实验六 串的模式匹配
- 格式:ppt
- 大小:121.00 KB
- 文档页数:2

串的模式匹配问题实验总结(用C实现)第一篇:串的模式匹配问题实验总结(用C实现)串的模式匹配问题实验总结1实验题目:实现Index(S,T,pos)函数。
其中,Index(S,T,pos)为串T在串S的第pos个字符后第一次出现的位置。
2实验目的:熟练掌握串模式匹配算法。
3实验方法:分别用朴素模式匹配和KMP快速模式匹配来实现串的模式匹配问题。
具体方法如下:朴素模式匹配:输入两个字符串,主串S和子串T,从S串的第pos个位置开始与T的第一个位置比较,若不同执行i=i-j+2;j=1两个语句;若相同,则执行语句++i;++j;一直比较完毕为止,若S中有与T相同的部分则返回主串(S字符串)和子串(T字符串)相匹配时第一次出现的位置,若没有就返回0。
KMP快速模式匹配:构造函数get_next(char *T,int *next),求出主串S串中各个字符的next值,然后在Index_KMP(char *S,char *T,int pos)函数中调用get_next(char *T,int *next)函数并调用next值,从S串的第pos 位置开始与T的第一个位置进行比较,若两者相等或j位置的字符next值等于0,则进行语句++i;++j;即一直向下进行。
否则,执行语句j=A[j];直到比较完毕为止。
若S中有与T相同的部分则返回主串(S字符串)和子串(T字符串)相匹配时第一次出现的位置,若没有就返回04实验过程与结果:(1)、选择1功能“输入主串、子串和匹配起始位置”,输入主串S:asdfghjkl, 输入子串T:gh,输入pos的值为:2。
选择2功能“朴素的模式匹配算法”,输出结果为 5;选择3功能“KMP快速模式匹配算法”,输出结果为 5;选择0功能,退出程序。
截图如下:(2)、选择1功能“输入主串、子串和匹配起始位置”,输入主串S:asdfghjkl, 输入子串T:wp, 输入pos的值为:2。

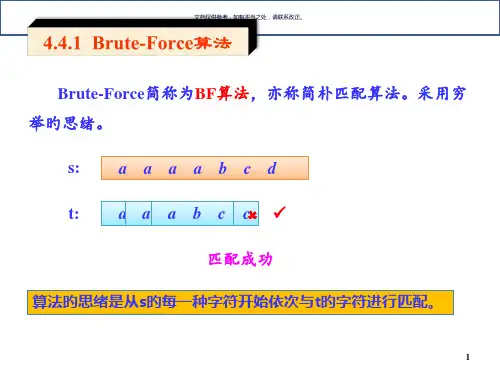
竭诚为您提供优质文档/双击可除串的模式匹配算法实验报告篇一:串的模式匹配算法串的匹配算法——bruteForce(bF)算法匹配模式的定义设有主串s和子串T,子串T的定位就是要在主串s中找到一个与子串T相等的子串。
通常把主串s称为目标串,把子串T称为模式串,因此定位也称作模式匹配。
模式匹配成功是指在目标串s中找到一个模式串T;不成功则指目标串s中不存在模式串T。
bF算法brute-Force算法简称为bF算法,其基本思路是:从目标串s的第一个字符开始和模式串T中的第一个字符比较,若相等,则继续逐个比较后续的字符;否则从目标串s的第二个字符开始重新与模式串T的第一个字符进行比较。
以此类推,若从模式串T的第i个字符开始,每个字符依次和目标串s中的对应字符相等,则匹配成功,该算法返回i;否则,匹配失败,算法返回0。
实现代码如下:/*返回子串T在主串s中第pos个字符之后的位置。
若不存在,则函数返回值为0./*T非空。
intindex(strings,stringT,intpos){inti=pos;//用于主串s中当前位置下标,若pos不为1则从pos位置开始匹配intj=1;//j用于子串T中当前位置下标值while(i j=1;}if(j>T[0])returni-T[0];elsereturn0;}}bF算法的时间复杂度若n为主串长度,m为子串长度则最好的情况是:一配就中,只比较了m次。
最坏的情况是:主串前面n-m个位置都部分匹配到子串的最后一位,即这n-m位比较了m次,最后m位也各比较了一次,还要加上m,所以总次数为:(n-m)*m+m=(n-m+1)*m从最好到最坏情况统计总的比较次数,然后取平均,得到一般情况是o(n+m).篇二:数据结构实验报告-串实验四串【实验目的】1、掌握串的存储表示及基本操作;2、掌握串的两种模式匹配算法:bF和Kmp。
