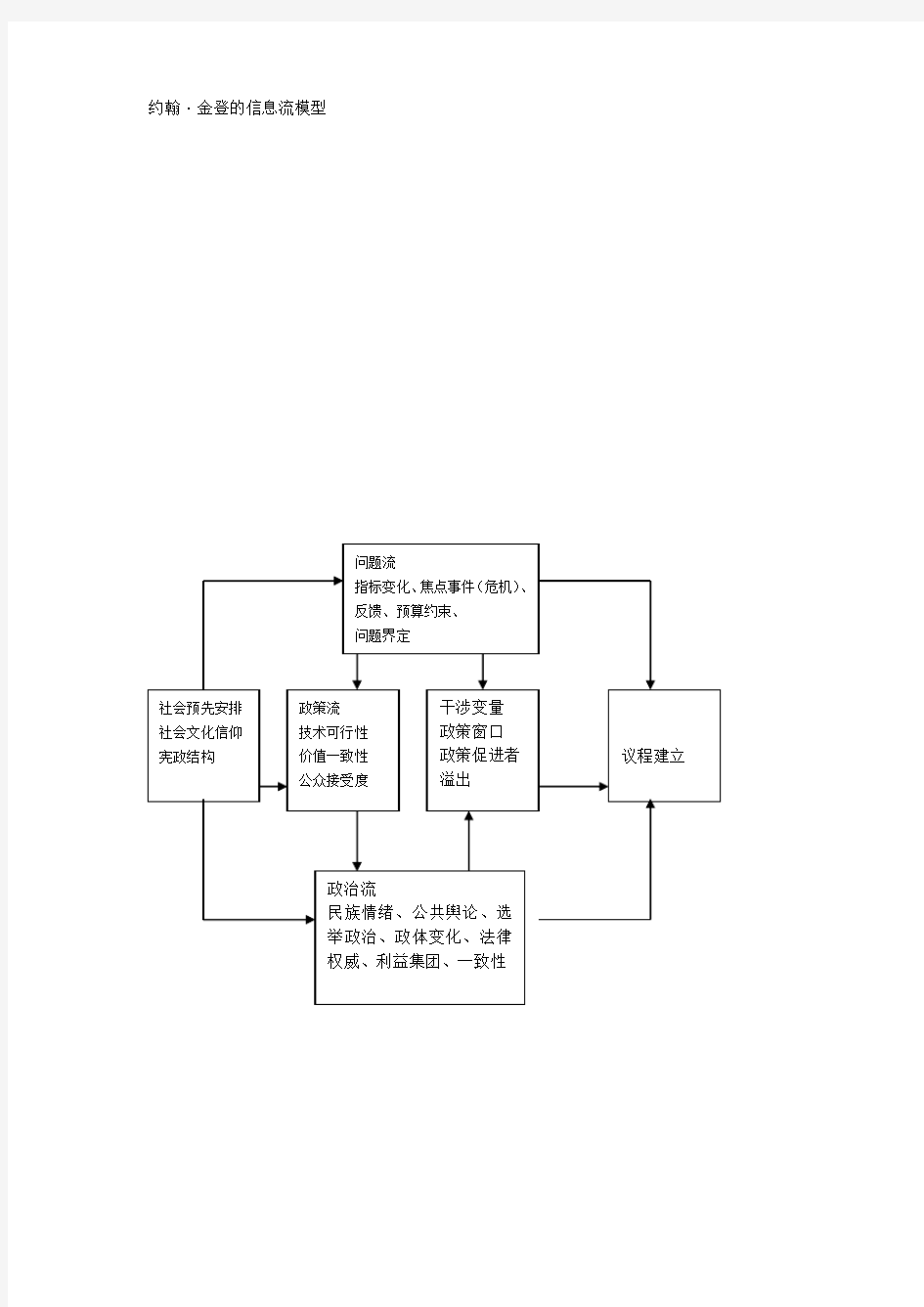
约翰·金登的信息流模型
毕业论文文献综述 信息与计算科学 数学建模中数学模型方法的研究 一、前言部分 数学建模[]1是将实际问题抽象、简化,明确变量和参数,然后根据某种“规律”建立变量和参数间的数学关系,再解析地或近似地求解并加以解释和验证这样一个多次迭代的过程。但要进行真正好的数学建模必须要有有关领域的专家、工作人员的通力合作,也就是说数学建模的过程往往是一个跨学科的合作过程。 应用某种“规律”建立变量、参数间的明确数学关系,这里的“规律”可以是人们熟知的物理学或其他学科的定律,例如牛顿第二定律、能量守恒定律等,也可以是实验规律。数学关系可以是等式、不等式及其组合的形式,甚至可以是一个明确的算法:能用数学语言把实际问题的诸多方面(关系)“翻译”成数学问题是极为重要的。 不同的建模者由于看问题角度不同所建立的模型往往是不同,我们通过介绍数学建模的几类方法和几个典型的数学模型,来让大家对数学模型有一个比较全面的认识和了解。二、主题部分 数学建模(Mathematical Modeling)把现实世界中的实际问题加以提炼,抽象为数学模型,求出模型的解,验证模型的合理性,并用该数学模型所提供的解答来解释现实问题,我们把数学知识的这一应用过程称为数学建模。简而言之,数学建模是利用各种数学方法解决生产生活中实际问题的一种方法。 数学建模是一门新兴的学科,20世纪70年代初诞生于英美等现代化工业国家。由于新技术特别是计算机技术的迅速的发展,大量的实际问题需要用计算机来解决,而计算机与实际问题之间需要数学模型来沟通,所以这门学科在短短几十年的时间迅速辐射至全球大部分国家和地区。(参见文献[2][3]) 纵观数学的发展历史,数千年来人类对于数学的研究一直是沿着纵横两个方向进行的。在纵向上,探讨客观世界在量的方面的本质和规律,发现并积累数学知识,然后运用公理化等方法建构数学的理论体系,这是对数学科学自身的研究。在横向上,则运用数学的知识去解决各门科学和人类社会生产与生活中的实际问题,这里首先要运用数学模型方法构建实际问题的数学模型,然后运用数学的理论和方法导出其结果,再返回原问题实现实际问题的解决,这是对数学科学应用的研究,由此可见,数学建模既是各门科学研究的经常性活动,具有方法论的重要价值,又是数学与生产实际相联系的中介和桥梁,对于发挥数学的社会功能具有重要的作用。
第二章 控制系统的数学模型 2—1 数字模型 在控制系统的分析和设计中,首先要建立系统的数学模型。 自动控制系统: 相同的数学模型进行描述,研究自动控制系统 其内在共性运动规律。 系统的数学模型,是描述系统内部各物理量之间动态关系的数学表达式。 常用的数学模型有: 数学模型 的建立方法 一般应尽可能采用线性定常数学模型描述控制系统。 如果描述系统的数学模型是线性微分方程,则称该系统为线性系统,若方程中的系数是常数,则称其为线性定常系统。线性系统的最重要特性是可以应用叠加原理,在动态研究中,如果系统在多个输入作用下的输出等于各输入单独作用下的输出和(可加性),而且当输入增大倍数时,输出相应增大同样倍数(均匀性),就满足叠加原理,因而系统可以看成线性系统。如果描述系统的数学模型是非线性微分方程,则相应系统称为非线性系统,其特性是不能应用叠加原理。 建立系统数学模型的主要目的,是为了分析系统的性能。由数学模型求取系统性能指标的主要途径如图2—1所示。由图可见,傅里叶变换和拉普拉斯变换是分析和设计线性定常连续控制系统的主要数学工具。 电气的、 机械的、 液压的 气动的等 微(差)分方程 传递函数(脉冲传递函数研究线性离散系统的数学模型) 经典控制理论 频率特性(在频域中研究线性控制系统的数学模型) 状态空间表达式(现代控制理论研究多输入—多输出控制系统) 结构图和信号流图,数学表达式的数学模型图示型式 解析法:依据系统及元件各变量之间所遵循的物理、化学定律, 列写出各变量之间的数学关系式 实验法:对系统施加典型信号(脉冲、阶跃或正弦),记录系统的时间响应 曲线或频率响应曲线,从而获得系统的传递函数或频率特性。 图2-1 求取性能指标的主要途径
第六章方差分析 方差分析(Analysis of Variance,ANOVA)是将待分析资料的总变异剖分为不同的变异来源,以获得不同变异来源的总体方差的估计值。通过F检验,完成多个样本平均数之间的差异显著性检验(即多重比较),若处理效应为随机模型时,则进行方差组分的估计。 6.1 方差分析的SAS过程 用于方差分析的主要过程有方差分析(ANOVA)和广义线性模型(GLM)。对于无缺省(缺值、缺组等)资料,或称平衡资料,一般采用(ANOVA)过程,对缺省资料(非平衡资料)应采用(GLM)过程。事实上根据效应模型的不同,还有VARCOME(方差组分)过程,MIXED(混合模型)过程等。 6.1.1 ANOVA过程 1. 名词解释 自变量与依变量在方差分析中,自变量可称为独立变量、定性变量(Qualitative Variale)、分类变量(Classiflcation Variable)或类别变量(Categorcal Variable),相当于因素处理、水平变量。依变量又称反应变量(Response Variable),相当于观察值变量。 实验效应方差分析的目的是找出对依变量产生的实验效应,这种效应可分为3种:主效应,常以自变量的英文字母表示,如A、B等。互作效应,常以星号联接自变量表示,如A*B。嵌套效应,以小括号表示,如A(B)表示A效应嵌套在B效应之内。 2 语句说明: CLASS指令必须出现在MODEL指令之前,如选用TEST、MANOVA指令,则它们必须出现在MODEL指令之后。MEANS、TEST及MANOVA等指令可重复使用,其他指令则只能出现一次。
