
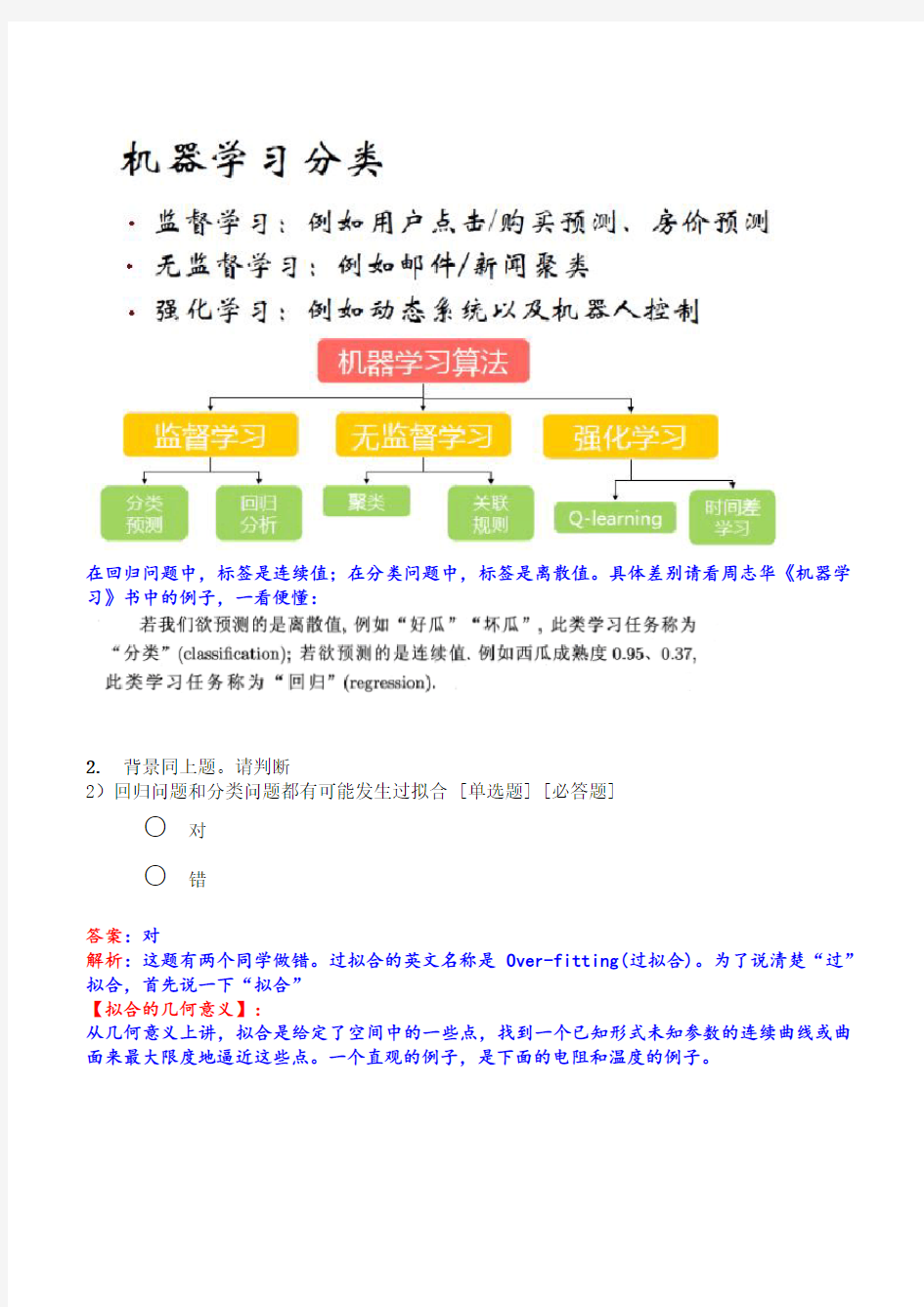
《机器学习》练习题与解答
1.小刚去应聘某互联网公司的算法工程师,面试官问他“回归和分类有什么相同点和不同点”,他说了以下言论,请逐条判断是否准确。
1)回归和分类都是有监督学习问题
[单选题] [必答题]
○对
○错
参考答案:对。
解析:这道题只有一个同学做错。本题考察有监督学习的概念。有监督学习是从标签化训练数据集中推断出函数的机器学习任务。
有监督学习和无监督学习的区别是:
机器学习算法的图谱如下:
在回归问题中,标签是连续值;在分类问题中,标签是离散值。具体差别请看周志华《机器学习》书中的例子,一看便懂:
2.背景同上题。请判断
2)回归问题和分类问题都有可能发生过拟合 [单选题] [必答题]
○对
○错
答案:对
解析:这题有两个同学做错。过拟合的英文名称是 Over-fitting(过拟合)。为了说清楚“过”拟合,首先说一下“拟合”
【拟合的几何意义】:
从几何意义上讲,拟合是给定了空间中的一些点,找到一个已知形式未知参数的连续曲线或曲面来最大限度地逼近这些点。一个直观的例子,是下面的电阻和温度的例子。
我们知道在物理学中,电阻和温度是线性的关系,也就是R=at+b。现在我们有一系列关于“温度”和“电阻”的测量值。一个最简单的思路,取两组测量值,解一个线性方程组,就可以求出系数a、b了!但是理想是丰满的,现实是残酷的!由于测量误差等的存在,我们每次测量得到的温度值和电阻值都是有误差的!因此,为了提高测量精度,我们会测量多次,得到多组的值,这样就相当于得到二维平面上的多个点,我们的目标是寻找一条直线,让这条直线尽可能地接近各个测量得到的点。
拟合的数学意义:
在数学的意义上,所谓拟合(fit)是指已知某函数的若干离散函数值{f1,f2,…,fn}(未必都是准确值,有个别可能是近似甚至错误值),通过调整该函数中若干待定系数f(λ1, λ2,…,λn),使得该函数与已知点集的差别(最小二乘意义)最小。
【说说过拟合】
古人云“过犹不及”。所谓“过”拟合,顾名思义,就是在学习的集合(也就是训练集)上拟合的很不错,但是有点过头了,什么意思?他能够在学过的数据上判断的很准,但是如果再扔给它一系列新的没学习过的数据,它判断的非常差!比如古时候有个教书先生教小明写数字,“一”字是一横,“二”字是两横,“三”字是三横。然后,小明说,老师你不用教我写数字了,我都会写。老师很惊讶,那你说“万”字怎么写,结果小明在纸上写下了无数个“横”。。用台湾大学林轩田老师的话说,过拟合是“书呆子”,“钻牛角尖”。如果用过于复杂的模型来刻画简单的问题,就有可能得到“聪明过头”的结果。比如下面预测房子的价格(price)和size之间关系的问题(来源于andrew ng的ppt)
通过五组数据,我们通过肉眼直观地看,可以初步判断房屋的价格和size之间是二次函数的关系,也就是中间这幅图所拟合的情况。而右边这幅图中,自作聪明地用了一个四次函数来拟和这五组数据,虽然在已知的五个数据上都是100%准确,却得出了“当房子的size大于某个值时房子的价格会随着房屋面积增大而越来越低”这样的荒谬结论!这样的是过拟合。左边这个用一条直线来拟合但是拟合的误差很大也不置信,这叫“欠拟合”。
在周志华老师的书中,举的例子是这样的:
发现了没有?周志华老师用的是“是不是树叶”这样的分类问题举例,andrew ng用的是“房价和房屋面积的关系”这样的回归问题举例。这说明,分类和回归都有可能过拟合。
3.背景同上题。请判断
3)一般来说,回归不用在分类问题上,但是也有特殊情况,比如logistic 回归可以用来解决0/1分类问题 [单选题] [必答题]
○对
○错
答案:对
解析:Logistic回归是一种非常高效的分类器。它不仅可以预测样本的类别,还可以计算出分
类的概率信息,在一线互联网公司中广泛的使用,比如应用于CTR预估这样的问题中。这里我们不详细说明其原理,后续课程会讲到。很多人对它的名字会产生疑问,挂着“回归”的头,卖的是“分类”的肉,别扭的慌。
其实我们不用纠结它到底是“回归”,还是“分类”,非得二选一。可以参考一下百度百科关于“logistic回归”的词条
其中举了一个富士康员工“自杀的日期”与“累计自杀人数”之间关系的例子,并通过logistic 回归分析来拟合出一条曲线。这说明logistic回归本身也有一定的解决“回归”问题的能力,只是工业界都用它来解决分类问题。
4.背景同上题。请判断
4)对回归问题和分类问题的评价最常用的指标都是准确率和召回率 [单选题] [必答题]○对
○错
答案:错
解析:本题有四个同学选错。这道题的用意是提醒大家注意,对回归问题的评价指标通常并不是准确率和召回率,从“房价与房屋面积之间关系预测”这个例子来说,一个已知数据点离预测的曲线之间的距离是多少时能够判定为“准确”,距离为多少时判定为“不准确”?没办法区别。准确率对于度量回归问题的效果其实并不适用。回归问题的误差一般通过“误差”来评估,比如RMSE等。在滴滴大数据竞赛中用的是这样的一个指标
很显然不是用的“准确率”来评定。
5.背景同上题。请判断
5)输出变量为有限个离散变量的预测问题是回归问题;
输出变量为连续变量的预测问题是分类问题; [单选题] [必答题]
○对
○错
答案:错
解析:说反了
6.向量x=[1,2,3,4,-9,0]的L1范数是多少 [单选题] [必答题]
○ 1
○19
○ 6
○sqrt(111)
答案:19
解析:这题错了三个同学,其实很简单。请记住:
L0范数是指向量中非0的元素的个数。
L1范数是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。
L2范数是指向量各元素的平方和然后求平方根。
7.小明参加某公司的大数据竞赛,他的成绩在大赛排行榜上原本居于前二十,后来他保持特征不变,对原来的模型做了1天的调参,将自己的模型在自己本地测试集上的准确率提升了5%,然后他信心满满地将新模型的预测结果更新到了大赛官网上,结果懊恼地发现自己的新模型在大赛官方的测试集上准确率反而下降了。对此,他的朋友们展开了讨论,请将说法正确的选项打勾(不定项选择题) [多选题] [必答题]
□小芳:从机器学习理论的角度,这样的情况不应该发生,快去找大赛组委会反应
□小刚:你这个有可能是由于过拟合导致的
□小月:早就和你说过了,乖乖使用默认的参数就好了,调参是不可能有收益的
