
语音识别系统调研报告
姓名:罗小嘉学号:2801305018 1、摘要:本文简要的介绍了语音识别系统的原理,发展和在各个方面的应用前景。
2、关键词:语音识别;应用
3、引言:语音识别主要是指用机器在各种情况下,根据信息执行人的各种意图,有效地了解、识别语音和其它声音。它是近十几年来发展起来的具有理论价值和实用价值的新兴学科:从计算机大学科角度看,可视为智能计算机的智能接口;从信息处理学科来看,可视为信息识别的一个重要分支;从自动控制学科来看,又可视为模式识别的一个重要组成部分. 早在18 世纪,人们就对语音学进行了科学研究,但由于各种条件的限制,语音识别仅在计算机技术迅速发展之后,才成为一个非常活跃的研究领域. 60 年代末期,面对语音识别的种种困难,人们开始研究特定人、孤立词、小词汇量的识别,从而使语音识别的问题能够在当时的条件下得以开展;70年代后期,特定人、孤立词、小词汇量的语音识别取得较为满意的效果,语音识别的研究则沿着特定人向非特定人、孤立词向连续词、小词汇量向大词汇量方向扩展研究领域和目标;80 年代中期以来,计算机技术、信息技术及模式识别等技术的迅猛发展,极大地促进了语音识别技术的发展.
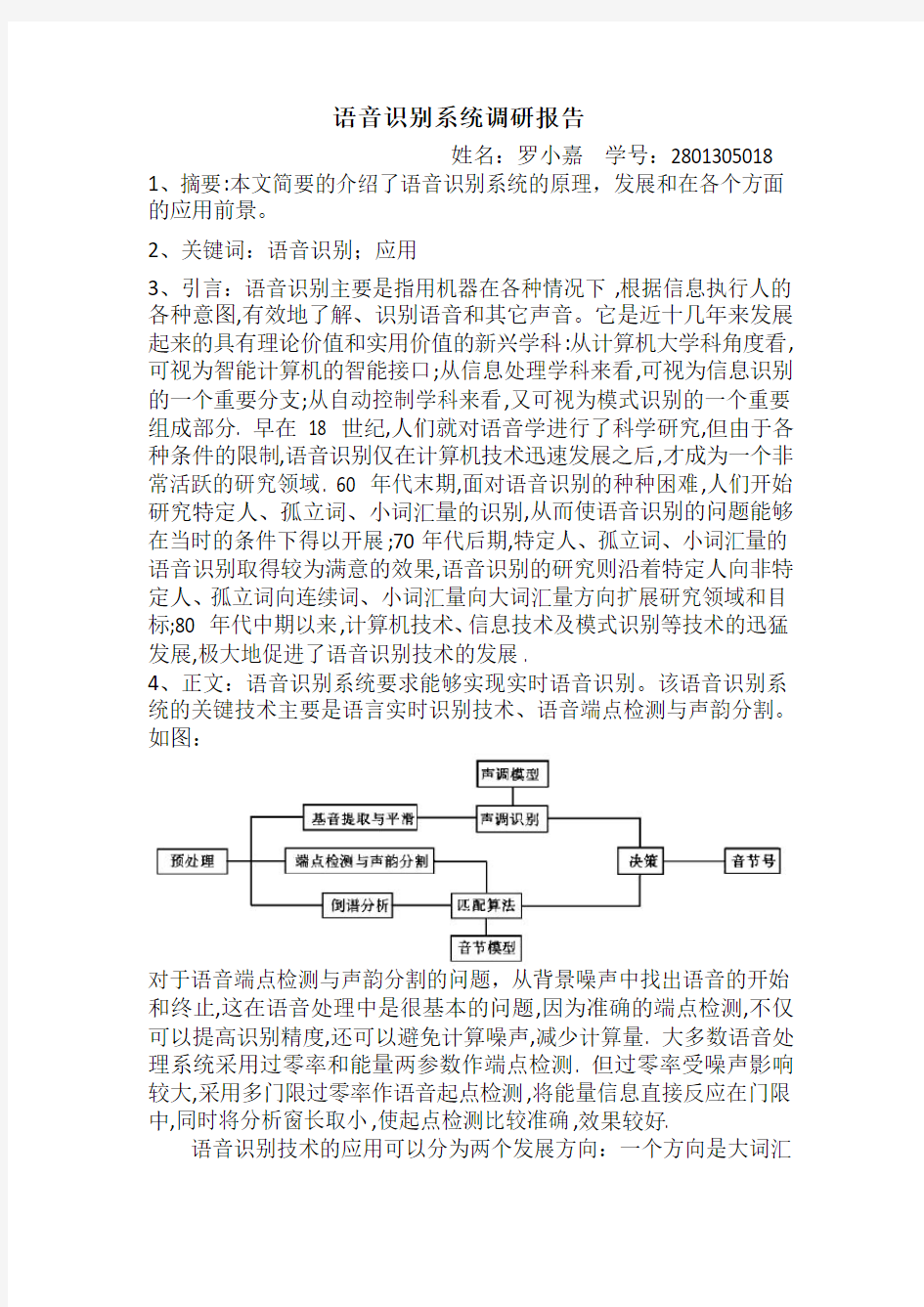
4、正文:语音识别系统要求能够实现实时语音识别。该语音识别系统的关键技术主要是语言实时识别技术、语音端点检测与声韵分割。如图:
对于语音端点检测与声韵分割的问题,从背景噪声中找出语音的开始和终止,这在语音处理中是很基本的问题,因为准确的端点检测,不仅可以提高识别精度,还可以避免计算噪声,减少计算量. 大多数语音处理系统采用过零率和能量两参数作端点检测. 但过零率受噪声影响较大,采用多门限过零率作语音起点检测,将能量信息直接反应在门限中,同时将分析窗长取小,使起点检测比较准确,效果较好.
