
2012年CCF自然语言处理与中文计算会议
中文微博情感分析评测结果
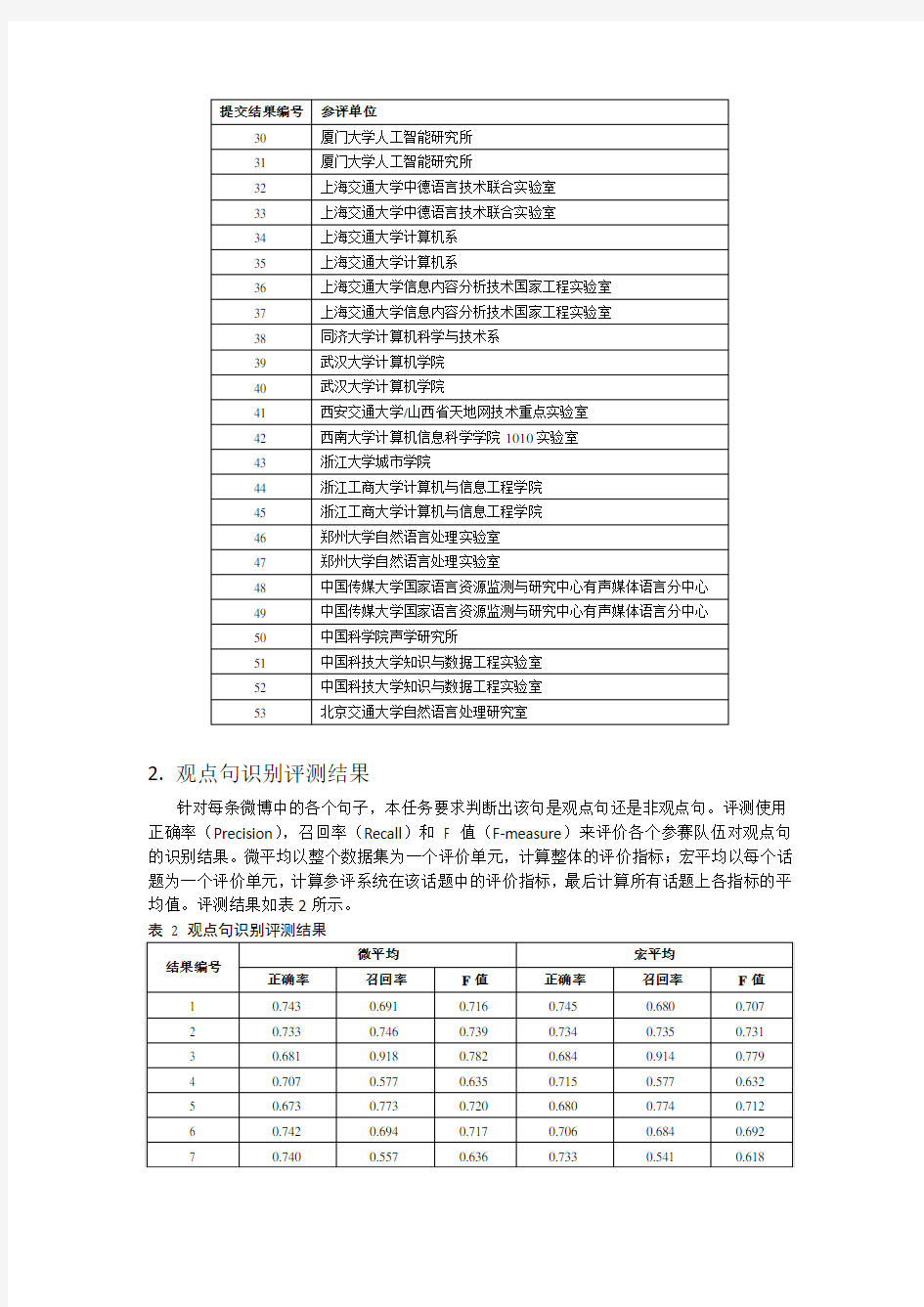
1.提交结果编号
本次评测共有34支队伍提交53组有效结果,提交结果编号及所属参评单位对应情况如表1所示。
表1 提交结果编号与参评单位对照表
提交结果编号参评单位
1 北京工商大学
2 北京工商大学
3 北京航空航天大学计算机学院
4 北京航空航天大学计算机学院
5 北京理工大学海量语言信息处理与云计算应用工程技术研究中心1
6 北京理工大学网络搜索挖掘与安全实验室
7 北京理工大学海量语言信息处理与云计算应用工程技术研究中心2
8 北京理工大学海量语言信息处理与云计算应用工程技术研究中心2
9 大连理工大学
10 大连理工大学
11 广东工业大学DMIR实验室
12 哈尔滨工业大学语言技术研究中心网络智能研究室
13 哈尔滨工业大学语言技术研究中心网络智能研究室
14 哈尔滨工业大学计算机科学与技术学院/机器智能与翻译研究室
15 哈尔滨工业大学计算机科学与技术学院/机器智能与翻译研究室
16 哈尔滨工业大学(威海)
17 海军工程大学信息安全系
18 黑龙江大学计算机科学技术学院
19 湖南工业大学计算机与通信学院
20 湖南工业大学计算机与通信学院
21 湖南科技大学外国语学院
22 华侨大学计算机科学与技术学院
23 华侨大学计算机科学与技术学院
24 华中科技大学
25 南京大学计算机科学与技术系自然语言处理研究组
26 南京理工大学
27 南京理工大学
28 清华大学计算机系智能技术与系统国家重点实验室信息检索组
29 清华大学计算机系智能技术与系统国家重点实验室信息检索组
1参评队伍联系人为刘全超
2参评队伍联系人为王金刚
提交结果编号参评单位
30 厦门大学人工智能研究所
31 厦门大学人工智能研究所
32 上海交通大学中德语言技术联合实验室
33 上海交通大学中德语言技术联合实验室
34 上海交通大学计算机系
35 上海交通大学计算机系
36 上海交通大学信息内容分析技术国家工程实验室
37 上海交通大学信息内容分析技术国家工程实验室
38 同济大学计算机科学与技术系
39 武汉大学计算机学院
40 武汉大学计算机学院
41 西安交通大学/山西省天地网技术重点实验室
42 西南大学计算机信息科学学院1010实验室
43 浙江大学城市学院
44 浙江工商大学计算机与信息工程学院
45 浙江工商大学计算机与信息工程学院
46 郑州大学自然语言处理实验室
47 郑州大学自然语言处理实验室
48 中国传媒大学国家语言资源监测与研究中心有声媒体语言分中心
49 中国传媒大学国家语言资源监测与研究中心有声媒体语言分中心
50 中国科学院声学研究所
51 中国科技大学知识与数据工程实验室
52 中国科技大学知识与数据工程实验室
53 北京交通大学自然语言处理研究室
2.观点句识别评测结果
针对每条微博中的各个句子,本任务要求判断出该句是观点句还是非观点句。评测使用正确率(Precision),召回率(Recall)和 F 值(F-measure)来评价各个参赛队伍对观点句的识别结果。微平均以整个数据集为一个评价单元,计算整体的评价指标;宏平均以每个话题为一个评价单元,计算参评系统在该话题中的评价指标,最后计算所有话题上各指标的平均值。评测结果如表2所示。
表2 观点句识别评测结果
结果编号
微平均宏平均
正确率召回率F值正确率召回率F值
1 0.743 0.691 0.716 0.745 0.680 0.707
2 0.73
3 0.746 0.739 0.73
4 0.73
5 0.731
3 0.681 0.918 0.782 0.68
4 0.914 0.779
4 0.707 0.577 0.63
5 0.715 0.577 0.632
5 0.673 0.773 0.720 0.680 0.774 0.712
6 0.742 0.694 0.71
7 0.706 0.684 0.692
7 0.740 0.557 0.636 0.733 0.541 0.618
正确率召回率F值正确率召回率F值
8 0.734 0.528 0.614 0.724 0.514 0.599
9 0.825 0.603 0.697 0.828 0.589 0.679
10 0.822 0.592 0.688 0.824 0.581 0.674
11 0.835 0.449 0.584 0.836 0.435 0.557
12 0.738 0.726 0.732 0.743 0.717 0.726
13 0.738 0.726 0.732 0.743 0.717 0.726
14 0.619 0.378 0.469 0.601 0.383 0.413
15 0.619 0.378 0.469 0.601 0.383 0.413
16 0.647 0.757 0.697 0.648 0.751 0.689
17 0.828 0.537 0.651 0.826 0.520 0.629
18 0.728 0.502 0.594 0.736 0.502 0.582
19 0.747 0.439 0.553 0.741 0.431 0.542
20 0.781 0.406 0.534 0.776 0.395 0.520
21 0.746 0.772 0.759 0.747 0.757 0.748
22 0.707 0.656 0.681 0.713 0.651 0.672
23 0.700 0.733 0.716 0.705 0.734 0.713
24 0.737 0.536 0.621 0.743 0.522 0.607
25 0.695 0.473 0.563 0.695 0.461 0.548
26 0.745 0.406 0.525 0.742 0.394 0.503
27 0.745 0.406 0.525 0.742 0.394 0.503
28 0.714 0.717 0.716 0.722 0.708 0.704
29 0.715 0.745 0.729 0.721 0.738 0.721
