DB2 HA双机集群
- 格式:docx
- 大小:30.24 KB
- 文档页数:7

Newstart HA 配置技巧NewStart HA是一款支持多种Linux平台的双机高可用软件,具有稳定可靠,简约易用等特性。
在很多电信级服务器中都有用。
本文主要介绍NewStart HA 的典型配置技巧。
Newstart HA提供命令行工具(cli)及web工具配置方式,下面就两种配置方式分别讲述。
为保证配置顺利进行,以下准备工作要提前做好:1.已安装主流linux操作系统(如suse 9/10/11,rehat5/6,cgslv3/v4等);2.两个节点的主机名不能相同;3.两个节点的心跳链路和工作链路的网卡名都要求相同(如nodeA工作链路网卡名为eth0,则nodeB工作链路网卡名必须为eth0),心跳链路建议配2条或以上,工作链路建议做bonding,然后配置好各个网卡的物理IP;4.串口,HA提供串口线组建串口心跳链路,如机子不具备串口设备,可不配,但要保证总的心跳链路数量在两条或以上;5.确定业务的浮动IP地址值;6.共享存储,如使用该类设备,请分别创建好两个节点上的挂载目录;7.两节点已分别安装好业务应用;8.HA安装程序放置服务器上,如果是iso文件,使用二进制方式上传,如果是光盘,把安装光盘放到服务器CDROM中。
HA程序安装:以上准备工作完成后,就可以进行HA的安装,以iso安装文件为例,挂载安装程序到mnt目录,然后进行安装,如:# mount -o loop nsha-3.0.1.07.iso /mnt#/mnt/install安装过程很简单,需注意3个地方已使用粗体标出,粗斜体表示注解。
NewStart HA Installation ProgramVersion: 3.0.1.07Support email: ha-support@1)NewStart HA Server Program and CLI Administrative Tool12)Web-based Administrative Tool (options)(version: 20121101)23)All components34)Cancel说明:1为主程序和cli管理工具,2为web管理工具,3为以上全部组件select the components to be installed [1-4]?3…(过程省略)please enter the SN: 00TB24-FC0TCF-629A1H-B00D46 //试用SN号…(过程省略)Do you want to start web-based administrative tool automatically as a system service? y(es) or n(o)? y //系统启动时是否自动启动Web管理工具…(过程省略)The component(s) is installed completely.主程序及其组件已安装完成,接下来是license的申请,做完这一步HA的安装才算真正完成,操作如下:1、把两台机子上的/etc/ha.d/lic/newstartha.key文件打包(名字区分好,如newstartha.key_node1/2,二进制(bin)方式下载),然后发送到邮箱:ha-support@进行license文件的申请。


新⽀点双机⾼可⽤集群软件NewStartHANewStartHA新⽀点双机⾼可⽤集群软件安装配置⼿册3.02011-08提⽰:安装配置中⽤户输⼊项⽤粗体标出。
第1章安装前准备1.1 HA安装环境准备在开始安装NewStartHA前,请确保下列各项均已准备好。
1.1.1 服务器2台服务器,每台⾄少2块⽹卡;⽤⼀块⽹卡或者bonding做⼯作链路,另外⼀块或者多块⽹卡做⼼跳链路(⽤两条⼼跳链路⽐配成⼀条bonding⼼跳更加可靠)1.1.2 Linux操作系统已安装完成,版本为SuSE 9/SuSE10/SuSE11,RedHat AS3以上或者兼容的系统。
1.1.3 ⽹卡建议全部配置成静态IP,并配置⽹络接⼝的永久命名(即接⼝名和MAC绑定,这是为了避免某些情况下机器重启后⽹卡接⼝名改变,具体参考后⾯的常见问题),⽤作⼯作链路的⽹卡必须配置有静态IP(也称为boot IP)。
1.1.4 业务HA管理的业务软件或者数据库已安装好1.2 HA正式版组件安装光盘⽤户说明书电⼦⽂档见光盘doc⼦⽬录产品授权书包含产品许可号(SN号)第2章安装推荐⽤户上公司⽹站下载安装最新版本(iso⽂件),⽹址见附录2.1安装NewStartHA1、安装软件将NewStartHA的安装CD放⼊服务器的CDROM中执⾏:# mount -o ro /dev/cdrom /mnt挂载光盘到/mnt⼦⽬录如果NewStartHA是iso⽂件,执⾏# mount -o loop xxxx.iso /mnt挂载⽂件到/mnt⼦⽬录# /mnt/install 执⾏安装脚本开始安装1)安装HA产品主程序包和cli命令⾏界⾯2) 安装HA产品WEB管理界⾯3)安装包括1)和2)两部分4)取消安装如果节点安装有旧版本HA,安装过程会提⽰⽤户卸载。
2、常见安装问题Linux系统中,ext2,ext3⽂件系统可以设置⽂件或者⽬录安全属性,即使是root⽤户也⽆法删除或者修改这些⽂件。

群集技术:三款主流服务器集群软件【导读】:在双机热备的架构中,除了要考虑切换时间外,要根据每个系统的作业环境,包括网路系统是单网或是双网,数据库的安装和作业内容及用户端的设备是经由广域网路、区域网路接入不同用户有不同的需求,而要求有不同的切换模式,所以选择不同的切换模式,可以使用户端的改变达到最少的程度。
ROSE HA根据不同的行业及各行业不同的需求设计多种备援模式以弹性的调适用户的最佳组合及选择。
LifeKeeper提供了基于Windows NT (2000),Linux,UNIX多平台操作系统的容错软件并同时支持远程灾难备份LifeKeeper提供数据、应用程序和通信资源的高度可用性。
LanderCluster产品系列包括双节点产品和多节点产品LanderCluster-MN。
主要解决用户关键业务系统的高可用性、可管理性、系统整合、系统配置优化的问题。
