
2007级预防行政班卫生统计学复习资料第三节统计工作的基本步骤
统计设计收集资料整理资料分析资料
一、统计设计
1、调查设计
2、实验设计
(详见第十三章)
二、收集资料
资料来源
(1)统计报表
(2)日常医疗工作原始记录和报告卡(3)专题调查
三、整理资料
1.目的将收集的原始资料系统化、条理化,便于进一步计算和分析
2.整理分组方式
(1)性质分组
(2)数量分组
三、分析资料
1、统计描述
2、统计推断
第四节统计图表
一、统计表
1、统计表的作用
代替冗长的文字叙述,便于计算、分析和对比。
2、统计表的结构
1)标题
2)标目横标目(主语):说明表各横行数字的涵义,通常列在表的左侧
纵标目(谓语):说明表各纵栏数字的涵义
主语和谓语连贯起来能读成一句完整而通顺的话
3、统计表的种类:
1)简单表:只按单一变量分组
2)组合表:按两个或两个以上变量分组
某地1980年男、女HBsAg阳性率
━━━━━━━━━━━━━━━━
性别调查数阳性数阳性率(%)
────────────────
男4234 303 7.16
女4530 181 4.00
──────────────
合计8764 484 5.52
━━━━━━━━━━━━━━━━
4、列表原则:重点突出,简单明了;主谓分明,层次分明
5、统计表的基本要求:
1)标题:概括地说明表的内容,必要时注明资料的时间和地点,写在表上方。常见的缺点:过于简略,甚至不写标题;或过于繁琐;或标题不确切。
2)标目:文字简明扼要,有单位的标目要注明单位。常见的缺点:标目过多,层次不清
3)线条:不宜过多,除上面的顶线,下面的底线,纵标目与合计之间的横线外,其余线条一般均省去。表的左上角不宜有斜线。
4)数字:
A、数字一律用阿拉伯数字表示
B、同一指标的小数位数应一致,位次对齐
C、表内不宜留空格,暂缺或未记录,用“…”表示,无数字,用“—”表示,数字为0,填写0
D、绝对数太小而无法计算指标,则用“…”代替。
5)备注:一般不列入表内,必要时可用“*”号标出,写在表的下面。
二、统计图
1、统计图作用:
通过点、线、面等形式表达统计资料,直观地反映事物之间的数量关系。但需注意,由于统计图对数量的表达较粗糙,不便于作深入细致的分析,一般需附相应的统计表。
2、常见统计图种类:
条图、百分条图,圆图,线图,半对数线图,直方图,散点图
3、制图的基本要求:
1)按资料的性质和分析目的,选用适合的图形
2)要有标题,扼要说明资料的内容,必要时注明时间、地点,一般写在图的下面。
3)横轴尺度从左到右,纵轴尺度从下而上,数量一律由小到大。横轴与纵轴坐标长度比例一般为5:7
4)比较不同事物,用不同线条或颜色表示,并附上图例说明。
第二章数值变量(计量)资料的统计分析
第一节计量资料的统计描述
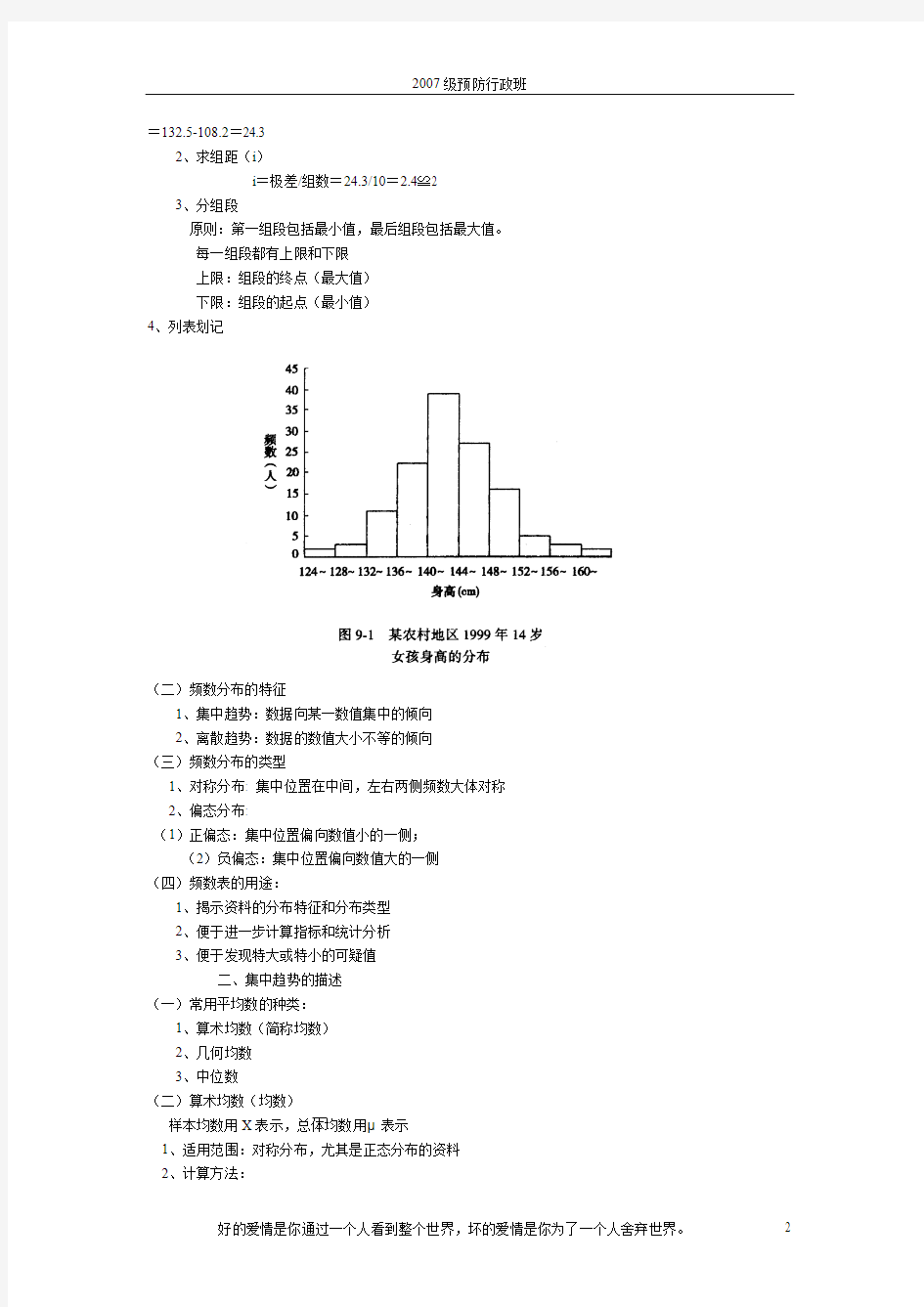
一、计量资料的频数分布
(一)频数表的编制
1、求极差(全距)
R=最大值-最小值
=132.5-108.2=24.3
2、求组距(i)
i=极差/组数=24.3/10=2.4≌2
3、分组段
原则:第一组段包括最小值,最后组段包括最大值。
每一组段都有上限和下限
上限:组段的终点(最大值)
下限:组段的起点(最小值)
4、列表划记
(二)频数分布的特征
1、集中趋势:数据向某一数值集中的倾向
2、离散趋势:数据的数值大小不等的倾向
(三)频数分布的类型
1、对称分布: 集中位置在中间,左右两侧频数大体对称
2、偏态分布:
(1)正偏态:集中位置偏向数值小的一侧;
(2)负偏态:集中位置偏向数值大的一侧
(四)频数表的用途:
1、揭示资料的分布特征和分布类型
2、便于进一步计算指标和统计分析
3、便于发现特大或特小的可疑值
二、集中趋势的描述
(一)常用平均数的种类:
1、算术均数(简称均数)
2、几何均数
3、中位数
(二)算术均数(均数)
样本均数用X表示,总体均数用μ表示
1、适用范围:对称分布,尤其是正态分布的资料
2、计算方法:
(1)直接法X=∑X / n
(2)加权法适用于频数表资料
X=∑fX / ∑f
其中X=组中值=(上限+下限)/ 2
f=频数
(三)几何均数(简记为G)
1、适用范围:
(1)等比级数资料,如血清滴度资料
(2)对数正态分布资料
2、计算方法:
(1)直接法
G=log-1(∑logX/n)
(2)加权法
G=log-1(∑flogX/∑f)
(四)中位数(简记M)
1、中位数的定义:
中位数: 将一组观察值从小到大按顺序排列,位次居中的观察值就是中位数。在全部观察值中,大于和小于中位数的观察值的个数相等。
2、中位数的适用范围:
(1)偏态分布资料
(2)分布不明资料
(3)分布末端无确定值资料(开口资料)
理论上,中位数可用于任何分布的计量资料,但实际应用中常用于偏态分布,特别是开口资料。在对称分布资料中,M=X
3、计算方法:
(1)直接法:适用于观察数少资料
n为奇数时,M=X(n+1)/2
n为偶数时,M=(Xn/2+X(n/2+1))/2
(2)频数表法:适用于频数表资料
步骤:①从小到大计算累计频数和累计频数;
②确定中位数所在组段;
③计算中位数M
M=LM+iM/fM(n/2-∑fL)
LM=M所在组段的下限
iM=M所在组段的组距
fM=M所在组段的频数
∑fL=小于L各组段的累计频数
M在8~组段
L=8
i=4
fX=48
∑fL=26
n=108
M=L+i/fX(n/2-∑fL)=10.33
(五)小结:常用平均数的意义及其应用场合
平均数意义应用场合
─────────────────────────
均数平均数量水平最适用于对称分布,特别是
正态分布
几何均数平均增(减)倍数等比资料或对数正态分布
中位数位次居中的观察值(1)偏态分布,(2)分布不明,
(3)分布末端无确定水平
三离散趋势的描述
甲组26, 28, 30, 32, 34. X甲=30
乙组24, 27, 30, 33, 36. X乙=30
丙组26, 29, 30, 31, 34. X丙=30
(一)反映离散程度的常用指标:
1、极差
2、四分位数间距
3、方差
4、标准差
5、变异系数
(二)极差(全距)R
1、计算公式:R=最大值-最小值
2、意义:R愈大,离散度愈大,R愈小,离散度愈小。
3、优点:计算简单,意义明了
4、缺点:(1)不能反映每一个观察值的变异;
(2)样本例数越大,R可能越大;
(3)R抽样误差大,不稳定。
(三)四分位数间距(简记Q)
1.百分位数(记作PX)
(1)定义:将一组观察值从小到大按顺序排列,一个百分位数将全部观察值分为两部分,理论上有x%的观察值比它小,有(100-x)%的观察值比它大。P50分位数也就是中位数。
(2)计算步骤与公式
①从小到大计算累计频数和累计频数;
②确定百分位数所在组段;
③计算百分位数Px
Px=L+i/fx(n.x%-∑fL)
L=Px所在组段的下限
i=Px所在组段的组距
fx=Px所在组段的频数
∑fL=小于L各组段的累计频数
如计算P25
P25 在8~组段
L25=8,i25=4 ,f25=48,∑fL=108,n=108
P25=L25+i25/f25(n.25%-∑fL)=8.083
P75 在12~组段
L75=12,i25=25 ,f75=4,∑fL =74,n=108 P75=L75+i75/f75(n.75%-∑fL )=13.120 2. 四分位数间距
(1)计算公式: P25: 下四分位数 简记QL P75: 上四分位数 简记QU 四分位数间距Q =QU -QL =13.120-8.083 =5.037
(2)意义:中间一半观察值的极差,与R 意义相似。 (3)特点:
A.比R 稳定,但仍未考虑每一个观察值的变异;
B.常用于描述偏态资料的离散度。
(四)方差(总体方差简记σ2,样本方差简记S2) 一组观察值的离均差平方和,取其均数,即方差。 1、计算公式:
N x ∑-=
2
2
)
(μσ
1)(2
2--=
∑n x x s
2、意义: 方差越大,离散度越大; 方差越小,离散度越小。
(五)标准差(总体标准差简记σ,样本标准差简记S ) 1、定义:方差的开方,即标准差。
N
x ∑-=
2
)
(μσ
1)(2
--=
∑n x x s
2、意义:与方差的意义相同
3、样本标准差计算方法: (1)直接法:
1/)(22--=
∑∑n n
x x s
(2)加权法:
1/)(2
2
--=
∑∑∑∑f f
fX fX s
(1)用于表示正态或近似正态分布资料的离散度;
(2)结合均数描述正态分布的特征;
(3)计算标准误。
