
汇编语言学习笔记之通用寄存器
从昨天开始,正式拉开了学习汇编语言的序幕,对于汇编语言的一些特点以及数据的表示及类型做了一番了解,由于这些东西每一种语言里都要介绍,而且一时半会也真弄不太明白它们的具体使用,也就粗略的看了一下,留待在今后的学习中结合实例加以体会吧。
而通用寄存器应该说是CPU内部重要的数据存储资源,学习汇编语言必须要掌握清它们的功能。因此汇编语言学习的第一篇学习笔记就从通用寄存器开始了。以下内容摘自汇编教程中。
寄存器是CPU内部重要的数据存储资源,是汇编程序员能直接使用的硬件资源之一。由于寄存器的存取速度比内存快,所以,在用汇编语言编写程序时,要尽可能充分利用寄存器的存储功能。
寄存器一般用来保存程序的中间结果,为随后的指令快速提供操作数,从而避免把中间结果存入内存,再读取内存的操作。在高级语言(如:C/C++语言)中,也有定义变量为寄存器类型的,这就是提高寄存器利用率的一种可行的方法。
另外,由于寄存器的个数和容量都有限,不可能把所有中间结果都存储在寄存器中,所以,要对寄存器进行适当的调度。根据指令的要求,如何安排适当的寄存器,避免操作数过多的传送操作是一项细致而又周密的工作。有关“寄存器的分配策略”在后续课程《编译原理》中会有详细的介绍。
由于16位/32位CPU是微机CPU的两个重要代表,所以,在此只介绍它们内部寄存器的名称及其主要功能。
1、16位寄存器组
16位CPU所含有的寄存器有:
4个数据寄存器(AX、BX、CX和DX),
2个变址和指针寄存器(SI和DI),
2个指针寄存器(SP和BP)
4个段寄存器(ES、CS、SS和DS),
1个指令指针寄存器(IP),
1个标志寄存器(Flags)
2、32位寄存器组
32位CPU除了包含了先前CPU的所有寄存器,并把通用寄存器、指令指针和标志寄存器从16位扩充成32位之外,还增加了2个16位的段寄存器:FS 和GS。
32位CPU所含有的寄存器有:
4个数据寄存器(EAX、EBX、ECX和EDX),
2个变址和指针寄存器(ESI和EDI),
2个指针寄存器(ESP和EBP)
6个段寄存器(ES、CS、SS、DS、FS和GS),
1个指令指针寄存器(EIP),
1个标志寄存器(EFlags)
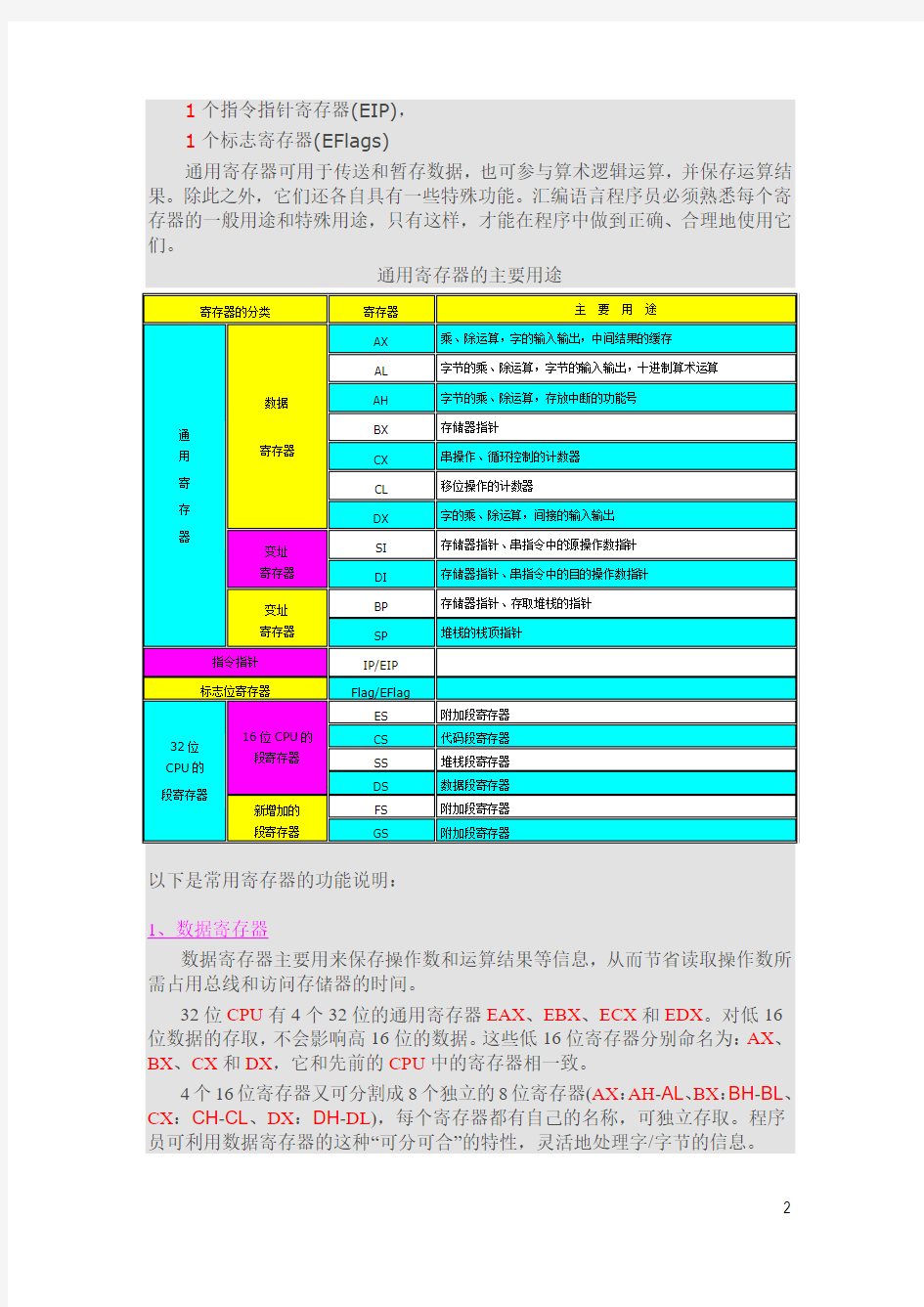
通用寄存器可用于传送和暂存数据,也可参与算术逻辑运算,并保存运算结果。除此之外,它们还各自具有一些特殊功能。汇编语言程序员必须熟悉每个寄存器的一般用途和特殊用途,只有这样,才能在程序中做到正确、合理地使用它们。
通用寄存器的主要用途
寄存器AX和AL通常称为累加器(Accumulator),用累加器进行的操
作可能需要更少时间。累加器可用于乘、除、输入/输出等操作,它们
的使用频率很高;
寄存器BX称为基地址寄存器(Base Register)。它可作为存储器指针
来使用;
寄存器CX称为计数寄存器(Count Register)。在循环和字符串操作时,
要用它来控制循环次数;在位操作中,当移多位时,要用CL来指明移
位的位数;
寄存器DX称为数据寄存器(Data Register)。在进行乘、除运算时,
它可作为默认的操作数参与运算,也可用于存放I/O的端口地址。
在16位CPU中,AX、BX、CX和DX不能作为基址和变址寄存器来存放存储单元的地址,但在32位CPU中,其32位寄存器EAX、EBX、ECX和EDX 不仅可传送数据、暂存数据保存算术逻辑运算结果,而且也可作为指针寄存器,所以,这些32位寄存器更具有通用性。详细内容请见第3.8节——32位地址的寻址方式。
2、变址寄存器
32位CPU有2个32位通用寄存器ESI和EDI。其低16位对应先前CPU中的SI和DI,对低16位数据的存取,不影响高16位的数据。
寄存器ESI、EDI、SI和DI称为变址寄存器(Index Register),它们主要用于存放存储单元在段内的偏移量,用它们可实现多种存储器操作数的寻址方式(在第3章有详细介绍),为以不同的地址形式访问存储单元提供方便。
变址寄存器不可分割成8位寄存器。作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。
它们可作一般的存储器指针使用。在字符串操作指令的执行过程中,对它们有特定的要求,而且还具有特殊的功能。具体描述请见第5.2.11节。
3、指针寄存器
32位CPU有2个32位通用寄存器EBP和ESP。其低16位对应先前CPU 中的SBP和SP,对低16位数据的存取,不影响高16位的数据。
寄存器EBP、ESP、BP和SP称为指针寄存器(Pointer Register),主要用于存放堆栈内存储单元的偏移量,用它们可实现多种存储器操作数的寻址方式(在第3章有详细介绍),为以不同的地址形式访问存储单元提供方便。
指针寄存器不可分割成8位寄存器。作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。
它们主要用于访问堆栈内的存储单元,并且规定:
BP为基指针(Base Pointer)寄存器,用它可直接存取堆栈中的数据;
段寄存器是根据内存分段的管理模式而设置的。内存单元的物理地址由段寄存器的值和一个偏移量组合而成的,这样可用两个较少位数的值组合成一个可访问较大物理空间的内存地址。
CPU内部的段寄存器:
CS——代码段寄存器(Code Segment Register),其值为代码段的段值;
DS——数据段寄存器(Data Segment Register),其值为数据段的段值;
ES——附加段寄存器(Extra Segment Register),其值为附加数据段的段值;
SS——堆栈段寄存器(Stack Segment Register),其值为堆栈段的段值;
FS——附加段寄存器(Extra Segment Register),其值为附加数据段的段值;
GS——附加段寄存器(Extra Segment Register),其值为附加数据段的段值。
在16位CPU系统中,它只有4个段寄存器,所以,程序在任何时刻至多有4个正在使用的段可直接访问;在32位微机系统中,它有6个段寄存器,所以,在此环境下开发的程序最多可同时访问6个段。
32位CPU有两个不同的工作方式:实方式和保护方式。在每种方式下,段寄存器的作用是不同的。有关规定简单描述如下:
