空间元数据库知识点一、知识点结构
二、知识点内容
知识点(优先级)描述定位
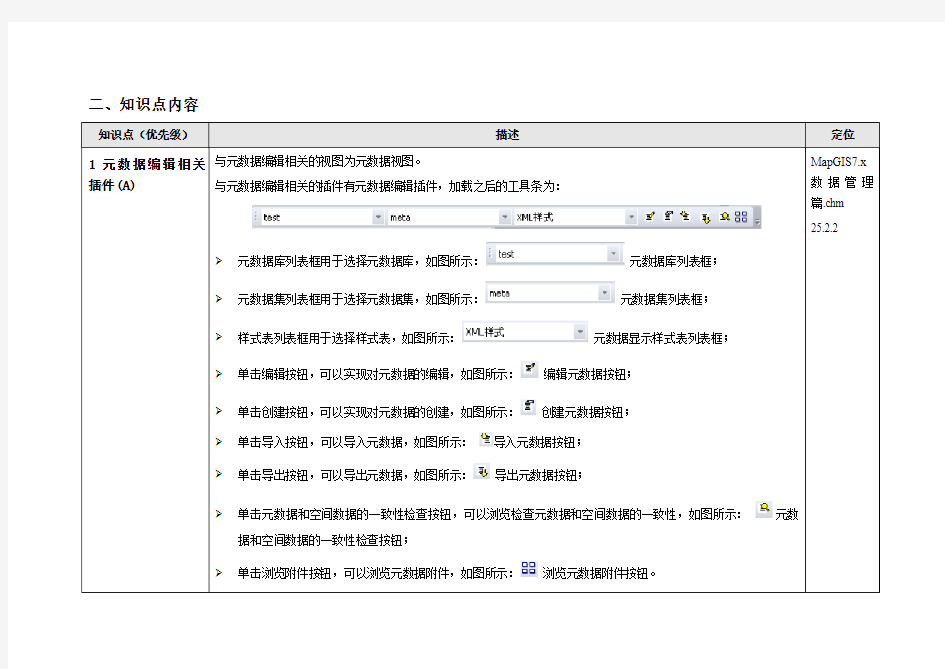
1元数据编辑相关插件(A) 与元数据编辑相关的视图为元数据视图。
与元数据编辑相关的插件有元数据编辑插件,加载之后的工具条为:
?元数据库列表框用于选择元数据库,如图所示:元数据库列表框;
?元数据集列表框用于选择元数据集,如图所示:元数据集列表框;
?样式表列表框用于选择样式表,如图所示:元数据显示样式表列表框;
?单击编辑按钮,可以实现对元数据的编辑,如图所示:编辑元数据按钮;
?单击创建按钮,可以实现对元数据的创建,如图所示:创建元数据按钮;
?单击导入按钮,可以导入元数据,如图所示:导入元数据按钮;
?单击导出按钮,可以导出元数据,如图所示:导出元数据按钮;
?单击元数据和空间数据的一致性检查按钮,可以浏览检查元数据和空间数据的一致性,如图所示:元数据和空间数据的一致性检查按钮;
?单击浏览附件按钮,可以浏览元数据附件,如图所示:浏览元数据附件按钮。
MapGIS7.x
数据管理
篇.chm
25.2.2
2元数据创建(A)1、创建元数据库和元数据集
在“元数据库”文件夹右键选择“创建”功能,输入元数据库的名称,如test。
展开元数据库,找到test点击右键选择创建元数据集,输入元数据集名称。
图1创建元数据库和元数据集
2、元数据的创建方法有多种,以下逐一介绍。
(1)在元数据集上右键点击元数据导入,其具体的操作参见元数据的批量导入。
(2)工具条上点击创建元数据按钮,如果当前选中的是“元数据库”,就会在元数据库文件夹下的第一个元数
据库中的第一个元数据集中建立元数据;如果选中的是某个元数据库(如test),就会在该元数据库中的最先建的
元数据集中建立元数据;如果选中的是某个元数据集(如meta),就会在该元数据集中建立元数据。
(3)为地理实体建立元关系,在建立了元关系的元数据集上右键点击,选择同步元数据,则会在元数据列表中新
建元数据,其具体的操作请参考创建同步和更新同步。
MapGIS7.x
数据管理
篇.chm
25.2.1
3元数据浏览(A)在MapGisCatalog目录树中选中某个元数据集,将视图切换到元数据视图,在元数据视图中的元数据列表中会列出
该元数据集下的所有元数据,选择某条元数据,在元数据视图中即会显示该条元数据的信息。
可以从下拉列表中,选择已有的显示方式对该条元数据的显示方式进行更改。
MapGIS7.x
数据管理
篇.chm
25.2.1
图元数据浏览界面
4元数据编辑器介
绍(A)
在元数据浏览的基础上,点击元数据编辑工具条上的元数据编辑按钮,通过此界面对元数据进行编辑。
图元数据编辑界面MapGIS7.x 数据管理篇.chm 25.3.1
5元数据编辑的常见内容(A)1、元素值的编辑
在列表网格中鼠标点击元素值对应的表格单元,如果元素具有子元素,则列表网格将自动转换为该元素的所
有子元素,如果不具有子元素,即是简单元素,则可编辑该元素对应的元素值,如下图所示。如果改变了元素的值,
MapGIS7.x
数据管理篇
25.3.2
则值来源一项将变为“编辑获得”,如果编辑的元素值不合法,将会弹出一个对话框提示用户重新输入。
图1元数据值编辑
2、元素的添加
可以将还未出现在元数据中的一些元素(通常是可选元素)添加到元数据中,如下图所示:
图2 元数据元素添加
3、元素的复制
当元数据中的某个元素在元数据结构中允许出现多次,可以借助编辑器提供的复制功能方便地实现相同元素的添加,如下图所示,当某个元素尚未达到允许出现的最大次数时,在该元素上单击鼠标右键,选择复制,即可复制出一个和该元素完全相同的元素,并且复制的元素自动添加到该元素之下,然后用户可以根据实际情况修改相应的值。如下图所示:
图3 元数据元素复制
4、元素的删除
如果元数据中的某个元素在元数据结构中允许出现0次,则可根据实际需要删除该元素已经出现的相关记录,具体操作如下图所示,当某个允许出现0次的元素在元数据记录中出现的次数大于0时,在该元素上单击鼠标右键,选择删除,将删除该元素。
图4 元数据元素删除
5、元素的替换
如果元数据中的某个元素在元数据结构中允许被其它元素替换,则可根据需要用其它元素替换该元素。具体操作如下图所示,在该元素上单击鼠标右键,选择“替换为”项后,选择替换的元素,即可完成替换。
图5 元数据元素替换
6、标准验证
单击验证按钮(如下图所示),将使用元数据的XML的DOM对象基于的标准对该条元数据的合法性进行验证,如
果不能通过验证,则对元数据的更改无效,直到符合标准为止。
7、更新元数据
单击保存按钮(如下图所示),将首先使用元数据的XML的DOM对象基于的标准对该条元数据的合法性进行验证,
如果通过验证,则将修改后的元数据保存到数据库中,同时退出编辑标准,如果未通过验证,则显示不符合标准的
相关元素。如下图所示:
8、退出编辑标准
单击退出按钮,将放弃修改直接退出编辑标准。如下图所示:
6元数据库管理(A)1、创建元数据库
在MapGIS7.x的MapGisCatalog目录树上的元数据库文件夹节点上单击鼠标右键,选择创建元数据库,将弹出新建
元数据库对话框,输入元数据库的名字,即可创建一个新的元数据库。
MapGIS7.x
数据管理
篇.chm
25.4.1
图1 创建元数据库
2、删除元数据库
在MapGIS7.x的MapGisCatalog目录树上的某个已经存在的元数据库节点上单击鼠标右键,选择删除元数据库,如下图所示。如果地理数据库基于本地文件(HDF)存储,则可直接删除该元数据库;如果地理数据库基于DBMS 数据库存储,若该元数据库下存在元数据集,则不可删除,而如果该元数据库下没有元数据集,则可以删除该元数据库。
图2 删除元数据库
3、元关系编辑
在MapGIS7.x的MapGisCatalog目录树上的“元数据库”节点上单击鼠标右键,选择元关系编辑,将弹出选择编辑元关系对话框;然后选择要进行编辑的元关系类型和元关系名称后,点击确定按钮,弹出元关系编辑对话框,如下图所示。
图3元关系编辑图4 选择元关系
图5元关系编辑器
7元数据集标准管理(A)1、注册元数据标准
在MapGIS7.x的MapGisCatalog目录树上的某个已经存在的元数据库节点(如test)上单击鼠标右键,选择元数据
标准管理,将弹出元数据标准管理对话框,如下图所示,输入元数据标准名称和描述信息,并指定元数据标准文件
的文件的位置,单击注册按钮,即可注册元数据标准。
图1 注册元数据标准
在模式创建成功后,会给出提示,是否创建映射,点击是,则出现下图:
MapGIS7.x
数据管理
篇.chm
25.4.2
在左侧的“自定义元数据标准”中选择某个描述,在右侧的“MapGis可同步元素”中选择某个描述,点击按钮,将两者进行关联,关联之后的即可在关联列表中显示,可以对已关联的进行删除,确定所有关联之后,点击完成。
提示映射成功。
2.注销元数据标准
