
用IDA反汇编动态库
最近,一直在学习如何利用IDA来反汇编动态库,这里把我的学习心得写下来。为简单起见,这里就自己所写的一个动态库里的一个简单函数进行一下反汇编,给出如何写出其C代码的详细过程,希望对新手有点帮助。废话少说,先给出其动态连接库的C代码如下_declspec(dllexport) int add(char a, int b, int c[2])
{
int d = a + b + c[0] + c[1];
return d;
}
至于为什么要设置这样的参数,待会在反汇编时进行说明。下面给出其详细的反汇编过程,并补充相关的经验总结。
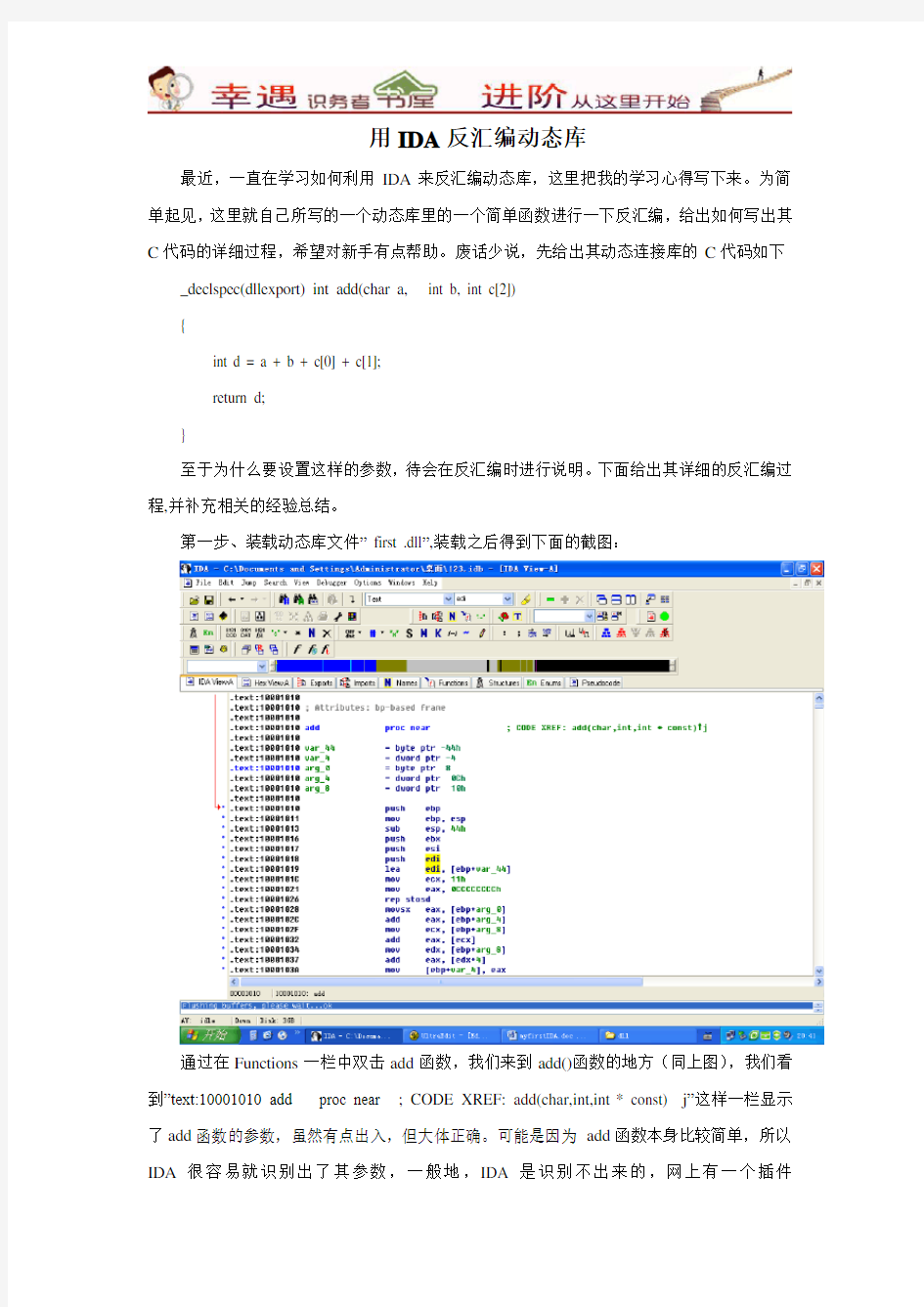
第一步、装载动态库文件” first .dll”,装载之后得到下面的截图:
通过在Functions一栏中双击add函数,我们来到add()函数的地方(同上图),我们看到”text:10001010 add proc near ; CODE XREF: add(char,int,int * const) j”这样一栏显示了add函数的参数,虽然有点出入,但大体正确。可能是因为add函数本身比较简单,所以IDA很容易就识别出了其参数,一般地,IDA是识别不出来的,网上有一个插件
为”Flair.v5.20”据说可以部分地解决函数的参数识别问题,但这个软件我没有下载到,就不说这个了。
第二步、我们看到”.text:10001010”这些栏有很多标示,在下面的汇编语句中会用到。我们看接下来的三行代码:
.text:10001010 push ebp
.text:10001011 mov ebp, esp
.text:10001013 sub esp, 44h
这三行代码模式基本上是固定的,(至少我遇到的都是这样)首先是保存ebp, 然后用ebp来保存esp的原始指向,再将esp的指向向上移动44h个字节,(当然这里44h不是固定的)为什么会有这样固定的代码呢?就代码“sub esp 44h”而言,在原esp的基础上向上移动44h 的字节空间,而esp ----- esp-44h这个44h的空间是为了存放一般变量的。其他两行相信读者很容易理解其理由。
第三步、看下面三行代码.