实方式:前4个段寄存器CS、DS、ES和SS与先前CPU中的所对应的段寄存器的含义完全一致,内存单元的逻辑地址仍为“段值:偏移量”的形
式。为访问某内存段内的数据,必须使用该段寄存器和存储单元的偏
移量。
保护方式:在此方式下,情况要复杂得多,装入段寄存器的不再是段值,而是称为“选择子”(Selector)的某个值。段寄存器的具体作用在此不作进一
步介绍了,有兴趣的读者可参阅其它科技资料。
5、指令指针寄存器
32位CPU把指令指针扩展到32位,并记作EIP,EIP的低16位与先前CPU 中的IP作用相同。
指令指针EIP、IP(Instruction Pointer)是存放下次将要执行的指令在代码段的偏移量。在具有预取指令功能的系统中,下次要执行的指令通常已被预取到指令队列中,除非发生转移情况。所以,在理解它们的功能时,不考虑存在指令队列的情况。
在实方式下,由于每个段的最大范围为64K,所以,EIP中的高16位肯定都为0,此时,相当于只用其低16位的IP来反映程序中指令的执行次序。
https://www.doczj.com/doc/385249854.html,/s/blog_5fc04b6d0100had7.html
“哎哟,哥们儿,还捣鼓汇编呢?那东西没用,兄弟用VB"钓"一个API就够你忙活个十天半月的,还不一定搞出来。”此君之言倒也不虚,那吾等还有无必要研他一究呢?(废话,当然有啦!要不然你写这篇文章干嘛。)别急,别急,让我把这个中原委慢慢道来:一、所有电脑语言写出的程序运行时在内存中都以机器码方式存储,机器码可以被比较准确的翻译成汇编语言,这是因为汇编语言兼容性最好,故几乎所有跟踪、调试工具(包括WIN95/98下)都是以汇编示人的,如果阁下对CRACK颇感兴趣……;二、汇编直接与硬件打交道,如果你想搞通程序在执行时在电脑中的来龙去脉,也就是搞清电脑每个组成部分究竟在干什么、究竟怎么干?一个真正的硬件发烧友,不懂这些可不行。三、如今玩DOS的多是“高手”,如能像吾一样混入(我不是高手)“高手”内部,不仅可以从“高手”朋友那儿套些黑客级“机密”,还可以自诩“高手”尽情享受强烈的虚荣感--#$%&“醒醒!” 对初学者而言,汇编的许多命令太复杂,往往学习很长时间也写不出一个漂漂亮亮的程序,以致妨碍了我们学习汇编的兴趣,不少人就此放弃。所以我个人看法学汇编,不一定要写程序,写程序确实不是汇编的强项,大家不妨玩玩DEBUG,有时CRACK出一个小软件比完成一个程序更有成就感(就像学电脑先玩游戏一样)。某些高深的指令事实上只对有经验的汇编程序员有用,对我们而言,太过高深了。为了使学习汇编语言有个好的开始,你必须要先排除那些华丽复杂的命令,将注意力集中在最重要的几个指令上(CMP LOOP MOV JNZ……)。但是想在啰里吧嗦的教科书中完成上述目标,谈何容易,所以本人整理了这篇超浓缩(用WINZIP、WINRAR…依次压迫,嘿嘿!)教程。大言不惭的说,看通本文,你完全可以“不经意”间在前辈或是后生卖弄一下DEBUG,很有成就感的,试试看!那么――这个接下来呢?――Here we go!(阅读时看不懂不要紧,下文必有分解) 因为汇编是通过CPU和内存跟硬件对话的,所以我们不得不先了解一下CPU和内存:(关于数的进制问题在此不提) CPU是可以执行电脑所有算术╱逻辑运算与基本I/O控制功能的一块芯片。一种汇编语言只能用于特定的CPU。也就是说,不同的CPU其汇编语言的指令语法亦不相同。个人电脑由1981年推出至今,其CPU发展过程为:8086→80286→80386→80486→PENTIUM →……,还有AMD、CYRIX等旁支。后面兼容前面CPU的功能,只不过多了些指令(如多能奔腾的MMX指令集)、增大了寄存器(如386的32位EAX)、增多了寄存器(如486的FS)。为确保汇编程序可以适用于各种机型,所以推荐使用8086汇编语言,其兼容性最佳。本文所提均为8086汇编语言。寄存器(Register)是CPU内部的元件,所以在寄存器之间的数据传送非常快。用途:1.可将寄存器内的数据执行算术及逻辑运算。2.存于寄存器内的地址可用来指向内存的某个位置,即寻址。3.可以用来读写数据到电脑的周边设备。8086有8个8位数据寄存器,这些8位寄存器可分别组成16位寄存器:AH&AL=AX:累加寄存器,常用于运算;BH&BL=BX:基址寄存器,常用于地址索引;CH&CL=CX:计数寄存器,常用于计数;DH&DL=DX:数据寄存器,常用于数据传递。为了运用所有的内存空间,8086设定了四个段寄存器,专门用来保存段地址:CS(Code Segment):代码段寄存器;DS(Data Segment):数据段寄存器;SS(Stack Segment):堆栈段寄存器;ES(Extra Segment):附加段寄存器。当一个程序要执行时,就要决定程序代码、数据和堆栈各要用到内存的哪些位置,通过设定段寄存器CS,DS,SS来指向这些起始位置。通常是将DS固定,而根据需要修改CS。所以,程序可以在可寻址空间小于64K的情况下被写成任意大小。所以,程序和其数据组合起来的大小,限制在DS所指的64K内,这就是COM文件不得大于64K的原因。8086以内存做为战场,用寄存器做为军事基地,以加速工作。除了前面所提的寄存器外,还有一些特殊功能的寄存器:IP(Intruction Pointer):指
汇编语言(应用)程序(80X86/Pentium) 设计:乐金松 广东工业大学电子与信息工程学院
;This program for:R0R1-R2R3=R4R5 ;---------------------------------------------------------------- ;define stack segment STACK SEGMENT STACK 'STACK' DB 1024 DUP (0) STACK ENDS ;define data segment DATA SEGMENT R0 DW (?) R1 DW (?) R2 DW (?) R3 DW (?) R4 DW (?) R5 DW (?) R6 DW (?) R7 DW (?) DATA ENDS ;define code segment NDWSUB SEGMENT ; MAIN PROC FAR ASSUME CS:NDWSUB,DS:DATA,SS:STACK ; START: PUSH DS ;return DOS standard program MOV AX,0 PUSH AX MOV AX,DATA ;set DS MOV DS,AX MOV AX,R1 SUB AX,R3 MOV R5,AX MOV AX,R0 SBB AX,R2 MOV R4,AX RET MAIN ENDP NDWSUB ENDS END START
