Red Hat Enterprise Linux在IBM xSeries服务器上的调优
- 格式:doc
- 大小:1.02 MB
- 文档页数:45

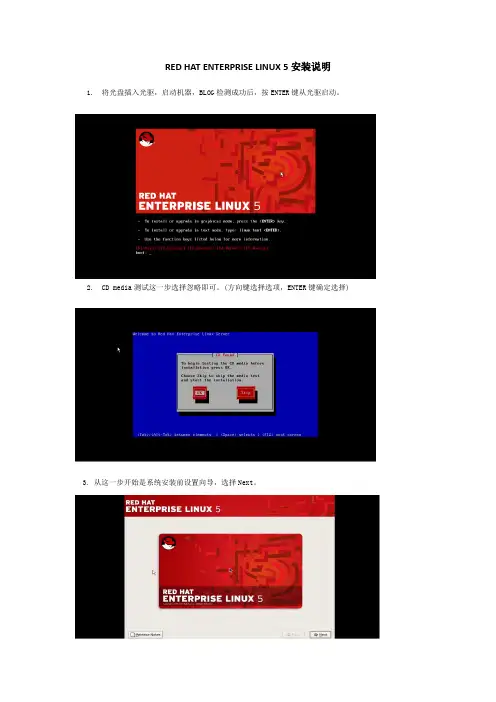
RED HAT ENTERPRISE LINUX 5安装说明1.将光盘插入光驱,启动机器,BLOG检测成功后,按ENTER键从光驱启动。
2.CD media测试这一步选择忽略即可。
(方向键选择选项,ENTER键确定选择)3. 从这一步开始是系统安装前设置向导,选择Next。
4.系统语言设置。
选择第一项简体中文。
注意,一定要选择’简体中文’.5. 键盘设置。
选择美国英语式键盘6. 输入安装号码2515dd4e215225dd 。
7. 硬盘分区设置。
硬盘分区选择‘建立自定义分区结构’,然后选择‘下一步’开始自定义硬盘分区.8. 如果硬盘已有默认分区,则删除这些分区至下图所示。
9. 硬盘分区----根目录设置。
点击新建开始编辑分区(如下图),挂载点选择‘/’,文件系统类型选择‘ext3’,大小输入40960(即4G),其他大小选项选择‘指定空间大小’。
10.上一步中编辑分区完成后,点击确定即可完成一个分区的编辑。
如下图所示。
11.硬盘分区----虚拟内存设置再次点击‘新建’到添加分区页面,如下图文件系统类型选择‘swap’,大小的值设置为与本机物理内存一样大即可,其他大小选项选择‘指定空间大小’,奔突设置的机器的物理内存为4G12.硬盘分区---user目录设置再次点击‘新建’进入添加分区页面(如下图)。
挂载点选择‘/usr’,文件系统类型选择‘ext3’,大小输入要设置的该分区的容量,其他大小选项选择‘使用全部可用空间’。
13. 硬盘分区完成根目录,虚拟内存,user目录分区配置完成后会得到如下图所示页面显示所有分区的信息。
核对分区信息如果分区无误,点击‘下一步’。
14.引导装载程序配置这一步使用默认选项,无须做修改,直接点击‘下一步’。
15.网络设置15.1 网络设置–接口设置点击‘编辑’进入编辑接口界面,选中Enable Ipv4 support,选择Manual configuration,IP Address 填写主机IP,Prefix添加子网掩码。

ZDNetChina服务器站x86服务器安装通常情况下,我们在刀片服务器上安装操作系统,如果只有一两片服务器,我们可以采用光驱来进行安装,但是如果刀片服务器数目较多,网络安装就比较适合,所以,下面,我们就介绍一下如果通过网络来进行Red Hat Enterprise Linux 4 的安装。
注意: LVM (Logical Volume Manager) 只有在图形界面的安装过程中才可以使用.首先,我们通过SSH连接到安装服务器,我们要在这台机器上配置NFS 服务,dhcp 服务,下面的例子是以Red Hat Enterprise Linux 4 为例。
如果auth服务是启用的,请禁用该服务,如果没有/etc/xinetd.d/auth文件,跳过此步编辑/etc/xinetd.d/auth,把disable = no 改成yes,并重新启动xinetd 服务service xinetd restart创建安装要使用的目录树mkdir -p /install/rhas4mount -o loop /root/rhas4u3-cd1.iso /mntcp -var /mnt/* /install/rhas4umount /mntmount -o loop /root/rhas4u3-cd2.iso /mntcp -var /mnt/* /install/rhas4umount /mntmount -o loop /root/rhas4u3-cd3.iso /mntcp -var /mnt/* /install/rhas4umount /mntmount -o loop /root/rhas4u3-cd4.iso /mntcp -var /mnt/* /install/rhas4umount /mntmount -o loop /root/rhas4u3-cd5.iso /mntcp -var /mnt/* /install/rhas4umount /mnt设置NFS服务echo “/install/rhas4 *(ro,sync,no_root_squash)” >> /etc/exportsservice nfs restartDHCP服务设置JS21的MAC地址可以telnet登录下管理模块,用命令info –T blade[x]来查看,也可以在Web界面中,Hardware VPD中找到编辑/etc/dhcpd.conf 文件,可以参与下面的例子## DHCP Server Configuration file.# see /usr/share/doc/dhcp*/dhcpd.conf.sample#ddns-update-style none;subnet 172.21.140.0 netmask 255.255.255.0 {option routers 172.21.140.1;option subnet-mask 255.255.255.0;host js21x {next-server 172.21.140.12x;hardware ethernet 12:34:56:78:AB:CD;fixed-address 172.21.140.13x;filename "rhas4u3.img";} # end of host section}根据实际情况,更改对应IP地址,MAC地址,文件名等信息启动DHCP服务service dhcpd restartTFTP服务设置编辑/etc/xinetd.d/tftp,把disable = yes 改成no启动TFTP服务service xinetd restart把启动用的Linux内核拷贝到/tftpboot目录下,在RHEL4的光盘中,提供了一个网络引导用的内核,我们可以用这个内核进行引导cp /install/rhas4/images/pseries/netboot.img /tftpboot/rhas4u3.imgpower on JS21 刀片服务器,并建立SOL会话[CODE]telnet 172.21.140.10 (管理模块的IP地址)power -T blade[X] -onconsole -T blade[X][/CODE]当出现下面信息时,按”1”,进入SMS菜单在主菜单中选择5 for “Select Boot Options” 按“Enter”.