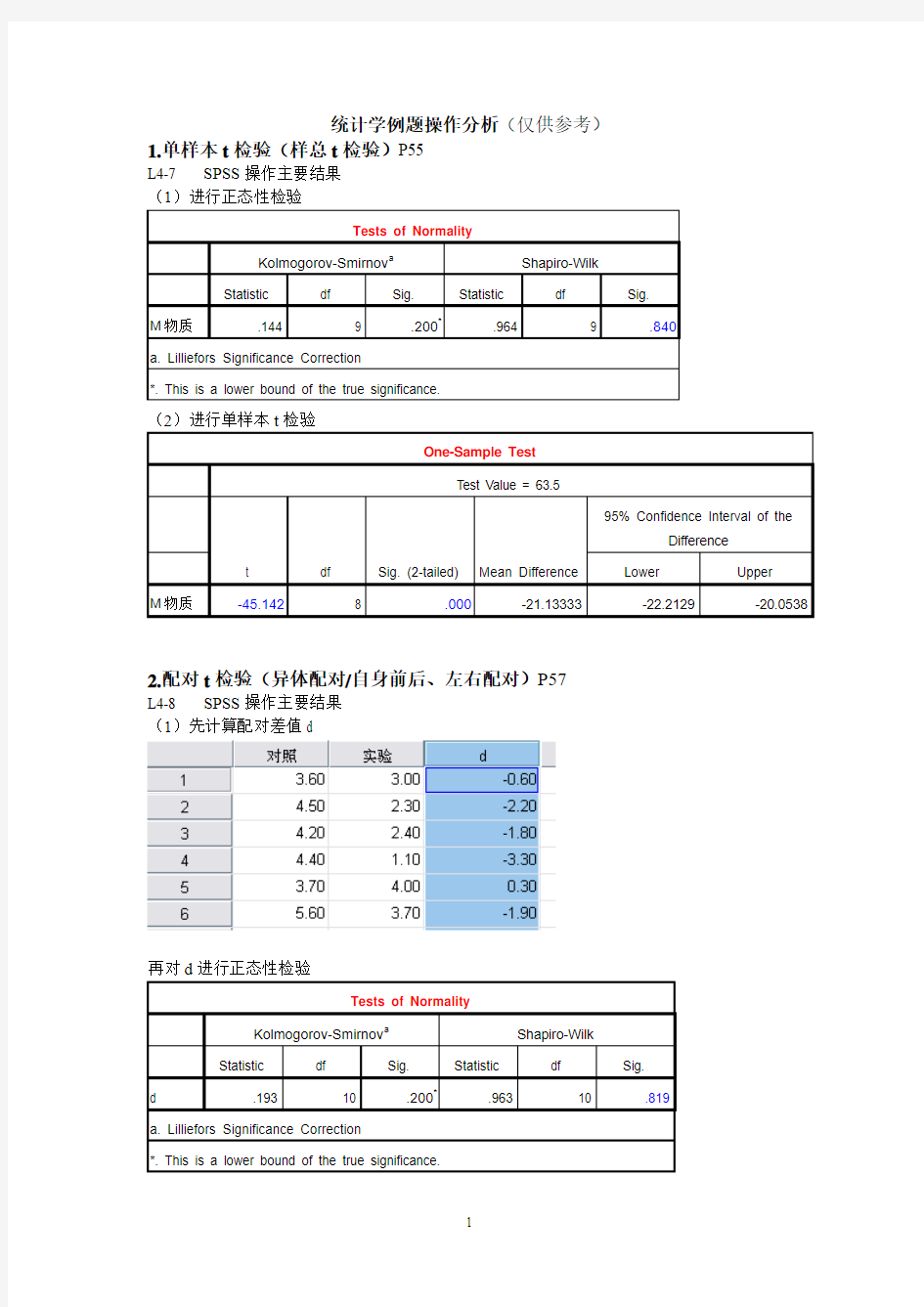

统计学例题操作分析(仅供参考)
1.单样本t 检验(样总t 检验)P55
L4-7 SPSS 操作主要结果 (1)进行正态性检验
Tests of Normality
Kolmogorov-Smirnov a
Shapiro-Wilk
Statistic
df
Sig. Statistic
df
Sig.
M 物质
.144
9
.200*
.964
9
.840
a. Lilliefors Significance Correction
*. This is a lower bound of the true significance.
(2)进行单样本t 检验
One-Sample Test
Test Value = 63.5
t df
Sig. (2-tailed)
Mean Difference
95% Confidence Interval of the
Difference
Lower Upper M 物质
-45.142
8
.000
-21.13333
-22.2129
-20.0538
2.配对t 检验(异体配对/自身前后、左右配对)P57
L4-8 SPSS 操作主要结果 (1)先计算配对差值d
再对d 进行正态性检验
Tests of Normality
Kolmogorov-Smirnov a
Shapiro-Wilk
Statistic
df
Sig. Statistic
df
Sig.
d
.193
10
.200*
.963
10
.819
a. Lilliefors Significance Correction
*. This is a lower bound of the true significance.
(2)进行配对t检验
Paired Samples Correlations
N Correlation Sig. Pair 1 对照& 实验10 .075.838
Paired Samples Test
Paired Differences
t df
Sig. (2-tailed)
Mean
Std.
Deviation
Std. Error
Mean
95% Confidence
Interval of the
Difference
Lower Upper
Pair 1 对照-
实验
2.1600
1.32094 .41772 1.21505 3.10495 5.1719 .001
3.两独立样本t检验(成组t检验)P59
L4-9 SPSS操作主要结果
(1)进行正态性和方差齐性检验
Tests of Normality
观察对象
Kolmogorov-Smirnov a Shapiro-Wilk Statistic df Sig. Statistic df Sig.
转铁蛋白含量正常人.116 12 .200*.986 12 .998患者.147 15 .200*.927 15 .245 a. Lilliefors Significance Correction
*. This is a lower bound of the true significance.
Test of Homogeneity of Variance
Levene Statistic df1 df2 Sig.
转铁蛋白含量Based on Mean 1.877 1 25 .183 Based on Median 1.127 1 25 .299
Based on Median and with
adjusted df
1.127 1 2
2.304 .300
Based on trimmed mean 1.798 1 25 .192 (2)再做成组t检验
4.完全随机设计资料ANOV A 与多重比较 P69
L5-2 SPSS 操作主要结果 (1)正态性和方差齐性检验
Tests of Normality
药物 Kolmogorov-Smirnov a
Shapiro-Wilk
Statistic
df
Sig. Statistic
df
Sig.
E-SFC
对照组 .179 9 .200*
.947 9 .653 淫羊霍 .136 10 .200* .956 10 .739 党参 .197 10 .200* .923 10 .380 黄芪
.151
10
.200*
.952
10
.692
a. Lilliefors Significance Correction
*. This is a lower bound of the true significance.
Test of Homogeneity of Variances
E-SFC
Levene Statistic
df1
df2
Sig.
2.601
3
35
.067
Independent Samples Test
Levene's Test for Equality of Variances
t-test for Equality of Means
95% Confidence Interval of the
Difference
F
Sig.
t
df Sig.
(2-taile d)
Mean Differen ce
Std.
Error Differen
ce
Lower Upper
转铁蛋白含量 Equal variances
assumed 1.877 .183 7.40
2
25
.000 36.6600
4.9528 26.4595
46.860
5
Equal variances not assumed
7.675 24.795
.000 36.6600
4.7764 26.8186
46.501
4
(2)单因素方差分析
ANOVA
E-SFC
Sum of Squares df Mean Square F Sig. Between Groups 1978.944 3 659.648 77.789 .000 Within Groups 296.800 35 8.480
Total 2275.744 38
Multiple Comparisons
Dependent Variable:E-SFC
(I) 药物(J) 药
物
Mean
Difference
(I-J)
Std.
Error Sig.
95% Confidence Interval
Lower
Bound
Upper
Bound
LSD对照组淫羊霍-20.067* 1.338 .000-22.78 -17.35
党参-7.667* 1.338 .000-10.38 -4.95
黄芪-8.067* 1.338 .000-10.78 -5.35 淫羊霍对照组20.067* 1.338 .000 17.35 22.78
党参12.400* 1.302 .000 9.76 15.04
黄芪12.000* 1.302 .000 9.36 14.64 党参对照组7.667* 1.338 .000 4.95 10.38
淫羊霍-12.400* 1.302 .000 -15.04 -9.76
黄芪-.400 1.302 .761-3.04 2.24 黄芪对照组8.067* 1.338 .000 5.35 10.78
淫羊霍-12.000* 1.302 .000 -14.64 -9.36
党参.400 1.302 .761 -2.24 3.04
Dunnett t (2-sided)a 淫羊霍对照组20.067* 1.338 .000 16.79 23.34 党参对照组7.667* 1.338 .000 4.39 10.94 黄芪对照组8.067* 1.338 .000 4.79 11.34
*. The mean difference is significant at the 0.05 level.
a. Dunnett t-tests treat one group as a control, and compare all other groups against it.
