试验2:参数估计
一、试验目的与要求
1.熟悉点估计概念与操作方法
2.熟悉区间估计的概念与操作方法
3.熟练掌握T检验的SPSS操作
4.学会利用T检验方法解决身边的实际问题
二、试验原理
1.参数估计的基本原理
2.假设检验的基本原理
三、试验演示内容与步骤
1.单个总体均值的区间估计
例题:为研究在黄金时段中,即每晚8:30-9:00 内,电视广告所占时间的多少。美国广告协会抽样调查了20个最佳电视时段中广告所占的时间(单位:分钟)。请给出每晚8:30 开始的半小时内广告所占时间区间估计,给定的置信度为95%。操作程序:
?打开SPSS,建立数据文件:“ 电视节目市场调查.sav”。这里,研究变量为:time,即每天看电视的时间。
?选择区间估计选项,方法如下:选择菜单【分析】—>【描述统计】—>【探索】” ,打开图3.1Explore 对话框。
?从源变量清单中将“time”变量移入Dependent List框中。
图3.1 Explore对话框
?单击上图右方的“统计量”按钮打开“探索:统计量”对话框。在设置均值的置信水平,如键入95%,完成后单击“继续”按钮回到主窗口。
图3.2 探索统计量设置窗口
?返回主窗口点击ok运行操作。
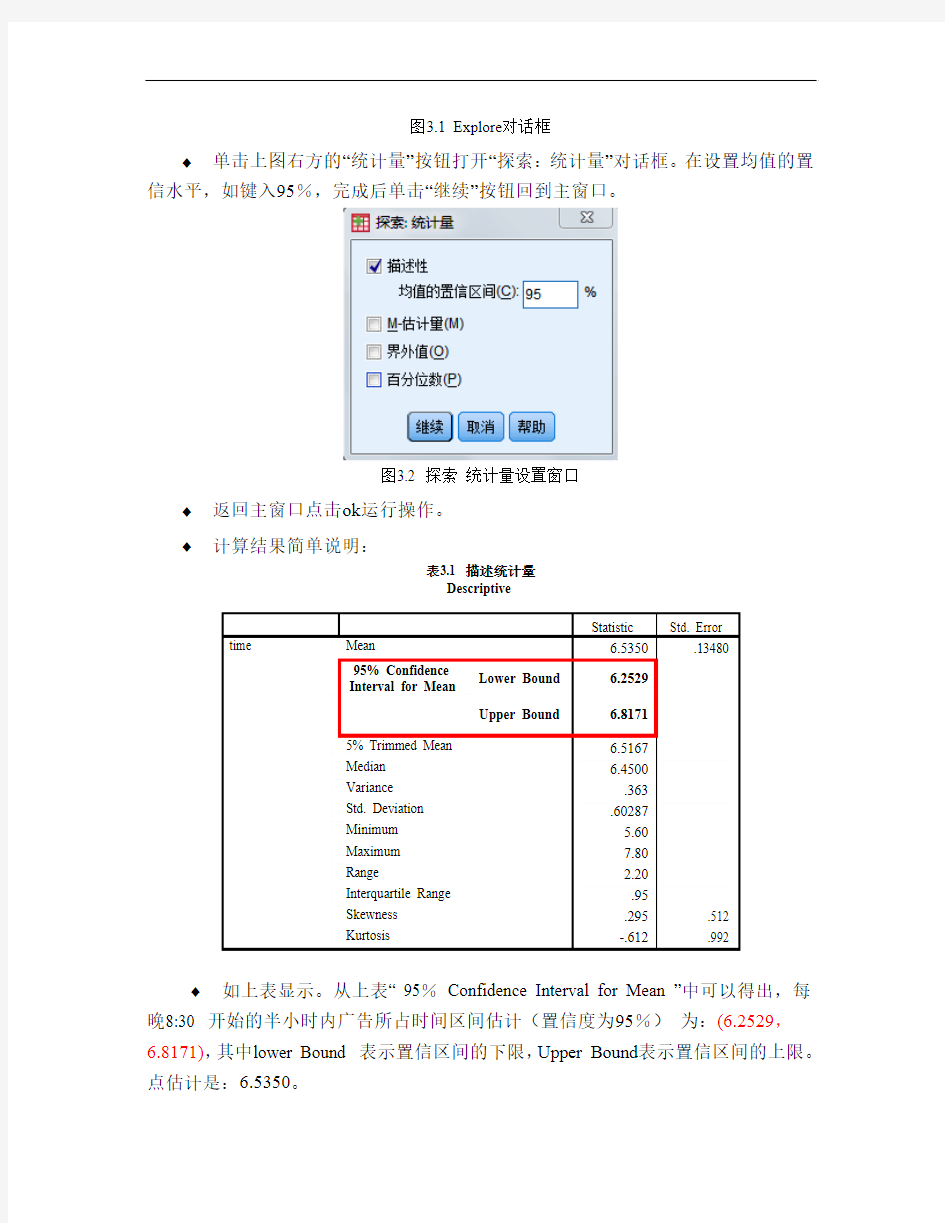
?计算结果简单说明:
表3.1 描述统计量
Descriptive
Statistic Std. Error
time Mean 6.5350.13480
95% Confidence
Lower Bound 6.2529
Interval for Mean
Upper Bound 6.8171
5% Trimmed Mean 6.5167
Median 6.4500
Variance .363
Std. Deviation .60287
Minimum 5.60
Maximum 7.80
Range 2.20
Interquartile Range .95
Skewness .295.512
Kurtosis -.612.992 ?如上表显示。从上表“ 95%Confidence Interval for Mean ”中可以得出,每晚8:30 开始的半小时内广告所占时间区间估计(置信度为95%)为:(6.2529,6.8171),其中lower Bound 表示置信区间的下限,Upper Bound表示置信区间的上限。点估计是:6.5350。
2.两个总体均值之差的区间估计
例题:The Wall Street Journal(1994,7 )声称在制造业中,参加工会的妇女比未参加工会的妇女的报酬要多2.5 美元。想通过统计方法,对这个观点是否正确给出检验。
假设抽取了7位女性工会会员与8位非工会会员女性报酬数据。要求对制造业中参加工会会员的女性报酬与未参加工会的女性报酬平均工资之差进行区间估计,预设的置信度为95%。
?打开SPSS,按如下图示格式输入原始数据,建立数据文件:“工会会员工资差别.spss”。这里,“会员”表示是否为工会会员的变量,y 表示是工会会员,n表示非工会会员,“报酬”表示女性员工报酬变量,单位:千美元。
?计算两总体均值之差的区间估计,采用“独立样本T 检验”方法。选择菜单“ 【分析】→【比较均值】→独立样本T检验”,打开对话框。
?变量选择
(1)从源变量清单中将“报酬”变量移入检验变量框中。表示要求该变量的均值的区间估计。
(2)从源变量清单中将“group”变量移入分组变量框中。表示总体的分类变量。
图3.3 独立样本T检验对话框
?定义分组单击定义组按钮,打开Define Groups 对话框。在Group1 中输入1,在Group2 中输入2(1表示非工会会员,2 表示工会会员)。完成后单击“继续”按
钮回到主窗口。
图3.4 define groups设置窗口
?计算结果单击上图中“OK”按钮,输出结果如下图所示。
(1)Group Statistics(分组统计量)表
分别给出不同总体下的样本容量、均值、标准差和平均标准误。从该表中可以看出,参加工会的妇女平均报酬为19.925,不参加工会的妇女平均报酬为20.1429。
表3.2 分组统计量
Group Statistics
会员N Mean Std. Deviation Std. Error Mean
1.00 819.9250.4652
2.16448
报酬
2.00 720.1429.52236.19743
(2)Independent Sample Test (独立样本T 检验)表
Levene’s Test for Equality of Variance,为方差检验,在Equal variances assumed (原假设:方差相等)下,F=0.623,因为其P-值大于显著性水平,即:Sig.=0.444>0.05,说明不能拒绝方差相等的原假设,接受两个总体方差是相等的假设。因此参加工会会员的女性报酬与未参加工会的女性报酬平均工资之差95%的区间估计为
[0.76842,0.33271]。
T-test for Equality of Means 为检验总体均值是否相等的t 检验,由于在本例中,其P-值大于显著性水平,即:Sig.=0.408>0.05,因此不应该拒绝原假设,也就是说参加工会的妇女跟未参加工会的妇女的报酬没有显著差异。本次抽样推断结论不支持The Wall Street Journal(1994,7 )提出的“参加工会的妇女比未参加工会的妇女的报酬要多2.5 美元”观点,即参加工会的妇女不比未参加工会的妇女的报酬多。
表3.3 独立样本T检验结果
Independent Samples Test
SPSS 应用软件试验指导手册
Levene's Test for Equality of Variances t-test for Equality of Means
F
Sig.
