名
称记号概率分布及其定义域、参数
条件
均值
E(X)
方差
D(X)
图形
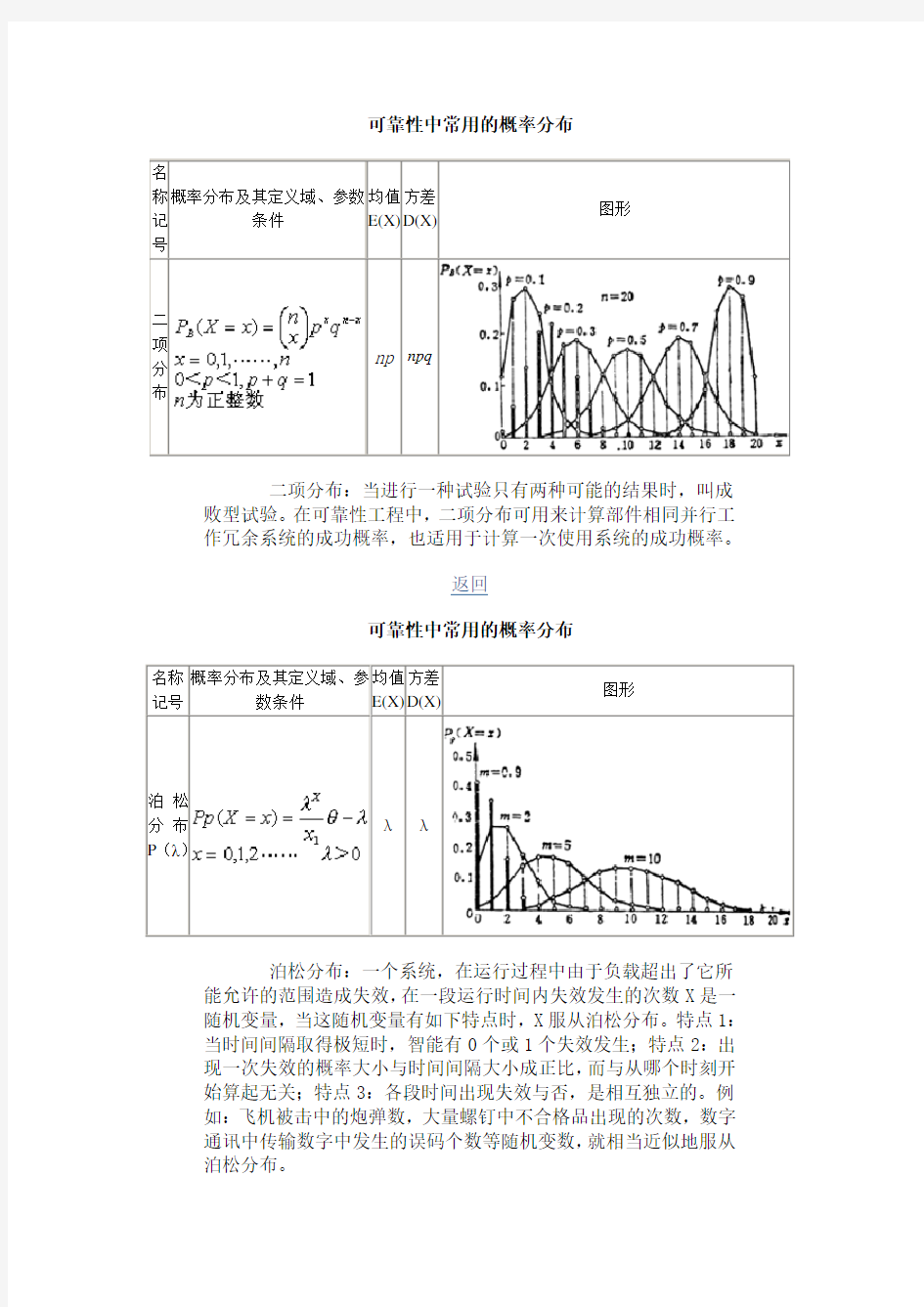
二
项
分
布
np npq
二项分布:当进行一种试验只有两种可能的结果时,叫成败型试验。在可靠性工程中,二项分布可用来计算部件相同并行工
作冗余系统的成功概率,也适用于计算一次使用系统的成功概率。
返回
可靠性中常用的概率分布
名称记号概率分布及其定义域、参
数条件
均值
E(X)
方差
D(X)
图形
泊松
分布
P(λ)
λλ
泊松分布:一个系统,在运行过程中由于负载超出了它所能允许的范围造成失效,在一段运行时间内失效发生的次数X是一
随机变量,当这随机变量有如下特点时,X服从泊松分布。特点1:当时间间隔取得极短时,智能有0个或1个失效发生;特点2:出
现一次失效的概率大小与时间间隔大小成正比,而与从哪个时刻开
始算起无关;特点3:各段时间出现失效与否,是相互独立的。例
如:飞机被击中的炮弹数,大量螺钉中不合格品出现的次数,数字
通讯中传输数字中发生的误码个数等随机变数,就相当近似地服从
泊松分布。
名称记号概率分布及其定义域、参数条件均值
E(X)
方差D(X)图形
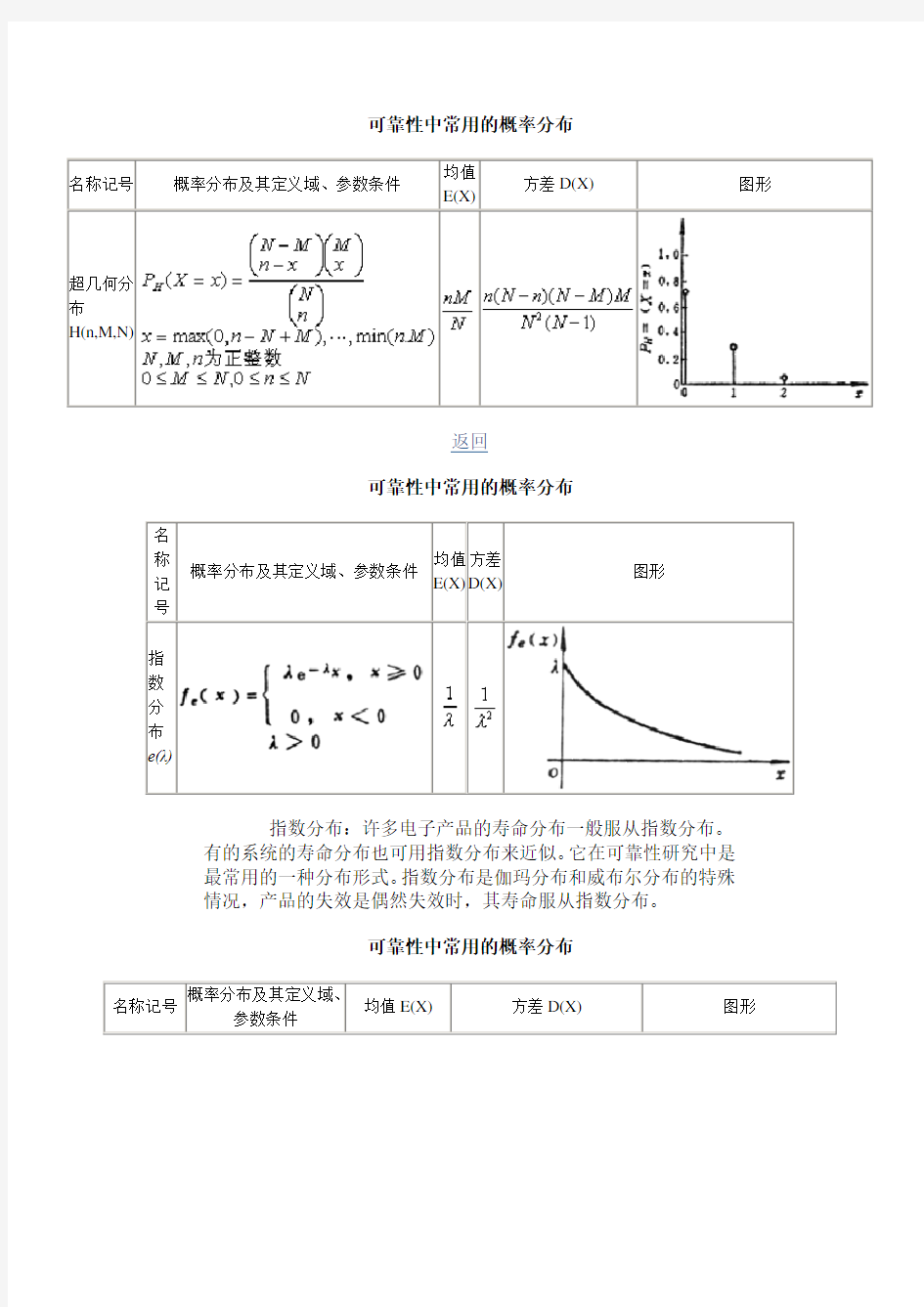
超几何分
布
H(n,M,N)
返回
可靠性中常用的概率分布名
称记号概率分布及其定义域、参数条件
均值
E(X)
方差
D(X)
图形
指
数
分
布
e(λ)
指数分布:许多电子产品的寿命分布一般服从指数分布。
有的系统的寿命分布也可用指数分布来近似。它在可靠性研究中是最常用的一种分布形式。指数分布是伽玛分布和威布尔分布的特殊情况,产品的失效是偶然失效时,其寿命服从指数分布。
可靠性中常用的概率分布
名称记号概率分布及其定义域、
参数条件
均值E(X)方差D(X)图形
威布尔分
布(Ⅲ型极
值分
布)W(k,a,b)
威布尔分布:在可靠性工程中被广泛应用,尤其适用于机电类产品的磨损累计失效的分布形式。由于它可以利用概率纸很容
易地推断出它的分布参数,被广泛应用与各种寿命试验的数据处
理。
可靠性中常用的概率分布
名称记号概率分布及其定义
域、参数条件
均值
E(X)
方差
D(X)
图形
正态分
布(高斯
分
布)N(μ,σ)
μσ2
正态分布:是在机械产品和结构工程中,研究应力分布和强度分布时,最常用的一种分布形式。它对于因腐蚀、磨损、疲劳而引起的失效分布特别有用。
关于可靠性分布函数 及其 工程应用的讨论 学号:071230320 姓名:喻浩文 ?目录 一、引言..................................................... 错误!未定义书签。 二、分布函数及其应用的讨论................................... 错误!未定义书签。 (一)、指数分布.......................................... 错误!未定义书签。 1.定义: ............................................. 错误!未定义书签。 2.指数分布的可靠度与不可靠度函数................... 错误!未定义书签。
3.图像分析.......................................... 错误!未定义书签。 4.应用?错误!未定义书签。 (二)、正态分布.......................................... 错误!未定义书签。 1.定义:?错误!未定义书签。 2.正态分布的可靠度与不可靠度函数.................... 错误!未定义书签。 3.失效率函数?错误!未定义书签。 4.图像分析........................................... 错误!未定义书签。 5.应用............................................... 错误!未定义书签。 (三)、对数正态分布?错误!未定义书签。 1.定义: .............................................. 错误!未定义书签。 2.对数正态分布的可靠度与不可靠度函数?错误!未定义书签。 3.对数正态分布失效率?错误!未定义书签。 4.图像分析........................................... 错误!未定义书签。 5应用............................................... 错误!未定义书签。 (四)、威布尔分布?错误!未定义书签。 1.三参数威布尔分布的定义:?错误!未定义书签。 2.可靠度与不可靠度函数?错误!未定义书签。 3.威布尔分布失效率?错误!未定义书签。 4.图像分析?错误!未定义书签。 5.应用.............................................. 错误!未定义书签。 三、小结..................................................... 错误!未定义书签。参考文献?错误!未定义书签。 附录?错误!未定义书签。