PROC ANOV A选项串中:⑴DA TA=输入数据集名称,指明对它执行ANOV A分析。⑵MANOV A 要求将含一个或一个以上依变量遗漏数据的观察值剔除。⑶OUTPUT=(含分析结果的)输出文件名称,包括平方和(SS),F检验值,以及各效应的显著程度。 CLASS变量名称串指明自变量,自变量可以是数值的或文字的。 MODEL指令定义分析所用的线性数学模型(见表6—1),删除号(/)后的选项:⑴NOUNI:不印出单变量方差分析的结果,适用于多变量的方差分析。⑵INT:要求SAS把线性模型内的截距(即资料的总平均数)当成一个参数,同时对这个截距作是否为零的假设检验。 MEANS指令前半部要求算出某些自变量(或互作)中各组的平均数,后半部(删除号后)共有24个选项,前17个选项分别对MEANS指令中所列的主效应平均数进行多种方法的多重比较。这些选项有:⑴BON:修正最小显著差异t检验。⑵DUNCAN:邓肯多重范围检验,即邓肯氏新复极差法。⑶DUNNETT(控制组组名):邓尼特控制差异检验。它是依据t分布由各组平均数与控制组(指定组如对照组)进行比较,采用双尾检验。⑷DUNNETTL(控制组组名):邓尼特小于控制均数检验。与控制组平均数的比较,采用单尾检验,临界值订在t分布的下端。⑸DUNNETTU(控制组组名):邓尼特大于控制均数检验。与控制组平均数的比较,采用单尾检验,临界值订在t分布的上端。⑹GABRIEL:贵博氏多重比较。⑺REGWF:R—E—G—W多重F检验。⑻REGWQ:R—E—G—W多种t 检验。⑼SCHEFFE:执行沙菲氏(Scheffe)的多重比较检验。⑽SIDAK:Sidak调整T检验。⑾SUM(或⑿GTI):Sidak独立样本t检验。当两组样本含量不等时为哈氏(Hochberg)的GTI检验。⒀SNK:纽曼—库尔多重范围检验,即q检验。⒁T(或⒂LSD):配对t检验或费歇尔最小显著差异检验。⒃TUKEY:图基固定极差检验。⒄W ALLER:娃尔—邓肯K—比率t检验。以上17种检验法最常用的为⑵、⑶、⑸、⒀、⒁。其它主要选项还有⒅ALPHA=P:界定检验的显著水准。内设值为P=0.05。当上面选项与选项⑵并用时,P值必须是0.10、0.05、0.01三者之一。与上面其他检验选项时,P可以是0.0001与0.9999间任何的值。⒆LINES:将显著性检验的平均数,由大到小排列。若某一对平均数之间无显著差异,则将它们印在同一行上,并以虚线将它们与其他有显著差异的平均数分开。当选用⑵、⑺、⑻、⒀或⒄等检验时,此选项会自动被包括在内,否则,必须附加此选项。⒇CLM:效应的各组平均数以置信区间方式表示。此项必须与⑴、⑹、⑼、⑽、⑾、⒁、⒂等联用。(21)CLDIFF:与(20)相仿,选用⑵、⑺、⑻、⒀、⒄时,附加此选项,将以置信区间方式显示各组平均数。(22)E=效应名称:它界定各显著检验的分母,缺省时以误差项的均方自动成为分母。 FREQ指令指明该变量值为各观察值重复出现的次数。 TEST指令用来指定F检验的分子与分母,H=分子,E=分母;一般而言,系统自动采用误差项的均方作为F检验的分母。但对于随机模型等,可选此项。 MANOV A指令主要用于执行多变量(多元)方差分析。 BY指令用于把数据文件分成几个小文件,然后逐一进行ANOV A分析,但文件内的数据必须先按照BY变量串的值做由小到大的重新排列。此步骤可籍PROC SORT达成。 以上指令中MODEL指令至关重要,同一资料,分析结果依模型不同而异。常用的模型定义语句有:MODEL Y=A;单因素方差分析,MODEL Y=A B两因素主效应模型,MODEL Y=A B A*B两因素带互作模型,MODEL Y=A B(A)嵌套(NESTED)模型用
Fama-French三因子计算过程说明 姜国华、叶昕、饶品贵、祝继高 (北京大学光华管理学院会计系,1000871) 一、数据来源 财务数据来源于CSMAR财务年报数据库。数据区间:资产负债表自1990年起,利润及利润分配表自1990年起,财务状况变动表自1992年起,现金流量表自1998年起,资产减值准备表自2001年起。 市场回报数据来源于CSMAR中国证券市场交易数据库。数据区间:上海A股从1990年12月19日起,深圳A股从1991年07月03日。市场回报数据包括月个股回报、月市场回报、综合月市场回报三个数据集。 无风险利率我们使用的是中国人民银行公布的人民币三个月整存整取利率调整后得到的,即将三个月整存整取利率除以12。 二、数据处理过程1 1.财务数据只保留年末数(Sgnyea='B')2,剔除年初数(Sgnyea='A');然后按公司和按年度将资产负债表、利润及利润分配表和现金流量表合并。 市场回报数据剔除B股数据,并将所有特殊值替换为缺失值,最后按月份将月个股回报、月市场回报和综合月市场回报进行合并。 2.以个股第t-1年12月31日的权益账面价值与市场价值的比值(Book-to-market ratio,简称BM)和第t年4月30日的市场价值(简称SIZE)为依据,对第t年5月至第t+1年4月期间内的公司观测进行分组(每个月进行分组)。 