.text:10001016 push ebx
.text:10001017 push esi
.text:10001018 push edi
当我们在函数的开头看到这样的代码时,而后面又没有紧跟着”call + function”时,我们大可不用理解,因为这些push语句目的都是为了不破坏原始ebx,esi,edi的值而将他们保存起来,并且这里我们可以看到,是保存在esp-44h之上的。也就是说,如果我们看到函数的开头出现将寄存器push进esp-x之上的空间(我们将”esp-x 至esp”的堆栈空间成为“一般变量栈空间”),这里就是指push进esp-44h之上的堆栈空间,我们不用去关心,在函数末尾肯定会有相应的代码将他们还原的。(待会我们会看到)
第四步、继续向下看,进入关键代码段。在做进一步解释之前我先画一幅堆栈图。如下:
好了,有了上一幅图,说明起来会容易些。看接下来的四条代码 :
.text:10001019 lea edi, [ebp+var_44]
.text:1000101C mov ecx, 11h
.text:10001021 mov eax, 0CCCCCCCCh
.text:10001026 rep stosd
这四条代码和上面的三条代码一样,其模式一般是固定不变的。其作用就是实现了“一般变量栈空间”的初始化。这里将图中所示的“一般变量栈空间“初始化为0xCCCCCCCC.其具体的代码解释如下 :
lea edi, [ebp+var_44] : edi = ebp + vat_44
edi
exi
ebx
一
般
变
量
堆
栈
空
间
can1
can2
can3 ebp = esp (假设这里是最先的esp , 且值为0x0013ff80, “1000101代码”) (esp-44h)指向,为(0x0013ff80-44h) esp-44h 之上的空间 ebp+arg_0 ebp+arg_4 ebp+arg_8
mov ecx, 11h :ecx = 0x11h
mov eax, 0CCCCCCCCh : eax = 0xCCCCCCCC;
rep stosd : for(int i1=0; i1 这里因为ecx=0x11(44h/4),所以将整个“一般变量栈空间”全部初始化为eax=0xCCCCCCCC; 这下就清楚了为什么上面的四条代码一般模式是固定的,原因就是对将要用到的“一般变量栈空间”进行初始化。 第五步、进入核心代码段 .text:10001028 movsx eax, [ebp+arg_0] .text:1000102C add eax, [ebp+arg_4] .text:1000102F mov ecx, [ebp+arg_8] .text:10001032 add eax, [ecx] .text:10001034 mov edx, [ebp+arg_8] .text:10001037 add eax, [edx+4] .text:1000103A mov [ebp+var_4], eax .text:1000103D mov eax, [ebp+var_4] 从图上我们可以知道arg_0,arg_4,arg_8分别是0x8,0xc,0x10。(要是从图上看不清,请参考文件”first.txt”)代码”movsx eax, [ebp+arg_0]”表示将[ebp+arg_0]的值进行有符号扩展后传给eax。但是这里的[ebp+arg_0]究竟是什么呢?我们假设[ebp+arg_0]=can1,如图,那么”movsx eax, [ebp+arg_0]”就表示”eax = (char)can1”。因为我们有源代码,我们知道函数add()的参数为int add(char a, int b, int c[2]),这样我们有理由怀疑(char)can1就是char a,即add的第一个参数。我们接着看下一条代码:”add eax, [ebp+arg_4]”,有了上面的猜想,我们不无理由认为[ebp+arg_4]就是can2,这样就实现了eax = can1+can2;再看代码”mov ecx, [ebp+arg_8]”和”add eax, [ecx]”,我们可以猜想得到[ebp+arg_8]其实是一个地址,因为后面有” add eax, [ecx]”这样的代码,表示为将ecx所指向的地址的值传给eax。所以肯定这就是can3,即一个int型的地址参数。”add eax, [ecx]”之后,eax = can1+can2+can3[0]。接下来的两行代码”mov edx, [ebp+arg_8”和”add eax, [edx+4]”与上面的相似,实现了eax = can1+can2+can3[0]+can3[1]。再看剩下的两行代码,”mov [ebp+var_4], eax”,” mov eax, [ebp+var_4]”,这两行代码是先将eax的值赋给[ebp+var_4],再将其值给eax。第一行代码其实是将结果储存在[ebp+var_4],第二行代码是将返回值给eax。(一般地,函数的返回值要是是int型的话,都会将返回值赋给exa,这也 可以看成是一种固定的模式)。到这里,函数基本上完成了,这里可以看出为什么将add函数的参数设置成char,int和int*了,目的就是为了认清楚原来的参数是放在堆栈中具体什么地方就目前可见,函数的第i个参数放在esp+4+i*4所指的堆栈中(i从1开始,esp是指最先的栈顶指针,后来传给了ebp)(一般第一个参数都是从[ebp+arg_0]开始,而arg_0一般为8,其他的参数依次放置)。同时我们也看到了参数返回的值会存放在寄存器eax中。这些到底是不是固定的,由于自己刚入门,不敢随便肯定。 第六步、接下来的代码基本上就是还原先前存储的寄存器,就不做详细解释了。 .text:10001040 pop edi .text:10001041 pop esi .text:10001042 pop ebx .text:10001043 mov esp, ebp .text:10001045 pop ebp .text:10001046 retn .text:10001046 add endp 好了,到这里,我们对用IDA反汇编动态库文件有了一定的认识和经验积累。但是这样反汇编成C语言似乎太慢了,对于这个简单的add()函数还好,遇到难一点的函数那就说不定了。好在我们有”hexray”这个将汇编代码转成C语言代码的插件,下面我们就用试着用这个插件来写C代码。 加载first.dll文件后,同样在”Functions”一栏双击函数add,来到view的add函数区。按F5键,得到如下的截图 “哎哟,哥们儿,还捣鼓汇编呢?那东西没用,兄弟用VB"钓"一个API就够你忙活个十天半月的,还不一定搞出来。”此君之言倒也不虚,那吾等还有无必要研他一究呢?(废话,当然有啦!要不然你写这篇文章干嘛。)别急,别急,让我把这个中原委慢慢道来:一、所有电脑语言写出的程序运行时在内存中都以机器码方式存储,机器码可以被比较准确的翻译成汇编语言,这是因为汇编语言兼容性最好,故几乎所有跟踪、调试工具(包括WIN95/98下)都是以汇编示人的,如果阁下对CRACK颇感兴趣……;二、汇编直接与硬件打交道,如果你想搞通程序在执行时在电脑中的来龙去脉,也就是搞清电脑每个组成部分究竟在干什么、究竟怎么干?一个真正的硬件发烧友,不懂这些可不行。三、如今玩DOS的多是“高手”,如能像吾一样混入(我不是高手)“高手”内部,不仅可以从“高手”朋友那儿套些黑客级“机密”,还可以自诩“高手”尽情享受强烈的虚荣感--#$%&“醒醒!” 