实验八:主成分回归
实验题目:对例5.5的Hald水泥问题用主成分方法建立模型,并与其他方法的结果进行比较。
例5.5如下:本例为回归经典的Hald水泥问题。某种水泥在凝固时放出的热量y(卡/克,cal/g)与水泥中的四种化学成分的含量(%)有关,这四种化学成分分别是x1铝酸三钙(3CaO.Al2O3),x2硅酸三钙(3CaO.SiO2),x3铁铝酸四钙(4CaO.Al2O3.Fe2O3),x4硅酸三钙(2CaO.SiO2)。现观测到13组数据,如表5-3所示。
表5-3
实验目的:
SPSS输出结果及答案:
一、主成分法:
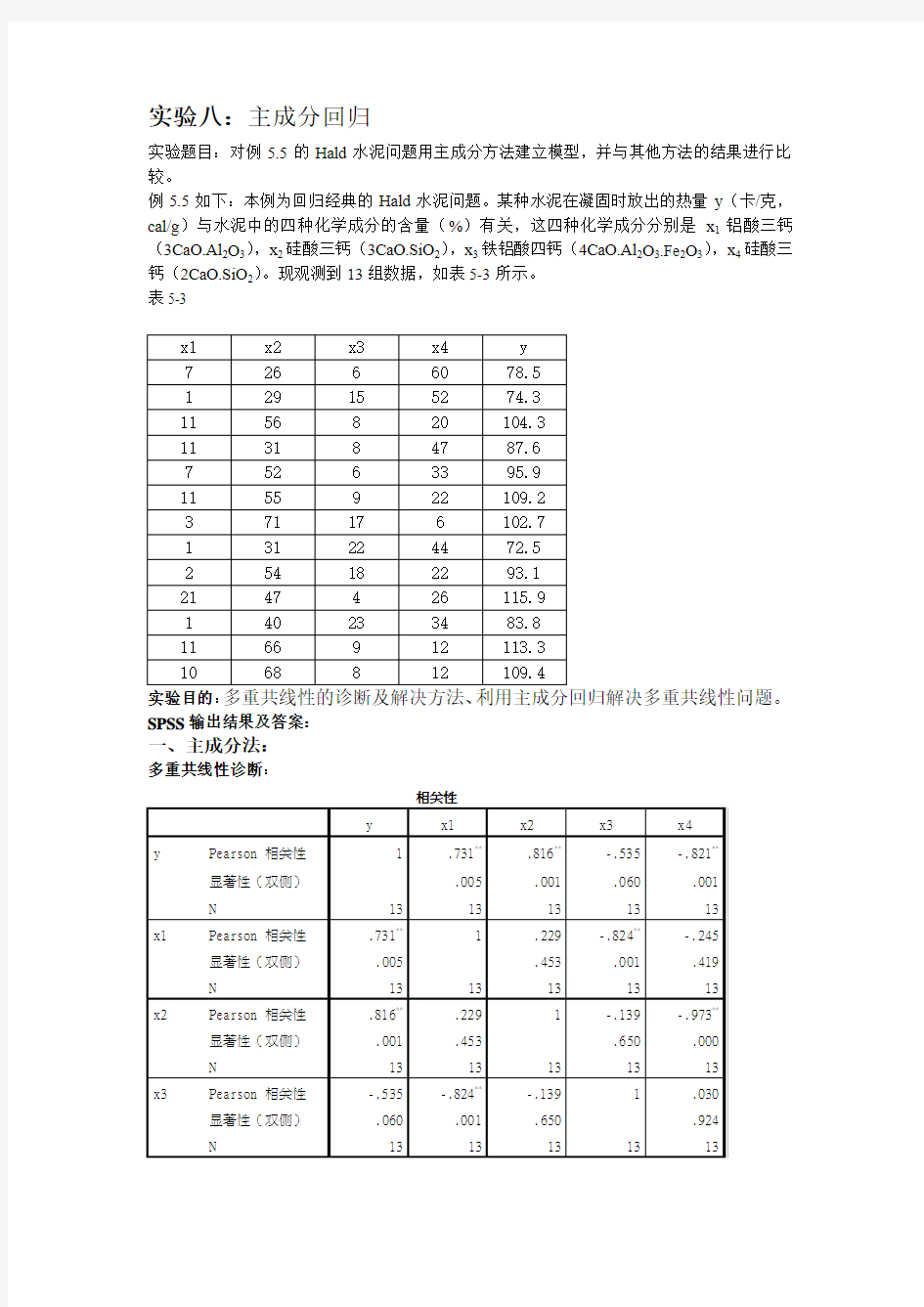
多重共线性诊断:
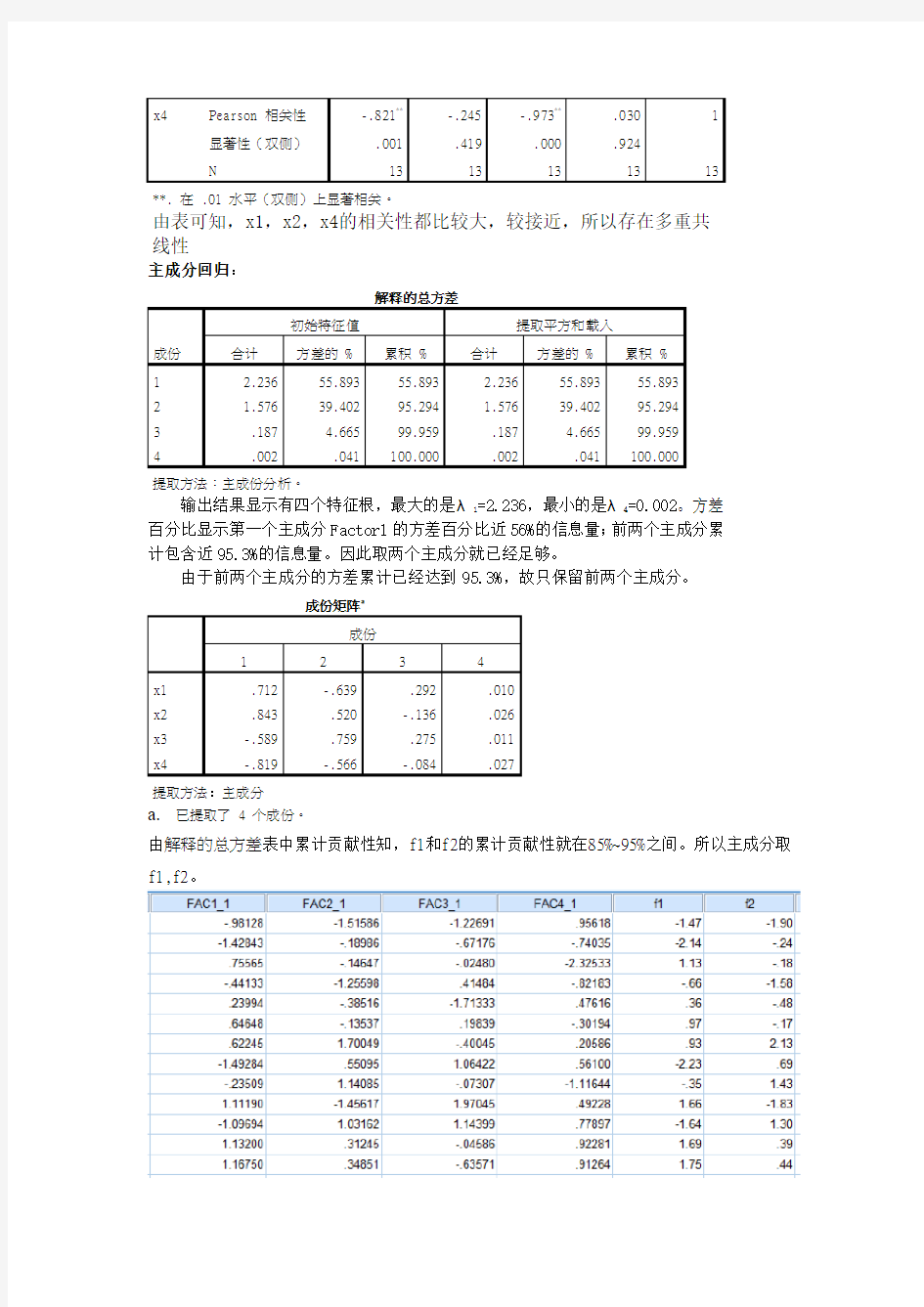
已提取了 4 个成份。
由解释的总方差表中累计贡献性知,f1和f2的累计贡献性就在85%~95%之间。所以主成分取f1,f2。
得到因子得分的数值,并对其进行处理:sqrt(2.236)*FAD1_1,sqrt(1.576)*FAD2_1可以得出
主成分表(f1 f2)。
对f1 f2进行普通最小二乘线性回归
f1=-0.643+0.081x1+0.036x2-0.062x3-0.033x4
对f2和x1x2x3x4进行回归
模型非标准化系数标准系数
t Sig.
B 标准误差试用版
1 (常量) -.938 .000 -1119037.661 .000
x1 -.087 .000 -.405 -9710099.545 .000
x2 .027 .000 .330 3071727.057 .000
x3 .094 .000 .482 10459854.955 .000
x4 -.027 .000 -.359 -3177724.589 .000 a.因变量: f2
f2=-0.938-0.087x1+0.027x2+0.094x3-0.027x4
所以还原后的主成分回归方程为:
^y=88.951624+0.789567x1+0.359127x2-0.600934x3-0.329481x4
从主成分法得出的方程中我们可以看出某种水泥在凝固时放出的热量与铝酸三钙,硅酸三钙成正比,与铝酸四钙和硅酸二钙成反比,且当该水泥放出1单位的热量时,需要消耗0.789567g的铝酸三钙和0.359127g的硅酸三钙;当该水泥吸收1单位的热量时,需要消耗0.600934g的铝酸四钙和0.329481g的硅酸二钙。
二.岭回归法
由系数表中的方差扩大因子VIF可以初步看出直接建立的线性模型具有严重的共线性,所以我们直接用岭回归方法进行处理,与再与主成分法进行比较。
岭回归
INCLUDE 'C:\Program Files\IBM\SPSS\Statistics\19\Samples\English\RIDGE regression.sps'. RIDGEREG enter x1 x2 x3 x4
/dep=y
R-SQUARE AND BETA COEFFICIENTS FOR ESTIMATED VALUES OF K
K RSQ x1 x2 x3 x4
______ ______ ________ ________ ________ ________
.00000 .98238 .606512 .527706 .043390 -.160287
.05000 .98092 .465987 .298422 -.092800 -.394132
.10000 .97829 .429975 .299810 -.115702 -.382409
.15000 .97492 .403545 .300180 -.129867 -.370747
.20000 .97105 .382726 .299130 -.139136 -.360181
.25000 .96676 .365601 .297070 -.145317 -.350594
.30000 .96212 .351071 .294335 -.149432 -.341806
.35000 .95717 .338452 .291156 -.152107 -.333674
.40000 .95195 .327295 .287687 -.153747 -.326089
.45000 .94649 .317289 .284036 -.154628 -.318970
.50000 .94082 .308211 .280279 -.154942 -.312254
.55000 .93497 .299900 .276467 -.154827 -.305892
.60000 .92897 .292231 .272638 -.154384 -.299846
.65000 .92284 .285109 .268820 -.153688 -.294083
.70000 .91660 .278460 .265032 -.152797 -.288577
.75000 .91027 .272222 .261287 -.151756 -.283306
.80000 .90386 .266349 .257597 -.150598 -.278251
.85000 .89740 .260798 .253968 -.149351 -.273396
.90000 .89089 .255537 .250406 -.148037 -.268726
.95000 .88436 .250537 .246913 -.146671 -.264228
1.0000 .87780 .245775 .243491 -.145269 -.259892
由上述的岭迹图可以看出,所有的回归系数的岭迹线的稳定性较强,整个系统呈现比较平稳的现象,所以我们可以对最小二乘有信心,且x1,x2的岭迹线一直在零的上,对y产生
正影响,而x3,x4系数的岭迹线一直小于零,所以对y产生负影响。
再做岭回归:
当岭参数k=0.2时,4个自变量的岭回归系数变化幅度较小,此时逐渐稳定,所以我们给定k=0.2,再做岭回归