分组方法如下:(1)按SIZE大小平均分为两组(Small组, Big组);(2)按BM从小到大分三组,即前30%(Growth组),中间40%(Neutral组),后30%(Value组),共形成六个组,即Small Growth组, Small Neutral组, Small Value组, Big Growth组, Big Neutral组, Big Value组。 个股的市场价值是指月个股总市值(Msmvttl),。若BM和SIZE为缺失值或负值,则予以删除。 3.以个股第t年4月30日的相对市场价值为权重(个股的市场价值与组内个股市场价值总和的比),对第t年5月至第t+1年4月期间内个股的月回报进行加权平均,从而求得 1数据处理采用SAS9.1统计软件。 2该符号为CSMAR数据库定义的变量名,下同。
课题研究之 数 学 建 模
目录 摘要……………………………………………………………………………Abstract……………………………………………………………………… 1.数学建模的定义…………………………………………………………… 2.数学建模的建立…………………………………………………………… 3. 数学建模的分类…………………………………………………………… 4. 数学建模的原则…………………………………………………………… 4.1可分析与推推导原则……………………………………………………… 4.2简化原则…………………………………………………………………… 4.3反映性原则………………………………………………………………… 5.应用模式的框架……………………………………………………………… 6.数学建模对大学生素质与能力的培养……………………………………… 6.1 问题的提出……………………………………………………………… 6.2 问题的讨论……………………………………………………………… 6.3 建模的准备……………………………………………………………… 6.4 建模……………………………………………………………………… 6.5 问题的补充………………………………………………………………… 7.设计总结……………………………………………………………………… 8.参考文献………………………………………………………………………
[摘要]数学建模与大学生能力的培养密切相关。本文依据现有文稿系统地分析了数学建模的各个方面,数学建模的定义、分类、建立、原则、框架等。同时,通过污染问题的引入和讨论,详细地阐述了建模的思维过程;并从该过程中映射出数学建模对四种重要思维能力的培养和提高,即综合应用分析能力,“双向”翻译能力、联想能力、洞察能力。从而,使数学建模对大学生能力的培养,不言而喻。 [关健词] 数学建模;思维过程;思维能力;环境污染。
新三因子模型及其在中证100的实证分析 罗小明 (吉水二中江西吉安 331600) 摘要:本文通过对FF-三因子模型的研究,并借鉴了国内外的研究成果,同时结合国内股市的具体特点,提出以下三个影响股票收益率因子:流通市值、市盈率、换手率。在FF-三因子模型的基础上,构建了国内特有的新三因子模型,进行了实证检验,并与FF-三因子模型进行了比较分析。 关键字:三因子模型;流通市值;市盈率;换手率 资产定价是金融学的核心任务之一, 各种资产定价模型总是试图找出投资者在投资决策时的相关经济环境变量, 由这些变量来解释股票的收益差异。本文在FF-三因子模型的基础上,并借鉴了国内外的研究成果,同时结合国内股市的具体特点构建了国内特有的新三因子模型,进行了实证检验,并与FF-三因子模型进行了比较分析,以便进一步认识中国股市 的股票定价机理。 一.国内股市的特点 1、股本结构 我国上市公司的股本按投资主体的不同性质可以分为国有股、法人股、社会公众股和外资股等不同的类型。由于我国的股权分置,投资者在股票市场买卖的股票都是流通股。此情形下,我国上市公司股票市场价格是在非流通股不能上市流通的前提下所形成的供求平衡价格,这就隐含了这一价格大大高于在全部股流通条件下的市场均衡价格,而股票的市场价格并不是非流通股的价格,这对资产定价模型产生较大影响。 2、存在价格操纵者 近年来,我国股票市场上庄家、庄股之说,并且成为广大投资者、中介机构和有关媒体十分关注的话题。所谓庄家,实际上就是股价操纵者,而庄股就是股价被操纵的股票;虽然从法律角度看,操纵股价的行为是违反《证券法》的,但由于操纵股价能为操纵者带来巨额的超常收益,所以操纵行为禁而不绝。当然,这种操纵行为的出现和演变,具有独特的市场机制和外部环境渊源。 3、考虑交易费用和所得税的情形 在我国,股票交易的费用主要由两部分构成,即交易印花税和佣金,而且这两项都按交易金额的一定比例提取,此外还有过户费(上海股市)、交易手续费(上海股市)。从费率的角度看,目前印花税和佣金有所降低,交易费用有所下降;但考虑到其他费用的存在,我国的股票交易费用仍然偏高。另外,股票收益包括股票股息收入、资本利得和公积金转增收益组成,其中股息又分为现金股息、股票股息、财产股息等多种形式;目前,在我国仅对现金股息征税,而对资本利得和其它股息均未征税。对于大多数股票来说,由于股票收益率绝大部
AWT事件处理模型
