《计量经济学》作业
班级:503班学号:1261150111 姓名:王雅媛
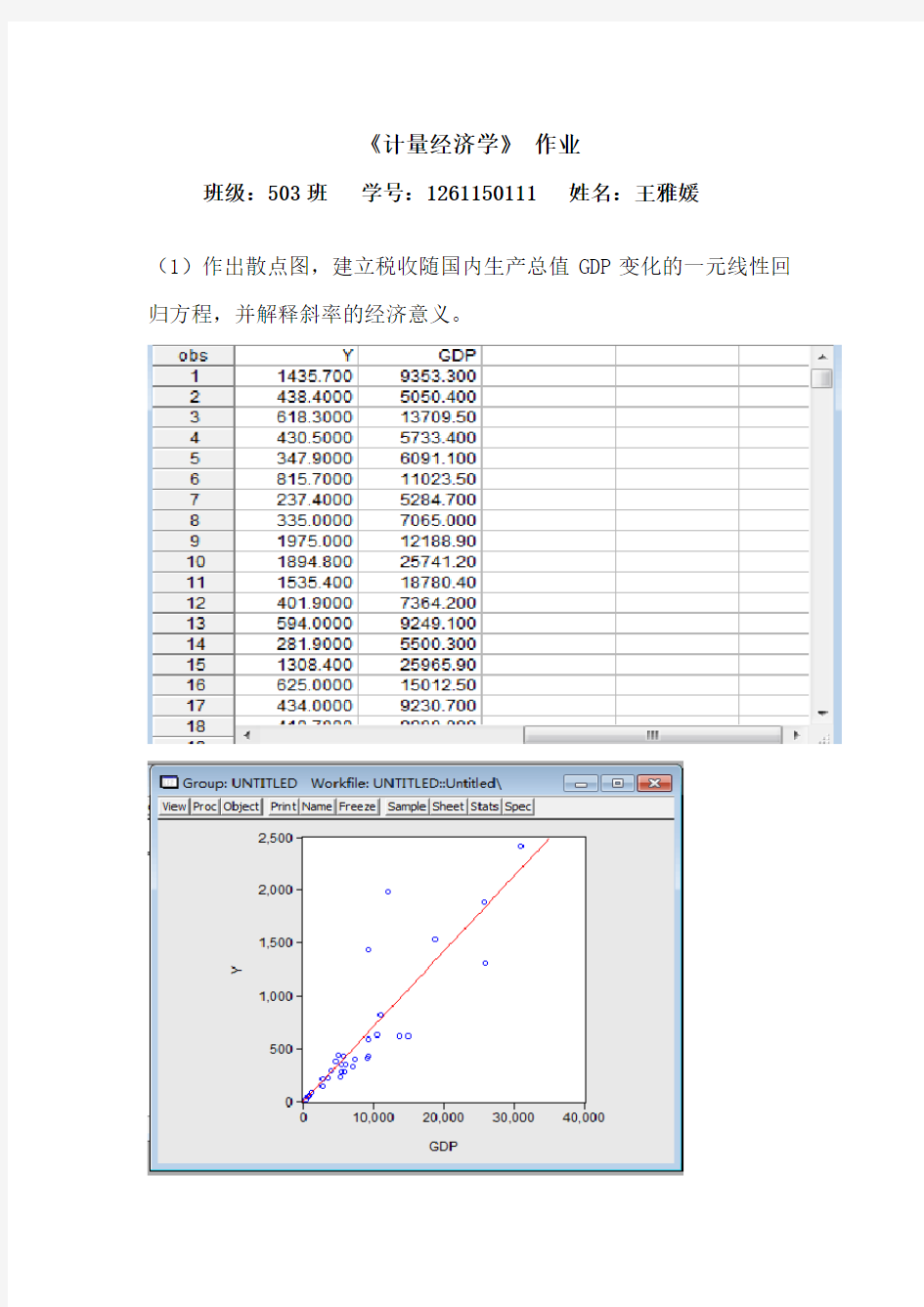
(1)作出散点图,建立税收随国内生产总值GDP变化的一元线性回归方程,并解释斜率的经济意义。
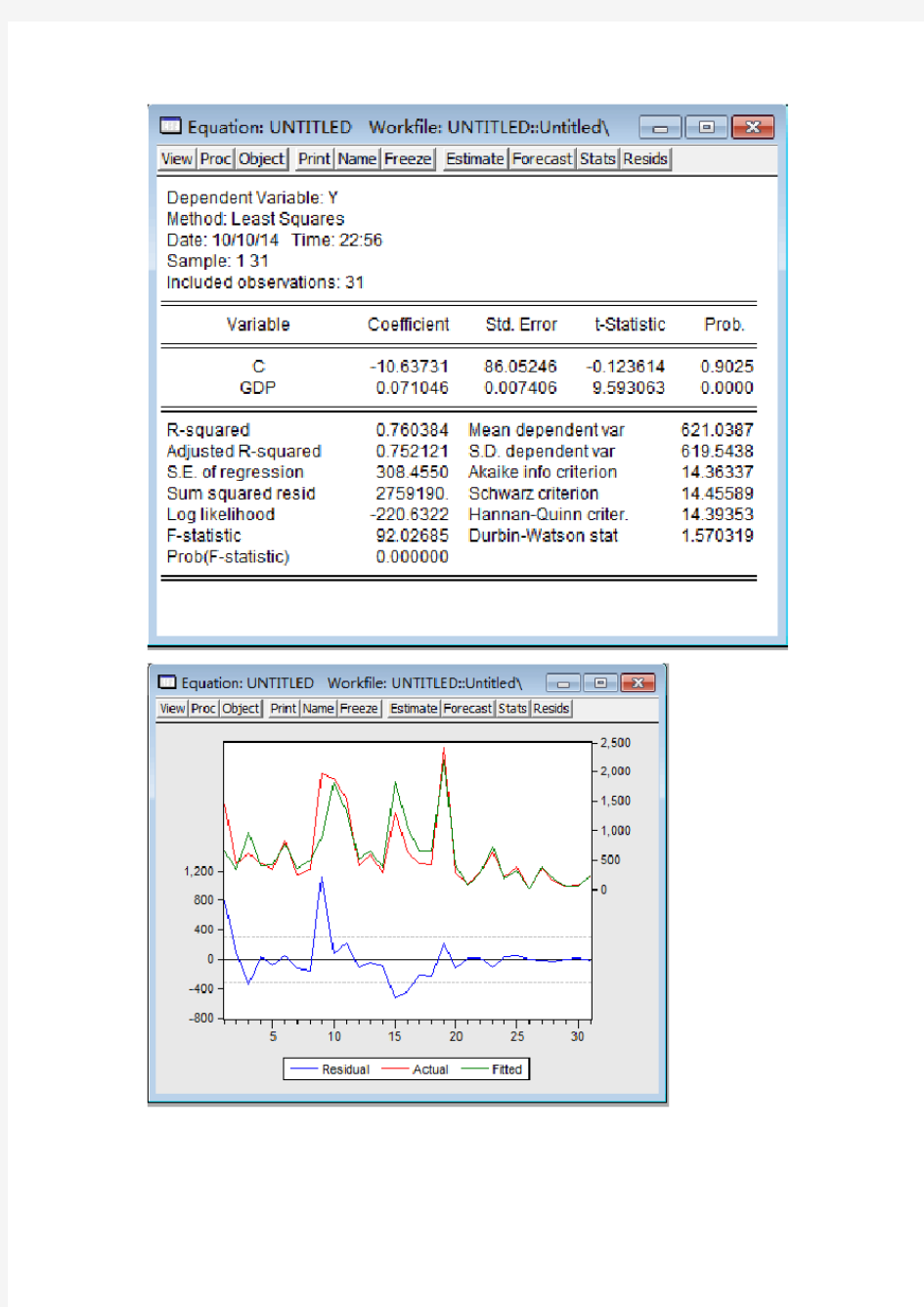
(2)对所建立的回归方程进行检验。
从回归的结果看,可决系数 ,
模型拟合地比较好,但不是非常的好,它表明各地区税收变化的76.03%可由国内生产总
值GDP 的变化来解释。
假设检验:
在5%的显著性水平下,自由度为29的 t 统计量的临界
值 ,由表可得 的 t 统计量检验值约
为9.59,显然大于2.05,拒绝原假设,说明GDP 对税收有显著性影
响,由其相应P=0.0000<0.05 ,拒绝原假设,也可得出GDP 对税收
有显著性影响。
7603.02≈R 0:10=βH 0
:11≠βH 05.2)29(025.0=t 1?β
在5%的显著性水平下, 第一自由度为1,第二自由度为 29
的F 检验的临界值 ,该模型的F
值为91.99198>4.18,即 , 拒绝原假设,说明回
归方程显著成立,也即总体Y 与X 线性显著;由其相应的 P=0.0000<0.05 ,拒绝原假设,也可得出总体线性显著。
由一元线性回归 t 检验与 F 检验一致,依然可以得
出模型总体线性显著的结论。
(3)若2008年某地区国内生产总值GDP 为8500亿元,求该
地区税收收入的预测值及预测区间。
18.4)29,1(05
.0=F 05.0F F >
由上可知进行预测所需的各数据分别为: 样本:
预测值:
样本均值:
样本方差: 残差平方和:
临界值:
由公式:
代入以上数据得总体条件均值的预测区间为: ( 479.51 , 707.02 )
由公式:
代入以上数据得个别预测值的预测区间为: ( -49.34 , 1235.88 )
85000=X 2667.593?0=Y 126.8891=x 64
.57823127)(=x Var 27603102=∑i e 05
.2)29(025.0=t
常用显著性检验 1.t检验 适用于计量资料、正态分布、方差具有齐性的两组间小样本比较。包括配对资料间、样本与均数间、两样本均数间比较三种,三者的计算公式不能混淆。 2.t'检验 应用条件与t检验大致相同,但t′检验用于两组间方差不齐时,t′检验的计算公式实际上是方差不齐时t检验的校正公式。 3.U检验 应用条件与t检验基本一致,只是当大样本时用U检验,而小样本时则用t检验,t检验可以代替U检验。 4.方差分析 用于正态分布、方差齐性的多组间计量比较。常见的有单因素分组的多样本均数比较及双因素分组的多个样本均数的比较,方差分析首先是比较各组间总的差异,如总差异有显著性,再进行组间的两两比较,组间比较用q检验或LST检验等。 5.X2检验 是计数资料主要的显著性检验方法。用于两个或多个百分比(率)的比较。常见以下几种情况:四格表资料、配对资料、多于2行*2列资料及组内分组X2检验。 6.零反应检验 用于计数资料。是当实验组或对照组中出现概率为0或100%
时,X2检验的一种特殊形式。属于直接概率计算法。 7.符号检验、秩和检验和Ridit检验 三者均属非参数统计方法,共同特点是简便、快捷、实用。可用于各种非正态分布的资料、未知分布资料及半定量资料的分析。其主要缺点是容易丢失数据中包含的信息。所以凡是正态分布或可通过数据转换成正态分布者尽量不用这些方法。 8.Hotelling检验 用于计量资料、正态分布、两组间多项指标的综合差异显著性检验。 计量经济学检验方法讨论 计量经济学中的检验方法多种多样,而且在不同的假设前提之下,使用的检验统计量不同,在这里我论述几种比较常见的方法。 在讨论不同的检验之前,我们必须知道为什么要检验,到底检验什么?如果这个问题都不知道,那么我觉得我们很荒谬或者说是很模式化。检验的含义是要确实因果关系,计量经济学的核心是要说因果关系是怎么样的。那么如果两个东西之间没有什么因果联系,那么我们寻找的原因就不对。那么这样的结果是没有什么意义的,或者说是意义不大的。那么检验对于我们确认结果非常的重要,也是评价我们的结果是否拥有价值的关键因素。所以要做统计检验。 t检验,t检验主要是检验单个ols估计值或者说是参数估计值的显著性,什么是显著性?也就是给定一个容忍程度,一个我们可以犯
计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R - ==12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数)1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差平方和的自由度,n-1为总体平方 和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设:H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 )1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临 