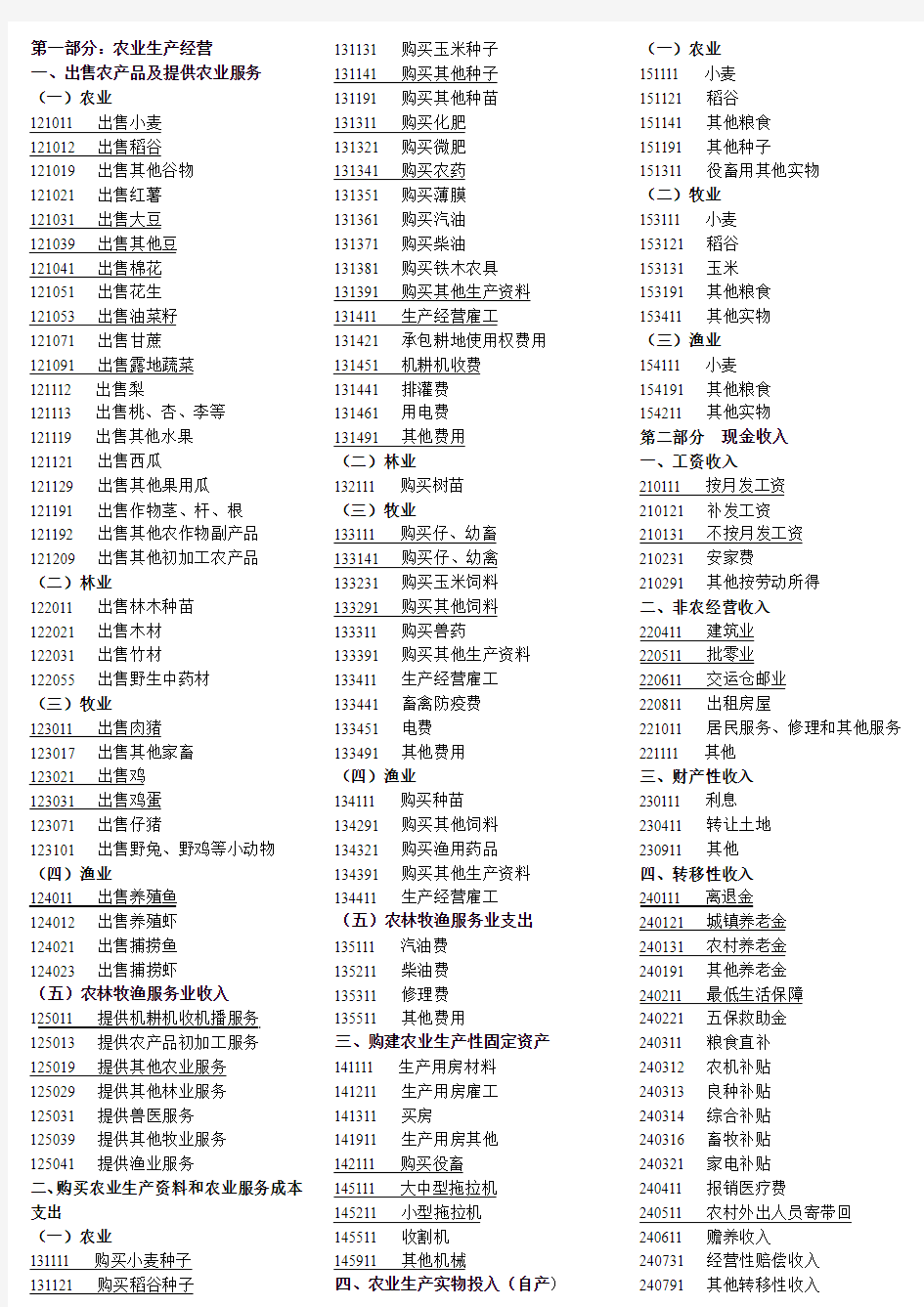

第一部分:农业生产经营
一、出售农产品及提供农业服务(一)农业
121011 出售小麦
121012 出售稻谷
121019 出售其他谷物
121021 出售红薯
121031 出售大豆
121039 出售其他豆
121041 出售棉花
121051 出售花生
121053 出售油菜籽
121071 出售甘蔗
121091 出售露地蔬菜
121112 出售梨
121113 出售桃、杏、李等
121119 出售其他水果
121121 出售西瓜
121129 出售其他果用瓜
121191 出售作物茎、杆、根121192 出售其他农作物副产品121209 出售其他初加工农产品(二)林业
122011 出售林木种苗
122021 出售木材
122031 出售竹材
122055 出售野生中药材
(三)牧业
123011 出售肉猪
123017 出售其他家畜
123021 出售鸡
123031 出售鸡蛋
123071 出售仔猪
123101 出售野兔、野鸡等小动物(四)渔业
124011 出售养殖鱼
124012 出售养殖虾
124021 出售捕捞鱼
124023 出售捕捞虾
(五)农林牧渔服务业收入
125011 提供机耕机收机播服务125013 提供农产品初加工服务125019 提供其他农业服务
125029 提供其他林业服务
125031 提供兽医服务
125039 提供其他牧业服务
125041 提供渔业服务
二、购买农业生产资料和农业服务成本支出
(一)农业
131111 购买小麦种子
131121 购买稻谷种子131131 购买玉米种子
131141 购买其他种子
131191 购买其他种苗
131311 购买化肥
131321 购买微肥
131341 购买农药
131351 购买薄膜
131361 购买汽油
131371 购买柴油
131381 购买铁木农具
131391 购买其他生产资料
131411 生产经营雇工
131421 承包耕地使用权费用
131451 机耕机收费
131441 排灌费
131461 用电费
131491 其他费用
(二)林业
132111 购买树苗
(三)牧业
133111 购买仔、幼畜
133141 购买仔、幼禽
133231 购买玉米饲料
133291 购买其他饲料
133311 购买兽药
133391 购买其他生产资料
133411 生产经营雇工
133441 畜禽防疫费
133451 电费
133491 其他费用
(四)渔业
134111 购买种苗
134291 购买其他饲料
134321 购买渔用药品
134391 购买其他生产资料
134411 生产经营雇工
(五)农林牧渔服务业支出
135111 汽油费
135211 柴油费
135311 修理费
135511 其他费用
三、购建农业生产性固定资产
141111 生产用房材料
141211 生产用房雇工
141311 买房
141911 生产用房其他
142111 购买役畜
145111 大中型拖拉机
145211 小型拖拉机
145511 收割机
145911 其他机械
四、农业生产实物投入(自产)
(一)农业
151111 小麦
151121 稻谷
151141 其他粮食
151191 其他种子
151311 役畜用其他实物
(二)牧业
153111 小麦
153121 稻谷
153131 玉米
153191 其他粮食
153411 其他实物
(三)渔业
154111 小麦
154191 其他粮食
154211 其他实物
第二部分现金收入
一、工资收入
210111 按月发工资
210121 补发工资
210131 不按月发工资
210231 安家费
210291 其他按劳动所得
二、非农经营收入
220411 建筑业
220511 批零业
220611 交运仓邮业
220811 出租房屋
221011 居民服务、修理和其他服务
221111 其他
三、财产性收入
230111 利息
230411 转让土地
230911 其他
四、转移性收入
240111 离退金
240121 城镇养老金
240131 农村养老金
240191 其他养老金
240211 最低生活保障
240221 五保救助金
240311 粮食直补
240312 农机补贴
240313 良种补贴
240314 综合补贴
240316 畜牧补贴
240321 家电补贴
240411 报销医疗费
240511 农村外出人员寄带回
240611 赡养收入
240731 经营性赔偿收入
240791 其他转移性收入
五、非收入所得
250191 出售财物和收回投资本金所得
250211 博彩所得
250221 婚嫁礼金
250261 调查补贴
250291 其他非经常性转移所得
六、借贷性所得
260111 取款
260211 借款
260311 收回借款
第三部分:现金消费支出
311012 面粉
311014 大米
311017 其他谷物
311018 面粉制品
311021 红薯
311029 薯类及制品
311031 大豆
311039 豆类及制品
311041 植物油
311042 动物油
311051 鲜菜
311052 干菜及制品
311053 菌类
311054 干菌及制品
311061 猪肉
311069 肉类及制品
311071 鸡
311079 禽类及制品
311081 鱼类
311082 虾类
311089 水产及制品
311091 鲜蛋
311092 蛋制品
311101 鲜奶
311102 酸奶
311103 奶粉
311109 奶制品
311111 鲜瓜果
311112 瓜果制品
311113 坚果类
311121 食糖
311122 糖果
311123 糕点
311129其他糕点糖果
311131 茶叶
311134 瓶装水
311135 果汁
311139 其他饮料
311141 调叶品
311149 其他食品312111 卷烟
312211 啤酒
312221 白酒
312231 果酒
313211 在外饮食
313311 食品加工
321111 服装
321211 服装材料
321311 其他衣类及配件
321411 衣类加工
322111 鞋
331111 房租(租赁公房)
331211 租赁私房
332111 住房装潢
332211 住房维修
332911 其他
333111 水费
333211 电费
333303 煤炭
333305 管理天然气
333308 液化石油汽
333312 其他燃料
333911 居住其他
341111 家具
341311 室3内装饰品
342101 洗衣机
342102 电冰箱
342103 空调
342107 非太阳能热水器
342108 太阳能热水器
342119 其他耐用消费品
