
序列比对及建树步骤
1.以细菌、病毒或寄生虫为例,参考分类生物学资料,从GenBank中查询相关序列,详述Blast寻找、CLUSTAL比对、建树及种系发育过程
以隐孢子虫actin基因为例做一叙述:
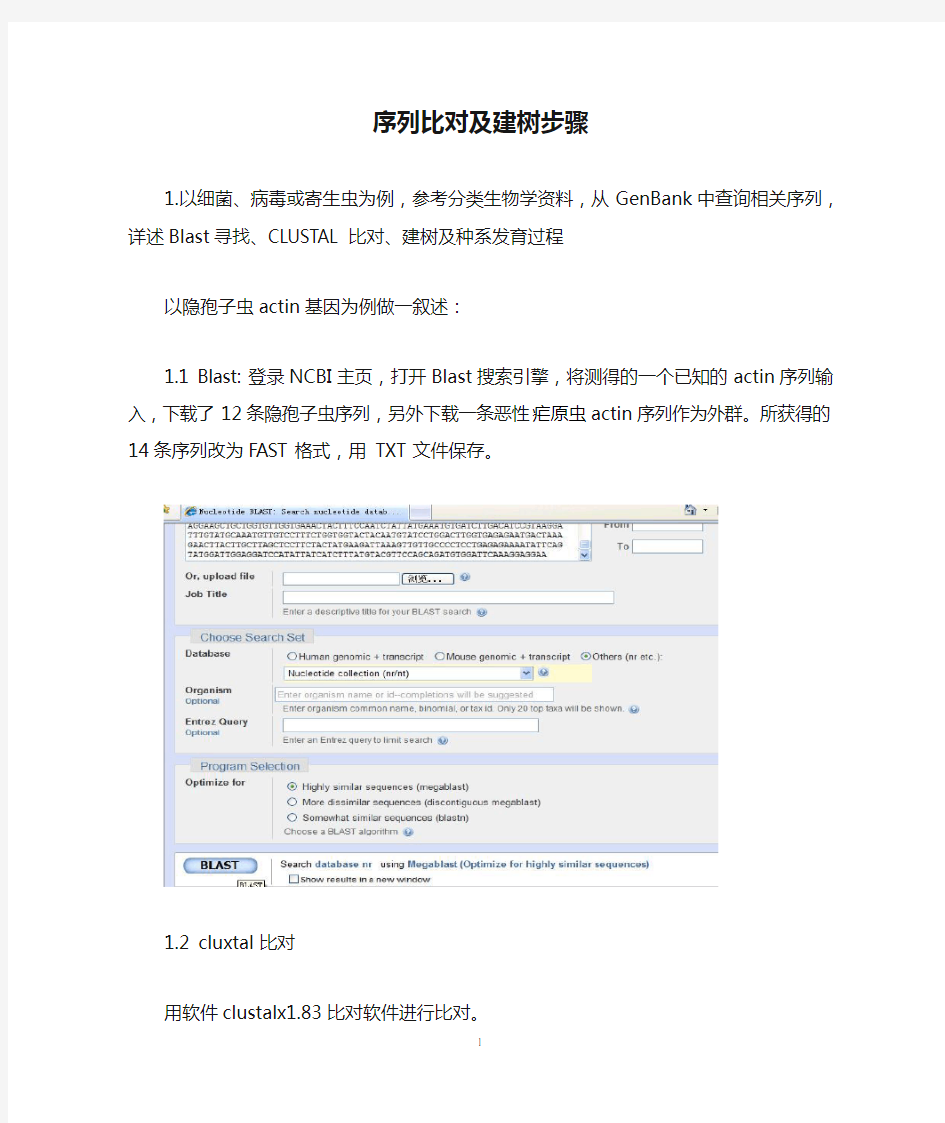
1.1 Blast: 登录NCBI主页,打开Blast搜索引擎,将测得的一个已知的actin序列输入,下
载了12条隐孢子虫序列,另外下载一条恶性疟原虫actin序列作为外群。所获得的14条序列改为FAST格式,用TXT文件保存。
1.2 cluxtal 比对
用软件clustalx1.83比对软件进行比对。
1.3 比对的精制
对比对结果可以进行一些简单的调整,删去目的序列比对效果最差的开头和结尾部分。可以用word文档打开比对所生成的aln.文件,在word文档下进行剪切。然后将剪切的文档再用ClustalX软件进行比对,并生成Phylip格式文件。
1.4 使用Phylip软件建树
以neighbour-jioning方法为例做一叙述。
1.4.1 先导树
将生成的PHY文件(*.phy)拷贝到Phylip软件包目录下,最好修改成比较简单的文件名,比如修改成1或a等(比较方便下边的输入运行)。运行DNADIST.EXE子软件,输入文件(比如1),打回车后弹出软件界面,打D可以选择不同的模型,在此选用Kimura 2-parameter模型。生成的outfile文件可以再修改成简单的文件名,比如修改成2。打开neighbor.exe子程序,输入文件2,打回车后运行完毕会生成两个文件,将文件outtree另存为.tre文件格式,即为所生成的先导树。
1.4.2 验证树
1.4.
2.1打开seqboot.exe
输入文件名:输入你用CLASTAL X生成的PHY文件(*.phy)。R为bootstrap的次数,一般为1000 (设你输入的值为M,即下两步DNADIST.EXE、NEIGHBOR.EXE中的M值也为1000)。odd number: (4N+1)(eg: 1、5、9…)
修改好了
打回车y
得到outfile(在phylip文件夹内)
改名为2
1.4.
2.2 打开Dnadist.EXE
输入2
修改M值,再按D,然后输入1000(M值)
打回车y
得到outfile(在phylip文件夹内)
改名为3
1.4.
