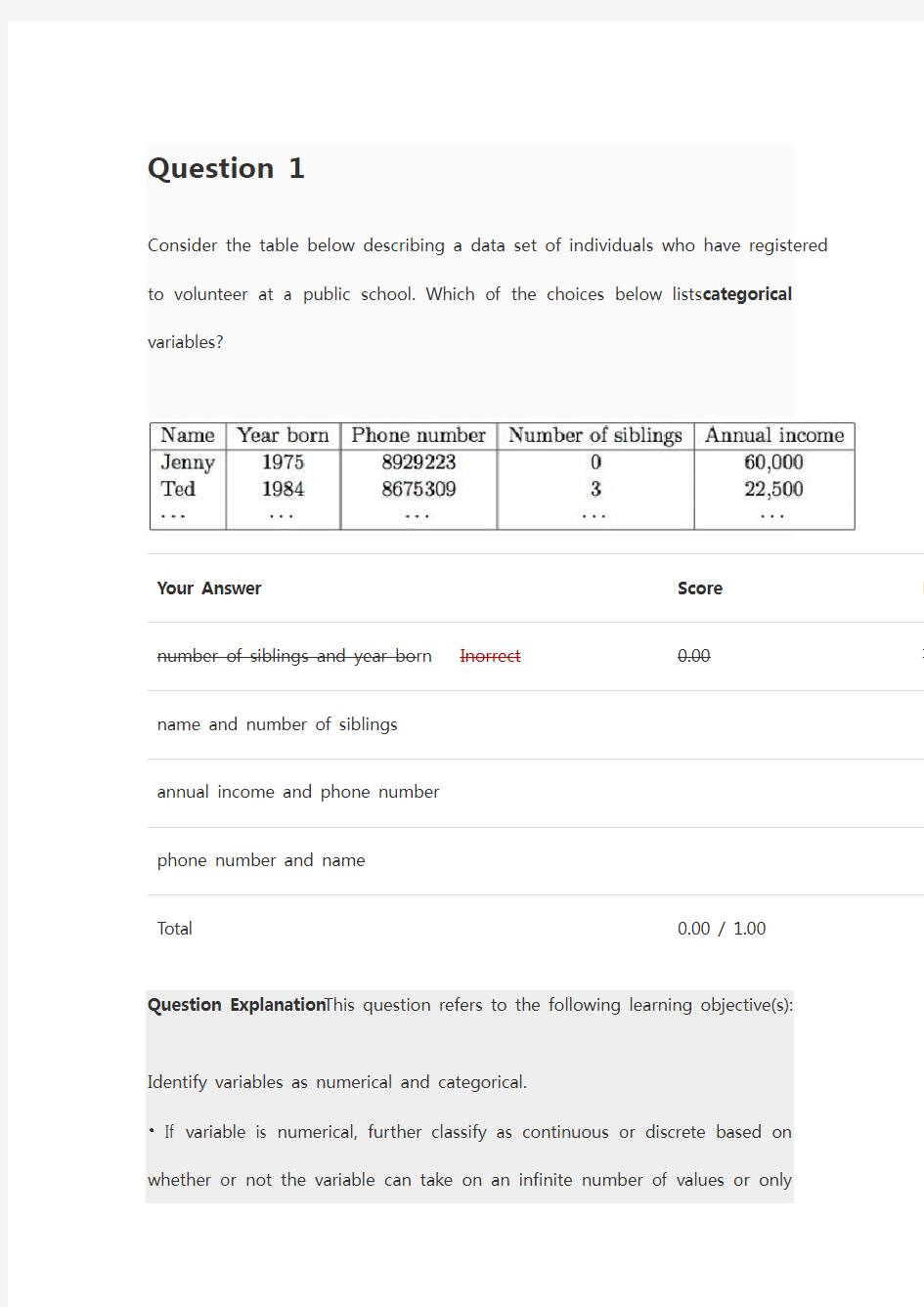

Question 1
Consider the table below describing a data set of individuals who have registered
to volunteer at a public school. Which of the choices below lists categorical
variables?
Your Answer Score Ex number of siblings and year born Inorrect0.00 Th name and number of siblings
annual income and phone number
phone number and name
Total 0.00 / 1.00
Question Explanation This question refers to the following learning objective(s):
Identify variables as numerical and categorical.
?If variable is numerical, further classify as continuous or discrete based on
whether or not the variable can take on an infinite number of values or only
non-negative whole numbers, respectively.
? If variable is categorical, determine if it is ordinal based on whether or not the levels have a natural ordering.
Question 2
The General Social Survey conducted annually in the United States asks how many friends people have and how they would rate their happiness level (very happy, pretty happy, not too happy). In order to evaluate the relationship between these two variables a researcher calculates the average number of friends for people who categorize themselves as very happy, pretty happy, and not too happy. Which of the following correctly identifies the variables used in the study as explanatory and response?
Your Answer Score Explanation
explanatory:number of friends
response:happiness level (categorical with 3 levels) Inorrect0.00 Having more friends might cause people to be ha
people to have more friends. So we can’t easily
explanatory and which the response based on wh
However in this particular analysis the happiness
we first divide the data into groups based on this
statistics of number of friends of people who fall
number of friends is the response variable.
explanatory:number of
friends
response: very happy, pretty
happy, not too happy
explanatory:very happy,
pretty happy, not too happy
response: number of friends
explanatory:happiness level
(categorical with 3 levels)
response: number of friends
Total 0.00 /
1.00
Question Explanation This question refers to the following learning objective(s):
Identify the explanatory variable in a pair of variables as the variable suspected of affecting the other, however note that labeling variables as explanatory and response does not guarantee that the relationship between the two is actually causal, even if there is an association identified between the two variables. Question 3
Past research suggests that students who study with fewer distractions (internet,
cell phone, etc.) tend to get higher grades. Which of the following is the best
scenario for being able to generalize this finding to the population of all students?
Your Answer Score Explanation None of the students in the sample has any misdemeanors;
their answers can’t be trusted.
A student list for the college is obtained and students are randomly selected from the list, and all selected students participate in the study. Correct 1.00 Random samplin
the population a
simple random s
A survey is emailed to all registered students, and the results
are based on the sample of returned surveys.
Sample only includes students who are in classes that the
researcher teaches.
Total 1.00 /
1.00 Question Explanation This question refers to the following learning objective(s):
Classify a study as observational or experimental, and determine whether the study’s results can be generalized to the population and whether they suggest
correlation or causation.
? If random sampling has been employed in data collection, the results should be generalizable to the target population.
