(完整word版)stata命令语句.docx
- 格式:docx
- 大小:39.40 KB
- 文档页数:27

第四章t 查验和单要素方差剖析命令与输出结果说明·单要素方差剖析单要素方差剖析又称为 OnewayANOVA, 用于比许多组样本的均数能否同样,并假定:每组的数据听从正态散布 , 拥有同样的方差,且互相独立,则无效假定。
原假定: H0 : 各组整体均数同样。
在 STATA中可用命令:oneway 察看变量分组变量[, means bonferroni]此中子命令 bonferroni是用于多组样本均数的两两比较查验。
例:测定健康男子各年纪组的淋巴细胞转变率 (%),结果见表,问: 各组的淋巴细胞转变率的均数之间的差异有无明显性?健康男子各年纪组淋巴细胞转变率 (%)的测定结果 :11-20 岁组: 58 61 61 62 63 68 70 70 74 78 41-50岁组: 54 57 57 58 60 60 63 64 66 61-75 岁组:43 52 55 56 60用变量 x 表示这些淋巴细胞转变率以及用分组变量group=1,2,3 分别表示11-20 岁组, 41-50岁组和 61-75 岁组 , 即:数据表示为:x586161626368707074785457 group111111111122x575860606364664352555660 group222222233333则用 STATA 命令:oneway x group, mean bonferroni| Summary of xgroup |Mean①-------------+------------1|23|------+------------Total |②Analysis of VarianceSource SS df MS F Prob > F-------------------------------------------------------------------------------Between groups③2④⑤ 9.77 ⑥ 0.0010 ⑦Within groups⑧21⑨⑴-------------------------------------------------------------------------------Total23(2) Bartlett's test for equal variances:chi2(2)( 3)Comparison of x by group(Bonferroni)Row Mean-|Col Mean|12-------------- --|--------------------------------------2|( 4)|( 5)|3|( 6)( 8)|( 7)( 9)①对应三个年纪组的淋巴细胞转变率的均数;②三组归并在一同的总的样本均数;③组间隔均差平方和;④组间隔均差平方和的自由度;⑤组间均方和 ( 即:⑤=③ / ④ ) ;⑧组内离均差平方和;⑨组内离均差平方和的自由度;( 1)组内均方和 ( 即:( 1)=⑧ / ⑨) ;⑥为 F 统计值 ( 即为⑤ / (1)) ;⑦为相应的 p 值;( 2)为方差齐性的 Bartlett 查验;( 3)方差齐性查验相应的 p 值;(4)第二组的淋巴细胞转变率样本均数—第一组的淋巴细胞转变率的样本均数的差;(5)第二和第一组均数差的明显性查验所对应 p 值;( 6)第三组的淋巴细胞转变率样本均数—第一组的淋巴细胞转变率的样本均数的差;(7)第三和第一组均数差的明显性查验所对应的 p 值;( 8)第三组的淋巴细胞转变率样本均数—第二组的淋巴细胞转变率的样本均数的差;(9)第三和第二组均数差的明显性查验所对应的 p 值。

********* 面板数据计量分析与软件实现 *********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。

*********面板数据计量分析与软件实现*********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计)* 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。

stata学习心得(网络版存盘)2009-03-25 18:06调整变量格式:format x1 %10.3f——将 x1的列宽固定为10,小数点后取三位format x1 %10.3g——将x1的列宽固定为10,有效数字取三位format x1 %10.3e——将x1的列宽固定为10,采用科学计数法format x1 %10.3fc——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符format x1 %10.3gc——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符format x1 %-10.3gc——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“- ”表示左对齐合并数据:桌面 \2006.dta", clear桌面 \1999.dta"——将 1999 和 2006 的数据按照样本(observation)排列的自然顺序合并起来桌面 \2006.dta", clear桌面 \1999.dta" ,unique sort——将 1999 和 2006 的数据按照唯一的(unique )变量 id 来合并,在合并时对id 进行排序( sort )建议采用第一种方法。
对样本进行随机筛选:sample 50在观测案例中随机选取50%的样本,其余删除在观测案例中随机选取50 个样本,其余删除查看与编辑数据:browse x1 x2 if x3>3(按所列变量与条件打开数据查看器)edit x1 x2 if x3>3(按所列变量与条件打开数据编辑器)数据合并( merge)与扩展( append)merge 表示样本量不变,但增加了一些新变量;append 表示样本总量增加了,但变量数目不变。