(4)计算变异系数
(六)变异系数(简记CV)
1、计算公式:CV=S/X×100%
2、用途:
(1)比较度量衡单位不同的多组资料的变异度
(2)比较均数相差悬殊的多组资料的变异度
例1
身高:X=166.06cm , S=4.95cm
体重:X=53.72kg , S=4.96kg
身高CV= 4.95cm/166.06cm×100%=2.98%
体重CV=4.96kg/53.72kg×100%=9.23%
例2
表2.6 某地不同年龄男子身高(cm)的变异程度
━━━━━━━━━━━━━━━━━━━━━━━
年龄组人数均数标准差变异系数(%)
───────────────────────
3-3.5岁300 96.1 3.1 3.2
30-35岁400 170.2 5.0 0.3
━━━━━━━━━━━━━━━━━━━━━━━
3、CV特点:没有单位,是相对数,便于资料间的比较。
第二节正态分布和参考值范围的估计
一、正态分布
(一)正态分布图形
两头低,中间高,左右对称,呈钟型的单峰曲线。
作u变换后:
u = (X-μ)/ σ
正态分布变成μ=0,σ=1 的标准正态分布。
(二)正态分布特征
1、曲线在横轴上方均数处最高;
2、以均数为中心,左右对称;
3、正态分布有两个参数:
(1)μ: 位置参数,确定曲线位置
当σ一定时,μ越大,曲线越向右移动;μ越小,曲线越向左移动。
(2)σ: 离散度参数,决定曲线的形态:
当μ一定时,σ越大,表示数据越分散,曲线越“胖”;σ越小,表示数据越集中,曲线越“瘦”。
4、正态分布曲线下的面积有一定的分布规律。
二、正态分布曲线下的面积分布规律。
以曲线下总面积为100%,则有:
1、μ±1σ的区间占总面积的68.27%,即μ±1σ的区间内包含的观察值个数占观察值总个数的68.27%。
1、μ±1.96σ的区间占总面积的95%,即μ±1.96σ的区间内包含的观察值个数占观察值总个数的95%。
3、μ±2.58σ的区间占总面积的99%,即μ±2.58σ的区间内包含的观察值个数占观察值总个数的99%。正态分布的应用
1.估计频数分布情况
2.估计参考值范围
三、参考值范围的估计
1.参考值范围意义:
参考值范围(亦称为正常值范围)是指正常人的解剖、生理、生化等各种指标的波动范围。它主要用于划分正常与异常的界限。
2.正常值范围制定的一般原则
(1)抽取足够数量的正常人作为调查对象
A.“正常人”-不是指任何一点小病都没有的人,而是指排除影响被研究指标的疾病和因素的人。
如制定SGPT(谷丙转氨酶)正常值范围,正常人的条件是:
a.无肝、肾、心、脑、肌肉等疾患;
b.近期无服用损肝的药物(如氯丙嗪,异烟肼)
c.测定前未作剧烈运动。
B.正常值范围制定所需的样本例数,一般要求n>100
(2)确定是否分组制定参考值范围
(3)确定取单侧还是双侧正常值范围。
A.白细胞数过高和过低均属于异常,则需同时制定正常值范围的下限(最小值)和上限(最大值),称双侧正常值范围。
B.肺活量只过低为异常,只需制定正常值范围的下限;尿铅只过高为异常,只需制定正常值范围的上限;均称单侧正常值范围。
(4)选定适当的百分界限。
正常值范围的意思:绝大多数正常人的某项观察值均在该范围之内。这个绝大多,习惯上指正常人的80%、90%、95%、99%(最常用是95%)。那么,在正常值范围之外的正常人有:
单侧:20%、10%、5%、1%
双侧每侧:10%、5%、 2.5%0.5%
根据所选定的百分界限,会造成假阳性或/和假阴性。
如SGPT,正常值单侧95%上限为146单位(King法)
按该范围,5%的正常人(>146)被错判为异常,称假阳性;
而肝功能异常者中,也可能有<146者,按该范围错判为正常,称假阴性。
显然,上限值提高,假阳性减少,假阴性增多;
上限值降低,假阳性增多,假阴性减少;
(5)选择适当制定方法。
3、正常值范围常用制定方法
(1)正态分布法.
A.适用范围:(近似)正态分布或对数正态分布资料
B.计算公式:
双侧95%X ±1.96S
99%X ±2.58S
单侧 上限 95% X + 1.645S 99% X + 2.326S
下限 95% X - 1.645S 99% X - 2.326S 例 1 14岁女孩身高95%参考值范围是: X ± 1.96S=143.08±1.96×6.58 =(130.18~155.98) (2)百分位数法 A .适用范围: 1、偏态分布资料 2、开口资料 B .计算公式:
双侧 95% P2.5~P97.5 99% P0.5~P99.5 单侧 上限 95% P95 99% P99 下限 95% P5 99% P1
第三节 计量资料的统计推断 一、均数的抽样误差与标准误 一、均数的抽样误差概念
由于总体中存在个体变异,所以由抽样得到的样本均数与总体均数之间存在差异,这种差异称均数的抽样误差。在抽样研究中,抽样误差是不可避免的,但可以估计其大小。 二、中心极限定理
1、在正态总体中,随机抽取例数为n 的样本,样本均数X 服从正态分布;
2、在偏态总体中随机抽样,当n 足够大时(n>50),X 也近似正态分布;
3、从均数为μ,标准差为σ的正态或偏态总体中,抽取例数为n 的样本, 样本均数X 的总体均数仍为μ,标准差为σx
三、标准误意义及其计算方法
1、意义: 说明均数抽样误差大小的指标,用σx 表示。σx 越大, 均数抽样误差越大;反之,σx 越小,均数抽样误差越小。
2、计算公式:
n x σ
σ=
.........(理论值)
n s
s x =
...........(估计值)
x s 与 s 成正比,与n 成反比,可以通过增加n 减小x s 。
3.均数的标准误的用途:
(1)说明均数抽样误差大小,反映均数的可靠性。σx 越大,用样本均数推论总体均数越可靠,反之亦然 (2)估计总体均数的可信区间 (3)用于进行假设检验 二、 t 分布 (一)t 分布含义: 由于
X 呈正态分布N(μ、x σ),则可以将一般正态变量X 变换成标准正态变量u :
x
X u σμ)
(-=
将一般的正态分布变换为标准正态分布N(0、1)。 在实际应用中,
x σ往往未知,用x s 代替,则只能对X 做t 变换而不是u 变换:
X s X t )(μ-=
=
n s X )(μ-
每个
X 可以算出一个t 值,t 值的分布称t 分布。
(二)t 分布特征:
1、以0为中心,左右对称的单峰分布;
2、t 分布的形态与自由度ν有关:
ν越小,t 分布曲线峰部越低平而尾部翘得越高;(t 分布与u 分布相差较大,即相同的曲线下面积,t 值>u 值)
ν逐渐增大,t 分布逼近标准正态分布;
ν=∞,t 分布=标准正态分布。(同样的曲线下面积,t 值=u 值)
自由度不同,t 分布曲线形态就不相同,因此t 分布是一簇曲线,则就是说,自由度不同,相同的t 值所对应的面积不同,或说,出现该t 值的概率不同。 (三)t 值表
对应于每一自由度取值,就有一条t 分布曲线,每条曲线都有自身曲线下t 值的分布规律,相同曲线下面积所对应的t 值不同,计算t 值较为繁杂。为此,统计学家已制成t 值表,通过查表即获得相应的t 值。查表须注意:
1、横标目(左边第一列)为自由度(
ν),纵标目为概率(P 或α),也就是t 界值以外单侧或双侧尾部
的面积占总面积的百分比,表中的数字就是对应于
ν和α的t 界值,用t α,ν表示;
2、t 值有正负值,由于t 分布是以0为中心的对称分布,故表中只列正值,查表时,不管t 值正负只用绝对值;
3、当ν一定时,t 值越大,P越小;
4、当P一定时,ν越大,t 值越小;ν=∞时,t =u ;
5、当ν和t 值一定时, 双侧P=2倍单侧P。 即 双侧t α,ν=单侧t α/2,ν。
例ν=10时:
单侧
10
,
05
.0
t
=1.812
即P(t≤-1.812)=0.05 或P(t≥1.812)=0.05
双侧
10
,
05
.0
t
=2.228
即P(t≤-2.228)+P(t≥2.228)=0.05
三、总体均数的估计
(一)估计方法:
1、点值估计:用样本均数直接作为总体均数的估计值
2、区间估计
(二)总体均数的区间估计
1、定义:按一定的概率(1-α)确定包含未知总体均数的可能范围。所确定的范围称为总体均数的可信区间(或置信区间,CI);1-α称可信度,最常用双侧95%。
2、估计方法:
(1)当σ未知,而且样本例数n较小(n<50)时,按t分布原理估计:
X±tα,ν. x s
(2)当σ已知,或σ未知但样本例数足够大(n>50)时,按标准正态分布原理估计:
A.σ已知:
(X-uα.