? If random assignment has been employed in study design, the results suggest causality.
Question 4
A school district is considering whether it will no longer allow students to park at
school after two recent accidents where students were severely injured. As a first
step, they survey parents of high school students by mail, asking them whether or
not the parents would object to this policy change. Of 5,799 surveys that go out,
1,209 are returned. Of these 1,209 surveys that were completed, 926 agreed with
the policy change and 283 disagreed. Which of the following statements is the
most plausible?
Your Answer Score It is possible that 80% of the parents of high school students disagree with
the policy change.
The survey is unlikely to have any bias because all parents were mailed a
Inorrect0.00 survey.
The school district has strong support from parents to move forward with the
policy approval.
Total 0.00 /
1.00 Question Explanation This question refers to the following learning objective(s):
Question confounding variables and sources of bias in a given study.
Question 5
As part of a statistics project, Andrea would like to collect data on household size in
her city. To do so, she asks each person in her statistics class for the size of their
household, and reports that her sample is a simple random sample. However, this is
not a simple random sample. Which of the following is the best reasoning for why
this is not a random sample that is appropriate for this research question?
Your Answer
Andrea did not block for any variables that might influence the response.
Andrea asked everybody in her class instead of asking her classmates to volunteer.
In this investigation of household size, each household represents a case. Andrea incorrectly sample individuals instead of households.
Andrea did not use a random number table to randomize the order in which she collected th students’ responses, so the sample cannot be random.
Total
Question Explanation This question refers to the following learning objective(s):
Distinguish between simple random, stratified, and cluster sampling, and recognize
the benefits and drawbacks of choosing one sampling scheme over another.
Question 6
True or False: Stratified sampling allows for controlling for possible confounders in
the sampling stage, while blocking allows for controlling for such variables during
random assignment.
Score Explanation
Your
Answer
False Inorrect0.00 Stratifying and blocking both allow for controlling for potential conf
study design. We stratify when we sample (divide population into st
stratum), and block in the process of random assignment (divide sam
from within each block to treatment groups).
True
Total 0.00 /
1.00
Question Explanation This question refers to the following learning objective(s): Identify the four principles of experimental design and recognize their purposes: ?control any possible confounders,
?randomize into treatment and control groups,
?replicate by using a sufficiently large sample or repeating the experiment, ?block any variables that might influence the response.
Question 7
Which of the below data sets has the lowest standard deviation? You do not need to calculate the exact standard deviations to answer this question.
Your Answer Score Explanation
100, 100, 100, 100, 100, 100, 101 Correct 1.00 The dataset with the most repeated observatio
lowest standard deviation.
0,1,2,3,4,5,6
0, 25, 50, 100, 125, 150,
1000
0,1,3,3,3,5,6
Total 1.00 /
1.00
Question Explanation This question refers to the following learning objective(s): Note that there are three commonly used measures of center and spread:
?center: mean (the arithmetic average), median (the midpoint), mode (the most frequent observation)
?spread: standard deviation (variability around the mean), range (max-min), interquartile range (middle 50% of the distribution)
Question 8
True or False: The statistic mean/median (mean divided by median) can be used as a measure of skewness (either right or left). If this statistic is less than 1, the distribution is most likely left skewed.
Score Explanation
Your
Answer
False
True Correct 1.00 In a left skewed distribution the median is greater than the mea
mean/median to be less than 1.
Total 1.00 /
1.00
Question Explanation This question refers to the following learning objective(s):
Identify the shape of a distribution as symmetric, right skewed, or left skewed, and
unimodal, bimodoal, multimodal, or uniform.
Question 9
Based on the relative frequency histogram below, which of the following
statements is supported by the plot?
Your Answer Score Explanation The IQR of the
distribution is
roughly 10.
The mean of
the distribution
is smaller than
its median.
The
distribution is
multimodal.
It is not
possible to estimate the median without knowing the sample size.
There are no outliers in the distribution. Inorrect0.00 Using the relative frequency histogram, we can tell that 10% of bin), 40% are between 5 and 10, 20% are between 10 and 15, a
Q1 is in the second bin (between 5 and 10) and Q3 is in the fou
confirms that the IQR is roughly 10. Using this same approach w
second bin, therefore we don’t need to know the sample size
observations more than 1.5×IQR below the first quartile, but th
1.5
×IQR above the third quartile, therefore there are indeed ou
Total 0.00 /
1.00
Question Explanation This question refers to the following learning objective(s):
Use histograms and box plots to visualize the shape, center, and spread of numerical distributions, and intensity maps for visualizing the spatial distribution of the data.
Question 10
A recent housing survey was conducted to determine the price of a typical home in a city that is mostly middle-class, with one very expensive suburb. The mean price of a house in this city is roughly $650,000. Which of the following statements is most likely to be true?
Your Answer Score Explanation
There are about as many houses
in this city that cost more than
$650,000 than less than this
amount.
Majority of houses in this city cost less than $650,000. Correct 1.00 Since the city is mostly middle-class, with one
expect the distribution to be right skewed, and
than the median. Since 50% of observations fa
observations (i.e. majority) will cost less than $ We need to know the standard
deviation to answer this
question
Majority of houses in this city
cost more than $650,000.
Total 1.00 /
1.00
Question Explanation This question refers to the following learning objective:
Define a robust statistic (e.g. median, IQR) as a statistics that is not heavily affected
by skewness and extreme outliers, and determine when such statistics are more
appropriate measures of center and spread compared to other similar statistics.
Question 11
Phi Delta Kappa (PDK) is an international professional organization for educators
that, in collaboration with Gallup, has been conducting polls on the public’s
attitudes toward the public schools since 1969. The following was one of the
questions on the 2011 poll:
”Most teachers in the nation now belong to unions or associations that bargain over salaries, working conditions, and the like. Has unionization, in your opinion, helped, hurt, or made no difference in the quality of public school education in the United States?”
The respondents’answers broken down by party affiliation are shown below. Which of the following statements is most justified by these data?
Your Answer Score Explanation
14% of Republicans and 58% of
Democrats think that teachers
belonging to unions or bargaining
associations helped the quality of
public school education in the United
States.
A histogram or a box plot would be useful for investigating if distribution of opinion on teachers belonging to unions or bargaining associations varies by political party affiliation.
The results of the survey suggest a relationship between opinion on teachers belonging to unions or bargaining associations and political party affiliation. Correct 1.00 35/290 ≈ 12% of Republicans, 146/341
20% of Independents think that teachers
associations helped the quality of public
Since there is considerable differences b
of the survey suggest a relationship betw
unions or bargaining associations and p
The results of the survey suggest that
opinion on teachers belonging to
unions or bargaining associations and
political party affiliation appear to be
independent.
