hbase shell 常用命令
- 格式:docx
- 大小:16.97 KB
- 文档页数:4

HBaseshell命令情况总结通过shell操作HBase(在C60U10版本)1.登录连接客户端所在服务器:**************.0.24进⼊安装⽬录:cd /opt/hadoopclient导⼊环境变量:source bigdata_env进⼊HBase: cd HBase/hbase/bin启动HBase: hbase shell注:此版本不需要认证(查看是否认证klist,认证kinit ⽤户名)(admin Huawei@123)2.HBase shell命令2.1.⼀般操作2.1.1.查询服务器状态:status语法:status⽰例:四个服务器2.1.2.查询HBase版本:version语法:version⽰例:2.1.3.查看当前⽤户:whoami语法:whoami⽰例:2.1.4.退出HBase shell:exit语法:exit⽰例:2.1.5.关闭HBase集群:shutdown语法:shutdown说明:shutdown表⽰关闭HBase服务,必须重新启动HBase才可以恢复,exit只是退出HBase shell,退出之后完全可以重新进⼊。
⽰例:2.1.6.帮助命令:help “命令”语法:help “命令”2.2.DDL操作2.2.1.创建表:create语法:create ‘表名’, {NAME=>’列族名’,VERSIONS=>版本数},{…},…说明:定义表的时候只需要指定列族名,列名在put时动态指定。
⽰例:创建⼀个表名为t1含有三个列族f1,f2,f3。
只指定列族名时可以如下简写。
2.2.2.删除表:drop语法:drop ‘表名’说明:⾸先disable,然后drop⽰例:2.2.3.查看表结构:describe语法:describe ‘表名’说明:只能查看到列族,对列族下的列怎么查看?⽰例:2.2.4.修改表结构:alter语法:说明:修改表结构前必须先disable⽰例1:添加⼀个列族,添加列族f4⽰例2:删除⼀个列族,删除列族f4.⽰例3:修改列族属性,将f1,f2,f3的VERSIONS修改为3⽰例4:修改表属性,如MAX_FILESIZE,MEMSTORE_FLUSHSIZE,READONLY, DEFERRED_LOG_FLUSH ⽰例5:添加⼀个表协同处理器2.2.5.列出所有表:list语法:list⽰例:下⾯显⽰三个表2.2.6.查询表是否存在:exists语法:exists ‘表名’⽰例:2.2.7.查询表是否可⽤:enable,disable,is_enabled,is_disabled语法:enable ‘表名’,disable ‘表名’,is_enabled ‘表名’,is_disabled ‘表名’⽰例:2.3.DML操作2.3.1.添加记录:put语法:put ‘表名’, ’⾏键名’, ’列族名:列名’, ’值’, ‘时间戳’说明:⼀次只能向指定⾏的⼀个列族中的⼀个列put⼀个值,因此必须指定⾏名,列族名:列名。

Hbaseshell命令基本操作Hbase shell命令基本操作1、进⼊Hbase shell客户端命令操作界⾯如果配置过hbase环境变量hbase shell如果没有配置过环境变量# 进⼊hbase⽂件夹中cd /hc/install/hbase-2.2.6/bin/hbase shell2、help帮助命令help# 查看具体命令的帮助信息help 'create'3、list查看有哪些表list4、create创建表创建user表,包含info、data两个列族使⽤create命令create 'user', 'info', 'data'#或者create 'user',{NAME => 'info', VERSIONS => '3'},{NAME => 'data'}5、put 插⼊数据操作向表中插⼊数据使⽤put命令#向user表中插⼊信息,row key为rk0001,列族info中添加名为name的列,值为zhangsanput 'user', 'rk0001', 'info:name', 'zhangsan'#向user表中插⼊信息,row key为rk0001,列族info中添加名为gender的列,值为femaleput 'user', 'rk0001', 'info:gender', 'female'#向user表中插⼊信息,row key为rk0001,列族info中添加名为age的列,值为20put 'user', 'rk0001', 'info:age', 20#向user表中插⼊信息,row key为rk0001,列族data中添加名为pic的列,值为pictureput 'user', 'rk0001', 'data:pic', 'picture'6、查询数据操作6.1 通过rowkey进⾏查询获取user表中row key为rk0001的所有信息(即所有cell的数据)使⽤get命令get 'user', 'rk0001'6.2 查看rowkey下某个列族的信息获取user表中row key为rk0001,info列族的所有信息get 'user', 'rk0001', 'info'6.3 查看rowkey指定列族指定字段的值获取user表中row key为rk0001,info列族的name、age列的信息get 'user', 'rk0001', 'info:name', 'info:age'6.4 查看rowkey指定多个列族的信息获取user表中row key为rk0001,info、data列族的信息get 'user', 'rk0001', 'info', 'data'#或者你也可以这样写get 'user', 'rk0001', {COLUMN => ['info', 'data']}#或者你也可以这样写,也⾏get 'user', 'rk0001', {COLUMN => ['info:name', 'data:pic']}6.5 指定rowkey与列值过滤器查询获取user表中row key为rk0001,cell的值为zhangsan的信息get 'user', 'rk0001', {FILTER => "ValueFilter(=, 'binary:zhangsan')"}4.6.6 指定rowkey与列名模糊查询获取user表中row key为rk0001,列标⽰符中含有a的信息get 'user', 'rk0001', {FILTER => "QualifierFilter(=,'substring:a')"}6.7 查询所有⾏的数据查询user表中的所有信息使⽤scan命令scan 'user'6.8 列族查询查询user表中列族为info的信息scan 'user', {COLUMNS => 'info'}#当把某些列的值删除后,具体的数据并不会马上从存储⽂件中删除;查询的时候,不显⽰被删除的数据;如果想要查询出来的话,RAW => true scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 5}scan 'user', {COLUMNS => 'info', RAW => true, VERSIONS => 3}6.9 多列族查询查询user表中列族为info和data的信息scan 'user', {COLUMNS => ['info', 'data']}6.10 指定列族与某个列名查询查询user表中列族为info、列标⽰符为name的信息scan 'user', {COLUMNS => 'info:name'}查询info:name列、data:pic列的数据scan 'user', {COLUMNS => ['info:name', 'data:pic']}查询user表中列族为info、列标⽰符为name的信息,并且版本最新的5个scan 'user', {COLUMNS => 'info:name', VERSIONS => 5}6.11 指定多个列族与条件模糊查询查询user表中列族为info和data且列标⽰符中含有a字符的信息scan 'user', {COLUMNS => ['info', 'data'], FILTER => "QualifierFilter(=,'substring:a')"}6.12 指定rowkey的范围查询查询user表中列族为info,rk范围是[rk0001, rk0003)的数据scan 