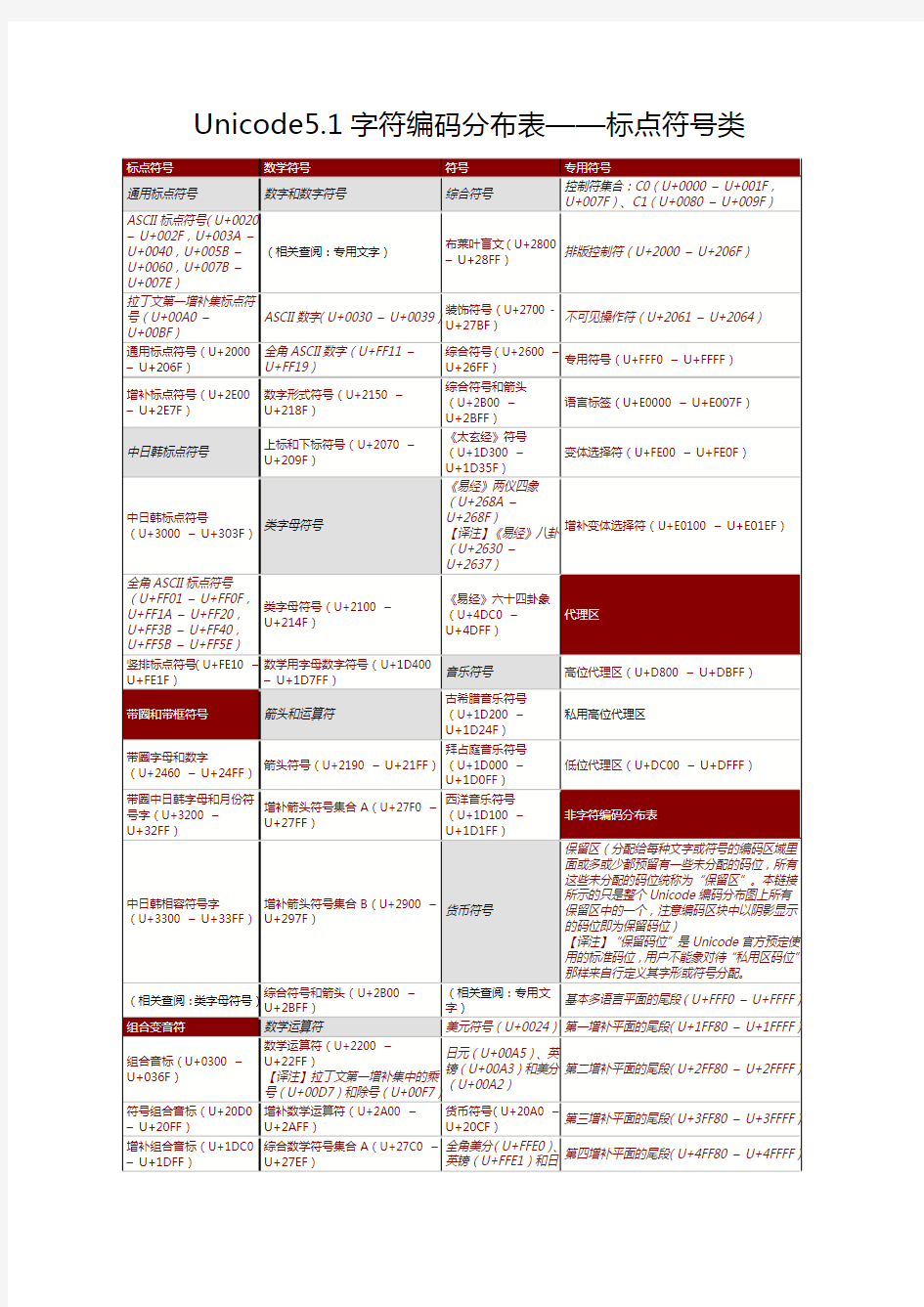
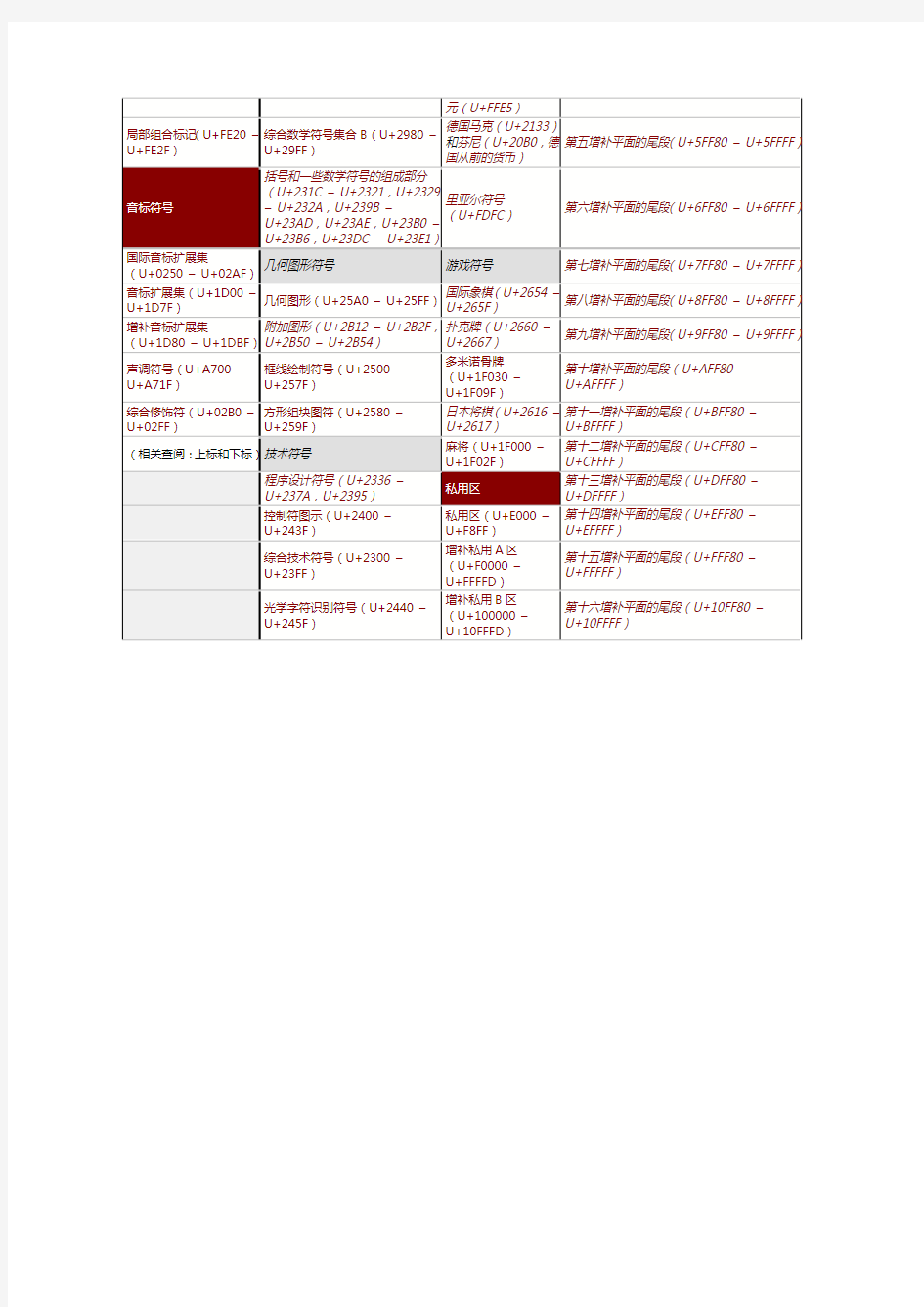
Unicode5.1字符编码分布表——标点符号类
**ASCII 码对照表完整版 信息在计算机上是用二进制表示的,这种表示法让人理解就很困难。因此计算机上都配有输入和输出设备,这些设备的主要目的就是,以一种人类可阅读的形式将信息在这些设备上显示出来供人阅读理解。为保证人类和设备,设备和计算机之间能进行正确的信息交换,人们编制的统一的信息交换代码,这就是ASCII码表,它的全称是“美国信息交换标准代码”。
ASCII 在Web开发时,如下的ASCII码只要加上&#和;就可以变成Web可以辨认的字符了在处理特殊字符的时候特别有用,如:' 单引号在数据库查询的时候是杀手,但是如果转换成'(注意:转换后的机构有:&# +字符的ASCII码值+; 三个部分组成)再来存数据库,就没有什么影响了。其他的字符与ASCII码的对照如下表 ASCII表
键盘常用ASCII码ESC键 VK_ESCAPE (27) 回车键: VK_RETURN (13) TAB键: VK_TAB (9) Caps Lock键: VK_CAPITAL (20) Shift键: VK_SHIFT ($10)
Ctrl键: VK_CONTROL (17) Alt键: VK_MENU (18) 空格键: VK_SPACE ($20/32) 退格键: VK_BACK (8) 左徽标键: VK_LWIN (91) 右徽标键: VK_LWIN (92) 鼠标右键快捷键:VK_APPS (93) Insert键: VK_INSERT (45) Home键: VK_HOME (36) Page Up: VK_PRIOR (33) PageDown: VK_NEXT (34) End键: VK_END (35) Delete键: VK_DELETE (46) 方向键(←): VK_LEFT (37) 方向键(↑): VK_UP (38) 方向键(→): VK_RIGHT (39) 方向键(↓): VK_DOWN (40) F1键: VK_F1 (112) F2键: VK_F2 (113) F3键: VK_F3 (114) F4键: VK_F4 (115) F5键: VK_F5 (116) F6键: VK_F6 (117) F7键: VK_F7 (118) F8键: VK_F8 (119) F9键: VK_F9 (120) F10键: VK_F10 (121) F11键: VK_F11 (122) F12键: VK_F12 (123) Num Lock键: VK_NUMLOCK (144) 小键盘0: VK_NUMPAD0 (96) 小键盘1: VK_NUMPAD0 (97) 小键盘2: VK_NUMPAD0 (98) 小键盘3: VK_NUMPAD0 (99) 小键盘4: VK_NUMPAD0 (100) 小键盘5: VK_NUMPAD0 (101) 小键盘6: VK_NUMPAD0 (102) 小键盘7: VK_NUMPAD0 (103) 小键盘8: VK_NUMPAD0 (104) 小键盘9: VK_NUMPAD0 (105) 小键盘.: VK_DECIMAL (110)
Unicode汉字编码表 1 unicode编码表 Unicode目前普遍采用的是UCS-2,它用两个字节来编码一个字符, 比如汉字"经"的编码是0x7ECF,注意字符编码一般用十六进制来表示,为了与十进制区分,十六进制以0x开头,0x7ECF转换成十进制就是32463,UCS-2用两个字节来编码字符,两个字节就是16位二进制, 2的16次方等于65536,所以UCS-2最多能编码65536个字符。 编码从0到127的字符与ASCII编码的字符一样,比如字母"a"的Unicode 编码是0x0061,十进制是97,而"a"的ASCII编码是0x61,十进制也是97, 对于汉字的编码,事实上Unicode 对汉字支持不怎么好,这也是没办法的, 简体和繁体总共有六七万个汉字,而UCS-2最多能表示65536个,才六万多个,所以Unicode只能排除一些几乎不用的汉字,好在常用的简体汉字也不过七千多个,为了能表示所有汉字,Unicode也有UCS-4规范,就是用4个字节来编码字符,不过现在普遍采用的还是UCS-2,只用两个字节来编码,看一下Unicode对汉字的编码: ------------------------------------------------------------------------ 2 汉字编码表 U+ 0 1 2 3 4 5 6 7 8 9 A B C D E F ----------------------------------------------------- 4e00 一丁丂七丄丅丆万丈三上下丌不与丏 4e10 丐丑丒专且丕世丗丘丙业丛东丝丞丟 4e20 丠両丢丣两严並丧丨丩个丫丬中丮丯