n
σ
,X+uα.
n
σ
)uα为u界值,X±uα.n
σ
B.σ未知但n足够大(n>50):
(X-uα.
n
S
, X+uα.
n
S
)
X±uα.n
s
按标准正态分布原理估计总体均数可信区间时,熟记下列常用区间:95%总体均数可信区间:X± 1.96n
σ
或X± 1.96
n s
99%总体均数可信区间:X± 2.58n
σ
或X± 2.58
n s
例9.10 n=20, X=118.4mmHg, s=10.8 mmHg, 估计其95%可信区间。
(
X -t α,ν. x s , X +t α,ν. x s )
t0.05,19=2.093 x s =
208.10=2.41 (118.4-2.093×2.41 , 118.7+2.093×2.41) (113.3,123.5)mmHg
例 n=200,
X =3.64mmol/L, s=1.20mmol/L, 估计其95%可信区间。
X ± u α.n s
(3.64- 1.96×
20020.1 ,3.64+1.96×20020.1)
(3.47,3.81)mmol/L 3、可信区间内涵义
以95%总体均数可信区间为例:
有95%的可能所计算出的区间包含了总体均数,即估计正确的概率为95%,错误5%。 4、可信区间两个要素:
(1)准确度:反映在可信度(1-α)的大小。1-α越接近1,越准确。 如可信度99%比95%准确。
(2)精确度:反映在区间范围宽窄。范围越摘越好。 95%可信区间精度优于99%。
在n 确定的情况下,准确度↑,精确度↓。 在兼顾准确度和精确度时,一般取95%可信区间。 在可信度确定的情况下,增加样本例数,可提高精确度。 5、可信区间与正常值范围区别:
(1)意义不同:正常值范围是指绝大多数观察值在某个范围; 可信区间是指按一定的可信度估计总体参数(均数)可能所在的范围; (2)计算公式不同 可信区间 X ±u α.X S (大样本) 正常值范围
X ±u α.S
前者用标准误,后者用标准差。
(3)用途不同:可信区间用于估计总体均数,参考值范围用于判断观察对象某项指标正常与否。 四、 假设检验的基本思想和步骤 (一)提出问题:
例:根据大量调查的资料,已知健康成年男子的脉搏均数为72次/分。某医生在山区随机抽取了25名健康成年男子,得其脉搏均数为74.2次/分,标准差为6.5次/分。问能否认为该山区成年男子的脉搏数高于一般人?
本研究目的是判断是否
μ>0μ(72次/分)。由于存在抽样误差,来自某一总体的随机样本其样本均
数(
X )与总体均数(μ)往往不等;从同一总体中抽取的两个随机样本的样本均数也往往不同。因此,在
比较一个样本均数与一个总体均数的差别,或比较两个样本均数的差别时,需要判断这种差别的性质和意义,造成这种差别有两种可能:
(1)总体均数不等(来自不同总体),有本质差别;
(2)总体均数相等(来自相同的总体),其差别由抽样误差所致,无本质差别。 要判断属于那种可能,需要通过假设检验来回答。 (二)假设检验原理(基本思想)
要检验两指标的差别是由抽样误差引起的,还是由于总体均数不同所致,运用反证法。首先建立检验假设,假设样本来自同一总体,在此假设的基础上计算有关的统计量,根据统计量的大小来判断假设成立的概率的大小。一般把概率P ≤0.05的事件称为小概率事件,小概率事件在一次观察中可以认为是不会发生的,如与这原则不符,则认为原先的假设是不正确的,就是说“假设”不能成立,则拒绝 这个“假设”。 否则不拒绝 原来的“假设”。这就是假设检验的基本思想。 (三)假设检验的一般步骤 A .建立假设 两种假设
(1)检验假设(无效假设)用H0表示: 即假设两总体均数相等,差别仅仅由于抽样误差所致; (2)备择假设 用H1表示: 是与H0对立的假设,当H0 被拒绝,则接受H1。 2、确定单双侧检验(常用双侧检验)
根据研究目的和专业知识还要确定是双侧检验还是单侧检验。若目的是推断两总体是否不等(如是否μ≠μ0),不管是μ>μ0还是μ<μ0,都是我们所关心的,则用双侧检验,此时H0 :μ=μ0,H1:μ≠μ0;若从专业知识已知不会μ<μ0(或不会μ>μ0),目的是推断是否μ>μ0 (或μ<μ0),则用单侧检验,此时H0:μ=μ0,H1:μ>μ0(或μ<μ0)。
注意:单侧检验更容易得到有统计学意义的结果,因此,做单侧检验要通过专业知识来确定,否则,一律做双侧检验,双侧检验更稳妥。
3.确定检验水准 检验水准用
α表示,α是拒绝或不拒绝H0的概率标准,也就是小概率事件标准,是人为选定的概
率值,一般取α=0.05(根据需要也可取0.2、0.15、0.1、0.01等)。 B 、选定检验方法和计算统计量
根据研究设计方案、资料类型、样本含量大小及分析目的选用适当的检验方法,并根据样本资料计算相应的检验统计量。不同的检验方法要用不同的公式计算现有样本的检验统计量(t ,u ,F 值)。检验统计量是在H0成立的前提下计算出来。 C 、确定P值
P值是指在H0所规定的总体中作随机抽样,获得等于及大于(或等于及小于)现有样本统计量的概率。P 也可以通俗地说,P 是指H0成立的概率大小。用计算所得的检验统计量(t 、u 值)与相应的界值比较,确定P值。
D 、作出推断结论 假设检验的结论:
(1)统计学结论(拒绝或接受H0 ,即有无统计学意义); (2)专业结论。 2、推断结论方法
(1)当P≤α时,结论是:拒绝H0,接受H1(差别有显著意义或有统计学意义);
(2)当P>α时,结论是:不拒绝H0。(差别无显著意义,或无统计学意义);
作出上述推断的理由
(1)如果P≤α,则按α水准拒绝H0 ,接受H1 。因为抽取一个样本,仅代表一次试验,现P≤α,为小概率事件,小概率事件在一次试验中竟然发生,与概率理论的一个基本原则:小概率事件在一次试验中不会发生产生矛盾,因此拒绝H0 。
(2)如果P>α,则按α水准不拒绝H0 ,因为概率较大,没有理由拒绝H0 ,认为其成立。所以,研究者只是在概率上从H0 与H1 两者中选择一个较为合理的判断。
由此可见,假设检验所作出的结论是具有概率性质的,不是绝对的肯定或否定。不论拒绝或不拒绝H0 都可能发生错误。
拒绝实际上是成立的H0,这类“弃真”的错误称Ⅰ型错误或第一类错误。
不拒绝(接受)实际上是不成立的H0,这类“存伪”的错误称Ⅱ型错误或第二类错误。
即拒绝H0,犯Ⅰ型错误;接受H1,犯Ⅱ型错误。
两类错误的关系
第一类错误的概率为α,第二类错误的概率为β
α越大,β越小,α越小,β越大。
第四节t检验和u检验
一、t检验和u检验用途
1、样本均数与总体均数的比较;
2、配对计量资料的比较;
3、两样本均数的比较;
二、t检验和u检验应用条件
1、t检验应用条件:
(1)样本来自正态总体;
(2)两小样本均数比较,还要求样本的总体方差相等。
2、u检验应用条件:
样本例数n较大(n>100),或n虽小而总体标准差已知(少见)。
三、单样本t检验(样本均数与总体均数比较t检验)
1、目的:检验样本均数X所代表的未知总体均数μ
是否等于以已知的总体均数
μ
。
已知的总体均数
0μ
指:
(1)理论值;
(2)标准值;
(3)经大量调查得到的稳定值。
2、检验公式
t=
n
s
x0μ
-
v=n-1
四、配对t检验
1、配对设计含义:将受试对象按一定条件配成对子,再随机分配每对的两个受试对象到不同的处理组。
2、配对设计形式
①同对的两个受试对象分别给予两种处理;
② 同一受试对象分别给予两种处理(如同一个样品用 两种方法检测,或同一受试对象不同部位某指标的值) ③ 同一受试对象处理前后比较
3、检验公式: t =n s d
d
v=n-1
五、两样本均数比较
(一)两大样本均数的u 检验 1、适用条件
两个样本含量均足够大(n1>50和n2>50) 2、检验公式:
2
22
1212
1n s n s x x u +-=
(二)两小样本均数的比较—t 检验 1、应用条件
(1)样本来自正态总体;
(2)两样本所来自的总体方差相等。 2、检验公式
)
11(2)()(212122222121212
1n n n n n x x n x x x x t +-+-+--=
∑∑∑∑
或 )
1
1(2)1()1(2
1212
222112
1n n n n s n s n x x t +-+-+--=
六、假设检验应注意的问题
(一)要有严密的抽样研究设计,考虑到被比较的样本的可比性,这是假设检验的前提。 (二)选用的假设检验方法应符合其应用条件。
(三)当所比较的差异无实际意义时,不必进行假设检验。 (四)正确理解差别有无显著性的统计意义。 (五)结论不能绝对化。 是否拒绝H0,取决于:
1、被研究的事物有无本质的差异
2、抽样误差大小:
(1)个体差异大小
(2)样本例数多少 3、检验水准α的高低
(六)报告结论时最好写出较确切的P 值, 并且单侧检验需作注明(习惯上采用双侧检验不需作注明) 第五节 方差分析(F 检验) ( analysis of variance ANOV A ) 一、方差分析的用途及应用条件 (一)用途
1、检验两个或多个样本均数间的差异有无统计学意义;
2、回归方程的线性假设检验;
3、检验两个或多个因素间有无交互作用。 (二)应用条件
1、各个样本是相互独立的随机样本;
2、各个样本来自正态总体;
3、各个处理组(样本)的总体方差方差相等,即方差齐。 二、 方差分析的基本思想 (一)方差分析中变异的分解 此资料的变异,可以分出三种:
1、总变异:表现为所有数据大小不等,用总的离均差平方和表示,记为SS 总。
∑∑-===k i n j ij i
X X SS 11
2
)(总(i 代表第i 个组, j 代表第j 个观察值)
总
SS 的大小还与总例数N 有关,确切讲是与总的自由度
总
ν有关,
总
ν=N-1。
2、组间变异:组间变异表现为各组均数i X 大小不等,
描述其大小指标 (1)用各组均数
i X 与总均数X 的离均差平方和表示,记为SS 组间
SS 组间的大小与处理因素的作 用、随机误差(测量误差和个体差异)和组间自由度有关。
)(1X X n SS i k
i i -∑==组间 ,;1-=k 组间
ν
(2)用SS 组间 除于组间自由度表示,称组间均方
组间
组间
组间νSS MS =
组间均方反映处理因素和随机误差的作用。
3、组内变异:组内变异表现为各组内部各个观察值大小不等。 描述其大小指标:
(1)用各组内部每个观察值
i X 与组均数X 的离均差平方和表示,记为SS 组内。SS 组内的大小与
随机误差(测量误差和个体差异)和组内自由度有关。
∑∑-===k i n j i ij i
X X SS 11
)
(组内,
;
k N -=组内ν
(2)用SS 组内除于组内自由度表示,称组内均方
组内
组内
组内νSS MS =
