数据仓库与数据挖掘实验
实验1、数据仓库与OLAP
■ Analysis Services→Analysis Manager的安装、启动与退出
◆安装:
◆启动:
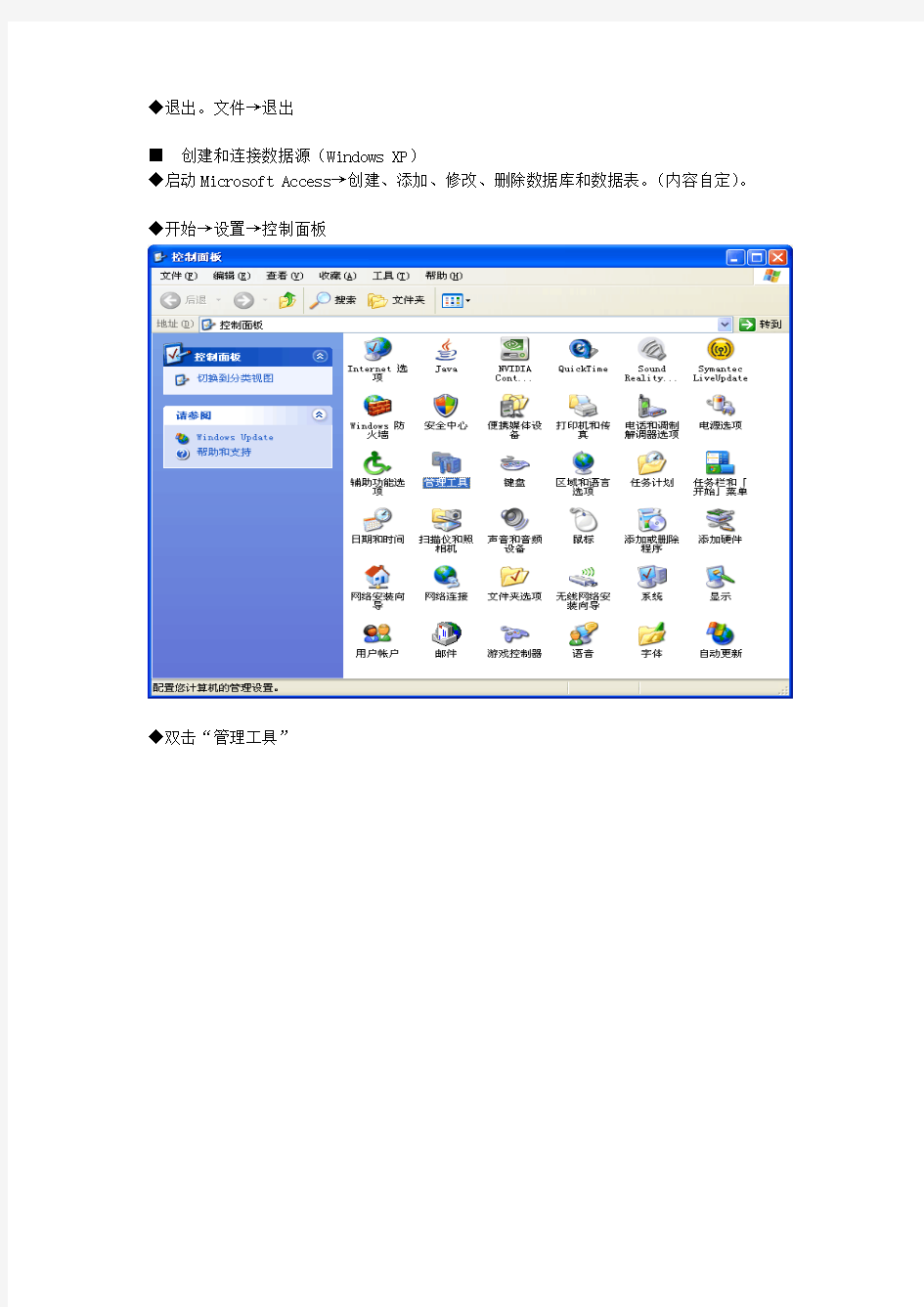
开始→程序→Microsoft SQL Server→Analysis Services→Analysis Manager
◆退出。文件→退出
■创建和连接数据源(Windows XP)
◆启动Microsoft Access→创建、添加、修改、删除数据库和数据表。(内容自定)。
◆开始→设置→控制面板
◆双击“管理工具”
◆双击“数据源(ODBC)”
◆选择“系统DSN”
◆如果已经存在数据源“FoodMart 2000”,则转向(******)处;或者单击“删除”,删除该数据源,然后按照下面的步骤练习如何建立数据源;
◆否则,单击“添加”
◆选择相应的驱动程序,本例选择“Microsoft Access Driver(*.mdb)”→单击“完成”
◆在“数据源名(N):”处,输入:FoodMart 2000→单击“选择”
◆选择“C:\Program Files\Microsoft Analysis Services\Samples”目录中的“foodmart 2000.mdb”→单击“确定”
◆单击“确定”
◆最后单击“确定”,关闭ODBC数据源管理器。
◆(******)对于已经存在数据源“FoodMart 2000”的情况,操作如下:选择“FoodMart 2000”→单击“配置”
◆单击“选择”
◆选择“C:\Program Files\Microsoft Analysis Services\Samples”目录中的“foodmart 2000.mdb”→单击“确定”
◆单击“确定”
◆最后单击“确定”,关闭ODBC数据源管理器。
■创建Analysis Services数据库(Windows XP)
◆启动:
开始→程序→Microsoft SQL Server→Analysis Services→Analysis Manager
→选择“新建数据库”
◆在“数据库名称(D)”下,输入“Sample”→单击“确定”
◆单击“Sample”→展开数据库
■创建和连接Analysis Services数据源(Windows XP)◆选择“Sample”→选择“数据源”→右击
◆选择“提供程序”选项卡→选择“Microsoft OLE DB Provider for ODBC Drivers”→选择“连接”选项卡
◆在“使用数据源名称(D)”下→选择“FoodMart 2000”→单击“测试连接”→测试连接成功对话框。
◆在测试连接成功对话框中→单击“确定”。
◆在数据连接属性对话框中→单击“确定”。成功连接后的画面如下图:
(一)数据质量的衡量标准、好处和问题 数据质量的好坏是决定一个数据仓库成功的关键,但是需要从那些方面衡量数据仓库中数据的质量呢?可以从下列方面衡量系统中的数据质量: 准确性:存储在系统中的关于一个数据元素的值是这个数据元素的正确值; 域完整性:一个属性的数值在合理且预定义的范围之内; 数据类型:一个数据属性的值通常是根据这个属性所定义的数据类型来存储的; 一致性:一个数据字段的形式和内容在多个源系统之间是相同的。 冗余性:相同的数据在一个系统中不能存储在超过一个地方; 完整性:系统中的属性不应该有缺失的值; 重复性:完全解决一个系统中记录的重复性的问题; 结构明确:在数据项的结构可以分成不同部分的任何地方,这个数据项都必须包含定义好的结构; 数据异常:一个字段必须根据预先定义的目的来使用; 清晰:一个数据元素必须有正确的定义,也就是需要一个正确的命名; 时效性:用户决定了数据的时效性; 有用性:数据仓库中的每一个数据元素必须满足用户的一些需求; 符合数据完整性的规则:源系统中的关系数据库中存储的数据必须符合实体完整性及参考完整性规则。 既然数据质量是成功的关键,那么,提高数据质量有那些好处: 对实时信息的分析:高质量的数据提供及时的信息,是为用户创造的一个重要益处;
更好的客户服务:完整而准确的信息能够大大提高客户服务的质量; 更多的机会:数据仓库中的高质量数据是一个巨大的市场机会,它给产品和部门之间的交叉销售打开了机会的大门; 减少成本和风险:如果数据质量不好,明显的风险就是战略决策可能会导致灾难性的后果。 提高生产率:用户可以从真个企业的角度来看待数据仓库的信息,而全面的信息促使流程和真个操作更顺畅, 从而提高生长率; 可靠的战略决策制定:如果数据仓库的数据是可靠而高质量的,那么基于这些信息进行的决策就是好的决策。 在数据处理过程中,会有那些数据质量问题: 字段中的虚假值 数据值缺失 对字段的非正规使用 晦涩的值 互相冲突的值 违反商业规则 主键重用 标志不唯一 不一致的值 不正确的值 一个字段多种用途
昆明理工大学信息工程与自动化学院学生实验报告 (2014 —2015 学年第 1 学期) 课程名称:数据库仓库与数据挖掘开课实验室:信自楼4442014 年12月28日 一、实验内容和目的 目的: 1.理解数据库与数据仓库之间的区别与联系; 2.掌握典型的关系型数据库及其数据仓库系统的工作原理以及应用方法; 3.掌握数据仓库建立的基本方法及其相关工具的使用。 二、实验原理及基本技术路线图(方框原理图) 数据库(DataBase,DB)是长期存储在计算机内、有组织的、统一管理的相关数据的集合。DB能为各种用户共享,具有较小的冗余度、数据间联系紧密而又有较高的数据独立性等特点。构成的三要素是数据结构、数据操作、约束性条件。 三、所用仪器、材料(设备名称、型号、规格等) PC机和Microsoft SQL Server 2008 四、实验方法、步骤
