
数据审计系统的设计与分析
摘要:随着经济的迅猛发展,公司的数据规模的日益增大以致于人工审计工作变得更加复杂,鉴于此,设计一数据审计系统成当务之急,它的设计能够提高审计工作人员的工作效率,促进经济的进一步快速发展。
关键字:数据采集,SQL Server数据库,C#.NET
Abstract:With the rapid development of economics,the datas increasing of company make the clerk’s of Audit works get worse!whereas,to develop a data audit system is becoming the first work now.his born will improve the efficient of works and advance the economics’ development!
Key:data collect,SQL Server,C#.NET
1、引言
随着全球信息化建设的加快及计算机被广泛应用于企业的经营管理、财务管理、生产建设等方方面面,进一步加快了企业的信息化程度,企业的生产经营运作方方面面带的数据管理具有了网络化的新特点,信息化程度的加深对审计工作提出了挑战,是我们认识到设计计算机审计条件刻不容缓。随着经济的发展、公司规模化的不断扩大使得数据的规模不断增大以致在审计时得投入大量的人力、物力、财力。若能设计出一个简单的数据采集分析系统,则能根本性的解决审计人员工作量大的烦恼。所以设计一个数据采集分析系统迫在眉睫。有了它审计人员就可以通过其来进行数据方面简单的计算、统计、查询及筛选。研究本系统的根本目的就是为了解决手工审计耗时耗力的缺陷。
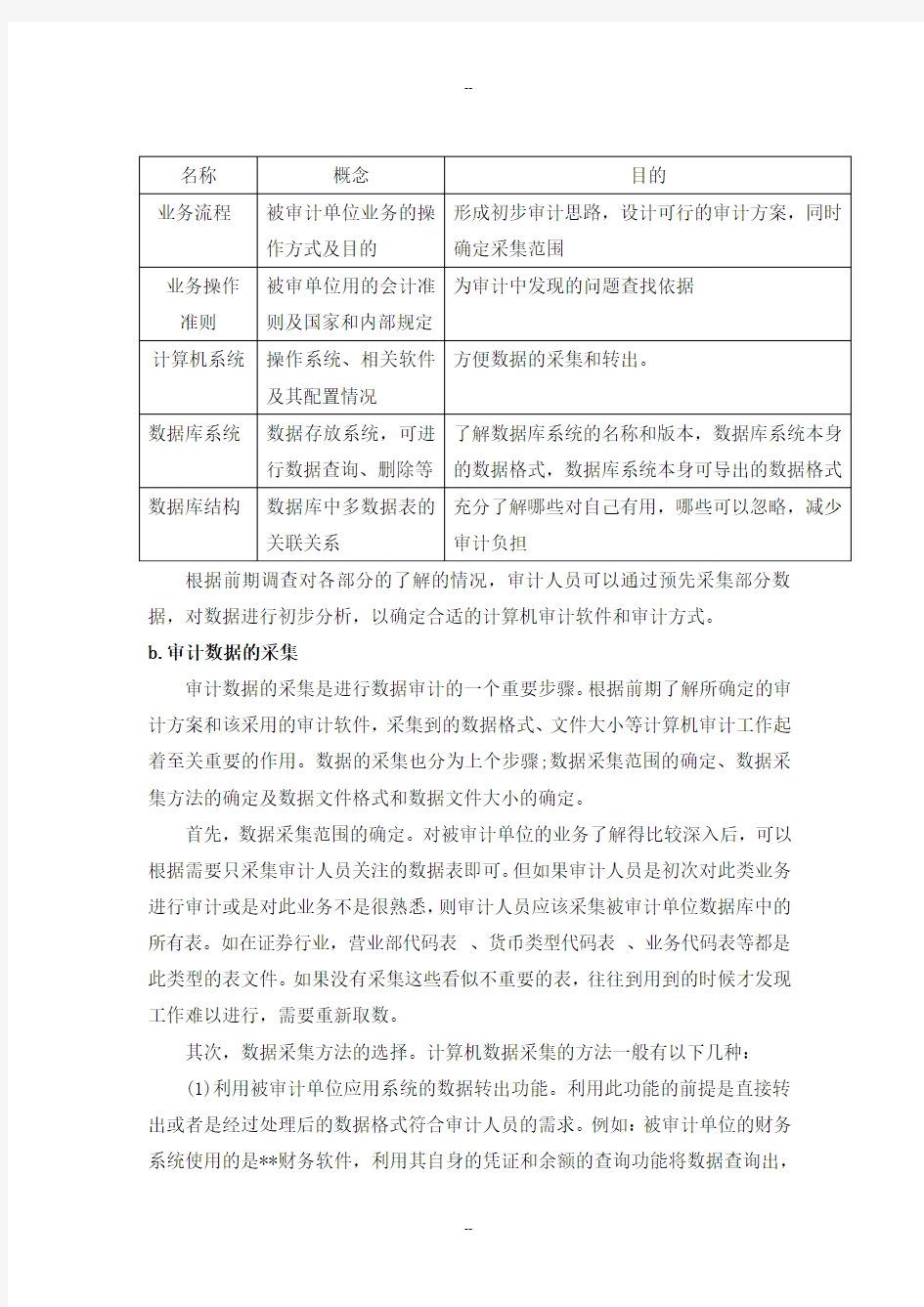
2、系统分析
a.前期调查
在审计之前要对被审计对象的基本情况进行了解,以便制定切实可行的审计方案,方便后续工作的展开。计算机审计方式的前期调查就如同系统设计前期的需求分析一样同样需要对被审计对象进行相关了解,而前期调查的内容主要有一下几个部分:
根据前期调查对各部分的了解的情况,审计人员可以通过预先采集部分数据,对数据进行初步分析,以确定合适的计算机审计软件和审计方式。
b.审计数据的采集
审计数据的采集是进行数据审计的一个重要步骤。根据前期了解所确定的审计方案和该采用的审计软件,采集到的数据格式、文件大小等计算机审计工作起着至关重要的作用。数据的采集也分为上个步骤;数据采集范围的确定、数据采集方法的确定及数据文件格式和数据文件大小的确定。
首先,数据采集范围的确定。对被审计单位的业务了解得比较深入后,可以根据需要只采集审计人员关注的数据表即可。但如果审计人员是初次对此类业务进行审计或是对此业务不是很熟悉,则审计人员应该采集被审计单位数据库中的所有表。如在证券行业,营业部代码表、货币类型代码表、业务代码表等都是此类型的表文件。如果没有采集这些看似不重要的表,往往到用到的时候才发现工作难以进行,需要重新取数。
其次,数据采集方法的选择。计算机数据采集的方法一般有以下几种:
(1)利用被审计单位应用系统的数据转出功能。利用此功能的前提是直接转出或者是经过处理后的数据格式符合审计人员的需求。例如:被审计单位的财务系统使用的是**财务软件,利用其自身的凭证和余额的查询功能将数据查询出,
然后利用其数据转出功能可将查询出的数据转存为.xls、.dbf、.txt文件。
(2)利用被审计单位业务系统所使用的数据库系统的转出功能。如:SQL数据库自身的”导入和导出数据”功能可以数据表全转存为其他格式文件。
(3)使用审计软件自带的数据转出工具软件。有的审计软件本身带有对特定软件的数据转出工具软件,其获取数据简单易行并完全符合审计软件的要求。例如:“审易”审计软件自身带有“Sqlserver备份数据取数”工具和“Sqlserver 数据取数”工具软件,可以方便的从SQL数据库备份数据和SQL数据库中将数据转存为.MDB格式文件。
(4)使用通用的数据转出工具ODBC。一般情况下,只要被审计单位的计算机系统中安装有数据库系统软件,都可以使用ODBC将数据库中的表全部导出,并可以选择导出多种常见的数据格式。例如:在对某证券公司审计时,其数据库为DB2,由于审计人员没有接触过此软件,我们直接使用ODBC将数据导出为ACCESS 文件。
虽说方法众多,但我们常用的方法是利用数据库本身的导入导出功能和ODBC方式,其他数据获取方式要根据本审计单位系统的功能和导出数据是否符合审计人员的要求确定。
最后,数据采集时数据文件的格式和大小。第一,采集数据的格式以满足审计人员的需求或审计软件的要求为标准,如果无法达到要求,则必须进行文件格式转换。第二,因审计人员的审计软件大多是小型数据库系统,其数据处理能力也是有限的,因此,采集数据前一定要确信所采集数据的大小未超过软件的处理能力,如果出现超过的情况这必须进行数据分割。如:采集了某公司的数据进行审计时发现文件打不开,分析原因认为此数据超过太大,超过了上年纪人员似乎据库系统的处理能力。在分析原始数据发现其存储的是3个年度的数据,再利用“导入和导出数据”功能按年度将数据导出为多个文件即可。
c.数据的处理和分析
大多数情况下,初次采集的业务数据进行审计前的整理,使其能较好的满足审计人员的需求。除数据采集过程种对数据格式和大小的处理之外对数据的处理还有以下几种:
(1)对关系表的处理。现实数据库系统低冗余度在具体的审计过程中给审计
人员也带来了诸多不便。比如在有些单位,其数据表中大多数字段的内容都是用代码来表示的,而代码的具体含义是由一个独立的表来说明的。在审计过程中,为了使审计人员对此有个直观的认识,就需要对这些表进行处理以便达到数据完整、直观的要求。当然,这步操作需视具体情况而定,如果代码很少或是审计人员熟悉就不需要做了。
(2)对字段类型的调整。字符型和某些特殊的其他类型是审计软件无法识别的,不便于审计人员利用其他工具软件对数据进行核算。出现类似的情况后,为了方便正常审计中的操作,就需要对某些字段的数据类型进行调整。
(3)分析数据结构。数据库表中的字段名称大多数是英文的,为了方便审计人员的使用需要将表字段名称转换为中文。在此过程重要特别注意金额型字段,因为有很多字段的英文名称都很相似。为了使数据看起来更直观,需要审计人员预先制作“标准帐表库”来修改字段的名称。再有就是取得的原始数据有很多字段可能对审计工作来说没有意义,为了简化数据可以将这些字段删除掉,但删除的前提是对表结构进行了全面地分析,并且要删除的字段对其他表来说也没有实质性的意义。
综上所述,数据的采集与处理是计算机审计的先决条件,为了能使计算机审计工作得以顺利开展,有效的降低审计人员的工作量,提高审计质量,规避审计风险,必须做好审计数据的采集与处理工作。
3、系统的设计
系统设计思想
本系统实现分析性和提高准确性。系统设计原则:第一;设计灵活、通用性强。本系统适用于任何投资人和审计人员对上市公司财务报告的分析。第二;页面简单、操作方便。使用本系统时,只要将需要的财务报表导入,然后选择相应的数据项查询分析即可实现对财务报表的审计。审计结果显示在系统中,清晰明了。第三;系统的安全性好。系统在本地计算机上运行,减少了网络中存在的风险;而且每一个用户在使用系统时都需要进行身份验证,避免了不同用户对分析结果的相互影响。第四;实现.xls和.dbf格式的互相转化,对导入的数据进行相关分层、分类查询和计算,旨在减少审计员手工审计的工作量,提高其工作效率和准确性。