正态概率图(normal probability plot) 方法演变:概率图,分位数-分位数图( Q- Q) 概述 正态概率图用于检查一组数据是否服从正态分布。是实数与正态分布数据之间函数关系的散点图。如果这组实数服从正态分布,正态概率图将是一条直线。通常,概率图也可以用于确定一组数据是否服从任一已知分布,如二项分布或泊松分布。 适用场合 ·当你采用的工具或方法需要使用服从正态分布的数据时; ·当有50个或更多的数据点,为了获得更好的结果时。 例如: ·确定一个样本图是否适用于该数据; ·当选择作X和R图的样本容量,以确定样本容量是否足够大到样本均值服从正态分布时;·在计算过程能力指数Cp或者Cpk之前; ·在选择一种只对正态分布有效的假设检验之前。 实施步骤 通常,我们只需简单地把数据输入绘图的软件,就会产生需要的图。下面将详述计算过程,这样就可以知道计算机程序是怎么来编译的了,并且我们也可以自己画简单的图。 1将数据从小到大排列,并从1~n标号。 2计算每个值的分位数。i是序号: 分位数=(i-0.5)/n 3找与每个分位数匹配的正态分布值。把分位数记到正态分布概率表下面的表A.1里面。然后在表的左边和顶部找到对应的z值。 4根据散点图中的每对数据值作图:每列数据值对应个z值。数据值对应于y轴,正态分位数z值对应于x轴。将在平面图上得到n个点。 5画一条拟合大多数点的直线。如果数据严格意义上服从正态分布,点将形或一条直线。将点形成的图形与画的直线相比较,判断数据拟合正态分布的好坏。请参阅注意事项中的典型图
形。可以计算相关系数来判断这条直线和点拟合的好坏。 示例 为了便于下面的计算,我们仅采用20个数据。表5. 12中有按次序排好的20个 值,列上标明“过程数据”。 下一步将计算分位数。如第一个值9,计算如下: 分位数=(i-0.5)/n=(1-0.5)/20=0.5/20=0.025 同理,第2个值,计算如下: 分位数=(i-0.5)/n=(2-0.5)/20=1.5/20=0.075 可以按下面的模式去计算:第3个分位数=2.5÷20,第4个分位数=3 5÷20 以此类推直到最后1个分位数=19. 5÷20。 现在可以在正态分布概率表中查找z值。z的前两 个阿拉伯数字在表的最左边一列,最后1个阿拉伯数 字在表的最顶端一行。如第1个分位数=0. 025,它位 于-1.9在行与0.06所在列的交叉处,故z=-1.96。 用相同的方式找到每个分位数。 如果分位数在表的两个值之间,将需要用插值法 进行求解。例如:第4个分位数为0. 175,它位于0.1736 与0.1762之间。0.1736对应的z值为-0.94,0.1762 对应的z值为-0.93,故 这两数的中间值为z=-0.935。 现在,可以用过程数据和相应的z值作图。图表5. 127显示了结果和穿过这些点的直线。注意:在图形的两端,点位于直线的上侧。这属于典型的右偏态数据。图表5.128显示了数据的直方图,可进行比较。 概率图( probability plot) 该方法可以用于检验任何数据的已知分布。这时我们不是在正态分布概率表中查找分位数,而是在感兴趣的已知分布表中查找它们。 分位数-分位数图(quantile-quantile plot) 同理,任意两个数据集都可以通过比较来判断是否服从同一分布。计算每个分布的分位数。一个数据集对应于x轴,另一个对应于y轴。作一条45°的参照线。如果这两个数据集来自同一分布,那么这些点就会靠近这条参照线。 注意事项 ·绘制正态概率图有很多方法。除了这里给定的程序以外,正态分布还可以用概率和百分数来表示。实际的数据可以先进行标准化或者直接标在x轴上。 ·如果此时这些数据形成一条直线,那么该正态分布的均值就是直线在y轴截距,标准差就是直线斜率。 ·对于正态概率图,图表5.129显示了一些常见的变形图形。 短尾分布:如果尾部比正常的短,则点所形成的图形左边朝直线上方弯曲,右边朝直线下方弯曲——如果倾斜向右看,图形呈S型。表明数据比标准正态分布时候更加集中靠近均值。 长尾分布:如果尾部比正常的长,则点所形成的图形左边朝直线下方弯曲,右边朝直线上方弯曲——如果倾斜向右看,图形呈倒S型。表明数据比标准正态分布时候有更多偏离的数据。
工程结构设计安全与可持续发展研讨会论文 2010年 非概率可靠性理论与边坡稳定分析 刘春原,张军其,龚攀,宋海超 (河北工业大学,天津 300401) 摘要:某高速公路的路线高填方路基左侧路基发生滑移,按常规计算(极限平衡法)的安全系数为K=1.55,其概率可靠度指标β=3.1,失效概率为P f =0.001。通过引入区间分析理论,建立非概率可靠性计算模型。其非概率可靠性指标η=0.7,表明非概率可靠性理论在没有足够的数据信息和可行的主观分布假设下也能得到比较准确的结果。 