3、了解串的应用。
【实验学时】2学时【实验预习】回答以下问题:1、串和子串的定义串的定义:串是由零个或多个任意字符组成的有限序列。

串的模式匹配算法在串的模式匹配算法中,最著名的算法包括暴力法、KMP算法、Boyer-Moore算法及其改进算法(Bad Character Rule和Good Suffix Rule)等。
下面将对这些算法进行详细介绍。
1. 暴力法(Brute Force):暴力法是最简单的模式匹配算法,其基本思想是从文本串的第一个字符开始与模式串逐个比较,如存在字符不匹配,则在文本串中向后移动一位重新开始匹配,直到找到匹配的位置或者遍历完整个文本串。
暴力法的时间复杂度为O(mn),其中m和n分别为文本串和模式串的长度。
2. KMP算法(Knuth-Morris-Pratt Algorithm):KMP算法是一种高效的模式匹配算法,利用已匹配的字符信息来避免不必要的匹配比较。
算法的核心思想是通过预处理模式串构建一个next数组(或称为部分匹配表),记录模式串中能够跳过的位置。
当出现字符不匹配时,根据next数组中的值来决定模式串的移动位置。
KMP算法的时间复杂度为O(m+n),其中m和n分别为文本串和模式串的长度。
3. Boyer-Moore算法:Boyer-Moore算法是一种基于“坏字符规则”(Bad Character Rule)和“好后缀规则”(Good Suffix Rule)的模式匹配算法。
坏字符规则指的是在字符串匹配过程中,若出现不匹配情况,则将模式串向右移动,直到模式串中的字符与坏字符对齐。
而好后缀规则则是根据好后缀在模式串中出现的位置来进行移动。
Boyer-Moore算法的时间复杂度为O(mn),但在实际应用中,其平均性能往往优于KMP算法。
4. 改进的Boyer-Moore算法:改进的Boyer-Moore算法对原始的Boyer-Moore算法进行了优化,提出了“坏字符规则”的改进和“好后缀规则”的改进。
其中,“坏字符规则”的改进包括“坏字符数组”(Bad Character Array)和“好后缀规则”的改进包括“好后缀数组”(Good Suffix Array)。

一、实验目的1. 理解串匹配算法的基本原理和实现方法。
2. 掌握KMP算法和朴素算法的原理和实现过程。
3. 通过实验对比分析两种算法的性能,验证算法的效率和适用场景。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.73. 开发工具:PyCharm三、实验内容1. 串匹配算法的原理介绍2. 朴素算法的实现与测试3. KMP算法的实现与测试4. 两种算法的性能对比四、实验步骤1. 串匹配算法的原理介绍串匹配算法是指在一个文本串中查找一个模式串的位置。
常用的串匹配算法有朴素算法和KMP算法。
(1)朴素算法(Brute-Force算法):通过逐个字符比较主串和待匹配串,如果匹配成功,则返回匹配位置;如果匹配失败,则回溯到主串上的一个新位置,并在待匹配串上从头开始比较。
(2)KMP算法:通过构建一个部分匹配表(next数组),记录模式串中每个位置对应的最长相同前缀后缀的长度。
在匹配过程中,当出现不匹配时,通过查阅next数组确定子串指针回退位置,从而避免重复比较。
