时间序列数据挖掘
阎相斌
Email:xbyan@https://www.doczj.com/doc/46476556.html,
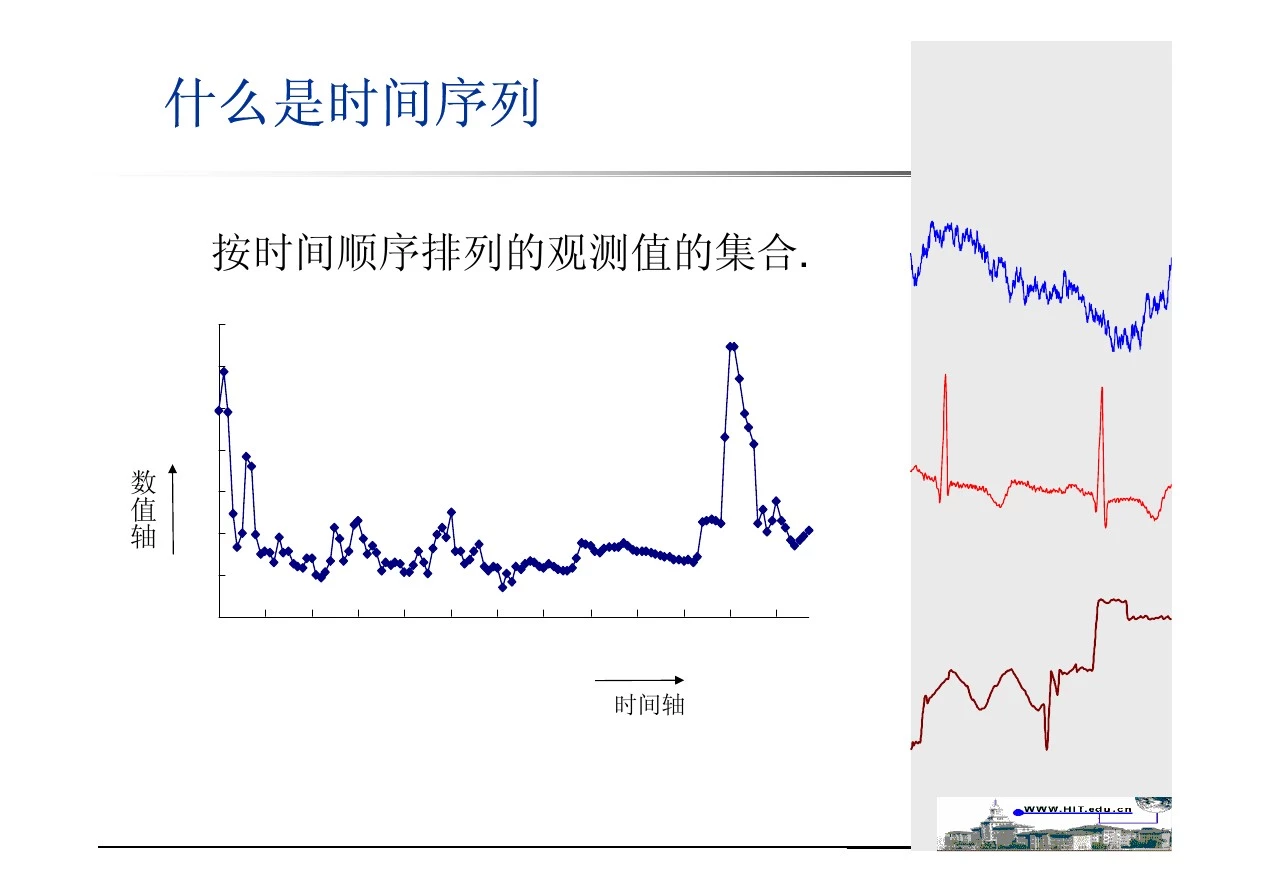
什么是时间序列
按时间顺序排列的观测值的集合.
数 值 轴
时间轴
时序数据普遍存在
人们测量...
?电视台的收视率. ?人或动物的血压. ?哈尔滨市的年降雨量. ?某股票的价值. ?网站的每秒点击率.
… 随着时间变化得到的数据.
从世界上15份报纸中随机抽取出4000张图形,其中75%的图形是时间 序列。 ——《The Visual Display of Quantitative Information》
时间序列在医疗、科学、经济、商业、工程领域存在广泛的应用
Working With Time Series is Difficult
g
very large databases 0 1 Hour of EKG data: 1 Gigabyte. / Typical Weblog: 5 Gigabytes per weekdealing with Weblog subjective notions of similarity.
g g
Miscellaneous data handling problems Numeric values
随机时间序列分析
g
n 阶自回归模型AR(n).
X t = θ (L) X t -1 + ε t where ε is a white noise error process and θ (L) X t -1 = θ 1 X t -1 +θ 2 X t - 2 ...θ n X t - n
g
q阶移动平均模型 MA(q).
X t = ζ (L)ω t where ω is a white noise error process
ζ (L)ω t = ω t + ζ 1 ω t -1 + ...+ ζ q ω t -q
g
自回归移动平均模型ARMA (n, q)
y = 19.653x + 95.451 R2 = 0.8678
20 01 19 99 19 97 19 95 19 93 19 91 19 89 19 87 19 85 19 83 19 81 19 79 19 77 19 75 19 73 19 71 19 69 19 67 19 65 19 63 19 61 19 59 19 57 19 55 19 53 19 51 19 49 19 47 19 45 19 43 19 41 19 39 19 37 19 35 19 33 19 31 19 29
Government consumption expenditures and gross investment
800
600
400
1800
1600
1400
1200
1000
200
0
神经网络方法
非线性时序数据
s(t) ≠ α ? a(t) + β ? b(t)
输 输
入 出
…………
延迟坐标相空间重构
g
相空间轨道
dx(t ) = σ (y(t ) ? x(t )) dt dy(t ) = ?x(t )z(t ) + rx(t ) ? y(t ) dt dz(t ) = x(t )y(t ) ? bz(t ) dt
延迟坐标相空间重构
g g
将数值序列嵌入到m 维空间 Vt={st-(1-1) ?T, st-(2-1) ?T , st-(3-1) ?T ,…, st-(m-1) ?T } 适当的m ,?T 的选择十分复杂
g
利用Vt 作为信号变量来重构动力学方程
时间序列数据挖掘
g 概念 g 研究对象 g 研究方法:data
mining (maybe some new techniques) knowledge
g 研究结果:
时序数据挖掘研究分类
g
g
从研究内容上划分 0 时间序列的特征表示 0 时间序列的相似性问题 0 时间序列的周期性问题 0 时间序列的局部模式发现问题 从研究手段上划分 0 时间序列数据的特征化和比较 0 时序聚类分析 0 时序分类 0 时序关联规则发现 0 时序结构分析 0 时序预测和趋势分析
需要研究的几个方面
1. 基础理论研究
2. 挖掘技术和算法的研究
3. 应用领域的拓展
时序数据挖掘的简要流程
关联规则发现
时序相似性问 题
分类
聚类 时序数据的相似性定 义是绝大多数时序数 据挖掘问题的研究基 础、立足点
规则发现
s = 0.5 c = 0.3
?