1、ROSE HA 服务器集群软件在双机热备的架构中,除了要考虑切换时间外,要根据每个系统的作业环境,包括网路系统是单网或是双网,数据库的安装和作业内容及用户端的设备是经由广域网路、区域网路接入不同用户有不同的需求,而要求有不同的切换模式,所以选择不同的切换模式,可以使用户端的改变达到最少的程度。
ROSE HA根据不同的行业及各行业不同的需求设计多种备援模式以弹性的调适用户的最佳组合及选择。
ROSE HA系统运作方式在正常的运作情形之下,主机之间透过冗余侦测线路互相侦测,当任一主机有错误产生时,ROSE HA提供严谨的判断与分析,确认主机出错之后,才完全启动备援接管动作。
※支持各种操作系统平台※支持众多的UNIX平台(如:IBM、DEC、HP、NCR、SUN、SGI、NEC、SIEMENS等)※支持众多的PC平台的Unix系统(如:SCO/Unix、Solraris X86等)※支持各种数据库:MS-SQL、Oracle 、Informix、Sysbase、Excheng 、Lotus/Nose、DB2等接管动作包括※文件系统( File System)※数据库( Database)※网络地址( IP Address)※应用程序(AP)※系统环境(OS)※容错备援运作过程自动侦测(Auto-Detect)阶段,由主机上的软件通过冗余侦测线,经由复杂的监听程序。
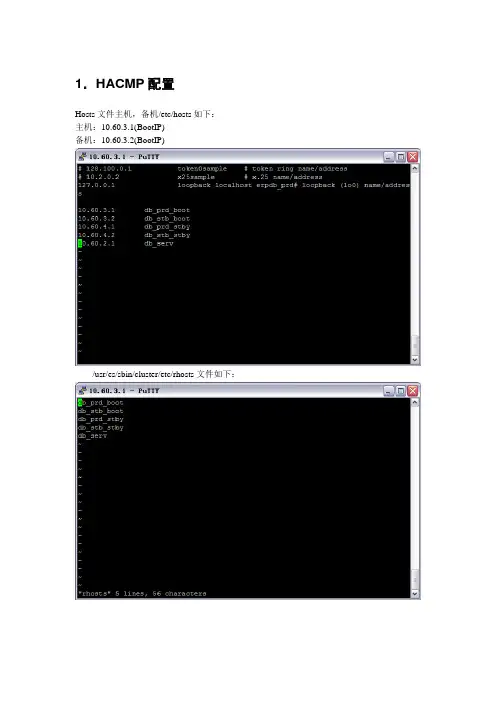
1.HACMP配置Hosts文件主机,备机/etc/hosts如下:主机:10.60.3.1(BootIP)备机:10.60.3.2(BootIP)/usr/es/sbin/cluster/etc/rhosts文件如下:在配置HACMP的过程中设定了两个资源组,分别为appa和appb,其中appa的脚本为:Start Script:/usr/es/sbin/cluster/script/appastart.shStop Script:/usr/es/sbin/cluster/script/appastop.sh资源组appb的脚本如下:Start Script:/usr/es/sbin/cluster/script/appbstart.shStop Script:/usr/es/sbin/cluster/script/appbstop.sh在HACMP的监控中设定了两个监控事件分别为mona,monb,其中mona的脚本为:/usr/es/sbin/cluster/script/db2mon.shCleanup Method为:/usr/es/sbin/cluster/script/appastop.shRestart Method为:/usr/es/sbin/cluster/script/appastart.sh其中时间间隔以及稳定时间建议值如图所示:monb的脚本为:/usr/es/sbin/cluster/script/db2mon2.sh其中时间间隔以及稳定时间建议值如图所示:2.HADR配置2.1HADR准备工作1.安装DB2,更新补丁,版本和主服务器一致2.创建相同的实例erpdbprd,服务端口:50000/usr/opt/db2_08_01/instance/db2icrt -a server -w 64 -p db2c_erpdbprd -u erpfusr erpdbprd3.更新DBM参数:db2 update dbm cfg using TP_MON_NAME CICS4.设置DB2的环境变量db2set DB2_PINNED_BP=YESdb2set AUTOSTART=NOdb2set DB2_HASH_JOIN=ONdb2set DB2COUNTRY=86db2set DB2COMM=TCPIPdb2set DB2CODEPAGE=1386db2set DB2AUTOSTART=NOdb2set DB2_SKIPINSERTED=ONdb2set DB2_EVALUNCOMMITTED=ONdb2set DB2_HADR_BUF_SIZE= N*LOGBUFSZ (N>2)5.恢复DB2数据库,并处于Rollforward Pending状态db2 restore db dberp from /dberpbackup to /dberpdb2 rollforward db erpdb to end of logs通过db2 get db cfg for dberp|grep -i rollforward查看数据库状态,结果是database(rollforward pending)2.2HADR配置工作1.在erpdb_prd和erpdb_stb上配置HADR服务和侦听端口用vi编辑/etc/services文件(需要切换到root用户),加入下面两行:DB2_HADR_1 55001/tcpDB2_HADR_2 55001/tcp2.在ERPDB_PRD上修改主数据库(ERPDB_PRD - DBERP)的配置参数:UPDATE DB CFG FOR DBERP USING LOGINDEXBUILD ONUPDATE DB CFG FOR DBERP USING INDEXREC RESTARTUPDATE DB CFG FOR DBERP USING HADR_LOCAL_HOST erpdb_prdUPDATE DB CFG FOR DBERP USING HADR_LOCAL_SVC DB2_HADR_1UPDATE DB CFG FOR DBERP USING HADR_REMOTE_HOST erpdb_stbUPDATE DB CFG FOR DBERP USING HADR_REMOTE_SVC DB2_HADR_2UPDATE DB CFG FOR DBERP USING HADR_REMOTE_INST erpdbprdUPDATE DB CFG FOR DBERP USING HADR_SYNCMODE NEARSYNCUPDATE DB CFG FOR DBERP USING HADR_TIMEOUT 253.