树(算法设计)习题练习答案
- 格式:docx
- 大小:23.87 KB
- 文档页数:13

算法设计与分析知到章节测试答案智慧树2023年最新天津大学第一章测试1.下列关于效率的说法正确的是()。
参考答案:提高程序效率的根本途径在于选择良好的设计方法,数据结构与算法;效率主要指处理机时间和存储器容量两个方面;效率是一个性能要求,其目标应该在需求分析时给出2.算法的时间复杂度取决于()。
参考答案:问题的规模;待处理数据的初态3.计算机算法指的是()。
参考答案:解决问题的有限运算序列4.归并排序法的时间复杂度和空间复杂度分别是()。
参考答案:O(nlog2n);O(n)5.将长度分别为m,n的两个单链表合并为一个单链表的时间复杂度为O(m+n)。
()参考答案:错6.用渐进表示法分析算法复杂度的增长趋势。
()参考答案:对7.算法分析的两个主要方面是时间复杂度和空间复杂度的分析。
()参考答案:对8.某算法所需时间由以下方程表示,求出该算法时间复杂度()。
参考答案:O(nlog2n)9.下列代码的时间复杂度是()。
参考答案:O(log2N)10.下列算法为在数组A[0,...,n-1]中找出最大值和最小值的元素,其平均比较次数为()。
参考答案:3n/2-3/2第二章测试1.可用Master方法求解的递归方程的形式为()。
参考答案:T(n)=aT(n/b)+f(n) , a≥1, b>1, 为整数, f(n)>0.2.参考答案:对3.假定,, 递归方程的解是. ( )参考答案:对4.假设数组A包含n个不同的元素,需要从数组A中找出n/2个元素,要求所找的n/2个元素的中点元素也是数组A的中点元素。
针对该问题的任何算法需要的时间复杂度的下限必为。
( )参考答案:错5.使用Master方法求解递归方程的解为().参考答案:6.考虑包含n个二维坐标点的集合S,其中n为偶数,且所有坐标点中的均不相同。
一条竖直的直线若能把S集合分成左右两部分坐标点个数相同的子集合,则称直线L为集合S的一条分界线。
若给定集合S,则可在时间内找到这条分界线L。
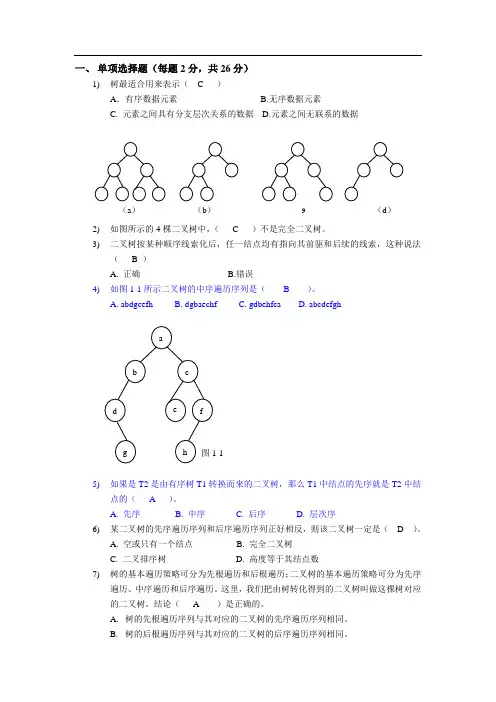
一、 单项选择题(每题2分,共26分)1) 树最适合用来表示( C )A .有序数据元素 B.无序数据元素C. 元素之间具有分支层次关系的数据D.元素之间无联系的数据2) 如图所示的4棵二叉树中,( C )不是完全二叉树。
3) 二叉树按某种顺序线索化后,任一结点均有指向其前驱和后续的线索,这种说法( B )A. 正确B.错误4) 如图1-1所示二叉树的中序遍历序列是( B )。
A. abdgcefhB. dgbaechfC. gdbehfcaD. abcdefgh5) 如果是T2是由有序树T1转换而来的二叉树,那么T1中结点的先序就是T2中结点的( A )。
A. 先序B. 中序C. 后序D. 层次序6) 某二叉树的先序遍历序列和后序遍历序列正好相反,则该二叉树一定是( D )。
A. 空或只有一个结点B. 完全二叉树C. 二叉排序树D. 高度等于其结点数7) 树的基本遍历策略可分为先根遍历和后根遍历;二叉树的基本遍历策略可分为先序遍历、中序遍历和后序遍历。
这里,我们把由树转化得到的二叉树叫做这棵树对应的二叉树。
结论( A )是正确的。
A. 树的先根遍历序列与其对应的二叉树的先序遍历序列相同。
B. 树的后根遍历序列与其对应的二叉树的后序遍历序列相同。
(a ) (b ) 9 (d )C. 树的先根遍历序列与其对应的二叉树的中序遍历序列相同。
D. 以上都不对8) 如图所示的T2是由森林T1转换而来的二叉树,那么森里T1有( C )个叶子结点。
A. 4B. 5C. 6D. 79) 深度为5的二叉树至多有( C )个结点。
A. 16B. 32C. 31D. 1010) 在一非空二叉树的中序遍历序列中,根结点的右边( A )。
A. 只有右子树上的所有结点B. 只有右子树的部分结点C. 只有左子树上的部分结点D. 只有左子树上的所有结点11) 设n ,m 为一棵二叉树上的两个结点,在中序遍历时,n 在m 前的条件是( C )。


树、图习题一、选择题1 已知一算术表达式的中缀形式为 A+B*C-D/E,后缀形式为ABC*+DE/-,其前缀形式为( D )A.-A+B*C/DE B. -A+B*CD/E C.-+*ABC/DE D. -+A*BC/DE2 一个具有1025个结点的二叉树的高h为( C )A.11 B.10 C.11至1025之间 D.10至1024之间3 二叉树的先序遍历和中序遍历如下:先序遍历:EFHIGJK;中序遍历: HFIEJKG 。