Run MATRIX procedure:
****** Ridge Regression with k = 0.2 ******
Mult R .976585082
RSquare .953718422
Adj RSqu .944462107
SE 3.545275735
ANOVA table
df SS MS
Regress 2.000 2590.073 1295.037
Residual 10.000 125.690 12.569
F value Sig F
103.0343460 .0000002
--------------Variables in the Equation----------------
B SE(B) Beta B/SE(B)
x1 1.2516409 .1468176 .4894165 8.5251441
x4 -.5251646 .0515969 -.5843168 -10.1782125
Constant 101.8388483 2.2617303 .0000000 45.0269638
------ END MATRIX -----
由上述输出结果可以得到岭回归建立的方程为:
y=101.8388483+1.2516409x1-0.5251646x4
从岭回归法得出的方程中我们可以看出某种水泥在凝固时放出的热量与铝酸三钙,硅酸三钙成正比,与铝酸四钙和硅酸二钙成反比,且当该水泥放出1单位的热量时,需要消耗1.2516409g的铝酸三钙和0.5251646g的硅酸三钙;当该水泥吸收热量时,需要消耗铝酸四钙和硅酸二钙。
(3)比较:岭回归后建立的方程跟主成分回归法建立的方程保留的系数相同,且得出的系数符号相同,大小相近,即得出的y与x1,x2,x3,x4关系也相同,所以可知主成分法得出的回归方程也解决了共线性问题。
PL S回归在消除多重共线性中的作用 王惠文 朱韵华 (北京航空航天大学管理学院,北京,100083) 摘 要 本文详细阐述了解释变量的多重共线性在回归建模与分析中的危害作用,并指出目前常用的几种消除多重线性影响的方法,以及它们的不足之处。本文结合实证研究指出:利用一种新的建模思路 PLS回归,可以更好地消除多重共线性对建模准确性与可靠性所带来的影响。 关键词:多重共线性 PLS回归 一、引 言 在多元回归的建模与分析中,解释变量之间存在高度相关性的现象十分普遍。在这种情况下,要很好地解释模型中某个自变量对因变量的效应,是非常困难的。然而,在从事建模工作过程中,为了更完备地描述系统,尽可能不遗漏一些举足轻重的系统特征,分析人员往往倾向于尽可能周到地选取有关指标,在这样构成的多变量系统中必然经常出现变量多重相关的现象。事实上,许多社会、经济及技术指标都有同步增长的趋势,因此,在多元回归建模实施过程中,变量多重相关的现象是很难避免的。 二、多重共线性在回归建模中的危害作用 1.危害性讨论 多重共线性的现象是由Fr isch.A.K在其著名论著 完全回归体系的统计合流分析 中首次提出的,用数学语言来描述,它是指变量之间存在着线性关系。在多重共线性现象存在的情况下,对多元回归分析会产生如下影响: (1)如果变量之间存在完全的多重共线性,那么将无法估计变量的回归系数。而由于各个自变量的回归系数无法估计,所以也就无法估计各个自变量单独对因变量的影响,自然也就无法判断自变量对因变量的效应,即使自变量之间不存在完全的多重共线性,但是当自变量有较高度的相关关系时,一个自变量的回归系数,在模型中只反映这个自变量对因变量边际的或部分的效应,因而所得到的回归模型是不准确的。 (2)回归系数的估计方差为无穷大。例如在一个简单的多元回归中,自变量X1和X2之间 收稿日期:1996年2月9日 *本文系国家自然科学基金资助项目
实验八:主成分回归 实验题目:对例5、5的Hald水泥问题用主成分方法建立模型,并与其她方法的结果进行比较。例5、5如下:本例为回归经典的Hald水泥问题。某种水泥在凝固时放出的热量y(卡/克,cal/g)与水泥中的四种化学成分的含量(%)有关,这四种化学成分分别就是x1铝酸三钙(3CaO、Al2O3),x2硅酸三钙(3CaO、SiO2),x3铁铝酸四钙(4CaO、Al2O3、Fe2O3),x4硅酸三钙(2CaO、SiO2)。现观测到13组数据,如表5-3所示。 实验目的: SPSS输出结果及答案: 一、主成分法: 多重共线性诊断:
N 13 13 13 13 13 **、在、01 水平(双侧)上显著相关。 由表可知,x1,x2,x4的相关性都比较大,较接近,所以存在多重共线性 主成分回归: 解释的总方差 成份 初始特征值提取平方与载入 合计方差的 % 累积 % 合计方差的 % 累积 % 1 2、236 55、893 55、893 2、236 55、893 55、893 2 1、576 39、402 95、294 1、576 39、402 95、294 3 、187 4、665 99、959 、187 4、665 99、959 4 、002 、041 100、000 、002 、041 100、000 提取方法:主成份分析。 输出结果显示有四个特征根,最大的就是λ1=2、236,最小的就是λ4=0、002。 方差百分比显示第一个主成分Factor1的方差百分比近56%的信息量;前两个主成 分累计包含近95、3%的信息量。因此取两个主成分就已经足够。 由于前两个主成分的方差累计已经达到95、3%,故只保留前两个主成分。 成份矩阵a 成份 1 2 3 4 x1 、712 -、639 、292 、010 x2 、843 、520 -、136 、026 x3 -、589 、759 、275 、011 x4 -、819 -、566 -、084 、027 提取方法:主成分 a.已提取了 4 个成份。 由解释的总方差表中累计贡献性知,f1与f2的累计贡献性就在85%~95%之间。所以主成分取f1,f2。 得到因子得分的数值,并对其进行处理:sqrt(2、236)* FAD1_1, sqrt(1、576)* FAD2_1可以得出主成分表(f1 f2)。