语音识别技术的应用可以分为两个发展方向:一个方向是大词汇
量连续语音识别系统,主要应用于计算机的听写机,以及与电话网或者互联网相结合的语音信息查询服务系统,这些系统都是在计算机平台上实现的;另外一个重要的发展方向是小型化、便携式语音产品的应用,如无线手机上的拨号、汽车设备的语音控制、智能玩具、家电遥控等方面的应用,这些应用系统大都使用专门的硬件系统实现,特别是近几年来迅速发展的语音信号处理专用芯片(Application Specific Integrated Circuit,ASIC)和语音识别片上系统(System on Chip,SOC)的出现,为其广泛应用创造了极为有利的条件。本文将主要介绍关于语音识别专用芯片的基本情况。
应用领域
语音识别专用芯片的应用领域,主要包括以下几个方面:
1、电话通信的语音拨号。特别是在中、高档移动电话上,现已普遍的具有语音拨号的功能。随着语音识别芯片的价格降低,普通电话上也将具备语音拨号的功能。
2、汽车的语音控制。由于在汽车的行驶过程中,驾驶员的手必须放在方向盘上,因此在汽车上拨打电话,需要使用具有语音拨号功能的免提电话通信方式。此外,对汽车的卫星导航定位系统(GPS)的操作,汽车空调、照明以及音响等设备的操作,同样也可以由语音来方便的控制。
3、工业控制及医疗领域。当操作人员的眼或手已经被占用的情况下,在增加控制操作时,最好的办法就是增加人与机器的语音交互界面。由语音对机器发出命令,机器用语音做出应答。
4、个人数字助理(Personal Digital Assistant,PDA)的语音交互界面。PDA的体积很小,人机界面一直是其应用和技术的瓶颈之一。由于在PDA上使用键盘非常不便,因此,现多采用手写体识别的方法输入和查询信息。但是,这种方法仍然让用户感到很不方便。现在业界一致认为,PDA的最佳人机交互界面是以语音作为传输介质的交互方法,并且已有少量应用。随着语音识别技术的提高,可以预见,在不久的将来,语音将成为PDA主要的人机交互界面。
5、智能玩具。通过语音识别技术,我们可以与智能娃娃对话,可以用语音对玩具发出命令,让其完成一些简单的任务,甚至可以制造具有语音锁功能的电子看门狗。智能玩具有很大的市场潜力,而其关键在于降低语音芯片的价格。
6、家电遥控。用语音可以控制电视机、VCD、空调、电扇、窗帘的操作,而且一个遥控器就可以把家中的电器皆用语音控起来,这样,可以让令人头疼的各种电器的操作变得简单易行。
除了上文中所提到的应用以外,语音识别专用芯片在其他方面的应用可以说是不胜枚举。随着语音识别专用芯片的技术不断提高,将
给人们带来极大的方便。
功能特点
对比语音识别技术的两个发展方向,由于基于不同的运算平台,因此具有不同的特点。大词汇量连续语音识别系统一般都是基于PC 机平台,而语音识别专用芯片的中心运算处理器则只是一片低功耗、低价位的智能芯片,与一台甚至多台PC机相比起来,其运算速度,存储容量都非常有限,因而这些由专用芯片实现的语音识别系统有如下几个特点:
1、多为中、小词汇量的语音识别系统,即只能够识别10~100词条。只有近一两年来,才有连续数码或连续字母语音识别专用芯片实现。
2、一般仅限于特定人语音识别的实现,即需要让使用者对所识别的词条先进行学习或训练这一类识别功能对语种、方言和词条没有限制。有的芯片也能够实现非特定人语音识别,即预先将所要识别的语句码本训练好而装入芯片,用户使用时不需要再进行学习而直接应用。但这一类识别功能只适用于规定的语种和方言,而且所识别的语句只限于预先已训练好的语句。
3、由此芯片组成一个完整的语音识别系统。因此,除了语音识别功能以外,为了有一个好的人机界面和识别正确与否的验证,该系统还必须具备语音提示(语音合成)及语音回放(语音编解码记录)功能。
4、多为实时系统,即当用户说完待识别的词条后,系统立即完成识别功能并有所回应,这就对电路的运算速度有较高的要求。
5、除了要求有尽可能好的识别性能外,还要求体积尽可能小、可靠性高、耗电省、价钱低等特点。
5、参考文献:《语音识别系统研究》--刘德平黄明生刘红侠
百度百科—语音识别系统
语音识别系统实验报告 专业班级:信息安全 学号: 姓名:
目录 一、设计任务及要求 (1) 二、语音识别的简单介绍 2.1语者识别的概念 (2) 2.2特征参数的提取 (3) 2.3用矢量量化聚类法生成码本 (3) 2.4VQ的说话人识别 (4) 三、算法程序分析 3.1函数关系 (4) 3.2代码说明 (5) 3.2.1函数mfcc (5) 3.2.2函数disteu (5) 3.2.3函数vqlbg (6)
3.2.4函数test (6) 3.2.5函数testDB (7) 3.2.6 函数train (8) 3.2.7函数melfb (8) 四、演示分析 (9) 五、心得体会 (11) 附:GUI程序代码 (12) 一、设计任务及要求 实现语音识别功能。 二、语音识别的简单介绍
基于VQ的说话人识别系统,矢量量化起着双重作用。在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。 语音识别系统结构框图如图1所示。 图1 语音识别系统结构框图 2.1语者识别的概念 语者识别就是根据说话人的语音信号来判别说话人的身份。语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。因此,近几年来,说话人识别越来越多的受到人们的重视。与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,
中国汽车语音识别系统行业现状调查分析及市场前景预测报告(2016年版) 报告编号:1622577
行业市场研究属于企业战略研究范畴,作为当前应用最为广泛的咨询服务,其研究成果以报告形式呈现,通常包含以下内容: 一份专业的行业研究报告,注重指导企业或投资者了解该行业整体发展态势及经济运行状况,旨在为企业或投资者提供方向性的思路和参考。 一份有价值的行业研究报告,可以完成对行业系统、完整的调研分析工作,使决策者在阅读完行业研究报告后,能够清楚地了解该行业市场现状和发展前景趋势,确保了决策方向的正确性和科学性。 中国产业调研网https://www.doczj.com/doc/3112989992.html,基于多年来对客户需求的深入了解,全面系统地研究了该行业市场现状及发展前景,注重信息的时效性,从而更好地把握市场变化和行业发展趋势。