对初学者而言,汇编的许多命令太复杂,往往学习很长时间也写不出一个漂漂亮亮的程序,以致妨碍了我们学习汇编的兴趣,不少人就此放弃。所以我个人看法学汇编,不一定要写程序,写程序确实不是汇编的强项,大家不妨玩玩DEBUG,有时CRACK出一个小软件比完成一个程序更有成就感(就像学电脑先玩游戏一样)。某些高深的指令事实上只对有经验的汇编程序员有用,对我们而言,太过高深了。为了使学习汇编语言有个好的开始,你必须要先排除那些华丽复杂的命令,将注意力集中在最重要的几个指令上(CMP LOOP MOV JNZ……)。但是想在啰里吧嗦的教科书中完成上述目标,谈何容易,所以本人整理了这篇超浓缩(用WINZIP、WINRAR…依次压迫,嘿嘿!)教程。大言不惭的说,看通本文,你完全可以“不经意”间在前辈或是后生卖弄一下DEBUG,很有成就感的,试试看!那么――这个接下来呢?――Here we go!(阅读时看不懂不要紧,下文必有分解) 因为汇编是通过CPU和内存跟硬件对话的,所以我们不得不先了解一下CPU和内存:(关于数的进制问题在此不提) CPU是可以执行电脑所有算术╱逻辑运算与基本I/O控制功能的一块芯片。一种汇编语言只能用于特定的CPU。也就是说,不同的CPU其汇编语言的指令语法亦不相同。个人电脑由1981年推出至今,其CPU发展过程为:8086→80286→80386→80486→PENTIUM →……,还有AMD、CYRIX等旁支。后面兼容前面CPU的功能,只不过多了些指令(如多能奔腾的MMX指令集)、增大了寄存器(如386的32位EAX)、增多了寄存器(如486的FS)。为确保汇编程序可以适用于各种机型,所以推荐使用8086汇编语言,其兼容性最佳。本文所提均为8086汇编语言。寄存器(Register)是CPU内部的元件,所以在寄存器之间的数据传送非常快。用途:1.可将寄存器内的数据执行算术及逻辑运算。2.存于寄存器内的地址可用来指向内存的某个位置,即寻址。3.可以用来读写数据到电脑的周边设备。8086有8个8位数据寄存器,这些8位寄存器可分别组成16位寄存器:AH&AL=AX:累加寄存器,常用于运算;BH&BL=BX:基址寄存器,常用于地址索引;CH&CL=CX:计数寄存器,常用于计数;DH&DL=DX:数据寄存器,常用于数据传递。为了运用所有的内存空间,8086设定了四个段寄存器,专门用来保存段地址:CS(Code Segment):代码段寄存器;DS(Data Segment):数据段寄存器;SS(Stack Segment):堆栈段寄存器;ES(Extra Segment):附加段寄存器。当一个程序要执行时,就要决定程序代码、数据和堆栈各要用到内存的哪些位置,通过设定段寄存器CS,DS,SS来指向这些起始位置。通常是将DS固定,而根据需要修改CS。所以,程序可以在可寻址空间小于64K的情况下被写成任意大小。所以,程序和其数据组合起来的大小,限制在DS所指的64K内,这就是COM文件不得大于64K的原因。8086以内存做为战场,用寄存器做为军事基地,以加速工作。除了前面所提的寄存器外,还有一些特殊功能的寄存器:IP(Intruction Pointer):指 先教大家一些基础知识,学习破解其实是要和程序打交道的,汇编是破解程序的必备知识,但有可能部分朋友都没有学习过汇编语言,所以我就在这里叫大家一些简单实用的破解语句吧! ---------------------------------------------------------------------------------------------------------------- 语句:cmp a,b //cmp是比较的意思!在这里假如a=1,b=2 那么就是a与b比较大小. mov a,b //mov是赋值语句,把b的值赋给a. je/jz //就是相等就到指定位置(也叫跳转). jne/jnz //不相等就到指定位置. jmp //无条件跳转. jl/jb //若小于就跳. ja/jg //若大于就跳. jge //若大于等于就跳. 这里以一款LRC傻瓜编辑器为例,讲解一下软件的初步破解过程。大家只要认真看我的操作一定会!假如还是不明白的话提出难点帮你解决,还不行的话直接找我!有时间给你补节课!呵呵! 目标:LRC傻瓜编辑器杀杀杀~~~~~~~~~ 简介:本软件可以让你听完一首MP3歌曲,便可编辑完成一首LRC歌词。并且本软件自身还带有MP3音乐播放和LRC歌词播放功能,没注册的软件只能使用15天。 工具/原料 我们破解或给软件脱壳最常用的软件就是OD全名叫Ollydbg,界面如图: 它是一个功能很强大的工具,左上角是cpu窗口,分别是地址,机器码,汇编代码,注释;注释添加方便,而且还能即时显示函数的调用结果,返回值. 右上角是寄存器窗口,但不仅仅反映寄存器的状况,还有好多东东;双击即可改变Eflag的值,对于寄存器,指令执行后发生改变的寄存器会用红色突出显示. cpu窗口下面还有一个小窗口,显示当前操作改变的寄存器状态. 左下角是内存窗口.可以ascii或者unicode两种方式显示内存信息. 右下角的是当前堆栈情况,还有注释啊. 步骤/方法 1. 我们要想破解一个软件就是修改它的代码,我们要想在这代码的海洋里找到我们破解关键的代码确实很棘 手,所以我们必须找到一定的线索,一便我们顺藤摸瓜的找到我们想要的东东,现在的关键问题就是什么 一个简单的 C++程序反汇编解析 本系列主要从汇编角度研究 c++语言机制和汇编的对应关系。第一篇自然应该从最简单的开始。 c++的源代码如下: class my_class { public : my_class( { m_member = 1; } void method(int n { m_member = n; } ~my_class( { m_member = 0; } private : int m_member; }; int _tmain(int argc, _tchar* argv[] { my_class a_class; a_class.method(10; return 0; } 可以直接 debug 的时候看到 assembly 代码,不过这样获得的代码注释比较少。比较理想的方法是利用 vc 编译器的一个选项 /fas来生成对应的汇编代码。 /fas还会在汇编代码中加入注释注明和 c++代码的对应关系,十分有助于分析。 build 代码便可以在输出目录下发现对应的 .asm 文件。本文将逐句分析汇编代码和 c++的对应关系。 首先是 winmain : _text segment _wmain proc push ebp ; 保存旧的 ebp mov ebp, esp ; ebp保存当前栈的位置 push -1 ; 建立 seh(structured exception handler链 ; -1表示表头 , 没有 prev push __ehhandler$_wmain ; seh异常处理程序的地址 mov eax, dword ptr fs:0 ; fs:0指向 teb 的内容,头 4个字节是当前 seh 链的地址 push eax ; 保存起来 sub esp, d8h ; 分配 d8h 字节的空间 push ebx push esi push edi lea edi, dword ptr [ebp-e4h] ; e4h = d8h + 4 * 3,跳过中间 ebx, esi, edi mov ecx, 36h ; 36h*4h=d8h,也就是用 36h 个 cccccccch 填满刚才分配的 d8h 字节空间 mov eax, cccccccch rep stosd mov eax, dword ptr ___security_cookie xor eax, ebp push eax ; ebp ^ __security_cookie压栈保存 lea eax, dword ptr [ebp-0ch] ; ebp-0ch 是新的 seh 链的结构地址(刚压入栈中的栈地址 mov dword ptr fs:0, eax ; 设置到 teb 中作为当前 active 的 seh 链表末尾 到此为止栈的内容是这样的: 低地址 security cookie after xor IAR 使用说明 关于文档(初版): 1.