系统总体结构设计
系统总体功能图如图2-1所示:
图2-1系统总体功能图
用户子模块功能图,如图2-2所示:
图2-2用户子模块功能图
用户子模块提供了超级管理员、普通用户的登陆两个功能。
用户在通过身份验证之后即可进行使用系统提供的五个功能。登录的方式很简单,只要输入用户名和相应的密码就可以了。其中超级管理员的默认用户名是admin,密码是123456,密码在系统中可以修改。超级管理员可以添加和查看普通用户。普通用户由超级管理员添加ID,默认密码是123456。普通用户在系统中可以修改密码。查询分析子模块设计功能图,如图2-3所示:
图2-3查询分析子模块图
用户在通过身份验证以后即可使用此功能模块提供的六个功能。
选择表,通过数据接口将通过导入生成的财务报表中的财务数据采集到本系
统的数据库内。
选择字段,每张表格中都有一些字段,但不是每个字段都是审计人员关心和需要审计的。此功能即可选择审计人员需要的字段,舍弃表格中多余的部分,有个表格简化的功能。
设置检索条件,财务报表中数据量庞大纷杂,而审计人员往往不需要审计所有数据,此功能提供了检索条件的设置,例如可以设置金额或者日期的范围来方便审计人员审计。如此审计人员即可方便查阅财务报表中金额较大、近期的相关数据。
计算字段,此功能可以添加报表中没有的字段,并且提供了新生字段的计算方法选择,例如:总金额=单价*数量。
排序,提供每个字段的数据排序功能,有升序,也有降序。例如可以按照单价以升序排序,如此可以方便审计人员整体了解财务信息,快速找到审查目标。同时可以双向排序,在按照单价以升序排序的同时,可以设置按照数量以降序排序。
显示结果,在这个模块中有生成sql语言功能,并且显示审计人员针对财务报表的操作结果,并且可以把结果以Excel表格的形式导出。
安全管理子模块设计:此子模块提供了系统安全管理功能,即审计人员临时离开电脑时点击系统锁定,系统即可返回登录界面,使用人员归来输入登录ID 和密码后即可回到离开时操作界面,操作数据系统自动保存。
系统管理模块:本模块功能提供用户(包括超级管理员和普通用户)修改密码功能。
用户管理模块:此模块供超级管理员使用,提供了用户查询和添加普通用户功能。用户查询可以查询包括超级管理员、普通管理员在内的所有用户ID,添加普通用户只需添加用户ID,系统共默认每个添加的普通用户密码都为123456,普通用户使用系统时可改密码。用户管理图如图2-4所示
图2-4用户管理图
系统实现是系统开发的代码编写阶段,在这个阶段包括系统的界面实现、系统的数据库实现系统的后台代码实现。
系统流程图
登陆模块流程图如图2-5所示:
图2-5登陆模块流程图
采集数据模块流程图如图2-6所示:
图2-6采集数据模块流程图用户属性图
用户属性图如图2-7所示:
图2-7 用户属性图
数据库设计
本系统采用了SQL2000 数据库,系统数据库名称为AUDITDB。数据库AUDITDB 中包含了2张数据表,以下为表的属性及字段说明:
(1) users(用户表):存放用户的信息。用户表如表2-1所示:
表2-1 用户表
字段名字段类型备注
userId nvarchar(50) 用户名,不可为空
Password nvarchar(50) 用户密码,不可为空
roletype bit 用户类型0和1 其中roletype设置用户类型:0为超级管理员;1为普通用户。
(2) Operate表 :用于记录用户对系统的操作。Operate表如表2-2所示:
表2-2 Operate表
数据库关系模式
系统关系模式如下(带有下划线的为主键):
用户(用户ID,用户密码,用户类型)
Operate(optid,Optuserid,Optcontent,Opttime)
数据库的代码实现
本系统是对公司的财务数据进行查询分析的,所以需要导入公司的财务数据,本系统主要针对公司的领料单、科目表、凭证表、入库单、商品销售表、余额表数据进行分析,所有数据均取自审计数据采集分析演示版2.0。Excel数据格式转化为sql server2000数据格式实现:
我在这里先定义了两种方法CallExcel()和 InsertSQLServer()。
CallExcel()方法用于获得一张临时存储Excel表格中数据的表dt,在这方法里定义了一个链接到需要转化的Excel表格的连接对象,用Select语句按照Sheet名查询到要导入的表格,接着用一个适配器关联连接对象和Select语句,再用Select语句把一个个单元格里的数据存储进dt表。而 InsertSQLServer ()是用来创建一张SqlServer表格,并把dt中的数据存储进这张表格中。在这个方法中先使用Select查询语句查看数据库中是否已有要建立的数据库,若没有则创建一个数据库,接着判断数据库是否已存在需要创建的表,若没有则创建新表。建表过程中先用Select语句查询到需要哪些字段,接着建立一张拥有这些字段的表格,用Select语句查询dt表格中每一个单元的数据,并一个一个单元的存储进SQl Server表格中。最后把结果显示在界面中。
4、系统实现
4.1开发工具介绍
在系统开发中,选用的是C#语言和Microsoft SQL Server 2000。
C#是一种简单、现代、面向对象和类型安全的编程语言,由C和C++发展而来。C#的目标在于把Visual Basic的高生产力和C++本身的能力结合起来。
C#作为Microsoft Visual Studio 7.0的一部分提供给用户。除了C#以外,Visual Studio还支持Visual Basic、Visual C++和描述语言VBScript和Jscript。所有这些语言都提供对Microsoft .NET平台的访问能力,它包括一个通用的执行引擎和一个丰富的类库。Microsoft .NET平台定义了一个“通用语言子集”(CLS),是一种混合语言,它可以增强CLS兼容语言和类库间的无缝协同工作能力。对于C#开发者,这意味着既是C#是一种新的语言,它已经可以对用老牌工具如Visual Basic和Visual C++使用的丰富类库进行完全访问。C#自己并没有包含一个类库。
SQL Server 是一个关系数据库管理系统,它最初是由Microsoft Sybase 和Ashton-Tate三家公司共同开发的,于1988 年推出了第一个OS/2 版本。在Windows NT 推出后,Microsoft与Sybase 在SQL Server 的开发上就分道扬镳了。Microsoft 将SQL Server 移植到Windows NT系统上专注于开发推广SQL Server 的Windows NT 版本,Sybase 则较专注于SQL Server在UNIX 操作系统上的应用。
Microsoft SQL Server 2000是美国微软公司推出的使用相当广泛的数据库管理系统,包含一套图形工具,如服务器管理(用于启动和关闭数据库服务)、企业管理器(用于创建和修改数据库及备份数据库等)和查询分析器(用于交互执行Transact-SQL 语句和过程并提供图形查询分析功能)等。