□小平:你可以考虑一下,使用交叉验证来验证一下是否发生了过拟合
答案:选择第二项、第四项
解析:大家都同意第二项,是过拟合导致的。设置第四项的目的,是提醒大家,交叉验证可以用于防止模型过于复杂而引起的过拟合。具体什么是交叉验证,请期待后续课程。
8.关于L1正则和L2正则下面的说法正确的是 [多选题] [必答题]
□L2范数可以防止过拟合,提升模型的泛化能力。但L1正则做不到这一点
□L2正则化标识各个参数的平方的和的开方值。
□L2正则化有个名称叫“Lasso regularization”
□L1范数会使权值稀疏
答案:第二项、第四项
解析:同第6题
9.判断这个说法对不对:给定 n 个数据点,如果其中一半用于训练,另一半用于测试,则训练误差和测试误差之间的差别会随着 n的增加而减小 [单选题] [必答题]
○对
○错
答案:对
解析:训练数据越多,拟合度越好,训练误差和测试误差距离自然越小
八卦:亲们,这道题曾经出现在《百度2016研发工程师笔试题》。
咱们有四个同学做错。
10.Consider a problem of building an online image advertisement system that shows the users the most relevant images. What features can you choose to use? [单选题] [必答题]
○concrete, abstract
○concrete, raw, abstract
○concrete, raw
○concrete
答案:B
解析:本题源于林轩田《机器学习基石》课件,给在线图片广告系统挑选特征。
concrete user features,
raw image features,and maybe abstract user/image IDs
大致理解一下特征的几种类型,请做错的同学去看一下林轩田老师的视频
11.【附加题】考虑回归一个正则化回归问题。在下图中给出了惩罚函数为二次正则函数,当正则化参数C取不同值时,在训练集和测试集上的log似然(mean log-probability)。请判断这个说法是否正确:随着C的增加,图中训练集上的log似然永远不会增加 [单选题] [必答题]
○对
○错
答案:对
第一章机器视觉系统构成与关键技术 1、机器视觉系统一般由哪几部分组成?机器视觉系统应用的核心目标是什么?主要的分 成几部分实现? 用机器来延伸或代替人眼对事物做测量、定位和判断的装置。组成:光源、场景、摄像机、图像卡、计算机。用机器来延伸或代替人眼对事物做测量、定位和判断。三部分:图像的获取、图像的处理和分析、输出或显示。 2、图像是什么?有那些方法可以得到图像? 图像是人对视觉感知的物质再现。光学设备获取或人为创作。 3、采样和量化是什么含义? 数字化坐标值称为取样,数字化幅度值称为量化。采样指空间上或时域上连续的图像(模拟图像)变换成离散采样点(像素)集合的操作;量化指把采样后所得的各像素的灰度值从模拟量到离散量的转换。采样和量化实现了图像的数字化。 4、图像的灰度变换是什么含义?请阐述图像反色算法原理? 灰度变换指根据某种目标条件按照一定变换关系逐点改变原图像中每一个像素灰度值,从而改善画质,使图像的显示效果更加清晰的方法。对于彩色图像的R、G、B各彩色分量取反。 第二章数字图像处理技术基础 1、对人类而言,颜色是什么?一幅彩色图像使用RGB色彩空间是如何定义的?24位真彩 色,有多少种颜色? 对人类而言,在人类的可见光范围内,人眼对不同波长或频率的光的主观感知称为颜色。 一幅图像的每个像素点由24位编码的RGB 值表示:使用三个8位无符号整数(0 到255)表示红色、绿色和蓝色的强度。256*256*256=16,777,216种颜色。 2、红、绿、蓝三种颜色为互补色,光照在物体上,物体只反射与本身颜色相同的色光而吸 收互补色的光。一束白光照到绿色物体上,人类看到绿色是因为? 该物体吸收了其他颜色的可见光,而主要反射绿光,所以看到绿色。 3、成像系统的动态范围是什么含义? 动态范围最早是信号系统的概念,一个信号系统的动态范围被定义成最大不失真电平和噪声电平的差。而在实际用途中,多用对数和比值来表示一个信号系统的动态范围,比如在音频工程中,一个放大器的动态范围可以表示为: D = lg(Power_max / Power_min)×20; 对于一个底片扫描仪,动态范围是扫描仪能记录原稿的灰度调范围。即原稿最暗点的密度(Dmax)和最亮处密度值(Dmin)的差值。 我们已经知道对于一个胶片的密度公式为D = lg(Io/I)。那么假设有一张胶片,扫描仪向其投射了1000单位的光,最后在共有96%的光通过胶片的明亮(银盐较薄)部分,而在胶片的较厚的部分只通过了大约4%的光。那么前者的密度为: Dmin=lg(1000/960)= 0.02; 后者的密度为: Dmax=lg(1000/40)= 1.40 那么我们说动态范围为:D=Dmax-Dmin=1.40-0.02=1.38。
2010年春硕士研究生机器学习试题 下列各题每个大题10分,共8道大题,卷面总分80分 注意:在给出算法时,非标准(自己设计的)部分应给出说明。特别是自己设置的参数及变量的意义要说明。 1.下面是一个例子集。其中,三个正例,一个反例。“P”为正例、“N”为反例。这些例子 。 其中:“产地”的值域为(Japan,USA)、“生产商”的值域为(Honda, Chrysler )、“颜色”的值域为(Blue ,Red )、“年代”的值域为(1980,1990 )。这里规定“假设”的形式为4个属性值约束的合取;每个约束可以为:一个特定值(比如J a p a n、Blue等)、?(表示接受任意值)和 (表示拒绝所有值)。例如,下面假设: (J a p a n,?,R e d,?) 表示日本生产的、红色的汽车。 1)根据上述提供的训练样例和假设表示,手动执行候选消除算法。特别是要写出处理了每一个训练样例后变型空间的特殊和一般边界; 2)列出最后形成的变型空间中的所有假设。 2. 写出ID3算法。(要求:除标准ID3算法外,要加入“未知属性值”和“过适合”两种情况的处理)。 3. 给出一个求最小属性子集的算法。 4. 给定训练例子集如下表。依据给定的训练例子,使用朴素贝叶斯分类器进行分类。 给定类别未知例子<高度=矮,头发=红,眼睛=兰>,计算这个例子的类别。(计算类别时要