组内均方只反映观察值的随机误差(个体差异及随机测量误差)。
三种变异的关系:SS 总=SS 组内+SS 组间 , 组间
组内总ν+ν=ν。
(二)方差分析思想
1、如果两个或多个样本来自同一个总体,或者处理因素的效应一样(没有差异),则组间和组内的变异相等,即:
MS 组间 =MS 组内 或两者相差不大,它们的比值用F 表示:
组内组间
MS MS F =
则F=1, 或F 与1相差不大。
2、若两个样本或多个样本来自不同总体,或者处理因素的效应不一样,则组间变异大于组内变异,即: MS 组间>MS 组内
则F 值明显大于1。要大到多大程度才有统计学意义? 按组间ν和组内ν查F 界值表,由F 值
确定P 值,按P 值大小作出推断。
方差分析基本思想:在方差分析时,根据资料的设计类型不同,将总的离均差平方和及自由度分解为两个或多个部分,除随机误差外,其余部分的变异反映处理因素的作用,通过比较不同来源的均方,借助F 分布原理作出统计推断,从而了解处理因素对观测指标有无影响。 三、单因素方差分析 (一)计算方法
单因素方差分析的计算公式
变异来源 SS υ MS F
组间
*
1
1
2
C n X k
i i
n j ij
i
-∑
∑== k-1
组间
组间
νSS
组内
组间
MS MS
组内(误差) SS 总 - SS 组间 N-k
组内
组内
νSS
总
*11
2C X k i n j ij
i
-∑∑== N-1
────────────────────────────
*
N
X C k i n j ij i
∑∑=
==11
2)(
四、分析步骤
1、建立假设和确定检验水准; H0: 4321μμμμ===
H1: 4321μμμμ≠≠≠或不全相等
05.0=α
2、计算检验统计量F 值
表9-15 例9-16 方差分析结果
变异来源 SS υ MS F P
组间 2.0276 3 0.6759 10.24 <0.01 组内 0.7918 12 总 2.8194 15
3、确定P 值和推断结论
以组间自由度组间ν为1ν,以组内自由度组内ν为2ν,查附表3,F 界值表:
12
,3,05.0F =3.49,
由于
>F 12
,3,05.0F
, 故P<0.05; 按
05.0=α,拒绝H0,接受H1, 可以认为四组均数不等或不全
相等。
注意:以上仅是总的结论,尚需对四个样本均数进行两两比较(见后)。 五、 多个样本均数的两两比较-q 检验
多个样本均数比较经F 检验后,若得出有统计学意义的结论后,要进一步推断哪些组之间有差别,哪些组之间没有差别,还是所有各组之间都有差别,要解决这些问题,就要进一步做均数间的两两比较了。 多个样本均数间的两两比较又称多重比较,由于涉及的对比组数大于2,就不能应用前面介绍的t 检验,只能使用下面介绍的方法。 若仍用前述前述的t 检验方法,对每两个对比组作比较,会使犯第一类错误(拒绝了实际上成立的H0所犯的错误)的概率α增大,即可能把本来无差别的两个总体均数判为有差别。
(一)检验统计量q 的计算公式为:
)(误差B A B A n n MS X X q 1
12)
(+-=
式中
B A X X , 为两个对比组的样本均数。误差MS 为方差分析中算得的组内均方),A n 和
B n 分别为两对比组的样本例数。
(二) q 检验的方法步骤 对例9-16资料作两两比较。 1、建立假设
H0:任两对比组的总体均数相等,即B A μμ=
H1:任两对比组的总体均数不等,B A μμ≠
050.=α
2、选择检验方法,计算统计量q
将四个样本均数从大到小顺序排列,并编上组次: 组次 1 2 3 4 均数 3.3200 3.0975 2.6850 2.4025 组别 D C B A 列出两两比较计算表,见表9-17
表9-17 四个样本均数两两比较的q 检验
对比组 两均数之差 标准误 q 值 组数 q 界值 P A 与B
B A X X - S B
X X A - a 0.05 0.01
(1) (2) (3) (4)=(2)/(3) (5) (6) (7) (8) 1与4 0.9175 0.1285 7.140 4 4.20 5.50 <0.01 1与3 0.6350 0.1285 4.942 3 3.77 5.05 <0.05 1与2 0.2225 0.1285 1.732 2 3.08 4.32 >0.05 2与4 0.6950 0.1285 5.409 3 3.77 5.05 <0.01 2与3 0.4125 0.1285 3.210 2 3.08 4.32 <0.05 3与4 0.2825 0.1285 2.198 2 3.08 4.32 >0.05
3、确定P 值,判断结果 第一节 分类资料的描述 一、相对数的意义和定义
对于分类资料常采用相对数进行描述。
收集到的分类资料,表现为绝对数,绝对数说明事物发生的实际水平,是进行统计分析的基础,但不便于事物进行深入地分析比较。
相对数:是两个有联系指标之比,说明事物发生的相对水平,便于对分类资料进行分析和比较。 二、常用的相对数
比(Ratio )亦称相对比,是A 、B 两个有关指标之比,说明A 是B 的多少倍或百分之几。
比(Ratio )=A/B (或×100%)
A 与
B 的性质可以相同,也可以不同,可以是绝对数也可以是相对数或平均数。
2、构成比(Proportion )又称构成指标,说明一事物内部各个组成部分所占的比重或分布,常以百分数表示,又称百分比。
%
100?=
观察单位总数同一事物各组成部分的位数
某一组成部分的观察单构成比
构成比两个特点:
(1)一组构成比之和等于100%或1;
(2)某部分构成增加或减少,则其它部分构成就相应减少或增加。
3、率(Rate )又称频率指标,是指在一定时间内发生某现象的观察单位数与可能发生该现象的总观察单位数之比,常以百分率(%)、千分率(?)、万分率(1/万)、十万分率(1/10万)等表示,它说明某现象发生的频率或强度。
K
?=单位总数可能发生该现象的观察数发生某现象的观察单位率
K 为比例基数,可以是百分率(%)、千分率(?)、万分率(1/万)或十万分率(1/10万),可根据习惯或使计算出的率保持一、二位整数。
人口出生率、死亡率、自然增长率、婴儿死亡率等采用千分率,某病死亡率采用十万分率。
三、 应用相对数时注意的问题 1、计算相对数的分母不宜过小
分母过小则计算所得的相对数不稳定,不可靠。如少于30例时,以绝对数表示较好。 2、分析时不能以比代率
3、对观察单位数不等的几个率,不能直接相加求平均率;
4、资料的对比应注意可比性;
5、率或构成比的比较要遵循随机抽样的原则,要做假设检验。 四、 率的标准化法 (一)概念
率的标准化:是指在比较两个或多个总率时,采用一个共同的内部构成标准,将两个或多个样本不同的内部 部构成调整为相同的内部构成,以消除因内部构成不同对总率产生的影响,使算得的标准化率具有可比性。
采用标准化方法计算得到的率简称标化率,又调整率。
基本思想:采用统一的标准内部构成(年龄、性别),在相同的内部构成条件下,计算预期的发生率(死亡率);
目的:消除因内部构成不同对总率产生的影响,使标化率具有可比性。 (二)标准化率计算步骤
1、选择计算方法:直接法和间接法。
(1)若已知被标化组各小组的率,即pi,采用直接法; (2)若已知被标化组各小组的人数,即ni,以及总率,采用间 接法。 2、选定标准
标准选择原则:
选择有代表性的、较稳定的、数量较大的人群,如全世界的、全国的、全省的、本地区的人群数; 选择相互比较的人群合并做标准; (3)选择相互比较的人群某一组做标准。 3、计算预期数及预期率,即标化率。 (1)直接法:按公式10.4 或 10.5 计算; (2)间接法:按公式10.6。 (三)应用标准化率注意事项
1、应用直接法计算标准化率时,由于所选定的标准人口不同,算得的标准化率也不同,因此,比较几个标准化率时,应采用同一标准人口;
2、当各年龄组的率出现明显交叉时,宜直接比较各年龄组的发生率,而不宜用标准化法;
3、两样本标准化率的比较应作假设检验;
第二节 分类资料统计推断 一、率的抽样误差与标准误 1、率的抽样误差含义
在抽烟研究中,样本率与总体率之间存在的差异称为率的抽样误差。 2、描述率的抽样误差大小的指标-率的标准误 计算公式
n
p )
1(ππσ-=
(理论值)
n p p S p )1(-=
(估计值)
二、总体率的估计 1、估计方法 (1)点估计 (2)区间估计 2、区间估计方法 (1)正态近似法
A .适用条件: np>5 且n (1-p )>5
B .常用两个区间的估计公式
总体率的95%的可信区间:p ±1.96Sp 总体率的99%的可信区间:p ±2.58Sp (2)查表法
A .适用条件:n ≤50,特别p 接近于0或1
B .查表方法:以样本含量n 和阳性数x 查统计学专著的附表 三、总体率的u 检验 (一)样本率与总体率的比较 1、适用条件:np>5 且n (1-p )>5 2、检验公式
卫生统计学试题及答案(一) 1.用某地6~16岁学生近视情况的调查资料制作统计图,以反映患者的年龄分布,可用图形种类为______. A.普通线图 B.半对数线图 C.直方图 D.直条图 E.复式直条图 【答案】C(6——16岁为连续变量,得到的是连续变量的频数分布) 直方图(适用于数值变量,连续性资料的频数表变量) 直条图(适用于彼此独立的资料) 2.为了反映某地区五年期间鼻咽癌死亡病例的年龄分布,可采用______. A.直方图 B.普通线图 C.半对数线图 D.直条图 E.复式直条图(一个检测指标,两个分组变量) 【答案】E ? 3.为了反映某地区2000~1974年男性肺癌年龄别死亡率的变化情况,可采用______. A.直方图 B.普通线图(适用于随时间变化的连续性资料,用线段的升降表示某事物在时间上的发展变化趋势) C.半对数线图(适用于随时间变化的连续性资料,尤其比较数值相差悬殊的多组资料时采用,线段的升降用来表示某事物的发展速度) D.直条图 E.复式直条图 【答案】E 4.调查某疫苗在儿童中接种后的预防效果,在某地全部1000名易感儿童中进行接种,经一定时间后从中随机抽取300名儿童做效果测定,得阳性人数228名。若要研究该疫苗在该地儿童中的接种效果,则______. A.该研究的样本是1000名易感儿童 B.该研究的样本是228名阳性儿童 C.该研究的总体是300名易感儿童 D.该研究的总体是1000名易感儿童 E.该研究的总体是228名阳性儿童 【答案】D 5.若要通过样本作统计推断,样本应是__________. A.总体中典型的一部分 B.总体中任一部分 C.总体中随机抽取的一部分 D.总体中选取的有意义的一部分 E.总体中信息明确的一部分 【答案】C 6.下面关于均数的正确的说法是______.