一、基本信息 报告名称:中国汽车语音识别系统行业现状调查分析及市场前景预测报告(2016年版)报告编号:1622577←咨询时,请说明此编号。 优惠价:¥7020 元可开具增值税专用发票 网上阅读:https://www.doczj.com/doc/3112989992.html,/R_JiaoTongYunShu/77/QiCheYuYinShiBieXiTongFaZhanXi anZhuangFenXiQianJingYuCe.html 温馨提示:如需英文、日文等其他语言版本,请与我们联系。 二、内容介绍 《中国汽车语音识别系统行业现状调查分析及市场前景预测报告(2016年版)》在多年汽车语音识别系统行业研究的基础上,结合中国汽车语音识别系统行业市场的发展现状,通过资深研究团队对汽车语音识别系统市场资讯进行整理分析,并依托国家权威数据资源和长期市场监测的数据库,对汽车语音识别系统行业进行了全面、细致的调研分析。 中国产业调研网发布的《中国汽车语音识别系统行业现状调查分析及市场前景预测报告(2016年版)》可以帮助投资者准确把握汽车语音识别系统行业的市场现状,为投资者进行投资作出汽车语音识别系统行业前景预判,挖掘汽车语音识别系统行业投资价值,同时提出汽车语音识别系统行业投资策略、营销策略等方面的建议。 正文目录 第一章汽车语音识别系统产业概述 1.1 汽车语音识别系统定义及产品技术参数 1.2 汽车语音识别系统分类 1.3 汽车语音识别系统应用领域 1.4 汽车语音识别系统产业链结构 1.5 汽车语音识别系统产业概述 1.6 汽车语音识别系统产业政策
https://www.doczj.com/doc/3112989992.html, 智能计算机论文参考文献 一、智能计算机论文期刊参考文献 [1].当代智能计算机的语义困境——兼论本体论语义学. 《武汉科技大学学报 《电子测试》.2014年10期.樊丽.杨宏.鱼莹. [5].《智能计算机与应用》征稿启事. 《智能计算机与应用》.2014年3期. [6].关于智能计算机. 《集宁师专学报》.2004年3期.刘宝娥. [7].基于deeplearning的语音识别. 《电子设计工程》.2015年18期.张炯.陶智勇. [8].《智能计算机与应用》征稿启事. 《智能计算机与应用》.2014年1期. [9].《智能计算机与应用》征稿启事. 《智能计算机与应用》.2015年4期. [10].基于Excel构建智能计算机考试系统. 《信息技术》.被中信所《中国科技期刊引证报告》收录ISTIC.2012年3期.甘伟明.潘东梅.白晓丽.刘兵兵. 二、智能计算机论文参考文献学位论文类 [1].中学生身体运动智能计算机情境化测评方法研究. 作者:李静.教育学;教育技术学南京师范大学2012(学位年度) [2].中学生视觉空间智能计算机情境化测评方法的研究.被引次数:1 作者:张丽霞.教育学;教育技术学南京师范大学2011(学位年度) [3].智能计算机配棉与纱线质量预测系统的研究与开发. 作者:袁静.纺织工程天津工业大学2012(学位年度) [4].基于网络的智能计算机辅助教学系统. 作者:韩静.计算机应用技术华东师范大学2005(学位年度)
https://www.doczj.com/doc/3112989992.html, [5]HPP体系结构下TCP/IP协议支持的研究与实现.被引次数:1 作者:康炜.计算机系统结构中国科学院计算技术研究所2007(学位年度) [6]模糊逻辑、神经网络与智能计算机研究. 作者:刘增良.计算机科学与技术北京航空航天大学1993(学位年度) [7]基于角色理论的情绪常识模型及应用研究. 作者:叶潇.计算机软件与理论华东理工大学2005(学位年度) [8].基于.NET技术的智能计算机考试系统. 作者:施长云.软件工程东南大学2015(学位年度) [9]智能计算机网络规划系统的设计与实现. 作者:梁伟晟.计算机软件与理论中山大学2000(学位年度) [10]智能计算机辅助教学系统探索与制作. 作者:刘常青.自动控制理论及应用西安电子科技大学1998(学位年度) 三、相关智能计算机论文外文参考文献 [1]IntelligentComputerAidedInstructionModelingandaMethodtoOptimiz eStudyStrategiesforParallelRobotInstruction. TanD.P.JiS.M.JinM.S.《IEEETransactionsonEducation》,被EI收录EI.被SCI收录SCI.20133 [2]Aparadigmforhandwritingbasedintelligenttutors. Anthony,L.Yang,J.Koedinger,K.R.《Internationaljournalofhumancomputerstudies》,被EI收录EI.被SCI收录SCI.201211 [3]Intelligentautomationofdesignandmanufacturinginmachinetoolsusi nganopenarchitecturemotioncontroller. https://www.doczj.com/doc/3112989992.html,vanya《JournalofManufacturingSystems》,被EI 收录EI.被SCI收录SCI.20131 [4]Anadaptationalgorithmforanintelligentnaturallanguagetutoringsy stem. AnnabelLathamKeeleyCrockettDavidMcLean《Computers&education》,被EI收录EI.被SCI收录SCI.2014Feb. [5]GuestEditors''Introduction:IntelligentSystemsforInteractiveEnt ertainment.