关键词:安全系数法路基边坡稳定性概率可靠性非概率可靠性区间分析模型 Non-probabilistic slope stability analysis LIU Chun-yuan, Zhang Jun-qi, Gong Pan, Song Hai-chao (Hebei University of Technology, Tianjin,300401, China) Abstract:A high filled subgrade of a highway slipped on the left of the line. According to conventional calculations (limit equilibrium method) ,we can know that the safety factor K = 1.55 and t he probability of reliability index β = 3.1, failure probability P f = 0.001. Through the introduction of interval analysis theory, non-probabilistic reliability calculation model is established, and the non-probabilistic reliability index is η = 0.7. Showing that the non-probabilistic reliability theory in the absence of adequate data distribution of information and possible subjective assumptions can also obtain more accurate result s Key words:safety factor method; subgrade slope stability; probabilistic reliability; non-probabilistic reliability; interval model 0前言 随着沿海地区高速公路建设的快速发展,软土地区高填方路基稳定性评价是沿海高速公路建设与施工中亟待解决的重要问题。同时路基失稳分析也是岩土工程中十分重要的研究课题之一,工程实践表明[1],用极限平衡理论计算得安全系数K不足以全面评价路基稳定性状态,而有关研究表明[2-6],概率可靠性模型在用于路基稳定性的可靠性分析时存在着两方面的重大缺陷。一是由于土体的性质存在很大的变异性,概率可靠性模型的适用性较差;二是土体的参数统计属于小样本问题,在主观的分布假设下,概率可靠性计 算的结果将会失真。因此,研究非概率的可靠性方法[7],不但可使可靠性理论进一步完善,使不确定性的评价更为合理,而且也是非常必要的。 九十年代,Ben-Haim[10]提出了基于凸集模型的非 概率可靠性方法。一些学者[11,12]也提出了基于非概率模型的结构优化设计方法。在工程数据(参数)缺乏足够数量难以准确定义概率模型时,非概率可靠性方法是一种较好的选择。在实际工程中一般都能容易的给出各参数的变化区间,而不是概率分布, 由于非概率模型对已知数据的要求相对较低,所以非概率可靠性分析方法具有较好的工程实用性。 1 非概率可靠度性分析方法 非概率可靠性的基本思想是通过系统波动范围与要求的变化范围相比较,以确定结构的安全性,有时也称 收稿日期: 作者简介:刘春原(1957年- ),男,陕西黄陵县人,河北工业大学教授、博士生导师。 基金项目:河北省自然科学基金(E2008000075)
2.4正态分布 复习引入: 总体密度曲线:样本容量越大,所分组数越多,各组的频率就越接近于总体在相应各组取值的概率.设想样本容量无限增大,分组的组距无限缩小,那么频率分布直方图就会无限接近于一条光滑曲线,这条曲线叫做总体密度曲线. 总体密度曲线 b 单位 O 频率/组距 a 它反映了总体在各个范围内取值的概率.根据这条曲线,可求出总体在区间(a,b)内取值的概率等于总体密度曲线,直线x=a,x=b及x轴所围图形的面积. 观察总体密度曲线的形状,它具有“两头低,中间高,左右对称”的特征,具有这种特征的总体密度曲线一般可用下面函数的图象来表示或近似表示: 2 2 () 2 , 1 (),(,) 2 x x e x μ σ μσ ? πσ - - =∈-∞+∞ 式中的实数μ、)0 (> σ σ是参数,分别表示总体的平均数与标准差,, ()x μσ ? 的图象为正态分布密度曲线,简称正态曲线. 讲解新课:
一般地,如果对于任何实数a b <,随机变量X 满足 ,()()b a P a X B x dx μσ?<≤=?, 则称 X 的分布为正态分布(normal distribution ) .正态分布完全由参数μ和σ确定,因此正态分布常记作),(2 σ μN .如果随机变量 X 服从正态分布,则记为X ~),(2σμN . 经验表明,一个随机变量如果是众多的、互不相干的、不分主次的偶然因素作用结果之和,它就服从或近似服从正态分布.例如,高尔顿板试验中,小球在下落过程中要与众多小木块发生碰撞,每次碰撞的结果使得小球随机地向左或向右下落,因此小球第1次与高尔顿板底部接触时的坐标 X 是众多随机碰撞的结果,所以它近似服从正态分布.在现实生活中,很多随机变量都服从或近似地服从正态分布.例如长度测量误差;某一地区同年龄人群的身高、体重、肺活量等;一定条件下生长的小麦的株高、穗长、单位面积产量等;正常生产条件下各种产品的质量指标(如零件的尺寸、纤维的纤度、电容器的电容量、电子管的使用寿命等);某地每年七月份的平均气温、平均湿度、降雨量等;一般都服从正态分布.因此,正态分布广泛存在于自然现象、生产和生活实际之中.正态分布在概率和统计中占有重要的地位. 说明:1参数μ是反映随机变量取值的平均水平的特征数,可以用样本均值去佑计;σ是衡量随机变量总体波动大小的特征数,可以用样本标准差去估计. 2.早在 1733 年,法国数学家棣莫弗就用n !的近似公式得到了正态分布.之后,德国数学家高斯在研究测量误差时从另一个角度导出了它,并研究了它的性质,因此,人们也称正态分布为高斯分布. 2.正态分布),(2 σ μN )是由均值μ和标准差σ唯一决定的分布 通过固定其中一个值,讨论均值与标准差对于正态曲线的影响