2.3 打开Neighboor.EXE
输入3
M=1000(M值)
打回车Y
得到outfile和outtree(在phylip文件夹内),改outtree为4,outfile删除或另存
1.4.
2.4 打开consense.exe
输入4
打回车y
得到outfile和outtree(在phylip文件夹内),Outfile可以改为*.txt文件,用记事本打开阅读或删除。而outtree文件即为我们所需要的验证树。
1.5 结果输出
在获得树文件后,常用Treeview软件打开,并可以用此软件对其进行修饰。
第8章时间序列分析 一、填空题: 1.平稳性检验的方法有__________、__________和__________。 2.单位根检验的方法有:__________和__________。 3.当随机误差项不存在自相关时,用__________进行单位根检验;当随机误差项存在自相关时,用__________进行单位根检验。 4.EG检验拒绝零假设说明______________________________。 5.DF检验的零假设是说被检验时间序列__________。 6.协整性检验的方法有__________和__________。 7.在用一个时间序列对另一个时间序列做回归时,虽然两者之间并无任何有意义的关系,但经常会得到一个很高的2R的值,这种情况说明存在__________问题。 8.结构法建模主要是以______________________________来确定计量经济模型的理论关系形式。 9.数据驱动建模以____________________作为建模的主要准则。 10.建立误差校正模型的步骤为一般采用两步:第一步,____________________;第二步,____________________。 二、单项选择题:
1. 某一时间序列经一次差分变换成平稳时间序列,此时间序列称为()。 A.1阶单整 ??? B.2阶单整??? C.K阶单整 ?? ?D.以上答案均不正确 2.? 如果两个变量都是一阶单整的,则()。 A.这两个变量一定存在协整关系 B.这两个变量一定不存在协整关系 C.相应的误差修正模型一定成立 D.还需对误差项进行检验 3.当随机误差项存在自相关时,进行单位根检验是由()来实现。 A DF检验 B.ADF检验 C.EG检验 D.DW检验 4.有关EG检验的说法正确的是()。 A.拒绝零假设说明被检验变量之间存在协整关系 B.接受零假设说明被检验变量之间存在协整关系 C.拒绝零假设说明被检验变量之间不存在协整关系 D.接受零假设说明被检验变量之间不存在协整关系
《时间序列分析及应用:R语言》读书笔记 姓名:石晓雨学号:1613152019 (一)、时间序列研究目的主要有两个:认识产生观测序列的随机机制,即建立数据生成模型;基于序列的历史数据,也许还要考虑其他相关序列或者因素,对序列未来的可能取值给出预测或者预报。通常我们不能假定观测值独立取自同一总体,时间序列分析的要点是研究具有相关性质的模型。 (二)、下面是书上的几个例子 1、洛杉矶年降水量 问题:用前一年的降水量预测下一年的降水量。 第一幅图是降水量随时间的变化图;第二幅图是当年降水量与去年降水量散点图。 win.graph(width=4.875, height=2.5,pointsize=8) #这里可以独立弹出窗口 data(larain) #TSA包中的数据集,洛杉矶年降水量 plot(larain,ylab='Inches',xlab='Year',type = 'o') #type规定了在每个点处标记一下 win.graph(width = 3,height = 3,pointsize = 8) plot(y = larain,x = zlag(larain),ylab = 'Inches',xlab = 'Previous Year Inches')#zlag 函数(TSA包)用来计算一个向量的延迟,默认为1,首项为NA
从第二幅图看出,前一年的降水量与下一年并没有什么特殊关系。 2、化工过程 win.graph(width = 4.875,height = 2.5,pointsize = 8) data(color) plot(color,ylab = 'Color Property',xlab = 'Batch',type = 'o') win.graph(width = 3,height = 3,pointsize = 8) plot(y = color,x = zlag(color),ylab = 'Color Property',xlab = 'Previous Batch Color Property') len <- length(color) cor(color[2:len],zlag(color)[2:len])#相关系数>0.5549 第一幅图是颜色属性随着批次的变化情况。
说明:答案请答在规定的答题纸或答题卡上,答在本试卷册上的无效。 一、填空题(本题总计25分) 1. 常用的时间序列数据,有年度数据、( )数据和( ) 数据。另外,还有以( )、小时为时间单位计算的数据。 2. 自相关系数j ρ的取值范围为( );j ρ与j -ρ之间的关系是( );0ρ=( )。 3.判断下表中各随机过程自相关系数和偏自相关系数的截尾性,并用 2. 如果随机过程{}t ε为白噪音,则 t t Y εμ+= 的数学期望为 ;j 不等于0时,j 阶自协方差等于 ,j 阶自相关系数等于 。因此,是一个 随机过程。 1.(2分)时间序列分析中,一般考虑时间( )的( )的情形。 3. (6分)随机过程{}t y 具有平稳性的条件是: (1)( )和( )是常数,与 ( )无关。 (2)( )只与( )有关,与 ( )无关。 7. 白噪音的自相关系数是:
1.白噪音{}t y 的性质是:t y 的数学期望为 ,方差为 ;t y 与j -t y 之间的协方差为 。 1.(4分)移动平均法的特点是:认为历史数据中( )的数据对未来的数值有影响,其权数为( ),权数之和为( );但是,( )的数据对未来的数值没有影响。 2. 指数平滑法中常数α值的选择一般有2种: (1)根据经验判断,α一般取 。 (2)由 确定。 3. (5分)下述随机过程中,自相关系数具有拖尾性的有( ),偏自相关系数具有拖尾性的有( )。 ①平稳(2) ②(1) ③平稳(1,2) ④白噪 音过程 4.(5分)下述随机过程中,具有平稳性的有( ),不具有平稳性的有( )。 ①白噪音 ②t t y 1.23t+ε=+ ③随机漂移过程 ④t t t 1y 16 3.2εε-=++ ⑤t t y 2.8ε=+ 2.(3分)白噪音{}t ε的数学期望为( );方差为( );j 不等于0时,j 阶自协方差等于( )。 (2)自协方差与( )无关,可能与 ( )有关。 3. (5分)下述随机过程中,自相关系数具有截尾性的有( ),偏自相关系数具有截尾性的有( )。
第七章时间序列分析习题 一、填空题 1.时间序列有两个组成要素:一是,二是。 2.在一个时间序列中,最早出现的数值称为,最晚出现的数值称为。 3.时间序列可以分为时间序列、时间序列和时间序列三种。其中是最基本的序列。 4.绝对数时间序列可以分为和两种,其中,序列中不同时间的数值相加有实际意义的是序列,不同时间的数值相加没有实际意义的是序列。 5.已知某油田1995年的原油总产量为200万吨,2000年的原油总产量是459万吨,则“九五”计划期间该油田原油总产量年平均增长速度的算式为。 6.发展速度由于采用的基期不同,分为和两种,它们之间的关系可以表达为。 7.设i=1,2,3,…,n,a i为第i个时期经济水平,则a i/a0是发展速度,a i/a i-1是发展速度。 8.计算平均发展速度的常用方法有方程式法和. 9.某产品产量1995年比1990年增长了105%,2000年比1990年增长了306.8%,则该产品2000年比1995增长速度的算式是。 10.如果移动时间长度适当,采用移动平均法能有效地消除循环变动和。 11.时间序列的波动可分解为长期趋势变动、、循环变动和不规则变动。 12.用最小二乘法测定长期趋势,采用的标准方程组是。 二、单项选择题 1.时间序列与变量数列( ) A都是根据时间顺序排列的B都是根据变量值大小排列的 C前者是根据时间顺序排列的,后者是根据变量值大小排列的 D前者是根据变量值大小排列的,后者是根据时间顺序排列的 2.时间序列中,数值大小与时间长短有直接关系的是( ) A平均数时间序列B时期序列C时点序列D相对数时间序列 3.发展速度属于( ) A比例相对数B比较相对数C动态相对数D强度相对数 4.计算发展速度的分母是( ) A报告期水平B基期水平C实际水平D计划水平 则该车间上半年的平均人数约为( ) A 296人 B 292人 C 295 人 D 300人 6.某地区某年9月末的人口数为150万人,10月末的人口数为150.2万人,该地区10月的人口平均数为( ) A150万人B150.2万人C150.1万人D无法确定 7.由一个9项的时间序列可以计算的环比发展速度( ) A有8个B有9个C有10个D有7个 8.采用几何平均法计算平均发展速度的依据是( )
时间序列分析法原理及步骤 ----目标变量随决策变量随时间序列变化系统 一、认识时间序列变动特征 认识时间序列所具有的变动特征, 以便在系统预测时选择采用不同的方法 1》随机性:均匀分布、无规则分布,可能符合某统计分布(用因变量的散点图和直方图及其包含的正态分布检验随机性, 大多服从正态分布 2》平稳性:样本序列的自相关函数在某一固定水平线附近摆动, 即方差和数学期望稳定为常数 识别序列特征可利用函数 ACF :其中是的 k 阶自 协方差,且 平稳过程的自相关系数和偏自相关系数都会以某种方式衰减趋于 0, 前者测度当前序列与先前序列之间简单和常规的相关程度, 后者是在控制其它先前序列的影响后,测度当前序列与某一先前序列之间的相关程度。实际上, 预测模型大都难以满足这些条件, 现实的经济、金融、商业等序列都是非稳定的,但通过数据处理可以变换为平稳的。 二、选择模型形式和参数检验 1》自回归 AR(p模型
模型意义仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用,不受模型变量互相独立的假设条件约束,所构成的模型可以消除普通回归预测方法中由于自变量选择、多重共线性的比你更造成的困难用 PACF 函数判别 (从 p 阶开始的所有偏自相关系数均为 0 2》移动平均 MA(q模型 识别条件
平稳时间序列的偏相关系数和自相关系数均不截尾,但较快收敛到 0, 则该时间序列可能是 ARMA(p,q模型。实际问题中,多数要用此模型。因此建模解模的主要工作时求解 p,q 和φ、θ的值,检验和的值。 模型阶数 实际应用中 p,q 一般不超过 2. 3》自回归综合移动平均 ARIMA(p,d,q模型 模型含义 模型形式类似 ARMA(p,q模型, 但数据必须经过特殊处理。特别当线性时间序列非平稳时,不能直接利用 ARMA(p,q模型,但可以利用有限阶差分使非平稳时间序列平稳化,实际应用中 d (差分次数一般不超过 2. 模型识别 平稳时间序列的偏相关系数和自相关系数均不截尾,且缓慢衰减收敛,则该时间序列可能是 ARIMA(p,d,q模型。若时间序列存在周期性波动, 则可按时间周期进
时间序列分析及其应用 摘要:本文介绍了目前时间序列分析的发展状况以及应用情况,对常见的几种趋势拟合及其预测方法进行了简要叙述。 关键词:时间序列趋势建模 1 引言 时间序列分析是一种动态数据处理的统计方法。该方法基于随机过程理论和数理统计学方法,研究随机数据序列所遵从的统计规律,以用于解决实际问题。它包括一般统计分析(如自相关分析,谱分析等),统计模型的建立与推断,以及关于时间序列的最优预测、控制与滤波等内容。经典的统计分析都假定数据序列具有独立性,而时间序列分析则侧重研究数据序列的互相依赖关系。后者实际上是对离散指标的随机过程的统计分析,所以又可看作是随机过程统计的一个组成部分。时间序列是按时间顺序的一组数字序列。时间序列分析就是利用这组数列,应用数理统计方法加以处理,以预测未来 事物的发展。时间序列分析是定量预测方法之一,它的基本原理:一是承认事物发展的延续性。应用过去数据,就能推测事物的发展趋势。二是考虑到事物发展的随机性。任何事物发展都可能受偶然因素影响,为此要利用统计分析中加权平均法对历史数据进行处理。 2 时间序列分析的趋势及建模 时间序列分析的成分有:(1)长期趋势,即时间序列随时间的变化而逐渐增加或减少的长期变化的趋势;(2)季节变动,即时间序列在一年中或固定时间内,呈现出的固定规则的变动;(3)循环变动,即