SQL Server 2000是为迅速提供可伸缩性电子商务、企业及数据仓库解决方案而开发的完整数据库与分析软件产品。SQL SERVER 2000定位于Internet背景下的数据库应用,它为用户的Web应用提供了一款完善的数据管理和数据分析解决方案。它极大地缩短了用户开发电子商务、数据仓库应用的时间。SQL SERVER 2000还提供对XML(Extensible Markup Language扩展标示语言支持)和HTTP的全方位支持。
在高性能和企业级可伸缩性领域,SQL Server 2000 设计成利用 Windows 2000 对更多处理器、更大的系统内存的支持,最终达到支持64位硬件平台。在不断提升可用性的努力过程中,SQL Server 2000 采用 Windows 2000 四路群集,提供了大大改进的群集支持。SQL Server 7.0 已经在可管理性和易用性方面在行业内领先,SQL Server 2000 通过与 Windows 2000 活动目录紧密结合进一步改进了这些功能。而且,SQL Server 2000 还包含对现有管理工具和实用程序的重大改进,并引入更具自我调节和自我管理的引擎功能。
SQL Server 2000 按照设计可以为部署和维护强大的、易于管理、支持商务活动的Web站点提供最好的性能,这些站点可以从事商家和商家之间或商家与客户之间的交易。在寻求一个支持您的电子商务解决方案的数据库时,需要考虑的项目包括:可用性、性能、可管理性和价格。
4.2系统实现
系统实现是系统开发的代码编写阶段,在这个阶段包括系统的界面实现、系统的数据库实现和系统的后台代码实现。
4.2.1系统界面实现
(1)登陆界面
通过对使用者的身份类别和密码的验证,满足以上条件的使用者才能进入相应的子系统,包括管理员和用户。管理员可以添加用户、删除已经注册的用户和对财务报表信息、历史数据信息进行维护,并且可以查看用户使用软件的记录,
电子商务公司网站分析几大模块 电子商务火热,客观上也让网站分析的需求激增,无论是出于何种目的,例如希望获得更多潜在客户,或是希望压缩成本,又或是希望提升用户体验,业务需求 一.业务需求: 1. 市场推广方式是否有效,以及能否进一步提效; 2. 访问网站的用户是否是目标用户,哪种渠道获取的用户更有价值(跟第一个需求有交集也有不同); 3. 用户对网站的感觉是好还是不好,除了商品本身之外的哪些因素影响用户的感觉; 4. 除了撒谎外,什么样的商业手段能够帮助说服客户购买; 5. 从什么地方能够进一步节约成本; 6. 新的市场机会在哪里,哪些未上架的商品能够带来新的收入增长。2.网站分析实施 1. 网站URL的结构和格式 2. 流量来源的标记 3. 端到端的ROI监测实施 4. 每个页面都正确置入了监测代码吗 三. 在线营销 1. SEO的效果衡量 2. SEM和硬广的效果衡量 3. EDM营销效果衡量 4. 所有营销方式的综合分析 4.网站上的影响、说服和转化 预置的影响点和说服点的评估 2. 识别潜在的影响点和说服点 3. 购物车和支付环节仍然是重中之重
五.访问者与网站的互动参与 访问者互动行为研究包括: (1)内部搜索分析; (2)新访问者所占的比例、数量趋势和来源; (3)旧访问者的访问数量趋势、比例和来源; (4)访问频次和访问间隔时间; (5)访问路径模式 商品研究包括: (1)关注和购买模型; (2)询价和购买模型;访问者来询价,还是来购买,在具体行为上是有区别的。 (3)内部搜索分析 其他重要的关联因素: 狭义的网站分析领域: 地域细分的销售额、访问者和商品关注情况; 客户端情况;例如操作系统,浏览器软件,带宽,访问网站的速度等等; 广义的网站分析领域: 网站分析测试:A/B测试和多变量测试 用户可用性测试; 调研; 用户人群属性研究; 站内IWOM分析; 站外IWOM分析 1. 市场推广方式是否有效,以及能否进一步提效; 网站分析能够全面衡量效果,并据此提效 2. 访问网站的用户是否是目标用户,哪种渠道获取的用户更有价值 3. 用户对网站的感觉是好还是不好,除了商品本身之外的哪些因素影响
大数据分析的六大工具介绍 2016年12月 一、概述 来自传感器、购买交易记录、网络日志等的大量数据,通常是万亿或EB的大小,如此庞大的数据,寻找一个合适处理工具非常必要,今天我们为大家分学在大数据处理分析过程中六大最好用的工具。 我们的数据来自各个方面,在面对庞大而复杂的大数据,选择一个合适的处理工具显得很有必要,工欲善其事,必须利其器,一个好的工具不仅可以使我们的工作事半功倍,也可以让我们在竞争日益激烈的云计算时代,挖掘大数据价值,及时调整战略方向。 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设il?的硬件和软件工具进行处理。该数据集通常是万亿或EB的大小。这些数据集收集自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章。大数据产生的其他例子包括购买交易记录、网络日志、病历、事监控、视频和图像档案、及大型电子商务。大数据分析是在研究大量的数据的过程中寻找模式, 相关性和其他有用的信息,可以帮助企业更好地适应变化,并做出更明智的决策。 二.第一种工具:Hadoop Hadoop是一个能够对大量数据进行分布式处理的软件框架。但是Hadoop是 以一种可黑、高效、可伸缩的方式进行处理的。Hadoop是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop还是可伸缩的,能够处理PB级数据。此外,Hadoop依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地 在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下儿个优点: ,高可黑性。Hadoop按位存储和处理数据的能力值得人们信赖。,高扩展性。Hadoop是 在可用的计?算机集簇间分配数据并完成讣算任务 的,这些集簇可以方便地扩展到数以千计的节点中。 ,高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动 态平衡,因此处理速度非常快。 ,高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败 的任务重新分配。 ,Hadoop带有用Java语言编写的框架,因此运行在Linux生产平台上是非 常理想的。Hadoop上的应用程序也可以使用其他语言编写,比如C++。 第二种工具:HPCC HPCC, High Performance Computing and Communications(高性能计?算与通信)的缩写° 1993年,山美国科学、工程、技术联邦协调理事会向国会提交了“重大挑战项 U:高性能计算与通信”的报告,也就是被称为HPCC计划的报告,即美国总统科学战略项U ,其U的是通过加强研究与开发解决一批重要的科学与技术挑战 问题。HPCC是美国实施信息高速公路而上实施的计?划,该计划的实施将耗资百亿 美元,其主要U标要达到:开发可扩展的计算系统及相关软件,以支持太位级网络 传输性能,开发千兆比特网络技术,扩展研究和教育机构及网络连接能力。