界值F α(k,n-k-1),由样本求出统计量F 的数值,通过F>F α(k,n-k-1)或F ≤F α(k,n-k-1)来拒绝或接受原假设H 0,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t 检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:βi =0 (i=1,2…k );H1:βi ≠0 给定显著性水平α,可得到临界值t α/2(n-k-1),由样本求出统计量t 的数值,通过 |t|> t α/2(n-k-1) 或 |t|≤t α/2(n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。 统计量 )1(~1??? ----'--= k n t k n c S t ii i i i i i e e βββββ 在(1-α)的置信水平下βi 的置信区间是 ( , ) ββααββ i i t s t s i i -?+?2 2 ,其中,t α/2为显著性 水平为α、自由度为n-k-1的临界值。 五、异方差检验 1. 帕克(Park)检验与戈里瑟(Gleiser)检验 试建立方程: i ji i X f e ε+=)(~2 或 i ji i X f e ε+=)(|~|
内蒙古科技大学 实验报告 课程名称:计量经济学实验项目名称:单方程线性回归模型中异方差的检验与补救 院(系):经济与管理学院专业班级:姓名: 学号: 内蒙古科技大学 实验地点: 实验日期: 2013年 5 月 15 日 实验目的:掌握利用EViews软件对模型中存在的异方差进行检验和补救。实验内容: 根据我国2000年部分地区城镇居民每个家庭平均全年可支配收入X与消费支出Y的统计数据,通过建立双变量线性回归模型分析人均可支配收入对人均消费支出的线性影响,并讨论异方差的检验与修正过程。 1、异方差的检验 1)图示法 2)Park检验 3)Glejser检验 4)Goldfeld-Quandt检验 5)White检验 2、异方差的补救 1)加权最小二乘法(WLS) 2)对数变换 实验方法、步骤和结果: 一、前期准备工作,数据粘贴file-new-workfile Quick-empty group
内蒙古科技大学 并对数据重命名 ser01-x ser02-y 二、异方差的检验 1、先对x、y进行估计。在quick中选择estimate equation编辑方程y c x
内蒙古科技大学 2、将x、y建组,并命名为group02,并在group02中view菜单下选择graph-scatter-simple scaterr画出散点图。 从图像中可看出,三点分布由集中到慢慢扩大,而且比较明显,所以说该模型可能存在异方差。 3、y的估计值与残差平方的散点图进行判断 首先在eq01中proc菜单下选择make residual series,命名为res,找到残差。如图:
计量经济学课后习题 1.什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别? 答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的交叉学科。 计量经济学方法揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。 4.建立与应用计量经济学模型的主要步骤有哪些? 答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。 5.模型的检验包括几个方面?其具体含义是什么? 答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。 4.如何缩小置信区间?(P46) 由上式可以看出(1).增大样本容量。样本容量变大,可使样本参数估计量的标准差减小;同时,在同样置信水平下,n越大,t分布表中的临界值越小。(2)提高模型的拟合优度。因为样本参数估计量的标准差和残差平方和呈正比,模型的拟合优度越高,残差平方和应越小。 1.为什么计量经济学模型的理论方程中必须包含随机干扰项? (经典模型中产生随机误差的原因) 答:计量经济学模型考察的是具有因果关系的随机变量间的具体联系方式。由于是随机变量,意味着影响被解释变量的因素是复杂的,除了解释变量的影响外,还有其他无法在模型中独立列出的各种因素的影响。这样,理论模型中就必须使用一个称为随机干扰项的变量宋代表所有这些无法在模型中独立表示出来的影响因素,以保证模型在理论上的科学性。 3.一元线性回归模型的基本假设主要有哪些? 违背基本假设的模型是否不可以估计? 答:线性回归模型的基本假设有两大类:一类是关于随机干扰项的,包括零均值,同方差,不序列相关,满足正态分布等假设;另一类是关于解释变量的,主要有:解释变量是非随机的,若是