'user', {COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'}6.13 指定rowkey模糊查询查询user表中row key以rk字符开头的数据scan 'user',{FILTER=>"PrefixFilter('rk')"}6.14 指定数据版本的范围查询查询user表中指定范围的数据(前闭后开)scan 'user', {TIMERANGE => [1392368783980, 1610288780669]}7、更新数据操作7.1 更新数据值更新操作同插⼊操作⼀模⼀样,只不过有数据就更新,没数据就添加使⽤put命令7.2 更新版本号将user表的info列族版本数改为5alter 'user', NAME => 'info', VERSIONS => 58、删除数据以及删除表操作8.1 指定rowkey以及列名进⾏删除删除user表row key为rk0001,列标⽰符为info:name的数据delete 'user', 'rk0001', 'info:name'8.2 指定rowkey,列名以及版本号进⾏删除删除user表row key为rk0001,列标⽰符为info:name,timestamp为1392383705316的数据delete 'user', 'rk0001', 'info:name', 13923837053168.3 删除⼀个列族删除⼀个列族:alter 'user', NAME => 'data', METHOD => 'delete'#或alter 'user', 'delete' => 'info'8.4 清空表数据truncate 'user'8.5 删除表⾸先需要先让该表为disable状态,使⽤命令:disable 'user'然后使⽤drop命令删除这个表drop 'user'(注意:如果直接drop表,会报错:Drop the named table. Table must first be disabled)。

HBase基础之Hbaseshell常⽤操作⼀般操作查看服务器状态status查看hbase版本versionDDL操作创建表create 'member','member_id','address','info'创建了3个列族,分别是member_id, address, info知识点回顾:cf是schema的⼀部分,⽽column不是。
查看表信息describe 'member'DESCRIPTION ENABLED'member', {NAME => 'address', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTE trueR => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => '2147483647', KEEP_DELETED_CELLS =>'false', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}, {NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => '2147483647', KEEP_DELETED_CELLS => 'false',BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}, {NAME => 'member_id', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW',REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => '2147483647', KEEP_DELETED_CELLS => 'false', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}1 row(s) in 0.1800 seconds查询所有的表list删除⼀个列族member表建了3个列族,但是发现member_id这个列族是多余的,因为他就是主键,所以我们要将其删除。

hbaseshell常⽤命令1、查看读取器状态status2、查看hbase版本version3、创建⼀个表:格式: create 表名,列簇1,列簇2...列簇Ncreate ‘member’,'member_id','address','info'4、查看表描述describe 'member'5、删除⼀个列簇:先关闭,再更新,再打开disable 'member'alter'member',NAME=>'member_id',METHOD=>'delete'enable 'member'6、列出所有表list7、删除⼀个表:先关闭,再删除disable 'member'drop 'member'8、查询表是否存在exists 'member'9、判断表是否enableis_enabled 'member'10、判断表是否disableis_disabled 'member'11、插⼊数据:在列簇中插⼊数据:格式:put 表名,⾏键id,列簇名:列名,值put 'member','xiaoming','address:contry','china'put 'member','xiaoming','address:province','sc'put 'member','xiaoming','address:city','cd'put 'member','xiaoming','info:age','25'put 'member','xiaoming','info:birthday','1992-10-21'put 'member','xiaoming','info:company','alibaba'12、获取⼀个id的所有数据get 'member','xiaoming'13、获取⼀个id,⼀个列族的所有数据get 'member','xubiao','info'14、获取⼀个id,⼀个列族中⼀个列的所有数据get 'member','xiaoming,'info:age'15、更新⼀条记录:给rowId重新put即可,put 'member','xiaoming','info:age','26' // 把xiaoming的age改为2616、通过timestamp来获取两个版本的数据get 'member','xiaoming',{COLUMN=>'info:age',TIMESTAMP=>1510840447626}17、全表扫描scan 'member'18、删除id为xiaomiing的值的'info:age'字段delete 'member','xiaoming','info:age'19、删除整⾏deteleall 'member','xiaoming'20、查询表中有多少⾏count 'member'21、将整张表清空:实际执⾏过程:hbase是先将表disable,然后drop,后重建表,来实现truncate的功能的truncate 'member'总结可以加深印象,同时还能为⼤家提供⽅便。

