A Dynamic MapReduce Scheduler for Heterogeneous Workloads
- 格式:pdf
- 大小:516.78 KB
- 文档页数:7

云计算学习笔记Hadoop+HDFS和MapReduce+架构浅析 34IT168文云计算学习笔记hadoop+hdfs和mapreduce+架构浅析-34-it168文hadoophdfs和mapreduce架构浅析前言hadoop是一个基于java的分布式密集数据处理和数据分析的软件框架。
hadoop在很大程度上是受google在2021年白皮书中阐述的mapreduce技术的启发。
mapreduce工作原理是将任务分解为成百上千个小任务,然后发送到计算机集群中。
每台计算机再传送自己那部分信息,mapreduce则迅速整合这些反馈并形成答案。
简单来说,就是任务的分解和结果的合成。
hadoop的扩展性非常杰出,hadoop可以处置原产在数以千计的低成本x86服务器排序节点中的大型数据。
这种高容量低成本的女团引人注目,但hadoop最迎合人的就是其处置混合数据类型的能力。
hadoop可以管理结构化数据,以及诸如服务器日志文件和web页面上涌的数据。
同时还可以管理以非结构化文本为中心的数据,如facebook和twitter。
1hadoop基本架构hadoop并不仅仅是一个用于存储的分布式文件系统,而是在由通用计算设备组成的大型集群上执行分布式应用的框架。
apachehadoop项目中包含了下列产品(见图1)。
图1hadoop基本共同组成pig和hive是hadoop的两个解决方案,使得在hadoop上的编程更加容易,编程人员不再需要直接使用javaapis。
pig可加载数据、转换数据格式以及存储最终结果等一系列过程,从而优化mapreduce运算。
hive在hadoop中饰演数据仓库的角色。
hive需向hdfs嵌入数据,并容许采用相似sql的语言展开数据查阅。
chukwa就是基于hadoop集群的监控系统,直观来说就是一个watchdog。
hbase就是一个面向列于的分布式存储系统,用作在hadoop中积极支持大型稠密表的列存储数据环境。

弹性MapReduce服务平台产品概述目录产品简介产品概述 (4)简介 (4)功能特性 (4)产品优势 (5)灵活 (5)可靠 (5)安全 (5)易用 (5)节约成本 (5)产品功能 (7)弹性伸缩 (7)存储计算分离 (7)运维支撑 (7)安全 (8)应用场景 (9)离线数据分析 (9)流式数据处理 (9)分析 COS 数据 (10)节点类型说明 (12)组件版本 (13)版本历史 (15)2019.12.26 (15)2019.12.17 (15)2019.11.04 (15)2019.10.17 (15)2019.09.18 (15)2019.08.07 (16)2019.08.01 (16)2019.07.05 (16)2019.06.18 (16)2019.05.17 (16)2019.05.07 (17)2019.03.29 (17)2019.03.04 (17)2019.01.15 (17)产品简介产品概述19-04-24 20:02:36简介弹性 MapReduce(EMR)是腾讯云提供的云上 Hadoop 托管服务,提供了便捷的 Hadoop 集群部署、软件安装、配置修改、监控告警、弹性伸缩等功能,为企业及用户提供安全稳定的大数据处理解决方案。
功能特性弹性 MapReduce 的软件完全源于开源社区中的 Hadoop 软件,您可以将现有的大数据集群无缝平滑迁移至腾讯云上。
弹性 MapReduce 产品中集成了社区中常见的热门组件,包括但不限于 Hive、Hbase、Spark、Presto、Sqoop、Hue 等,可以满足您对大数据的离线处理、流式计算等全方位需求。
弹性 MapReduce 无缝集成了腾讯云对象存储(COS)服务,您可将原本存储于 HDFS 中的文件放置在可无限扩展、存储成本低且高可靠的 COS 中,实现计算存储分离。
依托于 COS,您可以在需要的时候创建集群,并在任务完成后销毁集群。

大数据华为认证考试(习题卷3)第1部分:单项选择题,共51题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]ElasticSearch 存放所有关键词的地方是()A)字典B)关键词C)词典D)索引答案:C解析:2.[单选题]DWS DN的高可用架构是:( )。
A)主备从架构B)一主多备架构C)两者兼有D)其他答案:A解析:3.[单选题]关于Hive与传统数据仓库的对比,下列描述错误的是:( )。
A)Hive元数据存储独立于数据存储之外,从而解耦合元数据和数据,灵活性高,二传统数据仓库数据应用单一,灵活性低B)Hive基于HDFS存储,理论上存储可以无限扩容,而传统数据仓库存储量有上限C)由于Hive的数据存储在HDFS上,所以可以保证数据的高容错,高可靠D)由于Hive基于大数据平台,所以查询效率比传统数据仓库快答案:D解析:4.[单选题]以下哪种机制使 Flink 能够实现窗口中无序数据的有序处理?()A)检查点B)窗口C)事件时间D)有状态处理答案:C解析:5.[单选题]下面( )不是属性选择度量。
A)ID3 使用的信息增益B)C4.5 使用的增益率C)CART 使用的基尼指数D)NNM 使用的梯度下降答案:D解析:C)HDFSD)DB答案:C解析:7.[单选题]关于FusionInsight HD Streaming的Supervisor描述正确的是:( )。
A)Supervisor负责资源的分配和任务的调度B)Supervisor负责接受Nimbus分配的任务,启动停止属于自己管理的Worker进程C)Supervisor是运行具体处理逻辑的进程D)Supervisor是在Topology中接收数据然后执行处理的组件答案:B解析:8.[单选题]在有N个节点FusionInsight HD集群中部署HBase时、推荐部署( )个H Master进程,( )个Region Server进程。

第四章分布式计算框架MapReduce4.1初识MapReduceMapReduce是一种面向大规模数据并行处理的编程模型,也一种并行分布式计算框架。
在Hadoop流行之前,分布式框架虽然也有,但是实现比较复杂,基本都是大公司的专利,小公司没有能力和人力来实现分布式系统的开发。
Hadoop的出现,使用MapReduce框架让分布式编程变得简单。
如名称所示,MapReduce主要由两个处理阶段:Map阶段和Reduce 阶段,每个阶段都以键值对作为输入和输出,键值对类型可由用户定义。
程序员只需要实现Map和Reduce两个函数,便可实现分布式计算,而其余的部分,如分布式实现、资源协调、内部通信等,都是由平台底层实现,无需开发者关心。
基于Hadoop开发项目相对简单,小公司也可以轻松的开发分布式处理软件。
4.1.1 MapReduce基本过程MapReduce是一种编程模型,用户在这个模型框架下编写自己的Map函数和Reduce函数来实现分布式数据处理。
MapReduce程序的执行过程主要就是调用Map函数和Reduce函数,Hadoop把MapReduce程序的执行过程分为Map和Reduce两个大的阶段,如果细分可以为Map、Shuffle(洗牌)、Reduce三个阶段。
Map含义是映射,将要操作的每个元素映射成一对键和值,Reduce含义是归约,将要操作的元素按键做合并计算,Shuffle在第三节详细介绍。
下面以一个比较简单的示例,形象直观介绍一下Map、Reduce阶段是如何执行的。
有一组图形,包含三角形、圆形、正方形三种形状图形,要计算每种形状图形的个数,见下图4-1。
图:4-1 map/reduce计算不同形状的过程在Map阶段,将每个图形映射成形状(键Key)和数量(值Value),每个形状图形的数量值是“1”;Shuffle阶段的Combine(合并),相同的形状做归类;在Reduce阶段,对相同形状的值做求和计算。
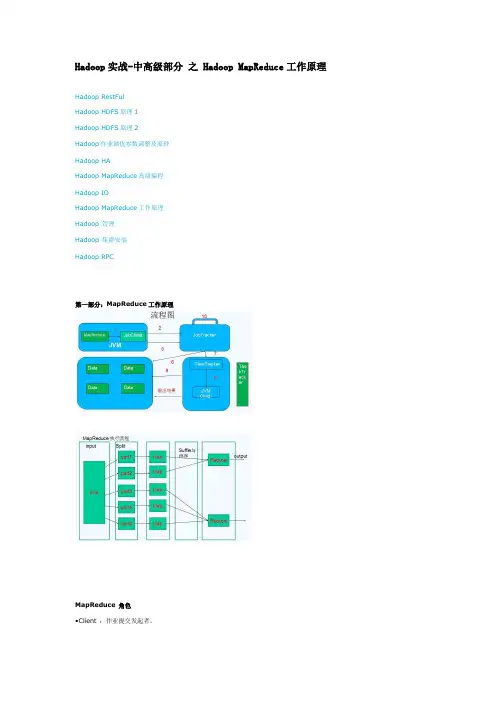
Hadoop实战-中高级部分之 Hadoop MapReduce工作原理Hadoop RestFulHadoop HDFS原理1Hadoop HDFS原理2Hadoop作业调优参数调整及原理Hadoop HAHadoop MapReduce高级编程Hadoop IOHadoop MapReduce工作原理Hadoop 管理Hadoop 集群安装Hadoop RPC第一部分:MapReduce工作原理MapReduce 角色•Client :作业提交发起者。
•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业。
•TaskTracker:保持JobTracker通信,在分配的数据片段上执行MapReduce任务。
提交作业•在作业提交之前,需要对作业进行配置•程序代码,主要是自己书写的MapReduce程序。
•输入输出路径•其他配置,如输出压缩等。
•配置完成后,通过JobClinet来提交作业的初始化•客户端提交完成后,JobTracker会将作业加入队列,然后进行调度,默认的调度方法是FIFO调试方式。
任务的分配•TaskTracker和JobTracker之间的通信与任务的分配是通过心跳机制完成的。
•TaskTracker会主动向JobTracker询问是否有作业要做,如果自己可以做,那么就会申请到作业任务,这个任务可以使Map 也可能是Reduce任务。
任务的执行•申请到任务后,TaskTracker会做如下事情:•拷贝代码到本地•拷贝任务的信息到本地•启动JVM运行任务状态与任务的更新•任务在运行过程中,首先会将自己的状态汇报给TaskTracker,然后由TaskTracker汇总告之JobTracker。
•任务进度是通过计数器来实现的。
作业的完成•JobTracker是在接受到最后一个任务运行完成后,才会将任务标志为成功。
•此时会做删除中间结果等善后处理工作。

hadoop选择题,判断题含解答选择题:1. Hadoop是一个开源的分布式计算框架,它的核心组件包括:A. HDFS和MapReduceB. HBase和HiveC. Hive和PigD. Spark和Flink答案:A2. Hadoop的分布式文件系统(HDFS)的主要特点是什么?A. 高可靠性、高容错性、高扩展性B. 低延迟、低吞吐量、低容错性C. 高延迟、高吞吐量、高容错性D. 低可靠性、低容错性、低扩展性答案:A3. Hadoop的MapReduce编程模型中,Mapper的主要任务是:A. 将输入数据切分成多个片段B. 对输入数据进行排序C. 对输入数据进行过滤和转换D. 对输入数据进行归约和聚合答案:C4. Hadoop的MapReduce编程模型中,Reducer的主要任务是:A. 将输入数据切分成多个片段B. 对输入数据进行排序C. 对输入数据进行过滤和转换D. 对输入数据进行归约和聚合答案:D5. Hadoop的YARN(Yet Another Resource Negotiator)负责:A. 存储管理B. 资源调度和任务管理C. 数据加密和解密D. 数据备份和恢复答案:B6. Hadoop的数据块大小默认是多少?A. 64MBB. 128MBC. 256MBD. 512MB答案:B7. Hadoop的NameNode主要负责什么功能?A. 数据块的存储和管理B. 数据块的读取和写入C. 元数据的存储和管理D. 数据块的复制和迁移答案:C8. Hadoop的Secondary NameNode主要负责什么功能?A. 数据块的存储和管理B. 数据块的读取和写入C. 元数据的存储和管理D. 数据块的复制和迁移答案:D9. Hadoop的高可用性是通过什么机制实现的?A. ZookeeperB. HDFS FederationC. DataNode FederationD. NameNode Federation答案:A10. Hadoop的MapReduce程序运行在哪个节点上?A. Master节点B. DataNode节点C. TaskTracker节点D. Client节点答案:C判断题:1. Hadoop只能在Linux操作系统上运行。

hadoop mapreduce工作原理
Hadoop MapReduce是一种分布式计算模型,用于处理大数据集。
它有两个主要组件:Map和Reduce。