沿着趋势线如钟摆般地循环变动;(4)不规则变动,即在时间序列中由于随机因素影响所引起的变动。 时间序列建模基本步骤是:用观测、调查、统计、抽样等方法取得被观测系统时间序列动态数据;根据动态数据作相关图,进行相关分析,求自相关函数。相关图能显示出变化的趋势和周期,并能发现跳点和拐点。跳点是指与其他数据不一致的观测值。如果跳点是正确的观测值,在建模时应考虑进去,如果是反常现象,则应把跳点调整到期望值。拐点则是指时间序列从上升趋势突然变为下降趋势的点。如果存在拐点,则在建模时必须用不同的模型去分段拟合该时间序列,例如采用门限回归模型。然后辨识合适的随机模型,进行曲线拟合,即用通用随机模型去拟合时间序列的观测数据。 主要的趋势拟合方法有平滑法、趋势线法和自回归模型。对于很多情况,时间序列具有季节趋势,比如气象学中的气温、降雨量,水文学中雨季和干季的河流水量等等。这就需要分析时间序列时,将季节趋势考虑在内。季节性预测法的基本步骤是(1)对原时间序列求移动平均,以消除季节变动和不规则变动,保留长期趋势;(2)将原序列y除以其对应的趋势方程值(或平滑值),分离出季节变动(含不规则变动),即季节系数=tsci/趋势方程值(tc或平滑值);(3)将月度(或季度)的季节指标加总,以由计算误差导致的值去除理论加总值,得到一个校正系数,并以该校正系数乘以季节性指标从而获得调整后季节性指标;(4)求预测模型,若求下一年度的预测值,延长趋势线即可;若求各月(季)的预测值,需以趋势值乘以各月份(季
第8 章时间序列分析 一、填空题: 1.平稳性检验的方法有___________ 、_________ 和__________ 。 2.单位根检验的方法有:__________ 和___________ 。 3.当随机误差项不存在自相关时,用____________ 进行单位根检验;当随机误差 项存在自相关时,用___________ 进行单位根检验。 4. ___________________________________________________ EG检验拒绝零假设说明_______________________________________________________ 。 5. __________________________________________ DF检验的零假设是说被检验时间序列___________________________________________ 。 6. ____________________________ 协整性检验的方法有和。 7. 在用一个时间序列对另一个时间序列做回归时,虽然两者之间并无任何有意 义的关系,但经常会得到一个很高的R2的值,这种情况说明存在____________ 问题。 8. ________________________________________________ 结构法建模主要是以____________________________________________________________ 来确定计量经济模型的理论关系形式。 9. _________________________________ 数据驱动建模以作为建模的主要准则。 10. 建立误差校正模型的步骤为一般采用两步:第一步,______________________
1.简述非平稳时间序列的确定性因素分解方法及其优缺点:确定性因素分解方法产生于长期的实践。序列的各种变化可以归纳为三大因素的影响:(1)长期趋势波动,包括长期趋势和无固定周期的循环波动(2)季节性变化,包括所有具有固定周期的循环波动(3)随机波动,包括除了长期趋势波动和季节性变化之外的其他因素的综合因素。优点:原理简单;操作方便;易于理解。缺点:(1)只能提取强劲的确定性信息,对随机性信息浪费严重(2)它把所有序列的变化归纳为四大因素的综合影响,却始终无法提供明确有效的方法判断各大因素之间明确的作用关系。 2.比较传统的统计分析与时间序列分析数据结构并说明引入序列平稳性的意义: (1)根据数理统计学常识,传统的统计分析的随机变量越少越好,而每个变量获得的样本信息越多越好。因为随机变量越少,分析的过程越简单,而样本容量越大,分析的结果越可靠。(2)时间序列数据分析的结构有它的特殊性。对随机序列{…,1x ,2x ,…t x …}而言,它在任意时刻t 的序列值t x 都是一个随机变量,而且由于时间的不可重复性,该变量在任意一个时刻只能获得唯一的一个样本观察值。(3)时间序列分析的数据结构的样本信息太少,如果没有其他的辅助信息,通常这种数据结构是没有办法进行分析的。序列的平稳性概念的提出可以有效地解决这个困难。 3.什么是模型识别?模型识别的基本原则是什么?计算出样本自相关系数和偏自相关系数的值之后,就要根据他们表现出来的性质,选择适当的ARMA 模型拟合观察值序列。这个根据样本自相关关系数和偏自相关系数的性质估计自相关阶数p ?和移动平均阶数q ?的过程即是模型识别过程。ARMA 模型定阶基本原则如下表: 4.简述单整和协整分析的含义。(1)单整是处理伪回归问题的一种方式。如果一个时间序列经过一次差分变成平稳的,则称原序列是1阶单整的,记为I (1)。一般地,如果时间序列经过d 次差分后变成平稳序列,而经过d-1次差分仍不平稳,则称原序列是d 阶单整序列,记为I (d )。(2)假定回归模型t k 1i it i 0t y εχββ++=∑=