HBaseShell脚本命令1、启动Hbase整个集群:$HBASE_HOME/bin/start-hbase.shbin/start-hbase.sh前者在服务器任意位置执⾏都ok,后者必须在安装路径下执⾏才有效,其实$HBASE_HOME的作⽤就是调⽤Hbase的安装路径2、停⽌Hbase整个集群:$HBASE_HOME/bin/stop-hbase.shbin/stop-hbase.sh前者在服务器任意位置执⾏都ok,后者必须在安装路径下执⾏才有效3、启动或停⽌,所有的regionserver或zookeeper或backup-master :$HBASE_HOME/bin/hbase-daemons.shbin/hbase-daemons.sh前者在服务器任意位置执⾏都ok,后者必须在安装路径下执⾏才有效4、启动或停⽌,单个master或regionserver或zookeeper :$HBASE_HOME/bin/hbase-daemon.shbin/hbase-daemon.sh前者在服务器任意位置执⾏都ok,后者必须在安装路径下执⾏才有效6、进⼊shell命令模式:$HBASE_HOME/bin/hbase shell7、HBase的⼀些基本操作命令,我列出了⼏个常⽤的HBase Shell命令,如下:8、脚本之间的调⽤关系:(1)、start-hbase.sh流程:a.运⾏hbase-config.sh(hbase-config.sh的作⽤是装载相关配置,如hbase_home⽬录,conf⽬录,regionserver机器列表,java_home⽬录等,他会调⽤$HBASE_HOME/conf/hbase-env.sh)b.解析参数(0.96后的版本可以带唯⼀参数autorestart(重启))c.调⽤hbase-daemon.sh来启动master;调⽤hbase-daemon.sh来启动regionserver、zookeeper、master-backup9、hbase-env.sh的作⽤:主要配置JVM及其GC参数,还可以配置log⽬录及参数,配置是否需要hbase管理zk,配置进程id⽬录等10、hbase-daemon.sh的作⽤:根据需要启动的进程,eg:为zookeeper,则调⽤zookeepers.sh;为regionserver,则调⽤regionserver.sh;为master-backup,则调⽤master-backup.sh11、zookeeper.sh的作⽤:如果hbase-env.sh中的HBASE_MANAGES_ZK=True/Flase,那么通过ZKServerTool这个类解析xml配置⽂件,获取ZK节点列表(即hbase.zookeeper.quorum的配置值),然后通过ssh向这些节点发送远程命令:cd ${HBASE_HOME}$bin/hbase-daemon.sh --config S{HBASE_CONF_DIR} start/stop zookeeper12、regionserver.sh的作⽤:与zookeepers.sh类似,通过${HBASE_CONF_DIR}/regionservers配置⽂件,获取regionserver机器列表,然后SSH向这些机器发送远程命令:cd ${HBASE_HOME};$bin/hbase-daemon.sh --config ${HBASE_CONF_DIR} start/stop regionserver13、master-backup.sh的作⽤:通过${HBASE_CONF_DIR}/backup-masters这个配置⽂件,获取backup-masters机器列表(默认配置中,这个配置⽂件是不存在的,所有并不会启动backup-master),然后ssh向这些机器发送远程命令:cd ${HBASE_HOME}$bin/hbase-daemon.sh --config ${HBASE_CONF_DIR} start/stop master --backup14、hbase-daemin.sh的作⽤:⽆论是zookeepers.sh还是regionservers.sh或是master-backup.sh,最终都会调⽤本地的hbase-daemon.sh,其执⾏过程如下:(1)、运⾏hbase-config.sh,装载各种配置(java环境、log配置、进程ID⽬录等)(2)、如果是start命令,滚动out输出⽂件,滚动gc⽇志⽂件,⽇志⽂件中输出启动时间+ulimit -a信息,如“Mon Nov 26 10:31:42 CST 2012 Starting master on dwxx.yy.taobao”"..open files (-n) 65536.."(3)、调⽤$HBASE_HOME/bin/hbase start master/regionserver/zookeeper(4)、执⾏wait,等待3中开启的进程结束(5)、执⾏cleanZNode,将regionserver在zk上登记的节点删除,这样做的⽬的是:在regionserver进程意外退出的情况下,可以免去3分钟的ZK⼼跳超时等待,直接由master进⾏宕机恢复(6)、如果是stop命令?根据进程ID,检查进程是否存在;调⽤kill命令,然后等待到进程不存在为⽌(7)、如果是restart命令,调⽤stop后,再调⽤start15、$HBASE_HOME/bin/hbase的作⽤:(1)、可以通过$HBASE_HOME/bin/hbase查看其usage(2)、bin/hbase shell,这个就是常⽤的shell⼯具,运维常⽤的DDL和DML都会通过此进⾏,其具体实现(对hbase的调⽤)是⽤ruby写的(3)、bin/hbase hbck, 运维常⽤⼯具,检查集群的数据⼀致性状态,其执⾏是直接调⽤ org.apache.hadoop.hbase.util.HBaseFsck中的main 函数(4)、bin/hbase hlog, log分析⼯具,其执⾏是直接调⽤org.apache.hadoop.hbase.regionserver.wal.HLogPrettyPrinter中的main函数(5)、bin/hbase hfile, hfile分析⼯具,其执⾏是直接调⽤org.apache.hadoop.hbase.io.hfile.HFile中的main函数(6)、bin/hbase zkcli,查看/管理ZK的shell⼯具,很实⽤,经常⽤,⽐如你可以通过(get /hbase-tianwu-94/master)其得知当前的active master,可以通过(get /hbase-tianwu-94/root-region-server)得知当前root region所在的server,你也可以在测试中通过(delete /hbase-tianwu-94/rs/dwxx.yy.taobao),模拟regionserver与ZK断开连接,其执⾏则是调⽤了org.apache.zookeeper.ZooKeeperMain的main函数(7)、回归到刚才hbase-daemon.sh对此脚本的调⽤为:$HBASE_HOME/bin/hbase start master/regionserver/zookeeper 其执⾏则直接调⽤org.apache.hadoop.hbase.master.HMasterorg.apache.hadoop.hbase.regionserver.HRegionServerorg.apache.hadoop.hbase.zookeeper.HQuorumPeer 的main函数,⽽这些main函数就是了new⼀个了RunnableHMaster/HRegionServer/QuorumPeer,在不停的Running(8)、bin/hbase classpath 打印classpath(9)、bin/hbase version 打印hbase版本信息(10)、bin/hbase CLASSNAME,这个很实⽤,所有实现了main函数的类都可以通过这个脚本来运⾏,⽐如前⾯的hlog hfile hbck⼯具,实质是对这个接⼝的⼀个快捷调⽤,⽽其他未提供快捷⽅式的class我们也可以⽤这个接⼝调⽤,如Region merge 调⽤:$HBASE_HOME/bin/hbase/org.apache.hadoop.hbase.util.Merge16、注意:(1)、hbase-daemon.sh start master 与 hbase-daemon.sh start master --backup,这2个命令的作⽤⼀样的,是否成为backup或active是由master的内部逻辑来控制的(2)、stop-hbase.sh 不会调⽤hbase-daemons.sh stop regionserver 来关闭regionserver,但是会调⽤hbase-daemons.sh stop zookeeper/master-backup来关闭zk和backup master,关闭regionserver实际调⽤的是hbaseAdmin的shutdown接⼝(3)、通过$HBASE_HOME/bin/hbase stop master关闭的是整个集群⽽⾮单个master,只关闭单个master的话使⽤$HBASE_HOME/bin/hbase-daemon.sh stop master(4)、$HBASE_HOME/bin/hbase stop regionserver/zookeeper 不能这么调,调了也会出错,也没有路径会调⽤这个命令,但是可以通过$HBASE_HOME/bin/hbase start regionserver/zookeeper 来启动rs或者zk,hbase-daemon.sh调⽤的就是这个命令。