Map阶段:在MapReduce任务中,数据被拆分成几个小块,
然后并行传输到不同的节点上。
每个节点上都运行着一个
Map任务。
在Map阶段,每个节点独立地对其分配到的数据
块进行处理。
这些数据块被输入给一个映射函数,该函数将输入数据转换成<Key, Value>对。
映射函数将生成许多中间<Key, Value>对,其中Key是一个唯一的标识符,Value是与该Key
相关联的数据。
Shuffle阶段:在Map阶段之后,中间的<Key, Value>对被分
区并按照Key进行排序。
然后,相同Key的值被分组在一起,并传输到下一个Reduce节点。
在此过程中,数据在不同的节
点之间进行移动,以便形成适合进行Reduce操作的数据分区。
Reduce阶段:在Reduce阶段,每个Reduce节点只处理与特
定Key相关联的所有Value。
Reduce节点将这些Value作为输
入传给一个归约函数。
归约函数可以对这些Value执行合并、
计算或其他操作来得到最终的输出结果。
整个MapReduce过程的主要思想是将大任务分解成更小的子
任务,然后并行执行这些子任务,并将结果进行合并以生成最终的输出。
这种计算模型能够充分利用分布式计算集群的处理能力,从而高效地处理大规模的数据集。

hadoop考试判断题Hadoop考试通常涉及许多方面,包括Hadoop的基本概念、架构、组件、工作原理、应用和实践等。
以下是一些可能涉及到的判断题:1. Hadoop是一个开源的分布式计算平台。
(判断题)。
答,是的,这是正确的。
Hadoop是一个开源的分布式计算平台,它提供了可靠、可扩展的分布式计算和存储解决方案。
2. Hadoop的核心组件包括HDFS和YARN。
(判断题)。
答,是的,这是正确的。
Hadoop的核心组件包括Hadoop分布式文件系统(HDFS)用于存储和YARN(Yet Another Resource Negotiator)用于资源管理和作业调度。
3. MapReduce是Hadoop中用于数据处理的编程模型。
(判断题)。
答,是的,这是正确的。
MapReduce是Hadoop中用于大规模数据处理的编程模型,它将作业分解成小的任务并在集群中并行执行。
4. Hadoop生态系统中的Hive是一个用于实时数据处理的工具。
(判断题)。
答,不对,这是错误的。
Hive是Hadoop生态系统中的一个数据仓库工具,它提供了类似SQL的查询语言HiveQL,用于在Hadoop上进行数据分析。
5. Hadoop的高可用性可以通过使用ZooKeeper来实现。
(判断题)。
答,是的,这是正确的。
Hadoop的高可用性可以通过使用ZooKeeper来实现,ZooKeeper是一个分布式的协调服务,可以用于管理Hadoop集群的状态信息。
以上是一些可能涉及到的Hadoop考试判断题,希望能够帮助到你。
如果你还有其他问题,欢迎继续提问。

Hadoop基础(习题卷5)说明:答案和解析在试卷最后第1部分:单项选择题,共54题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]使用下面那个命令可以将HDFS目录中所有文件合并到一起A)putmergeB)getmergeC)remergeD)mergeALL2.[单选题]下列关于Map/Reduce并行计算模型叙述正确的一项为________。
A)Map/Reduce把待处理的数据集分割成许多大的数据块B)大数据块经Map()函数并行处理后输出新的中间结果C)reduce()函数把多任务处理后的中间结果进行汇总D)reduce阶段的作用接受来自输出列表的迭代器3.[单选题]Hadoop伪分布式是()A)一个操作系统B)一台机器C)一个软件D)一种概念4.[单选题]在MapReduce任务中,下列哪一项会由hadoop自动排序?A)keys of mapper's outputB)values of mapper's outputC)keys of reducer's outputD)values of reducer's output5.[单选题]使配置的环境变量生效的命令是( )A)vi ~/.bashrcB)source ~/bashrcC)cat ~/.bashrcD)source ~/.bashrc6.[单选题]在命令模式中,以下那个命令不会进入输入模式?A)qB)oC)iD)a7.[单选题]DataNode默认存放目录为()A)/opt/hadoop-record/softC)/home/hadoop-record/softD)/opt/hadoop-record/data8.[单选题]HDFS 2.x默认Block Size ( )A)16MBB)32MBC)64MBD)128MB9.[单选题]在本次项目实施中,需求调研前的准备不包括( )。

分布式计算框架-MapReduce基本原理(MP⽤于分布式计算)hadoop最主要的2个基本的内容要了解。
上次了解了⼀下HDFS,本章节主要是了解了MapReduce的⼀些基本原理。
MapReduce⽂件系统:它是⼀种编程模型,⽤于⼤规模数据集(⼤于1TB)的并⾏运算。
MapReduce将分为两个部分:Map(映射)和Reduce(归约)。
当你向mapreduce框架提交⼀个计算作业,它会⾸先把计算作业分成若⼲个map任务,然后分配到不同的节点上去执⾏,每⼀个map任务处理输⼊数据中的⼀部分,当map任务完成后,它会⽣成⼀些中间⽂件,这些中间⽂件将会作为reduce任务的输⼊数据。
Reduce任务的主要⽬标就是把前⾯若⼲个map的数据汇总到⼀起并输出。
MapReduce的体系结构:主从结构:主节点,只有⼀个:JobTracker;从节点,有很多个:Task TrackersJobTracker负责:接收客户提交的计算任务;把计算任务分给Task Trackers执⾏;监控Task Tracker的执⾏情况;Task Trackers负责:执⾏JobTracker分配的计算任务。
MapReduce是⼀种分布式计算模型,由google提出,主要⽤于搜索领域,解决海量数据的计算问题。
MR由两个阶段组成:Map和Reduce,⽤户只需要实现map()和reduce()两个函数,即可实现分布式计算,⾮常简单。
这两个函数的形参是key、value,表⽰函数的输⼊信息。
MapReduce执⾏流程:MapReduce原理:执⾏步骤:1. map任务处理1.1 读取输⼊⽂件内容,解析成key、value对。
对输⼊⽂件的每⼀⾏,解析成key、value对。
每⼀个键值对调⽤⼀次map函数。
1.2 写⾃⼰的逻辑,对输⼊的key、value处理,转换成新的key、value输出。
1.3 对输出的key、value进⾏分区。

Computer Knowledge and Technology 电脑知识与技术计算机工程应用技术本栏目责任编辑:梁书第7卷第22期(2011年8月)Hadoop 集群性能优化技术研究辛大欣,刘飞(西安工业大学,陕西西安710032)摘要:Hadoop 技术已经在互联网领域得到广泛的应用,同时也得到了学术界的普遍关注。
该文介绍了Hadoop 作为基础数据处理平台仍然存在的问题,阐明了Hadoop 性能优化技术研究的必然性,并介绍了当前Hadoop 优化的三个主要思路:从应用程序角度进行优化、对Hadoop 系统参数进行优化和对Hadoop 作业调度算法进行优化。
Hadoop 集群优化对于提高系统性能和执行效率具有重大的意义。
关键词:Hadoop 集群;性能优化;配置参数;作业调度中图分类号:TP14文献标识码:A 文章编号:1009-3044(2011)22-5484-03Research of Hadoop Performance Tuning TechnologyXIN Da-xin,LIU Fei(Xi'an Technological University,Xi'an 710032,China)Abstract:Hadoop technology had been wildly used and research around the internet and academics.The article introduce the reminded problems of Hadoop data processing platform and Illustra Configuration parameters imization the hadoop performace to increase the system performace and efficiency.Key words:Hadoop cluster;performance optimization;configuration parameters;job schedulerhadoop 是隶属于Apache 软件基金会(Apache Software Foundation )的开源JAVA 项目,它是一个分布式的具有可靠性和可扩展性的存储与计算平台。
软件工程师题库150_5月试题与答案软件工程师题库150_5月试题与答案1. Hadoop运行模式不包括() [单选题] *A.分布式B.中心版(正确答案)C.单机版D.伪分布式2. 哪一个方法不在FileInputFormat类中(),不用考虑方法参数。
[单选题] *A. addInputPath()B. getPathStrings()C. getSplits()D. List()(正确答案)3. HIVE与传统SQL数据库对比,下面描述不正确的是() [单选题] *A. 对于查询语言:HIVE使用HQL,传统SQL数据库使用SQLB. 对于数据存储:HIVE使用HDFS存储,传统SQL数据库使用本地磁盘C. 最终执行者:HIVE使用MapReduce和Excutor执行,传统SQL数据库使用Excutor执行器(正确答案)D. 执行延迟:HIVE属于高,传统SQL数据库属于低4. Namenode在启动时自动进入安全模式,在安全模式阶段,说法错误的是()[单选题] *A.安全模式目的是在系统启动时检查各个DataNode上数据块的有效性B.根据策略对数据块进行必要的复制或删除C.当数据块最小百分比数满足的最小副本数条件时,会自动退出安全模式D.文件系统允许有修改(正确答案)5. Hive数据仓库和关系型数据库mysql的区别() *A.Hive不支持事务而mysql支持事务B.hive高延迟而mysql相对低延迟。
(正确答案)C.Hive不支持索引而mysql支持索引。
(正确答案)D.Hive的分区和mysql的分区都用表内字段。
6. 以下hive sql语法正确的是() [单选题] *A.select * from a inner join b on a.id<>b.idB.select * from a where a.id in (select id from b)C.select sum(a.amt) as total from a where a.total>20D.select * from a inner join b on a.id=b.id(正确答案)7. 有关HIVE中ORDER BY 和 SORT BY 用法正确的是( ) [单选题] *SORT BY 用于分组汇总SORT BY 用于局部排序,ORDER BY用于全局排序(正确答案)使用完全一致其他说法都不对8. 在hive中下列哪些命令可以实现去重( ) [单选题] *distinct(正确答案)group byrow_numberhaving9. 如果需要配置Apache版本的hadoop的完全分布式,需要更改哪些xml配置文件( ) *hdfs-site.xml(正确答案)mapred-site.xml(正确答案)yarn-site.xml(正确答案)10. 下列哪些参数可以影响切片数量?( ) *MinSize(正确答案)MaxSize(正确答案)blockSize(正确答案)premisson答案解析:默认切片公式computeSliteSize(Math.max(minSize,Math.min(maxSize,bloc ksize)))=blocksize=128M 11. Yarn的调度几种方式( ) [单选题] * FIFO SchedulerCapacity SchedulerFairScheduler以上都是(正确答案)12. 以下哪一项不属于 YARN的进程是() [单选题] *A.ResourceManagerB.NodeManagerC.MRAppMasterD.Master(正确答案)13. HDFS2.X默认 Block size的大小是() [单选题] *A 32MBB 64MBD.256M答案解析:HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。