1、登录SQL Server 登录名:localhost 2、使用SQL语句构建数据库(1)还原数据库
(2)建立数据 --建立数据 USE cd CREATE DATABASE[DW]ON PRIMARY (NAME=N'DW',FILENAME=N'G:\DW.mdf') LOG ON (NAME=N'DW_log',FILENAME=N'G:\DW_log.ldf') GO (3)建立数据库:数据库→新建数据库 (4)建维表 ①SQL语句 USE DW -------------------------------- --1、建维表 /*1.1 订单方式*/ CREATE TABLE DIM_ORDER_METHOD (ONLINEORDERFLAG INT,DSC VARCHAR(20)) /*1.2 销售人员及销售地区*/ CREATE TABLE DIM_SALEPERSON (SALESPERSONID INT, DSC VARCHAR(20), SALETERRITORY_DSC VARCHAR(50))
数据仓库与数据挖掘 第一章课后习题 一:填空题 1)数据库中存储的都是数据,而数据仓库中的数据都是一些历史的、存档的、归纳的、计算的数据。 2)数据仓库中的数据分为四个级别:早起细节级、当前细节级、轻度综合级、高度综合级。3)数据源是数据仓库系统的基础,是整个系统的数据源泉,通常包括业务数据和历史数据。4)元数据是“关于数据的数据”。根据元数据用途的不同将数据仓库的元数据分为技术元数据和业务元数据两类。 5)数据处理通常分为两大类:联机事务处理和联机事务分析 6)Fayyad过程模型主要有数据准备,数据挖掘和结果分析三个主要部分组成。 7)如果从整体上看数据挖掘技术,可以将其分为统计分析类、知识发现类和其他类型的数据挖掘技术三大类。 8)那些与数据的一般行为或模型不一致的数据对象称做孤立点。 9)按照挖掘对象的不同,将Web数据挖掘分为三类:web内容挖掘、web结构挖掘和web 使用挖掘。 10)查询型工具、分析型工具盒挖掘型工具结合在一起构成了数据仓库系统的工具层,它们各自的侧重点不同,因此适用范围和针对的用户也不相同。 二:简答题 1)什么是数据仓库?数据仓库的特点主要有哪些? 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支
持管理决策。 主要特点:面向主题组织的、集成的、稳定的、随时间不断变化的、数据的集合性、支持决策作用 2)简述数据挖掘的技术定义。 从技术角度看,数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际数据中,提取隐含在其中的、人们不知道的、但又是潜在有用的信息和知识的过程。 3)什么是业务元数据? 业务元数据从业务角度描述了数据仓库中的数据,它提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员也能够读懂数据仓库中的数据 4)简述数据挖掘与传统分析方法的区别。 本质区别是:数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先前未知、有效和实用三个特征。 5)简述数据仓库4种体系结构的异同点及其适用性。 a.虚拟的数据仓库体系结构 b.单独的数据仓库体系结构 c.单独的数据集市体系结构 d.分布式数据仓库结构
数据仓库数据库设计的心得总结 数据仓库是企业商业智能分析环境的核心,它是建立决策支持系统的基础。一个良好的数据仓库设计应该是构建商业智能和数据挖掘系统不懈的追求。下面把数据仓库数据库设计的心得做一小结。 一透彻理解数据仓库设计过程 商业智能和数据挖掘归根到底是“从实践中来,到实践中去”。也就是说现实需求决定系统需求,业务数据决定系统构架,最终使用的时候又必须作用于现实需求,同时通过决策的行为影响业务。那么可以把数据仓库的设计看做是前一部分,即“从实践中来”,数据仓库的应用可以看做是“到实践中去”。把“从实践中来”这个过程进行抽象,数据仓库的设计就是“客观世界→主观世界→关系世界”的过程。 在前面几节完成了6个任务:选择被建模主题的商业过程、确定事实表的粒度、区分每一个事实表的维和层、区分事实表的度量、确定每一个维表的属性、在D BMS中创建和管理数据仓库。实际上这些任务都可以归结到从客观世界到关系世界的过程。那么把这个过程再进行归纳,可以得到如图3-61所示的综合了模型、方法和过程的示意图。 图3-61 数据仓库设计过程的模型和方法示意图 二把握设计的关键环节
如果将时间、精力、金钱和人事优先花在前面的20%,那么这20%会创造出80% 的价值。这就是有名的2/8原则。下面将介绍在数据仓库设计中,哪些因素是属于这20%的范围。 1.需求 需求分析在任何如见项目中都是最为重要的因素之一。企业模型是从企业的各个视点对企业数据需求及数据间关系的抽象。通过将企业模型映射到数据库系统,可以很快地了解现有数据库系统完成了企业模型中的哪些部分,还缺少哪些部分。然后再将企业模型映射到数据仓库系统,发现企业需要的(或可以构造的)主题。通过这样的过程完成对企业数据需求和现有数据的了解,达到明了原有系统和需要建设的主题域间共性的目的。 2.关键性能指标(KPI) 一般而言,一个决策支持系统最重要的就是要呈现决策数据。而KPI就是决策过程中要显示的数据结果的部分,如销售数量、销售金额、毛利和运费等数值部分的数据。这些KPI是通过与相关的维表进行连接而映射出来的。在分析星形模式时,往往要首先确定KPI。 3.信息对象 信息对象是指在每个分析过程中那些会影响到决策的因素。