5.随机区组(配伍组)设计资料两因素ANOV A与多重比较P72 L5-3 SPSS操作主要结果
Tests of Between-Subjects Effects
Dependent Variable:治愈天数
Source Type III Sum of
Squares df Mean Square F Sig.
Corrected Model43.467a 6 7.244 16.718.000 Intercept 1520.067 1 1520.067 3507.846 .000 年龄24.933 4 6.233 14.385.001疗法18.533 2 9.267 21.385.001 Error 3.467 8 .433
Total 1567.000 15
Corrected Total 46.933 14
a. R Squared = .926 (Adjusted R Squared = .871)
Pairwise Comparisons
Dependent Variable:治愈天数
(I) 疗法(J) 疗法Mean Difference
(I-J) Std. Error Sig.a
95% Confidence Interval for
Difference a
Lower Bound Upper Bound
中西结合中医-.600 .416 .188-1.560 .360西医-2.600*.416 .000-3.560 -1.640 中医中西结合.600 .416 .188 -.360 1.560 西医-2.000*.416 .001-2.960 -1.040 西医中西结合 2.600*.416 .000 1.640 3.560 中医 2.000*.416 .001 1.040 2.960 Based on estimated marginal means
a. Adjustment for multiple comparisons: Least Significant Difference (equivalent to no adjustments).
*. The mean difference is significant at the .05 level.
6.拉丁方设计资料三因素ANOV A P76
L5-4 SPSS操作主要结果
Tests of Between-Subjects Effects
Dependent Variable:斑块面积
Source Type III Sum of
Squares df Mean Square F Sig.
Corrected Model1726.562a9 191.840 14.145 .002 Intercept 146115.063 1 146115.063 10773.461 .000 中药1608.688 3 536.229 39.538 .000窝别18.687 3 6.229 .459 .721 饲料99.187 3 33.062 2.438 .163 Error 81.375 6 13.563
Total 147923.000 16
Corrected Total 1807.937 15
a. R Squared = .955 (Adjusted R Squared = .887)
Pairwise Comparisons
Dependent Variable:斑块面积
(I) 中药(J) 中药Mean Difference
(I-J) Std. Error Sig.a
95% Confidence Interval for
Difference a
Lower Bound Upper Bound
A B -12.000* 2.604 .004 -18.372 -5.628
C 10.000* 2.604 .009 3.628 16.372
D -15.250* 2.604 .001 -21.622 -8.878
B A 12.000* 2.604 .004 5.628 18.372
C 22.000* 2.604 .000 15.628 28.372
D -3.250 2.604 .259 -9.622 3.122 C A -10.000* 2.604 .009-16.372 -3.628
B -22.000* 2.604 .000-28.372 -15.628
D -25.250* 2.604 .000-31.622 -18.878 D A 15.250* 2.604 .001 8.878 21.622
B 3.250 2.604 .259 -3.122 9.622
C 25.250* 2.604 .000 18.878 31.622 Based on estimated marginal means
*. The mean difference is significant at the .05 level.
a. Adjustment for multiple comparisons: Least Significant Difference (equivalent to no adjustments).
7.2x2析因设计资料的ANOV A P77
Tests of Between-Subjects Effects Dependent Variable:胆固醇降低量(mg%)
Source Type III Sum of
Squares df Mean Square F Sig.
Corrected Model5298.917a 3 1766.306 41.077 .000 Intercept 21252.083 1 21252.083 494.234 .000 a药4144.083 1 4144.083 96.374 .000 b药884.083 1 884.083 20.560 .002 a药* b药270.750 1 270.750 6.297 .036 Error 344.000 8 43.000
Total 26895.000 12
Corrected Total 5642.917 11
a. R Squared = .939 (Adjusted R Squared = .916)
8.2x2交叉设计资料ANOV A P78
L5-6 SPSS操作主要结果
Tests of Between-Subjects Effects
Dependent Variable:巴氏小胃盐酸分泌量(mol/h)
Source Type III Sum of
Squares df Mean Square F Sig.
Corrected Model1128.000a13 86.769 4.132 .015 Intercept 8664.000 1 8664.000 412.571 .000 阶段24.000 1 24.000 1.143 .310 狗号1008.000 11 91.636 4.364 .014药物96.000 1 96.000 4.571 .058 Error 210.000 10 21.000
Total 10002.000 24
Corrected Total 1338.000 23
a. R Squared = .843 (Adjusted R Squared = .639)
9.组内分组设计资料两因素ANOV A P79
Tests of Between-Subjects Effects Dependent Variable:M物质
Source Type I Sum of
Squares df Mean Square F Sig.
Corrected Model 6.114a 4 1.529 12.778 .000 Intercept 138.539 1 138.539 1158.124 .000 产地 5.850 2 2.925 24.452 .000 部位.264 2 .132 1.104 .363 Error 1.435 12 .120
Total 146.089 17
Corrected Total 7.550 16
a. R Squared = .810 (Adjusted R Squared = .746)
Pairwise Comparisons
Dependent Variable:M物质
(I) 产地(J) 产地Mean Difference
(I-J) Std. Error Sig.a
95% Confidence Interval for
Difference a
Lower Bound Upper Bound
ⅠⅡ 1.327*.210 .000 .869 1.785 Ⅲ.306 .223 .196 -.181 .792 ⅡⅠ-1.327*.210 .000-1.785 -.869 Ⅲ-1.021*.233 .001-1.528 -.514 ⅢⅠ-.306 .223 .196 -.792 .181 Ⅱ 1.021*.233 .001 .514 1.528 Based on estimated marginal means
*. The mean difference is significant at the .05 level.
a. Adjustment for multiple comparisons: Least Significant Difference (equivalent to no adjustments).
Pairwise Comparisons
Dependent Variable:M物质
(I) 部位(J) 部位Mean Difference
(I-J) Std. Error Sig.a
95% Confidence Interval for
Difference a
Lower Bound Upper Bound
当归头当归身-.266.180 .164-.658 .125 当归尾-.192.309 .546-.865 .481 当归身当归头.266 .180 .164 -.125 .658 当归尾.075 .298 .807 -.575 .724 当归尾当归头.192 .309 .546 -.481 .865 当归身-.075 .298 .807 -.724 .575 Based on estimated marginal means
a. Adjustment for multiple comparisons: Least Significant Difference (equivalent to no adjustments).
10.完全随机设计两组协方差分析P103
L6-10 SPSS操作主要结果
(1)用散点图初步判断两比较组是否有直线趋势
(2)用交互项来检验两比较组总体直线回归系数β是否相等,结果如下
Tests of Between-Subjects Effects
Dependent Variable:用药后
Source Type I Sum of
Squares df Mean Square F Sig.
Corrected Model1389.299a 3 463.100 21.357 .000 Intercept 256514.286 1 256514.286 11829.679 .000 组别326.904 1 326.904 15.076 .001用药前1029.541 1 1029.541 47.479 .000 组别* 用药前32.854 1 32.854 1.515 .230 Error 520.415 24 21.684
Total 258424.000 28
Corrected Total 1909.714 27
a. R Squared = .727 (Adjusted R Squared = .693)
(3)比较修正均数是否相等
Tests of Between-Subjects Effects
Dependent Variable:用药后
Source Type III Sum of
Squares df Mean Square F Sig.
Corrected Model1356.445a 2 678.223 30.646 .000 Intercept 14.025 1 14.025 .634 .433
组别251.320 1 251.320 11.356 .002用药前1029.541 1 1029.541 46.521 .000 Error 553.269 25 22.131
Total 258424.000 28
Corrected Total 1909.714 27
a. R Squared = .710 (Adjusted R Squared = .687)
11.随机区组(配伍组)设计资料的协方差分析P104
L6-11 SPSS操作主要结果
(1)用散点图初步判断三组的进食量与体重增量是否都有直线趋势
(2)用交互项来检验三组总体直线回归系数β相等,结果如下
Tests of Between-Subjects Effects
Dependent Variable:体重增量
Source Type I Sum of
Squares df Mean Square F Sig.
Corrected Model73210.103a16 4575.631 37.601 .000 Intercept 161952.588 1 161952.588 1330.885 .000 饲料47809.096 2 23904.548 196.441 .000 窝别19137.032 11 1739.730 14.297 .000进食量6197.424 1 6197.424 50.929 .000 饲料* 进食量66.550 2 33.275 .273 .764 Error 2312.070 19 121.688
Total 237474.760 36
Corrected Total 75522.172 35
a. R Squared = .969 (Adjusted R Squared = .944)
(3)比较修正均数是否相等
Tests of Between-Subjects Effects
Dependent Variable:体重增量
Source Type III Sum of
Squares df Mean Square F Sig.