在erpdb_stb上修改备用数据库(erpdb_stb - DBERP)的配置参数:UPDATE DB CFG FOR DBERP USING LOGINDEXBUILD ONUPDATE DB CFG FOR DBERP USING INDEXREC RESTARTUPDATE DB CFG FOR DBERP USING HADR_LOCAL_HOST erpdb_stbUPDATE DB CFG FOR DBERP USING HADR_LOCAL_SVC DB2_HADR_2UPDATE DB CFG FOR DBERP USING HADR_REMOTE_HOST erpdb_prdUPDATE DB CFG FOR DBERP USING HADR_REMOTE_SVC DB2_HADR_1UPDATE DB CFG FOR DBERP USING HADR_REMOTE_INST erpdbprdUPDATE DB CFG FOR DBERP USING HADR_SYNCMODE NEARSYNCUPDATE DB CFG FOR DBERP USING HADR_TIMEOUT 252.3HADR启动1.停止应用2.启动备机HADR#su – erpdbadm$db2start$db2 start hadr on db dberp as standby3.检查HADR是否是standby状态$db2pd –hadr –db dberp4.启动主机HADR$db2start$db2 start hadr on db dberp as primary5.检查HADR是否是peer状态,建议在peer状态后才可以启动HACMP $db2pd –hadr –db dberp6.启动备机HACMP在erpdb_stb机器上,执行#smitty clstart7.启动主机HACMP在erpdb_prd机器上,执行#smitty clstart检查主机HACMP的状态,看serviceIP是否已经工作2.4 HADR停止在停止DB2 HADR之前,需要保证Hadr Primary运行在主机之上,同时Hadr Standby 运行在备机之上。

双机热备产品比较目前双机市场上的产品较多,也比较混乱,对用户来说选择一个比较好的产品十分必要,不但要考虑到产品的功能、还要考虑到产品的后续服务、厂家的支持能力等多方面问题。
下面对市场上的产品进行简单的分类:?Veritas的VCS、Microsoft的MSCS、Legato 的LAAM等产品属于高端产品,价格昂贵(一个双机基本上要多出5万投资),而且系统的维护、实施相当复杂,虽然有不少用户在使用,但真正能够的到厂商支持的,并不多,都处于自行维护状态。
总体上讲,性价比非常的差。
?而NCR的LifeKeeper、Legato 的Co-standby Server市场定位上属于第二集团,他们价格定位在2万左右,但由于是国外产品,同样存在技术支持的问题,而且,目前这两个产品盗版很多,用户常常会无端受害。
对于这样的产品,其定位还是偏高了,因为技术上,这两个产品并无太多可圈可点之处。
?而其他产品就是以Rose为主的台湾品牌,他们包括RoseHA、Dataware等,还有很多不知出处的产品,比如SuperHA、Pluswell、Goldenlife、LHA等,这里面就更加混乱,因为真正能够支持到位的产品很少,因为这些产品除了RoseHA以外,都是以硬件销售为主、或者是OEM的产品。
这些产品有的功能简单,没有开发团队,有的为了推销磁盘阵列而OEM一个,更有的纯粹盗版,用户的合法权利没法保障,其使用双机的目的就是为系统更加可靠,所以在选择产品要注意。
?LanderCluster是完全自主产权的国内产品,由上海联鼎软件技术有限公司研发,在该产品研发推广上,公司投入了超过800万人民币和大量人力,产品从低端到支持高端多节点、小型机平台环境。
是一个产品线非常完整的系列,曾经实现多个国内第一:第一个在SCO OpenServer5上实现银行中间业务系统整合(5节点集群)、第一个在企业ERP关键业务环境/纯光纤环境下实现UnixWare多节点集群、第一个集中管理环境下并支持中文环境的Windows集群。

集群存储软件与双机热备的性能对比集群存储软件是几乎和双机热备一同产生的技术,但是为什么在市场占有率上失去了优势,这是一直都在探究的问题,下面我们就详细的了解下集群存储软件的相关知识。
在双机热备应用方面,有两大类软件产品。
一类是双机软件(HA),另一类则称作集群存储软件(Cluster),这两类软件是有差异的。
它们都是为实现系统的高可用性服务的,都解决了一台服务器出现故障时,由其他服务器接管应用,从而持续可靠地提供服务的问题。
它们都是通过心跳技术在进行系统检测。
但是,双机软件只能支持两台服务器以主从方式或互备方式工作。
而集群存储软件除了支持双机工作外,还可以支持多台服务器(Multi Node)工作,同时部署多个应用,并在多个服务器间灵活地设置接管策略。
在两种情况下需要使用集群存储软件:一是有超过两个应用,本身就需要部署三台或更多的服务器。
二是只有两个应用,但每个应用的负载均较大,不宜采用双机互备的方式,而是需要由第三台服务器来作为这两个应用的备机。
一般地讲,集群存储软件具有更多的技术含量,具备更高的可靠性。
同时,往往价格(平均到每台服务器)也高于双机软件。
在选择产品时,应根据应用的实际情况来确定。
最理想的方式,则是在应用数量少、负载不是很大时先使用双机软件,然后在应用数量增多、负载增大时平滑过渡到集群存储软件。
双机备份和集群的原理与比较什么是双机热备?所谓双机热备就是使用互为备份的两台服务器共同执行同一服务,其中一台主机为工作机(Primary Server),另一台主机为备份机(Standby Server)。
在系统正常情况下,工作机为应用系统提供服务,备份机监视工作机的运行情况(工作机同时也在检测备份机是否正常),当工作机出现异常,不能支持应用系统运营时,备份机主动接管工作机的工作,继续支持关键应用服务,保证系统不间断的运行。
什么情况下需要采用双机热备?用户可以根据系统的重要性以及终端用户对服务中断的容忍程度决定是否使用双机热备。

手把手教你使用Newstart HA什么是newstart HA?有什么作用?如何搭建?如何使用?当我们接触到新的知识时,会带有一系列的疑问,下面我们带着疑问共同探索一番。
