HTK Book 第一篇 教程概览
- 格式:doc
- 大小:876.50 KB
- 文档页数:41

方法是在边栏中选择“词汇表”或者点按词汇表工具栏
从格式栏
从工具栏的“显示”弹出式菜单在“布局”面板
从工具栏的“显示”弹出式菜单在“布局”面板
不要选择最后一个分段符,否则占位符文本被替换时整个段落会被删除。
若要查看分段符,请从工具栏的“显示”弹出式菜单
可见元素”。
如果“布局”面板未打开,请从工具栏的“显示”弹出式菜单“显示布局”。
如果样式抽屉未打开,请点按格式栏中的“样式抽屉”按钮
如果样式抽屉未打开,请点按格式栏中的“样式抽屉”按钮
如果样式抽屉未打开,请点按格式栏中的“样式抽屉”按钮
如果样式抽屉未打开,请点按格式栏中的“样式抽屉”按钮如果样式抽屉未打开,请点按格式栏中的“样式抽屉”按钮
您也可以从格式栏中的“绕排”弹出式菜单绕排文本。
在格式栏中,从“列表”弹出式菜单在“文本”
请从工具栏的“显示”弹出式菜单
请从工具栏的“显示”弹出式菜单
请从工具栏的“显示”弹出式菜单。

think书自学操作流程English Answer:1. Create a Thinkbook account: Visit the Thinkbook website and click on the "Sign Up" button. Enter your email address, create a password, and click on the "Sign Up" button.2. Create a new notebook: Once you are logged in, click on the "New Notebook" button. Enter a name for your notebook and click on the "Create Notebook" button.3. Add a page to your notebook: Click on the "New Page" button. Enter a title for your page and click on the "Create Page" button.4. Start writing: You can now start writing in your new page. Thinkbook provides a rich text editor that allows you to format your text, add images, and create tables.5. Share your notebook: Once you are finished writing, you can share your notebook with others. Click on the "Share" button and enter the email addresses of the people you want to share your notebook with.中文回答:1. 创建 Thinkbook 账户,访问 Thinkbook 网站并点击“注册”按钮。
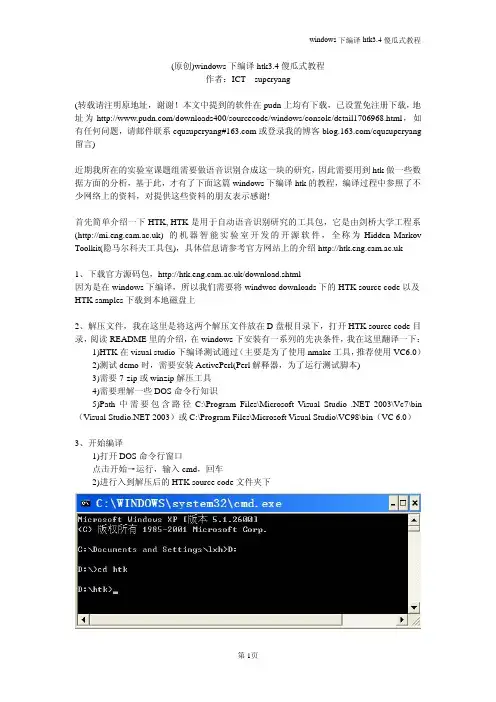
(原创)windows下编译htk3.4傻瓜式教程作者:ICT superyang(转载请注明原地址,谢谢!本文中提到的软件在pudn上均有下载,已设置免注册下载,地址为/downloads400/sourcecode/windows/console/detail1706968.html,如有任何问题,请邮件联系cqusuperyang#或登录我的博客/cqusuperyang 留言)近期我所在的实验室课题组需要做语音识别合成这一块的研究,因此需要用到htk做一些数据方面的分析,基于此,才有了下面这篇windows下编译htk的教程,编译过程中参照了不少网络上的资料,对提供这些资料的朋友表示感谢!首先简单介绍一下HTK,HTK是用于自动语音识别研究的工具包,它是由剑桥大学工程系()的机器智能实验室开发的开源软件,全称为Hidden Markov Toolkit(隐马尔科夫工具包),具体信息请参考官方网站上的介绍1、下载官方源码包,/download.shtml因为是在windows下编译,所以我们需要将windwos downloads下的HTK source code以及HTK samples下载到本地磁盘上2、解压文件,我在这里是将这两个解压文件放在D盘根目录下,打开HTK source code目录,阅读README里的介绍,在windows下安装有一系列的先决条件,我在这里翻译一下:1)HTK在visual studio下编译测试通过(主要是为了使用nmake工具,推荐使用VC6.0)2)测试demo时,需要安装ActivePerl(Perl解释器,为了运行测试脚本)3)需要7-zip或winzip解压工具4)需要理解一些DOS命令行知识5)Path中需要包含路径C:\Program Files\Microsoft Visual 2003\Vc7\bin (Visual 2003)或C:\Program Files\Microsoft Visual Studio\VC98\bin(VC6.0)3、开始编译1)打开DOS命令行窗口点击开始→运行,输入cmd,回车2)进行入到解压后的HTK source code文件夹下图1由C盘换到D盘需要输入D:,进入D盘下目录需要输入cd htk,我这里的是D:\htk,3)在本目录下创建一名为bin.win32的文件夹图2当然也可以用鼠标创建该文件夹,在该目录下右击→新建文件夹,并命名为bin.win32即可,这个文件夹是用来存放htk生成的各个exe程序4)运行VCV ARS32找到VC6.0的安装目录下bin文件夹,我的是在C:\Program Files\Microsoft Visual Studio\VC98\Bin,将该路径添加到path变量中,在cmd中输入path=%path%;C:\Program Files\Microsoft Visual Studio\VC98\Bin即可,添加完成后继续输入path,查看有没有添加成功,如果添加成功,输入VCV ARS32图35)编译HTKLib进入到HTKLib目录里,cd HTKLib,在命令行中输入nmake/f htk_htklib_nt.mkf all进行编译,如果报错htk_htklib_nt.mkf(6):fatal error U1035:syntax error:expected‘:’or‘=’separator Stop.这主要是由于格式编码的问题,我们需要手工修改一下文件的格式,用UltraEdit打开HTKLib目录下文件htk_htklib_nt.mkf,会出现图4所示对话框图4我们选择“是”,会出现图5所示界面图5按我在图中的标示,将文件中所有空白的行去掉,并选择"另存为",这时会提示是否替换原文件,我们选择是即可,如图6所示:图6现在我们重新回到命令行下,输入nmake/f htk_htklib_nt.mkf all,并回车,会出现图7所示界面:图7一段时间后,OK,我们编译成功6)编译HTKTools先在命令行中输入cd..,表示返回上一层目录,再输入cd HTKTools,进行HTKTools 目录,输入nmake/f htk_htktools_nt.mkf all编译该目录下文件,如果遇到同样的问题请参考步骤57)编译HLMLib先在命令行中输入cd..,表示返回上一层目录,再输入cd HLMLib,进行HLMLib目录,输入nmake/f htk_hlmlib_nt.mkf all编译该目录下文件,如果遇到同样的问题请参考步骤58)编译HLMTools先在命令行中输入cd..,表示返回上一层目录,再输入cd HLMTools,进行HLMTools 目录,输入nmake/f htk_hlmtools_nt.mkf all编译该目录下文件,如果遇到同样的问题请参考步骤5这时我们已经编译完所有有exe程序,我们可以打开bin.win32文件夹看一下,如果如图8所示,则证明已经编译成功图84、测试编译生成的程序是否正确1)为了能在命令行中使用我们编译生成的工具,我们要将生成的工具路径加入到path 中。