t
df
Sig. (2-tailed)
Mean Difference
Std. Error Difference
95% Confidence Interval of the
Difference
Lower Upper 报酬 Equal variances assumed .623 .444 -.85513 .408 -.21786 .25485 -.76842 .33271
Equal
variances not assumed
-.848
12.187
.413
-.21786
.25697
-.77679
.34108
3.单个总体均值的假设检验 (单样本T 检验)
例子:某种品牌的沐浴肥皂制造程序的设计规格中要求每批平均生产120 块肥皂,高于或低于该数量均被认为是不合理的,在由10 批产品所组成的一个样本中,每批肥皂的产量数据见下表,在0.05 的显著水平下,检验该样本结果能否说明制造过程运行良好?
? 判断检验类型 该例属于“大样本、总体标准差σ未知。假设形式为:
H 0:μ=μ0, H 1 :μ≠μ0
? 软件实现程序 打开已知数据文件,然后选择菜单“【分析】→【比较均值】→单样本T 检验”,打开One-Sample T Test 对话框。从源变量清单中将“产品数量”向右移入“Test Variables”框中。
图3.5 one-sample T test 窗口
在“Test Value” 框里输入一个指定值(即假设检验值,本例中假设为120),T 检验
过程将对每个检验变量分别检验它们的平均值与这个指定数值相等的假设。
? “One-Sample T Test”窗口中“OK”按钮,输出结果如下表所示。
(1)“One-Sample Statistics”(单个样本的统计量)表 分别给出样本的容量、均值、标准差和平均标准误。本例中,产品数量均值为118.9000。
表3.4 单样本统计量 One-Sample Statistics
N Mean Std. Deviation Std. Error Mean 产品数量
10
118.9000
4.93176
1.55956
(2)“One-Sample Test”(单个样本的检验)表 表中的t 表示所计算的T 检验统计量的数值,本例中为-0.705。 表中的“df”,表示自由度,本例中为9。 表中的“Sig”(双尾T 检验), 表示统计量的P-值, 并与双尾T 检验的显著性的大小进行比较:Sig.=0.498>0.05,说明这批样本的平均产量与120 无显著差异。 表中的“Mean Difference”, 表示均值差,即样本均值与检验值120 之差, 本例中为-1.1000。表中的“95% Confidence Internal of the Difference”, 样本均值与检验值偏差的95%置信区间为(-4.628,2.428),置信区间包括数值0,说明样本数量与120 无显著差异,符合要求。
表3.5 单样本T 检验结果
One-Sample Test
Test Value = 120
95% Confidence Interval
of the Difference t df
Sig. (2-tailed)
Mean Difference Lower Upper 产品数量 -.705
9
.498
-1.10000
-4.6280
2.4280
4.两独立样本的假设检验(两独立样本T 检验)
例题:The Wall Street Journal (1994,7 )声称在制造业中,参加工会的妇女比未参加工会的妇女的报酬要多2.5 美元。想通过统计方法,对这个观点是否正确给出检验。
假设抽取了7位女性工会会员与8位非工会会员女性报酬数据。要求对制造业中参加工会会员的女性报酬与未参加工会的女性报酬平均工资之差进行区间估计,预设的置信度为95%。
? 打开SPSS ,按如下图示格式输入原始数据,建立数据文件:“工会会员工资差别.sav”。这里,“会员”表示是否为工会会员的变量,y 表示是工会会员,n 表示非
工会会员,“报酬”表示女性员工报酬变量,单位:千美元。
?计算两总体均值之差的区间估计,采用“独立样本T 检验”方法。选择菜单“ 【分析】→【比较均值】→【独立样本T检验】”。
(1)从源变量清单中将“报酬”变量移入检验变量框中。表示要求该变量的均值的检验。
(2)从源变量清单中将“会员”变量移入分组变量框中。表示总体的分类变量。
图3.6 sample T test 窗口
?定义分组单击Grouping Variable 框下面的Define Groups 按钮,打开Define Groups 对话框。在Group1 中输入1,在Group2 中输入2(1表示非工会会员,2 表示工会会员)。完成后单击“继续”按钮返回主窗口。
图3.7 define groups对话框
?计算结果单击上图中“OK”按钮,输出结果如下图所示。
(1)Group Statistics(分组统计量)表
分别给出不同总体下的样本容量、均值、标准差和平均标准误。从该表中可以看出,参加工会的妇女平均报酬为19.925,不参加工会的妇女平均报酬为20.1429。
表3.6 分组统计量
Group Statistics
会员N Mean Std. Deviation Std. Error Mean
1.00 819.9250.4652
2.16448
报酬
2.00 720.1429.52236.19743
(2)Independent Sample Test (独立样本T 检验)表
Levene’s Test for Equality of Variance,为方差检验,在Equal variances assumed (原假设:方差相等)下,F=0.623,因为其P-值大于显著性水平,即:Sig.=0.444>0.05,说明不能拒绝方差相等的原假设,接受两个总体方差是相等的假设。
T-test for Equality of Means 为检验总体均值是否相等的t 检验,由于在本例中,其P-值大于显著性水平,即:Sig.=0.408>0.05,因此不应该拒绝原假设,也就是说参加工会的妇女跟未参加工会的妇女的报酬没有显著差异。本次抽样推断结论不支持The Wall Street Journal(1994,7 )提出的“参加工会的妇女比未参加工会的妇女的报酬要多2.5 美元”观点,即参加工会的妇女不比未参加工会的妇女的报酬多。
表3.7 独立样本T检验结果
Independent Samples Test
Levene's
Test for
Equality of
Variances
t-test for Equality of Means
F Sig. t df Sig.
(2-tailed)
Mean
Difference
Std. Error
Difference
95% Confidence
Interval of the
Difference
Lower Upper
报酬Equal
variances
assumed
.623 .444 -.85513 .408 -.21786 .25485 -.76842 .33271
Equal
variances not
assumed
-.84812.187 .413 -.21786 .25697 -.77679 .34108 5.配对样本T检验
配对样本是对应独立样本而言的,配对样本是指一个样本在不同时间做了两次试验,或者具有两个类似的记录,从而比较其差异;独立样本检验是指不同样本平均数的比较,而配对样本检验往往是对相同样本二次平均数的检验。
配对样本T检验的前提条件为:第一,两样本必须是配对的。即两样本的观察值数目相同,两样本的观察值顺序不随意更改。第二,样本来自的两个总体必须服从正态分布。例如针对试验前学习成绩何智商相同的两组学生,分别进行不同教学方法的训练,进行一段时间试验教学后,比较参与试验的两组学生的学习成绩是否存在显著性差异。
假设某校为了检验进行新式培训前后学生的学习成绩是否有了显著提高,从全校学生中随机抽出30名进行测试,这些学生培训前后的考试成绩放置于数据文件“学生培训.sav”中。在SPSS中对这30名学生的成绩进行配对样本t检验的操作步骤如下:?选择菜单【分析】→【比较均值】→【配对样本T检验】,打开对话框,如图3.8所示,将两个配对变量移入右边的Pair Variables列表框中。移动的方法是先选择其中的一个配对变量,再选择第二个配对变量,接着单击中间的箭头按钮。
图3.8 Paired-Samples T Test对话框
?选项按钮的用于设置置信度选项,这里保持系统默认的95%
?在主对话框中单击ok按钮,执行操作。
?实例结果分析
表3.8和表3.9给出了培训前后学生考试成绩的均值、标准差、均值标准误差以及培训前后成绩的相关系数。从表3.8来看,培训前后平均成绩并没有发生显著的提高。
表3.10给出了配对样本t检验结果,包括配对变量差值的均值、标准差、均值标准误差以及差值的95%置信度下的区间估计。当然也给出了最为重要的t统计量和p 值。结果显示p=0.246>0.05,所以,学校的所谓新式培训并未带来学生成绩的显著变化。
表3.8 培训前后成绩的描述统计量Paired Samples Statistics
Mean N Std. Deviation Std. Error Mean
培训前67.003014.734 2.690 Pair 1
培训后68.603012.947 2.364
表3.9 培训前后成绩的相关系数
Paired Samples Correlations
N Correlation Sig.