主元分析(PCA)理论分析及应用 什么是PCA? PCA是Principal component analysis的缩写,中文翻译为主元分析/主成分分析。它是一种对数据进行分析的技术,最重要的应用是对原有数据进行简化。正如它的名字:主元分析,这种方法可以有效的找出数据中最“主要”的元素和结构,去除噪音和冗余,将原有的复杂数据降维,揭示隐藏在复杂数据背后的简单结构。它的优点是简单,而且无参数限制,可以方便的应用与各个场合。因此应用极其广泛,从神经科学到计算机图形学都有它的用武之地。被誉为应用线形代数最价值的结果之一。 在以下的章节中,不仅有对PCA的比较直观的解释,同时也配有较为深入的分析。首先将从一个简单的例子开始说明PCA应用的场合以及想法的由来,进行一个比较直观的解释;然后加入数学的严格推导,引入线形代数,进行问题的求解。随后将揭示PCA与SVD(Singular Value Decomposition)之间的联系以及如何将之应用于真实世界。最后将分析PCA理论模型的假设条件以及针对这些条件可能进行的改进。 一个简单的模型 在实验科学中我常遇到的情况是,使用大量的变量代表可能变化的因素,例如光谱、电压、速度等等。但是由于实验环境和观测手段的限制,实验数据往往变得极其的复杂、混乱和冗余的。如何对数据进行分析,取得隐藏在数据背后的变量关系,是一个很困难的问题。在神经科学、气象学、海洋学等等学科实验中,假设的变量个数可能非常之多,但是真正的影响因素以及它们之间的关系可能又是非常之简单的。 下面的模型取自一个物理学中的实验。它看上去比较简单,但足以说明问题。如图表 1所示。这是一个理想弹簧运动规律的测定实验。假设球是连接在一个无质量无摩擦的弹簧之上,从平衡位置沿轴拉开一定的距离然后释放。
多元线性回归中多重共线问题的解决方法综述 摘 要 在回归分析中,当自变量之间出现多重共线性现象时,常会严重影响到参数估计,扩大模型误差,并破坏模型的稳健性,因此消除多重共线性成为回归分析中参数估计的一个重要环节。现在常用的解决多元线性回归中多重共线性的回归模型有岭回归(Ridge Regression )、主成分回归(Principal Component Regression 简记为PCR)和偏最小二乘回归(Partial Least Square Regression 简记为PLS)。 关键词:多重共线性;岭回归;主成分回归;偏最小二乘回归 引言 在多元线性回归分析中,变量的多重相关性会严重影响到参数估计,增大模型误差,并破坏模型的稳健性 由于多重共线性问题在实际应用中普遍存在,并且危害严重,因此设法消除多重性的不良影响无疑具有巨大的价值常用的解决多元线性回归中多重共线问题的回归模型主要有主成分回归岭回归以及偏最小二乘回归。 1、 多元线性回归模型 1.1 回归模型的建立 设Y 是一个可观测的随机变量,它受m 个非随机因素X 1,X 2,…,X p-1和随机因素ε的影响, 若有如下线性关系 我们对变量进行了n 次观察,得到n 组观察数据(如下),对回归系数 进行估计 一般要求n>P 。于是回归关系可写为 采用矩阵形式来表示 0112211p p Y X X X ββββε--=+++++n i X X X Y p i i i i ,,1,,,,)1(2,1???=???-1011121211(1)1 2012122212(1)2 011221(1)p p p p n n n p n p n Y X X X Y X X X Y X X X ββββεββββεββββε------=+++++??=+++++?? ? ?=+++++?11121,(1)121222,(1)212,(1)111, 1 p p n n n n p n n p X X X Y X X X Y Y X Y X X X ---??????????????==??????????????)1(10,,,p -???βββ
多重共线性问题的几种解决方法 在多元线性回归模型经典假设中,其重要假定之一是回归模型的解释 变量之间不存在线性关系,也就是说,解释变量X 1,X 2 ,……,X k 中的任何一个 都不能是其他解释变量的线性组合。如果违背这一假定,即线性回归模型中某一个解释变量与其他解释变量间存在线性关系,就称线性回归模型中存在多重共线性。多重共线性违背了解释变量间不相关的古典假设,将给普通最小二乘法带来严重后果。 这里,我们总结了8个处理多重共线性问题的可用方法,大家在遇到多重共线性问题时可作参考: 1、保留重要解释变量,去掉次要或可替代解释变量 2、用相对数变量替代绝对数变量 3、差分法 4、逐步回归分析 5、主成份分析 6、偏最小二乘回归 7、岭回归 8、增加样本容量 这次我们主要研究逐步回归分析方法是如何处理多重共线性问题的。 逐步回归分析方法的基本思想是通过相关系数r、拟合优度R2和标准误差三个方面综合判断一系列回归方程的优劣,从而得到最优回归方程。具体方法分为两步: 第一步,先将被解释变量y对每个解释变量作简单回归: 对每一个回归方程进行统计检验分析(相关系数r、拟合优度R2和标准误差),并结合经济理论分析选出最优回归方程,也称为基本回归方程。
第二步,将其他解释变量逐一引入到基本回归方程中,建立一系列回归方程,根据每个新加的解释变量的标准差和复相关系数来考察其对每个回归系数的影响,一般根据如下标准进行分类判别: 1.如果新引进的解释变量使R2得到提高,而其他参数回归系数在统计上和经济理论上仍然合理,则认为这个新引入的变量对回归模型是有利的,可以作为解释变量予以保留。 2.如果新引进的解释变量对R2改进不明显,对其他回归系数也没有多大影响,则不必保留在回归模型中。 3.如果新引进的解释变量不仅改变了R2,而且对其他回归系数的数值或符号具有明显影响,则认为该解释变量为不利变量,引进后会使回归模型出现多重共线性问题。不利变量未必是多余的,如果它可能对被解释变量是不可缺少的,则不能简单舍弃,而是应研究改善模型的形式,寻找更符合实际的模型,重新进行估计。如果通过检验证明回归模型存在明显线性相关的两个解释变量中的其中一个可以被另一个很好地解释,则可略去其中对被解释变量影响较小的那个变量,模型中保留影响较大的那个变量。 下边我们通过实例来说明逐步回归分析方法在解决多重共线性问题上的具体应用过程。 具体实例 例1设某地10年间有关服装消费、可支配收入、流动资产、服装类物价指数、总物价指数的调查数据如表1,请建立需求函数模型。 表1 服装消费及相关变量调查数据