宽字符处理函数函数与普通函数对照表 字符分类:宽字符函数普通C函数描述 iswalnum()isalnum()测试字符是否为数字或字母 iswalpha()isalpha()测试字符是否是字母 iswcntrl()iscntrl()测试字符是否是控制符 iswdigit()isdigit()测试字符是否为数字 iswgraph()isgraph()测试字符是否是可见字符 iswlower()islower()测试字符是否是小写字符 iswprint()isprint()测试字符是否是可打印字符 iswpunct()ispunct()测试字符是否是标点符号 iswspace()isspace()测试字符是否是空白符号 iswupper()isupper()测试字符是否是大写字符 iswxdigit()isxdigit()测试字符是否是十六进制的数字 大小写转换: 宽字符函数普通C函数描述 towlower()tolower()把字符转换为小写 towupper()toupper()把字符转换为大写 字符比较:宽字符函数普通C函数描述 wcscoll()strcoll()比较字符串 日期和时间转换: 宽字符函数描述 strftime()根据指定的字符串格式和locale设置格式化日期和时间 wcsftime()根据指定的字符串格式和locale设置格式化日期和时间,并返回宽字符串strptime()根据指定格式把字符串转换为时间值,是strftime的反过程 打印和扫描字符串: 宽字符函数描述 fprintf()/fwprintf()使用vararg参量的格式化输出 fscanf()/fwscanf()格式化读入 printf()使用vararg参量的格式化输出到标准输出 scanf()从标准输入的格式化读入 sprintf()/swprintf()根据vararg参量表格式化成字符串 sscanf()以字符串作格式化读入 vfprintf()/vfwprintf()使用stdarg参量表格式化输出到文件 vprintf()使用stdarg参量表格式化输出到标准输出 vsprintf()/vswprintf()格式化stdarg参量表并写到字符串
汉字编码选择题复习 1、一个汉字的内码长度为2个字节,其每个字节的最高二进制位的值依次分别是________。 A)0,0 B)0,1 C)1,0 D)1,1 【解析】国标码是汉字信息交换的标准编码,但因其前后字节的最高位为0,与ASCII码发生冲突,于是,汉字的机内码采用变形国标码,其变换方法为:将国标码的每个字节都加上128,即将两个字节的最高位由0改1,其余7位不变,因此机内码前后字节最高位都为1。 2、、一个汉字的16×16点阵字形码长度的字节数是________。 A)16 B)24 C)32 D)40 【解析】每个点阵用一个0或1代替,需要16*16个0或1,因为8位为一字节,换算成字节就是16*16/8. 3、根据汉字国标GB2312-80的规定,一个汉字的内码码长为________。 A)8bit B)12bit C)16bit D)24bit 【解析】一个汉字是两个字节,一字节是8bit,所以就是16bit。 4、下列4个4位十进制数中,属于正确的汉字区位码的是________。 A)5601 B)9596 C)9678 D)8799 【解析】区位码:94×94阵列,区号范围:1~94,位号范围:1~94。 5、存储1024个24×24点阵的汉字字形码需要的字节数是________。 A)720B B)72KB C)7000B D)7200B 【解析】在24×24的网格中描绘一个汉字,整个网格分为24行24列,每个小格用1位二进制编码表示,每一行需要24个二进制位,占3个字节,24行共占24×3=72个字节。1024个需要1024×72=73728字节。 6、在计算机中,对汉字进行传输、处理和存储时使用汉字的________。 A)字形码 B)国标码 C)输入码D)机内码 【解析】显示或打印汉字时使用汉字的字形码,在计算机内部时使用汉字的机内码。 7、区位码输入法的最大优点是________。 A)只用数码输入,方法简单、容易记忆 B)易记易用 C)一字一码,无重码 D)编码有规律,不易忘记 【解析】区位码输入是利用国标码作为汉字编码,每个国标码对应一个汉字或一个符号,没有重码。 8、下列关于汉字编码的叙述中,错误的是________。 A)BIG5码是通行于香港和台湾地区的繁体汉字编码 B)一个汉字的区位码就是它的国标码
unicode編碼區對照表 2150-218F Number Forms 數字形式 2190-21FF Arrows 箭頭符號 2200-22FF Mathematical Operators 數學運算符號 2300-23FF Miscellaneous Technical 混合專門符號 3000-303F CJK Symbols and Punctuation 中日韓符號和標點3040-309F Hiragana 平假名 30A0-30FF Katakana 片假名 3100-312F Bopomofo 注音符號 31C0-31EF CJK Strokes 中日韓筆畫部件 31F0-31FF Katakana Phonetic Extensions 片假名音標擴充3200-32FF Enclosed CJK Letters and Months 中日韓括號字母及月份 3300-33FF CJK Compatibility 中日韓相容字元 3400-4DBF CJK Unified Ideographs Extension A 中日韓統一表意文字擴充A 4DC0-4DFF Yijing Hexagram Symbols 易經六十四卦象 4E00-9FFF CJK Unified Ideographs 中日韓統一表意文字 其他。。。。