主要是为了给IAR的绝对新手作参考用 2.emot制件,由Zigbee & IAR 学习小组保持修订权 3.希望用IAR朋友能将它修订完善 4.任何人可无偿转载、传播本文档,无须申请许可,但请保留文档来源及标志 5.如无重大升级,请沿用主版本号 版本 版本号制作时间制定人/修改人说明 1.00 2008/7/27 emot 初版(仅供新手参考) 1.01 2010/8/19 Emot 增加 下载程序(第四章) 在线调试程序(第五章) 序: 其实IAR和keil区别也没有多大,不过很多人就是怕(当初我也怕)。怕什么呢,怕学会了,真的就是害怕学习的心理让新手觉得IAR是个不好用的或者说“还不会用的”一个工具吧。我也是一个刚毕业的小子,如果说得不妥,还请大家来点砖头,好让小组筑高起来。(Zigbee & IAR 学习小组地址是https://www.doczj.com/doc/415536351.html,/673) 初版我将会说明以下3个问题,IAR的安装、第一个IAR工程的建立和工作编译。这是我写的第一个使用说明,不足的以后补充吧。 一、IAR软件安装图解 1.打开IAR软件安装包进入安装界面 打开软件开发包 软件安装界面 2.按照提示步骤执行,一直到授权页面,输入序列号,IAR中有两层序列号,所以要输入两 组序列号。 输入第一组序列号 3.选择安装路径(最好默认,不默认也不影响使用) 路径选择页面 修改路径4.选择全部安装(Full) 选择全部安装5.按提示知道安装完成。 安装完成页面 二、新建第一个IAR工程 用IAR首先要新建的是工作区,而不是工程。在工作区里再建立工程,一个工作区里似乎也不能建多个工程(我试过,但没成功,不知道IAR里提出workspace的概念是为什么?)要不打IAR的help来看,说清楚也是头痛的事,先知道有要在工作空间里建工程就对了。新建IAR工作空间,首先是菜单File里选择Open再选择Workspace,为方便说明再遇到菜 单我就直接说成File-Open-Workspace这样了。看了下面图上的红圈就知道是怎么回事了。 接着就会看到一片空白。这时就是新的“办公区”了。 计算机寄存器分类简介: 32位CPU所含有的寄存器有: 4个数据寄存器(EAX、EBX、ECX和EDX) 2个变址和指针寄存器(ESI和EDI) 2个指针寄存器(ESP和EBP) 6个段寄存器(ES、CS、SS、DS、FS和GS) 1个指令指针寄存器(EIP) 1个标志寄存器(EFlags) 1、数据寄存器 数据寄存器主要用来保存操作数和运算结果等信息,从而节省读取操作数所需占用总线和访问存储器的时间。 32位CPU有4个32位的通用寄存器EAX、EBX、ECX和EDX。 对低16位数据的存取,不会影响高16位的数据。 这些低16位寄存器分别命名为:AX、BX、CX和DX,它和先前的CPU中的寄存器相一致。 4个16位寄存器又可分割成8个独立的8位寄存器(AX:AH-AL、BX:BH-BL、CX:CH-CL、DX:DH-DL),每个寄存器都有自己的名称,可独立存取。 程序员可利用数据寄存器的这种“可分可合”的特性,灵活地处理字/字节的信息。 寄存器EAX通常称为累加器(Accumulator),用累加器进行的操作可能需要更少时间。可用于乘、除、输入/输出等操作,使用频率很高; 寄存器EBX称为基地址寄存器(Base Register)。它可作为存储器指针来使用; 寄存器ECX称为计数寄存器(Count Register)。 在循环和字符串操作时,要用它来控制循环次数;在位操作中,当移多位时,要用CL来指明移位的位数; 寄存器EDX称为数据寄存器(Data Register)。在进行乘、除运算时,它可作为默认的操作数参与运算,也可用于存放I/O的端口地址。在16位CPU中,AX、BX、CX和DX不能作为基址和变址寄存器来存放存储单元的地址, 在32位CPU中,其32位寄存器EAX、EBX、ECX和EDX不仅可传送数据、暂存数据保存算术逻辑运算结果, 而且也可作为指针寄存器,所以,这些32位寄存器更具有通用性。 2、变址寄存器 32位CPU有2个32位通用寄存器ESI和EDI。 其低16位对应先前CPU中的SI和DI,对低16位数据的存取,不影响高16位的数据。 寄存器ESI、EDI、SI和DI称为变址寄存器(Index Register),它们主要用于存放存储单元在段内的偏移量, 用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。 变址寄存器不可分割成8位寄存器。作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。 它们可作一般的存储器指针使用。在字符串操作指令的执行过程中,对它们有特定的要求,而且还具有特殊的功能。 3、指针寄存器 其低16位对应先前CPU中的BP和SP,对低16位数据的存取,不影响高16位的数据。 32位CPU有2个32位通用寄存器EBP和ESP。 它们主要用于访问堆栈内的存储单元,并且规定: EBP为基指针(Base Pointer)寄存器,用它可直接存取堆栈中的数据; 汇编学习从入门到精通Step By Step 2007年12月15日星期六00:34 信息来源:https://www.doczj.com/doc/415536351.html,/hkbyest/archive/2007/07/22/1702065.aspx Cracker,一个充满诱惑的词。别误会,我这里说的是软件破解,想做骇客的一边去,这年头没人说骇客,都是“黑客”了,嘎嘎~ 公元1999年的炎热夏季,我捧起我哥留在家的清华黄皮本《IBM-PC汇编语言程序设计》,苦读。一个星期后我那脆弱的小心灵如玻璃般碎裂了,为了弥补伤痛我哭爹求妈弄了8k大洋配了台当时算是主流的PC,要知道那是64M内存!8.4G硬盘啊!还有传说中的Celeon 300A CPU。不过很可惜的是在当时那32k小猫当道的时代,没有宽带网络,没有软件,没有资料,没有论坛,理所当然我对伟大的计算机科学体系的第一步探索就此夭折,此时陪伴我的是那些盗版光盘中的游戏,把CRACK_XXX文件从光盘复制到硬盘成了时常的工作,偶尔看到光盘中的nfo 文件,心里也闪过一丝对破解的憧憬。 上了大学后有网可用了,慢慢地接触到了一些黑客入侵的知识,想当黑客是每一个充满好奇的小青年的神圣愿望,整天看这看那,偷偷改了下别人的网页就欢喜得好像第一次偷到鸡的黄鼠狼。 大一开设的汇编教材就是那不知版了多少次的《IBM-PC汇编语言程序设计》,凭着之前的那星期苦读,考试混了个80分。可惜当时头脑发热,大学60分万岁思想无疑更为主流,现在想想真是可惜了宝贵的学习时间。 不知不觉快毕业了,这时手头上的《黑客防线》,《黑客X档案》积了一大摞,整天注来注去的也厌烦了,校园网上的肉鸡一打一打更不知道拿来干什么。