10
1 2
查询
Query Q
(template)
6 7 8 9 10 Database C
3 4 5
时序相似性问题
Query Q
(template)
1:全序列匹配(Whole Matching)
1 2 3 4 5
6 7 8 9 10 Database C
C6 为查询结果.
给定一个查询序列 Q, 数据库 C 和一种聚类函数, 找到序列 Ci 与待查 序列 Q最匹配.
时序相似性问题
Query Q
(template)
2: 子序列匹配(Subsequence Matching)
数据库 C
最为相似的子序列
给定一个查询序列 Q, 数据库 C 和一种距离函数, 从序列 中找到与 与待查序列 Q最匹配子序列段.
通过移动窗口的方法可以将子序列匹配问题转化为全序列匹配
An Example
Query Q Database Distance 0.98
n datapoints
Rank 4
Euclidean Distance between two time series Q = {q1, q2, …, qn} and S = {s1, s2, …, sn}
0.07
1
Q S
0.21
2
D (Q , S ) ≡
i =1
∑ (q i ? s i )
n
2
n datapoints
0.43
3
Mapping to Multidimensional Space
Database
S1
S1
Query Q
S2
Q S2
n datapoints
S3 S4
n datapoints
S3
S4
n-dimensional space Index the n-d space using a multidimensional index structure to avoid slow sequential scanning, especially for large databases, e.g., EKG data (1GB/hr), Weblogs (5 GB/week), Space Shuttle database (158GB +), Macho Database (1TB +)
定义距离函数
定义: 设 O1 和 O2 为两个数据对象. 则距离函数(相 异度) 为 D(O1,O2) 距离函数应该满足的性质?
? D(A,B) = D(B,A) ? D(A,A) = 0 ? D(A,B) = 0 IIf A= B ? D(A,B) ≤ D(A,C) + D(B,C)
对称性 自相似 正确性 三角不等式
数据挖掘 引言 数据挖掘是一门交叉学科,涉及到了机器学习、模式识别、归纳推理、统计学、数据库、高性能计算等多个领域。 所谓的数据挖掘(Data Mining)指的就是从大量的、模糊的、不完全的、随机的数据集合中提取人们感兴趣的知识和信息,提取的对象一般都是人们无法直观的从数据中得出但又有潜在作用的信息。从本质上来说,数据挖掘是在对数据全面了解认识的基础之上进行的一次升华,是对数据的抽象和概括。如果把数据比作矿产资源,那么数据挖掘就是从矿产中提取矿石的过程。与经过数据挖掘之后的数据信息相比,原始的数据信息可以是结构化的,数据库中的数据,也可以是半结构化的,如文本、图像数据。从原始数据中发现知识的方法可以是数学方法也可以是演绎、归纳法。被发现的知识可以用来进行信息管理、查询优化、决策支持等。而数据挖掘是对这一过程的一个综合性应用。
目录 引言 (1) 第一章绪论 (3) 1.1 数据挖掘技术的任务 (3) 1.2 数据挖掘技术的研究现状及发展方向 (3) 第二章数据挖掘理论与相关技术 (5) 2.1数据挖掘的基本流程 (5) 2.2.1 关联规则挖掘 (6) 2.2.2 .Apriori算法:使用候选项集找频繁项集 (7) 2.2.3 .FP-树频集算法 (7) 2.2.4.基于划分的算法 (7) 2.3 聚类分析 (7) 2.3.1 聚类算法的任务 (7) 2.3.3 COBWEB算法 (9) 2.3.4模糊聚类算法 (9) 2.3.5 聚类分析的应用 (10) 第三章数据分析 (11) 第四章结论与心得 (14) 4.1 结果分析 (14) 4.2 问题分析 (14) 4.2.1数据挖掘面临的问题 (14) 4.2.2 实验心得及实验过程中遇到的问题分析 (14) 参考文献 (14)
数据挖掘课程体会 学习数据挖掘这门课程已经有一个学期了,在这十余周的学习过程中,我对数据挖掘这门课程的一些技术有了一定的了解,并明确了一些容易混淆的概念,以下主要谈一下我的心得体会。 近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。数据挖掘就是从大量的数据中,抽取出潜在的、有价值的知识、模型或规则的过程。作为一类深层次的数据分析方法,它利用了数据库、人工智能和数理统计等多方面的技术。 要将庞大的数据转换成为有用的信息,必须先有效率地收集信息。随着科技的进步,功能完善的数据库系统就成了最好的收集数据的工具。数据仓库,简单地说,就是搜集来自其它系统的有用数据,存放在一整合的储存区内。所以其实就是一个经过处理整合,且容量特别大的关系型数据库,用以储存决策支持系统所需的数据,供决策支持或数据分析使用。 数据挖掘的研究领域非常广泛,主要包括数据库系统、基于知识的系统、人工智能、机器学习、知识获取、统计学、空间数据库和数据可视化等领域。主要是可以做以下几件事:分类、估计、预测、关联分析、聚类分析、描述和可视化、复杂数据类型挖掘。在这里就不一一介绍了。 在学习关联规则的时候,提出了一个关于啤酒与纸尿布的故事:在一家超市里,纸尿布与啤酒被摆在一起出售,但是这个奇怪的举措却使得啤酒和纸尿布的销量双双增加了。其实,这是由于这家超市对其顾客的购物行为进行购物篮分析,在这些原始交易数据的基础上,利用数据挖掘方法对这些数据进行分析和挖掘。从而意外的发现跟纸尿布一起购买最多的商品竟是啤酒。按我们的常规思维,啤酒与纸尿布是两个毫无关联的商品,但是借助数据挖掘技术对大量交易数据进行挖掘分析后,却可以寻求到这一有价值的规律。这个故事在一定程度上说明了数据挖掘技术的巨大价值。 总之,非常感谢周教员在这十余周的精彩授课,让我受益匪浅,我会继续学习这门课程,努力为今后的课题研究或论文打好基础。