计量经济学多元线性回归、多重共线性、异方差实验报告记录
————————————————————————————————作者:————————————————————————————————日期:
计量经济学实验报告
多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到亿人次,同比增长%,国内旅游收入万亿元,同比增长%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β 1 X 1 +β 2 X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元
一、引言 回归分析是一种比较成熟的预测模型,也是在预测过程中使用较多的模型,在自然科学管理科学和社会经济中有着非常广泛的应用,但是经典的最小二乘估计,必需满足一些假设条件,多重共线性就是其中的一种。实际上,解释变量间完全不相关的情形是非常少见的,大多数变量都在某种程度上存在着一定的共线性,而存在着共线性会给模型带来许多不确定性的结果。 二、认识多重共线性 (一)多重共线性的定义 设回归模型01122p p y x x x ββββε=+++?++如果矩阵X 的列向量存在一组不全 为零的数012,,p k k k k ?使得011220i i p i p k k x k x k x +++?+=, i =1,2,…n ,则称其存在完全共线性,如果022110≈+?+++p i p i i x k x k x k k , i =1,2,…n ,则称其存在 近似的多重共线性。 (二)多重共线性的后果 1.理论后果 对于多元线性回归来讲,大多数学者都关注其估计精度不高,但是多重共线性不可 能完全消除,而是要用一定的方法来减少变量之间的相关程度。多重共线性其实是由样本容量太小所造成的后果,在理论上称作“微数缺测性”,所以当样本容量n 很小的时候,多重共线性才是非常严重的。 多重共线性的理论后果有以下几点: (1)保持OLS 估计量的BLUE 性质; (2) 戈德伯格提出了近似多重共线性其实是样本观测数刚好超过待估参数个数时出现的 情况。所以多重共线性并不是简单的自变量之间存在的相关性,也包括样本容量的大小问题。 (3)近似的多重共线性中,OLS 估计仍然是无偏估计。无偏性是一种多维样本或重复抽样 的性质;如果X 变量的取值固定情况下,反复对样本进行取样,并对每个样本计算OLS 估计量,随着样本个数的增加,估计量的样本值的均值将收敛于真实值。 (4)多重共线性是由于样本引起的。即使总体中每一个X 之间都没有线性关系,但在具体 取样时仍存在样本间的共线性。 2.现实后果 (1)虽然存在多重共线性的情况下,得到的OLS 估计是BLUE 的,但有较大的方差和协方差, 估计精度不高; (2)置信区间比原本宽,使得接受0H 假设的概率更大;
定义:线性回归模型中的解释变量有多个。一般表现形式:多元线性回归模型k :解释变量个数;i =1,2…,n βj :回归参数(Regression Coefficient );j=1,2…,k 习惯上:把常数项看成为一虚变量的系数,该虚变量的样本观测值始终取1。这样: i ki k i i i X X X Y μββββ++???+++=22110虚变量 X 0=1模型中解释变量的数目为(k+1) 指2个或2个以上
多元线性回归模型总体回归函数的随机表达形式: i ki k i i i X X X Y μββββ++???+++=22110总体回归函数非随机表达式: ki k i i ki i i i X X X X X X Y E ββββ+???+++=2211021),,|( 偏回归系数βj :在其他解释变量保持不变的情况下,X j 每变化1个单位时,Y 的均值E(Y)的变化;或者说X j 的单位变化对Y 均值的“直接”或“净”(不含其他变量)影响。 方程表示:各变量X 值给定时Y 的平均响应。
总体回归模型n 个随机方程的矩阵表达式为 μ X βY +=)1(212221212111111+?????????????=k n kn n n k k X X X X X X X X X X 121????? ????????=n n Y Y Y Y 1)1(210?+????????????????=k k ββββ β1 21?????????????=n n μμμ μ其中n :样本容量k :解释变量的个数
e i 称为残差或剩余项(Residuals),μi 的近似替代样本回归函数: ki ki i i i X X X Y ββββ?????22110++++= 其随机表示式: i ki ki i i i e X X X Y +++++=ββββ????22110 βX Y ??=e βX Y +=???????? ??=k βββ????10 β?????? ? ??=n e e e 21e 其中 或样本回归函数的矩阵表达:
实验六-多元线性回归和多重共线性
