
我国农民收入影响因素的回归分析
自改革开放以来,虽然中国经济平均增长速度为9.5 % ,但二元经济结构给经济发展带来的问题仍然很突出。农村人口占了中国总人口的70 %多,农业产业结构不合理,经济不发达,以及农民收入增长缓慢等问题势必成为我国经济持续稳定增长的障碍。正确有效地解决好“三农”问题是中国经济走出困境,实现长期稳定增长的关键。其中,农民收入增长是核心,也是解决“三农”问题的关键。本文力图应用适当的多元线性回归模型,对有关农民收入的历史数据和现状进行分析,寻找其根源,探讨影响农民收入的主要因素,并在此基础上对如何增加农民收入提出相应的政策建议。
农民收入水平的度量,通常采用人均纯收入指标。影响农民收入增长的因素是多方面的,既有结构性矛盾因素,又有体制性障碍因素。但可以归纳为以下几个方面:一是农产品收购价格水平。目前农业收入仍是中西部地区农民收入的主要来源。二是农业剩余劳动力转移水平。中国的农业目前仍以农户分散经营为主,农业比较效益低,尽快地把农业剩余劳动力转移出去是有效改善农民收入状况的重要因素。三是城市化、工业化水平。中国多数地区城市化、工业化水平落后于世界平均水平,这种状况极大地影响了农民收入的增长。四是农业产业结构状况。农林牧渔业对农民收入增长贡献率是不同的。随着我国“入世”后农产品市场的开放和人民生活水平的提高、农产品需求市场的改变,农业结构状况直接影响着农民收入的增长。五是农业投入水平。农民收入与财政农业支出、农村集体投入、农户个人投入以及信贷投入都有显著的正相关关系。农业投入是农民收入增长的重要保证。但考虑到农业投入主体的多元性,既有国家、集体和农户的投入,又有银行、企业和外资的投入,考虑到复杂性和可行性,所以对农业投入与农民收入,本文暂不作讨论。因此,以全国为例,把农民收入与各影响因素关系进行线性回归分析,并建立数学模型。
一、计量经济模型分析
(一)、数据搜集
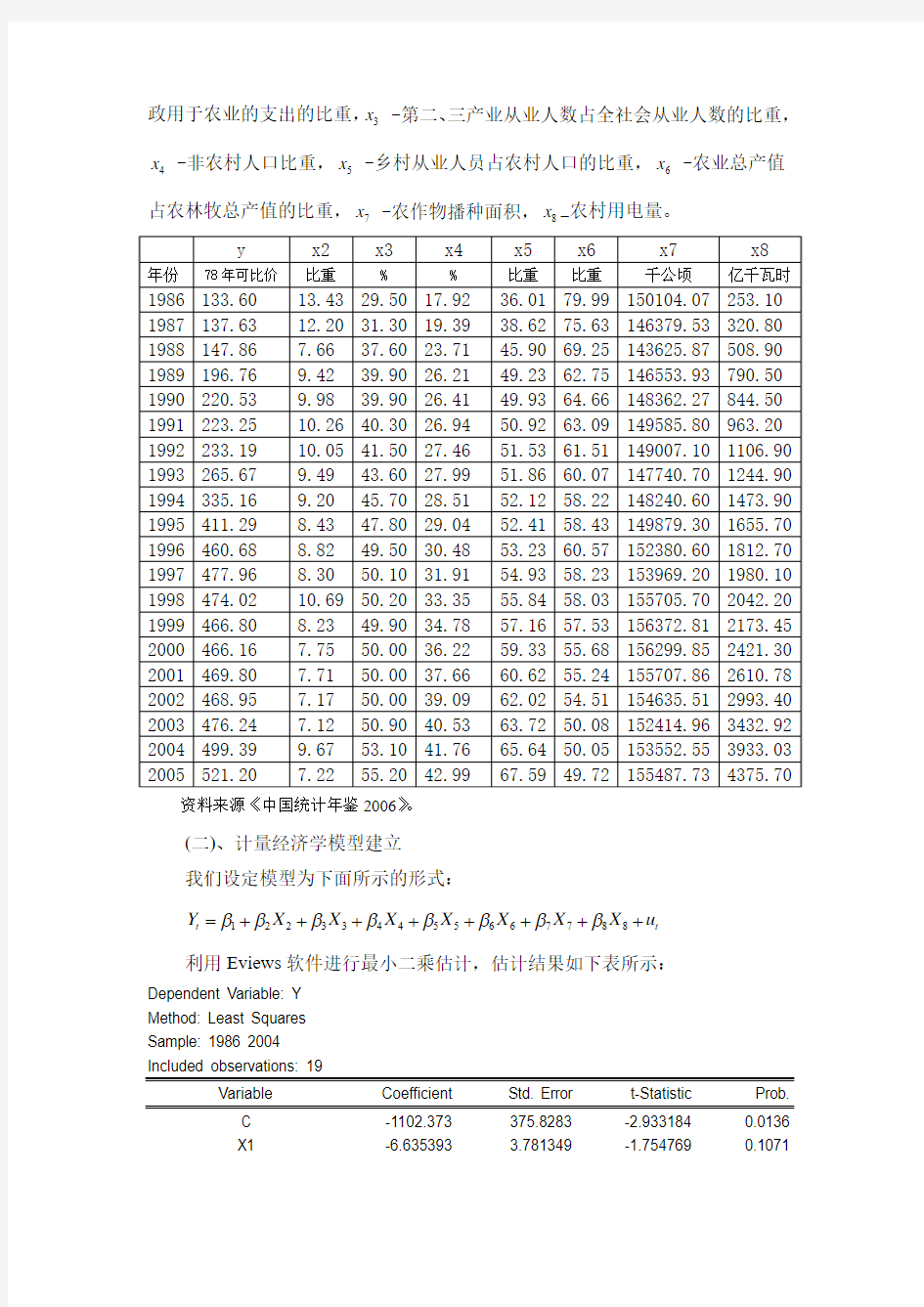
根据以上分析,我们在影响农民收入因素中引入7个解释变量。即:
x-财
2
政用于农业的支出的比重,3x -第二、三产业从业人数占全社会从业人数的比重,4x -非农村人口比重,5x -乡村从业人员占农村人口的比重,6x -农业总产值
占农林牧总产值的比重,7x -农作物播种面积,8x —农村用电量。
资料来源《中国统计年鉴2006》。
(二)、计量经济学模型建立 我们设定模型为下面所示的形式:
122334455667788t t Y X X X X X X X u ββββββββ=++++++++
利用Eviews 软件进行最小二乘估计,估计结果如下表所示:
Dependent Variable: Y Method: Least Squares Sample: 1986 2004 Variable Coefficient Std. Error t-Statistic Prob. C -1102.373 375.8283 -2.933184 0.0136 X1
-6.635393
3.781349
-1.754769
0.1071
X3 18.22942 2.066617 8.820899 0.0000 X4 2.430039 8.370337 0.290316 0.7770 X5 -16.23737 5.894109 -2.754847 0.0187 X6 -2.155208 2.770834 -0.777819 0.4531 X7 0.009962 0.002328 4.278810 0.0013 R-squared
0.995823 Mean dependent var 345.5232 Adjusted R-squared 0.993165 S.D. dependent var 139.7117 S.E. of regression 11.55028 Akaike info criterion 8.026857 Sum squared resid 1467.498 Schwarz criterion 8.424516 Log likelihood -68.25514 F-statistic 374.6600 Durbin-Watson stat
1.993270 Prob(F-statistic)
0.000000
表1 最小二乘估计结果
回归分析报告为:
()
()()()()()()()()()()()()()()()
2345678
2? -1102.373-6.6354X +18.2294X +2.4300X -16.2374X -2.1552X +0.0100X +0.0634X 375.83 3.7813 2.066618.37034 5.8941 2.77080.002330.02128 -2.933 1.7558.820900.20316 2.7550.778 4.27881 2.97930.99582i Y SE t R ===---=230.99316519 1.99327374.66
R Df DW F ====二、计量经济学检验
(一)、多重共线性的检验及修正
①、检验多重共线性 (a)、直观法
从“表1 最小二乘估计结果”中可以看出,虽然模型的整体拟合的很好,但是x4 x6的t 统计量并不显著,所以可能存在多重共线性。
(b)、相关系数矩阵
X2
X3
X4
X5
X6
X7
X8
X2 1.000000 -0.717662 -0.695257 -0.731326 0.737028 -0.332435 -0.594699 X3 -0.717662 1.000000 0.922286 0.935992 -0.945701 0.742251 0.883804 X4 -0.695257 0.922286 1.000000 0.986050 -0.937751 0.753928 0.974675 X5 -0.731326 0.935992 0.986050 1.000000 -0.974750 0.687439 0.940436 X6 0.737028 -0.945701 -0.937751 -0.974750 1.000000 -0.603539 -0.887428 X7 -0.332435 0.742251 0.753928 0.687439 -0.603539 1.000000 0.742781 X8
-0.594699 0.883804 0.974675 0.940436 -0.887428 0.742781 1.000000
表2 相关系数矩阵
从“表2 相关系数矩阵”中可以看出,个个解释变量之间的相关程度较高,所以应该存在多重共线性。
②、多重共线性的修正——逐步迭代法
A、一元回归
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
C 820.3133 151.8712 5.401374 0.0000
R-squared 0.372041 Mean dependent var 345.5232 Adjusted R-squared 0.335102 S.D. dependent var 139.7117 S.E. of regression 113.9227 Akaike info criterion 12.40822 Sum squared resid 220632.4 Schwarz criterion 12.50763 Log likelihood -115.8781 F-statistic 10.07183
表3 y对x2的回归结果
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
C -525.8891 64.11333 -8.202492 0.0000
R-squared 0.917421 Mean dependent var 345.5232 Adjusted R-squared 0.912563 S.D. dependent var 139.7117 S.E. of regression 41.31236 Akaike info criterion 10.37950 Sum squared resid 29014.09 Schwarz criterion 10.47892 Log likelihood -96.60526 F-statistic 188.8628 Durbin-Watson stat 0.598139 Prob(F-statistic) 0.000000
表4 y对x3的回归结果
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Variable Coefficient Std. Error t-Statistic Prob.
C -223.1905 69.92322 -3.191937 0.0053
X4 18.65086 2.242240 8.317956 0.0000 R-squared 0.802758 Mean dependent var 345.5232 Adjusted R-squared 0.791155 S.D. dependent var 139.7117 S.E. of regression 63.84760 Akaike info criterion 11.25018 Sum squared resid 69300.77 Schwarz criterion 11.34959 Log likelihood -104.8767 F-statistic 69.18839