第八章时间数列分析 一、单项选择题 1.时间序列与变量数列 ( ) A 都是根据时间顺序排列的 B 都是根据变量值大小排列的 C 前者是根据时间顺序排列的,后者是根据变量值大小排列的 D 前者是根据变量值大小排列的,后者是根据时间顺序排列的C 2. 时间序列中,数值大小与时间长短有直接关( ) A 平均数时间序列 B 3. 发展速度属 B 时期序 列 C 时点序列 D 相对数时间 序列 ) B 比较相对数 C 动态相对数 D 强度相对数 C 4. 计算发展速度的分母是 ( ) A 报告期水平 B 基期水平 C 实际水平 D 计划水平 B 5. 某车间月初工人人数资料如下: 则该车间上半年的平均人数约为 ( ) A 296 人 B 292 人 C 295 人 D 300 人 C 6.某地区某年 9月末的人口数为 150万人, 10 月末的人口数为 150.2 万人,该地区 10 月的人口平均数为 ( ) A 150 万人 B 150. 2万人 C 150.1 万人 D 无法确定 C 7.由一个 9 项的时间序列可以计算的环比发展速度 ( ) A 有 8个 B有 9个C有 10个D有 7个 A 8.采用几何平均法计算平均发展速度的依据是 ( ) A 各年环比发展速度之积等于总速度 B 各年环比发展速度之和等于总速度 C 各年环比增长速度之积等于总速度 D 各年环比增长速度之和等于总速度 A 9.某企业的科技投入, 2010年比 2005年增长了 58.6%,则该企业 2006—2010 年间科技投入的平均发展速度为 ( ) A 558.6% B 5158.6% C 658.6% D 6158.6% B 10.根据牧区每个月初的牲畜存栏数计算全牧区半年的牲畜平均存栏数,采用的公式是 ( ) A 简单平均法 B 几何平均法 C 加权序时平均法 D 首末折半法 D 11.在测定长期趋势的方法中,可以形成数学模型的是( ) A 时距扩大法 B 移动平均法 C 最小平方法 D 季节指数法
1、某股票连续若干天的收盘价如下表: 304 303 307 299 296 293 301 293 301 295 284 286 286 287 284 282 278 281 278 277 279 278 270 268 272 273 279 279 280 275 271 277 278 279 283 284 282 283 279 280 280 279 278 283 278 270 275 273 273 272 275 273 273 272 273 272 273 271 272 271 273 277 274 274 272 280 282 292 295 295 294 290 291 288 288 290 293 288 289 291 293 293 290 288 287 289 292 288 288 285 282 286 286 287 284 283 286 282 287 286 287 292 292 294 291 288 289 选择适当模型拟合该序列的发展,并估计下一天的收盘价。 解:根据上面的图和SAS软件编辑程序得到时序图,程序如下: data shiyan7_1; input x@@; time=_n_; cards; 304 303 307 299 296 293 301 293 301 295 284 286 286 287 284 282 278 281 278 277 279 278 270 268 272 273 279 279 280 275 271 277 278 279 283 284 282 283 279 280 280 279 278 283 278 270 275 273 273 272 275 273 273 272 273 272 273 271 272 271 273 277 274 274 272 280 282 292 295 295 294 290 291 288 288 290 293 288 289 291 293 293 290 288 287 289 292 288 288 285 282 286 286 287 284 283 286 282 287 286 287 292 292 294 291 288 289 ; proc print data=shiyan7_1; proc gplot data=shiyan7_1; plot x *time=1; symbol1c=red v=star i=spline; run; 通过SAS运行上述程序可得到如下结果:
时间序列实验考题汇总(蒋世辉) 实验二 时间序列纯随机性检验和平稳性检验 【理论知识】 一、序列纯随机性检验 1、纯随机序列的定义 若序列满足如下两条性质 2(1),,(2)(,),,0,t EX t T t s t s t s T t s μσγ=?∈?==?∈?≠? 则称序列为纯随机序列。 2、纯随机性检验 (1)检验原理(Barlett 定理) 如果一个时间序列是纯随机的,得到一个观察期数为n 的观察序列,那么该序列的延迟非零期的样本自相关函数将近似服从均值为零,方差为序列观察期数 倒数的正态分布,即1?~(0, ) ,0k N k N ρ?≠ 。 (2)假设条件 原假设:延迟期数小于或等于m 期的序列值之间相互独立,即 0120,1m H m ρρρ====?≥ : 备择假设:延迟期数小于或等于m 期的序列值之间有相关性,即 10,1k H m k m ρ≠?≥≤:至少存在某个, (3)检验统计量 Q 统计量 :221 ?~()m k k Q n m ρ χ==∑ LB 统计量 :2 2 1 ?(2)( )~()m k k LB n n m n k ρ χ==+-∑ (4)判别原则 拒绝原假设 当检验统计量大于21()m αχ-分位点,或该统计量的P 值小于α时,则可以以1α -的置信水平拒绝原假设,认为该序列为非白噪声序列。 接受原假设 当检验统计量小于21()m αχ-分位点,或该统计量的P 值大于α时,则认为在1α -的置信水平下无法拒绝原假设,即不能显著拒绝序列为纯随机序列的假定。 3、Eviews 操作方法 打开要检验的序列,单击View\Correlogram