matlab语音识别系统(源代码)最新版
目录 一、设计任务及要求 (1) 二、语音识别的简单介绍 2.1语者识别的概念 (2) 2.2特征参数的提取 (3) 2.3用矢量量化聚类法生成码本 (3) 2.4VQ的说话人识别 (4) 三、算法程序分析 3.1函数关系 (4) 3.2代码说明 (5) 3.2.1函数mfcc (5) 3.2.2函数disteu (5) 3.2.3函数vqlbg (6) 3.2.4函数test (6) 3.2.5函数testDB (7) 3.2.6 函数train (8) 3.2.7函数melfb (8) 四、演示分析 (9) 五、心得体会 (11) 附:GUI程序代码 (12)
一、设计任务及要求 用MATLAB实现简单的语音识别功能; 具体设计要求如下: 用MATLAB实现简单的数字1~9的语音识别功能。 二、语音识别的简单介绍 基于VQ的说话人识别系统,矢量量化起着双重作用。在训练阶段,把每一个说话者所提取的特征参数进行分类,产生不同码字所组成的码本。在识别(匹配)阶段,我们用VQ方法计算平均失真测度(本系统在计算距离d时,采用欧氏距离测度),从而判断说话人是谁。 语音识别系统结构框图如图1所示。 图1 语音识别系统结构框图 2.1语者识别的概念 语者识别就是根据说话人的语音信号来判别说话人的身份。语音是人的自然属性之一,由于说话人发音器官的生理差异以及后天形成的行为差异,每个人的语音都带有强烈的个人色彩,这就使得通过分析语音信号来识别说话人成为可能。用语音来鉴别说话人的身份有着许多独特的优点,如语音是人的固有的特征,不会丢失或遗忘;语音信号的采集方便,系统设备成本低;利用电话网络还可实现远程客户服务等。因此,近几年来,说话人识别越来越多的受到人们的重视。与其他生物识别技术如指纹识别、手形识别等相比较,说话人识别不仅使用方便,而且属于非接触性,容易被用户接受,并且在已有的各种生物特征识别技术中,是唯一可以用作远程验证的识别技术。因此,说话人识别的应用前景非常广泛:今天,说话人识别技术已经关系到多学科的研究领域,不同领域中的进步都对说话人识别的发展做出了贡献。说话人识别技术是集声学、语言学、计算机、信息处理和人工智能等诸多领域的一项综合技术,应用需求将十分广阔。在吃力语音信号的时候如何提取信号中关键的成分尤为重要。语音信号的特征参数的好坏直接导致了辨别的准确性。
基于单片机的语音识别系统毕业设计 目录 摘要..................................... 错误!未定义书签。Abstract ................................. 错误!未定义书签。目录..................................................... I 前言.. (1) 1 方案介绍及设计简介 (2) 1.1小车的控制要求及设计方案 (2) 1.1.1小车的控制要求 (2) 1.1.2方案设计与论证 (2) 1.2SPCE061A 简介 (3) 1.2.1SPCE061A单片机概述 (5) 1.2.2SPCE061A的介绍 (7) 1.2.3SPCE061A的结构 (7) 1.3SPCE061A 单片机强大的语音功能 (7) 1.3.1语音识别的原理 (8) 1.3.2系统的结构框图 (9) 1.4语音控制小车设计要求 (10) 1.4.1功能要求 (10) 1.4.2语音控制小车的主要功能 (10) 1.4.3参数说明 (10) 1.4.4注意事项 (10) 2电路设计及程序设计 (11) 2.1电路设计基础知识 (11) 2.2电路方框图及说明 (13) 2.3各部分电路设计 (13) 2.3.1电机的选择 (14)
2.3.2继电器驱动电路的设计 (14) 2.3.3行驶状态控制电路设计 (15) 2.3.4麦克录音输入及AGC电路 (16) 2.3.5语音播报电路 (18) 3软件设计 (19) 3.1软件流程图及设计思路说明 (19) 3.1.1程序设计 (20) 3.2模块设计 (20) 3.2.1中断流程图部分 (20) 3.2.2语音识别部分 (22) 4连接和操作说明 (25) 4.1硬件模块连接图 (25) 4.1.1功能说明 (25) 4.1.2代码下载 (26) 4.1.3训练小车 (27) 4.1.4声控小车 (28) 4.1.5重新训练 (28) 总结 (30) 致谢 (31) 参考文献 (32) 附件1 系统程序说明 (33)
语音识别 在计算机技术中,语音识别是指为了达到说话者发音而由计算机生成的功能,利用计算机识别人类语音的技术。(例如,抄录讲话的文本,数据项;经营电子和机械设备;电话的自动化处理),是通过所谓的自然语言处理的计算机语音技术的一个重要元素。通过计算机语音处理技术,来自语音发音系统的由人类创造的声音,包括肺,声带和舌头,通过接触,语音模式的变化在婴儿期、儿童学习认识有不同的模式,尽管由不同人的发音,例如,在音调,语气,强调,语调模式不同的发音相同的词或短语,大脑的认知能力,可以使人类实现这一非凡的能力。在撰写本文时(2008年),我们可以重现,语音识别技术不只表现在有限程度的电脑能力上,在其他许多方面也是有用的。 语音识别技术的挑战 古老的书写系统,要回溯到苏美尔人的六千年前。他们可以将模拟录音通过留声机进行语音播放,直到1877年。然而,由于与语音识别各种各样的问题,语音识别不得不等待着计算机的发展。 首先,演讲不是简单的口语文本——同样的道理,戴维斯很难捕捉到一个note-for-note曲作为乐谱。人类所理解的词、短语或句子离散与清晰的边界实际上是将信号连续的流,而不是听起来: I went to the store yesterday昨天我去商店。单词也可以混合,用Whadd ayawa吗?这代表着你想要做什么。第二,没有一对一的声音和字母之间的相关性。在英语,有略多于5个元音字母——a,e,i,o,u,有时y和w。有超过二十多个不同的元音, 虽然,精确统计可以取决于演讲者的口音而定。但相反的问题也会发生,在那里一个以上的信号能再现某一特定的声音。字母C可以有相同的字母K的声音,如蛋糕,或作为字母S,如柑橘。 此外,说同一语言的人使用不相同的声音,即语言不同,他们的声音语音或模式的组织,有不同的口音。例如“水”这个词,wadder可以显著watter,woader wattah等等。每个人都有独特的音量——男人说话的时候,一般开的最低音,妇女和儿童具有更高的音高(虽然每个人都有广泛的变异和重叠)。发音可以被邻近的声音、说话者的速度和说话者的健康状况所影响,当一个人感冒的时候,就要考虑发音的变化。