5. 给定线性函数n n x w x w w x f +++= 110)(?及误差定义 ∑∈-=D x x f x f E 2 ))(?)((2 1 其中,i x 是例子x 的第i 个属性值,f(x)是目标函数,D 是训练例子集合。请给出一个算法, 这个算法能求出一组Wi 值,使得线性函数)(?x f 逼近目标函数f(x)(本题要求写出算法的步骤,算法步骤的详细程度要符合书中算法的标准)。 6. 给定例子集(如下表),要求:1)用平面图直观画出例子的分布;2)给出一种规则好坏 7. 简述题 1) 简述“机器发现”的三个定律; 2) KBANN 、EBNN 、FOCL 是分析学习和归纳学习结合的三个算法。简述这三个算法与单纯的 归纳学习方法相比,分别有什么区别或优点。 8. 关于模式定理 1) 分析“选择步”对群体遗传的影响:令m(s,t)是群体中模式s 在时间t (或第t 代)的 实例数量,f(h)是个体h 的适应度,)(t f 是时间t (或第t 代)群体中所有个体的平均 适应度,n 为群体中个体的总数量,),(?t s u 是时间t (或第t 代)群体中模式s 的实例的平均适应度。在“选择步”中,每个个体被选中的概率为Pr(h)(Pr(h)的计算见公式 (1)),如果共进行了n 次独立选择,请给出在第(t+1)代(即下一代)的群体中,模式s 的实例存在的期望数量E[m(s,t+1)](要求给出分析过程)。 ∑ == n i i h f h f h 1 ) () ()Pr( (1) 2) 分析“变异步”对群体遗传的影响:令m(s,t)是群体中模式s 在时间t (或第t 代)的实例数量。设在模式s 中有R(s)个确定位,变异操作以概率Pm 选择一位并改变这位上的值。如果只考虑变异步对群体遗传的影响,请给出在第(t+1)代(即下一代)的群体
本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除! == 本文为word格式,下载后可方便编辑和修改! == 机器视觉实验报告 实验报告 课程名称: 班级: 姓名: 学号: 实验时间: 实验一 一.实验名称 Matlab软件的使用 二.实验内容 1.打开MATLAB软件,了解菜单栏、工具栏、状态栏、命令窗口等; 2.了解帮助文档help中演示内容demo有哪些; 3.找到工具箱类里面的Image Processing工具箱,并进行初步学习,为后续实验做准备。 三.实验原理: 通过matlab工具箱来进行图像处理 四.实验步骤 1. 双击桌面上的matlab图标,打开matlab软件 2. 了解菜单栏、工具栏、状态栏、命令窗口等
如下图1-1所示 图 1-1 3. 了解帮助文档help中演示内容demo有哪些; 步骤如下图1-2 图1-2 打开help内容demo后,里面的工具箱如图所示。 图1-3 4. 找到工具箱类里面的Image Processing工具箱,并进行初步学习,为后续实验做准备。找到并打开Image Processing工具箱,窗口如图1-4 ,图1-5所示 图 1-4 图 1-5 五.实验总结和分析 通过实验前的理论准备和老师的讲解,对matlab有了一定认识,在实验中,了解了实际操作中的步骤以及matlab中的图像处理工具箱及其功能,为后续的学习打下了基础,并把理论与实际相结合,更加深入的理解图像处理。 实验二 一.实验名称 图像的增强技术 二.实验内容 1.了解图像增强技术/方法的原理; 2.利用matlab软件,以某一用途为例,实现图像的增强; 3.通过程序的调试,初步了解图像处理命令的使用方法。 三.实验原理: 通过matlab工具箱来进行图像处理,通过输入MATLAB可以识别的语言命令来让MATLAB执行命令,实现图像的增强。
机器学习复习重点 判断题(共30分,每题2分,打√或×) 1、如果问题本身就是非线性问题,使用支持向量机(SVM )是难以取得好的预测效果的。(×) 2、只要使用的半监督学习方法合适,利用100个标记样本和1000个无标记样本的预测效果,同样可以达到利用1100个标记样本使用监督学习方法的预测效果。(×) 3、深度学习中应该尽量避免过拟合。(×) 4、在随机森林Bagging 过程中,每次选取的特征个数为m ,m 的值过大会降低树之间的关联性和单棵树的分类能力。(×) 5、决策树学习的结果,是得到一组规则集,且其中的规则是可以解释的。(√) 6、在FCM 聚类算法中交替迭代优化目标函数的方法不一定得到最优解。(√) 7、在流形学习ISOMAP 中,测地距离即是欧氏距离。(×) 8、贝叶斯决策实质上是按后验概率进行决策的。(√) 9、非参数估计需要较大数量的样本才能取得较好的估计结果。(√) 10、不需要显示定义特征是深度学习的优势之一。(√) 判断题为反扣分题目;答对得2分,不答得0分,答错得-2分; 问答题(共60分) 1、 从样本集推断总体概率分布的方法可以归结为哪几种类型?请分别简要解释之。 监督参数估计:样本所属的类别和各类的类条件概率密度函数的形式是已知的,而表征概率密度函数的某些参数是未知的。 非监督参数估计:已知总体概率密度函数形式,但未知样本所属类别,要求判断出概率密度函数的某些参数。 非参数估计:已知样本所属类别,但未知各类的概率密度函数的形式,要求我们直接推断概率密度函数本身。 2、什么是k-近邻算法? k-近邻算法的基本思想(3分):未知样本x ,根据度量公式得到距离x 最近的k 个样本。统计这k 个样本点中,各个类别的数量。数量最多的样本是什么类别,我们就把这个数据点定为什么类别。 ,argmax (),K m n n n x m k k n ω==是个样本中第类的样本个数 m 为所求类别。 3、 决策树的C4.5算法与ID3算法相比主要有哪些方面的改进? 1) 用信息增益比来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足; 2) 增加了后剪枝操作。 3) 能够完成对连续属性的离散化处理;