本人刚开始学习HTK,在网上下了一份《HTK(V3.1)基础指南》资料,根据上面提供的步骤创建一个yes/no识别系统,但是在中间发现很多地方说的不够明白(也可能是本人悟性不够),很多代码输入会有错误,所以根据自己的理解写了一份文档,希望对大家有用。
首先说明一下注意事项(1)在输入命令时,有文件作为参数时,都应在文件名前加上相应的路径,不然找不到文件。
(2)输入命令前,最好先单纯的打一遍命令,不输入任何参数,参看函数用法。
预先建立文件夹我做的时候没有创建新的根目录,根目录为htk文件夹。
(1)data/ :存储训练和测试数据(语音信号、标签等等),包括一个子目录data/train,而train包括2个子目录,data/train/sig(用以存储步骤1接下来录制的训练语音数据) 和data/train/mfcc(用来存储步骤二中训练数据转化后的mfcc参数);(2)model/:存储识别系统的模型(HMMs)的相关文件;(3)def/:存储任务定义的相关文件;(4)test/:存储测试相关文件。
《HTK(V3.1)基础指南》中在本步骤中用到了标签,我做的时候试着用了标签,报错了。
感觉可能是因为录制的训练语音中,静音或者是语音的长度有问题,导致了错误,但是也不知道怎么解决,所以干脆没用了,希望大牛们可以帮助解答这个问题。
第一步:创建训练文件DOS下打开htk/data/train/sig文件夹,命令:HSLabyes.sig创建10个yes音,10个no 音,10个sil(静音)。
保存在htk/data/train/sig下。
第二步:声学分析抽取yes和no的mfcc特征参数。
保存在htk/train/mfcc下。
命令:HCopy–C analysis.conf–S targetlist.txt其中analysis.conf(在htk文件夹下)为抽取参数配置文件,内容为:## Example of an acoustical analysis configuration file#SOURCEFORMAT = HTK # Gives the format of the speech filesTARGETKIND = MFCC_D_A_0 # Identifier of the coefficients to use# Unit = 0.1 micro-second :WINDOWSIZE = 250000.0 # = 25 ms = length of a time frameTARGETRATE = 100000.0 # = 10 ms = frame periodicityNUMCEPS = 12 # Number of MFCC coeffs (here from c1 to c12) USEHAMMING = T # Use of Hamming function for windowing frames PREEMCOEF = 0.97 # Pre-emphasis coefficientNUMCHANS = 26 # Number of filterbank channelsCEPLIFTER = 22 # Length of cepstralliftering# The Endtargetlist.txt(在htk文件夹下)说明抽取源文件路径和目标文件的保存路径,内容如下:data\train\sig\yes10.sig data\train\mfcc\yes10.mfccdata\train\sig\yes1.sig data\train\mfcc\yes1.mfccdata\train\sig\yes2.sig data\train\mfcc\yes2.mfccdata\train\sig\yes3.sig data\train\mfcc\yes3.mfccdata\train\sig\yes4.sig data\train\mfcc\yes4.mfccdata\train\sig\yes5.sig data\train\mfcc\yes5.mfccdata\train\sig\yes6.sig data\train\mfcc\yes6.mfccdata\train\sig\yes7.sig data\train\mfcc\yes7.mfccdata\train\sig\yes8.sig data\train\mfcc\yes8.mfccdata\train\sig\yes9.sig data\train\mfcc\yes9.mfccdata\train\sig\no10.sig data\train\mfcc\no10.mfccdata\train\sig\no1.sig data\train\mfcc\no1.mfccdata\train\sig\no2.sig data\train\mfcc\no2.mfccdata\train\sig\no3.sig data\train\mfcc\no3.mfccdata\train\sig\no4.sig data\train\mfcc\no4.mfccdata\train\sig\no5.sig data\train\mfcc\no5.mfccdata\train\sig\no6.sig data\train\mfcc\no6.mfccdata\train\sig\no7.sig data\train\mfcc\no7.mfccdata\train\sig\no8.sig data\train\mfcc\no8.mfccdata\train\sig\no9.sig data\train\mfcc\no9.mfccdata\train\sig\sil10.sig data\train\mfcc\sil10.mfccdata\train\sig\sil1.sig data\train\mfcc\sil1.mfccdata\train\sig\sil2.sig data\train\mfcc\sil2.mfccdata\train\sig\sil3.sig data\train\mfcc\sil3.mfccdata\train\sig\sil4.sig data\train\mfcc\sil4.mfccdata\train\sig\sil5.sig data\train\mfcc\sil5.mfccdata\train\sig\sil6.sig data\train\mfcc\sil6.mfccdata\train\sig\sil7.sig data\train\mfcc\sil7.mfccdata\train\sig\sil8.sig data\train\mfcc\sil8.mfccdata\train\sig\sil9.sig data\train\mfcc\sil9.mfcc第三步:HMM原型定义建立文件hmm_yes.hmm、hmm_no.hmm、hmm_sil.hmm保存在htk/model/proto下。

HMM的理论基础一、HMM定义1.N:模型中状态的数目,记t时刻Markov链所处的状态为2.M:每个状态对应的可能的观察数目,记t时刻观察到的观察值为:初始状态概率矢量,,,3.4.A:状态转移概率矩阵,,,5.B:观察值概率矩阵(适用于离散HMM),,,;对于连续分布的HMM,记t时刻的观察值概率为一个离散型的HMM模型可以简约的记为。
二、关于语音识别的HMM的三个基本问题1. 已知观察序列和模型参数,如何有效的计算。