回归方程及回归系数验检性著显的. 3 回归方程及回归系数的显著性检验§ 1、回归方程的显著性检验回归平方和与剩余平方和(1) 是否确实存在线性关系呢?这, 回归效果如何呢?因变量与自变量建立回归方程以后我们要进一步研究因变量, 取值的变化规律。的每是需要进行统计检验才能加以肯定或否定, 为此常用该次观侧值每次观测值的变差大小, 次取值是有波动的, 这种波动常称为变差, 次观测值的总变差可由而全部, 的差(称为离差)来表示与次观测值的平均值总的离差平方和, : 其中它反映了自变量称为回归平方和 , 是回归值与均值之差的平方和, 。)为自变量的个数的波动的变化所引起的, 其自由度(, ), 是实测值与回归值之差的平方和或称残差平方和称为剩余平方和(的自由度为其自由度。总的离差平方和。它是由试验误差及其它因素引起的, , , 是确定的即, 如果观测值给定则总的离差平方和是确定的, 因此大则反之小, 或者, 与, 大所以且回归平方和都可用来衡量回归效果, 越大则线性回归效果越显著小则如果越小回归效果越显著, ; 则线性回大, 说剩余平方和0, =如果则回归超平面过所有观测点归效果不好。复相关系数(2) 人们也常引用无量纲指标, 为检验总的回归效果, (3.1)
或. , (3.2) 称为复相关系数。因为回归平方和实际上是反映回归方程中全部自变量的“方差贡献”, 因此因此的相关程度。显然, 就是这种贡献在总回归平方和中所占的比例表示全部自变量与因变量 因此它可以作为检验总的回归效果的一个指标。但, 回归效果就越好, 。复相关系数越接近1 常有较大的并不很大时, 相对于, 与回归方程中自变量的个数及观测组数有关, 当应注意 一般认为应取, 的适当比例的5到10至少为倍为宜。值与, 因此实际计算中应注意 检验(3)
1.研究目的和意义 我们研究的对象是各地区居民消费支出的差异。居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城市居民家庭每人每年的平均消费支出”来比较,而这正是可国家统计局中获得数据的变量。所以模型的被解释变量Y选定为“城市居民家庭平均每人生活消费支出”。 因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。因此建立的是2007年的截面数据模型。 影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,另外,居民消费支出具有一定的惯性,也就是说居民当年的消费支出在一定程度上受上一年已经实现的消费支出的影响。其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。为了与“城市居民家庭人均消费支出”相对应,选择在国家 X,统计局中可以获得的“各地区城市居民家庭人均可支配收入”作为解释变量 1 X。 “上年各地区城镇居民家庭平均每人生活消费支出”作为 2 从国家统计局中得到表1的数据: 表 1 城镇居民家庭平均每人生活消费支出与各地区城镇居民家庭人均可支配收入 地区Y X1 X2 北京14825.41 19977.52 13244.20 天津10548.05 14283.09 9653.26 河北7343.49 10304.56 6699.67 山西7170.94 10027.70 6342.63 内蒙古7666.61 10357.99 6928.60
方程显著性的检验 方程显著性可用方程的F比值(F比值=回归平方和÷残差平方和)和复相关系数描述,当α等于0.05以下,方程的可靠程度的概率超过95%。复相关系数r接近1较好,随着项数的引进多,R会自动增加,容易形成假象。所以,α的可靠性比R高。 样本的预留检验,是用预留的样本值直观检验回归方程预报值的拟合精度。如果这几批都与预报值相差很大,再预报其它值还有可靠性吗? 三种检验方法各有优缺点。通常,样本数少、试验误差大、检测不准是造成检验难过关的主要原因。 1.F统计值 在建模时,F临界值是用于引入或剔除一个变量时的一种尺度。临界 值高,在引入方程时,将显著性好的变量引入。剔除时,又可将引 入方程的变量再次检验,将变得不显著的剔除,使方程处于优化状 态。 引入和剔除的F临界值是怎样确定呢?选择α=?时的F分布表, 查该表的第N1列、第n-N1-1行的值,该值即为该表α=?时的f 临界值。其中n为样本个数,N1为方程中引入的变量模式数。 当N1=1时,是引入一个变量,所得F临界值用于建模。若是回归方 程中引入了5个自变量或是其组合项,此时N1=5,所得的F临界是 用于描述方程拟合得好与坏。 在方差分析中,回归平方和是由自变量X的变化引起的,它的大小 反映了自变量X的重要程度。剩余平方和是由试验误差以及其它为 加控制的因素引起的它的大小反映了试验误差及其它因素对试验结 果的影响。平方和除自由度为均方,两个均方相除得F比值。 在不同的显著性水平α下,F临界值不一样。F比值高于F临界值, 表明在显著性水平α=?时,回归方程显著。F比值值高,则显著性 水平好,此时的α是反映回归方程拟合的程度。 2.显著性水平α 显著性水平α在统计检验中具有重要作用,α=0.05,意味着回归 方程的有效性为95%,α=0.01,为99%的可靠性。通常α=0.01, 为高度显著;α=0.05,为一般显著;α=0.10以上,方程可靠性 大为下降。 3.复相关系数R