什么是机器视觉技术?试论述其基本概念和目的。答:机器视觉技术是是一门涉及人工智能、神经生物学、心理物理学、计算机科学、图像处理、模式识别等诸多领域的交叉学科。机器视觉主要用计算机来模拟人的视觉功能,从客观事物的图像中提取信息,进行处理并加以理解,最终用于实际检测、测量和控制。机器视觉技术最大的特点是速度快、信息量大、功能多。机器视觉是用机器代替人眼来完成观测和判断,常用于大批量生产过程汇总的产品质量检测,不适合人的危险环境和人眼视觉难以满足的场合。机器视觉可以大大提高检测精度和速度,从而提高生产效率,并且可以避免人眼视觉检测所带来的偏差和误差。机器视觉系统一般由哪几部分组成?试详细论述之。答:机器视觉系统主要包括三大部分:图像获取、图像处理和识别、输出显示或控制。图像获取:是将被检测物体的可视化图像和内在特征转换成能被计算机处理的一系列数据。 该部分主要包括,照明系统、图像聚焦光学系统、图像敏感元件(主要是CCD和CMOS采 集物体影像。 图像处理和识别:视觉信息的处理主要包括滤波去噪、图像增强、平滑、边缘锐化、分割、图像识别与理解等内容。经过图像处理后,图像的质量得到提高,既改善了图像的视觉效果又便于计算机对图像进行分析、处理和识别。 输出显示或控制:主要是将分析结果输出到显示器或控制机构等输出设备。试论述机器视觉技术的现状和发展前景。 答:。机器视觉技术的现状:机器视觉是近20?30年出现的新技术,由于其固有的柔性好、 非接触、快速等特点,在各个领域得到很广泛的应用,如航空航天、工业、军事、民用等等领域。 发展前景:随着光学传感器、信息技术、信号处理、人工智能、模式识别研究的不断深入和计算机性价比的不断提高,机器视觉技术越来越成熟,特别是市面上已经有针对机器视觉系统开发的企业提供配套的软硬件服务,相信越来越多的客户会选择机器视觉系统代替人力进行工作,既便于管理又节省了成本。价格持续下降、功能逐渐增多、成品小型化、集成产品增多。 机器视觉技术在很多领域已得到广泛的应用。请给出机器视觉技术应用的三个实例并叙述之。答:一、在激光焊接中的应用。通过机器视觉系统,实时跟踪焊缝位置,实现实时控制,防止偏离焊缝,造成产品报废。 二、在火车轮对检测中的应用,通过机器视觉系统抓拍轮对图像,找出轮对中有缺陷的轮对,提高检测精度和速度,提高效率。 三、大批量生产过程中的质量检查,通过机器视觉系统,对生产过程中的产品进行质量检查 跟踪,提高生产效率和准确度。 什么是傅里叶变换,分别绘出一维和二维的连续及离散傅里叶变换的数学表达式。论述图像傅立叶变换的基本概念、作用和目的。 答:傅里叶变换是将时域信号分解为不同频率的正弦信号或余弦函数叠加之和。一维连续函数的傅里叶变换为:一维离散傅里叶变换为:二维连续函数的傅里叶变换为:二维离散傅里叶变换为: 图像傅立叶变换的基本概念:傅立叶变换是数字图像处理技术的基础,其通过在时空域和频率域来回切换图像,对图像的信息特征进行提取和分析,简化了计算工作量,被喻为描述图像信息的第二种语言,广泛应用于图像变换,图像编码与压缩,图像分割,图像重建等。作用和目的:图像的频率是表征图像中灰度变化剧烈程度的指标,是灰度在平面空间上的梯度。傅立叶变换的物理意义是将图像的灰度分布函数变换为图像的频率分布函数,傅立叶逆变换是将图像的频率分布函数变换为灰度分布函数。图像灰度变换主要有哪几种形式?各自的特点和作用是什么? 答:灰度变换:基于点操作,将每一个像素的灰度值按照一定的数学变换公式转换为一个新的灰度值。灰度变换是图像增强的一种重要手段,它可以使图像动态范围加大,使图像的对比度扩展,
模式识别与机器学习期末考查 试卷 研究生姓名:入学年份:导师姓名:试题1:简述模式识别与机器学习研究的共同问题和各自的研究侧重点。 答:(1)模式识别是研究用计算机来实现人类的模式识别能力的一门学科,是指对表征事物或现象的各种形式的信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程。主要集中在两方面,一是研究生物体(包括人)是如何感知客观事物的,二是在给定的任务下,如何用计算机实现识别的理论和方法。机器学习则是一门研究怎样用计算机来模拟或实现人类学习活动的学科,是研究如何使机器通过识别和利用现有知识来获取新知识和新技能。主要体现以下三方面:一是人类学习过程的认知模型;二是通用学习算法;三是构造面向任务的专用学习系统的方法。两者关心的很多共同问题,如:分类、聚类、特征选择、信息融合等,这两个领域的界限越来越模糊。机器学习和模式识别的理论和方法可用来解决很多机器感知和信息处理的问题,其中包括图像/ 视频分析(文本、语音、印刷、手写)文档分析、信息检索和网络搜索等。 (2)机器学习和模式识别是分别从计算机科学和工程的角度发展起来的,各自的研究侧重点也不同。模式识别的目标就是分类,为了提高分类器的性能,可能会用到机器学习算法。而机器学习的目标是通过学习提高系统性能,分类只是其最简单的要求,其研究更
侧重于理论,包括泛化效果、收敛性等。模式识别技术相对比较成熟了,而机器学习中一些方法还没有理论基础,只是实验效果比较好。许多算法他们都在研究,但是研究的目标却不同。如在模式识别中研究所关心的就是其对人类效果的提高,偏工程。而在机器学习中则更侧重于其性能上的理论证明。试题2:列出在模式识别与机器学习中的常用算法及其优缺点。答:(1)K 近邻法算法作为一种非参数的分类算法,它已经广泛应用于分类、 回归和模式识别等。在应用算法解决问题的时候,要注意的两个方面是样本权重和特征权重。 优缺点:非常有效,实现简单,分类效果好。样本小时误差难控制,存储所有样本,需要较大存储空间,对于大样本的计算量大。(2)贝叶斯决策法 贝叶斯决策法是以期望值为标准的分析法,是决策者在处理 风险型问题时常常使用的方法。 优缺点:由于在生活当中许多自然现象和生产问题都是难以完全准确预测的,因此决策者在采取相应的决策时总会带有一定的风险。贝叶斯决策法就是将各因素发生某种变动引起结果变动的概率凭统计资料或凭经验主观地假设,然后进一步对期望值进行分析,由于此概率并不能证实其客观性,故往往是主观的和人为的概率,本身带有一定的风险性和不肯定性。虽然用期望的大小进行判断有一些风险,但仍可以认为贝叶斯决策是一种兼科学性和实效性于一身的比较完善的用于解决风险型决策问题的方法,在实际中能够广泛应
机械系统动力学 简化串联机器人的运动学与动力学仿真分析 学院:机械工程学院 专业:机械设计制造 及其自动化 学生姓名: 学号: 指导教师: 完成日期: 2015.01.09
