
实验12回归分析
化工系分7陈龙2007011832
『实验目的』
1.了解回归分析的基本原理,掌握MATLAB 实现的方法;
2.练习用回归分析解决实际问题。
『实验内容』
一、题目1:
用切削机床加工时,为实时地调整机床需测定刀具的磨损速度,每隔一小时测量刀具的厚度得到以下数据,建立刀具厚度对于切削时间的回归模型,对模型和回归系数进行检验,并预测7.5h 和15h 后的刀具厚度,用(30)和(31)式两种办法计算预测区间,解释计算结果。
时间/h 012345678910刀具厚度/cm 30.6
29.1
28.4
28.1
28.0
27.7
27.5
27.2
27.0
26.8
26.5
【模型建立】
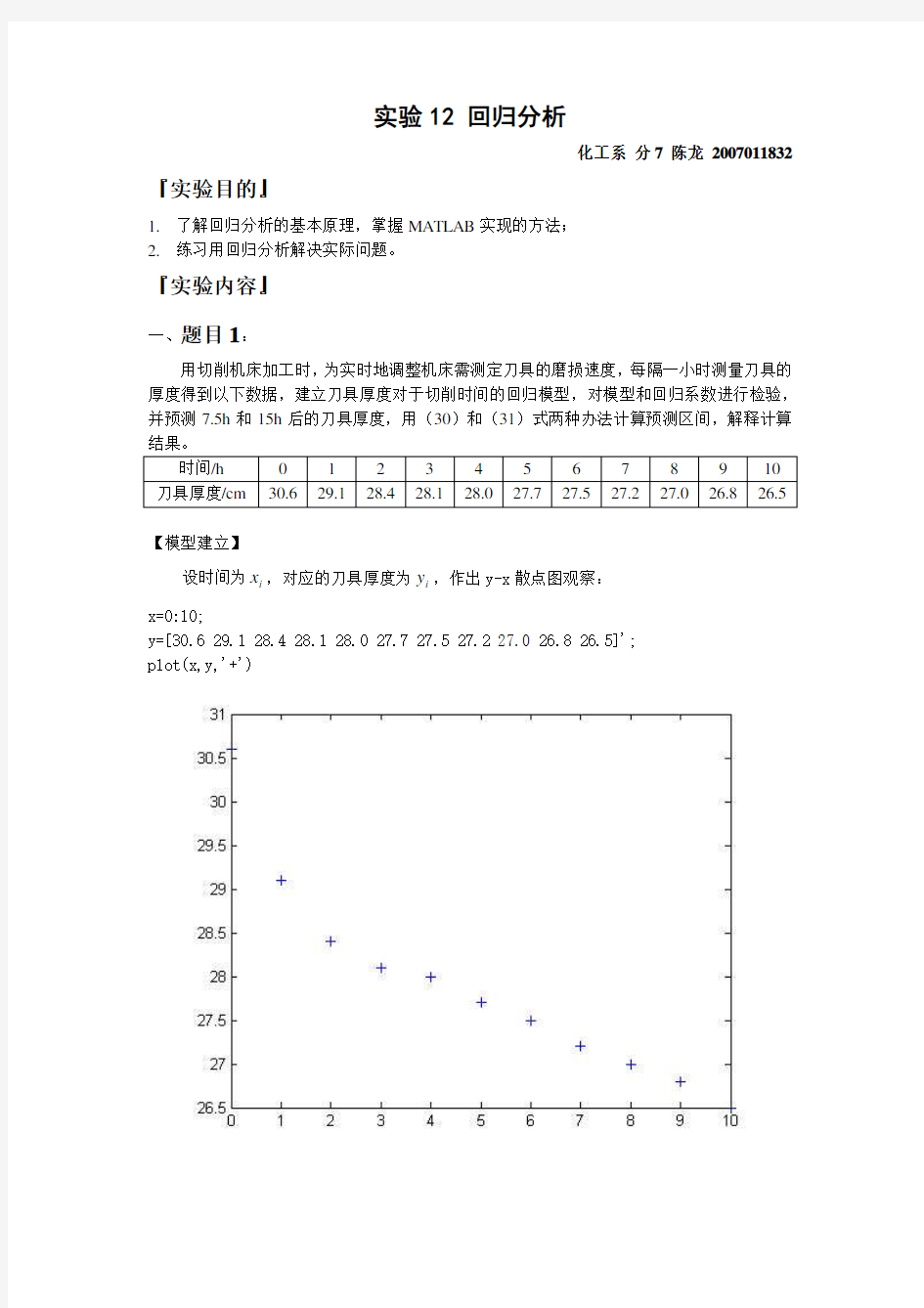
设时间为i x ,对应的刀具厚度为i y ,作出y-x 散点图观察:x=0:10;
y=[30.629.128.428.128.027.727.527.227.026.826.5]';plot(x,y,'+')
可以观察出,y-x 是可以建立线性回归模型的。设x y 10ββ+=,下面用MATLAB 计算回归系数。
【模型求解】X=[ones(11,1),x'];
[b,bint,r,rint,s]=regress(y,X,0.05);b,bint,s
rcoplot(r,rint)得到的结果为:b =29.5455
-0.3291
bint =28.976930.1140
-0.4252-0.2330s =0.869660.00180.0000
0.1985
观察到第一个数据的残差的置信区间不包含零点,是异常数据,应舍去。x(1)=[];y(1)=[];
X=[ones(10,1),x'];
[b,bint,r,rint,s]=regress(y,X,0.05);b,bint,s
rcoplot(r,rint)得到的结果为:
b=29.0533
-0.2588
bint=28.833429.2732
-0.2942-0.2233
s=0.9726283.55990.00000.0195
可见剩下的第一个数据的残差的置信区间仍不包含零点,还是不满足要求,应再剔除。
x(1)=[];
y(1)=[];
X=[ones(9,1),x'];
[b,bint,r,rint,s]=regress(y,X,0.05);
b,bint,s
rcoplot(r,rint)
得到的结果为:
b=28.8667
-0.2333
bint=28.779628.9537
-0.2467-0.2200
s=0.995917150.00000.0019
可见去掉了前两个数据后,余下的9个数据没有异常情况,并且回归系数的置信区间小了,F 值大了,剩余方差小了,都对回归分析有利。
取第三次计算得到的b ,可以得到回归模型为x y 2333.08667.28-=。下面作图检验该线性回归方程:
【模型应用】
用以上建立的模型,可以得到预测值:
1)当时间为7.5h 时,y(7.5)=28.8667-0.2333*7.5=27.1167;a1=tinv(1-0.05/2,7);x(1:2)=[];sxx=var(x)*8;
c1=a1*sqrt(s(4))*sqrt((7.5-mean(x))^2/sxx+1/9+1)
得到c1=0.1104,所以用(30)式算得的预测区间为[27.0063,27.2271];a2=norminv(0.975,0,1);c2=a2*s(4)
得到c2=0.0855,所以用(31)式算得的预测区间为[27.0311,27.2022]。2)当时间为15h 时,y(15)=28.8667-0.2333*15=25.3667。c3=a1*sqrt(s(4))*sqrt((15-mean(x))^2/sxx+1/9+1);
得到c3=0.1569,所以用(30)式算得的预测区间为[25.2098,25.5236];c4=c2=0.0855,所以用(31)式算得的预测区间为[25.2811,25.4522]。
【结果解释】
用(30)式与(31)式算的预测区间不大一样,后者是当n 较大且x0接近x 的平均值时的极限结果,因此不确定的范围会小一些,而前者则是在n 有限的情况下得到的,为了使结果准确,预测区间的范围就应该大一点。
----------------------------------------------------------------------------------------------------------------------
二、题目2:
电影院调查电视广告费用和报纸广告费用对每周收入的影响,得到下面的数据,建立回归模型并进行检验,诊断异常点的存在并进行处理。
每周收入9690959295959494电视广告费用 1.5 2.0 1.5 2.5 3.3 2.3 4.2 2.5报纸广告费用
5.0
2.0
4.0
2.5
3.0
3.5
2.5
3.0
【模型假设】
设电视广告费用为x1,报纸广告费用为x2,每周收入为y ,x1=[1.52.01.52.53.32.34.22.5]’x2=[5.02.04.02.53.03.52.53.0]’x=[x1,x2];
y=[9690959295959494]’;rstool(x,y,'linear',0.05)
在命令窗口中分别调整model ,依次对linear,purequadratic,interaction,quadratic 四种形式进行计算,比较剩余标准差,结果如下:
linear 0.6998,purequadratic 0.2497,interaction 0.4527,quadratic 0.1415。
因此对于全体数据,采用quadratic 模式,即包含线性项和完全二次项的形式是最佳的。但是出于方便,先考虑剩余标准差最大的线性回归形式:22110x x y βββ++=。之后再讨论
【模型求解】
X=[ones(8,1)x];
[b,bint,r,rint,s]=regress(y,X);
b,bint,s
rcoplot(r,rint)