最全计量经济学检验汇总 现代计量经济学的检验包括以下三个大类: §1.1 系数检验 一、Wald 检验——系数约束条件检验 Wald 检验没有把原假设定义的系数限制加入回归,通过估计这一无限制回归来计算检验统计量。Wald 统计量计算无约束估计量如何满足原假设下的约束。如果约束为真,无约束估计量应接近于满足约束条件。 考虑一个线性回归模型:εβ+=X y 和一个线性约束:0:0=-r R H β,R 是一个已知的k q ?阶矩阵,r 是q 维向量。Wald 统计量在0H 下服从渐近分布)(2q χ,可简写为: )())(()(112r Rb R X X R s r Rb W -'''-=-- 进一步假设误差ε独立同时服从正态分布,我们就有一确定的、有限的样本F-统计量 q W k T u u q u u u u F /) /(/)~~(=-''-'= u ~是约束回归的残差向量。F 统计量比较有约束和没有约束计算出的残差平方和。如果约束有效,这两个残差平方和差异很小,F 统计量值也应很小。EViews 显示2χ和F 统计量以及相应的p 值。 假设Cobb-Douglas 生产函数估计形式如下: εβα+++=K L A Q log log log (1) Q 为产出增加量,K 为资本投入,L 为劳动力投入。系数假设检验时,加入约束1=+βα。 为进行Wald 检验,选择View/Coefficient Tests/Wald-Coefficient Restrictions ,在编辑对话框中输入约束条件,多个系数约束条件用逗号隔开。约束条件应表示为含有估计参数和常数(不可以含有序列名)的方程,系数应表示为c(1),c(2)等等,除非在估计中已使用过一个不同的系数向量。 为检验规模报酬不变1=+βα的假设,在对话框中输入下列约束:c(2)+c(3)=1 二、遗漏变量检验 这一检验能给现有方程添加变量,而且询问添加的变量对解释因变量变动是否有显著作用。原假设 0H 是添加变量不显著。 选择View/Coefficient Tests/Omitted Variables —Likehood Ration ,在打开的对话框中,列出检验统计量名,用至少一个空格相互隔开。例如:原始回归为 LS log(q) c log(L) log(k) ,输入:K L ,EViews 将显示含有这两个附加解释变量的无约束回归结果,而且显示假定新变量系数为0的检验统计量。 三、冗余变量 冗余变量检验可以检验方程中一部分变量的统计显著性。更正式,可以确定方程中一部分变量系数是否为0,从而可以从方程中剔出去。只有以列出回归因子形式,而不是公式定义方程,检验才可以进行。 选择View/Coefficient Tests/Redundant Variable —likelihood Ratio ,在对话框中,输入每一检验的变量名,相互间至少用一空格隔开。例如:原始回归为: Ls log(Q) c log(L) log(K) K L ,如果输入K L ,EViews 显示去掉这两个回归因子的约束回归结果,以及检验原假设(这两个变量系数为0)的统计量。 §1.2 残差检验 一、相关图和Q —统计量 在方程对象菜单中,选择View/Residual Tests/Correlogram-Q-Statistics ,将显示直到定义滞后阶数的残差自相关性和偏自相关图和Q-统计量。在滞后定义对话框中,定义计算相关图时所使用的滞后数。如果残差不存在序列相关,在各阶滞后的自相关和偏自相关值都接近于零。所有的Q -统计量不显著,并且有大
中国经济增长影响因素实证分析 一、研究对象 经济增长问题既受各国政府和居民的关注,也是经济学理论研究的一个重要方面。在1978—2008年的31中,我国经济年均增长率高达9.6%,综合国力大大增强,居民收入水平与生活水平不断提高,居民的消费需求的数量和质量有了很大的提高。但是,我国目前仍然面临消费需求不足问题。因此,研究消费需求对经济增长的影响,并对我国消费需求对经济增长的影响程度进行实证分析,可以更好的理解消费对我国经济增长的作用。 二、数据收集与模型的建立 (一)数据收集 表2.1 中国经济增长影响因素模型时间序列表 年份国内生产总 值(y) 年末从业 人员数 (x1) 全社会固定资 产投资总额 (x2) 居民消费价格指 数(上年=100) (x3) 1980 4545.6 42361 910.9 107.5 1981 4891.6 43725 961 102.5 1982 5323.4 45295 1230.4 102 1983 5962.7 46436 1430.1 102 1984 7208.1 48197 1832.9 102.7 1985 9016 49873 2543.2 109.3 1986 10275.2 51282 3120.6 106.5 1987 12058.6 52783 3791.7 107.3 1988 15042.8 54334 4753.8 118.8 1989 16992.3 55329 4410.4 118 1990 18667.8 64749 4517 103.1 1991 21781.5 65491 5594.5 103.4 1992 26923.5 66152 8080.1 106.4 1993 35333.9 