HA,全称High Availability(即高可用性),而newstart HA,作为一款实现高可用性的双机集群软件,用于保证业务持续性运行,在大多数对业务持续性运行(N*24小时)要求比较高的企业,如通信行业的企业,经常会用到。
在简单了解一些概念及其作用后,下面详细讲解如何在linux下双机集群搭建和使用。
一、准备工作工欲善其事必先利其器,要在linux系统下高效地搭建及使用newstarth HA,前期工作要准备好。
1、一些概念:●节点:指运行高可用双机集群软件中的计算机。
●工作链路(work link):指集群向外提供服务的链路,从服务器到交换机的链路。
●心跳链路(heartbeat link):维持高可用集群软件内部互联,传送心跳信息的链路。
●服务(service):是与用户应用相关的一组资源的集合,一般包括:管理用户进程资源的应用脚本(application),网络资源,存储资源;譬如说用户的一个 Oracle数据库,该服务包括管理Oracle的脚本(用于启动,关闭和监控), IP地址和所需要 mount的磁盘;服务可以是其中几种或全部资源的组合。
2、硬件(两台物理机子,以下信息相同):●三张网卡:两张网卡做bonding(工作链路),一张网卡做心路链路(要保证心跳链路总数不少于2条)●串口:组串口心跳链路,加上上面网口心跳链路,达到2条●磁阵:存放共享数据,建议从中划分一个30~50M的分区用于组建仲裁盘(保障数据安全性的一种机制,可选但推荐,这里为/dev/sdb1)3、软件:●操作系统sles11,主流平台都可支持,如sles9/10/11,redhat5/6,cgslv3/4等●HA版本3.0.1.07,已从newstart官网获取,目前是最新的。

db2原理DB2是一种关系数据库管理系统(RDBMS),它提供了数据存储、检索和管理的功能。
它具有高度可靠性、可扩展性和安全性,并且支持大规模企业级应用。
DB2的核心原理是基于关系模型。
关系模型是一种用于组织和管理数据的结构化方法,它使用表、行和列来表示和存储数据。
DB2通过使用关系模型来定义和管理数据之间的关系,从而实现数据的一致性和完整性。
DB2还使用了ACID(原子性、一致性、隔离性和持久性)属性来确保数据的可靠性。
ACID是一组数据库事务特性,它们共同保证了在数据库中的操作是可靠的和可恢复的。
当一个事务被提交时,DB2会确保该事务对数据库的变化是持久的,并且不会意外地对其他事务产生干扰。
DB2还使用了索引和查询优化器来提高数据检索的性能。
索引是一种数据结构,它可以加快数据的查找速度。
通过使用索引,DB2可以快速定位和访问数据,并避免在整个数据库中进行全表扫描。
查询优化器是DB2的一部分,它会分析查询语句并选择最有效的执行计划。
通过选择最佳的执行计划,查询优化器可以减少查询的执行时间和资源消耗。
此外,DB2还支持高可用性和故障转移。
它可以配置成高可用性集群,通过将数据和工作负载分布在多个节点上,提供了故障恢复和负载均衡的功能。
当一个节点发生故障时,DB2可以自动将工作负载转移到其他节点上,并继续提供服务,从而确保系统的连续可用性。
总结起来,DB2是一种高可靠性、可扩展性和安全性的关系数据库管理系统。
它通过使用关系模型、ACID属性、索引和查询优化器来管理和检索数据,并支持高可用性和故障转移。
这些特性使得DB2成为企业级应用的理想选择。

使用Q复制实现DB2数据库系统的高可用性和双活展开全文数据是古代企业最主要的营业资产之一,特殊是症结数据。
假天命据弗成用或没有遭到珍重,企业可以会在每小时的营业宕机时辰内损丢失落数百万美元,同时还会给企业抽象带来负面影响。
对进展在瞬息万变的竞争情形中获得胜利的企业来说,构建一个具有高可用性架构的数据中央至关主要。
在本文笔者将引见若何行使IBM InfoSphere Data Replication 产物中的 Q 复制手艺完成 DB2 数据库零星的高可用性和双活。
1. 概述数据库是古代企业数据中央的焦点,用于支持症结的企业运用。
对数据库的要求,除高功效,高靠得住性,功用雄厚,易行使,易珍重外,还要求有很好的灾备和高可用性计划合营,提高数据的平安和可用性。
1.1 数据库灾祸恢复 (DR) 的概念望文生义,数据库灾祸恢复计划为灾祸事宜准备的数据库备份和恢复计划,简称灾备计划。
这里涵盖的灾祸包括各类自然和工资灾祸事宜,若有洪水、地震、飓风、海啸等各类极端自然天色和气象,和爆炸、失落火、电网缺点等工资异常事宜。
这些灾祸会对数据中央的根蒂根抵举动装备组成影响,损坏数据中央的存储介质,致使数据库中的数据丧丢失落。
灾祸的特色参数包括它影响的地舆局限,延续的时辰长短,和对举动装备和数据的损坏水平。
为了避免这些事宜完整息灭企业的数据,企业需求设计有呼应的灾备装备,在灾祸影响局限之外安装备用数据中央和寄存备份数据,这样当灾祸真的发生发火时才华够在备份数据中央连续睁开营业。
灾备计划需求凭证针对的灾祸特色来设计。
好比对影响局限局限在数据中央内部的灾祸(局限几百米),同城的灾备中央就可以恢复营业。
对影响局限除夜到整座城市的灾祸(局限为几十千米),就需求安装在异地甚至很远处的灾备中央来恢复营业运转。
理想中经常据说的同城灾备中央和异地灾备中央就是指灾备节点处于同城局限或异地局限。
对灾备计划,次要有两个手艺目的:1.数据损丢失落目的 RPO (Recovery Point Objective),泄漏表现在该灾备计划下可以的数据丧丢失落量,以时辰单元来泄漏表现,好比丧丢失落三个小时的营业数据。
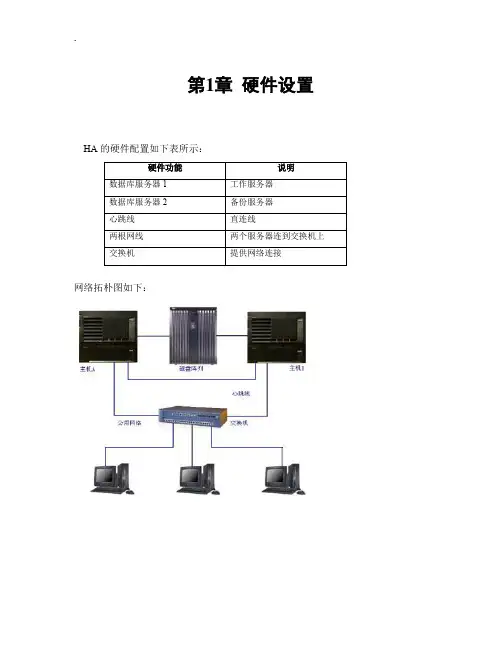
第1章硬件设置HA的硬件配置如下表所示:网络拓朴图如下:第2章操作系统设置要配置数据库的HA,首先要配置操作系统的HA。
因此操作系统必须为Windows Advanced Server 或Windows DataCenter。
操作步骤如下:1.将服务器与盘柜断开,再将两台服务器的所有硬盘应该做成NTFS。
安装完操作系统并加到域中后,全部关闭。
2.将盘柜和两台服务器之间连接好后,都在关闭状态3.启动盘柜,并将盘柜做成三个物理分区,R,S和T,注意一定要是物理分区,不能是逻辑分区。