名 称记号概率分布及其定义域、参数 条件 均值 E(X) 方差 D(X) 图形 二 项 分 布 np npq 二项分布:当进行一种试验只有两种可能的结果时,叫成败型试验。在可靠性工程中,二项分布可用来计算部件相同并行工 作冗余系统的成功概率,也适用于计算一次使用系统的成功概率。 返回 可靠性中常用的概率分布 名称记号概率分布及其定义域、参 数条件 均值 E(X) 方差 D(X) 图形 泊松 分布 P(λ) λλ 泊松分布:一个系统,在运行过程中由于负载超出了它所能允许的范围造成失效,在一段运行时间内失效发生的次数X是一 随机变量,当这随机变量有如下特点时,X服从泊松分布。特点1:当时间间隔取得极短时,智能有0个或1个失效发生;特点2:出 现一次失效的概率大小与时间间隔大小成正比,而与从哪个时刻开 始算起无关;特点3:各段时间出现失效与否,是相互独立的。例 如:飞机被击中的炮弹数,大量螺钉中不合格品出现的次数,数字 通讯中传输数字中发生的误码个数等随机变数,就相当近似地服从 泊松分布。
名称记号概率分布及其定义域、参数条件均值 E(X) 方差D(X)图形 超几何分 布 H(n,M,N) 返回 可靠性中常用的概率分布名 称记号概率分布及其定义域、参数条件 均值 E(X) 方差 D(X) 图形 指 数 分 布 e(λ) 指数分布:许多电子产品的寿命分布一般服从指数分布。 有的系统的寿命分布也可用指数分布来近似。它在可靠性研究中是最常用的一种分布形式。指数分布是伽玛分布和威布尔分布的特殊情况,产品的失效是偶然失效时,其寿命服从指数分布。 可靠性中常用的概率分布 名称记号概率分布及其定义域、 参数条件 均值E(X)方差D(X)图形
几种常见的概率分布 一、 离散型概率分布 1. 二项分布 n 次独立的贝努利实验,其实验结果的分布(一种结果出现x 次的概率是多少的分布)即为二项分布 应用二项分布的重要条件是:每一种实验结果在每次实验中都有恒定的概率,各实验之间是重复独立的 平均数: (Y)np X E μ== 方差与标准差:2(1)X np P σ=- ;X σ=特例:(0-1)分布 若随机变量X 的分布律为 1(x k)p (1p)k k p -==- k=0,1;0 复抽样,抽样成功的次数X 的概率分布服从超几何分布,如福利彩票 二、 连续型概率分布 1. 均匀分布 若随机变量X 具有概率密度函数 (x)f = 则称X 在区间(a ,b )上服从均匀分布,记为X ~ U(a ,b) 在区间(a ,b )上服从均匀分布的随机变量X 的分布函数为 0F(x),1 x a x a a x b b a b x ? 是常数, 则称X 服从以λ 为参数的指数分布,记作~()X E λ ,X 的分布函数为 1,0(x)0,0 x e x F x λ-?-≥=? 参考医学 正态分布概率表 1 — f? 0( u )= t P⑴t F(t)t F(0t卩⑴0.00 0.000 00.230. 181 9 0.46 0.354 5 W9 0. 50 9 8 0.01 0.008 00.24 0. 1H9 70.47 0.361 6 0.70 0,516 1 0+02 0,0160 0. 25 0,197 4 0,48 0.368 80+71 0.522 3 0.03 0*023 9(1. 26 0.205 1 0.49 0.375 9 0.72 0. 52 8 5 044 0.031 9(1.27 0,212 8 0.50O.3R2 9 0.73 "4 6 0R5 0039 90.28 0.220 5 0,51 0.389 9 0.74 0.540 7 0.06 0.047 80.29 0.228 20.52 036 9 0.75 0*546 7 0+07 0 €55 g0,30 0,235 8 0,53 0.403 9 276 0.552 7 0+08 0.063 80 31 0.243 4 0.54 0.410 8 0+77 0.558 7 0+09 (1.(171 7(J. 32 0.251 00.55 0.417 70.78 0.564 6 0. 10 0.0797 fl. 33 0.258 6 0.56 0,424 50.79 0.570 5 0.110,(J87 60.34 0.266 1 0.57 0.431 3 0.B0 0.576 3 0.12 0.09$ 50. 35 0.273 7 0.5S 0.43S 10.S1 O.5S2 1 0+13 OJ03 40. 36 0.281 20.59 0.444 8 0+82 0.587 8 0+14 (1.111 3 0. 37 0.288 6 0.60 0.451 5 M3 0.593 5 0.15 0J19 2 0. 38 0.296 1 0.61 0.458 10.84 0.599 1 0+160.127 10.39 0. 