结果如下:
b=83.2116
1.2985
2.3372
bint=78.805887.6174
0.4007 2.1962
1.4860 3.1883
s=0.908924.94080.00250.4897
很遗憾,第一组数据的残差区间未包含零点,舍弃该数据再做尝试。
x(1,:)=[];
y(1)=[];
X=[ones(7,1)x];
[b,bint,r,rint,s]=regress(y,X);
b,bint,s
rcoplot(r,rint)
b =81.4881
1.2877
2.9766
bint =78.787884.1883
0.7964 1.77902.3281 3.6250s =0.976884.38420.0005
0.1257
这样得到的残差区间均符合要求,因此可以采用线性模型
219766.22877.14181.81x x y ++=。
在去掉了第一组数据后,再用rstool 命令运算一遍,会发现linear,purequadratic,interaction,quadratic 四种形式依次输出的剩余标准差为0.3545,0.2648,0.1495,0.1600,于是最佳形式为interaction :21217369.05753.17137.03290.85x x x x y ++-=。
第一章 绪论 1.设0x >,x 的相对误差为δ,求ln x 的误差。 解:近似值* x 的相对误差为* **** r e x x e x x δ-= = = 而ln x 的误差为()1 ln *ln *ln ** e x x x e x =-≈ 进而有(ln *)x εδ≈ 2.设x 的相对误差为2%,求n x 的相对误差。 解:设()n f x x =,则函数的条件数为'() | |() p xf x C f x = 又1 '()n f x nx -=Q , 1 ||n p x nx C n n -?∴== 又((*))(*)r p r x n C x εε≈?Q 且(*)r e x 为2 ((*))0.02n r x n ε∴≈ 3.下列各数都是经过四舍五入得到的近似数,即误差限不超过最后一位的半个单位,试指 出它们是几位有效数字:*1 1.1021x =,*20.031x =, *3385.6x =, *456.430x =,* 57 1.0.x =? 解:* 1 1.1021x =是五位有效数字; *20.031x =是二位有效数字; *3385.6x =是四位有效数字; *456.430x =是五位有效数字; *57 1.0.x =?是二位有效数字。 4.利用公式(2.3)求下列各近似值的误差限:(1) ***124x x x ++,(2) ***123x x x ,(3) **24/x x . 其中**** 1234,,,x x x x 均为第3题所给的数。 解:
*4 1* 3 2* 13* 3 4* 1 51()1021()1021()1021()1021()102 x x x x x εεεεε-----=?=?=?=?=? *** 124***1244333 (1)()()()() 1111010102221.0510x x x x x x εεεε----++=++=?+?+?=? *** 123*********123231132143 (2)() ()()() 111 1.10210.031100.031385.610 1.1021385.610222 0.215 x x x x x x x x x x x x εεεε---=++=???+???+???≈ ** 24**** 24422 *4 33 5 (3)(/) ()() 11 0.0311056.430102256.43056.430 10x x x x x x x εεε---+≈ ??+??= ?= 5计算球体积要使相对误差限为1,问度量半径R 时允许的相对误差限是多少? 解:球体体积为343 V R π= 则何种函数的条件数为 2 3'4343 p R V R R C V R ππ===g g (*)(*)3(*)r p r r V C R R εεε∴≈=g 又(*)1r V ε=Q
7、设y0=28,按递推公式 y n=y n?1? 1 100 783,n=1,2,… 计算y100,若取≈27.982,试问计算y100将有多大误差? 答:y100=y99?1 100783=y98?2 100 783=?=y0?100 100 783=28?783 若取783≈27.982,则y100≈28?27.982=0.018,只有2位有效数字,y100的最大误差位0.001 10、设f x=ln?(x? x2?1),它等价于f x=?ln?(x+ x2?1)。分别计算f30,开方和对数取6位有效数字。试问哪一个公式计算结果可靠?为什么? 答: x2?1≈29.9833 则对于f x=ln x?2?1,f30≈?4.09235 对于f x=?ln x+2?1,f30≈?4.09407 而f30= ln?(30?2?1) ,约为?4.09407,则f x=?ln?(x+ x2?1)计算结果更可靠。这是因为在公式f x=ln?(x? x2?1)中,存在两相近数相减(x? x2?1)的情况,导致算法数值不稳定。 11、求方程x2+62x+1=0的两个根,使它们具有四位有效数字。 答:x12=?62±622?4 2 =?31±312?1 则 x1=?31?312?1≈?31?30.98=?61.98 x2=?31+312?1= 1 31+312?1 ≈? 1 ≈?0.01613
12.(1)、计算101.1?101,要求具有4位有效数字 答:101.1?101= 101.1+101≈0.1 10.05+10.05 ≈0.004975 14、试导出计算积分I n=x n 4x+1dx 1 的一个递推公式,并讨论所得公式是否计算稳定。 答:I n=x n 4x+1dx 1 0= 1 4 4x+1x n?1?1 4 x n?1 4x+1 dx= 1 1 4 x n?1 1 dx?1 4 x n?1 4x+1 dx 1 = 1 4n ? 1 4 I n?1,n=1,2… I0= 1 dx= ln5 1 记εn为I n的误差,则由递推公式可得 εn=?1 εn?1=?=(? 1 )nε0 当n增大时,εn是减小的,故递推公式是计算稳定的。