one-to-one merge:数据源自stata tutorial中的exampw1和exampw2第一步:将exampw1按 v001 ~ v003 这三个编码排序,并建立临时数据库tempw1clearuse "t:\statatut\exampw1.dta"su—— summarize 的简写sort v001 v002 v003save tempw1第二步:对exampw2做同样的处理clearuse "t:\statatut\exampw2.dta"susort v001 v002 v003save tempw2第三步:使用tempw1 数据库,将其与tempw2 合并:clearmerge v001 v002 v003 using tempw2第四步:查看合并后的数据状况:ta _merge——tabulate _merge的简写su第五步:清理临时数据库,并删除_merge,以免日后合并新变量时出错erase tempw1.dtaerase tempw2.dtadrop _merge数据扩展append:数据源自stata tutorial中的fac19和newfacclearuse "t:\statatut\fac19.dta"ta regionappend using "t:\statatut\newfac"ta region合并后样本量增加,但变量数不变茎叶图:stem x1,line(2)(做x1的茎叶图,每一个十分位的树茎都被拆分成两段来显示,前半段为0~ 4,后半段为5~ 9)stem x1,width(2)(做x1的茎叶图,每一个十分位的树茎都被拆分成五段来显示,每个小树茎的组stem x1,round(100)(将x1除以100后再做x1的茎叶图)直方图采用 auto 数据库histogram mpg, discrete frequency normal xlabel(1(1)5)(discrete表示变量不连续,frequency表示显示频数,normal加入正太分布曲线,xlabel设定x轴,1和5为极端值, (1) 为单位)histogram price, fraction norm(fraction表示y轴显示小数,除了frequency和fraction这两个选择之外,该命令可替换为“ percent”百分比,和“ density ”密度;未加上discrete就表示将price当作连续变量来绘图)histogram price, percent by(foreign)(按照变量“ foreign ”的分类,将不同类样本的“price ”绘制出来,两个图分左右排布)histogram mpg, discrete by(foreign, col(1))(按照变量“ foreign ”的分类,将不同类样本的“mpg”绘制出来,两个图分上下排布)histogram mpg, discrete percent by(foreign, total) norm(按照变量“ foreign ”的分类,将不同类样本的“mpg”绘制出来,同时绘出样本整体的“总”直方图)二变量图:graph twoway lfit price weight || scatter price weight(作出 price和weight的回归线图——“ lfit”,然后与price和weight的散点图相叠加)twoway scatter price weight,mlabel(make)(做 price和weight的散点图,并在每个点上标注“make”,即厂商的取值)twoway scatter price weight || lfit price weight,by(foreign)(按照变量foreign的分类,分别对不同类样本的price和weight做散点图和回归线图的叠加,两图呈左右分布)twoway scatter price weight || lfit price weight,by(foreign,col(1))(按照变量foreign的分类,分别对不同类样本的price和weight做散点图和回归线图的叠加,两图呈上下分布)twoway scatter price weight [fweight= displacement],msymbol(oh)(画出 price和weight的散点图,“ msybol(oh)”表示每个点均为中空的圆圈,[fweight=displacement]表示每个点的大小与displacement的取值大小成比例)twoway connected y1 time,yaxis(1) || y2 time,yaxis(2)(画出 y1 和 y2 这两个变量的时间点线图,并将它们叠加在一个图中,左边“yaxis(1) ”为y1 的度量,右边“yaxis(2) ”为y2 的)twoway line y1 time,yaxis(1) || y2 time,yaxis(2)(与上图基本相同,就是没有点,只显示曲线)graph twoway scatter var1 var4 || scatter var2 var4 || scatter var3 var4(做三个点图的叠加)graph twoway line var1 var4 || line var2 var4 || line var3 var4(做三个线图的叠加)graph twoway connected var1 var4 || connected var2 var4 || connected var3 var4(叠加三个点线相连图)更多变量:graph matrix a b c y(画出一个散点图矩阵,显示各变量之间所有可能的两两相互散点图)graph matrix a b c d,half(生成散点图矩阵,只显示下半部分的三角形区域)用 auto 数据集:graph matrix price mpg weight length,half by(foreign,total col(1) )(根据 foreign变量的不同类型绘制price等四个变量的散点图矩阵,要求绘出总图,并上下排列】=具)其他图形:graph box y,over(x) yline(.22)(对应 x 的每一个取值构建y 的箱型图,并在y 轴的 0.22 处划一条水平线)graph bar (mean) y,over(x)对应 x 的每一个取值,显示y 的平均数的条形图。

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=xy itiit固定效应模型μβit +=xy ititεαμit+=itit随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量 gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0。
0000,检验结果表明固定效应模型优于混合OLS模型.●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui"之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型.●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。

stata命令大全(全)资料********* 面板数据计量分析与软件实现 *********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA 教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。