hbase shell 常用命令HBase Shell 是用于与 HBase 进行交互的命令行工具。
它提供了丰富的命令来管理和操作 HBase 数据库。
下面会详细介绍一些常用的 HBase Shell 命令。
1. 创建表命令:create 'table_name', 'column_family'这个命令用于创建一个新的表。
你需要指定表的名称和列族名称。
列族是表的主要组成部分,用于组织数据。
2. 查看表列表命令:list使用该命令可以列出当前 HBase 中所有的表。
3. 查看表结构命令:describe 'table_name'此命令用于获取指定表的详细结构信息,包括表名、列族以及相关选项。
4. 插入数据命令:put 'table_name', 'row_key', 'column_family:column', 'value'使用该命令可以向指定的表中插入数据。
你需要提供表名、行键、列族、列和值。
5. 查询数据命令:get 'table_name', 'row_key'通过该命令可以根据行键从指定的表中获取数据。
6. 扫描表命令:scan 'table_name'该命令用于扫描整个表的数据,返回结果包括表中的所有行。
7. 删除数据命令:delete 'table_name', 'row_key', 'column_family:column'使用该命令可以删除表中指定行键和列族的数据。
8. 禁用表命令:disable 'table_name'9. 删除表命令:drop 'table_name'该命令用于永久删除指定的表及其所有相关数据。
10. 退出 HBase Shell:exit使用 exit 命令可以退出 HBase Shell。

Hbase常⽤操作命令Hbase常⽤操作命令1. 进⼊hbase./hbase shell参数说明1. 进⼊到hbase⽬录并进⼊hbase2. 浏览所有表list参数说明1. 查看表列表3. 查看表结构describe 'BizvaneV2.VipSearch'参数说明1. describe 动作命令,BizvaneV2.VipSearch 为要查看表结构的表名4. 创建表create 'UserInfo', { NAME => 'info', REPLICATION_SCOPE => '1' }参数说明1. create 动作命令,UserInfo 为要创建的表名2. NAME 列族名,info 为列族名称3. REPLICATION_SCOPE 是否复制,0为不复制,1为复制5. 修改表结构disable 'UserInfo'alter 'UserInfo', {NAME => 'extendInfo', REPLICATION_SCOPE => '1'}describe 'UserInfo'参数说明修改表结构要使表不启⽤状态1. disable 动作命令,使要修改结构的表⽆效,UserInfo 为表名2. 修改命令1. alter 动作命令2. UserInfo 要修改的表名称3. {NAME => 'extendInfo', REPLICATION_SCOPE => '1'} 要修改的结构体3. describe 动作命令,查看表结构描述,验证是否修改成功6. 添加数据put 'UserInfo','row_1','info:firstname','liu'参数说明1. 添加命令1. put 动作命令,2. UserInfo 要添加数据的表名称3. row_1 数据⾏4. info:firstname 列及列名字5. liu 要添加的值7. 查看数据scan 'UserInfo'参数说明1. scan 动作命令1. 要查看表的名称8. 修改数据put 'UserInfo','row_1','info:firstname','liu_copy'参数说明1. 添加命令1. put 动作命令,2. UserInfo 要修改数据的表名称3. row_1 数据⾏4. info:firstname 列及列名字5. liu 新数据值9. 删除数据delete 'UserInfo','row_1','info:firstname'参数说明1. 删除命令1. delete 动作命令,2. UserInfo 要修改数据的表名称3. row_1 数据⾏4. info:firstname 列及列名字10. 删除表disable 'UserInfo'drop 'UserInfo'参数说明修改表结构要使表不启⽤状态1. 删除命令1. disable 使表不启⽤,UserInfo 要不启⽤的表名称2. drop 删除命令 UserInfo 要删除的表名称11. 帮助help参数说明1. help 帮助命令,可以查看Hbase提供的命令清单。

hbase shell的基本命令HBase是一个分布式、可扩展的面向列的NoSQL数据库,它运行在Hadoop集群之上。
HBase提供了一个交互式的命令行工具——HBase Shell,用于与HBase进行交互操作。
本文将介绍HBase Shell的基本命令,包括创建表、插入数据、查询数据、删除数据等操作。
一、连接HBase我们需要使用HBase Shell连接到HBase数据库。
在命令行中输入"hbase shell",即可进入HBase Shell环境。
二、创建表创建表是使用HBase的第一步。
在HBase Shell中,使用"create"命令可以创建表。
例如,我们可以创建一个名为"student"的表,其中包含"info"和"score"两个列族。
具体命令如下:create 'student', 'info', 'score'三、插入数据创建完表之后,我们可以使用"put"命令向表中插入数据。
插入数据需要指定表名、行键、列族、列和值。
以下是插入一条学生信息的命令示例:put 'student', '1001', 'info:name', 'Tom'put 'student', '1001', 'score:math', '90'put 'student', '1001', 'score:english', '85'四、查询数据使用HBase Shell可以方便地查询表中的数据。
通过"get"命令可以根据行键获取对应的数据。
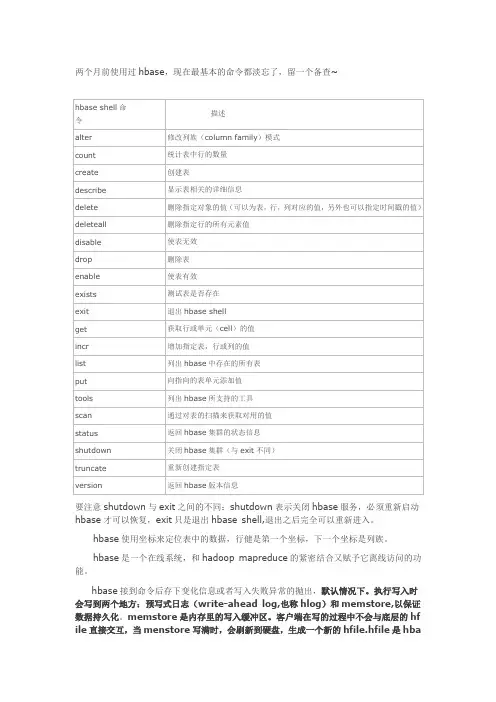
两个月前使用过hbase,现在最基本的命令都淡忘了,留一个备查~要注意shutdown与exit之间的不同:shutdown表示关闭hbase服务,必须重新启动hbase才可以恢复,exit只是退出hbase shell,退出之后完全可以重新进入。
hbase使用坐标来定位表中的数据,行健是第一个坐标,下一个坐标是列族。
hbase是一个在线系统,和hadoop mapreduce的紧密结合又赋予它离线访问的功能。
hbase接到命令后存下变化信息或者写入失败异常的抛出,默认情况下。
执行写入时会写到两个地方:预写式日志(write-ahead log,也称hlog)和memstore,以保证数据持久化。
memstore是内存里的写入缓冲区。
客户端在写的过程中不会与底层的hf ile直接交互,当menstore写满时,会刷新到硬盘,生成一个新的hfile.hfile是hbase使用的底层存储格式。
menstore的大小由hbase-site.xml文件里的系统级属性h base.hregion.memstore.flush.size来定义。
hbase在读操作上使用了lru缓存机制(blockcache),blockcache设计用来保存从hfile里读入内存的频繁访问的数据,避免硬盘读。
每个列族都有自己的blockcache。
b lockcache中的block是hbase从硬盘完成一次读取的数据单位。
block是建立索引的最小数据单位,也是从硬盘读取的最小数据单位。
如果主要用于随机查询,小一点的block会好一些,但是会导致索引变大,消耗更多内存,如果主要执行顺序扫描,大一点的bloc k会好一些,block变大索引项变小,因此节省内存。
LRU是Least Recently Used 近期最少使用算法。
内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据。

hbase shell命令总结HBase Shell是HBase的命令行界面,用于与HBase进行交互。