30 0.740 0.646 0.690 0.744 0.639 0.680
31 0.733 0.683 0.707 0.737 0.678 0.702
32 0.671 0.944 0.784 0.674 0.942 0.783
33 0.671 0.944 0.784 0.674 0.942 0.783
34 0.805 0.588 0.680 0.807 0.581 0.671
35 0.745 0.789 0.767 0.748 0.782 0.760
36 0.674 0.891 0.768 0.679 0.892 0.764
37 0.660 0.871 0.751 0.663 0.869 0.747
38 0.704 0.562 0.625 0.699 0.557 0.615
39 0.725 0.632 0.675 0.723 0.618 0.661
40 0.708 0.649 0.677 0.708 0.634 0.663
41 0.638 0.221 0.328 0.630 0.217 0.320
42 0.783 0.338 0.472 0.792 0.337 0.452
43 0.780 0.455 0.575 0.781 0.443 0.557
44 0.696 0.348 0.464 0.686 0.348 0.446
45 0.645 0.959 0.772 0.649 0.960 0.770
46 0.765 0.647 0.701 0.760 0.641 0.680
47 0.779 0.542 0.639 0.767 0.529 0.615
48 0.756 0.802 0.779 0.758 0.788 0.769
正确率召回率F值正确率召回率F值
49 0.756 0.812 0.783 0.757 0.797 0.773
50 0.773 0.119 0.206 0.766 0.112 0.181
51 0.728 0.658 0.691 0.732 0.651 0.686
52 0.716 0.716 0.716 0.719 0.712 0.711
53 0.701 0.334 0.452 0.707 0.341 0.454
3.情感倾向性判断评测结果
本任务要求判断微博中每条观点句的情感倾向。本任务同样使用正确率(Precision),召回率(Recall)和F 值(F-measure)作为评价标准。评测结果如表3所示。
表3 情感倾向性判断评测结果
结果编号
微平均宏平均
正确率召回率F值正确率召回率F值
1 0.831 0.574 0.679 0.823 0.563 0.666
2 0.824 0.614 0.704 0.825 0.608 0.698
3 0.761 0.698 0.728 0.768 0.702 0.733
4 0.764 0.440 0.559 0.758 0.44
5 0.559
5 0.734 0.568 0.640 0.738 0.574 0.642
6 0.782 0.565 0.656 0.783 0.562 0.653
7 0.724 0.403 0.518 0.708 0.387 0.496
8 0.718 0.379 0.496 0.703 0.365 0.477
9 0.841 0.507 0.633 0.849 0.497 0.620
10 0.833 0.493 0.619 0.843 0.487 0.611
11 0.426 0.426 0.426 0.413 0.413 0.413
12 0.881 0.640 0.741 0.878 0.632 0.733
13 0.863 0.626 0.726 0.860 0.619 0.718
14 0.258 0.097 0.141 0.341 0.105 0.139
15 0.261 0.099 0.143 0.342 0.107 0.141
16 0.559 0.559 0.559 0.561 0.561 0.561
17 0.772 0.415 0.540 0.776 0.404 0.523
18 0.809 0.406 0.541 0.791 0.407 0.530
19 0.598 0.262 0.365 0.583 0.253 0.350
20 0.594 0.241 0.343 0.578 0.232 0.328
21 0.796 0.614 0.693 0.789 0.600 0.679
24 0.643 0.344 0.449 0.641 0.335 0.437
25 0.803 0.379 0.515 0.800 0.370 0.502
26 0.647 0.399 0.493 0.641 0.390 0.482
28 0.788 0.565 0.658 0.780 0.562 0.649
29 0.794 0.591 0.678 0.786 0.590 0.671
30 0.740 0.478 0.580 0.734 0.472 0.572
31 0.725 0.495 0.588 0.725 0.490 0.583
正确率召回率F值正确率召回率F值
34 0.893 0.481 0.625 0.895 0.481 0.622
35 0.886 0.631 0.737 0.888 0.630 0.733
36 0.587 0.587 0.587 0.579 0.579 0.579
37 0.850 0.850 0.850 0.854 0.854 0.854
38 0.691 0.389 0.498 0.693 0.387 0.491
39 0.809 0.511 0.627 0.799 0.496 0.607
40 0.740 0.480 0.582 0.731 0.465 0.565
41 0.832 0.184 0.301 0.829 0.181 0.293
42 0.288 0.288 0.288 0.289 0.289 0.289
43 0.879 0.400 0.550 0.872 0.391 0.533
44 0.803 0.266 0.399 0.733 0.263 0.375
45 0.804 0.771 0.787 0.809 0.778 0.793