Pair 1 培训前&培训后30.865.000
表3.10 配对样本T检验结果
Paired Samples Test
Paired Differences t df
Sig. (2-tailed)
Mean
Std.
Deviation
Std. Error
Mean
95% Confidence
Interval of the
Difference
Lower Upper
Pair 1 培训前-培训后-1.600 7.398 1.351-4.362 1.162-1.185 29 .246四、备择试验
1.某省大学生四级英语测验平均成绩为65,现从某高校随机抽取20份试卷,其分
数为:72、76、68、78、62、59、64、85、70、75、61、74、87、83、54、76、56、66、68、62,问该校英语水平与全区是否基本一致?设α=0.05
2.分析某班级学生的高考数学成绩是否存在性别上的差异。数据如表所示:
某班级学生的高考数学成绩
性别数学成绩
男(n=18)85 89 75 58 86 80 78 76 84 89 99 95 82 87 60 85
75 80
女(n=12)92 96 86 83 78 87 70 65 70 65 70 78 72 56 3.SPSS自带的数据文件world95.sav中,保存了1995年世界上109个国家和地区
的部分指标的数据,其中变量“lifeexpf”,“lifeexpm”分别为各国或地区女性和男性人
口的平均寿命。假设将这两个指标数据作为样本,试用配对样本T检验,女性人口
的平均寿命是否确实比男性人口的平均寿命长,并给出差异的置信区间。(设α=0.05)
试验2 之二(方差分析)
一、试验目标与要求
1.帮助学生深入了解方差及方差分析的基本概念,掌握方差分析的基本思想和原理
2.掌握方差分析的过程。
3.增强学生的实践能力,使学生能够利用SPSS统计软件,熟练进行单因素方差分析、两因素方差分析等操作,激发学生的学习兴趣,增强自我学习和研究的能力。
二、试验原理
在现实的生产和经营管理过程中,影响产品质量、数量或销量的因素往往很多。例如,农作物的产量受作物的品种、施肥的多少及种类等的影响;某种商品的销量受商品价格、质量、广告等的影响。为此引入方差分析的方法。
方差分析也是一种假设检验,它是对全部样本观测值的变动进行分解,将某种控制因素下各组样本观测值之间可能存在的由该因素导致的系统性误差与随即误差加以比较,据以推断各组样本之间是否存在显著差异。若存在显著差异,则说明该因素对各总体的影响是显著的。
方差分析有3个基本的概念:观测变量、因素和水平。观测变量是进行方差分析所研究的对象;因素是影响观测变量变化的客观或人为条件;因素的不同类别或不通取值则称为因素的不同水平。在上面的例子中,农作物的产量和商品的销量就是观测变量,作物的品种、施肥种类、商品价格、广告等就是因素。在方差分析中,因素常常是某一个或多个离散型的分类变量。
根据观测变量的个数,可将方差分析分为单变量方差分析和多变量方差分析;根据因素个数,可分为单因素方差分析和多因素方差分析。在SPSS中,有One-way ANOVA(单变量-单因素方差分析)、GLM Univariate(单变量多因素方差分析);GLM Multivariate (多变量多因素方差分析),不同的方差分析方法适用于不同的实际情况。本节仅练习最为常用的单因素单变量方差分析。
三、试验演示内容与步骤
单因素方差分析也称一维方差分析,对两组以上的均值加以比较。检验由单一因素影响的一个分析变量由因素各水平分组的均值之间的差异是否有统计意义。并可以进行两两组间均值的比较,称作组间均值的多重比较。主要采用One-way ANOVA过程。
采用One-way ANOVA过程要求:因变量属于正态分布总体,若因变量的分布明
显是非正态,应该用非参数分析过程。若对被观测对象的试验不是随机分组的,而是进行的重复测量形成几个彼此不独立的变量,应该用Repeated Measure菜单项,进行重复测量方差分析,条件满足时,还可以进行趋势分析。
假设某汽车经销商为了研究东部、西部和中部地区市场上汽车的销量是否存在显著差异,在每个地区随机抽取几个城市进行调查统计,调查数据放置于数据文件“汽车销量调查.sav”中。在SPSS中试验该检验的步骤如下:
?步骤1:选择菜单【分析】→【比较均值】→【单因素方差分析】,依次将观测变量销量移入因变量列表框,将因素变量地区移入因子列表框。
图4.1 One-Way ANOV A对话框
?单击两两比较按钮,如图4.2,该对话框用于进行多重比较检验,即各因素水平下观测变量均值的两两比较。
方差分析的原假设是各个因素水平下的观测变量均值都相等,备择假设是各均值不完全相等。假如一次方差分析的结果是拒绝原假设,我们只能判断各观测变量均值不完全相等,却不能得出各均值完全不相等的结论。各因素水平下观测变量均值的更为细致的比较就需要用多重比较检验。
图4.2 两两比较对话框
假定方差齐性选项栏中给出了在观测变量满足不同因素水平下的方差齐性条件下的多种检验方法。这里选择最常用的LSD检验法;未假定方差齐性选项栏中给出了在观测变量不满足方差齐性条件下的多种检验方法。这里选择Tamhane’s T2检验法;Significance level输入框中用于输入多重比较检验的显示性水平,默认为5%。
?单击选项按钮,弹出options子对话框,如图所示。在对话框中选中描述性复选框,输出不同因素水平下观测变量的描述统计量;选择方差同质性检验复选框,输出方差齐性检验结果;选中均值图复选框,输出不同因素水平下观测变量的均值直线图。
?在主对话框中点击ok按钮,可以得到单因素分析的结果。试验结果分析:表4.1给出了不同地区汽车销量的基本描述统计量以及95%的置信区间。
图4.3 选项子对话框
表4.1 各个地区汽车销量描述统计量
Descriptive
销量 N Mean Std. Deviation
Std. Error
95% Confidence Interval for Mean Minimum
Maximum
Lower Bound
Upper Bound
西 10 157.90
22.278 7.045141.96
173.84
120 194中 9 176.44 19.717 6.572161.29191.60 135 198东 7 196.14 30.927 11.689167.54224.75 145 224Total
26
174.62
27.845
5.461
163.37
185.86
120
224
表4.2给出了Levene 方差齐性检验结果。从表中可以看到,Levene 统计量对应的p 值大于0.05,所以得到不同地区汽车销量满足方差齐性的结论。
表4.3是单因素方差分析,输出的方差分析表解释如下:总离差SST =19384.154,组间平方和SSR =6068.174,组内平方和或残差平方和SSE =13315.979,相应的自由度分别为25,2,23;组间均方差MSR =3034.087,组内均方差578.956,F =5.241,由于p =0.013<0.05说明在α=0.05显著性水平下,F 检验是显著的。即认为各个地区的汽车销量并不完全相同。
表4.3 单因素方差分析结果
ANOVA
销量
Sum of Squares df
Mean Square
F Sig.
Between Groups 6068.174 23034.087
5.241
.013
Within Groups 13315.979 23578.956
Total 19384.154
25
表4.4 多重比较检验结果 Multiple Comparisons
Dependent Variable: 销量
95% Confidence Interval
(I) 地区 (J) 地区 Mean Difference (I-J) Std. Error
Sig.