;This program for:R0R1+R2R3=R4R5 ;---------------------------------------------------------------- ;define stack segment STACK SEGMENT STACK 'STACK' DB 1024 DUP (0) STACK ENDS ;define data segment DATA SEGMENT R0 DW (?) R1 DW (?) R2 DW (?) R3 DW (?) R4 DW (?) R5 DW (?) R6 DW (?) R7 DW (?) DATA ENDS ;define code segment NDWADD SEGMENT ; MAIN PROC FAR ASSUME CS:NDWADD,DS:DATA,SS:STACK ; START: PUSH DS ;return DOS standard program MOV AX,0 PUSH AX MOV AX,DATA MOV DS,AX MOV AX,R1 ADD AX,R3 MOV R5,AX MOV AX,R0 ADC AX,R2 MOV R4,AX RET MAIN ENDP ;end process NDWADD ENDS ;end segment END START
Knowledge 问题 谁在DSP的汇编语言中加入了NOP指令? NOP指令加入的条件是什么? About DSP 1.DSP是实时数字信号处理的核心和标志。 2.DSP分为专用和通用两种类型。专用DSP一般采用定点数据结构(一般不支持小数), 数据结构简单,处理速度快;通用DSP灵活性好,但是处理速度有所降低。 3.DSP采用取指、译码、执行三个阶段的流水线(Pipeline)技术,缩短了执行时间,提高了 运行速率。DSP具有8个Functional unit,如果并行处理的话,以600MHz的时钟计算,如果执行的指令是single cycle指令,则可以4800MIPS(指令每秒)。 4.DSP的8个functional Unit,具有独特的功能,对滤波、矩阵运算、FFT(傅里叶变换) 具有 哈弗结构 把指令空间与数据空间隔离的存储方式。 这样实现是为了实现指令的连续读取,而实现pipeline流水线结构。 传统哈弗结构:两个独立的存储空间,还使用独立总线。让取指与执行存储独立,加快执行速度。 改进型哈弗结构:指令与数据的存储空间还是独立的。但是使用公共的总线(地址总线与数据总线)。这样实现的原因是因为出现了CACHE,数据的存储动作大部分被内部的CACHE 总线承接了,所以总线冲突的情况会大大减少。同时让总线的结构与控制变得简单,CACHE 存储的速度也明显快于外设存储器。 冯诺依曼结构:是指令空间与数据空间共享的存放方式。它不能实现pipeline的执行过程。 Pipeline(流水线)技术 是把指令的取指-译码和指令的执行独立开来的技术。虽然每条指令的过程还是要经过取指-译码-执行三个阶段最少3个CPU Cycle。但是多个指令同时并行先后进行,保证总体的指
阅读反汇编后的汇编程序挺麻烦,尤其是在c语言程序的子函数参数中有数组参数,同时当子函数里有循环操作时,反汇编后的代码中频繁出现ptr指令操作。该指令的用法十分灵活,有时候读入(或写入)的是某内存地址,有时候读入(写入)的是某内存地址中存储的值,初学时总感觉很迷惑,分不清什么时候读内存地址,什么时候读内存地址中值,参考相关文献和书籍后作如下总结。 例如一段简单的C语言程序: int mywork(int a[9], int b[9], int c[9]) { int i; for ( i=0; i<9; i++) c[i] =a[i] +b[i]; } 这段代码debug版反汇编后代码很简单,但是里面有许多小细节值得推敲。 int mywork(int a[9], int b[9], int c[9]) ;原c代码 … … ;这里为开始调用函数时当前寄存器数据保存 for ( i = 0 ; i < 9 ; i ++) mov dword ptr [i], 0;这里为i初始化,值为0 jmp mywork+xx1h ;进入循环体内部 mov eax, dword ptr [i]; add eax, 1 mov dword ptr [i], eax mywork+xx1h:cmp dword ptr [i], 9 jge mywork+xx2h ;如果i等于或大于9,跳出循环 c[i] =a[i] +b[i]; mov eax, dowrd ptr [i] ;读入参数i mov ecx, dword ptr [a] ;这里是读入参数数组a的首地址 mov edx, dword ptr [b] ;这里是读入参数数组b的首地址 mov eax, dword ptr [ecx + eax*4] ;读入a add eax, dword ptr [edx +eax*4] ; eax = a[i]+b[i] mov edi, dword ptr [c] ;这里是读入参数数组c的首地址 mov dword ptr [edi+ eax*4], eax ;这里保存计算结果,c[i]= a[i]+b[i] inc eax jmp mywork+xx1h mywork+xx2h: … … ;一些数据恢复操作,主要是出栈等 ret 文中用红色标记处两处涉及ptr指令的地方。 第一处为mov eax, dword ptr [i] 本条mov指令的结果是将变量i的值读入到eax寄存器中,至于从i变量存储地址处读取几个字节,由dword修饰符指定(4个字节)。 第二处为mov ecx, dword ptr [a] 这里表示将参数数组a的首地址读入到ecx寄存器中。 同样两个mov 寄存器, dword ptr [变量]操作,为何第一个寄存器eax读入数值,而第二个ecx寄存器读入的为地址呢?