语音识别系统调研报告 姓名:罗小嘉学号:2801305018 1、摘要:本文简要的介绍了语音识别系统的原理,发展和在各个方面的应用前景。 2、关键词:语音识别;应用 3、引言:语音识别主要是指用机器在各种情况下,根据信息执行人的各种意图,有效地了解、识别语音和其它声音。它是近十几年来发展起来的具有理论价值和实用价值的新兴学科:从计算机大学科角度看,可视为智能计算机的智能接口;从信息处理学科来看,可视为信息识别的一个重要分支;从自动控制学科来看,又可视为模式识别的一个重要组成部分. 早在18 世纪,人们就对语音学进行了科学研究,但由于各种条件的限制,语音识别仅在计算机技术迅速发展之后,才成为一个非常活跃的研究领域. 60 年代末期,面对语音识别的种种困难,人们开始研究特定人、孤立词、小词汇量的识别,从而使语音识别的问题能够在当时的条件下得以开展;70年代后期,特定人、孤立词、小词汇量的语音识别取得较为满意的效果,语音识别的研究则沿着特定人向非特定人、孤立词向连续词、小词汇量向大词汇量方向扩展研究领域和目标;80 年代中期以来,计算机技术、信息技术及模式识别等技术的迅猛发展,极大地促进了语音识别技术的发展. 4、正文:语音识别系统要求能够实现实时语音识别。该语音识别系统的关键技术主要是语言实时识别技术、语音端点检测与声韵分割。如图: 对于语音端点检测与声韵分割的问题,从背景噪声中找出语音的开始和终止,这在语音处理中是很基本的问题,因为准确的端点检测,不仅可以提高识别精度,还可以避免计算噪声,减少计算量. 大多数语音处理系统采用过零率和能量两参数作端点检测. 但过零率受噪声影响较大,采用多门限过零率作语音起点检测,将能量信息直接反应在门限中,同时将分析窗长取小,使起点检测比较准确,效果较好. 语音识别技术的应用可以分为两个发展方向:一个方向是大词汇
开放实验项目报告 项目名称:语音识别机器人 专业 学生姓名 班级学号 指导教师 指导单位 2012/2013学年第一学期 一.设计背景
在科学日新月异的今天,电子设备的便捷化,人性化,智能化已成为不可逆转的潮流,而语音控制智能,更是其中研究发展的热点。凌阳SPCE061以其便捷的操作,可靠的性能,成为了各位电子爱好者的首选。本实验采用凌阳61板和运动小车(迷你型)模组设计的语音控制小车。凌阳板嵌入小车模型顶部。语音处理技术不仅包括语音的录制和播放,还涉及语音的压缩编码和解码、语音的识别等各种处理技术。本设计的语音控制小车,借助于SPCE061A在语音处理方面的特色,不仅具有前进、后退、左转、右转、停止等基本程序控制功能,而且还具备语音控制功能。 二.总流程图
三.主要模块 1、凌阳SPCE061是继μ’nSP?系列产品SPCE500A等之后凌阳科技推出的又一款16 位结构的微控制器。与SPCE500A不同的是,在存储器资源方面考虑到用户的较少资源的需求以及便于程序调试等功能,SPCE061A里只内嵌32K字的闪存(FLASH )。较高的处理速度使μ’nSP?能够非常容易地、快速地处理复杂的数字信号。因此,与SPCE500A相比,以μ’nSP?为核心的SPCE061A 微控制器是适用于数字语音识别应用领域产品的一种最经济的选择。 其性能如下: A、16 位μ’nSP?微处理器; B、工作电压(CPU) VDD 为2.4~3.6V (I/O) VDDH 为2.4~5.5V C、CPU 时钟:0.32MHz~49.152MHz ; D、内置2K 字SRAM; E、内置32K FLASH; F、可编程音频处理; G、晶体振荡器; H、系统处于备用状态下(时钟处于停止状态),耗电仅为2μA@3.6V ; I、2 个16 位可编程定时器/计数器(可自动预置初始计数值); J、2 个10 位DAC(数-模转换)输出通道; K、32 位通用可编程输入/输出端口; L、14 个中断源可来自定时器A / B ,时基,2 个外部时钟源输入,键唤醒;
语音识别是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。语音识别技术正逐步成为计算机信息处理技术中的关键技术,语音技术的应用已经成为一个具有竞争性的新兴高技术产业。 1语音识别的基本原理 语音识别系统本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元,它的基本结构如下图所示: 未知语音经过话筒变换成电信号后加在识别系统的输入端,首先经过预处理,再根据人的语音特点建立语音模型,对输入的语音信号进行分析,并抽取所需的特征,在此基础上建立语音识别所需的模板。而计算机在识别过程中要根据语音识别的模型,将计算机中存放的语音模板与输入的语音信号的特征进行比较,根据一定的搜索和匹配策略,找出一系列最优的与输入语音匹配的模板。然后根据此模板的定义,通过查表就可以给出计算机的识别结果。显然,这种最优的结果与特征的选择、语音模型的好坏、模板是否准确都有直接的关系。2语音识别的方法 目前具有代表性的语音识别方法主要有动态时间规整技术(DTW)、隐马尔可夫模型(HMM)、矢量量化(VQ)、人工神经网络(ANN)、支持向量机(SVM)等方法。 动态时间规整算法(Dynamic Time Warping,DTW)是在非特定人语音识别中一种简单有效的方法,该算法基于动态规划的思想,解决了发音长短不一的模板匹配问题,是语音识别技术中出现较早、较常用的一种算法。在应用DTW算法进行语音识别时,就是将已经预处理和分帧过的语音测试信号和参考语音模板进行比较以获取他们之间的相似度,按照某种距离测度得出两模板间的相似程度并选择最佳路径。 隐马尔可夫模型(HMM)是语音信号处理中的一种统计模型,是由Markov链演变来的,所以它是基于参数模型的统计识别方法。由于其模式库是通过反复训练形成的与训练输出信号吻合概率最大的最佳模型参数而不是预先储存好的模式样本,且其识别过程中运用待识别语音序列与HMM参数之间的似然概率达到最大值所对应的最佳状态序列作为识别输出,因此是较理想的语音识别模型。 矢量量化(Vector Quantization)是一种重要的信号压缩方法。与HMM相比,矢量量化主要适用于小词汇量、孤立词的语音识别中。其过程是将若干个语音信号波形或特征参数的标量数据组成一个矢量在多维空间进行整体量化。把矢量空间分成若干个小区域,每个小区域寻找一个代表矢量,量化时落入小区域的矢量就用这个代表矢量代替。矢量量化器的设计就是从大量信号样本中训练出好的码书,从实际效果出发寻找到好的失真测度定义公式,设计出最佳的矢量量化系统,用最少的搜索和计算失真的运算量实现最大可能的平均信噪比。在实际的应用过程中,人们还研究了多种降低复杂度的方法,包括无记忆的矢量量化、有记忆的矢量量化和模糊矢量量化方法。 人工神经网络(ANN)是20世纪80年代末期提出的一种新的语音识别方法。其本质上是一