以销售分析为例,时间、产品、员工与客户就是影响决策的大因子,而每个因子又可以分离出多个分层结构,如时间可分为年、季度、月、周和日等,员工可分为年龄层、年龄、年薪层、年薪和员工所在城市等,也就是影响决策的详细因子。这些都是信息对象。从这里我们可以看出,每个大因子如时间、产品、员工与客户等就可以构成如时间维表、产品维表、员工维表与客户维表等。而时间维表又可分为年、季度和日等字段。在分析和设计这些信息对象组成的维度时,需要注意维的唯一性和公用性,千万不要在不同的主题中定义多个表示同一内容的维,如果有可能,一个维表要尽量被多个主题共享。 4.数据粒度 在数据仓库的每个主题中,都必须考虑事实数据的粒度。粒度的具体划分将直接影响到数据仓库中的数据量及查询质量。在数据仓库开始进行分析时。就需要建立合适的数据粒度模型,指导数据仓库设计和其他问题的解决。如果数据粒度定义不当,将会影响数据仓库的使用效果,使数据仓库达不到设计数据仓库的目的。 5.数据之间的联系 在数据仓库中,不同主题的数据之间的物理约束或许不再存在,但无论这些数据如何变化,要知道必须有一些“键”在逻辑上保持着不同数据之间的联系,这样
数据仓库与数据挖掘
实 验 指 导 书
东北石油大学计算机与信息技术系 王浩畅
实验一 Weka 实验环境初探
一、实验名称: Weka 实验环境初探
二、实验目的: 通过一个已有的数据集,在 weka 环境下,测试常用数据挖掘算法,熟悉 Weka
环境。 三、实验要求
1. 熟悉 weka 的应用环境。 2. 了解数据挖掘常用算法。 3. 在 weka 环境下,测试常用数据挖掘算法。 四、实验平台 新西兰怀卡托大学研制的 Weka 系统 五、实验数据 Weka 安装目录下 data 文件夹中的数据集 weather.nominal.arff,weather.arff
六、实验方法和步骤 1、首先,选择数据集 weather.nominal.arff,操作步骤为点击 Explorer,进入主界 面,点击左上角的“Open file...”按钮,选择数据集 weather.nominal.arff 文件, 该文件中存储着表格中的数据,点击区域 2 中的“Edit”可以看到相应的数据:
选择上端的 Associate 选项页,即数据挖掘中的关联规则挖掘选项,此处要 做的是从上述数据集中寻找关联规则。点击后进入如下界面:
2、现在打开 weather.arff,数据集中的类别换成数字。
选择上端的 Associate 选项页,但是在 Associate 选项卡中 Start 按钮为灰色的, 也就是说这个时候无法使用 Apriori 算法进行规则的挖掘,原因在于 Apriori 算法 不能应用于连续型的数值类型。所以现在需要对数值进行离散化,就是类似于将 20-30℃划分为“热”,0-10℃定义为“冷”,这样经过对数值型属性的离散化, 就可以应用 Apriori 算法了。Weka 提供了良好的数据预处理方法。第一步:选 择要预处理的属性 temperrature
数据仓库与数据挖掘技术复习资料 一、单项选择题 1.数据挖掘技术包括三个主要的部分( C ) A.数据、模型、技术 B.算法、技术、领域知识 C.数据、建模能力、算法与技术 D.建模能力、算法与技术、领域知识 2.关于基本数据的元数据是指: ( D ) A.基本元数据与数据源,数据仓库,数据集市和应用程序等结构相关的信息; B.基本元数据包括与企业相关的管理方面的数据和信息; C.基本元数据包括日志文件和简历执行处理的时序调度信息; D.基本元数据包括关于装载和更新处理,分析处理以及管理方面的信息。 3.关于OLAP和OLTP的说法,下列不正确的是: ( A) A.OLAP事务量大,但事务内容比较简单且重复率高 B.OLAP的最终数据来源与OLTP不一样 C.OLTP面对的是决策人员和高层管理人员 D.OLTP以应用为核心,是应用驱动的 4.将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?( C ) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘5.下面哪种不属于数据预处理的方法? ( D ) A.变量代换 B.离散化 C. 聚集 D. 估计遗漏值 6.在ID3 算法中信息增益是指( D ) A.信息的溢出程度 B.信息的增加效益 C.熵增加的程度最大 D.熵减少的程度最大 7.以下哪个算法是基于规则的分类器 ( A ) A. C4.5 B. KNN C. Bayes D. ANN 8.以下哪项关于决策树的说法是错误的( C ) A.冗余属性不会对决策树的准确率造成不利的影响 B.子树可能在决策树中重复多次 C.决策树算法对于噪声的干扰非常敏感 D.寻找最佳决策树是NP完全问题 9.假设收入属性的最小与最大分别是10000和90000,现在想把当前值30000映射到区间[0,1],若采用最大-最小数据规范方法,计算结果是( A )
数据仓库数据平台与数据中台对比 在大数据时代,凡是AI类项目的落地,都需要具备数据、算法、场景、计算力四个基本元素,缺一不可。处理大数据已经不能仅仅依靠计算力就能够解决问题,计算力只是核心的基础,还需要结合不同的业务场景与算法相互结合,沉淀出一个完整的智能化平台。数据中台就是以云计算为数据智能提供的基础计算力为前提,与大数据平台提供的数据资产能力与技术能力相互结合,形成数据处理的能力框架赋能业务,为企业做到数字化、智能化运营。 目前,外界与业内很多人对于数据中台的理解存在误区,一直只是在强调技术的作用,强调技术对于业务的推动作用,但在商业领域落地的层面上,更多时候技术的发展和演进都是需要跟着业务走,技术的发展和进步需要基于业务方的需求与数据场景应用化的探索来反向推动。这个也就是为什么最近知乎、脉脉都在疯传阿里在拆“大中台”?个人猜想,原因是没有真正理解中台的本质,其实阿里在最初建设数据中台的目的主要是为了提升效率和解决业务匹配度问题,最终达到降本增效,所以说“拆”是假的,在“拆”的同时一定在“合”,“拆”的一个方面是企业战略布局层面上的规划,架构升级,如果眼界不够高,格局不够大,看到的一定只是表面;另一方面不是由于组织架构庞大而做“拆”的动作,而是只有这样才能在效率和业务匹配度上,做到最大利益化的解耦。