实验六多元线性回归和多重共线性 姓名:何健华 学号:201330110203 班级:13金融数学2班 一 实验目的: 掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二 实验要求: 应用教材P140例子4.3.1案例做多元线性回归模型,并识别和修正多重共线性。 三 实验原理: 普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。 四 预备知识: 最小二乘法估计的原理、t 检验、F 检验、R 2值。 五 实验步骤: 有关的研究分析表明,影响国内旅游市场收入的主要因素,除了国内旅游人数和旅游支出外,还可能与基础设施有关。因此考虑影响国内旅游收入Y (单位为亿元)的以下几个因素:国内旅游人数X1、城镇居民人均旅游支出X2(单位为元)、农村居民人均旅游支出X3(单位为元)、并以公路里程X4(单位为万公里)和铁路里程X5(单位为万公里)作为相关设施的代表,根据这些变量建立如下的计量经济模型: 01122334455y x x x x x ββββββμ=++++++ 为了估计上述模型,从《中国统计年鉴》收集到1994年到2003年的有关统计数据。 Year Y X1 X2 X3 X4 X5 1994 1023.5 52400 414.7 54.9 111.78 5.9 1995 1375.7 62900 464 61.5 115.7 5.97 1996 1638.4 63900 534.1 70.5 118.58 6.49 1997 2112.7 64400 599.8 145.7 122.64 6.6 1998 2391.2 69450 607 197 127.85 6.64
实验八:主成分回归 实验题目:对例5.5的Hald水泥问题用主成分方法建立模型,并与其他方法的结果进行比较。 例5.5如下:本例为回归经典的Hald水泥问题。某种水泥在凝固时放出的热量y(卡/克,cal/g)与水泥中的四种化学成分的含量(%)有关,这四种化学成分分别是x1铝酸三钙(3CaO.Al2O3),x2硅酸三钙(3CaO.SiO2),x3铁铝酸四钙(4CaO.Al2O3.Fe2O3),x4硅酸三钙(2CaO.SiO2)。现观测到13组数据,如表5-3所示。 表5-3 实验目的: SPSS输出结果及答案: 一、主成分法: 多重共线性诊断:
已提取了 4 个成份。 由解释的总方差表中累计贡献性知,f1和f2的累计贡献性就在85%~95%之间。所以主成分取f1,f2。
得到因子得分的数值,并对其进行处理:sqrt(2.236)*FAD1_1,sqrt(1.576)*FAD2_1可以得出 主成分表(f1 f2)。 对f1 f2进行普通最小二乘线性回归 f1=-0.643+0.081x1+0.036x2-0.062x3-0.033x4 对f2和x1x2x3x4进行回归 模型非标准化系数标准系数 t Sig. B 标准误差试用版 1 (常量) -.938 .000 -1119037.661 .000 x1 -.087 .000 -.405 -9710099.545 .000 x2 .027 .000 .330 3071727.057 .000 x3 .094 .000 .482 10459854.955 .000 x4 -.027 .000 -.359 -3177724.589 .000 a.因变量: f2 f2=-0.938-0.087x1+0.027x2+0.094x3-0.027x4
数值实验03:奇异值分解与主成分分析 选作问题(研究性的) 6、 假设数据源是一系列的图像,每幅图像都是一个矩阵。分别用经典的主成分分析方法和奇异值分解方法计算特征脸。注意数据的中心化与归一化处理的影响。 (1)奇异值分解:是一个能够适用于任意矩阵的一种分解方法: A m*n U m*mm*n V n*n T U为M*M 方阵( U里面的正交向量称为左奇异向量), 是一个M*N的矩阵(除了对角线的元素都是 0,对角线上的元素称为奇异值), V T是一个N*N 的方(V 里面正交的向量称为右奇异向量)。 我们将一个矩阵 A的转置乘以 A,并对 A T A 求特征值 (A T A)v i=λi v i 则v就为右奇异向量,且奇异值i ,左奇异值u i= 就为奇异值,u就为奇异向量。奇异值 跟特征值类似,在矩阵Σ中也是从大到小排列,而且的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,部分奇异值分解: A mn U m r rr V T rn (r是一个远小于 m、n的数) 给定一幅 M*N大小的图像,将它表示成 M*N*1 维向量,向量中元素为像素点的 灰度,按行存储,则如下公式分别表示第 i 张图片和 n 张图片的平均值: 令 M*N*n 矩阵 X 为: 即中心化,将坐标原点移动到平均值位置。设Q XX T,则Q是一个MN * MN 矩阵:
Q 被称为协方差矩阵。 那么X中每一个元素x j可以表达成: 其中e i是非零特征值对应的特征向量,对于 M*N 图像,e1,e2,...,en 是M*N*1 维相互正交的向量。尺度g ji 是x j在空间中的坐标。为了降维,可以对特征值设定阈值或按照其他准则,寻找协方差矩阵Q中前 k个特征向量。Q为 M*N*M*N,通常很庞大。考虑矩阵 P X T X Q 的大小为 M*N*M*N,而P的大小为 n*n,N 为训练样本图像数量,通常n< 一、作业 教材P214 三。 二、自我练习 (一)教材P213 一。 (二)是非题 1.当一组资料的自变量为分类变量时,对这组资料不能做多重线性回归分析。( ) 2.若多重线性方程模型有意义.则各个偏回归系数也均有统计学意义。〔) 3.回归模型变量的正确选择在根本上依赖于所研究问题本身的专业知识。() 4.从各自变量偏回归系数的大小.可以反映出各自变量对应变量单位变化贡献的大小。( ) 5.在多元回归中,若对某个自变量的值都增加一个常数,则相应的偏回归系数不变。( ) (三)选择题 1. 多重线性回归分析中,共线性是指(),导致的某一自变量对Y的作用可以由其他自变量的线性函数表示。 A. 自变量相互之间存在高度相关关系 B. 因变量与各个自变量的相关系数相同 C. 因变量与自变量间有较高的复相关关系 D. 因变量与各个自变量之间的回归系数相同 2. 多重线性回归和Logistic 回归都可应用于()。 A. 预测自变量 B. 预测因变量Y 取某个值的概率π C. 预测风险函数h D. 筛选影响因素(自变量) 3.