数据挖掘课程报告 学习“数据挖掘”这门课程已经有一个学期了,在这十余周的学习过程中,我对数据挖掘这门技术有了一定的了解,明确了一些以前经常容易混淆的概念,并对其应用以及研究热点有了进一步的认识。以下主要谈一下我的心得体会,以及我对数据挖掘这项课题的见解。 随着数据库技术和计算机网络的迅速发展以及数据库管理系统的广泛应用,
人们积累的数据越来越多,而数据挖掘(Data Mining)就是在这样的背景下诞生的。 简单来说,数据挖掘就是从大量的数据中,抽取出潜在的、有价值的知识、模型或规则的过程。作为一类深层次的数据分析方法,它利用了数据库、人工智能和数理统计等多方面的技术。从某种角度上来说,数据挖掘可能并不适合进行科学研究,因为从本质上来说,数据挖掘这个技术是不能证明因果的,以一个最典型的例子来说,例如数据挖掘技术可以发现啤酒销量和尿布之间的关系,但是显然这两者之间紧密相关的关系可能在理论层面并没有多大的意义。不过,仅以此来否定数据挖掘的意义,显然就是对数据挖掘这项技术价值加大的抹杀,显然,数据挖掘这项技术从设计出现之初,就不是为了指导或支持理论研究的,它的重要意义在于,它在应用领域体现出了极大地优越性。 首先有一点是我们必须要明确的,即我们为什么需要数据挖掘这门技术?这也是在开课前一直困扰我的问题。数据是知识的源泉,然而大量的数据本身并不意味信息。尽管现代的数据库技术使我们很容易存储大量的数据,但现在还没有一种成熟的技术帮助我们分析、理解这些数据。数据的迅速增加与数据分析方法的滞后之间的矛盾越来越突出,人们希望在对已有的大量数据分析的基础上进行研究,但是目前所拥有的数据分析工具很难对数据进行深层次的处理,使得人们只能望“数”兴叹。数据挖掘正是为了解决传统分析方法的不足,并针对大规模数据的分析处理而出现的。数据挖掘可以帮助人们对大规模数据进行高效的分析处理,以节约时间,将更多的精力投入到更高层的研究中,从而提高科研工作的效率。 那么数据挖掘可以做些什么呢?数据挖掘的研究领域非常广泛,主要包括数据库系统、基于知识的系统、人工智能、机器学习、知识获取、统计学、空间数据库和数据可视化等领域。具体来说,它可以做这七件事情:分类,估计,预测,关联分析,聚类分析,描述和可视化,复杂数据类型挖掘。在本学期的学习过程中,我们对大部分内容进行了较为详细的研究,并且建立了一些基本的概念,对将来从事相关方向的研究奠定了基础。由于篇幅限制,就不对这些方法一一讲解了,这里只谈一下我在学习工程中的一些见解和心得。 在学习关联规则的时候,我们提到了一个关于“尿布与啤酒”的故事:在一
文献综述 信息与计算科学 时间序列预测――在股市预测中的应用 时间序列是一种重要的高维数据类型, 它是由客观对象的某个物理量在不同时间点的采样值按照时间先后次序排列而组成的序列, 在经济管理以及工程领域具有广泛应用. 例如证券市场中股票的交易价格与交易量、外汇市场上的汇率、期货和黄金的交易价格以及各种类型的指数等, 这些数据都形成一个持续不断的时间序列. 利用时间序列数据挖掘, 可以 ]1[ 获得数据中蕴含的与时间相关的有用信息, 实现知识的提取. 时间序列分析方法最早起源于1927年, 数学家耶尔(Yule)提出建立自回归(AR)模型来预测市场变化的规律, 接着, 在1931年, 另一位数学家瓦尔格(Walker)在A R模型的启发下, 建立了滑动平均(MA)模型和自回归、滑动平均(ARMA)混合模型, 初步奠定了时间序列分析方法的基础, 当时主要应用在经济分析和市场预测领域. 20世纪60年代,时间序列分析理论和方法迈入了一个新的阶段, 伯格(Burg)在分析地震信号时最早提出最大熵谱(MES)估计理论, 后来有人证明AR模型的功率谱估计与最大熵谱估计是等效的, 并称之为现代谱估计. 它克服了用传统的傅里叶功率谱分析(又称经典谱分析)所带来的分辨率不高和频率漏泄严重等固有的缺点, 从而使时间序列分析方法不仅在时间域内得到应用, 而且扩展到频率域内, 得到更加广泛的应用, 特别是在各种工程领域内应用功率谱的概念更加方便和普遍. 到20世纪70年代以后, 随着信号处理技术的发展, 时间序列分析方法不仅在理论上更趋完善, 尤其是在参数估计算法、定阶方法及建模过程等方面都得到了许多改进, 进一步地迈向实用化, 各种时间序列分析软件也不断涌现, 逐渐成为分析随机数据序列不可缺少的有效工具 ]2[ 之一. 随着时间序列分析方法的日趋成熟, 其应用领域越来越广泛, 主要集中在预报预测领域, 例如气象预报、市场预测、地震预报、人口预测、汛情预报、产量预测, 等等. 另一个应用领域是精密测控, 例如精密仪器测量、精密机械制造、航空航天轨道跟踪和监控,以及遥控遥测、精细化工控制等. 再一个应用领域是安全检测和质量控制. 在工程施工和维修中经常会出现异常险情, 采用仪表监测和时间序列分析方法可以随时发现问题, 及早排除故障, 以保证生产安全和质量要求. 以上仅仅列举了某些应用领域,实际上还有许多应用, 不胜 ]4,3[ 枚举. 股票市场在中国社会经济生活中起着越来越重要的作用. 截至2006年底, 沪深两市总市值为89403.89亿元, 市值规模上升至全球第10位, 亚洲第3位. 由于中国股票市场在国民经济中的地位和作用不断提高, 无论是从政府宏观决策层面还是从具体投资者微观层面
《统计学》课程教学大纲 英文名:Statistics 课程类别:专业基础课 课程性质:专业课 学分:3学分 课时:54课时 前置课:政治经济学、线性代数、微积分、概率论 主讲教师:徐健腾 选定教材:徐国祥,统计学,上海人民出版社,2007 课程概述: 本课程是运用统计数量分析的基本理论和方法,紧密结合社会经济实践,分析社会经济现象的数量表现、数量关系和数量变化规律的一门方法论科学。该课程首先对统计学的基本问题作了描述,包括统计学的概念、统计学的发展简史、统计工作的程序、统计分析软件、统计学的应用领域;其次介绍了统计学的核心概念,包括统计学的常用术语、统计指标与统计指标体系、统计方法和模型构建;再次介绍了描述统计学的基本内容,包括数据的计量与种类、统计数据的搜集与整理、统计表与统计图、集中趋势的测度、离散程度的测度、分布偏态与峰度的测度、指数体系与因素分析、几种常用的经济指数以及综合评价指数等;最后介绍了推断统计学的基本内容,包括抽样推断、假设检验、方差分析、相关与回归分析、时间序列分析等。 教学目的: 通过本课程的学习,要求学生能够全面掌握统计学的基本理论和基本方法,了解统计学发展的简单历史过程,熟悉统计工作的基本程序和统计学的应用领域;同时要求学生能根据统计研究的目的、统计数据的来源渠道和数据类型的不同,选择恰当的数学模型来对社会经济现象进行拟合。为了结合非统计学专业学生的学习要求和教学内容的完整性,要求学生能够掌握必需的统计分析方法和基本的统计指标知识,为深入进行经济分析和理论研究提供依据。 教学方法: 使用本教材要注意理论与实践相结合,着重培养学生综合的分析问题和解决问题的能力、培养他们的实际动手能力。教学过程中应尽量避开繁琐的数学公式推导,以案例为依托,结合实际例子讲清楚统计公式的应用方法。在内容上,立足于“大统计”的角度,从统计数据出发,以统计数据的处理和分析为核心,并根据统计教学的实际需要构建本课程的内容体系。在方法上,力求简明易