Corrected Model73143.552a14 5224.539 46.126 .000 Intercept 1708.436 1 1708.436 15.083 .001 饲料478.912 2 239.456 2.114 .146
窝别 3796.275 11 345.116 3.047 .014 进食量 6197.424 1 6197.424 54.715
.000
Error 2378.620 21 113.268
Total
237474.760 36 Corrected Total
75522.172
35
a. R Squared = .969 (Adjusted R Squared = .948)
12.四格表的Pearson χ2检验 P121
L8-1 SPSS 操作主要结果
Chi-Square Tests
Value
df
Asymp. Sig.
(2-sided) Exact Sig. (2-sided)
Exact Sig. (1-sided)
Pearson Chi-Square 56.772a
1 .000 .000 .000
Continuity Correction b
53.619 1 .000 Likelihood Ratio 49.468
1
.000
Fisher's Exact Test
Linear-by-Linear Association 56.621 1
.000
N of Valid Cases
376
a. 0 cells (.0%) have expected count less than 5. The minimum expected count is 8.24.
b. Computed only for a 2x2 table
注: Pearson Chi-Square 适用条件 n ≥40 且T ≥5 Continuity Correction
b
n ≥40 且1≦T<5
Fisher's Exact Test n <40 且T<1
13.RxC 表χ2检验与多重比较 P126
L8-4 SPSS 操作主要结果
Chi-Square Tests
Value
df
Asymp. Sig.
(2-sided)
Pearson Chi-Square 9.596a
6 .143 Likelihood Ratio
9.741 6 .136 Linear-by-Linear Association
4.015
1
.045
N of Valid Cases 199
a. 2 cells (16.7%) have expected count less than 5. The minimum expected count is 3.59.
14.方表资料检验(Pearson,McNemar,Kappa)P130 L8-9 SPSS操作主要结果
Chi-Square Tests
Value Exact Sig. (2-sided)
McNemar Test .454a
N of Valid Cases 168
a. Binomial distribution used.
Symmetric Measures
Value Asymp. Std.
Error a Approx. T b Approx. Sig.
Measure of Agreement Kappa.809.045 10.500 .000 N of Valid Cases 168
a. Not assuming the null hypothesis.
b. Using the asymptotic standard error assuming the null hypothesis.
15.完全随机设计两组计量资料Wilcoxon秩和检验P142
16.完全随机设计两组等级资料Mann-Whitney U检验P143
L9-3 SPSS操作主要结果
Test Statistics b
抑制率
Mann-Whitney U15.000
Wilcoxon W43.000
Z-.857
Asymp. Sig. (2-tailed) .391
Exact Sig. [2*(1-tailed Sig.)] .445a
a. Not corrected for ties.
b. Grouping Variable: 葛根剂量
17.完全随机设计多组计量资料Kruskal-Wallis H检验P144
L9-5 SPSS操作主要结果
Test Statistics a,b
死亡率
Chi-Square9.740
df 2
Asymp. Sig. .008
a. Kruskal Wallis Test
b. Grouping Variable: 药物
18.两个大样本等级资料Ridit分析 P152
19.多个大样本等级资料Ridit分析
L9-11 SPSS操作主要结果
(1)计算标准组
(2)计算标准组疗效各等级R值
(3)计算对比组总体R均值的置信区间
Descriptives
Statistic Std. Error
PROPORTION of 疗效using RANKIT Mean.497047.0158699 95% Confidence Interval for
Mean
Lower Bound .465754
Upper Bound .528340
5% Trimmed Mean .478254
Median .361111
Variance .051
Std. Deviation .2255539
Minimum .3611
Maximum .9810
Test Statistics b
死亡率
N 15
Median24.0000
Chi-Square10.179a
df 2
Asymp. Sig. .006
a. 6 cells (100.0%) have expected frequencies less than 5. The
minimum expected cell frequency is 2.3.
b. Grouping Variable: 药物
Range .6199
Interquartile Range .4532
Skewness 1.119 .171
Kurtosis -.611 .341
20.圆形分布资料两角均数的比较 P163
L10-5 (1)参数法Watson-William检验(适用于有集中趋势的资料r≥0.7)/非参数法Watson's U2检验;(2)正态性检验;(3)两样本平均角比较的t检验。
21.多应变量多组Wilks' lambda检验(多元方差分析)P231
L16-3 SPSS操作结果
Multivariate Tests c
Effect Value F Hypothesis df Error df Sig. Intercept Pillai's Trace .987 994.174a 2.000 26.000 .000 Wilks' Lambda.013 994.174a 2.000 26.000 .000
Hotelling's Trace 76.475 994.174a 2.000 26.000 .000
Roy's Largest Root 76.475 994.174a 2.000 26.000 .000
贫血类别Pillai's Trace .553 5.159 4.000 54.000 .001 Wilks' Lambda.511 5.192a 4.000 52.000 .001
Hotelling's Trace .834 5.209 4.000 50.000 .001
Roy's Largest Root .638 8.614b 2.000 27.000 .001
a. Exact statistic
b. The statistic is an upper bound on F that yields a lower bound on the significance level.
c. Design: Intercept + 贫血类别
Pairwise Comparisons
Dependent Variable (I) 贫血
类别
(J) 贫血
类别
Mean Difference
(I-J) Std. Error Sig.a
95% Confidence Interval for
Difference a
Lower Bound Upper Bound
血红蛋白 A B -11.033* 3.154 .002 -17.505 -4.561
C -.333 3.362 .922 -7.233 6.566
B A 11.033* 3.154 .002 4.561 17.505
C 10.700* 3.494 .005 3.530 17.870
C A .333 3.362 .922 -6.566 7.233
B -10.700* 3.494 .005 -17.870 -3.530 红细胞计数A B -.353.180 .060-.723 .016
C -.483*.192 .018-.877 -.089
B A .353 .180 .060 -.016 .723
C -.130 .200 .520 -.540 .280
C A .483*.192 .018 .089 .877
B .130 .200 .520 -.280 .540 Based on estimated marginal means
*. The mean difference is significant at the .05 level.
a. Adjustment for multiple comparisons: Least Significant Difference (equivalent to no adjustments).
22.重复测量资料的ANOV A P233
L16-4 SPSS 操作主要结果
Multivariate Tests b
Effect Value F Hypothesis df Error df Sig.
factor1 Pillai's Trace .854 20.469a 2.000 7.000 .001 Wilks' Lambda .146 20.469a 2.000 7.000 .001
Hotelling's Trace 5.848 20.469a 2.000 7.000 .001
Roy's Largest Root 5.848 20.469a 2.000 7.000 .001
factor1 * 组别Pillai's Trace .449 2.857a 2.000 7.000 .124 Wilks' Lambda .551 2.857a 2.000 7.000 .124
Hotelling's Trace .816 2.857a 2.000 7.000 .124
Roy's Largest Root .816 2.857a 2.000 7.000 .124
a. Exact statistic
b. Design: Intercept + 组别
Within Subjects Design: factor1
Mauchly's Test of Sphericity b
Measure:MEASURE_1
Within Mauchly's Approx. df Sig. Epsilon a
Subjec ts Effect W Chi-Square
Greenhouse
-Geisser
Huynh-Fel
dt
Lower-boun
d
factor1 .571 3.921 2 .141.700 .909 .500 Tests the null hypothesis that the error covariance matrix of the orthonormalized transformed dependent variables is proportional to an identity matrix.
a. May be used to adjust the degrees of freedom for the averaged tests of significance. Corrected tests are displayed in the Tests of Within-Subjects Effects table.
b. Design: Intercept + 组别
Within Subjects Design: factor1
Tests of Within-Subjects Effects
Measure:MEASURE_1
Source Type III Sum of
Squares df Mean Square F Sig.
factor1 Sphericity Assumed 190.067 2 95.033 34.246 .000 Greenhouse-Geisser 190.067 1.400 135.789 34.246 .000
Huynh-Feldt 190.067 1.818 104.566 34.246 .000
Lower-bound 190.067 1.000 190.067 34.246 .000 factor1 * 组别Sphericity Assumed 24.867 2 12.433 4.480 .029 Greenhouse-Geisser 24.867 1.400 17.766 4.480 .048
Huynh-Feldt 24.867 1.818 13.680 4.480 .033
Lower-bound 24.867 1.000 24.867 4.480 .067 Error(factor1) Sphericity Assumed 44.400 16 2.775
Greenhouse-Geisser 44.400 11.198 3.965
Huynh-Feldt 44.400 14.541 3.053
Lower-bound 44.400 8.000 5.550
23.多重线性回归P241
L17-1 SPSS操作主要结果
Model Summary c
Model R R Square Adjusted R
Square
Std. Error of the
Estimate
1 .820a.673 .648 1.6533
2 .986b.972.968 .5019
a. Predictors: (Constant), 大鼠体重
b. Predictors: (Constant), 大鼠体重, 常咯啉剂量
c. Dependent Variable: 延缓心律失常时间
ANOVA c
Model Sum of Squares df Mean Square F Sig.