在Multiboot 菜单选择1 for “Select Install/Boot Device” 按“Enter”.在Select Device Type 菜单中选择6 for “Network” 按“Enter”.在Select Device 菜单中选择1 for “Ethernet ” 按“Enter”.如果该网卡之前设置过IP地址,要把IP地址的相关信息删掉,包括Client IP, Server IP, Gateway IP.在Select Task 菜单中选择2 for “Normal Mode Boot” 按“Enter”.在下个菜单中选择1 for “Yes” ,退出SMS 并安装JS21.选择合适的语言,选“OK”.安装方法选择NFS image 然后“OK”.选择1st ethernet device (eth0) 然后“OK”.按空格键取消动态获取IP地址,输入对应JS21的IP地址, 掩码, 网关. 然后选“OK”.输入NFS 服务器IP地址以及安装目录(/install/rhas4). 然后选择“OK”.选择“OK” 开始安装。


IBM XSeries 346 服务器安装系统教程(RAID1硬盘阵列,win2003)本教程适合初次安装的新人们亦可作为IBM服务器各种型号的安装参考。
1、准备光碟,IBM启动引导光碟(Setup Guide7.3.05版本以上)和windows2003系统安装光盘。
01.JPG2、启动服务器,按键盘“F1”键进入BIOS设置,进行设置启动设备。
02.JPG3、启动的过程中,可以看到两块同样的硬盘。
03.JPG4、进入BIOS设置界面,选择“Start Options”进入启动设备设置。
05.JPG5、在第一项“Startup Sequence Options”回车,进入详细选择。
06.JPG6、如图所示:第一启动选择CD ROM,第二选项选择hard disk 0。
完毕按键盘“Esc”退出菜单至初始界面。
07.JPG7、选择“Save Settings"保存设置。
08.JPG8、再次按“回车”确认保存设置。
最后退出BIOS设置,重启将以光驱启动继续安装。
09.JPG9、光驱启动后进入以下画面•12.JPG10、选择“English”后点击下一步。
13.JPG11、选择键盘布局以及国家或地区画面,在这里全部选择“United States”,然后点击下一步。
14.JPG12、点击同意协议“I accept”方可继续下一步。
15.JPG13、进入ServerGuide功能概述页面,如果你看得懂,可以慢慢看,否则直接下一步吧。
16.JPG14、这一步很重要选择你要安装的系统版本17.JPG15、这里有个列表,显示了下来将要做的配置,目前提示要设置日期和时间,点击下一步:18.JPG16、设置服务器的时间。
19.JPG17、这一步提示将清除硬盘上所有数据,点击下一步:20.JPG18、这一步很关键有两个选项:a:“Skip this task”如果您想保留RAID卡上的原有阵列信息,可以选择此项跳过b:“Clear all hard disk drives and restore ServeRAID to defaults”(注意这一步将清除硬盘上所有数据,并将两个硬盘重新进行同步组建RAID阵列模式。

Linux企业级操作系统的详细介绍Linux在企业方面的应用越来越受欢迎。
下面由店铺为大家整理了Linux企业级操作系统的详细介绍,希望对大家有帮助!一、Linux企业级操作系统的详细介绍Linux企业级操作系统1、Red Hat(红帽):最受关注的企业版对于Linux来说,企业应用中的使用还是非常普遍的,而Red Hat 无疑是其中最受关注的版本。
一顶红色的小帽子是很多人对于Linux 的印象。
红帽公司为诸多重要IT技术如操作系统、存储、中间件、虚拟化和云计算提供关键任务的软件与服务。
Red Hat的开放源码模式提供跨物理、虚拟和云端环境的企业运算解决方案,以帮助企业降低成本并提升效能、稳定性与安全性。
Red Hat公司同时也为全球客户或通过领先合作伙伴为客户提供技术支持、培训和咨询服务。
在最近时间里,Red Hat不但引进新技术,同时也与微软公司及其Azure 云端平台宣布策略性合作关系,藉此强化其在开放性混合云方面的领导地位。
Red Hat的计划重心是让客户能在多个环境和基础架构当中建构、部署并管理其应用程序。
毫无疑问,Red Hat仍然目前的霸主,但是也并非高枕无忧,他现在收到了来自SUSE和Ubuntu 的挑战。
Linux企业级操作系统2、SUSE:个人版和企业版都很出色在Linux版本中,有一些版本可能只是针对桌面版本的,而有一些可能更专注企业级,但是SUSE来说,他们在个人版和企业版表现的都非常出色。
SUSE 最初是德国的一个linux发行版本,在欧洲很流行,有广阔的市场。
在2003年的时候被美国公司NOVELL收购,成为其旗下的一个产品。
NOVELL公司SUSE 有两个linux版本,一个是open SUSE,另一个是Enterprise linux,Enterprise linux是为企业而设计的,要长期使用,需要收一定的费用的。
而前一个是完全按照开源社区的要求,是免费的和放开源代码的。