在多重回归中,若对某个自变量的值都增加一个常数,则相应的偏回归系数: A.不变 B.增加相同的常数 C.减少相同的常数 D.增加但数值不定 4.在多元回归中,若对某个自变量的值都乘以一个相同的常数k,则: A.该偏回归系数不变 B.该偏回归系数变为原来的 1/k倍 C.所有偏回归系数均发生改变 D.该偏回归系数改变,但数值不定 5.作多重线性回归分析时,若降低进入的F 界值,则进入方程的变量一般会: A.增多 B.减少 C.不变 D.可增多也可减少(四)筒答题 1.为什么要做多重线性回归分析? 岭回归分析 一、普通最小二乘估计带来的问题 当设计矩阵X 呈病态时,X 的列向量之间有较强的线性相关性,即解释变量间出现严重的多重共线性,在这种情况下,用普通最小二乘法估计模型参数,往往参 数估计的方差太大,即jj jj j L C 2)?var(σβ=很大,j β?就很不稳定,在具体取值上与真值有较大的偏差,有时会出现与实际经济意义不符的正负号。下面看一个例子,可以说明这一点。 假设已知1x ,2x 与y 的关系服从线性回归模型:ε+++=213210x x y ,给定1x ,2x 的10个值,如下表1,2行所示: 表7.1 然后用模拟的方法产生10个正态随机数,作为误差项ε,见表第3行。然后再由回归模型i i i i x x y ε+++=213210计算出10个i y 值,见表第4行。现在假设回归系数与误差项是未知的,用普通最小二乘法求回归系数的估计得:0 ?β=11.292,1?β=11.307,2 ?β=-6.591,而原模型的参数0β=10,1β=2,2β=3看来相差太大。计算1x ,2x 的样本相关系数得12r =0.986,表明1x 与2x 之间高度相关。通过这个例子可以看到解释变量之间高度相关时,普通最小二乘估计明显变坏。 二、岭回归的定义 当自变量间存在多重共线性,|X X '|≈0时,设想给X X '加上一个正常数矩阵kI (k>0)那么X X '+kI 接近奇异的程度就会比X X '接近奇异的程度小得多。考虑到变量的量纲问题,先要对数据标准化,标准化后的设计矩阵仍用X 表示,定义y X kI X X k '+'=-1)()(?β称为β的岭回归估计,其中,k 称为岭参数。由于假设X 已经标准化,所以X X '就是自变量样本相关阵。y 可以标准化也可以未标准化, 如果y 也经过标准化,那么计算的实际是标准化岭回归估计。)(?k β 作为β的估计应比最小二乘估计β ?稳定,当k=0时的岭回归估计)0(?β就是普通的最小二乘估计。因为岭参数k 不是唯一确定的,所以得到的岭回归估计)(?k β 实际是回归参数β的一个估计族。 浅析主成分分析法的原理 张小丽 (武汉大学遥感信息工程学院,湖北武汉,430079) 【摘要】图像特征是图像分析的重要依据,获取图像特征信息的操作称为特征提取。它作为模式识别,图像理解或信息量压缩的基础是很重要的。在目前的遥感图像处理研究中,多利用光谱特征。主成分分析也称为K-L变换,是在统计特征基础上的多维(如多波段)正交线性变换,也是遥感数字图像处理中最常用的一种变换算法。本文就对光谱特征提取的主成分分析方法分析其原理,具体步骤及优缺点。 【关键词】遥感图像;特征提取;光谱特征;主成分分析 1 引言 以计算机自动分类为研究方向的遥感图像解译技术的一般工作流程是图像预处理、特征提取、特征选择、分类处理。在这三项工作中,特征提取、特征选择是保证遥感图像分类精度的关键。 遥感图像模式的特征主要表现为光谱特征、纹理特征以及形状特征三种。特征提取分为光谱特征提取、纹理特征提取,形状特征提取。光谱特征提取和纹理特征提取分别对应于影像要素级序中的初级和第二级影像要素,目前应用较多的是光谱特征提取。光谱特征提取常采用K-T变换、K-L变换。 2 光谱特征 光谱特征是图像中目标物的颜色及灰度或者波段间的亮度比等。光谱特征通过原始波段的点运算获得。光谱特征的特点是,它对应于每个像元,但与像元的排列等空间结构无关。光谱特征是一种地物区别于另一种地物的本质特征,是组成地物成分、结构等属性的反映,正常情况下不同地物具有不同的光谱特征(在一些特殊情况下会出现同物异谱、同谱异物现象),因此根据地物光谱特征可以对遥感图像进行特征提取。在遥感图像的所有信息中最直接应用的是地物的光谱信息,地物光谱特性可通过光谱特征曲线来表达。遥感图像中每个像素的亮度值代表的是该像素中地物的平均辐射值,它随地物的成分、纹理、状态、表面特征及所使用电磁波波段的不同而变化。 3 K-L变换(主成分分析) 3.1原理 K-L变换即主成分分析。主成分变换具有方差浓聚、重新分配、数据量压缩的作用,并且可更准确、特征地揭示多波段数据结构内部的遥感信息。 主成分分析是着眼于变量之间的相互关系,尽可能不丢失信息地用几个综合性指标汇集多个变量的测量值而进行描述的方法。把P个变量(P维)的测量值汇集于m个(m维)主成分。在多光谱图像中,由于各波段的数据间存在相关的情况很多,通过采用主成分分析可以把图像中所含的大部分信息用假想的少数波段显示出来,几乎不丢失信息但数据量大大减少。 多重共线性和非线性回归的问题 (1)多重共线性问题 我们都知道在进行多元回归的时候,特别是进行经济上指标回归的时候,很多变量存在共同趋势相关性,让我们得不到希望的回归模型。这里经常用到的有三种方法,而不同的方法有不同的目的,我们分别来看看: 第一个,是最熟悉也是最方便的——逐步回归法。 逐步回归法是根据自变量与因变量相关性的大小,将自变量一个一个选入方法中,并且每选入一个自变量都进行一次检验。最终留在模型里的自变量是对因变量有最大显著性的,而剔除的自变量是与因变量无显著线性相关性的,以及与其他自变量存在共线性的。用逐步回归法做的多元回归分析,通常自变量不宜太多,一般十几个以下,而且你的数据量要是变量个数3倍以上才可以,不然做出来的回归模型误差较大。比如说你有10个变量,数据只有15组,然后做拟合回归,得到9个自变量的系数,虽然可以得到,但是精度不高。这个方法我们不仅可以找到对因变量影响显著的几个自变量,还可以得到一个精确的预测模型,进行预测,这个非常重要的。