摘要 在机器人研究中,串联机器人研究得较为成熟,其具有结构简单、成本低、控制简单、运动空间大等优点,已成功应用于很多领域。本文在ADAMS 中用连杆模拟两自由度的串联机器人(机械臂),对其分别进行运动学分析、动力学分析。得出该机构在给出工作条件下的位移、速度、加速度曲线和关节末端的运动轨迹。 关键词:机器人;ADAMS;曲线;轨迹 一、ADAMS软件简介 ADAMS,即机械系统动力学自动分析(Automatic Dynamic Analysis of Mechanical Systems),该软件是美国MDI公司(Mechanical Dynamics Inc.) (现已并入美国MSC公司)开发的虚拟样机分析软件。目前,ADAMS已经被全世界各行各业的数百家主要制造商采用。ADAMS软件使用交互式图形环境和零件库、约束库、力库,创建完全参数化的机械系统几何模型,其求解器采用多刚体系统动力学理论中的拉格朗日方程方法,建立系统动力学方程,对虚拟机械系统进行静力学、运动学和动力学分析,输出位移、速度、加速度和反作用力曲线。ADAMS软件的仿真可用于预测机械系统的性能、运动范围、碰撞检测、峰值载荷以及计算有限元的输入载荷等。 二、简化串联机器人的运动学仿真 (1)启动ADAMS/View。 在欢迎对话框中选择新建模型,模型取名为robot,并将单位设置为MMKS,然后单击OK。 (2)打开坐标系窗口。 按下F4键,或者单击菜单【View】→【Coordinate Window】后,打开坐标系窗口。当鼠标在图形区移动时,在坐标窗口中显示了当前鼠标所在位置的坐标值。
一、单选题 1、以下关于感知器算法与支持向量机算法说法有误的是 A. 由于支持向量机是基于所有训练数据寻找最大化间隔的超平面,而感知器算法却是相对随意的找一个分开两类的超平面,因此大多数时候,支持向量机画出的分类面往往比感知器算法好一些。 B.支持向量机是把所有训练数据都输入进计算机,让计算机解全局优化问题 C.感知器算法相比于支持向量机算法消耗的计算资源和内存资源更少,但是耗费的计算资源更多 D. 以上选项都正确 正确答案:C 2、假设你在训练一个线性回归模型,有下面两句话: 如果数据量较少,容易发生过拟合。 如果假设空间较小,容易发生过拟合。 关于这两句话,下列说法正确的是? A.1正确,2错误 B.1和2都错误 C.1和2都正确 D.1错误,2正确 正确答案:A 3、下面哪一项不是比较好的学习率衰减方法?t表示为epoch数。 α0 A.α=1 1+2?t α0 B. α= √t C. α=0.95tα0 D.α=e tα0
正确答案:D 4、你正在构建一个识别足球(y = 1)与篮球(y = 0)的二元分类器。你会使用哪一种激活函数用于输出层? A.ReLU B. tanh C.sigmoid D. Leaky ReLU 正确答案:C 5、假设你建立一个神经网络。你决定将权重和偏差初始化为零。 以下哪项陈述是正确的? A.第一个隐藏层中的每个神经元将在第一次迭代中执行相同的计算。但经过一次梯度下降迭代后,他们将会计算出不同的结果。 B.第一个隐藏层中的每个神经元节点将执行相同的计算。所以即使 经过多次梯度下降迭代后,层中的每个神经元节点都会计算出与其 他神经元节点相同的结果。 C.第一个隐藏层中的每一个神经元都会计算出相同的结果,但是不 同层的神经元会计算不同的结果。 D.即使在第一次迭代中,第一个隐藏层的神经元也会执行不同的计算,他们的参数将以各自方式进行更新。 正确答案:B 6、某个神经网络中所有隐藏层神经元使用tanh激活函数。那么如 果使用np.random.randn(…,…)* 1000将权重初始化为相对较大 的值。会发生什么? A.这不会对训练产生影响。只要随机初始化权重,梯度下降不受权 重大小的影响。
---------------------------------------------------------------最新资料推荐------------------------------------------------------ 机器视觉思考题及其答案 1.什么是机器视觉技术?试论述其基本概念和目的。 答:机器视觉技术是是一门涉及人工智能、神经生物学、心理物理学、计算机科学、图像处理、模式识别等诸多领域的交叉学科。 机器视觉主要用计算机来模拟人的视觉功能,从客观事物的图像中提取信息,进行处理并加以理解,最终用于实际检测、测量和控制。 机器视觉技术最大的特点是速度快、信息量大、功能多。 机器视觉是用机器代替人眼来完成观测和判断,常用于大批量生产过程汇总的产品质量检测,不适合人的危险环境和人眼视觉难以满足的场合。 机器视觉可以大大提高检测精度和速度,从而提高生产效率,并且可以避免人眼视觉检测所带来的偏差和误差。 2.机器视觉系统一般由哪几部分组成?试详细论述之。 答:机器视觉系统主要包括三大部分:图像获取、图像处理和识别、输出显示或控制。 图像获取:是将被检测物体的可视化图像和内在特征转换成能被计算机处理的一系列数据。 该部分主要包括,照明系统、图像聚焦光学系统、图像敏感元件(主要是 CCD 和 CMOS)采集物体影像。 图像处理和识别:视觉信息的处理主要包括滤波去噪、图像增强、 1/ 19
平滑、边缘锐化、分割、图像识别与理解等内容。 经过图像处理后,图像的质量得到提高,既改善了图像的视觉效果又便于计算机对图像进行分析、处理和识别。 输出显示或控制:主要是将分析结果输出到显示器或控制机构等输出
《机器学习》练习题与解答 1.小刚去应聘某互联网公司的算法工程师,面试官问他“回归和分类有什么相同点和不同点”,他说了以下言论,请逐条判断是否准确。 1)回归和分类都是有监督学习问题 [单选题] [必答题] ○对 ○错 参考答案:对。 解析:这道题只有一个同学做错。本题考察有监督学习的概念。有监督学习是从标签化训练数据集中推断出函数的机器学习任务。 有监督学习和无监督学习的区别是: 机器学习算法的图谱如下:
在回归问题中,标签是连续值;在分类问题中,标签是离散值。具体差别请看周志华《机器学习》书中的例子,一看便懂: 2.背景同上题。请判断 2)回归问题和分类问题都有可能发生过拟合 [单选题] [必答题] ○对 ○错 答案:对 解析:这题有两个同学做错。过拟合的英文名称是 Over-fitting(过拟合)。为了说清楚“过”拟合,首先说一下“拟合” 【拟合的几何意义】: 从几何意义上讲,拟合是给定了空间中的一些点,找到一个已知形式未知参数的连续曲线或曲面来最大限度地逼近这些点。一个直观的例子,是下面的电阻和温度的例子。