Lower Bound
Upper Bound
中 -18.54411.055.107-41.41 4.33西 东 -38.243(*)11.858.004-62.77
-13.71
中 西 18.54411.055.107-4.33 41.41东 -19.69812.126.118-44.78 5.39东
西 38.243(*)11.858.00413.71 62.77LSD
中 19.69812.126.118-5.39 44.78Tamhane 西 中 -18.5449.635.199-44.05 6.96东 -38.24313.648.054-77.10 .61中 西 18.5449.635.199-6.96 44.05东 -19.69813.410.436-58.31 18.91东
西
38.243
13.648.054-.61 77.10中 19.698
13.410
.436
-18.91
58.31
如前所述,拒绝单因素方差分析原假设并不能得出各地区汽车销量均值完全不等的结论。各地区销量均值的两两比较要看表4.4所示的多重比较检验结果。表中上半部分为LSD 检验结果,下半部分为Tamhane 检验结果。由于方差满足齐性,所以这里应该看LSD 检验结果。表中的Mean difference 列给出了不同地区汽车销量的平均值之差。其中后面带“﹡”号的表示销量有显著差异,没有带“﹡”号的表示没有显著差异。可以看出,东部和西部汽车销量存在显著差异,而中部与东部、中部与西部汽车销量并没有什么显著差异。这一结论也可以从表中Sig 列给出的p 值大小得到印证。
四、备择试验
1. 用SPSS 进行单因素方差分析。某个年级有三个小班,他们进行了一次数据考试,现从各班随机地抽取了一些学生,记录其成绩如表。原始数据文件保存为“数学考试成绩.sav”。试在显著性水平0.05下检验各班级的平均分数有无显著差异。
数学考试成绩表
ⅠⅡⅢ
73 66 88 77 68 41
89 60 78 31 79 59
82 45 48 78 56 68
43 93 91 62 91 53
80 36 51 76 71 79
73 77 85 96 71 15
78 79 74 80 87 75
76 87 56 85 97 89
2.某学校给3组学生以3种不同方式辅导学习,一个学期后,学生独立思考水平提高
的成绩如表所示。
学生独立思考水平提高的成绩
方式1 37 42 42 43 41 42 45 46 41 40 方式2 49 48 48 48 47 45 46 47 48 49 方式3 33 33 35 32 31 35 34 32 32 33 问:该数据中的因变量是什么?因素又是什么?如何建立数据文件?对该数据进行方差分析,检验3种方式的影响是否存在显著差异?
SPSS实践题 习题1 分析此班级不同性别的学生的物理和数学成绩的均值、最高分和最低分。
Std. Deviation Minimum Maximum 结论:男生数学成绩最高分: 95 最低分: 72 平均分: 物理成绩最高分: 87 最低分: 69 平均分: 女生数学成绩最高分: 99 最低分: 70 平均分: 物理成绩最高分: 91 最低分: 65 平均分: 习题2 分析此班级的数学成绩是否和全国平均成绩85存在显著差异。 One-Sample Statistics N Mean Std. Deviation Std. Error Mean 数学26 结论:由分析可知相伴概率为,小于显著性水平,因此拒绝零假设,即此班级数学成绩和全国平均水平85分有显著性差异 习题3 分析兰州市2月份的平均气温在90年代前后有无明显变化。
Group Statistics 分组N Mean Std. Deviation Std. Error Mean 二月份气温011.3628400 118.3065729 结论:由分析可知, 方差相同检验相伴概率为,大于显著性水平,因此接受零假设,90年代前后2月份温度方差相同。双侧检验相伴概率为, 小于显著性水平,拒绝零假设,即2月份平均气温在90年代前后有显著性差异 习题4 分析15个居民进行体育锻炼3个月后的体质变化。 Paired Samples Statistics Mean N Std. Deviation Std. Error Mean
Paired Samples Correlations N Correlation Sig. Pair 1锻炼前 & 锻炼后15.277 结论:由分析可知,锻炼前后差值与零比较,相伴概率小于显著性水平, 拒绝零假设,即锻炼前后有显著性差异 习题5 为了农民增收,某地区推广豌豆番茄青菜的套种生产方式。为了寻找该 种方式下最优豌豆品种,进行如下试验:选取5种不同的豌豆品种,每 一品种在4块条件完全相同的田地上试种,其它施肥等田间管理措施完 全一样。根据表中数据分析不同豌豆品种对平均亩产的影响是否显著。 ANOVA 产量 Sum of Squares df Mean Square F Sig.
spss-非参数检验-K多个独立样本检验( Kruskal-Wallis检验)案例解析 2011-09-19 15:09 最近经常失眠,好痛苦啊!大家有什么好的解决失眠的方法吗?希望知道的能够告诉我,谢谢啦,今天和大家一起探讨和分下一下SPSS-非参数检验--K个独立样本检验( Kruskal-Wallis检验)。 还是以SPSS教程为例: 假设:HO: 不同地区的儿童,身高分布是相同的 H1:不同地区的儿童,身高分布是不同的 不同地区儿童身高样本数据如下所示: 提示:此样本数为4个(北京,上海,成都,广州)每个样本的样本量(观察数)都为5个 即:K=4>3 n=5, 此时如果样本逐渐增大,呈现出自由度为K-1的平方的分布,
(即指:卡方检验) 点击“分析”——非参数检验——旧对话框——K个独立样本检验,进入如下界面: 将“周岁儿童身高”变量拖入右侧“检验变量列表”内,将“城市(CS)变量” 拖入“分组变量”内,点击“定义范围” 输入“最小值”和“最大值”(这里的变量类型必须为“数字型”)如果不是数字型,必须要先定义或者重新编码。 在“检验类型”下面选择“秩和检验”( Kruskal-Wallis检验)点击确定 运行结果如下所示:
对结果进行分析如下: 1:从“检验统计量a,b”表中可以看出:秩和统计量为:13.900 自由度为:3=k-1=4-1 下面来看看“秩和统计量”的计算过程,如下所示: 假设“秩和统计量”为 kw 那么:
其中:n+1/2 为全体样本的“秩平均” Ri./ni 为第i个样本的秩平均 Ri.代表第i个样本的秩和, ni代表第i个样本的观察数) 最后得到的公式为: 北京地区的“秩和”为:秩平均*观察数(N) = 14.4*5=72 上海地区的“秩和”为:8.2*5=41 成都地区的“秩和”为:15.8*5=79 广州地区的“秩和”为:3.6*5=18
单样本T检验 按规定苗木平均高达1.60m以上可以出圃,今在苗圃中随机抽取10株苗木,测定的苗木高度如下: 1.75 1.58 1.71 1.64 1.55 1.72 1.62 1.83 1.63 1.65 假设苗高服从正态分布,试问苗木平均高是否达到出圃要求?(要求α=0.05) 解:1)根据题意,提出: 虚无假设H0:苗木的平均苗高为H0=1.6m; 备择假设H1:苗木的平均苗高H1>1.6m; 2)定义变量:在spss软件中的“变量视图”中定义苗木苗高, 之后在“数据视图”中输入苗高数据; 3)分析过程 在spss软件上操作分析,输出如下:
表1.1:单个样本统计量 表1.2:单个样本检验 由图1.1和表1.1数据分析可知,变量苗木苗高成正态分布,平均值为1.6680m,标准差为0.0843,说明样本的离散程度较小,标准误为0.0267,说明抽样误差较小。 由表1.3数据分析可知,T检验值为2.55,样本自由度为9,t检
验的p值为0.031<0.05,说明差异性显著,因此,否定无效假设H0,取备择假设H1。 由以上分析知:在显著水平为0.05的水平上检验,苗木的平均苗高大于1.6m,符合出圃的要求。 独立样本T检验 从两个不同抚育措施育苗的苗圃中各以重复抽样的方式抽得样本如下: 样本1苗高(CM):52 58 71 48 57 62 73 68 65 56 样本2苗高(CM):56 75 69 82 74 63 58 64 78 77 66 73 设苗高服从正态分布且两个总体苗高方差相等(齐性),试以显著水平α=0.05检验两种抚育措施对苗高生长有无显著性影响。 解:1)根据题意提出: 虚无假设H0:两种抚育措施对苗木生长没有显著的影响; 备择假设H1:两种抚育措施对苗高生长影响显著; 2)在spss中的“变量视图”中定义变量“苗高1”,“抚育措施”,之后在“数据视图”中输入题中的苗高数据,及抚育措施,其中措施一定义为“1”措施二定义为“2”; 3)分析过程 在spss软件上操作分析输出分析数据如下;
秩 group N 秩均值 秩和 频数 对照组 26 18.88 491.00 治疗组 30 36.83 1105.00 总数 56 Z 值为-4.234,p <0.001,拒绝H 0 经检验,某治疗方法有效,治疗组效果优于对照组。 秩和检验 应用条件 ①总体分布形式未知或分布类型不明; ②偏态分布的资料: 组别 n 痊愈 显效 有效 无效 总有效率 治疗组 30 16(53.3%) 8(26.7%) 6(20.0%) 0(0.0%) 30(100.0%) 对照组 26 5(19.2%) 6(23.1%) 8(30.7%) 7(26.9%) 19(73.1%)
③等级资料:不能精确测定,只能以严重程度、优劣等级、次序先后等表示; ④不满足参数检验条件的资料:各组方差明显不齐。 ⑤数据的一端或两端是不确定数值,如“>50mg”等。 一、配对资料的Wilcoxon符号秩和检验(Wilcoxon signed-rank test) 例1对10名健康人分别用离子交换法与蒸馏法,测得尿汞值,如表9.1的第(2)、(3)栏,问两种方法的结果有无差别? 表1 10名健康人用离子交换法与蒸馏法测定尿汞值(μg/l) 样品号(1)离子交换法 (2) 蒸馏法 (3) 差值 (4)=(2) (3) 秩次 (5) 1 0.5 0.0 0.5 2 2 2.2 1.1 1.1 7 3 0.0 0.0 0.0 — 4 2.3 1.3 1.0 6 5 6.2 3.4 2.8 8 6 1.0 4.6 -3.6 -9 7 1.8 1.1 0.7 3.5 8 4.4 4.6 -0.2 -1 9 2.7 3.4 -0.7 -3.5 10 1.3 2.1 -0.8 -5 T+=+26. 5 T-=-18.5
SPSS的参数检验 1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。 步骤:依题目录入数据,采用单样本T检验(原假设H0:u=u0,总体均值与检验值之间不存在显著差异.);菜单选项:分析——比较均值——单样本T检验;指定检验值:在“检验值”后的框中输入检验值(填75),最后“确定”!分析:N=11人的平均值(mean)为,标准差()为,均值标准误差(std error mean)为统计量观测值为,t统计量观测值的双尾概率p-值(sig.(2-tailed))为,六七列是总体均值与原假设值差的95%的置信区间,为,,由此采用双尾检验比较a和p。T统计量观测值的双尾概率p-值(sig.(2-tailed))为>a=所以不能拒绝原假设;且总体均值的95%的置信区间为,,所以均值在~内,75包括在置信区间内,所以经理的话是可信的。 2、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。然而心理学家则倾向于认为提出事实的方式是有关系的。为验证哪种观点更站得住脚,调查者分别以下面两种不同的方式随机访问了足球球迷。 l 方式一:假设你已经买了100元一张的足球票,当你来到足球场门口时,发现票丢了且再也找不到了。球场还有票出售。你会再掏出100元买一张球票吗(1.买 0.不买)。随机访问了200人,其中:92人回答买; l 方式二:你想看足球赛,100元一张票。当你来到足球场买票时,发现丢了100元钱。你口袋中还有钱,此时你还会付100元买一张球票吗(1.买 0.不买)。随机访问了183人,其中:161人回答买; 请恰当建立SPSS数据文件,并利用本章所学习的参数检验方法,说明你更倾向于那种观点,为什么 步骤:菜单选项:分析——比较均值——独立样本T检验;选择若干变量作为检验变量到“检验变量”框(填TD态度);选择代表不同总体的变量(FS方式)作为分组变量到“分组变量”框;定义分组变量的分组情况“定义组”……:(填1,2)。分析:从分析结果上可以
第7章 SPSS 的参数检验 7-1 统计推断的基本方法 一、统计推断的概念 1、定义:根据已经收集到的样本数据,推断样本来自的总体的分布或总体均值、方差等总体参数。 2、统计推断的原因 (1)总体数据无法全部收集到 如:企业里面的质量检验 (2)收集总体数据的成本很高 3、两种类型(对于小样本而言) (1)假设总体分布已知——参数检验 (2)总体分布未知——非参数检验 二、统计推断的基本方法 1、步骤 (1)根据推断检验的目标,对待推断的总体参数或分不做一个基本假设H 0 (2)利用收集到的数据和基本假设计算某检验统计量,该统计量服从或近似服从某种统计分布。 (3)根据该统计量得到的相伴概率值,该值是该统计量在某个特定的极端区域取值在H 0 成立时的概率。 (4)做出判断。 2、注意 (1)显著性水平使弃真的概率 (2)比较相伴概率与显著性水平 三、统计推断的基本内容 1、单样本 (1)大样本n ≧50 2 ~(,)X N n σμ, 其中:μ为总体均值,2σ为总体方差,n 为样本容量 当2σ未知时,用样本方差s 2代替2σ 标准化: ~(0,1)X Z N = 同理,μ2~(,)P P N P σ P 为总体成数,n 为样本容量 2(1)p pq p p n n σ-= = 标准化: μ μ~(0,1)p P p Z N σ-== (2)小样本 2σ 已知:~(0,1)Z N = 2σ 未知:0 ~(1)X X t t n μσ-==- 2、两个独立样本 (1)大样本
22~(, )A B A B A B A B X X N n n σσμμ--+ 标准化统计量: ~(0,1)Z N = 如果22,A B σσ未知,则用S 2A ,S 2B 代替 (2)小样本 如果22,A B σσ已知 22~(, )A B A B A B A B X X N n n σσμμ--+ 标准化统计量: (~(0,1)X X Z N = 如果22,A B σσ未知,但要求22A B σσ= ()~(2)A B X X t n n -- S 为S A ,S B 的加权平均 ☆方差比检验 22~(1,1)A A B B S F F n n S =-- 3、配对样本 X A , X B 满足正态分布,但并不要求22,A B σσ相等。 当A B μμ= 配对数据可以看作来自均值为0的总体D: 2~(0,)D N σ 所以,2 ~(0,)d N n σ i i i A B d X X =- 若2 σ未知,则用 221 1()1n d i i S d d n ==--∑代替 0~(1)d t t n S -=- n 为配对数.