事件类别描述信息接口名方法ActionEvent 激活组件ActionListener actionPerformed(ActionEvent) ItemEvent 选择了某些项目ItemListener itemStateChanged(ItemEvent) MouseEvent 鼠标移动 MouseMotionListener mouseDragged(MouseEvent) mouseMoved(MouseEvent) 鼠标点击等MouseListener mousePressed(MouseEvent) mouseReleased(MouseEvent) mouseEntered(MouseEvent) mouseExited(MouseEvent) mouseClicked(MouseEvent) KeyEvent 键盘输入KeyListener keyPressed(KeyEvent) keyReleased(KeyEvent) keyTyped(KeyEvent) FocusEvent 组件收到或失去焦 点 FocusListener focusGained(FocusEvent) focusLost(FocusEvent) AdjustmentEvent 移动了滚动条等组 件AdjustmentListener adjustmentValueChanged(AdjustmentEvent) ComponentEvent 对象移动缩放显示 隐藏等ComponentListener componentMoved(ComponentEvent) componentHidden(ComponentEvent) componentResized(ComponentEvent) componentShown(ComponentEvent) WindowEvent 窗口收到窗口级事 件 WindowListener windowClosing(WindowEvent) windowOpened(WindowEvent) windowIconified(WindowEvent) windowDeiconified(WindowEvent) windowClosed(WindowEvent) windowActivated(WindowEvent) windowDeactivated(WindowEvent) ContainerEvent 容器中增加删除了 组件ContainerListener componentAdded(ContainerEvent) componentRemoved(ContainerEvent) TextEvent 文本字段或文本区TextListener textValueChanged(TextEvent)
《数学模型》考试大纲 适应专业:数学与应用数学、信息与计算科学、统计学、应用统计学专业 一、课程性质与目的要求 数学模型课亦称为数学建模课,它是数学与应用数学、信息与计算科学、统计学、应用统计学专业必修课或限选课,教育部1998年颁布的高等学校本科专业目录中,把“数学模型”课作为数学类专业的必开课。数学模型是架于实际问题与数学理论之间的桥梁。数学模型就是应用数学语言和方法,对于现实世界中的实际问题进行抽象、简化和假设所得到的数学结构。本课程是研究数学建模的理论、思想和方法,研究建立数学模型、简单的优化模型、数学规划模型、微分方程模型、代数方程与差分方程模型、稳定性模型、离散模型、概率模型等。 数学模型课需要用到数学分析、高等代数、微分方程、图论、概率统计、运筹学等数学知识,它是学生所学数学知识的综合应用,是培养学生综合素质以及应用数学知识解决实际问题的能力的良好课程。该课程的考试评价依据是按照课程目标、教学内容和要求,把握合适的难易程度出试卷,用笔试的方法对学生学习情况和学习成绩做出评价。 二、课程内容和考核要求 第一章建立数学模型 1、考核知识点: 数学建模的背景及重要意义、数学模型与数学建模、数学模型的分类与特点、数学建模的基本方法和步骤、数学建模举例等。 2、考核要求: (1)理解数学建模的背景及意义、原型、模型、数学模型、数学建模等概念。 (2)理解数学模型的各种分类、数学模型的特点。 (3)理解数学建模的基本方法和步骤、通过实例初步了解数学建模的思想和方法。 第二章简单的优化模型 1、考核知识点: 存储模型、生猪的出售时机、森林救火、冰山运输等。
2、考核要求: (1)掌握应用微积分理论建立存储问题模型。 (2)理解应用微积分理论建立生猪的出售时机模型和森林灭火模型。 (3)理解应用微积分理论建立冰山运输问题模型。 第三章数学规划模型 1、考核知识点: 数学规划问题的基本概念、数学规划问题图解法步骤、生产安排问题、奶制品的生产与销售等。 2、考核要求: (1)掌握数学规划问题的基本概念、数学规划问题图解法步骤。 (2)掌握生产安排问题的模型及图解法。 (3)理解奶制品的生产与销售的模型及求解。 第四章微分方程模型 1、考核知识点: 传染病模型、正规战与游击战、药物在体内的分布与排除、香烟过滤嘴的作用等。 2、考核要求: (1)理解传染病问题的建模及讨论。 (2)理解战争问题、房室问题的建模及讨论。 (3)了解香烟过滤嘴作用问题的建模及讨论。 第五章代数方程与差分方程模型 1、考核知识点: 量纲、量纲齐次原理、量纲分析法、差分方程的基本概念、市场经济中蛛网模型、节食与运动问题等。 2、考核要求: (1)掌握量纲、量纲齐次原理、量纲分析法建模及解法步骤。 (2)掌握市场经济中蛛网模型及解法步骤。 (3)理解理解差分方程的基本概念、减肥问题的建模思想。 第六章稳定性模型