0000-007F Basic Latin 基本拉丁字母 0080-00FF Latin-1 Supplement 拉丁字母補充-1 0100-017F Latin Extended-A 拉丁字母擴充-A 0180-024F Latin Extended-B 拉丁字母擴充-B 0250-02AF IPA Extensions 國際音標擴充 02B0-02FF Spacing Modifier Letters 進格修飾字元 0300-036F Combining Diacritical Marks 組合音標附加符號0370-03FF Greek and Coptic 希臘字母 0400-04FF Cyrillic 西里爾字母 0500-052F Cyrillic Supplement 西里爾字母補充 0530-058F Armenian 亞美尼亞文 0590-05FF Hebrew 希伯來文 0600-06FF Arabic 基本阿拉伯文 0700-074F Syriac 敘利亞文 0750-077F Arabic Supplement 阿拉伯文補充 0780-07BF Thaana 塔納文 07C0-07FF N'Ko 0900-097F Devanagari 天城體梵文字母 0980-09FF Bengali 孟加拉文 0A00-0A7F Gurmukhi 古爾穆基文 0A80-0AFF Gujarati 古吉拉特文 0B00-0B7F Oriya 奧里亞文
ASCII码对照表 ASCII码对照表 ASCII, American Standard Code for Information Interchange 念起来像是 "阿斯key",定义从 0 到 127 的一百二十八个数字所代表的英文字母或一样的结果与 意义。由于只使用7个位元(bit)就可以表示从0到127的数字,大部分的电脑都使 用8个位元来存取字元集(character set),所以从128到255之间的数字可以用来代 表另一组一百二十八个符号,称为 extended ASCII。 ASCII码键盘ASCII 码键盘ASCII码键盘ASCII 码键盘 27ESC32SPACE33!34" 35#36$37%38& 39'40(41)42* 43+44'45-46. 47/480491502 513524535546 55756857958: 59;60<61=62> 63?64@65A66B 67C68D69E70F 71G72H73I74J 75K76L77M78N 79O80P81Q82R 83S84T85U86V 87W88X89Y90Z 91[92\93]94^ 95_96`97a98b 99c100d101e102f 103g104h105i106j 107k108l109m110n 111o112p113q114r 115s116t117u118v 119w120x121y122z 123{124|125}126~ 目前计算机中用得最广泛的字符集及其编码,是由美国国家标准局(ANSI)制定的ASCII码 (American Standard Code for Information Interchange,美国标准信息交换码),它已被国际标准化组织(ISO)定为国际标准,称为ISO 646标准。适用于所有拉丁文字字母,ASCII码有7位码和8位码两种形式。 因为1位二进制数可以表示(21=)2种状态:0、1;而2位二进制数可以表示(22)=4种状态:00、01、10、11;依次类推,7位二进制数可以表示(27=)128种状态,每种状态都唯一地编为一个7位的二进制码,对应一个字符(或控制码),这些码可以排列成一个十进制序号0~127。所以,7位ASCII码是用七位二进制数进行编码的,可以表示128个字符。
编码表 平面0 (0000–FFFF): 基本多文种平面(Basic Multilingual Plane, BMP). 平面1 (10000–1FFFF): 多文种补充平面(Supplementary Multilingual Plane, SMP). 平面2 (20000–2FFFF): 表意文字补充平面(Supplementary Ideographic Plane, SIP). 平面3 (30000–3FFFF): 表意文字第三平面(Tertiary Ideographic Plane, TIP). 平面4 to 13 (40000–DFFFF)尚未使用 平面14 (E0000–EFFFF): 特别用途补充平面(Supplementary Special-purpose Plane, SSP) 平面15 (F0000–FFFFF)保留作为私人使用区(Private Use Area, PUA) 平面16 (100000–10FFFF),保留作为私人使用区(Private Use Area, PUA) 注意1 现在网上大多数用于判断中文字符的是U+4E00..U+9FA5这个范围是只是“中日韩统一表意文字”这个区间,但这不是全部,如果要全部包含,则还要他们的扩展集、部首、象形字、注间字母等等; 2E80-A4CF加上F900-FAFF加上FE30-FE4F。 其中: 2E80-A4CF 包含了中日朝部首补充、康熙部首、表意文字描述符、中日朝符号和标点、日文平假名、日文片假名、注音字母、谚文兼容字母、象形字注释标志、注音字母扩展、中日朝笔画、日文片假名语音扩展、带圈中日朝字母和月份、中日朝兼容、中日朝统一表意文字扩展A、易经六十四卦符号、中日韩统一表意文字、彝文音节、彝文字根 F900-FAFF 中日朝兼容表意文字 FE30-FE4F 中日朝兼容形式 所以,一般用4E00-9FA5已经可以,如果要更广,则用2E80-A4CF || F900-FAFF||FE30-FE4F 注意2 全角ASCII、全角中英文标点、半宽片假名、半宽平假名、半宽韩文字母:FF00-FFEF