RedHat Linux 9 下Web服务器的安装与配置(转贴) 收藏1.安装Apache服务器在安装Red Hat Linux 9.0时,会提示是否安装Apache服务器。
如果不能确定是否已经安装,可以在终端命令窗口输入以下命令:[root@ahpeng root] rpm -qa grep httpd如果结果显示为“httpd-2.0.40-21”,则说明系统已经安装Apache服务器。
如果安装Red Hat Linux 9.0时没有选择Apache服务器,则可以在图形环境下单击“主菜单→系统设置→添加删除应用程序”菜单项,在出现的“软件包管理”对话框里确保选中“万维网服务器”选项,然后单击“更新”按钮,按照屏幕提示插入安装光盘即可开始安装。
另外,你也可以直接插入第1张安装光盘,定位到/RedHat/RPMS下的httpd-2.0.40-21.i386.rpm安装包,然后在终端命令窗口运行以下命令即可开始安装进程:[root@ahpeng RPMS] rpm -ivh httpd-2.0.40-21.i386.rpm安装好Apache服务器,可以在终端命令窗口运行以下命令来启动Apache服务:[root@ahpeng root] /etc/rc.d/init.d/httpd start重新启动Apache服务:[root@ahpeng root] /etc/rc.d/init.d/httpd restart关闭Apache服务:[root@ahpeng root]/etc/rc.d/init.d/httpd stop确认Apache服务已经启动后,我们可以在Web浏览器里输入以下地址,如果可以看到默认的Apache首页,则说明Apache服务器工作正常。
Htpp://WebServerAddress此处的WebServerAddress指代Web服务器的IP地址或者域名。
即是说We bServerAddress应该用实际的Web服务器的IP地址或者域名来代替。

Red Hat Enterprise Linux 8使用 SELinux防止用户和进程使用增强安全的 Linux (SELinux)与文件和设备执行未授权的交互Last Updated: 2023-07-26Red Hat Enterprise Linux 8 使用 SELinux防止用户和进程使用增强安全的 Linux (SELinux)与文件和设备执行未授权的交互法律通告Copyright © 2023 Red Hat, Inc.The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version.Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law.Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates.XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries.Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project.The OpenStack ® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation's permission. We are not affiliated with, endorsed or sponsored by the OpenStack Foundation, or the OpenStack community.All other trademarks are the property of their respective owners.摘要通过配置 SELinux,您可以增强系统的安全性。
双机备份方案1.1 双机备份方案描述现代IT 技术认为,一个成功系统中数据及作业的重要性已远超过硬件设备本身,在一套完善的系统中对数据的安全及保障有着极高的要求。
双机容错系统是由IBM 公司提出的全套集群解决方案,结合IBM 服务器产品的安全可靠性和集群技术的优点,为用户提供一个完善的系统。
1.1.1 双机备份方案的原理两台服务器通过磁盘阵列或纯软件模式,连接成为互为备份的双机系统,当主服务器停机后,备份服务器能继续工作,防止用户的工作被中断。
1.1.2 双机备份方案的适用范围用户对系统的连续工作性和实时性要求较高,系统停机对系统的影响很大,造成很大的损失。
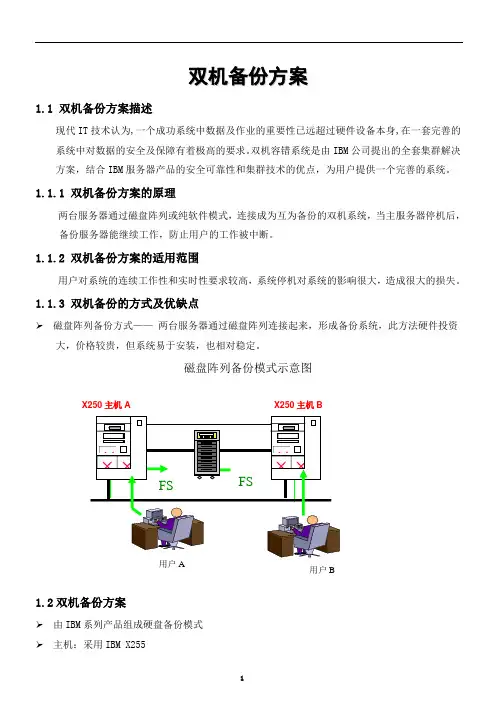
1.1.3 双机备份的方式及优缺点磁盘阵列备份方式—— 两台服务器通过磁盘阵列连接起来,形成备份系统,此方法硬件投资大,价格较贵,但系统易于安装,也相对稳定。
磁盘阵列备份模式示意图1.2双机备份方案由IBM 系列产品组成硬盘备份模式 主机:采用IBM X255X250主机BX250主机A主机网卡:采用IBM 10/100/1000MM 网卡 磁盘阵列:采用EXP300 磁盘阵列, 配制RAID 5具体实现方法参见后面章节附图和说明IBM X255结合EXP300磁盘阵列的双机方案系统简述:整个系统由两台IBM 高端服务器X255和EXP 300磁盘阵列构成双机备份模式,双台服务器互为备份,当一台服务器出现问题停机时,另一台服务器能实时接管中断的工作,保证业务系统的正常运行。
EXP 300磁盘柜磁盘具有热插拔功能,具可以灵活组成RAID 模式,当一块硬盘损坏,数据可以恢复,保证数据不丢失。
1 .3 IBM PC 服务器双机容错系统解决方案由于采用了双机容错的集群结构,系统具有极高的可靠性。
两台服务器可以作为一个整体对网络提供服务,且相互间互为监控。
集群具有一定的负载平衡功能,可将一个任务的多个进程分摊到两台服务上运行,提高系统的整体性能。
当一台服务器发生故障时,其上所运行的进程及服务可以自动地由另一台服务器接管,保证网络用户的工作不受影响。
