数据,但其所来自的总体分布不是正态的,出现上述两种情况中的任何一种,都不能计算积差相关系数。这时要求两列变量或多列变量的相关,就要用等级相关的方法。 1. 斯皮尔曼(Spearman)等级相关 斯皮尔曼等级相关系数用R r 表示,它适用于两列具有等级顺序的测量数据,或总体为非正态的等距、等比数据。 浅析空间自相关的内容及意义摘要:本文主要介绍了空间自相关的含义、测度指标及研究空间自相关的意义。首先,明确空间自相关是检验某一要素的属性值是否显著地与其相邻空间点上的属性值相关联的重要指标,揭示空间参考单元与其邻近的空间单元属性特征值之间的相似性或相关性。其次,介绍用来测度空间自相关性的指标,可以分为全局指标和局部指标,常用的指标有:Moran’s I、Geary’s C和Getis-Ord G。最后,进一步阐述了空间自相关的研究意义。关键字:空间自相关;全局指标;局部指标The content and research significance of spatial autocorrelation analysisAbstract: In this paper, the content, the index and the research significance of spatial autocorrelation were analyzed. Firstly, the content of spatial autocorrelation is discussed. Spatial autocorrelation is related to the correlation of the same variables, and also can be used to measure the degree of concentration of the attribute value, in order to reveal the correlation between the space reference unit and its near unit, including global spatial autocorrelation and local spatial autocorrelation. Secondly, it analyzes the index of spatial autocorrelation, the main index included Moran’s I, Geary’s C and Getis-Ord G. Thirdly, this paper discussed the research signification of spatial autocorrelation analysis. Key words: spatial autocorrelation; global index; local index 引言空间 1工作分析方法介绍 观察法是工作人员在不影响被观察人员正常工作的条件下,通过观察将有关的工作内容、方法、程序、设备、工作环境等信息记录下来,最后将取得的信息归纳整理为适合使用的结果的过程。 采用观察法进行岗位分析时,应力求结构化,根据岗位分析的目的和组织现有的条件,事先确定观察内容、观察时间、观察位置、观察所需的记录单,做到省时高效。 观察法的优点是:取得的信息比较客观和正确。但它要求观察者有足够的实际操作经验;主要用于标准化的、周期短的以体力活动为主的工作,不适用于工作循环周期长的、以智力活动为主的工作;不能得到有关任职者资格要求的信息。观察法常与访谈法同时使用。 访谈法是访谈人员就某一岗位与访谈对象,按事先拟定好的访谈提纲进行交流和讨论。访谈对象包括:该职位的任职者、对工作较为熟悉的直接主管人员、与该职位工作联系比较密切的工作人员、任职者的下属。为了保证访谈效果,一般要事先设计访谈提纲,事先交给访谈者准备。 访谈法通常用于工作分析人员不能实际参与观察的工作,其优点是既可以得到标准化工作信息,又可以获得非标准化工作的信息;既可以获得体力工作的信息,又可以获得脑力工作的信息;同时可以获取其他方法无法获取的信息,比如工作经验、任职资格等,尤其适合对文字理解有困难的人。其不足之处是被访谈者对访谈的动机往往持怀疑态度,回答问题是有所保留,信息有可能会被扭曲。因此,访谈法一般不能单独用于信息收集,需要与其他方法结合使用。 问卷调查是根据工作分析的目的、内容等事先设计一套调查问卷,由被调查者填写,再将问卷加以汇总,从中找出有代表性的回答,形成对工作分析的描述信息。问卷调查法是工作分析中最常用的一种方法。问卷调查法的关键是问卷设计,主要有开放式和封闭式两种形式。开放式调查表由被调查人自由回答问卷所提问题;封闭式调查表则是调查人事先设计好答案,由被调查人选择确定。 1.提问要准确 2.问卷表格设计要精练 3.语言通俗易懂,问题不能模凌两可 4.问卷表前面要有导语 5.问题排列应有逻辑,能够引起被调查人兴趣的问题放在前面 一、实验目的 1、掌握ArcGIS缓冲区分析、叠置分析、网络分析方法。 