1 Regression 73.041 1 73.041 26.720 .000a
Residual 35.536 13 2.734
Total 108.577 14
2 Regression 105.555 2 52.777 209.539 .000b
Residual 3.022 12 .252
Total 108.577 14
a. Predictors: (Constant), 大鼠体重
b. Predictors: (Constant), 大鼠体重, 常咯啉剂量
c. Dependent Variable: 延缓心律失常时间
Coefficients a
Model Unstandardized
Coefficients
Standardi
zed
Coefficien
ts
t Sig.
95.0% Confidence
Interval for B
Collinearity
Statistics B
Std.
Error Beta
Lower
Bound
Upper
Bound
Toleran
ce VIF
1 (Consta
nt)
52.973 6.569 8.064 .000 38.781 67.165
大鼠体
重
-.147 .029 -.820 -5.169 .000 -.209 -.086 1.000 1.000
2 (Consta
nt) 45.110 2.111 21.37
1
.000 40.510 49.709
大鼠体重-.123 .009 -.682 -13.72
9
.000 -.142 -.103 .940 1.064
常咯啉
剂量
28.844 2.539 .564 11.362 .000 23.312 34.375 .940 1.064
a. Dependent Variable: 延缓心律失常时间
? =45.110+28.844x常格啉剂量—0.123x大鼠体
24.Logistic回归P251
L18-1 SPSS操作主要结果
Variables in the Equation
B S.E. Wald df Sig. Exp(B)
95% C.I.for
EXP(B) Lower Upper
Step 1a吸烟.082 .119 .475 1 .491 1.085 .860 1.369 避孕药.226 .084 7.270 1 .007 1.254 1.064 1.478 吸烟by 避
孕药
.194 .170 1.300 1 .254 1.214 .870 1.696 Constant -1.708 .063 725.930 1 .000 .181
a. Variable(s) entered on step 1: 吸烟, 避孕药, 吸烟* 避孕药 .
P =1/1+exp(1.708-0.82x吸烟-0.226x避孕药-0.194x避孕药*吸烟)
25.聚类分析P269
L19-1 SPSS操作主要结果
Cluster Membership
Case
Number Cluster Distance
1 2 10.346
2 2 12.054
3 2 2.132
4 3 .000
5 2 6.368
6 2 9.914
7 1 .000
8 2 10.609
9 2 13.174
10 2 9.736
26.判别分析P275
L19-3 SPSS操作主要结果
Tests of Equality of Group Means
Wilks' Lambda
F df1
df2
Sig.
皮质醇 .040 286.546 1 12 .000 淋巴细胞
.199
48.282
1
12
.000
Wilks' Lambda
Test of Functio n(s)
Wilks' Lambda
Chi-square
df
Sig.
1
.036
36.575
2
.000
标准化典则函数 分型=0.924x 皮质醇+0.331x 淋巴细胞 非标准化函数 辩证分型=0.661x 皮质醇+0.137x 淋巴细胞-21.447
实热证=11.601x 皮质醇+11.725x 淋巴细胞-558.679 虚寒证=5.265x 皮质醇+10.408x 淋巴细胞-353.095
27因子分析 P286 L20-2
28.正交设计试验方差分析 P304 L20-4 29.均匀设计试验多重线性回归 P313 L20-8 30.统计表与统计图 P360
Canonical Discriminant Function Coefficients
Function
1
皮质醇 .661 淋巴细胞 .137 (Constant)
-21.447
Unstandardized coefficients Standardized Canonical Discriminant Function
Coefficients
Function
1
皮质醇 .924 淋巴细胞
.331
Classification Function Coefficients
辨证分型
实热证 虚寒证
皮质醇 11.601 5.265 淋巴细胞 11.725 10.408 (Constant)
-558.679
-353.095
Fisher's linear discriminant functions
第四章 1. 某企业1982年12月工人工资的资料如下: 要求:(1)计算平均工资;(79元) (2)用简捷法计算平均工资。 2. 某企业劳动生产率1995年比1990年增长7%,超额完成计划2%,试确定劳动生产率计划增长数。7%-2%=5% 3. 某厂按计划规定,第一季度的单位产品成本比去年同期降低8%。实际 执行结果,单位产品成本较去年同期降低4%。问该厂第一季度产品单位成本计划的完成程度如何?104.35%( (1-4%)/(1-8%)*100%=96%/92%*100%=104.35%结果表明:超额完成4.35%( 104.35%-100%)) 4. 某公社农户年收入额的分组资料如下:
要求:试确定其中位数及众数。中位数为774.3(元)众数为755.9(元) 求中位数: 先求比例:(1500-720)/(1770-720)=0.74286 分割中位数组的组距:(800-700)*0.74286=74.286 加下限700+74.286=774.286 求众数: D1=1050-480=570 D2=1050-600=450 求比例:d1/(d1+d2)=570/(570+450)=0.55882 分割众数组的组距:0.55882*(800-700)=55.882 加下限:700+55.882=755.882 5.1996年某月份某企业按工人劳动生产率高底分组的生产班组数和产量资料如下: 64.43(件/人) (55*300+65*200+75*140+85*60)/(300+200+140+60) 6.某地区家庭按人均月收入水平分组资料如下:
根据表中资料计算中位数和众数。中位数为733.33(元) 众数为711.11(元) 求中位数: 先求比例:(50-20)/(65-20)=0.6667 分割中位数组的组距:(800-600)*0.6667=66.67 加下限:600+66.67=666.67 7.某企业产值计划完成103%,比去年增长5%。试问计划规定比去年增长 多少?1.94% (上年实际完成1.03/1.05=0.981 本年实际计划比上年增长 (1-0.981)/0.981=0.019/0.981=1.937%) 8.甲、乙两单位工人的生产资料如下: 试分析:(1)哪个单位工人的生产水平高? (2)哪个单位工人的生产水平整齐? % 3.33V %7.44V /8 .1x /5.1x ====乙甲乙甲人)(件人)(件9.在 计算平均数里,从每个标志变量中减去75个单位,然后将每个差数 缩小10倍,利用这个变形后的标志变量计算加权算术平均数,其中各个变量的权数扩大7倍,结果这个平均数等于0.4个单位。试计算这个平均标志变量的实际平均数,并说明理由。79 10.某地区1998~1999年国内生产总值资料如下表:(单位:亿元)
电大专科统计学原理计算题试题及答案 计算题 1某单位40名职工业务考核成绩分别为 68 89 8884 86 87 75 73 72 68 75 82 9758 81 54 79 76 95 76 71 60 9065 76 72 76 85 89 92 64 57 83 81 78 77 72 61 70 81 单位规定:60分以下为不及格,60 — 70分为及格,70 — 80分为中,80 — 90 分为良,90 — 100分为优。 要求: (1)将参加考试的职工按考核成绩分为不及格、及格、中、良、优五组并编制一张考核成绩次数分配表; (2)指出分组标志及类型及采用的分组方法; (3)分析本单位职工业务考核情况。 解:(1) (2)分组标志为”成绩",其类型为" 的开放组距式分组,组限表示方法是重叠组限; (3)本单位的职工考核成绩的分布呈两头小,中间大的”正态分布”的形态, 说明大多数职工对业务知识的掌握达到了该单位的要求。 2.2004年某月份甲、乙两农贸市场农产品价格和成交量、成交额资料如下 价格(元/斤) 甲市场成交额(万元) 乙市场成交量(万斤) 品种