2. 朴素算法的实现与测试(1)实现朴素算法```pythondef brute_force_search(text, pattern):n = len(text)m = len(pattern)for i in range(n - m + 1):j = 0while j < m:if text[i + j] != pattern[j]:breakj += 1if j == m:return ireturn -1```(2)测试朴素算法```pythontext = "ABABDABACDABABCABAB"pattern = "ABABCABAB"print(brute_force_search(text, pattern)) # 输出:10 ```3. KMP算法的实现与测试(1)实现KMP算法```pythondef kmp_search(text, pattern):def build_next(pattern):next_array = [0] len(pattern)k = 0for i in range(1, len(pattern)):while k > 0 and pattern[k] != pattern[i]: k = next_array[k - 1]if pattern[k] == pattern[i]:k += 1next_array[i] = kreturn next_arrayn = len(text)m = len(pattern)next_array = build_next(pattern)k = 0for i in range(n):while k > 0 and text[i] != pattern[k]:k = next_array[k - 1]if text[i] == pattern[k]:k += 1if k == m:return i - m + 1return -1```(2)测试KMP算法```pythontext = "ABABDABACDABABCABAB"pattern = "ABABCABAB"print(kmp_search(text, pattern)) # 输出:10```4. 两种算法的性能对比为了对比两种算法的性能,我们分别测试了不同的文本串和模式串长度,并记录了运行时间。

简述串的模式匹配原理嘿,咱聊聊串的模式匹配原理呗!这串的模式匹配,听着挺神秘,其实也不难理解。
就像在一堆宝藏里找宝贝。
啥是串的模式匹配呢?简单说,就是在一个大字符串里找一个小字符串。
这就像在一片大海里找一条小鱼。
你得有办法才能找到它。
比如说,你想在一篇文章里找一个特定的词,这就是串的模式匹配。
那怎么找呢?有好几种方法呢。
一种是暴力匹配。
这就像一个愣头青,一个一个地比对。
从大字符串的开头开始,一个字符一个字符地和小字符串比对。
如果不一样,就往后移一个字符,继续比对。
这就像在一堆沙子里找一颗小石子,得一颗一颗地找。
虽然有点笨,但是有时候也能管用。
还有一种是KMP 算法。
这就像一个聪明的侦探,有自己的一套方法。
它会先分析小字符串的特点,然后根据这些特点来快速匹配。
比如说,如果在比对的过程中发现不一样了,它不会像暴力匹配那样从头开始,而是根据之前的分析,直接跳到合适的位置继续比对。
这就像你知道了宝藏的线索,就能更快地找到宝藏。
串的模式匹配有啥用呢?用处可大了。
比如说,在文本编辑软件里,你想查找一个特定的词或者句子,就用到了串的模式匹配。
还有在搜索引擎里,也是用串的模式匹配来找到你想要的信息。
这就像你有一把神奇的钥匙,能打开知识的大门。
你说要是没有串的模式匹配,那会咋样呢?那找东西可就麻烦了。
就像在一个乱七八糟的房间里找东西,没有头绪,得翻个底朝天。
有了串的模式匹配,就像有了一个指南针,能让你更快地找到你想要的东西。
总之,串的模式匹配就像一个神奇的工具,能在大字符串里找到小字符串。
咱可得好好理解它,让它为我们的生活带来更多的便利。


串的数据结构实验报告串的数据结构实验报告一、引言在计算机科学中,串(String)是一种基本的数据结构,用于存储和操作字符序列。