如何绘制频数表? 求组距 确定各组段的两个端点 归组计数 频数分布表与分布图作用 1.揭示变量分布形态 2.揭示变量分布趋势 3.便于发现特大的或特小的极端值 4.便于进一步计算统计指标和分析 5.作为一种数据陈述的形式 算数应用条件: 对称分布,尤其正态分布 几何应用条件: 1.对数对称分布、等比资料 2.变量值中不能有0;不能同时有正值和负值;若全是负值,计算时可先把负号去掉,得出结果后再加上负号。 中位数条件: 所有分布、尤其偏态分布: 1.变量值中出现个别特小或特大的数值 2.资料的分布呈明显偏态 3.含有不确定数值 4.资料的分布不清 极差应用条件:所有分布、尤其偏态分布 不足: 不能全面的反映所有值的偏离程度 不稳定、小样本小于大样本、样本小于总体 四分位数间距应用条件 所有分布、尤其偏态分布: 1.变量值中出现个别特小或特大的数值 2.资料的分布呈明显偏态 3.含有不确定数值 4.资料的分布不清 方差应用条件: 对称分布,尤其正态分布 变异系数应用 1.量纲不一致
散点图作用 观察两组数据的总体趋势和明显偏离趋势的观察点 判断两组数据的关联形式、方向和密切程度 相关分类 线性相关 秩相关 分类变量相关 线性相关意义 r>0表示正相关,r=1表示完全正相关;r<0表示负相关,r=-1表示完全负相关。 |r|→0表示相关性越弱,|r|→1表示相关性越强。 r=0表示没有线性相关,不代表没有相关。 如何判断线性相关 画散点图 计算线性相关系数 假设检验 如何进行秩相关 编秩次 计算秩相关系数 假设检验 回归分析:利用样本信息,找到变量间数量依存关系。 线性回归分析:利用样本信息,找到变量间线性数量依存关系。 决定系数:反映回归贡献的相对程度,即Y的变异被X解释的比例。 如何进行分类变量的相关分析 交叉表的制作,计算各种概率 计算列联系数 假设检验 相关分析的条件 线性相关系数:二元正态分布的定量变量 秩相关系数:非二元正态分布的定量变量、有序分类变量 列联系数:无序分类变量 轶闻数据:由坊间流传或各种媒体报道的一些个案数据,由于其特殊性往往给公众留下突出和深刻的印象。 特点:缺乏代表性,常诱导人们进行简单的推论,得到一些具有倾向性的结论。 可得数据:为了某些特定目的已收集或积累的数据。如:各类监测数据、统计年鉴等。
t分布与标准正态分布有一定的关系,下述错误的叙述是_____ A.参数数目不同 B.t分布中的自由度趋于无穷大时,曲线逼近标准正态分布 C.为单峰分布 D.对称轴位置在0 E.曲线下面积的分布规律相同 在抽样研究中,当样本例数逐渐增多时_____. A.标准误逐渐加大 B.标准差逐渐加大 C.标准差逐渐减小 D.标准误逐渐减小 E.标准差趋近于0 抽样误差是指。 A.不同样本指标之间的差别 B.样本指标与总体指标之间由于抽样产生的差别(参数与统计量之间由于抽样而产生的差别) C.样本中每个个体之间的差别 D.由于抽样产生的观测值之间的差别 E.测量误差与过失误差的总称 下面说法中不正确的是_____. A.没有个体差异就不会有抽样误差 B.抽样误差的大小一般用标准误来表示 C.好的抽样设计方法,可避免抽样误差的产生 D.医学统计资料主要来自统计报表、医疗工作记录、专题调查或实验等 E.抽样误差是由抽样造成的样本统计量与总体参数间的差别及样本统计量间的差别 t分布与正态分布存在如下哪一种关系。 A.二者均以0为中心,左右对称 B.曲线下中间95%面积对应的分位点均为±1.96 C.当样本含量无限大时,二都分布一致 D.当样本含量无限大时,t分布与标准正态分布一致 E.当总体均数增大时,分布曲线的中心位置均向右移 抽样研究中,适当增加观察单位数,可() A.减小Ⅰ型错误 B.减小Ⅱ型错误 C.减小抽样误差 D.提高检验效能 E.以上均正确
说明两个有关联的同类指标之比为。 A.率 B.构成比 C.频率 D.相对比 E.频数 构成比用来反映。 A.某现象发生的强度 B.表示两个同类指标的比 C.反映某事物内部各部分占全部的比重 D.表示某一现象在时间顺序的排列 E.上述A与C都对 以下属于分类变量的是___________. A.IQ得分 B.心率 C.住院天数 D.性别 E.胸围 计算麻疹疫苗接种后血清检查的阳转率,分母为______. A.麻疹易感人群 B.麻疹患者数 C.麻疹疫苗接种人数 D.麻疹疫苗接种后的阳转人数 E.麻疹疫苗接种后的阴性人数 关于构成比,不正确的是_____. A.构成比中某一部分比重的增减相应地会影响其他部分的比重 B.构成比说明某现象发生的强度大小 C.构成比说明某一事物内部各组成部分所占的分布 D.若内部构成不同,可对率进行标准化 E.构成比之和必为100% 甲乙两地某病的死亡率进行标准化计算时,其标准的选择______. A.不能用甲地的数据 B.不能用乙地的数据 C.不能用甲地和乙地的合并数据 D.可用甲地或乙地的数据 E.以上都不对 用均数与标准差可全面描述资料的分布特征() A.正态分布和近似正态分布 B.正偏态分布 C.负偏态分布 D.任意分布
. 统计试题题库 1. 下列那个是对标化后总死亡率的正确描述? A A.仅仅作为比较的基础,它反映了一种相对水平 B.它反映了实际水平 C.它不随标准选择的变化而变化 D.它反映了事物实际发生的强度 E.以上都不对 2. 两样本作均数差别的t检验,要求资料分布近似正态,还要求: D A.两样本均数相近,方差相等 B.两样本均数相近 C.两样本方差相等 D.两样本总体方差相等 E.两样本例数相等 3. 四格表资料的卡方检验时无需校正,应满足的条件是: D A.总例数大于40 B.理论数大于5 C.实际数均大于l D.总例数大于40且理论数均大于或等于5 E.总例数小于40 4. 总体应该是由: D
. A.研究对象组成 B.研究变量组成 C.研究目的而定 D.同质个体组成 E.任意个体组成 5. 两样本均数比较的t检验中,结果为P<0.05,有统计意义。P愈小则: E A.说明两样本均数差别愈大 B.说明两总体均数差别愈大 C.说明样本均数与总体均数差别愈大 D.愈有理由认为两样本均数不同 E.愈有理由认为两总体均数不同 6. 抽样误差是指: D A.总体参数与总体参数间的差异 B.个体值与样本统计量间的差异 C.总体参数间的差异 D.样本统计量与总体统计量间的差异 E.以上都不对 7. 抽签的方法属于下列那种抽样: D A.分层抽样 B.系统抽样 C.整群抽样 D.单纯随机抽样 E.分级抽样
8. 以舒张压≥12.7KPa为高血压,测量1000人,结果有990名非高血压患者,有10名高血压患者,该资料属下列那类资料: B A.计算 B.计数 C.计量 D.等级 E.都对 9. 实验设计中要求严格遵守四个基本原则,其目的是为了: D A.便于统计处理 B.严格控制随机误差的影响 C.便于进行试验 D.减少和抵消非实验因素的干扰 E.以上都不对 10. 两个样本作t检验,除样本都应呈正态分布以外,还应具备的条件是: B A.两样本均数接近 B.两S2数值接近 C.两样本均数相差较大 D.两S2相差较大 E.以上都不对 11. 同一总体的两个样本中,以下哪种指标值小的其样本均数估计总体均数更可靠?A A.Sx B.S C.X D.CV
对两个变量进行直线相关分析,r=0.46,P>0.05,说明两变量之间______. A.有相关关系 B.无任何关系 C.无直线相关关系 D.无因果关系 E.有伴随关系 若分析肺活量和体重之间的数量关系,拟用体重值预测肺活量,则采用_____. A.直线相关分析 B.秩相关分析 C.直线回归分析 D.方差分析 E.病例对照研究 四格表资料的χ2检验应使用校正公式而未使用时,会导致。 A.χ2增大,P值减小 B.χ2减小,P值也减小 C.χ2增大,P值也增大 D.χ2减小,P值增大 E.视数据不同而异 配对设计四格表资料比较两个率有无差别的无效假设为。 A.μ1=μ2 B.π1=π2 C.μ1≠μ2 D.π1≠π2 E.b=c 四格表χ2检验的校正公式应用条件为。 A.n>40且T>5 B.n<40且T>5 C.n>40且1<T<5 D.n<40且1<T<5 E.n>40且T<1 两组设计两样本均数比效的t检验公式中,位于分母位置上的是。 A.两样本均数之差 B.两样本均数之差的方差 C.两样本均数之差的标准误 D.两样本均数方差之差
E.两样本均数标准误之差 两组数据中的每个变量值减去同一常数后,作两个样本均数比较的假设检验______. A.t值不变 B.t值变小 C.t值变大 D.t值变小或变大 E.不能判断 在假设检验中,P值和α的关系为。 A.P值越大,α值就越大 B.P值越大,α值就越小 C.P值和α值均可由研究者事先设定 D.P值和α值都不可以由研究者事先设定 E.P值的大小与α值的大小无关 t分布与正态分布存在如下哪一种关系。 A.二者均以0为中心,左右对称 B.曲线下中间95%面积对应的分位点均为±1.96 C.当样本含量无限大时,二都分布一致 D.当样本含量无限大时,t分布与标准正态分布一致 E.当总体均数增大时,分布曲线的中心位置均向右移 下面关于均数的正确的说法是______. A.当样本含量增大时,均数也增大 B.均数总大于中位数 C.均数总大于标准差 D.均数是所有观察值的平均值 E.均数是最大和最小值的平均值 从同一正态总体中随机抽取多个样本,用样本均数来估计总体均数的可信区间,下列哪一样本得到的估计精度高。 A.均数大的样本 B.均数小的样本 C.标准差小的样本 D.标准误小的样本 E.标准误大的样 以一定概率由样本均数估计总体均数,宜采用。 A.抽样误差估计 B.点估计 C.参考值范围估计 D.区间估计