数据挖掘分类算法研究综述 程建华 (九江学院信息科学学院软件教研室九江332005 ) 摘要:随着数据库应用的不断深化,数据库的规模急剧膨胀,数据挖掘已成为当今研究的热点。特别是其中的分类问题,由于其使用的广泛性,现已引起了越来越多的关注。对数据挖掘中的核心技术分类算法的内容及其研究现状进行综述。认为分类算法大体可分为传统分类算法和基于软计算的分类法两类。通过论述以上算法优缺点和应用范围,研究者对已有算法的改进有所了解,以便在应用中选择相应的分类算法。 关键词:数据挖掘;分类;软计算;算法 1引言 1989年8月,在第11届国际人工智能联合会议的专题研讨会上,首次提出基于数据库的知识发现(KDD,Knowledge DiscoveryDatabase)技术[1]。该技术涉及机器学习、模式识别、统计学、智能数据库、知识获取、专家系统、数据可视化和高性能计算等领域,技术难度较大,一时难以应付信息爆炸的实际需求。到了1995年,在美国计算机年会(ACM)上,提出了数据挖掘[2](DM,Data Mining)的概念,由于数据挖掘是KDD过程中最为关键的步骤,在实践应用中对数据挖掘和KDD这2个术语往往不加以区分。 基于人工智能和信息系统,抽象层次上的分类是推理、学习、决策的关键,是一种基础知识。因而数据分类技术可视为数据挖掘中的基础和核心技术。其实,该技术在很多数据挖掘中被广泛使用,比如关联规则挖掘和时间序列挖掘等。因此,在数据挖掘技术的研究中,分类技术的研究应当处在首要和优先的地位。目前,数据分类技术主要分为基于传统技术和基于软计算技术两种。 2传统的数据挖掘分类方法 分类技术针对数据集构造分类器,从而对未知类别样本赋予类别标签。在其学习过程中和无监督的聚类相比,一般而言,分类技术假定存在具备环境知识和输入输出样本集知识的老师,但环境及其特性、模型参数等却是未知的。 2.1判定树的归纳分类 判定树是一个类似流程图的树结构,其中每个内部节点表示在一个属性上的测试,每个分支代表一个测试输出,而每个树叶节点代表类或类分布。树的最顶层节点是根节点。由判定树可以很容易得到“IFTHEN”形式的分类规则。方法是沿着由根节点到树叶节点的路径,路径上的每个属性-值对形成“IF”部分的一个合取项,树叶节点包含类预测,形成“THEN”部分。一条路径创建一个规则。 判定树归纳的基本算法是贪心算法,它是自顶向下递归的各个击破方式构造判定树。其中一种著名的判定树归纳算法是建立在推理系统和概念学习系统基础上的ID3算法。 2.2贝叶斯分类 贝叶斯分类是统计学的分类方法,基于贝叶斯公式即后验概率公式。朴素贝叶斯分类的分类过程是首先令每个数据样本用一个N维特征向量X={X1,X2,?X n}表示,其中X k是属性A k的值。所有的样本分为m类:C1,C2,?,C n。对于一个类别的标记未知的数据记录而言,若P(C i/X)>P(C j/X),1≤ j≤m,j≠i,也就是说,如果条件X下,数据记录属于C i类的概率大于属于其他类的概率的话,贝叶斯分类将把这条记录归类为C i类。 建立贝叶斯信念网络可以被分为两个阶段。第一阶段网络拓扑学习,即有向非循环图的——————————————————— 作者简介:程建华(1982-),女,汉族,江西九江,研究生,主要研究方向为数据挖掘、信息安全。
摘要文章对数据挖掘中软计算方法及应用作了综述。对模糊逻辑、遗传算法、神经网络、粗集等软计算方法,以及它们的混合算法的特点进行了分析,并对它们在数据挖掘中的应用进行了分类。 关键词数据挖掘;软计算;模糊逻辑;遗传算法;神经网络;粗集 1 引言 在过去的数十年中,随着计算机软件和硬件的发展,我们产生和收集数据的能力已经迅速提高。许多领域的大量数据集中或分布的存储在数据库中[1][2],这些领域包括商业、金融投资业、生产制造业、医疗卫生、科学研究,以及全球信息系统的万维网。数据存储量的增长速度是惊人的。大量的、未加工的数据很难直接产生效益。这些数据的真正价值在于从中找出有用的信息以供决策支持。在许多领域,数据分析都采用传统的手工处理方法。一些分析软件在统计技术的帮助下可将数据汇总,并生成报表。随着数据量和多维数据的进一步增加,高达109的数据库和103的多维数据库已越来越普遍。没有强有力的工具,理解它们已经远远超出了人的能力。所有这些显示我们需要智能的数据分析工具,从大量的数据中发现有用的知识。数据挖掘技术应运而生。 数据挖掘就是指从数据库中发现知识的过程。包括存储和处理数据,选择处理大量数据集的算法、解释结果、使结果可视化。整个过程中支持人机交互的模式[3]。数据挖掘从许多交叉学科中得到发展,并有很好的前景。这些学科包括数据库技术、机器学习、人工智能、模式识别、统计学、模糊推理、专家系统、数据可视化、空间数据分析和高性能计算等。数据挖掘综合以上领域的理论、算法和方法,已成功应用在超市、金融、银行[4]、生产企业 [5]和电信,并有很好的表现。 软计算是能够处理现实环境中一种或多种复杂信息的方法集合。软计算的指导原则是开发利用那些不精确性、不确定性和部分真实数据的容忍技术,以获得易处理、鲁棒性好、低求解成本和更好地与实际融合的性能。通常,软计算试图寻找对精确的或不精确表述问题的近似解[6]。它是创建计算智能系统的有效工具。软计算包括模糊集、神经网络、遗传算法和粗集理论。 2 数据挖掘中的软计算方法 目前,已有多种软计算方法被应用于数据挖掘系统中,来处理一些具有挑战性的问题。软计算方法主要包括模糊逻辑、神经网络、遗传算法和粗糙集等。这些方法各具优势,它们是互补的而非竞争的,与传统的数据分析技术相比,它能使系统更加智能化,有更好的可理解性,且成本更低。