串的数据结构在实际应用中具有广泛的用途,例如文本处理、搜索引擎、数据库等。
本实验旨在通过实践掌握串的基本操作和应用。
二、实验目的1. 理解串的概念和基本操作;2. 掌握串的存储结构和实现方式;3. 熟悉串的常见应用场景。
三、实验内容1. 串的定义和基本操作在本实验中,我们采用顺序存储结构来表示串。
顺序存储结构通过一个字符数组来存储串的字符序列,并使用一个整型变量来记录串的长度。
基本操作包括:- 初始化串- 求串的长度- 求子串- 串的连接- 串的比较2. 串的模式匹配串的模式匹配是串的一个重要应用场景。
在实验中,我们将实现朴素的模式匹配算法和KMP算法,并比较它们的性能差异。
四、实验步骤1. 串的定义和基本操作首先,我们定义一个结构体来表示串,并实现初始化串、求串的长度、求子串、串的连接和串的比较等基本操作。
2. 串的模式匹配a. 实现朴素的模式匹配算法朴素的模式匹配算法是一种简单但效率较低的算法。
它通过逐个比较主串和模式串的字符来确定是否匹配。
b. 实现KMP算法KMP算法是一种高效的模式匹配算法。
它通过利用已匹配字符的信息,避免不必要的比较,从而提高匹配效率。
3. 性能比较与分析对比朴素的模式匹配算法和KMP算法的性能差异,分析其时间复杂度和空间复杂度,并讨论适用场景。
五、实验结果与讨论1. 串的基本操作经过测试,我们成功实现了初始化串、求串的长度、求子串、串的连接和串的比较等基本操作,并验证了它们的正确性和效率。
2. 串的模式匹配我们对两种模式匹配算法进行了性能测试,并记录了它们的运行时间和内存占用情况。
结果表明,KMP算法相较于朴素算法,在大规模文本匹配任务中具有明显的优势。
六、实验总结通过本实验,我们深入学习了串的数据结构和基本操作,并掌握了串的模式匹配算法。

实验题目:串的模式匹配一、实验目的1、加深理解串的基本操作;2、理解并实现串的朴素模式匹配算法。
二、实验内容输入主串S和模式T,在S中查找T出现的第一个位置。
三、设计与编码1、基本思想1,在串S和串T中设置比较的起始下标i和j;2,如果S[i]=T[j],继续比较S和T的下一对字符,否则将下标i,j回溯,准备下一趟比较;3,如果T中所有字符都比较完,则匹配成功,返回匹配的开始位置,否则返回0;2、编码#include<iostream>#include<string>using namespace std;class BF{private:char *s,*t;public:BF(char a[],char b[]){s=a;t=b;}int bf(){int i=0,j=0;while((s[i]!='\0')&&(t[j]!='\0')){if(s[i]==t[j]){i++;j++;}else{i=i-j+1;j=0;}}if(t[j]=='\0')return i-j+1;}};int main(){char s[100],t[100];cin>>s>>t;BF A(s,t);cout<<"主串S:"<<s<<'\n'<<"模式T:"<<t<<endl;cout<<A.bf()<<endl;return 0;}四、调试与运行1、调试时遇到的主要问题及解决答:基本没有大的错误,大多是一些细节问题,就是字符串的上传问题,我最后直接用指针搞定。
2、运行结果(输入及输出,可以截取运行窗体的界面)输入:abcdefgh defg;输出:五、实验心得答:通过本次的实验,让我加深了理解了串的操作。

数据结构—串的模式匹配数据结构—串的模式匹配1.介绍串的模式匹配是计算机科学中的一个重要问题,用于在一个较长的字符串(称为主串)中查找一个较短的字符串(称为模式串)出现的位置。
本文档将详细介绍串的模式匹配算法及其实现。