而往往通过逐步回归只能得到几个自变量进入方程中,有时甚至只有一两个,令我们非常失望,这是因为自变量很多都存在共线性,被剔除了,这时可以通过第二个方法来做回归。 第二个,通过因子分析(或主成分分析)再进行回归。 这种方法用的也很多,而且可以很好的解决自变量间的多重共线性。首先通过因子分析将几个存在共线性的自变量合为一个因子,再用因子分析得到的几个因子和因变量做回归分析,这里的因子之间没有显著的线性相关性,根本谈不上共线性的问题。通过这种方法可以得到哪个因子对因变量存在显著的相关性,哪个因子没有显著的相关性,再从因子中的变量对因子的载荷来看,得知哪个变量对因变量的影响大小关系。而这个方法只能得到这些信息,第一它不是得到一个精确的,可以预测的回归模型;第二这种方法不知道有显著影响的因子中每个变量是不是都对因变量有显著的影响,比如说因子分析得到三个因子,用这三个因子和因变量做回归分析,得到第一和第二个因子对因变量有显著的影响,而在第一个因子中有4个变量组成,第二个因子有3个变量组成,这里就不知道这7个变量是否都对因变量存在显著的影响;第三它不能得到每个变量对因变量准确的影响大小关系,而我们可以通过逐步回归法直观的看到自变量前面的系数大小,从而判断自变量对因变量影响的大小。 第三个,岭回归。 通过逐步回归时,我们可能得到几个自变量进入方程中,但是有时会出现自变量影响的方向出现错误,比如第一产业的产值对国民收入是正效应,而可能方程中的系数为负的,这种肯定是由于共线性导致出现了拟合失真的结果,而这样的结果我们只能通过自己的经验去判断。通常我们在做影响因素判断的时候,不仅希望得到各个因素对因变量真实的影响关系,还希望知道准确的影响大小,就是每个自变量系数的大小,这个时候,我们就可以通过岭回归的方法。 岭回归是在自变量信息矩阵的主对角线元素上人为地加入一个非负因子k,从而使回归系数的估计稍有偏差、而估计的稳定性却可能明显提高的一种回归分析方法,它是最小二乘法的一种补充,岭回归可以修复病态矩阵,达到较好的效果。在SPSS中没有提供岭回归的模块,可以直接点击使用,只能通过编程来实现,当然在SAS、Matlab中也可以实现。做岭回归的时候,需要进行多次调试,选择适当的k值,才能得到比较满意的方程,现在这个方法应用 第二章 回归分析概要 第五节 多元线性回归分析 一 模型的建立与假定条件 在一元线性回归模型中,我们只讨论了包含一个解释变量的一元线性回归模型,也就是假定被解释变量只受一个因素的影响。但是在现实生活中,一个被解释变量往往受到多个因素的影响。例如,商品的消费需求,不但受商品本身的价格影响,还受到消费者的偏好、收入水平、替代品价格、互补品价格、对商品价格的预测以及消费者的数量等诸多因素的影响。在分析这些问题的时候,仅利用一元线性回归模型已经不能够反映各变量间的真实关系,因此,需要借助多元线性回归模型来进行量化分析。 1. 多元线性回归模型的基本概念 如果一个被解释变量(因变量)t y 有k 个解释变量(自变量)tj x ,k j ,...,3,2,1=, 同时,t y 不仅是tk x 的线性函数,而且是参数0β和k i i ,...3,2,1=,β(通常未知)的线性函数,随即误差项为t u ,那么多元线性回归模型可以表示为: ,...22110t tk k t t t u x x x y +++++=ββββ ),..,2,1(n t = 这里tk k t t t x x x y E ββββ++++=...)(22110为总体多元线性回归方程,简称总体回归方程。 其中,k 表示解释变量个数,0β称为截距项,k βββ...21是总体回归系数。k i i ,...3,2,1=,β表示在其他自变量保持不变的情况下,自变量tj X 变动一个单位所引起的因变量Y 平均变动的数量,因而也称之为偏回归系数。 当给定一个样本n t x x x y tk t t t ,...2,1),,...,,(21=时,上述模型可以表示为: ???? ??? ???????????+++++=+++++=+++++=+++++=t tk k t t t k k k k k k u x x x y u x x x y u x x x y u x x x y ββββββββββββββββ (22110333223110322222211021112211101) 此时,t y 与tj x 已知,i β与t u 未知。 其相应的矩阵表达式为: 实验六多元线性回归和多重共线性 姓名:何健华 学号:201330110203 班级:13金融数学2班 一 实验目的: 掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二 实验要求: 应用教材P140例子4.3.1案例做多元线性回归模型,并识别和修正多重共线性。 三 实验原理: 普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。 四 预备知识: 最小二乘法估计的原理、t 检验、F 检验、R 2值。 五 实验步骤: 有关的研究分析表明,影响国内旅游市场收入的主要因素,除了国内旅游人数和旅游支出外,还可能与基础设施有关。因此考虑影响国内旅游收入Y (单位为亿元)的以下几个因素:国内旅游人数X1、城镇居民人均旅游支出X2(单位为元)、农村居民人均旅游支出X3(单位为元)、并以公路里程X4(单位为万公里)和铁路里程X5(单位为万公里)作为相关设施的代表,根据这些变量建立如下的计量经济模型: 01122334455y x x x x x ββββββμ=++++++ 为了估计上述模型,从《中国统计年鉴》收集到1994年到2003年的有关统计数据。 