表5 y对x4的回归结果
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Variable Coefficient Std. Error t-Statistic Prob.
C -494.1440 118.1449 -4.182526 0.0006
R-squared 0.751850 Mean dependent var 345.5232 Adjusted R-squared 0.737253 S.D. dependent var 139.7117 S.E. of regression 71.61463 Akaike info criterion 11.47978 Sum squared resid 87187.14 Schwarz criterion 11.57919 Log likelihood -107.0579 F-statistic 51.50691 Durbin-Watson stat 0.318959 Prob(F-statistic) 0.000002
表6 y对x5的回归结果
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Variable Coefficient Std. Error t-Statistic Prob.
C 1288.009 143.8088 8.956395 0.0000
X6 -15.52398 2.351180 -6.602635 0.0000 R-squared 0.719448 Mean dependent var 345.5232 Adjusted R-squared 0.702945 S.D. dependent var 139.7117 S.E. of regression 76.14674 Akaike info criterion 11.60250 Sum squared resid 98571.54 Schwarz criterion 11.70192 Log likelihood -108.2238 F-statistic 43.59479 Durbin-Watson stat 0.395893 Prob(F-statistic) 0.000004
表7 y对x6的回归结果
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Included observations: 19
C -4417.766 681.1678 -6.485577 0.0000
X7 0.031528 0.004507 6.994943 0.0000 R-squared 0.742148 Mean dependent var 345.5232 Adjusted R-squared 0.726980 S.D. dependent var 139.7117 S.E. of regression 73.00119 Akaike info criterion 11.51813 Sum squared resid 90595.96 Schwarz criterion 11.61754
Log likelihood -107.4222 F-statistic 48.92923 Durbin-Watson stat 0.572651 Prob(F-statistic) 0.000002
表8 y对x7的回归结果
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
C 140.1625 28.96616 4.838835 0.0002
R-squared 0.799739 Mean dependent var 345.5232 Adjusted R-squared 0.787959 S.D. dependent var 139.7117 S.E. of regression 64.33424 Akaike info criterion 11.26536 Sum squared resid 70361.21 Schwarz criterion 11.36478 Log likelihood -105.0209 F-statistic 67.88941
表9 y对x8的回归结果
综合比较表3~9的回归结果,发现加入x3的回归结果最好。以x3为基础顺次加入其他解释变量,进行二元回归,具体的回归结果如下表10~15所示:
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
C -754.4481 149.1701 -5.057637 0.0001
X3 21.78865 1.932689 11.27375 0.0000
X2 13.45070 8.012745 1.678663 0.1126 R-squared 0.929787 Mean dependent var 345.5232 Adjusted R-squared 0.921010 S.D. dependent var 139.7117 S.E. of regression 39.26619 Akaike info criterion 10.32254 Sum squared resid 24669.34 Schwarz criterion 10.47167 Log likelihood -95.06417 F-statistic 105.9385 Durbin-Watson stat 0.595954 Prob(F-statistic) 0.000000
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
C -508.6781 75.73220 -6.716802 0.0000
X3 17.88200 3.752121 4.765837 0.0002
R-squared 0.918481 Mean dependent var 345.5232 Adjusted R-squared 0.908291 S.D. dependent var 139.7117 S.E. of regression 42.30965 Akaike info criterion 10.47185 Sum squared resid 28641.71 Schwarz criterion 10.62097 Log likelihood -96.48254 F-statistic 90.13613
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Included observations: 19
C -498.1550 67.21844 -7.410986 0.0000
X3 23.97516 3.967183 6.043370 0.0000
R-squared 0.924405 Mean dependent var 345.5232 Adjusted R-squared 0.914956 S.D. dependent var 139.7117 S.E. of regression 40.74312 Akaike info criterion 10.39639 Sum squared resid 26560.02 Schwarz criterion 10.54551 Log likelihood -95.76570 F-statistic 97.82772
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Included observations: 19
C -1600.965 346.9265 -4.614709 0.0003
X3 29.93768 3.534753 8.469528 0.0000
X6 9.980135 3.184176 3.134291 0.0064 R-squared 0.948835 Mean dependent var 345.5232 Adjusted R-squared 0.942440 S.D. dependent var 139.7117 S.E. of regression 33.51927 Akaike info criterion 10.00606 Sum squared resid 17976.66 Schwarz criterion 10.15518 Log likelihood -92.05754 F-statistic 148.3576 Durbin-Watson stat 1.125188 Prob(F-statistic) 0.000000
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Variable Coefficient Std. Error t-Statistic Prob.