hadoop中的mapreduce的核心概念MapReduce是Apache Hadoop中的一个核心模块,用于处理大规模数据集的分布式计算。
它借鉴了函数式编程的思想,并将数据处理的复杂过程分解为简单的Map和Reduce两个阶段,以实现高效、可扩展的大数据处理。
核心概念:1. 分布式计算模型:MapReduce模型是一种分布式计算模型,它将大规模数据集划分为多个小型数据集,并在多个计算节点上并行处理这些小型数据集。
这种分布式计算模型充分利用了大量节点并行计算的优势,加速数据处理速度。
2. Map函数:Map函数是MapReduce中的第一个阶段,它执行一个映射操作,将输入数据集映射为<key, value>对。
Map函数可以独立地处理每个输入记录,并产生零个或多个<key, value>对作为中间结果。
Map函数负责将输入数据的某种属性或特征提取出来,并附加上适当的键值对标签。
3. Reduce函数:Reduce函数是MapReduce中的第二个阶段,它执行一个归约操作,将Map函数产生的中间结果进行合并和聚合。
Reduce函数的输入是所有与特定键相关的值的集合,它们可以是来自不同Mapper的结果。
Reduce 函数对这些值进行处理,并生成最终的输出结果。
4. 分区(Partitioning):在MapReduce中,分区是将中间结果按照键进行划分的过程。
每个Reduce任务会被分配到特定的分区,所有相同键的<key, value>对会被分发到同一个Reduce任务进行处理。
分区可以帮助提高计算效率和负载均衡,确保相同键的数据会被发送到同一个Reduce任务中进行归约操作。
5. 排序(Sorting):在MapReduce的Reduce阶段之前,中间结果需要进行全局排序,以确保具有相同键的所有记录聚集在一起。
这个排序过程可以通过分区和排序(shuffle and sort)阶段来完成。
MapReduce编程模型的实现什么是MapReduceMapReduce是一种用于处理大规模数据集的编程模型和算法。
它由Google公司提出,并在2004年的一篇论文中进行了详细描述。
MapReduce将数据处理任务分为两个阶段:Map和Reduce。
在Map阶段,输入数据被分割成多个小块,每个小块由一个Map任务处理。
Map任务将输入数据映射为(key, value)对,并将这些对作为中间结果输出。
在Reduce阶段,所有Map任务的输出被合并并按照key进行分组。
每组数据由一个Reduce任务处理。
Reduce任务对每个(key, value)对执行特定的操作,并生成最终的输出结果。
通过将大规模数据集划分为多个小块,并并行处理这些小块,MapReduce能够高效地处理大规模数据集,提供可扩展性和容错性。
MapReduce编程模型的实现实现MapReduce编程模型需要具备以下几个关键要素:分布式计算框架要实现MapReduce编程模型,需要使用一种分布式计算框架来管理任务调度、数据分发和结果收集等操作。
目前比较常用的分布式计算框架有Apache Hadoop、Apache Spark等。
Map函数在实现过程中,需要定义一个Map函数来执行特定的映射操作。
Map函数将输入数据映射为(key, value)对,并将这些对作为中间结果输出。
Map函数通常是独立的,可以并行执行,每个Map任务处理一部分输入数据。
Map 函数的具体实现取决于具体的应用场景和需求。
Reduce函数除了Map函数,还需要定义一个Reduce函数来执行特定的合并和计算操作。
Reduce函数对每个(key, value)对执行特定的操作,并生成最终的输出结果。
Reduce函数也是独立的,可以并行执行,每个Reduce任务处理一组(key, value)对。
Reduce函数的具体实现同样取决于具体的应用场景和需求。
数据分割和分发在实现过程中,需要将输入数据分割成多个小块,并将这些小块分发给不同的Map任务进行处理。
mapreduce并行编程原理-回复为什么需要并行编程?随着计算机系统的发展,数据量的爆炸性增长推动了对计算能力的巨大需求。
然而,传统的单线程编程模型已经无法满足这一需求,因为它们无法充分利用现代计算机系统中的多核处理器和分布式计算资源。
为了提高计算效率,人们开始使用并行编程来实现任务的并发执行。
并行编程是一种编程模式,它可以在多个处理单元或计算资源上同时执行不同的任务。
这种模式允许任务之间以并行方式协同工作,从而提高整体系统的处理能力。
并行编程的一个重要应用领域是数据处理,而MapReduce是一种常用的并行编程框架。
MapReduce是一种用于大规模数据处理的并行编程框架,它由Google 提出,并被广泛应用于分布式计算领域。
它提供了一种简单而有效的方式来处理大量的数据,无论是在单机还是分布式环境中。
MapReduce的核心原理是将任务分解为两个阶段:映射(Map)和归约(Reduce)。
在映射阶段中,系统将输入数据集分割为若干个小块,并对每个小块应用相同的映射函数。
映射函数将输入数据转换为键值对的形式,并输出中间结果。
在归约阶段中,系统将相同键的中间结果进行合并,并通过归约函数将它们转换为最终结果。
为了实现MapReduce,并行处理框架需要进行任务的分配和调度。
在分布式环境中,MapReduce框架可以自动将数据和任务分配到可用的计算资源上,从而实现任务的并行执行。
这种分布式任务调度可以大大提高数据处理的效率,充分利用了计算资源的并行性。
为了更好地理解MapReduce,并行编程的原理,我们可以通过一个例子来说明。
假设我们有一个包含1亿条日志记录的文件,我们希望统计每个IP地址出现的次数。
传统的单线程方法可能需要花费很长时间来处理这么大的数据集,而使用MapReduce并行编程框架可以有效地加快处理速度。
首先,我们需要将输入数据集分割为若干个小块,并将它们分发给不同的节点进行处理。
每个节点将接收到的数据块应用映射函数,将其中的IP 地址作为键,并将出现的次数作为值输出。
A Dynamic MapReduce Scheduler for HeterogeneousWorkloadsChao Tian12, Haojie Zhou1,Yongqiang He 12, Li Zha11Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100080, China2 Graduate University of the Chinese Academy of Sciences, Beijing 100039, Chinatianchao@, zhouhaojie@, heyongqiang@, char@Abstract—MapReduce is an important programming model for building data centers containing ten of thousands of nodes. In a practical data center of that scale, it is a common case that I/O-bound jobs and CPU-bound jobs, which demand different resources, run simultaneously in the same cluster. In the MapReduce framework, parallelization of these two kinds of job has not been concerned. In this paper, we give a new view of the MapReduce model, and classify the MapReduce workloads into three categories based on their CPU and I/O utilization. With workload classification, we design a new dynamic MapReduce workload predict mechanism, MR-Predict, which detects the workload type on the fly. We propose a Triple-Queue Scheduler based on the MR-Predict mechanism. The Triple-Queue scheduler could improve the usage of both CPU and disk I/O resources under heterogeneous workloads. And it could improve the Hadoop throughput by about 30% under heterogeneous workloads.Keywords-component; MapReduce; Schdule; heterogeneous workloads;I.I NTRODUCTIONAs the Internet scale keeps growing up, enormous data needs to be processed in many Internet Service Providers. MapReduce framework is now becoming a leading example solution for this. MapReduce is designed for building large commodity cluster, which consists of thousands of nodes by using commodity hardware. Hadoop, a popular open source implementation of MapReduce framework, developed primarily by Yahoo, is already used for processing hundreds of terabytes of data on at least 10,000 cores [3]. In this environment, many people share the same cluster for different purpose. This situation led that different kinds of workloads need to run on the same data center. For example, these clusters could be used for mining data from logs which mostly depends on CPU capability. At the same time, they also could be used for processing web text which mainly depends on I/O bandwidth.The performance of a parallel system like MapReduce system closely ties to its task scheduler. Many researchers have shown their interest in the schedule problem. Current scheduler in Hadoop uses a single queue for scheduling jobs with a FCFS method. Yahoo’s capacity scheduler [4] as well as Facebook’s fair scheduler [5] uses multiple queues for allocating different resources in the cluster. Using these scheduler, people could assign