2.算法一:暴力匹配法暴力匹配法是最简单直观的一种模式匹配算法,它通过逐个比较主串和模式串的字符进行匹配。
具体步骤如下:1.从主串的第一个字符开始,逐个比较主串和模式串的字符。
2.如果当前字符匹配成功,则比较下一个字符,直到模式串结束或出现不匹配的字符。
3.如果匹配成功,返回当前字符在主串中的位置,否则继续从主串的下一个位置开始匹配。
3.算法二:KMP匹配算法KMP匹配算法是一种改进的模式匹配算法,它通过构建一个部分匹配表来减少不必要的比较次数。
具体步骤如下:1.构建模式串的部分匹配表,即找出模式串中每个字符对应的最长公共前后缀长度。
2.从主串的第一个字符开始,逐个比较主串和模式串的字符。
3.如果当前字符匹配成功,则继续比较下一个字符。
4.如果当前字符不匹配,则根据部分匹配表的值调整模式串的位置,直到模式串移动到合适的位置。
4.算法三:Boyer-Moore匹配算法Boyer-Moore匹配算法是一种高效的模式匹配算法,它通过利用模式串中的字符出现位置和不匹配字符进行跳跃式的匹配。
具体步骤如下:1.构建一个坏字符规则表,记录模式串中每个字符出现的最后一个位置。
2.从主串的第一个字符开始,逐个比较主串和模式串的字符。
3.如果当前字符匹配成功,则继续比较下一个字符。
4.如果当前字符不匹配,则根据坏字符规则表的值调整模式串的位置,使模式串向后滑动。
5.算法四:Rabin-Karp匹配算法Rabin-Karp匹配算法是一种基于哈希算法的模式匹配算法,它通过计算主串和模式串的哈希值进行匹配。
具体步骤如下:1.计算模式串的哈希值。
2.从主串的第一个字符开始,逐个计算主串中与模式串长度相同的子串的哈希值。

一、实验目的1. 理解串的定义、性质和操作;2. 掌握串的基本操作,如串的创建、复制、连接、求子串、求逆序、求长度等;3. 熟练运用串的常用算法,如串的模式匹配算法(如KMP算法);4. 培养编程能力和算法设计能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 开发环境:Visual Studio 2019三、实验内容1. 串的创建与初始化2. 串的复制3. 串的连接4. 串的求子串5. 串的求逆序6. 串的求长度7. 串的模式匹配算法(KMP算法)四、实验步骤1. 串的创建与初始化(1)创建一个串对象;(2)初始化串的长度;(3)初始化串的内容。
2. 串的复制(1)创建一个目标串对象;(2)使用复制构造函数将源串复制到目标串。
3. 串的连接(1)创建一个目标串对象;(2)使用连接函数将源串连接到目标串。
4. 串的求子串(1)创建一个目标串对象;(2)使用求子串函数从源串中提取子串。
5. 串的求逆序(1)创建一个目标串对象;(2)使用逆序函数将源串逆序。
6. 串的求长度(1)获取源串的长度。
7. 串的模式匹配算法(KMP算法)(1)创建一个模式串对象;(2)使用KMP算法在源串中查找模式串。
五、实验结果与分析1. 串的创建与初始化实验结果:成功创建了一个串对象,并初始化了其长度和内容。
2. 串的复制实验结果:成功将源串复制到目标串。
3. 串的连接实验结果:成功将源串连接到目标串。
4. 串的求子串实验结果:成功从源串中提取了子串。
5. 串的求逆序实验结果:成功将源串逆序。
6. 串的求长度实验结果:成功获取了源串的长度。
7. 串的模式匹配算法(KMP算法)实验结果:成功在源串中找到了模式串。
六、实验总结通过本次实验,我对串的定义、性质和操作有了更深入的了解,掌握了串的基本操作和常用算法。
在实验过程中,我遇到了一些问题,如KMP算法的编写和调试,但在老师和同学的指导下,我成功地解决了这些问题。
简述串的模式匹配算法概念-回复串的模式匹配算法是指在一个文本串中寻找一个模式串出现的位置的算法。