a. 直接计算2-1当N=5,T=100时大概需进行次乘法!b. 前向算法定义t时刻的前向变量(forward variable),可以通过迭代的方法来计算各个时刻的前向变量:1)初始化(Initialization)当t=1时2-2 2)递归(Induction)当时即: 2-33)终结(Termination)2-4 乘法次数大约为:N2Tc. 后向算法定义t时刻的后向变量(backward variable),可以通过迭代的方法来计算各个时刻的后向变量:1)初始化(Initialization)当t=T时, 2-52)递归(Induction)当时即:, 2-63)终结(Termination)2-7 乘法计算次数约为:N2T2. 已知观察序列和模型参数,在最佳意义上确定一个状态序列。
定义一个后验概率变量(posteriori probability variable)2-7 则最优序列可以通过, 2-7求得。
不过,这样求得的最优序列有些问题。
如果,那么这个最优序列本身就不存在。
这里讨论的最佳意义上的最优序列,是使最大化时的确定的状态序列。
即,使最大化时确定的状态序列。
定义为t时刻沿一条路径,且,输出观察序列的最大概率,即:2-8下面介绍迭代计算的Viterbi算法:1)初始化(Initialization),回溯变量:,2)递归(Induction)即: 2-82-93)终结(Termination)2-102-11 4)回溯状态序列, 2-12 3. 已知观察序列和模型参数,如何调整模型参数使最大。

HTML 语言超文本标记语言HTML 是当前网页设计领域最基础的应用语言,使用HTML 语言所编写超文本文件(或称HTML 文档)成为万维网上最普遍的网页形式之一。
HTML 语言来源于著名的标准通用标记语言SGML (Standard Generalized Markup Language ),由万维网之父Tim Berners-Lee 于1990年创建一个基于超文本的分布式应用系统时提出。
作为SGML 语言的子集,HTML 语言摒弃了SGML 语言过于复杂、不利于信息传递和解析的不足,选用最基本的元素——标记(Tags )进行超文本描述,达到了简化、易懂的目的。
本章主要介绍HTML 语言的基本结构和基本标记。
2.1 HTML 概述 2.1.1基本形式HTML 文档主要是由将要显示在网页上的文档内容和一系列标记所组成。
当用户浏览HTML 文档时,浏览器就会把这些标记解释成它应有的含义,并按照一定的格式,将这些被标识的文档内容显示在浏览器窗口中。
在HTML 文档中有些标记必须以“<标记>”开始,而以“</标记>”结束,这些标记称之为“成对标记”;有些标记并不需要确定作用域,称之为“非成对标记”。
其基本格式如下:一、成对标记<标记 参数1 参数2 参数3……>内容</标记>其中,标记与参数、参数与参数之间使用空格分隔,参数可省略。
例如,使用“斜体”标记,<I >上海大学</I >。
通过浏览器查看时,“上海大学”是以斜体的形式显示的。
二、非成对标记<标记 参数1 参数2 参数3……>内容例如,使用“水平分隔”标记,<HR >。
通过浏览器查看时,会显示一条水平分隔线。
注意:对于HTML 标记,大、小写或混写均可。
例如:<HTML >、<html >或<HtmL >,其结果都是一样的。
同时如果不特别注明,浏览器会忽略HTML 文档中的空格(多个空格认作一个空格)、制表符和回车等符号。
2.1.2 基本结构一个标准的HTML 文档具有如下的结构:一、<HTML >标记<HTML >标记是成对标记。

一个简单的HTK入门参考例子主要参考HTKBook和HTK(v.3.1): Basic Tutorial――Nicolas Moreau1 综述目标:建立一个孤立词识别系统,只包含yes和no两个词。
步骤:1.1A: 创建一个语料库,yes和no各录5次B: 声学分析,把waveform的声音文件转换为mfcc格式C: 模型定义: 为词典里的每一个词建立一个HMM原型D: 模型训练: HMM模型初始化和迭代E: 问题定义,即语法定义F: 对测试集合进行识别G: 评测建立一些文件夹1.2HTK工具的一些标准选项1.32 创建语料库我们来录yes和no的读音,这些要用来做训练。
同时,每段语音都要被标注,也就是说有一个文本文件与其对应描述它的内容。
录音和标注可以用HSLab完成。
name.sigHSLab打开了录音和标注的图形界面。
录音2.1按Rec开始录音,按Stop结束。
这样一个名字为name_0.sig的声音文件就被记录在当前目录了。
如果你接着录音,name_1.sig就会被记录。
Sig是HTK的格式。
标注2.2按Mark选择你要标注的段落,然后按Lableas键入名字,然后回车。
我们的每段语音分成三部分,静音(sil), yes或者no, 静音(sil)。
相邻的段不能重叠,可以有小的间隔。
按Save 存储,Quit退出。
标注文件.lab格式如下:4171250 9229375 sil9229375 15043750 yes15043750 20430625 sil重命名2.33 声学分析从原始的声音文件转换为特征矢量文件:Hcopy –A –D –C analysis.conf –S targetlist.txtanalysis.conf是一个配置文件,说明了特征矢量的特性。
targetlist.txt列出了源文件和目的文件的位置,即声音文件和特征文件。
配置文件3.1其中#后代表注释,参数意义以后详细说。


操作手册https://操作手册目录目录前言:简介 (1)第一章:注册 & 登入 (2)第一节:注册 (2)第二节:登入 (3)第二章:撰写作业 (5)第一节:开始写新作业 (5)第二节:储存作业 (8)第三节:打印或EMAIL转寄作业 (9)第四节:统计作业的字数 (9)第五节:后续编辑&完成作业 (10)第三章:检视已批作业 & 修改作业 (11)第一节:查看已批作业 (11)第二节:打印&备份已批作业 (12)第三节:AI智能诊断作业 (13)第四节:订正&改写作业 (14)第四章:常见问题与解答 (15)第一节:注册 (15)第二节:忘记账号或密码 (15)第三节:文章书写 (17)第四节:查看已批作业 (17)操作手册1前言:简介学习软件即服务(Software as a Service, SaaS),为云端软件在线学习服务,可在Google Chrome、IE、Safari、Firefox等学习软件即服务特色包括:1. 不须安装或下载软件,只需上网登入,即可使用软件,并可下载电子书。
2. 操作简易,随时随地皆可练习。
3. 可携智能型手机、平板、笔电等设备无线上网登入,在课堂实作。
4. 可在每页之上方任选操作接口语言。
此外,QBook写作中心亦会在作业缴交截止日的前2日内电邮提醒各学员记得完成作业。
5. 开启新作业后,若未完成或欲再编辑,在作业未到期前,皆可随时登入修改作业。
6. 系统自动储存与缴交作业,不用上传,email或打印作业给老师。
7. 内建各论文章节的写法、格式及范例,铿锵有力的写作指引引导写作,提供全方位的演练。
8. 每一个操作页面皆有说明短片,展示该页面的操作示范。
9. 可依据已批改过的文章所显示的错误和评语,修正错误并补强文意,提升教学效能,以达到「做中教、做中学、做中求进步」之目的。
10. 可收集、追踪并分析历次作业,有效掌握学习进度与瓶颈,以利辅导并增进学习成效。

OuickBooks Premier—Accountant Edition 2014操作手册一、 File (1)(一) New Company新建一个公司 (1)(二) Open or Restore Company打开备份、删除备份记录 (1)(三)Open Previous Company打开最近账套 (6)(四) Bacu Up Company备份数据 (7)(五)Open Second Company 同时打开多个账套界面…………………………………………………………….。
...。
.。