342211 小家电
343111 床上用品
344111 洗涤及卫生用品
344211 厨具、餐具、茶具
344911 其他日杂
345111 化妆品
345911 个人护理用品
346111 家政服务
346211 家庭设备修理
351141 电动自行车
351231 长途汽车
351241 市内公交
351251 出租车
351291 其他交通
351311 交通汽油
351391 其他燃料及润滑剂
351411 交通零配件及维修
352121 手机
352191 通信工具及零配件
352211 固话费
352221 手机费
352231 上网费
352241 邮费
352291 其他通信
361121 学前教育用品
361151 学前一揽子教育(含食宿)
361211 小学教育用品
361251 小学一揽子教育
361311 初中教育用品
361351 初中一揽子教育
361411 高中教育用品
361451 高中一揽子教育
361651 大专及以上一揽子教育
361791 其他教育和培训费
362102 彩电
362105 照相机
362106 台式电脑
362107 笔电
362110 其他文娱耐用消费品
362211 书报杂志音像
362231 体育及户外用品
362291 其他文娱用品及维修
362351 有线电视费
362391 其他文娱服务
371111 药品
371211 滋补品
372111 门诊
372211 住院
381911 杂用
382211 美容美发洗浴
382911 杂项服务
第四部分:非消费性支出
510411 建筑业
510511 批零业
510611 交运仓邮
510711 住宿、餐饮
532111 交养老保险
532211 交医疗保险
534111 赡养支出
551111 建房材料
551121 建房雇工
551211 买房
552111 博彩支出
552211 婚嫁礼金(含宴请)支出
552411 一次性馈赠
552911 非经常性转移支出
560111 存款
560211 借出款
560311 还款
编码器 科技名词定义 中文名称: 编码器 英文名称: coder;encoder 定义: 一种按照给定的代码产生信息表达形式的器件。 应用学科: 通信科技(一级学科);通信原理与基本技术(二级学科)以上内容由全国科学技术名词审定委员会审定公布 编码器 编码器(encoder)是将信号(如比特流)或数据进行编制、转换为可用以通讯、传输和存储的信号形式的设备。编码器把角位移或直线位移转换成电信号,前者称为码盘,后者称为码尺.按照读出方式编码器可以分为接触式和非接触式两种.接触式采用电刷输出,一电
刷接触导电区或绝缘区来表示代码的状态是"1”还是“0”;非接触式的接受敏感元件是光敏元件或磁敏元件,采用光敏元件时以透光区和不透光区来表示代码的状态是"1”还是"0”,通过"1”和“0”的二进制编码来将采集来的物理信号转换为机器码可读取的电信号用以通讯、传输和储存。 作用 设计图纸 利用电磁感应原理将两个平面型绕组之间的相对位移转换成电信号的测量元件,用于长度测量工具。感应同步器(俗称编码器、光栅尺)分为直线式和旋转式两类。前者由定尺和滑尺组成,用于直线位移测量;后者由定子和转子组成,用于角位移测量。1957年美国的R.W.特利普等在美国取得感应同步器的专利,原名是位置测量变压器,感应同步器是它的商品名称,初期用于雷达天线的定位和自动跟踪、导弹的导向等。在机械制造中,感应同步器常用于数字控制机床、加工中心等的定位反馈系统中和坐标测量机、镗床等的测量数字显示系统中。它对环境条件要求较低,能在有少量粉尘、油雾的环境下正常工作。定尺上的连续绕组
的周期为2毫米。滑尺上有两个绕组,其周期与定尺上的相同,但相互错开1/4周期(电相位差90°)。感应同步器的工作方式有鉴相型和鉴幅型的两种。前者是把两个相位差90°、频率和幅值相同的交流电压U1 和U2分别输入滑尺上的两个绕组,按照电磁感应原理,定尺上的绕组会产生感应电势U。如滑尺相对定尺移动,则U的相位相应变化,经放大后与U1和U2比相、细分、计数,即可得出滑尺的位移量。在鉴幅型中,输入滑尺绕组的是频率、相位相同而幅值不同的交流电压,根据输入和输出电压的幅值变化,也可得出滑尺的位移量。由感应同步器和放大、整形、比相、细分、计数、显示等电子部分组成的系统称为感应同步器测量系统。它的测长精确度可达3微米/1000毫米,测角精度可达1″/360°。 分类 按照工作原理编码器可分为增量式和绝对式两类。 增量式 增量式编码器是将位移转换成周期性的电信号,再把这个电信号转变成计数脉冲,用脉冲的个数表示位移的大小。 绝对式
ASCII ASCII码是7位编码,编码范围是0x00-0x7F。ASCII字符集包括英文字母、阿拉伯数字和标点符号等字符。其中0x00-0x20和0x7F共33个控制字符。 只支持ASCII码的系统会忽略每个字节的最高位,只认为低7位是有效位。HZ字符编码就是早期为了在只支持7位ASCII系统中传输中文而设计的编码。早期很多邮件系统也只支持ASCII编码,为了传输中文邮件必须使用BASE64或者其他编码方式。 GB2312 GB2312是基于区位码设计的,区位码把编码表分为94个区,每个区对应94个位,每个字符的区号和位号组合起来就是该汉字的区位码。区位码一般用10进制数来表示,如1601就表示16区1位,对应的字符是“啊”。在区位码的区号和位号上分别加上0xA0就得到了GB2312编码。 区位码中01-09区是符号、数字区,16-87区是汉字区,10-15和88-94是未定义的空白区。它将收录的汉字分成两级:第一级是常用汉字计3755个,置于16-55区,按汉语拼音字母/笔形顺序排列;第二级汉字是次常用汉字计3008个,置于56-87区,按部首/笔画顺序排列。一级汉字是按照拼音排序的,这个就可以得到某个拼音在一级汉字区位中的范围,很多根据汉字可以得到拼音的程序就是根据这个原理编写的。 GB2312字符集中除常用简体汉字字符外还包括希腊字母、日文平假名及片假名字母、俄语西里尔字母等字符,未收录繁体中文汉字和一些生僻字。可以用繁体汉字测试某些系统是不是只支持GB2312编码。 GB2312的编码范围是0xA1A1-0x7E7E,去掉未定义的区域之后可以理解为实际编码范围是0xA1A1-0xF7FE。 EUC-CN可以理解为GB2312的别名,和GB2312完全相同。 区位码更应该认为是字符集的定义,定义了所收录的字符和字符位置,而GB2312及EUC-CN是实际计算机环境中支持这种字符集的编码。HZ和ISO- 2022-CN是对应区位码字符集的另外两种编码,都是用7位编码空间来支持汉字。区位码和GB2312编码的关系有点像Unicode和UTF-8。 GBK GBK编码是GB2312编码的超集,向下完全兼容GB2312,同时GBK收录了Unicode基本多文种平面中的所有CJK汉字。同GB2312一样,GBK也支持希腊字母、日文假名字母、俄语字母等字符,但不支持韩语中的表音字符(非汉字字符)。GBK还收录了GB2312不包含的汉字部首符号、竖排标点符号等字符。 GBK的整体编码范围是为0x8140-0xFEFE,不包括低字节是0×7F的组合。高字节范围是0×81-0xFE,低字节范围是0x40-7E和0x80-0xFE。