在元数据标准管理器中已有标准列表中选择欲删除的标准,单击删除按钮,即可删除该标准(注意:删除标准前请确认无元数据集与该标准关联,否则删除不成功。
8元数据集管理(A)1、创建元数据集
在MapGIS7.x的MapGisCatalog目录树上的某个已经存在的元数据库节点上单击鼠标右键,选择“创建元数据集”
菜单,将弹出创建元数据集对话框,如下图1左图所示,输入元数据集的名称和描述信息,并选择元数据集基于的
标准;单击显示设置按钮,可以设置元数据的显示字段,如图2 所示;最后单击图1右图所示对话框中的创建按
钮,即可创建元数据集。
图1 创建元数据集MapGIS7.x 数据管理篇.chm 25.4.3
图2 设置元数据显示信息
2、删除元数据集
在MapGIS7.x的MapGisCatalog目录树上的某个已经存在的元数据集节点上单击鼠标右键,选择删除元数据集,即可删除该元数据集。
9元数据的批量导入(A)元数据的批量导入工具支持三种格式的导入:XML文件、普通TXT文本文件和树状TXT文本文件,支持两种方
式的导入:文件的导入和整个文件夹的导入,导入操作步骤如下:
1、在MapGIS7.x的MapGisCatalog目录树上的某个已经存在的元数据集节点上单击鼠标右键,选择元数据导入菜
单,将弹出如下图所示的对话框:
图1 导入元数据
2、导入目标,导入目标所在的元数据库和元数据集已经自动设定。
3、设置导入源,选择导入方式(导入文件夹或者导入文件),然后单击按钮定位到导入的位置。
4、设置导入文本的格式,单击导入文本格式设置,将弹出如下图所示的对话框,在该对话框中对导入的TXT类型
的文本格式进行选择,然后单击确定按钮。
MapGIS7.x
数据管理
篇.chm
25.4.4
图2 导入元数据格式设置
5、单击导入按钮即可完成符合条件的文件的导入。
6、单击查看日志按钮可以查看元数据导入信息的日志文件。
7、单击退出按钮退出元数据的批量导入。
10元数据查询工具(A)元数据查询工具是对某个元数据集中的全部元数据进行查询,根据用户输入的查询表达式,将符合条件的所有元数
据查询出来并显示给用户。执行一次元数据查询的具体步骤为:
1、在MapGIS7.x的MapGisCatalog目录树上的某个已经存在的元数据集节点上单击鼠标右键,选择元数据查询,
如下图所示:
图1 元数据查询
MapGIS7.x
数据管理
篇.chm
25.5
2、然后系统会弹出元数据查询对话框,如下图:
图2元数据查询对话框
3、在左边的元数据结构树中,选择查询元素并将其添加到查询元素列表中;接着对每一个查询元素设置其查询条件,在“操作符”字段中选择操作符,在“条件值”字段中输入查询条件;最后将查询元素和对话框下方的查询符号进行适当组合,便会形成一个查询表达式。
4、点击执行按钮来执行查询表达式,系统会弹出对话框报告执行结果。
图3 元数据查询提示
5、点击退出查询按钮,关闭元数据查询对话框,则查询结果集便会显示在元数据列表中。
11创建同步(A)1、创建一个元关系类。在MapGisCatalog树中选择关系类文件夹节点,点右键,在弹出的菜单中点击创建菜单项,则会弹出如下所示的对话框。MapGIS7.x 数据管理篇.chm 25.6.1
图1元关系创建
选择元关系,然后进入下一步,如下图所示。在这个对话框中,选择要创建关系类的原始对象类和目的对象类,并给该关系类命名。点击下一步,直至完成。
图2元关系标签
2、将在上一步中选择为原始对象类的元数据集设置为当前元数据集。在元数据编辑工具条的元数据集下拉列表中选择适当的元数据集为当前元数据集。
3、在MapGisCatalog树中选择在第一步中为目的对象类的地理实体,点击右键,在弹出的菜单中点选同步元数据菜单项,元数据同步发生,在元数据视图中会看到创建的元数据。
元数据的概念 元数据(Metadata),即关于数据的数据,是对数据和信息资源进行描述的信息。通常认为,元数据是为了更为有效地管理和使用数据而对它进行说明的信息。所以元数据与其描述的数据内容有着密切联系,不同领域的数据的元数据在内容 上差异很大。地理空间数据的元数据是地理空间的空间数据和属性数据以外的描述地理信息空间数据集的内容、质量、状态和其它特性的一类数据,它是实现地理空间信息共享的核心标准之一。其中,对空间数据某一特征的描述,称为一个空间元数据元素。空间元数据是一个由若干复杂或简单的元数据项组成的集合。它与非空间元数据的主要区别在于其内容中包含大量与空间位置有关的描述性信息。 研究元数据的作用和意义 元数据可用来帮助数据提供者和数据使用者解决数据转换、沟通和理解的问题。归纳起来,元数据主要有下列几个方面的作用: 1)、用来组织、管理和维护空间数据,建立数据文档,并保证即使其主要工作人员退休或调离时,也不会失去对数据情况的了解 2)、提供数据存储、数据分类、数据内容、数据质量及数据分发等方面的信息,帮助数据使用者查询检索所需地理空间数据 3)、用来建立空间信息的数据目录和数据交换中心,提供通过网络对数据进行查询检索的方法或途径,以及与数据交换和传输有关的辅助信息 4)、通过空间元数据,人们可以接受并理解空间信息,帮助数据使用者了解数据, 以便就数据是否能满足其需求作出正确的判断并与自己的空间信息集成在一起,进行不同方面的科学分析和决策。 元数据是使数据充分发挥作用的重要条件之一。它可以用于许多方面,包括数据文档建立、数据发布、数据浏览、数据转换等。元数据对于促进数据的管理、使用和共享均有重要的作用。元数据对于建立空间数据交换网络是十分重要的,往往网络中心通过设在中心的元数据库可以实时地连接各个分发数据的分节点元数据库,帮助潜在的用户找到其特定应用所需要的数据,实现数据共享。 一个完整的元数据系统通常包括三部分,即元数据标准、元数据管理工具和元数据库。不同的元数据库可能采用不同的管理工具,唯一能够在不同数据管理软件间交换元数据的途径是统一元数据标准,只有在统一的标准前提下,才能跨越操作系统平台和数据库软件平台进行数据的互操作,实现数据共享。 DIF 元数据标准
一、描述统计描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策 树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W 检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数卩与已知的某一总体均数卩0 (常为理论值或标准值)有无差别; B 配对样本t 检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t 检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10 以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析用于分析离散变量或定型变量之间是否存在相关。对于二维表,可进行卡 方检验,对于三维表,可作Mentel-Hanszel 分层分析列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以