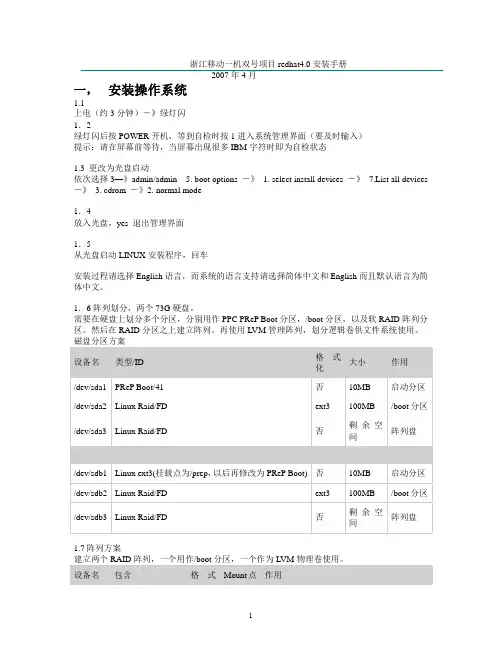
浙江移动一机双号项目redhat4.0安装手册2007年4月一,安装操作系统1.1上电(约3分钟)―》绿灯闪1.2绿灯闪后按POWER开机,等到自检时按1进入系统管理界面(要及时输入)提示:请在屏幕前等待,当屏幕出现很多IBM字符时即为自检状态1.3 更改为光盘启动依次选择3—》admin/admin 5. boot options -》1. select install devices -》7.List all devices -》3. cdrom -》2. normal mode1.4放入光盘,yes 退出管理界面1.5从光盘启动LINUX安装程序,回车安装过程请选择English语言,而系统的语言支持请选择简体中文和English而且默认语言为简体中文。
1.6阵列划分,两个73G硬盘。
需要在硬盘上划分多个分区,分别用作PPC PReP Boot分区,/boot分区,以及软RAID阵列分区。
然后在RAID分区之上建立阵列。
再使用LVM管理阵列,划分逻辑卷供文件系统使用。
磁盘分区方案设备名类型/ID 格式化大小作用/dev/sda1 PReP Boot/41 否10MB 启动分区/dev/sda2 Linux Raid/FD ext3 100MB /boot分区/dev/sda3 Linux Raid/FD 否剩余空间阵列盘/dev/sdb1 Linux ext3(挂载点为/prep,以后再修改为PReP Boot) 否10MB 启动分区/dev/sdb2 Linux Raid/FD ext3 100MB /boot分区/dev/sdb3 Linux Raid/FD 否剩余空间阵列盘1.7阵列方案建立两个RAID阵列,一个用作/boot分区,一个作为LVM物理卷使用。
设备名包含格式Mount点作用1.8 LVM方案建立卷组后再建立各个逻辑卷,格式化后给/,/swap目录使用。
逻辑卷格式化尺寸Mount点swaplv swap 2000MB 无rootlv ext3 剩余空间/二,系统安装完后需要做的工作:2.1阵列同步安装完成后重启进入系统,这时候系统才进行阵列的构建,大概需要1.5小时,要等阵列都构建完毕才可以进行其他操作。

linux加载磁阵的方法及IBM磁阵管理工具的简介目前SAS平台除话单保存服务器(172.16.80.128)挂载的磁阵不是IBM产品外,其它磁阵均为IBM产品。
其中:话单FTP服务器(172.16.80.28)挂载的磁阵为DS3400备用话单FTP服务器(172.16.80.26)挂载的磁阵为DS3400营销服务器(172.16.80.21&22)挂载的共享磁阵为DS4700备份介质服务器(172.16.30.40)挂载的磁阵为DS400(由于型号较老,目前使用命令行方式进行配置和管理,图形工具较老难使用)1.IBM磁阵管理工具简介IBM的磁阵管理工具--IBM System Storage DS4000 Storage Manager V9 可用来配置和管理DS4000系列的IBM磁阵,磁阵配置可导入导出。
IBM System Storage DS3000 Storage Manager V2可用来配置和管理DS3000系列的IBM磁阵,磁阵配置是否可导入导出未知,是否有更有效的统一管理工具未知。
IBM磁阵控制器的默认IP地址为192.168.128.101(左controler)和192.168.128.102(右controler),现在DS4700已被改为172.16.80.51(左controler)和172.16.80.52(右controler)。
DS400为192.168.70.123,DS3400仍为默认。
(1)I BM System Storage DS3000 Storage Manager V2的使用用网线连接电脑与磁阵的controler并ping通后,在电脑上启动DS3000 Storage Manager程序,就会进入下图所示画面:然后在菜单中选择“tools”中的”auto discover”,让管理工具自已查找磁阵,找到后在图形中会出现绿色三角形图案。
一般来说,新的机器在部署操作系统之前,客户要求将所有服务器的固件升级到最新版,同时还提出要对硬盘做RAID ,对于有些客户可能还要求对服务器的BIOS 、uFEI 或者IMM 做相应的设置。
如果这些工作手动完成,会耗费大量的时间和人力。
这篇文章主要介绍如何使用IBM Toolscenter 中的Linux ServerGuide Scripting Toolkit 来做大规模固件、RAID 和BIOS (uEFI 、IMM )的部署。
本文章所涉及的软件和硬件环境:一台3650安装Redhat5u2_x86_64操作系统,安装Linux ServerGuide Scripting Toolkit v1.01,同时这台机器作为DHCP 和TFTP 服务器进行镜像部署服务器。
这台机器要能够上公网。
用一台LS22来作为部署的目标服务器,对它进行firmware 的升级、配置两块硬盘成RAID0,升级BIOS 和BMC,DSA 的微码.如果要更改LS22的启动顺序为Legacy Only –> CD/DVD Rom –> Hard Disk 0 –> PXE Network –> Hard Disk 1 –> Hard Disk 2 –> Floppy Disk 。