一、描述统计描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策 树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W 检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数卩与已知的某一总体均数卩0 (常为理论值或标准值)有无差别; B 配对样本t 检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t 检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10 以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析用于分析离散变量或定型变量之间是否存在相关。对于二维表,可进行卡 方检验,对于三维表,可作Mentel-Hanszel 分层分析列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以
《数据分析方法》 课程实验报告 1.实验内容 (1)掌握回归分析的思想和计算步骤; (2)编写程序完成回归分析的计算,包括后续的显著性检验、残差分析、Box-Cox 变换等内容。 2.模型建立与求解(数据结构与算法描述) 3.实验数据与实验结果 解:根据所建立的模型在MATLAB中输入程序(程序见附录)得到以下结果:(1)回归方程为: 说明该化妆品的消量和该城市人群收入情况关系不大,轻微影响,与使用该化妆品的人数有关。 的无偏估计: (2)方差分析表如下表: 方差来源自由度平方和均方值 回归() 2 5384526922 56795 2.28
误差()12 56.883 4.703 总和()14 53902 从分析表中可以看出:值远大于的值。所以回归关系显著。 复相关,所以回归效果显著。 解:根据所建立的模型,在MATLAB中输入程序(程序见附录)得到如下结果:(1)回归方程为: 在MTLAB中计算学生化残差(见程序清单二),所得到的学生化残差r的值由残差可知得到的r的值在(-1,1)的概率为0.645,在(-1.5,1.5)的概率为0.871,在(-2,2)之间的概率为0.968. 而服从正态分布的随机变量取值在(-1,1)之间的概率为0.68,在(-1.5,1.5)之间的概率为0.87,在(-2.2)之间的概率为0.95,所以相差较大,所以残差分析不合理,需要对数据变换。 取=0.6进行Box-Cox变换 在MATLAB中输入程序(见程序代码清单二) 取,所以得到r的值(r的值见附录二)其值在(-1,1)之间的个数大约为20/31=0.65,大致符合正态分布,所以重新拟合为: 拟合函数为: 通过F值,R值可以检验到,回归效果显著 (3)某医院为了了解病人对医院工作的满意程度和病人的年龄,病情的严重程度和病人的忧虑程度之间的关系,随机调查了该医院的23位病人,得数据如下表:
第二课显示管理系统 一、显示管理系统窗口 1.显示管理系统(Display Manager)三个主要窗口: ●PROGRAM EDITOR窗口:提供一个编写SAS程序的文本 编缉器 ●LOG窗口:显示有关程序运行的信息 ●OUTPUT窗口:显示程序运算结果的输出 2.显示管理系统的常用窗口 ●KEYS 查看及改变功能键的设置 ●LIBNAME 查看已经存在的SAS数据库 ●DIR 查看某个SAS数据库的内容 ●VAR 查看SAS数据集的有关信息 ●OPTIONS 查看及改变SAS的系统设置 假设我们准备自定义F12功能键为OPTIONS命令,打开KEYS窗口后在F12的右边的空白区键入OPTIONS,完毕之后在命令框中键入END命令退出KEYS窗口。 二、显示管理系统命令 1.显示管理系统命令的发布 有四种命令的发布方式都可达到相同结果。 ●在命令框中直接键入命令 ●按功能键 ●使用下拉式菜单 ●使用工具栏 例如,我们要增加一个OUTPUT窗口,相应地四种操作如下: ●命令框中直接键入OUTPUT和Enter ●功能键F7 ●Window/Output ●Options / Edit tools ①Add按钮选择Tool,新增了一个空白按钮 ②Command命令框中输入:OUTPUT;Help Text命令框中输入:Add new button create by DZX;Tip Text命令框中输入:Output。
③再单击Browse命令挑选一个合适的按钮。 ④单击Move Dn按钮将OUTPUT按钮移动到最后Help按钮之后。 ⑤单击Add按钮选择Separator,使Help按钮和新增OUTPUT命令按钮 之间有一个空白的分组间隙。 ⑥单击Save按钮。 2.文本编辑行命令 文本编辑行命令的主要作用是为在PROGRAM EDITOR窗口方便和高效地输入和修改SAS程序提供一组编辑命令。文本编辑行命令可归为两个子类: ●命令行命令——在命令框中输入NUMS命令 ●行命令——在行号上键入执行指定功能的字母来完成编辑功能 例如,我们在PROGRAM EDITOR窗口中的第一行到第三行输入假设的数据和程序:“Data and program line one ”,“Data and program line two”,“Data and program line three”。 若想在第1行与第2行之间插入空行: ●在第1行的行号前键入i(或I,或i1、I1) ●若想保存和调入程序: ●在命令框中键入:FILE "D:\SAS\ABC02.SAS" ●先把光标定位到指定某行,再在命令框中键入:INCLUDE "D:\SAS\ABC02.SAS" 三、SAS系统的几组重要命令 1.向SAS系统寻求帮助命令 ●F1键和F2键提供信息相当于简明的SAS使用手册 2.显示管理系统命令框常用命令 类型命令描述 显示管理命令BYE 退出SAS CLEAR [window-name] 清除指定的窗口中的内容 END 退出当前窗口 FILE "filename" 存储到指定文件 HELP 帮助 INCLUDE "filename" 引入指定文件 KEYS 进入KEYS窗口 LIBNAME 确认SAS数据库的内容 LOG 进入LOG窗口 NUMS 打开和关闭文本编辑器的数字区OPTIONS 进入OPTIONS窗口 OUTPUT 进入OUTPUT窗口