GPIOB_BASE是一个地址,这个地址是GPIOB一系列寄存器的首地址,后面地址依次是GPIOB 的寄存器,将这个地址转换为结构体形式,并将后面寄存器按顺序定义在结构体里面,这样访问寄存器就可以通过引用结构体的形式了而不必书写寄存器的地址来访问寄存器。 寄存器用途: 1.可将寄存器内的数据执行算术及逻辑运算; 2.存于寄存器内的地址可用来指向内存的某个位置,即寻址; 3.可以用来读写数据到电脑的周边设备。 AX 累加器,得名原因是最初常使用ADD AX,n这样的指令 CX 计数器,得名原因是最常使用CX的值作为重复操作的次数 BX 常用作地址寄存器,如MOV AX,[BX],把BX所指地址中的数取到AX中去 DX 通用寄存器 所讲的寄存器都是以x86为基础的,那么这种CPU内,寄存器可分为以下几种: 1.EAX、EBX、ECX、EDX等通用寄存器——从通用上来讲,它所存储的东西,只要它的容积所容许的话,什么都是可以存储的; 2.CS、SS、ES等段寄存器——它所存储的只能是地址,它的作用是从寻址上可以体现出来; 3.EIP,也称为指令指针 4.EFLAGS寄存器,俗称为标志寄存器——所存储的是与CPU的每一个执行的指令有关。是关系到CPU每一个指令的执行相关内容与特殊的关联,即CPU所执行的指令是否违规,它的指令是否有进位,它的指令是否有溢出,都是在标志寄存器中能表现与表达出来; 5.浮点单元,这里面之所以只浮点单元,是因为在它里面还有一些小的寄存分类,主要是数学上的浮点上的计算 6.MMX指令使用的8个64位寄存器 7.单指令、多数据操作(SIMD,single-instruction,multiple-data)使用的8个128位XMM寄存器
汇编语言入门教程 对初学者而言,汇编的许多命令太复杂,往往学习很长时间也写不出一个漂漂亮亮的程序,以致妨碍了我们学习汇编的兴趣,不少人就此放弃。所以我个人看法学汇编,不一定要写程序,写程序确实不是汇编的强项,大家不妨玩玩DEBUG,有时CRACK出一个小软件比完成一个程序更有成就感(就像学电脑先玩游戏一样)。某些高深的指令事实上只对有经验的汇编程序员有用,对我们而言,太过高深了。为了使学习汇编语言有个好的开始,你必须要先排除那些华丽复杂的命令,将注意力集中在最重要的几个指令上(CMP LOOP MOV JNZ……)。但是想在啰里吧嗦的教科书中完成上述目标,谈何容易,所以本人整理了这篇超浓缩(用WINZIP、WINRAR…依次压迫,嘿嘿!)教程。大言不惭的说,看通本文,你完全可以“不经意”间在前辈或是后生卖弄一下DEBUG,很有成就感的,试试看!那么――这个接下来呢?――Here we go!(阅读时看不懂不要紧,下文必有分解) 因为汇编是通过CPU和内存跟硬件对话的,所以我们不得不先了解一下CPU和内存:(关于数的进制问题在此不提) CPU是可以执行电脑所有算术╱逻辑运算与基本I/O 控制功能的一块芯片。一种汇编语言只能用于特定的CPU。也就是说,不同的CPU其汇编语言的指令语法亦不相同。个人电脑由1981年推出至今,其CPU发展过程为:8086→80286→80386→80486→PENTIUM →……,还有AMD、CYRIX等旁支。后面兼容前面CPU的功能,只不过多了些指令(如多能奔腾的MMX指令集)、增大了寄存器(如386的32位EAX)、增多了寄存器(如486的FS)。为确保汇编程序可以适用于各种机型,所以推荐使用8086汇编语言,其兼容性最佳。本文所提均为8086汇编语言。寄存器(Register)是CPU内部的元件,所以在寄存器之间的数据传送非常快。用途:1.可将寄存器内的数据执行算术及逻辑运算。2.存于寄存器内的地址可用来指向内存的某个位置,即寻址。3.可以用来读写数据到电脑的周边设备。8086 有8个8位数据寄存器,这些8位寄存器可分别组成16位寄存器:AH&AL=AX:累加寄存器,常用于运算;BH&BL=BX:基址寄存器,常用于地址索引;CH&CL=CX:计数寄存器,常用于计数;DH&DL=DX:数据寄存器,常用于数据传递。为了运用所有的内存空间,8086设定了四个段寄存器,专门用来保存段地址:CS(Code Segment):代码段寄存器;DS(Data Segment):数据段寄存器;SS(Stack Segment):堆栈段寄存器;ES(Extra Segment):附加段寄存器。当一个程序要执行时,就要决定程序代码、数据和堆栈各要用到内存的哪些位置,通过设定段寄存器CS,DS,SS 来指向这些起始位置。通常是将DS固定,而根据需要修改CS。所以,程序可以在可寻址空间小于64K的情况下被写成任意大小。所以,程序和其数据组合起来的大小,限制在DS 所指的64K内,这就是COM文件不得大于64K的原因。8086以内存做为战场,用寄存器做为军事基地,以加速工作。除了前面所提的寄存器外,还有一些特殊功能的寄存器:IP(Intruction Pointer):指令指针寄存器,与CS配合使用,可跟踪程序的执行过程;SP(Stack Pointer):堆栈指针,与SS配合使用,可指向目前的堆栈位置。BP(Base Pointer):基址指针寄存器,可用作SS 的一个相对基址位置;SI(Source Index):源变址寄存器可用来存放相对于DS段之源变址指针;DI(Destination Index):目的变址寄存器,可用来存放相对于ES 段之目的变址指针。还有一个标志寄存器FR(Flag Register),有九个有意义的标志,将在下文用到时详细说明。 内存是电脑运作中的关键部分,也是电脑在工作中储存信息的地方。内存组织有许多可存放