城镇居民家庭收入的逐步回归分析 07级数学1班盛平0707021012 摘要:用多元统计中逐步回归分析的方法和SAS软件解决了可支配收入与其他收入之间的关系,并用此模型预测在以后几年里居民平均每人全年家庭可支配收入。 关键词:逐步回归分析多元统计SAS软件 正文 1 模型分析 各地区城镇居民平均每人全年家庭可支配收入y与工薪收入x1、经营净收入x2、财产性收入x3和转移性收入x4有关,共观测了15组数据,试用逐步回归法求‘最优’回归方程。 各地区城镇居民平均每人全年家庭收入来源(2007年) 单位:元 2模型的理论 (1)基本思想:逐个引入自变量,每次引入对y影响最显著的自变量,并对方程中的老变量逐个进行检验,把变为不显著的变量逐个从方程中剔除掉,最终得到的方程中既不漏掉对Y影响显著的变量,又不包含对Y影响不显著的变量。 (2)逐步筛选的步骤:首先给出引入变量的显著性水平 和剔除变量的显著性 in
水平 ;然后按图4.1的框图筛选变量。 out 3模型的求解 (1)源程序: data ch; input x1 x2 x3 x4 x5 y @@; cards; 28.2 47.9 44.1 3.8 23.9 100.0 31.3 47.1 43.6 3.5 21.6 100.0 30.2 48.2 43.9 4.3 21.6 100.0 ?? 31.9 46.1 41.9 4.2 22.0 100.0 33.4 44.8 40.6 4.1 21.8 100.0 33.2 44.4 39.9 4.5 22.4 100.0 32.1 43.1 38.7 4.4 24.8 100.0 28.4 42.9 38.3 4.6 28.7 100.0 ?? 27.2 43.7 38.6 5.1 29.1 100.0
实验五:残差分析 【实验目的】 (1)通过残差检验,掌握残差分析的方法 (2)异常值检验 【仪器设备】 计算机、spss软件、何晓群《实用回归分析》表和表的数据 【实验内容、步骤和结果】 对何晓群《实用回归分析》表的数据进行残差分析 原始数据如表1,其中y表示货运总量(亿吨)x1表示工业总产值(亿元)x2表示农业总产值(亿元)x3表示居民非商业支出(亿元) 表1. 对表1数据用spss软件进行分析得以下各表
由上表可知复相关系数R=,决定系数R方=,由决定系数看出回归方程的显著性不高,接下来看方差分析表3 由表3知F值为较小,说明x1、x2、x3整体上对y的影响不太显著。 表4系数 模型非标准化系数标准系数 t Sig. B标准误差试用版 1(常量).096 x1.385.100 x2.535.049 x3.277.284
表4系数 模型 非标准化系数 标准系数 t Sig. B 标准 误差 试用版 1 (常量) .096 x1 .385 .100 x2 .535 .049 x3 .277 .284 回归方程为 123348.280 3.7547.10112.447y x x x =-+++
图1.学生化残差
差 残差: 对数据用spss进行分析得 表6异常值的诊断分析
数据不存在异常值.绝对值最大的删除学生化残差为SDR=,因而根据学生化删除残差诊断认为第6个数据为异常值.其中中心化杠杆值,cook距离为位于第一大.因此第6个数据为异常值. 对何晓群《实用回归分析》表的数据进行残差分析 原始数据为 : 表个啤酒品牌的广告费用和销售量
高等数值计算实践题目一 1. 实践目的 本次计算实践主要是在掌握共轭梯度法,Lanczos 算法与MINRES 算法的基础上,进一步探讨这3种算法的数值性质,主要研究特征值特征向量对算法收敛性的影响。 2. 实践过程 (一)生成矩阵 (1)作5个100阶对角阵i D 如下: 1D 对角元:1,1,...,20,1+0.1(-20),21,...,100j j d j d j j ==== 2D 对角元:1,1,...,20,1+(-20),21,...,100j j d j d j j ==== 3D 对角元:,1,...,80,81,81,...,100j j d j j d j ==== 4D 对角元:,1,...,40,41,41,...,60,41+(60),61,...,100j j j d j j d j d j j =====-= 5D 对角元:,1,...,100j d j j == 记i D 的最大模特征值和最小模特征值分别为1i λ和i n λ,则i D 特征值分布有如下特点: 1D 的特征值有较多接近于i n λ,并且1/i i n λλ较小, 2D 的特征值有较多接近于i n λ,并且1/i i n λλ较大, 3D 的特征值有较多接近于1i λ,并且1/i i n λλ较大, 4D 的特征值有较多接近于中间模特征值,并且1/i i n λλ较大, 5D 的特征值均匀分布,并且1/i i n λλ较大 (2)随机生成10个100阶矩阵j M : (100(100))j M fix rand = 并作它们的QR 分解,得j Q 和j R ,这样可得50个对称的矩阵T ij j i j A Q DQ =,其中i D 的对角元就是ij A 的特征值,若它们都大于0,则ij A 正定,j Q 的列就是相应的特征向量。结合(1)可知,ij A 都是对称正定阵。
陕西科技大学实验报告 课 程: 数理金融 实验日期: 2014 年 5 月 22 日 班 级: 数学112 交报告日期: 2013 年 5 月 23 日 姓 名: 常海琴 报告退发: (订正、重做) 学 号: 201112010101 教 师: 刘利明 实验名称: 多元回归分析 一、实验预习: 1.多元回归模型。 2.多元回归模型参数的检验。 3.多元回归模型整体的检验。 二、实验的目的和要求: 通过案例分析掌握多元回归模型的建立方法和检验的标准;并掌握分析解决实际金融问题的能力。 三、实验过程:(实验步骤、原理和实验数据记录等) 软件:Eviews3.1 数据:给定美国机动车汽油消费量研究数据。 实验原理:最小二乘法拟合多元线性回归方程 数据记录: 实例中1950年到1987年机动汽车的消费量、汽车保有量、汽油价格、人口数、国民生产总值 图1各个量之间的关系