它是计算机科学领域中的经典问题,应用广泛。
不论是搜索引擎中的关键词匹配,还是代码编辑器中的查找替换功能,在实际的编程开发中都需要用到串的模式匹配算法。
在深入理解串的模式匹配算法之前,我们需要先了解什么是串。
串是指由零个或多个字符组成的有限序列。
在计算机中,串通常是以字符串的形式存在,它是一种非常基础的数据结构,用于表示文本。
在串的模式匹配算法中,有几种常见的思想和算法。
1.暴力匹配算法暴力匹配算法也被称为朴素匹配算法,它是最简单直接的模式匹配算法。
它的思想是从文本串的第一个字符开始,逐个与模式串进行匹配,如果匹配失败,则将文本串向后移动一个字符,再次与模式串进行匹配。
这个过程会一直重复,直到找到匹配的位置或者搜索到文本串的末尾。
暴力匹配算法的时间复杂度为O(n*m),其中n为文本串的长度,m为模式串的长度。
虽然时间复杂度较高,但暴力匹配算法是一种简单易懂、实现容易的模式匹配算法。
2.KMP算法KMP算法是一种高效的模式匹配算法,它的核心思想是通过利用已经匹配过的信息,避免不必要的重复匹配。
KMP算法首先构建模式串的最长前缀后缀表,该表记录了模式串中每个位置之前的字符串中,最长的既是前缀又是后缀的子串的长度。
通过这个表,可以在匹配过程中根据已经匹配的部分直接跳跃到下一个可能匹配的位置,从而避免了重复匹配。
KMP算法的时间复杂度为O(n+m),其中n为文本串的长度,m为模式串的长度。
相比于暴力匹配算法,KMP算法在匹配过程中减少了不必要的比较次数,大大提高了匹配效率。
3.Boyer-Moore算法Boyer-Moore算法是一种根据字符在模式串中出现的位置进行跳跃匹配的算法。
它的核心思想是从模式串的末尾开始,逐个比较模式串和文本串的字符,并根据预处理的跳跃表进行匹配位置的选择。
Boyer-Moore算法分别预处理了两个跳跃表:bad character表和good suffix表。
简述串的模式匹配算法概念
串的模式匹配算法是指在一个较长的字符串中寻找一个较短的模式字符串是否出现的一种算法。
常见的串的模式匹配算法包括朴素模式匹配算法、KMP算法、Boyer-Moore算法和Rabin-Karp算法等。
朴素模式匹配算法是一种简单的模式匹配算法,它从主串的第一个字符开始逐个字符与模式串进行比较,如果发现不匹配,则主串的比较位置向后移动一位,并重新与模式串的第一个字符进行比较。
这个过程一直重复直到找到匹配的位置或主串遍历完毕。
KMP算法是一种高效的模式匹配算法,它利用模式串中的重复信息避免无效的比较。
KMP算法先对模式串进行预处理,生成一个部分匹配表(即next数组),然后根据该表的信息进行匹配。
当发生不匹配时,KMP算法通过查找部分匹配表中的值来决定模式串的移动位置,从而避免了不必要的比较操作,提高匹配的效率。
Boyer-Moore算法是一种更加高效的模式匹配算法,它利用了模式串中的字符出现位置进行快速的移动。
Boyer-Moore算法从主串的末尾开始比较,遇到不匹配的字符时,根据模式串中的字符出现位置,选择合适的位移量进行移动。
这样可以快速地将模式串与主串对齐,减少不必要的比较次数。
Rabin-Karp算法是一种基于哈希的模式匹配算法,它利用哈希函数对子串进行哈希运算,并与模式串的哈希值进行比较,从
而确定是否匹配。
Rabin-Karp算法通过将字符串转化为数值进行比较,避免了字符比较的开销,提高了匹配的效率。
但是Rabin-Karp算法可能出现哈希冲突的情况,需要额外的处理。
这些模式匹配算法的思想不同,适用于不同的场景和问题,选择合适的算法可以提高模式匹配的效率。
一、实验目的本次实验旨在让学生熟悉并掌握模式匹配的基本概念、算法及其应用。
通过实验,学生能够了解模式匹配算法的原理,掌握几种常见的模式匹配算法(如KMP算法、BF算法等)的实现方法,并能够运用这些算法解决实际问题。