303 50.62 0.464 7 0.85 0.604 7 0.17 0.135 0 040 0330 8 0.63 0.471 3 0.S6 0.610 2 0+18 0.142 S0.41 0.318 20,64 0.477 8 0.87 0.6157 0+19 0.150 7 0 42 0, 325 50.650.484 3 0.88 0.621 1 0,20 0J58 5(J. 43 0. 332 8 0.66 0.490 10.89 0 . 62 6 5 0,21 0J66 3(J.44 0,340 1 0.67 0.497 10.90 0.631 9 0 + 220.174 10.45 0347 3 0.68 0.503 50.91 0.637 2 几种常见的概率分布 离散型概率分布 1.二项分布 n次独立的贝努利实验,其实验结果的分布(一种结果出现x次的概率是多少的分布)即为二项分布 应用二项分布的重要条件是:每一种实验结果在每次实验中都有恒定的概率,各实验之间是重复独立的 平均数:\二E(Y)二叩 方差与标准差:▽ X = np(1- P) ; = J np(1- p) 特例:(0-1 )分布 若随机变量x的分布律为 p(x = k) = p k(1 - p)1* k=o,i ;0 复抽样,抽样成功的次数X的概率分布服从超几何分布,如福利彩票 二、连续型概率分布 1?均匀分布 若随机变量X具有概率密度函数 f(X)二 则称X在区间(a,b)上服从均匀分布,记为X?U(a,b)在区间(a,b)上服从均匀分布的随机变量X的分布函数为 x v a F(x)X— ,a 乞x b b — a , X x 2指数分布 若随机变量X具有概率密度函数f(X)= e ' x - 0其中0是常数, 0,x< 0 则称X服从以’为参数的指数分布,记作X?E(' ),X的分布函数为 F(x)=」1 -e ,x 色0 j 0,x<0 3.正态分布 正态随机变量X的概率密度函数的形式如下: 1 f (x) e 2 $ ,—:::: x ::: 式中,」为随机变量X的均值;、;2为随机变量X的方差通常对具有均值卩,方差为62的正态概率分布,记为N (卩,62)。于是有正态随机变量X~N ( '2)。 第一章随机事件和概率 (1)排列组合公式 )! ( ! n m m P n m- =从m个人中挑出n个人进行排列的可能数。 )! (! ! n m n m C n m- =从m个人中挑出n个人进行组合的可能数。 (2)加法和乘法原理加法原理(两种方法均能完成此事):m+n 某件事由两种方法来完成,第一种方法可由m种方法完成,第二种方法可由n种方法来完成,则这件事可由m+n 种方法来完成。 乘法原理(两个步骤分别不能完成这件事):m×n 某件事由两个步骤来完成,第一个步骤可由m种方法完成,第二个步骤可由n 种方法来完成,则这件事可由m×n 种方法来完成。 (3)一些常见排列重复排列和非重复排列(有序)对立事件(至少有一个) 顺序问题 (4)随机试验和随机事件如果一个试验在相同条件下可以重复进行,而每次试验的可能结果不止一个,但在进行一次试验之前却不能断言它出现哪个结果,则称这种试验为随机试验。试验的可能结果称为随机事件。 (5)基本事件、样本空间和事件在一个试验下,不管事件有多少个,总可以从其中找出这样一组事件,它具有如下性质: ①每进行一次试验,必须发生且只能发生这一组中的一个事件; ②任何事件,都是由这一组中的部分事件组成的。 这样一组事件中的每一个事件称为基本事件,用ω来表示。 基本事件的全体,称为试验的样本空间,用Ω表示。 一个事件就是由Ω中的部分点(基本事件ω)组成的集合。通常用大写字母A,B,C,…表示事件,它们是Ω的子集。 Ω为必然事件,?为不可能事件。 不可能事件(?)的概率为零,而概率为零的事件不一定是不可能事件;同理,必然事件(Ω)的概率为1,而概率为1的事件也不一定是必然事件。 (6)事件的关系与运算①关系: 如果事件A的组成部分也是事件B的组成部分,(A发生必有事件B发生):B A? 如果同时有B A?,A B?,则称事件A与事件B等价,或称A等于B:A=B。 A、B中至少有一个发生的事件:A B,或者A+B。 属于A而不属于B的部分所构成的事件,称为A与B的差,记为A-B,也可表示为A-AB或者B A,它表示A发生而B不发生的事件。 A、B同时发生:A B,或者AB。A B=?,则表示A与B不可能同时发生,称 事件A与事件B互不相容或者互斥。基本事件是互不相容的。 Ω-A称为事件A的逆事件,或称A的对立事件,记为A。它表示A不发生的 第二章 随机变量及其分布 复习 一、随机变量. 1. 随机试验的结构应该是不确定的.试验如果满足下述条件: ①试验可以在相同的情形下重复进行;②试验的所有可能结果是明确可知的,并且不止一个;③每次试验总是恰好出现这些结果中的一个,但在一次试验之前却不能肯定这次试验会出现哪一个结果. 它就被称为一个随机试验. 2. 离散型随机变量:如果对于随机变量可能取的值,可以按一定次序一一列出,这样的随机变量叫做离散型随机变量.若ξ是一个随机变量,a ,b 是常数.则b a +=ξη也是一个随机变量.一般地,若ξ是随机变量,)(x f 是连续函数或单调函数,则)(ξf 也是随机变量.也就是说,随机变量的某些函数也是随机变量. 3、分布列:设离散型随机变量ξ可能取的值为: ,,,,21i x x x ξ取每一个值),2,1( =i x 的概率p x P ==)(ξ,则表称为随机变量ξ的概率分布,简称ξ的分布列. 