陕西科技大学理学院实验报告 - 2 - 1、录入数据 图2录入数据 2、回归分析 443322110X X X X Y βββββ++++= 图3运行结果 Y=24553723+1.418520x1-27995762x2-59.87480x3-30540.88x4 S (25079670) (0.266) (5027085) (198.5517) (9557.981) T (0.979) (5.314) (-5.568) (-0.301) (-3.195) 2R =0.966951 F=241.3764 - R =0.9629 dw=0.6265 四、实验总结:(实验数据处理和实验结果讨论等) 用残差和最小确定直线位置是一个途径。计算残差和有相互抵消的问题。用残差绝对值和最小确定直线位置也是一个途径绝对值计算起来比较麻烦。最小二乘法用绝对值平方和最小确定直线位置。0β、1β、2β、3β、4β具有线性特性,无偏特性,有效性。-R =0.9629基本上接近于1,拟合效果较好。
《实用回归分析》教学大纲 授课专业:统计学学时:56 学分:3.5 课程性质 本课程是统计专业的一门专业必修课,该课程主要介绍了回归分析的主要方法和思想,这些方法在经济、管理、医学、生物、社会学等各个领域得到了广泛的应用。 教学目的 通过本课程的学习,让学生会应用回归分析中的诸多方法进行数据分析和建模,通过和不同的学科知识相结合,对所考虑具体问题给出合理的推断。帮助学生获得回归分析的基本知识,掌握基本应用技能,了解本学科的特点和发展前沿。让学生在接受知识熏陶的同时,思维能力得以加强,数学修养得以提高。引导学生既重视理论知识又重视实际应用,努力把他们培养成复合型实用人才。 教学内容 了解建立实际问题回归模型的过程,掌握一元线性回归、多元线性回归模型的参数估计和回归方差的显著性检验,了解异常值和强影响值,掌握异方差性的诊断、自相关性的诊断、多重共线性的诊断和它们的建模处理;理解逐步回归和飞线性回归,会分析模型的结果和进行上机操作。 教学时数分配 56学时含实验8学时。 教学48学时 第一章2学时第二章4学时第三章8学时第四章8学时 第五章8学时第六章4学时第七章4学时第八章4学时 第九章4学时第十章4学时 实验教学8学时
根据实验操作结果、实验报告和实验考勤等方面,给出该课程的实验成绩,计入该课程的总成绩中。实验成绩占总成绩的20%。 实验指导书及主要参考书: (一) 何晓群编著,《实用回归分析》,高等教育出版社,2005年8月 。 教学方式 教学以课内讲授为主,配合计算机和专门软件上机演示和操作等多种教学形式。 第一章 统计学基础 教教学学要要求求 了解统计数据的整理和描述、几种重要的概率分布,掌握假设检验和参数估计。 教教学学要要点点 1、几种重要的概率分布 2、假设检验 3、 参数估计 第二章 回归分析概述 教教学学要要求求 了解和理解变量间的相关关系、回归方差和回归名称的由来,理解回归分析的主要内容及其一般模型,掌握建立实际问题回归模型的过程。 教教学学要要点点 1、变量间的相关关系 2、回归方差和回归名称的由来 3、回归分析的主要内容及其一般模型 4、建立实际问题回归模型的过程 第三章 一元线性回归 教教学学要要求求 了解一元线性回归模型的特点和基本假设,掌握回归模型的参数估计,理解最小二乘
高等数值分析第二次实验作业
T1.构造例子特征值全部在右半平面时, 观察基本的Arnoldi 方法和GMRES 方法的数值性态, 和相应重新启动算法的收敛性. Answer: (1) 构造特征值均在右半平面的矩阵A : 根据实Schur 分解,构造对角矩阵D 由n 个块形成,每个对角块具有如下形式,对应一对特 征值i i i αβ± i i i i i S αββα-?? = ??? 这样D=diag(S 1,S 2,S 3……S n )矩阵的特征值均分布在右半平面。生成矩阵A=U T AU ,其中U 为 正交阵,则A 矩阵的特征值也均在右半平面。不妨构造A 如下所示: 2211112222 /2/2/2/2N N A n n n n ?-?? ? ? ?- ? = ? ? ? - ? ?? ? 由于选择初值与右端项:x0=zeros(2*N,1);b=ones(2*N,1); 则生成矩阵A 的过程代码如下所示: N=500 %生成A 为2N 阶 A=zeros(2*N); for a=1:N A(2*a-1,2*a-1)=a; A(2*a-1,2*a)=-a; A(2*a,2*a-1)=a; A(2*a,2*a)=a; end U = orth(rand(2*N,2*N)); A1 = U'*A*U; (2) 观察基本的Arnoldi 和GMRES 方法 编写基本的Arnoldi 函数与基本GMRES 函数,具体代码见附录。 function [x,rm,flag]=Arnoldi(A,b,x0,tol,m) function [x,rm,flag]=GMRES(A,b,x0,tol,m) 输入:A 为方程组系数矩阵,b 为右端项,x0为初值,tol 为停机准则,m 为人为限制的最大步数。 输出:x 为方程的解,rm 为残差向量,flag 为解是否收敛的标志。 外程序如下所示: e=1e-6; m=700;
一元线性回归在公司加班 制度中的应用 院(系): 专业班级: 学号姓名: 指导老师: 成 绩: 完成时间 :