收稿日期:2008-05-04 作者简介:杨立波(1975-),男,工程师,主要从事调度自动化系统应用开发及维护。 全景数据分析系统在SCA DA 系统中的应用 Application of Full Scenario Data Analysis System in SCADA System 杨立波,杨玉瑞 (河北省电力公司,石家庄 050021) 摘要:介绍了河北省南部电网SCA DA 系统中全景数据记录分析系统的开发应用情况,详细阐述了全景数据分析系统在全景数据记录、全景数据回放、全景数据展现过程中所采用的压缩算法、存储算法、数据记录、数据反演等技术细节,并分析了该系统的应用效果,对其他SCAD A 系统相似功能的设计和实现有借鉴作用。 关键词:SCAD A 系统;全景数据;事故追忆;P DR Abstract :T his paper intro duce s the deve lopment and applica -tion o f the F ull Scena rio Data A nalysis Sy stem in the SCADA sy stem of H ebei South N etw ork ,and describes many de tails of the de sign and develo pment about full Scenario data r e -co rding ,data reg ene rating and data representation ,such a s the com pr ess algo rithm ,storag e method and file fo rmat .It is ho ped that ca n pro vide useful reference to the o ther SCADA sy stem structur es desig n and implement . Key words :SCA DA sy stem ;full scenario data ;po st disturb -ance review ;PD R 中图分类号:TM 734文献标志码:B 文章编号:1001-9898(2008)05-0015-03 河北省南部电网(简称“河北南网”)SCADA 系 统是2001年7月从加拿大SNC 公司引进的第三代能量控制系统。系统的事故追忆功能延用了传统的设计思想,完全依赖开关变位和总事故信号的触发,记录可靠性较差,数据断面记录间隔为2~10s ,仅能保存时长为5min 的事故,无法记录和再现较长时间的电网运行状况。随着电网规模的不断扩大和电网调度运行工作日益精细化,原有的PDR 功能已经不能满足需求,因此在SCADA 系统中自主开发了全景数据分析系统取代了原有事故追忆功能,并取得了良好的效果。 1 系统结构 全景数据分析系统是对SCADA 系统原有PDR 功能的改进、提高和创新,系统分为数据记录、 数据回放、数据展现3个主要部分。数据记录模块 位于SCADA 系统内,根据SCADA 采集节点发布的数据变化信息生成数据文件,并通过安全装置将数据文件传递到信息管理大区的全景数据文件FTP 服务器上,供数据回放和展现模块使用。数据回放是利用全景数据文件将电网当时的运行数据加载到内存中,实现快速的数据检索,断面保存,故障辨识等功能;数据展现是系统的人机界面部分,充分利用图表、曲线、列表、厂站单线图等形式将全景数据进行展现、分析和比对。系统结构示意见图1 。 图1 系统结构示意 2 系统功能的实现 2.1 全景数据记录 全景数据记录是系统的核心部分,负责对SCADA 系统中的实时数据进行采集、解码、压缩和记录。全景数据记录模块充分利用了SCADA 系统的编程环境和接口,实现了双机进程级的热备用和数据的同步;通过对压缩算法和文件读写方式的优化,使该模块进程仅占用1%~2%的CPU 负载,对原有的功能没有任何不利影响;通过配置独立磁盘和循环队列算法的文件存储模式,数据记录系统能够存储28天的全景数据文件,超过存储期限的数据通过安全装置传输到信息管理大区的文件备份系统长期保存。 · 15·
数据分析系统 操作手册 目录 一、前言 (2) 1.1、编写目的 (2) 1.2、读者对象 (2) 二、系统综述 (3) 2.1、系统架构 (3) 2.1.1系统浏览器兼容 (3) 三、功能说明 (4) 3.1、登录退出 (4) 3.1.1、登录 (4) 3.1.2、退出 (4) 3.1.3、用户信息 (5) 3.2、仪表盘 (5) 3.2.1、报表选择 (6) 3.2.2、布局方式 (7) 3.2.3、仪表盘管理 (8) 3.2.4、单个报表 (10) 3.3、应用中心 (13) 3.3.1、数据搜索 (13) 3.4、策略配置 (39)
3.4.1、数据采集 (39) 3.4.2、报表 (46) 3.4.3、数据类型 (53) 3.4.4、预设搜索 (58) 3.5、系统管理 (61) 3.5.1、代理注册设置 (61) 3.5.2、用户角色 (62) 3.5.3、系统用户 (65) 四、附件 (67) 一、前言 1.1、编写目的 本文档主要介绍日志分析系统的具体操作方法。通过阅读本文档,用户可以熟练的操作本系统,包括对服务器的监控、系统的设置、各类设备日志源的配置及采集,熟练使用日志查询、日志搜索功能,并掌握告警功能并能通过告警功能对及日志进行定位及分析。 1.2、读者对象 系统管理员:最终用户
项目负责人:即所有负责项目的管理人员 测试人员:测试相关人员 二、系统综述 2.1、系统架构 系统主界面为所有功能点的入口点,通过主菜单可快速定位操作项。系统主要分为四大模块,分别为 1):仪表盘 2):应用中心 3):策略配置 4):系统管理 2.1.1系统浏览器兼容 支持的浏览器 IE版本IE8至IE11等版本 Chrome 36及以上版本 Google chrome(谷歌 浏览器) Firefox 30及以以上版本 Mozilla Firefox (火 狐浏览器)
以下是我在近三年做各类计量和统计分析过程中感受最深的东西,或能对大家有所帮助。当然,它不是ABC的教程,也不是细致的数据分析方法介绍,它只是“总结”和“体会”。由于我所学所做均甚杂,我也不是学统计、数学出身的,故本文没有主线,只有碎片,且文中内容仅为个人观点,许多论断没有数学证明,望统计、计量大牛轻拍。 于我个人而言,所用的数据分析软件包括EXCEL、SPSS、STATA、EVIEWS。在分析前期可以使用EXCEL进行数据清洗、数据结构调整、复杂的新变量计算(包括逻辑计算);在后期呈现美观的图表时,它的制图制表功能更是无可取代的利器;但需要说明的是,EXCEL毕竟只是办公软件,它的作用大多局限在对数据本身进行的操作,而非复杂的统计和计量分析,而且,当样本量达到“万”以上级别时,EXCEL的运行速度有时会让人抓狂。 SPSS是擅长于处理截面数据的傻瓜统计软件。首先,它是专业的统计软件,对“万”甚至“十万”样本量级别的数据集都能应付自如;其次,它是统计软件而非专业的计量软件,因此它的强项在于数据清洗、描述统计、假设检验(T、F、卡方、方差齐性、正态性、信效度等检验)、多元统计分析(因子、聚类、判别、偏相关等)和一些常用的计量分析(初、中级计量教科书里提到的计量分析基本都能实现),对于复杂的、前沿的计量分析无能为力;第三,SPSS主要用于分析截面数据,在时序和面板数据处理方面功能了了;最后,SPSS兼容菜单化和编程化操作,是名副其实的傻瓜软件。 STATA与EVIEWS都是我偏好的计量软件。前者完全编程化操作,后者兼容菜单化和编程化操作;虽然两款软件都能做简单的描述统计,但是较之 SPSS差了许多;STATA与EVIEWS都是计量软件,高级的计量分析能够在这两个软件里得到实现;STATA的扩展性较好,我们可以上网找自己需要的命令文件(.ado文件),不断扩展其应用,但EVIEWS 就只能等着软件升级了;另外,对于时序数据的处理,EVIEWS较强。 