二、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 开发环境:Visual Studio 2019三、实验内容1. 模式匹配基本概念- 模式匹配:在给定的文本中查找一个特定模式的过程。
- 模式:要查找的字符串。
- 文本:包含可能包含模式的字符串。
2. KMP算法- KMP算法(Knuth-Morris-Pratt)是一种高效的字符串匹配算法,其核心思想是避免重复比较已经确定不匹配的字符。
- 实现步骤:1. 构造一个部分匹配表(next数组)。
2. 遍历文本和模式,比较字符,并使用next数组调整模式的位置。
3. BF算法- BF算法(Boyer-Moore)是一种高效的字符串匹配算法,其核心思想是利用坏字符规则和好后缀规则来减少不必要的比较。
- 实现步骤:1. 计算坏字符规则。
2. 计算好后缀规则。
3. 遍历文本和模式,比较字符,并使用坏字符规则和好后缀规则调整模式的位置。
4. 模式匹配算法比较- 比较KMP算法和BF算法的时间复杂度、空间复杂度及适用场景。
四、实验步骤1. 初始化- 定义文本和模式字符串。
- 初始化模式匹配算法的参数。
2. 构造next数组(KMP算法)- 根据模式字符串构造部分匹配表(next数组)。
3. 计算坏字符规则和好后缀规则(BF算法)- 根据模式字符串计算坏字符规则和好后缀规则。
4. 遍历文本和模式- 使用KMP算法或BF算法遍历文本和模式,比较字符,并调整模式的位置。
5. 输出结果- 输出匹配结果,包括匹配的位置和匹配次数。
五、实验结果与分析1. KMP算法- 时间复杂度:O(nm),其中n为文本长度,m为模式长度。
- 空间复杂度:O(m)。
数据结构—串的模式匹配数据结构—串的模式匹配1:引言1.1 背景在计算机科学中,模式匹配是一个常见的问题,涉及到在给定的文本字符串中查找特定的模式串。
串的模式匹配是一种重要的算法,广泛应用于字符串处理、数据查询和自然语言处理等领域。
1.2 目的本文档旨在介绍串的模式匹配算法的基本原理和常用的实现方法,以及其在实际应用中的一些应用场景。
通过阅读本文档,读者将能够理解串的模式匹配算法的工作原理,并能够根据具体的应用需要选择合适的算法进行实现。
2:基本概念2.1 字符串字符串是由字符组成的有限序列,在计算机中通常以字符数组或字符指针的形式来表示。
字符串是计算机科学中常用的数据类型之一,用于表示文本数据。
2.2 模式串模式串是在字符串匹配中需要查找的特定模式,它是一个想要在文本串中查找的子串。
3:算法实现3.1 简单匹配算法简单匹配算法,也称为朴素匹配算法,是最简单直观的一种模式匹配算法。
它的基本思想是,从文本串的第一个字符开始,逐个字符地与模式串进行匹配,如果匹配失败,则从文本串的下一个字符重新开始匹配。
3.2 KMP算法KMP算法是一种高效的模式匹配算法,它利用了模式串本身的信息来加速匹配过程。
该算法基于一个重要观察结果,即当模式串在某一位置匹配失败时,它的前缀与后缀可能存在一定的重叠,从而可以避免无效的匹配。
3.3 Boyer-Moore算法Boyer-Moore算法是一种高效的模式匹配算法,它利用了模式串和文本串的不同之处来加速匹配过程。
该算法在匹配失败时,根据坏字符规则和好后缀规则,可以跳过一定数量的字符,从而避免无效的匹配。
4:应用场景4.1 文本搜索串的模式匹配算法可以应用于文本搜索中,用于在大量文本数据中查找特定模式的出现位置。
4.2 数据处理串的模式匹配算法可以应用于数据处理中,用于对字符串数据进行匹配处理、替换等操作。
4.3 自然语言处理串的模式匹配算法可以应用于自然语言处理中,用于识别特定语义模式或词组的出现。