stata学习心得(网络版存盘)2009-03-25 18:06调整变量格式:format x1 %10.3f ——将x1的列宽固定为10,小数点后取三位format x1 %10.3g ——将x1的列宽固定为10,有效数字取三位format x1 %10.3e ——将x1的列宽固定为10,采用科学计数法format x1 %10.3fc ——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符format x1 %10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符format x1 %-10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“-”表示左对齐合并数据:use "C:\Documents and Settings\xks\桌面\2006.dta", clearmerge using "C:\Documents and Settings\xks\桌面\1999.dta"——将1999和2006的数据按照样本(observation)排列的自然顺序合并起来use "C:\Documents and Settings\xks\桌面\2006.dta", clearmerge id using "C:\Documents and Settings\xks\桌面\1999.dta" ,unique sort——将1999和2006的数据按照唯一的(unique)变量id来合并,在合并时对id进行排序(sort)建议采用第一种方法。
对样本进行随机筛选:sample 50在观测案例中随机选取50%的样本,其余删除sample 50,count在观测案例中随机选取50个样本,其余删除查看与编辑数据:browse x1 x2 if x3>3 (按所列变量与条件打开数据查看器)edit x1 x2 if x3>3 (按所列变量与条件打开数据编辑器)数据合并(merge)与扩展(append)merge表示样本量不变,但增加了一些新变量;append表示样本总量增加了,但变量数目不变。

*********面板数据计量分析与软件实现*********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计)* 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog 生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/ gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。

********* 面板数据计量分析与软件实现 *********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。

*********面板数据计量分析与软件实现*********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计)* 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog 生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/ gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
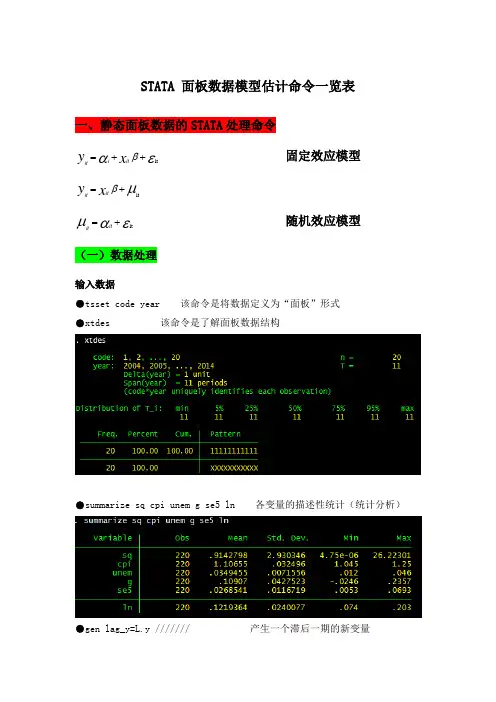
STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
stata命令总结.docStata命令总结引言Stata是一款强大的统计分析软件,广泛应用于经济学、社会学、医学等领域。
Stata命令是进行数据处理、统计分析、图形展示等操作的基础。
本文将对Stata中常用的命令进行总结,以帮助用户更高效地使用Stata进行数据分析。
Stata基础命令1. 数据管理导入数据:import excel, import delimited导出数据:export excel, export delimited数据集保存:save, saveold2. 变量管理创建变量:generate, egen修改变量:replace删除变量:drop3. 数据清洗数据类型转换:destring, encode, format缺失值处理:mvdecode, drop if missing()异常值检测:tabulate, summarize描述性统计分析1. 基本统计量描述性统计:summarize频率统计:tabulate相关系数:correlate2. 分组统计分组描述:bysort, xtsum 分组汇总:collapse3. 数据转换数据长格式:reshape long 数据宽格式:reshape wide 推断性统计分析1. 假设检验t检验:ttest方差分析:anova卡方检验:tabulate, chi2 2. 回归分析线性回归:regress逻辑回归:logit泊松回归:poisson3. 时间序列分析时间序列描述:tsreport自回归模型:arima高级统计分析1. 面板数据分析面板数据描述:xtset, xtsum固定效应模型:xtreg fe随机效应模型:xtreg re2. 多层次模型多层次线性模型:xtmelogit3. 结构方程模型结构方程模型:sem绘图与可视化1. 基本图形散点图:scatter线图:line柱状图:bar2. 高级图形箱线图:boxplot直方图:histogram核密度估计图:kdensity3. 交互式图形交互式图形:twoway, graph edit编程与自动化1. 循环与条件语句循环:foreach, forvalues条件语句:if, else2. 脚本与批处理脚本编写:do-file批处理:batch3. 宏与用户定义命令宏:macro用户定义命令:program define结语Stata命令的掌握是进行高效数据分析的前提。
********* 面板数据计量分析与软件实现 *********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
Stata统计分析常用命令汇总一、winsorize极端值处理范围:一般在1%和99%分位做极端值处理,对于小于1%的数用1%的值赋值,对于大于99%的数用99%的值赋值。
1、Stata中的单变量极端值处理:stata 11。
0,在命令窗口输入“findit winsor”后,系统弹出一个窗口,安装winsor模块安装好模块之后,就可以调用winsor命令,命令格式:winsor var1, gen(new var) p(0。
01)或者在命令窗口中输入:ssc install winsor安装winsor命令.winsor命令不能进行批量处理。
2、批量进行winsorize极端值处理:打开链接:http://personal。
/judson。
caskey/data。