Total 1.00 /
1.00
Question Explanation This question refers to the following learning objective(s):
Use contingency tables and segmented bar plots or mosaic plots to assess the relationship between two categorical variables.
Question 12
In 1948, Austin Bradford Hill, designed a study to test a new treatment for tuberculosis that at the beginning of the study there was no evidence whether it would be any better or worse than bed rest. He randomly assigned some patients who volunteered to be a part of this study to receive the treatment Streptomycin, an antibiotic. The other patients received only bed rest as the control group. Hill then observed the patients’ outcomes: which patients died and which recovered. The results of the study are shown below.
We use the following simulation test if there is a difference between the recovery rates under the two treatments: We write “died”on 18 index cards and “survived” on 89 index cards to indicate whether or not a patient died. Next, we shuffle the cards and deal them into two groups of 52 and 55, for control and treatment, respectively. We then calculate the simulated difference between the recovery rates in Streptomycin and control groups (p Streptomycin ? p Control),
and record this value. We repeat this simulation 100 times. The histogram below shows the distribution simulated difference between the recovery rates in these 100 simulations.
Which of the following is correct? Choose all that apply (there are multiple correct answers).
Your Answer Score Explanation
The conclusion of this study is generalizable
to
all
tuberculosis patients.
Correct 0.11 Since the sample is comprised of volunteers, we tuberculosis patients.
The alternative hypothesis should be that there is a difference between the recovery rates under the two treatments. Correct0.11 The evidence could go either way so we should c
two treatments.
Streptomycin treatment appears to be effective in treating tuberculosis since the observed difference in recovery rates would be considered unusual based on the simulation results. Inorrect0.00
The observed difference betwe
is p^Streptomycin?p^control=5155?
There is 1 simulation where the simulated differe
two sided hypothesis test, the p-value is 0.01×
low.
Based on this study we can
conclude a causal relationship
between Streptomycin and
better tuberculosis recovery
rate.
Correct0.11 Also, since this is an experiment we can deduce
Streptomycin treatment does not appear to be effective in treating tuberculosis since the Inorrect0.00
The observed difference betwe
is p^Streptomycin?p^control=5155?
There is 1 simulation where the simulated differe
observed number of deaths in the treatment group would not be considered unusual based on the simulation results. two sided hypothesis test, the p-value is 0.01×low, and hence we would reject the null hypothe suggest a difference between the two treatment
The alternative hypothesis is that the Streptomycin treatment is more effective than bed rest. Inorrect0.00 The evidence could go either way so we should c
two treatments.
If Streptomycin and bed rest are equally effective in curing tuberculosis, the probability of observing a difference in the recovery rates at least as high as the one observed is 2%. Inorrect0.00
The observed difference betwe
is p^Streptomycin?p^control=5155?