网络环境如下图Step One :安装和配置Linux ServerGuide Scripting Toolkit从IBM Support 网站下在Linux ServerGuide Scripting Toolkit ,拷贝到HS21上,/systems/support/supportsite.wss/docdisplay?lndocid=SERV-TOOLKIT &brandind=5000016在当前目录下执行:rpm –ivh ibm_utl_sgtklnx_1.01.noarch.rpmPXE serverUpdate firmwareUpdate firmwareUpdate firmware完成安装后,进入/opt/ibm/sgtk 目录cd /opt/ibm/sgtk然后执行sgtklinux.sh脚本./sgtklinux.sh选择y,让它自动去IBM网站下载ibm_utl_boot_tools-110_anyos_x86-64-full.zip 包如果已经有ibm_utl_boot_tools-110_anyos_x86-64-full.zip,可以选择n,然后指定此文件所在位置进入sgtk,开始进行初始设置Step ONE:下载最新的firmware点击Acquire new UXSPs,选择从IBM网站下载,下一步,选择相应机器的型号,本例中医LS22和LS42为例,从左侧添加至右侧下一步,将左侧需要的操作系统类型添加到右侧选择相应的目标操作系统,为了保证完整性和方便性,可将所有的类型都选中,加入到右边,(我们在实施的时候,发现在redhat5.2下面只需要添加suse系统的文件即可)在制作firmware升级镜像的时候,sgtk会自动从下载的升级包中选择需要的升级文件。
IBM xSeries 服务器故障信息收集指导前言收集故障信息对于判断、诊断故障原因,修复系统非常重要。
现场信息收集完整有助于问题的快速解决。
要点1.客户信息2.硬件及配置信息(尽可能详尽)3.软件及配置信息(尽可能详尽)4.周围环境5.完整的故障现象描述。
即用户第一次遇到的故障现象,发现故障后做过的操作(清晰的描述).弄清楚系统发生了什么问题.系统现在能做什么?不能做什么?.故障什么时候发生的?.有没有做平时不同的操作?.故障有没有规律?定时还是不定时?发生的频率有多高?.是一台机器出现故障还是多台机器故障?故障现象是否相同?.最近有没有做改动?如安装了新的硬件、软件,改变了系统的一些设置。
故障描述总故障描述:1 故障发生条件,即怎样的环境/操作下可以看到故障现象?2 故障对哪些使用功能的造成什么影响?3 人体对机器部件运行是否正常的描述(整机或相关部件声音、用触摸感觉相关部件发热成度有没有异常,如风扇有没特别响,哪个部件是不是感觉温度很高等)4 故障频率?5 报警信息描述?(从光通路①,post②自检信息)6 客户是如何发现故障的?7 第一次发生故障的时间?8 在第一次发生故障前做过什么操作?(包括硬件的安装与移除、软件或驱动程序的安装)有的话写出它们的名称与对应操作。
9 该客户故障机器共几台?10该客户同类机器共几台?11 有其它客户报相同问题吗?有的话故障机器数量是多少?12 你想补充的话?信息收集表格需要收集给IBM进行分析的文件:一、非NEBS标准的服务器:xSeries服务器(除x343外)1.收集工具的准备a)DSA工具如下附件Dsa110p.exe,其最新的版本请从Web:/pc/support/site.wss/document.do?lndocid=MIGR-59988获得;b)Egather工具请见如下附件Egather2.exe,其最新的版本请从Web:/pc/support/site.wss/document.do?lndocid=MIGR-4R5VKC获得;c)Dumplog工具请见如下附件Dumplog30.exe,其最新的版本请从Web:/support/docview.wss?uid=psg1MIGR-4UD223获得;2.工具的运行环境a)DSA的运行环境:32位Windows2000、Windows2003和WindowsXP系统;b)Egather运行环境:32位Windows NT、Windows2000、Windows2003和WindowsXP系统;如需在Linux平台上收集数据,请从上面的网站上获取Linux的版本Egather;c)Dumplog运行环境:DOS(用该盘启动)、32位Windows2000、Windows2003和WindowsXP系统;如需在其它平台上收集数据,请从上面的网站上获取Linux的相应的版本。
xSeries 226 安装配置指南2007年01月26日星期五15:40xSeries 226 安装配置指南一.安装系统前的设置工作1. SATA机型的设置若想使用本机Adaptec Embedded SATA HostRAID 功能。
请按以下步骤配置硬盘,否则跳过。
启动SATA RAID:主机自检时按F1进入BIOS "Configuration/Setup Utility",选择Device and I/O Ports将SATA RAID Enable设置为"Enable"。
配置阵列:方法一:使用Adaptec Embedded SATA HostRAID MiniConfig工具进行配置。
a) 重启主机自检到Adaptec Embedded SATA HostRAID 时,按CTRL-A进入配置菜单,进入Array Configuration Utility 后,按回车继续;b) 选择Array Configuration Utility;c) 按"C"创建阵列;d) 分别将光标移动到每一块硬盘上,按<INS>键选择RAID成员,按回车接受选择;e) 从列表中选择需要创建阵列的块硬盘(按空格键选择);f) 选择需要创建的阵列级别RAID-1(或者RAID 0);g) 输入所创建阵列的标示;h) 在选择创建阵列的方式时,选择Quick Int;i) 按照提示完成阵列的配置(新建阵列可以全部按照默认值设置),最后选择Done完成阵列的配置;j) 退出后重新启动服务器方法二:使用Server Guide: Setup and Installation光盘配置,详见后文。
2. SCSI机型设置若想使用本机Adaptec Embedded SCSI HostRAID 功能。