下面主要对各种软计算方法及其混合算法做系统性的阐述,并着重强调它们在数据挖掘中的应用情况。 2.1 模糊逻辑 模糊逻辑是1965年由泽德引入的,它为处理不确定和不精确的问题提供了一种数学工具。模糊逻辑是最早、应用最广泛的软计算方法,模糊集技术在数据挖掘领域也占有重要地位。从数据库中挖掘知识主要考虑的是发现有兴趣的模式并以简洁、可理解的方式描述出来。模糊集可以对系统中的数据进行约简和过滤,提供了在高抽象层处理的便利。同时,数据挖掘中的数据分析经常面对多种类型的数据,即符号数据和数字数据。nauck[7]研究了新的算法,可以从同时包含符号数据和数字数据中生成混合模糊规则。数据挖掘中模糊逻辑主要应用于以下几个方面: (1)聚类。将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程被称为聚类。聚类分析是一种重要的人类行为,通过聚类,人能够识别密集的和稀疏的区域,因而发现全局的分布模式,以及数据属性之间有趣的关系。模糊集有很强的搜索能力,它对发现的结构感兴趣,这会帮助发现定性或半定性数据的依赖度。在数据挖掘中,这种能力可以帮助
海南大学数据挖掘论文
题目:股票交易日线数据挖掘 学号:20100602310002 姓名: 专业:10信管 指导老师: 分数: 目录 目录 (2) 1. 数据挖掘目的 (3) 2.相关基础知识 (3) 2.1 股票基础知识 (3) 2.2 数据挖掘基础知识 (4) 2.2.2数据挖掘的任务 (5) 3.数据挖掘方案 (6) 3.1. 数据挖掘软件简介 (6) 3.2. 股票数据选择 (7) 3.3. 待验证的股票规律 (7) 4. 数据挖掘流 (8) 4.1数据挖掘流图 (8) 4.2规律验证 (9) 4.2.2规律2验证 (10) 4.2.3规律三验证 (12)
4.3主要节点说明 (14) 5.小结 (15) 1.数据挖掘目的 数据挖掘的目的就是得出隐藏在数据中的有价值的信息,发现数据之间的内在联系与规律。对于本次数据挖掘来说,其目的就是学会用clementine对股票的历史数据进行挖掘,通过数据的分析,找出存在股票历史数据中的规律,或者验证已存在的股票规律。同时也加深自己对股票知识的了解和对clementine软件的应用能力。为人们决策提供指导性信息,为公司找出其中的客户为公司带来利润的规律,如二八原则、啤酒与尿布的现象等。 2.相关基础知识 2.1 股票基础知识 2.1.1 股票 是一种有价证券,是股份公司在筹集资本时向出资人公开或私下发行的、用以证明出资人的股本身份和权利,并根据持有人所持有的股份数享有权益和承担义务的凭证。股票代表着其持有人(股东)对股份公司的所有权,每一股同类型股票所代表的公司所有权是相等的,即“同股同权”。股票可以公开上市,也可以不上市。在股票市场上,股票也是投资和投机的对象。对股票的某些投机炒作行为,例如无货沽空,可以造成金融市场的动荡。 2.1.2 开盘价 开盘价又称开市价,是指某种证券在证券交易所每个交易日开市后的第一笔买卖成交价格。世界上大多数证券交易所都采用成交额最大原则来确定开盘价。 2.1.3 收盘价 收盘价是指某种证券在证券交易所一天交易活动结束前最后一笔交易的成 交价格。如当日没有成交,则采用最近一次的成交价格作为收盘价,因为收盘价是当日行情的标准,又是下一个交易日开盘价的依据,可据以预测未来证券市场行情;所以投资者对行情分析时,一般采用收盘价作为计算依据。. 2.1.4 最高价 指某种证券在每个交易日从开始到收市的交易过程中所产生的最高价。 2.1.5最低价 指某种证券在每个交易日从开始到收市的交易过程中所产生的最低价。 2.1.6成交量 成交量是指一个时间单位内对某项交易成交的数量。一般情况下,成交量大且价格上涨的股票,趋势向好。成交量持续低迷时,一般出现在熊市或股票整理阶段,市场交投不活跃。成交量是判断股票走势的重要依据,对分析主力行为提供了重要的依据。 2.1.7 K 线 K 线图这种图表源处于日本德川幕府时代(1603~1867 年),被当时日本米
Southwest university of science and technology 数据挖掘课程报告 数据仓库与数据挖掘的综述 学院名称计算机科学与技术 专业名称计科 学生姓名 学号 指导教师吴珏 二〇一六年11月
摘要 通过对数据仓库与数据挖掘的学习和大致的了解,主要提出了一种基于数据仓库的数据挖掘系统的决策支持系统的框架。该文章把数据仓库、数据挖掘工具和知识库结合在一起,提高了数据挖掘的效率。增加了挖掘数据的效率和价值实用性! 一、概述 近十几年来,人们利用信息技术生产和搜集数据的能力大幅度提高,千万万个数据库被用于商业管理、政府办公、科学研究和工程开发等等,并且这一势头仍将持续发展下去。于是,一个新的挑战被提了出来:在这被称之为信息爆炸的时代,信息过量几乎成为人人需要面对的问题。如何才能不被信息的汪洋大海所淹没,从中及时发现有用的知识,提高信息利用率呢?要想使数据真正成为一个公司的资源,只有充分利用它为公司自身的业务决策和战略发展服务才行,否则大量的数据可能成为包袱,甚至成为垃圾。因此,面对"人们被数据淹没,人们却饥饿于知识的挑战,数据挖掘和知识发现(DMKD)技术应运而生,并得以蓬勃发展,越来越显示出其强大的生命力。 数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。还有很多和这一术语相近似的术语,如从数据库中发现知识(KDD)、数据分析、数据融合(Data Fusion)
以及决策支持等。人们把原始数据看作是形成知识的源泉,就像从矿石中采矿一样。原始数据可以是结构化的,如关系数据库中的数据,也可以是半结构化的,如文本、图形、图像数据,甚至是分布在网络上的异构型数据。发现知识的方法可以是数学的,也可以是非数学的;可以是演绎的,也可以是归纳的。发现了的知识可以被用于信息管理、查询优化、决策支持、过程控制等,还可以用于数据自身的维护。因此,数据挖掘是一门很广义的交叉学科,它汇聚了不同领域的研究者,尤其是数据库、人工智能、数理统计、可视化、并行计算等方面的学者和工程技术人员。 数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。 今天,越来越多的企业认识到要从以往的事务处理和决策中总结经验,利用现有的数据进行分析和推理,建立企业的决策支持系统(DSS)以提高决策的质量。企业如果不能快速精确的收集和分析信息,将无法进行科学而有效的决策。建立数据仓库(Data warehouse)将能很的解决这一问题,使企业从大量的业务信息中筛选出所需的信息,并做出正确的决策。数据仓库不是单一的产品,而是综合了多种信息技术的计算环境。它将全企业的运行数据汇集到一个精心设计的关系数据库中,并将它们转换成面向主题(Subject-oriented)的形