2、熟悉ArcGIS的空间统计、栅格计算方法。 3、综合利用矢量数据空间分析中的缓冲区分析和叠置分析解决实际问题。 4、学会用ArcGIS9 进行各种类型的最短路径分析,了解内在的运算机理。 5、熟练掌握利用ArcGIS上述空间分析功能分析和结果类似学校选址的实际应用问题的基本流程和操作过程。 二、主要实验器材(软硬件、实验数据等) 计算机硬件:lenovoideapadY460N 计算机软件:ArcGIS10.0软件 实验数据:《ArcGIS地理信息系统空间分析实验教程》随书光盘的第七章、第八章等 三、实验内容与要求 1、空间缓冲区分析。 (1)为点状、线状、面状要素建立缓冲区。 1)打开菜单“自定义”下的“自定义模式”,在对话框中选择“命令”,在“类别” 中选择“工具”,在右边的框中选择“缓冲向导”(如图 1 所示),拖动其放置 到工具栏上的空处。 图1提出“缓冲向导” 2)利用选择工具选择要进行分析的点状要素,然后点击,在“缓冲向导” 对话框设置缓冲区信息,如图2及图3所示。 图2 线状缓冲区信息设置1 图3线状缓冲区信息设置2 3)利用选择工具选择要进行分析的线状要素,然后点击,在“缓冲向导” 对话框设置缓冲区信息。 4)利用选择工具选择要进行分析的面状要素,然后点击,在“缓冲向导” 对话框设置缓冲区信息,如图4所示。 图4 面状缓冲区信息设置 2、学校选址。 要求: (1) 新学校选址需注意如下几点: 1)新学校应位于地势较平坦处; 2)新学校的建立应结合现有土地利用类型综合考虑,选择成本不高的区域; 3)新学校应该与现有娱乐设施相配套,学校距离这些设施愈近愈好; 4)新学校应避开现有学校,合理分布。 (2) 各数据层权重比为:距离娱乐设施占0.5,距离学校占0.25,土地利用类型和地势 位置因素各占0.125。 (3) 实现过程运用ArcGIS的扩展模块(Extension)中的空间分析(Spatial Analyst)部 分功能,具体包括:坡度计算、直线距离制图功能、重分类及栅格计算器等功能完 成。 (4) 最后必须给出适合新建学校的适宜地区图,并对其简要进行分析。 具体操作: (1)打开加载地图文档对话框,选择E:\Chp8\Ex1\school.mxd。 (2)从DEM 数据提取坡度数据集: 打开工具箱→“Spatial Analyst 工具”→“表面分析”→“坡度”工具;在打开对话框中设置,如图5所示;生成坡度图,如图6所示。 图5 “坡度”对话框设置 图6 坡度图 第六章 相关与回归分析方法 第一部分 习题 一、单项选择题 1.单位产品成本与其产量的相关;单位产品成本与单位产品原材料消耗量的相关 ( )。 A.前者是正相关,后者是负相关 B.前者是负相关,后者是正相关 C.两者都是正相关 D.两者都是负相关 2.样本相关系数r 的取值范围( )。 A.-∞<r <+∞ B.-1≤r ≤1 C. -l <r <1 D. 0≤r ≤1 3.当所有观测值都落在回归直线 01y x ββ=+上,则x 与y 之间的相关系数( )。 A.r =0 B.r =1 C.r =-1 D.|r|=1 4.相关分析与回归分析,在是否需要确定自变量和因变量的问题上( )。 A.前者无需确定,后者需要确定 B.前者需要确定,后者无需确定 C.两者均需确定 D.两者都无需确定 5.直线相关系数的绝对值接近1时,说明两变量相关关系的密切程度是( )。 A.完全相关 B.微弱相关 C.无线性相关 D.高度相关 6.年劳动生产率x(千元)和工人工资y(元)之间的回归方程为y=10+70x ,这意味着年劳动生产率每提高1千元时,工人工资平均( )。 A.增加70元 B.减少70元 C.增加80元 D.减少80元 7.下面的几个式子中,错误的是( )。 A. y= -40-1.6x r=0.89 B. y= -5-3.8x r =-0.94 C. y=36-2.4x r =-0.96 D. y= -36+3.8x r =0.98 8.下列关系中,属于正相关关系的有( )。 A.合理限度内,施肥量和平均单产量之间的关系 B.产品产量与单位产品成本之间的关系 C.商品的流通费用与销售利润之间的关系 D.流通费用率与商品销售量之间的关系 9.直线相关分析与直线回归分析的联系表现为( )。 A.相关分析是回归分析的基础 B.回归分析是相关分析的基础 C.相关分析是回归分析的深入 D.相关分析与回归分析互为条件 10.进行相关分析,要求相关的两个变量( )。 A.都是随机的 B.都不是随机的 C.一个是随机的,一个不是随机的 D.随机或不随机都可以 11.相关关系的主要特征是( )。 A.某一现象的标志与另外的标志之间存在着确定的依存关系 B.某一现象的标志与另外的标志之间存在着一定的关系,但它们不是确定的关系 C.某一现象的标志与另外的标志之间存在着严重的依存关系 D.某一现象的标志与另外的标志之间存在着函数关系 12.相关分析是研究( )。 A.变量之间的数量关系 B.变量之间的变动关系 C.变量之间相互关系的密切程度 D.变量之间的因果关系 13.现象之间相互依存关系的程度越低,则相关系数( )。 