一元线性回归在公司加班制度中的应用 一、实验目的 掌握一元线性回归分析的基本思想与操作,可以读懂分析结果,并写出回归方程,对回归方程进行方差分析、显著性检验等的各种统计检验 二、实验环境 SPSS21、0 windows10、0 三、实验题目 一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。经10周时间,收集了每周加班数据与签发的新保单数目,x 为每周签发的新保单数目,y 为每周加班时间(小时),数据如表所示 y 3、5 1、0 4、0 2、0 1、0 3、0 4、5 1、5 3、0 5、0 1. 画散点图。 2. x 与y 之间大致呈线性关系? 3. 用最小二乘法估计求出回归方程。 4. 求出回归标准误差σ∧ 。 5. 给出0 β∧ 与1 β∧ 的置信度95%的区间估计。 6. 计算x 与y 的决定系数。 7. 对回归方程作方差分析。 8. 作回归系数1 β∧ 的显著性检验。 9. 作回归系数的显著性检验。 10. 对回归方程做残差图并作相应的分析。 11. 该公司预测下一周签发新保单01000x =张,需要的加班时间就是多少?
12.给出0y的置信度为95%的精确预测区间。 13.给出 () E y的置信度为95%的区间估计。 四、实验过程及分析 1、画散点图 如图就是以每周加班时间为纵坐标,每周签发的新保单为横坐标绘制的散点图,从图中可以瞧出,数据均匀分布在对角线的两侧,说明x与y之间线性关系良好。 2、最小二乘估计求回归方程 系数a 模型非标准化系数标准系数t Sig、 B 的 95、0% 置信区间 B 标准误差试用版下限上限
《实用回归分析与实验》课程教学大纲 一、课程基本信息 二、课程简介 “回归分析”是现代统计学中理论丰富且应用广泛的一个分支,研究的是具有相关关系的变量间的统计规律性。它包括线性回归模型,方差分析模型等应用十分广泛的许多模型,其理论和方法也是学习和研究其它统计方法的基础.通过本课程的教学,使学生掌握回归分析的基本原理、基本方法,培养学生初步具有能结合实际情况对所获取的数据或具体的项目进行处理和分析的能力,能够用它们初步解决实际应用问题,为他们进一步从事理论研究或实际应用打下扎实的基础。 三、课程目标 本课程为专业主干课。培养学生获得回归分析的基本知识,掌握基本应用技能,了解本学科的特点和发展前沿,让学生在接受知识熏陶的同时,思维能力得以加强,数学修养得以提高,引导学生既重视理论知识又重视实际应用,努力把他们培养成复合型实用人才。 四、教学内容及要求 第一章回归分析概述(2 学时) (1)掌握回归分析应用及建立实际问题回归模型的过程; (2)熟悉回归分析的基本概念、回归分析的主要内容及其一般模型; (3)理解回归分析的主要内容; (4)了解回归方程与回归名称的由来; (5)初步了解回归分析发展述评。 第二章一元线性回归(6学时) (1)掌握参数的估计,最小二乘估计的性质,回归方程的显著性检验,残差分析;回归模型建立及预测;(2)熟悉一元线性回归模型及应用,回归系数的区间估计; (3)了解一元线性回归模型的一般应用; (4)初步了解一元线性回归模型的控制问题。 第三章多元线性回归(9学时) (1)掌握多元线性回归模型回归参数的估计、参数估计量的性质回归方程的显著性检验及应用;
实验报告 实验课程:[信息分析] 专业:[信息管理与信息系统] 班级:[ ] 学生姓名:[ ] 指导教师:[请输入姓名] 完成时间:2013年6月28日
一.实验目的 多元线性回归简单地说是涉及多个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。本实验要求掌握附带残差分析的多元线性回归理论与方法。 二.实验环境 实验室308教室 三.实验步骤与内容 1打开应用统计学实验指导书,新建excel表 2.打开SPSS,将数据输入。 3.调用SPSS主菜单的分析——>回归——>线性命令,打开线性回归对话框,指定因变量(工业GDP比重)和自变量(工业劳动者比重、固定资产比重、定额资金流动比重),以及回归方式;逐步回归(图1)
图1 线性对话框 4.在统计栏中,选择估计以输出回归系数B的估计值、t统计量等,选择Duribin-watson以进行DW检验;选择模型拟合度输出拟合优度统计量值,如R^2、F统计量值等(图2)。 图2 统计量栏
5.在线性回归栏中选择直方图和正态概率图以绘制标准化残差的直方图和残差分析与正态概率比较图,以标准化预测值为纵坐标,标准化残差值为横坐标,绘制残差与Y的预测值的散点图,检验误差变量的方差是否为常数(图3)。 图3 绘制栏 6.提交分析,并在输出窗口中查看结果,以及对结果进行分析。 系统在进行逐步分析的过程中产生了两个回归模型,模型1先将与因变量(销售收入)线性关系的自变量地区人口引入模型,建立他们之间的一元线性关系。而后逐步引入其他变量,表1中模型2表明将自变量人均收入引入,建立二元线性回归模型,可见地区人口和人均收入对销售收入的影响同等重要。
清华大学杨顶辉数值分析第6次作业
9.令*()(21),[0,1]n n T x T x x =-∈,试证*{()}n T x 是在[0,1]上带权 2 ()x x x ρ= -****0123(),(),(),()T x T x T x T x . 证明: 1 1 **2 1 1 * *20 12 2 1**20 ()()()(21)(21)211()()()()()211()22 ()()1()1()()()()()1n m n m n m n m n m n n m n m x T x T x dx x T x dx x x t x x T x T x dx t T t dt t t t T t dt t T x x x T x T x dx t T t t ρρρ---=---=-=++-= --= -???? ?令,则 由切比雪夫多项式1 01=02 m n dt m n m n ππ ≠??? =≠??==??? 所以*{()}n T x 是在[0,1]上带权2 ()x x x ρ= - *00*11* 2 2 2 2*33233()(21)1()(21)21 ()(21)2(21)188()(21)4(21)3(21)3248181 T x T x T x T x x T x T x x x x T x T x x x x x x =-==-=-=-=--=-=-=---=-+- 14.已知实验数据如下: i x 19 25 31 38 44 i y 19.0 32.3 49.0 73.3 97.8 用最小二乘法求形如2y a bx =+的经验公式,并求均方误差 解: 法方程为