46 0.902 0.584 0.709 0.899 0.578 0.690
47 0.857 0.464 0.602 0.855 0.452 0.579
48 0.842 0.675 0.749 0.840 0.663 0.739
49 0.844 0.685 0.756 0.842 0.672 0.745
50 0.108 0.108 0.108 0.102 0.102 0.102
51 0.476 0.341 0.397 0.459 0.329 0.382
52 0.476 0.341 0.397 0.459 0.329 0.382
53 0.450 0.150 0.225 0.435 0.151 0.222
4.情感要素抽取评测结果
本任务要求找出微博中每条观点句作者的评价对象,即情感对象,同时判断针对情感对象的观点极性。本任务采用严格评价和宽松评价两种方式,均使用准确率、召回率以及F 值作为评价标准。
4.1严格评价指标
在严格评价中,要求提交的情感对象的offset 和答案完全相同并且情感对象极性也相同时才算正确。评测结果如表4 所示。
表4 情感要素抽取(严格评价指标)评测结果
结果编号
微平均宏平均
正确率召回率F值正确率召回率F值
3 0.066 0.147 0.091 0.070 0.14
4 0.093
4 0.06
5 0.102 0.080 0.068 0.101 0.080
6 0.028 0.039 0.032 0.031 0.040 0.035
9 0.485 0.066 0.116 0.474 0.066 0.113
10 0.425 0.077 0.131 0.417 0.076 0.126 17 0.311 0.177 0.225 0.324 0.174 0.220 21 0.081 0.005 0.010 0.031 0.005 0.009 24 0.120 0.089 0.102 0.133 0.090 0.105
正确率召回率F值正确率召回率F值
25 0.182 0.100 0.129 0.196 0.101 0.132
32 0.160 0.160 0.160 0.172 0.169 0.170
33 0.112 0.112 0.112 0.121 0.118 0.119
38 0.006 0.003 0.004 0.006 0.003 0.004
39 0.135 0.078 0.099 0.149 0.081 0.103
40 0.120 0.071 0.089 0.125 0.073 0.091
44 0.126 0.027 0.045 0.121 0.027 0.042
45 0.106 0.062 0.078 0.109 0.064 0.081
46 0.260 0.164 0.201 0.271 0.172 0.205
47 0.117 0.058 0.077 0.123 0.062 0.081
48 0.303 0.273 0.288 0.306 0.263 0.278
49 0.303 0.275 0.288 0.305 0.265 0.278
50 0.241 0.063 0.100 0.244 0.058 0.084
53 0.031 0.009 0.014 0.029 0.010 0.015
4.2宽松评价指标
在宽松评价中,评价指标通过提交的结果与答案之间的覆盖率计算。评测结果如表5所示。
表5情感要素抽取(宽松评价指标)评测结果
结果编号
微平均宏平均
正确率召回率F值正确率召回率F值
3 0.26
4 0.32
5 0.291 0.269 0.330 0.291
4 0.241 0.213 0.226 0.246 0.219 0.227 6 0.086 0.073 0.078 0.092 0.074 0.080
9 0.636 0.086 0.152 0.643 0.086 0.149
10 0.569 0.099 0.169 0.572 0.098 0.165 17 0.404 0.223 0.287 0.420 0.219 0.279 21 0.137 0.007 0.013 0.071 0.007 0.012
24 0.198 0.138 0.163 0.219 0.139 0.167
25 0.279 0.140 0.186 0.286 0.138 0.183
32 0.290 0.220 0.250 0.302 0.229 0.257
33 0.287 0.189 0.228 0.300 0.196 0.234
38 0.107 0.028 0.045 0.110 0.029 0.045
39 0.232 0.105 0.145 0.243 0.106 0.145
40 0.254 0.114 0.157 0.252 0.113 0.153
44 0.257 0.040 0.070 0.239 0.040 0.066
45 0.236 0.098 0.139 0.241 0.102 0.142
46 0.398 0.249 0.307 0.400 0.258 0.301
47 0.201 0.110 0.142 0.201 0.115 0.136
48 0.388 0.354 0.371 0.393 0.342 0.359
正确率召回率F值正确率召回率F值
49 0.387 0.356 0.371 0.391 0.344 0.359
50 0.422 0.082 0.137 0.387 0.075 0.115 53 0.091 0.019 0.032 0.093 0.020 0.032