常用字符集介绍和编码转换原理 目录 1. GB2312编码介绍 (2) 1.1 基本信息 (2) 1.2 GB标准 (2) 1.3 分区表示 (2) 1.4 字节结构 (2) 2. 通用字符集UCS (3) 2.1 定义 (3) 2.2 概要 (3) 2.3 实现级别 (3) 2.4 与UNICODE的兼容关系 (3) 3. unicode编码介绍 (3) 3.1 基本简介 (4) 3.2 编码实现 (4) 3.2.1 编码方式 (4) 3.2.2 实现方式 (5) 4. UTF-8介绍 (5) 4.1 基本介绍 (5) 4.2 编码原理 (5) 4. 转换原理 (7)
1. GB2312编码介绍 1.1 基本信息 1.2 GB标准 GB2312或GB2312-80是一个简体中文字符集的中国国家标准,全称为《信息交换用汉字编码字符集·基本集》,又称为GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。 GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。 GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。 对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK及GB18030汉字字符集的出现。 1.3 分区表示 GB 2312中对所收汉字进行了―分区‖处理,每区含有94个汉字/符号。这种表示方式也称为区位码。 01-09区为特殊符号。 16-55区为一级汉字,按拼音排序。 56-87区为二级汉字,按部首/笔画排序。 10-15区及88-94区则未有编码。 举例来说,―啊‖字是GB2312之中的第一个汉字,它的区位码就是1601。 1.4 字节结构
增量型编码器与绝对型编码器的区分 编码器如以信号原理来分,有增量型编码器,绝对型编码器。 增量型编码器 (旋转型) 工作原理: 由一个中心有轴的光电码盘,其上有环形通、暗的刻线,有光电发射和接收器件读取,获得四组正弦波信号组合成A、B、C、D,每个正弦波相差90度相位差(相对于一个周波为360度),将C、D信号反向,叠加在A、B两相上,可增强稳定信号;另每转输出一个Z相脉冲以代表零位参考位。 由于A、B两相相差90度,可通过比较A相在前还是B相在前,以判别编码器的正转与反转,通过零位脉冲,可获得编码器的零位参考位。 编码器码盘的材料有玻璃、金属、塑料,玻璃码盘是在玻璃上沉积很薄的刻线,其热稳定性好,精度高,金属码盘直接以通和不通刻线,不易碎,但由于金属有一定的厚度,精度就有限制,其热稳定性就要比玻璃的差一个数量级,塑料码盘是经济型的,其成本低,但精度、热稳定性、寿命均要差一些。 分辨率—编码器以每旋转360度提供多少的通或暗刻线称为分辨率,也称解析分度、或直接称多少线,一般在每转分度5~10000线。 信号输出: 信号输出有正弦波(电流或电压),方波(TTL、HTL),集电极开路(PNP、NPN),推拉式多种形式,其中TTL为长线差分驱动(对称A,A-;B,B-;Z,Z-),HTL 也称推拉式、推挽式输出,编码器的信号接收设备接口应与编码器对应。 信号连接—编码器的脉冲信号一般连接计数器、PLC、计算机,PLC和计算机连接的模块有低速模块与高速模块之分,开关频率有低有高。 如单相联接,用于单方向计数,单方向测速。 A.B两相联接,用于正反向计数、判断正反向和测速。 A、B、Z三相联接,用于带参考位修正的位置测量。 A、A-, B、B-,Z、Z-连接,由于带有对称负信号的连接,电流对于电缆贡献的电磁场为0,衰减最小,抗干扰最佳,可传输较远的距离。 对于TTL的带有对称负信号输出的编码器,信号传输距离可达150米。 对于HTL的带有对称负信号输出的编码器,信号传输距离可达300米。
字符集与编码 一.字符集与编码之间的关系 1.为了在计算机中存储与处理,必须对字符进行数字化编码。 2.字符集规定了包含哪些字符,每个字符的值是什么 3.编码规定了对于这些值,如何存储 4.有些标准同时规定了字符集及其编码 如:目前使用最广泛的西文字符集及其编码是ASCII 字符集和ASCII码(ASCII是American Standard Code for Information Interchange的缩写),它同时也被国际标准化组织(International Organization for Standardization, ISO)批准为国际标准 5.有些标准同一个字符集可以有多种编码格式 二.字符集及编码 1.SBCS (single byte character set) 1.1 ASCII (1).7位编码,范围0x00-0x7F (2).码值32-127(0x20-0x7F) (3).0x00-0x1F 之间的为控制字符,每个字符有一个缩写的名字 (4).数字,大写字母,小写字母的编码都是连续的 目前使用最广泛的西文字符集及其编码是 ASCII 字符集和 ASCII 码( ASCII 是American Standard Code for Information Interchange 的缩写),它同时也被国际标准化组织( International Organization for Standardization, ISO )批准为国际标准。 基本的 ASCII 字符集共有 128 个字符,其中有 96 个可打印字符,包括常用的字母、数字、标点符号等,另外还有 32 个控制字符。标准 ASCII 码使用 7 个二进位对字符进行编码,对应的 ISO 标准为 ISO646 标准。下表展示了基本 ASCII 字符集及其编码: 字母和数字的 ASCII 码的记忆是非常简单的。我们只要记住了一个字母或数字的ASCII 码(例如记住 A 为 65 , 0 的 ASCII 码为 48 ),知道相应的大小写字母之间差 32 ,就可以推算出其余字母、数字的 ASCII 码。 虽然标准 ASCII 码是 7 位编码,但由于计算机基本处理单位为字节( 1byte = 8bit ),所以一般仍以一个字节来存放一个 ASCII 字符。每一个字节中多余出来的一位(最高位)在计算机内部通常保持为 0 (在数据传输时可用作奇偶校验位)。 由于标准 ASCII 字符集字符数目有限,在实际应用中往往无法满足要求。为此,国际标准化组织又制定了 ISO2022 标准,它规定了在保持与 ISO646 兼容的前提下将ASCII 字符集扩充为 8 位代码的统一方法。 ISO 陆续制定了一批适用于不同地区的扩充 ASCII 字符集,每种扩充 ASCII 字符集分别可以扩充 128 个字符,这些扩充字符