空间数据质量特性与质量控制 范志坚1,2,方源敏1,汪虹2 (1.昆明理工大学国土资源工程学院昆明 650093;2.云南省基础地理信息中心昆明 650034) 摘要:本文主要讨论空间数据质量特性、质量控制所涉及的内容。结合笔者最近从事空间数 据库建库的具体实践和工作体会,探讨从位置精度、属性精度、时间精度、数据完整性和逻辑一致性等方面对数据质量进行全面控制,最终建成一个质量可靠的空间数据库。 关键词:地理信息系统;空间数据库;空间数据;质量特性;质量控制 Quality characteristic and Quality control of Spatial data Fan Zhi-jian1,2,Fang Yuan-min1,Wang-Hong2 (1.Faculty of Land Resources Engineering,Kunming University of Science and Technology,Kunming 650093,China;2.Yunnan Provincial Geomatics center,Kunming 650034,China) Abstract:This paper mainly talks over contents which are involved with quality characteristic and quality control of spatial data.Integrating with concrete practice and work experience which the writer has recently been engaged in establishing spatial database,a very comprehensive control of data quality should be discussed from aspects of positional accuracy、attribute accuracy、temporal accuracy、data compression、as well as logic conformance and so on.Finally,a dependable spatial database should be set up. Key words:GIS;spatial database;spatial data;quality characteristic;quality control 0 引言 空间数据库是随着地理信息系统(GIS)的开发和应用而发展起来的数据库新技术,它是地理信息系统的重要组成部份,是地理信息系统应用部份的前题和基础。空间数据库为此建立了如实体、关系、数据独立性、完整性、数据操作、资源共享等一系列基本概念。以空间数据存储和操作为对象的空间数据库,把被管理的数据从一维推向了二维、三维甚至更高维。空间数据库是一种应用于空间数据处理与信息分析领域的具有工程性质的数据库,它所管理的对象主要是空间实体。在空间数据库中,空间数据质量的好坏,直接影响到空间数据库的经济效益和社会效益。 要得到高质量的空间数据,最重要的是在空间数据生产和使用过程中进行质量管理和质量控制。通过质量管理和质量控制,可以分析影响产品质量的原因,进而提高空间数据的质量。空间数据的质量是空间数据库生存和发展的保障,缺少质量指标的空间数据将无法得到用户的信任,且直接影响到地理信息系统应用、分析、决策的正确性和可靠性。由此可知,空间数据质量是空间数据库的生
最新初中数学数据分析解析 一、选择题 1.在一次数学答题比赛中,五位同学答对题目的个数分别为7,5,3,5,10,则关于这组数据的说法不正确的是() A.众数是5 B.中位数是5 C.平均数是6 D.方差是3.6 【答案】D 【解析】 【分析】 根据平均数、中位数、众数以及方差的定义判断各选项正误即可. 【详解】 A、数据中5出现2次,所以众数为5,此选项正确; B、数据重新排列为3、5、5、7、10,则中位数为5,此选项正确; C、平均数为(7+5+3+5+10)÷5=6,此选项正确; D、方差为1 5 ×[(7﹣6)2+(5﹣6)2×2+(3﹣6)2+(10﹣6)2]=5.6,此选项错误; 故选:D. 【点睛】 本题主要考查了方差、平均数、中位数以及众数的知识,解答本题的关键是熟练掌握各个知识点的定义以及计算公式,此题难度不大. 2.某校组织“国学经典”诵读比赛,参赛10名选手的得分情况如表所示: 那么,这10名选手得分的中位数和众数分别是() A.85.5和80 B.85.5和85 C.85和82.5 D.85和85 【答案】D 【解析】 【分析】 众数是一组数据中出现次数最多的数据,注意众数可以不只一个; 找中位数要把数据按从小到大的顺序排列,位于最中间的一个数(或两个数的平均数)为中位数. 【详解】 数据85出现了4次,最多,故为众数; 按大小排列第5和第6个数均是85,所以中位数是85. 故选:D. 【点睛】 本题主要考查了确定一组数据的中位数和众数的能力.一些学生往往对这个概念掌握不清
楚,计算方法不明确而误选其它选项.注意找中位数的时候一定要先排好顺序,然后再根据奇数和偶数个来确定中位数,如果数据有奇数个,则正中间的数字即为所求.如果是偶数个则找中间两位数的平均数. 3.在只有15人参加的演讲比赛中,参赛选手的成绩各不相同,若选手要想知道自己是否进入前8名,只需要了解自己的成绩以及全部成绩的( ) A.平均数B.中位数C.众数D.以上都不对 【答案】B 【解析】 【分析】 此题是中位数在生活中的运用,知道自己的成绩以及全部成绩的中位数就可知道自己是否进入前8名. 【详解】 15名参赛选手的成绩各不相同,第8名的成绩就是这组数据的中位数, 所以选手知道自己的成绩和中位数就可知道自己是否进入前8名. 故选B. 【点睛】 理解平均数,中位数,众数的意义. 4.某校四个绿化小组一天植树的棵数如下:10,x,10,8,已知这组数据的众数与平均数相等,则这组数据的中位数是( ) A.8 B.9 C.10 D.12 【答案】C 【解析】 【分析】 根据这组数据的众数与平均数相等,可知这组数据的众数(因10出现了2次)与平均数都是10;再根据平均数是10,可求出这四个数的和是40,进而求出x的数值;然后把这四个数据按照从大到小的顺序排列,由于是偶数个数据,则中间两个数的平均数就是中位数. 【详解】 当x=8时,有两个众数,而平均数只有一个,不合题意舍去. 当众数为10,根据题意得(10+10+x+8)÷4=10,解得x=12, 将这组数据按从小到大的顺序排列为8,10,10,12, 处于中间位置的是10,10, 所以这组数据的中位数是(10+10)÷2=10. 故选C. 【点睛】 本题为统计题,考查平均数、众数与中位数的意义,解题时需要理解题意,分类讨论.