There is 1 simulation where the simulated differe
two sided hypothesis test, the p-value is 0.01×
The difference between the survival rates in the control and treatment groups appear to be simply due to chance. Correct0.11
The observed difference betwe
is p^Streptomycin?p^control=5155?
There is 1 simulation where the simulated differe
two sided hypothesis test, the p-value is 0.01×
数据分析方法及软件应用 (作业) 题目:4、8、13、16题 指导教师: 学院:交通运输学院 姓名: 学号:
4、在某化工生产中为了提高收率,选了三种不同浓度,四种不同温度做试验。在同一浓度与温度组合下各做两次试验,其收率数据如下面计算表所列。试在α=0.05显著性水平下分析 (1)给出SPSS数据集的格式(列举前3个样本即可); (2)分析浓度对收率有无显著影响; (3)分析浓度、温度以及它们间的交互作用对收率有无显著影响。 解答:(1)分别定义分组变量浓度、温度、收率,在变量视图与数据视图中输入表格数据,具体如下图。 (2)思路:本问是研究一个控制变量即浓度的不同水平是否对观测变量收率产生了显著影响,因而应用单因素方差分析。假设:浓度对收率无显著影响。 步骤:【分析-比较均值-单因素】,将收率选入到因变量列表中,将浓度选入到因子框中,确定。 输出: 變異數分析 收率 平方和df 平均值平方 F 顯著性 群組之間39.083 2 19.542 5.074 .016 在群組內80.875 21 3.851 總計119.958 23 显著性水平α为0.05,由于概率p值小于显著性水平α,则应拒绝原假设,认为浓度对收率有显著影响。
(3)思路:本问首先是研究两个控制变量浓度及温度的不同水平对观测变量收率的独立影响,然后分析两个这控制变量的交互作用能否对收率产生显著影响,因而应该采用多因素方差分析。假设,H01:浓度对收率无显著影响;H02:温度对收率无显著影响;H03:浓度与温度的交互作用对收率无显著影响。 步骤:【分析-一般线性模型-单变量】,把收率制定到因变量中,把浓度与温度制定到固定因子框中,确定。 输出: 主旨間效果檢定 因變數: 收率 來源第 III 類平方 和df 平均值平方 F 顯著性 修正的模型70.458a11 6.405 1.553 .230 截距2667.042 1 2667.042 646.556 .000 浓度39.083 2 19.542 4.737 .030 温度13.792 3 4.597 1.114 .382 浓度 * 温度17.583 6 2.931 .710 .648 錯誤49.500 12 4.125 總計2787.000 24 校正後總數119.958 23 a. R 平方 = .587(調整的 R 平方 = .209) 第一列是对观测变量总变差分解的说明;第二列是观测变量变差分解的结果;第三列是自由度;第四列是均方;第五列是F检验统计量的观测值;第六列是检验统计量的概率p值。可以看到观测变量收率的总变差为119.958,由浓度不同引起的变差是39.083,由温度不同引起的变差为13.792,由浓度和温度的交互作用引起的变差为17.583,由随机因素引起的变差为49.500。浓度,温度和浓度*温度的概率p值分别为0.030,0.382和0.648。 浓度:显著性<0.05说明拒绝原假设(浓度对收率无显著影响),证明浓度对收率有显著影响;温度:显著性>0.05说明不拒绝原假设(温度对收率无显著影响),证明温度对收率无显著影响;浓度与温度: 显著性>0.05说明不拒绝原假设(浓度与温度的交互作用对收率无显著影响),证明温浓度与温度的交互作用对收率无显著影响。 8、以高校科研研究数据为例:以课题总数X5为被解释变量,解释变量为投入人年数X2、投入科研事业费X4、专著数X6、获奖数X8;建立多元线性回归模型,
时间 2015-1-31 数据分析——基础知识 一、新登用户数 日新登用户数 每日新注 并登录游 的用户数 周新登用户数 本周7天日新登用户数累计之和 新登用户数: 本 30天日新登用户数累计之和 可解决的问题: 1)渠道贡献的新用户份额情况 2)宏 走势,是否需要进行投放 3)是否存在渠道作弊行 二、一次会话用户数 日一次会话用户数 即新登用户中只 一次会话,且会话时长 于规定阈值 周一次会话用户数: 本周7天日一次会话用户数累计之和 一次会话用户数: 本 30天日一次会话用户数累计之和 可解决的问题: 1) 广渠道是否 刷量作弊行
2)渠道 广 量是否合格 3)用户导入是否存在障碍点,如 网络状况 载时间等; 4)D步SU 于评估新登用户 量,进一 分析则需要定 活跃用户的 一次 会话用户数 三、用户获取 本 CAC 用户获 本义 广 本/ 效新登用户 可解决的问题: 1)获 效新登用户的 本是多少 2)如何选择 确的渠道优化投放 3)渠道 广 本是多少 四、用户活跃 Activation 日活跃用户数 DAU :每日登录过游 的用户数 周活跃用户数 WAU 截至当日,最 一周 含当日的7天 登录游 的用户数,一般按照自然周进行计算
活跃用户数 正AU 截至当日,最 一个 含当日的30天 登录过游 的用户数,一般按照自然 计算 可解决的问题: 1)游 的 心用户规模是多少 游 的总体用户规模是多少 2)游 产品用户规模稳定性 游 产品周期 化趋势衡量 3)游 产品老用户流失 活跃情况 渠道活跃用户 存周期 4)游 产品的粘性如何 正AU结合 广效果评估 备注 正AU层级的用户规模 化相对较小,能够表现用户规模的稳定性,但某个时期的 广和版本更新对正AU的影响也可能比较明显 外游 命周期处于 同时期,正AU的 化和稳定性也是 同的 五、日参与次数 DEC 日参 次数 用户对移 游 的使用记 一次参 ,即日参 次数就是用户每日对游 的参 总次数 可解决的问题: 1)衡量用户粘性 日 均参 次数
《统计分析软件》试(题)卷 班级xxx班xxx 学号xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel 数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。
E X C E L数据处理题库题 目 The pony was revised in January 2021
Excel数据处理 ==================================================题号:15053 注意:下面出现的所有文件都必须保存在考生文件夹下。 提示:[答题]按钮只会自动打开题中任意一个文件。 在[D:\exam\考生文件夹\Excel数据处理\1]下, 找到文件或文件: 1. 在考生文件夹下打开文件, (1)将Sheet1工作表的A1:E1单元格合并为一个单元格,内容水平居中; (2)在E4单元格内计算所有考生的平均分数 (利用AVERAGE函数,数值型,保留小数点后1位), 在E5和E6单元格内计算笔试人数和上机人数(利用COUNTIF函数), 在E7和E8单元格内计算笔试的平均分数和上机的平均分数 (先利用SUMIF函数分别求总分数,数值型,保留小数点后1位); (3)将工作表命名为:分数统计表