综上,各款软件有自己的强项和弱项,用什么软件取决于数据本身的属性及分析方法。EXCEL适用于处理小样本数据,SPSS、 STATA、EVIEWS可以处理较大的样本;EXCEL、SPSS适合做数据清洗、新变量计算等分析前准备性工作,而STATA、EVIEWS在这方面较差;制图制表用EXCEL;对截面数据进行统计分析用SPSS,简单的计量分析SPSS、STATA、EVIEWS可以实现,高级的计量分析用 STATA、EVIEWS,时序分析用EVIEWS。 关于因果性 做统计或计量,我认为最难也最头疼的就是进行因果性判断。假如你有A、B两个变量的数据,你怎么知道哪个变量是因(自变量),哪个变量是果(因变量)? 早期,人们通过观察原因和结果之间的表面联系进行因果推论,比如恒常会合、时间顺序。但是,人们渐渐认识到多次的共同出现和共同缺失可能是因果关系,也可能是由共同的原因或其他因素造成的。从归纳法的角度来说,如果在有A的情形下出现B,没有A的情形下就没有B,那么A很可能是B的原因,但也可能是其他未能预料到的因素在起作用,所以,在进行因果判断时应对大量的事例进行比较,以便提高判断的可靠性。 有两种解决因果问题的方案:统计的解决方案和科学的解决方案。统计的解决方案主要指运用统计和计量回归的方法对微观数据进行分析,比较受干预样本与未接受干预样本在效果指标(因变量)上的差异。需要强调的是,利用截面数据进行统计分析,不论是进行均值比较、频数分析,还是方差分析、相关分析,其结果只是干预与影响效果之间因果关系成立的必要条件而非充分条件。类似的,利用截面数据进行计量回归,所能得到的最多也只是变量间的数量关系;计量模型中哪个变量为因变量哪个变量为自变量,完全出于分析者根据其他考虑进行的预设,与计量分析结果没有关系。总之,回归并不意味着因果关系的成立,因果关系的判定或推断必须依据经过实践检验的相关理论。虽然利用截面数据进行因果判断显得勉强,但如果研究者掌握了时间序列数据,因果判断仍有可为,其
数据分析报告范文 数据分析报告范文数据分析报告范文: 目录 第一章项目概述 此章包括项目介绍、项目背景介绍、主要技术经济指标、项目存在问题及推荐等。 第二章项目市场研究分析 此章包括项目外部环境分析、市场特征分析及市场竞争结构分析。 第三章项目数据的采集分析 此章包括数据采集的资料、程序等。第四章项目数据分析采用的方法 此章包括定性分析方法和定量分析方法。 第五章资产结构分析 此章包括固定资产和流动资产构成的基本状况、资产增减变化及原因分析、自西汉结构的合理性评价。 第六章负债及所有者权益结构分析 此章包括项目负债及所有者权益结构的分析:短期借款的构成状况、长期负债的构成状况、负债增减变化原因、权益增减变化分析和权益变化原因。 第七章利润结构预测分析
此章包括利润总额及营业利润的分析、经营业务的盈利潜力分析、利润的真实决定性分析。 第八章成本费用结构预测分析 此章包括总成本的构成和变化状况、经营业务成本控制状况、营业费用、管理费用和财务费用的构成和评价分析。 第九章偿债潜力分析此章包括支付潜力分析、流动及速动比率分析、短期偿还潜力变化和付息潜力分析。第十章公司运作潜力分析此章包括存货、流动资产、总资产、固定资产、应收账款及应付账款的周转天数及变化原因分析,现金周期、营业周期分析等。 第十一章盈利潜力分析 此章包括净资产收益率及变化状况分析,资产报酬率、成本费用利润率等变化状况及原因分析。 第十二章发展潜力分析 此章包括销售收入及净利润增长率分析、资本增长性分析及发展潜力状况分析。第十三章投资数据分析 此章包括经济效益和经济评价指标分析等。 第十四章财务与敏感性分析 此章包括生产成本和销售收入估算、财务评价、财务不确定性与风险分析、社会效益和社会影响分析等。 第十五章现金流量估算分析 此章包括全投资现金流量的分析和编制。
第一课SAS 系统简介 一.SAS 系统 1什么是SAS 系统 SAS 系统是一个模块化的集成软件系统。所谓软件系统就是一组在一起作业的计算机程序。 SAS 系统是一种组合软件系统。基本部分是Base SAS 软件 2 SAS 系统的功能 SAS 系统是大型集成应用软件系统,具有完备的以下四大功能: ●数据访问 ●数据管理 ●数据分析 ●数据显示 它是美国软件研究所(SAS Institute Inc.)经多年的研制于1976年推出。目前已被许多 国家和地区的机构所采用。SAS 系统广泛应用于金融、医疗卫生、生产、运输、通信、政府、科研和教育等领域。它运用统计分析、时间序列分析、运筹决策等科学方法进行质量管理、财务管理、生产优化、风险管理、市场调查和预测等等业务,并可将各种数据以灵活多样的各种报表、图形和三维透视的形式直观地表现出来。在数据处理和统计分析领域,SAS 系统一直被誉为国际上的标准软件系统。 3 SAS 系统的主要模块 SAS 系统包含了众多的不同的模块,可完成不同的任务,主要模块有: ●●●●●●●● ●●●SAS/BASE(基础)——初步的统计分析 SAS/STAT(统计)——广泛的统计分析 SAS/QC(质量控制)——质量管理方面的专门分析计算 SAS/OR(规划)——运筹决策方面的专门分析计算 SAS/ETS(预测)——计量经济的时间序列方面的专门分析计算 SAS/IML(距阵运算)——提供了交互矩阵语言 SAS/GRAPH(图形)——提供了许多产生图形的过程并支持众多的图形设备 SAS/ACCESS(外部数据库接口)——提供了与大多数流行数据库管理系统的方便接口并自身也能进行数据管理 SAS/ASSIST(面向任务的通用菜单驱动界面)——方便用户以菜单方式进行操作SAS/FSP(数据处理交互式菜单系统) SAS/AF(面向对象编程的应用开发工具) 另外SAS系统还将许多常用的统计方法分别集成为两个模块LAB和INSIGHT,供用户
大数据可视化分析平台 一、背景与目标 基于邳州市电子政务建设得基础支撑环境,以基础信息资源库(人口库、法人库、宏观经济、地理库)为基础,建设融合业务展示系统,提供综合信息查询展示、信息简报呈现、数据分析、数据开放等资源服务应用。实现市府领导及相关委办得融合数据资源视角,实现数据信息资源融合服务与创新服务,通过系统达到及时了解本市发展得综合情况,及时掌握发展动态,为政策拟定提供依据。 充分运用云计算、大数据等信息技术,建设融合分析平台、展示平台,整合现有数据资源結合政务大数据得分析能力与业务编排展示能力,以人口、法人、地理人口与地理法人与地理实现基础展示与分析,融合公安、交通、工业、教育、旅游等重点行业得数据综合分析,为城市管理、产业升级、民生保障提供有效支撑。 二、政务大数据平台 1、数据采集与交换需求:通过对各个委办局得指定业务数据进行汇聚,将分散得数据进行物理集中与整合管理,为实现对数据得分析提供数据支撑。将为跨机构得各类业务系统之间得业务协同,提供统一与集中得数据交互共享服务。包括数据交换、共享与ETL等功能。 2、海量数据存储管理需求:大数据平台从各个委办局得业务系统里抽取得数据量巨大,数据类型繁杂,数据需要持久化得存储与访问。不论就是结构化数据、半结构化数据,还就是非结构化数据,经过数据存储引擎进行建模后,持久化保存在存储系统上。存储系统要具备髙可靠性、快速查询能力。 3、数据计算分析需求:包括海量数据得离线计算能力、髙效即席数