html,找到winsorizeJ,点击右键,另存为到stata中的ado/plus/目录下即可。
命令格式:winsorizeJ var1var2var3,suffix(w)即可,这样会生成三个新变量,var1w var2w var3w,而且默认的是上下1%winsorize。
如果要修改分位点,则写成如下格式:winsorizeJ var 1 var2 var3,suffix(w) cuts(5 95)。
3、Excel中的极端值处理:(略)winsor2 命令使用说明简介:winsor2 winsorize or trim (if trim option is specified) the variables in varlist at particular percentiles specified by option cuts(# #)。
In defult, new variables will be generated with a suffix "_w” or "_tr", which can be changed by specifying suffix() option。
*********面板数据计量分析与软件实现*********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计)* 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog 生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
********* 面板数据计量分析与软件实现*********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计)* 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现,6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/ gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省20xx年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
(完整)stata命令总结,推荐文档stata11 常用命令注:JB统计量对应的p大于0.05 ,则表明非正态,这点跟sktest 和swilk 检验刚好相反;dta 为数据文件;gph 为图文件;do 为程序文件;注意stata 要区别大小写;不得用作用户变量名:_all _n _N _skip _b _coef _cons _pi _pred _rc _weight double float long int in if using with 命令:读入数据一种方式input x y142 5.53 6.247.758.5endsu/summarise/sum x 或su/summarise/sum x,d 对分组的描述:sort group by group:su x%%%%%tabstat economy,stats(max)%返回变量economy的最大值%%stats括号里可以是:mean,count(非缺失观测值个数),sum(总和),max,min,range ,%% sd ,var ,cv(变易系数=标准差/ 均值),skewness,kurtosis ,median,p1(1 %分位%% 数,类似地有p10, p25, p50, p75, p95, p99),iqr (interquantile range = p75 –p25)_all %描述全部_N 数据库中观察值的总个数。
_n 当前观察值的位置。
_pi 圆周率π 的数值。
list gen/generate % 产生数列egen wagemax=max(wage)clearuseby(分组变量)set more 1/0count % 计数 gsort +x ( 升序 ) gsort -x ( 降序 ) sort x 升序;并且其它变量顺序会跟着改变label var y " 消费 " %添加标签describe %描述数据文件的整体,包括观测总数,变量总数,生成日期,每个变量的存储类型 (storage type) ,标签 (label) replace x5=2*y if x!=3 % 替换变量值replace age = 25 in 107 %令第 107 个观测中 age 为 25rename y2 u %改变变量名drop in 2 %删除全部变量的第 2 行drop if x==. 删去 x 为缺失值的所有记录keep if x<2 %保留小于 2 的数据,其余变量跟随 x 改变 keep in 2/10 %保留第 2-10 个数 keep x1-x5 %保留数据库中介于 x1 和 x5 间的所有变量 ( 包括 x1 和 x5) ,其余变量删除ci x1 x2,by(group) %算出置信区间 , 不过先前对 group 要先排序,即sort group ;%by 的意思逐个进行cii 12 3.816667 0.2710343, level(90) %已知均值,方差,计算 90%的置信区间cii 10 2%obs=10,mean=2,以二项分布形式,计算置信区间centile x,centile(2.5 25 50 75 97.5) %取分位数correlate/corr x y z%相关系数pwcorr x y,sig %给出原假设 r=0 的命令%如果变量非服从正态分布,则spearman x y regress/reg mean year % 回归方程建立 reg y x,noconstant % 无常数项 predict meanhat %预测拟合值predict e,residual % 得到残差estat hettest % 异方差检验dwstat % Durbin-Watson 自相关检验 vif % 方差膨胀因子取 0或 1,是被解释变量, x1-x3 是被解释变量 ) %logit取 0 或 1 ,是被解释变量, x1-x3 是被解释变量 ) %probit 取值在 0和 1之间,是被解释变量, x1-x3 是被解释变sktest e % 残差正态性检验p>0.05 则接受原假设,即服从正态分布; %% sktest 是基于变量的偏度和斜度 (正态分布的偏度为 0,斜度为 3) swilk x %基于 Shapiro-Wilk 检验%%p 值越小,越倾向于拒绝零假设,也就是变量越有可能不服从正态分布 xi %生成虚拟变量tabulat gender,summ(math) %用 gender 指标对 math 进行分类,返回两类 mathlogit y x1 x2 x3 (y回归 probit y x1 x2 x3 (y 回归tobit y x1 x2 x3 (y 量 ) %tobit 回归的mean、std 