试问哪一个市场农产品的平均价格较高?并说明原因 解:先分别计算两个市场的平均价格如下: 甲市场平均价格 X m 5.5 1.375 (元 /斤) m/x 4 乙市场平均价格 X xf 5.3 1.325 (元 / 斤) f 4 说明:两个市场销售单价是相同的,销售总量也是相同的,影响到两个市场 平均价格高低不同的原因就在于各种价格的农产品在两个市场的成交量不同 3. 某车间有甲、乙两个生产组,甲组平均每个工人的日产量为 36件, 标准差为9.6件;乙组工人日产量资料如下:
2014年7月高等教育自学考试 统计学原理试卷及答案 (课程代码 00974) 一、单项选择题(本大题共20小题,每小题1分,共20分) 1.构成统计总体的每一个别事物,称为 C A .调查对象 B .调查单位 C .总体单位 D .填报单位 2.对事物进行度量,最精确的计量尺度是A A .定比尺度 B .定序尺度 C .定类尺度 D .定距尺度 3.《中华人民共和国统计法》对我国政府统计的调查方式做的概括中指出,调查方式的主体是C A .统计报表 B .重点调查 C .经常性抽样调查 D .周期性普查 4.是非标志的成数p 和q 的取值范围是D A .大于零 B .小于零 C .大于1 D .界于0和1之间 5.在经过排序的数列中位置居中的数值是A A .中位数 B .众数 C .算术平均数 D .平均差 6.确定中位数的近似公式是A A .d f S f L m m ?-+ -∑1 2 B .d L ??+??+ 2 11 C .∑∑? f f x D . ∑-)(x x 7.反映现象在一段时间内变化总量的是B A .时点指标 B .时期指标 C .动态指标 D .绝对指标 8.重置抽样与不重置抽样的抽样误差相比A A .前者大 B .后者大 C .二者没有区别 D .二者的区别需要其他条件来判断 9.如果总体内各单位差异较大,也就是总体方差较大,则抽取的样本单位数A A .多一些 B .少一些 C .可多可少 D .与总体各单位差异无关 10.进行抽样调查时,样本对总体的代表性受到一些可控因素的影响,下列属于可控因素的是D A .样本数目 B .样本可能数目 C .总体单位数 D .样本容量 11.在12个单位中抽取4个,如果进行不重置抽样,样本可能数目M 为B A .4 12 B . ! 8!4! 12 C .12×4 D .12 4 12.方差是各变量值对算术平均数的A A .离差平方的平均数 B .离差平均数的平方根 C .离差平方平均数的平方根 D .离差平均数平方的平方根
计算分析题解答参考 1.1.某厂三个车间一季度生产情况如下: 计算一季度三个车间产量平均计划完成百分比和平均单位产品成本。 解:平均计划完成百分比=实际产量/计划产量=733/(198/0.9+315/1.05+220/1.1) =101.81% 平均单位产量成本 X=∑xf/∑f=(15*198+10*315+8*220)/733 =10.75(元/件) 1.2.某企业产品的有关资料如下: 试分别计算该企业产品98年、99年的平均单位产品成本。 解:该企业98年平均单位产品成本 x=∑xf/∑f=(25*1500+28*1020+32*980)/3500 =27.83(元/件) 该企业99年平均单位产品成本x=∑xf /∑(m/x)=101060/(24500/25+28560/28+48000/32) =28.87(元/件) 年某月甲、乙两市场三种商品价格、销售量和销售额资料如下: 1.3.1999 解:三种商品在甲市场上的平均价格x=∑xf/∑f=(105*700+120*900+137*1100)/2700 =123.04(元/件) 三种商品在乙市场上的平均价格x=∑m/∑(m/x)=317900/(126000/105+96000/120+95900/137) =117.74(元/件) 2.1.某车间有甲、乙两个生产小组,甲组平均每个工人的日产量为22件,标准差为 3.5件;乙组工人日产量资料:
试比较甲、乙两生产小组中的哪个组的日产量更有代表性? 解:∵X 甲=22件 σ甲=3.5件 ∴V 甲=σ甲/ X 甲=3.5/22=15.91% 列表计算乙组的数据资料如下: ∵x 乙=∑xf/∑f=(11*10+14*20+17*30+20*40)/100 =17(件) σ乙= √[∑(x-x)2 f]/∑f =√900/100 =3(件) ∴V 乙=σ乙/ x 乙=3/17=17.65% 由于V 甲<V 乙,故甲生产小组的日产量更有代表性。 2.2.有甲、乙两个品种的粮食作物,经播种实验后得知甲品种的平均产量为998斤,标准差为162.7斤;乙品种实验的资料如下: 试研究两个品种的平均亩产量,确定哪一个品种具有较大稳定性,更有推广价值? 解:∵x 甲=998斤 σ甲=162.7斤 ∴V 甲=σ甲/ x 甲=162.7/998=16.30% 列表计算乙品种的数据资料如下:
计算题例题及答案: 1、某校社会学专业同学统计课成绩如下表所示。 社会学专业同学统计课成绩表 学号成绩学号成绩学号成绩101023 76 101037 75 101052 70 101024 91 101038 70 101053 88 101025 87 101039 76 101054 93 101026 78 101040 90 101055 62 101027 85 101041 76 101056 95 101028 96 101042 86 101057 95 101029 87 101043 97 101058 66 101030 86 101044 93 101059 82 101031 90 101045 92 101060 79 101032 91 101046 82 101061 76 101033 80 101047 80 101062 76 101034 81 101048 90 101063 68 101035 80 101049 88 101064 94 101036 83 101050 77 101065 83 要求: (1)对考试成绩按由低到高进行排序,求出众数、中位数和平均数。
(2)对考试成绩进行适当分组,编制频数分布表,并计算累计频数和累计频率。答案: (1)考试成绩由低到高排序: 62,66,68,70,70,75,76,76,76,76,76,77,78,79, 80,80,80,81,82,82,83,83,85,86,86,87,87,88, 88,90,90,90,91,91,92,93,93,94,95,95,96,97, 众数:76 中位数:83 平均数: =(62+66+……+96+97)÷42 =3490÷42 =83.095 (2) 按成绩 分组频数频率(%) 向上累积向下累积 频数频率(%) 频数频率(%) 60-69 3 7.143 3 7.143 42 100.000 70-79 11 26.190 14 33.333 39 92.857 80-89 15 35.714 29 69.048 28 66.667
《统计学原理(第五版)》习题计算题答案详解 第二章 统计调查与整理 1. 见教材P402 2. 见教材P402-403 3. 见教材P403-404 第三章 综合指标 1. 见教材P432 2. %86.12270 25 232018=+++= 产量计划完成相对数 3. 所以劳动生产率计划超额%完成。 4. %22.102% 90% 92(%)(%)(%)=== 计划完成数实际完成数计划完成程度指标 一季度产品单位成本,未完成计划,还差%完成计划。 5. %85.011100%8% 110% 1=?++==计划完成数实际完成数计划完成程度指标计划完成数;所以计划完成数实际完成数标因为,计划完成程度指%105%103= = 1.94%%94.101% 103% 105,比去年增长解得:计划完成数==()得出答案)将数值带入公式即可以计算公式, 上的方程,给大家一个很多同学都不理解也可以得出答案,鉴于(根据第三章天)。 个月零天(也即是个月零(月)也就是大约)(上年同季(月)产量达标季(月)产量超出计划完成产量 达标期完成月数计划期月数超计划提前完成时间达标期提前完成时间完成计划的时间万吨。根据公式:提前多出万吨,比计划数万吨产量之和为:季度至第五年第二季度方法二:从第四年第三PPT PPT 6868825.8316-32070 -7354-60--3707320181718=+=+=+==+++()天完成任务。个月零 年第四季度为止提前(天),所以截止第五)(根据题意可设方程:万吨完成任务。天达到五年第二季度提前万吨。根据题意,设第万吨达到原计划,还差万吨产量之和为:季度至第五年第一季度方法一:从第四年第二6866891 -91*20)181718(1916707016918171816=++++=+++x x x