其中T作为仲裁盘,其大小为1G,R放DB2和DB2I2两个实例,S放DB2I1实例。
然后关闭盘柜。
4.只打开主服务器。
注意:开机的顺序是先开盘柜再开服务器,并且如果没有做好HA之前,绝对不能两台机器同时开。
5.在“网络和拨号连接”中可以看到两个网卡,找到心跳线所连的网卡,将其名称改为“Master_Private”,再将连到交换机的网卡改为”“Master_Public”。
6.关闭主服务器,打开备份服务器,在“网络和拨号连接”中可以看到两个网卡,找到心跳线所连的网卡,将其名称改为“Back_Private”,再将连到交换机的网卡改为”“Back_Public”。
并将两台机器的IP进行如下规划:A : public IP :23.47.0.8(规划)private IP :10.0.0.1B: public IP :23.47.0.9(规划)private IP:10.0.0.27 关闭两台服务器后,打开磁盘柜。
8 打开主服务器进行磁盘设置。
2.1 磁盘设置通过磁盘设置可以让两台服务器都能访问到盘柜,设置的步骤如下:进入计算机管理,点击磁盘管理,由于连上了盘柜,因此,系统弹出创建分区向导的对话框点击下一步选择主磁盘分区点击下一步输入主磁盘分区的容量,由于已经做过物理分区,因此容量即按所能分配的最大容量进行分配。
作好一个盘后,同样再做其它两个盘。
海康威视视频云存储解决方案正文目录第一章概述.............................................1.1 系统简介........................................1.2 设计原则........................................1.3 设计目标........................................1.4 术语及缩略语解释................................1.4.1 术语解释 (8)1.4.2 英文/缩略语解释............................. 第二章总体设计.........................................2.1 需求说明........................................2.1.1 功能性需求说明..............................2.1.2 非功能性需求说明............................2.2 技术路线........................................2.3 逻辑架构........................................2.4 系统特点........................................2.4.1 高效灵活的空间管理..........................2.4.2 海量数据的快速检索..........................2.4.3 持续可靠的数据服务..........................2.4.4 高可扩展的应用支撑..........................2.4.5 开放透明的兼容系统......... 错误!未指定书签。
DB2的参数配置说明1.数据库配置参数:-DFT_DEGREE:默认配置为1,表示数据库服务器可以并行处理的任务数量。
可以根据服务器硬件配置调整此参数,以提高并行处理能力。
-MAXAPPLS:默认配置为100,表示数据库支持的最大并发连接数。
如果数据库负载较高,可以适当增加此值。
-LOCKLIST:默认配置为200,表示数据库锁的最大数量。
如果数据库经常出现锁冲突,可以适当增加此值。
-SHEAPTHRES:默认配置为0,表示数据库共享内存区域的大小。
可以根据数据库工作负载的大小调整此值,以提高性能。
2.缓冲池参数配置:-PCKCACHESZ:控制预编译包缓冲池的大小,为了提高性能,可以根据实际需求调整此参数。
-HADR_SYNCMODE:用于配置DB2的高可用性和灾难恢复功能。
可以根据实际需求选择异步或同步模式。
-LOGFILSIZ:表示数据库日志文件的最大大小。
可以根据数据库运行情况和可用存储空间来调整此参数。
-UTIL_HEAP_SZ:用于配置数据库工具的堆大小。
可以根据数据库工具的需求来调整此值,以提高操作效率。
3.SQL优化参数配置:-STMTHEAP:用于配置SQL语句的堆大小。
可以根据SQL语句的复杂度和数据量来调整此参数,以提高查询性能。
-STMM:表示是否开启自动内存管理功能。
可以根据实际需求选择开启或关闭。
-OPT_MEMORY:表示查询优化器使用的内存大小。
可以根据查询复杂度和数据量来调整此值,以提高查询性能。
-DIAGLEVEL:用于配置记录诊断信息的级别。
可以根据需要调整此参数,进行问题排查和性能优化。
以上是一些常见的DB2参数配置说明,根据实际需求和数据库运行情况,可以调整这些参数来达到最佳的性能和可靠性。
需要注意的是,调整参数配置时应谨慎,并进行充分测试和验证,以避免潜在的风险和问题。
双机应用实战:高手教你用Veritas Cluster Server for DB2双机-入门【IT168 专稿】双机热备这一概念有两种不太相同的意义:从广义上来说也称为双机互备,指的是对于重要的服务,使用两台服务器协同工作,共同执行同一个服务。
当一台服务器出现故障时,可以由另一台服务器暂时相应原有的两个机器的所有服务,等待故障机的恢复和重新加入集群,从而在不需要人工干预的情况下,自动保证系统能持续提供服务。
这种集群一般被称为高性能集群(High performance cluster. HPC)。
从狭义上讲,双机热备特指基于active/standby方式的服务器热备,这也是双机热备最常用的含义,服务器数据包括数据库数据同时往两台或多台服务器写,或者使用一个共享的存储设备,但在同一时间内只有一台服务器运行。
当其中运行着的一台服务器出现故障无法启动时,另一台备份服务器会被集群软件激活,保证应用在短时间内完全恢复正常使用。