、freqtabulate=tab %gen f=int((shengao-164)/3)*3+164 组距为3 tabulate 变量名[, generate( 新变量) missing nofreq nolabel plot ] %%%%%generate( 新变量) // 按分组变量产生哑变量nofreq // 不显示频数nolabel// 不显示数值标记plot // 显示各组频数图示missing // 包含缺失值cell // 显示各小组的构成比( 小组之和为1) column // 按栏显示各组之构成( 各栏总计为1) row // 按行显示各组之构成( 各行总计为1) %%%%% 求和,求最小?mod(x,y) % 求余数means %返回三种平均值di normprob(1.96) di invnorm(0.05) di binomial(20,5,0.5) di invbinomial(20,5,0.5) di tprob(10,2) di invt(10.0.05) di fprob(3,27,1) di invfprob(3,27,0.05) di chi2(3,5) di invchi2(3,0.05) stack x y z,into(e)%把三列合成一列xpose,clear %矩阵转置append using d:\0917.dta %把已打开的文件(x y z )跟0917 里的(x y z )合并,是竖向合并,即观察值合并;merge using D:\0917.dta %把已打开的文件(x y z )跟0917 里的( a b )合并,是横向合并,即变量合并;format x %9.2e %科学记数format x %9.2f %2 位小数%产生随机数%1 产生20 个在(0 ,1)区间上均匀分布的随机数uniform()set seed 100set obs 20gen r=uniform()list%clear 清除内存set seed 200 设置种子数为200 set obs 20 设置样本量为20 range no 1 20gen r=uniform()gen group=1为1sort rreplace group=2 in 11/20建立编号 1 至20产生在(0,1) 均匀分布的随机数设置分组变量group 的初始值对随机数从小到大排序设置最大的10 个随机数所对应的记录为第 2 组,即:最小的10 个随机数所对应的记录为第 1 组sort no list 按照编号排序显示随机分组的结果也可以list if group==1 和list no if group==1%2 产生10 个服从正态分布N( 100,6^2)的随机数invnorm(uniform())*sigma+u clear清除内存set seed 200 set obs 10设置种子数为200设置样本量为10gen x=invnorm(uniform())*6+100 产生服从N(100 ,6^2) 的随机数list画图注意有些图前面要加histogram 直方图line 折线图scatter 散点图scatter y x,c(l) s(d) b2("(a)") graph twoway connected y x 连点图graph bar (sum) var2,over(var1) blabel(total) % 条形图. graph bar p52 p72,by(d) . graph bar p52 p72,over(d) . graph bar p52p72,by(d) stack . graph bar p52 p72,over(d) stack //////////// 数据如下%d p52 p72 %1 163.2 27.4 %2 72.5 83.6 %3 57.2 178.2 histogram x,bin(8) norm%画直方图,加正态分数线graph pie a b o ab if area==1,plabel(_all percent) % 画饼图graph pie var2, over(var1) plabel(_all percent) %饼图graph pie p52 p72,by(d) % 饼图graph box y1 % 箱体图qnorm x %qq 图 lfit y x %回归直线graph matrix gender economy math 多变量散点图line yhat x||scatter y x,c(.l) s(O.) xline(12) yline(5.4) %线形图 & 散点图有一些通用的选项可以给图形“润色”:标题title( “string ” ) ( string 可为任意的字符串,下同) 脚注note( “string ”) 横座标标题xtitle( “string ”) 纵座标标题ytitle( “sting ”) 横座标范围xaxis(a,b) (a// 连接各散点的方式, c 表示: . 不连接 ( 缺省值 ) l L m s J || [varname] 用变量的取值代码表示 [_n] 用点的记录号表示数学函数等都要与 generate 、 replace 、display 一起使用,不能单独使用程序文件 do use d:\0917.dta reg y xconnect(c...c) 或简写为 c(c...c)II 同 ||,个短横Symbol(s...s)// 表示各散点的图形, s 表示:或简写为 s(s...s) O 大圆圈 ( 缺省值 )S 大方块 T 大三角形 o 小圆圈 d 小菱形p 小加号用直线连接沿x 方向只向前不向后直线连接计算中位数并用直线连接用三次平滑曲线连接以阶梯式直线条连接用直线连接在同一纵向上的两点只是线的顶部和底部有一 i 小点无符号corr y xline y x,saving(d:\d4) 按ctrl+D 执行字符串操作函数:length(s)%长度函数,计算s 的长度, 如,disp length("ab") 的结果是substr(s,n1,n2)%子串函数,获得从s 的n1 个字符开始的n2个字符成的字符串,dispsubstr("abcdef",2,3)的结果是"bcd"string(n)%将数值n 转换成字符串函数,如,dispstring(41)+"f" 的结果是"41f"real(s)%将字符串s 转换成数值函数,如,dispreal("5.2")+1 的结果是6.2upper(s)%转换成大写字母函数,如,dispupper("this")的结果是"THIS"lower(s)%转换成小写字母函数,如displower("THIS")的结果是"this"index(s1,s2)%子串位置函数,计算s2 在s1 中第一次出现的起始位置, 如果s2 不在s1 中, 则结果为0。