ARM汇编指令集: 指令:汇编指令是CPU机器指令的助记符,经过编译后会得到一串1、0组成的机器码,可以由CPU读取执行 伪指令:在编译过程中间起作用,用来指导编译过程,经过编译后不会生成机器码 ***ARM汇编特点1:LDR/STR架构:在RISC架构中,cpu读写内存需要通过CPU内部的寄存器(CISC的CPU可以直接和内存通信) ***ARM汇编特点2:8中寻址方式 #寄存器寻址mov r1,r2 把r2里面的内容送到r1里面去(寄存器靠名字找的) #立即寻址(立即数)mov r0,#0xFF00 加#表示数字 #寄存器移位寻址mov r0, r1, lsl #3 lsl左移指令,把r1的值左移三位,然后把左移后生成的那个数赋值给r0 #寄存器间接寻址ldr r1, [r2] [r2]表明内存地址存在r2中,然后把内存地址里面存储的那个值赋给r1 基址变址寻址ldr r1, [r2, #4] [r2,#4]中存储的地址为r2中的地址+4构成的地址,r2里面存储的地址称为基地址,后面的数字就是需要的变址数这条指令的意思:把r2存储的内存地址加4的地址的值赋值给r1 #多寄存器寻址ldmia r1!, {r2-r7, r12} 一次访问多个寄存器//////r1放的内存地址,把r1理解为数组,r2-r7,r12表示7个寄存器,这句指令的意思就是:r1当中存储的内存地址为基地址,然后把从这个地址开始的连续七个地址当中存储的值,依次放在后面对应的寄存器中 #堆栈寻址stmfd sp!, {r2-r7, lr} #相对寻址beq flag flag:标号 ***ARM汇编特点3:指令后缀 同一指令经常附带不同后缀,变成不同的指令。经常使用的后缀有: B(byte)功能不变,操作长度变为8位 H(half word)功能不变,长度变为16位 S(signed)功能不变,操作数变为有符号 如ldr ldrb ldrh ldrsb ldrsh S(S标志)功能不变,影响CPSR标志位一般用在数据传输指令 如mov和movs movs r0, #0 ***ARM汇编特点4:条件执行后缀 mov r0,r1 @相当于C语言的r0 = r1 moveq r0,r1 @如果eq后缀成立,则执行本句指令,反之,则不执行 条件后缀执行注意两点: 1.条件后缀是否成立,不是取决于本句代码,而是取决于这句代码之前的代码运行后的结果 2.条件后缀决定了本句代码是否会执行,而不会影响上一句或下一句代码是否会执行 ***ARM汇编特点5:多级指令流水线 pc指向正在被取指的指令,而非正在执行的指令
ARM 处理器有二十七个寄存器,其中一些是在一定条件下使用的,所以一次只能使用十六 个。 R0~R7:是通用寄存器并可以用做任何目的。 R8~R12:是通用寄存器,但是在切换到FIQ模式的时候,使用它们的影子(shadow)寄存器。 R13:被称为栈指针寄存器,常用来保存栈指针。 R14:链接寄存器,常用来保存函数返回地址 R15:是程序指针PC CPSR:(Current Program Status Register)当前程序状态寄存器,CPSR 寄存期保存当前程序运行的状态。 0 0 0 0 0 User26 模式 0 0 0 0 1 FIQ26 模式 0 0 0 1 0 IRQ26 模式 0 0 0 1 1 SVC26 模式 1 0 0 0 0 User 模式 1 0 0 0 1 FIQ 模式 1 0 0 1 0 IRQ 模式 1 0 0 1 1 SVC 模式 1 0 1 1 1 ABT 模式 1 1 0 1 1 UND 模式
ARM寻址方式 1.立即数寻址 ARM 指令的立即数寻址是一种特殊的寻址方式,操作数本身就在指令中给出,只要取出指令也就取到了操作数。这个操作数被称为立即数。ADD R0,R0,#1 ;R0←R0 + 1 ADD R0,R0,#0x3A ;R0←R0 + 0x3A 在以上 2 条指令中,第2个源操作数即为立即数,实际使用时以“#”符
号为前缀。 2.寄存器寻址 寄存器寻址就是利用寄存器中的数值作为操作数,这种寻址方式是各类微处理器经常采 用的一种方式,也是一种执行效率较高的寻址方式。如以下的指令。 ADD R0,R1,R2 ;R0←R1 + R2 该指令的执行效果是将寄存器R1和R2的内容相加,其结果存放在寄存器R0中。 3.寄存器间接寻址 寄存器间接寻址就是以寄存器中的值作为操作数的地址,而操作数本身存放在存储器 中。例如以下指令。 ADD R0,R1,[R2] ;R0←R1 + [R2] LDR R0,[R1] ;R0←[R1] 在第1 条指令中,以寄存器R2 的内容作为操作数的地址,然后与R1相加,其结果存入 寄存器R0中。 第2条指令将以 R1 的值为地址的存储器中的内容送到寄存器R0中。 4.基址变址寻址 基址变址的寻址方式就是将寄存器(该寄存器一般称作基址寄存器)的内容与指令中给 出的地址偏移量相加,从而得到一个操作数的有效地址。如下面的几条指令所示。 LDR R0,[R1,#0x0A] ;R0←[R1 + 0x0A] LDR R0,[R1,#0x0A]!;R0←[R1 + 0x0A]、R1←R1 + 0x0A 在第1条指令中,将寄存器R1 的内容加上0x3A 形成操作数的有效地址,将该地址处的 操作数送到寄存器R0中。 在第2条指令中,将寄存器R1的内容加上0x0A形成操作数的有效地址,从而取得操作数存入寄存器R0中,然后,R1的内容自增0x0A个字节。 5.多寄存器寻址 采用多寄存器寻址方式,一条指令可以完成多个寄存器值的传送。这种寻址方式可以用 一条指令完成传送最多 16 个通用寄存器的值。比如下面的指令。LDMIA R0,{R1,R2,R3,R4} ;R1←[R0] ;R2←[R0 + 4]
汇编语言基本关键字 aaa对非压缩BCD码加法之和调整 aas 对非压缩BCD码减法之差调整 aam乘法调整aad被除数调整 add不带进位标志位的加法adc带进位标志位的加法 and逻辑与 assume指定段寄存器 bswap双字单操作数内部交换 bt位测试bts位测试并置一 btr位测试并清零btc位测试并取反 bsf/bsr正,反向位扫描 call调用 cbw字节转换为字cwd字转换为双字cwde字转换为扩展的双字cdq双字转换为四字 cmp比较cmpxchg比较并交换 cmps串比较 code定义简化代码段 const定义简化常数数据段 daa对压缩BCD码加法之和调整das对压缩BCD码减法之差调整 data定义简化数据段 db/dw/dd/dq/dt定义字节/字/双字/四字/十字变量 dec减一