以下是一些常用的HBase Shell命令和它们的功能总结:1. `help 'command'`:显示指定命令的帮助信息。
2. `status`:显示HBase集群的状态信息。
3. `list`:列出当前存在的所有表。
4. `create 'table', 'column_family'`:创建一个新表,并指定列族。
5. `disable 'table'`:禁用指定的表。
6. `enable 'table'`:启用指定的表。
7. `describe 'table'`:显示指定表的结构信息。
8. `alter 'table', {NAME=>'column_family', VERSIONS=>num}`:修改表的列族属性,如版本数。
9. `put 'table', 'rowkey', 'column_family:column', 'value'`:向指定表中插入或更新数据。
10. `get 'table', 'rowkey'`:获取指定表中指定行的数据。
11. `scan 'table'`:扫描指定表中的所有数据。
12. `delete 'table', 'rowkey', 'column_family:column'`:删除指定表中指定行列的数据。
13. `deleteall 'table', 'rowkey'`:删除指定表中指定行的所有数据。
14. `truncate 'table'`:删除指定表的所有数据。

HBaseshell常⽤命令总结 HBase shell常⽤命令总结 作者:尹正杰版权声明:原创作品,谢绝转载!否则将追究法律责任。
⼀.查看hbase脚本的帮助信息[root@ ~]# hbase #在命令⾏中直接敲击"hbase"就会弹出该脚本的帮助信息。
Usage: hbase [<options>] <command> [<args>]Options:--config DIR Configuration direction to use. Default: ./conf--hosts HOSTS Override the list in'regionservers'file--auth-as-server Authenticate to ZooKeeper using servers configuration--internal-classpath Skip attempting to use client facing jars (WARNING: unstable results between versions)Commands:Some commands take arguments. Pass no args or -h for usage.shell Run the HBase shellhbck Run the HBase 'fsck' tool. Defaults read-only hbck1.Pass '-j /path/to/HBCK2.jar' to run hbase-2.x HBCK2.snapshot Tool for managing snapshotswal Write-ahead-log analyzerhfile Store file analyzerzkcli Run the ZooKeeper shellmaster Run an HBase HMaster noderegionserver Run an HBase HRegionServer nodezookeeper Run a ZooKeeper serverrest Run an HBase REST serverthrift Run the HBase Thrift serverthrift2 Run the HBase Thrift2 serverclean Run the HBase clean up scriptclasspath Dump hbase CLASSPATHmapredcp Dump CLASSPATH entries required by mapreducepe Run PerformanceEvaluationltt Run LoadTestToolcanary Run the Canary toolversion Print the versioncompletebulkload Run BulkLoadHFiles toolregionsplitter Run RegionSplitter toolrowcounter Run RowCounter toolcellcounter Run CellCounter toolpre-upgrade Run Pre-Upgrade validator toolhbtop Run HBTop toolCLASSNAME Run the class named CLASSNAME[root@ ~]#⼆.hbase shell常⽤命令总结1>.进⼊HBase的交互式命令⾏[root@ ~]# hbase shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/yinzhengjie/softwares/ha/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/yinzhengjie/softwares/hbase-2.2.4/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See /codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]HBase ShellUse "help" to get list of supported commands.Use "exit" to quit this interactive shell.For Reference, please visit: /2.0/book.html#shellVersion 2.2.4, r67779d1a325a4f78a468af3339e73bf075888bac, 2020年 03⽉ 11⽇星期三12:57:39 CSTTook 0.0020 secondshbase(main):001:0>[root@ ~]# hbase shell2>.查看帮助命令hbase(main):001:0> helpHBase Shell, version 2.2.4, r67779d1a325a4f78a468af3339e73bf075888bac, 2020年 03⽉ 11⽇星期三12:57:39 CSTType 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.COMMAND GROUPS:Group name: generalCommands: processlist, status, table_help, version, whoamiGroup name: ddlCommands: alter, alter_async, alter_status, clone_table_schema, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, list_regions, locate_region, show_filtersGroup name: namespaceCommands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tablesGroup name: dmlCommands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserveGroup name: toolsCommands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, cleaner_chore_enabled, cleaner_chore_run, cleaner_chore_switch, clear_block_cache, clear_compaction_queue , compact, compact_rs, compaction_state, compaction_switch, decommission_regionservers, flush, hbck_chore_run, is_in_maintenance_mode, list_deadservers, list_decommissioned_regionservers, major_compact, merge_region, move, norma Group name: replicationCommands: add_peer, append_peer_exclude_namespaces, append_peer_exclude_tableCFs, append_peer_namespaces, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication, get_peer_config, l ted_tables, remove_peer, remove_peer_exclude_namespaces, remove_peer_exclude_tableCFs, remove_peer_namespaces, remove_peer_tableCFs, set_peer_bandwidth, set_peer_exclude_namespaces, set_peer_exclude_tableCFs, set_peer_n Group name: snapshotsCommands: clone_snapshot, delete_all_snapshot, delete_snapshot, delete_table_snapshots, list_snapshots, list_table_snapshots, restore_snapshot, snapshotGroup name: configurationCommands: update_all_config, update_configGroup name: quotasCommands: disable_exceed_throttle_quota, disable_rpc_throttle, enable_exceed_throttle_quota, enable_rpc_throttle, list_quota_snapshots, list_quota_table_sizes, list_quotas, list_snapshot_sizes, set_quotaGroup name: securityCommands: grant, list_security_capabilities, revoke, user_permissionGroup name: proceduresCommands: list_locks, list_proceduresGroup name: visibility labelsCommands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibilityGroup name: rsgroupCommands: add_rsgroup, balance_rsgroup, get_rsgroup, get_server_rsgroup, get_table_rsgroup, list_rsgroups, move_namespaces_rsgroup, move_servers_namespaces_rsgroup, move_servers_rsgroup, move_servers_tables_rsgroup, move_ta rsgroupSHELL USAGE:Quote all names in HBase Shell such as table and column names. Commas delimitcommand parameters. Type <RETURN> after entering a command to run it.Dictionaries of configuration used in the creation and alteration of tables areRuby Hashes. They look like this:{'key1' => 'value1', 'key2' => 'value2', ...}and are opened and closed with curley-braces. Key/values are delimited by the'=>' character combination. Usually keys are predefined constants such asNAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type'Object.constants' to see a (messy) list of all constants in the environment.If you are using binary keys or values and need to enter them in the shell, usedouble-quote'd hexadecimal representation. For example:hbase> get 't1', "key\x03\x3f\xcd"hbase> get 't1', "key\003\023\011"hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added.For more on the HBase Shell, see /book.htmlhbase(main):002:0>hbase(main):001:0> help #会显⽰所有命令的帮助信息3>.查看当前名称空间有哪些表hbase(main):003:0> list #对于刚刚搭建的HBase集群,默认的数据库中是空的。
基本hbase shell操作指令hbase shell是hadoop数据库的命令行界面,可以使用hbase shell进行hadoop数据库的操作。
它的基本操作指令如下:1.启动hbase shell:在命令行中输入“hbase shell”,即可启动hbase shell。
2.查看hbase所有的表:使用list命令,输入“list”,即可查看当前hbase所有的表。
3.查看hbase某个表的列族:使用describe命令,输入“describe 'table_name'”,即可查看表名为table_name的表中的所有列族。
4.新建表:使用create命令,输入“create 'table_name','column_family_name'”,即可新建一个名字为table_name的表,其中包含一个名字为column_family_name的列族。
5.修改表:使用alter命令,输入“alter 'table_name','column_family_name', 'option'”,即可修改表名为table_name的表中的列族为column_family_name的选项为option。
6.删除表:使用drop命令,输入“drop 'table_name'”,即可删除表名为table_name的表。
7.插入数据:使用put命令,输入“put 'table_name','row_key', 'column_family_name:column_name', 'value'”,即可在表名为table_name中插入一条数据,它的行键为row_key,列名为column_family_name:column_name,值为value。