stata学习心得(网络版存盘)2009-03-25 18:06调整变量格式:format x1 %10.3f——将 x1的列宽固定为10,小数点后取三位format x1 %10.3g——将x1的列宽固定为10,有效数字取三位format x1 %10.3e——将x1的列宽固定为10,采用科学计数法format x1 %10.3fc——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符format x1 %10.3gc——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符format x1 %-10.3gc——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“- ”表示左对齐合并数据:桌面 \2006.dta", clear桌面 \1999.dta"——将 1999 和 2006 的数据按照样本(observation)排列的自然顺序合并起来桌面 \2006.dta", clear桌面 \1999.dta" ,unique sort——将 1999 和 2006 的数据按照唯一的(unique )变量 id 来合并,在合并时对id 进行排序( sort )建议采用第一种方法。
对样本进行随机筛选:sample 50在观测案例中随机选取50%的样本,其余删除在观测案例中随机选取50 个样本,其余删除查看与编辑数据:browse x1 x2 if x3>3(按所列变量与条件打开数据查看器)edit x1 x2 if x3>3(按所列变量与条件打开数据编辑器)数据合并( merge)与扩展( append)merge 表示样本量不变,但增加了一些新变量;append 表示样本总量增加了,但变量数目不变。
one-to-one merge:数据源自stata tutorial中的exampw1和exampw2第一步:将exampw1按 v001 ~ v003 这三个编码排序,并建立临时数据库tempw1clearuse "t:\statatut\exampw1.dta"su—— summarize 的简写sort v001 v002 v003save tempw1第二步:对exampw2做同样的处理clearuse "t:\statatut\exampw2.dta"susort v001 v002 v003save tempw2第三步:使用tempw1 数据库,将其与tempw2 合并:clearmerge v001 v002 v003 using tempw2第四步:查看合并后的数据状况:ta _merge——tabulate _merge的简写su第五步:清理临时数据库,并删除_merge,以免日后合并新变量时出错erase tempw1.dtaerase tempw2.dtadrop _merge数据扩展append:数据源自stata tutorial中的fac19和newfacclearuse "t:\statatut\fac19.dta"ta regionappend using "t:\statatut\newfac"ta region合并后样本量增加,但变量数不变茎叶图:stem x1,line(2)(做x1的茎叶图,每一个十分位的树茎都被拆分成两段来显示,前半段为0~ 4,后半段为5~ 9)stem x1,width(2)(做x1的茎叶图,每一个十分位的树茎都被拆分成五段来显示,每个小树茎的组stem x1,round(100)(将x1除以100后再做x1的茎叶图)直方图采用 auto 数据库histogram mpg, discrete frequency normal xlabel(1(1)5)(discrete表示变量不连续,frequency表示显示频数,normal加入正太分布曲线,xlabel设定x轴,1和5为极端值, (1) 为单位)histogram price, fraction norm(fraction表示y轴显示小数,除了frequency和fraction这两个选择之外,该命令可替换为“ percent”百分比,和“ density ”密度;未加上discrete就表示将price当作连续变量来绘图)histogram price, percent by(foreign)(按照变量“ foreign ”的分类,将不同类样本的“price ”绘制出来,两个图分左右排布)histogram mpg, discrete by(foreign, col(1))(按照变量“ foreign ”的分类,将不同类样本的“mpg”绘制出来,两个图分上下排布)histogram mpg, discrete percent by(foreign, total) norm(按照变量“ foreign ”的分类,将不同类样本的“mpg”绘制出来,同时绘出样本整体的“总”直方图)二变量图:graph twoway lfit price weight || scatter price weight(作出 price和weight的回归线图——“ lfit”,然后与price和weight的散点图相叠加)twoway scatter price weight,mlabel(make)(做 price和weight的散点图,并在每个点上标注“make”,即厂商的取值)twoway scatter price weight || lfit price weight,by(foreign)(按照变量foreign的分类,分别对不同类样本的price和weight做散点图和回归线图的叠加,两图呈左右分布)twoway scatter price weight || lfit price weight,by(foreign,col(1))(按照变量foreign的分类,分别对不同类样本的price和weight做散点图和回归线图的叠加,两图呈上下分布)twoway scatter price weight [fweight= displacement],msymbol(oh)(画出 price和weight的散点图,“ msybol(oh)”表示每个点均为中空的圆圈,[fweight=displacement]表示每个点的大小与displacement的取值大小成比例)twoway connected y1 time,yaxis(1) || y2 time,yaxis(2)(画出 y1 和 y2 这两个变量的时间点线图,并将它们叠加在一个图中,左边“yaxis(1) ”为y1 的度量,右边“yaxis(2) ”为y2 的)twoway line y1 time,yaxis(1) || y2 time,yaxis(2)(与上图基本相同,就是没有点,只显示曲线)graph twoway scatter var1 var4 || scatter var2 var4 || scatter var3 var4(做三个点图的叠加)graph twoway line var1 var4 || line var2 var4 || line var3 var4(做三个线图的叠加)graph twoway connected var1 var4 || connected var2 var4 || connected var3 var4(叠加三个点线相连图)更多变量:graph matrix a b c y(画出一个散点图矩阵,显示各变量之间所有可能的两两相互散点图)graph matrix a b c d,half(生成散点图矩阵,只显示下半部分的三角形区域)用 auto 数据集:graph matrix price mpg weight length,half by(foreign,total col(1) )(根据 foreign变量的不同类型绘制price等四个变量的散点图矩阵,要求绘出总图,并上下排列】=具)其他图形:graph box y,over(x) yline(.22)(对应 x 的每一个取值构建y 的箱型图,并在y 轴的 0.22 处划一条水平线)graph bar (mean) y,over(x)对应 x 的每一个取值,显示y 的平均数的条形图。