实验报告 实验目的: 1.构建一元及多元回归模型,并作出估计 2.熟练掌握假设检验 3.对构建的模型进行回归预测 实验内容: 对1970——1982年某国实际通货膨胀率、失业率和预期通货膨胀率进行分析,根据下表(表一)提供的数据进行模型设定,假设检验及回归预测。 表一 年份Y X2 X3 1970 5.92 4.90 4.78 1971 4.30 5.90 3.84 1972 3.30 5.60 3.31 1973 6.23 4.90 3.44 1974 10.97 5.60 6.84 1975 9.14 8.50 9.47 1976 5.77 7.70 6.51 1977 6.45 7.10 5.92 1978 7.60 6.10 6.08 1979 11.47 5.80 8.09 1980 13.46 7.10 10.01 1981 10.24 7.60 10.81 1982 5.99 9.70 8.00 实验步骤: 1.模型设定: 为分析实际通货膨胀率(Y)分别和失业率(X2)、预期通货膨胀率(X3)之间的关系,作出如下图所示的散点图。 图一
从上示散点图可以看出实际通货膨胀率(Y)分别和失业率(X2)不呈线性关系,与预期通货膨胀率(X3)大体呈现为线性关系,为分析实际通货膨胀率(Y)分别和失业率(X2)、预期通货膨胀率(X3)之间的数量关系,可以建立单线性回归模型和多元线性回归模型:
1231 Y X ββμ=++ 123322Y X X βββμ=+++ 2.估计参数 在Eviews 命令框中输入 “ls y c x2”,按回车,对所给数据做简单的一元线性回归分析。分析结果见表二。 表二 Dependent Variable: Y Method: Least Squares Date: 10/09/11 Time: 17:23 Sample: 1970 1982 Included observations: 13 Variable Coefficient Std. Error t-Statistic Prob. C 1.323831 1.626284 0.814022 0.4329 X3 0.960163 0.228633 4.199588 0.0015 R-squared 0.615875 Mean dependent var 7.756923 Adjusted R-squared 0.580955 S.D. dependent var 3.041892 S.E. of regression 1.969129 Akaike info criterion 4.333698 Sum squared resid 42.65216 Schwarz criterion 4.420613 Log likelihood -26.16904 F-statistic 17.63654 Durbin-Watson stat 1.282331 Prob(F-statistic) 0.001487 由回归分析结果可估计出参数1β、2β 即^ 31.3238310.960163Y X =+ (1.626284)(0.228633) ()()0.814022 4.199588 t = 2 0.615875R = F=17.63654 n=13
实验报告三课程应用回归分析 学生姓名陆莹 学号20121315021 学院数学与统计学院 专业统计学 任课教师宋凤丽 二O一四年四月十七日
(1) shuju<-read.table("E:/4.14.txt") namesdata<-c("y",paste("x",1:2,sep="")) colnames(shuju)<-namesdata lm.shuju<-lm(y~.,data=shuju) summary(lm.shuju) Call: lm(formula = y ~ ., data = shuju) Residuals: Min 1Q Median 3Q Max -747.71 -229.80 -2.15 267.23 547.68 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -574.0624 349.2707 -1.644 0.1067 x1 191.0985 73.3092 2.607 0.0121 * x2 2.0451 0.9107 2.246 0.0293 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘’ 1 Residual standard error: 329.7 on 49 degrees of freedom Multiple R-squared: 0.2928, Adjusted R-squared: 0.264 F-statistic: 10.15 on 2 and 49 DF, p-value: 0.0002057 >plot(lm.shuju,2) 由上图可知,残差通过正态性检验,原假设成立。
自相关问题的建模处理 实验目的: 对数据模型进行回归分析及自相关性诊断,并用迭代法和差分法进行模型改进与评价。 实验准备: 计算机、SPSS软件、何晓群《实用回归分析》表7.7。 实验内容、步骤与结果: 一、回归分析及自相关性诊断: 1.搜集数据。从何晓群的《实用回归分析》中得到某软件公司月销售额数据,见表1。其中自变量x为总公司的月销售额(万元),因变量y为某分公司的月销售额(万元)。 表1:某软件公司月销售额数据
2.用SPSS软件录入数据,执行“图形、旧对话框、散点点状/散点图”并保存相应的x、y等,得到该软件公司月销售额数据的散点图,由散点图可以看出x 和y呈线性关系变化,见图1。 图1:某软件公司月销售额数据 3.执行“分析、回归、线性估计”保存相应的变量,得到输出结果。由系数表可以得出y对x的回归方程为: y=—1.453+0.176x 回归系数β 0、β 1 的检验t值分别为—5.903、107.928,各项的P值等于0.000, 说明x对y高度显著,见表2。 表2:系数表 4.由方差分析表可以看出:检验值F=11648.559,F>F0.05(1,118)=4.41,显著性si g≈0.00,表明回归方程高度显著,说明x对y有高度显著的线性影响,见表3。