(4)选取"准考证号"和"分数"两列单元格区域的内容建立 "带数据标记的折线图",数据系列产生在"列", 在图表上方插入图表标题为"分数统计图",图例位置靠左, 为X坐标轴和Y坐标轴添加次要网格线, 将图表插入到当前工作表(分数统计表)内。 (5)保存工作簿文件。 2. 打开工作簿文件, 对工作表"图书销售情况表"内数据清单的内容按主要关键字 "图书名称"的升序次序和次要关键字"单价"的降序次序进行排序,对排序后的数据进行分类汇总,汇总结果显示在数据下方, 计算各类图书的平均单价,保存文件。 题号:15059 注意:下面出现的所有文件都必须保存在考生文件夹下。 提示:[答题]按钮只会自动打开题中任意一个文件。 在[.\考生文件夹\Excel数据处理\1]下,找到文件或exc文件:
《SPSS统计基础》课程数据分析报告 (2016— 2017学年度第二学期) 题目:关于381名大学生学习适应情况的分析报告 班级:14小教2班 学号: 姓名: 2017年6月
381名大学生学习适应性调查数据分析报告 姓名:学号:班级: 一、数据分析目的及内容 (一)数据分析的目的 通过对师范学院学生学习适应现状及其影响因素的调查研究,了解我院学生对自己所学专业在适应学习动机、适应教学模式、使用学习能力、适应学习态度、适应环境因素、适应总分六个维度的基本情况。本文拟在以往研究的基础上对大学生学习适应状况进行调查,并探讨影响大学生学习适应的因素,从而让大学生能更快更好地适应大学生活。 (二)数据分析的内容 1. 381名大学生在适应学习动机、适应教学模式、使用学习能力、适应学习态度、适应 环境因素五个维度的得分及适应总分. 2.对年级、专业、生源地变量的容量等数据分布指标的描述,了解数据分布的全貌。 3.对适应学习动机、适应教学模式、使用学习能力、适应学习态度、适应环境因素五个 维度的极大值、极小值、均值和标准差的统计。 4.学习适应各因子之间的相关分析。 5.学习适应五因子及适应总分的相关性分析。 二、数据库介绍 (一)数据来源: 1被试分布:总容量为381、年级(大一156人、大二136人、大三89人)、专业(小学教育140人、学前教育本科113人、学前教育专科128人)、生源地(城镇145人、农村236人)等方面的人数分布; 2、调查工具:《大学生学习适应量表》由冯廷勇等人编制,共29 个题目,量表采 用Likert5 点计分法,即完全不符合计 1 分,比较不符合计 2 分,不确定计 3 分,较符合计4 分,完全符合计 5 分。各维度和总量表分数越高,表明适应状况越好。总分低于58分,表明学习适应状态较差需要做较大调整;总分在59到87分之间,表明学习适应状态中等,需要做适当的调整;总分在88到116分之间,表明学习适应状态良好;总分在117到145分之间,表明学习适应状态良好。量表的效度为0.85,信度为0.87。该量表由五个维度构成: (1)学习动机(8题):1、6、7、8、9、13、17、23 (2)教学模式(7题):2、3、10、14、18、22、24 (3)学习能力(6题):4、11、15、21、25、26 (4)学习态度(4题):5、12、20、27 (5)环境因素(4题):16、19、28、29 (二)变量介绍: 1、本次问卷调查有三个变量; 2、变量名称为:专业,年级,生源地; 3、变量名称的取值为:专业:1=“小学教育”,2=“学前教育本科”,3=“学前教育专 科”;年级:1=“大一”,2=“大二”,3=“大三”,4=“大四”;生源地:1=“城镇”,2=“农村”。 三、数据统计与分析
《统计分析软件》试(题)卷 班级 xxx班姓名 xxx 学号 xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: 描述统计量 性别N极小值极大值均值标准差 男数学477.0085.0082.2500 3.77492有效的 N (列表状态)4 女数学1667.0090.0078.50007.09930有效的 N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
一、填空题 1.Web挖掘可分为、和3大类。 2.数据仓库需要统一数据源,包括统一、统一、统一和统一数据特征 4个方面。 3.数据分割通常按时间、、、以及组合方法进行。 4.噪声数据处理的方法主要有、和。 5.数值归约的常用方法有、、、和对数模型等。 6.评价关联规则的2个主要指标是和。 7.多维数据集通常采用或雪花型架构,以表为中心,连接多个表。 8.决策树是用作为结点,用作为分支的树结构。 9.关联可分为简单关联、和。 10.B P神经网络的作用函数通常为区间的。 11.数据挖掘的过程主要包括确定业务对象、、、及知识同化等几个步 骤。 12.数据挖掘技术主要涉及、和3个技术领域。 13.数据挖掘的主要功能包括、、、、趋势分析、孤立点分析和偏 差分析7个方面。 14.人工神经网络具有和等特点,其结构模型包括、和自组织网络 3种。 15.数据仓库数据的4个基本特征是、、非易失、随时间变化。 16.数据仓库的数据通常划分为、、和等几个级别。 17.数据预处理的主要内容(方法)包括、、和数据归约等。 18.平滑分箱数据的方法主要有、和。 19.数据挖掘发现知识的类型主要有广义知识、、、和偏差型知识五种。 20.O LAP的数据组织方式主要有和两种。 21.常见的OLAP多维数据分析包括、、和旋转等操作。 22.传统的决策支持系统是以和驱动,而新决策支持系统则是以、建 立在和技术之上。 23.O LAP的数据组织方式主要有和2种。 24.S QL Server2000的OLAP组件叫,OLAP操作窗口叫。 25.B P神经网络由、以及一或多个结点组成。 26.遗传算法包括、、3个基本算子。 27.聚类分析的数据通常可分为区间标度变量、、、、序数型以及混合 类型等。 28.聚类分析中最常用的距离计算公式有、、等。 29.基于划分的聚类算法有和。
吉林财经大学 《SPSS统计软件分析》作业(2010——2011学年第一学期) 学院信息学院 专业班级电子商务0806班 学生姓名王瑞霞 学号1403080616
1、对未分组资料频数分析 从中国统计局中获得从11月21日至30日国内50个城市主要食品平均价格变动情况,以该数据为例为例,进行频数分析。 首先输入数据: 选择Analyze中Descriptive Statistics——Frequencies,打开Frequencies对话框;将需处理的变量键入变量框中
单击Statistics…按钮统计量子对话框12指标,选中所需要计算的指标: 单击Charts …按钮,选择需绘制的统计图: 单击OK按钮开始运行,运行结果为:
从上图中可以看出数据中缺失值为0,花生油的平均价格104.84是最高的,而巴氏牛奶的平均价格1.81最低,全部食品平均价格的平均数为16.5327,标准差为22.4668,各种食品的平均价格差距较大。
条形图、饼形图以及直方图是用不同的图形表示方法来说明数据的指标,其实质是一样的,从图中可以看出平均价格在0—22元之间的食品是最多的,20—40元之间的食品数次之,接下来是40—60元之间的食品,不存在平均价格在60—100之间的食品。 2、以食品平均价格为依据对数据进行分组并对分组后的数据进行频数分析: Transform —Recode—Into same V ariables ,将要分组的变量放入Numeric 栏中,单击Old and new V alues分组:
分组结果如下图所示: 回到数据编辑窗,定义变量的V alue labels : 再对食品平均价格进行频数分析,分析结果如下截图所示