这时兴趣自然转向了crack,看着杂志上天书般的汇编代码,望望手头还算崭新的汇编课本,叹了口气,重新学那已经忘光了的汇编语言吧。咬牙再咬牙,看完寻址方式那章后我还是认输,不认不行啊,头快裂了,第三次努力终告失败。虽然此时也可以爆破一些简单的软件,虽然也知道搞破解不需要很多的汇编知识,但我还是固执地希望能学好这门基础中的基础课程。 毕业了,进入社会了,找工作,上班,换工作成了主流旋律,每天精疲力尽的哪有时间呢?在最初的中国移动到考公务员再到深圳再到家里希望的金融机构,一系列的曲折失败等待耗光了我的热情,我失业了,赋闲在家无所事事,唯一陪伴我的是那些杂志,课本,以及过时的第二台电脑。我不想工作,我对找工作有一种恐惧,我靠酒精麻醉自己,颓废一段日子后也觉得生活太过无聊了,努力看书考了个CCNA想出去,结果还是被现实的就业环境所打败。三年时间,一无所获。 再之后来到女朋友处陪伴她度过刚毕业踏入社会工作的适应时期,这段时间随便找了个电脑技术工作,每月赚那么个几百块做生活费。不过这半年让我收获比较大的就是时间充裕,接触到了不少新东西,我下定决心要把汇编学好,这时我在网上看到了别人推荐的王爽《汇编语言》,没抱什么希望在当当网购了人生中的第一次物,19块6毛,我记得很清楚,呵呵。 废话终于完了,感谢各位能看到这里,下面进入正题吧。 在bin文件中,就是一条条的机器指令,每条指令4个字节。 在ADS中打开一个.s文件,选择project->disassemble 可以看到汇编的机器码 汇编代码如下(ADS中的一个例程\ARM\ADSv1_2\Examples\asm\armex.s): AREA ARMex, CODE, READONL Y ; name this block of code ENTRY ; mark first instruction ; to execute start MOV r0, #10 ; Set up parameters MOV r1, #3 ADD r0, r0, r1 ; r0 = r0 + r1 stop MOV r0, #0x18 ; angel_SWIreason_ReportException LDR r1, =0x20026 ; ADP_Stopped_ApplicationExit SWI 0x123456 ; ARM semihosting SWI END ; Mark end of file 执行project->disassemble后: ** Section #1 'ARMex' (SHT_PROGBITS) [SHF_ALLOC + SHF_EXECINSTR + SHF_ENTRYSECT] Size : 28 bytes (alignment 4) start $a ARMex 0x00000000: e3a0000a .... MOV r0,#0xa 0x00000004: e3a01003 .... MOV r1,#3 0x00000008: e0800001 .... ADD r0,r0,r1 stop 0x0000000c: e3a00018 .... MOV r0,#0x18 0x00000010: e59f1000 .... LDR r1,0x18 0x00000014: ef123456 V4.. SWI 0x123456 $d 0x00000018: 00020026 &... DCD 131110 使用UltraEdit看bin文件如下: 可以看到,与上面的一样。 其中MOV的机器码如下(ARM体系结构pdf:p156): Windows X86-64位汇编语言入门 Windows X64汇编入门(1) 最近断断续续接触了些64位汇编的知识,这里小结一下,一是阶段学习的回顾,二是希望对64位汇编新手有所帮助。我也是刚接触这方面知识,文中肯定有错误之处,大家多指正。 文章的标题包含了本文的四方面主要内容: (1)Windows:本文是在windows环境下的汇编程序设计,调试环境为Windows Vista 64位版,调用的均为windows API。 (2)X64:本文讨论的是x64汇编,这里的x64表示AMD64和Intel的EM64T,而不包括IA64。至于三者间的区别,可自行搜索。 (3)汇编:顾名思义,本文讨论的编程语言是汇编,其它高级语言的64位编程均不属于讨论范畴。 (4)入门:既是入门,便不会很全。其一,文中有很多知识仅仅点到为止,更深入的学习留待日后努力。其二,便于类似我这样刚接触x64汇编的新手入门。 本文所有代码的调试环境:Windows Vista x64,Intel Core 2 Duo。 1. 建立开发环境 1.1 编译器的选择 对应于不同的x64汇编工具,开发环境也有所不同。最普遍的要算微软的MASM,在x64环境中,相应的编译器已经更名为ml64.exe,随Visual Studio 2005一起发布。因此,如果你是微软的忠实fans,直接安装VS2005既可。运行时,只需打开相应的64位命令行窗口(图1),便可以用ml64进行编译了。 第二个推荐的编译器是GoASM,共包含三个文件:GoASM编译器、GoLINK链接器和GoRC 资源编译器,且自带了Include目录。它的最大好外是小,不用为了学习64位汇编安装几个G 的VS。因此,本文的代码就在GoASM下编译。 第三个Yasm,因为不熟,所以不再赘述,感兴趣的朋友自行测试吧。 不同的编译器,语法会有一定差别,这在下面再说。 1.2 IDE的选择 搜遍了Internet也没有找到支持asm64的IDE,甚至连个Editor都没有。因此,最简单的方法是自行修改EditPlus的masm语法文件,这也是我采用的方法,至少可以得到语法高亮。当然,如果你懒得动手,那就用notepad吧。 没有IDE,每次编译时都要手动输入不少参数和选项,做个批处理就行了。 1.3 硬件与操作系统 硬件要求就是64位的CPU。操作系统也必须是64位的,如果在64位的CPU上安装了 OllyICE反汇编教程及汇编命令详解[转] 2009-02-11 08:09 OllyICE反汇编教程及汇编命令详解 内容目录 计算机寄存器分类简介 计算机寄存器常用指令 一、常用指令 二、算术运算指令 三、逻辑运算指令 四、串指令 五、程序跳转指令 ------------------------------------------ 计算机寄存器分类简介: 32位CPU所含有的寄存器有: 4个数据寄存器(EAX、EBX、ECX和EDX) 2个变址和指针寄存器(ESI和EDI) 2个指针寄存器(ESP和EBP) 6个段寄存器(ES、CS、SS、DS、FS和GS) 1个指令指针寄存器(EIP) 1个标志寄存器(EFlags) 1、数据寄存器 数据寄存器主要用来保存操作数和运算结果等信息,从而节省读取操作数所需占用总线和访问存储器的时间。 32位CPU有4个32位的通用寄存器EAX、EBX、ECX和EDX。 对低16位数据的存取,不会影响高16位的数据。 这些低16位寄存器分别命名为:AX、BX、CX和DX,它和先前的CPU中的寄存器相一致。4个16位寄存器又可分割成8个独立的8位寄存器(AX:AH-AL、BX:BH-BL、CX:CH-CL、DX:DH-DL),每个寄存器都有自己的名称,可独立存取。 程序员可利用数据寄存器的这种“可分可合”的特性,灵活地处理字/字节的信息。 寄存器EAX通常称为累加器(Accumulator),用累加器进行的操作可能需要更少时间。可用于乘、除、输入/输出等操作,使用频率很高; 寄存器EBX称为基地址寄存器(Base Register)。