医学统计方法选择题一: 医学统计方法概述 l.统计中所说的总体是指:A A根据研究目的确定的同质的研究对象的全体 B随意想象的研究对象的全体 C根据地区划分的研究对象的全体 D根据时间划分的研究对象的全体 E根据人群划分的研究对象的全体 2.概率P=0,则表示B A某事件必然发生B某事件必然不发生C某事件发生的可能性很小D某事件发生的可能性很大E以上均不对 3.抽签的方法属于 D A分层抽样B系统抽样C整群抽样D单纯随机抽样E二级抽样 4.测量身高、体重等指标的原始资料叫:B A计数资料B计量资料C等级资料D分类资料E有序分类资料5.某种新疗法治疗某病患者41人,治疗结果如下: 治疗结果治愈显效好转恶化死亡 治疗人数8 23 6 3 1 该资料的类型是:D A计数资料B计量资料C无序分类资料D有序分类资料E数值变量资料6.样本是总体的C A有价值的部分B有意义的部分C有代表性的部分 D任意一部分E典型部分 7.将计量资料制作成频数表的过程,属于¬¬统计工作哪个基本步骤:C A统计设计B收集资料C整理资料D分析资料E以上均不对 8.统计工作的步骤正确的是 C A收集资料、设计、整理资料、分析资料B收集资料、整理资料、设计、统计推断 C设计、收集资料、整理资料、分析资料D收集资料、整理资料、核对、分析资料 E搜集资料、整理资料、分析资料、进行推断 9.良好的实验设计,能减少人力、物力,提高实验效率;还有助于消除或减少:B A抽样误差B系统误差C随机误差D责任事故E以上都不对 10.以下何者不是实验设计应遵循的原则D A对照的原则B随机原则C重复原则 D交叉的原则E以上都不对 第八章数值变量资料的统计描述 11.表示血清学滴度资料平均水平最常计算 B A算术均数B几何均数C中位数D全距E率 12.某计量资料的分布性质未明,要计算集中趋势指标,宜选择C A X B G C M D S E CV 13.各观察值均加(或减)同一数后:B A均数不变,标准差改变B均数改变,标准差不变 C两者均不变D两者均改变E以上均不对 14.某厂发生食物中毒,9名患者潜伏期分别为:16、2、6、3、30、2、lO、2、24+(小时),
医师资格考试蓝宝书-预防医学 令狐文艳 医学统计学方法 第一节基本概念和基本步骤(非常重要) 一、统计工作的基本步骤 设计(最关键、决定成败)、搜集资料、整理资料、分析资料。 总体:根据研究目的决定的同质研究对象的全体,确切地说,是性质相同的所有观察单位某一变量值的集合。总体的指标为参数。 实际工作中,经常是从总体中随机抽取一定数量的个体,作为样本,用样本信息来推断总体特征。样本的指标为统计量。 由于总体中存在个体变异,抽样研究中所抽取的样本,只包含总体中一部分个体,这种由抽样引起的差异称为抽样误差。抽样误差愈小,用样本推断总体的精确度愈高;反之,其精确度愈低。 某事件发生的可能性大小称为概率,用P表示,在0~1之间,0和1为肯定不发生和肯定发生,介于之间为偶然事件,<0.05或0.01为小概率事件。
二、变量的分类 变量:观察单位的特征,分数值变量和分类变量。 第二节数值变量数据的统计描述(重要考点) 一、描述计量资料的集中趋势的指标有 1.均数均数是算术均数的简称,适用于正态或近似正态分布。 2.几何均数适用于等比资料,尤其是对数正态分布的计量资料。对数正态分布即原始数据呈偏态分布,经对数变换后(用原始数据的对数值lgX代替X)服从正态分布,观察值不能为0,同时有正和负。 3.中位数一组按大小顺序排列的观察值中位次居中的数值。可用于描述任何分布,特别是偏态分布资料的集中位置,以及分布不明或分布末端无确定数据资料的中心位置。不能求均数和几何均数,但可求中位数。百分位数是个界值,将全部观察值分为两部分,有X%比小,剩下的比大,可用于计算正常值范围。 二、描述计量资料的离散趋势的指标 1.全距和四分位数间距。 2.方差和标准差最为常用,适于正态分布,既考虑了离均差(观察值和总体均数之差),又考虑了观察值个数,方差使原来的单位变成了平方,所以开方为标准差。均为数值越 小,观察值的变异度越小。 3.变异系数多组间单位不同或均数相差较大的情况。变
医学统计方法选择题一 医学统计方法概述 l .统计中所说的总体是指: A A 根据研究目的确定的同质的研究对象的全体 B 随意想象的研究对象的全体 C 根据地区划分的研究对象的全体 D 根据时间划分的研究对象的全体 E 根据人群划分的研究对象的全体 2. 概率P=0,则表示B A 某事件必然发生 B 某事件必然不发生 D 某事件发生的可能性很大 E 以上均不对 7. 将计量资料制作成频数表的过程,属于 A 统计设计 B 收集资料 C 整理资料 8. 统计工作的步骤正确的是 C A 收集资料、设计、整理资料、分析资料 C 设计、收集资料、整理资料、分析资料 E 搜集资料、整理资料、分析资料、进行推断 ¬¬ 统计工作哪个基本步骤: C D 分析资料 E 以上均不对 B 收集资料、整理资料、设计、统计推断 D 收集资料、整理资料、核对、分析资料 B 10. 以下何者不是实验设计应遵循的原则 D A 对照的原则 B 随机原则 C 重复原则 D 交叉的原则 E 以上都不对 第八章 数值变量资料的统计描述 11. 表示血清学滴度资料平均水平最常计算 B A 算术均数 B 几何均数 C 中位数 D 全距 E 率 12. 某计量资料的分布性质未 明,要计算集中趋势指标,宜选择 C A X B G C M D S E CV 13. 各观察值均加(或减)同一数后: B A 均数不变,标准差改变 B 均数改变,标准差不变 C 两者均不变 D 两者均改变 E 以上均不对 14. 某厂发生食物中毒,9名患者潜伏期分别为:16、2、6、3、30、2、10、2、24+(小时), 问 3.抽签的方法属于 D A 分层抽样 B 系统抽样 C 整群抽样 4.测量身高、体重等指标的原始资料叫: A 计数资料 B 计量资料 某种新疗法治疗某病患者 治愈 8 D 单纯随机抽样 E 二级抽样 5. 治疗结果 治疗人数 该资料的类型是: A 计数资料 6.样本是总体的 A 有价值的部分 D 任意一部分 显效 23 B C 等级资料 41 人, 好转 6 D 分类资料 治疗结果如下: 恶化 3 E 有序分类资料 计量资料 C B 有意义的部分 C 有代表性的部分 E 典型部分 C 无序分类资料 死亡 1 D 有序分类资料 E 数值变量资料 A 抽样误差 B 系统误差 C 随机误差 D 责任事故 E 以上都不对 C 某事件发生的可能性很小 9.良好的实验设计,能减少人力、物力,提高实验效率;还有助于消除或减少:
统计试题题库 1. 下列那个是对标化后总死亡率的正确描述? A A.仅仅作为比较的基础,它反映了一种相对水平 B.它反映了实际水平 C.它不随标准选择的变化而变化 D.它反映了事物实际发生的强度 E.以上都不对 2. 两样本作均数差别的t检验,要求资料分布近似正态,还要求: D A.两样本均数相近,方差相等 B.两样本均数相近 C.两样本方差相等 D.两样本总体方差相等 E.两样本例数相等 3. 四格表资料的卡方检验时无需校正,应满足的条件是: D A.总例数大于40 B.理论数大于5 C.实际数均大于l D.总例数大于40且理论数均大于或等于5 E.总例数小于40 4. 总体应该是由: D
A.研究对象组成 B.研究变量组成 C.研究目的而定 D.同质个体组成 E.任意个体组成 5. 两样本均数比较的t检验中,结果为P<0.05,有统计意义。P愈小则: E A.说明两样本均数差别愈大 B.说明两总体均数差别愈大 C.说明样本均数与总体均数差别愈大 D.愈有理由认为两样本均数不同 E.愈有理由认为两总体均数不同 6. 抽样误差是指: D A.总体参数与总体参数间的差异 B.个体值与样本统计量间的差异 C.总体参数间的差异 D.样本统计量与总体统计量间的差异 E.以上都不对 7. 抽签的方法属于下列那种抽样: D A.分层抽样 B.系统抽样 C.整群抽样 D.单纯随机抽样 E.分级抽样
8. 以舒张压≥12.7KPa为高血压,测量1000人,结果有990名非高血压患者,有10名高血压患者,该资料属下列那类资料: B A.计算 B.计数 C.计量 D.等级 E.都对 9. 实验设计中要求严格遵守四个基本原则,其目的是为了: D A.便于统计处理 B.严格控制随机误差的影响 C.便于进行试验 D.减少和抵消非实验因素的干扰 E.以上都不对 10. 两个样本作t检验,除样本都应呈正态分布以外,还应具备的条件是: B A.两样本均数接近 B.两S2数值接近 C.两样本均数相差较大 D.两S2相差较大 E.以上都不对 11. 同一总体的两个样本中,以下哪种指标值小的其样本均数估计总体均数更可靠?A A.Sx B.S C.X D.CV