语音识别技术概述 摘要:本文简要介绍了语音识别技术理论基础及分类方式,所采用的关键技术以及所面临的困难与挑战,最后讨论了语音识别技术的发展前景和应用。 关键词:语音识别;特征提取;模式匹配;模型训练 Abstract:This text briefly introduces the theoretical basis of the speech-identification technology,its mode of classification,the adopted key technique and the difficulties and challenges it have to face.Then,the developing prospect ion and application of the speech-identification technology are discussed in the last part. Keywords:Speech identification;Character Pick-up;Mode matching;Model training 一、语音识别技术的理论基础 语音识别技术:是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高级技术。语音识别以语音为研究对象,它是语音信号处理的一个重要研究方向,是模式识别的一个分支,涉及到生理学、心理学、语言学、计算机科学以及信号处理等诸多领域,甚至还涉及到人的体态语言(如人在说话时的表情、手势等行为动作可帮助对方理解),其最终目标是实现人与机器进行自然语言通信。 不同的语音识别系统,虽然具体实现细节有所不同,但所采用的基本技术相似,一个典型语音识别系统主要包括特征提取技术、模式
语音识别技术的原理和应用语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。语音识别技术主要包括特征提取技术、模式匹配准则及模型训练技术三个方面。 在语音识别的特征提取过程中,主要有语音信息量大,语音的模糊性,重音、音调、音量和音速的变化,环境噪声和干扰等难点。导致语音识别在互联网和传媒行业一直没有得到广泛的应用。但是近几年来,借助机器学习领域深度学习研究的发展,以及大数据语料的积累,硬件的性能的提升和算法的改进,语音识别技术得到突飞猛进的发展。例如音频指纹技术和音频二维码技术等。下面本文具体讨论这两种技术。 音频二维码 音频二维码技术 二维码技术经过多年的发展,已成为大家耳熟能详的名词了。二维码取代传统的键盘树盘输入技术的部分功能,成为互联网行业的第二大入口方式。但是普通的二维码技术只是将文本信息进行加码和解码。这导致二维码只能传输普通的文本信息。如果将音频技术和二维码的概念相结合,利用声音实现终端之间的近距离信息传输,那么毫
无疑问音频信息将成为互联网行业的第三大入口方式。 音频二维码技术采用仿生学技术,利用声音实现文件的快速传输。采用跨平台的技术,实现手机、电脑、智能机顶盒等智能设备间的图片、文字、链接的传输。音频二维码技术能在一定程度上取代图像二维码、近磁场传输和蓝牙等技术。 2012年底蛐蛐儿创始人朱连兴开发了一套音频二维码的引擎,名字叫蛐蛐儿SDK。在朱连兴推出了蛐蛐儿SDK之后,音频二维码的开发也变的比以前更加快速和简单。蛐蛐儿通过声音传输的不是文件,而是在发送端生成一个四位的二进制数。这四位二进制数是待发送文件的ID。发送端向接收端发送的其实只是上述生成的ID。发送端在向客户端发送ID的同时向云端发送ID和数据。在接收端接收到ID后,通过该ID向云端获取对应的数据。 音频二维码应用 音频二维码的应用非常广泛。音频二维码通过声音传递信息。广播和电视也通过声音传递信息。如果结合音频二维码技术和广播电视技术,将使二者相得益彰。音频二维码可以使广播电视用户不再是单一的受众,也是参与者。通过音频二维码可以让用户的手机等终端设备接入电视屏幕或者广播。用户在欣赏电视节目或者收听广播节目的同时,也可以通过手持终端参与节目互动环节。这会在给用户带来更好体验的同时,拉动广播电视行业的收视率和收听率。 例如在非诚勿扰的节目播放结束时,孟非不需要说那么长的一串
语音识别技术综述 The summarization of speech recognition 张永双 苏州大学 摘要 本文回顾了语音识别技术的发展历史,综述了语音识别系统的结构、分类及基本方法,分析了语音识别技术面临的问题及发展方向。 关键词:语音识别;特征;匹配 Abstact This article review the courses of speech recognition technology progress ,summarize the structure,classifications and basic methods of speech recognition system and analyze the direction and the issues which speech recognition technology development may confront with. Key words: speech recognition;character;matching 引言 语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。语音识别是一门交叉学科,所涉及的领域有信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等,甚至还涉及到人的体态语言(如人民在说话时的表情手势等行为动作可帮助对方理解)。其应用领域也非常广,例如相对于键盘输入方法的语音输入系统、可用于工业控制的语音控制系统及服务领域的智能对话查询系统,在信息高度化的今天,语音识别技术及其应用已成为信息社会不可或缺的重要组成部分。 1.语音识别技术的发展历史 语音识别技术的研究开始二十世纪50年代。1952年,AT&Tbell实验室的Davis等人成功研制出了世界上第一个能识别十个英文数字发音的实验系统:Audry系统。