它可作为存储器指针来使用; 寄存器ECX称为计数寄存器(Count Register)。 在循环和字符串操作时,要用它来控制循环次数;在位操作中,当移多位时,要用CL来指明移位的位数; 寄存器EDX称为数据寄存器(Data Register)。在进行乘、除运算时,它可作为默认的操作数参与运算,也可用于存放I/O的端口地址。 在16位CPU中,AX、BX、CX和DX不能作为基址和变址寄存器来存放存储单元的地址,在32位CPU中,其32位寄存器EAX、EBX、ECX和EDX不仅可传送数据、暂存数据保存算术逻辑运算结果, 而且也可作为指针寄存器,所以,这些32位寄存器更具有通用性。 2、变址寄存器 32位CPU有2个32位通用寄存器ESI和EDI。 其低16位对应先前CPU中的SI和DI,对低16位数据的存取,不影响高16位的数据。 寄存器ESI、EDI、SI和DI称为变址寄存器(Index Register),它们主要用于存放存储单元在段内的偏移量, 汇编语言入门教程 对初学者而言,汇编的许多命令太复杂,往往学习很长时间也写不出一个漂漂亮亮的程序,以致妨碍了我们学习汇编的兴趣,不少人就此放弃。所以我个人看法学汇编,不一定要写程序,写程序确实不是汇编的强项,大家不妨玩玩DEBUG,有时CRACK出一个小软件比完成一个程序更有成就感(就像学电脑先玩游戏一样)。某些高深的指令事实上只对有经验的汇编程序员有用,对我们而言,太过高深了。为了使学习汇编语言有个好的开始,你必须要先排除那些华丽复杂的命令,将注意力集中在最重要的几个指令上(CMP LOOP MOV JNZ……)。但是想在啰里吧嗦的教科书中完成上述目标,谈何容易,所以本人整理了这篇超浓缩(用WINZIP、WINRAR…依次压迫,嘿嘿!)教程。大言不惭的说,看通本文,你完全可以“不经意”间在前辈或是后生卖弄一下DEBUG,很有成就感的,试试看!那么――这个接下来呢?――Here we go!(阅读时看不懂不要紧,下文必有分解) 因为汇编是通过CPU和内存跟硬件对话的,所以我们不得不先了解一下CPU和内存:(关于数的进制问题在此不提) CPU是可以执行电脑所有算术╱逻辑运算与基本I/O 控制功能的一块芯片。一种汇编语言只能用于特定的CPU。也就是说,不同的CPU其汇编语言的指令语法亦不相同。个人电脑由1981年推出至今,其CPU发展过程为:8086→80286→80386→80486→PENTIUM →……,还有AMD、CYRIX等旁支。后面兼容前面CPU的功能,只不过多了些指令(如多能奔腾的MMX指令集)、增大了寄存器(如386的32位EAX)、增多了寄存器(如486的FS)。为确保汇编程序可以适用于各种机型,所以推荐使用8086汇编语言,其兼容性最佳。本文所提均为8086汇编语言。寄存器(Register)是CPU内部的元件,所以在寄存器之间的数据传送非常快。用途:1.可将寄存器内的数据执行算术及逻辑运算。2.存于寄存器内的地址可用来指向内存的某个位置,即寻址。3.可以用来读写数据到电脑的周边设备。8086 有8个8位数据寄存器,这些8位寄存器可分别组成16位寄存器:AH&AL=AX:累加寄存器,常用于运算;BH&BL=BX:基址寄存器,常用于地址索引;CH&CL=CX:计数寄存器,常用于计数;DH&DL=DX:数据寄存器,常用于数据传递。为了运用所有的内存空间,8086设定了四个段寄存器,专门用来保存段地址:CS(Code Segment):代码段寄存器;DS(Data Segment):数据段寄存器;SS(Stack Segment):堆栈段寄存器;ES(Extra Segment):附加段寄存器。当一个程序要执行时,就要决定程序代码、数据和堆栈各要用到内存的哪些位置,通过设定段寄存器CS,DS,SS 来指向这些起始位置。通常是将DS固定,而根据需要修改CS。所以,程序可以在可寻址空间小于64K的情况下被写成任意大小。所以,程序和其数据组合起来的大小,限制在DS 所指的64K内,这就是COM文件不得大于64K的原因。8086以内存做为战场,用寄存器做为军事基地,以加速工作。除了前面所提的寄存器外,还有一些特殊功能的寄存器:IP(Intruction Pointer):指令指针寄存器,与CS配合使用,可跟踪程序的执行过程;SP(Stack Pointer):堆栈指针,与SS配合使用,可指向目前的堆栈位置。BP(Base Pointer):基址指针寄存器,可用作SS 的一个相对基址位置;SI(Source Index):源变址寄存器可用来存放相对于DS段之源变址指针;DI(Destination Index):目的变址寄存器,可用来存放相对于ES 段之目的变址指针。还有一个标志寄存器FR(Flag Register),有九个有意义的标志,将在下文用到时详细说明。 内存是电脑运作中的关键部分,也是电脑在工作中储存信息的地方。内存组织有许多可存放 第二章逆向与反汇编工具 知道了一些反汇编的背景知识后,在开始深入学习IDA pro之前,了解一些其他用于逆向工程的工具知识也会非常有用。这些工具大部分都要早于IDA出生并且依然是很好的快速分析二进制文件的工具,同时它们也可以用来与IDA对照。就如我们所见到的,IDA已把这些工具的许多功能都集合到了它的用户界面中,这为逆向工程提供了一个简一的,集成的环境。然而,尽管IDA拥有一个集成的调试器,但我们并不打算讨论它,因为单就这个主题就可以出本书了。 分类工具(Classification Tools) 当我们一开始遇到一个不熟悉的文件时,问一些比较简单的问题,如“这是什么文件”,通常会很有用的。回答这问题的首要原则就是千万不要依靠这文件的扩展名来决定它是什么类型的文件。这甚至也是第二、三、四条原则。一旦你已经明白了文件扩展名对确定文件的类型没有任何意义之后,你也就会考虑学习使用如下的几个工具了。 file file是一个标准的工具,存在于*NIX类操作系统和Windows下的Cygwin[1]程序中。file试图通过检查文件里的某些特定域来确认文件的类型。在某些情况下,file能检测出常见的字符串,如“#!/bin/sh”(shell 脚本文件),或“”(HTML 文件)。然而检测某些非ASCII 文件将会变得更加困难,在这种情况下,file首先判断该文件是否是符合某定已知的文件格式。在大多情况下,它是通过搜索一个唯一的已知特征值(通常被称为幻数(magic number)[2])来决定文件的类型的。下面的十六进制表列出了一些常用文件类型的幻数。 file可以识别大量的文件格式,这其中包括许多ASCII文本格式,许多可执行文件格式和一些数据文件格式。file使用magic file来管理幻数检测。不同的操作系统拥有不同的magic flie,但是一般情况下位于/usr/share/file/magic,/usr/share/misc/magic或/edt/magic文件里。请参阅file的文档查询更多关于magic file的信息。 1. 更多资料请访问https://www.doczj.com/doc/415536351.html,/. 2. 幻数(magic number)被很多文件格式规范用来表明该文件符合该文件格式。有时候幻数的选择还伴随着有趣的原由呢,如,MS-DOS可执行文件文件头的MZ特征值是由一位最初的MS-DOS结构师Mark Zbikowski的名字的每个单词的第一个字母组成,又如,十六进制数0xcafebabe是众所周知的Java .class文件的幻数,选择它仅公是因为它是一个很容易记的十六进制串。 