括号中的“mean”也可换成median 、 sum、sd 、 p25、 p75 等graph bar a1 a2,over(b) stack(对应在 b 的每一个取值,显示a1 和 a2 的条形图, a1 和 a2 是叠放成一根条形柱。
若不写入“stack ”,则a1和 a2 显示为两个并排的条形柱)graph dot (median)y,over(x)(画点图,沿着水平刻度,在x 的每一个取值水平所对应的y 的中位数上打点)qnorm x(画出一幅分位- 正态标绘图)rchart a1 a2 a2(画出质量控制R 图,显示a1 到 a3 的取值范围)简单统计量的计算:ameans x(计算变量x 的算术平均值、几何平均值和简单调和平均值,均显示样本量和置信区间)mean var1 [pweight = var2](求取分组数据的平均值和标准误,var1 为各组的赋值,var2 为每组的频数)summarize y x1 x2,detail(可以获得各个变量的百分比数、最大最小值、样本量、平均数、标准差、方差、峰度、偏度)*** 注意 ***stata中summarize所计算出来的峰度skewness 和偏度 kurtosis有问题,与ECELL和SPSS有较大差异,建议不采用 stata的结果。
summarize var1 [aweight = var2], detail(求取分组数据的统计量,var1 为各组的赋值,var2 为每组的频数)tabstat X1,stats(mean n q max min sd var cv)(计算变量X1 的算术平均值、样本量、四分位线、最大最小值、标准差、方差和变异系数)概率分布的计算:(1 )贝努利概率分布测试:webuse quickbitest quick==0.3,detail(假设每次得到成功案例‘1’的概率等于0.3 ,计算在变量quick 所显示的二项分布情况下,各种累计概率和单个概率是多少)bitesti 10,3,0.5,detail(计算当每次成功的概率为0.5 时,十次抽样中抽到三次成功案例的概率:低于或高于三次成功的累计概率和恰好三次成功概率)(2 )泊松分布概率:display poisson(7,6).44971106(计算均值为7 ,成功案例小于等于 6 个的泊松概率)display poissonp(7,6).14900278(计算均值为7 ,成功案例恰好等于 6 个的泊松概率)display poissontail(7,6).69929172(计算均值为7 ,成功案例大于等于 6 个的泊松概率)(3 )超几何分布概率:display hypergeometricp(10,3,4,2).3(计算在样本总量为10,成功案例为 3 的样本总体中,不重置地抽取 4 个样本,其中恰好有 2 个为成功案例的概率)display hypergeometric(10,3,4,2).96666667(计算在样本总量为10,成功案例为 3 的样本总体中,不重置地抽取 4 个样本,其中有小于或等于 2 个为成功案例的概率)检验极端值的步骤:常见命令: tabulate、stem、codebook、summarize、list、histogram、graph box、gragh matrixstep1. 用 codebook 、 summarize 、 histogram 、 graph boxs、graph matrix、stem看检验数据的总体情况:codebook y x1 x2summarize y x1 x2,detailhistogram x1,norm(正态直方图)graph box x1(箱图)graph matrix y x1 x2,half(画出各个变量的两两x-y 图)stem x1 (做 x1 的茎叶图)可以看出数据分布状况,尤其是最大、最小值step2. 用 tabulate、list细致寻找极端值tabulate code if x1==极端值(作出x1 等于极端值时code 的频数分布表,code 表示地区、年份等序列变量,这样便可找出那些地区的数值出现了错误)list code if x1==极端值(直接列出x1 等于极端值时code 的值,当x1 的错误过多时,不建议使用该命令)list in -20/l(l表示last one,-20表示倒数第20 个样本,该命令列出了从倒数第20 个到倒数第一个样本的各变量值)step3. 用 replace命令替换极端值replace x1=? if x1==极端值去除极端值:keep if y<1000drop if y>1000对数据排序:sort xgsort +x(对数据按x 进行升序排列)gsort -x(对数据按x 进行降序排列)gsort -x, generate(id) mfirst(对数据按x 进行降序排列,缺失值排最前,生成反映位次的变量id )对变量进行排序:order y x3 x1 x2(将变量按照y 、x3 、 x1 、 x2 的顺序排列)生成新变量:gen logx1=log(x1)(得出x1的对数)gen x1`=exp(logx1)(将logx1反对数化)gen r61_100=1 if rank>=61&rank<=100 (若 rank 在 61 与 100 之间,则新变量r61_100 的取值为1,其他为缺失值)replace r61_100 if r61_100!=1(“!