文本情感分析综述? 赵妍妍+, 秦兵, 刘挺 (哈尔滨工业大学计算机科学与技术学院信息检索研究中心, 黑龙江哈尔滨 150001) A Survey of Sentiment Analysis * ZHAO Yan-Yan+, QIN Bing, LIU Ting (School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China) + Corresponding author: Phn: +86-451-86413683 ext 800, E-mail: zyy@https://www.doczj.com/doc/4716000077.html, Abstract: Sentiment analysis is a novel research topic with the quick development of online reviews, which has drawn interesting attention due to its research value and extensive applications. This paper surveys the state-of-the-art research on sentiment analysis. First, three important tasks of sentiment analysis are summarized and analyzed in detail, including sentiment extraction, sentiment classification, sentiment retrieval and summarization; then the evaluation and corpus for sentiment analysis are introduced; finally the applications of sentiment analysis are concluded. This paper aims to take a deep insight into the mainstream methods and recent progress in this field, making detailed comparison and analysis. It is expected to be helpful to the future research. Key words: sentiment analysis; sentiment extraction; sentiment classification; sentiment retrieval and summarization; evaluation; corpus 摘 要: 文本情感分析是随着网络评论的海量增长而迅速兴起的一个新兴研究课题,其研究价值和应用价值受到人们越来越多的重视.本文对文本情感分析的研究现状与进展进行了总结.首先将文本情感分析归纳为三项主要任务,即情感信息抽取,情感信息分类以及情感信息的检索与归纳,并对它们进行了细致的介绍和分析;进而介绍了文本情感分析的国内外评测和资源建设情况;最后介绍了文本情感分析的应用.文本重在对文本情感分析研究的主流方法和前沿进展进行概括,比较和分析,以期对后续研究有所助益. 关键词: 文本情感分析;情感信息抽取;情感信息分类;情感信息的检索与归纳;评测;资源建设 中图法分类号: TP391文献标识码: A 随着Web2.0的蓬勃发展,互联网逐渐倡导“以用户为中心,用户参与”的开放式构架理念.互联网用户由单纯的“读”网页,开始向“写”网页、“共同建设”互联网发展,并由被动地接收互联网信息向主动创造互联网信息迈进.因此,互联网(如:博客和论坛)上产生了大量的用户参与的,对于诸如人物、事件、产品等有价值的评论信息.这些评论信息表达了人们的各种情感色彩和情感倾向性,如“喜”、“怒”、“哀”、“乐”,和“批评”、“赞扬”等.基于此,潜在的用户就可以通过浏览这些主观色彩的评论,来了解大众舆论对于某一事件或产品的看法.由于越来越多的用户乐于在互联网上分享自己的观点或体验,这类评论信息迅速膨胀,仅靠人工的方法难以应对网上海量信 ?Supported by the National Natural Science Foundation of China under Grant Nos. 60803093, 60975055 (国家自然科学基金) and the “863” National High-Tech Research and Development of China via grant 2008AA01Z144(863计划探索类专题项目)
情感分析简述 分类:NLP2012-04-08 12:38 1022人阅读评论(3) 收藏举报情感classification算法测试translationmatrix 情感分析,我研究了也有半年有余了,ACL Anthology上关于情感分析的论文也基本看过了一遍,但是到目前还没有什么成就的。以下是我为一位同学毕业设计写的情感分析方面的综述,引用的论文基本上是ACL 和COLING还有EMNLP上历年关于情感分析的论文,本文应该学术性比较强一点,本文虽不打算发表,但由于将来可能还有用,以及关于学术上的原因,请大家如果要引用请务必标明出处 (https://www.doczj.com/doc/4716000077.html,/s/blog_48f3f8b10100irhl.html)。 概述 情感分析自从2002年由Bo Pang提出之后,获得了很大程度的研究的,特别是在在线评论的情感倾向性分析上获得了很大的发展,目前基于在线评论文本的情感倾向性分析的准确率最高能达到90%以上,但是由于深层情感分析必然涉及到语义的分析,以及文本中情感转移现象的经常出现,所以基于深层语义的情感分析以及篇章级的情感分析进展一直不是很大。情感分析还存在的一个问题是尚未存在一个标准的情感测试语料库,虽然Bo Pang实验用的电影评论数据集(https://www.doczj.com/doc/4716000077.html,/people/pabo/movie-review-data/)以及Theresa Wilson等建立的MPQA(https://www.doczj.com/doc/4716000077.html,/mpqa/)是目前广泛使用的两类情感分析数据集,但是并没有公认的标准加以确认。 目前情感分析的研究基本借鉴文本分类等机器学习的方法,还没有根据自身的特点形成一套独立的研究方法,当然在某种程度上也可以把情感分析看出一种特殊的文本分类。