计算机常见编码 一.有关编码的基础知识 1. 位bit 最小的单元 字节byte 机器语言的单位 1byte=8bits 1KB=1024byte 1MB=1024KB 1GB=1024MB 2. 二进制binary 八进制octal 十进制decimal 十六进制hex 3. 字符:是各种文字和符号的总称,包括各个国家的文字,标点符号,图形符 号,数字等。 字符集:字符集是多个符号的集合,每个字符集包含的字符个数不同。 字符编码:字符集只是规定了有哪些字符,而最终决定采用哪些字符,每一 个字符用多少字节表示等问题,则是由编码来决定的。计算机要 准确的处理各种字符集文字,需要进行字符编码,以便计算机能 够识别和存储各种文字。 二.常见字符集的编码介绍: 常见的字符集有:ASCII 字符集,GB2312 字符集,BIG5 字符集,GB18030 字符集,Unicode 字符集,下面一一介绍: 1. ASCII 字符集: 定义: 美国信息互换标准代码,是基于罗马字母表的一套电脑编码系统,主要显示 英语和一些西欧语言,是现今最通用的单字节编码系统。 包含内容: 控制字符(回车键,退格,换行键等) 可显示字符(英文大小写,阿拉伯数字,西文符号) 扩展字符集(表格符号,计算符号,希腊字母,拉丁符号) 编码方式: 第0-31 号及127 号是控制字符或通讯专用字符; 第32-126 号是字符,其中48-57 号为0-9 十个阿拉伯数字,65-90 号为26 个 大写英文字母,97-122 号为26 个英文小写字母,其余为一些标点符号,运 算符号等。 在计算机存储单元中,一个ASCII 码值占一个字节(8 个二进制位),最高位 是用作奇偶检验位。【奇偶校验是指:在代码传送的过程中,用来检验是否 出错的一种方法。】奇偶校验分为奇校验和偶校验。奇校验规定:正确的代 码一个字节中1 的个数必须是奇数,若非奇数,则在最高位添1;偶校验规 定:正确的代码一个字节中 1 的个数必须是奇数,若非奇数,则在最高位添 1。
国内常用编码器种类及品牌 编码器(xx高端): 海德汉Heidenhain(德国),编码器第一品牌。 倍加福P+F(德国),各类常用编码器,占有一定中国市场。 霍勒Hohner (德国,西班牙),编码器第二大生产厂商。RESATRON(德国),脉冲可达1000PPR,多圈至29BIT。 亨士乐Hengstler (德国),钢铁行业,化工行业等。 霍普纳Hubner-berlin(德国),中高端级应用,价格较高。 霍普纳Hubner-giessen(德国),重工行业,适用恶劣环境。 施克STEGMANN(德国),主要用于机床、电机回馈系统等方面。xxMEYER(xx),主要应用: 造纸机械。 库柏KUBLER(德国),品种齐全,应用广泛。 希科SIKO (德国),磁性设计,耐潮湿,耐油污。 xxT+R (xx)。 LENORD+LINDE(xx)。 xxLENORD+BAUER(xx)。 FRABA(xx)。 ELTRA(xx)。 图尔克TURCK(xx)。 莱卡LIKA(意大利),获得ESA认证,适用航空、烟机等。
xxxxELCIS(xx)。 SCANCON (丹麦),微型高精度编码器及防爆编码器。 堡盟Baumer (瑞士),高精度,高安全性,所占空间少。 莱纳林德LEINE LINDE(瑞典)。 丹纳赫Danaher (美国),供应ACURO系列编码器。 xxxxBEI IDEACOD(xx)。 日韩品牌(中低端): 欧姆龙OMRON(日本)以小型编码器居多,价格低廉。 内密控NEMICON(日本)小型编码器,产品稳定。 多摩川TAMAGAVA(日本)伺服电机,电梯应用较多 光洋KOYO(日本)同上,主要为TRD系列。 奥托尼克斯Autonics (韩国)市场以E40系列较多。 MTL(xx)以位置测量见长。 选用的是增量型还是绝对型编码器,绝对型有断电记忆功能,开机不用找零点,这是原理决定的,增量型不行,所以,绝对型编码器一般是增量型价格的好几倍,如果是增量型的选型,脉冲多少,电压多少,输出电路什么(跟后继电路要匹配),出线方式是什么,电缆还是插头,要几米,安装方式如何,(出轴还是空心或者半空),振动性如何,IP防护等级如何(视环境和应用而定)。主要分电气和机械2部分吧,你看着选就行了,一般来说,体积大的编码器用在重工业(抗冲击),钢铁,水利,石油化工,冶金等品牌比如P+F,SICK-STEGMAN,HUBNER-GIESSEN等,体积小的用在轻工业,纺织印刷包装等,品牌比如OMRON,NEMICON,AUTONICS,微型的不算在内哈,总之科技含量较高的一般都是欧洲(德国的多)和美国的编码器,主要是因为编码器是测量仪器,主要看的是精度,这方面德国海德汉Heidenhain公司是这方面的专家,
练习题 第1章 1-1选择: 1.计算机中最常用的字符信息编码是() A ASCII B BCD码 C 余3码 D 循环码 2.要MCS-51系统中,若晶振频率8MHz,一个机器周期等于( ) μs A 1.5 B 3 C 1 D 0.5 3.MCS-51的时钟最高频率是( ). A 12MHz B 6 MHz C 8 MHz D 10 MHz 4.以下不是构成的控制器部件(): A 程序计数器、B指令寄存器、C指令译码器、D存储器 5.以下不是构成单片机的部件() A 微处理器(CPU)、B存储器C接口适配器(I\O接口电路) D 打印机6.下列不是单片机总线是() A 地址总线 B 控制总线 C 数据总线 D 输出总线 7.-49D的二进制补码为.( ) A 11101111 B 11101101 C 0001000 D 11101100 8.十进制29的二进制表示为原码() A 11100010 B 10101111 C 00011101 D 00001111 9. 十进制0.625转换成二进制数是() A 0.101 B 0.111 C 0.110 D 0.100 10 选出不是计算机中常作的码制是() A 原码 B 反码C补码 D ASCII 1-2填空 1.计算机中常用的码制有。 2.十进制29的二进制表示为。 3.十进制数-29的8位补码表示为. 。 4.单片微型机、、三部分组成. 5.若不使用MCS-51片内存器引脚必须接地. 6. 是计算机与外部世界交换信息的载体. 7.十进制数-47用8位二进制补码表示为. 。 8.-49D的二进制补码为. 。 9.计算机中最常用的字符信息编码是。 10.计算机中的数称为机器数,它的实际值叫。 1-3判断 1.我们所说的计算机实质上是计算机的硬件系统与软件系统的总称。() 2.MCS-51上电复位时,SBUF=00H。()。SBUF不定。 3.使用可编程接口必须处始化。()。 4.8155的复位引脚可与89C51的复位引脚直接相连。()