Unicode汉字编码表 1 Unicode编码表 Unicode目前普遍采用的是UCS-2,它用两个字节来编码一个字符, 比如汉字"经"的编码是0x7ECF,注意字符编码一般用十六进制来 表示,为了与十进制区分,十六进制以0x开头,0x7ECF转换成十进制 就是32463,UCS-2用两个字节来编码字符,两个字节就是16位二进制, 2的16次方等于65536,所以UCS-2最多能编码65536个字符。 编码从0到127的字符与ASCII编码的字符一样,比如字母"a"的Unicode 编码是0x0061,十进制是97,而"a"的ASCII编码是0x61,十进制也是97, 对于汉字的编码,事实上Unicode对汉字支持不怎么好,这也是没办法的, 简体和繁体总共有六七万个汉字,而UCS-2最多能表示65536个,才六万 多个,所以Unicode只能排除一些几乎不用的汉字,好在常用的简体汉字 也不过七千多个,为了能表示所有汉字,Unicode也有UCS-4规范,就是用 4个字节来编码字符,不过现在普遍采用的还是UCS-2,只用两个字节来 编码,看一下Unicode对汉字的编码:
------------------------------------------------------------------------ 2 汉字编码表 U+ 0 1 2 3 4 5 6 7 8 9 A B C D E F ----------------------------------------------------- 4e00 一丁丂七丄丅丆万丈三上下丌不与丏 4e10 丐丑丒专且丕世丗丘丙业丛东丝丞丟 4e20 丠両丢丣两严並丧丨丩个丫丬中丮丯 4e30 丰丱串丳临丵丶丷丸丹为主丼丽举丿 4e40 乀乁乂乃乄久乆乇么义乊之乌乍乎乏 4e50 乐乑乒乓乔乕乖乗乘乙乚乛乜九乞也 4e60 习乡乢乣乤乥书乧乨乩乪乫乬乭乮乯 4e70 买乱乲乳乴乵乶乷乸乹乺乻乼乽乾乿 4e80 亀亁亂亃亄亅了亇予争亊事二亍于亏 4e90 亐云互亓五井亖亗亘亙亚些亜亝亞亟 4ea0 亠亡亢亣交亥亦产亨亩亪享京亭亮亯 4eb0 亰亱亲亳亴亵亶亷亸亹人亻亼亽亾亿 4ec0 什仁仂仃仄仅仆仇仈仉今介仌仍从仏 4ed0 仐仑仒仓仔仕他仗付仙仚仛仜仝仞仟 4ee0 仠仡仢代令以仦仧仨仩仪仫们仭仮仯 4ef0 仰仱仲仳仴仵件价仸仹仺任仼份仾仿 4f00 伀企伂伃伄伅伆伇伈伉伊伋伌伍伎伏 4f10 伐休伒伓伔伕伖众优伙会伛伜伝伞伟 4f20 传伡伢伣伤伥伦伧伨伩伪伫伬伭伮伯
A S C I I码对照表完整版 Revised final draft November 26, 2020
好用的A S C I I码对照表完整版 信息在计算机上是用二进制表示的,这种表示法让人理解就很困难。因此计算 机上都配有输入和输出设备,这些设备的主要目的就是,以一种人类可阅读的形式 将信息在这些设备上显示出来供人阅读理解。为保证人类和设备,设备和计算机之 间能进行正确的信息交换,人们编制的统一的信息交换代码,这就是ASCII码表,
在Web开发时,如下的ASCII码只要加上&#和;就可以变成Web可以辨认的字符了在处理特殊字符的时候特别有用,如:'单引号在数据库查询的时候是杀手,但是如果转换成'(注意:转换后的机构有:&#+字符的ASCII码值+;三个部分组成)再来存数据库,就没有什么影响了。其他的字符与ASCII码的对照如下表 ASCII表
键盘常用ASCII码 ESC键VK_ESCAPE(27)回车键:VK_RETURN(13)TAB键:VK_TAB(9)CapsLock键: VK_CAPITAL(20)Shift键:VK_SHIFT($10)Ctrl键:VK_CONTROL(17)Alt键: VK_MENU(18)空格键:VK_SPACE($20/32)退格键:VK_BACK(8)左徽标键:VK_LWIN(91)右徽标键:VK_LWIN(92)鼠标右键快捷键:VK_APPS(93) Insert键:VK_INSERT(45)Home键:VK_HOME(36)PageUp:VK_PRIOR(33)PageDown:VK_NEXT(34)End键:VK_END(35)Delete键:VK_DELETE(46) 方向键(←):VK_LEFT(37)方向键(↑):VK_UP(38)方向键(→):VK_RIGHT(39)方向键(↓):VK_DOWN(40) F1键:VK_F1(112)F2键:VK_F2(113)F3键:VK_F3(114)F4键:VK_F4(115)F5键:
最全ASCII码对照表 Bin Dec Hex 缩写/字符解释 0000 0000 0 00 NUL (null) 空字符0000 0001 1 01 SOH (start of handing) 标题开始0000 0010 2 02 STX (start of text) 正文开始0000 0011 3 03 ETX (end of text) 正文结束0000 0100 4 04 EOT (end of transmission) 传输结束0000 0101 5 05 ENQ (enquiry) 请求 0000 0110 6 06 ACK (acknowledge) 收到通知0000 0111 7 07 BEL (bell) 响铃 0000 1000 8 08 BS (backspace) 退格 0000 1001 9 09 HT (horizontal tab) 水平制表符0000 1010 10 0A LF (NL line feed, new line) 换行键 0000 1011 11 0B VT (vertical tab) 垂直制表符0000 1100 12 0C FF (NP form feed, new page) 换页键 0000 1101 13 0D CR (carriage return) 回车键0000 1110 14 0E SO (shift out) 不用切换0000 1111 15 0F SI (shift in) 启用切换0001 0000 16 10 DLE (data link escape) 数据链路转义0001 0001 17 11 DC1 (device control 1) 设备控制1 0001 0010 18 12 DC2 (device control 2) 设备控制2 0001 0011 19 13 DC3 (device control 3) 设备控制3 0001 0100 20 14 DC4 (device control 4) 设备控制4 0001 0101 21 15 NAK (negative acknowledge) 拒绝接收0001 0110 22 16 SYN (synchronous idle) 同步空闲0001 0111 23 17 ETB (end of trans. block) 传输块结束0001 1000 24 18 CAN (cancel) 取消 0001 1001 25 19 EM (end of medium) 介质中断0001 1010 26 1A SUB (substitute) 替补 0001 1011 27 1B ESC (escape) 溢出 0001 1100 28 1C FS (file separator) 文件分割符0001 1101 29 1D GS (group separator) 分组符0001 1110 30 1E RS (record separator) 记录分离符0001 1111 31 1F US (unit separator) 单元分隔符 0010 0000 32 20 空格 0010 0001 33 21 ! 0010 0010 34 22 " 0010 0011 35 23 # 0010 0100 36 24 $ 0010 0101 37 25 % 0010 0110 38 26 & 0010 0111 39 27 "
例说UNICODE字符集中特有汉字的输入方法 有个字读音“xi”字型为上“亩”下“心”,遇到手写不了的证件,只能用拼音代替,或者打成其他的字再到单位开证明,有时要跑好几趟才能办成诸如存取款、买保险、购机票等事情。下面结合这个“上‘亩’下‘心’”的汉字为例,谈谈UNICODE字符集中特有汉字的输入方法: 1.这个汉字属于超大字符集《CJK统一汉字扩充B》,Unicode字符代码是20164。 2.为了顺利处理UNICODE汉字中特有汉字,在Windows XP操作系统中需安装“配套超大字集支持包”(https://www.doczj.com/doc/359151145.html,/software/UniFonts.exe,目前版本是6.0版),不过安装支持包时选择“完全安装”的话会影响到一极少部分软件的使用(例如会引起“企业电子报税管理系统”的申报主界面出现重复图形按钮及字体变大的现象,影响正常显示和使用,又如会引起中国电信“天翼宽带客户端V1.1.5”拨号软件在拨号过程中显示的字体变小,经测试,多个版本都有这个问题,但在卸载这个“超大字集支持包”并重启后,可以恢复正常,如果安装时不选择“自动链接系统外文显示字体”也不会出现这些异常),因此建议选择“核心安装”或在选择“自定义安装”后不选择“自动链接系统外文显示字体”。另外在Windows 2000中系统还需要首先安装补丁(surreg.exe)方可使用超大字符集。 3.Windows Viata和Windows 7中都支持UNICODE汉字(包括CJK、CJK-ExtA、CJK-ExtB),用海峰五笔(目前最新版本为9.5,官方下载地址:1. https://www.doczj.com/doc/359151145.html,/software/SunWb.exe)可以直接打出来,86版和98版的五笔编码都是ylnu,还有一些五笔输入法,例如菩提五笔、新概念五笔输入法等都能完成UNICODE汉字的输入,在word、Excel等中输入后,会自动调用“宋体-方正超大字符集”显示。 4.使用郑码输入法 5.0版或 6.0版也可以免费输入:windows xp和windows7中均内置了郑码输入法(xp为5.0版、windows7为6.0版),可以替换码表为“全汉字集郑码码表”(本郑码码表包含CJK、CJK-A、CJK-B、CJK-C、CJK-D 全汉字集单字、以及简体、繁体词组,附目前可用下载地址:https://www.doczj.com/doc/359151145.html,/)或者“超大字集郑码【官方大字集郑码】+扩展B,70296个字35000条(windows7下使用,附目前可用下载地址:https://www.doczj.com/doc/359151145.html,/)”(xp的码表是winzm.MB,window 7的码表是TableTextServiceSimplifiedZhengMa.txt)然后轻松输入。