A.越接近于0 B.越接近于-1 C.越接近于1 D.越接近于0.5 14.在回归直线01y x ββ=+中,若10 β<,则x 与y 之间的相关系数( )。 A. r=0 B. r=1 C. 0<r <1 D. —l <r <0 15.当相关系数r=0时,表明( )。 A.现象之间完全无关 B.相关程度较小 C.现象之间完全相关 D.无直线相关关系 16.已知x 与y 两变量间存在线性相关关系,且2 10,8,7,100x y xy n σσσ===-=,则x 与y 之间存在着( )。 空间自相关分析 1.1 自相关分析 空间自相关分析是指邻近空间区域单位上某变量的同一属性值之间的相关程度,主要用空间自相关系数进行度量并检验区域单位的这一属性值在空间区域上是否具有高高相邻、低低相邻或者高低间错分布,即有无聚集性。若相邻区域间同一属性值表现出相同或相似的相关程度,即属性值在空间区域上呈现高(低)的地方邻近区域也高(低),则称为空间正相关;若相邻区域间同一属性值表现出不同的相关程度,即属性值在空间区域上呈现高(低)的地方邻近区域低(高),则称为空间负相关;若相邻区域间同一属性值不表现任何依赖关系,即呈随机分布,则称为空间不相关。 空间自相关分析分为全局空间自相关分析和局部空间自相关分析,全局自相关分析是从整个研究区域内探测变量在空间分布上的聚集性;局域空间自相关分析是从特定局部区域内探测变量在空间分布上的聚集性,并能够得出具体的聚集类型及聚集区域位置,常用的方法有Moran's I 、Gear's C 、Getis 、Morans 散点图等。 1.1.1 全局空间自相关分析 全局空间自相关分析主要用Moran's I 系数来反映属性变量在整个研究区域范围内的空间聚集程度。首先,全局Moran's I 统计法假定研究对象之间不存在任何空间相关性,然后通过Z-score 得分检验来验证假设是否成立。 Moran's I 系数公式如下: 11 2 11 1 ()()I ()()n n ij i j i j n n n ij i i j i n w x x x x w x x =====--= -∑∑∑∑∑(式 错误!文档中没有指定样式的文字。-1) 其中,n 表示研究对象空间的区域数;i x 表示第i 个区域内的属性值,j x 表示第j 个区域内的属性值,x 表示所研究区域的属性值的平均值;ij w 表示空间权重矩阵,一般为对称矩阵。 Moran's I 的Z-score 得分检验为: 企业工作分析中的常见问题及解决方法 一、员工恐惧 员工恐惧,是指由于员工害怕工作分析会对其已熟悉的工作环境带来变化或者会引起自身利益的损失,而对工作分析小组成员及其工作采取不合作甚至敌视的态度。 一般而言,如果在工作分析过程中,工作分析小组遇到以下一些现象,我们就认为存在员工恐惧: 访谈过程中,员工对工作分析小组的工作有抵触情绪,不支持其访谈或调查工作; 员工提供有关工作的虚假情况,故意夸大其所在岗位的实际工作责任、工作内容,而对其他岗位的工作予以贬低。 造成这些现象的原因,我们认为主要有以下几个方面: 首先,员工通常认为工作分析会对他们目前的工作、薪酬水平造成威胁。因为在过去,工作分析一直是企业在减员降薪时经常使用的一种手段。在过去,企业如果无缘无故地辞退员工,无疑会引起被辞退者的控告、在职者的不满和恐惧;如果无缘无故地降低员工工资,同样会引起员工的愤慨,从而影响员工的工作绩效。但如果企业的这些决定是在工作分析基础上做出的,它就有了一个所谓的科学的理由。因此员工就对工作分析存在着一种天生的恐惧之情; 其次,为提高员工生产效率,企业也经常使用工作分析。在霍桑实验中,实验者发现员工在工作中一般不会用最高的效率从事工作,而只是追从团队中的中等效率。这是因为员工不仅仅有经济方面的需求,更有团队归属需求。而且,员工认为,如果自己的工作效率太高,上级会再增加自己的工作强度。因此,员工对工作分析的恐惧也有其现实意义。 企业或者工作分析专家想要更为成功地实施工作分析,就必须首先克服员工对工作分析的恐惧,从而使其提供真实的信息。一个较为有效的解决方法就是尽可能将员工及其代表纳人到工作分析过程之中。 首先,在工作分析开始之前,应该向员工解释清楚以下几方面的内容: 实施工作分析的原因; 工作分析小组成员组成; 工作分析都会对员工产生何种影响; 为什么员工提供的信息资料对工作分析是十分重要的。因为只有当员工了解了工作分析的实际情况,并且参与到整个工作分析过程中之后,才会忠于工作分析,也才会提供真实可靠的信息; 最后,但也是最重要的,工作分析小组也许应该做出书面的承诺,企业绝对不会因工作分析的结果而解雇任何员工,决不会降低员工的工资水平,也决不会减少整个企业工作的总数。 其次,在工作分析实施过程中和工作分析完结之后,也应及时向员工反馈工作分析的阶段性成果和最终结果。以上这些措施也许会让工作分析专家可以从员工那里获得更为可靠、全面的信息资料。 二、动态环境 动态环境指的是由于经济和社会等的变化发展,引起企业内外部环境的变化,从而引发的企业组织结构、工作构成、人员结构等不断的变动。 