该二叉树根的右子树的根是:( C )A、 EB、 FC、 GD、 H4 引入二叉线索树的目的是( A )A.加快查找结点的前驱或后继的速度 B.为了能在二叉树中方便的进行插入与删除C.为了能方便的找到双亲 D.使二叉树的遍历结果唯一5 设森林F中有三棵树,第一,第二,第三棵树的结点个数分别为M1,M2和M3。
与森林F对应的二叉树根结点的右子树上的结点个数是( D )。
A.M1 B.M1+M2 C.M3 D.M2+M36 有n个叶子的哈夫曼树的结点总数为( D )。
A.不确定 B.2n C.2n+1 D.2n-17 一个有n个结点的图,最少有( B )个连通分量,最多有( D )个连通分量。
A.0 B.1 C.n-1 D.n8 无向图G=(V,E),其中:V={a,b,c,d,e,f},E={(a,b),(a,e),(a,c),(b,e),(c,f),(f,d),(e,d)},对该图进行深度优先遍历,得到的顶点序列正确的是( D )。
A.a,b,e,c,d,f B.a,c,f,e,b,d C.a,e,b,c,f,d D.a,e,d,f,c,b 9 已知有向图G=(V,E),其中V={V1,V2,V3,V4,V5,V6,V7},E={<V1,V2>,<V1,V3>,<V1,V4>,<V2,V5>,<V3,V5>,<V3,V6>,<V4,V6>,<V5,V7>,<V6,V7>},G的拓扑序列是( A )。

数据结构-树习题第六章树⼀、选择题1、⼆叉树的深度为k,则⼆叉树最多有( C )个结点。
A. 2kB. 2k-1C. 2k-1D. 2k-12、⽤顺序存储的⽅法,将完全⼆叉树中所有结点按层逐个从左到右的顺序存放在⼀维数组R[1..N]中,若结点R[i]有右孩⼦,则其右孩⼦是(B )。
A. R[2i-1]B. R[2i+1]C. R[2i]D. R[2/i]3、设a,b为⼀棵⼆叉树上的两个结点,在中序遍历时,a在b前⾯的条件是( B )。
A. a在b的右⽅B. a在b的左⽅C. a是b的祖先D. a是b的⼦孙4、设⼀棵⼆叉树的中序遍历序列:badce,后序遍历序列:bdeca,则⼆叉树先序遍历序列为()。
A. adbceB. decabC. debacD. abcde5、在⼀棵具有5层的满⼆叉树中结点总数为(A)。
A. 31B. 32C. 33D. 166、由⼆叉树的前序和后序遍历序列( B )惟⼀确定这棵⼆叉树。
A. 能B. 不能7、某⼆叉树的中序序列为ABCDEFG,后序序列为BDCAFGE,则其左⼦树中结点数⽬为( C )。
A. 3B. 2C. 4D. 58、若以{4,5,6,7,8}作为权值构造哈夫曼树,则该树的带权路径长度为( C )。
A. 67B. 68C. 69D. 709、将⼀棵有100个结点的完全⼆叉树从根这⼀层开始,每⼀层上从左到右依次对结点进⾏编号,根结点的编号为1,则编号为49的结点的左孩⼦编号为( A )。
A. 98B. 99C. 50D. 4810、表达式a*(b+c)-d的后缀表达式是( B )。
A. abcd+-B. abc+*d-C. abc*+d-D. -+*abcd11、对某⼆叉树进⾏先序遍历的结果为ABDEFC,中序遍历的结果为DBFEAC,则后序遍历的结果是( B )。
A. DBFEACB. DFEBCAC. BDFECAD. BDEFAC12、树最适合⽤来表⽰( C )。

第一章测试1.解决一个问题通常有多种方法。
若说一个算法“有效”是指( )A:这个算法能在人的反应时间内将问题解决B:(这个算法能在一定的时间和空间资源限制内将问题解决)和(这个算法比其他已知算法都更快地将问题解决)C:这个算法能在一定的时间和空间资源限制内将问题解决D:这个算法比其他已知算法都更快地将问题解决答案:B2.农夫带着狼、羊、白菜从河的左岸到河的右岸,农夫每次只能带一样东西过河,而且,没有农夫看管,狼会吃羊,羊会吃白菜。
请问农夫能不能过去?()A:不一定B:不能过去C:能过去答案:C3.下述()不是是算法的描述方式。
A:自然语言B:程序设计语言C:E-R图D:伪代码答案:C4.有一个国家只有6元和7元两种纸币,如果你是央行行长,你会设置()为自动取款机的取款最低限额。
A:40B:42C:29D:30答案:D5.算法是一系列解决问题的明确指令。
()A:对B:错答案:A6.程序=数据结构+算法()A:错B:对答案:B7.同一个问题可以用不同的算法解决,同一个算法也可以解决不同的问题。
()A:错答案:B8.算法中的每一条指令不需有确切的含义,对于相同的输入不一定得到相同的输出。