jobs to queues which could manually guarantee their specific resource share.In this work, we concentrate on the problem that how to improve the hardware utilization rate when different kinds of workloads run on the clusters in MapReduce framework. In practical, different kinds of jobs often simultaneously run in the data center. These different jobs make different workloads on the cluster, including the I/O-bound and CPU-bound workloads. But currently, the characters of workloads are not aware by Hadoop’s scheduler which prefers to simultaneously run map tasks from the same job on the top of queue. This may reduce the throughput of the whole system which seriously influences the productivity of data center, because tasks from the same job always have the same character. However, the usage of I/O and CPU are actually complementary [7]. A task that performs I/O is blocked, and is prevented from utilizing the CPU until the I/O completes. When diverse workloads run on this environment, machines could contribute different part of resource for different kinds of work.We design a new triple-queue scheduler which consist of a workload predict mechanism MR-Predict and three different queues (CPU-bound queue, I/O-bound queue and wait queue). We classify MapReduce workloads into three types, and our workload predict mechanism automatically predicts the class of a new coming job based on this classification. Jobs in the CPU-bound queue or I/O-bound queue are assigned separately to parallel different type of workloads. Our experiments show that our approach could increase the system throughput up to 30% in the situation of co-exiting diverse workloads.The rest of the paper is organized as follows. Section 2 describes the related work of this article. Section 3 shows our analysis on MapReduce schedule procedure and give a classification of MapReduce workloads. Section 4 introduces our new scheduler. Section 5 validates the performance increase of our new scheduler through a suit of experiments.II.R ELATED WORKThe scheduling of a set of tasks in a parallel system has been investigated by many researchers. Many schedule algorithms has been proposed [11, 12, 13, 16, 17]. [16, 17] focus on scheduling tasks on heterogeneous hardware, and [11,This work is supported in part by the National Science Foundation ofChina (Grant No. 90412010),the Hi-Tech Research and Development (863)Program of China (Grant No. 2006AA01A106, 2006AA01Z121), and theNational Basic Research (973) Program of China (Grant No. 2005CB321807).2009 Eighth International Conference on Grid and Cooperative Computing12, 13] focus on the system performance under diverse workload. The heterogeneity of workloads is also in our assumptions.In fact, it is nontrivial to balance the use of the resources in applications that have different workloads such as large computation and I/O requirements [10]. [6, 14] discussed the problem of how I/O-bound jobs affect system performance, and [7] shown a gang schedule algorithm which parallel the CPU-bound jobs and IO-bound jobs to increasing the utilization of hardware. Our work shares the some ideas with these work However, we depict the different kinds of workloads in the MapReduce system.The schedule problem in MapReduce also attracted manyattentions. [2] addressed the problem of how to robustly perform speculative execution mechanism under heterogeneous hardware environment. [9] derive a new family of scheduling policies specially targeted to sharable workloads.Hadoop is a popular open source implementation of MapReduce [1] and Google File System [15]. Yahoo and Facebook also designed schedulers of Hadoop as Capacity scheduler [4] and Fair scheduler [5]. These two schedulers used multiple queues for allocating different resources in the cluster. They both provide short response times to small jobs in a shared Hadoop cluster. Our work has some thing in common with these two schedulers. However, our work focuses on the utilization of hardware under heterogeneous workloads. We give an automatic workload predicting mechanism for detecting the workload type on the fly. Then the triple-queue scheduler use two different queues for assign tasks of different types.III.M AP R EDUCE ANALYSIS AND WORKLOADSCLASSIFICATIONIn this section, we analyze the MapReduce job working procedure, and give a classification of workloads on MapReduce. Then we discuss the schedule model in Hadoop, and express the problem on this model when diverse workloads run on the current implementation of Hadoop.A.MapReduce procedure analysisMapReduce contains a map phase grouping data in specified key and a reduce phase aggregating data shuffled from map nodes. Map tasks are a bag of independent tasks which use different input. They are assigned to different nodes in cluster. In the other hand, reduce tasks depend on the output of map tasks. They keep fetching map result data from other nodes. Shuffle actions which are I/O-bound often intercross in the map phase, for maximizing the utility of I/O resource. As shown in Figure 1, after all needed intermediate data getshuffled, the reducer begins to compute.Figure 1. The MapReduce data process phasesWe decompose the MapReduce procedure into two sub phases which are Map-Shuffle phase and Reduce-Computing phase. In the Map-Shuffle phase, every node dose five actions: 1) init input data; 