外部环境的变化。当今的社会是高速发展的社会,有人曾这样描述过:“当今社会,惟一不变的就是变化。”企业作为社会的基本构成单元,也是处于高速变化当中的。当我们为了更好地管理企业而进行工作分析时,却往往会因组织的变革所引发的工作变革导致这些工作分析的成果不能适应于企业现在的实际状况,而只能被束之高阁; 企业生命周期的变化。企业处于不同的企业生命周期,其战略目标也相应地会有所不同。在处于幼稚期时,企业追求的可能仅仅是生存,与此相应的,企业重视的是那些研发人员,公司中大量存在的岗位就是研发岗位,研发人员的主要职责就是研究出新颖的产品;而当企业在市场中站稳脚跟进入发展期后,其目标就会相应改变。追求的可能是企业的市场占有率,市场营销也就逐渐提高到管理日程上来,营销策划人员也会相应增加,其主 相关性分析 相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。相关性不等于因果性,也不是简单的个性化,相关性所涵盖的范围和领域几乎覆盖了我们所见到的方方面面,相关性在不同的学科里面的定义也有很大的差异。 差时,他们的相关性就会受到削弱。 世界上的任何事物之间存在的关系无非三种: 1、函数关系,如时间和距离, 2、没有关系,如你老婆的头发颜色和目前的房价 3、相关关系,两者之间有一定的关系,但不是函数关系。这种密切程度可以用一个数值来表示,|1|表示相关关系达到了函数关系,从1到-1之间表示两者之间关系的密切程度,例如0.8。 相关分析用excel可以实现 说判定有些严格,其实就是观察一下各个指标的相关程度。一般来说相关性越是高,做主成分分析就越是成功。主成分分析是通过降低空间维度来体现所有变量的特征使得样本点分散程度极大,说得直观一点就是寻找多个变量的一个加权平均来反映所有变量的一个整体性特征。 评价相关性的方法就是相关系数,由于是多变量的判定,则引出相关系数矩阵。 评价主成分分析的关键不在于相关系数的情况,而在于贡献率,也就是根据主成分分析的原理,计算相关系数矩阵的特征值和特征向量。 相关系数越是高,计算出来的特征值差距就越大,贡献率等于前n个大的特征值除以全部特征值之和,贡献率越是大说明主成分分析的效果越好。反之,变量之间相关性越差。 举个例子来说,在二维平面内,我们的目的就是把它映射(加权)到一条直线上并使得他们分散的最开(方差最大)达到降低维度的目的,如果所有样本点都在一条直线上(也就是相关系数等于1或者-1),这样的效果是最好的。再假设样本点呈现两条垂直的形状(相关系数等于零),你要找到一条直线来做映射就很难了。 SPSS软件的特点 一、集数据录入、资料编辑、数据管理、统计分析、报表制作、图形绘制为一体。从理论上说,只要计算机硬盘和内存足够大,SPSS可以处理任意大小的数据文件,无论文件中包含多少个变量,也不论数据中包含多少个案例。 二、统计功能囊括了《教育统计学》中所有的项目,包括常规的集中量数和差异量数、相关分析、回归分析、方差分析、卡方检验、t检验和非参数检验;也包括近期发展的多元统计技术,如多元回归分析、聚类分析、判别分析、主成分分析和因子分析等方法,并能在屏幕(或打印机)上显示(打印)如正态分布图、直方图、散点图等各种统计 大数据并不是说它大,而是指其全面。它收集全方位的信息来交叉验证,应用在各个领域。比如银行,你可以去银行贷款,而银行可能会把钱借给你,为什么??因为在大数据时代,它可以通过一系列信息,通过交叉复现得知你很多东西,比如你的住址,是什么样的校区? 在SPSS软件相关分析中,pearson(皮尔逊), kendall(肯德尔)和spearman(斯伯曼/斯皮尔曼)三种相关分析方法有什么异同 两个连续变量间呈线性相关时,使用Pearson积差相关系数,不满足积差相关分析的适用条件时,使用Spearman秩相关系数来描述. Spearman相关系数又称秩相关系数,是利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围要广些。对于服从Pearson相关系数的数据亦可计算Spearman相关系数,但统计效能要低一些。Pearson相关系数的计算公式可以完全套用Spearman相关系数计算公式,但公式中的x和y用相应的秩次代替即可。 Kendall's tau-b等级相关系数:用于反映分类变量相关性的指标,适用于两个分类变量均为有序分类的情况。对相关的有序变量进行非参数相关检验;取值范围在-1-1之间,此检验适合于正方形表格; 计算积距pearson相关系数,连续性变量才可采用;计算Spearman秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据; 计算Kendall秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。 