121i 注意:若随机变量可以取某一区间内的一切值,这样的变量叫做连续型随机变量.例如:]5,0[∈ξ即ξ可以取0~5之间的一切数,包括整数、小数、无理数. 典型例题: 1、随机变量ξ的分布列为(),1,2,3(1) c P k k k k ξ== =+……,则P(13)____ξ≤≤= 2、袋中装有黑球和白球共7个,从中任取两个球都是白球的概率为1 7 ,现在甲乙两人从袋中轮流摸去一 球,甲先取,乙后取,然后甲再取……,取后不放回,直到两人中有一人取到白球时终止,用ξ表示取球的次数。(1)求ξ的分布列(2)求甲取到白球的的概率 3、5封不同的信,放入三个不同的信箱,且每封信投入每个信箱的机会均等,X 表示三哥信箱中放有信件树木的最大值,求X 的分布列。 4 已知在全部50人中随机抽取1人抽到喜爱打篮球的学生的概率为5 . (1)请将上面的列联表补充完整; (2)是否有99.5%的把握认为喜爱打篮球与性别有关?说明你的理由; (3)已知喜爱打篮球的10位女生中,12345,,A A A A A ,,还喜欢打羽毛球,123B B B ,,还喜欢打乒乓球,12C C ,还喜欢踢足球,现再从喜欢打羽毛球、喜欢打乒乓球、喜欢踢足球的女生中各选出1名进行其他方面的调查,求1B 和1C 不全被选中的概率. (参考公式:2 ()()()()() n ad bc K a b c d a c b d -=++++,其中n a b c d =+++) Generated by Foxit PDF Creator ? Foxit Software https://www.doczj.com/doc/3c4391548.html, For evaluation only. 图 6-2 正态分布概率密度函数的曲线 正态曲线可用方程式表示。当n→∞时,可由二项分布概率函数方程推导出正态分布曲线的方程: f(x)= (6.16 ) 式中: x —所研究的变数; f(x) —某一定值 x 出现的函数值,一般称为概率密度函数(由于间断性分布已转变成连续性分布,因而我们只能计算变量落在某一区间的概率,不能计算变量取某一值,即某一点时的概率,所以用“概率密度”一词以与概率相区分),相当于曲线 x 值的纵轴高度; p —常数,等于 3.14 159 ……; e —常数,等于 2.71828 ……;μ为总体参数,是所研究总体的平均数,不同的正态总体具有不同的μ,但对某一定总体的μ是一个常数;δ也为总体参数,表示所研究总体的标准差,不同的正态总体具有不同的δ,但对某一定总体的δ是一个常数。 上述公式表示随机变数 x 的分布叫作正态分布,记作 N( μ , δ2 ) ,读作“具平均数为μ,方差为δ 2 的正态分布”。正态分布概率密度函数的曲线叫正态曲线,形状见图 6-2 。 (二)正态分布的特性 1 、正态分布曲线是以 x= μ为对称轴,向左右两侧作对称分布。因的数值无论正负,只要其绝对值相等,代入公式( 6.16 )所得的 f(x) 是相等的,即在平均数μ的左方或右方,只要距离相等,其 f(x) 就相等,因此其分布是对称的。在正态分布下,算术平均数、中位数、众数三者合一位于μ点上。 2 、正态分布曲线有一个高峰。随机变数 x 的取值范围为( - ∞,+ ∞ ),在( - ∞ ,μ)正态曲线随 x 的增大而上升,;当 x= μ时, f(x) 最大;在(μ,+ ∞ )曲线随 x 的增大而下降。 3 、正态曲线在︱x-μ︱=1 δ处有拐点。曲线向左右两侧伸展,当x →± ∞ 时,f(x) →0 ,但 f(x) 值恒不等于零,曲线是以 x 轴为渐进线,所以曲线全距从 -∞到+ ∞。 4 、正态曲线是由μ和δ两个参数来确定的,其中μ确定曲线在 x 轴上的位置 [ 图 6-3] ,δ确定它的变异程度 [ 图 6-4] 。μ和δ不同时,就会有不同的曲线位置和变异程度。所以,正态分布曲线不只是一条曲线,而是一系列曲线。任何一条特定的正态曲线只有在其μ和δ确定以后才能确定。 5 、正态分布曲线是二项分布的极限曲线,二项分布的总概率等于 1 ,正态分布与 x 轴之间的总概率(所研究总体的全部变量出现的概率总和)或总面积也应该是等于 1 。而变量 x 出现在任两个定值 x1到x2(x1≠x2)之间的概率,等于这两个定值之间的面积占总面积的成数或百分比。正态曲线的任何两个定值间的概率或面积,完全由曲线的μ和δ确定。常用的理论面积或概率如下: 区间μ ± 1 δ面积或概率 =0.6826 μ ± 2 δ =0.9545 μ ± 3 δ=0.9973 μ± 1.960δ=0.9500 μ ±2.576 δ =0.9900 4.6 可靠性设计的基本概念与方法 一、结构可靠性设计概念 1.可靠性含义 可靠性是指一个产品在规定条件下和规定时间内完成规定功能的能力;而一个工业产品(包括像飞机这样的航空飞行器产品)由于内部元件中固有的不确定因素以及产品构成的复杂程度使得对所执行规定功能的完成情况及其产品的失效时间(寿命)往往具有很大的随机性,因此,可靠性的度量就具有明显的随机特征。一个产品在规定条件下和规定时间内规定功能的概率就称为该产品的可靠度。作为飞机结构的可靠性问题,从定义上讲可以理解为:“结构在规定的使用载荷/环境作用下及规定的时间内,为防止各种失效或有碍正常工作功能的损伤,应保持其必要的强刚度、抗疲劳断裂以及耐久性能力。”可靠度则应是这种能力的概率度量,当然具体的内容是相当广泛的。