C -2153.028 327.1248 -6.581673 0.0000
X3 14.40497 1.358355 10.60472 0.0000
R-squared 0.967884 Mean dependent var 345.5232 Adjusted R-squared 0.963869 S.D. dependent var 139.7117 S.E. of regression 26.55648 Akaike info criterion 9.540364 Sum squared resid 11283.94 Schwarz criterion 9.689485 Log likelihood -87.63345 F-statistic 241.0961
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Included observations: 19
C -400.5635 103.0301 -3.887832 0.0013
X3 15.54271 2.916358 5.329493 0.0001
R-squared 0.927840 Mean dependent var 345.5232 Adjusted R-squared 0.918820 S.D. dependent var 139.7117 S.E. of regression 39.80687 Akaike info criterion 10.34990 Sum squared resid 25353.40 Schwarz criterion 10.49902 Log likelihood -95.32401 F-statistic 102.8643 Durbin-Watson stat 0.559772 Prob(F-statistic) 0.000000
综合表10~15所示,加入x7的模型的R最大,以x3、x7为基础顺次加入其他解释变量,进行三元回归,具体回归结果如下表16~20所示:
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
C -2133.921 340.6965 -6.263406 0.0000
X3 14.96023 2.094645 7.142134 0.0000
X7 0.011843 0.002786 4.250908 0.0007
R-squared 0.968153 Mean dependent var 345.5232 Adjusted R-squared 0.961783 S.D. dependent var 139.7117 S.E. of regression 27.31242 Akaike info criterion 9.637224
Sum squared resid 11189.52 Schwarz criterion 9.836053 Log likelihood -87.55363 F-statistic 151.9988 Durbin-Watson stat 0.712258 Prob(F-statistic) 0.000000
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
C -2226.420 353.4425 -6.299243 0.0000
X3 15.66729 2.443113 6.412839 0.0000
X7 0.012703 0.002589 4.906373 0.0002
R-squared 0.968705 Mean dependent var 345.5232 Adjusted R-squared 0.962445 S.D. dependent var 139.7117 S.E. of regression 27.07472 Akaike info criterion 9.619741 Sum squared resid 10995.60 Schwarz criterion 9.818571 Log likelihood -87.38754 F-statistic 154.7677 Durbin-Watson stat 0.704178 Prob(F-statistic) 0.000000
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Included observations: 19
C -2110.381 306.2690 -6.890613 0.0000
X3 18.60156 2.617381 7.106937 0.0000
X7 0.012139 0.002285 5.311665 0.0001
R-squared 0.973760 Mean dependent var 345.5232 Adjusted R-squared 0.968512 S.D. dependent var 139.7117 S.E. of regression 24.79152 Akaike info criterion 9.443544 Sum squared resid 9219.289 Schwarz criterion 9.642373 Log likelihood -85.71367 F-statistic 185.5507
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Included observations: 19
C -2418.859 323.7240 -7.471979 0.0000
X3 20.99887 3.397120 6.181374 0.0000
X7 0.009920 0.002495 3.976660 0.0012
X6 5.359184 2.571950 2.083705 0.0547 R-squared 0.975093 Mean dependent var 345.5232 Adjusted R-squared 0.970112 S.D. dependent var 139.7117 S.E. of regression 24.15359 Akaike info criterion 9.391407 Sum squared resid 8750.940 Schwarz criterion 9.590236 Log likelihood -85.21837 F-statistic 195.7489 Durbin-Watson stat 1.084023 Prob(F-statistic) 0.000000
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Variable Coefficient Std. Error t-Statistic Prob.
C -2013.355 361.8657 -5.563818 0.0001
X3 13.01578 2.032420 6.404078 0.0000
X7 0.011615 0.002558 4.540322 0.0004
X8 0.012375 0.013416 0.922401 0.3709 R-squared 0.969608 Mean dependent var 345.5232 Adjusted R-squared 0.963529 S.D. dependent var 139.7117 S.E. of regression 26.68115 Akaike info criterion 9.590455 Sum squared resid 10678.26 Schwarz criterion 9.789285 Log likelihood -87.10933 F-statistic 159.5158 Durbin-Watson stat 0.672264 Prob(F-statistic) 0.000000
综合上述表16~20的回归结果所示,其中加入x6的回归结果最好,以x3 x6 x7为基础一次加入其他解释变量,作四元回归估计,估计结果如表21~24所示:
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
C -2405.108 339.7396 -7.079269 0.0000
X3 21.26850 3.699787 5.748573 0.0001
X6 5.310543 2.665569 1.992273 0.0662
X7 0.009689 0.002766 3.503386 0.0035
R-squared 0.975187 Mean dependent var 345.5232 Adjusted R-squared 0.968098 S.D. dependent var 139.7117 S.E. of regression 24.95411 Akaike info criterion 9.492888
Sum squared resid 8717.904 Schwarz criterion 9.741424 Log likelihood -85.18244 F-statistic 137.5567 Durbin-Watson stat 1.082771 Prob(F-statistic) 0.000000
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
C -2401.402 316.2980 -7.592215 0.0000
X3 22.10570 3.420783 6.462174 0.0000
X6 9.089033 3.781330 2.403660 0.0307
X7 0.007086 0.003247 2.182005 0.0466
R-squared 0.977847 Mean dependent var 345.5232 Adjusted R-squared 0.971517 S.D. dependent var 139.7117 S.E. of regression 23.57887 Akaike info criterion 9.379513 Sum squared resid 7783.481 Schwarz criterion 9.628049 Log likelihood -84.10537 F-statistic 154.4909
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Variable Coefficient Std. Error t-Statistic Prob.