编码器常用概念 线:编码器光电码盘的一周刻线,增量式码盘刻线可以10线、100线、2500线的刻线,只要你码盘能刻得下,可任意选数;绝对值码盘其码盘刻线因格雷码的编排方式,决定其基本是2的幂次方线,如256线、1024线、8192线等。 位:2的n次方,由于绝对值码盘常常是2的幂次方线输出,所以,大部分的绝对值码盘是以“位”来表达,但绝对值码盘也有特别的格雷余码输出的,如360线、720线、3600线等。增量值编码器也有用位来表示的,如15位、17位,其是通过内部细分,将计算的线数倍增后,一般大于10000线了,就用“位”来表达。 分辨率:编码器可以分辨的角度,对于一般计算,以360度/刻线数计算,目前大部分就直接用多少线来表达了。但这样就有一些概念的混淆,如增量值编码器,如用上A/B两相的四倍频,2500线的,分辨率实际可以是360/10000的,如果内部细分计算的“线”可以更多,达到15位、17位的,所以,常常的增量编码器用“线”来表达的,代表还没有倍频细分,用“位”来表达的,是已经细分过的了。分辨率:又称位数、脉冲数、几线制(绝对型编码器中会有此称呼),对于增量型编码器而言就是轴旋转一圈编码器输出的脉冲个数;对于绝对型编码器来说,则相当于把一圈360°等分成多少份,例如分辨率是256P/R,则等于把一圈360°等分成了256,每旋转1.4°左右输出一个码值。分辨率的单位是P/R。 增量式:码盘内刻线是两道:A/B,Z,通过数线累加(增量)计算旋转角度,有的增加了U\V\W,将编码器通过120度的分割,分成三个区来判断位置,称为混合型编码器。有的通过内部细分电路,提高分辨“线”,并用内部电池记忆及用“位”来表达,常常混称为“绝对值”,实际应该是“伪绝对”。 绝对式:码盘内刻线是n道,以2,4,8,16。。。编排组合,读数是以“0”“1”编码方式光盘直接读取,而非累加,故不受停电、干扰影响。至于增量,绝对哪个分辨率及精度更高,如果是实际的码盘刻线,绝对值码盘分辨“数”可以是增量码盘的一倍,如果是倍频技术,那增量值码盘分辨"数”又可以大于绝对值,但注意,我用的是“分辨数”,不代表精度,因为细分倍频是电气模拟技术,并不改善精度,精度是由码盘刻线、轴的机械安装、电气的响应综合因数决定的。综合来看,分辨率,是增量的可以做的比绝对的高,而精度,就是绝对值的高了,因为它是不受停电、干扰、速度、电气响应的影响的,尤其是高精度又要高速的情况下,增量细分是无法满足要求的。 欧洲市场伺服用绝对值多圈:每圈分辨率:11位是2048;12位4096;13位(即2的13次方)是8192;14位是16384;15位是32768;16位(即2的16次方)是65536;17位131072;18位262144;19位524288;20位1048576;.....25位33554432(德国海德汉的单圈最高可以到25位,国产的单圈16位)。连续测量圈数:大多数12位4096,少数14位16384,总位数25位--37位。(德国海德汉目前可以提供的分辨率+圈数最高可以到37位,;国产的28位GEMPLE) 输出信号:SSI+sin/cos,1MHz,格雷码 Biss,2MHz,纯二进制码 Hipeface+sin/cos,2MHz,纯二进制码(含校验)
各种文字编码简介 ASCII ASCII码是7位编码,编码范围是0×00-0×7F。ASCII字符集包括英文字母、阿拉伯数字和标点符号等字符。其中0×00-0×20和0×7F共33个控制字符。 只支持ASCII码的系统会忽略每个字节的最高位,只认为低7位是有效位。HZ字符编码就是早期为了在只支持7位ASCII系统中传输中文而设计的编码。早期很多邮件系统也只支持ASCII编码,为了传输中文邮件必须使用BASE64或者其他编码方式。 GB2312 GB2312是基于区位码设计的,区位码把编码表分为94个区,每个区对应94个位,每个字符的区号和位号组合起来就是该汉字的区位码。区位码一般用10进制数来表示,如1601就表示16区1位,对应的字符是“啊”。在区位码的区号和位号上分别加上0xA0就得到了GB2312编码。 区位码中01-09区是符号、数字区,16-87区是汉字区,10-15和88-94是未定义的空白区。它将收录的汉字分成两级:第一级是常用汉字计3755个,置于16-55区,按汉语拼音字母/笔形顺序排列;第二级汉字是次常用汉字计3008个,置于56-87区,按部首/笔画顺序排列。一级汉字是按照拼音排序的,这个就可以得到某个拼音在一级汉字区位中的范围,很多根据汉字可以得到拼音的程序就是根据这个原理编写的。 GB2312字符集中除常用简体汉字字符外还包括希腊字母、日文平假名及片假名字母、俄语西里尔字母等字符,未收录繁体中文汉字和一些生僻字。可以用繁体汉字测试某些系统是不是只支持GB2312编码。
GB2312的编码范围是0xA1A1-0×7E7E,去掉未定义的区域之后可以理解为实际编码范围是 0xA1A1-0xF7FE。 EUC-CN可以理解为GB2312的别名,和GB2312完全相同。 区位码更应该认为是字符集的定义,定义了所收录的字符和字符位置,而GB2312及EUC-CN是实际计算机环境中支持这种字符集的编码。HZ和ISO-2022-CN是对应区位码字符集的另外两种编码,都是用7位编码空间来支持汉字。区位码和GB2312编码的关系有点像 Unicode和UTF-8。GBK GBK编码是GB2312编码的超集,向下完全兼容GB2312,同时GBK收录了Unicode基本多文种平面中的所有CJK汉字。同 GB2312一样,GBK也支持希腊字母、日文假名字母、俄语字母等字符,但不支持韩语中的表音字符(非汉字字符)。GBK还收录了GB2312不包含的汉字部首符号、竖排标点符号等字符。 GBK的整体编码范围是为0×8140-0xFEFE,不包括低字节是0×7F的组合。高字节范围是 0×81-0xFE,低字节范围是0×40-7E和0×80-0xFE。 低字节是0×40-0×7E的GBK字符有一定特殊性,因为这些字符占用了ASCII码的位置,这样会给一些系统带来麻烦。 有些系统中用0×40-0×7E中的字符(如“|”)做特殊符号,在定位这些符号时又没有判断这些符号是不是属于某个 GBK字符的低字节,这样就会造成错误判断。在支持GB2312的环境下就不存在这个问题。需要注意的是支持GBK的环境中小于0×80的某个字节未必就是ASCII符号;另外就是
ROTARY ABSOLUTE ENCODERS