例如,结构元件或结构系统的静强度可靠性是指结构元件或结构系统的强度大于工作应力的概率,结构安全寿命的可靠性是指结构的裂纹形成寿命小于使用寿命的概率;结构的损伤容限可靠性则一方面指结构剩余强度大于工作应力的概率,另一方面指结构在规定的未修使用期间内,裂纹扩展小于裂纹容限的概率.可靠性的概率度量除可靠度外,还可有其他的度量方法或指标,如结构的失效概率F(c),指结构在‘时刻之前破坏的概率;失效率^(().指在‘时刻以前未发生破坏的条件下,在‘时刻的条件破坏概率密度;平均无故障时间MTTF(MeanTimeToFailure),指从开始使用到发生故障的工作时间的期望值。除此而外,还有可靠性指标、可靠寿命、中位寿命,对可修复结构还有维修度与有效度等许多可靠性度量方法。 2..结构可靠性设计的基本过程与特点 设计一个具有规定可靠性水平的结构产品,其内容是相当丰富的,应当贯穿于产品的预研、分析、设计、制造、装配试验、使用和管理等整个过程和各个方面。从研究及学科划分上可大致分为三个方面。 (1)可靠性数学。主要研究可靠性的定量描述方法。概率论、数理统计,随机过程等是它的重要基础。 (2)可靠性物理。研究元件、系统失效的机理,物理成固和物理模型。不同研究对象的失效机理不同,因此不同学科领域内可靠性物理研究的方法和理论基础也不同. (3)可靠性工程。它包含了产品的可靠性分析、预测与评估、可靠性设计、可靠性管理、可靠性生产、可靠性维修、可靠性试验、可靠性数据的收集处理和交换等.从产品的设计到产品退役的整个过程中,每一步骤都可包含于可靠性工程之中。 由此我们可以看出,结构可靠性设计仅是可靠性工程的其中一个环节,当然也是重要的环节,从内容上讲,它包括了结构可靠性分析、结构可靠性设计和结构可靠性试验三大部分。结构可靠性分析的过程大致分为三个阶段。 一是搜集与结构有关的随机变量的观测或试验资料,并对这些资料用概率统计的方法进行分析,确定其分布概率及有关统计量,以作为可靠度和失效概率计算的依据。 1.编号1,2,3的三位学生随意入座编号为 1, 2 , 3的三个座位,每位学生坐一个座位 设与座位编号相同的学生的个数是 X. (1) 求随机变量X 的分布列; (2) 求随机变量X 的数学期望和方差. 解(1)P ( X=0)= _L =1 - A 33 ; P ( X=1)=-C3 = 1 ; P ( X=3)= 2 =丄; A 3 2 A 3 6 (2) E (X ) =1 X 丄 +3 X 丄=1. 2 6 D (X ) =(1-0) 2 1 +(1-1) 2 丄+(3-1) 2 1 =1. 3 2 6 2某商场举行抽奖促销活动,抽奖规则是:从装有9个白球、1个红球的箱子中每次 随机地摸岀一个球,记下颜色后放回,摸岀一个红球可获得奖金 10元;摸岀两个红 球可获得奖金50元.现有甲、乙两位顾客,规定:甲摸一次,乙摸两次,令X 表示 甲、乙两人摸球后获得的奖金总额.求: (1 ) X 的分布列; (2) X 的均值. 解 (1 ) X 的所有可能取值为0,10,20,50,60. 9 1 9 P(X=50)= X =- 10 102 1 000 1 1 P(X=60)= 3 = . ' 103 1 000 故X 的分布列为 P (X=0 ) @ 1 = 729 10 = 1 000 P ( X=10)」X 「2 X C 2 X 丄 10 〔0 丿 10 10 9 X 一 = 243 1 000 P(X=20)= 丄 X C 2 X 丄 X ?= 10 10 10 18 1 000 729 243 18 9 (2 ) E ( X ) =0 X +10 X -243+20 X 18+50 X — +60 X 1 000 1 000 1 000 1 000 1 =3.3(兀). 1 000 ' ' 3 (本小题满分13分) 为了解甲、乙两厂的产品质量,采用分层抽样的方法从甲、乙两厂生 产的产品中分别抽出取14件和5件,测量产品中的微量元素x,y的含 (1)已知甲厂生产的产品共有98件,求乙厂生产的产品数量; (2)当产品中的微量元素x,y满足x》175 ,且y》75时,该产品为优等 品。用上述样本数据估计乙厂生产的优等品的数量; (3)从乙厂抽出的上述5件产品中,随机抽取2件,求抽取的2件产品中优等品数?的分布列极其均值(即数学期望)。 & 98 解:(1)7,5 7=35,即乙厂生产的产品数量为35件。 14 (2)易见只有编号为 2 , 5的产品为优等品,所以乙厂生产的产品中 概率论中几种常用的重要的分布 摘要:本文主要探讨了概率论中的几种常用分布,的来源和他们中间的关系。其在实际中的应用。 关键词 1 一维随机变量分布 随机变量的分布是概率论的主要内容之一,一维随机变量部分要介绍六中常用分布,即( 0 -1) 分布、二项分布、泊松分布、均匀分布、指数分布和正态分布. 下面我们将对这六种分布逐一地进行讨论. 随机事件是按试验结果而定出现与否的事件。它是一种“定性”类型的概念。为了进一步研究有关随机试验的问题,还需引进一种“定量”类型的概念,即,根据试验结果而定取什么值(实值或向量值)的变数。称这种变数为随机变数。本章内将讨论取实值的这种变数—— 一维随机变数。 定义1.1 设X 为一个随机变数,令 ()([(,)])([]),()F x P X x P X x x =∈-∞=-∞+∞p p p . 