数据中台出现的意义在于降本增效,是用来赋能企业沉淀业务能力,提升业务效率,最终完成数字化转型。前一篇数据中台建设的价值和意义,提到过企业需要根据自身的实际情况,打造属于自己企业独有的中台能力。 因为,数据中台本身绝对是不可复制的,从BCG矩阵的维度结合各家市场资源、市场环境、市场地位以及业务方向来看,几乎所有企业的战略目标都是不一样的。如果,有人说能把中台卖给你、对于中台的解读只讲技术,不讲业务,只讲产品,不讲业务,不以结合企业业务目标来解决效率和匹配度为目的的都有耍流氓嫌疑。数据中台的使命和愿景是让数据成为如水和电一般的资源,随需获取,敏捷自助,与业务更多连接,使用更低成本,通过更高效率的方式让数据极大发挥价值,推动业务创新与变革。 为了进一步统一大家的认知,更加清晰的认识数据中台出现的意义,本篇按顺序介绍如下: ? ? ? ? 数据中台演进的过程数据仓库、数据平台和数据中台的概念数据仓库、数据平台和数据中台的架构数据仓库、数据平台和数据中台的区别与联系
数据仓库应用实验 Analysis Service的安装与启动 为了使用SQL Server 2000 的数据仓库进行在线数据分析,除了安装数据库服务器外,还必须安装Analysis Service。 1.安装 下载提供的“Analysis Service”压缩包,解压后,双击“autorun”,依次单击“SQL Server 2000 组件”\“安装Analysis Service”。 2.启动 单击“开始”\“程序”\“Microsoft SQL Server”\“Analysis Service”,即可进入Analysis Manager 的工作界面。 一、使用SQL Server创建数据仓库 在SQL Server 2000中,创建数据仓库(多维数据集)的总体步骤包括:设置ODBC数据源、建立数据库、建立数据库与ODBC数据源的连接、建立多维数据集、编辑多维数据集、设计存储和处理多维数据集。 (一)设置ODBC数据源 Microsoft SQL Server 2000的Analysis Service提供了一个样本数据集,存放在名为foodmart2000.mdb的ACCESS数据库中,在安装时已经自动建立了数据源。如果是用户自己建立的数据集,则在开始使用Analysis Manager之前,必须先在ODBC数据源管理器中设置相应的系统数据源,以便Analysis Service能够通过系统数据源与源数据连接,从而进行联机分析处理。如果源数据本身就存放在SQL Server中的,则不需要本过程。 以样本数据集foodmart2000.mdb为例,设置系统数据源的方法: (1)进入数据源管理器 对于Windows NT4.0的用户:单击“开始”—“设置”—“控制面板”—双击“数据源(ODBC)”; 对于Windows 2000 的用户:单击“开始”—“设置”—“控制面板”—双击“管理工具”—双击“数据源(ODBC)”。 (2)在“系统DSN”选项卡上单击“添加”按钮 (3)选择相应的驱动程序,本例为“Microsoft Access Driver(*.mdb)”,单击“完成”,弹出新的对话框。 (4)在“数据源名”框中输入用户自定义的数据源名称,此处为“FootMart2000”,然后在“数据库”下单击“选择”。 (5)在“选择数据库”对话框中浏览到“C:\Program Files\Microsoft Analysis Services\Samples”,然后单击“FoodMart2000.mdb”,单击“确定”。(假定Analysis Services 的安装目录为C:\Program Files\Microsoft Analysis Services)。 (6)单击“确定”,在“ODBC数据源管理器”对话框中再一次单击“确定”,完成数据源的设置。 (二)建立数据库 在设计多维数据集前,需要建立一个数据库结构,该数据库是存放多维数据集、角色、数据源、共享维度和挖掘模型的一种结构。然后和早期在ODBC数据源管理器中建立的数
武汉大学计算机学院 20XX级研究生“数据仓库和数据挖掘”课程期末考试试题 要求:所有的题目的解答均写在答题纸上,需写清楚题目的序号。每张答题纸都要写上姓名和学号。 一、单项选择题(每小题2分,共20分) 1. 下面列出的条目中,()不是数据仓库的基本特征。B A.数据仓库是面向主题的 B.数据仓库是面向事务的 C.数据仓库的数据是相对稳定的 D.数据仓库的数据是反映历史变化的 2. 数据仓库是随着时间变化的,下面的描述不正确的是()。 A.数据仓库随时间的变化不断增加新的数据内容 B.捕捉到的新数据会覆盖原来的快照 C.数据仓库随事件变化不断删去旧的数据内容C D.数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合 3. 以下关于数据仓库设计的说法中()是错误的。A A.数据仓库项目的需求很难把握,所以不可能从用户的需求出发来进行数据仓库的设计,只能从数据出发进行设计 B.在进行数据仓库主题数据模型设计时,应该按面向部门业务应用的方式来设计数据模型 C.在进行数据仓库主题数据模型设计时要强调数据的集成性 D.在进行数据仓库概念模型设计时,需要设计实体关系图,给出数据表的划分,并给出每个属性的定义域 4. 以下关于OLAP的描述中()是错误的。A A.一个多维数组可以表示为(维1,维2,…,维n) B.维的一个取值称为该维的一个维成员 C.OLAP是联机分析处理 D.OLAP是数据仓库进行分析决策的基础 5. 多维数据模型中,下列()模式不属于多维模式。D A.星型模式 B.雪花模式 C.星座模式 D.网型模式 6. 通常频繁项集、频繁闭项集和最大频繁项集之间的关系是()。C A.频繁项集?频繁闭项集?最大频繁项集 B.频繁项集?最大频繁项集?频繁闭项集 C.最大频繁项集?频繁闭项集?频繁项集 D.频繁闭项集?频繁项集?最大频繁项集