计算相关系数:当资料不服从双变量正态分布或总体分布未知,或原始数据用等级表示时,宜用 spearman或kendall相关 Pearson 相关复选项积差相关计算连续变量或是等间距测度的变量间的相关分析 Kendall 复选项等级相关计算分类变量间的秩相关,适用于合并等级资料 Spearman 复选项等级相关计算斯皮尔曼相关,适用于连续等级资料 注: 1若非等间距测度的连续变量因为分布不明-可用等级相关/也可用Pearson 相关,对于完全等级离散变量必用等级相关 2当资料不服从双变量正态分布或总体分布型未知或原始数据是用等级表示时,宜用Spearman 或 Kendall相关。 3 若不恰当用了Kendall 等级相关分析则可能得出相关系数偏小的结论。则若不恰当使用,可能得相关系数偏小或偏大结论而考察不到不同变量间存在的密切关系。对一般情况默认数据服从正态分布的,故用Pearson分析方法。 在SPSS里进入Correlate-》Bivariate,在变量下面Correlation Coefficients复选框组里有3个选项: Pearson 重庆各区县乡村人口所占比例的空间自相关分析 选题: 在ArcGIS中分别计算全局Moran’I 指数和局部Moran’I指数,分析重庆各区县乡村人口所占比例的空间关联程度。 实验目的: 根据重庆市各区县之间的邻接关系,采用二进制邻近权重矩阵,选取各区县2008年的重庆各区县的总人口及乡村人口,计算出重庆各区县乡村人口所占的比例,在ArcGIS里面分别计算全局Moran’I 指数和局部Moran’I指数,分析空间关联程度。 实验数据: 1.重庆统计年鉴中2008年重庆市各区县的总人口及乡村人口数量(excel表格) 2.重庆市各区县的矢量图(shp.文件) 软件: ArcGIS10.2 操作过程与结果分析: 第一步:导入Excel数据文件和重庆市各区县的矢量图,并建立关联 1. Catalog——Folder Connections,在对应的文件夹下打开重庆市各区县城镇化率的EXCEL表格及重庆市各区县shp文件 为关联字段,将两个文件关联起来 3.右键单击关联后的重庆区县界shp.文件,导出为Export_Output文件,新文件的属性表如下: 第二步:计算全局Morans I 1.打开ArcToolbox,选择Spatial Statistics Tools——Analying Patterns——Spatial Autocorrelation(Morans I)选择二进制邻接矩阵方法来确定空间权重矩阵(即当区域i和具有公共边或公共点时,两区域的距离矩阵设为1,若不相邻接,其距离矩阵设为0),选择欧式距离作为计算距离的方法,对数据进行标准化处理后计算全局Moran’I指数度量空间自相关 ARCGIS空间分析基本操作 一、实验目的 1. 了解基于矢量数据和栅格数据基本空间分析的原理和操作。 2. 掌握矢量数据与栅格数据间的相互转换、栅格重分类(Raster Reclassify)、栅格计算-查询符合条件的栅格(Raster Calculator)、面积制表(Tabulate Area)、分区统计(Zonal Statistic)、缓冲区分析(Buffer) 、采样数据的空间内插(Interpolate)、栅格单元统计(Cell Statistic)、邻域统计(Neighborhood)等空间分析基本操作和用途。 3. 为选择合适的空间分析工具求解复杂的实际问题打下基础。 二、实验准备 预备知识: 空间数据及其表达 空间数据(也称地理数据)是地理信息系统的一个主要组成部分。空间数据是指以地球表面空间位置为参照的自然、社会和人文经济景观数据,可以是图形、图像、文字、表格和数字等。它是GIS所表达的现实世界经过模型抽象后的内容,一般通过扫描仪、键盘、光盘或其它通讯系统输入GIS。 在某一尺度下,可以用点、线、面、体来表示各类地理空间要素。 有两种基本方法来表示空间数据:一是栅格表达; 一是矢量表达。两种数据格式间可以进行转换。 空间分析 空间分析是基于地理对象的位置和形态的空间数据的分析技术,其目的在于提取空间信息或者从现有的数据派生出新的数据,是将空间数据转变为信息的过程。 空间分析是地理信息系统的主要特征。空间分析能力(特别是对空间隐含信息的提取和传输能力)是地理信息系统区别与一般信息系统的主要方面,也是评价一个地理信息系统的主要指标。 空间分析赖以进行的基础是地理空间数据库。 空间分析运用的手段包括各种几何的逻辑运算、数理统计分析,代数运算等数学手段。 空间分析可以基于矢量数据或栅格数据进行,具体是情况要根据实际需要确定。 空间分析步骤 根据要进行的空间分析类型的不同,空间分析的步骤会有所不同。通常,所有的空间分析都涉及以下的基本步骤,具体在某个分析中,可以作相应的变化。 空间分析的基本步骤: a)确定问题并建立分析的目标和要满足的条件 b)针对空间问题选择合适的分析工具 c)准备空间操作中要用到的数据。 d)定制一个分析计划然后执行分析操作。 e)显示并评价分析结果 相关分析步骤 相关分析 双变量相关分析检验是否符合正态分布(K-S检验) 偏相关分析不需检验 距离分析不需检验 X/Y 度量(S)序号(O)名义(N)度量(S)Pearson相关系数Spearman等级相关系数/ 序号(O)Spearman等级相关系数Spearman等级相关系数 Kendall ?