干货&神图:数据分析师的完整流程与知识结构体系 【编者注】此图整理自微博分享,作者不详。一个完整的数据分析流程,应该包括以下几个方面,建议收藏此图仔细阅读。完整的数据分析流程:1、业务建模。2、经验分析。3、数据准备。 4、数据处理。 5、数据分析与展现。 6、专业报告。 7、持续验证与跟踪。 (注:图保存下来,查看更清晰) 作为数据分析师,无论最初的职业定位方向是技术还是业务,最终发到一定阶段后都会承担数据管理的角色。因此,一个具有较高层次的数据分析师需要具备完整的知识结构。 1. 数据采集 了解数据采集的意义在于真正了解数据的原始面貌,包括数据产生的时间、条件、格式、内容、长度、限制条件等。这会帮助数据分析师更有针对性的控制数据生产和采集过程,避免由于违反数据采集规则导致的数据问题;同时,对数据采集逻辑的认识增加了数据分析师对数据的理解程度,尤其是数据中的异常变化。比如: Omniture中的Prop变量长度只有100个字符,在数据采集部署过程中就不能把含有大量中文描述的文字赋值给Prop变量(超过的字符会被截断)。 在Webtrekk323之前的Pixel版本,单条信息默认最多只能发送不超过2K的数据。当页面含有过多变量或变量长度有超出
限定的情况下,在保持数据收集的需求下,通常的解决方案是采用多个sendinfo方法分条发送;而在325之后的Pixel版本,单条信息默认最多可以发送7K数据量,非常方便的解决了代码部署中单条信息过载的问题。(Webtrekk基于请求量付费,请求量越少,费用越低)。 当用户在离线状态下使用APP时,数据由于无法联网而发出,导致正常时间内的数据统计分析延迟。直到该设备下次联网时,数据才能被发出并归入当时的时间。这就产生了不同时间看相同历史时间的数据时会发生数据有出入。 在数据采集阶段,数据分析师需要更多的了解数据生产和采集过程中的异常情况,如此才能更好的追本溯源。另外,这也能很大程度上避免“垃圾数据进导致垃圾数据出”的问题。 2.数据存储 无论数据存储于云端还是本地,数据的存储不只是我们看到的数据库那么简单。比如: o数据存储系统是MySql、Oracle、SQL Server还是其他系统。 o数据仓库结构及各库表如何关联,星型、雪花型还是其他。 o生产数据库接收数据时是否有一定规则,比如只接收特定类型字段。 o生产数据库面对异常值如何处理,强制转换、留空还是返回错误。
课程名称:《SPSS分析方法与应用》 课程号: 2007422 一、单项选择题(共112小题) 1、试题编号:1000110,答案:RetEncryption(D)。 SPSS的安装类型有() A. 典型安装 B.压缩安装 C.用户自定义安装 D.以上都是 2、试题编号:1000310,答案:RetEncryption(D)。 数据编辑窗口的主要功能有() A.定义SPSS数据的结构 B.录入编辑和管理待分析的数据 C.结果输出 和B 3、试题编号:1000410,答案:RetEncryption(A)。 ()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。 4、试题编号:1000510,答案:RetEncryption(D)。 ()是SPSS为用户提供的基本运行方式。 A.完全窗口菜单方式 B.程序运行方式 C.混合运行方式 D.以上都是 5、试题编号:1000810,答案:RetEncryption(D)。 ()是SPSS中有可用的基本数据类型 A.数值型 B.字符型 C.日期型 D.以上都是 6、试题编号:1000910,答案:RetEncryption(D)。 spss数据文件的扩展名是( ) A..htm B..xls C..dat D..sav 7、试题编号:1001010,答案:RetEncryption(B)。 数据编辑窗口中的一行称为一个() A.变量 B.个案 C.属性 D.元组 8、试题编号:1001110,答案:RetEncryption(C)。
变量的起名规则一般:变量名的字符个数不多于() A. 6 B. 7 C. 8 D. 9 9、试题编号:1001210,答案:RetEncryption(A)。 统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 B.定距型数据 C.定序型数据 D.定类型数据 10、试题编号:1001310,答案:RetEncryption(A)。 在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 B.降序排序 C.不排序 D.可升可降 11、试题编号:1001810,答案:RetEncryption(A)。 SPSS算术表达式中,字符型()应该用引号引起来。 A 常量 B变量 C算术运算符 D函数 12、试题编号:1001910,答案:RetEncryption(A)。 复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 B AND C OR D都不是 13、试题编号:1002010,答案:RetEncryption(A)。 数据选取的方法中,()是按符合条件的数据进行选取。 A 按指定条件选取 B 随即选取 C选取某一区域内样本 D过滤变量选取 14、试题编号:1002110,答案:RetEncryption(B)。 通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的。 A 数据转置 B 加权处理 C 数据才分 D以上都是 15、试题编号:1002210,答案:RetEncryption(A)。 SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 B 加权处理 C 数据才分 D以上不都是 16、试题编号:1002310,答案:RetEncryption(B)。 SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。 A、哈佛大学 B、斯坦福大学 C、波士顿大学 D、剑桥大学 17、试题编号:1002710,答案:RetEncryption(D)。 SPSS中进行参数检验应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 18、试题编号:1002810,答案:RetEncryption(A)。 SPSS中进行输出结果的保存应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 19、试题编号:1002910,答案:RetEncryption(C)。 SPSS中进行数据的排序应选择()主窗口菜单。 A、视图 B、编辑 C、数据 D、分析
一、名词解释:(20分) 1. 准确度和精确度:同一处理观察值彼此的接近程度同一处理的观察值与其真值的接近程度 2. 重复和区组:试验中同一处理的试验单元数将试验空间按照变异大小分成若干个相对均匀的局部,每个局部 就叫一个区组 3回归分析和相关分析:对能够明确区分自变数和因变数的两变数的相关关系的统计方法: 对不能够明确区分自变数和因变数的两变数的相关关系的统计方法 4?总体和样本:具有共同性质的个体组成的集合从总体中随机抽取的若干个个体做成的总体 5. 试验单元和试验空间:试验中能够实施不同处理的最小试验单元所有试验单元构成的空间 二、填空:(20分) 1. 资料常见的特征数有:(3空)算术平均数方差变异系数 2. 划分数量性状因子的水平时,常用的方法:等差法等比法随机法(3空) 3. 方差分析的三个基本假定是(3空)可加性正态性同质性 4. 要使试验方案具有严密的可比性,必须(2空)遵循“单一差异”原则设置对照 5. 减小难控误差的原则是(3空)设置重复随机排列局部控制 6. 在顺序排列法中,为了避免同一处理排列在同一列的可能,不同重复内各处理的排列方式常采用(2空)逆向式 阶梯式 7. 正确的取样技术主要包括:()确定合适的样本容量采用正确的取样方法 8. 