大数据理论与技术读书报告 -----K最近邻分类算法 指导老师: 陈莉 学生姓名: 李阳帆 学号: 201531467 专业: 计算机技术 日期 :2016年8月31日
摘要 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地提取出有价值的知识模式,以满足人们不同应用的需要。K 近邻算法(KNN)是基于统计的分类方法,是大数据理论与分析的分类算法中比较常用的一种方法。该算法具有直观、无需先验统计知识、无师学习等特点,目前已经成为数据挖掘技术的理论和应用研究方法之一。本文主要研究了K 近邻分类算法,首先简要地介绍了数据挖掘中的各种分类算法,详细地阐述了K 近邻算法的基本原理和应用领域,最后在matlab环境里仿真实现,并对实验结果进行分析,提出了改进的方法。 关键词:K 近邻,聚类算法,权重,复杂度,准确度
1.引言 (1) 2.研究目的与意义 (1) 3.算法思想 (2) 4.算法实现 (2) 4.1 参数设置 (2) 4.2数据集 (2) 4.3实验步骤 (3) 4.4实验结果与分析 (3) 5.总结与反思 (4) 附件1 (6)
1.引言 随着数据库技术的飞速发展,人工智能领域的一个分支—— 机器学习的研究自 20 世纪 50 年代开始以来也取得了很大进展。用数据库管理系统来存储数据,用机器学习的方法来分析数据,挖掘大量数据背后的知识,这两者的结合促成了数据库中的知识发现(Knowledge Discovery in Databases,简记 KDD)的产生,也称作数据挖掘(Data Ming,简记 DM)。 数据挖掘是信息技术自然演化的结果。信息技术的发展大致可以描述为如下的过程:初期的是简单的数据收集和数据库的构造;后来发展到对数据的管理,包括:数据存储、检索以及数据库事务处理;再后来发展到对数据的分析和理解, 这时候出现了数据仓库技术和数据挖掘技术。数据挖掘是涉及数据库和人工智能等学科的一门当前相当活跃的研究领域。 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地抽取出有价值的知识模式,以满足人们不同应用的需要[1]。目前,数据挖掘已经成为一个具有迫切实现需要的很有前途的热点研究课题。 2.研究目的与意义 近邻方法是在一组历史数据记录中寻找一个或者若干个与当前记录最相似的历史纪录的已知特征值来预测当前记录的未知或遗失特征值[14]。近邻方法是数据挖掘分类算法中比较常用的一种方法。K 近邻算法(简称 KNN)是基于统计的分类方法[15]。KNN 分类算法根据待识样本在特征空间中 K 个最近邻样本中的多数样本的类别来进行分类,因此具有直观、无需先验统计知识、无师学习等特点,从而成为非参数分类的一种重要方法。 大多数分类方法是基于向量空间模型的。当前在分类方法中,对任意两个向量: x= ) ,..., , ( 2 1x x x n和) ,..., , (' ' 2 ' 1 'x x x x n 存在 3 种最通用的距离度量:欧氏距离、余弦距 离[16]和内积[17]。有两种常用的分类策略:一种是计算待分类向量到所有训练集中的向量间的距离:如 K 近邻选择K个距离最小的向量然后进行综合,以决定其类别。另一种是用训练集中的向量构成类别向量,仅计算待分类向量到所有类别向量的距离,选择一个距离最小的类别向量决定类别的归属。很明显,距离计算在分类中起关键作用。由于以上 3 种距离度量不涉及向量的特征之间的关系,这使得距离的计算不精确,从而影响分类的效果。
浅谈数据仓库中的元数据管理技术 孙力君仇道霞方峻峰宋楠 山东省烟草公司信息中心 摘要:数据仓库是数据库的发展方向之一,对企业管理和决策支持起着重要的辅助作用。简要介绍了数据仓库和元数据的基本概念,重点阐述了元数据的概念、作用、CWM标准、来源,并就元数据具体应用进行了初步的研究和探讨。 关键词:数据仓库;元数据; 1. 引言 随着市场竞争的越来越激烈,烟草行业的信息化建设不断的深入发展,全行业形成了“以信息化带动烟草行业现代化建设”的基本共识,明确了“统一标准、统一平台、统一数据库、统一网络”,逐步实现系统集成、资源整合、信息共享的信息化建设总体要求,走过了“由基础性向应用性、由局部性向全局性、由分散性向集中性建设”的三个转变历程,初步形成了“数字烟草”的行业信息化建设格局,既对行业数据中心的建设提出了迫切的要求,也为行业数据中心建设奠定了坚实的基础。 随着数据库技术尤其是数据仓库技术的发展,人类能更容易获得自己需要的数据和信息,由于元数据是数据仓库中非常重要的组成部分,因此讨论和研究元数据在数据仓库中的作用和应用,具有非常重要的意义。 元数据管理是山东烟草数据中心建设的重要组成部分,元数据管理平台为用户提供高质量、准确、易于管理的数据,它贯穿数据中心构建、运行和维护的整