我们知道在物理学中,电阻和温度是线性的关系,也就是R=at+b。现在我们有一系列关于“温度”和“电阻”的测量值。一个最简单的思路,取两组测量值,解一个线性方程组,就可以求出系数a、b了!但是理想是丰满的,现实是残酷的!由于测量误差等的存在,我们每次测量得到的温度值和电阻值都是有误差的!因此,为了提高测量精度,我们会测量多次,得到多组的值,这样就相当于得到二维平面上的多个点,我们的目标是寻找一条直线,让这条直线尽可能地接近各个测量得到的点。 拟合的数学意义: 在数学的意义上,所谓拟合(fit)是指已知某函数的若干离散函数值{f1,f2,…,fn}(未必都是准确值,有个别可能是近似甚至错误值),通过调整该函数中若干待定系数f(λ1, λ2,…,λn),使得该函数与已知点集的差别(最小二乘意义)最小。 【说说过拟合】 古人云“过犹不及”。所谓“过”拟合,顾名思义,就是在学习的集合(也就是训练集)上拟合的很不错,但是有点过头了,什么意思?他能够在学过的数据上判断的很准,但是如果再扔给它一系列新的没学习过的数据,它判断的非常差!比如古时候有个教书先生教小明写数字,“一”字是一横,“二”字是两横,“三”字是三横。然后,小明说,老师你不用教我写数字了,我都会写。老师很惊讶,那你说“万”字怎么写,结果小明在纸上写下了无数个“横”。。用台湾大学林轩田老师的话说,过拟合是“书呆子”,“钻牛角尖”。如果用过于复杂的模型来刻画简单的问题,就有可能得到“聪明过头”的结果。比如下面预测房子的价格(price)和size之间关系的问题(来源于andrew ng的ppt)
机器学习期末试题 Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】
中国科学院大学 课程编号:712008Z? 试 题 专 用 纸 课程名称:机器学习 任课教师:卿来云 —————————————————————————————————————— ————————— 姓名 学号 成绩 一、基础题(共36分) 1、请描述极大似然估计MLE 和最大后验估计MAP 之间的区别。请解释为什么MLE 比MAP 更容易过拟合。(10分) 2、在年度百花奖评奖揭晓之前,一位教授问80个电影系的学生,谁将分别获得8个奖项(如最佳导演、最佳男女主角等)。评奖结果揭晓后,该教授计算每个学生的猜中率,同时也计算了所有80个学生投票的结果。他发现所有人投票结果几乎比任何一个学生的结果正确率都高。这种提高是偶然的吗请解释原因。(10分) 3、假设给定如右数据集,其中A 、B 、C 为二值随机变量,y 为待预测的二值变量。 (a) 对一个新的输入 A =0, B =0, C =1,朴素贝叶斯分类器将会怎样预测y (10分) (b) 假设你知道在给定类别的情况下 A 、 B 、 C 是独立的随机变量,那么其 他分类器(如Logstic 回归、SVM 分类器等)会比朴素贝叶斯分类器表现更好吗为什么(注意:与上面给的数据集没有关系。)(6分) 二、回归问题。(共24分) 现有N 个训练样本的数据集 (){}1,N i i i x y ==,其中,i i x y 为实数。 1. 我们首先用线性回归拟合数据。为了测试我们的线性回归模型,我们随机选择一些样 本作为训练样本,剩余样本作为测试样本。现在我们慢慢增加训练样本的数目,那么
机器视觉习题 一、证明题 1. 请证明:平面内共线四点的交比为射影变换不变量。 2.请证明:“仿射变换保持平行性”与“仿射变换将无穷远点变换为无穷远点”这两个命题是等价的。 3. 请证明:若某点的齐次坐标为123(,,)x x x ,非齐次坐标为(,)x y ,则有如下关系成立: 123 3 ,x x x y x x = = 4. 请证明:平面内过一点的线束比等于任一直线截该线束得到的共线四点的交比。 5. 设二维仿射变换的变换矩阵为: 11 121321 2223 31 32 33a a a T a a a a a a ?? ??=?????? 请证明必有31320a a ==。 6. 在视觉测量中,经常遇到A x =的齐次方程组形式 。证明上述方程组的解一 定是矩阵T A A 的最小特征值所对应的特征向量。 7. 请证明:平面上无穷远直线的方程可以表示为30x =。 8. 请证明:共线四点的交比是射影变换不变量。 9. 证明:仿射变换将无穷远点变换为无穷远点。 10. 证明:若平面上两点的齐次坐标分别为x ~和'~x ,则过该两点的直线可表示为: '~ ~~x x l ?= 11. 证明:仿射变换保持平行性
12.证明:若平面上两条直线分别为l ~和'~ l ,则该两条直线的交点可表示为: '~~~l l x ?= 二、简答题 1. 三维刚体变换的旋转矩阵R 为什么是正交的? 2. 在摄像机的线性标定中,加约束31=m 可以提高解算的稳定性。请说明该约束的含义? 3. 在Zhang 的平面靶标自由移动摄像机标定中,若平面靶标为等间隔正方形的棋盘格形状,则在这种情况下,即使正方形棋盘格的边长未精确已知,也不影响摄像机内部参数的标定。请说明为什么。 4. 在Tsai 的摄像机径向约束两步标定方法中,如何确定y T 的符号?并说明为什么可以这样确定。 5. 在双目立体匹配中,若极线约束未知,应如何利用极线约束更好地实现双目立体匹配。请给出实现步骤。 6. 请给出线结构光视觉传感器的几何本质解释。 7. 摄像机的标定已经完成。若已知空间两点A 和B 的距离,则可以确定A 和B 两点在摄像机坐标系下的三维坐标。请判断上述结论是否正确,并给出详细解释。 8. 请解释平行双目的三维测量模型中,视差D=0时的含义。 9. 基于平行纹理在摄像机上所成的像,如何确定在摄像机坐标系下,平行纹理所在空间平面的法向矢量? 10. 在基于基线长度的双目视觉传感器标定中,系数α的符号如何确定? 11. Hessian 矩阵的一维中心点提取中,要加判据011 ()[,]22x x -∈-,请解释为什 么? 12. 请给出双目视觉传感器极线约束表达式的几何含义。 13. 基于2D 平面靶标自由移动的摄像机标定中,若第二个位置的靶标平面平行 于第一个位置的靶标平面,则第二个位置的靶标平面与摄像机之间的二维摄
机器视觉实验报告
目录 一实验名称 (2) 二试验设备 (2) 三实验目的 (2) 四实验内容及工作原理 (2) (一)kinect for windows (2) (二)手持式自定位三维激光扫描仪 (3) (三)柔性三坐标测量仪 (9) (四)双面结构光 (10) 总结与展望 (14) 参考文献 (16)