请按以下步骤配置硬盘,否则跳过。
启动SCSI RAID:a) 开机屏幕提示press <CTRL><A> for SCSISelect Utility 时,按Ctrl+A;b) 选择要设置的SCSI Channel(默认情况下硬盘在第二通道上,即Channel B);c) 选择Configure/View SCSI Controller Settings,然后选HostRAID;d) 选择Enabled;e) 按Esc,并选择yes保存退出。
在Linux上安装配置WAS6.11.安装前的准备工作1>确保Linux系统执行权限配置本次选用的是Red Hat Enterprise 5.1,以root用户登录,执行以下命令查看用户创建文件的默认权限:# umask确保umask的值为022,如果不符,执行以下命令设置:# umask 022umask设置了用户创建文件的默认权限,它与chmod的效果刚好相反,umask设置的是权限“补码”,而chmod设置的是文件权限码。
一般在/etc/profile、$ [HOME]/.bash_profile或$[HOME]/.profile中设置umask值。
umask 命令允许你设定文件创建时的缺省模式,对应每一类用户(文件属主、同组用户、其他用户)存在一个相应的umask值中的数字。
对于文件来说,这一数字的最大值分别是6。
系统不允许你在创建一个文本文件时就赋予它执行权限,必须在创建后用chmod命令增加这一权限。
目录则允许设置执行权限,这样针对目录来说,umask中各个数字最大可以到7。
2>确保Linux系统中已经安装好firefox确保使用的Linux系统中已经安装了Web应用程序包,其中包括firefox浏览器,以便后面安装的时候需要调用到图形界面的浏览器应用。
3>添加ulimit设置以root用户登录,在root家目录的.bashrc中添加ulimit -n 8192后保存# cd ~# vi .bashrculimit -n 8192设置ulimit主要目的是避免出现addNode和importWasprofile的错误。
4>确保Linux系统中WAS所需的程序包已经安装compat-libstdc++-33-3.2.3-61compat-db-4.2.52-5.1libXp-1.0.0-8可以在使用rpm –q 命令查看当前Linux系统中是否已经安装以上程序包,# rpm –q compat-libstdc++如果缺失,可以在Linux光盘或者ISO安装文件中找到相应的程序包通过rpm –ivh命令安装5>确认WAS6.1安装程序包下面使用的WebSphere Application Server Network Deployment V6.1 for Linux on x86, 32-bit的安装包首先就WAS6.1安装程序包上传到Linux服务,然后用tar命令提取解压:# tar zxvf C88STML.tar.gzThe command completes successfully with no errors when the Java 2 SDK is intact.提取解压后,进入以下目录确认JDK版本# cd JDK/jre.pak/repository/package.java.jre/java/jre/bin# ./java -versionjava version "1.5.0"Java(TM) 2 Runtime Environment, Standard Edition (build pxi32dev-20060511 (SR2))IBM J9 VM (build 2.3, J2RE 1.5.0 IBM J9 2.3 Linux x86-32 j9vmxi3223-20060504 (JIT enabled)J9VM - 20060501_06428_lHdSMRJIT - 20060428_1800_r8GC - 20060501_AA)JCL - 20060511a2.安装WebSphere Application Server 6.1下面将安装的主要步骤以图片及文字形式进行说明,拿到的Linux系统是RedHat Enterprise5.1中文版,避免安装WAS的时候界面乱码,设置LANG环境变量[root@was61 ~]# export LANG=en_US.UTF-8WAS安装程序包解压后,可以找到launchpa.sh文件执行,进入图形界面安装# ./launchpad.sh选择WebSphere Application Server Network Deployment点击进入进入WebSphere Application Server Network Deployment安装向导,NEXT默认选择接受,NEXT进入系统要求检查确认,如果不是官方推荐版本,可能或出现Fail,可以暂时忽略,继续安装,如果有报错信息,可以根据Log排查选则安装样例应用,NEXT保持默认安装路径,NEXTWebshpere Application Sever环境类型选择,这里选择Application Server,当然也可以选择其他类型,各种类型的区别见以下描述cell profile(单元概要文件):一个单元概要文件包含一个部署管理器概要文件和一个应用程序服务器结点概要文件。
硬件、软件和假定条件下面的硬件和软件都可以用来执行本文中描述的任务:∙IBM System x346∙Red Hat Enterprise Linux Version 4.0,Update 4,x86 32 位版本安装步骤本文介绍了 TEXT 模式的安装。
要执行安装,请执行以下步骤:1.将 CD #1 或 DVD 插入计算机的 CD-ROM 设备,并重新系统。
在重启之后,您会看到如图 1 所示的屏幕。
图 1. 引导屏幕2.在命令行中输入 linux text(在 boot: 之后)。