数据挖掘综述 1、产生背景 随着计算机的产生和大量数字化的存储方法的出现,我们借助计算机来收集和分类各种数据资料,但是不同存储结构存放的大量数据集合很快被淹没,便导致了结构化数据库以及DBMS的产生。 但是随着信息时代的到来,信息量远远超过了我们所能处理的范围,从商业交易数据、科学资料到卫星图片、文本报告和军事情报,以及生活中各种信息,这也就是“数据爆炸但知识贫乏”的网络时代,面对巨大的数据资料,出现了新的需求,希望能够更好的利用这些数据,进行更高层次的分析,从这些巨大的数据中提取出对我们有意义的数据,这就是知识发现(KDD,Knowledge Discovery in Databases),数据挖掘应运而生。 2、数据库系统技术的演变 1)20世纪60年代和更早 这个时期是数据收集和数据库创建的过程,原始文件的处理2)20世纪70年代---80年代初期 有层次性数据库、网状数据库、关系数据库系统 3)20世纪80年代中期—现在 高级数据库系统,可以应用在空间、时间的、多媒体的、主动的、流的和传感器的、科学的和工程的。 4)20世纪80年代后期—现在
高级数据分析:数据仓库和数据挖掘 5)20世纪90年代—现在 基于web的数据库,与信息检索和数据信息的集成6)现在---将来 新一代的集成数据域信息系统 3、数据挖掘概念 数据挖掘(Data Mining),就是从大量数据中获取有效的、新颖的、潜在的有用的,最终可以理解的模式的非平凡过程。数据挖掘,又称为数据库中知识发现(KDD,Knowledge Discovery in Databases),也有人把数据挖掘作为数据库中知识发现过程的一个基本步骤。 数据挖掘基于的数据库类型主要有:关系型数据库、面向对象数据库、事务数据库、演绎数据库、时态数据库、多媒体数据库、主动数据库、空间数据库、遗留数据库、异质数据库、文本型、Internet信息库以及新兴的数据仓库等。 4、数据挖掘特点和任务 4.1数据挖掘具有以下几个特点: 1)处理的数据规模十分庞大,达到GB,TB数量级,甚至更大2)查询一般是决策制定者(用户)提出的即时随机查询,往往不能形成精确的查询要求,需要靠系统本身寻找其可能感兴 趣的东西。 3)在一些应用(如商业投资等)中,由于数据变化迅速,因此
网络流量分类识别 1.课题内容概述 网络安全实验室的课题中包含对网络流量进行分类识别的任务。 对网络流量按照应用类型准确地识别和分类是许多网络管理任务的重要组成部分,如流量优先级控制,流量定形、监管、诊断监视等。比如说,网络管理员可能需要识别并节流来自P2P协议的文件共享流量来管理自己的带宽预算,确保其他应用的网络性能。与网络管理任务类似,许多网络工程问题,如负载特征提取和建模,容量规划,路由配置也得益于准确地识别网络流量。 实时的流量统计有能力帮助网络服务提供商和他们的设备供应商解决困难的网络管理问题。网络管理员需要随时知道什么流量穿过了他们的网络,才能迅速采取应对措施来保障多样的商业服务目标。流量分类可能是自动入侵检测系统的核心组成部分,用来检测拒绝服务攻击,可以触发针对优先客户的自动网络资源重分配,或者识别哪些违背了服务条款的网络资源使用。 如今各种不同的网络应用层出不穷,网络流量的复杂性和多样性给流量分类问题带来了巨大的挑战。很多研究人员开始寻找接近于数据挖掘的技术来解决流量分类问题。 2.流量识别任务中数据挖掘技术的应用 2.1流量识别任务流程 如图2-1所示,基于机器学习的流量分类主要分为三个阶段,预处理阶段,学习阶段和预测阶段。预处理阶段包括对原始网络数据的整流,特征值计算以及特征值约简,学习阶段是训练模型学习规则的过程,预测阶段是对实际流量进行分类的过程。机器学习方法重点研究通过特征选择和训练进行分类模型的构造,即分类器的学习阶段。
图2-1机器学习的流量分类 (1)数据预处理 原始的网络数据集记录了每个数据包的到达时间和数据包内容,在预处理阶段首先要根据五元组进行整流,在每个TCP或UDP流上区分流量方向,然后在每个流上计算感兴趣的流量特征,如数据包大小的分布,数据包间隔时间,连接持续时间等。 (2)降维 经过数据预处理后的网络流是一个有各项特征值的向量,可以作为机器学习算法的输入,但网络流特征冗余会影响分类结果的准确性,也会增加训练的计算开销,可以将高维向量投影到低维空间中,再用以训练。 (3)特征约简 将可获得的特征都用来训练分类器并不一定是最好的选择,因为不相关的特征和冗余的特征会对算法的性能产生负作用。可以通过一些算法进行评估,选择具有很强代表性的特征子集,来训练模型。 (4)训练 从训练数据集中构建分类模型的过程,主要任务是建立一个从网络流特征到应用类别的映射,有不同的分类模型可以选择。 (5)测试 依据训练的分类模型,对未知的网络流进行预测,得出网络流所属的应用类别。该阶段涉及到对分类模型的评估,有很多流量分类度量指标可以选择。评估还可以分为以流计算和以字节计算两个方向,前者侧重于对流识别能力的评估,后者侧重于识别那些占据主要通信量的大流。 2.2特征值归约方法 采用信息增益率评估,特征集合为S,假设根据特征A划分训练集,划分前