df定义32位便宜地址的远地址指针 div无符号数除法 equ等价textequ文本等价 even取偶偏移地址 fardata,fardata定义简化独立数据段 group定义段组 idiv有符号整数除法 imul有符号整数乘法 in输入 inc加一 ins/outs输入/输出串元素 jcxz/jecxz若cx=0/ecx=0,跳转 jmpdopd无条件跳转到DOPD 处取出指令继续执行 label为$定义符号 Lahf 标志位低八位送AH lea 偏移地址送通用寄存器lda传送进入数据段的地址指针 les传送进入附加数据段的地址指针lfs传送进入FS段的地址指针lgs传送进入GS段的地址指针lss传送进入堆栈段的地址指针 local说明局部变量 lods读出串元素 Loop/loopd无条件循环cx/ecx为循环次数 loopnz/loopnzd非零或不等时循环,cx/ecx为循环次数
汇编语言学习笔记之通用寄存器 从昨天开始,正式拉开了学习汇编语言的序幕,对于汇编语言的一些特点以及数据的表示及类型做了一番了解,由于这些东西每一种语言里都要介绍,而且一时半会也真弄不太明白它们的具体使用,也就粗略的看了一下,留待在今后的学习中结合实例加以体会吧。 而通用寄存器应该说是CPU内部重要的数据存储资源,学习汇编语言必须要掌握清它们的功能。因此汇编语言学习的第一篇学习笔记就从通用寄存器开始了。以下内容摘自汇编教程中。 寄存器是CPU内部重要的数据存储资源,是汇编程序员能直接使用的硬件资源之一。由于寄存器的存取速度比内存快,所以,在用汇编语言编写程序时,要尽可能充分利用寄存器的存储功能。 寄存器一般用来保存程序的中间结果,为随后的指令快速提供操作数,从而避免把中间结果存入内存,再读取内存的操作。在高级语言(如:C/C++语言)中,也有定义变量为寄存器类型的,这就是提高寄存器利用率的一种可行的方法。 另外,由于寄存器的个数和容量都有限,不可能把所有中间结果都存储在寄存器中,所以,要对寄存器进行适当的调度。根据指令的要求,如何安排适当的寄存器,避免操作数过多的传送操作是一项细致而又周密的工作。有关“寄存器的分配策略”在后续课程《编译原理》中会有详细的介绍。 由于16位/32位CPU是微机CPU的两个重要代表,所以,在此只介绍它们内部寄存器的名称及其主要功能。 1、16位寄存器组 16位CPU所含有的寄存器有: 4个数据寄存器(AX、BX、CX和DX), 2个变址和指针寄存器(SI和DI), 2个指针寄存器(SP和BP) 4个段寄存器(ES、CS、SS和DS), 1个指令指针寄存器(IP), 1个标志寄存器(Flags) 2、32位寄存器组 32位CPU除了包含了先前CPU的所有寄存器,并把通用寄存器、指令指针和标志寄存器从16位扩充成32位之外,还增加了2个16位的段寄存器:FS 和GS。 32位CPU所含有的寄存器有: 4个数据寄存器(EAX、EBX、ECX和EDX), 2个变址和指针寄存器(ESI和EDI), 2个指针寄存器(ESP和EBP) 6个段寄存器(ES、CS、SS、DS、FS和GS),
实验二通用寄存器实验 一、实验目的 1.熟悉通用寄存器的数据通路。 2.了解通用寄存器的构成和运用。 二、实验要求 掌握通用寄存器R3~R0的读写操作。 三、实验原理 实验中所用的通用寄存器数据通路如下图所示。由四片8位字长的74LS574组成R1 R0(CX)、R3 R2(DX)通用寄存器组。图中X2 X1 X0定义输出选通使能,SI、XP控制位为源选通控制。RWR为寄存器数据写入使能,DI、OP为目的寄存器写选通。DRCK信号为寄存器组打入脉冲,上升沿有效。准双向I/O输入输出端口用于置数操作,经2片74LS245三态门与数据总线相连。 图2-3-3 通用寄存器数据通路
四、实验内容 1. 实验连线 K23~K0置“1”,灭M23~M0控位显示灯。然后按下表要求“搭接”部件控制电路。 连线 信号孔 接入孔 作用 有效电平 1 DRCK CLOCK 单元手动实验状态的时钟来源 上升沿打入 2 X2 K10(M10) 源部件译码输入端X2 三八译码 八中选一 低电平有效 3 X1 K9(M9) 源部件译码输入端X1 4 X0 K8(M8) 源部件译码输入端X0 5 XP K7(M7) 源部件奇偶标志:0=偶寻址,1=奇寻址 6 SI K20(M20) 源寄存器地址:0=CX ,1=DX 7 RWR K18(M18) 通用寄存器写使能 低电平有效 8 DI K17(M17) 目标寄存器地址:0=CX ,1=DX 9 OP K16(M16) 目标部件奇偶标志:0=偶寻址,1=奇寻址 2. 寄存器的读写操作 ① 目的通路 当RWR=0时,由DI 、OP 编码产生目的寄存器地址,详见下表。 通用寄存器“手动/搭接”目的编码 目标使能 通用寄存器目的编址 功能说明 RW(K18) DI(K17) OP(K16) T 0 0 0 ↑ R0写 0 0 1 ↑ R1写 0 1 0 ↑ R2写 0 1 1 ↑ R3写 ② 通用寄存器的写入 通过“I/O 输入输出单元”向R0、R1寄存器分别置数27h 、37h ,操作步骤如下: 通过“I/O 输入输出单元”向R2、R3寄存器分别置数47h 、57h ,操作步骤如下: ③ 源通路 当X2~X0=001时,由SI 、XP 编码产生源寄存器,详见下表。 通用寄存器“手动/搭接”源编码 置数 I/O=XX01h 数据来源 I/O 单元 寄存器 R0=01h K10~K7=1000 按【单拍】按钮 置数 I/O=XX11h 寄存器 R1=11h 按【单拍】按钮 K18~K16=000 K18~K16=001 置数 I/O=XX21h 数据来源 I/O 单元 寄存器 R2=21h K10~K7=1000 按【单拍】按钮 置数 I/O=XX31h 寄存器 R3=31h 按【单拍】按钮 K18~K16=010 K18~K16=011