这种集群一般被称为高可用集群(High Availability cluster. HAC)。
双机热备由备用的服务器解决了在主服务器故障时服务不中断的问题。
但在实际应用中,可能会出现多台服务器的情况,即服务器集群。
在广义的双机互备中,N台服务器同时工作,硬件资源的利用率最高;在狭义的双机热备中,需要m台机器(m不小于1)作为后备服务器,那么至多只能用(N-m)台机器工作,资源的利用率低于双机互备。
(一般软件公司都会将多机同时工作作为一个特殊的功能来卖,价格比两台机器的总和可能还要高,所有一般中小企业用户都会选择后一种热备方式,牺牲一些可用性)。
在IBM的DB2数据库产品中,包括了上述的两种热备方式:均衡多处理模式(Symmetric Multiprocessing, SMP)和大数据并行处理模式(Massively Parallel Processing, MPP)。
SMP是指一台数据库工作,另一台数据库作为后备,当工作的数据库发生故障的时候,集群会将数据库服务所需的所有服务转移到后备的服务器上面。
HA配置的一个实例作者:Jian Lee邮件:aybhlj@主页:集群环境:(通过eth1接口,用以太网双机直连网线做为心跳线)webdb1:eth0: 10.10.8.31eth1: 192.168.10.10webdb2:eth0: 10.10.8.32eth1: 192.168.10.11APC电源设备:apc1: 10.10.8.45apc2: 10.10.8.46user:apc passwd:apc机器型号: hp580 8CPU系统: Red Hat Enterprise Linux AS release 4 (Nahant Update 4)Linux webdb2 2.6.9-42.ELsmp #1 SMP Wed Jul 12 23:27:17 EDT 2006 i686 i686 i386 GNU/Linux局域网环境:已经有一个HA,名字默认都叫“alpha_cluster”步骤1、运行system-config-cluster第一次运行,由于还没有/etc/cluster/cluster.conf这个文件,所有会出现下面这个提示框,点击”Create New Configuration”,创建一个新的/etc/cluster/cluster.conf文件。
如果删除/etc/cluster/cluster.conf文件,再次运行system-config-cluster还会出现这个提示框。
2、做完上面步骤,就会出现下面对话框。
这里选择“DLM”,由于我们使用双机直连网线,所已不必使用”Use Multicast”。
3、点击“Cluster”,在点击“Edit Cluster Properties”4、编辑集群的名字5、添加节点先点左边“Cluster Nodes”再点右下角“Add a Cluster Node”给节点命名6、配置APC先点击左边“Fence Devices”再点击右下角“Add a Fence Device”添加两个APC7、为每个节点配置Fence设备先点击左边“webdb1”再点击右下角“Manage Fencing For This Node”8、点击“Add a New Fence Level”9、先点击“Fence-Level-1”再点击“Add a New Fence to this Level”10、选择“apc1”填写Port,Switch11、同上,先点击“webdb1”,增加“Fence-Level-2”再点击“Fence-Level-2”,增加apc2,(下图有误,抱歉)12、同理配置webdb2的Fence设备。
什么是服务器HA技术[整理]高可用性(HA)集群实现不间断应用2006-02-24 09:32:01高可用性(HA)集群通过一组计算机系统提供透明的冗余处理能力,从而实现不间断应用的目标。
高可用性(High Availability,简称HA)集群是共同为客户机提供网络资源的一组计算机系统。
其中每一台提供服务的计算机称为节点(Node)。
当一个节点不可用或者不能处理客户的请求时,该请求会及时转到另外的可用节点来处理,而这些对于客户端是透明的,客户不必关心要使用资源的具体位置,集群系统会自动完成。
HA集群系统硬件拓扑形式基于共享磁盘的HA集群系统通过共享盘柜实现集群中各节点的数据共享,包含主服务器、从服务器、存储阵列三种主要设备,以及设备间的心跳连接线。
而基于磁盘镜像的HA集群系统不包含存储阵列。
集群中两种服务器的本地硬盘通过数据镜像技术,实现集群中各节点之间的数据同步,从而实现集群的功能。
实际应用中,将节点1配置成“主服务器”,节点2配置成“从服务器”,主从服务器有各自的IP地址,通过HA集群软件控制,主从服务器有一个共同的虚拟IP地址,客户端仅需使用这个虚拟IP,而不需要分别使用主从IP地址。
这种措施是HA集群的首要技术保证,该技术确保集群服务的切换不会影响客户IP层的访问。
公网(Public Network)是应用系统实际提供服务的网络,私网(Private Network)是集群系统内部通过心跳线连接成的网络。
心跳线是HA集群系统中主从节点通信的物理通道,通过HA集群软件控制确保服务数据和状态同步。
不同HA集群软件对于心跳线的处理有各自的技巧,有的采用专用板卡和专用的连接线,有的采用串并口或USB口处理,有的采用TCP/IP网络处理,其可靠性和成本都有所不同。
近几年,基于TCP/IP技术的心跳线因其成本低、性能优异而被广泛采用。
具体实现中主从服务器上至少各需配置两块网卡。
HA集群软件体系结构HA集群软件是架构在操作系统之上的程序,其主要由守护进程、应用程序代理、管理工具、开发脚本等四部分构成,应用服务系统是为客户服务的应用系统程序,比如MS SQL Server,Oracle,Sybase,DB2 UDB,Exchange,Lotus Notes等应用系统软件。
DB2HA双机集群数据是现代随需应变业务的⾎液;存储和移动数据的系统(服务器、⽹络、数据库)是这个系统的⼼脏。
但是如果没有heartbeat ——对这些数据具有可靠⽽快速的访问,且宕机时间最少——那么这两者都是惰性组件。