在直线相关分析中,用(相关系数)表示相关的性质,用(决定系数)表示相关的程度。 三、选择:(20分) 1试验因素对试验指标所引起的增加或者减少的作用,称作(C) A、主要效应 B、交互效应 C、试验效应 D、简单效应 2. 统计推断的目的是用(A) A、样本推总体 B、总体推样本 C、样本推样本 D、总体推总体 3. 变异系数的计算方法是(B) 4. 样本平均数分布的的方差分布等于(A) 5. t检验法最多可检验(C)个平均数间的差异显著性。 6. 对成数或者百分数资料进行方差分析之前,须先对数据进行(B) A、对数 B、反正弦 C、平方根 D、立方根 7. 进行回归分析时,一组变量同时可用多个数学模型进行模拟,型的数据统计学标准是(B) A、相关系数 B、决定性系数 C、回归系数 D、变异系数 8. 进行两尾测验时,u0.10=1.64,u0.05=1.96,u0.01=2.58,那么进行单尾检验,u0.05=(A) 9. 进行多重比较时,几种方法的严格程度(LSD\SSR\Q)B 10. 自变量X与因变量Y之间的相关系数为0.9054,则Y的总变异中可由X与Y的回归关系解释的比例为(C) A、0.9054 B、0.0946 C、0.8197 D、0.0089 四、简答题:(15分) 1. 回归分析和相关分析的基本内容是什么?(6分)配置回归方程,对回归方程进行检验,分析多个自变量的主次 效益,利用回归方程进行预测预报: 计算相关系数,对相关系数进行检验 2. 一个品种比较试验,4个新品种外加1个对照品种,拟安排在一块具有纵向肥力差异的地块中,3次重复(区组),各重复内均随机排列。请画出田间排列示意图。(2分) 3. 田间试验中,难控误差有哪些?(4分)土壤肥力,小气候,相邻群体间的竞争差异,同一群体内个体间的竞争 差异。 4随即取样法包括哪几种方式?(3分)简单随机取样法分层随机取样法整群简单随机取样法 五、计算题(25分) 1. 研究变数x与y之间的关系,测得30组数据,经计算得出:x均值=10,y均值=20,l xy =60, l yy=300,r=0.6。根
---------------------------------------------装--------------------------------- --------- 订 -----------------------------------------线---------------------------------------- 班级 姓名 学号 - 广 东 财 经 大 学 答 题 纸(格式二) 课程 数据处理技术与SPSS 20 15 -20 16 学年第 1 学期 成绩 评阅人 评语: ========================================== (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课”现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面,帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷,回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。
SPSS在教育研究中的应用某大学学生对本校的满意度调查 学院:教育学院 专业:课程与教学论 学号:201411000156 姓名:李平 2014年12月13日
目录 一、研究问题的提出 (3) 二、研究内容与方法 (3) (一) 研究内容 (3) (二) 研究方法 (3) 三、调查对象及人数 (4) 四、问卷分析 (5) (一)回收情况 (5) (二)信度分析 (5) 五、数据统计与分析 (6) (一)数据输入 (6) (二)数据分析 (7) 1.描述统计 (7) (1)多选题描述统计 (7) (2)单选题描述统计 (9) 2.推断统计 (12) (1)独立样本T检验 (12) (2)单一样本T检验 (15) (3)单因素方差分析 (17) (4) X2检验 (21) 3.相关分析 (22) (1)变量间相关分析 (22) (2)维度间相关分析 (23) 六、结论 (27) 七、附录 (28)
一、研究问题的提出 学生的学校生活和成长密切相关。我们通过对他们的大学生活满意度的调查结果向有关部门提出建议,并希望能引起学校对这一系列问题的关注,最终希望大学生对其大学的满意度有所提升,大学生是一个庞大的群体,特别是近几年,随着高校的扩招,我国越来越多人能够上大学。上大学是很多人的梦想,他们都憧憬着大学校园的生活,然而当他们进了大学后才发现大学生活并非所想的美好,取而代之的却是对校园生活的不满,大学生是十分宝贵的人才资源,他们对校园生活的体验和感受,与他们的更好的学习。 二、研究内容与方法 (一)研究内容 了解学生对于学校的师资水平、环境、日常管理等各方面的满意度。 (二)研究方法 1.问卷编制 本研究采用自编问卷,问卷共由两部分组成:基本情况部分包括被调查者的性别、年级等,问卷主体部分包括师资水平、学校环境、日常管理三大维度,细分为12个三级指标(见表2-1),问卷采用五点制计分法,即“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”,分别赋值5分、4分、3分、2分、1分。 表2-1 某大学学生对本校的满意度测评指标体系 一 级指标 二级指标(潜在变量)三级指标(观测变量) 对自己师资水平对教师教学方法、对教师工作态 度、对教师人品修养、对师资配备 学校的意学校环境对学习环境、对就餐环境、对居住 环境、对校园绿化环境 满度指数日常管理对专业课时安排、对收费标准、对 奖、助学金制度、对学校治安
一、名词解释:(20分) 1.准确度和精确度:同一处理观察值彼此的接近程度同一处理的观察值与其真值的接近程度 2.重复和区组:试验中同一处理的试验单元数将试验空间按照变异大小分成若干个相对均匀的局部,每个局部就叫一个区组 3回归分析和相关分析:对能够明确区分自变数和因变数的两变数的相关关系的统计方法: 对不能够明确区分自变数和因变数的两变数的相关关系的统计方法 4.总体和样本:具有共同性质的个体组成的集合从总体中随机抽取的若干个个体做成的总体 5.试验单元和试验空间:试验中能够实施不同处理的最小试验单元所有试验单元构成的空间 二、填空:(20分) 1.资料常见的特征数有:(3空)算术平均数方差变异系数 2.划分数量性状因子的水平时,常用的方法:等差法等比法随机法(3空) 3.方差分析的三个基本假定是(3空)可加性正态性同质性 4.要使试验方案具有严密的可比性,必须(2空)遵循“单一差异”原则设置对照 5.减小难控误差的原则是(3空)设置重复随机排列局部控制 6.在顺序排列法中,为了避免同一处理排列在同一列的可能,不同重复内各处理的排列方式常采用(2空)逆向式阶梯式 7.正确的取样技术主要包括:()确定合适的样本容量采用正确的取样方法 8.在直线相关分析中,用(相关系数)表示相关的性质,用(决定系数)表示相关的程度。 三、选择:(20分) 1试验因素对试验指标所引起的增加或者减少的作用,称作(C) A、主要效应 B、交互效应 C、试验效应 D、简单效应 2.统计推断的目的是用(A) A、样本推总体 B、总体推样本 C、样本推样本 D、总体推总体 3.变异系数的计算方法是(B) 4.样本平均数分布的的方差分布等于(A) 5.t检验法最多可检验(C)个平均数间的差异显著性。 6.对成数或者百分数资料进行方差分析之前,须先对数据进行(B) A、对数 B、反正弦 C、平方根 D、立方根 7.进行回归分析时,一组变量同时可用多个数学模型进行模拟,型的数据统计学标准是(B) A、相关系数 B、决定性系数 C、回归系数 D、变异系数 8.