汇编语言》-王爽-完美高清版-零基础汇编语言入门书籍PDF格式 同时按ctrl+要下载的地址既可下载对应的视频 下载地址:https://www.doczj.com/doc/415536351.html,/file/f61cb107c8 001第一章- 基础知识01 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6806f45b8 002第一章- 基础知识02 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6ec42d4d3 003第一章- 基础知识03 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6deb05ec4 004第一章-基础知识04 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6e51f6838 005第一章- 基础知识05 下载地址:https://www.doczj.com/doc/415536351.html,/file/f66edaf8d3 006第二章- 寄存器(CPU工作原理)01 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6d07e07b9 007第二章- 寄存器(CPU工作原理)02 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6d7f585a8 008第二章- 寄存器(CPU工作原理)03 下载地址:https://www.doczj.com/doc/415536351.html,/file/f639d8b3cf 009第二章- 寄存器(CPU工作原理)04 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6dcadbde6 010第二章- 寄存器(CPU工作原理)05 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6ea3f01c1 011第二章- 寄存器(CPU工作原理)06 下载地址:https://www.doczj.com/doc/415536351.html,/file/f65b96a06f 012第二章- 寄存器(CPU工作原理)07 下载地址:https://www.doczj.com/doc/415536351.html,/file/f682da085a 013第三章- 寄存器(内存访问)01 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6486e698 014第三章- 寄存器(内存访问)02 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6b7491d9f 015第三章- 寄存器(内存访问)03 下载地址:https://www.doczj.com/doc/415536351.html,/file/f622b7f9a7 016第三章- 寄存器(内存访问)04 下载地址:https://www.doczj.com/doc/415536351.html,/file/f64e2424b9 017第三章- 寄存器(内存访问)05 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6e5132d4d 018第三章- 寄存器(内存访问)06 下载地址:https://www.doczj.com/doc/415536351.html,/file/f655c10e86 019第三章- 寄存器(内存访问)07 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6b22e64e6 020第四章- 第一个程序01 下载地址:https://www.doczj.com/doc/415536351.html,/file/f6812126a4 计算机寄存器分类简介 32位CPU所含有的寄存器有: 4个数据寄存器(EAX、EBX ECX和EDX) 2个变址和指针寄存器(ESI和EDI) 2个指针寄存器(ESP和EBP) 6个段寄存器(ES、CS SS DS FS和GS) 1个指令指针寄存器(EIP) 1个标志寄存器(EFlags) 1、数据寄存器 数据寄存器主要用来保存操作数和运算结果等信息,从而节省读取操作数所需占用总线和访问存储器的时间。 32位CPU有4个32位的通用寄存器EAX EBX ECX和EDX 对低16位数据的存取,不会影响高16位的数据。 这些低16位寄存器分别命名为:AX、BX、CX和DX,它和先前的CPU中的寄存器相一致。 4个16位寄存器又可分割成8个独立的8位寄存器(AX:AH-AL、BX BH-BL、CX CH-CL、DX DH-DL),每个寄存器都有自己的名称,可独立存取。 程序员可利用数据寄存器的这种“可分可合”的特性,灵活地处理字/字节的信息。 寄存器EAX通常称为累加器(Accumulator),用累加器进行的操作可能需要更少时间。可用于乘、除、输入/输出等操作,使用频率很高; 寄存器EBX称为基地址寄存器(Base Register)。它可作为存储器指针来使用; 寄存器ECX称为计数寄存器(Count Register) 在循环和字符串操作时,要用它来控制循环次数;在位操作中,当移多位时,要用 CL来指明移位的位数; 寄存器EDX称为数据寄存器(Data Register)。在进行乘、除运算时,它可作为默认的操作数参与运算,也可用于存放I/O的端口地址。在16位CPU中,AX BX CX和DX不能作为基址和变址寄存器来存放存储单元的地址, 在32位CPU中,其32位寄存器EAX EBX ECX和EDX不仅可传送数据、暂存数据保存算术逻辑运算结果, 而且也可作为指针寄存器,所以,这些32位寄存器更具有通用性。 2、变址寄存器 32位CPU有2个32位通用寄存器ESI和EDI。 其低16位对应先前CPU中的SI和DI,对低16位数据的存取,不影响高16位的数据 寄存器ESI、EDI、SI和DI称为变址寄存器(Index Register),它们主要用于存放存储单元在段内的偏移量, 用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。 变址寄存器不可分割成8位寄存器。作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。 它们可作一般的存储器指针使用。在字符串操作指令的执行过程中,对它们有特定的要求,而且还具有特殊的功能。 3、指针寄存器 其低16位对应先前CPU中的BP和SP,对低16位数据的存取,不影响高16位的数据 32位CPU有2个32位通用寄存器EBP和ESR 它们主要用于访问堆栈内的存储单元,并且规定: 快速入门单片机汇编语 言 文档编制序号:[KKIDT-LLE0828-LLETD298-POI08] 快速入门单片机汇编语言 简要: 单片机有通用型和专用型之分。专用型是厂家为固定程序的执行专门开发研制的一种单片机,其程序不可更改。通用型单片机是常用的一种供学习或自主编制程序的单片机,其程序需要自己写入,可更改。单片机根据其基本操作处理位数不同可以分为:1位、4位、8位、16、32位单片机。 正文: 在此我们主要讲解美国ATMEL公司的89C51单片机。 