C -2375.188 430.7065 -5.514631 0.0001
X3 20.83493 3.657414 5.696629 0.0001
X6 4.629196 5.252860 0.881272 0.3930
X7 0.010217 0.003171 3.221953 0.0061
R-squared 0.975139 Mean dependent var 345.5232 Adjusted R-squared 0.968036 S.D. dependent var 139.7117 S.E. of regression 24.97818 Akaike info criterion 9.494817 Sum squared resid 8734.736 Schwarz criterion 9.743353 Log likelihood -85.20076 F-statistic 137.2849 Durbin-Watson stat 1.023211 Prob(F-statistic) 0.000000
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Included observations: 19
C -2212.242 259.5324 -8.523951 0.0000
X3 22.06629 2.662231 8.288647 0.0000
X6 9.595653 2.380088 4.031638 0.0012
X7 0.006115 0.002260 2.705978 0.0171
R-squared 0.985936 Mean dependent var 345.5232 Adjusted R-squared 0.981918 S.D. dependent var 139.7117 S.E. of regression 18.78702 Akaike info criterion 8.925144 Sum squared resid 4941.332 Schwarz criterion 9.173681 Log likelihood -79.78887 F-statistic 245.3639
综合表21~24所示的回归结果,其中加入x8的回归结果最好,以x3 x6 x7 x8为基础顺次加入其他的解释变量,其回归结果如表25~27所示:
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Included observations: 19
C -2207.020 272.6061 -8.096005 0.0000
X3 22.17495 2.903190 7.638133 0.0000
X6 9.566731 2.480057 3.857464 0.0020
X7 0.006028 0.002451 2.458949 0.0287
X8 0.036846 0.011674 3.156195 0.0076
R-squared 0.985952 Mean dependent var 345.5232 Adjusted R-squared 0.980549 S.D. dependent var 139.7117 S.E. of regression 19.48522 Akaike info criterion 9.029279 Sum squared resid 4935.759 Schwarz criterion 9.327523 Log likelihood -79.77815 F-statistic 182.4791
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Included observations: 19
C -1373.136 279.4825 -4.913137 0.0003
X3 20.09330 1.928486 10.41921 0.0000
X6 0.480401 2.845972 0.168800 0.8686
X7 0.008497 0.001692 5.021410 0.0002
X8 0.060502 0.009873 6.128146 0.0000
X5 -11.23292 2.844094 -3.949560 0.0017 R-squared 0.993607 Mean dependent var 345.5232 Adjusted R-squared 0.991148 S.D. dependent var 139.7117 S.E. of regression 13.14457 Akaike info criterion 8.241984 Sum squared resid 2246.136 Schwarz criterion 8.540228 Log likelihood -72.29885 F-statistic 404.1009 Durbin-Watson stat 1.704834 Prob(F-statistic) 0.000000
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
Variable Coefficient Std. Error t-Statistic Prob.
C -2056.366 236.8112 -8.683569 0.0000
X3 20.60220 2.413096 8.537661 0.0000
X6 5.264834 2.804292 1.877420 0.0831
X7 0.008853 0.002306 3.839446 0.0020
X8 0.071742 0.018026 3.980036 0.0016
X4 -9.861231 4.279624 -2.304228 0.0384 R-squared 0.990014 Mean dependent var 345.5232 Adjusted R-squared 0.986174 S.D. dependent var 139.7117 S.E. of regression 16.42798 Akaike info criterion 8.687938 Sum squared resid 3508.420 Schwarz criterion 8.986182 Log likelihood -76.53541 F-statistic 257.7752 Durbin-Watson stat 1.965748 Prob(F-statistic) 0.000000
据表25~27所示,分别加入x2 x4 x5后R均有所增加,但是参数的T检验均不显著,所以最终的计量模型如下表所示:
Dependent Variable: Y
Method: Least Squares
Sample: 1986 2004
C -2212.242 259.5324 -8.523951 0.0000
X3 22.06629 2.662231 8.288647 0.0000
X6 9.595653 2.380088 4.031638 0.0012
X7 0.006115 0.002260 2.705978 0.0171 R-squared 0.985936 Mean dependent var 345.5232
Adjusted R-squared 0.981918 S.D. dependent var 139.7117 S.E. of regression 18.78702 Akaike info criterion 8.925144 Sum squared resid 4941.332 Schwarz criterion 9.173681 Log likelihood -79.78887 F-statistic 245.3639 Durbin-Watson stat
2.186293 Prob(F-statistic)
0.000000
回归分析报告为:
()
()()()()()()()()()
3678
22? -2212.242+22.0663X +9.5956X +0.00612X +0.03692X 259.5324 2.6622 2.3800.002260.0112398.5239518.28865 4.032 2.70598 3.2853540.9859360.98191819 2.186293245.3639
i Y SE t R R Df DW F ===-=====
(二)、异方差的检验 A 、相关图形分析
图1
图 2
图3
图4
从图1~4可以看出y 并不随着x的增大而变得更离散,表明模型可能不存在异方差。
B、残差分析图
图5
图6
图7
图8
从图5~8看出,e2并不随x 的增大而变化,表明模型可能不存在异方差。 C 、 A RCH 检验
F-statistic 0.558635 Probability 0.652331
Test Equation:
Dependent Variable: RESID^2 Method: Least Squares Sample(adjusted): 1989 2004
Variable Coefficient Std. Error t-Statistic Prob. C 279.7407 120.1889 2.327509 0.0382 RESID^2(-1) 0.051971 0.251414 0.206717 0.8397 RESID^2(-2) -0.223409 0.241815 -0.923887 0.3737 RESID^2(-3)
-0.157992
0.249154
-0.634115
0.5379 R-squared
0.122544 Mean dependent var 204.2351 Adjusted R-squared -0.096820 S.D. dependent var 286.6884 S.E. of regression 300.2464 Akaike info criterion 14.45940 Sum squared resid 1081774. Schwarz criterion 14.65255 Log likelihood -111.6752 F-statistic 0.558635 Durbin-Watson stat