系数 / 名义(N)/ 卡方值Pearson卡方值(Chi-Square) Pearson相关系数K-S检验是否必须符合正态分布 Spearman等级相关系数不需检验 Kendall ?系数不需检验 一双变量相关分析(Pearson、Spearma、Kendall ) 1 判断使用哪种相关系数,例检验是否满足使用Pearson相关系数的前提要求 2计算样本的相关系数r 按变量类型选择对应的相关系数种类,名义,度量,有序。 一般认为,当相关系数的绝对值大于0.8时,两变量具有较强的线性关系(Linear Relationship);而相关系数的绝对值小于0.3时,两变量间的线性关系较弱。 3 对两个样本来自的总体是否存在显著的线性关系进行判断 显著性检验来证明相关系数的大小是否显著。 1检验是否满足使用Pearson相关系数的前提要求 (1)【分析】——【非参数检验】——【单样本K-S检验】 (2)结果分析 单样本Kolmogorov-Smirnov 检验 年均衣着消费个人年收入家庭年收入 N 50 51 51 正态参数a,,b均值 1.44 1.33 2.25 标准差.733 .816 1.197 最极端差别绝对值.406 .462 .192 正.406 .462 .192 负-.274 -.342 -.147 Kolmogorov-Smirnov Z 2.870 3.302 1.372 渐近显著性(双侧) .000 .000 .046 a. 检验分布为正态分布。 . 根据数据计算得到。 H0:样本服从总体的正态分布。0.046<0.05,拒绝原假设。 单样本检验的结果显示变量不服从正态分布,可以用Pearson相关系数检验变量之间的线性相关程度。 2 双变量相关分析 (1)【分析】→【相关】→【双变量】 职位分析的内容包括: 1.设立岗位的目的 这个岗位为什么存在,如果不设立这个岗位会有什么后果。 2.工作职责和内容 这是最重要的部分。我们可以按照职责的轻重程度列出这个职位的主要职责,每项职责的衡量标准是什么;列出工作的具体活动,发生的频率,以及它所占总工作量的比重。 在收集与分析信息的时候,可以询问现在的任职者,他从事了哪些和本职无关的工作,或者他认为他从事的这些工作应该由哪个部门去做,就可以区分出他的、别人的和他还没有做的工作。 3.职位的组织结构图 组织结构图包括:职位的上级主管是谁,职位名称是什么,跟他平行的是谁,他的下属是哪些职位以及有多少人,以他为中心,把各相关职位画出来。 4.职位的权力与责任 (1)财务权:资金审批额度和范围。 (2)计划权:做哪些计划及做计划的周期。 (3)决策权:任职者独立做出决策的权利有哪些。 (4)建议权:是对公司政策的建议权,还是对某项战略以及流程计划的建议权。 (5)管理权:要管理多少人,管理什么样的下属,下属中有没有管理者,有没有技术人员,这些管理者是中级管理者,还是高级管理者。 (6)自我管理权:工作安排是以自我为主,还是以别人为主。 (7)经济责任:要承担哪些经济责任,包括直接责任和间接责任等。 5.职位的任职资格 (1)从业者的学历和专业要求。 (2)工作经验。 (4)专业知识和技能要求。 (5)职位所需要的能力:沟通能力、领导能力、决策能力、写作能力、外语水平、计算机水平、空间想象能力、创意能力等等。 6.劳动强度和工作饱满的程度 7.工作特点 一是工作的独立性程度。有的工作独立性很强,需要自己做决策,不需要参考上一级的指示或意见。而有的工作需要遵从上级的指示,不能擅自做主。 二是复杂性。要分析问题、提出解决办法,还是只需要找出办法。需要创造性还是不能有创造性。 8.职业发展的道路 这个职位可以晋升到哪些职位,可以转换到哪些职位,以及哪些职位可以转换到这个职位,这些有助于未来做职业发展规划时使用 9.对该职位考核方式是什么?怎么考核? 地理信息系统(GIS)具有很强的空间信息分析功能,这是区别于计算机地图制图系统的显著特征之一。利用空间信息分析技术,通过对原始数据模型的观察和实验,用户可以获得新的经验和知识,并以此作为空间行为的决策依据。 空间信息分析的内涵极为丰富。作为GIS的核心部分之一,空间信息分析在地理数据的应用中发挥着举足轻重的作用。 叠置分析(Overlay Analysis) 覆盖叠置分析是将两层或多层地图要素进行叠加产生一个新要素层的操作,其结果将原来要素分割生成新的要素,新要素综合了原来两层或多层要素所具有的属性。也就是说,覆盖叠置分析不仅生成了新的空间关系,还将输入数据层的属性联系起来产生了新的属性关系。覆盖叠置分析是对新要素的属性按一定的数学模型进行计算分析,进而产生用户需要的结果或回答用户提出的问题。 1)多边形叠置 这个过程是将两层中的多边形要素叠加,产生输出层中的新多边形要素,同时它们的属性也将联系起来,以满足建立分析模型的需要。一般GIS软件都提供了三种多边形叠置: (1)多边形之和(UNION):输出保留了两个输入的所有多边形。 (2)多边形之积(INTERSECT):输出保留了两个输入的共同覆盖区域。 (3)多边形叠合(IDENTITY):以一个输入的边界为准,而将另一个多边形与之相匹配,输出内容是第一个多边形区域内二个输入层所有多边形。 多边形叠置是个非常有用的分析功能,例如,人口普查区和校区图叠加,结果表示了每一学校及其对应的普查区,由此就可以查到作为校区新属性的重叠普查区的人口数。 2)点与多边形叠加 点与多边形叠加,实质是计算包含关系。叠加的结果是为每点产生一个新的属性。例如,井位与规划区叠加,可找到包含每个井的区域。 3)线与多边形叠加 将多边形要素层叠加到一个弧段层上,以确定每条弧段(全部或部分)落在哪个多边形内。 网络分析(Network Analysis) 对地理网络(如交通网络)、城市基础设施网络(如各种网线、电力线、电话线、供排水管线等)进行地理分析和模型化,是地理信息系统中网络分析功能的主要目的。网络分析是运筹学模型中的一个基本模型,它的根本目的是研究、筹划一项网络工程如何按排,并使其运行效果最好,如一定资源的最佳分配,从一地到另一地的运输费用最低等。其基本思想则在于人类 (岗位分析)常用岗位分析 方法分析 常用岗位分析方法分析 当目标计划等等规划方面的东西确定下来以后,实施就成为重中之重,而实施过程中采用的方法又是实施成败的关键。同样的于岗位分析过程中,根据目标、岗位特点、实际条件等选择采取合适的分析方法也就成为了关键。 目前岗位分析的方法有很多种,这里只讨论几种比较常用的方法。 1、访谈法 访谈是访谈人员就某壹岗位和访谈对象,按事先拟订好的访谈提纲进行交流和讨论。访谈对象包括:该职位的任职者;对工作较为熟悉的直接主管人员;和该职位工作联系比较密切的工作人员;任职者的下属。为了保证访谈效果,壹般要事先设计访谈提纲,事先交给访谈者准备。访谈法分为个体访谈:结构化、半结构化、无结构;壹般访谈、深度访谈;群体访谈:壹般座谈、团体焦点访谈。 进行访谈时要坚持的原则有: 1)明确面谈的意义 2)建立融洽的气氛 3)准备完整的问题表格 4)要求按工作重要性程度排列 5)面谈结果让任职者及其上司审阅修订。 麦考米克于1979年提出了面谈法的壹些标准,它们是: 1)所提问题要和职位分析的目的有关; 2)职位分析人员语言表达要清楚、含义准确; 3)所提问题必须清晰、明确,不能太含蓄; 4)所提问题和谈话内容不能超出被谈话人的知识和信息范围; 5)所提问题和谈话内容不能引起被谈话人的不满,或涉及被谈话人的隐私。 其优点是能够得到标准和非标准的、体力、脑力工作以及其他不易观察到的多方面信息。其不足之处是被访谈者对访谈的动机往往持怀疑态度,回答问题时有所保留,且面谈者易从自身利益考虑而导致信息失真。因此,访谈法壹般不能单独使用,最好和其他方法配合使用。此外,分析者的观点影响工作信息正确的判断;职务分析者问些含糊不清的问题,影响信息收集。 该方法适合于不可能实际去做某项工作,或不可能去现场观察以及难以观察到某种工作时。及适用于短时间的生理特征的分析,也适用于长时间的心理特征的分析。适用于对文字理解有困难的人。访谈法也适合于脑力职位者,如开发人员、设计人员、高层管理人员等。2、问卷调查法 问卷调查法就是根据岗位分析的目的、内容等,事先设计壹套岗位问卷,由被调查者填写,再将问卷加以汇总,从中找出有代表性的回答,形成对岗位分析的描述信息。问卷调查的关键是问卷设计。问卷设计形式分为开放型和封闭型俩种。开放型:由被调查人根据问题自由回答。封闭型:调查人事先设计好答案,由被调查人选择确定。设计问卷时要做到:①提问要准确;②问卷表格要精炼;③语言通俗易懂,问题不可模棱俩可;④问卷表前面要有指导语;⑤引进被调查人兴趣的问题放于前面,问题排列要有逻辑。 问卷调查法的具体实施有,职位分析人员首先要拟订壹套切实可行、内容丰富的问卷,然后由员工进行填写。正式进行工作分析前,考量各部门之工作内容及可行时间,先行拟定了进行时间表,若不可行,则可弹性调整。 (1)问卷发放 进行各部门之工作分析问卷发放时,先集合各部门之各级主管进行半小时之说明,说明内容有工作分析目的、工作分析问卷填答、及问题解答,且清楚告知此次活动之进行不会影响到员工现有权益,确定各主管皆明了如何进行后,由主管辅导下属进行工作分析问卷之填答。 空间分析的概念空间分析:是基于地理对象的位置和形态特征的空间数据分析技术,其目的在于提取和传输空间信息。包括空间数据操作、空间数据分析、空间统计分析、空间建模。 空间数据的类型空间点数据、空间线数据、空间面数据、地统计数据 属性数据的类型名义量、次序量、间隔量、比率量 属性:与空间数据库中一个独立对象(记录)关联的数据项。属性已成为描述一个位置任何可记录特征或性质的术语。 空间统计分析陷阱1)空间自相关:“地理学第一定律”—任何事物都是空间相关的,距离近的空间相关性大。空间自相关破坏了经典统计当中的样本独立性假设。避免空间自相关所用的方法称为空间回归模型。2)可变面元问题MAUP:随面积单元定义的不同而变化的问题,就是可变面元问题。其类型分为:①尺度效应:当空间数据经聚合而改变其单元面积的大小、形状和方向时,分析结果也随之变化的现象。