比较成熟的方法是基于监督学习的机器学习方法,半监督学习和无监督学习目前的研究不是很多,单纯的基于规则的情感分析这两年已很少研究了。既然目前很多情感分析的研究基于机器学习,那么特征选择就是一个很重要的问题,N元语法等句法特征是使用最多的一类特征,而语义特征(语义计算)和结构特征(树核函数)从文本分类的角度看效果远没有句法特征效果好,所以目前的研究不是很多的。 由于基于监督学习情感分析的研究已经很成熟了,而且在真实世界中由于测试集的数量要远远多于训练集的数量,并且测试集的领域也不像在监督学习中被限制为和训练集一致,也就是说目前情感分析所应用的归纳偏置假设在真实世界中显得太强的,为了和真实世界相一致,基于半监督学习或弱指导学习的情感分析和跨领域的情感分析势必是将来的研究趋势之一。 在情感分析的最初阶段基于语义和基于规则的情感分析曾获得了比较大的重视,但是由于本身实现的复杂性以及文本分类和机器学习方法在情感分析应用上获得的成功,目前关于这方面的研究以及很少了,但是事实上,语义的相关性和上下文的相关性正是情感分析和文本分类最大的不同之处,所以将基于语义和规则的情感分析与基于机器学习的情感分析相结合也将是未来的研究趋势之一。 以下将分别对情感分析的起源,目前基于监督学习,无监督学习,基于规则和跨领域的情感分析的一些研究工作进行简单的介绍。 起源 虽然之前也有一些相关工作,但目前公认的情感分析比较系统的研究工作开始于(Pang et al., 2002)基于监督学习(supervised learning)方法对电影评论文本进行情感倾向性分类和(Turney,2002)基于无监督学习(unsupervised learning)对文本情感情感倾向性分类的研究。(Pang et al., 2002)基于文本的N元语法(ngram)和词类(POS)等特征分别使用朴素贝叶斯(Naive Bayes),最大熵(Maximum Entropy)和支持向量机(Support Vector Machine,SVM)将文本情感倾向性分为正向和负向两类,将文本的情感进行二元划分的做法也一直沿用至今。同时他们在实验中使用电影评论数据集目前已成为广泛使用的情感分析的测试集。(Turney ,2002)基于点互信息(Pointwise Mutual Information,PMI)计算文本中抽取的关键词和种子词(excellent,poor)的相似度来对文本的情感倾向性进行判别(SO-PMI算法)。 在此之后的大部分都是基于(Pang et al., 2002)的研究。而相对来说,(Turney et al.,2002)提出的无监督学习的方法虽然在实现上更加简单,但是由于单词之间的情感相似度难以准确的计算和种子词的难以确定,继续在无监督学习方向的研究并不是很多的,但是利用SO-PMI算法计算文本情感倾向性的思想却被很多研究者所继承了。 监督学习 目前,基于监督学习的情感分析仍然是主流,除了(Li et al.,2009)基于非负矩阵三分解(Non-negative Matrix Tri-factorization),(Abbasi et al.,2008)基于遗传算法(Genetic Algorithm)的情感分析之外,使用的最多的监督学习算法是朴素贝叶斯,k最近邻(k-Nearest Neighbor,k-NN),最大熵和支持向量机的。而对于算法的改进主要在对文本的预处理阶段。 一个和文本分类不同地方就是情感分析有时需要提取文本的真正表达情感的句子。(Pang et al., 2004)基于文本中的主观句的选择和(Wilson el al.,2009)基于文本中的中性实例(neutral instances)的分析,都是为了能够尽量获得文本中真正表达情感的句子。(Abbasi et al.,2008)提出通过信息增益(Information Gain,IG)的方法来选择大量特征集中对于情感分析有益的特征。 而对于特征选择,除了N元语法和词类特征之外,(Wilson el al.,2009)提出混合单词特征,否定词特征,情感修饰特征,情感转移特征等各类句法特征的情感分析,(Abbasi et al.,2008)提出混合句子的句法(N元语法,词类,标点)和结构特征(单词的长度,词类中单词的个数,文本的结构特征等)的情感分析。 除了对于文本的预处理,对于监督学习中情感分析还进行了以下方面的研究的。(Melville et al., 2009)和(Li et al.,2009)提出结合情感词的先验的基于词典的情感倾向性和训练文本中后验的基于上下文的情感情感倾向性共同判断文本的情感倾向性。(Taboada et al.,2009)提出结合文本的题材(描述,评论,背景,解释等)和文本本身的特征共同判断文本的情感倾向性。(Tsutsumi et al.,2007)提出利用多分类器融合技术来对文本情感分类。(Wan, 2008)和(Wan, 2009)提出结合英文中丰富的情感分析资源来提高中文情感分析的效果。 基于规则/无监督学习
文本情感分析研究现状 机器之心专栏 作者:李明磊 作为NLP领域重要的研究方向之一,情感分析在实际业务场景中 存在巨大的应用价值。在此文中,华为云NLP算法专家李明磊为 我们介绍了情感分析的概念以及华为云在情感分析方面的实践和 进展。 基本概念 为什么:随着移动互联网的普及,网民已经习惯于在网络上表达意见和建议,比 如电商网站上对商品的评价、社交媒体中对品牌、产品、政策的评价等等。这些评价中都蕴含着巨大的商业价值。比如某品牌公司可以分析社交媒体上广大民众对该品牌的评价,如果负面评价忽然增多,就可以快速采取相应的行动。而这种正负面评价的分析就是情感分析的主要应用场景。 是什么:文本情感分析旨在分析出文本中针对某个对象的评价的正负面,比如「华为手机非常好」就是一个正面评价。情感分析主要有五个要素,(entity/实体, aspect/属性,opinio n/观点,holder/观点持有者,time/时间),其中实体和属性合并称为评价对象(target)。情感分析的目标就是从非结构化的文本评论中抽取出这五个要素