Web数据挖掘综述 摘要:过去几十年里,Web的迅速发展使其成为世界上规模最大的公共数据源,因此如何从Web庞大的数据中提取出有价值的信息成为一大难题。Web数据挖掘正是为了解决这一难题而提出的一种数据挖掘技术。本文将从Web数据挖掘的概念、分类、处理流程、常用技术等几方面对Web数据挖掘进行介绍,并分析了Web 数据挖掘的应用及发展趋势。 关键词:Web数据挖掘;分类;处理流程;常用技术;应用;发展趋势 Overview of Web Data Mining Abstract:Over the past few decades,the rapid development of Web makes it becoming the world’s largest public data sources.So how to extract valuable information from the massive data of Web has become a major problem.Web data mining is the data mining technology what is in order to solve this problem.This article introduces the Web data mining from its concept, classification,processing,and common techniques,and analyzes the application and the development tendency of Web data mining. Key words:Web Data Mining;Classification;Processing;Common Techniques;Application; Development Tendency 0.引言 近些年来,互联网技术的飞速发展,带来了网络信息生产和消费行为的快速拓展。电脑、手机、平板电脑等终端的普及,SNS、微博等Web2.0应用的快速发展,促进了互联网信息数量的急剧增长,信息资源前所未有的丰富。但同时,海量级、碎片化的信息增加了人们获取有效信息的时间和成本[1]。因此,迫切需要找到这样的工具,能够从Web上快速有效地发现资源,发现隐含的规律性内容,提高在Web上检索信息、利用信息的效率,解决数据的应用问题,Web数据挖掘正是一个很好的解决方法。
一、需求分析: 一、应用背景: 运输业是国家经济的一个重要的组成部分,其发展水平已经成为一个国家和地区综合实力的重要体现。随着经济全球化,我国对物流的需求将大幅度的增加,物流将呈现跳跃式发展趋势。企业开始改变那种以商品为导向的观念,开始注重发掘,通过收集整理繁多的信息,量化分析需求,提供优质的售后服务,保持稳定的关系等措施,来加强对客户关系的管理。 CRM的主要含义就是通过对详细资料的深入分析,来提高满意程度,从而提高企业的竞争力的一种手段,CRM最大程度地改善、提高了整个关系生命周期的绩效。CRM整合了、公司、员工等资源,对资源有效地、结构化地进行分配和重组,便于在整个关系生命周期及时了解、使用有关资源和知识;简化、优化了各项业务流程,使得公司和员工在销售、服务、市场营销活动中,能够把注意力集中到改善关系、提升绩效的重要方面与核心业务上,提高员工对的快速反应和反馈能力;也为带来了便利,能够根据需求迅速获得个性化的商品、方案和服务。要在激烈的市场竞争中获得主动,越来越多的民航企业把保持客户作为企业的重要任务,谁能留住那些能给企业带来丰厚利润的关键客户,并获得他们长久的信任和支持,谁就能获得满意的回报,进而赢得持续的竞争优势。 在航空业,客户关系管理的应用有其特别的原因。面对航空公司的管理需求,急需引入先进的客户关系管理理念。在航空公司引入电子商务后,公司关注的重点由提高部效率向尊重外部转移。而CRM理念正是基于对客户的尊重,要求公司完整地认识整个客户生命周期,提供与客户沟通的统一平台,提高员工与接触的效率和反馈率。随着“以客户为中心"的客户关系管理技术在航空业的不断应用和发展,航空服务质量的改善提高的同时,产生了大量的客户数据,充分挖掘这些数据中隐藏的有用信息可以为航空公司的经营决策带来极大的帮助。 二、应用价值与意义: 概括来讲,数据仓库与数据挖掘在航空公司CRM中的商业价值主要体现在以 下三个方面: 1、有助于航空公司提高收益 一个成功的CRM系统可以给航空公司带来明显的收益增长,在客户的整个生命周期,最大化利润贡献。例如: (1)购买总量的增长,通过分析(市场购物篮分析)得到对航空公司货运客户的消费模式,找出有效的商品组合,实现交叉销售; (2)客户群体数量的增加,通过利润模型找出客户的一些共同特征,并通过聚类分析对客户进行分群,再通过模式分析预测得到潜在的客户群体以提高成功率。 (3)客户保持时间的增长,通过流失模型分析得到可能流失客户的,然后采取相应的预防措施降低客户流失率。
数据挖掘中聚类算法的综述 摘要:数据挖掘技术在当前研究领域中算是比较热门的一项技术,从国外发展到中国,具有广阔的商业应用前景。本文主要概述了当前数据挖掘的七大方法(分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘)和十大经典算法 (C4.5,K-Means,SVM,Apriori,EM,PageRank,AdaBoost,kNN,Naive Bayes,CART),以及数据挖掘的发展趋势。 关键词:数据挖掘,常用方法,经典算法 1 引言 在当今信息爆炸的时代,伴随着社会事件和自然活动的大量产生(数据的海量增长),人类正面临着“被信息所淹没,但却饥渴于知识”的困境。随着计算机软硬件技术的快速发展、企业信息化水平的不断提高和数据库技术的日臻完善,人类积累的数据量正以指数方式增长。面对海量的、杂乱无序的数据,人们迫切需要一种将传统的数据分析方法与处理海量数据的复杂算法有机结合的技术。数据挖掘技术就是在这样的背景下产生的。它可以从大量的数据中去伪存真,提取有用的信息,并将其转换成知识。 数据挖掘是一个多学科领域,它融合了数据库技术、人工智能、机器学习、模式识别、模糊数学和数理统计等最新技术的研究成果,可以用来支持商业智能应用和决策分析。例如顾客细分、交叉销售、欺诈检测、顾客流失分析、商品销量预测等等,目前广泛应用于银行、金融、医疗、工业、零售和电信等行业。数据挖掘技术的发展对于各行各业来说,都具有重要的现实意义。 2 数据挖掘的概念 2.1 什么是数据挖掘 数据挖掘(Data Mining),也叫数据开采,数据采掘等,是按照既定的业务目标从海量数据中提取出潜在、有效并能被人理解的模式的高级处理过程.在较浅的层次上,它利用现有数据库管理系统的查询、检索及报表功能,与多维分析、统计分析方法相结合,进行联机分析处理(O乙心),从而得出可供决策参考的统计分析数据.在深层次上,则从数据库中发现前所未有的、隐含的知识.OLAF'的出现早于数据挖掘,它们都是从数据库中抽取有用信息的方法,就决策支持的需要而言两者是相辅相成的。 OLAP可以看作一种广义的数据挖掘方法,它旨在简化和支持联机分析,而数据挖掘的目的是便这一过程尽可能自动化。 数据挖掘基于的数据库类型主要有:关系型数据库、面向对象数据库、事务数据库、演绎数据库、时态数据库、多媒体数据库、主动数据库、空间数据库、遗留数据库、异质数据库、文本型、