2) compute map task; 3) store output result to local disk; 4) shuffle map tasks result data out; and 5) shuffle reduce input data in. The Map-Shuffle phase is the first step. And in Reduce-Computing phase, tasks could directly begin to run the application logic because the input data is already shuffled in memory or local disk.In this view of MapReduce, Map-Shuffle phase is critical to the whole procedure. In this phase, every node performs their map task logic which is similar in one job, and shuffles result data to all reducer nodes. All reducer nodes are not able to begin computing because just one map node slows down. Our work focuses on this phase in MapReduce. We predict map tasks behavior by analyzing job’s Map-Shuffle phase history. I/O-bound map tasks and CPU-bound map tasks could be distinguished by our scheduler. Then we parallel the different kinds of workloads.B. Classification of workloads on MapReduceAccording to the utilization of I/O and CPU, we give a classification of workloads on the Map-Shuffle phase of MapReduce. As we say, every node in the Map-Shuffle phase does five actions. The ratio of the amount of map input data (MID) and map output data (MOD) in a single map task depends on the type of workload. We define a variable ρ as the application logic of particular workload where:MID*MODρ= (1) Shuffle out data (SOD) is the same as the MOD, because MOD is the source of shuffle. Different with the others, the shuffle in data (SID) in a node is not determined by map tasks but the proportion of local reducers’ number and the whole reducers’ number.The first class of workload refers to the tasks of CPU-bound. This class job’s CPU utilization can be maximized to 100% by paralleling more executing tasks. We assume that tasks in the same job have the same ρ value. We define a variable n as the number of concurrent running tasks on one node. We define MTCT which means the Map Task Completed Time and DIOR which means Disk I/O Rate.We use formula 2 to define the type of CPU-Bound workload. As for a map task, the operations of the I/O in disk include input, output, shuffle out and shuffle in. In the process of program running, every node has n map tasks which are synchronously running. Multiple tasks share the disk I/O bandwidth when the system stably runs. In our opinion, if the summation of MID+MOD+SOD+SID of n map tasks divided by MTCT is still smaller than the bandwidth of disk I/O, then this kind of task is CPU-bound. This is an upper-bound of CPU-bound jobs. Formula 2 witnesses this conclusion, and it indicates the estimation of the program action.DIOR <++=+++MTCTSID) )MID 2(1 (*n MTCT SID)SOD MOD (MID *n ρ (2) The second class of workload is different with the formerone. Its map tasks are CPU-Bound without shuffle action. However when shuffle action begins, they block in I/O bandwidth. In this class, the ratio of the I/O data of map tasks to the runtime is less than DIOR. But when reduce phase begins, shuffle will generate lots of disk I/O, and it will make map task block in disk I/O. The CPU utilization ratio of this kind of job wouldn’t reach 100%. We name this class of job as Class Sway. This class means:DIOR≥++=+++MTCTSID) )MID 2(1 (*n MTCTSID)SOD MOD (MID *n ρ (3) Formula 4 define the type of I/O-Bound workload. In this class, every map task would generate lots of I/O operations in short time. And when n map tasks synchronously run on every node, there will be contention among different tasks. Even if reduce shuffle doesn’t start, map task will be still bound to I/O. Formula 4 shows this relation. With our analyzing of single task, we could conclude that if n tasks of this kind synchronously run in the system, it will make application block at disk IO.DIORMTCTMIDMTCT ≥+=)1(*n MOD)+(MID *n ρ (4)We assume that every reducer have a similar size data input.So the SID in MapReduce depends on the distribution of reducer in the cluster. The shuffle input data in every node relies on the proportion of running reducer number (RRN) to the whole reducer number (WRN).So the SID equals the following formula.number nodes *SOR *WRNRRNSID =(5)In these formulas, the MTCT is a variable which may beinfected by the nodes’ workload runtime status. The workload on a machine may make the MTCT longer than the ideal value. This means that if a job is defined as an I/O-bound class according to my formals, it is definitely I/O-bound. But if the job is defined as a CPU-bound class, it may be not CPU-bound class. However, we have got another defect-modify modular torectify this. In details, we make a test to get the execution time of the jobs which simultaneously run with the testing jobs, if the execution time doesn’t get longer, we could confirm the testing job is CPU-bound class.C. Hadoop schedule modelCurrent Hadoop scheduler serves as a FCFS queue with priority. In the MapReduce framework, assigning happens when a TaskTracker which is in charge of the running jobs in the cluster heartbeats the JobTraker. The TaskTracker do heartbeat in every interval (default as 5 second) or when a task in that node finishes. Hadoop also uses a concept of slotnumber for each node to control maximal tasks running number of that node. The slot number actually depicts the maximal parallelizability of the machines. It can be configured in an xml file on every machine based on the hardware of that node. The