据查询需求与低时延得实时计算能力。随着数据量得不断增加, 需要数据平台具备线性扩展能力与强大得分析能力,支撑不断增长得数据量,满足未来政务各类业务工作得发展需要,确保业务系统得不间断且有效地工作。 4、数据关联集中需求:对集中存储在数据管理平台得数据,通过正确得技术手段将这些离散得数据进行数据关联,即:通过分析数据间得业务关系,建立关键数据之间得关联关系,将离散得数据串联起来形成能表达更多含义信息集合,以形成基础库、业务库、知识库等数据集。 5、应用开发需求:依靠集中数据集,快速开发创新应用,支撑实际分析业务需要。 6、大数据分析挖掘需求:通过对海量得政务业务大数据进行分析与挖掘,辅助政务决策,提供资源配置分析优化等辅助决策功能,促进民生得发展。
修订日:2010.12.8实证论文数据分析方法详解 (周健敏整理) 名称变量类型在SPSS软件中的简称(自己设定的代号) 变革型领导自变量1 zbl1 交易型领导自变量2 zbl2 回避型领导自变量3 zbl3 认同和内部化调节变量 TJ 领导成员交换中介变量 ZJ 工作绩效因变量 YB 调节变量:如果自变量与因变量的关系是变量M的函数,称变量M为调节变量。也就是, 领 导风格(自变量)与工作绩效(因变量)的关系受到组织认同(调节变量)的影 响,或组织认同(调节变量)在领导风格(自变量)对工作绩效(因变量)影响 关系中起到调节作用。具体来说,对于组织认同高的员工,变革型领导对工作绩 效的影响力,要高于组织认同低的员工。 中介变量:如果自变量通过影响变量N 来实现对因变量的影响,则称N 为中介变量。也就 是,领导风格(自变量)对工作绩效(因变量)影响作用是通过领导成员交换(中 介变量)的中介而产生的。 研究思路及三个主要部分组成: (1)领导风格对于员工工作绩效的主效应(Main Effects)研究。 (2)组织认同对于不同领导风格与员工工作绩效之间关系的调节效应(Moderating Effects)研究。 (3)领导成员交换对于不同领导风格与员工工作绩效之间关系的中介效应(Mediator Effects)研究。
目录 1.《调查问卷表》中数据预先处理~~~~~~~~~~~~~~ 3 1.1 剔除无效问卷~~~~~~~~~~~~~~~~~~~~ 3 1.2 重新定义控制变量~~~~~~~~~~~~~~~~~~ 3 2. 把Excel数据导入到SPSS软件中的方法~~~~~~~~~~ 4 3. 确认所有的变量中有无“反向计分”项~~~~~~~~~~~4 3.1 无“反向计分”题~~~~~~~~~~~~~~~~~~ 5 3.2 有“反向计分”题~~~~~~~~~~~~~~~~~~ 5 4. 效度分析~~~~~~~~~~~~~~~~~~~~~~~~6 5. 信度分析~~~~~~~~~~~~~~~~~~~~~~~~8 6. 描述统计~~~~~~~~~~~~~~~~~~~~~~~~9 7. 各变量相关系数~~~~~~~~~~~~~~~~~~~~ 12 7.1 求均值~~~~~~~~~~~~~~~~~~~~~~~12 7.2 相关性~~~~~~~~~~~~~~~~~~~~~~~12 8. 回归分析~~~~~~~~~~~~~~~~~~~~~~~13 8.1 使用各均值来分别求Z值~~~~~~~~~~~~~~~13 8.2 自变量Z值与调节变量Z值的乘积~~~~~~~~~~~13 8.3 进行回归运算~~~~~~~~~~~~~~~~~~~~14 8.3.1 调节作用分析~~~~~~~~~~~~~~~~~~14 8.3.2 中介作用分析~~~~~~~~~~~~~~~~~~18 8.4 调节作用作图~~~~~~~~~~~~~~~~~~~~22
大数据处理综合处理服务平台的设计与实现 (广州城市职业学院广东广州510405) 摘要:在信息技术高速发展的今天,金融业面临的竞争日趋激烈,信息的高度共享和数据的安全可靠是系统建设中优先考虑的问题。大数据综合处理服务平台支持灵活构建面向数据仓库、实现批量作业的原子化、参数化、操作简单化、流程可控化,并提供灵活、可自定义的程序接口,具有良好的可扩展性。该服务平台以SOA为基础,采用云计算的体系架构,整合多种ETL技术和不同的ETL工具,具有统一、高效、可拓展性。该系统整合金融机构的客户、合约、交易、财务、产品等主要业务数据,提供客户视图、客户关系管理、营销管理、财务分析、质量监控、风险预警、业务流程等功能模块。该研究与设计打破跨国厂商在金融软件方面的垄断地位,促进传统优势企业走新型信息化道路,充分实现了“资源共享、低投入、低消耗、低排放和高效率”,值得大力发展和推广。 关键词:面向金融,大数据,综合处理服务平台。 一、研究的意义 目前,全球IT行业讨论最多的两个议题,一个是大数据分析“Big Data”,一个是云计算“Cloud Computing”。
中国五大国有商业银行发展至今,积累了海量的业务数据,同时还不断的从外界收集数据。据IDC(国际数据公司)预测,用于云计算服务上的支出在接下来的5 年间可能会出现3 倍的增长,占据IT支出增长总量中25%的份额。目前企业的各种业务系统中数据从GB、TB到PB量级呈海量急速增长,相应的存储方式也从单机存储转变为网络存储。传统的信息处理技术和手段,如数据库技术往往只能单纯实现数据的录入、查询、统计等较低层次的功能,无法充分利用和及时更新海量数据,更难以进行综合研究,中国的金融行业也不例外。中国五大国有商业银行发展至今,积累了海量的业务数据,同时还不断的从外界收集数据。通过对不同来源,不同历史阶段的数据进行分析,银行可以甄别有价值潜力的客户群和发现未来金融市场的发展趋势,针对目标客户群的特点和金融市场的需求来研发有竞争力的理财产品。所以,银行对海量数据分析的需求是尤为迫切的。再有,在信息技术高速发展的今天,金融业面临的竞争日趋激烈,信息的高度共享和数据的安全可靠是系统建设中优先考虑的问题。随着国内银行业竞争的加剧,五大国有商业银行不断深化以客户为中心,以优质业务为核心的经营理念,这对银行自身系统的不断完善提出了更高的要求。而“云计算”技术的推出,将成为银行增强数据的安全性和加快信息共享的速度,提高服务质量、降低成本和赢得竞争优势的一大选择。
决策分析系统APP端建设方案
目录 1. 概述 (3) 1.1. 项目背景 (3) 1.2. 建设目标 (3) 2. 设计方案 (4) 2.1. 系统建设的思路如下: (4) 2.2. 系统架构 (4) 2.3. 运行环境 (5) 2.4. 系统组成 (5) 3. 建设原则 (5) 3.1. 实用性 (5) 3.2. 先进性 (6) 3.3. 前瞻性和整体性 (6) 3.4. 集成性 (6) 3.5. 扩展性 (6) 3.6. 经济性 (6) 3.7. 可管理性和可维护性 (7) 3.8. 安全性 (7) 3.9. 稳定性和可靠性 (7) 3.10. 可重构性 (7) 3.11. 设计规范 (7) 4. 架构设计 (8) 5. 功能设计概述 (12) 6. 表样设计 (13)