可以按 F2 获得更多安装选项,例如 linux noprobe 选项将禁用硬件配置,linux askmethod 可以指定安装类型。
3.如果需要的话,可以对 CD 介质进行测试,或者通过点击 Skip 按钮跳过这个步骤,如图 2 所示。
图 2. 找到 CD 屏幕现在会看到欢迎消息,如图 3 所示。
图 3. 欢迎屏幕点击 OK 按钮。
现在会看到一个如图 4 所示的屏幕,它提示您选择安装过程使用的语言。
图 4. 语言选择屏幕∙选择 English,然后单击 OK 按钮。
下一屏幕(图 5)提示您为正确的键定义选择键盘类型。
图 5. 键盘选择屏幕∙选择 us,然后单击 OK 按钮。
在下一屏幕中,您可以选择分区工具,可以是Autopartition 或 Disk Druid,如图 6 所示。
图 6. 磁盘分区设置屏幕Autopartition(或自动分区)会根据所选择的安装类型来设置分区。
创建分区之后,您也可以对分区进行定制。
Disk Druid 是手动磁盘分区工具。
它让您可以在交互环境中创建分区。
您可以使用它来设置文件系统类型、挂载点、分区大小等等。
Disk Druid 工具只能在安装阶段使用。
有关磁盘分区的详细信息,请参看参考资料。
∙请单击 Disk Druid 来设置自己的分区。
下一个屏幕提示您定义所选的分区,如图 7 所示。
Red Hat Enterprise Linux在IBM xSeries服务器上的调优适用机型:所有服务器文档内容:一.理解Linux的性能我们可以在文章的开始就列出一个列表,列出可能影响Linux操作系统性能的一些调优参数,但这样做其实并没有什么价值。
因为性能调优是一个非常困难的任务,它要求对硬件、操作系统、和应用都有着相当深入的了解。
如果性能调优非常简单的话,那些我们要列出的调优参数早就写入硬件的微码或者操作系统中了,我们就没有必要再继续读这篇文章了。
正如下图所示,服务器的性能受到很多因素的影响。
当面对一个使用单独IDE硬盘的有20000用户的数据库服务器时,即使我们使用数周时间去调整I/O子系统也是徒劳无功的,通常一个新的驱动或者应用程序的一个更新却可以使这个服务器的性能得到明显的提升。
正如我们前面提到的,不要忘记系统的性能是受多方面因素影响的。
理解操作系统管理系统资源的方法将帮助我们在面对问题时更好的判断应该对哪个子系统进行调整。
下面的部分对Linux操作系统的架构进行了简单的介绍,对Linux内核的完整的分析超出了我们这本红皮书的内容,感兴趣的读者可以寻找相关文档做更深入的研究。
本书对Linux性能的调整主要针对Red Hat发行版本。
1.Linux的CPU调度任何计算机的基本功能都十分简单,那就是计算。
为了实现计算的功能就必须有一个方法去管理计算资源、处理器和计算任务(也被叫做线程或者进程)。
非常感谢Ingo Molnar,他为Linux内核带来了O(1)CPU调度器,区别于旧有的O(n)调度器,新的调度器是动态的,可以支持负载均衡,并以恒定的速度进行操作。
新调度器的可扩展性非常好,无论进程数量或者处理器数量,并且调度器本身的系统开销更少。
新调取器的算法使用两个优先级队列。
·活动运行队列·过期运行队列调度器的一个重要目标是根据优先级权限有效地为进程分配CPU 时间片,当分配完成后它被列在CPU的运行队列中,除了CPU 的运行队列之外,还有一个过期运行队列。
当活动运行队列中的一个任务用光自己的时间片之后,它就被移动到过期运行队列中。
在移动过程中,会对其时间片重新进行计算。
如果活动运行队列中已经没有某个给定优先级的任务了,那么指向活动运行队列和过期运行队列的指针就会交换,这样就可以让过期优先级列表变成活动优先级的列表。
通常交互式进程(相对与实时进程而言)都有一个较高的优先级,它占有更长的时间片,比低优先级的进程获得更多的计算时间,但通过调度器自身的调整并不会使低优先级的进程完全被饿死。
新调度器的优势是显著的改变Linux内核的可扩展性,使新内核可以更好的处理一些有大量进程、大量处理器组成的企业级应用。
新的O(1)调度器包含仔2.6内核中,但是也向下兼容2.4内核。
新调度器另外一个重要的优势是体现在对NUMA(non-uniform memory architecture)和SMP(symmetric multithreading processors)的支持上,例如INTEL@的超线程技术。
改进的NUMA支持保证了负载均衡不会发生在CECs或者NUMA节点之间,除非发生一个节点的超出负载限度。
Linux的CPU调度器没有使用大部分UNIX和Windows 操作系统使用的进程-线程模式,它只使用了线程。
在Linux中一个进程表示为一组线程,可以用线程组ID或者TDGID代替标准UNIX中的进程ID或者PID。
然而大多数Linux命令例如ps和top都使用PIDs表达,因此在下面的文章中我们会经常使用进程和线程组。
2.Linux的内存架构今天我们面对选择32位操作系统还是64位操作系统的情况。
对企业级用户它们之间最大的区别是64位操作系统可以支持大于4GB的内存寻址。
从性能角度来讲,我们需要了解32位和64位操作系统都是如何进行物理内存和虚拟内存的映射的。
在下面图示中我们可以看到64位和32位Linux内核在寻址上有着显著的不同。
探究物理内存到虚拟内存的映射超出了本文研究的范围,因此这里我们只是着重研究一下Linux内存架构的特点。
在32位架构中,比如IA-32,Linux内核可以直接寻址的范围只有物理内存的第一个GB(如果去掉保留部分还剩下896MB),访问内存必须被映射到这小于1GB的所谓ZONE_NORMAL空间中,这个操作是由应用程序完成的。
但是分配在ZONE_HIGHMEM中的内存页将导致性能的降低。
在另一方面,64位架构比如x86-64(也称作EM64T或者AMD64)。
ZONE_NORMAL空间将扩展到64GB或者128GB(实际上可以更多,但是这个数值受到操作系统本身支持内存容量的限制)。