时间序列分析法原理及步骤 ----目标变量随决策变量随时间序列变化系统 一、认识时间序列变动特征 认识时间序列所具有的变动特征,以便在系统预测时选择采用不同的方法 1》随机性:均匀分布、无规则分布,可能符合某统计分布(用因变量的散点图和直方图及其包含的正态分布检验随机性, 大多服从正态分布) 2》平稳性:样本序列的自相关函数在某一固定水平线附近摆动,即方差和数学期望稳定为常数 识别序列特征可利用函数ACF:其中是的k阶自 协方差,且 平稳过程的自相关系数和偏自相关系数都会以某种方式衰减趋于0,前者测度当前序列与先前序列之间简单和常规的相关程度,后者是在控制其它先前序列的影响后,测度当前序列与某一先前序列之间的相关程度。实际上,预测模型大都难以满足这些条件,现实的经济、金融、商业等序列都是非稳定的,但通过数据处理可以变换为平稳的。 二、选择模型形式和参数检验 1》自回归AR(p)模型
模型意义仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用,不受模型变量互相独立的假设条件约束,所构成的模型可以消除普通回归预测方法中由于自变量选择、多重共线性的比你更造成的困难用PACF函数判别(从p阶开始的所有偏自相关系数均为0) 2》移动平均MA(q)模型 识别条件 平稳时间序列的偏相关系数和自相关系数均不截尾,但较快收敛到0, 则该时间序列可能是ARMA(p,q)模型。实际问题中,多数要用此模型。因此建模解模的主要工作时求解p,q和φ、θ的值,检验和的值。 模型阶数
实际应用中p,q一般不超过2. 3》自回归综合移动平均ARIMA(p,d,q)模型 模型含义 模型形式类似ARMA(p,q)模型,但数据必须经过特殊处理。特别当线性时间序列非平稳时,不能直接利用ARMA(p,q)模型,但可以利用有限阶差分使非平稳时间序列平稳化,实际应用中d(差分次数)一般不超过2. 模型识别 平稳时间序列的偏相关系数和自相关系数均不截尾,且缓慢衰减收敛,则该时间序列可能是ARIMA(p,d,q)模型。若时间序列存在周期性波动,则可按时间周期进行差分,目的是将随机误差有长久影响的时间序列变成仅有暂时影响的时间序列。即差分处理后新序列符合ARMA(p,q)模型,元序列符合ARIMA(p,d,q)模型。 一个平稳的随机过程有以下要求:均数不随时间变化,方差不随时间变化,自相关系数只与时间间隔有关,而与所处的时间无关。 偏自相关函数(PACF)解决如下问题:
时间序列分析练习题 一、填空题 1. 从统计意义上讲,所谓的时间序列就是将某一指标在(不同时间)上的不同数值,按时间的先后顺序排列而成的数列。 2. 从统计意义上看,时间序列就是某一系统在(不同时间)的响应。 3. 按所研究对象的多少分,时间序列有(一元)时间序列和(多元)时间序列。 4. 按时间的连续性可将时间序列分为(离散)时间序列和(连续)时间序列。 5. 按序列的统计特性分,时间序列有(平稳)时间序列和(非平稳)时间序列。 6. 按时间的分布规律来分,时间序列有(高斯型)时间序列和(非高斯型)时间序列。 7. 如果序列的一二阶矩存在,而且对任意的时刻t 满足: ①( 均值为常数 ) ②( 协方差为时间间隔τ的函数 ) 则称该序列为宽平稳时间序列,也叫广义平稳时间序列。 8. 对于一个纯随机过程来说,若其期望和方差(均为常数),则称之为白噪声过程。白噪声过程是一个(宽平稳)过程。 9. 时间序列分析方法按其采用的手段不同可概括为数据图法,指标法和(模型法) 10.AR (1)模型为:X t =1?X t-1+a t 11.AR (2)模型为:X t =1?X t-1+2?X t-2+a t 12.AR (n )模型为:X t =1?X t-1+2?X t-2+……n ?X t-n +a t 13.MA (1)模型为:X t =a t -1θa t-1 14.MA (m )模型为:X t =a t -1θa t-1-2θa t-2……-m θa t-m 15.ARMA(2.1) 模型为:X t -1?X t-1-2?X t-2 =a t -1θa t-1 16.AR(1)模型是一个使相关数据转化为独立数据的变化器。
应用时间序列分析Newly compiled on November 23, 2020
国内生产总值与财政支出总额关系的分析 摘要:许多文献已经论证过财政政策在实现经济长期增长中的作用,我们在前人研究的基础上从财政支出结构角度分析我国政府财政支出和国内生产总值的相关关系,研究财政支出对经济增长的促进作用。同时,尝试探讨存在财政风险和积极财政政策淡出的情况下,应该如何优化财政支出结构,积极的财政政策应怎么样淡出,以避免财政风险的扩大,并进一步提出相关的建议。我们此次是采用时间序列分析的方法分析财政支出总额对GDP的影响。 关键词:国内生产总值财政支出总额时间序列分析 一、引言 财政支出与GDP之间的关系一直是经济学界关注的话题。20世纪30年代,凯恩斯提出了财政支出乘数理论,认为在有效的需求不足的情况下,增加政府支出,扩大社会总需求,从而减少失业,促进经济的增长;当需求过大时,通过减少财政支出抑制社会总需求,以实现供求平衡,促进经济的稳定和增长。随着新增长理论的出现,一部分经济学家认为政府可以实行一定的财政支出政策和税收政策,促进技术的进步,从而可以促进经济的增长,已经有许多的文献研究了财政支出和经济增长之间的关系。 国内生产总值是指在一定时期内(一个季度或一年),一个国家或地区的经济中所生产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标。它不但可反映一个国家的经济表现,更可以反映一国的国力与财富。 财政支出也称公共财政支出,是指在市场经济条件下,政府为提供公共产品和服务,满足社会共同需要而进行的财政资金的支付。财政支出是国家将通过各种形式筹集上来的财政收入进行分配和使用的过程,它是整个财务分配活动的第二阶段。财政支出增长的原因有经济原因、政治原因,社会性原因和国际关系等。 经济增长离不开政府的宏观调控,货币政策和财政政策作为宏观调控的主要手段,货币政策由国家统一实施,对于地方政府财政政策的制定与实施是地方政府效能的一种体现。财政政策的核心是通过政府的收入和支出调节有效需求,实现一定的政策目标。它包括一是财政收入政策,即通过增税或减税及税种的选择投资和消费需求,实现收入和资金的再分配。二是财政支出政策,即通过政府预算支出的增减及财政赤字的增减影响总需求。三是财政补贴。 本文应用时间序列分析的相关方法,旨在研究我国财政支出与GDP的关系,以反映我国财政对宏观经济运行的调控。 二、数据的选取 本文选取的数据来自《中国统计年鉴2009》1981—2008年的国内生产总值时间序列和财政支出总额的时间序列,记国内生产总值的年度数据序列为{X t},记财政支出总额的年度数据序列为{Y t}。详见表1:
智能控制课程期末作业 授课教师:刘晓东 姓名:赵聪 专业:控制理论与控制工程 学号:21109166
一、利用西德数据对收入、消费、投资进行一步预测 %AR(2)模型 clear all; clc; k=3; p=2; T=75; %本模型训练样本的个数 Orig_data=zeros(100,3); Orig_data(:,1)=[180;179;185;192;211;202;207;214;231;229;234;237;206;250;259;263;264;280;2 82;292;286;302;304;307;317;314;306;304;292;275;273;301;280;289;303;322;315;339;364;371;3 75;432;453;460;475;496;494;498;526;519;516;531;573;551;538;532;558;524;525;519;526;510;5 19;538;549;570;559;584;611;597;603;619;635;658;675;700;692;759;782;816;844;830;853;852;8 33;860;870;830;801;824;831;830;]; Orig_data(:,2)=[451;465;485;493;509;520;521;540;548;558;574;583;591;599;610;627;642;653;6 60;694;709;734;751;763;766;779;808;785;794;799;799;812;837;853;876;897;922;949;979;988;1 025;1063;1104;1131;1137;1178;1211;1256;1290;1314;1346;1385;1416;1436;1462;1493;1516;155 7;1613;1642;1690;1759;1756;1780;1807;1831;1873;1897;1910;1943;1976;2018;2040;2070;2121; 2132;2199;2253;2276;2318;2369;2423;2457;2470;2521;2545;2580;2620;2639;2618;2628;2651;]; Orig_data(:,3)=[415;421;434;448;459;458;479;487;497;510;516;525;529;538;546;555;574;574;5 86;602;617;639;653;668;679;686;697;688;704;699;709;715;724;746;758;779;798;816;837;858;8 81;905;934;968;983;1013;1034;1064;1101;1102;1145;1173;1216;1229;1242;1267;1295;1317;135 5;1371;1402;1452;1485;1516;1549;1567;1588;1631;1650;1685;1722;1752;1774;1807;1831;1842; 1890;1958;1948;1994;2061;2056;2102;2121;2145;2164;2206;2225;2235;2237;2250;2271;]; %此数据来源于老师提供的课件资料 data=zeros(100,3); data(:,1)=log10(Orig_data(:,1)); data(:,2)=log10(Orig_data(:,2)); data(:,3)=log10(Orig_data(:,3)); New_data=zeros(91,3); for i=2:99 New_data(i-1,:)=data(i,:)-data(i-1,:); end Z=zeros(k,T); Y=zeros(k*p+1,T); v=zeros(k,1); phai_1=zeros(k,k); phai_2=zeros(k,k); for n=1:T Z(:,n)=(New_data(n,:))'; end for i=1:T Y(1,i)=1; if (i-p) <= 0
时间序列分析法原理及步骤----目标变量随决策变量随时间序列变化系统 一、认识时间序列变动特征 认识时间序列所具有的变动特征,以便在系统预测时选择采用不同的方法 1》随机性:均匀分布、无规则分布,可能符合某统计分布(用因变量的散点图和直方图及其包含的正态分布检验随机性,大多服从正态分布 2》平稳性:样本序列的自相关函数在某一固定水平线附近摆动,即方差和数学期望稳定为常数 识别序列特征可利用函数ACF :其中是的k阶自 协方差,且 平稳过程的自相关系数和偏自相关系数都会以某种方式衰减趋于0,前者测度 当前序列与先前序列之间简单和常规的相关程度,后者是在控制其它先前序列的影响后,测度当前序列与某一先前序列之间的相关程度。实际上,预测模型大都难以满足这些条件,现实的经济、金融、商业等序列都是非稳定的,但通过数据处理可以变换为平稳的。 二、选择模型形式和参数检验 1》自回归AR(p模型