以下是我在近三年做各类计量和统计分析过程中感受最深的东西,或能对大家有所帮助。当然,它不是ABC的教程,也不是细致的数据分析方法介绍,它只是“总结”和“体会”。由于我所学所做均甚杂,我也不是学统计、数学出身的,故本文没有主线,只有碎片,且文中内容仅为个人观点,许多论断没有数学证明,望统计、计量大牛轻拍。 于我个人而言,所用的数据分析软件包括EXCEL、SPSS、STATA、EVIEWS。在分析前期可以使用EXCEL进行数据清洗、数据结构调整、复杂的新变量计算(包括逻辑计算);在后期呈现美观的图表时,它的制图制表功能更是无可取代的利器;但需要说明的是,EXCEL毕竟只是办公软件,它的作用大多局限在对数据本身进行的操作,而非复杂的统计和计量分析,而且,当样本量达到“万”以上级别时,EXCEL的运行速度有时会让人抓狂。 SPSS是擅长于处理截面数据的傻瓜统计软件。首先,它是专业的统计软件,对“万”甚至“十万”样本量级别的数据集都能应付自如;其次,它是统计软件而非专业的计量软件,因此它的强项在于数据清洗、描述统计、假设检验(T、F、卡方、方差齐性、正态性、信效度等检验)、多元统计分析(因子、聚类、判别、偏相关等)和一些常用的计量分析(初、中级计量教科书里提到的计量分析基本都能实现),对于复杂的、前沿的计量分析无能为力;第三,SPSS主要用于分析截面数据,在时序和面板数据处理方面功能了了;最后,SPSS兼容菜单化和编程化操作,是名副其实的傻瓜软件。 STATA与EVIEWS都是我偏好的计量软件。前者完全编程化操作,后者兼容菜单化和编程化操作;虽然两款软件都能做简单的描述统计,但是较之 SPSS差了许多;STATA与EVIEWS都是计量软件,高级的计量分析能够在这两个软件里得到实现;STATA的扩展性较好,我们可以上网找自己需要的命令文件(.ado文件),不断扩展其应用,但EVIEWS 就只能等着软件升级了;另外,对于时序数据的处理,EVIEWS较强。 综上,各款软件有自己的强项和弱项,用什么软件取决于数据本身的属性及分析方法。EXCEL适用于处理小样本数据,SPSS、 STATA、EVIEWS可以处理较大的样本;EXCEL、SPSS适合做数据清洗、新变量计算等分析前准备性工作,而STATA、EVIEWS在这方面较差;制图制表用EXCEL;对截面数据进行统计分析用SPSS,简单的计量分析SPSS、STATA、EVIEWS可以实现,高级的计量分析用 STATA、EVIEWS,时序分析用EVIEWS。 关于因果性 做统计或计量,我认为最难也最头疼的就是进行因果性判断。假如你有A、B两个变量的数据,你怎么知道哪个变量是因(自变量),哪个变量是果(因变量)? 早期,人们通过观察原因和结果之间的表面联系进行因果推论,比如恒常会合、时间顺序。但是,人们渐渐认识到多次的共同出现和共同缺失可能是因果关系,也可能是由共同的原因或其他因素造成的。从归纳法的角度来说,如果在有A的情形下出现B,没有A的情形下就没有B,那么A很可能是B的原因,但也可能是其他未能预料到的因素在起作用,所以,在进行因果判断时应对大量的事例进行比较,以便提高判断的可靠性。 有两种解决因果问题的方案:统计的解决方案和科学的解决方案。统计的解决方案主要指运用统计和计量回归的方法对微观数据进行分析,比较受干预样本与未接受干预样本在效果指标(因变量)上的差异。需要强调的是,利用截面数据进行统计分析,不论是进行均值比较、频数分析,还是方差分析、相关分析,其结果只是干预与影响效果之间因果关系成立的必要条件而非充分条件。类似的,利用截面数据进行计量回归,所能得到的最多也只是变量间的数量关系;计量模型中哪个变量为因变量哪个变量为自变量,完全出于分析者根据其他考虑进行的预设,与计量分析结果没有关系。总之,回归并不意味着因果关系的成立,因果关系的判定或推断必须依据经过实践检验的相关理论。虽然利用截面数据进行因果判断显得勉强,但如果研究者掌握了时间序列数据,因果判断仍有可为,其
《元数据的作用[元数据的构成方式]》 (徐枫宦茂盛)通过元数据的描述,能够使信息资源的使用者了解数据的内容、特征、作用、获取方式等信息。元数据是关于数据的数据,在建立信息资源目录体系的过程中,元数据主要是对信息资源从外部特征进行而非从内部结构进行描述。通俗地讲,元数据就是信息资源的标签或卡片,通过元数据的描述,可以使信息资源的使用者能够了解数据的内容、特征、作用、获取方式等信息,能够对信息资源是否满足特定的应用需求做出适当的评价,并根据评价的结果决定是否采取进一步的措施来获取该信息资源。 元数据是信息资源目录体系建立的基础,构建一个信息资源目录体系首要和基础性的工作就是建立描述各个信息资源的元数据库,元数据库中存储的是描述各种来源、各种类型的信息资源的描述信息。无论用户以何种方式查询信息资源目录,包括以分类目录的形式进行查询、或者以多关键词的形式进行查询,其本质都是对后台元数据库的检索,只是从表现层提供了不同形式的人机查询接口。根据所描述的信息资源对象的不同,可以建立不同的元数据库,分别对各类信息资源进行描述。 元数据的组成 为能够对信息资源进行准确和高效的描述,元数据本身具有自身的逻辑结构。一般来说,元数据本身是层次化、树状结构的。处于树状结构最底端的叶子节点称之为元数据元素,包含了元数据元素的节点称之为元数据实体,当然元数据实体也可以只包含元数据实体。根