统计学原理试题(6) 一、单项选择题:(每小题1分,共20分) 1、设某地区有200家独立核算得工业企业,要研究这些企业得产品生产情 况,总体就是( )。 A、每一家工业企业 B、200家工业企业 C、每一件产品 D、200家工业企业得全部工业产品 2、有600家公司每位职工得工资资料,如果要调查这些公司得工资水平情 况,则总体单位就是( )。 A、600家公司得全部职工 B、600家公司得每一位职工 C、600家公司所有职工得全部工资 D、600家公司每个职工得工资 3、一个统计总体( )。 A、只能有一个指标 B、可以有多个指标 C、只能有一个标志 D、可以有多个标志 4、以产品等级来反映某种产品得质量,则该产品等级就是( )。 A、数量标志 B、品质标志 C、数量指标 D、质量指标 5、在调查设计时,学校作为总体,每个班作为总体单位,各班学生人数就是( )。 A、变量值 B、变量 C、指标值 D、指标 6、年龄就是( )。 A、变量值 B、连续型变量 C、离散型变量 D、连续型变量,但在实际应用中常按离散型处理 7、人口普查规定统一得标准时间就是为了( )。 A、登记得方便 B、避免登记得重复与遗漏 C、确定调查得范围 D、确定调查得单位 8、以下哪种调查得报告单位与调查单位就是一致得( )。 A、职工调查 B、工业普查 C、工业设备调查 D、未安装设备调查 9、通过调查大庆、胜利、辽河等油田,了解我国石油生产得基本情况。这 种调查方式就是( )。 A、典型调查 B、抽样调查 C、重点调查 D、普查 10、某市进行工业企业生产设备普查,要求在10月1日至15日全部调查完 毕,则这一时间规定就是( )。 A、调查时间 B、登记期限 C、调查期限 D、标准时间 11、统计分组得关键问题就是( )。 A、确定分组标志与划分各组界限 B、确定组距与组中值
统计学练习题——计算题 1、某企业工人按日产量分组如下: 单位:(件) 试计算7、8月份平均每人日产量,并简要说明8月份比7月份平均每人日产量变化的原因。 7月份平均每人日产量为:37360 13320 == = ∑∑f Xf X (件) 8月份平均每人日产量为:44360 15840 == = ∑∑ f Xf X (件) 根据计算结果得知8月份比7月份平均每人日产量多7件。其原因是不同组日产量水平的工人所占比重发生变化所致。7月份工人日产量在40件以上的工人只占全部工人数的40%,而8月份这部分工人所占比重则为66.67%。
2、某纺织厂生产某种棉布,经测定两年中各级产品的产量资料如下: 解: 2009年棉布的平均等级= 250 10 3 40 2 200 1? + ? + ? =1.24(级) 2010年棉布的平均等级= 300 6 3 24 2 270 1? + ? + ? =1.12(级) 可见该厂棉布产品质量2010年比2009年有所提高,其平均等级由1.24级上升为1.12级。质量提高的原因是棉布一级品由80%上升为90%,同时二级品和三级品分别由16%及4%下降为8%及2%。
试比较和分析哪个企业的单位成本高,为什么? 解: 甲企业的平均单位产品成本=1.0×10%+1.1×20%+1.2×70%=1.16(元) 乙企业的平均单位产品成本=1.2×30%+1.1×30%+1.0×40%=1.09(元) 可见甲企业的单位产品成本较高,其原因是甲企业生产的3批产品中,单位成本较高(1.2元)的产品数量占70%,而乙企业只占30%。
第 1 页/共 12 页 1、下表是某保险公司160名推销员月销售额的分组数据。书p26 按销售额分组(千元) 人数(人) 向上累计频数 向下累计频数 12以下 6 6 160 12—14 13 19 154 14—16 29 48 141 16—18 36 84 112 18—20 25 109 76 20—22 17 126 51 22—24 14 140 34 24—26 9 149 20 26—28 7 156 11 28以上 4 160 4 合计 160 —— —— (1) 计算并填写表格中各行对应的向上累计频数; (2) 计算并填写表格中各行对应的向下累计频数; (3)确定该公司月销售额的中位数。 按上限公式计算:Me=U- =18-0.22=17,78 2、某厂工人按年龄分组资料如下:p41 工人按年龄分组(岁) 工人数(人) 20以下 160 20—25 150 25—30 105 30—35 45 35—40 40 40—45 30 45以上 20 合 计 550 要求:采用简捷法计算标准差。《简捷法》 3、试根据表中的资料计算某旅游胜地2004年平均旅游人数。P50 表:某旅游胜地旅游人数 时间 2004年1月1日 4月1日 7月1日 10月1日 2005年1月1 日 旅游人数(人) 5200 5000 5200 5400 5600 4、某大学2004年在册学生人数资料如表3-6所示,试计算该大学2004年平均在册学生人数. 时间 1月1日 3月1日 7月1日 9月1日 12月31日 在册学生人数(人) 3408 3528 3250 3590 3575
统计学原理练习题及答案 2007-12-7 9:32:24 阅读数:6162 《统计学原理》综合练习题 一、判断题(把正确的符号“√”或错误的符号“×”填写在题后的括号中。) 1、社会经济统计的研究对象是社会经济现象总体的各个方面。() 2、在全国工业普查中,全国企业数是统计总体,每个工业企业是总体单位。() 3、总体单位是标志的承担者,标志是依附于单位的。() 4、数量指标是由数量标志汇总来的,质量指标是由品质标志汇总来的。() 5、全面调查和非全面调查是根据调查结果所得的资料是否全面来划分的()。 6、调查单位和填报单位在任何情况下都不可能一致。() 7、在统计调查中,调查标志的承担者是调查单位。() 8、对全同各大型钢铁生产基地的生产情况进行调查,以掌握全国钢铁生产的基本情况。这种调查属于非全面调查。() 9、统计分组的关键问题是确定组距和组数( ) 10、按数量标志分组的目的,就是要区分各组在数量上的差别( ) 11、总体单位总量和总体标志总量是固定不变的,不能互相变换。() 12、相对指标都是用无名数形式表现出来的。() 13、众数是总体中出现最多的次数。() 14、国民收入中积累额与消费额之比为1:3,这是一个比较相对指标。() 15、总量指标和平均指标反映了现象总体的规模和一般水平。但掩盖了总体各单位的差异情况,因此通过这两个指标不能全面认识总体的特征。() 16、抽样推断是利用样本资料对总体的数量特征进行估计的一种统计分析方法,因此不可避免的会产生误差,这种误差的大小是不能进行控制的。() 17、从全部总体单位中按照随机原则抽取部分单位组成样本,只可能组成一个样本。() 18、在抽样推断中,作为推断的总体和作为观察对象的样本都是确定的、唯一的。() 19、抽样估计置信度就是表明抽样指标和总体指标的误差不超过一定范围的概率保证程度。() 20、在其它条件不变的情况下,提高抽样估计的可靠程度,可以提高抽样估计的精确度。() 21、抽样平均均误差反映抽样的可能误差范围,实际上每次的抽样误差可能大于抽样平均误差,也可能小于抽样平均误差。() 22、施肥量与收获率是正相关关系。() 23、计算相关系数的两个变量都是随机变量() 24、利用一个回归方程,两个变量可以互相推算()
应用统计学练习题 第一章绪论 一、填空题 1.统计工作与统计学的关系是__统计实践____和___统计理论__的关系。 2.总体是由许多具有_共同性质_的个别事物组成的整体;总体单位是__总体_的组成单位。 3.统计单体具有3个基本特征,即__同质性_、__变异性_、和__大量性__。 4.要了解一个企业的产品质量情况,总体是_企业全部产品__,个体是__每一件产品__。 5.样本是从__总体__中抽出来的,作为代表_这一总体_的部分单位组成的集合体。 6.标志是说明单体单位特征的名称,按表现形式不同分为__数量标志_和_品质标志_两种。 7. 8.统计指标按其数值表现形式不同可分为__总量指标__、__相对指标_和__平均指标__。 9.指标与标志的主要区别在于: (1)指标是说明__总体__特征的,而标志则是说明__总体单位__特征的。 (2)标志有不能用__数量__表示的_品质标志_与能用_数量_表示的_数量标志_,而指标都是能用_数量_表示的。 10.一个完整的统计工作过程可以划分为_统计设计_、_统计调查_、_统计整理_和__统计分析__4个阶段。 二、单项选择题 1.统计总体的同质性是指(A)。 A.总体各单位具有某一共同的品质标志或数量标志 B.总体各单位具有某一共同的品质标志属性或数量标志值 C.总体各单位具有若干互不相同的品质标志或数量标志 D.总体各单位具有若干互不相同的品质标志属性或数量标志值 2.设某地区有800家独立核算的工业企业,要研究这些企业的产品生产情况,总体是( D)。
A.全部工业企业 B.800家工业企业 C.每一件产品 D.800家工业企业的全部工业产品 3.有200家公司每位职工的工资资料,如果要调查这200家公司的工资水平情况,则统计总体为(A)。 A.200家公司的全部职工 B.200家公司 C.200家公司职工的全部工资 D.200家公司每个职工的工资 4.一个统计总体( D)。 A.只能有一个标志 B.可以有多个标志 C.只能有一个指标 D.可以有多个指标 5.以产品等级来反映某种产品的质量,则该产品等级是(C)。 A.数量标志 B.数量指标 C.品质标志 D.质量指标 6.某工人月工资为1550元,工资是( B )。 A.品质标志 B.数量标志 C.变量值 D.指标 7.某班4名学生金融考试成绩分别为70分、80分、86分和95分,这4个数字是( D)。 A.标志 B.指标值 C.指标 D.变量值 8.工业企业的职工人数、职工工资是(D)。 A.连续变量 B.离散变量 C.前者是连续变量,后者是离散变量 D.前者是离散变量,后者是连续变量 9.统计工作的成果是(C)。 A.统计学 B.统计工作 C.统计资料 D.统计分析和预测 10.统计学自身的发展,沿着两个不同的方向,形成(C)。 A.描述统计学与理论统计学 B.理论统计学与推断统计学 C.理论统计学与应用统计学 D.描述统计学与推断统计学