《机器视觉》实验报告 一、实验名称 对kinect for windows、三维激光扫描仪、柔性三坐标测量仪和双面结构光等设备结构功能的认识。 二、实验设备 kinect for windows、三维激光扫描仪、柔性三坐标测量仪、双面结构光。 三、实验目的 让同学们对机器视觉平时所使用的仪器设备以及机器视觉在实际运用中的具体实现过程有一定的了解。熟悉各种设备的结构功能和操作方法,以便于进行二次开发。其次,深化同学们对机器视觉系统的认识,拓宽同学们的知识面,以便于同学们后续的学习。 四、实验内容及工作原理 (一)kinect for windows 1.Kinect简介 Kinectfor Xbox 360,简称Kinect,是由微软开发,应用于Xbox 360 主机的周边设备。它让玩家不需要手持或踩踏控制器,而是使用语音指令或手势来操作Xbox360 的系统界面。它也能捕捉玩家全身上下的动作,用身体来进行游戏,带给玩家“免控制器的游戏与娱乐体验”。2012年2月1日,微软正式发布面向Windows系统的Kinect版本“Kinect for Windows”。 2.硬件组成 Kinect有三个镜头[1],如图1-1所示。中间的镜头是RGB 彩色摄影机,用来采集彩色图像。左右两边镜头则分别为红外线发射器和红外线CMOS 摄影机所构成的3D结构光深度感应器,用来采集深度数据(场景中物体到摄像头的距离)。彩色摄像头最大支持1280*960分辨率成像,红外摄像头最大支持640*480成像。Kinect还搭配了追焦技术,底座马达会随着对焦物体移动跟着转动。Kinect也内建阵列式麦克风,由四个麦克风同时收音,比对后消除杂音,并通过其采集声音进行语音识别和声源定位[2][3]。
机器人动力学研究的典型方法和应用 (燕山大学 机械工程学院) 摘 要:本文介绍了动力学分析的基础知识,总结了机器人动力学分析过程中比较常用的动力学分析的方法:牛顿—欧拉法、拉格朗日法、凯恩法、虚功原理法、微分几何原理法、旋量对偶数法、高斯方法等,并且介绍了各个方法的特点。并通过对PTl300型码垛机器人弹簧平衡机构动力学方法研究,详细分析了各个研究方法的优越性和方法的选择。 前 言:机器人动力学的目的是多方面的。机器人动力学主要是研究机器人机构的动力学。机器人机构包括机械结构和驱动装置,它是机器人的本体,也是机器人实现各种功能运动和操作任务的执行机构,同时也是机器人系统中被控制的对象。目前用计算机辅助方法建立和求解机器人机构的动力学模型是研究机器人动力学的主要方法。动力学研究的主要途径是建立和求解机器人的动力学模型。所谓动力学模指的是一组动力学方程(运动微分方程),把这样的模型作为研究力学和模拟运动的有效工具。 报告正文: (1)机器人动力学研究的方法 1)牛顿—欧拉法 应用牛顿—欧拉法来建立机器人机构的动力学方程,是指对质心的运动和转动分别用牛顿方程和欧拉方程。把机器人每个连杆(或称构件)看做一个刚体。如果已知连杆的表征质量分布和质心位置的惯量张量,那么,为了使连杆运动,必须使其加速或减速,这时所需的力和力矩是期望加速度和连杆质量及其分布的函数。牛顿—欧拉方程就表明力、力矩、惯性和加速度之间的相互关系。 若刚体的质量为m ,为使质心得到加速度a 所必须的作用在质心的力为F ,则按牛顿方程有:ma F = 为使刚体得到角速度ω、角加速度εω= 的转动,必须在刚体上作用一力矩M , 则按欧拉方程有:εωI I M += 式中,F 、a 、M 、ω、ε都是三维矢量;I 为刚体相对于原点通过质心并与刚
实训一机器视觉技术 (一)机器视觉技术 1.目标→图像摄取装置(CMOS和CCD)→图像信号→图像处理系统→数字化信号 2.机器视觉系统组成部分:光源、镜头、相机、图像处理单元、图 象处理软件、监视器、输入/输出控制单元。 3.特点:提高生产的柔性和自动化程度。 4.应用:生产流水线的检测系统(汽车零件、纸币印刷质量)、智能 交通管理系统、金相分析、医疗图象分析、无人机、机器人等。 (二)机器视觉实训系统 大恒DHLAB-BASE-PY-AF型平移式机器视觉教学实验平台 组成部分:相机安装模块、光源安装模块、平台方形载板、运动控制面板 由组成部分可推测,在机器视觉系统识别物体时,相机的焦距、光源的种类、光圈的大小、曝光时间的长短、载板移动速度的大小都将会对获取图像产生不同的影响。 平台:速度可调;手动或自动运动模式; 摄像头:紧凑型数字摄像机 感光元件:1/1.8”CCD;分辨率为1628(H)x 1236(V);像素尺寸4.4um x 4.4um。
(三)实训内容 【1】一维条码检测 1. 条形码(barcode)是将宽度不等的多个黑条和空白,按照一定的编码规则排列,用以表达一组信息的图形标识符,在商品流通、图书管理、邮政管理、银行系统等许多领域都得到广泛的应用。 2. 摄像机位置离检测平面大概47cm,光源离检测平面约36cm。 3. 实验步骤如下: ①放置条形码在载物平台上,使其处于镜头正下方; ②调整焦距、改变光圈大小,使物体清晰,对比度高、明暗适中; ③利用计算机软件控制相机对物体成像; ④通过改变曝光量、增益、光源、载物台移动速度,观察成像结果并加以比较。 ⑤结果如下: 条形码A 不开光圈、无速度曝光量增益识别结果 1000 0 没有图像 2500 0 不能识别 60000 0 正确识别 60000 5 正确识别 60000 6.4 错误识别 60000 7 没有图像条形码B 不开光圈、无速度曝光量增益识别结果 60000 2 没有图像 60000 6.4 正确识别 60000 20 错误识别 35000 6.4 不能识别 40000 6.4 正确识别 开光圈曝光量增益识别结果 60000 6.4 没有图像 2000 6.4 正确识别 速度曝光量增益识别结果 小60000 6.4 正确识别