( )A:错B:对答案:A9.可以用同样的方法证明算法的正确性与错误性 ( )A:对B:错答案:B10.求解2个数的最大公约数至少有3种方法。
( )A:错B:对答案:A11.没有好的算法,就编不出好的程序。
()A:对B:错答案:A12.算法与程序没有关系。
( )A:错B:对答案:A13.我将来不进行软件开发,所以学习算法没什么用。
( )A:对B:错答案:B14.gcd(m,n)=gcd(n,m m od n)并不是对每一对正整数(m,n)都成立。
( )A:错B:对答案:A15.既然程序设计语言可以描述算法,所以算法就是程序。
( )A:错B:对答案:A第二章测试1.并不是所有的算法,规模更大的输入需要更长的运行时间。
( )A:对答案:B2.算法效率分析框架主要关心一个算法的基本操作次数的增长次数,并把它作为算法效率的主要指标。

数据结构——树习题解答1、单词查找树(word.pas)【问题描述】在进行文法分析的时候,通常需要检测一个单词是否在我们的单词列表中。
为了提高查找和定位的速度,通常都画出与单词列表所对应的单词查找树,其特点如下:(1)根节点不包含字母,除根街店为每一个节点都包含一个大写英文字母;(2)从根节点到某一节点,路径上经过的字母依次连起来所构成的字母序列,称为该结点对应的单词。
单词列表中的每个单词,都是该单词查找树某个节点所对应的单词;(3)在满足上述条件下,该单词查找树的节点数最少。
要求:对一个确定的单词列表,请统计对应的单词查找树的结点数(包括根节点).输入:输入文件名为word.in,该文件为一个单词列表,每行仅包含一个单词和一个换行/回车符。
每个单词仅由大写字母组成,长度不超过63个字符。
文件总长度不超过32K,至少有一行数据。
输出:输出文件名为word.out,该文件仅包含一个整数,该整数为单词列表对应的单词查找树的结点数。
【样例输入】AANASPASASCASCIIBASBASIC【样例输出】13【题解】首先要对建树的过程有一个了解。
对于当前被处理的单词和当前树:在根节点的子节点中找单词的为第一位字母,若存在则进而在该节点的子节点中寻找第二位……,如此直到单词结束,既不需要在该书中添加节点;若单词的第n个字母不能找到,即将单词的第n个字母及其后的字母依次加入单词查找树中。
但本题只是问你结点总数,而非建树方案,且有32K大小的单词文件,所以应该考虑能不能通过不建树就直接算出结点数。
为了说明问题本质,我们定义单词相对于另一个单词的差:设单词1的长度为L,且与单词2从第N位开始不一致,则定义单词1相对于单词2的差为L-N+1,这是描述单词相似程度的量。
可见,将一个单词加入单词树的时候,须加入的节点数等于该单词树中已有的单词的差得最小值。
单词的字典顺序排列后的序列则具有类似的特性,即在一个字典顺序序列中,第m个单词相对于第m-1个单词的差必定是它对于前m-1个单词的差中最小的。


第三单元课后练习题(参考答案)知识点范围:第6章树与二叉树、第7章图一、选择题(每小题1分,共25分)1.树最适合用来表示 C 。
A.有序数据元素B.无序数据元素C.元素之间具有分支层次关系的数据D.元素之间无联系的数据2.深度为5的二叉树至多有 C 个结点。
A.16 B.32 C.31 C.103.对一个满二叉树,m个叶子,n个结点,深度为h,则 D 。
A.n = h+m B.h+m = 2n C.m = h-1 D.n = 2h-14.任何一棵二叉树的叶子结点在前序、中序和后序遍历序列中的相对次序 A 。
A.不发生改变B.发生改变C.不能确定D.以上都不对5.设一棵二叉树中,度为2的结点数为9,则该二叉树的叶结点的数目为:AA.10 B.11 C.12 D.不确定6.在下述论述中,正确的是 D 。
①只有一个结点的二叉树的度为0;②二叉树的度为2;③二叉树的左右子树可任意交换;④深度为K的顺序二叉树的结点个数小于或等于深度相同的满二叉树。
A.①②③B.②③④C.②④D.①④7.设森林F对应的二叉树为B,它有m个结点,B的根为p,p的右子树的结点个数为n,森林F中第一棵树的结点的个数是 A 。
A.m-n B.m-n-1 C.n+1 D.不能确定8.若一棵二叉树具有10个度为2的结点,5个度为1的结点,则度为0的结点的个数是 B 。
A.9 B.11 C.15 D.不能确定9.具有10个叶子结点的二叉树中有 B 个度为2的结点。
A.8 B.9 C.10 D.1110.在一个无向图中,所有顶点的度数之和等于所有边数的 C 倍。
A.1/2 B. 1 C.2 D. 411.设按照从上到下、从左到右的顺序从1开始对完全二叉树进行顺序编号,则编号为i结点的左孩子结点的编号为( B )。