5.由模型汇总表可知:复相关系数R=0.999,决定系数R2=0.998,由决定系数R2可以看出回归方程高度显著,见表4。 6.由回归未标准化残差散点图可以看出自变量y的残差大概在正负2σ的范围之中变化,说明回归模型满足基本假设,见图2。 图2:回归未标准化残差散点图 7.由相关性表可以看出自变量x与因变量y相关系数r=0.999,显著性p值等于0.000,认为自变量x与因变量y高度相关,见表。
9.令*()(21),[0,1]n n T x T x x =-∈,试证*{()}n T x 是在[0,1] 上带权()x ρ=的正交多项式,并求****0123(),(),(),()T x T x T x T x . 证明: 1 1 * *0 1 1 * *011**0 ()()()(21)(21)211()()()()()2()()()()()()()()n m n m n m n m n m n n m n m x T x T x dx x T x dx t x x T x T x dx t T t dt t T t dt T x x T x T x dx t T t ρρρ---=--=-== = ???? ?令,则 由切比雪夫多项式1 01=02 m n dt m n m n ππ ≠??? =≠??==??? 所以*{()}n T x 是在[0,1] 上带权()x ρ= *00*11* 22 2 2*33233()(21)1()(21)21 ()(21)2(21)188()(21)4(21)3(21)3248181 T x T x T x T x x T x T x x x x T x T x x x x x x =-==-=-=-=--=-=-=---=-+- 14.已知实验数据如下: 用最小二乘法求形如2y a bx =+的经验公式,并求均方误差 解: 法方程为
22222(1,)(1,1)(1,)(,)(,1)(,)a y x b x y x x x ?????? =???? ?????? ?? 即 5 5327271.453277277699369321.5a b ??????=???????????? 解得 0.972579 0.050035a b =?? =? 拟合公式为20.9725790.050035y x =+ 均方误差 2 4 2 2 0[]0.015023i i i y a bx σ==--=∑ 21.给出()ln f x x =的函数表如下: 用拉格朗日插值求ln 0.54的近似值并估计误差(计算取1n =及2n =) 解:1n =时,取010.5,0.6x x == 由拉格朗日插值定理有 1 100.60.5 0.693147 0.510826 0.50.(60.60.51.82321)0 1.()6047()52 j j j x x x L x f x l x ==------=-=∑ 所以1ln0.54(0.54)0.620219L ≈=- 误差为ln 0.54(0.620219)= 0.004032ε=-- 2n =时,取0120.4,0.5,0.6x x x === 由拉格朗日插值定理有
一元线性回归在公司加班制度中的应用 院(系): 专业班级: 学号姓名: 指导老师: 成绩: 完成时间:
一元线性回归在公司加班制度中的应用 一、实验目的 掌握一元线性回归分析的基本思想和操作,可以读懂分析结果,并写出回归方程,对回归方程进行方差分析、显著性检验等的各种统计检验 二、实验环境 SPSS21.0 windows10.0 三、实验题目 一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。经10周时间,收集了每周加班数据和签发的新保单数目,x 为每周签发的新保单数目,y 为每周加班时间(小时),数据如表所示 y 3.5 1.0 4.0 2.0 1.0 3.0 4.5 1.5 3.0 5.0 2. x 与y 之间大致呈线性关系? 3. 用最小二乘法估计求出回归方程。 4. 求出回归标准误差σ∧ 。 5. 给出0 β∧与1 β∧ 的置信度95%的区间估计。 6. 计算x 与y 的决定系数。 7. 对回归方程作方差分析。 8. 作回归系数1 β∧ 的显著性检验。 9. 作回归系数的显著性检验。 10.对回归方程做残差图并作相应的分析。
11.该公司预测下一周签发新保单01000 x=张,需要的加班时间是多少? 12.给出0y的置信度为95%的精确预测区间。 13.给出 () E y的置信度为95%的区间估计。 四、实验过程及分析 1.画散点图 如图是以每周加班时间为纵坐标,每周签发的新保单为横坐标绘制的散点图,从图中可以看出,数据均匀分布在对角线的两侧,说明x和y之间线性关系良好。 2.最小二乘估计求回归方程
用SPSS 求得回归方程的系数01,ββ分别为0.118,0.004,故我们可以写出其回归方程如下: 0.1180.004y x =+ 3.求回归标准误差σ∧ 由方差分析表可以得到回归标准误差:SSE=1.843 故回归标准误差: 2= 2SSE n σ∧-,2σ∧=0.48。 4.给出回归系数的置信度为95%的置信区间估计。 由回归系数显著性检验表可以看出,当置信度为95%时:
我国农民人均生活收入及消费支出分析 学院:理学院 班级:统计1001班 姓名:于海龙