中国科学院大学 课程编号:712008Z 试 题 专 用 纸 课程名称:机器学习 任课教师:卿来云 ——————————————————————————————————————————————— 姓名 学号 成绩 一、基础题(共36分) 1、请描述极大似然估计MLE 和最大后验估计MAP 之间的区别。请解释为什么MLE 比MAP 更容易过拟合。(10分) 2、在年度百花奖评奖揭晓之前,一位教授问80个电影系的学生,谁将分别获得8个奖项(如最佳导演、最佳 男女主角等)。评奖结果揭晓后,该教授计算每个学生的猜中率,同时也计算了所有80个学生投票的结果。他发现所有人投票结果几乎比任何一个学生的结果正确率都高。这种提高是偶然的吗?请解释原因。(10分) 3、假设给定如右数据集,其中A 、B 、C 为二值随机变量,y 为待预测的二值变量。 (a) 对一个新的输入A =0, B =0, C =1,朴素贝叶斯分类器将会怎样预测y ?(10分) (b) 假设你知道在给定类别的情况下A 、B 、C 是独立的随机变量,那么其他分类器(如Logstic 回归、SVM 分类器等)会比朴素贝叶斯分类器表现更好吗?为什么?(注意:与上面给的数据集没有关系。)(6分) 二、回归问题。(共24分) 现有N 个训练样本的数据集(){}1 ,N i i i x y ==D ,其中,i i x y 为实数。 1. 我们首先用线性回归拟合数据。为了测试我们的线性回归模型,我们随机选择一些样本作为训练样本,剩余样本 作为测试样本。现在我们慢慢增加训练样本的数目,那么随着训练样本数目的增加,平均训练误差和平均测试误差将会如何变化?为什么?(6分) 平均训练误差:A 、增加 B 、减小 平均测试误差:A 、增加 B 、减小 2. 给定如下图(a)所示数据。粗略看来这些数据不适合用线性回归模型表示。因此我们采用如下模型: ()exp i i i y wx ε=+,其中()~0,1i N ε。假设我们采用极大似然估计w ,请给出log 似然函数并给出w 的估计。 (8分) 3. 给定如下图(b)所示的数据。从图中我们可以看出该数据集有一些噪声,请设计一个对噪声鲁棒的线性回归模型, 并简要分析该模型为什么能对噪声鲁棒。(10分)
什么是机器视觉技术?试论述其基本概念和目的。 答:机器视觉技术是是一门涉及人工智能、神经生物学、心理物理学、计算机科学、图像处理、模式识别等诸多领域的交叉学科。机器视觉主要用计算机来模拟人的视觉功能,从客观事物的图像中提取信息,进行处理并加以理解,最终用于实际检测、测量和控制。机器视觉技术最大的特点是速度快、信息量大、功能多。 机器视觉是用机器代替人眼来完成观测和判断,常用于大批量生产过程汇总的产品质量检测,不适合人的危险环境和人眼视觉难以满足的场合。机器视觉可以大大提高检测精度和速度,从而提高生产效率,并且可以避免人眼视觉检测所带来的偏差和误差。 机器视觉系统一般由哪几部分组成?试详细论述之。 答:机器视觉系统主要包括三大部分:图像获取、图像处理和识别、输出显示或控制。 图像获取:是将被检测物体的可视化图像和内在特征转换成能被计算机处理的一系列数据。该部分主要包括,照明系统、图像聚焦光学系统、图像敏感元件(主要是CCD和CMOS)采集物体影像。 图像处理和识别:视觉信息的处理主要包括滤波去噪、图像增强、平滑、边缘锐化、分割、图像识别与理解等内容。经过图像处理后,图像的质量得到提高,既改善了图像的视觉效果又便于计算机对图像进行分析、处理和识别。 输出显示或控制:主要是将分析结果输出到显示器或控制机构等输出设备。 试论述机器视觉技术的现状和发展前景。 答:。机器视觉技术的现状:机器视觉是近20~30年出现的新技术,由于其固有的柔性好、非接触、快速等特点,在各个领域得到很广泛的应用,如航空航天、工业、军事、民用等等领域。 发展前景:随着光学传感器、信息技术、信号处理、人工智能、模式识别研究的不断深入和计算机性价比的不断提高,机器视觉技术越来越成熟,特别是市面上已经有针对机器视觉系统开发的企业提供配套的软硬件服务,相信越来越多的客户会选择机器视觉系统代替人力进行工作,既便于管理又节省了成本。价格持续下降、功能逐渐增多、成品小型化、集成产品增多。 机器视觉技术在很多领域已得到广泛的应用。请给出机器视觉技术应用的三个实例并叙述之。答:一、在激光焊接中的应用。通过机器视觉系统,实时跟踪焊缝位置,实现实时控制,防止偏离焊缝,造成产品报废。 二、在火车轮对检测中的应用,通过机器视觉系统抓拍轮对图像,找出轮对中有缺陷的轮对,提高检测精度和速度,提高效率。 三、大批量生产过程中的质量检查,通过机器视觉系统,对生产过程中的产品进行质量检查跟踪,提高生产效率和准确度。 什么是傅里叶变换,分别绘出一维和二维的连续及离散傅里叶变换的数学表达式。论述图像傅立叶变换的基本概念、作用和目的。 答:傅里叶变换是将时域信号分解为不同频率的正弦信号或余弦函数叠加之和。 一维连续函数的傅里叶变换为: 一维离散傅里叶变换为: 二维连续函数的傅里叶变换为: 二维离散傅里叶变换为: 图像傅立叶变换的基本概念:傅立叶变换是数字图像处理技术的基础,其通过在时空域和频率域来回切换图像,对图像的信息特征进行提取和分析,简化了计算工作量,被喻为描述图
《机器视觉应用实验报告》 姓 名 黄柱汉 学 号 201341304523 院 系 机械与汽车工程学院 专 业 仪器仪表工程 指导教师 全燕鸣 教授 2015年04月16日
华南理工大学实验报告 课程名称:机器视觉应用 机械与汽车工程学院系仪器仪表工程专业姓名黄柱汉 实验名称机器视觉应用实验日期2015.4.16 指导老师全燕鸣 一、实验目的 主要目的有以下几点: 1.实际搭建工业相机、光源、被摄物体图像获取系统,自选Labview或Matlab、 Halcon、Ni Vision软件平台,用打印标定板求解相机内外参数以及进行现场 系统标定; 2.进行一个具体实物体的摄像实验,经图像预处理和后处理,获得其主要形状 尺寸的测量(二维) 3.进行一个具体实物体的摄像实验,经图像预处理和后处理,识别出其表面缺 陷和定位。 二、实验原理 “机器视觉”是用机器代替人眼来进行识别、测量、判断等。机器视觉系统是通过摄像头将拍摄对象转换成图像信号,然后再交由图像分析系统进行分析、测量等。一个典型的机器视觉系统包括照明、镜头、相机、图像采集卡和视觉处理器5个部分。 HALCON是在世界范围内广泛使用的机器视觉软件,拥有满足各类机器视觉应用的完善开发库。HALCON也包含Blob分析、形态学、模式识别、测量、三维摄像机定标、双目立体视觉等杰出的高级算法。HALCON支持Linux和Windows,并且可以通过C、C++、C#、Visual Basic和Delphi语言访问。另外HALCON与硬件无关,支持大多数图像采集卡及带有DirectShow和IEEE 1394驱动的采集设备,用户可以利用其开放式结构快速开发图像处理和机器视觉应用软件,具有良好的跨平台移植性和较快的执行速度。 本实验包括对被测工件进行尺寸测量和表面缺陷检测。尺寸测量是通过使用机器视觉来对考察对象的尺寸、形状等信息进行度量;缺陷检测是通过机器视觉手段来分析零部件信息,从而判断其是否存在缺陷。