据实际需求,元数据实体或者元数据元素可以多次出现。例如,信息资源可以有不同的分类,可以按照信息资源的来源进行分类,也可以按照信息资源的不同应用主题进行分类,因此,“信息资源分类”元数据实体就可以出现多次。 元数据一般分三个方面对信息资源进行描述。 一是对信息资源基本内容的描述。包括信息资源的标题、摘要、关键词等基本信息。标题是信息资源的名称,通过标题使用者能够初步掌握信息资源的基本范围。其次,使用者可以通过摘要,了解信息资源的主要内容、用途等各种信息。一般情况下,用户主要通过摘要作为信息资源适用性评价的主要依据。所以,在信息资源元数据的著录过程中,摘要的填写一般都由专业人员完成,只有专业人员才能够对信息资源的内容有准确的把握和深入的理解,能够提供有关信息资源内容的更加权威的解释。根据信息资源对象的不同,描述信息资源基本内容的元数据实体和元数据元素还可以进行有选择的增加。例如,描述空间信息资源时,可以增加空间参照系、图示表达等元数据实体,描述科学数据资源时需要增加数据质量等元数据实体。 二是对信息资源的获取方式进行描述。包括信息资源的分发者信息、信息资源的在线获取地址信息等。通过提供分发者联系信息,使用者可以直接联系信息资源的分发部门,这对于不能直接在网络上进行数据交换的信息资源获取非常有效。其次,使用者还可以通过信息资源的在线地址来下载、查询、浏览信息资源。使用者甚至可以提供专门的电子订单处理系统,并将入口信息加入到元数据内容中,方便
空间分析的概念空间分析:是基于地理对象的位置和形态特征的空间数据分析技术,其目的在于提取和传输空间信息。包括空间数据操作、空间数据分析、空间统计分析、空间建模。 空间数据的类型空间点数据、空间线数据、空间面数据、地统计数据 属性数据的类型名义量、次序量、间隔量、比率量 属性:与空间数据库中一个独立对象(记录)关联的数据项。属性已成为描述一个位置任何可记录特征或性质的术语。 空间统计分析陷阱1)空间自相关:“地理学第一定律”—任何事物都是空间相关的,距离近的空间相关性大。空间自相关破坏了经典统计当中的样本独立性假设。避免空间自相关所用的方法称为空间回归模型。2)可变面元问题MAUP:随面积单元定义的不同而变化的问题,就是可变面元问题。其类型分为:①尺度效应:当空间数据经聚合而改变其单元面积的大小、形状和方向时,分析结果也随之变化的现象。②区划效应:给定尺度下不同的单元组合方式导致分析结果产生变化的现象。3)边界效应:边界效应指分析中由于实体向一个或多个边界近似时出现的误差。生态谬误在同一粒度或聚合水平上,由于聚合方式的不同或划区方案的不同导致的分析结果的变化。(给定尺度下不同的单元组合方式) 空间数据的性质空间数据与一般的属性数据相比具有特殊的性质如空间相关性,空间异质性,以及有尺度变化等引起的MAUP效应等。一阶效应:大尺度的趋势,描述某个参数的总体变化性;二阶效应:局部效应,描述空间上邻近位置上的数值相互趋同的倾向。 空间依赖性:空间上距离相近的地理事物的相似性比距离远的事物的相似性大。 空间异质性:也叫空间非稳定性,意味着功能形式和参数在所研究的区域的不同地方是不一样的,但是在区域的局部,其变化是一致的。 ESDA是在一组数据中寻求重要信息的过程,利用EDA技术,分析人员无须借助于先验理论或假设,直接探索隐藏在数据中的关系、模式和趋势等,获得对问题的理解和相关知识。 常见EDA方法:直方图、茎叶图、箱线图、散点图、平行坐标图 主题地图的数据分类问题等间隔分类;分位数分类:自然分割分类。 空间点模式:根据地理实体或者时间的空间位置研究其分布模式的方法。 茎叶图:单变量、小数据集数据分布的图示方法。 优点是容易制作,让阅览者能很快抓住变量分布形状。缺点是无法指定图形组距,对大型资料不适用。 茎叶图制作方法:①选择适当的数字为茎,通常是起首数字,茎之间的间距相等;②每列标出所有可能叶的数字,叶子按数值大小依次排列;③由第一行数据,在对应的茎之列,顺序记录茎后的一位数字为叶,直到最后一行数据,需排列整齐(叶之间的间隔相等)。 箱线图&五数总结 箱线图也称箱须图需要五个数,称为五数总结:①最小值②下四分位数:Q1③中位数④上四分位数:Q3⑤最大值。分位数差:IQR = Q3 - Q1 3密度估计是一个随机变量概率密度函数的非参数方法。 应用不同带宽生成的100个服从正态分布随机数的核密度估计。 空间点模式:一般来说,点模式分析可以用来描述任何类型的事件数据。因为每一事件都可以抽象化为空间上的一个位置点。 空间模式的三种基本分布:1)随机分布:任何一点在任何一个位置发生的概率相同,某点的存在不影响其它点的分布。又称泊松分布
第7 章空间数据分析模型 7.1 空间数据 按照空间数据的维数划分,空间数据有四种基本类型:点数据、线数据、面数据和体数据。 点是零维的。从理论上讲,点数据可以是以单独地物目标的抽象表达,也可以是地理单元的抽象表达。这类点数据种类很多,如水深点、高程点、道路交叉点、一座城市、一个区域。 线数据是一维的。某些地物可能具有一定宽度,例如道路或河流,但其路线和相对长度是主要特征,也可以把它抽象为线。其他的线数据,有不可见的行政区划界,水陆分界的岸线,或物质运输或思想传播的路线等。 面数据是二维的,指的是某种类型的地理实体或现象的区域范围。国家、气候类型和植被特征等,均属于面数据之列。 真实的地物通常是三维的,体数据更能表现出地理实体的特征。一般而言,体数据被想象为从某一基准展开的向上下延伸的数,如相对于海水面的陆地或水域。在理论上,体数据可以是相当抽象的,如地理上的密度系指单位面积上某种现象的许多单元分布。 在实际工作中常常根据研究的需要,将同一数据置于不同类别中。例如,北京市可以看作一个点(区别于天津),或者看作一个面(特殊行政区,区别于相邻地区),或者看作包括了人口的“体”。 7.2 空间数据分析 空间数据分析涉及到空间数据的各个方面,与此有关的内容至少包括四个领域。 1)空间数据处理。空间数据处理的概念常出现在地理信息系统中,通常指的是空间分析。就涉及的内容而言,空间数据处理更多的偏重于空间位置及其关系的分析和管理。 2)空间数据分析。空间数据分析是描述性和探索性的,通过对大量的复杂数据的处理来实现。在各种空间分析中,空间数据分析是重要的组成部分。空间数据分析更多的偏重于具有空间信息的属性数据的分析。 3)空间统计分析。使用统计方法解释空间数据,分析数据在统计上是否是“典型”的,或“期望”的。与统计学类似,空间统计分析与空间数据分析的内容往往是交叉的。 4)空间模型。空间模型涉及到模型构建和空间预测。在人文地理中,模型用来预测不同地方的人流和物流,以便进行区位的优化。在自然地理学中,模型可能是模拟自然过程的空间分异与随时间的变化过程。空间数据分析和空间统计分析是建立空间模型的基础。 7.3 空间数据分析的一些基本问题 空间数据不仅有其空间的定位特性,而且具有空间关系的连接属性。这些属性主要表现为空间自相关特点和与之相伴随的可变区域单位问题、尺度和边界效应。传统的统计学方法在对数据进行处理时有一些基本的假设,大多都要求“样本是随机的”,但空间数据可能不一定能满足有关假设,因此,空间数据的分析就有其特殊性(David,2003)。