姚鑫强 贷款行业百度信息流最优投放模型研究 2018 2019年6月12 日星期三
姚鑫强 营销策略总监 曾任百度营销咨询部金融行业IMS,6年SEM及精准营销从业经验,现任齐欣互动华南区营销策略总监。服务过金融、游戏、教育等效果类行业客户1. 贷款行业&信息流合作空间 分析国内小额贷款行业的发展历程、百度信息流的更新迭代和核心优势,贷款行业信息流推广投放需求日益旺盛且空间巨大 2. 贷款行业百度信息流投放现状 研究主流贷款公司业务模式:贷款平台和贷款超市,探讨两种业务模式下对应的KPI考核方式和考核指标 3. 贷款行业百度信息流最优投放模型研究 基于贷款行业标准化程度高的特点,通过实战分析,研究贷款行业在百度原生信息流上的最优投放模型,提升广告主投放效率 目录 4. 贷款行业百度信息流投放展望 探讨贷款行业百度信息流投放前景和本文对百度信息流行业研究的借鉴意义
国内小额贷款行业发展迅猛,市场空间广阔 95.07% 0-20万 20-100万100-1000万1000万以上95%单月借款小于20万 2017年数千亿资金涌入网贷行业,网贷市场业务增长迅猛,借款人数增长200%。 -400.0% 100.0% 600.0% 2000040000 2012 2013 2014 20152016e 2017e 2018e 2019e 2012-2019年中国消费类与非消费类网络借贷规模 消费类网络借贷交易规模(亿元)
信息流逐渐成为广告主线上获客的主流渠道 2006|Facebook 2011|Twitter 2012|新浪微博 2013|腾讯新闻 2014|今日头条 2015|微信朋友圈、一点资讯 2016|UC信息流、百度信息流 2017|微博超级粉丝通
数学模型是近些年发展起来的新学科,是数学理论与实际问题相结合的一门科学。它将现实问题归结为相应的数学问题,并在此基础上利用数学的概念、方法和理论进行深入的分析和研究,从而从定性或定量的角度来刻画实际问题,并为解决现实问题提供精确的数据或可靠的指导。 根据研究目的,对所研究的过程和现象(称为现实原型或原型)的主要特征、主要关系、采用形式化的数学语言,概括地、近似地表达出来的一种结构,所谓“数学化”,指的就是构造数学模型.通过研究事物的数学模型来认识事物的方法,称为数学模型方法.简称为MM方法。 数学模型是数学抽象的概括的产物,其原型可以是具体对象及其性质、关系,也可以是数学对象及其性质、关系。数学模型有广义和狭义两种解释.广义地说,数学概念、如数、集合、向量、方程都可称为数学模型,狭义地说,只有反映特定问题和特定的具体事物系统的数学关系结构方数学模型大致可分为二类:(1)描述客体必然现象的确定性模型,其数学工具一般是代效方程、微分方程、积分方程和差分方程等,(2)描述客体或然现象的随机性模型,其数学模型方法是科学研究相创新的重要方法之一。在体育实践中常常提到优秀运动员的数学模型。如经调查统计.现代的世界级短跑运动健将模型为身高1.80米左右、体重70公斤左右,100米成绩10秒左右或更好等。 用字母、数字和其他数学符号构成的等式或不等式,或用图表、图像、框图、数理逻辑等来描述系统的特征及其内部联系或与外界联系的模型。它是真实系统的一种抽象。数学模型是研究和掌握系统运动规律的有力工具,它是分析、设计、预报或预测、控制实际系统的基础。数学模型的种类很多,而且有多种不同的分类方法。
应急事件处置流程建模及其过程协同研究基于应急预案的应急决策生成问题是一个复杂条件下决策的科学问题。临机决策过程的实质是迅速生成突发事件的应急处置方案。在临机决策过程中基于应急预案的决策生成是应急决策的基础问题,目前由于突发公共事件的多样性和复杂性,针对突发事件的处置往往需要基于多个应急预案进行临机决策生成过程。在临机决策过程中,往往会发生以下两个问题:应急任务的过程协作和应急资源的冲突与协调。 本文首先对应急事件处理过程进行建模,并基于该模型对这两个问题进行深入研究,具体研究内容如下;(1)提出了一个应急事件处理过程模型EEP_ETCPN。该模型借鉴了模型驱动体系结构的思想,基于赋时层次着色Petri网这一形式化模型,对应急事件处理过程进行描述、分析验证及仿真运行,且模型独立于具体流程描述语言;模型将应急事件处理过程的描述细化到应急任务的执行操作,而且同时可描述应急事件状态流程,支持层次化应急任务组合描述,并以图形方式表示应急事件处理过程,精确、全面、清晰、直观地刻画了应急事件处理过程。(2)EEP_ETCPN模型的事件状态流程正确性分析与检测。给出了EEP_ETCPN模型中应急事件状态进程网的形式化定义及其变迁规则,参照工作流模型合理性给出了状态进程网的正确性定义并利用转移矩阵的方法进行正确性分析与检测,着重对状态进程网的死锁进行分析检测且给出死锁消除策略。 (3)EEP_ETCPN模型应急任务协作的分析与检测。首先分析了应急任务协作类型,给出了单组织内基本的应急任务协作模式和跨组织的组合应急任务协作模式,分析了几种错误的应急任务协作类型,给出了应急任务协作的分析与检测算法。(4)EEP_ETCPN模型资源协调的分析与检测。分析了应急过程中的资源冲突和资源协调,定义了资源冲突和资源协调,给出了EEP_ETCPN模型的资源协调检测算法,分析了EEP_ETCPN模型的应急任务时间特征并给出了基于应急任务时间特征的资源协调检测算法,基于关键任务路径和最小应急过程处理时间策略给出了EEP_ETCPN模型的资源协调求解算法。 (5)应急事件处理仿真系统的设计及原型实现,提供图形化的应急事件处理过程设计、正确性分析检测功能,并给出应急事件处理过程的仿真实现和性能分析。