这个“上‘亩’下‘心’” 的汉字“”的郑码是skwz,具体资源如果不可下载时请通过搜索得到。 5.在系统已支持UNICODE字符集时,不使用输入法,也可以直接在文档中插 入Unicode字符代码,例20164就是“”的Unicode字符代码,可以将代码20164 输入文档,然后按Alt+X将其转换成字符。 6.操作系统支持的字符集正在一步步地扩大,当年只支持GB-2312,现在已广泛支持GBK了,而且Windows Viata和Windows 7都开始支持UNICODE汉字(包括CJK、CJK-ExtA、CJK-ExtB)了。能全面输入、显示或者说广泛支持UNICODE汉字,只是迟早的事。 7.目前,要让更多的人也能顺利打出此字,需要大家一起努力。要让人家会处理你要的汉字,必要时要能说服人家,安装一些你早已准备好的软件等。
汉字编码简明对照表 说明: 1、下列汉字取自国标(GB 2312-80)中的分级与排列内容;包含所有的第一级汉字和第二级汉字中的常用部分。 2、第一级汉字(16—55区的汉字)以拼音字母为序进行排列,同音字以笔形顺序横、竖、撇、捺、折为序,起笔相同的按第二笔,依次类推;第二级汉字(56-87区的汉字)按部首为序进行排列。 3、对于多音字,仅在表中出现一次。如:柏,音(bai,bo),表中仅出现在“bai”中。 4、汉字区位码用阿拉伯数字表示,每个汉字对应4个数字。 5、本汉字代码表摘自《字符集和信息编码国家标准汇编》,(中国标准出版社,1998年编)。 a 啊 1601 阿 1602 吖 6325 嗄 6436 腌 7571 锕 7925 ai 埃 1603 挨 1604 哎 1605 唉 1606 哀 1607 皑 1608 癌 1609 蔼 1610 矮 1611 艾 1612 碍 1613 爱 1614 隘 1615 捱 6263 嗳 6440 嗌 6441 嫒 7040 瑷 7208 暧 7451 砹 7733 锿 7945 霭 8616 an 鞍 1616 氨 1617 安 1618 俺 1619 按 1620 暗 1621 岸 1622 胺 1623 案 1624 谙 5847 埯 5991 揞 6278 犴 6577 庵 6654 桉 7281 铵 7907 鹌 8038 黯 8786 ang 肮 1625 昂 1626 盎 1627 ao
凹 1628 敖 1629 熬 1630 翱 1631 袄 1632 傲 1633 奥 1634 懊 1635 澳 1636 坳 5974 拗 6254 嗷 6427 岙 6514 廒 6658 遨 6959 媪 7033 骜 7081 獒 7365 聱 8190 螯 8292 鏊 8643 鳌 8701 鏖 8773 ba 芭 1637 捌 1638 扒 1639 叭 1640 吧 1641 笆 1642 八 1643 疤 1644 巴 1645 拔 1646 跋 1647 靶 1648 把 1649 耙 1650 坝 1651 霸 1652 罢 1653 爸 1654 茇 6056 菝 6135 岜 6517 灞 6917 钯 7857 粑 8446 鲅 8649 魃 8741 bai 白 1655 柏 1656 百 1657 摆 1658 佰 1659 败 1660 拜 1661 稗 1662 捭 6267 呗 6334 掰 7494 ban 斑 1663 班 1664 搬 1665 扳 1666 般 1667 颁 1668 板 1669 版 1670 扮 1671 拌 1672 伴 1673 瓣 1674 半 1675 办 1676 绊 1677 阪 5870 坂 5964 钣 7851 瘢 8103 癍 8113 舨 8418 bang 邦 1678 帮 1679 梆 1680 榜 1681 膀 1682 绑 1683 棒 1684 磅 1685 蚌 1686 镑 1687 傍 1688 谤 1689 蒡 6182 浜 6826 bao 苞 1690 胞 1691 包 1692 褒 1693 剥 1694 薄 1701 雹 1702 保 1703 堡 1704 饱 1705 宝 1706 抱 1707 报 1708 暴 1709 豹 1710 鲍 1711 爆 1712 葆 6165 孢 7063 煲 7650 鸨 8017 褓 8157 趵 8532 龅 8621 bei 杯 1713 碑 1714 悲 1715 卑 1716 北 1717 辈 1718 背 1719 贝 1720 钡 1721 倍 1722 狈 1723 备 1724 惫 1725 焙 1726 被 1727 孛 5635 陂 5873 邶 5893 蓓 6177 悖 6703 碚 7753 鹎 8039 褙 8156 鐾 8645 鞴 8725 ben 奔 1728 苯 1729 本 1730 笨 1731 畚 5946 坌 5948 贲 7458 锛 7928 beng 崩 1732 绷 1733 甭 1734 泵 1735 蹦 1736 迸 1737 嘣 6452 甏 7420 bi