地理信息系统(GIS)的基础是空间数据,空间数据的核心是质量,空间数据的生产与质量控制是一个相互作用的过程,生产数据是为了应用,而数据质量是一个关系到数据可靠性和系统可靠性的重要问题。随着数据质量在建设数字地球、进行矿产预测的计算机模拟中发挥着越来越重要的作用,但如果空间数据的质量及其精度未能引起足够的重视,由这些空间数据进行重新运算和组合产生的空间数据就不是最终需要的结果,可能导致最终决策错误。要提高空间数据的质量,减小空间数据误差,就要对空间数据误差产生和扩散的所有过程和环节进行控制。在数据采集时对元数据进行跟踪,采取相应的措施提高数据质量。以地图数字化为例,对纸质地图进行数字化前应对其进行校正或配准,选用精度比较高的数字化仪和扫描仪提高栅格数据的精度等;根据空间数据质量评价的标准还应制定相应的细则来提高数据质量;对采集和处理空间数据人员进行岗前培训等也都能减小误差的传播。 1 GIS 空间数据质量控制研究现状 GIS 空间数据的质量优劣直接影响着GIS应用中分析结果的可靠程度及应用的真正实现,也影响着GIS产业的健康发展。因此,近年来国内外越来越关注GIS数据的精度和质量控制的研究。GIS数据的质量控制问题涉及面很广,包括数据质量的衡量标准、表示方法,数据误差的来源和性质,评价方法和控制方法及相关政策等。如政府部门积极制定法规保障数据质量;将数据作为产品,采用管理产品质量的方法管理数据质量;数据质量的教育、培训与咨询;初步形成了地理数据质量的系列国际标准,如ISO 19100系列标准中地理信息质量标准;方法上,主要成果和结论,包括直线不确定性模型的改进、曲线不确定性模型的建立;将平差理论引入GIS数据误差处理和质量控制,并提出了实用方法;对GIS 数字化误差的性质、分布进行了深入研究;从抽样检验的理论出发,探讨了GIS 产品的质量控制技术和方法。 2 空间数据质量的概念 2.1空间数据的质量 空间数据是有关空间位臵、专题特征以及时间信息的符号记录,而数据质量是空间数据在表达这3个基本要素时所能达到的准确性、一致性、完整性以及它们三者之间统一性的程度。由于现实世界的复杂性、模糊性以及人类认识和表达能力的局限性,空间数据在表达上不可能完全达到真值,只能在一定程度上接近真值。用户根据需要对空间数据的处理也会导致出现一定的质量问题。所以空间数据的误差产生于各种数据源及空间数据的输入和处理过程中。 2.2与空间数据质量相关的几个概念 2.2.1误差(Error)反映了数据与真实值或公认的真值之间的差异,它是一种常用的数据准确性的表达方式。
数据分析经典测试题含答案解析 一、选择题 1.某校九年级数学模拟测试中,六名学生的数学成绩如下表所示,下列关于这组数据描述正确的是() A.众数是110 B.方差是16 C.平均数是109.5 D.中位数是109 【答案】A 【解析】 【分析】 根据众数、中位数的概念求出众数和中位数,根据平均数和方差的计算公式求出平均数和方差. 【详解】 解:这组数据的众数是110,A正确; 1 6 x=×(110+106+109+111+108+110)=109,C错误; 21 S 6 = [(110﹣109)2+(106﹣109)2+(109﹣109)2+(111﹣109)2+(108﹣109)2+ (110﹣109)2]=8 3 ,B错误; 中位数是109.5,D错误; 故选A. 【点睛】 本题考查的是众数、平均数、方差、中位数,掌握它们的概念和计算公式是解题的关键. 2.一组数据2,x,6,3,3,5的众数是3和5,则这组数据的中位数是() A.3 B.4 C.5 D.6 【答案】B 【解析】 【分析】 由众数的定义求出x=5,再根据中位数的定义即可解答. 【详解】 解:∵数据2,x,3,3,5的众数是3和5, ∴x=5,
则数据为2、3、3、5、5、6,这组数据为35 2 =4. 故答案为B. 【点睛】 本题主要考查众数和中位数,根据题意确定x的值以及求中位数的方法是解答本题的关键. 3.如图,是根据九年级某班50名同学一周的锻炼情况绘制的条形统计图,下面关于该班50名同学一周锻炼时间的说法错误的是() A.平均数是6 B.中位数是6.5 C.众数是7 D.平均每周锻炼超过6小时的人数占该班人数的一半 【答案】A 【解析】 【分析】 根据中位数、众数和平均数的概念分别求得这组数据的中位数、众数和平均数,由图可知锻炼时间超过6小时的有20+5=25人.即可判断四个选项的正确与否. 【详解】 A、平均数为1 50 ×(5×7+18×6+20×7+5×8)=6.46,故本选项错误,符合题意; B、∵一共有50个数据, ∴按从小到大排列,第25,26个数据的平均值是中位数, ∴中位数是6.5,故此选项正确,不合题意; C、因为7出现了20次,出现的次数最多,所以众数为:7,故此选项正确,不合题意; D、由图可知锻炼时间超过6小时的有20+5=25人,故平均每周锻炼超过6小时的人占总数的一半,故此选项正确,不合题意; 故选A. 【点睛】 此题考查了中位数、众数和平均数的概念等知识,中位数是将一组数据从小到大(或从大到小)重新排列后,最中间的那个数(最中间两个数的平均数),叫做这组数据的中位数,如果中位数的概念掌握得不好,不把数据按要求重新排列,就会错误地将这组数据最中间的那个数当作中位数.