一、89C51单片机PDIP(双列直插式)封装引脚图: 其引脚功能如下: P0口(—):为双向三态口,可以作为输入/输出口。但在实际应用中通常作为地址/数据总线口,即为低8位地址/数据总线分时复用。低8位地址在ALE信号的负跳变锁存到外部地址锁存器中,而高8位地址由P2口输出。 P1口(—):其每一位都能作为可编程的输入或输出线。 P2口(—):每一位也都可作为输入或输出线用,当扩展系统外设时,可作为扩展系统的地址总线高8位,与P0口一起组成16位地址总线。对89c51单片机来说,P2口一般只作为地址总线使用,而不作为I/O线直接与外设相连。 P3口(—):其为双功能口,作为第一功能使用时,其功能与P1口相同。当作为第二功能使用时,每一位功能如下表所示。 P3口第二功能 Rst\Vpd:上电复位端和掉电保护端。 XTAL1(xtal2):外接晶振一脚,分别接晶振的一端。 Gnd:电源地。 Vcc:电源正级,接+5V。 PROG\ALE:地址锁存控制端 PSEN:片外程序存储器读选通信号输出端,低电平有效。 EA\vpp:访问外部程序储存器控制信号,低电平有效。当EA为高电平时访问片内存储器,若超出范围则自动访问外部程序存储器。当EA为低电平时只访问外部程序存储器。 二、常用指令及其格式介绍: 1、指令格式: [标号:]操作码 [ 目的操作数][,操作源][;注释] 例如:LOOP:ADD A,#0FFH ;(A)←(A)+FFH 2、常用符号: Ri和Rn:R表示工作寄存器,i表示1和0,n表示0~7。 rel:相对地址、地址偏移量,主要用于无条件相对短转移指令和条件转移指令。 #data:包含于指令中的8位立即数。 #data16:包含于指令中的16位立即数。 ——啊冲 第二节常用汇编指令 说明:汇编语言也是一门语言,其指令相当的多,非常丰富,在此我只介绍几个常用的、简单的汇编指令,让大家与我一同入门。其实在超多的计算机知识领域里我和大家一样只是个学生而已。所以,我所要求的同学级别(本视频所针对的对象)是:有一点编程经验,对反汇编感兴趣、零基础的朋友。 堆栈操作指令PUSH和POP ?格式: PUSH XXXX ?POP XXXX ?功能: 实现压入操作的指令是PUSH指令;实现弹出操作的指令是POP指令. ? 加减法操作add和sub指令 ?格式: ADD XXXX1,XXXX2 ?功能: 两数相加 ?格式: SUB XXXX1,XXXXX2 ?功能: 两个操作数的相减,即从OPRD1中减去OPRD2,其结果放在OPDR1中. 调用和返回函数CALL和RET(RETN) ?过程调用指令CALL ?格式: CALL XXXX ?功能: 过程调用指令 ?返回指令RET ?格式: RET ?功能: 当调用的过程结束后实现从过程返回至原调用程序的下一条指令,本指令不影响标志位. ? 数据传送MOV 格式: MOV XXXX1,XXXX2 ?功能: 本指令将一个源操作数送到目的操作数中,即XXXX1<--XXXX2. ? 逻辑异或运算XOR ?格式: XOR OPRD1,OPRD2 ?功能: 实现两个操作数按位‘异或’运算,结果送至目的操作数中. ? 逻辑或指令OR ?格式: OR OPRD1,OPRD2 ?功能: OR指令完成对两个操作数按位的‘或’运算,结果送至目的操作数中,本指令可以进行字节或字的‘或’运算. 有效地址传送指令LEA ?格式: LEA OPRD1,OPRD2 ?功能: 将源操作数给出的有效地址传送到指定的的寄存器中. ?实际上,有时候lea用来做mov同样的事情,比如赋值: ?Lea edi,[ebp-0cch] ? 字符串存储指令STOS ?格式: STOS OPRD ?功能: 把AL(字节)或AX(字)中的数据存储到DI为目的串地址指针所寻址的存储器单元中去.指针DI将根据DF的值进行自动调整. ?说明:在VC的DEBUG版里经常用来为局部变量空间写上cccccccc指令 ? 比效指令CMP(CoMPare) ?格式: CMP OPRD1,OPRD2 ?功能: 对两数进行相减,进行比较. ?说明:经常与跳转指令相配合来形成循环或跳出操作 ? 跳转指令JXX ?JMP:无条件转移指令 内容目录 计算机寄存器分类简介 计算机寄存器常用指令 一、常用指令 二、算术运算指令 三、逻辑运算指令 四、串指令 五、程序跳转指令 ------------------------------------------ 计算机寄存器分类简介: 32位CPU所含有的寄存器有: 4个数据寄存器(EAX、EBX、ECX和EDX) 2个变址和指针寄存器(ESI和EDI) 2个指针寄存器(ESP和EBP) 6个段寄存器(ES、CS、SS、DS、FS和GS) 1个指令指针寄存器(EIP) 1个标志寄存器(EFlags) 1、数据寄存器 数据寄存器主要用来保存操作数和运算结果等信息,从而节省读取操作数所需占用总线和访问存储器的时间。 32位CPU有4个32位的通用寄存器EAX、EBX、ECX和EDX。 对低16位数据的存取,不会影响高16位的数据。 这些低16位寄存器分别命名为:AX、BX、CX和DX,它和先前的CPU中的寄存器相一致。 4个16位寄存器又可分割成8个独立的8位寄存器(AX:AH-AL、BX:BH-BL、CX:CH-CL、DX:DH-DL),每个寄存器都有自己的名称,可独立存取。 程序员可利用数据寄存器的这种“可分可合”的特性,灵活地处理字/字节的信息。 寄存器EAX通常称为累加器(Accumulator),用累加器进行的操作可能需要更少时间。可用于乘、除、输入/输出等操作,使用频率很高; 寄存器EBX称为基地址寄存器(Base Register)。它可作为存储器指针来使用; 寄存器ECX称为计数寄存器(Count Register)。 在循环和字符串操作时,要用它来控制循环次数;在位操作中,当移多位时,要用CL来指明移位的位数;寄存器EDX称为数据寄存器(Data Register)。在进行乘、除运算时,它可作为默认的操作数参与运算,也可用于存放I/O的端口地址。 在16位CPU中,AX、BX、CX和DX不能作为基址和变址寄存器来存放存储单元的地址, 在32位CPU中,其32位寄存器EAX、EBX、ECX和EDX不仅可传送数据、暂存数据保存算术逻辑运算结果, 而且也可作为指针寄存器,所以,这些32位寄存器更具有通用性。 2、变址寄存器 32位CPU有2个32位通用寄存器ESI和EDI。 其低16位对应先前CPU中的SI和DI,对低16位数据的存取,不影响高16位的数据。 寄存器ESI、EDI、SI和DI称为变址寄存器(Index Register),它们主要用于存放存储单元在段内的偏移量,用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。 变址寄存器不可分割成8位寄存器。作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。 它们可作一般的存储器指针使用。在字符串操作指令的执行过程中,对它们有特定的要求,而且还具有特殊的功能。 3、指针寄存器汇编语言 快速入门
软件破解入门教程
一个简单的C程序反汇编解析.
IAR -arm 入门教程
反汇编基础知识
6、汇编学习从入门到精通(荐书)
arm反汇编.
Windows X86-64位汇编语言入门
OllyICE反汇编教程及汇编命令详解
汇编语言入门
第二章逆向与反汇编工具
汇编语言-王爽-完美高清版视频教程
反汇编基础知识
快速入门单片机汇编语言
反汇编 第二节 常用汇编指令
反汇编语言常用指令
相关主题
文本预览