A. 2i+1 B. 2i C. i/2 D. 2i-112.某二叉树结点的中序序列为ABCDEFG,后序序列为BDCAFGE,则其左子树中结点数目为: CA.3 B.2 C.4 D.513.已知一算术表达式的中缀形式为A+B *C–D/E,后缀形式为ABC *+DE/–,其前缀形式为 D 。

2020智慧树知到《算法分析与设计》章节测试完整答案智慧树知到《算法分析与设计》章节测试答案第一章1、给定一个实例,如果一个算法能得到正确解答,称这个算法解答了该问题。
答案: 错2、一个问题的同一实例可以有不同的表示形式答案: 对3、同一数学模型使用不同的数据结构会有不同的算法,有效性有很大差别。
答案: 对4、问题的两个要素是输入和实例。
答案: 错5、算法与程序的区别是()A:输入B:输出C:确定性D:有穷性答案: 有穷性6、解决问题的基本步骤是()。
(1)算法设计(2)算法实现(3)数学建模(4)算法分析(5)正确性证明A:(3)(1)(4)(5)(2)B:(3)(4)(1)(5)(2)C:(3)(1)(5)(4)(2)D:(1)(2)(3)(4)(5)答案: (3)(1)(5)(4)(2)7、下面说法关于算法与问题的说法错误的是()。
A:如果一个算法能应用于问题的任意实例,并保证得到正确解答,称这个算法解答了该问题。
B:算法是一种计算方法,对问题的每个实例计算都能得到正确答案。
C:同一问题可能有几种不同的算法,解题思路和解题速度也会显著不同。
D:证明算法不正确,需要证明对任意实例算法都不能正确处理。
答案: 证明算法不正确,需要证明对任意实例算法都不能正确处理。
8、下面关于程序和算法的说法正确的是()。
A:算法的每一步骤必须要有确切的含义,必须是清楚的、无二义的。
B:程序是算法用某种程序设计语言的具体实现。
C:程序总是在有穷步的运算后终止。
D:算法是一个过程,计算机每次求解是针对问题的一个实例求解。
答案: 算法的每一步骤必须要有确切的含义,必须是清楚的、无二义的。
,程序是算法用某种程序设计语言的具体实现。
,算法是一个过程,计算机每次求解是针对问题的一个实例求解。
9、最大独立集问题和()问题等价。
A: 最大团B:最小顶点覆盖C:区间调度问题D:稳定匹配问题答案: 最大团,最小顶点覆盖10、给定两张喜欢列表,稳定匹配问题的输出是( ) 。

一、基础知识题6.1设树T的度为4,其中度为1,2,3和4的结点个数分别为4,2,1,1,求树T中的叶子数。
【解答】设度为m的树中度为0,1,2,…,m的结点数分别为n0, n1, n2,…, nm,结点总数为n,分枝数为B,则下面二式成立n= n0+n1+n2+…+nm (1)n=B+1= n1+2n2 +…+mnm+1 (2)由(1)和(2)得叶子结点数n0=1+即: n0=1+(1-1)*4+(2-1)*2+(3-1)*1+(4-1)*1=86.2一棵完全二叉树上有1001个结点,求叶子结点的个数。
【解答】因为在任意二叉树中度为2 的结点数n2和叶子结点数n0有如下关系:n2=n0-1,所以设二叉树的结点数为n, 度为1的结点数为n1,则n= n0+ n1+ n2n=2n0+n1-11002=2n0+n1由于在完全二叉树中,度为1的结点数n1至多为1,叶子数n0是整数。
本题中度为1的结点数n1只能是0,故叶子结点的个数n0为501.注:解本题时要使用以上公式,不要先判断完全二叉树高10,前9层是满二叉树,第10层都是叶子,……。
虽然解法也对,但步骤多且复杂,极易出错。
6.3 一棵124个叶结点的完全二叉树,最多有多少个结点。
【解答】由公式n=2n0+n1-1,当n1为1时,结点数达到最多248个。
6.4.一棵完全二叉树有500个结点,请问该完全二叉树有多少个叶子结点?有多少个度为1的结点?有多少个度为2的结点?如果完全二叉树有501个结点,结果如何?请写出推导过程。
【解答】由公式n=2n0+n1-1,带入具体数得,500=2n0+n1-1,叶子数是整数,度为1的结点数只能为1,故叶子数为250,度为2的结点数是249。
若完全二叉树有501个结点,则叶子数251,度为2的结点数是250,度为1的结点数为0。
6.5 某二叉树有20个叶子结点,有30个结点仅有一个孩子,则该二叉树的总结点数是多少。
树及其表示方法练习题(含解析)树及其表示方法练题(含解析)问题1. 什么是树结构?2. 树的主要特点是什么?3. 请列举几种常见的树的表示方法。
4. 什么是二叉树?5. 二叉树的特点是什么?6. 请解释前序遍历、中序遍历和后序遍历。