医学统计方法概述 l.统计中所说的总体是指:A根据研究目的确定的同质的研究对象的全体 2.概率P=0,则表示B某事件必然不发生 3.抽签的方法属于D单纯随机抽样 4.测量身高、体重等指标的原始资料叫:B计量资料 5.某种新疗法治疗某病患者41人,治疗结果如下:该资料的类型是:D有序分类资料 治疗结果治愈显效好转恶化死亡 治疗人数8 23 6 3 1 6.样本是总体的C有代表性的部分 7.将计量资料制作成频数表的过程,属于¬¬统计工作哪个基本步骤:C整理资料 8.统计工作的步骤正确的是C设计、收集资料、整理资料、分析资料 9.良好的实验设计,能减少人力、物力,提高实验效率;还有助于消除或减少:B系统误差10.以下何者不是实验设计应遵循的原则D交叉的原则 11.表示血清学滴度资料平均水平最常计算B几何均数 12.某计量资料的分布性质未明,要计算集中趋势指标,宜选择C M 13.各观察值均加(或减)同一数后:B均数改变,标准差不变 14.某厂发生食物中毒,9名患者潜伏期分别为:16、2、6、3、30、2、lO、2、24+(小时),问该食物中毒的平均潜伏期为多少小时 C 6 15.比较12岁男孩和18岁男子身高变异程度大小,宜采用的指标是:D变异系数 16.下列哪个公式可用于估计医学95%正常值范围 A X±1.96S 17.标准差越大的意义,下列认识中错误的是B观察个体之间变异越小 18.正态分布是以E均数为中心的频数分布 19.确定正常人的某项指标的正常范围时,调查对象是B排除影响研究指标的疾病和因素的人20.均数与标准差之间的关系是E标准差越小,均数代表性越大 21.从一个总体中抽取样本,产生抽样误差的原因是A总体中个体之间存在变异 22.两样本均数比较的t检验中,结果为P<0.05,有统计意义。P愈小则E愈有理由认为两总体均数不同 23.由10对(20个)数据组成的资料作配对t检验,其自由度等于C 9 24.t检验结果,P>0.05,可以认为B两样本均数差别无显着性 25.下列哪项不是t检验的注意事项D分母不宜过小 26.在一项抽样研究中,当样本量逐渐增大时B标准误逐渐减少 27.t<t0.05(v),统计上可认为C两样本均数,差别无显着性 28.两样本均数的t检验中,检验假设(H0)是 B μ1=μ2 29.同一总体的两个样本中,以下哪种指标值小的其样本均数估计总体均数更可靠A. Sx 30.标准差与标准误的关系是:C前者大于后者 31在同一正态总体中随机抽取含量为n的样本,理论上有95%的总体均数在何者范围内C均数加减1.96倍的标准误 32.同一自由度下,P值增大C t值减小 33.两样本作均数差别的t检验,要求资料分布近似正态,还要求D两样本总体方差相等 34.构成比的重要特点是各组成部分的百分比之和C一定等于1 35.计算相对数的目的是C为了便于比较
第一章绪论 1.统计学(statistics)是一门处理数据中变异性的科学与艺术,内容包括收集、分析、解释和表达数据,目的是求得可靠的结果。 2.▲总体(population)用来表示大同小异的对象全体,例如一个国家的所有成年人;某地的所有小学生。可分为目标总体和研究总体。若试图对某个总体下结论,这个总体便称为目标总体(target population);资料常来源于目标总体中的一个部分,它称为研究总体(study population)。需要谨慎的是,就研究总体所下的结论未必适用于目标总体。 3.▲样本(sample)是指从研究总体中抽取的一部分有代表性的个体。获取样本的过程称为抽样(sampling)。抽样研究的目的是用样本数据推断总体的特征。需要注意的是,统计学的结论从来就不是完全肯定或完全否定的,能不能成功地达到从样本推断总体的目的,关键是抽样的方法、样本的代表性和推断的技术。 4.▲同质(homogeneity)是指同一总体中个体的主要性质相同。 5.▲变异(variation)是指同质的个体之间存在的差异。 6.▲变量的类型 二分类变量 分类变量或名义变量 定性变量多分类变量 变量有序变量或等级变量 定量变量离散型变量 连续型变量 变量的转化:只能由“高级”向“低级”转化,即由信息量多的向信息量少的类型转化,如:定量有序分类二值 7.▲参数(parameter)是反映总体特征的指标,参数的大小是客观存在的,是一个常数,不会发生变化,然而往往是未知的,需要通过样本资料来估计,如总
体均数μ,总体标准差σ。 8.▲统计量(statistic)又称样本统计量,是反映样本特征的指标,是由观察资料计算出来的,如样本均数 X,样本标准差S。 统计学的任务就是依据样本统计量来推断总体参数。 9.▲概率与频率的区别:概率是参数,频率是统计量;频率总是围绕概率上下波动。当某事件发生的概率≤0.05时,即P≤0.05,统计学习惯上称该事件为小概率事件。 10.▲误差:表示统计量与参数之间的差别或测量值与真值之间的差别。可分为系统误差和随机误差,其中系统误差呈现倾向性偏大或偏小现象,是可以避免的;而随机误差,是非人为偶然因素所致,不可避免,但可通过增大样本量等措施使其减小。 11.因果与联系:存在联系未必有因果关系,需排除虚假关联、间接关联。大多数观察性研究,单靠统计学分析只能考察变量之间的联系,难以证明因果关系。
《卫生统计学》考试题库 目录 第一章绪论 第二章定量资料的统计描述 第三章正态分布 第四章总体均数的估计和假设检验 第五章方差分析 第六章分类资料的统计描述 第七章二项分布与Poisson分布及其应用 第八章χ2检验 第九章秩和检验 第十章回归与相关 第十一章常用统计图表 第十二章实验设计 第十三章调查设计
第十四章医学人口统计与疾病统计常用指标第十五章寿命表 第十六章随访资料的生存分析 附录:单项选择题参考答案
第一章绪论 一、名词解释 1. 参数(parameter) 2. 统计量(statistic) 3. 总体 (population) 4. 样本(sample) 5. 同质(homogeneity) 6. 变异 (variation) 7. 概率 (probability) 8. 抽样误差 (sampling error) 二、单选题 1.在实际工作中,同质是指: A.被研究指标的影响因素相同 B.研究对象的有关情况一样 C.被研究指标的主要影响因素相同 D.研究对象的个体差异很小 E.以上都对 2. 变异是指: A.各观察单位之间的差异 B.同质基础上,各观察单位之间的差异 C.各观察单位某测定值差异较大 D.各观察单位有关情况不同 E.以上都对3.统计中所说的总体是指: A.根据研究目的而确定的同质的个体之全部 B.根据地区划分的研究对象的全体 C.根据时间划分的研究对象的全体 D.随意想象的研究对象的全体 E.根据人群划分的研究对象的全体 4. 统计中所说的样本是指: A.从总体中随意抽取一部分 B.有意识地选择总体中的典型部分 C.依照研究者的要求选取有意义的一部分 D.从总体中随机抽取有代表性的一部分 E.以上都不是 5.按随机方法抽取的样本特点是:
2004~2005学年第(1)学期预防医学专业本科 期末考试试卷 (卫生统计学课程) 姓名____________________ 班级____________________ 学号____________________ 考试时间:200 年月日午 —(北京时间)
一、选择题(每题1分,共60分) 1、A1、A2型题 A. 48.0 B. 49.0 C. 52.0 D .53.0 E.55.0 2. 比较7岁男童与17岁青年身高的变异程度,宜用: A. 极 差 B. 四分位数间距 C. 方差 D. 标准差 E. 变异系数 3. 根据观测结果,已建立y 关于x 的回归方程? 2.0 3.0y x =+,该回归方程表示x 每增加1个单位,y 平均增加几个单位? A. 1 B. 2 C. 3 D. 4 E.5 4. 设从 5.11=μ的总体中作五次随机抽样(n =5),问哪一个样本的数据既精确又准确? A. 8,9,10,11,12 B. 6,8,10,12,14 C. 6,10,12,14,18 D. 8,10,12,14,16 E. 10,11,12,13,14 5. 为表示某地近20年来婴儿死亡率的变化情况,宜绘制 A.散点图 B. 直条图 C. 百分条图 D. 普通线图 E. 直方图 6. 临床上用针灸治疗某型头痛,有效的概率为60%现用该法治疗5例,问其中至少2例有效的概率约为 A. 0.913 B. 0.087 C. 0.230 D.0.317 E. 以上都不对 7.二项分布、Poisson 分布、正态分布各有几个参数? A. 1,1,2 B. 2,1,2 C. 1,2,2 D. 2,2,2 E. 1,2,1 8. 假定某细菌的菌落数服从Poisson 分布,经观察得平均菌落数为9,问菌落数的标准差为: A. 18 B. 9 C. 3 D. 81 E. 27 9. 对于同一资料的直线相关系数与回归系数,下列论断有几句是正确的? 相关系数越大,回归系数也越大。 相关系数与与回归系数符号一致。 相关系数的t r 等于回归系数的t b 。 相关系数描述关联关系,回归系数描述因果关系。 A.1句 B.2句 C. 3句 D. 4句 E. 0句 10.下列四句话有几句是正确的? 标准差是用来描述随机变量的离散程度的。 标准误是用来描述统计量的变异程度的。 t 检验只用于检验两样本均数的差别。 χ2可用来比较两个或多个率的差别。 A. 0句 B. 1句 C. 2句 D. 3句 E. 4句