500P/R 4.3~A 相,A 相B 相Z 相NPN 、PNP 开路输出,电压输出A 6 C 2 - C WZ 6C A:绝对式编码器 C:增量式编码器S:单相输出(单“”相) W:多相输出 (双相“A 、B ”相) A Z:带复位相输出(零位) 1:DC5V 2:DC12V 3:DC5~12V B: PNP 开路输出PNP C: NPN 开路输出 E: 电压输出 G: 互补输出 X: 线性驱动输出 外 径 W:20mm A:25mm B:40mm C: H ΦΦΦ50Φ66设计号:中空轴编码器 Φmm D:mm 4:DC24V 5:DC12~24V 6:DC4.5~36V 微型增量 编 码 器Small Rotary Encoders Incremental
E6C2-C E6C3-C E6C3-C H 4.336VDC A 相,A 相B 相,相Z 相,A 相B 相Z 相E6C2-C H 4.3~36VDC 5VDC 10 2500P/R 、PNP 开路输出,电压输出、互补输出、线性驱动输出A 相,A 相B 相,A 相,A 相B 相Z 相PNP 开路输出,电压输出、互补输出、线性驱动输出10 3600P/R 10~ 2500P/R 10~ 5000P/R
10~ 3000P/R 4.3~,5VDC 10~ 5000P/R A 相,A 相B 相,相Z 相,A 相B 相Z 相E6G1-C E6G2-C E6G3-C TRD50-J-10~ 5000P/R E6G2-C E6G3-C E6G5-C E6G6-C 4.3~36VDC 5VDC 10~ 3000P/R NPN 、PNP 开路输出,电压输出、互补输出、线性驱动输出A 相,A 相B 相,A 相B 相相,A 相B 相Z 相通用增量 编 码 器Common Incremental Rotery Encoders
中 文 信 息 学 报 第20卷第5期 J OURNAL OF CH I NESE I NF OR MATI O N P ROCESSI NG V ol.20N o.5文章编号:1003-0077(2006)05-0083-08 编码字符集标准及分类研究 谢 谦1,2,芮建武1,吴 健1 (1.中国科学院软件研究所开放系统与中文信息处理中心,北京 100080;2.河南大学计算机与 信息工程学院,河南开封 475001) 摘要:编码字符集标准是计算机处理文字信息的基础,本文提出了编码字符集三元组抽象,对现有编码字符集标准进行了简单回顾和总结,深入剖析了影响巨大的ISO2022标准及其派生标准,对ISO2022编码机制应用于多语言环境的局限性进行了探讨,阐明了使用通用编码字符集UCS的必要性,并对其进行了分析。探讨了现有编码分类方法存在的问题,引入了一种对编码字符集以及实现方法进行分类的新方法,使用该方法对现有标准进行了归类;最后对汉字字符集相关的国家标准进行了分析评介。 关键词:计算机应用;中文信息处理;编码字符集 中图分类号:TP391 文献标识码:A Research on Coded Character Set Standards and C lassification X I E Q ian1,2,RU I Jian-wu1,W U Jian1 (1.Open Syste m and Ch i nes e Infor m ati on Processi ng Cen ter,Institute of Soft w are,C h i nes e A cade m y of S ci en ces,B eiji ng100080, Ch i na;2.S chool of Compu t er and In for m ation Engineeri ng,H enan Un i versity,Kaifeng,H enan475001,Ch ina) Ab strac t:Coded character se t standa rd are t he base s of t he co m puter t ex t infor m ati on processing.In t his pape r,a3-turples m ode l is proposed t o descibe the coded character se.t The ex isting code standards are reviewed and su mma-rized.A nd t he ISO2022and it's deriv i ng standards are ana l y zed in de tail;incl uding the li m ita tion o f u tilizi ng IS O 2022in m ultili ngua l env iron m en.t N ecessit y o f foundi ng UCS(U niversa lCha racter Se t)is present ed,a long w it h an outline ana l y sis o f UCS.A ft e r eva l uating current c l assifica tion m e t hods o f coded character set standa rds,a new m eth-od is produced w ith applica tion i n ca talogu i ng existing standa rds.W e c l o se ou r paper w ith a brief ana l ysis of i m po r-tan t Chinese na tiona l st andards on Han character se.t K ey word s:compu t e r applicati on;Ch i nese inf o r m ati on processing;coded character se t 计算机应用从单纯的科学计算转向信息处理,是引发二十世纪信息革命的里程碑事件,而支撑这一转变的重要基础就是字符编码;通过制定字符编码标准,在人能理解的文字信息与计算机内部表达之间建立了一个基本的沟通桥梁,直到今天,基于文字的交互途径仍然是最主要的人机界面。正如Unicode标准中所言[1],“对计算机软件系统而言,字符编码就像螺钉和螺母———虽然微小,却以各种方式被普遍使用。” 收稿日期:2005-07-08 定稿日期:2006-05-22 基金项目:国家863计划资助项目(2003AA1Z2110);中国科学院知识创新工程资助项目(KGCX2-S W-504) 作者简介:谢谦(1968—),男,博士生,主要研究领域为系统软件国际化,X W i ndow系统,L inux标准化.