7. 什么是二叉查找树?8. 请解释平衡二叉树。
9. 请介绍一种常见的平衡二叉树。
解析1. 树结构是一种非线性的数据结构,它由节点和边组成。
每个节点可以有零个或多个子节点,其中只有一个节点没有父节点,该节点被称为根节点。
2. 树的主要特点包括:- 每个节点有零个或多个子节点。
- 除了根节点外,每个节点有且仅有一个父节点。
- 每个节点都通过边与其他节点连接起来。
- 在树中,从根节点到任意节点有且只有一条路径。
3. 常见的树的表示方法包括:- 儿子-兄弟表示法(又称为左孩子右兄弟表示法)- 邻接表表示法- 邻接矩阵表示法4. 二叉树是一种特殊的树结构,每个节点最多有两个子节点。
5. 二叉树的特点包括:- 每个节点最多有两个子节点,分别称为左子节点和右子节点。
- 左子节点的值小于等于父节点的值,右子节点的值大于等于父节点的值。
- 左子树和右子树也是二叉树。
6. - 前序遍历:先访问根节点,然后递归地对左子树进行前序遍历,最后递归地对右子树进行前序遍历。
- 中序遍历:先递归地对左子树进行中序遍历,然后访问根节点,最后递归地对右子树进行中序遍历。
- 后序遍历:先递归地对左子树进行后序遍历,然后递归地对右子树进行后序遍历,最后访问根节点。
7. 二叉查找树(BST)是一种特殊的二叉树,它满足以下条件:- 对于任意节点,其左子树上的节点的值小于该节点的值,右子树上的节点的值大于该节点的值。
- 左子树和右子树也是二叉查找树。
8. 平衡二叉树是一种二叉查找树,它的左子树和右子树的高度差不超过1。
9. AVL树是一种常见的平衡二叉树,它通过旋转操作来保持树的平衡性。
在AVL树中,任意节点的左子树和右子树的高度差不超过1,并且左子树和右子树也都是AVL树。
7数据结构复习题(二叉树)一.判断题(下列各题,正确的请在前面的括号内打√;错误的打╳)(√)(1)树结构中每个结点最多只有一个直接前驱。
(ㄨ)(2)完全二叉树一定是满二查树。
(ㄨ)(3)在中序线索二叉树中,右线索若不为空,则一定指向其双亲。
(√)(4)一棵二叉树中序遍历序列的最后一个结点,必定是该二叉树前序遍历的最后一个结点。
(√)(5)二叉树的前序遍历中,任意一个结点均处于其子女结点的前面。
(√)(6)由二叉树的前序遍历序列和中序遍历序列,可以推导出后序遍历的序列。
(√)(7)在完全二叉树中,若一个结点没有左孩子,则它必然是叶子结点。
(ㄨ)(8)在哈夫曼编码中,当两个字符出现的频率相同,其编码也相同,对于这种情况应该做特殊处理。
(ㄨ)(9)含多于两棵树的森林转换的二叉树,其根结点一定无右孩子。
(√)(10)具有n个叶子结点的哈夫曼树共有2n-1个结点。
二.填空题(1)在树中,一个结点所拥有的子树数称为该结点的度。
(2)度为零的结点称为叶(或叶子,或终端)结点。
(3)树中结点的最大层次称为树的深度(或高度)。
(4)对于二叉树来说,第i层上至多有2i-1个结点。
(5)深度为h的二叉树至多有2h-1 个结点。
(6)由一棵二叉树的前序序列和中序序列可唯一确定这棵二叉树。
(7)有20个结点的完全二叉树,编号为10的结点的父结点的编号是 5 。
(8)哈夫曼树是带权路径长度最小的二叉树。
(9)由二叉树的后序和中序遍历序列,可以唯一确定一棵二叉树。
(10)某二叉树的中序遍历序列为: DEBAC,后序遍历序列为:EBCAD。
则前序遍历序列为:DABEC 。
(11)设一棵二叉树结点的先序遍历序历为:ABDECFGH,中序遍历序历为:DEBAFCHG,则二叉树中叶结点是:E、F、H 。
(12)已知完全二叉树的第8层有8个结点,则其叶结点数是68 。
(13)由树转换成二叉树时,其根结点无右子树。
(14)采用二叉链表存储的n个结点的二叉树,一共有2n 个指针域。
第6章树(2008年1月)8、树的先根序列等同于与该树对应的二叉树的()A、先序序列B、中序序列C、后序序列D、层序序列21、假设一棵完全二叉树含1000个结点,则其中度为2的结点数为___________。
27、已知二叉树的先序序列和中序序列分别为ABDEHCFI和DBHEACIF,(1)画出该二叉树的二叉链表存储表示;(2)写出该二叉树的后序序列。
(1)(2)32、已知以二叉链表作二叉树的存储结构,阅读算法f32,并回答问题:(1)设二叉树T如图所示,写出执行f32(T)的返回值;(2)简述算法f32的功能。