1.概述 1.1.项目背景 移动互联,是基于“个人移动数字信息终端”(如:手机、平板电脑、PDA 等)接入互联网,用户在移动的状态下同时能使用的互联网的业务。移动设备能力不断加强,操作界面不断优化,外观时尚轻薄,能满足8小时以上的连续户外操作的需求,价格也不断下降,智能手机的用户不断增加;同时,随着中国联通、中国电信、中国移动等运营上的3G网络不断发展,覆盖面至少到乡镇一级,理论速度都提升少2M以上;根据摩根(Morgan)的报告,移动互联时代的设备将超过100亿台,一个“人人有手机、时时在移动、处处在互联”的时代,将势不可挡的来临,企业将移动互联网技术应到工作业务中,为工作人员的工作带来方便快捷。 XXXX在建的数据分析系统,为营销工作带来方便快捷的数据查询服务器,为了使用人员能在脱离办公场所在外的地方进行数据查询分析服务,应用移动互联网技术对数据分析系统进行模块升级扩展,建设数据分析系统APP移动客户端,方便使用人员在移动的环境下快速进行获数据查询分析工作,更有效率的开展工作。 1.2.建设目标 将先进的便携终端/移动通讯技术与现代卷烟营销模式紧密结合,不断提升卷烟营销运作、管理和决策支持水平。 (1)在管理决策层面,及时掌握卷烟营销情况,为决策、调度提供信息依据。充分利用营销业务数据库、经营分析数据库等为领导层搭建宏观层面的监控
数据分析指标体系 信息流、物流和资金流三大平台是电子商务的三个最为重要的平台。而电子商务信息系统最核心的能力是大数据能力,包括大数据处理、数据分析和数据挖掘能力。无论是电商平台还是在电商平台上销售产品的商户,都需要掌握大数据分析的能力。越成熟的电商平台,越需要以通过大数据能力驱动电子商务运营的精细化,更好的提升运营效果,提升业绩。因此构建系统的电子商务数据分析指标体系是数据电商精细化运营的重要前提。 电商数据分析指标体系可以分为八大类指标:包括总体运营指标、网站流量指标、销售转化指标、客户价值指标、商品类目指标、营销活动指标、风险控制指标和市场竞争指标。不同类别指标对应电商运营的不同环节,如网站流量指标对应的是网站运营环节,销售转化、客户价值和营销活动指标对应的是电商销售环节。能否灵活运用这些指标,将是决定电商平台运营成败的关键。 1.1.1.1总体运营指标 总订单数量:即访客完成网上下单的订单数之和。 销售金额:销售金额是指货品出售的金额总额。 客单价:即总销售金额与总订单数量的比值。 销售毛利:销售收入与成本的差值。销售毛利中只扣除了商品原始成本,不扣除没有计入成本的期间费用(管理费用、财务费用、营业费用)。
毛利率:衡量电商企业盈利能力的指标,是销售毛利与销售收入的比值。 ~ 1.1.1.2网站流量指标 独立访客数(UV):指访问电商网站的不重复用户数。对于PC网站,统计系统会在每个访问网站的用户浏览器上添加一个cookie来标记这个用户,这样每当被标记cookie的用户访问网站时,统计系统都会识别到此用户。在一定统计周期内如(一天)统计系统会利用消重技术,对同一cookie在一天内多次访问网站的用户仅记录为一个用户。而在移动终端区分独立用户的方式则是按独立设备计算独立用户。 页面访问数(PV):即页面浏览量,用户每一次对电商网站或者移动电商应用中的每个网页访问均被记录一次,用户对同一页面的多次访问,访问量累计。 人均页面访问数:即页面访问数(PV)/独立访客数(UV),该指标反映的是网站访问粘性。 单位访客获取成本:该指标指在流量推广中,广告活动产生的投放费用与广告活动带来的独立访客数的比值。单位访客成本最好与平均每个访客带来的收入以及这些访客带来的转化率进行关联分析。若单位访客成本上升,但访客转化率和单位访客收入不变或下降,则很可能流量推广出现问题,尤其要关注渠道推广的作弊问题。 跳出率(Bounce Rate):为浏览单页即退出的次数/该页访问次数,跳出率只能衡量该页做为着陆页面(LandingPage)的访问。如果花钱做推广,着落页的跳出率高,很可能是因为推广渠道选择出现失误,推广渠道目标人群和和被推广网站到目标人群不够匹配,导致大部分访客来了访问一次就离开。 页面访问时长:页访问时长是指单个页面被访问的时间。并不是页面访问时长越长越好,要视情况而定。对于电商网站,页面访问时间要结合转化率来看,如果页面访问时间长,但转化率低,则页面体验出现问题的可能性很大。 人均页面浏览量:人均页面浏览量是指在统计周期内,平均每个访客所浏览的页面量。人均页面浏览量反应的是网站的粘性。
常用数据分析方法详解 目录 1、历史分析法 2、全店框架分析法 3、价格带分析法 4、三维分析法 5、增长率分析法 6、销售预测方法 1、历史分析法的概念及分类 历史分析法指将与分析期间相对应的历史同期或上期数据进行收集并对比,目的是通过数据的共性查找目前问题并确定将来变化的趋势。 *同期比较法:月度比较、季度比较、年度比较 *上期比较法:时段比较、日别对比、周间比较、 月度比较、季度比较、年度比较 历史分析法的指标 *指标名称: 销售数量、销售额、销售毛利、毛利率、贡献度、交叉比率、销售占比、客单价、客流量、经营品数动销率、无销售单品数、库存数量、库存金额、人效、坪效 *指标分类: 时间分类 ——时段、单日、周间、月度、季度、年度、任意 多个时段期间 性质分类 ——大类、中类、小类、单品 图例 2框架分析法 又叫全店诊断分析法 销量排序后,如出现50/50、40/60等情况,就是什么都能卖一点但什么都不 好卖的状况,这个时候就要对品类设置进行增加或删减,因为你的门店缺少 重点,缺少吸引顾客的东西。 如果达到10/90,也是品类出了问题。 如果是20/80或30/70、30/80,则需要改变的是商品的单品。 *单品ABC分析(PSI值的概念) 销售额权重(0.4)×单品销售额占类别比+销售数量权重(0.3) × 单品销售数量占类别比+毛利额权重(0.3)单品毛利额占类别比 *类别占比分析(大类、中类、小类) 类别销售额占比、类别毛利额占比、 类别库存数量占比、类别库存金额占比、
类别来客数占比、类别货架列占比 表格例 3价格带及销售二维分析法 首先对分析的商品按价格由低到高进行排序,然后 *指标类型:单品价格、销售额、销售数量、毛利额 *价格带曲线分布图 *价格带与销售对数图 价格带及销售数据表格 价格带分析法 4商品结构三维分析法 *一种分析商品结构是否健康、平衡的方法叫做三维分析图。在三维空间坐标上以X、Y、Z 三个坐标轴分别表示品类销售占有率、销售成长率及利润率,每个坐标又分为高、低两段,这样就得到了8种可能的位置。 *如果卖场大多数商品处于1、2、3、4的位置上,就可以认为商品结构已经达到最佳状态。以为任何一个商品的品类销售占比率、销售成长率及利润率随着其商品生命周期的变化都会有一个由低到高又转低的过程,不可能要求所有的商品同时达到最好的状态,即使达到也不可能持久。因此卖场要求的商品结构必然包括:目前虽不能获利但具有发展潜力以后将成为销售主力的新商品、目前已经达到高占有率、高成长率及高利润率的商品、目前虽保持较高利润率但成长率、占有率趋于下降的维持性商品,以及已经决定淘汰、逐步收缩的衰退型商品。 *指标值高低的分界可以用平均值或者计划值。 图例 5商品周期增长率分析法 就是将一段时期的销售增长率与时间增长率的比值来判断商品所处生命周期阶段的方法。不同比值下商品所处的生命周期阶段(表示) 如何利用商品生命周期理论指导营运(图示) 6销售预测方法[/hide] 1.jpg (67.5 KB) 1、历史分析法