西安交大统计学考试试卷 一、单项选择题(每小题2分,共20分) 1.在企业统计中,下列统计标志中属于数量标志的是( C) A、文化程度 B、职业 C、月工资 D、行业 2.下列属于相对数的综合指标有(B ) A、国民收入 B、人均国民收入 C、国内生产净值 D、设备台数 3.有三个企业的年利润额分别是5000万元、8000万元和3900万元,则这句话中有( B)个变量 A、0个 B、两个 C、1个 D、3个 4.下列变量中属于连续型变量的是(A ) A、身高 B、产品件数 C、企业人数 D、产品品种 5.下列各项中,属于时点指标的有(A ) A、库存额 B、总收入 C、平均收入 D、人均收入 6.典型调查是(B )确定调查单位的 A、随机 B、主观 C、随意 D盲目 7.总体标准差未知时总体均值的假设检验要用到( A ): A、Z统计量 B、t统计量 C、统计量 D、X统计量 8. 把样本总体中全部单位数的集合称为(A ) A、样本 B、小总体 C、样本容量 D、总体容量 9.概率的取值范围是p(D ) A、大于1 B、大于-1 C、小于1 D、在0与1之间 10. 算术平均数的离差之和等于(A ) A、零 B、 1 C、-1 D、2 二、多项选择题(每小题2分,共10分。每题全部答对才给分,否则不计分) 1.数据的计量尺度包括( ABCD ): A、定类尺度 B、定序尺度 C、定距尺度 D、定比尺度 E、测量尺度 2.下列属于连续型变量的有( BE ): A、工人人数 B、商品销售额 C、商品库存额 D、商品库存量 E、总产值 3.测量变量离中趋势的指标有( ABE ) A、极差 B、平均差 C、几何平均数 D、众数 E、标准差 4.在工业企业的设备调查中( BDE ) A、工业企业是调查对象 B、工业企业的所有设备是调查对象 C、每台设备是 填报单位 D、每台设备是调查单位 E、每个工业企业是填报单位 5.下列平均数中,容易受数列中极端值影响的平均数有( ABC ) A、算术平均数 B、调和平均数 C、几何平均数 D、中位数 E、众数 三、判断题(在正确答案后写“对”,在错误答案后写“错”。每小题1分,共10分) 1、“性别”是品质标志。(对) 2、方差是离差平方和与相应的自由度之比。(错) 3、标准差系数是标准差与均值之比。(对) 4、算术平均数的离差平方和是一个最大值。(错) 5、区间估计就是直接用样本统计量代表总体参数。(错) 6、在假设检验中,方差已知的正态总体均值的检验要计算Z统计量。(错)
《统计学》计算题型 (第二章)1.某车间40名工人完成生产计划百分数(%)资料如下:9065 100 102 100 104 112 120 124 98 110110 120 120 114 100 109 119 123 107 110 99 132 135 107 107 109 102 102 101 110 109 107 103 103 102 102 102 104 104 要求: (1)编制分配数列;(4分) (2)指出分组标志及其类型;(4分) (3)对该车间工人的生产情况进行分析。(2分) 解答: (1)
(2)分组标志:生产计划完成程度 类型:数量标志 (3)从分配数列可以看出,该计划未能完成计划的有4人,占10%,超额完成计划在10%以内的有22人,占55%,超额20%完成的有7人,占17.5%。反映该车间,该计划完成较好。 (第三章)2.2005年9份甲、乙两农贸市场某农产品价格和成交量、成交额资料如下: 试问哪一个农贸市场农产品的平均价格较高?(8分)并分析说明原因。(2分) 解答: (1)x 甲=∑∑m x m 1=24 8.41 6.36.314.24.21246.34.2?+?+?++=30/7=4.29(元) x 乙= ∑∑f xf = 1 241 8.426.344.2++?+?+?=21.6/7=3.09(元) (2)原因分析:甲市场在价格最高的C 品种成交量最高,而乙市场是在最低的价格A 品种成交量最高,根据权数越大其对应的变量值对平均数的作用越大的原理,可知甲市场平均价格趋近于C ,而乙市场平均价格却趋近于A ,所以甲市场平均价格高于乙市场平均价格。
《统计学原理》 计算题 1.某地区国民生产总值(GNP)在1988-1989年平均每年递增15%,1990-1992年平均每年递增12%,1993-1997年平均每年递增9%,试计算: 1)该地区国民生产总值这十年间的总发展速度及平均增长速度 答:该地区GNP在这十年间的总发展速度为 115%2×112%3×109%5=285.88% 平均增长速度为 111.08% == 2)若1997年的国民生产总值为500亿元,以后每年增长8%,到2000年可达到多少亿元? 答:2000年的GNP为 500(1+8%)13=1359.81(亿元) 2.某地有八家银行,从它们所有的全体职工中随机动性抽取600人进行调查,得知其中的486人在银行里有个人储蓄存款,存款金额平均每人3400元,标准差500元,试以95.45%的可靠性推断:(F(T)为95.45%,则t=2) 1)全体职工中有储蓄存款者所占比率的区间范围 答:已知:n=600,p=81%,又F(T)为95.45%,则t=2所以 0.1026% == 故全体职工中有储蓄存款者所占比率的区间范围为 81%±0.1026% 2)平均每人存款金额的区间范围 3.某厂产品产量及出厂价格资料如下表: 要求:对该厂总产值变动进行因素分析。(计算结果百分数保留2位小数) 答:①总产值指数 11 00500010012000604100020 104.08% 600011010000504000020 p q p q ?+?+? ==?+?+? ∑ ∑ 总成本增加量 Σp1q1-Σp0q0=2040000-1960000=80000(元)②产量指数
统计学计算题例题
第四章 1. 某企业1982年12月工人工资的资料如下: 要求:(1)计算平均工资;(79元) (2)用简捷法计算平均工资。 2. 某企业劳动生产率1995年比1990年增长7%,超额完成计划2%,试确定劳动生产率计划增长数。 7%-2%=5% 3. 某厂按计划规定,第一季度的单位产品成本比去年同期降低8%。实际 执行结果,单位产品成本较去年同期降低4%。问该厂第一季度产品单位成本计划的完成程度如何?104.35%( (1-4%)/(1-8%)*100%=96%/92%*100%=104.35%结果表明:超额完成4.35%(104.35%-100%)) 4. 某公社农户年收入额的分组资料如下:
要求:试确定其中位数及众数。中位数为774.3(元)众数为755.9(元) 求中位数: 先求比例:(1500-720)/(1770-720)=0.74286 分割中位数组的组距:(800-700)*0.74286=74.286 加下限700+74.286=774.286 求众数: D1=1050-480=570 D2=1050-600=450 求比例:d1/(d1+d2)=570/(570+450)=0.55882 分割众数组的组距:0.55882*(800-700)=55.882 加下限:700+55.882=755.882 5.1996年某月份某企业按工人劳动生产率高底分组的生产班组数和产量资料如 下: 率。64.43(件/人)
(55*300+65*200+75*140+85*60)/(300+200+140+60) 6.某地区家庭按人均月收入水平分组资料如下: 根据表中资料计算中位数和众数。中位数为733.33(元) 众数为711.11(元) 求中位数: 先求比例:(50-20)/(65-20)=0.6667 分割中位数组的组距:(800-600)*0.6667=66.67 加下限:600+66.67=666.67 7.某企业产值计划完成 103%,比去年增长5%。试问计划规定比去年增长 多少?1.94% (上年实际完成1.03/1.05=0.981 本年实际计划比上年增长 (1-0.981)/0.981=0.019/0.981=1.937%) 8.甲、乙两单位工人的生产资料如下:
2014统计学练习题及答案 一判断题 1、某企业全部职工的劳动生产率计划在去年的基础上提高8%,计划执行结果仅提高4%,则劳动生产率的任务仅实现一半。(错) 2、在统计调查中,调查标志的承担者是调查单位。( 错) 3、制定调查方案的首要问题是确定调查对象。( 错) 4、正相关指的就是因素标志和结果标志的数量变动方向都是上升的。( 错) 5、现象之间的函数关系可以用一个数学表达式反映出来。(对) 6.上升或下降趋势的时间序列,季节比率大于1,表明在不考虑其他因素影响时,由于季.的影响使实际值高于趋势值,(对) 7.特点是“先对比,后综合。”(错 8.隔相等的时点数列计算平均发展水平时,应用首尾折半的方法。( 错) 9.均数指数的计算特点是:先计算所研究对象各个项目的个体指数;然后将个体指数进行加权平均求得总指数。( 错) 10.和样本指标均为随机变量。( 错) 11.距数列中,组数等于数量标志所包含的变量值的个数。(对) 12.中值是各组上限和下限之中点数值,故在任何情况下它都能代表各组的一般水平。( 错) 13.标志和数量标志都可以用数值表示,所以两者反映的内容是相同的。(错) 14.变异度指标越大,均衡性也越好。( 对) 15.于资料的限制,使综合指数的计算产生困难,就需要采用综合指数的变形公式平均数指数。( 错) 16.计量是随机变量。(对) 17.数虽然未知,但却具有唯一性。(错) 18.标和数量标志都可以用数值表示,所以两者反映的内容是相同的(错) 19.以经常进行,所以它属于经常性调查(错) 20.样本均值来估计总体均值,最主要的原因是样本均值是可知的。()答案未 21.工业普查中,全国工业企业数是统计总体,每个工业企业是个体。(错) 22.标志的承担者,标志是依附于个体的。(对) 23.志表明个体属性方面的特征,其标志表现只能用文字来表现,所以品质标志不能转化为统计指标。(错) 24.标和数量标志都可以用数值表示,所以两者反映的内容是相同的。(错) 25.计指标都是用数值表示的,所以数量标志就是统计指标。(错) 26.标及其数值可以作为总体。(错) 27.润这一标志可以用定比尺度来测定。(错) 28.统计学考试成绩分别为55分,78分,82分,96分,这4个数字是数量指标。(错) 29.术学派注重对事物性质的解释,而国势学派注重数量分析。(错) 30.是统计研究现象总体数量的前提。(对) 31.析中,平均发展速度的计算方法分水平法和方程两种。(错) 32.数值越大,说明相关程度越高:同理,相关系数的数值越小,说明相关程度越低(对 33.志是总体同质性特征的条件,而不变标志是总体差异性特征的条件。(错) 34.度具有另外三种尺度的功能。(对) 35.民旅游意向的问卷中,“你最主要的休闲方式是什么?”,这一问题应归属于事实性问题
第四章 六、计算题 月工资(元) 甲单位人数(人) 乙单位人数比重(%) 400以下 400~600 600~800 800~1000 1000以上 4 25 84 126 28 2 8 30 42 18 合 计 267 100 工资更具有代表性。 1、(1) 430025500267 x f x f ?+?+ == = ∑∑甲工资总额 总人数 3002%5008%7003%f x x f =? =?+?+?+ ∑∑乙 (2) 计算变异系数比较 ()2 x x f f σ-=∑∑甲甲 甲甲 () 2 x x f f σ-∑∑乙乙 乙乙 V x σσ= 甲 甲 甲 V x σσ= 乙乙乙 根据V σ甲 、V σ乙 大小判断,数值越大,代表性越小。 甲品种 乙品种 田块面积(亩) 产量(公斤) 田块面积(亩) 产量(公斤) 1.2 0.8 1.5 1.3 600 405 725 700 1.0 1.3 0.7 1.5 500 675 375 700 4.8 2430 4.5 2250 假定生产条件相同,试研究这两个品种的收获率,确定那一个品种具有稳定性和推广价值。 2、(1) 收获率(平均亩产) 2430 528.254.8 x = ==甲总产量总面积 2250 5004.5 x = =乙 (2) 稳定性推广价值(求变异指标) 2 2 2 2 600405725700506 1.25060.8506 1.5506 1.31.20.8 1.5 1.34.8 σ???????? -?+-?+-?+-? ? ? ? ?? ???????=甲
2 2 2 2 500675375700500 1.0500 1.35000.7500 1.51.0 1.30.7 1.54.5 σ???????? -?+-?+-?+-? ? ? ? ?? ???????=乙 求V σ甲 、V σ乙 ,据此判断。 8.某地20个商店,1994年第四季度的统计资料如下表4-6。 表4-6 按商品销售计划完成情 况分组(%) 商店 数目 实际商品销售额 (万元) 流通费用率 (%) 80-90 90-100 100-110 110-120 3 4 8 5 45.9 68.4 34.4 94.3 14.8 13.2 12.0 11.0 试计算 (1)该地20个商店平均完成销售计划指标 (2)该地20个商店总的流通费用率 (提示:流通费用率=流通费用/实际销售额) 8、(1) () 101%1 % f f x = = =?∑∑ 20实际销售额计划销售额 实际销售额 计划完成 (2) 据提示计算:2012.7%x = 品 种 价格 (元/公斤) 销售额(万元) 甲市场 乙市场 甲 乙 丙 0.30 0.32 0.36 75.0 40.0 45.0 37.5 80.0 45.0 13、提示:= 销售额 平均价格销售量 企业序号 计划产量(件) 计划完成程度(%) 实际一级品率 (%) 1 2 3 4 5 350 500 450 400 470 102 105 110 97 100 98 96 90 85 91
北京工业大学经济与管理学院2007-2008年度 第一学期期末应用统计学 主考教师 专业:学号:姓名:成绩: 1 C 2 B 3 A 4 C 5 B 6 B 7 A 8 A 9 C 10 C 一.单选题(每题2分,共20分) 1.在对工业企业的生产设备进行普查时,调查对象是 A 所有工业企业 B 每一个工业企业 C 工业企业的所有生产设备 D 工业企业的每台生产设 备 2.一组数据的均值为20, 离散系数为, 则该组数据的标准差为 A 50 B 8 C D 4 3.某连续变量数列,其末组为“500以上”。又知其邻组的组中值为480,则末组的组中值为
A 520 B 510 C 530 D 540 4. 已知一个数列的各环比增长速度依次为5%、7%、9%,则最后一期的定基增长速度为 A .5%×7%×9% B. 105%×107%×109% C .(105%×107%×109%)-1 D. 1%109%107%1053- 5.某地区今年同去年相比,用同样多的人民币可多购买5%的商品,则物价增(减)变化的百分比为 A. –5% B. –% C. –% D. % 6.对不同年份的产品成本配合的直线方程为x y 75.1280? -=, 回归系数b= -表示 A. 时间每增加一个单位,产品成本平均增加个单位 B. 时间每增加一个单位,产品成本平均下降个单位 C. 产品成本每变动一个单位,平均需要年时间 D. 时间每减少一个单位,产品成本平均下降个单位 7.某乡播种早稻5000亩,其中20%使用改良品种,亩产为600 公
斤,其余亩产为500 公斤,则该乡全部早稻亩产为 A. 520公斤 B. 530公斤 C. 540公斤 D. 550公斤 8.甲乙两个车间工人日加工零件数的均值和标准差如下: 甲车间:x=70件,σ=件乙车间: x=90件, σ=件哪个车间日加工零件的离散程度较大: A甲车间 B. 乙车间 C.两个车间相同 D. 无法作比较 9. 根据各年的环比增长速度计算年平均增长速度的方法是 A 用各年的环比增长速度连乘然后开方 B 用各年的环比增长速度连加然后除以年数 C 先计算年平均发展速度然后减“1” D 以上三种方法都是错误的 10. 如果相关系数r=0,则表明两个变量之间 A. 相关程度很低 B.不存在任何
一、主要术语 描述统计 ....:研究数据收集、处理和描述的统计学分支。 推断统计 ....:研究如何利用样本数据来推断总体特征的统计学分支。 观测数据 ....:在没有对事物进行人为控制的条件下,通过调查或观测而收集到的数据。 实验数据 ....:在实验中控制实验对象而收集到的数据。 异众比率 ....:非众数组的频数占总频数的比率。 四分位差 ....:也称为内距或四分间距,上四分位数与下四分位数之差. 。 显著性水平 .....:假设检验中发生第Ⅰ类错误的概率,记为 P-.值.:也称观察到的显著性水平或实测显著性水平,是根据样本观测值计算出来的概率。 拟合优度检验 ......:根据样本观测结果与原假设为真条件下期望结果的吻合程度,来检验总体是否服从某种分布。一般地,可以用于任何假设的概率分布。 独立性检验 .....:检验两个分类变量之间是否存在相关关系。 多个总体比例差异检验 ..........:检验多个总体比例是否都相等。 消费者物价指数 .......:又称居民消费价格指数,反映一定时期内城乡居民所购买的生活消费品价格和服务项目价格的变动程度的一种相对数。 生产者价格指数 .......:反映企业产品出厂价格变动趋势和变动程度的一种相对数。 股票价格指数 ......:是反映某一股票市场上多种股票价格变动趋势的一种相对 二.简答和计算P41—P42: 2.2比较概率抽样和非概率抽样的特点。举例说明什么情况下适合采用概率抽样,什么情况下适合采用非概率抽样。 概率抽样的特点:简单随机抽样、系统抽样(等距抽样)、分层抽样(类型抽样)和整群抽样。非概率抽样的特点:方便抽样、定额抽样、立意抽样、滚雪球抽样和空间抽样。 2.6你认为应当如何控制调查中的回答误差? 回答误差是指被调查者接受调查时给出的答案与实际不符。导致回答误差的原因有多种,主要有理解误差、记忆误差及意识误差。 调查一方在调查时可协助被调查者一方共同完成调查,被调查方不了解的调查方可帮助解释、阐明,这样可减少误差。 2.7怎样减少无回答?请通过一个例子,说明你所考虑到的减少无回答的具体措施。 可通过优选与培训采访人员、加强调查队伍管理、准确定位调查对象、保证问卷的送达率等加以预防,采取物质奖励、消除疑虑、提前告知和事中提醒等加以控制,采用多次访问、替换被调查单位、随机化回答技术等方法来降低无回答率。 2.8如何设计调查方案? 第一步:确定调查目的 第二步:确定调查对象和调查单位 第三步:确定调查项目和调查表 第四步:调查表格和问卷的设计 第五步:确定调查时间和调查方法等