实验一 语音信号的时域分析 一、 实验目的、要求 (1)掌握语音信号采集的方法 (2)掌握一种语音信号基音周期提取方法 (3)掌握语音信号短时能量和短时过零率计算方法 (4)了解Matlab 的编程方法 二、 实验原理 语音是一时变的、非平稳的随机过程,但由于一段时间内(10-30ms)人的声带和声道形状的相对稳定性,可认为其特征是不变的,因而语音的短时谱具有相对稳定性。在语音分析中可以利用短时谱的这种平稳性,将语音信号分帧。 10~30ms 相对平稳,分析帧长一般为20ms 。 语音信号的分帧是通过可移动的有限长度窗口进行加权的方法来实现的。几种典型的窗函数有:矩形窗、汉明窗、哈宁窗、布莱克曼窗。 语音信号的能量分析是基于语音信号能量随时间有相当大的变化,特别是清音段的能量一般比浊音段的小得多。定义短时平均能量 [][]∑∑+-=∞-∞=-=-= n N n m m n m n w m x m n w m x E 122)()()()( 下图说明了短时能量序列的计算方法,其中窗口采用的是直角窗。 过零就是信号通过零值。对于连续语音信号,可以考察其时域波形通过时间轴的情况。而对于离散时间信号,如果相邻的取样值改变符号则称为过零。由此可以计算过零数,过零数就是样本改变符号的次数。单位时间内的过零数称为平
均过零数。 语音信号x (n )的短时平均过零数定义为 ()[]()[]()()[]()[]() n w n x n x m n w m x m x Z m n *--=---= ∑∞ -∞=1sgn sgn 1sgn sgn 式中,[]?sgn 是符号函数,即 ()[]()()()()???<-≥=01 01sgn n x n x n x 短时平均过零数可应用于语音信号分析中。发浊音时,尽管声道有若干个共振峰,但由于声门波引起了谱的高频跌落,所以其语音能量约集中干3kHz 以下。而发清音时.多数能量出现在较高频率上。既然高频率意味着高的平均过零数,低频率意味着低的平均过零数,那么可以认为浊音时具有较低的平均过零数,而清音时具有较高的平均过零数。然而这种高低仅是相对而言,没有精确的数值关系。 短时平均过零的作用 1.区分清/浊音: 浊音平均过零率低,集中在低频端; 清音平均过零率高,集中在高频端。 2.从背景噪声中找出是否有语音,以及语音的起点。 基音是发浊音时声带震动所引起的周期性,而基音周期是指声带震动频率的倒数。基音周期是语音信号的重要的参数之一,它描述语音激励源的一个重要特征,基音周期信息在多个领域有着广泛的应用,如语音识别、说话人识别、语音分析与综合以及低码率语音编码,发音系统疾病诊断、听觉残障者的语音指导等。因为汉语是一种有调语言,基音的变化模式称为声调,它携带着非常重要的具有辨意作用的信息,有区别意义的功能,所以,基音的提取和估计对汉语更是一个十分重要的问题。 由于人的声道的易变性及其声道持征的因人而异,而基音周期的范围又很宽,而同—个人在不同情态下发音的基音周期也不同,加之基音周期还受到单词发音音调的影响,因而基音周期的精确检测实际上是一件比较困难的事情。基音提取的主要困难反映在:①声门激励信号并不是一个完全周期的序列,在语音的
摘要 语音识别主要是让机器听懂人说的话,即在各种情况下,准确地识别出语音的内容,从而根据其信息执行人的各种意图。语音识别技术既是国际竞争的一项重要技术,也是每一个国家经济发展不可缺少的重要技术支撑。本文基于语音信号产生的数学模型,从时域、频域出发对语音信号进行分析,论述了语音识别的基本理论。在此基础上讨论了语音识别的五种算法:动态时间伸缩算法(Dynamic Time Warping,DTW)、基于规则的人工智能方法、人工神经网络(Artificial Neural Network,ANN)方法、隐马尔可夫(Hidden Markov Model,HMM)方法、HMM和ANN的混合模型。重点是从理论上研究隐马尔可夫(HMM)模型算法,对经典的HMM模型算法进行改进。 语音识别算法有多种实现方案,本文采取的方法是利用Matlab强大的数学运算能力,实现孤立语音信号的识别。Matlab 是一款功能强大的数学软件,它附带大量的信号处理工具箱为信号分析研究,特别是文中主要探讨的声波分析研究带来极大便利。本文应用隐马尔科夫模型(HMM) 为识别算法,采用MFCC(MEL频率倒谱系数)为主要语音特征参数,建立了一个汉语数字语音识别系统,其中包括语音信号的预处理、特征参数的提取、识别模板的训练、识别匹配算法;同时,提出利用Matlab图形用户界面开发环境设计语音识别系统界面,设计简单,使用方便,系统界面友好。经过统计,识别效果明显达到了预期目标。 关键词:语音识别算法;HMM模型;Matlab;GUI ABSTRACT Speech Recognition is designed to allow machines to understand what people say,and accurately identify the contents of voice to execute the intent of people.Speech recognition technology is not only an important internationally competed technology,but also an indispensable foundational technology for the national economic development.Based on the mathematical model from the speech signal,this paper analyze audio signal from the time
噪音环境下的语音识别 1.1引言 随着社会的不断进步和科技的飞速发展,计算机对人们的帮助越来越大,成为了人们不可缺少的好助手,但是一直以来人们都是通过键盘、鼠标等和它进行通信,这限制了人与计算机之间的交流,更限制了消费人群。为了能让多数人甚至是残疾人都能使用计算机,让计算机能听懂人的语言,理解人们的意图,人们开始了对语音识别的研究. 语音识别是语音学与数字信号处理技术相结合的一门交叉学科,它和认知学、心理学、语言学、计算机科学、模式识别和人工智能等学科都有密切关系。 1,2语音识别的发展历史和研究现状 1.2.1国外语音识别的发展状况 国外的语音识别是从1952年贝尔实验室的Davis等人研制的特定说话人孤立数字识别系统开始的。 20世纪60年代,日本的很多研究者开发了相关的特殊硬件来进行语音识别RCA实验室的Martin等人为解决语音信号时间尺度不统一的问题,开发了一系列的时问归正方法,明显地改善了识别性能。与此同时,苏联的Vmtsyuk提出了采用动态规划方法解决两个语音的时闻对准问题,这是动态时间弯折算法DTW(dymmic time warping)的基础,也是其连续词识别算法的初级版.20世纪70年代,人工智能技术走入语音识别的研究中来.人们对语音识别的研究也取得了突破性进展.线性预测编码技术也被扩展应用到语音识别中,DTw也基本成熟。 