空间元数据库知识点一、知识点结构
二、知识点内容 知识点(优先级)描述定位 1元数据编辑相关插件(A) 与元数据编辑相关的视图为元数据视图。 与元数据编辑相关的插件有元数据编辑插件,加载之后的工具条为: ?元数据库列表框用于选择元数据库,如图所示:元数据库列表框; ?元数据集列表框用于选择元数据集,如图所示:元数据集列表框; ?样式表列表框用于选择样式表,如图所示:元数据显示样式表列表框; ?单击编辑按钮,可以实现对元数据的编辑,如图所示:编辑元数据按钮; ?单击创建按钮,可以实现对元数据的创建,如图所示:创建元数据按钮; ?单击导入按钮,可以导入元数据,如图所示:导入元数据按钮; ?单击导出按钮,可以导出元数据,如图所示:导出元数据按钮; ?单击元数据和空间数据的一致性检查按钮,可以浏览检查元数据和空间数据的一致性,如图所示:元数据和空间数据的一致性检查按钮; ?单击浏览附件按钮,可以浏览元数据附件,如图所示:浏览元数据附件按钮。 MapGIS7.x 数据管理 篇.chm 25.2.2
2元数据创建(A)1、创建元数据库和元数据集 在“元数据库”文件夹右键选择“创建”功能,输入元数据库的名称,如test。 展开元数据库,找到test点击右键选择创建元数据集,输入元数据集名称。 图1创建元数据库和元数据集 2、元数据的创建方法有多种,以下逐一介绍。 (1)在元数据集上右键点击元数据导入,其具体的操作参见元数据的批量导入。 (2)工具条上点击创建元数据按钮,如果当前选中的是“元数据库”,就会在元数据库文件夹下的第一个元数 据库中的第一个元数据集中建立元数据;如果选中的是某个元数据库(如test),就会在该元数据库中的最先建的 元数据集中建立元数据;如果选中的是某个元数据集(如meta),就会在该元数据集中建立元数据。 (3)为地理实体建立元关系,在建立了元关系的元数据集上右键点击,选择同步元数据,则会在元数据列表中新 建元数据,其具体的操作请参考创建同步和更新同步。 MapGIS7.x 数据管理 篇.chm 25.2.1 3元数据浏览(A)在MapGisCatalog目录树中选中某个元数据集,将视图切换到元数据视图,在元数据视图中的元数据列表中会列出 该元数据集下的所有元数据,选择某条元数据,在元数据视图中即会显示该条元数据的信息。 可以从下拉列表中,选择已有的显示方式对该条元数据的显示方式进行更改。 MapGIS7.x 数据管理 篇.chm 25.2.1
空间数据分析报告 —使用Moran's I统计法实现空间自相关的测度1、实验目的 (1)理解空间自相关的概念和测度方法。 (2)熟悉ArcGIS的基本操作,用Moran's I统计法实现空间自相关的测度。2、实验原理 2.1空间自相关 空间自相关的概念来自于时间序列的自相关,所描述的是在空间域中位置S 上的变量与其邻近位置Sj上同一变量的相关性。对于任何空间变量(属性)Z,空间自相关测度的是Z的近邻值对于Z相似或不相似的程度。如果紧邻位置上相互间的数值接近,我们说空间模式表现出的是正空间自相关;如果相互间的数值不接近,我们说空间模式表现出的是负空间自相关。 2.2空间随机性 如果任意位置上观测的属性值不依赖于近邻位置上的属性值,我们说空间过程是随机的。 Hanning则从完全独立性的角度提出更为严格的定义,对于连续空间变量Y,若下式成立,则是空间独立的: 式中,n为研究区域中面积单元的数量。若变量时类型数据,则空间独立性的定义改写成 式中,a,b是变量的两个可能的类型,i≠j。 2.3Moran's I统计 Moran's I统计量是基于邻近面积单元上变量值的比较。如果研究区域中邻近面积单元具有相似的值,统计指示正的空间自相关;若邻近面积单元具有不相似的值,则表示可能存在强的负空间相关。
设研究区域中存在n 个面积单元,第i 个单位上的观测值记为y i ,观测变量在n 个单位中的均值记为y ,则Moran's I 定义为 ∑∑∑∑∑======n i n j ij n i n j ij n i W W n I 11 11j i 1 2i ) y -)(y y -(y )y -(y 式中,等号右边第二项∑∑==n 1i n 1j j i ij )y -)(y y -(y W 类似于方差,是最重要的项,事 实上这是一个协方差,邻接矩阵W 和) y -)(y y -(y j i 的乘积相当于规定)y -)(y y -(y j i 对邻接的单元进行计算,于是I 值的大小决定于i 和j 单元中的变量值对于均值的偏离符号,若在相邻的位置上,y i 和y j 是同号的,则I 为正;y i 和y j 是异号的, 则I 为负。在形式上Moran's I 与协变异图 {}{}u ?-)Z(s u ?-)Z(s N(h)1(h)C ?j i ∑=相联系。 Moran's I 指数的变化范围为(-1,1)。如果空间过程是不相关的,则I 的期望接近于0,当I 取负值时,一般表示负自相关,I 取正值,则表示正的自相关。用I 指数推断空间模式还必须与随机模式中的I 指数作比较。 通过使用Moran's I 工具,会返回Moran's I Index 值以及Z Score 值。如果Z score 值小于-1.96获大于1.96,那么返回的统计结果就是可采信值。如果Z score 为正且大于1.96,则分布为聚集的;如果Z score 为负且小于-1.96,则分布为离散的;其他情况可以看作随机分布。 3、实验准备 3.1实验环境 本实验在Windows 7的操作系统环境中进行,使用ArcGis 9.3软件。 3.2实验数据 此次实习提供的数据为以湖北省为目标区域的bount.dbf 文件。.dbf 数据中包括第一产业增加值,第二产业增加值万元,小学在校学生数,医院、卫生院床位数,乡村人口万人,油料产量,城乡居民储蓄存款余额,棉花产量,地方财政一般预算收入,年末总人口(万人),粮食产量,普通中学在校生数,肉类总产量,规模以上工业总产值现价(万元)等属性,作为分析的对象。
初中数学数据分析知识点总复习含解析 一、选择题 1.在创建平安校园活动中,九年级一班举行了一次“安全知识竞赛”活动,第一小组6名同学的成绩(单位:分)分别是:87,91,93,87,97,96,下列关于这组数据说正确的是() A.中位数是90 B.平均数是90 C.众数是87 D.极差是9 【答案】C 【解析】 【分析】 根据中位数、平均数、众数、极差的概念求解. 【详解】 解:这组数据按照从小到大的顺序排列为:87,87,91,93,96,97, 则中位数是(91+93)÷2=92, 平均数是(87+87+91+93+96+97)÷6=915 6 , 众数是87, 极差是97﹣87=10. 故选C. 【点睛】 本题考查了中位数、平均数、众数、极差的知识,掌握各知识点的概念是解答本题的关键. 2.一组数据2,x,6,3,3,5的众数是3和5,则这组数据的中位数是() A.3 B.4 C.5 D.6 【答案】B 【解析】 【分析】 由众数的定义求出x=5,再根据中位数的定义即可解答. 【详解】 解:∵数据2,x,3,3,5的众数是3和5, ∴x=5, 则数据为2、3、3、5、5、6,这组数据为35 2 =4. 故答案为B. 【点睛】 本题主要考查众数和中位数,根据题意确定x的值以及求中位数的方法是解答本题的关键. 3.已知一组数据a、b、c的平均数为5,方差为4,那么数据a+2、b+2、c+2的平均数和