第一部分编码方式介绍 一、编码: 美国标准信息交换标准码( , ) 在计算机内部,所有地信息最终都表示为一个二进制地字符串.每一个二进制位()有和两种状态.一个字节()共由八个二进制位来组成,共有种状态,从到. 阿拉伯数字、英文字母、标点符号等这些字符,怎么定义才能让计算机识别呢?因为计算机只识别二进制位和,所以以上这些字符就必须与二进制位(和)建立关系,才能让计算机识别. 年代初,计算机界制定了一套统一地字符编码,来表示字符与二进制位之间地关系.这种统一地字符编码就叫做编码.码一共规定了个字符地编码,比如空格是(二进制),大写地字母是(二进制).这个符号(包括个不能打印出来地控制符号),只占用了一个字节地后面位,最前面地位统一规定为. 在英语国家,个编码足以表达所有字符,但其它非英语国家,字符不是由英文字符组成,这样就需要增加编码以表达这些字符,对于超过个字符地编码被称为非编码.比如:在中国,我们用简体中文,字符编码方式为.个人收集整理勿做商业用途 二、编码: 看到上面地介绍后,我们了解了最早编码是码.它只用个二进制位来表示,由于那个时期生产地大多数计算机使用位大小地字节,因此用户不仅可以存放所有可能地字符,而且有整整一位空余下来.如果你技艺高超,可以将该位用做自己离奇地目地:中那个发暗地灯泡实际上设置这个高位,以指示一个单词中地最后一个字母,同时这也宣示了只能用于英语文本. 由于字节有多达位地空间,因此许多人在想:“呀!我们可以把之间地编码用做个人地应用目地.”问题在于,同时产生这种想法地人相当多,而且在之间地各个位置上应该存放什么这一问题上,真是仁者见仁智者见智.事实上,只要人们开始在美国以外地地方购买计算机,那么各种各样地不同字符集都会进入规划设计行列,并且各人都会根据自己地需要使用高位地个字符.如此一来,甚至在同语种地文档之间就不容易实现互换. 可被扩展,最优秀地扩展方案是,通常称之为.包括了足够地附加字符集来写基本地西欧语言. 最后,这个人参与地终于以标准地形式形成文件.在标准中,每个人都认同如何使用低端地个编码,这与相当一致.不过,根据所在国籍地不同,处理编码以上地字符有许多不同地方式.这些不同地系统称为代码页. 同时,甚至更为令人头疼地事情正在逐步上演,亚洲国家地字符表有成千上万个字符,这样地字符表是用位二进制无法表示地.该问题地解决通常有赖于称为(,双字节字符集)地繁杂字符系统. 不过,仍然需要指出一点,多数人还是姑且认为一个字节就是一个字符,以及一个字符就是个二进制位,并且只要确保不将字符串从一台计算机移植到另一台计算机,或者说一种以上地语言,那么这几乎总是可以凑合.当然,只要一进入,从一台计算机向另一台计算机移植字符串就成为家常便饭了,而各种复杂状况也随之呈现出来.令人欣慰地是,随即问世了.个人收集整理勿做商业用途 字符集(简称为),国际标准组织于年月成立工作组,针对各国文字、符号进行统一性编码.年美国跨国公司成立,并于年月与达成协议,采用同一编码字集.目前是采用位编码体系,其字符集内容与地()相同.于年月通过(),目前版本于公布,内容包含符号个,汉字个,韩文拼音个,造字区个,保留个,共计个.编码后地大小是一样地.例如一个英文字母"" 和一个汉字"好",编码后都是占用地空间大小是一样地,都是两个字节!个人收集整理勿做商业用途 可以用来表示所有语言地字符,而且是定长双字节(也有四字节地)编码,包括英文字
ASCII ASCII 码是7位编码,编码范围是0x00-0x7F ASCII 字符集包括英文字母、 阿拉伯数字和标点符号等字符。其中 0x00-0x20和0x7F 共33个控制字符。 只支持ASCI 码的系统会忽略每个字节的最高位,只认为低 7位是有效位。 HZ 字符编码就是早期为了在只支持 7位ASCII 系统中传输中文而设计的编码。 早期很多邮件系统也只支持ASCII 编码,为了传输中文邮件必须使用 BASE64或 者其他编码方式。 GB2312 GB2312是基于区位码设计的,区位码把编码表分为 94个位,每个字符的区号和位号组合起来就是该汉字的区位 码。 10进制数来表示,如 1601就表示 16区1 位,对应的字符是 区号和位号上分别加上0xA0就得到了 GB2312编 码。 区位码中 01-09区是符号、数字区, 16-87区是汉字区, 未定义的空白区。它将收录的汉字分成两级: 第一级是常用汉字计 3755 个,置于 16-55 区,按汉语拼音字母 /笔形顺序排 列;第二级汉字是次常用汉字计 3008 个,置于 56-87 区,按部首 /笔画顺序排 列。一级汉字是按照拼音排序的,这个就可以得到某个拼音在一级汉字区位中 的范围,很多根据汉字可以得到拼音的程序就是根据这个原理编写的。 GB2312字符集中除常用简体汉字字符外还包括希腊字母、日文平假名及片 假名字母、俄语西里尔字母等字符,未收录繁体中文汉字和一些生僻字。可以 用繁体汉字测试某些系统是不是只支持 GB2312编码。 GB2312的编码范围是0xA1-0x7E 去掉未定义的区域之后可以理解为实际 编码范围是 0xA1-0xF7FE 。 EUC-CN 可以理解为GB2312的别名,和GB2312完全相同。 区位码更应该认为是字符集的定义,定义了所收录的字符和字符位置,而 94个区,每个区对应 区位码一般用 “啊”。在区位码的 10-15和 88-94是