hbase基本shell命令1、hbase中的shell命令help查看命令的使⽤描述help '命令名'whoami⾝份(root、user)whoamiversion返回hbase版本信息versionstatus返回hbase集群的状态信息statustable_help查看如何操作表table_helpcreate创建表create '表名', '列族名1', '列族名2', '列族名N'alter修改列族添加列族:alter '表名', NAME=>'列族名'删除列族:alter '表名', {NAME=> '列族名', METHOD=> 'delete'} describe显⽰表相关的详细信息describe '表名'list列出hbase中存在的所有表listexists测试表是否存在exists '表名'put添加或修改的表的值put '表名', '⾏键', '列族名', '列值'put '表名', '⾏键', '列族名:列名', '列值'scan通过对表的扫描来获取对⽤的值scan '表名'扫描某个列族:scan '表名',{COLUMN=>'列族名',FORMATTER =>'toString'}扫描某个列族的某个列:scan '表名', {COLUMN=>'列族名:列名'}查询同⼀个列族的多个列: scan '表名', {COLUMNS => [ '列族名1:列名1', '列族名1:列名2' …]}get获取⾏或单元(cell)的值get '表名', '⾏键'get '表名', '⾏键', '列族名'count统计表中⾏的数量count '表名'incr增加指定表⾏或列的值incr '表名', '⾏键', '列族:列名', 步长值get_counter获取计数器get_counter '表名', '⾏键', '列族:列名'delete删除指定对象的值(可以为表,⾏,列对应的值,另外也可以指定时间戳的值)删除列族的某个列: delete 表名', '⾏键', '列族名:列名' deleteall删除指定⾏的所有元素值deleteall '表名', '⾏键'truncate重新创建指定表(清空表)truncate '表名'enable使表有效enable '表名'is_enabled是否启⽤is_enabled '表名'disable使表⽆效(删除表之前先禁⽤)disable '表名'is_disabled是否⽆效is_disabled '表名'drop删除表drop的表必须是disable的disable '表名'drop '表名'shutdown关闭hbase集群(与exit不同) shutdowntools列出hbase所⽀持的⼯具 toolsexit退出hbase shell1、使⽤help获得全部命令的列表,使⽤help ‘command_name’获得某⼀个命令的详细信息。
Hbase_02、Hbase的常⽤的shell命令Hbase的DDL操作Hbase的DML。
阅读⽬录前⾔笔者在分类中的Hbase栏⽬之前已经分享了hbase的安装以及⼀些常⽤的shell命令的使⽤,这⾥不仅仅重新复习⼀下shell命令,还会介绍hbase的DDL以及DML的相关操作。
⼀、hbase的shell操作1.1启动hbase shell在hbase的安装⽬录的bin⽬录下⾯启动我们的hbase,执⾏命令:hbase shell,执⾏效果以>结束,如下执⾏效果:hbase shell1.2执⾏hbase shell的帮助⽂档输⼊help并按Enter键,可以显⽰HBase Shell的基本使⽤信息,和我们接下来会列举的⼀些命令类似。
需要注意的是,表名,⾏,列都必须包含在引号内。
执⾏效果:help1.3退出hbase shell使⽤quit命令,退出HBase Shell 并且断开和集群的连接,但此时HBase仍然在后台运⾏。
1.4使⽤status命令查看hbase现在的状态hbase(main):004:0> status1 active master, 0 backup masters,2 servers, 0 dead, 1.0000 average load从上⾯可以看出⼀个master在运⾏,并且下⾯有两个服务器...没有备份的master,没有死亡的服务。
1.5使⽤version命令查看hbase的相关的版本hbase(main):005:0> version1.3.1, r930b9a55528fe45d8edce7af42fef2d35e77677a, Thu Apr 6 19:36:54 PDT 2017从上⾯可以看出版本是1.3.1版本的。
1.6table_help此命令将引导如何使⽤表引⽤的命令。
下⾯给出的是使⽤这个命令的语法:table_help1.7whoami该命令返回HBase⽤户详细信息。
HBASE常⽤shell命令,增删改查⽅法1、⾸先给出本次操作的数据create 'student','info','address'put 'student','1','info:age','20'put 'student','1','info:name','wang'put 'student','1','info:class','1'put 'student','1','address:city','zhengzhou'put 'student','1','address:area','High-tech zone'put 'student','2','info:age','21'put 'student','2','info:name','yang'put 'student','2','info:class','1'put 'student','2','address:city','beijing'put 'student','2','address:area','CBD'put 'student','3','info:age','22'put 'student','3','info:name','zhao'put 'student','3','info:class','2'put 'student','3','address:city','shanghai'put 'student','3','address:area','pudong'scan 'student'2、⾸先执⾏,创建表,增加数据操作,执⾏脚本 /bin/hbase shell ./student.txt,然后查看内容 scan ‘student' hbase(main):001:0> scan 'student'ROW COLUMN+CELL1 column=address:area, timestamp=1491533426260, value=High-tech zone1 column=address:city, timestamp=1491533426239, value=zhengzhou1 column=info:age, timestamp=1491533426179, value=201 column=info:class, timestamp=1491533426218, value=11 column=info:name, timestamp=1491533426211, value=wang2 column=address:area, timestamp=1491533426297, value=CBD2 column=address:city, timestamp=1491533426292, value=beijing2 column=info:age, timestamp=1491533426269, value=212 column=info:class, timestamp=1491533426287, value=12 column=info:name, timestamp=1491533426277, value=yang3 column=address:area, timestamp=1491533426329, value=pudong3 column=address:city, timestamp=1491533426323, value=shanghai3 column=info:age, timestamp=1491533426305, value=223 column=info:class, timestamp=1491533426317, value=23 column=info:name, timestamp=1491533426311, value=zhao3 row(s) in 0.1940 seconds3、修改操作也是⽤put命令,就是重新添加内容把,把以前的内容覆盖。