current scheduler in Hadoop always assigns tasks from the job in the top of queue. It makes that map tasks from the same jobs are always running together. Because map tasks from the same job in MapReduce have similar behaviors, this kind of one queue scheduler could not efficiently use both CPU and I/O resource of the cluster. The contention among the similar tasks decreases the system throughput. In our work, we use three queues to separately execute different type of jobs.Our experiment has shown that our approach can increase thesystem throughput in 30%. IV. T RIPLE -QUEUE S CHEDULERCurrent Hadoop scheduler implementation assigns tasks sequentially by using one queue. Other map tasks wouldn’t be assigned until tasks from the job in the top of queue finish. This FCFS strategy works well when the jobs in the queue are of the same class. However, I/O-bound tasks cause the CPUs to be idle too much time, when other tasks can run. At the same time, the effect of the disk performance is on the opposite: I/O-bound tasks keep the disks busy, while CPU-bound tasks leave them idle. This phenomenon raises the problem of inadequately using of resource. This could happen in a real data center where diverse kinds of workloads often run on it simultaneously. The main idea of our work is that balancing different kinds of tasks could increase the utilization rate of both CPU and I/O bandwidth. The rationale for such paralleling is that these different tasks will hardly interfere each other’s work, as they use different devices [7]. Therefore, they will work well separately in the system. If the I/O operations’ time is not negligible relative to the CPU time, such an overlap of the I/O activity with CPU work can be efficient [6].A. MR-Predict In this triple-queue scheduler, the predicting of workload type is essential. The characteristics of a task can be assessed by looking over its history. We assume that tasks from one job have similar characteristics. It means we can predict tasks’ behavior from the tasks already ran. We propose a new MapReduce workload predict mechanism called MR-Predict. As shown in Figure 2, our scheduler determines a job’s type based on the Formula 2, 3 and 4 which we proposed in previous chapter, and then jobs will run in two different queueswith feedback. When a new job comes in, it will be put into the waiting queue first. Then the scheduler will assign one map task of that job to every TaskTracker when it has idle slots. When these map tasks finish, we calculate the MTCT, MID and MOD by using the data form these tasks. Then jobs can be divided into three types. Each type can be determined by using these data by using our classification of MapReduce framework.In this triple-queue scheduler, the predicting of workload type is essential. The characteristics of a task can be assessed by looking over its history. We assume that tasks from one job have similar characteristics. It means we can predict tasks’ behavior from the tasks already ran. We propose a new MapReduce workload predict mechanism called MR-Predict. As shown in Figure 2, our scheduler determines a job’s type based on the Formula 2, 3 and 4 which we proposed in previous chapter, and then jobs will run in two different queues with feedback. When a new job comes in, it will be put into the waiting queue first. Then the scheduler will assign one map task of that job to every TaskTracker when it has idle slots. When these map tasks finish, we calculate the MTCT, MID and MOD by using the data form these tasks. Then jobs can be divided into three types. Each type can be determined by using these data by using our classification of MapReduce framework.Figure 2. Pseudo-code of the schedule policyAmong all the classifications we discussed above, IO-bound is one conservative class. Because every node may have existed jobs, their contention for resource would lead longer runtime of tasks. Consequently, certain kinds of tasks are likely to be classified as CPU-bound according to our formulas. Therefore, our workload predict system includes one defect-modify mechanism. After one task is assigned to the CPU-Bound queue, the system will monitor the running tasks in IO-Bound queue, if the MTCT of recent tasks increase to a certain threshold, which we define as 140% in our system, then we get the conclusion that the task which we just assigned shouldn’t be allocated to the CPU queue, we need to re-allocate it to the I/O-Bound queue.B.Schedule policysThe triple-queue tasks scheduler contains a CPU-bound queue where jobs of CPU-Bound Class stand in, an I/O-bound queue where jobs of I/O-bound Class stand in, and a waiting queue where all jobs stand in before their type is determined. When a new job comes in, it will be added to the waiting queue. Then the scheduler assigns one map tasks to every TaskTracker for predicting the job type. As shown in the figure 3, if both the CPU-bound queue and I/O-bound queue are empty at that time, the job on the top of waiting queue would move to the idle queue and keep running until its type is determined. And then, as shown in Figure 4, if the undetermined job is found stand in a wrong queue, it will move to the right one.CPU-BoundqueueI/O-BoundQueueWaitQueueFigure 3. The schedule policy when both queues are emptyCPU-Bound QueueI/O-BoundQueue WaitQueueFigure 4. Jobs which are detected