、 (entity 体, 输入文木 holder/?点持有者,time/ 时 |i 图i情感分析五要素 举例如下图: 我觉得华为手机非常牛逼。(华为手机* 图2情感分析五要素例子 上例中左侧为非结构化的评论文本,右侧为情感分析模型分析出的五个要素中的四个(不包括时间)。其中实体「华为手机」和属性「拍照」合并起来可以作为评价对象。评价对象又可细分为评价对象词抽取和评价对象类别识别。如实体可 以是实体词和实体类别,实体词可以是「餐馆」、「饭店」、「路边摊」,而实 体类别是「饭店」;属性可以是属性词和属性类别,如属性词可以是「水煮牛肉」、 「三文鱼」等,都对应了属性类别「食物」。实体类别和属性类别相当于是对实体词和属性词的一层抽象和归类,是一对多的关系。词和类别分别对应了不同的
文本情感分析 赵妍妍,秦兵,刘挺- 软件学报, 2010 - https://www.doczj.com/doc/4716000077.html, 按粒度,情感分析可分为词语级、短语级、句子级、篇章级、多篇章级;按文本类别,可分为基于新闻评论和基于产品的情感分析。 情感分析的研究任务:情感信息的抽取、分类以及检索与归纳。 一、情感信息抽取(评价词语、评价对象、观点持有者) 1.评价词语的抽取:基于语料库的抽取;基于词典的抽取;基于图的方法。 2.评价对象的抽取:基于规则/模板的方法(词序列、词性、句法规则、关联规则挖掘);评 价对象最为产品属性,考察评价对象与领域指示词的关联度来获取;多粒度的话题模型方法。 3.观点持有者抽取:命名实体识别技术(人名或机构名)、语义角色标注;分类任务,看做 序列标注问题,使用CRF融合特征抽取;名词短语作为候选,使用ME模型计算。 4.组合评价单元的抽取: 主观表达式:Wiebe的主观表达式库(抽取n元词语/词组作为候选,对比训练预料判断) 评价短语抽取(程度副词-评价词语):情感词典的方法;依存句法解构(ADV,ATT,DE)。 评价搭配抽取(评价词语-评价对象):基于模板的方法(8个共现模板、句法关系模板)。 二、情感信息分类 1.主客观信息分类:文本是否含情感知识方法;组合评价单元判断;情感模板识别;基于 分类器和分类特征的二元分类任务(词语特征,标点、人称代词、数字特征,基于图); 2.主观信息情感分类(句子级、篇章级):基于情感知识、基于特征分类的方法(n-gram词语 特征和词性特征、位置特征、评价词特征)。 三、情感信息的检索与归纳 1.情感信息检索 2.情感信息归纳 基于产品属性的情感文摘:识别评论信息中的产品属性,抽取描述产品属性的情感句,判断其倾向性。 基于情感标签的情感文摘:标签可定义为评价搭配形式,建立标签库,相似度聚类的方法聚类得到相似的情感标签,每一类视为潜在的话题(即产品属性)。 基于新闻评论的文摘 四、情感分析的评测与资源 1.情感分析的评测:TREC,NTCIR的MOAT(新闻观点检测,情感问答,跨语言情感分析), 国内的COAE。 2.情感分析的语料:康奈尔大学的影评数据集,UIC的Hu和Liu的产品领域的评论语料, Wiebe的MPQA新闻评论深度标注语料,MIT的多角度餐馆评论语料,中科院的中文酒店评论语料。 3.词典资源:GI(general inquirer)评价词词典,NTU评价词词典(繁体中文),主观词词典(英 文),HowNet评价词词典(简体中文、英文) 问题:情感信息抽取忽略词语所在语境的影响;评价对象的情感分类,而非句子级或篇章级;基于情感标签的情感文摘的深入研究;
2012年CCF自然语言处理与中文计算会议 中文微博情感分析评测结果 1.提交结果编号 本次评测共有34支队伍提交53组有效结果,提交结果编号及所属参评单位对应情况如表1所示。 表1 提交结果编号与参评单位对照表 提交结果编号参评单位 1 北京工商大学 2 北京工商大学 3 北京航空航天大学计算机学院 4 北京航空航天大学计算机学院 5 北京理工大学海量语言信息处理与云计算应用工程技术研究中心1 6 北京理工大学网络搜索挖掘与安全实验室 7 北京理工大学海量语言信息处理与云计算应用工程技术研究中心2 8 北京理工大学海量语言信息处理与云计算应用工程技术研究中心2 9 大连理工大学 10 大连理工大学 11 广东工业大学DMIR实验室 12 哈尔滨工业大学语言技术研究中心网络智能研究室 13 哈尔滨工业大学语言技术研究中心网络智能研究室 14 哈尔滨工业大学计算机科学与技术学院/机器智能与翻译研究室 15 哈尔滨工业大学计算机科学与技术学院/机器智能与翻译研究室 16 哈尔滨工业大学(威海) 17 海军工程大学信息安全系 18 黑龙江大学计算机科学技术学院 19 湖南工业大学计算机与通信学院 20 湖南工业大学计算机与通信学院 21 湖南科技大学外国语学院 22 华侨大学计算机科学与技术学院 23 华侨大学计算机科学与技术学院 24 华中科技大学 25 南京大学计算机科学与技术系自然语言处理研究组 26 南京理工大学 27 南京理工大学 28 清华大学计算机系智能技术与系统国家重点实验室信息检索组 29 清华大学计算机系智能技术与系统国家重点实验室信息检索组 1参评队伍联系人为刘全超 2参评队伍联系人为王金刚
面向微博文本的情感分析模型研究 随着互联网和移动通讯的飞速发展,人们参与网络活动越来越频繁,微博每天都产生了大量数据,其包含了用户对事物的情感表达和 评论分析,如何从这些信息中挖掘出情感倾向有着巨大的价值。因此,本文对微博文本展开了情感分析模型的研究。通过调研国内外文献,目前对于情感分析模型的研究主要有情感词典方法、机器学习方法和深度学习方法。本文通过爬取微博数据,对这三种方法进行对比实验,寻找最优的情感分析模型。基于传统情感词典方法的研究。利用波森情感词典,将文本数据分词后遍历词典并加权得到其情感极性,然后 在此基础上利用添加情感副词的方式提升情感词典的效果。情感词典方法的优点是速度快,易于判断主观情感比较明确的句子,但是其缺 点是针对不同场景的迁移能力弱,并且人工构建针对某一领域的情感词典耗时耗力。基于机器学习方法的研究。首先对文本数据进行数据预处理,将经过预处理后的数据分词结果通过Word2vec中Skip-gram 方法转化为词向量,同时利用腾讯开源词向量进行对比输入,然后利 用主流的机器学习分类方法(Logistic回归、随机梯度下降法、朴素贝叶斯、支持向量机、随机森林、XGBoost)进行有监督学习,最后对比每种模型的测试集混淆矩阵,发现腾讯开源词向量训练的模型效果均优于Word2vec方法训练出来的词向量。在这些方法中,随机森林、XGBoost这类利用集成思想方法训练的模型效果远远优于单一的分类模型。虽然机器学习方法模型的准确率对比传统情感词典有了很大的提升,但是不足之处是每个训练器都涉及到大量的调参,并对于不同