汇编语言基础知识 汇编语言是直接在硬件之上工作的编程语言,首先要了解硬件系统的结构,才能有 效地应用汇编语言对其编程,因此,本章对硬件系统结构的问题进行部分探讨,首先介绍了计算机的基本结构、Intel 公司微处理器的发展、计算机的语言以及汇编语言的特点,在此基础上重点介绍寄存器、内存组织等汇编语言所涉及到的基本知识。 1.1 微型计算机概述 微型计算机由中央处理器(Central Processing Unit ,CPU )、存储器、输入输出接口电路和总线构成。CPU 如同微型计算机的心脏,它的性能决定了整个微型计算机的各项关键指标。存储器包括随机存储器(Random Access Memory ,RAM )和只读存储器(Read Only Memory ,ROM )。输入输出接口电路用来连接外部设备和微型计算机。总线为CPU 和其他部件之间提供数据、地址和控制信息的传输通道。如图1.1所示为微型计算机的基本结构。 外部设备存储器输入输出接口电路中央处理器 CPU 地址总线 数据总线 控制总线 图1.1 微型计算机基本结构 特别要提到的是微型计算机的总线结构,它使系统中各功能部件之间的相互关系变 为各个部件面向总线的单一关系。一个部件只要符合总线结构标准, 就可以连接到采用这种总线结构的系统中,使系统功能得到扩展。 数据总线用来在CPU 与内存或其他部件之间进行数据传送。它是双向的,数据总线 的位宽决定了CPU 和外界的数据传送速度,8位数据总线一次可传送一个8位二进制数据(即一个字节),16位数据总线一次可传送两个字节。在微型计算机中,数据的含义是广义的,数据总线上传送的不一定是真正的数据,而可能是指令代码、状态量或控制量。 地址总线专门用来传送地址信息,它是单向的,地址总线的位数决定了 CPU 可以直接寻址的内存范围。如 CPU 的地址总线的宽度为N ,则CPU 最多可以寻找2N 个内存单 元。
一、计算X+Y=Z,将结果Z存入某存储单元。 (1). 实验程序如下: STACK SEGMENT STACK DW 64 DUP(?) STACK ENDS DATA SEGMENT XL DW ? ;请在此处给X低位赋值 XH DW ? ;请在此处给X高位赋值 YL DW ? ;请在此处给Y低位赋值 YH DW ? ;请在此处给Y高位赋值 ZL DW ? ZH DW ? DATA E NDS CODE S EGMENT ASSUME CS:CODE,DS:DATA START: MOV AX,DATA MOV DS,AX MOV AX,XL ;X低位送AX ADD AX,YL ;X低位加Y低位 MOV ZL,AX ;存低位和 MOV AX,XH ;X高位送AX ADC AX,YH ;X高位加Y高位 MOV ZH,AX A1: JMP A1 CODE E NDS END START 二、计算X-Y=Z,其中X、Y、Z为BCD码。实验程序及流程如下:STACK SEGMENT STACK DW 64 DUP(?) STACK ENDS DATA SEGMENT X DW ? ;请在此处给X赋值 Y DW ? ;请在此处给Y赋值 Z DW ? DATA ENDS CODE SEGMENT ASSUME CS:CODE,DS:DATA START: MOV AX,DATA MOV DS,AX MOV AH,00H SAHF MOV CX,0002H LEA SI, X LEA DI, Z A1: MOV AL,[SI] SBB AL,[SI+02H] DAS PUSHF AND AL,0FH
汇编语言符号和教材符号汇总 (8088/8086 IBM PC计算机) --学习笔记" "∶教材符号 +、-、*、/∶算术运算符。 &∶宏处理操作符。宏扩展时不识别符号和字符串中的形式参数,如果在形式参数前面加上一个& 记号,宏汇编程序就能够用实在参数代替这个形式参数了。 $∶地址计数器的值——记录正在被汇编程序翻译的语句地址。每个段均分配一个计数器,段内定义的所有标号和变量的偏移地址就是当前汇编地址计数器的值。 ?∶操作数。在数据定义语句中,操作数用?,其作用是分配并保留存储空间,但不存入确定的数据。 =∶等号伪指令——符号定义。对符号进行定义和赋值,功能与EQU相似,但允许(重复)再定义。 :∶修改属性运算符(操作符)——段操作符。用来临时给变量、标号或地址表达式指定一个段属性(不用缺省的段寄存器),自动生成一个“跨段前缀字节”。注意,段寄存器CS和ES不能被跨越,堆栈操作时也不能跨越SS。 ;∶注释符号。 %∶特殊宏操作符,用来将其后的表达式(通常是符号常数,不能是变量名和寄存器名)转换成它所代表的数值,并将此数值的ASCII码嵌入到宏扩展中。 ( )∶1.运算符——用来改变运算符的优先级别。2.教材符号,表示括号内存储单元(或寄存器)的内容。 < >∶宏调用时用来将带间隔符(如空格,逗号等)的字符串(作为实参)括起来。 ∶运算符。方括号括起来的数是数组变量的下标或地址表达式。带方括号的地址表[ ] 1. ② 达式必须遵循下列原则,①只有BX、BP、SI、DI这四个寄存器可在方括号内出现;BX 或BP可单独出现在各方括号中,也可以与常数、SI或DI一起出现在方括号内,但不 ③和DI可以单独出现在各方括号内,也可允许BX和BP出现在同一个方括号内;SI 以与常数、BP或BX一起出现在方括号内,但不允许SI和DI出现在同一个方括号内; ④一个方括号内包含多个寄存器时,它们只能作加法运算;⑤若方括号内包含基址指针BP,则隐含使用堆栈段寄存器SS提供段基址,否则均隐含使用数据段寄存器DS提供段基址。2.教材符号,表示其中的内容可省略。
AMR寄存器的别名+ APCS 默认情况下,arm处理器中的通用寄存器被称为:r0、r1...r14等,在APCS中为arm通用寄存器定义了别名。 在某些情况下(比如多人协作编辑汇编代码,或需要修改其它人所写的汇编代码时),使用APCS所定义的别名有助于提高代码的可读性和兼容性。 arm通用寄存器及其别名对照表:
The following register names are predeclared: r0-r15 and R0-R15 a1-a4 (argument, result, or scratch registers, synonyms for r0 to r3) v1-v8 (variable registers, r4 to r11) sb and SB (static base, r9) ip and IP (intra-procedure-call scratch register, r12) sp and SP (stack pointer, r13) lr and LR (link register, r14) pc and PC (program counter, r15). arm中r12的用途 原文作者在维护1个以前的程序,该程序包括应用、库文件以及linux device driver。该程序原来使用arm-linux-gcc 3.4.3编译,现在改用arm-linux-gcc 4.1.1进行编译时发现程序无法运行。 经原文作者测试,发现当使用shared library形式编译程序后无法运行,而使用static linking形式编译程序后可正常运行。