文献综述 信息与计算科学 数学建模中数学模型方法的研究 一、前言部分 数学建模[]1是将实际问题抽象、简化,明确变量和参数,然后根据某种“规律”建立变量和参数间的数学关系,再解析地或近似地求解并加以解释和验证这样一个多次迭代的过程。但要进行真正好的数学建模必须要有有关领域的专家、工作人员的通力合作,也就是说数学建模的过程往往是一个跨学科的合作过程。 应用某种“规律”建立变量、参数间的明确数学关系,这里的“规律”可以是人们熟知的物理学或其他学科的定律,例如牛顿第二定律、能量守恒定律等,也可以是实验规律。数学关系可以是等式、不等式及其组合的形式,甚至可以是一个明确的算法:能用数学语言把实际问题的诸多方面(关系)“翻译”成数学问题是极为重要的。 不同的建模者由于看问题角度不同所建立的模型往往是不同,我们通过介绍数学建模的几类方法和几个典型的数学模型,来让大家对数学模型有一个比较全面的认识和了解。二、主题部分 数学建模(Mathematical Modeling)把现实世界中的实际问题加以提炼,抽象为数学模型,求出模型的解,验证模型的合理性,并用该数学模型所提供的解答来解释现实问题,我们把数学知识的这一应用过程称为数学建模。简而言之,数学建模是利用各种数学方法解决生产生活中实际问题的一种方法。 数学建模是一门新兴的学科,20世纪70年代初诞生于英美等现代化工业国家。由于新技术特别是计算机技术的迅速的发展,大量的实际问题需要用计算机来解决,而计算机与实际问题之间需要数学模型来沟通,所以这门学科在短短几十年的时间迅速辐射至全球大部分国家和地区。(参见文献[2][3]) 纵观数学的发展历史,数千年来人类对于数学的研究一直是沿着纵横两个方向进行的。在纵向上,探讨客观世界在量的方面的本质和规律,发现并积累数学知识,然后运用公理化等方法建构数学的理论体系,这是对数学科学自身的研究。在横向上,则运用数学的知识去解决各门科学和人类社会生产与生活中的实际问题,这里首先要运用数学模型方法构建实际问题的数学模型,然后运用数学的理论和方法导出其结果,再返回原问题实现实际问题的解决,这是对数学科学应用的研究,由此可见,数学建模既是各门科学研究的经常性活动,具有方法论的重要价值,又是数学与生产实际相联系的中介和桥梁,对于发挥数学的社会功能具有重要的作用。
由Eugene F. Fama和Kenneth R. French撰写Journal of Financial Economics2015年第4期论文“A five-factor asset pricing model”对原有的Fama-French(1993)三因素模型进行了改进,在原有的市场、公司市值(即SML,small minus large)以及账面市值比(即HML,high minus low)三因子的基础上,加入了盈利能力(profitability)因子(即RMW,robust minus weak)和投资模式(investment patterns)因子(即CMA,conservative minus aggressive),从而能够更好地解释股票横截面收益率的差异。然而,有些小企业的股票收益率,和投资水平高、盈利能力低的公司相似。作者指出,五因素模型的主要不足就在于无法解释这类小企业的股票平均收益率为何如此之低。此外,引入RMW和CMA因子后,1963至2013年的美国股市数据表明,HML因子是“多余”的。 Fama和French于1993年提出的三因素模型在金融圈几乎无人不知,该模型很好地捕捉到了股票收益率与其市值和账面市值比之间的关系。三因素模型也一直是众多学者检验和挑战的对象。Novy-Marx (2013)发现,总盈利-资产比率(gross profits-to-assets)对股票横截面平均收益率,具有接近于HML 因子的解释能力。Aharoni, Grundy和Zeng (2013)指出,公司投资水平和股票平均收益率显著相关(亦可参见Haugen和Baker,1996、Titman, Wei和Xie, 2004、Fama和French,2006、2008等)。由此可见,三因素模型对预期收益率的描述并不全面,因为三个因子并不能解释由公司盈利能力与投资模式所造成的股票收益率差异。 基于上述理论及实证研究,Fama和French在原有的三因素模型中,加入了代表盈利能力的RMW因子和代表投资模式的CMA因子。与之前因子的构建方式类似,RMW是营业利润率(operating profitability)高的多元化投资组合的收益率,减去营业利润率低的多元化组合的收益率。CMA则是投资水平低(“保守”)的多元化投资组合的收益率,减去投资水平高(“积极”)的多元化组合的收益率。其中,营业利润率的衡量标准,是上一财年的总收入,扣除主营业务成本、利息支出和销售、一般及行政费用,再除以上一财年末账面权益总额。而对投资的衡量,则是用上一财年相对于之前财年的总资产增加额,除以之前财年末的总资产金额。 