standing in a wrong queue will switch toanother queueCPU-Bound queue and I/O-bound queue have their own map slot number and reduce slot number which can be configured by users based on the information of cluster hardware. Each queue works independently, and serves a FCFS with priority strategy just like Hadoop’s current job queue. On every node, both of the queues have their own slots for running certain kind of jobs unless one queue becomes empty. In this situation, idle slots will be fully used by the running job until a new job adds in the empty queue.V.E VALUATIONWe start our evaluation by compiling statistic of jobs to verify our workload classification. Then we do a couple of experiments to validate that one queue schedule can not raise the utilization of both I/O and CPU. At last we run a suit of mixed type jobs for validating the triple queue scheduler works well in a multiple workloads environment.We use a local cluster to test our triple queue scheduler which contains 6 DELL1950 nodes connected by gigabit Ethernet. Each node has 2 Quard Core 2.0GHz CPU, 4GB memory, 2 SATA disks.A. Resource utilizationsWe run a couple of jobs to evaluate the hardware utilization of the current one queue scheduler. We choose three jobs which belong to the three different workload types.[2] says that short jobs are a major use of MapReduce. For example, Yahoo won the TeraSort 1TB benchmark using 910 nodes in 209 second[8], and the average MapReduce job at Google in September 2007 was 395 seconds long [1]. So we choose the input data set as 15GB for each job which could simulate the situation in a real product environment. In these experiments, we set the map slots and the reduce slot to 8. So the n of formula 2, 3 and 4 is 8.We use a testing program called DIO to get the DIOR value of ideal performing Hadoop system. This program runs without reduce phase, and its programming act is simply to read and write on the disk. Therefore, it is totally IO intensive. We could estimate the system’s DIOR value according to the average runtime of single task in this program. In our experiment, we showed that our DIOR is almost 31.2 MB/S.TABLE I. TEST JOBSProgram MIDMOD MTCT TeraSort 64M64M8sec Grep-Count 64M1M 92sec WordCount 64M 64M 35secDIO 64M64M4.1secAs shown in table 1, the first job is TeraSort [8] which is a famous total order sort benchmark. TeraSort is essentially a sequential I/O benchmark. Its MID is 64M, MOD is almost64M in average. The MTCT of this program is 8 second. According to our formula 4, this job belongs to I/O-bound class.The second job is Grep-Count which based on the commonly used program Grep in Linux. The Grep-Count program accepts a regular expression and the files as the input parameters. Unlike Grep in Linux, this Grep-Count output the occupation number of the same lines matching the input regular expression in the documents rather than output all lines matching the regular expression. The computing complexity depends on the input regular expression. In our test case, we use [.]* as the regular expression which make the job be CPU-Bound. Its MID is 64M and MOD is almost 1M in average. According to our formula 2, this job belongs to I/O-bound class.The third job is WordCount. It splits the input text into words, shuffles every word in map phase and counts its occupation number in reduce phase. Its MID is 64M and MODis almost 64M in average. According to our formula 3, this job belongs to Sway class.Figure 5. The average CPU utilization rate of the clusterAmong the testing results, the CPU utilization rate of TeraSort always keeps in low level. That’s because the task is IO-bound, and the CPU utilization rate couldn’t rise. On the contrary, in the tests to Grep-Count, the CPU utilization rate is always nearly 100%. This also verifies that this task is of the class of CPU intensive. The performance of WordCount differs from the two programs above. When the program starts, because reduce task doesn’t begin, the CPU utilization rate reaches 80%; but after reduce task begins, the CPU utilization rate rapidly decreases.B.Triple queue scheduler experimentsIn the previous section, our experiments have shown that current Hadoop scheduler indeed could not efficiently use both of the CPU and I/O resource. In this section, we design a new scene that is multiple jobs run together. We define three clients which submit the three different kinds of jobs in their separate sessions. One client submits one kind of job, and sequentially submits the same job after the previous one finishes. This scène is used for simulating the real product environment which periodically does the same kinds of job everyday.We choose the task used in last chapter as testing task. We use three different clients to constantly request for running these three kinds of tasks. Every job runs five times, and in total 15 jobs will run. The three jobs are of different type. According to the throughput and complete time of these tasks, we could analyze the improvement of performance because of paralleling IO bound and CPU bound tasks.In our experiments, the sequence of task executing would influence the result of the test. The time of Reduce-compute phase in TeraSort and WordCount is a little longer, while that in Grep-count is a little shorter. TeraSort under Reduce-compute phase is CPU bound, and wordCount under Reduce-compute