66808 13072.3 114.7 1994 48197.9 67455 17042.1 124.1 1995 60793.7 68065 20019.3 117.1 1996 71176.6 68950 22913.5 108.3 1997 78973 69820 24941.1 102.8 1998 84402.3 70637 28406.2 99.2 1999 89677.1 71394 29854.7 98.6 2000 99214.6 72085 32917.7 100.4 2001 109655.2 73025 37213.5 100.7 2002 120332.7 73740 43499.9 99.2 2003 135822.8 74432 55566.6 101.2 2004 159878.3 75200 70477.4 103.9 2005 184937.4 75825 88773.6 101.8 2006 216314.4 76400 109998.2 101.5 2007 265810.3 76990 137323.9 104.8
显著性检验 T检验 零假设,也称稻草人假设,如果零假设为真,就没有必要把X纳入模型,因此如果X确定属于模型,则拒绝零假设Ho,接受备择假设 H1,(Ho:B2=0 H1:B2≠0) 假设检验的显著性检验法: t=(b2-B2)/Se(b2)服从自由度为(n-2)的t分布,如果令Ho:B2=B2*,B2*就是B2的某个数值(若B2*=0)则t=(b2-B2*)/Se(b2)=(估计量—假设值)/假设量的标准误。可计算出的t值作为检验统计量,它服从自由度为(n-2)的t分布,相应的检验过程称为t检验。 T检验时需知:①,对于双变量模型,自由度为(n-2);②,在检验分析中,常用的显著水平α有1%,5%或10%,为避免选择显著水平的随意性,通常求出p值,p值充分小,拒绝零假设;③可用半边或双边检验。 双边T检验:若计算的ItI超过临界t值,则拒绝零假设。 显著性水平临界值t 0、01 3、355 0、05 2、306 0、10 1、860 单边检验:用于B2系数为正,假设为Ho:B2<=0, H1:B2>0 显著性水平临界值t 0、01 2、836 0、05 1、860 0、10 1、397 F检验(多变量)(联合检验) F=[R2/(k-1)]/(1-R2)(n-k)=[ESS(k-1)]/RSS(n-k)、n为观察值的个数,k 为包括截距在内的解释变量的个数,ESS(解释平方 与)= ∑y^i2RSS(残差平方与)= ∑ei2TSS(总平方 与)= ∑yi2=ESS+RSS、判定系数r2=ESS/TSS F与R2同方向变动,当R2=0(Y与解释变量X不想关),F为0,R2值越大,F值也越大,当R2取极限值1时,F值趋于无穷大。 F检验(用于度量总体回归直线的显著性)也可用于检验R2的显著性—R2就是否显著不为0,即检验零假设式(Ho:B2=B3=0)与检验零假设R2为0就是等价的。 虚拟变量 虚拟变量即定性变量,通常表明具备或不具备某种性质,虚拟变量用D表示。 方差分析模型:仅包含虚拟变量的回归模型。 若:Yi=B1+B2Di+Ui,Di—1,女性;—0,男性 B2为差别截距系数,表示两类截距值的差异,B2=E(Yi/Di=1)-E(Yi/Di=0) 通常把取值为0的一类称为基准类、基础类、参照类、比较类,研究结论与基准类的选择没有关系。 定型变量有m种分类时,则需引入(m-1)个虚拟变量,否则会陷入虚拟变量陷阱即完全共线性或多重共线性。 多重共线性 例:收入变量(X2)完全线性相关,而R2(=r2)=1
选择题(单选题1-10 每题1 分,多选题11-15 每题2 分,共20 分) 1、在多元线性回归中,判定系数R2随着解释变量数目的增加而 B A.减少 B.增加 C.不变 D.变化不定 2、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近1,则表明模型中 存在 C A.异方差性 B.序列相关 C.多重共线性 D.拟合优度低 3、经济计量模型是指 D A.投入产出模型 B.数学规划模 C.模糊数学模型 D.包含随机方程的经济数学模型 4、当质的因素引进经济计量模型时,需要使用 D A.外生变量 B.前定变量 C.生变量 D.虚拟变量 5、将生变量的前期值作解释变量,这样的变量称为 D A.虚拟变量 B.控制变量 C.政策变量 D.滞后变量 6、根据样本资料已估计得出人均消费支出Y对人均收入X的回归模型Ln Y=5+0.75LnX,这表明 人均收入每增加1%,人均消费支出将预期增加 B A.0.2% B.0.75% C.5% D.7.5% 7、对样本相关系数r,以下结论中错误的是 D A.越接近于1,Y与X之间线性相关程度越高 B.越接 近于0,Y与X之间线性相关程度越弱 C.-1≤r≤1