8二、 Lists (2)(一) Item Lists产品的查看、编辑、增加、删除 (2)(二)Fixed Asset Item List固定资产的查看、编辑、增加和删除 (2)(三)Currency List汇率的转换 (2)三、Accountant (2)(一)Chart of Accounts会计科目的增加、修改、删除等 (2)(二)Chart of Accounts录入凭证 (3)(三)Working Trial Balance试算平衡表 (3)四、Customers (3)(一)Customer Center客户的查看、添加、删除 (3)(二)Create Invoices销售订单(主营业务收入)的录入 (4)(三)Reveive Payments应收账款的录入 (4)(四)Credit Memo 销售订单退订(冲销主营业务收入)的录入..。
...。
..。
.。
..。
.。
.。
....。
...。
五、Vendors (4)(一)Vender Center供应商的查看、编辑、添加和删除 (4)(二)Pay Bill应付账款的录入..。
...。
.。
..。
..。
.......。
.。
.。
.。
.。
..。
..。
.。
.。
...六、Employees (39)(一)Empolyees Center员工信息的查看、编辑、添加和删除 (39)七、Bank。

Chromebooks are fast, secure, and portable computers that make it easy forstudents to learn in and out of the classroom. Schools can use Chromebooks toadminister secure student assessments, including state standardized tests fromthe Smarter Balanced Assessment Consortium (SBAC) and the Partnership forAssessment of Readiness for College and Careers (PARCC). With the web-basedAdmin Console, you can quickly set up any number of Chromebooks as securedevices for online testing.Why Chromebooks?Simple, flexible devices let you focus on what’s most importantEasy to manage & configureThe Google Admin Console puts you in control of all of your devices. Whether you’remanaging 10 devices or 10,000, just a few clicks gets you setup for testing.Secure for testingSwitch to testing mode to secure Chromebook hardware and disable features likeinternet browsing, screenshot functions, and USB ports. Teachers spend less timemonitoring students and more time helping them.ReliableThe simple and fast ChromeOS with a battery life that lasts the school day meansyou don’t have to worry about devices during critical testing periods.Flexible for both classroom & testing useThe same Chromebooks students use in class in the morning to write essays canbe used for testing in the afternoon. Configuration takes just minutes.How do I set up a Chromebook for Online Assessments?Below are two of the most common configuration modes (other options:http://goo.gl/Wstb83)Single App KioskUse this method when the testingprovider has published an assessmentapp. Many state standard tests areadministered this way.• L og into the management consoleto enable single app kiosk mode•D eploy the assessment app tothe select devices, and launch theapp from the startup screen tobegin testingPublic Session URLUse this method for a test providedby your own school or district.•L og into the management consoleto enable public session mode•U se URL blocking features to limitaccess to the testing site only•A fter testing, the students’ sessionis wiped from the deviceSetup in Admin Console Deploy App/URL Student TestingUsing Chromebooks for OnlineStudent AssessmentsChromebooks are an easy answer to thedifficult question of how to administeronline assessments.“ T he Chromebooks were by far the mostsuccessful device we used to deliver the newnational standardized PARCC trial test. Overthe last two weeks administering the test, theTestNav app in single app kiosk mode workednearly flawlessly. ”— S ean McMahon, Network Security Manager,Boston Public School DistrictWhich tests will work withChromebooks?In addition to the Smarter Balancedand PARCC assessments, schools havethe flexibility to securely administer manyother online assessments. Devices can beset up to deliver tests that schools createthemselves, as well as a number ofindividual state-based tests.Engineering specs can change without prior notice. Battery times are estimates, depend on many factors, and may decline over time. Assessment provider requirements may vary; contact your assessment provider to confirm supported platforms. Google is not responsible for damage caused by changes in certification rules, or changes in supported platforms for assessments.