方差分别为() A.7,6 B.7,4 C.5,4 D.以上都不对【答案】B 【解析】 【分析】 根据数据a,b,c的平均数为5可知a+b+c=5×3,据此可得出1 3 (-2+b-2+c-2)的值;再由 方差为4可得出数据a-2,b-2,c-2的方差. 【详解】 解:∵数据a,b,c的平均数为5,∴a+b+c=5×3=15, ∴1 3 (a-2+b-2+c-2)=3, ∴数据a-2,b-2,c-2的平均数是3;∵数据a,b,c的方差为4, ∴1 3 [(a-5)2+(b-5)2+(c-5)2]=4, ∴a-2,b-2,c-2的方差=1 3 [(a-2-3)2+(b-2-3)2+(c--2-3)2] = 1 3 [(a-5)2+(b-5)2+(c-5)2]=4, 故选B. 【点睛】 本题考查了平均数、方差,熟练掌握平均数以及方差的计算公式是解题的关键. 4.2022年将在北京﹣﹣张家口举办冬季奥运会,很多学校为此开设了相关的课程,下表记录了某校4名同学短道速滑成绩的平均数x和方差S2,根据表中数据,要选一名成绩好又发挥稳定的运动员参加比赛,应选择() A.队员1 B.队员2 C.队员3 D.队员4 【答案】B 【解析】 【分析】
空间分析实习报告 学院遥感信息工程学院班级 学号 姓名 日期
一、实习内容简介 1.实验目的: (1)通过实习了解ArcGIS的发展,以及10.1系列软件的构成体系 (2)熟练掌握ArcMap的基本操作及应用 (3)了解及应用ArcGIS的分析功能模块ArcToolbox (4)加深对地理信息系统的了解 2.实验内容: 首先是对ArcGIS有初步的了解。了解ArcGIS的发展,以及10.1系列软件的构成体系,了解桌面产品部分ArcMap、ArcCatalog和ArcToolbox的相关基础知识。 实习一是栅格数据空间分析,ArcGIS软件的Spatial Analyst模块提供了强大的空间分析工具,可以帮助用户解决各种空间分析问题。利用老师所给的数据可以创建数据(如山体阴影),识别数据集之间的空间关系,确定适宜地址,最后寻找一个区域的最佳路径。 实习二是矢量数据空间分析,ArcToolbox软件中的Analysis Tools和Network Analyst Tools提供了强大的矢量数据处理与分析工具,可以帮助用户解决各种空间分析问题。利用老师所给的数据可以通过缓冲区分析得到矢量面数据,通过与其它矢量数据的叠置分析、临近分析来辅助选址决策过程;可以构建道路平面网络模型,进而通过网络分析探索最优路径,从而服务于公交选线、智能导航等领域。 实习三是三维空间分析,学会用ArcCatalog查找、预览三维数据;在ArcScene中添加数据;查看数据的三维属性;从二维要素与表面中创建新的三维要素;从点数据源中创建新的栅格表面;从现有要素数据中创建TIN表面。 实习四是空间数据统计分析,利用地统计分析模块,你可以根据一个点要素层中已测定采样点、栅格层或者利用多边形质心,轻而易举地生成一个连续表面。这些采样点的值可以是海拔高度、地下水位的深度或者污染值的浓度等。当与ArcMap一起使用时,地统计分析模块提供了一整套创建表面的工具,这些表面能够用来可视化、分析及理解各种空间现象。 实习五是空间分析建模,空间分析建模就是运用GIS空间分析方法建立数学模型的过程。按照建模的目的,可分为以特征为主的描述模型(descriptive model)和提供辅助决策信息和解决方案为目的的过程模型(process model)两类。本次实习主要是通过使用ArcGIS的模型生成器(Model Builder)来建立模型,从而处理涉及到许多步骤的空间分析问题。 二、实习成果及分析 实习一: 练习1:显示和浏览空间数据。利用ArcMap和空间分析模块显示和浏览数据。添加和显示各类空间数据集、在地图上高亮显示数值、查询指定位置的属性值、分析一张直方图和创建一幅山体阴影图。
常用数据分析方法详解 目录 1、历史分析法 2、全店框架分析法 3、价格带分析法 4、三维分析法 5、增长率分析法 6、销售预测方法 1、历史分析法的概念及分类 历史分析法指将与分析期间相对应的历史同期或上期数据进行收集并对比,目的是通过数据的共性查找目前问题并确定将来变化的趋势。 *同期比较法:月度比较、季度比较、年度比较 *上期比较法:时段比较、日别对比、周间比较、 月度比较、季度比较、年度比较 历史分析法的指标 *指标名称: 销售数量、销售额、销售毛利、毛利率、贡献度、交叉比率、销售占比、客单价、客流量、经营品数动销率、无销售单品数、库存数量、库存金额、人效、坪效 *指标分类: 时间分类 ——时段、单日、周间、月度、季度、年度、任意 多个时段期间 性质分类 ——大类、中类、小类、单品 图例 2框架分析法 又叫全店诊断分析法 销量排序后,如出现50/50、40/60等情况,就是什么都能卖一点但什么都不 好卖的状况,这个时候就要对品类设置进行增加或删减,因为你的门店缺少 重点,缺少吸引顾客的东西。 如果达到10/90,也是品类出了问题。 如果是20/80或30/70、30/80,则需要改变的是商品的单品。 *单品ABC分析(PSI值的概念) 销售额权重(0.4)×单品销售额占类别比+销售数量权重(0.3) × 单品销售数量占类别比+毛利额权重(0.3)单品毛利额占类别比 *类别占比分析(大类、中类、小类) 类别销售额占比、类别毛利额占比、 类别库存数量占比、类别库存金额占比、
类别来客数占比、类别货架列占比 表格例 3价格带及销售二维分析法 首先对分析的商品按价格由低到高进行排序,然后 *指标类型:单品价格、销售额、销售数量、毛利额 *价格带曲线分布图 *价格带与销售对数图 价格带及销售数据表格 价格带分析法 4商品结构三维分析法 *一种分析商品结构是否健康、平衡的方法叫做三维分析图。在三维空间坐标上以X、Y、Z 三个坐标轴分别表示品类销售占有率、销售成长率及利润率,每个坐标又分为高、低两段,这样就得到了8种可能的位置。 *如果卖场大多数商品处于1、2、3、4的位置上,就可以认为商品结构已经达到最佳状态。以为任何一个商品的品类销售占比率、销售成长率及利润率随着其商品生命周期的变化都会有一个由低到高又转低的过程,不可能要求所有的商品同时达到最好的状态,即使达到也不可能持久。因此卖场要求的商品结构必然包括:目前虽不能获利但具有发展潜力以后将成为销售主力的新商品、目前已经达到高占有率、高成长率及高利润率的商品、目前虽保持较高利润率但成长率、占有率趋于下降的维持性商品,以及已经决定淘汰、逐步收缩的衰退型商品。 *指标值高低的分界可以用平均值或者计划值。 图例 5商品周期增长率分析法 就是将一段时期的销售增长率与时间增长率的比值来判断商品所处生命周期阶段的方法。不同比值下商品所处的生命周期阶段(表示) 如何利用商品生命周期理论指导营运(图示) 6销售预测方法[/hide] 1.jpg (67.5 KB) 1、历史分析法