适用于 下列Microsoft Office 程序的2003 版本:Access 2003、 Excel 2003、FrontPage? 2003、InfoPath? 2003、OneNote? 2003、 Outlook? 2003、PowerPoint? 2003、Project 2003、Publisher 2003、 Visio? 2003 和Word 2003 下列Microsoft Office 程序的2002 版本:Access 2002、 Excel 2002、FrontPage? 2002、Outlook? 2002、PowerPoint? 2002、 Project 2002、Publisher 2002、Visio? 2002 和Word 2002 数字代表计算机的语言。您的计算机如何使用字母来与程序和其他计算机进行通信?一种方法是把字符集(字符集:一组共享一些关系的字母、数字和其他字符。例如,标准ASCII 字符集包括字母、数字、符号和组成ASCII 代码方案的控制代码。)转换为数字形式。 在20 世纪60 年代,标准化的需要带来了美国标准信息交换码(ASCII)(ASCII:将英语中的字符表示为数字的代码。为每个字符分配一个介于0 到127 之间的数字。大多数计算机都使用ASCII 表示文本和在计算机之间传输数据。)(发音为ask-kee)。ASCII 表包含128 个数字,分配给了相应的字符(字符:字母、数字、标点或符号。)。ASCII 为计算机提供了一种存储数据和与其他计算机及程序交换数据的方式。 ASCII 格式的文本不包含像黑体、斜体或字体等格式信息。当您使用Microsoft 记事本或把文件作为纯文本保存在Microsoft Office Word 中时,就会使用ASCII。您可能读到过招聘广告,公司要求提供ASCII 格式的简历。这意味着无论您是用电子邮件、传真或打印文本发送简历,公司希望您的简历中不含任何特殊格式。大公司可能用光学字符识别(OCR)(OCR:将文本图像(如扫描的文档)转换为实际的文本字符。也称为文本识别。)扫描软件来扫描简历和ASCII 格式的文本。 在文档中插入ASCII 字符 注释该功能需要Excel、FrontPage、InfoPath、OneNote、Outlook、PowerPoint、Project、Publisher、Word 或V isio。 除了在键盘上键入字符外,您也可以使用该符号的字符代码作为键盘快捷键。例如,要插入度数符号,在按住ALT 的同时在数字键盘上键入0176。 要从下面的图表中插入ASCII 字符,在按住ALT 的同时键入等价的十进制数字。 例如,要插入度数符号,在按住ALT 的同时在数字键盘上键入0176。 注释必须使用数字键盘来键入数字,而不是键盘。如果您的键盘需要打开Num Lock 键才能在数字键盘上键入数字,请务必打开它。 ASCII 打印字符 数字32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。数字127 代表DELETE 命令。 ASCII 打印字符表 十进制字符十进制字符 32space80P 33!81Q 34"82R 35#83S 36$84T
字符编码之间的相互转换UTF8与GBK C++ UTF8编码转换CChineseCode 一预备知识 1,字符:字符是抽象的最小文本单位。它没有固定的形状(可能是一个字形),而且没有值。“A”是一个字符,“€”(德国、法国和许多其他欧洲国家通用货币的标志)也是一个字符。“中”“国”这是两个汉字字符。字符仅仅代表一个符号,没有任何实际值的意义。 2,字符集:字符集是字符的集合。例如,汉字字符是中国人最先发明的字符,在中文、日文、韩文和越南文的书写中使用。这也说明了字符和字符集之间的关系,字符组成字符集(iso8859-1,GB2312/GBK,unicode)。 3,代码点:字符集中的每个字符都被分配到一个“代码点”。每个代码点都有一个特定的唯一数值,称为标值。该标量值通常用十六进制表示。 4,代码单元:在每种编码形式中,代码点被映射到一个或多个代码单元。“代码单元”是各个编码方式中的单个单元。代码单元的大小等效于特定编码方式的位数:UTF-8 :UTF-8 中的代码单元由8 位组成;在UTF-8 中,因为代码单元较小的缘故,每个代码点常常被映射到多个代码单元。代码点将被映射到一个、两个、三个或四个代码单元;UTF-16 :UTF-16 中的代码单元由16 位组成;UTF-16 的代码单元大小是8 位代码单元的两倍。所以,标量值小于U+10000 的代码点被编码到单个代码单元中;UTF-32:UTF-32 中的代码单元由32 位组成;UTF-32 中使用的32 位代码单元足够大,每个代码点都可编码为单个代码单元;GB18030:GB18030 中的代码单元由8 位组成;在GB18030 中,因为代码单元较小的缘故,每个代码点常常被映射到多个代码单元。代码点将被映射到一个、两个或四个代码单元。 