© 2014 Google Inc. All rights reserved. Google and the Google logo are trademarks of Google Inc. All other company and product names may be trademarks of the respective companies with which they are associated.140508Step-by-Step Guide for Chromebook Setup for Standardized Assessments (using Single App Kiosk mode)Chromebooks allow configuration for a number of individual state-specific tests in addition to large-scale standardized testing. Chromebook devices meet the hardware and operating system requirements and are supported for use withboth PARCC and Smarter Balanced Assessment consortia for online assessments. AIRSecureTest This app is published for use with Smarter Balanced standardized tests More than 20 states support Smarter Balanced state testing. See if your state is included:/about/member-statesTestNav This app is published for use with PARCC standardized assessments More than 15 states support PARCC for state testing. See if your state is included:/parcc-states Administrators can use the Admin Console to automatically deploy a secure assessment app for standardized tests to any Chromebook they want in the domains they manage. Before you get started, check the Settings menu under Help to ensure you are running the latest ChromeOS.1. L og into your Admin Console (https:// ).2. N avigate to Device management > Chrome > Device settings 3. O n the Device settings page, make sure you have the correct organizational unit selected under the Organizations heading. The following changes will apply to all devices within this group. – S croll down to the “Kiosk Settings” section. Single App Kiosk should be set to “Allow Single App Kiosk”4. N ext, add the secure testing app. This app will be different depending on which standardized assessment your state is using. Click the [Manage Kiosk Applications ] link. –Click [Chrome Web Store ]. – I n the search box, type “AIRSecureTest” (for Smarter Balanced testing) or “TestNav” (for PARCC testing) and press [Enter ]. – T he app will appear. Click the [Add ] link. The app will appear in the “Total to install” section. –Click [Save ].Once these steps are complete, the assessment application will appear on all Chromebook devices within the organizational unit selected. When students start up the Chromebooks they will see a menu of kiosk apps in the system tray on the login screen. The student simply needs to select the testing app to begin the assessment. Note: Students do not have to sign-in to the Chromebook or have Google Apps for Education to take the secure assessment.What are AIRSecureTest and TestNav?AIRSecureTest and TestNav are web-based applications created for use inonline standardized testing. These testsmeasure student progress toward federalCommon Core Standards . The content ofthe assessments is created by state-ledconsortia groups, and these testing appsare used to securely deliver the tests.Additional HelpFor more details on configuring forassessments, visit: goo.gl/Wstb83Chromebooks for Education• Chromebook devices• Web-based management console• 24/7 support from Google• Limited hardware warrantyFor more information or to speak witha Google EDU representative, visit:/edu/solutions。