中国农民人均生活收入及消费支出简要分析 论文摘要:通过本学期对实用回归分析课程的学习,对于一些实际问题作出以下分析。实 用回归分析中的方法在经济、管理、医学及心理学等方面的研究起着很重要的作用,在我国的国民经济问题中,增加农民收入是我国扩大内需与真正走向共同富裕的关键,通过运用SPSS软件分析方法对我国农民的收入及消费支出进行了各种细致分析, 以便能够更好地了解我国农村居民的收入结构和消费结构与消费行为等。 关键词:农民生活收入消费支出多元线性回归分析 正文: 一、农民人均生活收入及消费支出分析 近年来,全国上下认真贯彻落实科学发展观,以农业增产、农民增收为目的,加大各项惠农政策措施落实力度,多措并举做好农村劳动力转移就业工作,克服金融危机和严重干旱等自然灾害带来的不利影响,使全市农村经济保持了稳定发展的良好态势,农民现金收入持续增长,生活消费水平继续提高。 我国是一个农业大国,至今仍有9亿农村人口,占全国人口总数的70%,农民是我国最大的群体,农村消费能力的提升直接关系到国民经济的全局。从农村市场看,中国有近六成人口生活在农村。农村城镇化的进程对经济增长的带动作用是非常明显的,世界上还没有哪个国家有规模如此巨大的城镇化。农村居民的收入虽然低于城市居民,但是基数巨大,且农村人口的收入也在稳定增长。 随着经济的发展,我国农民的收入水平和消费水平的结构也发生了很大变化,农民生活水平的提高和消费的增加对于实现国民经济又好又快发展、正确处理好内需和外需的关系至关重要。但从总体来看,农民消费水平仍然较低,调查显示有的地区都不及城市居民人均消费支出的三分之一。而且消费结构不合理,局限于食品类等生存基本需求品,消费在衣着装饰等方面的极少。而影响农民消费水平的根本原因是农民的收入。 农民生活消费支出主要包括食品、衣着、医疗卫生、教育文化、家庭设备、交通等方面,本文只挑选了四种典型的消费支出作为代表来分析农村居民的消费结构。 二、数据来源说明 1、农村居民家庭基本情况. 数据来源于《2008中国统计年鉴》。 项目1990 1995 2000 2006 2007 平均每人年收入(元) 总收入990.38 2337.87 3146.21 5025.08 5791.12 现金收入676.67 1595.56 2381.60 4301.93 4958.40 工资性收入136.43 352.88 700.41 1373.76 1595.30 家庭经营收入481.19 1116.73 1498.81 2609.41 2978.28 财产性收入59.05 38.19 38.89 83.80 100.95 转移性收入87.76 143.49 234.96 283.88 平均每人年支出(元)
第1部分 方法介绍 奇异值分解(SVD )定理: 设m n A R ?∈,则存在正交矩阵m m V R ?∈和n n U R ?∈,使得 T O A V U O O ∑??=?? ?? 其中12(,, ,)r diag σσσ∑=,而且120r σσσ≥≥≥>,(1,2, ,)i i r σ=称为A 的 奇异值,V 的第i 列称为A 的左奇异向量,U 的第i 列称为A 的右奇异向量。 注:不失一般性,可以假设m n ≥,(对于m n <的情况,可以先对A 转置,然后进行SVD 分解,最后对所得的SVD 分解式进行转置,就可以得到原来的SVD 分解式) 方法1:传统的SVD 算法 主要思想: 设()m n A R m n ?∈≥,先将A 二对角化,即构造正交矩阵1U 和1V 使得 110T B n U AV m n ?? =?? -?? 其中1200n n B δγγδ??? ???=?????? 然后,对三角矩阵T T B B =进行带Wilkinson 位移的对称QR 迭代得到:T B P BQ =。 当某个0i γ=时,B 具有形状12B O B O B ?? =? ??? ,此时可以将B 的奇异值问题分解为两个低阶二对角阵的奇异值分解问题;而当某个0i δ=时,可以适当选取'Given s 变换,使得第i 行元素全为零的二对角阵,因此,此时也可以将B 约化为两个低 阶二对角阵的奇异值分解问题。 在实际计算时,当i B δε∞≤或者() 1j j j γεδδ-≤+(这里ε是一个略大于机器精度的正数)时,就将i δ或者i γ视作零,就可以将B 分解为两个低阶二对角阵的奇异值分解问题。
《数据分析实务与案例实验报告》 曲线估计 学号: 204 班级: 2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院
一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++ 上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对经
统计学专业培养方案 一、专业历史沿革 同济大学数学系始建于1945年,程其襄、杨武之、朱言钧、樊映川、张国隆、陆振邦等一大批知名专家曾在此任教。解放后,几经国家调整,本系时有间断。于1980年,(应用)数学系正式恢复,陆续引进一批国内外培养的具有博士学位的青年教师,充实了教学与科研力量。当时只设有数学与应用数学专业,。概率统计方向含在数学与应用数学专业内,并且1980年已开始招收概率统计方向的研究生。1999年由国家教育部批准成立同济大学“统计学”专业并招生。统计专业经过十年的建设成效显著,专业排名已有了很大的提升。在统计理论和统计方法的教学方面,力求结合统计方法在金融、保险、管理等领域的应用,从而使学生提高了运用概率统计知识解决实际问题的能力。在统计的理论研究方面如半参数统计模型的研究、相依数据的统计模型、不完全数据的统计分析方法等领域,得到了一系统的研究成果,受到了国内外统计学界的关注。已毕业的学生有在国内外继续深造的,也有很多学生在金融、保险、经济管理、统计信息管理、数据分析等行业成为骨干。 二、学制与授予学位 四年制本科。 本专业所授学位为理学学士。 三、基本学分要求 四、专业培养目标
本专业主要以统计方法及其应用为研究对象,培养具备良好的基础数学与概率论基础,掌握统计学的基本思想、理论和方法,具有熟练应用计算机软件处理统计数据的能力,了解某一相关应用领域(如保险、经济、金融等)知识的具有综合应用能力及国际视野的复合型高级专门人才。毕业生能在企事业单位、经济管理及金融、保险、医药等部门从事统计调查、数据分析、风险决策、统计信息管理等工作,或在国内外科研、教育部门从事研究和教学工作。 五、专业培养标准