D.若r=0,则X与Y独立 8、当DW>4-d L,则认为随机误差项εi A.不存在一阶负自相关 B.无一阶序列相关 C.存在一阶正自相关D.存在一阶负自相关 9、如果回归模型包含二个质的因素,且每个因素有两种特征,则回归模型中需要引入 A.一个虚拟变量B.两个虚拟变量 C.三个虚拟变量 D.四个虚拟变量 10、线性回归模型中,检验H0: i =0(i=1,2,…,k) 时,所用的统计量t ?i 服从 var(?i ) A.t(n-k+1) B.t(n-k-2) C.t(n-k-1) D.t(n-k+2) 11、对于经典的线性回归模型,各回归系数的普通最小二乘法估计量具有的优良特性有ABC A.无偏性 B.有效性 C.一致性 D.确定性 E.线性特性 12、经济计量模型主要应用于ABCD A.经济预测 B.经济结构分析 C.评价经济政策 D.政策模拟 13、常用的检验异方差性的方法有ABC、 A.戈里瑟检验 B.戈德菲尔德-匡特检验 C.怀特检验 D.DW检验 E.方差膨胀因子检测 14、对分布滞后模型直接采用普通最小二乘法估计参数时,会遇到的困难有BCE A.不能有效提高模型的拟合优度 B.难以客观确定滞后期的长度 C.滞后期长而样本小时缺乏足够自由度 D.滞后的解释变量存在序列相关问题 E.解释变量间存在多重共线性问题
大学生月消费支出调查报告 一、引言 在当前尚且低迷,尚未完全复苏的经济环境下,消费问题被大家广泛关注。物价的连续上涨,直接反映了社会的消费和需求问题。当前的消费市场中,大学生作为一个特殊的消费群体正受到越来越大的关注。由于大学生年龄较轻,群体较特别,他们有着不同于社会其他消费群体的消费心理和行为。一方面,他们有着旺盛的消费需求,另一方面,他们尚未获得经济上的独立,消费受到很大的制约。消费观念的超前和消费实力的滞后,都对他们的消费有很大影响。特殊群体自然有自己特殊的特点,同时难免存在一些非理性的消费甚至一些消费的问题。为了调查清楚大学生的消费情况,我决定在身边的同学中进行一次消费的调研,对大家的消费进行归宗和分析。 二、理论综述 我们主要对大学生每人每月消费支出进行多因素分析,并从周围同学搜集相关数据,建立模型,对此进行数量分析。 影响大学生每人每月消费支出的主要因素如下: 1、学习支出 2、消费收入 3、生活支出 三、模型设定 Y:每人每月消费支出 X1:学习支出X2:消费收入 X3:生活支出 四、数据搜集 1、数据说明 我们特对周围大学生的消费水平做了简单调查,再用计量经济学的知识分析其影响因素。 2、数据的搜集情况 人数每人每月消 费 支出Y 学习支出 (X1) 消费收入(X2)生活支出(X3) 1760310800450 2630230600400 311002301350880 4420170450250 59601601000800 6580280500300 78702201000650 8300110400190 910501501300900 10126016015001100 11130030015001000 12500190550310 13600180750420 149001401000760
1、计量经济学 计量经济学是一门从数量上研究物质资料的生产、交换、分配、消费等经济关系和经济活动规律及其应用的科学。 2、数据质量 数据满足明确或隐含需求程度的指标 3、相关分析 主要研究变量之间的相互关联程度,用相关系数表示。包括简单相关和多重相关(复相关)。 4、回归分析(Regression Analysis) 研究一个变量(因变量)对于一个或多个其他变量(解释变量)的数量依存关系。其目的在于根据已知的解释变量的数值来估计或预测因变量的总体平均值。 5.内生变量 指由模型系统内决定的变量,取值在系统内决定 6、面板数据 时间序列数据和截面数据的混合 7.异方差: 总体回归函数中的随机误差项满足同方差性,即它们都有相同的方差。如果这一假定不满足,则称线性回归模型存在异方差性。 8.自相关 自相关是在时间序列资料中按时间顺序排列的观测值之间的相关或在横截面资料中按空间顺序排列的观测值之间的相关 9.多重共线性 解释变量之间存在完全的线性关系或近似的线性关系。解释变量存在完全的线性关系叫完全多重共线;解释变量之间存在近似的线性关系叫不完全多重共线。 10.虚拟变量 虚拟变量:在建立模型时,有一些影响经济变量的因素无法定量描述 构造只取“0”或“1”的人工变量,通常称为虚拟变量,记为D 11.平稳序列 是指时间序列的统计规律不会随着时间的推移而发生变化。
12.伪回归 所谓“伪回归”,是指变量间本来不存在相依关系,但回归结果却得出存在相依关系的错误结论。 13.协整 所谓协整,是指多个非平稳变量的某种线性组合是平稳的 14.前定变量 所有的外生变量和滞后的内生变量。前定变量=外生变量+滞后内生变量+滞后外生变量 15.恰好识别 恰好识别:能够唯一地估计出结构参数值。 16.结构式模型 体现经济理论中经济变量之间的关系结构的联立方程模型,称为结构式模型17.过度识别 过度识别:结构参数的估计值具有多个确定值 18.自回归模型 自回归模型:指模型中的解释变量仅是X 的当期值与被解释变量Y 的若干期滞后值,它由于被解释变量的滞后期值对被解释变量现期做了回归,故叫做自回归模型。 利用前期若干时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型。 19.拟合优度2R:拟合优度检验:指检验模型对样本观测值的拟合程度 20.修正的拟合优度2R 二、.