HTK工具包孤立词识别系统(详细过程)1.前言介绍HTK工具包建立孤立词识别系统,包含详细过程和可能出现的错误,分享错误分析和解决心得。
主要参考书籍博客:HTK,/jamesju/blog/1161512.孤立词识别系统2.1搭建流程A:创建语料库,brightness,channel,color各录制5次。
B:声学分析,把wavform的声音文件转换为mfcc格式。
C:模型定义,为词典里面的每一个词建立一个HMM原型。
D:模型训练,HMM模型初始化和迭代。
E:问题定义,即语法定义。
F:对测试结合进行识别G:评测2.2.工作环境的搭建创建如下目录结构:(1) data/: 存储训练和测试数据(语音文件、语音标签、特征矢量文件)。
子目录:data/train/lab data/train/wav data/train/mfcc data/test/lab data/test/wav data/test/mfcc(2)analysis/:存储声学分析步骤的文件(3)training/:存储初始化和训练步骤的文件(4)model/:存储识别系统的模型(HMMS)的相关文件。
子目录:model/proto(5)def/:存储任务定义的相关文件。
(6)test/:存储测试相关文件2.3.标准HTK工具选项一些标准选项对每个HTK工具都是通用的。
将使用以下一些选项:1. -A :显示命令行参数2. -D :显示配置设置3.-T 1:显示算法动作的相关信息3.语料库的准备录制{brightness,channel,color}这三个词的读音。
每个读9次。
同时对每个录音都要进行标注,也就是有一个文本文件与其对应描述它的内容。
3.1语料库的准备每个词各录制9次,保存为wav格式。
5次存放在data/train/wav/brightnessdata/train/wav/channeltrain/train/wav/color4次作为测试音频,存放在:data/test/wav/brightnessdata/test/wav/channeltrain/test/wav/color3.2 语音标注我使用的是praat软件进行语音标注。
Using HTKHidden Markov Model ToolkitChi-Yueh Lin2006/07/17HTKHTK (Hidden Markov Model Toolkit) ਢطᏦࢬ࿇ऱឆ(HMM)Δ៶طHTKHMMऱΖHTKΔࠃऱᇷΚ–უᙃᢝऱڗᇿী–(Speech Corpus)ᚾ(Transcription/Label files)–شڗᐋऱᑓীΔᝫऱᑓীHTK–HCopy––HInit& HRest–ী(Label)–HCompV& HERest-ী(Transcription)–HHEd–ী–HParse–ᙃᢝऱ֮–HVite–ᙃᢝ૽ግ໘ࢤHCopy-abstractHCopyਢHTK ऱਐΔ،––ऱյ–ࢨऱפਢشᑇΔڕPCMऱंMFCCHCopy–block diagramΔא֗ᐷconfig֗script ᚾHCopy–config file (1)(2)NATURALREADORDER=TRUENATURALWRITEORDER=TRUE–ຍࠟႈࡳᇿᖲᕴΕ܂ΔԫࡳTRUE SOURCEFORMAT=NOHEAD–ᚾਢڶᚾᙰऱSOURCEKIND=WAVEFORM–ᚾਢTARGETKIND=MFCC_E_D_A–ऱᚾਢMFCCΔאenergy (E), delta (D), delta-delta (A)–SOURCEFORMAT ࡳHTKHCopy–config file (3)SOURCERATE=1250–ᚾ࠷0.125 msTARGETRATE=100000–ऱၴ10 msWINDOWSIZE=250000–ऱ९25 msࣹრΚΚڇHTKΔழۯ100ns ࣹრHCopy–config file (4) ZMEANSOURCE=T–zero meanΔܛDCଖ USEHAMMING=T–Hamming WindowPREEMCOEF=0.97–0.97HCopy–config file (5) NUMCHANS=31–ڇMel 31ଡ᙮USEPOWER=F–c(0)NUMCEPS=13–13ၸMFCCHCopy–config file (7)SAVECOMPRESSED=F–HTKऱᚾΔԫFalseSAVEWITHCRC=F–HTKڇขऱᚾ৵CRCΔԫFalseHCopy–script fileScript ᚾਢܫHCopyᚾڇΔא֗ऱؾऱᚾΖ/source/dir/001.wav /target/dir/001.mfc/source/dir/002.wav /target/dir/002.mfc/source/dir/003.wav /target/dir/003.mfcΔؐsourceΔڶtargetHCopy-Usage$ Hcopy-T 1 -C XXX.config-S XXX.script –-T 1 Trace Level 1Δຍڇᘛࠩhcopyऱመ–-C () configᚾூΔᚾټᚾټૡΔԫᚾټconfigࢨcfg–-S () script ᚾூHMM -definitionHMMऱط<BeginHMM> ࡉ<EndHMM>ࢬץ<NumStates> 5–5Δ3+2ኔ᧯णኪऱ<Mean> ࡉ<Variance>–<Mean> 3939 ଡ0.0–<Variance> 3939 ଡ1.0HMM -TrainingΔૹऱਢᒔऱᑑᚾਢ᥆–Label :0 180000 sil180000 450000 voc450000 610000 voc–Transcription :silvocvocHMM -TrainingऱਢLabel ᚾ–شHinit+ HRestऱਢTranscription ᚾ–شHCompV+ HERest?–شHinitࡉHRest Label ऱᚾூΔ٦شHCompVࡉHERest Transcription ᚾூHMM -TrainingHMM -TrainingHCompV–ڇHTK flat start–Δ٦ऱMeanࡉVarianceHMM -TrainingHCompV–$ HCompV-C config-S script -M dir1 -l aa-o aa-I label.mlf proto–config۩SOURCEFORMAT=HTKSOURCEKIND=MFCC_E_D_A–scriptஞࠐಝऱᚾூ।–-l aa–o aa aaऱHMMᚾூΔࠀaa–-M dir1 ژᚾூऱؾ–-I master label fileΔٍش–L–protoऱHMM prototype ᚾHMM -TrainingHERest–$ HERest-C config-S script -I label.mlf-d dir1-M dir2 hmmlist-Iࡳmaster label fileΔٍ–L ࡳؾ-d HMMᚾூऱؾ(ൕHCompVऱ)-MࡳᚏHMMऱؾhmmlist HMMऱټ–۩ݙ৵Δᄎڇdir2ऱHMM Macro FileHMM –mixture incrementingHHEd–split.hedᚾ–MU 16 {*.state[2-4].mix}ଡHMMऱኔ(2~4)16ଡmixture –MU 8 {aa.state[2-4].mix}aaऱHMM(2~4)8ଡmixture –$ HHed-M mix2 -w newHMM-d mix1 split.hed -M mix2ऱHMMᚾᄎڇmix2-w newHMMऱHMMᚾټ-d mix1ڇmix1ऱHMMᚾHMM –mixture