⑴模.式(■「越小越好*但不能为0: t为0表示只受以前Y的历史的形响不受具他内索感响) y产di卅I十中汕-寸+ 4syr+ £c 式中假设’兀的变化?上鉴匚时间序列的历史数据有关,与此它因素无 关* J不同时刻互不和关,F「与趴历史序列不相关。式中符号:P模型的阶次"滞后的时问周期,迪过实验和参数确定;久当前预测值 ?与自身过去观测值畑?“ y「是同一序列不同时刻的随机变呈,相互间冇 线性关系,也反映时间滞后关系: 弗小g、..... 、同一平稳序列fit去D个时期的观 测值; % ……* 0,自回归系數,通过计算得出的权数?表达头依赖十过去的程 度,」1?这种依赖关系恒定小变; 「随机十扰浜益项,是0沟值、常方茎凡独立的白噪声序利* Jjfi 过佈计 指定的模型扶得F 模型意义仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用,不受模型变量互相独立的假设条件约束,所构成的模型可以消除普通回归预测方法中由 于自变量选择、多重共线性的比你更造成的困难用PACF函数 判别(从p阶开始的所有偏自相关系数均为0 2》移动平均MA(q模型 ⑴模或形式< j越小越好*但不能为0: v为。表小鼻受以前Y的历史的愚响不受其他 因素諺响) y产0|竹1十*浮心+.+ R|jr+ £t 式中假设^ 口的变化主要与时间斥列的刃史数拡启关,与人它冈素无关; E ;不同时刻互不和关,J打趴历史序列不和关。 式中符号=P模型的阶次”滞后的时间周期,通过实验和参数确定;乩肖前 预测值,与自身过去观测值y小…円趴屣同一序列不同时刻的随机变屋, 相互间有线性关系,也反映时问滞后关系: y小m ……> 冋一平稳序列过去D个时期的观 测任 小<11 ...... * 自1口1比1 玄劇r ?hWJ?driVilv *fr 生和ir 的
国内生产总值与财政支出总额关系的分析摘要:许多文献已经论证过财政政策在实现经济长期增长中的作用,我们在前人研究的基础上从财政支出结构角度分析我国政府财政支出和国内生产总值的相关关系,研究财政支出对经济增长的促进作用。同时,尝试探讨存在财政风险和积极财政政策淡出的情况下,应该如何优化财政支出结构,积极的财政政策应怎么样淡出,以避免财政风险的扩大,并进一步提出相关的建议。我们此次是采用时间序列分析的方法分析财政支出总额对GDP的影响。 关键词:国内生产总值财政支出总额时间序列分析 一、引言 财政支出与GDP之间的关系一直是经济学界关注的话题。20世纪30年代,凯恩斯提出了财政支出乘数理论,认为在有效的需求不足的情况下,增加政府支出,扩大社会总需求,从而减少失业,促进经济的增长;当需求过大时,通过减少财政支出抑制社会总需求,以实现供求平衡,促进经济的稳定和增长。随着新增长理论的出现,一部分经济学家认为政府可以实行一定的财政支出政策和税收政策,促进技术的进步,从而可以促进经济的增长,已经有许多的文献研究了财政支出和经济增长之间的关系。 国内生产总值是指在一定时期内(一个季度或一年),一个国家或地区的经济中所生产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标。它不但可反映一个国家的经济表现,更可以反映一国的国力与财富。 财政支出也称公共财政支出,是指在市场经济条件下,政府为提供公共产品和服务,满足社会共同需要而进行的财政资金的支付。财政支出是国家将通过各种形式筹集上来的财政收入进行分配和使用的过程,它是整个财务分配活动的第二阶段。财政支出增长的原因有经济原因、政治原因,社会性原因和国际关系等。 经济增长离不开政府的宏观调控,货币政策和财政政策作为宏观调控的主要手段,货币政策由国家统一实施,对于地方政府财政政策的制定与实施是地方政府效能的一种体现。财政政策的核心是通过政府的收入和支出调节有效需求,实现一定的政策目标。它包括一是财政收入政策,即通过增税或减税及税种的选择投资和消费需求,实现收入和资金的再分配。二是财政支出政策,即通过政府预算支出的增减及财政赤字的增减影响总需求。三是财政补贴。 本文应用时间序列分析的相关方法,旨在研究我国财政支出与GDP的关系,以反映我国财政对宏观经济运行的调控。 二、数据的选取 本文选取的数据来自《中国统计年鉴2009》1981—2008年的国内生产总值 },时间序列和财政支出总额的时间序列,记国内生产总值的年度数据序列为{X t 记财政支出总额的年度数据序列为{Y }。详见表1: t
时间序列模型各实验的操作步骤 各个实验以课本上面的各个例子为基本,时间序列的平稳性检验,包括例9.1.4,例9.1.8,;时间序列模型(ARMA)的估计,包括例9.2.3,例9.2.4;协整检验和误差模型的建立,包括例9.3.1,例9.3.2。其中还有在例9.1.4中的数据的输入过程和查看ACF和PACF值的过程,例9.1.8中的单位根检验过程,LM检验和方程的估计的过程,例9.2.3残差序列的获取等基本操作,这些操作过程会在实验的操作步骤中穿插进行,不再单独列出。实验的使用EVIEWS6进行。 例9.1.4 检验中国支出法GDP时间序列的平稳性---自相关函数和偏自相关函数值 数据如下: 步骤一:输入数据。 在软件中,选择“File\New\Work File”,得到下面的对话框 在框中的Start data和end data两栏(图中红色框出部分)中输入数据的开始年份和结束年份。本例中,分别输入的是1978和2000然后点击OK键即可得到一个新的,未命名的工作 文件。
在红框中就是前一步输入的数据的开始年份和结束的年份。然后再界面的空白处输入命令符“data 变量名1 变量名2 …”。然后点击回车键,就可以得到一个变量的数据框。讲excel表中的数据复制后粘贴在eviews的数据框中就可得到用来做分析的数据了。输入数据的步骤结束。注意:变量名的顺序要和数据表格中的顺序相同,各个命令符中间空格数为1。 本例中得到未命名的工作文件后,输入命令“data gdp”,点击回车键后就可以得到一个从1987年到2000年的时间序列框。图中上面的红框内显示的输入的命令,下面红框中是打开的未粘贴数据的GDP的时间序列。 将表中数据复制,粘贴到GDP序列中,得到完整的时间序列。 这个时候,就可以进行下一步操作:进行序列的稳定性检验。 步骤二:稳定性检验。查看自相关和偏相关函数值(correlogram)。选择“View\Correlogram”,在得到的对话框中有两个选项,上面红框中表示检验是对当前的序列进行检验(level),还