②区划效应:给定尺度下不同的单元组合方式导致分析结果产生变化的现象。3)边界效应:边界效应指分析中由于实体向一个或多个边界近似时出现的误差。 生态谬误在同一粒度或聚合水平上,由于聚合方式的不同或划区方案的不同导致的分析结果的变化。(给定尺度下不同的单元组合方式) 空间数据的性质空间数据与一般的属性数据相比具有特殊的性质如空间相关性,空间异质性,以及有尺度变化等引起的MAUP效应等。一阶效应:大尺度的趋势,描述某个参数的总体变化性;二阶效应:局部效应,描述空间上邻近位置上的数值相互趋同的倾向。 空间依赖性:空间上距离相近的地理事物的相似性比距离远的事物的相似性大。 空间异质性:也叫空间非稳定性,意味着功能形式和参数在所研究的区域的不同地方是不一样的,但是在区域的局部,其变化是一致的。 ESDA是在一组数据中寻求重要信息的过程,利用EDA技术,分析人员无须借助于先验理论或假设,直接探索隐藏在数据中的关系、模式和趋势等,获得对问题的理解和相关知识。常见EDA方法:直方图、茎叶图、箱线图、散点图、平行坐标图 主题地图的数据分类问题等间隔分类;分位数分类:自然分割分类。 空间点模式:根据地理实体或者时间的空间位置研究其分布模式的方法。 茎叶图:单变量、小数据集数据分布的图示方法。 优点是容易制作,让阅览者能很快抓住变量分布形状。缺点是无法指定图形组距,对大型资料不适用。 茎叶图制作方法:①选择适当的数字为茎,通常是起首数字,茎之间的间距相等;②每列标出所有可能叶的数字,叶子按数值大小依次排列;③由第一行数据,在对应的茎之列,顺序记录茎后的一位数字为叶,直到最后一行数据,需排列整齐(叶之间的间隔相等)。 箱线图&五数总结 箱线图也称箱须图需要五个数,称为五数总结:①最小值②下四分位数:Q1③中位数④上四分位数:Q3⑤最大值。分位数差:IQR = Q3 - Q1 3密度估计是一个随机变量概率密度函数的非参数方法。 应用不同带宽生成的100个服从正态分布随机数的核密度估计。 空间点模式:一般来说,点模式分析可以用来描述任何类型的事件数据。因为每一事件都可以抽象化为空间上的一个位置点。 空间模式的三种基本分布:1)随机分布:任何一点在任何一个位置发生的概率相同,某点的存在不影响其它点的分布。又称泊松分布 2)均匀分布:个体间保持一定的距离,每一个点尽量地远离其周围的邻近点。在单位(样方) 数据分析与统计软件 一、问卷的设计 (一)问卷中的题目设计分为单选题和多选题,其中单选题的设计一般采用李克特(Likert)五点量表法。 (二)问卷分析的步骤: 拟编预试问卷—预试—整理问卷与编号—项目分析—因素分析—信度分析—再测信度 1.项目分析 目的:利用t检验方法对预试问卷中的题目进行筛选。 步骤:P41-42(吴) 2.因素分析(效度分析、维度分析) (1)探索性因素分析 目的:利用因子分析方法(主成分)对预试问卷的效度进行分析。(2)验证性因素分析 目的:利用因子分析方法(主成分)对预试问卷的效度进行验证。3.信度分析 目的:利用信度分析方法对预试问卷调查所得数据的可信性进行分析。 4.再测信度 目的:利用相关分析方法对预试问卷的前后两次调查所得数据的可信性进行分析。 二、问卷数据的分析 1.多重响应分析:Analyze→Multiple Response 作用:分析多项选择题,包括多项选择题题集的定义及频数分析。特别:列联表分析:Analyze→Descriptive Statistics →Crosstabs 作用:分析属性变量间是否相互独立。 2.均值检验(t-检验) 3.方差分析 4.协方差分析 5.相关分析 6.回归分析(路径分析) 7.聚类分析 多重响应分析 多重响应分析也称为多(复)选题分析。在量化研究中,除了单选题、李克特量表外,常见的回答发生即是复选题。 所谓复选题即是题目的可选答案不止一个,答案的选项可以多重选择或者题项可勾选其中多个选项。 下面是一份问卷(其中部分): 1.您的性别:□男□女 2.您对数学学习的兴趣: □非常感兴趣□一般□无兴趣 3.您平时喜欢的文学作品: (1)□外国的(2)□中国的(3)□古代的 (4)□近代的(5)□现代的 4.您平时喜欢的体育项目: (1)□爬山(2)□游水(3)□跑步(4)□打篮球 其中1、2题为单选题,3、4题为多(复)选题。 下面介绍与单、多选题有关的软件处理方法。 一、变量的编码方法 1.对单选题 一个题目用一个变量即可。 如第1题用A1(取值为1或者2——要做标签) 第2题用A2(取值为1或2或3——要做标签)。常用相关分析方法及其计算
浅析空间自相关的内容及意义.
工作分析方法及案例
ARCGIS10.0 空间分析方法与GIS典型应用例证
第六章相关与回归分析方法
空间统计-空间自相关分析
企业工作分析中的常见问题及解决方法
相关性分析
pearson,kendall和spearman三种相关分析方法
空间自相关--Morans'I
ARCGIS空间分析操作步骤
相关分析步骤
工作岗位分析-七大方法
GIS空间分析方法
(岗位分析)常用岗位分析方法分析
空间分析复习重点
问卷分析方法
相关主题
文本预览