incrementingHHEd–ش֮ڗᒳࠐऱnewHMMΔױmixtureऱᦞΔڂച۩HERestΔऴࠩઌַΖ–ऱᑓীΔܛऱHMMীΔຍHMM.model໘ࢤRecognition –Dictionary & WordNet Dictionary ऱشHTKΔ܃ऱଃਢୌ? ਢطୌHMMࢬΖRecognition –Dictionary & WordNet WordNetऱ֮Recognition -HViteᅝWordNetΕDictionary ᅝΔױHVite–$ HVite–C config–w –H HMM.modelphone.dic hmmlist XXX.wavXXX.recᚾΔܛ0 700000 sil-428.991882700000 1100000 b -276.1031491100000 1700000 t -493.9649661700000 3000000 weng-1099.999023Recognition -WaveSurferRecognition -WaveSurfer༙b t wengиছ”Ԃ”ᙃګ”ԁ”+”Ԇ”ঊj yingиᙃګ“ᙩ”ऱଃݛh wangиᙃګ“႓”ऱଃڇz aiᄎh wei৵h ou। b yaoقsh FNULL1。
GitBook安装、配置、制作电子书GitBook 是一款基于Node.js 开发的开源的工具,可以通过命令行的方式创建电子书项目,再使用 MarkDown 编写电子书内容,然后生成 PDF、ePub、mobi 格式的电子书,或生成一个静态站点。
除此之外,还可以利用Git 命令管理电子书版本。
如果你是GitHub 的重度使用者,还可以把你的 GitBook 帐户和 GitHub 帐户关联起来,这样不论在任何一方修改了内容,都可以互相同步。
一、安装 Node.js由于 GitBook 是基于 Node.js 开发的,所以依赖 Node.js 环境。
如果您的系统中还未安装Node.js,请点击下面的链接,根据你所使用的系统下载对应的版本。
如果已安装则略过本步骤。
Node.js 下载页面:Windows 版和 Mac 版的 Node.js 都是常规的安装包,连续下一步安装即可。
Lunix 版可以参照官方文档通过yum、apt-get 之类的工具安装,也可以通过源码包安装,如下所示:$ wget /dist/v5.4.1/node-v5.4.1.tar.gz$ tar zxvf node-v5.4.1.tar.gz$ cd node-v5.4.1$ ./configure$ make$ make install 二、安装 GitBook打开“命令提示符”(Mac 系统打开“终端”)输入以下命令安装 GitBook:$ npm install gitbook-cli -g由于网络的原因,安装的时间可能会较长一些,请耐心等待直到安装完成。
安装完成后可以输入以下命令,以查看GitBook 版本的方式检查是否安装成功:$ gitbook -V三、创建电子书项目新建一个目录,并进入该目录使用gitbook 命令初始化电子书项目。
举个例子,现在要创建一个名为“MyFirstBook”的空白电子书项目,如下所示:$ mkdir MyFirstBook$ cd MyFirstBook$ gitbook init四、编辑电子书内容初始化后的目录中会出现“README.md(电子书简介文件)”和“SUMMARY.md(导航目录文件)”两个基本文件。
阅读时,您可以查看阅读进度,更改文本显示设置,停留在当前阅读位置时快速浏览其他页面和章节. Kindle Voyage(第7代)、Kindle Paperwhite(第7代)、Kindle(第7代)和Kindle Paperwhite(第6代)帮助。
查看您的阅读进度剩余阅读时间功能会根据您的平均阅读速度,估算出您读完当前章节或本书还需多少时间。
您特有的阅读速度仅保存在您的Kindle设备上,而不是保存在亚马逊服务器上。
使用剩余阅读时间:1.阅读时,点击屏幕顶部以显示阅读工具栏.2.点击【菜单】图标,然后点击【阅读进度】。
3.在屏幕底部选择您喜欢的阅读进度显示方式。
o【书中位置】o【书中页码】(如果适用)o【章节剩余阅读时间】o【图书剩余阅读时间】o【无】注意: 不是所有Kindle电子书都有实际页码.前往电子书中的特定位置阅读电子书时,您可以使用快速翻书功能,就像在纸质书中一样,快速翻看该Kindle电子书的其他页面或章节,或者前后快速跳转,而不会丢失您现在的阅读位置。
1.点击屏幕顶部以显示阅读工具栏,然后点击屏幕底部,以显示预览窗口和阅读进度条。
2.在预览窗口中查看书中的其他位置:o在预览窗口中左右滑动,或者点击窗口左右两侧的箭头。
o对于Kindle Voyage(第7代):点击向前翻页键或向后翻页键,直到您感觉到轻微震动。
o按住屏幕底部进度条上的圆形按钮左右拖动,可以向前或向后翻。
3.点击预览窗口中的页面可转至书中对应位置,点击右上角的【X】可返回当前位置。
更改字体、行间距或页边距注意:菜单和其他屏幕的字体大小是固定的,无法进行更改.您无法更改PDF 文件的文字外观。
1.阅读时,点击屏幕顶部以显示阅读工具栏,然后点击【Aa】。
2.选择文本大小和字体类型.注意:o字体最小可以选择8磅,最大可以选择36磅.o如果出版方支持,您可以选择出版方字体,以出版字体阅读电子书.o许多Kindle电子书(包括Kindle样章)均会提供在您的Kindle上以阅读障碍字体显示文本的选项。
第一篇教程概览 1 HTK基础1.1MM基本原理1.2立词识别1.3出概率说明1.4aum-Welch Re-Estimation1.5别和Viterbi解码1.6续语音识别1.7话者适应2 HTK工具包概览2.1TK软件架构2.2TK工具的一般属性2.3具包2.3.1据准备工具2.3.2练工具2.3.3别工具2.3.4析工具2.4本3.4中的更新2.4.1本3.3中的更新2.4.2本3.2中的更新2.4.3本3.1中的更新2.4.4本2.2中的更新2.4.5本2.1中的新特征3 一个教程示例3.1据准备3.1.1骤一任务语法3.1.2骤二字典3.1.3骤三录制语音数据3.1.4骤四创建脚本文件3.1.5骤五语音数据编码3.2建单元音HMM3.2.1骤六创建Flat start单元音3.2.2骤七确定Silence模型3.2.3骤八Realigning训练数据3.3建Tied-Stated三元音3.3.1骤九从单元音创建三元音3.3.2骤十创建Tied-Stated三元音3.4别器评估3.4.1骤十一识别测试数据3.5行识别器3.6MM自适应3.6.1骤十二准备自适应数据3.6.2骤十三生成Transforms(转移矩阵)3.6.3适应系统评估3.7emi-Stated和HLDA Transform3.8结第一章HTK基础HTK是一个用于构建隐马尔可夫模型(HMM)的工具包。
隐马模型可用于对任意时间序列建模,与此类似,HTK的核心部分也是具有通用性的。
然而,HTK主要还是用于构建基于HMM的语音处理工具,特别是语音识别工具。
因此HTK的在基层架构上提供的功能,主要是为了完成这个任务。
如上图所示,这个任务主要由两个阶段构成。
首先,HTK的训练工具基于语音数据和关联的脚本进行HMM参数的估算,其次,未知的语音数据被HTK的识别工具识别,输出识别结果。
本教程主要关注于以上两个处理过程的机制。
然而在深入细节之前,理解HMM的一些基本原理是有必要的,对HTK工具包有一个大概的认识也是有帮助的。
本书的第一篇提供这些内容。
本章介绍了HMM的基本思想及其在语音识别中的用处。
第二章则对HTK进行概括介绍,并着重描述了 2.0版本以后的版本差异。
最后,在第三章,你将看到如何基于HTK构建一个语音识别器,该章描述了一个简单的小词汇量连续语音识别器的构造过程。
本书的第二篇则详细论述了HMM的各种细节,此篇可以和本书的第三篇一起阅读,第三篇提供了一个HTK的参考手册,包括对每种工具的描述,总结,以及用于配置HTK的各种参数和错误信息列表。