=”表示不等于,若r61_100 取值不为 1,则将 r61_100 替换为 0 ,就是将上式中的缺失值替换为0)gen abs(x)(取x的绝对值)gen ceil(x)(取大于或等于x 的最小整数)gen trunc(x)(取x的整数部分)gen round(x)(对x进行四舍五入)gen round(x,y)(以y为单位,对x 进行四舍五入)gen sqrt(x)(取x的平方根)gen mod(x,y)(取x/y的余数)gen reldif(x,y)(取x与y的相对差异,即|x-y|/(|y|+1))gen logit(x)(取ln[x/(1-x)])gen x=autocode(x,n,xmin,xmax)(将x的值域,即xmax-xmin ,分为等距的n 份)gen x=cond(x1>x2,x1,x2)(若x1>x2成立,则取x1 ,若 x1>x2 不成立,则取x2 )sort xgen gx=group(n)(将经过排序的变量x 分为尽量等规模的n 个组)egen zx1=std(x1) (得出 x1的标准值,就是用 (x1-avgx1)/sdx1 )egen zx1=std(x1),m(0) s(1)(得出 x1 的标准分,标准分的平均值为0,标准差为 1 )egen sdx1=sd(x1)(得出x1的标准差)egen meanx1=mean(x1) (得出 x1 的平均值)egen maxx1=max(x1) (最大值)egen minx1=min(x1)(最小值)egen medx1=med(x1) (中数)egen modex1=mode(x1) (众数)egen totalx1=total(x1)(得出x1的总数)egen rowsd=sd(x1 x2 x3)(得出 x1、 x2和 x3 联合的标准差)egen rowmean=mean(x1 x2 x3) (得出 x1、 x2 和 x3 联合的平均值)egen rowmax=max(x1 x2 x3)(联合最大值)egen rowmin=min(x1 x2 x3)(联合最小值)egen rowmed=med(x1 x2 x3)(联合中数)egen rowmode=mode(x1 x2 x3)(联合众数)egen rowtotal=total(x1 x2 x3)(联合总数)egen xrank=rank(x)(在不改变变量x 各个值排序的情况下,获得反映x 值大小排序的xrank )数据计算器 display命令:display x[12](显示 x 的第十二个观察值)display chi2(n,x)(自由度为 n 的累计卡方分布)display chi2tail(n,x)(自由度为 n 的反向累计卡方分布,chi2tail(n,x)=1-chi2(n,x))display invchi2(n,p)(卡方分布的逆运算,若chi2(n,x)=p,那么 invchi2(n,p)=x)display invchi2tail(n,p)(chi2tail的逆运算)display F(n1,n2,f)(分子、分母自由度分别为n1 和 n2 的累计 F 分布)display Ftail(n1,n2,f)(分子、分母自由度分别为n1 和 n2 的反向累计 F 分布)display invF(n1,n2,P)(F 分布的逆运算,若F(n1,n2,f)=p,那么 invF(n1,n2,p)=f)display invFtail(n1,n2,p)(Ftail的逆运算)display tden(n,t)(自由度为n 的 t 分布)display ttail(n,t)(自由度为n 的反向累计t 分布)display invttail(n,p)(ttail的逆运算)给数据库和变量做标记:label data "~~~"(对现用的数据库做标记,"~~~" 就是标记,可自行填写)label variable x "~~~"(对变量 x 做标记)label values x label1(赋予变量 x 一组标签 :label1 )label define label1 1 "a1" 2 "a2"(定义标签的具体内容:当x=1 时,标记为a1,当 x=2 时,标记为a2)频数表:tabulate x1,sorttab1 x1-x7,sort(做x1到x7的频数表,并按照频数以降序显示行)table c1,c(n x1 mean x1 sd x1)(在分类变量c1 的不同水平上列出x1 的样本量和平均值)二维交互表:auto 数据库:table rep78 foreign, c(n mpg mean mpg sd mpg median mpg) center row col(rep78 ,foreign均为分类变量,rep78 为行变量, foreign为列变量,center表示结果显示在单元格中间,row 表示计算行变量整体的统计量,col表示计算列变量整体的统计量)tabulate x1 x2,all(做 x1 和 x2 的二维交互表,要求显示独立性检验chi2 、似然比卡方独立性检验lrchi2、对定序变量适用的等级相关系数gamma和 taub 、以及对名义变量适用的V)tabulate x1 x2,column chi2 (做 x1 和 x2 的二维交互表,要求显示列百分比和行变量和列变量的独立性检验——零假设为变量之间独立无统计关系)tab2 x1-x7,all nofreq(对x1到x7这七个变量两两地做二维交互表,不显示频数:nofreq )三维交互表:by x3,sort:tabulate x1 x2,nofreq col chi2(同时进行x3 的每一个取值内的x1 和 x2 的二维交互表,不显示频数、显示列百分比和独立性检验)四维交互表:table x1 x2 x3,c(ferq mean x1 mean x2 mean x3) by(x4)tabstat X1 X2,by(X3) stats(mean n q max min sd var cv) col(stats)tabstat X1 X2,by(X3) stats(mean range q sd var cv p5 p95 median),[aw=X4](以X4为权重求X1、X2 的均值,标准差、方差等)ttest X1=1count if X1==0count if X1>=0gen X2=1 if X1>=0corr x1 x2 x3(做x1、x2、x3的相关系数表)swilk x1 x2 x3(用Shapiro-Wilk W test对x1、x2、x3进行正太性分析)sktest x1 x2 x3(对x1、x2、x3进行正太性分析,可以求出峰度和偏度)ttest x1=x2(对x1、x2的均值是否相等进行T 检验)ttest x1,by(x2) unequal(按x2的分组方式对x1 进行 T 检验,假设方差不齐性)sdtest x1=x2(方差齐性检验)sdtest x1,by(x2)(按x2的分组方式对x1 进行方差齐性检验)聚分析:cluster kmeans y x1 x2 x3, k(3)——依据y、 x1 、x2 、 x3 ,将本分n ,聚的核随机取cluster kmeans y x1 x2 x3, k(3) measure(L1) start(everykth)—— "start"用于确定聚的核,"everykth"表示将通构造三本得聚核:构造方法将本id 1 、1+3、1+3×2、1+3×3⋯⋯分一、将本id2、2+3、2+3×2、2+3×3⋯⋯分第二,以此推,将三的均作聚的核;"measure" 用于算相似性和相异性的方法,"L1" 表示采用欧式距离的,也直接可采用欧式距离(L2)和欧式距离的平方(L2squared )。