Year Y X1 X2 X3 X4 X5 1994 1023.5 52400 414.7 54.9 111.78 5.9 1995 1375.7 62900 464 61.5 115.7 5.97 1996 1638.4 63900 534.1 70.5 118.58 6.49 1997 2112.7 64400 599.8 145.7 122.64 6.6 1998 2391.2 69450 607 197 127.85 6.64 1999 2831.9 71900 614.8 249.5 135.17 6.74 2000 3175.5 74400 678.6 226.6 140.27 6.87 2001 3522.4 78400 708.3 212.7 169.8 7.01 2002 3878.4 87800 739.7 209.1 176.52 7.19 2003 3442.3 87000 684.9 200 180.98 7.3 1、 请用普通最小二乘方法估计模型参数; 2、 检验模型是否存在多重共线性,如果存在共线性,试采用适当的方法消除共线性。 解决多重共线性之岭回归分析 展开全文 上篇文章,我们介绍了几种处理共线性的方法。比如逐步回归法、手动剔除变量法是最常使用的方法,但是往往使用这类方法会剔除掉我们想要研究的自变量,导致自己希望研究的变量无法得到研究。因而,此时就需要使用更为科学的处理方法即岭回归。 岭回归岭回归分析(Ridge Regression)是一种改良的最小二乘法,其通过放弃最小二乘法的无偏性,以损失部分信息为代价来寻找效果稍差但回归系数更符合实际情况的模型方程。 简单来说,当方程变量中存在共线性时,一个变量的变化也会导致其他变量改变。岭回归就是在原方程的基础上加入了一个会产生偏差,但可以保证回归系数稳定的正常数矩阵KI。虽然会导致信息丢失,但可以换来回归模型的合理估计。分析步骤岭回归分析步骤共为2步:(1)结合岭迹图寻找最佳K值;(2)输入K值进行回归建模。 第一步:拖入数据,生成岭迹图,寻找最合适的K值。 SPSSAU岭迹图 K值的选择原则是各个自变量的标准化回归系数趋于稳定时的最小K值。K值越小则偏差越小,当K值为0时则为普通线性OLS回归;SPSSAU提供K值智能建议,也可通过主观识别判断选择K值。 第二步:对于K值,其越小越好,通常建议小于1;确定好K值后,即可输入K值,得出岭回归模型估计,查看分析结果。 岭回归分析案例(1)背景 现测得胎儿身高、头围、体重和胎儿受精周龄数据,希望建立胎儿身高、头围、体重去和胎儿受精周龄间的回归模型。根据医学常识情况(同时结合普通线性最小二乘法OLS回归测量),发现三个自变量之间有着很强的共线性,VIF值高于200;可知胎儿身高、体重之间肯定有着很强的正相关关系, 多重共线性和非线性回归的问题 前几天她和我说,在百度里有个人连续追着我的回答,三次说我的回答错了。当时非常惊讶,赶紧找到那个回答的问题,看看那个人是怎么说。最终发现他是说多重共线性和非线性回归的问题,他认为多个自变量进行不能直接回归,存在共线性的问题,需要进行因子分析(或主成分分析);说非线性回归不能转换成线性回归的方法,这里我详细说说这两方面的问题到底是怎么回事(根据我的理解),我发现很多人很怕这个多重共线性的问题,听到非线性回归,脑袋就更大了。。。 (1)多重共线性问题 我们都知道在进行多元回归的时候,特别是进行经济上指标回归的时候,很多变量存在共同趋势相关性,让我们得不到希望的回归模型。这里经常用到的有三种方法,而不同的方法有不同的目的,我们分别来看看: 第一个,是最熟悉也是最方便的——逐步回归法。 逐步回归法是根据自变量与因变量相关性的大小,将自变量一个一个选入方法中,并且每选入一个自变量都进行一次检验。最终留在模型里的自变量是对因变量有最大显著性的,而剔除的自变量是与因变量无显著线性相关性的,以及与其他自变量存在共线性的。用逐步回归法做的多元回归分析,通常自变量不宜太多,一般十几个以下,而且你的数据量要是变量个数3倍以上才可以,不然做出来的回归模型误差较大。比如说你有10个变量,数据只有15组,然后做拟合回归,得到9个自变量的系数,虽然可以得到,但是精度不高。这个方法我们不仅可以找到对因变量影响显著的几个自变量,还可以得到一个精确的预测模型,进行预测,这个非常重要的。而往往通过逐步回归只能得到几个自变量进入方程中,有时甚至只有一两个,令我们非常失望,这是因为自变量很多都存在共线性,被剔除了,这时可以通过第二个方法来做回归。 第二个,通过因子分析(或主成分分析)再进行回归。 这种方法用的也很多,而且可以很好的解决自变量间的多重共线性。首先通过因子分析将几个存在共线性的自变量合为一个因子,再用因子分析得到的几个因子和因变量做回归分析,这里的因子之间没有显著的线性相关性,根本谈不上共线性的问题。通过这种方法可以得到哪个因子对因变量存在显著的相关性,哪个因子没有显著的相关性,再从因子中的变量对因子的载荷来看,得知哪个变量对因变量的影响大小关系。而这个方法只能得到这些信息,第一它不是得到一个精确的,可以预测的回归模型;第二这种方法不知道有显著影响的因子中每个变量是不是都对因变量有显著的影响,比如说因子分析得到三个因子,用这三个因子和因变量做回归分析,得到第一和第二个因子对因变量有显著的影响,而在第一个因子中有4个变量组成,第二个因子有3个变量组成,这里就不知道这7个变量是否都对因变量存在显著的影响;第三它不能得到每个变量对因变量准确的影响大小关系,而我们可以通过逐步回归法直观的看到自变量前面的系数大小,从而判断自变量对因变量影响的大小。 第三个,岭回归。 通过逐步回归时,我们可能得到几个自变量进入方程中,但是有时会出现自变量影响的方向出现错误,比如第一产业的产值对国民收入是正效应,而可能方程中的系数为负的,这种肯定是由于共线性导致出现了拟合失真的结果,而这样的结果我们只能通过自己的经验去判断。通常我们在做影响因素判断的时候,不仅希望得到各个因素对因变量真实的影响关系,还希望知道准确的影响大小,就是每个自变量系数的大小,这个时候,我们就可以通过岭回归的方法。多重线性回归分析
岭回归分析
主成分分析
多重共线性和非线性回归及解决方法
回归分析概要(多元线性回归模型)
实验六多元线性回归和多重共线性
解决多重共线性之岭回归分析
多重共线性和非线性回归的问题
相关主题
文本预览