这样规定的函数()F x 的定义域是整个实轴、函数值在区间[0,1]上。它是一个普通的函数。成这个函数为随机函数X 的分布函数。 有的随机函数X 可能取的值只有有限多个或可数多个。更确切地说:存在着有限多个值或可数多个值12,,...,a a 使得 12([{,,...}])1P X a a ∈= 称这样的随机变数为离散型随机变数。称它的分布为离散型分布。 【例1】下列诸随机变数都是离散型随机变数。 (1)X 可能取的值只有一个,确切地说,存在着一个常数a ,使([])1P X a ==。称这种随机变数的分布为退化分布。一个退化分布可以用一个常数a 来确定。 (2)X 可能取的值只有两个。确切地说,存在着两个常数a ,b ,使([{,}])1P X a b ∈=.称这种随机变数的分布为两点分布。如果([])P X b p ==,那么,([])1P X a p ===-。因此,一个两点分布可以用两个不同的常数,a b 及一个在区间(0,1)内的值p 来确定。 特殊地,当,a b 依次为0,1时,称这两点分布为零-壹分布。从而,一个零-壹分布可以用一个在区间(0,1)内的值p 来确定。 (3)X 可能取的值只有n 个:12,...,a a (这些值互不相同),且,取每个i a 值 常用的概率分布类型及其特征 3.1 二点分布和均匀分布 1、两点分布 许多随机事件只有两个结果。如抽检产品的结果合格或不合格;产品或者可靠的工作,或者失效。描述这类随机事件变量只有两个取值,一般取0和1。它服从的分布称两点分布。 其概率分布为: 其中 Pk=P(X=Xk),表示X取Xk值的概率: 0≤P≤1。 X的期望 E(X)=P X的方差 D(X)=P(1—P) 2、均匀分布 如果连续随机变量X的概率密度函数f(x)在有限的区间[a,b]上等于一个常数,则X服从的分布为均匀分布。 其概率分布为: X的期望 E(X)=(a+b)/2 X的方差 D(X)=(b-a)2/12 3.2 抽样检验中应用的分布 3.2.1 超几何分布 假设有一批产品,总数为N,其中不合格数为d,从这批产品中随机地抽出n 件作为被检样品,样品中的不合格数X服从的分布称超几何分布。 X的分布概率为: X=0,1,…… X的期望 E(X)=nd/N X的方差 D(X)=((nd/N)((N-d)/N)((N-n)/N))(1/2)3.2.2 二项分布 超几何分布的概率公式可以写成阶乘的形式,共有9个阶乘,因而计算起来十分繁琐。二项分布就可以看成是超几何分布的一个简化。 假设有一批产品,不合格品率为P,从这批产品中随机地抽出n件作为被检样品,其中不合格品数X服从的分布为二项分布。 X的概率分布为: 0 X的方差 D(X)=np(1-p) 3.2.3 泊松分布 泊松分布比二项分布更重要。我们从产品受冲击(指瞬时高电压、高环境应力、高负载应力等)而失效的事实引入泊松分布。假设产品只有经过一定的冲击次数后,产品才失效,又设这些冲击满足三个条件: (1)、两个不相重叠的时间间隔内产品所受冲击次数相互独立; (2)、在充分小的时间间隔内发生两次或更多次冲击的机会可忽略不计; (3)、在单位时间内发生冲击的平均次数λ(λ>0)不随时间变化,即在时间间隔Δt内平均发生λΔt次冲击,它和Δt 的起点无关。 则在[0,t]时间内发生冲击的次数X服从泊松分布,其分布概率为: X的期望 E(X)=λt X的方差 D(X)=λt 假设仪表受到n次冲击即发生故障,则仪表在[0,t]时间内的可靠度为: 其中:x =0,1,2,……,λ>0,t>0。正态分布概率表
几种常见的概率分布
概率统计公式大全(复习重点)汇总
随机变量及其分布考点总结
正态分布概率公式(部分)
图 62正态分布概率密度函数的曲线 正态曲线可用方程式表示。 n 当 →∞时,可由二项分布概率函数方程推导出正态 分布曲线的方程:
fx= (61 ) () .6
式中: x—所研究的变数; fx —某一定值 x出现的函数值,一般称为概率 () 密度函数 (由于间断性分布已转变成连续性分布,因而我们只能计算变量落在某 一区间的概率, 不能计算变量取某一值, 即某一点时的概率, 所以用 “概率密度” 一词以与概率相区分),相当于曲线 x值的纵轴高度; p—常数,等于 31 .4 19……; e— 常数,等于 2788……; μ 为总体参数,是所研究总体 5 .12 的平均数, 不同的正态总体具有不同的 μ , 但对某一定总体的 μ 是一个常数; δ 也为总体参数, 表示所研究总体的标准差, 不同的正态总体具有不同的 δ , 但对某一定总体的 δ 是一个常数。 上述公式表示随机变数 x的分布叫作正态分布, 记作 N μ ,δ2 ), “具 ( 读作 2 平均数为 μ,方差为 δ 的正态分布”。正态分布概率密度函数的曲线叫正态 曲线,形状见图 62。 (二)正态分布的特性
1、正态分布曲线是以 x μ 为对称轴,向左右两侧作对称分布。因 =
的
数值无论正负, 只要其绝对值相等, 代入公式 61 ) ( .6 所得的 fx 是相等的, () 即在平均数 μ 的左方或右方,只要距离相等,其 fx 就相等,因此其分布是 () 对称的。在正态分布下,算术平均数、中位数、众数三者合一位于 μ 点上。正态分布概率公式(部分)
可靠性设计的基本概念与方法讲解
概率分布期望方差汇总
概率论中几种常用的重要的分布
常用的概率分布类型及其特征
相关主题
文本预览