一、计量资料的常用统计描述指标 1.平均数平均数表示的是一组观察值(变量值)的平均水平或集中趋势。平均数 计算公式: 式中:X为变量值、Σ为总和,N为观察值的个数。 2.标准差(S) 标准差表示的是一组个体变量间的变异(离散)程度的大小。S愈小,表示观察值的变异程度愈小,反之亦然,常写成。标准差计算公式: 式中:∑X2 为各变量值的平方和,(∑X)2为各变量和的平方,N-1为自由度3.标准误(S?x)标准误表示的是样本均数的标准差,用以说明样本均数的分布情况,表示和估量群体之间的差异,即各次重复抽样结果之间的差异。S?x愈小,表示抽样误差愈小,样本均数与总体均数愈接近,样本均数的可靠性也愈大,反之亦然,常写 作。标准误计算公式: 三、显著性检验 抽样实验会产生抽样误差,对实验资料进行比较分析时,不能仅凭两个结果(平均数或率)的不同就作出结论,而是要进行统计学分析,鉴别出两者差异是抽样误差引起的,还是由特定的实验处理引起的。 1.显著性检验的含义和原理显著性检验即用于实验处理组与对照组或两种不同处理的效应之间是否有差异,以及这种差异是否显著的方法。 2.无效假设显著性检验的基本原理是提出“无效假设”和检验“无效假设”成立的机率(P)水平的选择。所谓“无效假设”,就是当比较实验处理组与对照组的结果时,假设两组结果间差异不显著,即实验处理对结果没有影响或无效。经统计学分析后,如发现两组间差异系抽样引起的,则“无效假设”成立,可认为这种差异为不显著(即实验处理无效)。若两组间差异不是由抽样引起的,则“无效假设”不成立,可认为这种差异是显著的(即实验处理有效)。 3.“无效假设”成立的机率水平检验“无效假设”成立的机率水平一般定为5%(常写为p≤0.05),其含义是将同一实验重复100次,两者结果间的差异有5次以上是由抽样误差造成的,则“无效假设”成立,可认为两组间的差异为不显著,常记为p>0.05。若两者结果间的差异5次以下是由抽样误差造成的,则“无效假设”不成立,可认为两组间的差异为显著,常记为p≤0.05。如果p≤0.01,则认为两组间的差异为非常显著。 (一)计量资料的显著性检验 1.t 检验 (1)配对资料(实验前后)的比较假设配对资料差数的总体平均数为零。其计算公
计量经济学考试重点整理 第一章: P1:什么是计量经济学?由哪三组组成? 定义:“用数学方法探讨经济学可以从好几个方面着手,但任何一个方面都不能和计量经济学混为一谈。计量经济学与经济统计学绝非一码事;它也不同于我们所说的一般经济理论,尽管经济理论大部分具有一定的数量特征;计量经济学也不应视为数学应用于经济学的同义语。经验表明,统计学、经济理论和数学这三者对于真正了解现代经济生活的数量关系来说,都是必要的,但本身并非是充分条件。三者结合起来,就是力量,这种结合便构成了计量经济学。” P9:理论模型的设计主要包含三部分工作,即选择变量,确定变量之间的数学关系,拟定模型中待估计参数的数值范围。 P12:常用的样本数据:时间序列,截面,虚变量数据 P13:样本数据的质量(4点) 完整性;准确性;可比性;一致性 P15-16:模型的检验(4个检验) 1、经济意义检验 2、统计检验 拟合优度检验 总体显著性检验 变量显著性检验 3、计量经济学检验 异方差性检验 序列相关性检验 共线性检验 4、模型预测检验 稳定性检验:扩大样本重新估计 预测性能检验:对样本外一点进行实际预测 P16计量经济学模型成功的三要素:理论、方法和数据。 P18-20:计量经济学模型的应用 1、结构分析 经济学中的结构分析是对经济现象中变量之间相互关系的研究。 结构分析所采用的主要方法是弹性分析、乘数分析与比较静力分析。 计量经济学模型的功能是揭示经济现象中变量之间的相互关系,即通过模型得到弹性、乘数等。 2、经济预测 计量经济学模型作为一类经济数学模型,是从用于经济预测,特别是短期预测而发展起来的。 计量经济学模型是以模拟历史、从已经发生的经济活动中找出变化规律为主要技术手段。 对于非稳定发展的经济过程,对于缺乏规范行为理论的经济活动,计量经济学模型预测功能失效。 模型理论方法的发展以适应预测的需要。
计量经济学实验报告 我国居民储蓄余额的影响因素的计量分析 XX学院 XX专业 小组成员:(姓名及学号)
我国居民储蓄余额的影响因素的计量分析 一.研究的目的要求 1.研究的背景 居民储蓄额作为一个国家经济增长中来源最稳定、数额最大的影响因素,它的高低对一国的经济发展、投资和居民生活等方面都有不同程度的影响。目前我国国内居民储蓄意愿强劲、储蓄额居高不下,形成了储蓄的超常增长,主要呈现以下特点:(1)储蓄率世界之冠;(2)储蓄增长速度高于经济和居民收入增长速度;(3)城乡之间差别大;(4)不同收入阶层分布不均匀;(5)不同地区分布极不平均。我国储蓄的超常增长一方面能为银行提供了充足的信贷资金,保证金融机构的稳健运行,还能为国家提供了物质基础;此外,面对世界的日益发展,高储蓄额还能帮助我国进一步改革。但是,在另一方面我还国存在金融机构对资本的运用效益不高、居民投资渠不多、投资效益不稳定等问题。这些问题导致我国现在储蓄存款过剩、消费不足和资本形成不足同时并存的局面。 2013年6月余额宝正式上线,在此后的一年中该产品的客户数量和管理资产出现爆炸式的增长。截止2014年3月余额宝资金规模已经达到5413亿元,截止2014年4月,居民人民币存款减少1.23万亿元。余额宝作为一条“鲶鱼”和随后出现的众多“宝宝”们一起加速了中国利率市场化的进程,对未来我国储蓄额有着重大影响。 为了分析我国居民储蓄存款如今的发展状况、更好地把握我国储蓄余额未来的走向,所以对我国储蓄余额的及其影响因素的研究是十分必要的。 2.影响因素的分析 为了研究影响中国储蓄余额高低的主要原因,分析居民储蓄余额增长规律,预测中国储蓄余额的增长趋势,需要建立计量经济模型。通过参考相关文献并结合我国经济发展的实际情况提出了以下几个变量。(1)收入水平。根据经济理论可以认为,收入水平是影响储蓄的最主要因素。(2)利率水平。利率作为消费的机会成本也会对储蓄产生影响。理论上认为,利率越高,居民消费的机会成本越高,所以会减少消费增加储蓄;反之,利率越低消费成本越低,居民会增加消费减少储蓄。(3)物价水平。物价水平会影响消费和储蓄。物价水平越高相同消费水平需要支付的货币更多。而且物价水