简介本系列的第⼀篇⽂章 Linux 上的⾼可⽤中间件,第 1 部分:Heartbeat 和Apache Web 服务器简要介绍了⾼可⽤(HA)的概念,以及如何安装并配置 heartbeat。
本篇⽂章是本系列的最后⼀篇⽂章,它将介绍如何在⼀个冷备份(cold standby)配置中使⽤ heartbeat 为 DB2 UDB 8.1 实现⼀个 HA ⽅案。
关于 heartbeatHeartbeat 是 Linux-HA 项⽬中提供的⼀个公⽤包。
Heartbeat 提供了 HA 系统所需要的基本功能,例如启动/停⽌资源,监视集群中系统的可⽤性,在集群节点之间切换共享的 IP 地址信息。
Heartbeat 还可以通过⼀个串⼝线或以太⽹接⼝来监视特定服务(或多个服务)的健康信息。
当前的版本⽀持⼀个两节点的配置,其中使⽤特殊的 heartbeat "pings" 来检查服务的状态和可⽤性。
在这种实现中,heartbeat 会检测主节点的失效情况,并发起故障迁移的过程:在主节点上停⽌ DB2 进程在主节点上释放共享磁盘在主节点上释放该服务的 IP 地址将这个服务的 IP 地址添加到备⽤节点上在备⽤节点上加载这个共享磁盘在备⽤机器上重新启动 DB2 进程为了最好地理解本⽂的内容,您需要对 DB2 UDB 和⾼可⽤集群有⼀个基本的理解。
本系列的第⼀篇⽂章介绍了对于软件的⾼可⽤性来说这意味着什么,以及如何在⼀个两节点的系统上使⽤ High-Availability Linux 项⽬安装并设置 heartbeat 软件。
DB2 UDB 和 HA 基础在 heartbeat 集群中使⽤的任何 DB2 UDB 都必须将数据全部存放在共享磁盘上,这样在发⽣节点失效的情况时,就可以在依然存活的机器上访问这些数据。
数据是现代随需应变业务的血液;存储和移动数据的系统(服务器、网络、数据库)是这个系统的心脏。
但是如果没有 heartbeat ——对这些数据具有可靠而快速的访问,且宕机时间最少——那么这两者都是惰性组件。
简介本系列的第一篇文章 Linux 上的高可用中间件,第 1 部分:Heartbeat 和Apache Web 服务器简要介绍了高可用(HA)的概念,以及如何安装并配置 heartbeat。
本篇文章是本系列的最后一篇文章,它将介绍如何在一个冷备份(cold standby)配置中使用 heartbeat 为 DB2 UDB 8.1 实现一个 HA 方案。
关于 heartbeatHeartbeat 是 Linux-HA 项目中提供的一个公用包。
Heartbeat 提供了 HA 系统所需要的基本功能,例如启动/停止资源,监视集群中系统的可用性,在集群节点之间切换共享的 IP 地址信息。
Heartbeat 还可以通过一个串口线或以太网接口来监视特定服务(或多个服务)的健康信息。
当前的版本支持一个两节点的配置,其中使用特殊的 heartbeat "pings" 来检查服务的状态和可用性。
在这种实现中,heartbeat 会检测主节点的失效情况,并发起故障迁移的过程:在主节点上停止 DB2 进程在主节点上释放共享磁盘在主节点上释放该服务的 IP 地址将这个服务的 IP 地址添加到备用节点上在备用节点上加载这个共享磁盘在备用机器上重新启动 DB2 进程为了最好地理解本文的内容,您需要对 DB2 UDB 和高可用集群有一个基本的理解。
本系列的第一篇文章介绍了对于软件的高可用性来说这意味着什么,以及如何在一个两节点的系统上使用 High-Availability Linux 项目安装并设置 heartbeat 软件。
DB2 UDB 和 HA 基础在 heartbeat 集群中使用的任何 DB2 UDB 都必须将数据全部存放在共享磁盘上,这样在发生节点失效的情况时,就可以在依然存活的机器上访问这些数据。
运行数据库实例的节点还必须在内部磁盘上维护很多文件。
这些文件包括与节点上的所有数据库有关的文件。
与数据库实例有关的文件会被分别存放在内部磁盘和外部磁盘上。
图 1 详细介绍了DB2 文件系统的组织,它介绍了在我们的测试中针对实例 db2inst1 和数据库 hadb 的设置。
图 1. DB2 对实例 db2inst1 和数据库 hadb 的高可用设置查看原图(大图)在该设置中:机器 ha1 用作主 DB2 UDB 数据库机器。
机器 ha2 用作节点 ha1 的备用机器。
每个节点都有所安装的 DB2 UDB 8.1 的一个本地副本。
数据库 hadb 特定的目录(db2inst1/NODE0000/SQL00001 和db2inst1/NODE0000/sqldbdir)将保留在共享文件系统(/ha)上。
安装数据库按照本节中介绍的步骤在主节点和备用节点上安装 DB2 UDB 8.1。
更多信息,请参考DB2 Information Center:以 root 用户身份登录。
使用下面的命令解压 DB2 UDB 8.1 的安装映像文件:rm -rf /tmp/db28.1-installmkdir /tmp/db28.1-installtar xf C48THML.tar -C /tmp/db28.1-install这里的 C48THML.tar 是安装的 tar 文件。
设置内核级别:export LD_ASSUME_KERNEL=2.4.19。
不要使用 IBM Developer Kit for Linux,即 DB2 安装光盘中提供的 Java 2 Technology Edition。
使用 IBM 1.4.2 JDK 来替换 DB2 中提供的 JDK。
cd /tmp/db28.1-install/009_ESE_LNX_32_NLVmv ./db2/linux/java ./db2/linux/java.db2ln -s /opt/IBMJava2-142 ./db2/linux/java使用下面的命令启动 DB2 安装向导:./db2setup。
在这个向导中,使用下面的信息:对于 Product to install,请使用 DB2 UDB Enterprise Server Edition。
对于 Group and User IDs,组 ID(gid)和用户 ID(uid)域的值在两台机器上必须匹配。