进行两尾测验时,u0.10=1.64,u0.05=1.96,u0.01=2.58,那么进行单尾检验,u0.05=(A) 9.进行多重比较时,几种方法的严格程度(LSD\SSR\Q)B 10.自变量X与因变量Y之间的相关系数为0.9054,则Y的总变异中可由X与Y的回归关系解释的比例为(C) A、0.9054 B、0.0946 C、0.8197 D、0.0089 四、简答题:(15分) 1.回归分析和相关分析的基本内容是什么?(6分)配置回归方程,对回归方程进行检验,分析多个自变量的主次效益,利用回归方程进行预测预报: 计算相关系数,对相关系数进行检验 2.一个品种比较试验,4个新品种外加1个对照品种,拟安排在一块具有纵向肥力差异的地块中,3次重复(区组),各重复内均随机排列。请画出田间排列示意图。(2分) 3.田间试验中,难控误差有哪些?(4分)土壤肥力,小气候,相邻群体间的竞争差异,同一群体内个体间的竞争差异。 4随即取样法包括哪几种方式?(3分)简单随机取样法分层随机取样法整群简单随机取样法 五、计算题(25分) 1.研究变数x与y之间的关系,测得30组数据,经计算得出:x均值=10,y均值=20,l xy=60, l yy=300,r=0.6。根据所得数据建立直线回归方程。(5分)a=2 b=1.8 y=2+1.8 x 2.完成下列方差分析表,计算出用LSR法进行多重比较时各类数据填下表:
●一。变量的赋值 1.乘方(**),例如二的三次方:2**3 2.不同规则的赋值:转换→计算变量(如果),每一个规则的赋值都要重新进行此步骤(但注意每一遍的变量名都不变,并且他都会问你要不要替换成新的变量,你选是就行了) 3.不同规则的赋值:(1)转换→重新编码为不同变量:输入变量,输出变量,要点击“变化量”才可保存输出变量→新值和旧值:值(直接选取取值)、范围(最大到最小的范围,包含端点值),点击“添加”成功保存新值和旧值→所有不同取值规则都完成后点击继续、确定,则在变量视图多出一个新变量(2)若不想包含端点值,可以采取小数的方式变换,eg. 899.9(小数位比该变量属性的小数位多一位就行了) (3)这种要先把BMI按照男女分开,然后再分组的,可以在对话框中点击“如果”选项进行设置,并且要分别对男女进行上述操作(一共做两遍)。 二。离散化 1可视离散化:转换→可视分箱,分割点:所以想生成几组,就定义几个分割点;填写第一个分割点的时候就必须填写最小值;一定要选中上端点排除。 三。排序 1.转换→自动重新编码:不分组,从头到尾排序 2.转换→个案排秩(1)多层次数据:基于A变量对B变量进行排序。(例如,基于职称对收入进行排序,就是不同职称各自组内排工资的高低)(2)设置秩1;绑定值 四。时间序列:转换→变动值 五。查找与计数:转换→对个案内的值计数(查找“基本工资800-900女职工”,生成新变量,满足这个条件的标为1,不符合这个标准的标为0,男职工标为缺失。范围:包含上限下限) ●六。数据→个案排序:把变量顺序完全按照你想要的标准排序,所有的变量顺序都会改变 七。拆分文件:要分男女进行数据统计:数据→拆分文件→比较组/按组输出,分组依据。不分男女进行数据统计:数据→拆分文件→分析所有个案 八。选择个案(例如只选择三年级的变量进行分析):数据→选择个案→如果条件满足:如果;随机个案样本;基于时间或个案范围;使用过滤变量(例如要把身高为缺失值和值为0的剔除)→输出:过滤(不符合条件的数据会画上“/”,原始数据并未删除);将选定个案复制到新数据集(形成一个新的SPSS数据文件,原始数据并未删除);删除未选定的个案(删除原始数据,不建议使用)→之后在分析的时候就只会分析三年级的变量。不想只分析三年及,记得重新做这一步。 九。加权个案:数据→加权个案(例。100分的有5人)。不想加权了,记得重新做这一步。 十。分类汇总(1)例如算不同年级的人的身高的均值、方差…(只能计算函数)(2)数据→汇总,分界变量(分类标准变量),变量摘要(计算变量),函数:选择计算变量函数,变量名称与标签:定义新生成变量的名称与标签 ●十一。长宽数据的转换 1.长数据变宽数据:索引变量消失变成score的尾缀 (1)数据→重组(重构)→个案重组为变量,标识变量,索引变量,电脑会自动帮你选出是xx xx要重构(不同疗程值不同的变量)。选完上述这些之后就一直点下一步&完成&立即重构&确定即可 (2)注意:当有多个变量需要重构时要自己决定“新变量组的顺序”。(A1A2B1B2;A1B1A2B2) 2.宽数据变长数据:score的尾缀消失变成索引变量 (1)数据→重组(重构)→变量重组为个案,个案组标识:使用选定变量,固定变量(手动选择,电脑不会自动帮你选出了),要转置的变量即值不固定的要重构的变量(手动选择,电脑不会自动帮你选出了)。选完上述这些之后就一直点击下一步&完成&立即重构数据&确定就行了 (2)当有多个变量需要重构时,这块的操作要特别注意:○1首先在“变量组数目”中选择“多个”○2然后在“选择变量”里要对于不同的“目标变量”分别定义“要转置的变量”(在本题中,即对于kidid目标变量定义一遍要转置的变量;对于age目标变量在定义一遍要转置的变量。其中,这两个要转置的变量必须是完全不同的)。但只需要定义一次“个案组标识”&“固定变量”(固定变量是相对于kidid & age都固定的那些变量;而不是说在对kidid进行转置的时候,age就是固定变量了;因此,固定变量只用定义一次且固定变量可以为空)。并且,你要特别注意,“个案组标识”里选择的变量& n个“要转置的变量”里选择的变量&“固定变量”里选择的变量都必须是完全不相同的。
大数据技术及应用题库单选题: 1 从大量数据中提取知识的过程通常称为(A)。 a. . 数据挖掘 b. . 人工智能 c. . 数据清洗 d. . 数据仓库 2 下列论据中,能够支撑“大数据无所不能”的观点的是( A )。 A、互联网金融打破了传统的观念和行为 B、大数据存在泡沫 C、大数据具有非常高的成本 D、个人隐私泄露与信息安全担忧 3 数据仓库的最终目的是(D)。 a. . 收集业务需求 b. . 建立数据仓库逻辑模型 c. . 开发数据仓库的应用分析 d. . 为用户和业务部门提供决策支持 4 大数据处理技术和传统的数据挖掘技术最大的区别是(A)。 a. . 处理速度快(秒级定律)
b. . 算法种类更多 c. . 精度更高 d. . 更加智能化 5 大数据的起源是( C )。 a. . 金融 b. . 电信 c. . 互联网 d. . 公共管理 6 大数据不是要教机器像人一样思考。相反,它是( A )。 a. . 把数学算法运用到海量的数据上来预测事情发生的可能性 b. . 被视为人工智能的一部 c. . 被视为一种机器学习 d. . 预测与惩罚 7 人与人之间沟通信息、传递信息的技术,这指的是(D)。 a. . 感测技术 b. . 微电子技术 c. . 计算机技术 d. . 通信技术
8 数据清洗的方法不包括(D)。 a. . 缺失值处理 b. . 噪声数据清除 c. . 一致性检查 d. . 重复数据记录处理 9. 下列关于舍恩伯格对大数据特点的说法中,错误的是(D) A. 数据规模大 B. 数据类型多样 C. 数据处理速度快 D. 数据价值密度高 10规模巨大且复杂,用现有的数据处理工具难以获取、整理、管理以及处理的数据,这指 的是(D)。 a. . 富数据 b. . 贫数据 c. . 繁数据 d. . 大数据 1大数据正快速发展为对数量巨大、来源分散、格式多样的数据进行采集、存储和关联分 析,从中发现新知识、创造新价值、提升新能力的(D)。 a. . 新一代信息技术 b. . 新一代服务业态 c. . 新一代技术平台 d. . 新一代信息技术和服务业态