正如我们看到的,使用64位操作系统我们排除了因ZONE_HIGHMEM部分内存对性能的影响的情况。
3.虚拟内存管理因为操作系统将内存都映射为虚拟内存,所以操作系统的物理内存结构对用户和应用来说通常都是不可见的。
如果想要理解Linux系统内存的调优,我们必须了解Linux 的虚拟内存机制。
应用程序并不分配物理内存,而是向Linux内核请求一部分映射为虚拟内存的内存空间。
如下图所示虚拟内存并不一定是映射物理内存中的空间,如果应用程序有一个大容量的请求,也可能会被映射到在磁盘子系统中的swap空间中。
另外要提到的是,通常应用程序不直接将数据写到磁盘子系统中,而是写入缓存和缓冲区中。
Bdflush守护进程将定时将缓存或者缓冲区中的数据写到硬盘上。
Linux内核处理数据写入磁盘子系统和管理磁盘缓存是紧密联系在一起的。
相对于其他的操作系统都是在内存中分配指定的一部分作为磁盘缓存,Linux处理内存更加有效,默认情况下虚拟内存管理器分配所有可用内存空间作为磁盘缓存,这就是为什么有时我们观察一个配置有数G内存的Linux系统可用内存只有20MB的原因。
同时Linux使用swap空间的机制也是相当高效率的,如下图所示虚拟内存空间是由物理内存和磁盘子系统中的swap空间共同组成的。
如果虚拟内存管理器发现一个已经分配完成的内存分页已经长时间没有被调用,它将把这部分内存分页移到swap空间中。
经常我们会发现一些守护进程,比如getty,会随系统启动但是却很少会被应用到。
这时为了释放昂贵的主内存资源,系统会将这部分内存分页移动到swap空间中。
上述就是Linux使用swap空间的机制,当swap分区使用超过50%时,并不意味着物理内存的使用已经达到瓶颈了,swap空间只是Linux内核更好的使用系统资源的一种方法。
4.模块化的I/O调度器就象我们知道的Linux2.6内核为我们带来了很多新的特性,这其中就包括了新的I/O调度机制。
旧的2.4内核使用一个单一的I/O调度器,2.6内核为我们提供了四个可选择的I/O调度器。
因为Linux系统应用在很广阔的范围里,不同的应用对I/O设备和负载的要求都不相同,例如一个笔记本电脑和一个10000用户的数据库服务器对I/O的要求肯定有着很大的区别。
(1).Anticipatoryanticipatory I/O调度器创建假设一个块设备只有一个物理的查找磁头(例如一个单独的SATA硬盘),正如anticipatory调度器名字一样,anticipatory调度器使用“anticipatory”的算法写入硬盘一个比较大的数据流代替写入多个随机的小的数据流,这样有可能导致写I/O操作的一些延时。
这个调度器适用于通常的一些应用,比如大部分的个人电脑。
(2).Complete Fair Queuing (CFQ)Complete Fair Queuing(CFQ)调度器是Red Hat Enterprise Linux使用的标准算法。
CFQ调度器使用QoS策略为系统内的所有任务分配相同的带宽。
CFQ调度器适用于有大量计算进程的多用户系统。
它试图避免进程被饿死和实现了比较低的延迟。
(3).Deadlinedeadline调度器是使用deadline算法的轮询的调度器,提供对I/O子系统接近实时的操作,deadline调度器提供了很小的延迟和维持一个很好的磁盘吞吐量。
如果使用deadline算法请确保进程资源分配不会出现问题。
(4).NOOPNOOP调度器是一个简化的调度程序它只作最基本的合并与排序。
与桌面系统的关系不是很大,主要用在一些特殊的软件与硬件环境下,这些软件与硬件一般都拥有自己的调度机制对内核支持的要求很小,这很适合一些嵌入式系统环境。
作为桌面用户我们一般不会选择它。
5.网络子系统新的网络中断缓和(NAPI)对网络子系统带来了改变,提高了大流量网络的性能。
Linux内核在处理网络堆栈时,相比降低系统占用率和高吞吐量更关注可靠性和低延迟。
所以在某些情况下,Linux建立一个防火墙或者文件、打印、数据库等企业级应用的性能可能会低于相同配置的Windows服务器。
在传统的处理网络封包的方式中,如下图蓝色箭头所描述的,一个以太网封包到达网卡接口后,如果MAC地址相符合会被送到网卡的缓冲区中。
网卡然后将封包移到操作系统内核的网络缓冲区中并且对CPU发出一个硬中断,CPU会处理这个封包到相应的网络堆栈中,可能是一个TCP端口或者Apache应用中。
这是一个处理网络封包的简单的流程,但从中我们可以看到这个处理方式的缺点。
正如我们看到的,每次适合网络封包到达网络接口都将对CPU发出一个硬中断信号,中断CPU正在处理的其他任务,导致切换动作和对CPU缓存的操作。
你可能认为当只有少量的网络封包到达网卡的情况下这并不是个问题,但是千兆网络和现代的应用将带来每秒钟成千上万的网络数据,这就有可能对性能造成不良的影响。
正是因为这个情况,NAPI在处理网络通讯的时候引入了计数机制。
对第一个封包,NAPI以传统的方式进行处理,但是对后面的封包,网卡引入了POLL的轮询机制:如果一个封包在网卡DMA环的缓存中,就不再为这个封包申请新的中断,直到最后一个封包被处理或者缓冲区被耗尽。
这样就有效的减少了因为过多的中断CPU对系统性能的影响。
同时,NAPI通过创建可以被多处理器执行的软中断改善了系统的可扩展性。
NAPI将为大量的企业级多处理器平台带来帮助,它要求一个启用NAPI的驱动程序。
在今天很多驱动程序默认没有启用NAPI,这就为我们调优网络子系统的性能提供了更广阔的空间。
6.Linux文件系统Linux作为一个开源操作系统的优势之一就是为用户提供了多种操作系统的支持。
现代Linux内核几乎可以支持所有计算机系统常用的文件系统,从基本的FAT到高性能的文件系统例如JFS。
因为Red Hat Enterprise Linux主要支持两种文件系统(ext2和ext3),我们将主要介绍它们的特点,对其他Linux文件系统我们仅做简要介绍。