int f32(BinTree T){int m, n;if(! T)return 0;else{m= f32(T–>lchild);n = f 32(T–>rchild);if(m>n)return m +1;else return n+1;}}(1)(2)(2008年10月)7、已知一棵含50个结点的二叉树中只有一个叶子结点,则该树中度为1的结点个数为()A、0B、1C、48D、4921、假设用<x,y>表示树的边(其中x是y的双亲),已知一棵树的边集为{<b,d>,<a,b>,<c,g>,<c,f>,<c,h>,<a,c>},该树的度是。
26、由森林转换得到的对应二叉树如图所示,写出原森林中第三棵树的前序序列和后序序列。
前序序列:后序序列:(2009年1月)7、高度为5的完全二叉树中含有的结点数至少为( )A、16B、17C、31D、328、已知在一棵度为3的树中,度为2的结点数为4,度为3的结点数为3,则该树中的叶子结点数为( )A、5B、8C、11D、189、下列所示各图中是中序线索化二叉树的是( )21、在含有3个结点a,b,c的二叉树中,前序序列为abc且后序序列为cba的二叉树有_________棵。
《树》练习题一、单项选择题1、在一棵度为3的树中,度为3的结点数为2个,度为2的结点数为1个,度为1的结点数为2个,则度为0的结点数为()个。
A. 4B. 5C. 6D. 72、假设在一棵二叉树中,双分支结点数为15,单分支结点数为30个,则叶子结点数为()个。
A. 15B. 16C. 17D. 473、假定一棵三叉树的结点数为50,则它的最小高度为()。
(根为第0层)A. 3B. 4C. 5D. 64、在一棵二叉树上第3层的结点数最多为()(根为第0层)。
A. 2B. 4C. 6D. 85、用顺序存储的方法将完全二叉树中的所有结点逐层存放在数组中R[1..n],结点R[i]若有左孩子,其左孩子的编号为结点()。
(若存放在R[0..n-1]则左孩子R[2i+1])A. R[2i+1]B. R[2i]C. R[i/2]D. R[2i-1]6、将含100个结点的完全二叉树,按照从上层到下层、同层从左到右的次序依次给它们编以从0开始的连续自然数,则编号为40的结点X的双亲的编号为( )。
A.19B.20C. 21D.397、由权值分别为3,8,6,2,5的叶子结点生成一棵哈夫曼树,它的带权路径长度为()。
A. 24B. 48C. 72D. 538、设n , m 为一棵二叉树上的两个结点,在中序遍历序列中n在m前的条件是()。
A. n在m右方B. n在m 左方C. n是m的祖先D. n是m的子孙9、如果F是由有序树T转换而来的二叉树,那么T中结点的前序就是F中结点的()。
A. 中序B. 前序C. 后序D. 层次序10、下面叙述正确的是()。
A. 二叉树不是树B. 二叉树等价于度为2的树C. 完全二叉树必为满二叉树D. 二叉树的左右子树有次序之分11、任何一棵二叉树的叶子结点在先序、中序和后序遍历序列中的相对次序()。
A. 不发生改变B. 发生改变C. 不能确定D. 以上都不对12、已知一棵完全二叉树的结点总数为9个,则最后一层的结点数为()。
第6xx(算法设计)习题练习答案*6.22二叉树的遍历算法可写为通用形式。
例如通用的中序遍历为:void Inorder(BinTree,T,void(* visit)(DataType x)){if (T){Inorder(T->lchild,Visit);//遍历左子树Visit(T->data);//通过函数指针调用它所指的函数来访问结点Inorder(T->rchild,Visit);//遍历右子树}}其中Visit是一个函数指针,它指向形如void f(DataType x)的函数。
因此我们可以将访问结点的操作写在函数f中通过调用语句Inorder(root,f)将f的地址传递给Visit,来执行遍历操作。
请写一个打印结点数据的函数,通过调用上述算法来完成书中6.3节的中序遍历。
解:函数如下:void PrintNode(BinTree T){printf("%c",T->data);}//定义二叉树链式存储结构typedef char DataType;//定义DataType类型typedef struct node{DataType data;struct node *lchild, *rchild;//左右孩子子树}BinTNode; //结点类型typedef BinTNode *BinTree ;//二叉树类型void Inorder(BinTree T,void(* Visit)(DataType x)){if(T){Inorder(T->lchild,Visit);//遍历左子树Visit(T->data); //通过函数指针调用它所指的函数访问结点Inorder(T->rchild,Visit);//遍历右子树}}6.23以二叉链表为存储结构,分别写出求二叉树结点总数及叶子总数的算法。