SPSS-非参数检验—两独立样本检验案例解析 2011-09-16 16:29 好想睡觉,写一篇博文,希望可以减少睡意,今天跟大家研究和分享一下:spss非参数检验——两独立样本检验, 我还是引用教程里面的案例,以:一种产品有两种不同的工艺生产方法,那他们的使用寿命分别是否相同 下面进行假设:1:一种产品两种不同的工艺生产方法,他们的使用寿命分布是相同的 2:一种产品两种不同的工艺生产方法,他们的使用寿命分布是不相同的 我们采用SPSS进行分析,数据如下所示: 点击“分析”选择“非参数检验” 再选择“旧对话框——2个独立样本检 验如下所示:
在检验类型下面选择"Mann-Whitney U “ 检验类型(Mann-whitney u 检验等同于对两组数据的Wilcoxon秩和检验和Kruskal-Wallis检验,主要检验两个样本的总体在某些位置上是否相等。) 两种工艺类型分别为:甲种工艺和乙种工艺分别用定义值为“1” 和 “2”将“工艺类型”变量拖入“分组变量”下拉框内,点击“定义组”按钮,在组别1 和组别 2 中分别填入 1和2,点击继续按钮 选择“使用寿命”作为“检验变量”点击确定,得到分析结果如下:
下面对结果,我将进行详细分解: 1:N 代表变量个数,甲种工艺秩和为 80 乙种工艺秩和为 40, 下面来分析“秩和”这个结果如何出来的 第一步:我们将”使用寿命“这个变量按照“从小到大”的顺序进行排序,得到如下结果:
得到数据如下: 甲种工 艺: 661 669 675 679 682 692 693 乙种工艺: 646 649 650 651 652 662 663 672 我们将“甲种工艺”和“乙种工艺”两组数据进行合并排序,并且对两组数据进行“秩次排序”分别用“序号”代替以上数据 序号分别为: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 得到以下结果: 甲种工艺为: 6 9 11 12 13 14 15 (加起来刚好等于80)
假设检验 一、单样本总体均值的假设检验 .................................................... 1 二、独立样本两总体均值差的检验 ................................................ 2 三、两匹配样本均值差的检验 ........................................................ 4 四、单一总体比率的检验 ................................................................ 5 五、两总体比率差的假设检验 .. (7) 一、单样本总体均值的假设检验 例题: 某公司生产化妆品,需要严格控制装瓶重量。标准规格为每瓶250 克,标准差为1 克,企业的质检部门每日对此进行抽样检验。某日从生产线上随机抽取16 瓶测重,以95%的保证程度进行总体均值的假设检验。 x t μ-= data6_01 样本化妆品重量 SPSS 操作: (1)打开数据文件,依次选择Analyze (分析)→Compare Means (比较均值)→One Sample T Test (单样本t 检验),将要检验的变量置入Test Variable(s)(检验变量); (2)在Test Value (检验值)框中输入250;点击Options (选项)按钮,在
Confidence Interval(置信区间百分比)后面的框中,输入置信度(系统默认为95%,对应的显著性水平设定为5%,即0.05,若需要改变显著性水平如改为0.01,则在框中输入99 即可); (3)点击Continue(继续)→OK(确定),即可得到如图所示的输出结果。 图中的第2~5 列分别为:计算的检验统计量t 、自由度、双尾检验p-值和样本均值与待检验总体均值的差值。使用SPSS 软件做假设检验的判断规则是:p-值小于设定的显著性水平?时,要拒绝原假设(与教材不同,教材的判断标准是p
spss的参数检验第五单元 分。、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为751请76 56, 79, 77,87, 80, 人参加考试,得分如下:81, 72, 60, 78, 65, 现从雇员中随机选出11 问该经理的宣称是否可信。u=u0=75 即原假设:样本均值等于总体均值t检验→相关设置→输出结果步骤:生成spss数据→分析→比较均值→单样本5-1 表 表 ,故不能拒绝原假设,且0.668>0.050.05的检验值下得到双侧检验值为分析:由上表可以看出,在在此区间,更加证明73.73一般六级成置信区间为(67.31,80.14),表中从置信区间上也可以看出绩为75 ,即认为该总经理的话可信。 2、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。然而心理学家则倾向于认为提出事实的方式是有关系的。为验证哪种观点更站得住脚,调查者分别以下面两种不同的方式随机访问了足球球迷。原假设:决策与提问方式无关,即u-u0=0 步骤:生成spss数据→分析→比较均值→两独立样本t检验→相关设置→输出结果 表5-3 组统计量 提问方式 N 均值标准差均值的标准误 .035 200 .46 丢票再买 .500 决策 .024 183 .88 丢钱再买 .326 表5-4
分析:由表5-3可以看出,提问方式不同所做的相同决策的平均比例是 46%和88%,认为决策者的决策与提问方式有关。由表5-4看出,独立样本在0.05的检验值为0,小于0.05,故拒绝原假设,认为决策者对事实所作出的反应与提问方式有关,心理学家的观点更站得住脚。 3、一种植物只开兰花和白花。按照某权威建立的遗传模型,该植物杂交的后代有75%的几率开株开了兰花,请利142颗,种植后发现200的几率开白花。现从杂交种子中随机挑选25%兰花, SPSS 进行分析,说明这与遗传模型是否一致?用u=u0=0.75 75%,即原假设:开蓝花的比例是 t 检验→相关设置→输出结果步骤:生成spss 数据→分析→比较均值→单样本5-5 表 5-6 表 0.75,1.23,1.35)值为0,小于0.05,故拒绝原假设,由于检验区间为(sig 分析:由于检验的结果 不在此区间内,进一步说明原假设不成立,故认为与遗传模型不一致。:同一鼠喂不同的饲料所测得的体1 给幼鼠喂以不同的饲料,用以下两种方法设计实验:方式4、所测得的钙留存量数29只喂饲料12只喂饲料1,乙组有内钙留存量数据如下: 方式2:甲组有请选用恰当方法对上述两种方式所获得的数据进行分析,研究不同饲料是否使幼鼠体内钙据如下 的留存量有显著不同。 原假设:不同饲料使幼鼠体内钙的留存量无显著不同。1方式 t 检验 →相关设置→输出结果步骤:生成spss 数据→分析→比较均值→配对样本5-7 表 5-8 表
检验步骤总结: 1、t检验 2、方差分析 3、卡方检验 4、秩和检验 5、相关分析 6、线性回归 1、t检验(要求数据来自正态总体,可能需要先做正态检验) (1)单一样本t检验 数据特征:单一样本变量均数与某固定已知均数进行比较 方法:ANALYZE-COMPARE MEANS-ONE SAMPLE t TEST (2)独立样本t检验 数据特征:两个独立、没有配对关系的样本(有专门变量表示组数) 方法:ANALYZE-COMPARE MEANS-INDEPENDENT SAMPLES t TEST 注意观察方差分析结果,判断查看的数据是哪一行! (3)配对样本t检验 数据特征:两个不独立的,有配对关系的样本(没有专门变量表示组数) 方法:ANALYZE-COMPARE MEANS-PAIRED SAMPLES t TEST 不需要方差分析结果 检验步骤: (1)正态性检验1(有同学推荐,老师没有强调,但依据理论应进行) (2)建立假设(H0:。。。。来自同一样本。H1:。。。。不来自同一样本) (3)确定检验水准 (4)计算统计量(依据上面不同样本类型选择检验方法,注意独立样本t检验要先注明方差分析结果) (5)确定概率值P (6)得出结论 2、方差分析(要求数据来自正态总体,可能需要先做正态检验) (1)单因素方差分析 数据特征:相互独立、来自正态总体、随机、方差齐性的多样本(有专门变量 表示组数,且组数大于2) 方法:ANALYZE-COMPARE MEANS-ONE WAY ANOVA 注意需要在options 里面选择homogeneity variance test 做方差分析 符合方差齐性才可以得出结论!(>0.1) (2)双因素方差分析 1正态性检验方法:analyze-explore-plot里面选择normality test
S P S S的参数检验和非 参数检验 公司内部档案编码:[OPPTR-OPPT28-OPPTL98-OPPNN08]