数据挖掘 课程名称:数据挖掘/ Data Mining 学时/学分:48学时/3学分 先修课程:数据库 适用专业:计算机科学与技术、软件工程及相关专业 开课院(系、部、室):数学与统计学院 一、课程的性质、教学目的与要求 本课程以数据挖掘为主要内容,主要介绍实现数据挖掘的各主要功能、挖掘算法和应用,并通过对实际数据的分析更加深入地理解常用的数据挖掘模型。掌握大型数据挖掘软件SAS Enterprise Miner的使用,培养学生数据分析和处理的能力。先修课程:《数据库原理》、《SAS软件基础》。 通过《数据挖掘》课程的教学,使学生理解数据挖掘的基本概念和方法,学习和掌握SAS Enterprise Miner中的数据挖掘方法。学生能够借助SAS Enterprise Miner软件工具进行具体数据的挖掘分析。 二、《数据挖掘》课程的基本要求、主要教学内容与学时分配(总学时48) 第一章数据挖掘导论(8学时) (一)教学目的和要求 本章主要介绍数据挖掘的基本概念和功能,并能熟悉掌握。同时要求了解数据挖掘的系统分类。 (二)主要内容 第一节数据挖掘发展概述 1、功能介绍 2、基本应用概述 第二节数据挖掘功能 1、概念描述:定性与对比 2、关联分析 3、分类与预测 4、聚类分析 5、异类分析 6、演化分析
第三节数据挖掘系统 1、系统分类 2、系统应用 3、数据挖掘在医学信息系统和社会保险领域的应用 (三)重点难点 重点、难点:掌握数据挖掘功能、数据挖掘系统的应用 第二章数据预处理(8学时) (一)教学目的与要求 主要介绍数据库中的知识发现处理过程,了解数据预处理的重要性,熟悉掌握数据预处理的方法。 (二)主要内容 第一节数据清洗 1、噪声数据处理 2、不一致数据处理 第二节数据集成与转换 1、数据集成处理 2、数据转换处理 (三)重点难点 重点、难点:掌握数据集成与转换 第三章分类与预测(12学时) (一)教学目的与要求 主要介绍分类与预测基本知识,要求掌握基本知识,并了解各项分类和预测方法的使用。 (二)主要内容 第一节分类与预测基本知识 1、分类基础 2、预测基础 第二节基于决策树的分类 第三节贝叶斯分类 第四节神经网络分类 第五节预测方法 1、线性与多变量回归
2006.07:我国时间序列分析研究工作综述(李锐向书坚) 国家统计局教育中心 2006-07-11 14:32:39 摘要:近年来我国学者对于时间序列的研究取得了极其丰硕的成果,主要体现在基础理论研究的不断加强(某些领域已经达到了国际前沿水平,而不再只是纯粹的吸收引进国外的先进成果);应用领域的不断拓展,在应用中求创新求发展,在部分应用领域中我们已经跟上了国际步伐。本文中我们将从理论与应用两个方面进行对我国时间序列分析研究的主要成果进行综述。 关键词:非线性;非平稳;非参数;数据挖掘 近年来我国学者对于时间序列的研究取得了极其丰硕的成果,主要体现在基础理论研究的不断加强(某些领域已经达到了国际前沿水平,而不再只是纯粹的吸收引进国外的先进成果);应用领域的不断拓展,在应用中求创新求发展,在部分应用领域中我们已经跟上了国际步伐。本文中我们将从理论与应用两个方面进行对我国时间序列分析研究的主要成果进行综述,主要介绍被SCI检索(2000-2004)的部分成果,以及在国内重点核心期刊(2000-2004)上发表的部分重要成果。 一、时间序列分析在理论上的进展 理论上的进展主要表现在两个方面:一是单位根理论;一是非线性模型理论,非线性模型理论的进展集中在几何遍历性问题和非线性过程的平稳性这两方面。我国学者在非线性时间序列分析方面取得了一系列高水平的成果。 汤家豪教授将有关非线性时间序列分析的研究与动力系统科学的模型连接而备受赞赏。现在他着眼于非参数时间序列模型的发展,并与生态学家进行大量的合作研究。 姚琦伟教授基于信息量,首次提出了描述一般随机系统对初始条件敏感性的度量及估计方法。在高维模型领域,姚琦伟教授提出用复系数线性模型近似高维非线性回归函数的新方法,以此克服高维非参数回归中样本量短缺的困难问题。此方法在生物、经济、金融等应用中获得了成功。在时间序列模型的最大似然估计方法的研究中,他完整地建立了在金融风险管理中有直接应用的ARCH和GARCH模型为最大似然估计的极限理论。对于重尾部(heavy-tailed)分布模型,提出了基于boostrap的新的估计方法以及稳健统计方法。他还首次建立了在空间域上空间ARMA 过程的最大似然估计理论,这一工作同时也对Hannan 1973年给出的关于时间序列
噪声数据处理综述 摘要:噪声数据是指数据中存在着错误或异常(偏离期望值)的数据,不完整数据是指感兴趣的属性没有值.不一致数据则是数据内涵出现不一致的情况。 为了更好的论述什么是噪声数据处理,给出了两种噪声数据处理的算法:在属性级别上处理噪声数据的数据清洗算法和一种改进的应用于噪声数据中的KNN算法。 关键词:噪声数据噪声数据处理数据清洗KNN算法 1.概述 噪声数据(noisy data)就是无意义的数据(meaningless data)。这个词通常作为损坏数据(corrupt data)的同义词使用。但是,现在它的意义已经扩展到包含所有难以被机器正确理解和翻译的数据,如非结构化文本。任何不可被创造它的源程序读取和运用的数据,不管是已经接收的、存储的还是改变的,都被称为噪声。 噪声数据未必增加了需要的存储空间容量,相反地,它可能会影响所有数据挖掘(data mining)分析的结果。统计分析可以运用历史数据中收集的信息来清除噪声数据从而促进数据挖掘。 引起噪声数据(noisy data)的原因可能是硬件故障、编程错误或者语音或光学字符识别程序(OCR)中的乱码。拼写错误、行业简称和俚语也会阻碍机器读取。 噪声数据处理是数据处理的一个重要环节,在对含有噪声数据进行处理的过程中,现有的方法通常是找到这些孤立于其他数据的记录并删除掉,其缺点是事实上通常只有一个属性上的数据需要删除或修正,将整条记录删除将丢失大量有用的、干净的信息。在数据仓库技术中,通常数据处理过程应用在数据仓库之前,其目的是提高数据的质量,使后继的联机处理分析(OLAP)和数据挖掘应用得到尽可能正确的结果。然而,这个过程也可以反过来,即利用数据挖掘的一些技术来进行数据处理,提高数据质量。