8086/8088汇编指令小结 一、数据传送指令; 二、算术指令; 三、逻辑指令; 四、串处理指令; 五、控制转移指令; 六、处理机控制指令。 (详情见全文) 一、数据传送指令 1.通用数据传送指令 MOV(Move)传送 PUSH(Push onto the stack)进栈 POP(Pop from the stack)出栈 XCHG(Exchange)交换 .MOV指令 格式为: MOV DST,SRC 执行的操作:(DST)<-(SRC) .PUSH进栈指令 格式为:PUSH SRC 执行的操作:(SP)<-(SP)-2 ((SP)+1,(SP))<-(SRC) .POP出栈指令 格式为:POP DST 执行的操作:(DST)<-((SP+1),(SP)) (SP)<-(SP)+2 .XCHG 交换指令 格式为:XCHG OPR1,OPR2 执行的操作:(OPR1)<-->(OPR2) 2.累加器专用传送指令 IN(Input) 输入 OUT(Output) 输出 XLAT(Translate) 换码 这组指令只限于使用累加器AX或AL传送信息. .IN 输入指令 长格式为: IN AL,PORT(字节) IN AX,PORT(字) 执行的操作: (AL)<-(PORT)(字节)
(AX)<-(PORT+1,PORT)(字) 短格式为: IN AL,DX(字节) IN AX,DX(字) 执行的操作: AL<-((DX))(字节) AX<-((DX)+1,DX)(字) .OUT 输出指令 长格式为: OUT PORT,AL(字节) OUT PORT,AX(字) 执行的操作: (PORT)<-(AL)(字节) (PORT+1,PORT)<-(AX)(字) 短格式为: OUT DX,AL(字节) OUT DX,AX(字) 执行的操作: ((DX))<-(AL)(字节) ((DX)+1,(DX))<-AX(字) 在IBM-PC机里,外部设备最多可有65536个I/O端口,端口(即外设的端口地址)为0000~FFFFH.其中前256个端口(0~FFH)可以直接在指令中指定,这就是长格式中的PORT,此时机器指令用二个字节表示,第二个字节就是端口号.所以用长格式时可以在指定中直接指定端口号,但只限于前256个端口.当端口 号>=256时,只能使用短格式,此时,必须先把端口号放到DX寄存器中(端口号可以从0000到0FFFFH),然后再用IN或OUT指令来传送信息. .XLAT 换码指令 格式为: XLAT OPR 或: XLAT 执行的操作:(AL)<-((BX)+(AL)) 3.有效地址送寄存器指令 LEA(Load effective address)有效地址送寄存器 LDS(Load DS with Pointer)指针送寄存器和DS LES(Load ES with Pointer)指针送寄存器和ES .LEA 有效地址送寄存器 格式为: LEA REG,SRC 执行的操作:(REG)<-SRC 指令把源操作数的有效地址送到指定的寄存器中. .LDS 指针送寄存器和DS指令 格式为: LDS REG,SRC 执行的操作:(REG)<-(SRC) (DS)<-(SRC+2) 把源操作数指定的4个相继字节送到由指令指定的寄存器及DS寄存器中.该指令常指定SI寄存器. .LES 指针送寄存器和ES指令 格式为: LES REG,SRC 执行的操作: (REG)<-(SRC) (ES)<-(SRC+2) 把源操作数指定的4个相继字节送到由指令指定的寄存器及ES寄存器中.该
一、寄存器 总共有14个16位寄存器,8个8位寄存器 通用寄存器: 数据寄存器: AH(8位) AL(8位) AX(16位) (AX和AL又称累加器) BH(8位) BL(8位) BX(16位) (BX又称基址寄存器,唯一作为存储器指针使用寄存器) CH(8位) CL(8位) CX(16位) (CX用于字符串操作,控制循环的次数,CL 用于移位) DH(8位) DL(8位) DX(16位) (DX一般用来做32位的乘除法时存放被除数或者保留余数) 指针寄存器: SP 堆栈指针(存放栈顶地址) BP 基址指针(存放堆栈基址偏移) 变址寄存器:主要用于存放某个存储单元地址的偏移,或某组存储单元开始地址的偏移, 即作为存储器(短)指针使用。作为通用寄存器,它们可以保存16位算术逻辑运算中的操 作数和运算结果,有时运算结果就是需要的存储单元地址的偏移. SI 源地址(源变址寄存器) DI 目的地址(目的变址寄存器) 控制寄存器: IP 指令指针 FLAG 标志寄存器 ①进位标志CF,记录运算时最高有效位产生的进位值。
②符号标志SF,记录运算结果的符号。结果为负时置1,否则置0。 ③零标志ZF,运算结果为0时ZF位置1,否则置0。 ④溢出标志OF,在运算过程中,如操作数超出了机器可表示数的范围称为溢出。溢出时OF位置1,否则置0。 ⑤辅助进位标志AF,记录运算时第3位(半个字节)产生的进位值。 ⑥奇偶标志PF,用来为机器中传送信息时可能产生的代码出错情况提供检验条件。当结果操作数中1的个数为偶数时置1,否则置0。 段寄存器 CS 代码段IP DS 数据段 SS 堆栈段SP BP ES 附加段 二、七种寻址方式: 1、立即寻址方式: 操作数就包含在指令中。作为指令的一部分,跟在操作码后存放在代码段。 这种操作数成为立即数。立即数可以是8位的,也可以是16位的。 例如: 指令: MOV AX,1234H 则: AX = 1234H 2、寄存器寻址方式: 操作数在CPU内部的寄存器中,指令指定寄存器号。 对于16位操作数,寄存器可以是:AX、BX、CX、DX、SI、DI、SP和BP等。对于8位操作数,寄存器可以是AL 、AH、BL、BH、CL、CH、DL、DH。 这种寻址方式由于操作数就在寄存器中,不需要访问存储器来取得操作数 因而可以取得较高的运算数度。