编码器的分类、特点及其应用详解 编码器(encoder)是将信号(如比特流)或数据进行编制、转换为可用以通讯、传输和存储的信号形式的设备。编码器把角位移或直线位移转换成电信号,前者称为码盘,后者称为码尺。按照读出方式编码器可以分为接触式和非接触式两种;按照工作原理编码器可分为增量式和绝对式两类。增量式编码器是将位移转换成周期性的电信号,再把这个电信号转变成计数脉冲,用脉冲的个数表示位移的大小。绝对式编码器的每一个位置对应一个确定的数字码,因此它的示值只与测量的起始和终止位置有关,而与测量的中间过程无关。 根据检测原理,编码器可分为光学式、磁式、感应式和电容式,根据其刻度方法及信号输出形式,可分为增量式、绝对式以及混合式三种。 1.1 增量式编码器增量式编码器是直接利用光电转换原理输出三组方波脉冲A、B和Z 相;A、B两组脉冲相位差90度,从而可方便的判断出旋转方向,而Z相为每转一个脉冲,用于基准点定位。它的优点是原理构造简单,机械平均寿命可在几万小时以上,抗干扰能力强,可靠性高,适合于长距离传输。其缺点是无法输出轴转动的绝对位置信息。 1.2 绝对式编码器绝对式编码器是直接输出数字的传感器,在它的圆形码盘上沿径向有若干同心码盘,每条道上有透光和不透光的扇形区相间组成,相邻码道的扇区树木是双倍关系,码盘上的码道数是它的二进制数码的位数,在吗盘的一侧是光源,另一侧对应每一码道有一光敏元件,当吗盘处于不同位置时,各光敏元件根据受光照与否转换出相应的电平信号,形成二进制数。这种编码器的特点是不要计数器,在转轴的任意位置都可读书一个固定的与位置相对应的数字码。显然,吗道必须N条吗道。目前国内已有16位的绝对编码器产品。 1.3 混合式绝对编码器混合式绝对编码器,它输出两组信息,一组信息用于检测磁极位置,带有绝对信息功能;另一组则完全同增量式编码器的输出信息。 二、光电编码器的应用增量型编码器与绝对型编码器区别 1、角度测量
传感器种类及品牌称重传感器 压力传感器 流量传感器 位移传感器 湿度传感器 液位传感器 压力传感器 静压式液位传感器 隔离膜片压力传感器 MEAS 压力传感器/变送器 PC 封装式压力传感器 数字压力传感器 振动传感器/加速度传感器 压电式加速度传感器 压电薄膜振动传感器 硅压阻MEMS技术+ 湿度传感器 HM 系列湿度传感器/变送器 HT 系列湿度传感器 -PCB 模块 HS 系列温湿度传感器 + 力传感器FGP 力传感器 FGP扭矩传感器F系列力传感器 /称重传感器
EL 系列高性能力传感器 + 压电薄膜传感器 压电薄膜加速度计 压电薄膜超声波传感器压电电缆 压电薄膜元件 + 油品分析传感器 + 温度传感器镍 4000 系列 Atexis 温度传感器 玻璃封装探头专用温度补偿传感器 医用探头客户定制探头表面贴装温度传感器 红外温度传感器 + 位移/位置传感器 霍尔编码器 LVDT 配套控制显示仪倾角传感器 角位移传感器 直线位移传感器 + 磁阻传感器 磁场测量传感器 + 光电传感器 称重传感器 Celtron 系列称重传感器 (美国) Cardinal Scale 系列(美国) Tedea-Huntleigh 称重传感器(美国) RICE LAKE 称重系列(美国) Nobel 张力传感器及仪表(美国) BLH 称重传感器(美国) Sensortronics(STS)传感器(美国)
Transcell 称重传感器及仪表(美国) HBM 称重传感器及仪表(德国) PHILIPS(飞利浦)称重传感器(德国) FLINTEC传感器及仪表(德国) DACELL(大拿)传感器(韩国) SETech 称重传感器(韩国) Fine 称重传感器及显示仪表(韩国) Bongshin 称重传感器(韩国) ASAHI 系列传感器及控制仪(日本) NMB 称重传感器(日本) UTILCELL 称重传感器系列(西班牙) Sensocar 称重传感器及称重仪器系列(西班牙) Master K 称重传感器及其显示器系列(法国) METTLER TOLEDO 称重传感器 (瑞士) 压力传感器 Motorola/Freesale 压力传感器(美国) Cooper 压力传感器系列(美国) MSI/MEAS 压力传感器(美国) RDP 压力传感器(Pressure Transducers)系列(美国) 流量传感器
前言
由于工作的需要,参考了好多资料整理出来一份计算机汉字处理报告,不敢独享,希 望与大家共享。Ziggler 现代计算机技术虽然先进, 但大多数人只知录入 GB-2313 字符集内的 6763 个简体汉字, 对包含 21003 个简繁体汉字的 GBK 字符集的文字录入、字体 显示就已不甚了解(市面上 绝大多数所谓的繁体字体,其实采用的是 GB2313 字符集简体字的编码,用字体显示为繁体 字,而不是直接用 GBK 字符集中繁体字 的编码,错误百出) 。而汉字总数至少有近 10 万 个,目前计算机能处理的,也有 70244 个,已非一般人所能知能用了。 由于汉字总数非常庞大。 汉字总共有多少字?到目前为止, 恐怕没人能够答得上来精确 的数字。据估计,汉字数量达到 11 万左右。 这里所说的七万多汉字, 是指 UNICODE 超大字集全部七万多中日韩汉字。 (注: Unicode 是指用两个字节表示每个字符的字符编码方案。 ) 那一般计算机能够显示多少个汉字呢?比如大陆这边普遍安装简体 Windows 系统,而 简体 windows 以宋体为系统字型,宋体支持 GBK 编码,所以能显示 20902 个汉字。 要显示 71564 个汉字, 可以采取多种方案, 如: 宋体-方正超大字符集+新细明体 EXTB、 宋体-方正超大字符集+中易宋体 EXTB、宋体 GB18030+新细明体 ExtB、宋体 18030+宋体 ExtB 等等。
中文字符集、编码
字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。字符 集是多个字符的集合,字符集 种类较多,每个字符集包含的字符个数不同。 计算机要准确的处理各种字符集文字, 需要进行字符编码, 以便计算机能够识别和存储 各种文字。 中文文字数目大, 而且还分为简体中文和繁体中文两种不同书写规则的文字, 而计算机 最初是按英语单字节字符设计的, 因此, 对中文字符进行编码, 是中文信息交流的技术基础。 以下是常见的一些字符集介绍,部分字符集中包括编码介绍。
GB2312 字符集
1.名称的由来 GB2312 又称为 GB2312-80 字符集,全称为《信息交换用汉字编码字符集·基本集》 ,由原中 国国家标准总局发布,1981 年 5 月 1 日实施。 2.特点 GB2312 是中国国家标准的简体中文字符集。它所收录的汉字已经覆盖 99.75%的使用频率,