为了清楚地观察各个因子与收益率的关系,本文使用1963年7月至2013年12月的美国股市数据,采用类似Fama和French (1993)的方法对样本数据进行分析。作者分别根据市值-账面市值比、市值-营业利润率和市值-投资水平,对股票进行了3次5×5均分,每次得到25个投资组合。作者发现,总体而言,存在价值、盈利能力以及投资效应:即在控制其他变量的情况下,股票的账面市值比越高,营业利润率越高,投资水平越低,其平均回报率越高,这些现象在市值较小的股票中尤为明显。 在构造SML、HML、RMW和CMA这4个因子时,作者提出了三种投资组合划分的方法。第一种:分别根据市值-账面市值比、市值-营业利润率和市值-投资水平,对股票进行3次2×3划分,每次得到6个投资组合。以市值-账面市值比划分为例,作者将市值以纽交所均值为分水岭,划分为大、小2类;对账面市值比,则以纽交所的第30和第70百分位数为分水岭,划分为高、中、低3类。第二种:分别根据市值-账面市值比、市值-营业利润率和市值-投资水平,以纽交所均值为分水岭,对股票进行3次2×2划分,每次得到4个投资组合。第三种:根据市值-账面市值比-盈营业利润率-投资水平,对股票进行1次2×2×2×2的划分,得到16个投资组合。作者认为,第二种方法在构建因子时,使用了全部股票,而第一种方法却没有使用第30至第70百分位数的股票,因此第二种方法构建的因子更为多元化;而第三种方法,则能更有效地从平均收益率中,分离出市值、账面市值比、营业利润率和投资水平的风险溢价。 作者进行回归分析,并按照Gibbons,Ross和Shanken(1989)的方法进行检验。GRS统计量表明,五因素模型并不能完全描述股票的期望收益率,但是五因素模型依然可以解释71%至94%的不同组合收益率在横截面水平上的差异。五因素模型的GRS统计量值小于三因素模型,回归的截距项(代表异常收益)
关于部分离散的单种群模型的研究 摘要生物数学是用数学方法研究和解决生物学问题,并对与生物有关的数学方法进行理论研究的一门学科。生命现象是非常复杂的,从生物学中提出的数学问题往往也是比较复杂,因此需要进行大量的计算工作,建立模型于是成了必需。数学模型能定量地描述生物现象,一个复杂的生物学问题借助数学模型能转变成一个数学问题,通过对数学模型的逻辑推理、求解和运算,通过获得的理论知识对生命或非生命现象进行研究。 1. 单种群模型建立的一般性原理 衡量一个模型是否完善的标准是看该模型是否是最一般化、最真实、最实用和最简单。为了使一个模型是有用的,并且是成功的,我们认为一个好的单种群模型应该满足: 1. 准确刻画自然现象并与实验数据相吻合; 2. 帮助理解未知的种群动态行为; 3. 能够自然地得到推广和改进并能考虑复杂的种内相互作用。 以下是建立单种群模型的几个基本原理。 (1)原理一:指数增长; 自然界中很多物种或个体都是以指数或几何级数增长的。 (2)原理二:合作; 生物种群为了生存、繁殖和防御外敌侵犯,个体之间需要有共同的合作行动。 (3)原理三:种内竞争; 物种竞争也是自然界中普遍存在的规律。比如,雄蝗虫为争夺雌蝗虫所发生的竞争以及雌蝗虫为了竞争产卵场所而发生的争夺空间的竞争等,都限制了蝗虫生物潜能的发挥。
2. 离散Malthus 人口模型和Berverton-Holt 模型 提到具有离散特征的单种群模型,人们首先想到的是离散Malthus 人口模型。英国人口学家Malthus (1766-1834) 根据百余年的人口统计资料,于1798提出了著名的人口指数增长模型。这个模型的基本假设是人口的增长率是常数,或者说,单位时间内人口的增长量与当时的人口数量成正比。 表1 美国1800-1860年的人口统计数据和相应的模型预测值 时间 观测数据 预测值 0 5.3 5.3 1 7. 2 7.1285 2 9.6 9.5878 3 12.9 12.8956 4 17.1 17.3446 5 23.2 23.3285 6 31.4 31.3769 离散Malthus 差分方程如下 1t t N RN += (2.1) 与连续Malthus 人口模型一样,我们也可以利用离散增长模型(2.1)来预测早期美国人口增长规律。 1R =,种群数量保持恒定; 01R <<种群数量下降; 0R =,雌体没有繁殖,种群在一代中灭亡。 对于1R >,因为空间、食物等资源的有限性以及种群自身的密度制约效应说明在模型(2.1)中引入密度制约的效应,即在净增长率R 中考虑种间竞争的影响。下面从几何直观我们给出一个具有密度制约效应的离散单种群模型的严格
(19)中华人民共和国国家知识产权局 (12)发明专利申请 (10)申请公布号 (43)申请公布日 (21)申请号 201910367646.6 (22)申请日 2019.05.05 (71)申请人 湖南大学 地址 410082 湖南省长沙市岳麓区麓山南 路1号 (72)发明人 廖鑫 陈嘉欣 秦拯 (51)Int.Cl. G06K 9/62(2006.01) (54)发明名称 基于混淆处理效应分离的图像操作链中操 作类型识别方法 (57)摘要 本发明涉及一种基于混淆处理效应分离的 图像操作链中操作类型识别方法。所述方法包括 构建基于盲源分离的数字图像操作链的操作分 离模型;估计数字图像特征的相关程度,初步识 别图像篡改操作类型;依据Dempster -Shafer证 据理论,估计篡改操作置信区间,精确识别图像 篡改操作类型。与现有技术相比,本发明提供的 一种基于混淆处理效应分离的图像操作链中操 作类型识别方法,面向更实际的JPEG图像多重篡 改场景。本发明的方法可行且有效,在识别图像 经历的篡改操作类型方面能取得良好的效果。权利要求书1页 说明书6页 附图2页CN 110097124 A 2019.08.06 C N 110097124 A