实验报告 SPSS的参数检验和非参数检验 学期:_2013__至2013_ 第_1_学期 课程名称:_数学建模专业:数学 实验项目__SPSS的参数检验和非参数检验实验成绩:_____ 一、实验目的及要求 熟练掌握t检验及其结果分析。熟练掌握单样本、两独立样本、多独立样本的非参数检验及各种方法的适用范围,能对结果给出准确分析。 二、实验内容 使用指定的数据按实验教材完成相关的操作。 1、给幼鼠喂以不同的饲料,用以下两种方法设计实验: 方式1:同一鼠喂不同的饲料所测得的体内钙留存量数据如下: 方式2:甲组有12只喂饲料1,乙组有9只喂饲料2,所测得的钙留存量数据如下:
请选用恰当方法对上述两种方式所获得的数据进行分析,研究不同饲料是否使幼鼠体内钙的留存量有显着不同。 2、为分析大众对牛奶品牌是否具有偏好,随机挑选超市收集其周一至 周六各天三种品牌牛奶的日销售额数据,如下表所示: 请选用恰当的非参数检验方法,以恰当形式组织上述数据进行分析,并说明分析结论。 实验报告附页 三、实验步骤 (一) 方式1: 1、打开SPSS软件,根据所给表格录入数据,建立数据文件; 2、选择菜单Analyze-Compare means-Paired-Samples T Test,出现窗口; 3、把检验变量饲料1,饲料2 选择到Paired Variables框,单击OK。方式2: 1、打开SPSS软件,根据所给表格录入数据,建立数据文件; 2、选择菜单Analyze-Compare means-Independent-Samples T Test,出现窗口 3、选择检验变量饲料到Test Variable(s)框中。 4、选择总体标志变量组号到Grouping Variables框中。 5、单击Define Groups按钮定义两总体的标志值1、2,单击OK。
Spss第 3 次作业 方差分析练习题: 第1题 (1)【实验目的】 学会单因素方差分析 (2)【实验内容】 1、入户推销有五种方法。某大公司想比较这五种方法有无显著的效果差异,设计了一项实验。从尚无推销经验的应聘人员中随机挑选一部分,并随机将他们分为五个组,每种用一种推销方 第一组20 16.8 17.9 21.2 23.9 26.8 22.4 第二组24.9 21.3 22.6 30.2 29.9 22.5 20.7 第三组16.0 20.1 17.3 20.9 22.0 26.8 20.8 第四组17.5 18.2 20.2 17.7 19.1 18.4 16.5 第五组25.2 26.2 26.9 29.3 30.4 29.7 28.2 (2)绘制各组的均值比对图,并利用LSD方法进行剁成比较检验。 (3)【操作步骤】 在数据编辑窗口输入组别和推销额→分析→比较平均值→单因素ANOVA检验→将“推销额”转入“因变量列表”→将“组别”转入“因子”→确定 分析→一般线性模型→单变量→将“推销额”转入“因变量”→将“组别”转入“固定因子”→事后比较→将“组别”转入“下列各项的事后检验”→选中“LSD”→继续→确定
(4)【输出结果】 ANOVA VAR00002 平方和自由度均方 F 显著性 组间405.534 4 101.384 11.276 .000 组内269.737 30 8.991 总计675.271 34 主体间因子 个案数 VAR00001 1.00 7 2.00 7 3.00 7 4.00 7 5.00 7
主体间效应检验因变量: VAR00002 源III 类平方 和自由度均方 F 显著性 修正模型405.534a 4 101.384 11.276 .000 截距17763.779 1 17763.779 1975.677 .000 VAR00001 405.534 4 101.384 11.276 .000 误差269.737 30 8.991 总计18439.050 35 修正后总计675.271 34 a. R 方 = .601(调整后 R 方 = .547)
假设检验的SPSS实现 、实验目的与要求 1. 掌握单样本 t检验的基本原理和 spss实现方法。 2. 掌握两样本 t检验的基本原理和 spss实现方法。 3. 熟悉配对样本 t检验的基本原理和 spss实现方法。 二、实验内容提要 1. 从一批木头里抽取 5根,测得直径如下(单位: cm),是否能认为这批木头的平均直径是1 2.3cm 12.3 12.8 12.4 12.1 12.7 2. 比较两批电子器材的电阻,随机抽取的样本测量电阻如题表2所示,试比较两批电子器 材的电阻是否相同(需考虑方差齐性的问题) 3. 配对 t检验的实质就是对差值进行单样本t检验,要求按此思路对例课本 13.4进行重新分析,比较其结果和配对 t检验的结果有什么异同。 4.一家汽车厂设计出 3种型号的手刹,现欲比较它们与传统手刹的寿命。分别在传统手刹,型号I、II、和型号 III中随机选取了 5只样品,在相同的试验条件下,测量其使用寿命(单位:月),结果如下: 传统手刹:21.213.417.015.212.0 型号 I :21.412.015.018.924.5 型号 II :15.219.114.216.524.5 型号 III :38.735.839.332.229.6 ( 1)各种型号间寿命有无差别 ? (2)厂家的研究人员在研究设计阶段,便关心型号III 与传统手刹寿命的比较结果。此时应 当考虑什么样的分析方法?如何使用 SPSS实现? 三、实验步骤 为完成实验提要 1. 可进行如下步骤 1. 在变量视图中新建一个数据,在数据视图中录入数据,在分析中选择比较均值,单样本t 检验,将直径添加到检验变量,点击确定。
组别n 痊愈显效有效无效总有效率治疗组30 16(53.3%) 8(26.7%) 6(20.0%) 0(0.0%) 30(100.0%) 对照组26 5(19.2%) 6(23.1%) 8(30.7%) 7(26.9%) 19(73.1%) 秩 group N 秩均值秩和 频数对照组26 18.88 491.00 治疗组30 36.83 1105.00 总数56 检验统计量a 频数 Mann-Whitney U 140.000 Wilcoxon W 491.000 Z -4.234 渐近显著性(双侧) .000 a. 分组变量: group Z值为-4.234,p<0.001,拒绝H0 经检验,某治疗方法有效,治疗组效果优于对照组。 秩和检验
应用条件 ①总体分布形式未知或分布类型不明; ②偏态分布的资料: ③等级资料:不能精确测定,只能以严重程度、优劣等级、次序先后等表示; ④不满足参数检验条件的资料:各组方差明显不齐。 ⑤数据的一端或两端是不确定数值,如“>50mg”等。 一、配对资料的Wilcoxon符号秩和检验(Wilcoxon signed-rank test) 例1对10名健康人分别用离子交换法与蒸馏法,测得尿汞值,如表9.1的第(2)、(3)栏,问两种方法的结果有无差别? 表1 10名健康人用离子交换法与蒸馏法测定尿汞值(μg/l) 样品号(1)离子交换法 (2) 蒸馏法 (3) 差值 (4)=(2) (3) 秩次 (5) 1 0.5 0.0 0.5 2 2 2.2 1.1 1.1 7 3 0.0 0.0 0.0 — 4 2.3 1.3 1.0 6 5 6.2 3.4 2.8 8 6 1.0 4.6 -3.6 -9 7 1.8 1.1 0.7 3.5 8 4.4 4.6 -0.2 -1 9 2.7 3.4 -0.7 -3.5 10 1.3 2.1 -0.8 -5
实验报告 ——(非参数检验) 实验目的: 1、学会使用SPSS软件进行非参数检验。 2、熟悉非参数检验的概念及适用范围,掌握常见的秩和检验计算方法。 实验内容: 1、某公司准备推出一个新产品,但产品名称还没有正式确定,决定进行抽样调 查,在受访200人中,52人喜欢A名称,61人喜欢B名称,87人喜欢C 名称,请问ABC三种名称受欢迎的程度有无差别?(数据表自建) SPSS计算结果如下: 此题为总体分布的卡方检验。 零假设:样本来自总体分布形态和期望分布没有显著差异。即ABC三种名称受欢迎的程度无差别,分布形态为1:1:1,呈均匀分布。 观察结果,上表为200个观察数据对A、B、C三个名称(分别对应1,2,3)的喜爱的期望频数以及实际观察频数和期望频数的差。从下表中可以看出相伴概
率值为0.007小于显著性水平0.05,因此拒绝零假设,认为样本来自的总体分布与制定的期望分布有显著差异,即A、B、C三种名称受欢迎的程度有差异。 2、某村庄发生了一起集体食物中毒事件,经过调查,发现当地居民是直接饮用 河水,研究者怀疑是河水污染所致,县按照可疑污染源的大致范围调查了沿河居民的中毒情况,河边33户有成员中毒(+)和均未中毒(-)的家庭分布如下:(案例数据run.sav) -+++*++++-+++-+++++----++----+---- 毒源 问:中毒与饮水是否有关? SPSS计算结果如下: 此题为单样本变量值随机检验 零假设:总体某变量的变量值是随机出现的。即中毒的家庭沿河分布的情况随机分布,与饮水无关。 相伴概率为0.036,小于显著性水平0.05,拒绝零假设,因此中毒与饮水有关。 3、某试验室用小白鼠观察某种抗癌新药的疗效,两组各10只小白鼠,以生存日数作为观察指标,试验结果如下,案例数据集为:npara1.sav,问两组小白鼠生存日数有无差别。 试验组:24 26 27 30 32 34 36 40 60 天以上 对照组:4 6 7 9 10 10 12 13 16 16 SPSS计算结果如下: 此题为两独立样本非参数检验。 (1)两独立样本Mann-Whitney U检验:
Z 值为-4.234,p <0.001,拒绝H 0 经检验,某治疗方法有效,治疗组效果优于对照组。 秩和检验 应用条件 ①总体分布形式未知或分布类型不明; ②偏态分布的资料: ③等级资料:不能精确测定,只能以严重程度、优劣等级、次序先后等表示; ④不满足参数检验条件的资料:各组方差明显不齐。 ⑤数据的一端或两端是不确定数值,如“>50mg ”等。 一、配对资料的Wilcoxon 符号秩和检验(Wilcoxon signed-rank test ) 组别 n 痊愈 显效 有效 无效 总有效率 治疗组 30 16(53.3%) 8(26.7%) 6(20.0%) 0(0.0%) 30(100.0%) 对照组 26 5(19.2%) 6(23.1%) 8(30.7%) 7(26.9%) 19(73.1%)
例1 对10名健康人分别用离子交换法与蒸馏法,测得尿汞值,如表9.1的第(2)、(3)栏,问两种方法的结果有无差别? 表1 10名健康人用离子交换法与蒸馏法测定尿汞值(μg /l ) 样品号 (1) 离子交换法 (2) 蒸馏法 (3) 差值 (4)=(2)-(3) 秩次 (5) 1 0.5 0.0 0.5 2 2 2.2 1.1 1.1 7 3 0.0 0.0 0.0 — 4 2.3 1.3 1.0 6 5 6.2 3.4 2.8 8 6 1.0 4.6 -3.6 -9 7 1.8 1.1 0.7 3.5 8 4.4 4.6 -0.2 -1 9 2.7 3.4 -0.7 -3.5 10 1.3 2.1 -0.8 -5 T +=+26.5 T -=-18.5 差值先进行正态性及方差齐性检验,看是否可以做参数检验,其检验效能高于非参数检验。(下同) H0:Md (差值的总体中位数)=0 H1:Md ≠0 α=0.05 T ++T -=1+2+3+…n=n(n+1)/2 ① 小样本(n ≤50)--查T 界值表 基本思想:如果无效假设H0成立,则正负秩和的绝对值从理论上说应相等,都等于n(n+1)/4,既使有抽样误差的影响正负T 值的绝对值相差也不应过大。反过来说,如果实际计算出的正负T 值绝对值相差很大,我们只能认为H0成立的可能性很小。 界值的判断标准 若下限
秩和检验 应用条件 ①总体分布形式未知或分布类型不明; ②偏态分布的资料: ③等级资料:不能精确测定,只能以严重程度、优劣等级、次序先后等表示; ④不满足参数检验条件的资料:各组方差明显不齐。 ⑤数据的一端或两端是不确定数值,如“>50mg”等。 一、配对资料的Wilcoxon符号秩和检验(Wilcoxon signed-rank test) 例1对10名健康人分别用离子交换法与蒸馏法,测得尿汞值,如表9.1的第(2)、(3)栏,问两种方法的结果有无差别? 表1 10名健康人用离子交换法与蒸馏法测定尿汞值(μg/l) 样品号(1)离子交换法 (2) 蒸馏法 (3) 差值 (4)=(2)-(3) 秩次 (5) 1 0.5 0.0 0.5 2 2 2.2 1.1 1.1 7 3 0.0 0.0 0.0 — 4 2.3 1.3 1.0 6 5 6.2 3.4 2.8 8 6 1.0 4.6 -3.6 -9 7 1.8 1.1 0.7 3.5 8 4.4 4.6 -0.2 -1 9 2.7 3.4 -0.7 -3.5 10 1.3 2.1 -0.8 -5 T+=+26.5 T-=-18.5 差值先进行正态性及方差齐性检验,看是否可以做参数检验,其检验效能高于非参数检验。(下同) H0:Md(差值的总体中位数)=0 H1:Md≠0 α=0.05 T++T-=1+2+3+…n=n(n+1)/2 ①小样本(n≤50)--查T界值表 基本思想:如果无效假设H0成立,则正负秩和的绝对值从理论上说应相等,都等于n(n+1)/4,既使有抽样误差的影响正负T值的绝对值相差也不应过大。反过来说,如果实际计算出的正负T值绝对值相差很大,我们只能认为H0成立的可能性很小。 界值的判断标准 若下限
第五单元spss的参数检验 1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。 现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请 问该经理的宣称是否可信。 原假设:样本均值等于总体均值即u=u0=75 步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;) 分析: 分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。 2、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。然而心理学家则倾向于认为提出事实的方式是有关系的。为验证哪种观点更站得住脚,调查者分别以下面两种不同的方式随机访问了足球球迷。 原假设:决策与提问方式无关,即u-u0=0 步骤:生成spss数据→分析→比较均值→两独立样本t检验→相关设置→输出结果
原文地址:SPSS学习笔记之——两配对样本的非参数检验(Wilcoxon符号秩检验)作者:王江源 一、概述 非参数检验对于总体分布没有要求,因而使用范围更广泛。对于两配对样本的非参数检验,首选Wilcoxon符号秩检验。它与配对样本t检验相对应。 二、问题 为了研究某放松方法(如听音乐)对于入睡时间的影响,选择了10名志愿者,分别记录未进行放松时的入睡时间及放松后的入睡时间(单位为分钟),数据如下笔。请问该放松方法对入睡时间有无影响。 本例可以采用配对样本t检验,但由于样本量少,数据可能不符合正太分布,所以考虑用非参数检验。 三、统计操作 数据视图
菜单选择 打开如下的对话框
该对话框有三个选项卡,第一个选项卡会根据第三个选项卡的设置自动设置,故一般不用手动设定。点击进入“字段”选项卡。将“放松前”、“放松后”均选入右边“检验字段”框中。 点击进入“设置”对话框,选择检验方法,切换为“自定义检验”,选择“Wilcoxon匹
配样本对符号秩(二样本)”复选框。“检验选项”可以设定显著性水平。 点击“运行”按钮,输出结果 四、结果解读 这就是输出结果。原假设示放松前好放松后差值的中位数等于0,P=0.015<0.05,拒绝原假设,认为放松前后有统计学差异。
双击该表格,会弹出如下的“模型浏览器”窗口,可以看到更详细的信息。如下图。
统计第十一课:SPSS 多相关样本的非参数检验(Friedman检验) 关键词:SPSS多相关样本非参数检验2015-07-14 00:00来源:互联网点击次数:5103 先讲讲什么是 Friedman 检验 Friedman 检验是利用秩实现对多个总体分布是否存在显著差异的非参数检验方法。 其原假设是:多个配对样本来自的多个总体分布无显著差异。 SPSS 将自动计算 Friedman 统计量和对应的概率 P 值。如果概率 P 值小于给定的显著性水平 0.05,则拒绝原假设,认为各组样本的秩存在显著差异,多个配对样本来自的多个总体的分布有显著差异。 反之,则不能拒绝原假设,可以认为各组样本的秩不存在显著性差异。 基于上述基本思路,多配对样本的 Friedman 检验时,首先以行为单位将数据按升序排序,并求得各变量值在各自行中的秩;然后,分别计算各组样本下的秩总和与平均秩。多配对样本的 Friedman 检验适于对定距型数据的分析。 看完这些,是不是有点儿晕,好吧,让我们进入实例来分析分析。
熟练使用SPSS 进行假设检验 [例] 某克山病区测得11例克山病患者与13名健康人的血磷值mmol/L如下,问该地急性克山病患者与健康人的血磷值是否不同。 表1 克山病区调查数据结果 患 者 健 康 人 1.录入数据。将组别设为g,可将患者组设为1,健康人设为2,血磷值设为x,如患者组中第一个测量到的血磷值为,则g为1,x为,其他数据均仿此录入,如下图所示。
图1 数据输入界面 2.统计分析。依次选择“Analyze”、“ Compare means”、“ Independent Samples T Test”。 图2 选择分析工具
3.弹出对话框如下图所示,将x选入Test Variables、g选入Grouping Variable,并单击下方的Define Groups按钮,弹出定义组对话框,默认选项为Use Specified Value,在Group1和Group2框中分别填入1和2,即要对组别变量值为1和2的两个组做t检验,另外Options 对话框中可选择置信度和处理缺失值的方法。 图3 选择变量进入右侧的分析列表SPSS输出的结果和结果说明: 图4 输出结果 表2 统计量描述列表
表3 假设检验结果表 第一个表格是统计描述,给出了两个组的样本数N、均值Mean、标准偏差、标准误差Std. Error Mean。 第二个表格分两部分 (1)方差齐次检验(Levene 检验)。F=、P(Sig)=。 (2)t 检验。因方差齐次与不齐方法不同,(Equal variances assumed 方差齐次和Equal variances not assumed 方差不齐),结果分两行给出。由使用者根据方差齐次检验结果来判断。本例尚不能认为方差不齐,故取方差齐次的结果t=,df 自由度