phase is IO bound. In the scheduler of Hadoop, after the Map phase of TeraSort finishes, map slot will be idle, if the next job in the queue is Grep-count, the map tasks of Grep-count and TeraSort could be parallel. It makes the integrity of the system improve in certain level. Therefore, in this test, we give the data under the best, the worst and the average condition.Figure 6. Makespan of the Triple-Queue scheduler against Hadoop nativeschedulerFigure 7. The throughput of map tasksAs shown in figure 5 and 6, the testing data has witnessed that with the scheduler of Hadoop, by adjusting the sequence of jobs, the performance of system is different. The makespan [18] of Hadoop native scheduler is about 7635 seconds in the best condition as well as 8540 seconds in the worst condition. The throughput of map tasks is 5.89 in the best condition and 5.44 in the worst condition.The triple queue scheduler can significantly improve the system performance. It improves the throughput by 30% in map-shuffle phase, and enhances the makespan by 20% under parallel workloads.VI.C ONCLUSION AND F UTURE WORKThis paper discusses the MapReduce performance under heterogeneous workloads. We analyze the typical MapReduce workloads on the MapReduce system, and classify them intothree catagories. We propose the Triple-Queue scheduler based on the classification. The triple-queue scheduler dynamically determines the category of one job. It contains a waiting queue to test-run new joined job and to predict the workload type of this job according to the result. It also includes a CPU-bound queue and an I/O-bound queue for paralleling different kinds of jobs. According to the experiment results, the scheduler can correctly distributes jobs into different queues in most situations. And then the job will run due to the resource appointed by the queue. Our experiments have shown that the Triple Queue Scheduler could increase the map tasks’ throughput of the system by 30%, and save the makespan by 20%.In our work, we assume that the distribution of workload isuniform. We then predict the future behaviors of tasks base onthese distribution. In our future work, we will try to predict theworkloads which are of different kinds of distribution and consider the hardware heterogeneity of the Hadoop cluster environment.[1] Jeffrey Dean and Sanjay Ghemawat, “MapReduce: Simplified DataProcessing on Large Clusters,” In Communications of the ACM,Volume 51, Issue 1, pp. 107-113, 2008.J. Clerk Maxwell, A Treatise onElectricity and Magnetism, 3rd ed., vol. 2. Oxford: Clarendon, 1892,pp.68–73.[2] Matei Zaharia, Andy Konwinski, Anthony D. Joseph, and Randy KatzIon Stoica, “Improving MapReduce Performance in HeterogeneousEnvironments,” Proceedings of the 8th conference on Symposium onOpearting Systems Design & Implementation[3] Yahoo! Launches World’s Largest HadoopProduction Application, Yahoo! Developer Network ,/blogs/hadoop/2008/02/yahoo-worlds-largest-production-hadoop.html.[4] Hadoop’s Capacity Scheduler/core/docs/current/capacity_scheduler.html.[5] Matei Zaharia, “The Hadoop Fair Scheduler” /blogs/hadoop/FairSharePres.ppt[6] E. Rosti, G. Serazzi, E. Smirni, and M.S. Squillante, “The Impact of I/Oon Program Behavior and Parallel Scheduling,” Proc. SIGMETRICS Conf. Measurement and Modeling of Computing Systems, 1998, pp. 56-65,[7] Yair Wiseman and Dror G. Feitelson, “Paired Gang Scheduling,” IEEETransactions on Parallel and Distributed System, vol. 14, no. 6, June 2003[8] Tera Sort Benchmark, /hosted/sortbenchmark/. [9] Parag Agrawal, Daniel Kifer, and Christopher Olston, “SchedulingShared Scans of Large Data Files,” PVLDB '08, August 2008, pp.23-28 [10] E. Rosti, G. Serazzi, E. Smirni, and M.S. Squillante, “Models of ParallelApplications with Large Computation and I/O Requirements,” IEEE Trans. Software Eng., vol. 28, no. 3, Mar.2002, pp. 286-307[11] M.J. Atallah, C.L. Black, D.C. Marinescu, H.J. Siegel and T.L.Casavant, “Models and algorithms for co-scheduling compute-intensive asks on a network of workstations,” Journal of Parallel and Distributed Computing 16, 1992, pp.319–327 [12] D.G. Feitelson and L. Rudolph, “Gang scheduling performance benefitsfor fine-grained synchronization,” Journal of Parallel andDistributed Computing 16(4),December 1992, pp.306–318 [13] J.K. Ousterhout, “Scheduling techniques for concurrent systems,” in Proc. of 3rd Int. Conf. on Distributed Computing Systems, May 1982,pp.22–30.[14] W. Lee, M. Frank, V. Lee, K. Mackenzie, and L. Rudolph, “Implications of I/O for Gang Scheduled Workloads,” Job Scheduling Strategies for Parallel Processing, 1997, pp. 215-237[15] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung, “The Google file system,” In Proceedings of 19th Symposium on Operating Systems Principles, 2003, pp. 29-43[16] H. Lee, D. Lee and R.S. Ramakrishna, “An Enhanced Grid Scheduling with Job Priority and Equitable Interval Job Distribution,” The first International Conference on Grid and Pervasive Computing, Lecture Notes in Computer Science, vol. 3947, May 2006, pp. 53-62[17] A.J. Page and T.J. Naughton, “Dynamic task scheduling using genetic algorithms for heterogeneous distributed computing,” in 19th IEEE International Parallel and Distributed Processing Symposium, 2005. [18] M. Pinedo, ``Scheduling: Theory, Algorithms, and Systems,'' Prentice Hall, Englewood Cliffs, NJ, 1995.。