个生命周期。同时,在数据中心构建的整个过程中,数据源分析、ETL过程、数据库结构、数据模型、业务应用主题的组织和前端展示等环节,均需要通过相应的元数据的进行支撑。元数据管理的生命周期包括元数据获取和建立、元数据的存储、元数据浏览、元数据分析、元数据维护等部分。 通过元数据管理,形成整个系统信息数据资的准确视图,通过元数据的统一视图,缩短数据清理周期、提高数据质量以便能系统性地管理数据中心项目中来自各业务系统的海量数据,梳理业务元数据之间的关系,建立信息数据标准完善对这些数据的解释、定义,形成企业范围内一致、统一的数据定义,并可以对这些数据来源、运作情况、变迁等进行跟踪分析。完善数据中心的基础设施,通过精确把握经营数据来精确把握瞬息万变的市场竞争形式,使山东烟草在市场竞争中保持优势。 总的来说,元数据管理平台集成相关的元数据,形成企业的全局数据视图,提供企业级共享元数据的平台,是烟草业务系统的基础设施,对业务系统的发展、应用和数据质量的提升有着深远影响。 2.数据仓库概述 目前有关数据仓库的概念有多种,其中最经典的,引用最为广泛的定义是W.H.Inmon在《Building the Data Warehouse》一书中给出的,他指出:“数据仓库是面向主题的、集成的、随时间变化的、非易失的数据集合,用于支持管理层的决策过程”。[1] 之所以要引入数据仓库,是因为随着信息时代的到来,如何从大量已存在的数据中提取出自己所感兴趣的信息并进行分析和预测越来越成为企业管理者和决策者所关心的问题。为了更好的进行管理和决策,许多企业都选择了数据仓库,利用数据仓库可以对各种源数据进行抽取、清理、加工
《数据仓库与数据挖掘技术》课程实验指导书 实验一:数据仓库模型设计 一、实验目的 1.掌握数据仓库需求分析方法。 2.掌握数据仓库体系统构设计方法。 3.掌握数据仓库概念模型、逻辑模型、物理模型的设计方法。 4.掌握数据仓库粒度模型设计方法。 5.熟悉PowerDesigner工具的应用。 二、实验题目 某大型连锁超市的业务涵盖了3个省范围的1000多家门市,每个门市都有较完整的日用品和食品销售部门,包括百货、杂货、冷冻食品、奶制品、肉制品和面包食品等,大约5万多种,其中大约45000种商品来自外部生产厂家,并在包装上印有条形码。每个条形码代表唯一的商品。为该超市建立一个能够提高市场竞争能力的数据仓库。 三、实验步骤 1、根据题目要求,查询相关资料进行有效的需求分析,并书写需求分析文档。 2、根据需求分析结果设计数据仓库体系统构,画出数据仓库体系结构图。 3、根据需求分析结果进行数据仓库模型设计。 1)确定主要主题域,画出主要主题域的概念模型(用ERD表示,参见书中P77图3.3)(手工设计) 2)画出星型模型。(手工设计) 3)将星型模型转成逻辑模型,给出事实表与维表。(手工设计) 4)进行物理模型设计。(手工设计) 5)进行粒度模型设计。 4、在PowerDesigner中建立星型模型并转成逻辑模型,在SQL SERVER2005中建立数据仓库数据库。(软件工具实现) 四、实验要求: 1)实验前将需求分析文档、数据仓库体系结构图、数据仓库模型设计文档 提交指导老师检阅,并与指导老师交流。 2)实验完成后,认真写出一份规范的实验报告,内容包括:实验名称、目的要求、设 计文档、实验结果分析、总结与讨论等。在报告中写出自己创新性,有独到之处的 见解,设计方案等。 3)将数据仓库数据库作好备份,以备下一个实验用。 五、实验小结
数据仓库与数据挖掘习题 1.1什么是数据挖掘?在你的回答中,强调以下问题: (a) 它是又一个骗局吗? (b) 它是一种从数据库,统计学和机器学习发展的技术的简单转换吗? (c) 解释数据库技术发展如何导致数据挖掘 (d) 当把数据挖掘看作知识发现过程时,描述数据挖掘所涉及的步骤。 1.2 给出一个例子,其中数据挖掘对于一种商务的成功至关重要的。这种商务需要什么数据挖掘功能?他们能够由数据查询处理或简单的统计分析来实现吗? 1.3 假定你是Big-University的软件工程师,任务是设计一个数据挖掘系统,分析学校课程数据库。该数据库包括如下信息:每个学生的姓名,地址和状态(例如,本科生或研究生),所修课程,以及他们累积的GPA(学分平均)。描述你要选取的结构。该结构的每个成分的作用是什么? 1.4 数据仓库和数据库有何不同?它们有那些相似之处? 1.5简述以下高级数据库系统和应用:面向对象数据库,空间数据库,文本数据库,多媒体数据库和WWW。 1.6 定义以下数据挖掘功能:特征化,区分,关联,分类,预测,聚类和演变分析。使用你熟悉的现实生活中的数据库,给出每种数据挖掘的例子。 1.7 区分和分类的差别是什么?特征化和聚类的差别是什么?分类和预测呢?对于每一对任务,它们有何相似之处? 1.8 根据你的观察,描述一种可能的知识类型,它需要由数据挖掘方法发现,但未在本章中列出。它需要一种不同于本章列举的数据挖掘技术吗? 1. 9 描述关于数据挖掘方法和用户交互问题的三个数据挖掘的挑战。 1. 10 描述关于性能问题的两个数据挖掘的挑战。 2.1 试述对于多个异种信息源的集成,为什么许多公司宁愿使用更新驱动的方法(构造使用数据仓库),而不愿使用查询驱动的方法(使用包装程序和集成程序)。描述一些情况,其中查询驱动方法比更新驱动方法更受欢迎。 2.2 简略比较以下概念,可以用例子解释你的观点 (a)雪花模式、事实星座、星型网查询模型 (b)数据清理、数据变换、刷新 (c)发现驱动数据立方体、多特征方、虚拟仓库 2.3 假定数据仓库包含三个维time,doctor和patient,两个度量count 和charge,其中charge 是医生对一位病人的一次诊治的收费。 (a)列举三种流行的数据仓库建模模式。 (b)使用(a)列举的模式之一,画出上面数据仓库的模式图。 (c)由基本方体[day,doctor,patient]开始,为列出2000年每位医生的收费总数,应当执行哪些OLAP操作? (d)为得到同样的结果,写一个SQL查询。假定数据存放在关系数据库中,其模式如下:fee(day,month,year,doctor,hospital,patient,count,charge) 2.4 假定Big_University的数据仓库包含如下4个维student, course, semester和instructor,2个度量count和avg_grade。在最低的概念层(例如对于给定的学生、课程、学期和教师的组合),度量avg_grade存放学生的实际成绩。在较高的概念层,avg_grade存放给定组合的