业务场景的迁移能力不强,机器学习方法已经发展到了瓶颈。基于深度学习方法的研究。通过对经典的多层感知机神经网络、循环神经网络、卷积神经网络和自注意力机制进行对比实验,各类深度学习模型的准确率比情感词典和机器学习的准确率有了较大的提升,其中自注意力机制模型在测试集的准确率达到了91.12%。通过对所有模型进行对比实验,发现自注意力机制所训练的模型无论在训练速度上还是在模型测试集的准确率等方面均优于其他模型。并且它利用序列内部的自我关注,加快了模型收敛的速度。所以,自注意力机制的模型是情感分析任务中综合表现效果最好的模型。
ISSN 1000-9825, CODEN RUXUEW E-mail: jos@https://www.doczj.com/doc/4716000077.html, Journal of Software, Vol.21, No.8, August 2010, pp.1834?1848 https://www.doczj.com/doc/4716000077.html, doi: 10.3724/SP.J.1001.2010.03832 Tel/Fax: +86-10-62562563 ? by Institute of Software, the Chinese Academy of Sciences. All rights reserved. ? 文本情感分析 赵妍妍+, 秦兵, 刘挺 (哈尔滨工业大学计算机科学与技术学院信息检索研究中心,黑龙江哈尔滨 150001) Sentiment Analysis ZHAO Yan-Yan+, QIN Bing, LIU Ting (Center for Information Retrieval, School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China) + Corresponding author: E-mail: yyzhao@https://www.doczj.com/doc/4716000077.html, Zhao YY, Qin B, Liu T. Sentiment analysis. Journal of Software, 2010,21(8):1834?1848. https://www.doczj.com/doc/4716000077.html,/ 1000-9825/3832.htm Abstract: This paper surveys the state of the art of sentiment analysis. First, three important tasks of sentiment analysis are summarized and analyzed in detail, including sentiment extraction, sentiment classification, sentiment retrieval and summarization. Then, the evaluation and corpus for sentiment analysis are introduced. Finally, the applications of sentiment analysis are concluded. This paper aims to take a deep insight into the mainstream methods and recent progress in this field, making detailed comparison and analysis. Key words: sentiment analysis; sentiment extraction; sentiment classification; sentiment retrieval and summarization; evaluation; corpus 摘要: 对文本情感分析的研究现状与进展进行了总结.首先将文本情感分析归纳为3项主要任务,即情感信 息抽取、情感信息分类以及情感信息的检索与归纳,并对它们进行了细致的介绍和分析;进而介绍了文本情感分 析的国内外评测和资源建设情况;最后介绍了文本情感分析的应用.重在对文本情感分析研究的主流方法和前 沿进展进行概括、比较和分析. 关键词: 文本情感分析;情感信息抽取;情感信息分类;情感信息的检索与归纳;评测;资源建设 中图法分类号: TP391文献标识码: A 随着Web2.0的蓬勃发展,互联网逐渐倡导“以用户为中心,用户参与”的开放式构架理念.互联网用户由单纯 的“读”网页,开始向“写”网页、“共同建设”互联网发展,并由被动地接收互联网信息向主动创造互联网信息迈进. 因此,互联网(如博客和论坛)上产生了大量的用户参与的、对于诸如人物、事件、产品等有价值的评论信息. 这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等.基于此,潜在的用 户就可以通过浏览这些主观色彩的评论来了解大众舆论对于某一事件或产品的看法.由于越来越多的用户乐 于在互联网上分享自己的观点或体验,这类评论信息迅速膨胀,仅靠人工的方法难以应对网上海量信息的收集 和处理,因此迫切需要计算机帮助用户快速获取和整理这些相关评价信息.情感分析(sentiment analysis)技术应 ?Supported by the National Natural Science Foundation of China under Grant Nos.60803093, 60975055 (国家自然科学基金); the National High-Tech Research and Development Plan of China under Grant No.2008AA01Z144 (国家高技术研究发展计划(863)) Received 2009-08-14; Revised 2009-12-25; Accepted 2010-03-11