20世纪80年代,语音识别研究的一个重要进展,就是识别算法从模式匹配技术转向基于统计模型的技术,更多地追求从整体统计的角度来建立最佳的语音识别系统。隐马尔可夫模型(hidden Markov model,删)技术就是其中一个典型技术。删的研究使大词汇量连续语音识别系统的开发成为可能。 20世纪90年代,人工神经网络(artificial neural network,ANN)也被应用到语音识别的研究中,并使相应的研究工作在模型的细化、参数的提取和优化以及系统的自适应技术等方面取得了一些关键性的进展,此时,语音识别技术进一步成熟,并走向实用。许多发达国家,如美国、日本、韩国,已经IBM、Microsoft、Apple、AT&T、Nrr等著名公司都为语音识别系统的实用化开发研究投以巨资。 当今,基于HMM和ANN相结合的方法得到了广泛的重视。而一些模式识别、机器学习方面的新技术也被应用到语音识别过程中,如支持向量机(support vector machine,SVM)技术、进化算法(evolutionary computation)技术等。
通信工程学院12级1班罗恒2012101032 实验一语音信号的低通滤波和短时分析综合实验 一、实验要求 1、根据已有语音信号,设计一个低通滤波器,带宽为采样频率的四分之一,求输出信号; 2、辨别原始语音信号与滤波器输出信号有何区别,说明原因; 3、改变滤波器带宽,重复滤波实验,辨别语音信号的变化,说明原因; 4、利用矩形窗和汉明窗对语音信号进行短时傅立叶分析,绘制语谱图并估计基音周期,分析两种窗函数对基音估计的影响; 5、改变窗口长度,重复上一步,说明窗口长度对基音估计的影响。 二、实验目的 1.在理论学习的基础上,进一步地理解和掌握语音信号低通滤波的意义,低通滤波分析的基本方法。 2.进一步理解和掌握语音信号不同的窗函数傅里叶变化对基音估计的影响。 三、实验设备 1.PC机; 2.MATLAB软件环境; 四、实验内容 1.上机前用Matlab语言完成程序编写工作。 2.程序应具有加窗(分帧)、绘制曲线等功能。 3.上机实验时先调试程序,通过后进行信号处理。 4.对录入的语音数据进行处理,并显示运行结果。 5. 改变滤波带宽,辨别与原始信号的区别。 6.依据曲线对该语音段进行所需要的分析,并且作出结论。 7.改变窗的宽度(帧长),重复上面的分析内容。 五、实验原理及方法 利用双线性变换设计IIR滤波器(巴特沃斯数字低通滤波器的设计),首先要设计出满足指标要求的模拟滤波器的传递函数Ha(s),然后由Ha(s)通过双线性变换可得所要设计的IIR滤波器的系统函数H(z)。如果给定的指标为数字滤波器的指标,则首先要转换成模拟滤波器的技术指标,这里主要是边界频率Wp和Ws 的转换,对ap和as指标不作变化。边界频率的转换关系为∩=2/T tan(w/2)。接着,按照模拟低通滤波器的技术指标根据相应设计公式求出滤波器的阶数N和3dB截止频率∩c ;根据阶数N查巴特沃斯归一化低通滤波器参数表,得到归一化传输函数Ha(p);最后,将p=s/ ∩c 代入Ha(p)去归一,得到实际的模拟滤波器传输函数Ha(s)。之后,通过双线性变换法转换公式s=2/T((1-1/z)/(1+1/z))得到所要设计的IIR滤波器的系统函数H(z)。
机电信息工程学院专业综合课程设计 系:信息与通信工程 专业:通信工程 班级:081班 设计题目:基于matlab的语音识别系统 学生姓名: 指导教师: 完成日期:2011年12月27日
一.设计任务及要求 1.1设计任务 作为智能计算机研究的主导方向和人机语音通信的关键技术,语音识别技术一直受到各国科学界的广泛关注。以语音识别开发出的产品应用领域非常广泛,有声控电话交换、语音拨号系统、信息网络查询、家庭服务、宾馆服务、旅行社服务系统、订票系统、声控智能玩具、医疗服务、银行服务、股票查询服务、计算机控制、工业控制、语音通信系统、军事监听、信息检索、应急服务、翻译系统等,几乎深入到社会的每个行业、每个方面,其应用和经济社会效益前景非常广泛。本次任务设计一个简单的语音识别系。 1.2设计要求 要求:使用matlab软件编写语音识别程序 二.算法方案选择 2.1设计方案 语音识别属于模式识别范畴,它与人的认知过程一样,其过程分为训练和识别两个阶段。在训练阶段,语音识别系统对输入的语音信号进行学习。学习结束后,把学习内容组成语音模型库存储起来;在识别阶段,根据当前输入的待识别语音信号,在语音模型库中查找出相应的词义或语义。 语音识别系统与常规模式识别系统一样包括特征提取、模式匹配、模型库等3个基本单元,它的基本结构如图1所示。 图1 语音识别系统基本结构图 本次设计主要是基于HMM模型(隐马尔可夫模型)。这是在20世纪80年代引入语音识别领域的一种语音识别算法。该算法通过对大量语音数据进行数据统计,建立识别词条的统计模型,然后从待识别语音信号中提取特征,与这些模
型进行匹配,通过比较匹配分数以获得识别结果。通过大量的语音,就能够获得一个稳健的统计模型,能够适应实际语音中的各种突发情况。并且,HMM算法具有良好的识别性能和抗噪性能。 2.2方案框图 图2 HMM语音识别系统 2.3隐马尔可夫模型 HMM过程是一个双重随机过程:一重用于描述非平稳信号的短时平稳段的统计特征(信号的瞬态特征);另一重随机过程描述了每个短时平稳段如何转变到下一个短时平稳段,即短时统计特征的动态特性(隐含在观察序列中)。人的言语过程本质上也是一个双重随机过程,语音信号本身是一个可观测的时变列。可见,HMM合理地模仿了这一过程,是一种较为理想的语音信号模型。其初始状态概率向量π,状态转移概率矩阵向量A,以及概率输出向量B一起构成了HMM的3个特征参量。HMM 模型通常表示成λ={π,A,B}。 2.4HMM模型的三个基本问题 HMM模型的核心问题就是解决以下三个基本问题: (1)识别问题:在给定的观测序列O和模型λ=(A,B,π)的条件下,如何有效地计算λ产生观测序列O的条件概率P(O︱λ)最大。常用的算法是前后向算法,它可以使其计算量降低到N2T次运算。 (2)最佳状态链的确定:如何选择一个最佳状态序列Q=q1q2…qT,来解释观察序列O。常用的算法是Viterbi算法。 (3)模型参数优化问题:如何调整模型参数λ=(A,B,π),使P(O︱λ)最大:这是三个问题中最难的一个,因为没有解析法可用来求解最大似然模型,所以只能使用迭代法(如Baum-Welch)或使用最佳梯度法。 第一个问题是评估问题,即已知模型λ=(A,B,π)和一个观测序列O,如何计算由该模型λ产生出该观测序列O的概率,问题1的求解能够选择出与给定的观测序列最匹配的HMM模型。 第二个问题力图揭露模型中隐藏着的部分,即找出“正确的”状态序列,这是一个典型的估计问题。