数据仓库与数据挖掘 实验报告 姓名:岩羊先生 班级:数技2011 学号:XXXXXX 实验日期:2013年11月14日
目录 实验 ........................................................................................................................ 错误!未定义书签。 【实验目的】....................................................................................... 错误!未定义书签。 1、熟悉SQLservermanager studio和VisualStudio2008软件功能和操作特点; ................................................................................................................ 错误!未定义书签。 2、了解SQLservermanager studio和VisualStudio2008软件的各选项面板和 操作方法; .............................................................................................. 错误!未定义书签。 3、熟练掌握SQLserver manager studio和VisualStudio2008工作流程。错误! 未定义书签。 【实验内容】....................................................................................... 错误!未定义书签。 1.打开SQLserver manager studio软件,逐一操作各选项,熟悉软件功能; (4) 2.根据给出的数据库模型“出版社销售图书Pubs”优化结构,新建立数据库并导 出; (4) 3.打开VisualStudio2008,导入已有数据库、或新建数据文件,设计一个“图书 销售分析”的多维数据集模型。并使用各种输出节点,熟悉数据输入输出。 (4) 【实验环境】....................................................................................... 错误!未定义书签。 【实验步骤】....................................................................................... 错误!未定义书签。 1.打开SQL Server manager studio; (5) 2.附加备份的数据库文件pubs_DW_Data.MDF和pubs_DW_Log.LDF并且做出
版本号: 数据仓库数据质量报告 项目名称:
变更记录 变更审阅
一、引言 1.编写目的 这部分说明文档编写目的,描述本系统特点及使用数据仓库技术实现的业务目标。 2.背景 这部分是项目背景描述。 3.参考资料 这部分列出本文档引用资料的名称,并说明文档上下级关系。 4.术语定义及说明 这部分列出本文档中使用的术语定义、缩写及其全名。 二、数据质量评估工作范围 1.本次数据质量评估的目标 这部分明确本次数据质量评估的目标,这些目标可能包括: ●识别数据质量的关键问题,以使这些问题可以通过源数据系统数据弥补、数据补充系统或者是ETL流程进行清洗等手段解决 ●建立管理和控制机制,并使之能在短期和长期均发挥监控数据环境的作用 ●建立在信贷信息数据仓库中管理及维护数据的长期计划 2.本次项目确定的数据质量标准 这部分将《软件需求说明书》中制定本项目数据质量标准复制到这里,作为本次数据质量评估交付时的标准。 3.参与本次评估的人员组成 这部分详细说明参与本次数据质量评估的人员组成和职责分工。 4.数据质量评估方法 这部分说明本次项目使用的数据质量评估方法,包括记录评估结果的表格样式、数据质量评估工作的流程、数据质量评估结果的认证流程、评估结果的交付流程等。
三、数据质量评估结果 1.数据源数据质量评估结果 这部分将《初级数据质量分析报告》作为附件添加到文档后。 2.数据仓库数据清洗转换规则 这部分根据《初级数据质量分析报告》的结果记录数据仓库数据清洗转换的规则,只针对重点数据域设计作出说明。 四、数据质量监控维护方案 1.数据质量监控团队组织 这部分将尽可能地定义数据质量监控团队人员的组成、角色和分工。 2.数据仓库数据质量问题管理 这部分记录明确执行数据仓库数据质量监控和修改流程的触发条件,包括质量问题的类型及质量分类的标准等。 3.数据仓库数据质量监控管理计划 这部分是针对可以预见的数据质量问题提出监控管理的计划,包括沟通途径、会议计划、管理流程等。 4.数据仓库数据质量修正方案 这部分将可能使用的数据质量修正方案列在其中,必要时需要提供详细的数据修改流程和计算公式。通用的修正方案包括在数据源中修改、在ETL程序中修改、在数据仓库里修改和使用数据补录程序修改。