1.767931 Prob(F-statistic)
0.652331
()()()()222
2
0.0537.81473,1.960709,1.96070937.81473,n p R n p R
αχχ
==-=-=<=在显著性水平的情况下,则有
所以接受源假设,表明模型中不存在异方差。
D 、White 检验
White Heteroskedasticity Test: F-statistic 5.378778 Probability 0.058152 Obs*R-squared
18.04165 Probability 0.204891
Test Equation:
Dependent Variable: RESID^2 Method: Least Squares Sample: 1986 2004 Included observations: 19
C 83312.19 792151.1 0.105172 0.9213 X3 8939.976 3785.514 2.361628 0.0775 X3^2 92.15690 56.34778 1.635502 0.1773 X3*X6
-23.05086
26.32794
-0.875529
0.4307
X3*X7 -0.094926 0.045467 -2.087801 0.1051 X3*X8 -0.965260 0.775504 -1.244688 0.2812 X6 14984.21 4130.063 3.628083 0.0222 X6^2 -53.86422 41.43287 -1.300036 0.2634 X6*X7 -0.045905 0.033365 -1.375837 0.2409 X6*X8 -0.395631 0.371854 -1.063942 0.3473 X7 -10.35154 12.19311 -0.848966 0.4437 X7^2 5.76E-05 4.21E-05 1.369855 0.2426 X7*X8 -7.38E-06 0.000266 -0.027789 0.9792 X8 62.90965 32.25761 1.950226 0.1229 R-squared
0.949560 Mean dependent var 260.0701 Adjusted R-squared 0.773022 S.D. dependent var 337.4753 S.E. of regression 160.7806 Akaike info criterion 13.01876 Sum squared resid 103401.7 Schwarz criterion 13.76437 Log likelihood -108.6782 F-statistic 5.378778 Durbin-Watson stat
3.254288 Prob(F-statistic)
0.058152
()()()()22220.051423.6848,18.04165,18.04165323.6848,n p R n p R αχχ==-=-=<=在显著性水平的情况下,则有
所以接受源假设,表明模型中不存在异方差。
综合上述4种方法得出的结论,说明模型中不存在异方差。
(三)、自相关检验及修正 ①自相关的检验 A 、DW 检验
已知DW= 2.185********,查表得DL=0.859 ,DU=1.848,所以4-DU=2.152 B 、图示法: 1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。 年份 Y/千 克 X/ 元 P 1/(元/千克) P 2/(元/千克) P 3/(元/千克) 年份 Y/千克 X/元 P 1/(元/ 千克) P 2/(元/ 千克) P 3/(元/千克) 1980 2.78 397 4.22 5.07 7.83 1992 4.18 911 3.97 7.91 11.40 1981 2.99 413 3.81 5.20 7.92 1993 4.04 931 5.21 9.54 12.41 1982 2.98 439 4.03 5.40 7.92 1994 4.07 1021 4.89 9.42 12.76 1983 3.08 459 3.95 5.53 7.92 1995 4.01 1165 5.83 12.35 14.29 1984 3.12 492 3.73 5.47 7.74 1996 4.27 1349 5.79 12.99 14.36 1985 3.33 528 3.81 6.37 8.02 1997 4.41 1449 5.67 11.76 13.92 1986 3.56 560 3.93 6.98 8.04 1998 4.67 1575 6.37 13.09 16.55 1987 3.64 624 3.78 6.59 8.39 1999 5.06 1759 6.16 12.98 20.33 1988 3.67 666 3.84 6.45 8.55 2000 5.01 1994 5.89 12.80 21.96 1989 3.84 717 4.01 7.00 9.37 2001 5.17 2258 6.64 14.10 22.16 1990 4.04 768 3.86 7.32 10.61 2002 5.29 2478 7.04 16.82 23.26 1991 4.03 843 3.98 6.78 10.48 (1) 求出该地区关于家庭鸡肉消费需求的如下模型: 01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。 先做回归分析,过程如下: 输出结果如下: 野外实习资料的数理统计分析 一元线性回归分析 一元回归处理的是两个变量之间的关系,即两个变量X和Y之间如果存在一定的关系,则通过观测所得数据,找出两者之间的关系式。如果两个变量的关系大致是线性的,那就是一元线性回归问题。 对两个现象X和Y进行观察或实验,得到两组数值:X1,X2,…,Xn和Y1,Y2,…,Yn,假如要找出一个函数Y=f(X),使它在 X=X1,X2, …,Xn时的数值f(X1),f(X2), …,f(Xn)与观察值Y1,Y2,…,Yn趋于接近。 在一个平面直角坐标XOY中找出(X1,Y1),(X2,Y2),…,(Xn,Yn)各点,将其各点分布状况进行察看,即可以清楚地看出其各点分布状况接近一条直线。对于这种线性关系,可以用数学公式表示: Y = a + bX 这条直线所表示的关系,叫做变量Y对X的回归直线,也叫Y对X 的回归方程。其中a为常数,b为Y对于X的回归系数。 对于任何具有线性关系的两组变量Y与X,只要求解出a与b的值,即可以写出回归方程。计算a与b值的公式为: 式中:为变量X的均值,Xi为第i个自变量的样本值,为因变量的均值,Yi为第i个因变量Y的样本值。n为样本数。 当前一般计算机的Microsoft Excel中都有现成的回归程序,只要将所获得的数据录入就可自动得到回归方程。 得到的回归方程是否有意义,其相关的程度有多大,可以根据相关系数的大小来决定。通常用r来表示两个变量X和Y之间的直线相关程度,r为X和Y的相关系数。r值的绝对值越大,两个变量之间的相关程度就越高。当r为正值时,叫做正相关,r为负值时叫做负相关。r 的计算公式如下: 式中各符号的意义同上。 在求得了回归方程与两个变量之间的相关系数后,可以利用F检验法、t检验法或r检验法来检验两个变量是否显著相关。具体的检验方法在后面介绍。 一元线性回归模型案例分析 一、研究的目的要求 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我们研究的对象是各地区居民消费的差异。居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。 因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。因此建立的是2002年截面数据模型。 影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。 从2002年《中国统计年鉴》中得到表2.5的数据: 表2.52002年中国各地区城市居民人均年消费支出和可支配收入 中国税收增长的分析 一、研究的目的要求 改革开放以来,随着经济体制的改革深化和经济的快速增长,中国的财政收支状况发生了很大的变化,中央和地方的税收收入1978年为519.28亿元到2002年已增长到17636.45亿元25年间增长了33倍。为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。 影响中国税收收入增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看,经济整体增长是税收增长的基本源泉。(2)公共财政的需求,税收收入是财政的主体,社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收入可能有一定的影响。(3)物价水平。我国的税制结构以流转税为主,以现行价格计算的DGP等指标和和经营者收入水平都与物价水平有关。(4)税收政策因素。我国自1978年以来经历了两次大的税制改革,一次是1984—1985年的国有企业利改税,另一次是1994年的全国范围内的新税制改革。税制改革对税收会产生影响,特别是1985年税收陡增215.42%。但是第二次税制改革对税收的增长速度的影响不是非常大。因此可以从以上几个方面,分析各种因素对中国税收增长的具体影响。 二、模型设定 为了反映中国税收增长的全貌,选择包括中央和地方税收的‘国家财政收入’中的“各项税收”(简称“税收收入”)作为被解释变量,以放映国家税收的增长;选择“国内生产总值(GDP)”作为经济整体增长水平的代表;选择中央和地方“财政支出”作为公共财政需求的代表;选择“商品零售物价指数”作为物价水平的代表。由于税制改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑。所以解释变量设定为可观测“国内生产总值(GDP)”、“财政支出”、“商品零售物价指数” 从《中国统计年鉴》收集到以下数据 财政收入(亿元) Y 国内生产总值(亿 元) X2 财政支出(亿 元) X3 商品零售价格指 数(%) X4 1978519.283624.11122.09100.7 1979537.824038.21281.79102 1980571.74517.81228.83106 多元线性回归模型 一、单项选择题 1.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算得多重决定 系数为,则调整后的多重决定系数为( D ) A. B. C. 下列样本模型中,哪一个模型通常是无效 的(B ) A. i C (消费)=500+i I (收入) B. d i Q (商品需求)=10+i I (收入)+i P (价格) C. s i Q (商品供给)=20+i P (价格) D. i Y (产出量)=0.6i L (劳动)0.4i K (资本) 3.用一组有30个观测值的样本估计模型01122t t t t y b b x b x u =+++后,在的显著性水平上对 1b 的显著性作t 检验,则1b 显著地不等于零的条件是其统计量t 大于等于( C ) A. )30(05.0t B. )28(025.0t C. )27(025.0t D. )28,1(025.0F 4.模型 t t t u x b b y ++=ln ln ln 10中,1b 的实际含义是( B ) A.x 关于y 的弹性 B. y 关于x 的弹性 C. x 关于y 的边际倾向 D. y 关于x 的边际倾向 5、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明 模型中存在( C ) A.异方差性 B.序列相关 C.多重共线性 D.高拟合优度 6.线性回归模型01122......t t t k kt t y b b x b x b x u =+++++ 中,检验0:0(0,1,2,...) t H b i k ==时,所用的统计量 服从( C ) (n-k+1) (n-k-2) (n-k-1) (n-k+2) 7. 调整的判定系数 与多重判定系数 之间有如下关系( D ) A.2 211n R R n k -=-- B. 22111 n R R n k -=--- C. 2211(1)1n R R n k -=-+-- D. 2211(1)1n R R n k -=---- 8.关于经济计量模型进行预测出现误差的原因,正确的说法是( C )。 A.只有随机因素 B.只有系统因素 C.既有随机因素,又有系统因素 、B 、C 都不对 9.在多元线性回归模型中对样本容量的基本要求是(k 为解释变量个数):( C ) A n ≥k+1 B n 多元线性回归模型案例分析 ——中国人口自然增长分析一·研究目的要求 中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的降到1980年,接近世代更替水平。此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。 影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。 二·模型设定 为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据 , 设定的线性回归模型为: 1222334t t t t t Y X X X u ββββ=++++ 三、估计参数 利用EViews 估计模型的参数,方法是: 1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对 话框“Workfile Range ”。在“Workfile frequency ”中选择“Annual ” (年 年份 @ 人口自然增长率 (%。) 国民总收入 (亿元) 居民消费价格指数增长 率(CPI )% 人均GDP (元) 1988 15037 1366 1989 … 17001 18 1519 1990 18718 1644 1991 【 21826 1893 1992 26937 2311 1993 . 35260 2998 1994 48108 4044 1995 — 59811 5046 1996 70142 5846 1997 ~ 78061 6420 1998 83024 6796 1999 【 88479 7159 2000 98000 7858 2001 [ 108068 8622 2002 119096 9398 2003 : 135174 10542 2004 159587 12336 2005 、 184089 14040 2006 213132 16024 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量y 受k 个自变量k x x x ,...,,21的影响,其n 组观测值为(ka a a a x x x y ,...,,,21),n a ,...,2,1=。那么,多元线性回归模型的结构形式为: a ka k a a a x x x y εββββ+++++=...22110(3、2、11) 式中: k βββ,...,1,0为待定参数; a ε为随机变量。 如果k b b b ,...,,10分别为k ββββ...,,,210的拟合值,则回归方程为 ?=k k x b x b x b b ++++...22110(3、2、12) 式中: 0b 为常数; k b b b ,...,,21称为偏回归系数。 偏回归系数i b (k i ,...,2,1=)的意义就是,当其她自变量j x (i j ≠)都固定时,自变量i x 每变化一个单位而使因变量y 平均改变的数值。 根据最小二乘法原理,i β(k i ,...,2,1,0=)的估计值i b (k i ,...,2,1,0=)应该使 ()[]min (2) 1 2211012 →++++-=??? ??-=∑∑==∧ n a ka k a a a n a a a x b x b x b b y y y Q (3、2、13) 有求极值的必要条件得 ???????==??? ??--=??=??? ??--=??∑∑=∧=∧n a ja a a j n a a a k j x y y b Q y y b Q 110) ,...,2,1(0202(3、2、14) 将方程组(3、2、14)式展开整理后得: 案例分析报告 (2014——2015学年第一学期) 课程名称:预测与决策 专业班级:电子商务1202 学号: 2204120202 学生姓名:陈维维 2014 年 11月 案例分析(一元线性回归模型) 我国城镇居民家庭人均消费支出预测 一、研究目的与要求 居民消费在社会经济的持续发展中有着重要的作用,居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。从理论角度讲,消费需求的具体内容主要体现在消费结构上,要增加居民消费,就要从研究居民消费结构入手,只有了解居民消费结构变化的趋势和规律,掌握消费需求的热点和发展方向,才能为消费者提供良好的政策环境,引导消费者合理扩大消费,才能促进产业结构调整与消费结构优化升级相协调,才能推动国民经济平稳、健康发展。例如,2008年全国城镇居民家庭平均每人每年消费支出为11242.85元,?最低的青海省仅为人均8192.56元,最高的上海市达人均19397.89元,上海是黑龙江的2.37倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定? 我研究的对象是各地区居民消费的差异。居民消费可分为城镇居民消费和农村居民消费,由于各地区的城镇与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城镇居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。 所以模型的被解释变量Y选定为“城镇居民每人每年的平均消费支出”。 因为研究的目的是各地区城镇居民消费的差异,并不是城镇居民消费在不同时间的变动,所以应选择同一时期各地区城镇居民的消费支出来建立模型。因此建立的是2008年截面数据模型。影响各地区城镇居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。 为了与“城镇居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。 以下是2008年各地区城镇居民人均年消费支出和可支配收入表 我国农民收入影响因素的回归分析 本文力图应用适当的多元线性回归模型,对有关农民收入的历史数据和现状进行分析,探讨影响农民收入的主要因素,并在此基础上对如何增加农民收入提出相应的政策建议。?农民收入水平的度量常采用人均纯收入指标。影响农民收入增长的因素是多方面的,既有结构性矛盾因素,又有体制性障碍因素。但可以归纳为以下几个方面:一是农产品收购价格水平。二是农业剩余劳动力转移水平。三是城市化、工业化水平。四是农业产业结构状况。五是农业投入水平。考虑到复杂性和可行性,所以对农业投入与农民收入,本文暂不作讨论。因此,以全国为例,把农民收入与各影响因素关系进行线性回归分析,并建立数学模型。 一、计量经济模型分析 (一)、数据搜集 根据以上分析,我们在影响农民收入因素中引入7个解释变量。即:2x -财政用于农业的支出的比重,3x -第二、三产业从业人数占全社会从业人数的比重,4x -非农村人口比重,5x -乡村从业人员占农村人口的比重,6x -农业总产值占农林牧总产值的比重,7x -农作物播种面积,8x —农村用电量。 资料来源《中国统计年鉴2006》。 (二)、计量经济学模型建立 我们设定模型为下面所示的形式: 利用Eviews 软件进行最小二乘估计,估计结果如下表所示: DependentVariable:Y Method:LeastSquares Sample: Includedobservations:19 Variable Coefficient t-Statistic Prob. C X1 X3 X4 X5 X6 X7 X8 R-squared Meandependentvar AdjustedR-squared 表1最小二乘估计结果 回归分析报告为: () ()()()()()()()()()()()()()()() 2345678 2? -1102.373-6.6354X +18.2294X +2.4300X -16.2374X -2.1552X +0.0100X +0.0634X 375.83 3.7813 2.066618.37034 5.8941 2.77080.002330.02128 -2.933 1.7558.820900.20316 2.7550.778 4.27881 2.97930.99582i Y SE t R ===---=230.99316519 1.99327374.66 R Df DW F ====二、计量经济学检验 (一)、多重共线性的检验及修正 ①、检验多重共线性 (a)、直观法 从“表1最小二乘估计结果”中可以看出,虽然模型的整体拟合的很好,但是x4x6 多元线性回归模型公式 HUA system office room 【HUA16H-TTMS2A-HUAS8Q8-HUAH1688】 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量y 受k 个自变量k x x x ,...,,21的影响,其n 组观测值为 (ka a a a x x x y ,...,,,21),n a ,...,2,1=。那么,多元线性回归模型的结构形式为: a ka k a a a x x x y εββββ+++++=...22110() 式中: k βββ,...,1,0为待定参数; a ε为随机变量。 如果k b b b ,...,,10分别为k ββββ...,,,210的拟合值,则回归方程为 ?=k k x b x b x b b ++++...22110() 式中: 0b 为常数; k b b b ,...,,21称为偏回归系数。 偏回归系数i b (k i ,...,2,1=)的意义是,当其他自变量j x (i j ≠)都固定时,自变量i x 每变化一个单位而使因变量y 平均改变的数值。 根据最小二乘法原理,i β(k i ,...,2,1,0=)的估计值i b (k i ,...,2,1,0=)应该使 ()[]min ...212211012→++++-=??? ??-=∑∑==∧n a ka k a a a n a a a x b x b x b b y y y Q () 有求极值的必要条件得 ???????==??? ??--=??=??? ??--=??∑∑=∧=∧n a ja a a j n a a a k j x y y b Q y y b Q 110),...,2,1(0202() 将方程组()式展开整理后得: ?????????????=++++=++++=++++=++++∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑===================n a a ka k n a ka n a ka a n a ka a n a ka n a a a k n a ka a n a a n a a a n a a n a a a k n a ka a n a a a n a a n a a n a a k n a ka n a a n a a y x b x b x x b x x b x y x b x x b x b x x b x y x b x x b x x b x b x y b x b x b x nb 11221211101 121221221121012111121211121011112121110)(...)()()(...)(...)()()()(...)()()()(...)()( () 方程组()式,被称为正规方程组。 如果引入一下向量和矩阵: 则正规方程组()式可以进一步写成矩阵形式 B Ab =(3.2.15’) 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量 y 受 k 个自变量 x 1, x 2 ,..., x k 的影响,其 n 组观测值为( y a , x 1 a , x 2 a ,..., x ka ), a 1,2,..., n 。那么,多元线性回归模型的结构形式为: y a 0 1 x 1a 2 x 2 a ... k x ka a () 式中: 0 , 1 ,..., k 为待定参数; a 为随机变量。 如果 b 0 , b 1 ,..., b k 分别为 0 , 1 , 2 ..., k 的拟合值,则回归方程为 ?= b 0 b 1x 1 b 2 x 2 ... b k x k () 式中: b 0 为常数; b 1, b 2 ,..., b k 称为偏回归系数。 偏回归系数 b i ( i 1,2,..., k )的意义是,当其他自变量 x j ( j i )都固定时,自变量 x i 每变 化一个单位而使因变量 y 平均改变的数值。 根据最小二乘法原理, i ( i 0,1,2,..., k )的估计值 b i ( i 0,1,2,..., k )应该使 n 2 n 2 Q y a y a y a b 0 b 1 x 1a b 2 x 2a ... b k x ka min () a 1 a 1 有求极值的必要条件得 Q n 2 y a y a b 0 a 1 () Q n 2 y a y a x ja 0( j 1,2,..., k) b j a 1 将方程组()式展开整理后得: SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示: 点击“分析”——回归——线性——进入如下图所示的界面: 将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0.05,当概率值大于等于0.1时将会被剔除) 线性回归方程中的相关系数r r=∑(Xi-X的平均数)(Yi-Y平均数)/根号下[∑(Xi-X平均数)^2*∑(Yi-Y平均数)^2] R2就是相关系数的平方, R在一元线性方程就直接是因变量自变量的相关系数,多元则是复相关系数 判定系数R^2 也叫拟合优度、可决系数。表达式是: R^2=ESS/TSS=1-RSS/TSS 该统计量越接近于1,模型的拟合优度越高。 问题:在应用过程中发现,如果在模型中增加一个解释变量,R2往往增大 这就给人一个错觉:要使得模型拟合得好,只要增加解释变量即可。 ——但是,现实情况往往是,由增加解释变量个数引起的R2的增大与拟合好坏无关,R2需调整。 这就有了调整的拟合优度: R1^2=1-(RSS/(n-k-1))/(TSS/(n-1)) 在样本容量一定的情况下,增加解释变量必定使得自由度减少,所以调整的思路是:将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响: 其中:n-k-1为残差平方和的自由度,n-1为总体平方和的自由度。 总是来说,调整的判定系数比起判定系数,除去了因为变量个数增加对判定结果的影响。R = R接近于1表明Y与X1,X2 ,…,Xk之间的线性关系程度密切; R接近于0表明Y与X1,X2 ,…,Xk之间的线性关系程度不密切 相关系数就是线性相关度的大小,1为(100%)绝对正相关,0为0%,-1为(100%)绝对负相关 相关系数绝对值越靠近1,线性相关性质越好,根据数据描点画出来的函数-自变量图线越趋近于一条平直线,拟合的直线与描点所得图线也更相近。 如果其绝对值越靠近0,那么就说明线性相关性越差,根据数据点描出的图线和拟合曲线相差越远(当相关系数太小时,本来拟合就已经没有意义,如果强行拟合一条直线,再把数据点在同一坐标纸上画出来,可以发现大部分的点偏离这条直线很远,所以用这个直线来拟合是会出现很大误差的或者说是根本错误的)。 分为一元线性回归和多元线性回归 线性回归方程中,回归系数的含义 一元: Y^=bX+a b表示X每变动(增加或减少)1个单位,Y平均变动(增加或减少)b各单位多元: Y^=b1X1+b2X2+b3X3+a 在其他变量不变的情况下,某变量变动1单位,引起y平均变动量 以b2为例:b2表示在X1、X3(在其他变量不变的情况下)不变得情况下,X2每变动1单位,y平均变动b2单位 SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2. Opening excel data source——OK. 第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear,Dependent (因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise. 进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、 Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue. 3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue. 回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 : 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: — 2010年中国各地区城市居民人均年消费支出和可支配收入 | 数据来源:《中国统计年鉴》2010年 2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1: 表2 模型汇总b — 模型 R R方调整R方标准估计的误差 - 1 .965a.932.930 ~ a.预测变量:(常量),可支配收入X(元)。 b.因变量:消费性支出Y(元) 表3 相关性 、 消费性支出Y (元) 可支配收入X(元) Pearson相关 性消费性支出Y(元)& .965 ! 