解:(1)求结点数的递归定义为:若为空树,结点数为0若只有根结点,则结点数为1;否则,结点数为根结点的左子树结点数+右子树结点数+1(2)求xx数的递归定义为:若为空树,xx数为0若只有根结点,则xx数为1;否则,叶子数为根结点的左子树叶子数+右子树叶子数typedef char DataType;//定义DataType类型typedef struct node{DataType data;struct node *lchild, *rchild;//左右孩子子树}BinTNode; //结点类型typedef BinTNode *BinTree ;//二叉树类型int Node(BinTree T){//算结点数if (T->lchild==NULL)&&(T->rchild==NULL)return 1;else return Node(T->lchild)+Node(T->rchild)+1;else return 0;}int Leaf(BinTree T){ //算xx数if(T)if (T->lchild==NULL)&&(T->rchild==NULL)return 1;else return Leaf(T->lchild)+Node(T->rchild);else return 0;}6.24以二叉链表为存储结构,分别写出求二叉树高度及宽度的算法,所谓宽度是指二叉树的各层上,具有结点数最多的那一层上的结点总数。
解:(1)根据递归定义:二叉树的高度为:当为空树时,高度为0;当只有一个结点时,高度为1;其他情况:高度为max(根的左子树高度,根的右子树高度)+1int Height(BinTree T){int hl,hr;{//非空树if(t->lchild==NUll)&&(t->rchild==NULL)//只含一个根结点return 1;else {hl=height(t->lchild);//根的左子树高度hr=height(t->rchild);//根的右子树高度if (hl>=hr)return hl+1;else return h2+1;}}else return 0;}(2)要求二叉树的宽度的话,则可根据树的高度设置一个数组temp。
temp[i]用于存放第i层上的结点数(即宽度)。
在访问结点时,把相应计算该结点下一层的孩子数并存入相应数组元素中,遍历左子树后向上返回一层计算右子树的宽度,并取出最大的一个数组元素作为树的宽度。
#define M 10 //假设二叉树最多的层数int Width(BinTree T){int static n[M];//向量存放各层结点数int static i=1;int static max=0;//最大宽度if(T){if(i==1) //若是访问根结点{n[i]++; //第1层加1i++; //到第2层if(T->lchild)//若有左孩子则该层加1n[i]++;if(T->rchild)//若有右孩子则该层加1n[i]++;}else{ //访问xx结点i++; //下一层结点数if(T->lchild)n[i]++;if(T->rchild)n[i]++;}if(max<n[i])max=n[i];//取出最大值Width(T->lchild);//遍历左子树i--; //往上退一层Width(T->rchild);//遍历右子树}return max;}//算法结束6.25以二叉链表为存储结构,写一算法交换各结点的左右子树。
答:要交换各结点的左右子树,最方便的办法是用后序遍历算法,每访问一个结点时把两棵子树的指针进行交换,最后一次访问是交换根结点的子树。
void ChangeBinTree(BinTree *T){ //交换子树if(*T){ //这里以指针为参数使得交换在实参的结点上进行后序遍历BinTree temp;ChangeBinTree(&(*T)->lchild);ChangeBinTree(&(*T)->rchild);temp=(*T)->lchild;(*T)->lchild=(*T)->rchild;(*T)->rchild=temp;}}6.26以二叉链表为存储结构,写一个拷贝二叉树的算法voidCopyTree(BinTree root,BinTree *newroot),其中新树的结点是动态申请的,为什么newroot要说明为BinTree型指针的指针?解:因为调用函数只能进行值传递,当返回类型为void时,就必须把实参的地址传给函数,否则函数不会对实际参数进行任何操作,也就得不到所需结果了。