4.4CRM数据仓库设计实验 从本节和第五节是CRM数据仓库的实验。利用SQL SERVER 2000为背景,介绍如何从无到有的生成CRM数据仓库,如何添加多维数据集,以及如何使用数据仓库进行多维分析等。使读者对客户关系数据仓库又一个直观的认识。本实验介绍客户关系管理数据仓库的设计,演示如何从已有的OLTP系统通过数据转移得到我们的数据仓库。 4.4.1SQL SERVER 2000数据仓库简介 为了满足现代企业对大规模数据进行有效分析和利用的要求,SQL Server 2000包含了一系列提取、分析、总结数据的工具,从而使联机分析处理成为可能。Microsoft将OLAP 功能集成到Microsoft SQL Server中,提供可扩充的基于COM的OLAP接口。它通过一系列服务程序支持数据仓库应用。数据传输服务DTS(Data Transformation Services)提供数据输入/输出和自动调度功能,在数据传输过程中可以完成数据的验证、清洗和转换等操作,通过与Microsoft Repository集成,共享有关的元数据;Microsoft Repository存储包括元数据在内的所有中间数据;SQL Server OLAP Services支持在线分析处理;PivotTable Services 提供客户端OLAP数据访问功能,通过这一服务,开发人员可以用VB或其他语言开发用户前端数据展现程序,PivotTable Services还允许在本地客户机上存储数据;MMC(Microsoft Management Console)提供日程安排、存储管理、性能监测、报警和通知的核心管理服务;Microsoft Office 2000套件中的Access和Excel可以作为数据展现工具,另外SQL Server 还支持第三方数据展现工具。 4.4.2概念模型设计 数据仓库的设计首先是概念模型的设计,这也是决定数据仓库实施效果的重要一步。数据仓库是是面向主题、集成的、相对稳定的、反映历史变化的数据集合。它整合了在线联机处理过程中的产生的零散的、杂乱的、面向处理的数据,形成统一的面向主题的数据集合。在客户关系管理中,客户数据的处理一般面向几个核心的主题:客户销售事实信息、客户销售机会信息、客户客户抱怨信息、客户关怀信息等。 数据仓库的数据模型多采用星型关系构架,以一个核心的主题数据表(称为事实表)为中心,其他关系表(维表)通过竹键外键关系同主体数据表关联,维表之间没有直接的关联关系。这同交易数据库中表与表之间的网状模型对应。例如,客户抱怨作为一个主题,其星型构架由一个实事表和五个维表构成,如图4.5。
数据仓库与数据挖掘学习心得 通过数据仓库与数据挖掘的这门课的学习,掌握了数据仓库与数据挖掘的一些基础知识和基本概念,了解了数据仓库与数据库的区别。下面谈谈我对数据仓库与数据挖掘学习心得以及阅读相关方面的论文的学习体会。 《浅谈数据仓库与数据挖掘》这篇论文主要是介绍数据仓库与数据挖掘的的一些基本概念。数据仓库是支持管理决策过程的、面向主题的、集成的、稳定的、不同时间的数据集合。主题是数据数据归类的标准,每个主题对应一个客观分析的领域,他可为辅助决策集成多个部门不同系统的大量数据。数据仓库包含了大量的历史数据,经集成后进入数据仓库的数据极少更新的。数据仓库内的数据时间一般为5年至10年,主要用于进行时间趋势分析。数据仓库的数据量很大。 数据仓库的特点如下: 1、数据仓库是面向主题的; 2、数据仓库是集成的,数据仓库的数据有来自于分散的操作型数据,将所需数据从原来的数据中抽取出来,进行加工与集成,统一与综合之后才能进入数据仓库; 3、数据仓库是不可更新的,数据仓库主要是为决策分析提供数据,所涉及的操作主要是数据的查询; 4、数据仓库是随时间而变化的,传统的关系数据库系统比较适合处理格式化的数据,能够较好的满足商业商务处理的需求,它在商业领域取得了巨大的成功。
作为一个系统,数据仓库至少包括3个基本的功能部分:数据获取:数据存储和管理;信息访问。 数据挖掘的定义:数据挖掘从技术上来说是从大量的、不完全的、有噪音的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在的有用的信息和知识的过程。 数据开采技术的目标是从大量数据中,发现隐藏于其后的规律或数据间的的关系,从而服务于决策。数据挖掘的主要任务有广义知识;分类和预测;关联分析;聚类。 《数据仓库与数据挖掘技术在金融信息化中的应用》论文主要通过介绍数据额仓库与数据挖掘的起源、定义以及特征的等方面的介绍引出其在金融信息化中的应用。在金融信息化的应用方面,金融机构利用信息技术从过去积累的、海量的、以不同形式存储的数据资料里提取隐藏着的许多重要信息,并对它们进行高层次的分析,发现和挖掘出这些数据间的整体特征描述及发展趋势预测,找出对决策有价值的信息,以防范银行的经营风险、实现银行科技管理及银行科学决策。 现在银行信息化正在以业务为中心向客户为中心转变6银行信息化不仅是数据的集中整合,而且要在数据集中和整合的基础上向以客为中心的方向转变。银行信息化要适应竞争环境客户需求的变化,创造性地用信息技术对传统过程进行集成和优化,实现信息共享、资源整合综合利用,把银行的各项作用统一起来,优势互补统一调配各种资源,为银行的客户开发、服务、综理财、管理、风险防范创立坚实的基础,从而适应日益发展的数据技术需要,全面提高银行竞争力,为金融创新和提高市场反映能力