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX 多元线性回归模型的案 例讲解 Document number:NOCG-YUNOO-BUYTT-UU986-1986UT 1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。 年份 Y/ 千克 X/元 P 1/(元/千克) P 2/(元/千克) P 3/(元/千克) 年份 Y/ 千克 X/元 P 1/(元/千克) P 2/(元/千克) P 3/(元/ 千克) 1980 397 1992 911 1981 413 1993 931 1982 439 1994 1021 1983 459 1995 1165 1984 492 1996 1349 1985 528 1997 1449 1986 560 1998 1575 1987 624 1999 1759 1988 666 2000 1994 1989 717 2001 2258 1990 768 2002 2478 1991 843 (1) 求出该地区关于家庭鸡肉消费需求的如下模型: 01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。 先做回归分析,过程如下: 输出结果如下: 所以,回归方程为: 123ln 0.73150.3463ln 0.5021ln 0.1469ln 0.0872ln Y X P P P =-+-++ 由上述回归结果可以知道,鸡肉消费需求受家庭收入水平和鸡肉价格的影响,而牛肉价格和猪肉价格对鸡肉消费需求的影响并不显着。 验证猪肉价格和鸡肉价格是否有影响,可以通过赤池准则(AIC )和施瓦茨准则(SC )。若AIC 值或SC 值增加了,就应该去掉该解释变量。 去掉猪肉价格P 2与牛肉价格P 3重新进行回归分析,结果如下: Variable Coefficient Std. Error t-Statistic Prob.?? C LOG(X) LOG(P1) R-squared ????Mean dependent var Adjusted R-squared ????. dependent var . of regression ????Akaike info criterion Sum squared resid ????Schwarz criterion Log likelihood ????F-statistic Durbin-Watson stat ????Prob(F-statistic) 二、多元线性回归模型 在多要素得地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联得情况。因此,多元地理回归模型更带有普遍性得意义。 (一)多元线性回归模型得建立 假设某一因变量y 受k 个自变量得影响,其n 组观测值为(),。那么,多元线性回归模型得结构形式为: (3.2.11) 式中: 为待定参数; 为随机变量。 如果分别为得拟合值,则回归方程为 ?=(3.2.12) 式中: 为常数; 称为偏回归系数。 偏回归系数()得意义就就是,当其她自变量()都固定时,自变量每变化一个单位而使因变量y 平均改变得数值。 根据最小二乘法原理,()得估计值()应该使 ()[]min (2) 1 2211012 →++++-=??? ??-=∑∑==∧ n a ka k a a a n a a a x b x b x b b y y y Q (3.2.13) 有求极值得必要条件得 (3.2.14) 将方程组(3.2.14)式展开整理后得: ??????????? ?? =++++=++++=++++=++++∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑===================n a a ka k n a ka n a ka a n a ka a n a ka n a a a k n a ka a n a a n a a a n a a n a a a k n a ka a n a a a n a a n a a n a a k n a ka n a a n a a y x b x b x x b x x b x y x b x x b x b x x b x y x b x x b x x b x b x y b x b x b x nb 11221211101 1 212212 2112101 21111212111210111 12121110)(...)()()(...)(...)()()()(...)()()()(...)()( (3.2.15) 方程组(3.2.15)式,被称为正规方程组。 如果引入一下向量与矩阵: ??? ??? ? ? ? ????????? ??==kn n n k k k kn k k k n n T x x x x x x x x x x x x x x x x x x x x x x x x X X A ...1..................1...1...1... ...... ... ............1 (1112132313222121211132) 1 2232221 1131211 SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要就是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程 为: 毫无疑问,多元线性回归方程应该 为: 上图中的 x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差, 其中随机误差分为:可解释的误差与不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须就是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示: 点击“分析”——回归——线性——进入如下图所示的界面: 将“销售量”作为“因变量”拖入因变量框内, 将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,您也可以选择其它的方式,如果您选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果您选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该就是跟“因变量”关系最为密切, 线性回归分析的SPSS操作 本节容主要介绍如何确定并建立线性回归方程。包括只有一个自变量的一元线性回归和和含 有多个自变量的多元线性回归。为了确保所建立的回归方程符合线性标准,在进行回归分析之前, 我们往往需要对因变量与自变量进行线性检验。也就是类似于相关分析一章中讲过的借助于散点 图对变量间的关系进行粗略的线性检验,这里不再重复。另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。 一、一元线性回归分析 1数据 以本章第三节例3的数据为例,简单介绍利用SPSS如何进行一元线性回归分析。数据编辑 窗口显示数据输入格式如下图7-8 (文件7-6-1.sav): 图7-8 :回归分析数据输入 2?用SPSS进行回归分析,实例操作如下: 2.1.回归方程的建立与检验 (1) 操作 ①单击主菜单An alyze / Regression / Li near ,?进入设置对话框如图7-9所示。从左边变量表 列中把因变量y选入到因变量(Depe ndent)框中,把自变量x选入到自变量 (I ndepe ndent)框中。在方法即Method —项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方 程时把所选中的全部自变量都保留在方程中。所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。具体如下图所示: ② 请单击Statistics 按钮,可以选择需要输出的一些统计量。 女口 Regression Coefficients (回 归 系数)中的Estimates ,可以输出回归系数及相关统计量,包括回归系数 B 、标准误、标准化回归 系数BETA 、T 值及显著性水平等。 Model fit 项可输出相关系数 R ,测定系数R 2,调整系数、 成后点击Continue 返回主对话框。 回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反 回归分析的假定,为此需进行多项残差分析。由于此部分容较复杂而且理论性较强,所以不在此 详细介绍,读者如有兴趣,可参阅有关资料。 ③ 用户在进行回归分析时,还可以选 择是否输出方程常数。单击 Options ??按钮,打开它的 对话框,可以看到中间有一项 Include constant in equation 可选项。选中该项可输出对常数的检验。 在Options 对话框中,还可以定义处理缺失值的方法和设置多元逐步回归中变量进入和排除方程 的准则,这里我们采用系统的默认设置,如图 7-11所示。设置完成后点击 Continue 返回主对话 框。 估计标准误及方差分析表。 上述两项为默认选项, 请注意保持选中。 设置如图7-10所示。设置完 图7-9线性回归分析主对话框 图7-10: 线性回归分析的 Statistics 选项 图7-11 :线性回归分析的 Options 选项多元线性回归模型的案例分析
excel一元及多元线性回归实例
一元线性回归模型案例分析
eviews多元线性回归案例分析
多元线性回归模型习题及答案
多元线性回归模型案例分析
多元线性回归模型公式
案例分析 一元线性回归模型
多元线性回归模型案例
多元线性回归模型公式定稿版
多元线性回归模型公式().docx
多元线性回归实例分析
线性回归方程中的相关系数r
SPSS多元线性回归分析实例操作步骤
SPSS线性回归分析案例
多元线性回归模型的案例讲解
多元线性回归模型公式
多元线性回归实例分析报告
SPSS多元线性回归分析教程
相关主题
文本预览