我们使用表 1 中给出的 ID 值。
对于 Partition,请选择 single-partition instance。
对于 DB2 Instance Name,请选择 db2inst1。
表 1. 安装 DB2 使用的组名/ ID、用户名/ ID组名GID 用户名UIDdasadm1 2001 dasusr1 2001db2grp1 2002 db2inst1 2002db2fgrp1 2003 db2fenc1 2003创建一个高可用的数据库按照下面的步骤创建高可用的数据库 hadb:以 db2inst1 用户的身份在主节点(ha1)和备用节点(ha2)上登录:su - db2inst1。
确保 DB2(R) 实例在 ha1 和 ha2 两个节点上都不会在启动时(以 db2inst1 的身份)使用 db2iauto 工具启动:cd sqllib/bin./db2iauto -off db2inst1修改 /etc/inittab 文件,以正确运行 DB2 HA。
在节点 ha1 和 ha2 上注释掉在系统启动时启动 DB2 的那一行,如下所示:#fmc:2345:respawn:/opt/IBM/db2/V8.1/bin/db2fmcd #DB2 Fault Monitor Coordinator。
在主节点 ha1 上启动 DB2:db2start。
在备用节点(ha2)上以 root 用户的身份使用下面的命令挂载文件系统 /ha:mount /ha。
在节点 ha1 上使用下面的命令创建数据库 hadb:db2 create database hadb on /ha。
在节点 ha1 上使用下面的命令确保可以连接到数据库 hadb 上:db2 connect to hadb。
如果成功,就使用这个命令断开连接:db2 connect reset。
在节点 ha1 上使用 db2stop 命令停止 DB2。
在备用节点(ha2)上以 root 用户的身份使用下面的命令挂载文件系统 /ha: mount /ha。
在备用节点上使用下面的命令启动 DB2:db2start。
以 db2instl 用户的身份在节点 ha2 上执行下面的命令,对数据库 hadb 进行catalog 操作:db2 catalog database hadb on /ha。
在节点 ha2 上使用 db2 connect to hadb 命令,确保可以连接到数据库 hadb 上。
如果成功,就使用 db2 connect reset 命令断开连接。
在节点 ha2 上使用 db2stop 命令停止 DB2。
配置 heartbeat 来管理 DB2现在配置 /etc/ha.d/haresources 文件(在主节点和备用节点上都要进行),使其包括管理 DB2 进程的脚本。
这个脚本是由 heartbeat 提供的。
修改文件的一部分如下所示: 9.22.7.46Filesystem:::/ha::/ha::nfs::rw,hard db2::db2inst1这一行说明在启动 heartbeat 时,hal 使用集群的 IP 地址,挂载共享文件系统,并启动数据库服务器。
在停止服务器时,heartbeat 首先要停止数据库服务器,然后卸载共享文件系统,最后放弃 IP 地址。
测试 DB2 UDB 的故障迁移本节将介绍如何对高可用的 DB2 数据库 hadb 进行测试。
这可能是本文中所介绍的最为棘手的一项工作,因此要仔细阅读以下的内容。
在主节点上启动 heartbeat 服务,然后在备用节点上也启动 hartbeat 服务。
您可以以 root 用户的身份执行 /etc/rc.d/init.d/heartbeat start 命令。
在成功启动 heartbeat 之后,您应该会看到一个新的接口,它使用了您在 ha.cf 文件中配置的 IP 地址。
在启动 heartbeat 之后,可以看一下主节点上的日志文件(默认是/var/log/ha-log),并确保它正在进行 IP 接管,然后又启动了 DB2。
使用 ps 命令确保 DB2 进程正在主节点上运行。
heartbeat 将不能在备用节点上启动任何上述进程,这只能在主节点失效之后才会发生。
在 ha1 节点上以 db2instl 的身份检查数据库的状态:db2 -tf/ha/hahbcode/db2/listdb.sql。
这个命令的输出如下所示:Active DatabasesDatabase name = HADBApplications connected currently = 0Database path = /ha/db2inst1/NODE0000/SQL00001/在节点 ha1 上以 db2instl 的身份创建一个测试表(hadb.TestHATable),方法如下:db2 -tf /ha/hahbcode/db2/createdb.sql。
现在,在节点 ha1 上以 db2instl 的身份向测试表中插入一行数据:db2 -tf/ha/hahbcode/db2/insertdb.sql。
在节点 ha1 上以 db2instl 的身份查看测试表的内容:db2 -tf/ha/hahbcode/db2/selectdb.sql。
您应该可以看到在上一个步骤中插入的数据行。
运行的结果如下:[db2inst1@ha1 db2inst1]$ db2 -tf /ha/hahbcode/db2/selectdb.sql Database Connection InformationDatabase server = DB2/LINUX 8.1.0SQL authorization ID = DB2INST1Local database alias = HADBCOL1 COL2----------- ------------10 Hello1 record(s) selected.DB20000I The SQL command completed successfully.为了模拟故障迁移的情况,我们只需要在主节点上以 root 用户的身份来停止heartbeat 即可:/etc/rc.d/init.d/heartbeat stop。