最后请注意,这本书只将HTK作为一个工具包来介绍,而没有提供使用HTK库作为编程环境的信息。
第一节HMM基本原理语音识别系统一般认为语音信号是被编码为一个或多个符号组成的序列的一些信息(见图1)。
对于一段语音,为了准确地识别出它内含的这个符号序列,一般会先将连续的语音波形进行转换,转换成一个相等间距的离散的参数向量的序列。
这个参数向量序列之所以被认为可以准确表达原始的语音数据,是基于这样的假设,即在一个单独的参数向量的持续时间内(一般是10毫秒左右),语音数据可以看作是固定不变的。
虽然这并不是完全准确的,但可以认为是合理的近似。
常见的典型参数化表示方法有smoothed spectra和线性预测系数,以及其它由他们派生的一些方法。
识别器的角色是在语音向量序列和语音包含的符号序列之间建立一个有效的映射。
有两个问题让这变得很困难,第一,从符号到语音数据的映射不是一对一的,因为不同的符号可以产生相似的声音,而且由于说话者的情绪、所处环境等差异,语音波形也会有很大的差异。
第二,符号之间的边界无法从语音波形中明显地确定下来。
因此,将语音波形当作一个由一系列静态的模式连接而成的序列是不可能的。
通过将任务限定在孤立词识别的范围内,可以避免第二个无法识别单词边界位置的问题。
如图1.2所示,这意味着语音波形与一个从固定的词汇中选择出来的符号(比如单词)相对应。
虽然这个简单的问题被作了人工限制,但它仍然在实际中有很多应用。
而且在深入更复杂的连续语音识别之前,可以通过它熟悉基于HMM的语音识别的基本方法。
因此下面将首先介绍孤立词的识别。
注:此处的符号,应该是指文本符号,比如单词或音节。
从图1可以看出,说话者阅读符号序列,然后输出语音波形数据,然后波形数据再被转换为参数向量序列。
最后的识别是基于这个向量序列进行的,目的是复原说话者所阅读的符号序列(文本)。
第二节孤立词识别假设每个单词的发音被表示为一个语音向量的序列,或者Observation O,定义为:(1.1)其中Ot是在时间t所观察到的语音向量。
那么孤立词识别问题可以认为就是计算(1.2)其中wi是词汇表中的第i个单词。
这个概率只有通过Bayes's Rule才能计算出来(1.3)这样,对于给定的先验概率集合P(wi),哪个单词是最有可能的,仅仅依赖于概率P(O|wi).注:用通俗的话讲,要想知道这段声音说的是哪个单词,那要看哪个单词最有可能被发出这种声音。
考虑到观察向量O的维度,从单词的语音采样直接估算联合概率P(o1,o2,...|wi)是不可能的。
然而,如果可以假设一个单词的参数模型,比如Markov模型,那么概率P(O|wi)则是可以估算出来的,因为对P(O|wi)的估算可以被更简单的问题,即估算Markov模型的参数来代替。
注:HMM基本知识1 三个基本问题(1)问题1:给定观察序列O=O1,O2,…O T,以及模型λ=(A,B,p i),如何计算P(O|λ)?前向/后向算法。
在语音识别中,即对于单词W(模型λ),读音为S(观察序列O)的概率是多大?此处每个单词W i都用一个H M M模型表示,每个单词都有自己的转移概率矩阵和状态观察概率参数。
(2)问题2:给定观察序列O=O1,O2,…O T,以及模型λ,如何选择一个对应的状态序列S=q1,q2,…q T,使得S能够最为合理的解释观察序列O?V i t e r b i算法。
在语音识别中,即对于发音S(观察序列O),(3)如何调整模型λ的参数,使得P(O|λ)最大?B a u c h-W e l m训练算法。
即对于单词W,怎样为它训练出来一个H M M模型,使得该模型能最符合发音S?在基于HMM的语音识别中,我们认为,和每个单词相对应的观察向量序列由如图1.3所示的Markov模型生成。
Markov模型实际上是一种有限状态机,每经过时间单元t它的状态会改变一次。
假设在时间t处于j状态,观察到语音向量Ot,则这个观察向量的概率记为bj(ot)。
另外,从状态i转移到状态j也是一个概率过程,记该离散概率变量为aij。
图1.3给出了一个具有6中状态的Markov模型,该模型随时间产生的状态序列记为X=1,2,3,4,5,6。
而相对应的观察到的向量序列是o1到o6。
注:一般称bj(ot)为输出概率,称aij为转移概率。
需要注意的是,在HTK中进入点和结束点的状态都是non-emitting的,这是为了方便构建更复杂的模型,我们在后文中会认识到这一点。
在上图中,给定Markov模型M,在状态序列X中观察到观察向量O的概率是一个联合概率,可以简单地将转移概率aij和发射概率bj(ot)依次相乘而计算出来。
(1.4)然而在现实中我们只能看到观察向量O,而不知道状态序列X是什么样子,因此这种模型被称为Hidden Markov Model。
既然状态序列X是未知的,那么计算观察到O的概率,就要把所有可能的状态序列X=x(1),x(2),x(3),...x(T)都考虑进来。
这个概率可以通过对在所有状态序列下观察到O的概率求和得到。
(1.5)其中x(0)是模型的起始状态,x(T+1)是模型的结束状态。
作为一种近似,可以认为给定模型M观察到O的概率,就是在最有可能的状态序列下观察到O的概率。
那么式1.5可以近似为(1.6)虽然直接计算式1.5和1.6是不太可能的,但是有更简单的递归算法(前向/后向算法)可以有效地计算式中的值。
在继续深入之前,需要注意的是,如果式1.2可以计算出来的话,那么语音的识别问题也就解决了。
对应单词集合Wi,有模型的集合Mi,式1.2可以通过式1.3和如下假设得到解决。
(1.7)当然对于模型Mi,它的转移概率{aji}和输出概率{bj(ot)}都应该是已知的。
这里可以认识到HMM的优雅和强大之处,对于一个特定的模型,给出一个训练样本集合,就可以通过一种健壮而有效的re-estimation过程来自动计算出它的参数。
这样,如果每个单词都有足够数量的训练语音样本,就可以构建出一个能够表示它的HMM模型。
图1.4给出了使用HMM进行孤立词识别的过程。
首先,根据每个单词的训练语音样本集合,训练出该单词的HMM模型,在这个例子中只考虑了三个单词的情况,分别是one,two,three。
然后,为了识别一个未知的单词语音,需要计算每个HMM模型会得到该发音的概率,概率最大的模型就对应着这个未知语音被识别出来的单词。
第三节输出概率说明在更详细地讨论HMM参数估计之前,需要先搞清楚输出概率bj(ot)的规则。
HTK主要用于基于连续概率密度的多元输出分布,对连续参数进行建模计算。
它也可以处理由离散符号构成的观察序列,这种情况的输出分布是离散概率的。
然而为了简化,本节假设是基于连续概率密度分布的。
离散概率的差异情况在第7章和第11章有详细讨论。
与其他大多数连续密度的HMM系统一样,HTK的输出分布也使用混合高斯分布来描述,然而在HTK中做了进一步的通用化。
HTK允许在时间t处的观察向量可以分割成S个独立的数据流Ost。
这样计算输出概率bj(ot)的公式为(1.8)其中Ms是数据流s中混合分量的个数,Cjsm是第m个分量的权重,是一个多元高斯分布,它的均值向量为,协方差矩阵是,即(1.9)其中n是向量o的维度。
指数是数据流的权重,它可用于突出特定的数据流,不过它的值只能手动设置。
HTK 现在还没有估算它的值的训练工具。
多个数据流可用于对多个数据源分别进行独立建模,在HTK中对流的处理是通用的。
然而在语音输入模块中假设数据源最多被分割为4个流,第5章会详细介绍。
现在只要记住这四个默认的流就行了,它们分别是基本参数向量、一阶差分系数、二阶差分系数和log能量值。
第四节Baum-Welch重估为确定一个HMM的参数,首先需要对参数作一个大致估计,然后可以使用所谓的Baum-Welch重估算法来得到更精确的参数值。
第8章给出了HTK使用的详细公式,这里仅做一个简单的非正式介绍。
首先,要注意多个数据流并没有对参数估计带来本质的影响,因为每个数据流被视为独立的。
其次,流内的混合分量被视为一种特殊形式的子状态,到这个字状态的转移概率是就是此分量的权重。