显著性检验 T检验 零假设,也称稻草人假设,如果零假设为真,就没有必要把X纳入模型,因此如果X确定属于模型,则拒绝零假设Ho,接受备择假设H1, (Ho:B2=0 H1:B2≠0) 假设检验的显著性检验法: t=(b2-B2)/Se(b2)服从自由度为(n-2)的t分布,如果令Ho:B2=B2*,B2*是B2的某个数值(若B2*=0)则t=(b2-B2*)/Se(b2)=(估计量—假设值)/假设量的标准误。可计算出的t值作为检验统计量,它服从自由度为(n-2)的t分布,相应的检验过程称为t检验。 T检验时需知:①,对于双变量模型,自由度为(n-2);②,在检验分析中,常用的显著水平α有1%,5%或10%,为避免选择显著水平的随意性,通常求出p值,p值充分小,拒绝零假设;③可用半边或双边检验。 双边T检验:若计算的ItI超过临界t值,则拒绝零假设。 显著性水平临界值t 0.01 3.355 0.05 2.306 0.10 1.860 单边检验:用于B2系数为正,假设为Ho:B2<=0, H1:B2>0 显著性水平临界值t 0.01 2.836 0.05 1.860 0.10 1.397 F检验(多变量)(联合检验) F=[R2/(k-1)]/(1-R2)(n-k)=[ESS(k-1)]/RSS(n-k).n为观察值的个数,k 为包括截距在内的解释变量的个数,ESS(解释平方 和)= ∑y^i2RSS(残差平方和)= ∑ei2TSS(总平方 和)= ∑yi2=ESS+RSS.判定系数r2=ESS/TSS F与R2同方向变动,当R2=0(Y与解释变量X不想关),F为0,R2值越大,F值也越大,当R2取极限值1时,F值趋于无穷大。 F检验(用于度量总体回归直线的显著性)也可用于检验R2的显著性—R2是否显著不为0,即检验零假设式(Ho:B2=B3=0)与检验零假设R2为0是等价的。 虚拟变量 虚拟变量即定性变量,通常表明具备或不具备某种性质,虚拟变量用D表示。 方差分析模型:仅包含虚拟变量的回归模型。 若:Yi=B1+B2Di+Ui,Di—1,女性;—0,男性 B2为差别截距系数,表示两类截距值的差异,B2=E(Yi/Di=1)-E(Yi/Di=0) 通常把取值为0的一类称为基准类、基础类、参照类、比较类,研究结论与基准类的选择没有关系。 定型变量有m种分类时,则需引入(m-1)个虚拟变量,否则会陷入虚拟变量陷阱即完全共线性或多重共线性。 多重共线性 例:收入变量(X2)完全线性相关,而R2(=r2)=1
《计量经济学》课程论文 城镇居民消费主要影响因素的实证分析 小组成员:何志滔李学贤吴晓天 指导教师:张子昱 日期:2010年12月23日
城镇居民消费主要影响因素的实证分析 摘要 中国经济的快速增长,城镇化步伐加快。城镇居民的消费在国民经济中占有极其重要的比重,城镇居民的消费水平对整个国名经济的的发展有重大的作用。面对这个巨大的消费,如何提高消费水平就成了扩大内需、拉动经济所面对的问题。本文运用计量经济学的方法,就城镇居民的消费水平的主要影响因素进行了简单的分析。 关键词:城镇居民;消费水平;影响因素 一问题的提出 经济危机以来,中国遭遇增长上的瓶颈。一直以来中国经济的增长主要依赖于投资、出口和消费三架马车,而又以投资和出口的拉动作用最大。虽然我国一直在强调要扩大内需,但经济危机中由于出口减少而引起经济的下滑还是说明国内经济对出口的依赖还是很大的。 西方经济学中有很多关于需求、消费的理论。微观经济学中供求和均衡价格理论中的需求定理阐述了需求的定义和影响因素。需求是指某一特定时期内,在各种可能的价格水平下,消费者愿意而且能够买到的某种商品的数量。影响需求的主要因素包括商品本身的价格、其他商品的价格、消费者的偏好、消费者收入及人们对未来的期望等。 由于数据的可获得性及影响的重要性,对于城镇居民的消费水平主要选取了以下两个影响因素;城镇居民家庭可支配纯收入及商品零售价格指数。 二1991年到2008年城镇居民消费水平及其影响因素的统计数据(表1)
三建立模型 由数据分析,初步建立模型Y=b0+b1*X1+b2*X2+ui b0表示在没有任何影响因素下城镇居民的消费水平;b1表示城镇家庭可支配纯收入对城镇居民消费水平的影响;b2表示商品零售价格指数对城镇居民的消费水平的影响;ui为随机扰动项 四模型的检验与修正 (一)模型的参数估计及经济意义和统计意义上的检验 利用Eviews软件,做Y对X1 X2的回归。回归结果如下表1: Dependent Variable: Y Method: Least Squares Date: 12/22/10 Time: 12:48 Sample: 1991 2008 Included observations: 18 Variable Coeffici ent Std. Error t-Statisti c Prob. C 3435.487 1604.745 2.140831 0.0491 X1 0.782495 0.024778 31.58077 0.0000 X2 -20.2479 0 14.85835 -1.362728 0.1931 R-squared 0.986696 Mean dependent var 6826.167 Adjusted R-squared 0.984922 S.D. dependent var 3180.842 S.E. of regression 390.5890 Akaike info 14.92420