开题报告(文献综述)-在线评论分析系统的情感分析本科毕业设计(论文)开题报告 论文题目在线评论分析系统的情感分析开题报告内容: 一、选题的背景及意义 近年来,在“大数据”(Big Data)时代的背景下,随着电子商务行业的蓬勃发展,网络购物平台、手机APP应用市场平台等不仅为用户提供了大量商品信息,同时还允许用户参与商品评论。它不仅为商家提供了一个信息的展示平台以发布新产品的规格数据,也为消费者提供了一个产品使用体验交流以及质量评价的平台。因此很多网络用户在购买或使用某类产品前,往往会选择先上网浏览一些该产品的相关信息,尤其是其他用户的使用体验,多方比较产品的性能,从而使自己的消费和选择更趋理性化。分析这些评论信息,蕴含着巨大的商业价值和社会价值,具有很大的现实意义。 然而,这些主观性评论文本每天以指数级的速度增长,仅靠人工方式难以进行 收集、处理和分析。因此采用计算机技术来自动地分析这些主观性文本表达的情感,成为目前数据挖掘(Data Mining)研究的一个热点,而这个热点的研究方向就是文本情感分析(Sentiment Analysis)。 文本情感分析,也称为意见挖掘(Opinion Mining),是指通过分析和挖掘文本中的表达情感、观点和立场的主观性信息并判断其情感倾向。它涉及自然语言处理(Natural Language Processing)、计算机语言学(Computational Linguistics)、机器学习(Machine Learning)、信息检索(Information Retrieval)等众多领域,在计算机科学、管理学、政治学、经济学和社会学方向都有广泛的应用。进入21 世纪以后,情感分析这个领域变得活跃起来,吸引越来越多的学者投入其中。目前
随着企业信息化与互联网的发展,信息以爆炸性速度飞速增长,其中包括了大量的非结构化与半结构化数据。非结构化与半结构化数据,主要是文本型数据,阐述5w问题,即who,when,where,what,Why。如何充分利用非结构化数据与半结构化数据,分析其包含的潜在信息,拥有支持决策,成为了众多企业与研究者关注的重点。尤其,针对互联网(如博客和论坛)上大量的用户参与的、对于诸如人物、事件、产品等有价值的评论信息。这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等。基于此,潜在的用户就可以通过浏览这些主观色彩的评论来了解大众舆论对于某一事件或产品的看法。由于越来越多的用户乐于在互联网上分享自己的观点或体验,这类评论信息迅速膨胀,仅靠人工的方法难以应对网上海量信息的收集和处理,因此迫切需要计算机帮助用户快速获取和整理这些相关评价信息。因此,如何从这些Web文本中进行情感挖掘,获取情感倾向已经成为当今商务智能领域关注的热点。情感分析(sentiment analysis)技术也就应运而生(本文中提及的情感分析,都是指文本情感分析)。 文本情感分析(sentiment analysis),又称为意见挖掘,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。其中,主观情感可以是他们的判断或者评价,他们的情绪状态,或者有意传递的情感信息。因此,情感分析的一个主要任务就是情感倾向性的判断,Pang等人在文献1中将情感倾向分为正面、负面和中性,即褒义、贬义和客观评价。研究初期,大量研究者都致力于针对词语和句子的倾向性判断研究,但随着互联网上大量主观性文本的出现,研究者们逐渐从简单的情感词语的分析研究过渡到更为复杂的情感句研究以及情感篇章的研究。文本情感分析主要可以归纳为3项层层递进的研究任务,即情感信息的抽取、情感信息的分类以及情感信息的检索与归纳[2]。情感信息抽取就是将无结构的情感文本转化为计算机容易识别和处理的结构化文本。情感信息分类则是利用情感信息抽取的结果将情感文本单元分为若干类别,供用户查看,如分为褒、贬、客观或者其他更细致的情感类别。情感信息检索和归纳可以看作是与用户直接交互的接口,强调检索和归纳的两项应用。 情感分析是一个新兴的研究课题,具有很大的研究价值和应用价值,正受到国内外众多研究者的青睐。目前实现情感分析的技术主要包括基于机器学习法和基于语义方法两类。本文主要针对这两大方法的研究进展进行比较分析,接着介绍国内外现有的资源建设情况,最后介绍情感分析的几个重要应用和展望它的发展趋势。 1 基于统计机器学习法 随着大规模语料库的建设和各种语言知识库的出现,基于语料库的统计机器学习方法进入自然语言处理的视野。多种机器学习方法应用到自然语言处理中并取得了良好的效果,促进了自然语言处理技术的发展。机器学习的本质是基于数据的学习(Learning from Data)。利用机器学习算法对统计语言模型进行训练,最后用训练好的分类器对新文本情感进行识别。2002年,Pang 等人就在文献[1]中提出用机器学习的方法进行情感倾向的挖掘工作,他们以互联网上的电影评论文本作为语料,采用了不同的特征选择方法,应用朴素贝叶斯(Naive Bayes)、最大熵(Maximum Entropy)、向量机(SVM)对电影评论分别进行分类,实验表明SVM 的分类性能最好,准确率达到87.5%。该研究引起学术界的关注,之后用于倾向性判断的机器学习算法的改进被陆续提出,基本的算法有:支持向量机(SVM)、朴素贝叶斯(NB)、K-近邻(KNN)、简单线性分类器(SLC)和最大熵(ME)等。他们在另一项工作中,将文本极性分类问题转换成求取句子连接图的最小分割问题,实现了一个基于minimum-cut的分类器。[7]。Whitelaw等人[11]关注研究带形容词的词组及其修饰语(如“extremely boring”或“not really verygood”),他们提取带形容词的词组作为特征,基于这些特征,用向量空间模型表示文