权 利 要 求 书1/1页CN 110097124 A 1.一种基于混淆处理效应分离的图像操作链中操作类型识别方法,其特征在于,所述方法包括: (1)构建基于盲源分离的数字图像操作链的操作分离模型; (2)依据数字图像特征的相关程度,初步识别篡改操作类型; (3)依据Dempster-Shafer证据理论,估计篡改操作置信区间,精确识别篡改操作类型。 2.根据权利要求1所述的基于混淆处理效应分离的图像操作链中操作类型识别方法,其特征在于,所述构建基于盲源分离的数字图像操作链的操作分离模型,具体包括:对从数字图像中提取的混合特征进行矩阵变换,获取基于盲源分离的数字图像操作链的操作分离模型,并依据该模型对数字图像操作链的混淆处理效应分离,获取单篡改操作的特征估计,为单篡改操作类型识别提供直接证据。 3.根据权利要求1或2所述的基于混淆处理效应分离的图像操作链中操作类型识别方法,其特征在于,所述依据数字图像特征的相关程度,初步识别篡改操作类型,具体包括:度量经历多重篡改后的数字图像的混合特征与依据所述操作分离模型获取的某篡改操作特征之间的相关性,得到两者之间的相关程度,初步判断所述待测图像是否经历该操作篡改伪造以及可能经历的篡改操作类型。 4.根据权利要求1或2所述的基于混淆处理效应分离的图像操作链中操作类型识别方法,其特征在于,所述依据Dempster-Shafer证据理论,估计篡改操作置信区间,精确识别篡改操作类型,具体包括: 联合单篡改操作取证的多个检测算法,挖掘不同图像特征;通过Dempster-Shafer证据理论的合成规则的决策融合,依据多个检测算法的融合结果,获得篡改操作置信区间估计,精确判别图像操作链中篡改操作类型。 2
一、经济背景 CAPM曾一度是资产定价的主要依据,引发了很多学者对其的实证检验。但是从结果来看,期望收益与市场beta并不相关,CAPM也便遭到了人们的质疑。 正是在这种对传统单因素beta资产定价的挑战下,出现了异象研究。 异象研究:人们发现,股票的平均收益与上市公司的财务特征相关,公司特征对截面收益的解释往往比传统单因素beta模型更加有力。 之后,人们进行了分析。 有的学者就提出,规模效应,size effect,小公司的股票平均收益率高于大公司股票。 还有的学者就提出,账面市值比效应,B/M effect,高账面市值比的股票比地账面市值比的股票有显著高的收益率。 除此之外,还有例如D/E债务权益比效应,E/P盈余价格比效应之类的解释。 二、B/M effect 学术界对于各种异象的研究主要集中于“BM 效应”产生的原因,即为什么高BM 的股票比低BM 的股票具有更高的收益。目前,主要有如下四种观点: 1.有的学者认为B/M 效应只是特定样本在特定检验期内才存在,是数据挖掘的结果。通俗来说,它就是个概率事件,样本局限性:选择性偏差造成BM 效应的存在。但肯尼思·弗伦奇等人通过检验美国之外的股市或拉长检验期后,仍发现B/M 效应显著存在,从而否定了此种解释。 2. 第二种观点(Fama 和French ,1992 ,1993 ,1996) 认为,B/M 代表的是一种风险因素———财务困境风险。具有困境的公司对商业周期因素如信贷条件的改变更加敏感,而高B/M 公司通常是盈利和销售等基本面表现不佳的公司,财务状况较脆弱,因此比低BM 公司具有更高风险。可见,高B/M公司所获得的高收益只是对其本身高风险的补偿,并非所谓不可解释的“异象”。—三因素模型前身。 同时,为了验证自己的结论并不是由于样本选择的原因,他们从国际股票市场的角度进行了考察,发现B/M效应在覆盖四大洲的13个主要国家的股票收益中同时出现,证明了这一现象并不仅局限于美国,否认了B/M效应的质疑。 3. 第三种观点认为,B/M 效应的出现是由于投资者对公司基本面过度反应造成的。高B/M 公司通常是基本面不佳的公司,因此投资者对高B/M公司的股票价值非理性地低估;低B/M公司则是基本面较好的公司,因此投资者对低B/M 公司的股票价值非理性地高估。可见,投资者通常对基本面不佳的公司过度悲观,对基本面优良的公司过度乐观。当过度反应得到纠正后,高BM 公司将比低BM 公司具有更高的收益。 4. 第四种观点也就是特征模型。 (Daniel 和Titman ,1997) 也认为BM 和SIZE 不是风险因素, 实际上,BM 和SIZE 代表的是公司的特征,简称“特征因素”—其代表投资者偏好,并决定收益的高低,而仅仅是特征本身决定了股票的预期收益率。 高B/M 公司由于基本面较差而价值被低估,故称“价值股”;反之,低B/M 公司由于基本面较好而价值被高估,故称“成长股”。 由于投资者偏好于持有基本面较好的成长股,而厌恶持有基本面不佳的价值股,结果导致高B/M 公司具有较高收益。 本文重点主要在论述三因素模型,并与特征模型进行了比较,证明了三因素模型的优势。 三、对三因素模型论述。 第一部分主要是在风险模型中对整体市场,公司规模以及价值溢价的一个整体说明。