所以,newroot要说明为BinTree型指针void CopyTree(BinTree root,BinTree *newroot){ //拷贝二叉树if(root)//如果结点非空{ //按前序序列拷贝*newroot=(BinTNode *)malloc(sizeof(BinTNode));//生成新结点(*newroot)->data=root->data;//拷贝结点数据CopyTree(root->lchild,&(*newroot)->lchild);//拷贝左子树CopyTree(root->rchild,&(*newroot)->rchild);//拷贝右子树}else //如果结点为空*newroot=NULL;//将结点置空}6.27以二叉链表为存储结构,分别写出在二叉树中查找值为x的结点及求x所在结点在树中层数的算法。
解:根据上几题的算法可以得出本题的算法如下:#define M 10 //假设二叉树最多的层数BinTree SearchBTree(BinTree *T,DataType x){//以前序遍历算法查找值为x的结点if(*T){if((*T)->data==x )return *T;SearchBTree(&(*T)->lchild,x);SearchBTree(&(*T)->rchild,x);}}int InLevel(BinTree T,DataType x){int static l=0;//设一静态变量保存层数if(T){if(l==0)//若是访问根结点{l++;//第1层if(T->data==x)return l;if(T->lchild||T->rchild)l++;//若根有子树,则层数加1}else{ //访问xx结点if(T->data==x)return l;if(T->lchild||T->rchild)l++;//若该结点有子树,则层数加1else return 0;}InLevel(T->lchild,x);//遍历左子树InLevel(T->rchild,x);//遍历右子树}}6.28一棵n个结点的完全二叉树以向量作为存储结构,试写一非递归算法实现对该树的前序遍历。
解:以向量为存储结构的完全二叉树,其存储在向量中的结点其实是按层次遍历的次序存放的,可以根据课本第74页的内容设计出算法:typedef char DataType;//设结点数据类型为char#define M 100//设结点数不超过100typedef DataType BinTree[M];void Preorder(BinTree T){ //前序遍历算法int n=T[0];int p[M];//设置一队列存放结点值int i,j;for(i=1;i<=n;i++){if (i==1)//根结点j=1;else if(2*j<=n)//左子树j=2*j;else if(j%2==0&&j<n)//右兄弟j=j+1;else if(j>1)//双亲之右兄弟j=j/2+1;p[i]=T[j];//入队printf("%c",p[i]);//打印结点值}}6.29以二叉链表为存储结构,一算法对二叉树进行层次遍历(层次遍历的定义见6.13).提示:应使用队列来保存各层的结点。
答:#define M 100 //假设结点数最多为100typedef char DataType;//队列结点值类型typedef struct//定义一个队列{int front;int rear;int count;DataType data[M];}QBTree;static QBTree Q;//设一全局静态变量保存遍历结果void Levelorder(BinTree T){//层次遍历if(T){if(QueEmpty(&Q)){ //根结点及子树结点入队EnQue(&Q,T->data);if(T->lchild)EnQue(&Q,T->lchild->data);if(T->rchild)EnQue(&Q,T->rchild->data);}else{ //xx结点入队if(T->lchild)EnQue(&Q,T->lchild->data);if(T->rchild)EnQue(&Q,T->rchild->data);}Levelorder(T->lchild);//遍历左子树Levelorder(T->rchild);//遍历右子树}}6.30以二叉链表为存储结构,写一算法用括号形式(key LT,RT)打印二叉树,其中key是根结点数据,LT和RT是括号形式的左子树和右子树。