进入hbase shell console$HBASE_HOME/bin/hbase shell如果有kerberos认证,需要事先使用相应的keytab进行一下认证(使用kinit命令),认证成功之后再使用hbase shell进入可以使用whoami命令可查看当前用户hbase(main)>whoami表的管理1)查看有哪些表hbase(main)> list2)创建表# 语法:create<table>, {NAME =><family>, VERSIONS =><VERSIONS>}# 例如:创建表t1,有两个family name:f1,f2,且版本数均为2hbase(main)> create 't1',{NAME => 'f1', VERSIONS => 2},{NAME => 'f2', VERSIONS => 2}3)删除表分两步:首先disable,然后drop例如:删除表t1hbase(main)> disable 't1'hbase(main)> drop 't1'4)查看表的结构# 语法:describe<table># 例如:查看表t1的结构hbase(main)> describe 't1'5)修改表结构修改表结构必须先disable# 语法:alter 't1', {NAME => 'f1'}, {NAME => 'f2', METHOD => 'delete'}# 例如:修改表test1的cf的TTL为180天hbase(main)> disable 'test1'hbase(main)> alter 'test1',{NAME=>'body',TTL=>'15552000'},{NAME=>'meta', TTL=>'15552000'} hbase(main)> enable 'test1'权限管理1)分配权限# 语法: grant <user><permissions><table><column family><column qualifier>参数后面用逗号分隔# 权限用五个字母表示:"RWXCA".# READ('R'), WRITE('W'), EXEC('X'), CREATE('C'), ADMIN('A')# 例如,给用户‘test'分配对表t1有读写的权限,hbase(main)> grant 'test','RW','t1'2)查看权限# 语法:user_permission<table># 例如,查看表t1的权限列表hbase(main)>user_permission 't1'3)收回权限# 与分配权限类似,语法:revoke<user><table><column family><column qualifier># 例如,收回test用户在表t1上的权限hbase(main)> revoke 'test','t1'表数据的增删改查1)添加数据# 语法:put<table>,<rowkey>,<family:column>,<value>,<timestamp># 例如:给表t1的添加一行记录:rowkey是rowkey001,family name:f1,column name:col1,value:value01,timestamp:系统默认hbase(main)> put 't1','rowkey001','f1:col1','value01'用法比较单一。
2)查询数据a)查询某行记录# 语法:get<table>,<rowkey>,[<family:column>,....]# 例如:查询表t1,rowkey001中的f1下的col1的值hbase(main)> get 't1','rowkey001', 'f1:col1'# 或者:hbase(main)> get 't1','rowkey001', {COLUMN=>'f1:col1'}# 查询表t1,rowke002中的f1下的所有列值hbase(main)> get 't1','rowkey001'b)扫描表# 语法:scan<table>, {COLUMNS => [ <family:column>,.... ], LIMIT =>num}# 另外,还可以添加STARTROW、TIMERANGE和FITLER等高级功能# 例如:扫描表t1的前5条数据hbase(main)> scan 't1',{LIMIT=>5}c)查询表中的数据行数# 语法:count<table>, {INTERVAL =>intervalNum, CACHE =>cacheNum}# INTERVAL设置多少行显示一次及对应的rowkey,默认1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度# 例如,查询表t1中的行数,每100条显示一次,缓存区为500hbase(main)> count 't1', {INTERVAL => 100, CACHE => 500}3)删除数据a )删除行中的某个列值# 语法:delete <table>, <rowkey>, <family:column> , <timestamp>,必须指定列名# 例如:删除表t1,rowkey001中的f1:col1的数据hbase(main)> delete 't1','rowkey001','f1:col1'注:将删除改行f1:col1列所有版本的数据b )删除行# 语法:deleteall<table>, <rowkey>, <family:column> , <timestamp>,可以不指定列名,删除整行数据# 例如:删除表t1,rowk001的数据hbase(main)>deleteall 't1','rowkey001'c)删除表中的所有数据# 语法:truncate<table># 其具体过程是:disable table -> drop table -> create table# 例如:删除表t1的所有数据hbase(main)> truncate 't1'Region管理1)移动region# 语法:move 'encodeRegionName', 'ServerName'# encodeRegionName指的regioName后面的编码,ServerName指的是master-status的Region Servers列表# 示例hbase(main)>move '4343995a58be8e5bbc739af1e91cd72d', ',60020,1390274516739'2)开启/关闭region# 语法:balance_switchtrue|falsehbase(main)>balance_switch3)手动split# 语法:split 'regionName', 'splitKey'4)手动触发major compaction#语法:#Compact all regions in a table:#hbase>major_compact 't1'#Compact an entire region:#hbase>major_compact 'r1'#Compact a single column family within a region:#hbase>major_compact 'r1', 'c1'#Compact a single column family within a table:#hbase>major_compact 't1', 'c1'配置管理及节点重启1)修改hdfs配置hdfs配置位置:/etc/hadoop/conf# 同步hdfs配置cat /home/hadoop/slaves|xargs -i -t scp /etc/hadoop/conf/hdfs-site.xml hadoop@{}:/etc/hadoop/conf/hdfs-site.xml#关闭:cat /home/hadoop/slaves|xargs -i -t sshhadoop@{} "sudo /home/hadoop/cdh4/hadoop-2.0.0-cdh4.2.1/sbin/hadoop-daemon.sh --config /etc/hadoop/conf stop datanode"#启动:cat /home/hadoop/slaves|xargs -i -t sshhadoop@{} "sudo /home/hadoop/cdh4/hadoop-2.0.0-cdh4.2.1/sbin/hadoop-daemon.sh --config /etc/hadoop/conf start datanode"2)修改hbase配置hbase配置位置:# 同步hbase配置cat /home/hadoop/hbase/conf/regionservers|xargs -i -t scp /home/hadoop/hbase/conf/hbase-site.xmlhadoop@{}:/home/hadoop/hbase/conf/hbase-site.xml# graceful重启cd ~/hbasebin/graceful_stop.sh --restart --reload --debug 。