5,举例:“中国北京香蕉是个大笨蛋”这是我定义的aka字符集; 各字符对应代码点为: 北00000001 京00000010 香10000001 蕉10000010 是10000100 个10001000 大10010000 笨10100000 蛋11000000 中00000100 国00001000 下面是我定义的zixia 编码方案(8位),可以看到它的编码中表示了aka字符集的所有字符对应的代码单元; 北10000001 京10000010 香00000001 蕉00000010 是00000100 个00001000 大00010000 笨00100000 蛋01000000 中10000100 国10001000 所谓文本文件就是我们按一定编码方式将二进制数据表示为对应的文本如00000001000000100000010000001000000100000010000001000000这样的文件。我用一个支持zixia编码和aka字符集的记事本打开,它就按照编码方案显示为“香蕉是个大笨蛋” 如果我把这些字符按照GBK 另存一个文件,那么则肯定不是这个,而是1100111111100011 1011110110110110 1100101011000111 1011100011110110 1011010011110011 1011000110111111 1011010110110000 110100001010 二,字符集
包含汉字: 的一是了我不人在他有这个上们来到时大地为子中你说生国年着就那和要她出也得里后自以会家可下而过天去能对小多然于心学么之 都好看起发当没成只如事把还用第样道想作种开美总从无情己面最女但现前些所同日手又行意动方期它头经长儿回位分爱老因很给 名法间斯知世什两次使身者被高已亲其进此话常与活正感见明问力理尔点文几定本公特做外孩相西果走将月十实向声车全信重 三机工物气每并别真打太新比才便夫再书部水像眼等体却加电主界门利海受听表德少克代员许稜先口由死安写性马光白或住难 望教命花结乐色更拉东神记处让母父应直字场平报友关放至张认接告入笑内英军候民岁往何度山觉路带万男边风解叫任金快原 吃妈变通师立象数四失满战远格士音轻目条呢病始达深完今提求清王化空业思切怎非找片罗钱紶吗语元喜曾离飞科言干流欢约 各即指合反题必该论交终林请医晚制球决窢传画保读运及则房早院量苦火布品近坐产答星精视五连司巴奇管类未朋且婚台夜青 北队久乎越观落尽形影红爸百令周吧识步希亚术留市半热送兴造谈容极随演收首根讲整式取照办强石古华諣拿计您装似足双妻 尼转诉米称丽客南领节衣站黑刻统断福城故历惊脸选包紧争另建维绝树系伤示愿持千史谁准联妇纪基买志静阿诗独复痛消社算 义竟确酒需单治卡幸兰念举仅钟怕共毛句息功官待究跟穿室易游程号居考突皮哪费倒价图具刚脑永歌响商礼细专黄块脚味灵改 据般破引食仍存众注笔甚某沉血备习校默务土微娘须试怀料调广蜖苏显赛查密议底列富梦错座参八除跑亮假印设线温虽掉京初 养香停际致阳纸李纳验助激够严证帝饭忘趣支春集丈木研班普导顿睡展跳获艺六波察群皇段急庭创区奥器谢弟店否害草排背止 组州朝封睛板角况曲馆育忙质河续哥呼若推境遇雨标姐充围案伦护冷警贝著雪索剧啊船险烟依斗值帮汉慢佛肯闻唱沙局伯族低 玩资屋击速顾泪洲团圣旁堂兵七露园牛哭旅街劳型烈姑陈莫鱼异抱宝权鲁简态级票怪寻杀律胜份汽右洋范床舞秘午登楼贵吸责 例追较职属渐左录丝牙党继托赶章智冲叶胡吉卖坚喝肉遗救修松临藏担戏善卫药悲敢靠伊村戴词森耳差短祖云规窗散迷油旧适 乡架恩投弹铁博雷府压超负勒杂醒洗采毫嘴毕九冰既状乱景席珍童顶派素脱农疑练野按犯拍征坏骨余承置臓彩灯巨琴免环姆暗 换技翻束增忍餐洛塞缺忆判欧层付阵玛批岛项狗休懂武革良恶恋委拥娜妙探呀营退摇弄桌熟诺宣银势奖宫忽套康供优课鸟喊降 夏困刘罪亡鞋健模败伴守挥鲜财孤枪禁恐伙杰迹妹藸遍盖副坦牌江顺秋萨菜划授归浪听凡预奶雄升碃编典袋莱含盛济蒙棋端腿 招释介烧误 unicode 编码 的一是了我不人在他有这%u4e2a上们来
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。随着计算机工作能力的增强,Unicode也在面世以来的十多年里得到普及。 Unicode 是基于通用字符集(Universal Character Set)的标准来发展,并且同时也以书本的形式(The Unicode Standard,目前第五版由Addison-Wesley Professional出版,ISBN-10: 0321480910)对外发表。 2006年6月的最新版本的 Unicode 是 2005年3月31日推出的Unicode 4.1.0 。另外,5.0 Beta已于2005年12月12日推出,以供各会员评价。 大概来说,Unicode 编码系统可分为编码方式和实现方式两个层次。 1.编码方式 Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。 Unicode字符集可以简写为UCS(Unicode Character Set)。早期的Unicode 标准有UCS-2、UCS-4的说法。UCS-2用两个字节编码,UCS-4用4个字节编码。UCS-4根据最高位为0的最高字节分成2^7=128个group。每个group再根据次高字节分为256个平面(plane)。每个平面根据第3个字节分为256行(row),每行有256个码位(cell)。group 0的平面0被称作BMP(Basic Multilingual Plane)。将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。 每个平面有2^16=65536个码位。Unicode计划使用了17个平面,一共有17*65536=1114112个码位。在Unicode 5.0.0版本中,已定义的码位只有238605