山东大学2019考研:353卫生综合参考书目及真题笔记资料汇总由于山东大学部分专业课官方没有公布参考书目由此给很多考生带来了很大的不便,对此精都考研网整理了山东大学本专业研究生初试用书及配套资料供大家参考 一、353卫生综合参考书目: ①《环境卫生学》 ②《流行病学》 ③《卫生统计学》 ④《营养与食品卫生学》 ⑤《职业卫生与职业医学》 二、配套精编复习资料 山东大学353卫生综合《复习全程通》精都考研组编 三、复习全程通内容简介 《复习全程通》由精都考研工作室依托多年为各大机构编写考研专业课资料以及学员辅导的经验,由本团队组织目标院校本专业的高分研究生共同合作编写而成,全书考点知识面覆盖全面,权威细致,编排结构科学合理,是专门为本届考研的考生量身定制的必备专业课资料。 通过本精编资料四大模块内容,结合考生每个阶段的复习,有助于考生深入了解目标院校以及专业考点重点,提高复习效率,拓展解题思路。 NO.1历年真题汇编 通过目标院校原版真题,了解命题老师的出题思路,且分析考点重点,快速了解目标院校出题风格及命题思路,提高复习效率,拓展解题思路 NO.2教辅一本通 本部分内容主要是由目标院校本专业研究生对应其初试参考书目整理汇编章节重点考点以及对应章节历年典型考题及答案解析,通过本书的配套复习,分析专业考点侧重,通过大量典型考题让充分掌握本门科目重点,确保考场应对自如。 NO.3冲刺模拟套卷 书在遵循专业课最新参考书目,结合历年考研真题规律,制定的模拟卷,并有详细的配套答案讲解,适用于考生在冲刺模拟阶段的专业课复习。 NO.4电子版赠送内容 本部分内容为购买全套资料的同学附赠的内容,主要是初试参考书目主编老师的教学讲义以及相关的扩充习题,此部分内容对于跨考的考生相对比较重要,通过讲义了解专业课基础复习侧重,达到专业知识点不缺不漏。 四、解析备考辅导班: 专业课一对一无忧全程班 专业课一对一标准全程班 山东大学在读研究生授课 以上内容是【精都考研网】整理发布,每天及时发布最新考研资讯、考研经验、考研真题。目前很多同学已加入2019山东大学考研总群640030269,抓紧时间加入了解你所不知道的考研信息。
1.表示均数抽样误差大小的统计指标是( C )。 A)标准差B)方差 C)均数标准误D)变异系数 2.抽样研究中,s为定值,若逐渐增大样本含量,则样本( B )。 A)标准误增大B)标准误减少 C)标准误不改变D)标准误的变化与样本含量无关 3.均数标准误越大,则表示此次抽样得到的样本均数( C )。 A)系统误差越大B)可靠程度越大 C)抽样误差越大D)可比性越差 4.假设已知某地35岁以上正常成年男性的收缩压的总体均数为120.2mmHg,标准差为11.2 mmHg,后者反映的是( A )。 A)个体变异B)抽样误差 C)总体均数不同D)抽样误差或总体均数不同 5.配对计数资料差别的卡方检验,其备择假设是( D )。 A)p1=p2 B)p1≠p2 C)B=C D)B≠C 6.下列关于总体均数可信区间的论述是正确的,除了( C )外。 A)总体均数的区间估计是一种常用的参数估计 B)总体均数可信区间所求的是在一定概率下的总体均数范围 C)求出总体均数可信区间后,即可推断总体均数肯定会在此范围内
D)95%是指此范围包含总体均数在内的可能性是95%,即估计错误的概率是5% 试题来源:【2016公卫执业医师考试宝典免 费下载】 小编教你如何快速通过公卫执业医师考试 查看其他试题,请扫描二维码,立即获得本 题库手机版详情咨询 7.总体率可信区间的估计符合下列( C )情况时,可以借用正态近似法处理。 A)样本例数n足够大时B)样本率p不太大时 C)np和n(1-p)大于5时D)p接近1或0时 8.正太近似法估计总体率95%可信区间用( D )。 A)p±1.96s B)p±1.96σ C)p±2.58σD)p±1.96sp 9.统计推断的内容( C )。 A)用样本指标估计相应总体指标B)假设检验 C)A和B答案均是D)估计参考值范围 10.关于假设检验,下列哪个是正确的( A )。 A)检验假设是对总体作的某种假设 B)检验假设是对样本作的某种假设
卫生统计学复习笔记 一、概述 1、卫生统计学的概念(熟练掌握) 统计学是研究数据的收集、整理和分析的一门科学,帮助人们分析所占有的信息,达到去伪存真、去粗取精、正确认识世界的一种重要手段。 卫生统计学是应用数统计学的原理与方法研究居民健康状况以及卫生服务领域中数据的收集、整理和分析的一门科学。 由此看出:统计学是处理资料中变异性的科学和艺术,是在收集、归类、分析和解释大量数据的过程中获取可靠结果的一门学科。这里强调了“过程”,但在实际工作中,许多人往往是忽略了设计、收集和归类(整理),到了分析数据时才想到统计学,此时难免发生“悔之晚矣”的憾事。作为统计学的应用者应充分认识到这一点。 卫生统计学的内容(了解): 1)健康统计:医学人口统计、疾病统计和生长发育统计等; 2)卫生服务统计:包括卫生资源利用、医疗卫生服务的需求、医疗保健体制改革等方面的统计学问题。 2、卫生统计学的工作步骤(熟练掌握) 统计学对统计工作的全过程起指导作用,任何统计工作和统计研究的全过程都可分为以下四个步骤: 1)、设计:在进行统计工作和研究工作之前必须有一个周密的设计。设计是在广泛查阅文献、全面了解现状、充分征询意见的基础上,对将要进行的研究工作所做的全面设想。其内容包括:明确研究目的和研究假说,确定观察对象、观察单位、样本含量和抽样方法,拟定研究方案、预期分析指标、误差控制措施、进度与费用等。设计是整个研究工作中最关键的一环,也是指导以后工作的依据 2)、收集资料:遵循统计学原理采取必要措施得到准确可靠的原始资料。及时、准确、完整是收集统计资料的基本原则。卫生工作中的统计资料主要来自以下三个方面:①统计报表:是由国家统一设计,有关医疗卫生机构定期逐级上报,提供居民健康状况和医疗卫生机构工作的主要数据,是制定卫生工作计划与措施、检查与总结工作的依据。如法定传染病报表,职业病报表,医院工作报表等。②经常性工作记录:如卫生监测记录、健康检查记录等。③专题调查或实验。 3)、整理资料:收集来的资料在整理之前称为原始资料,原始资料通常是一堆杂乱无章的数据。整理资料的目的就是通过科学的分组和归纳,使原始资料系统化、条理化,便于进一步计算统计指标和分析。其过程是:首先对原始资料进行准确性审查(逻辑审查与技术审查)和完整性审查;再拟定整理表,按照“同质者合并,非同质者分开”的原则对资料进行质量分组,并在同质基础上根据数值大小进行数量分组;最后汇总归纳。 4)、分析资料:其目的是计算有关指标,反映数据的综合特征,阐明事物的内在联系和规律。统计分析包括统计描述和统计推断。前者是用统计指标与统计图(表)等方法对样本资料的数量特征及其分布规律进行
盛年不重来,一日难再晨。及时宜自勉,岁月不待人。 最佳选择题 1.收集资料的方法是:E A.收集各种报表 B.收集各种工作记录 C.进行专题调查 D.进行科学实验 E.以上都对 2.统计工作的基本步骤是:D A.调查资料、审核资料、整理资料 B.收集资料、审核资料、分析资料 C.调查资料、整理资料、分析资料 D.收集资料、整理资料、分析资料 E.以上都对 3.在抽样研究中样本是:D A.总体中的一部分 B.总体中任意一部分 C.总体中典型部分 D.总体中有代表性的一部分 E.总体中有意义的一部分 4.计量资料、计数资料和等级资料的关系是:C A.计量资料兼有计数资料和等级资料的一些性质 B.计数资料兼有计量资料和等级资料的一些性质 C.等级资料兼有计量资料和计数资料的一些性质 D.计数资料有计量资料的一些性质 E.以上都不是 5.用图形表示某地解放以来三种疾病的发病率在各年度的升降速度,宜绘制D : A.普通线图 B.直方图 C.构成比直条图 D.半对数线图 E.直条图 6.直方图可用于: A.某现象的内部构成 B.各现象的比较 C.某现象的比较 D.某现象的频数分布 E.某现象的发展速度 7.统计图表的要求是: A.简单明了 B.层次清楚 C.说明问题明确 D.避免臃肿复杂 E.以上都对 8.在列频数表时,分组数目一般为: A.5-10 B.8-15 C.10-30 D.15-20 E.>20 9.平均数作为一种统计指标是用来分析: A.计数资料 B.计量资料 C.等级分组资料 D.调查资料 E.以上都不对 10.表示变量值变异情况的常用指标是: A.全距 B.标准差 C.方差 D.变异系数 E.以上均是 11.确定正常人某个指标正常值范围时,调查对象是: A.从未患过病的人 B.健康达到了要求的人 C.排除影响被研究指标的疾病和因素的人 D.只患 过小病但不影响研究指标的人 E.排除了患过某病或接触过某因素的人 12.标准误: A.与标准差呈反比 B.与标准差呈正比 C.与标准差的平方呈反比 D.与标准差平方呈正比 E.以上都不对 13.是指: A.所有观察值对总体均数的离散程度 B.某一个样本均数的离散程度 C.所有样本均数对总体均数的离散程度 D.某些样本均数对总体均数的离散程度 E.所有含量相同的样本均数对总体均数的离散程度 x
1.表示均数抽样误差大小的统计指标是(C ) A)标准差B)方差 C)均数标准误D)变异系数 2?抽样研究中,s为定值,若逐渐增大样本含量,则样本(B )。 A)标准误增大B)标准误减少 C)标准误不改变D)标准误的变化与样本含量无关 3. 均数标准误越大,则表示此次抽样得到的样本均数(C )。 A)系统误差越大B)可靠程度越大 C)抽样误差越大D)可比性越差 4. 假设已知某地35岁以上正常成年男性的收缩压的总体均数为 120.2mmHg,标准差为11.2 mmHg,后者反映的是(A )。 A)个体变异B)抽样误差 C)总体均数不同D)抽样误差或总体均数不同 5. 配对计数资料差别的卡方检验,其备择假设是(D )。 A)p1=p2 B)p1 Mp2 C)B=C D)B 丸 6. 下列关于总体均数可信区间的论述是正确的,除了( C )外。 A)总体均数的区间估计是一种常用的参数估计 B)总体均数可信区间所求的是在一定概率下的总体均数范围 C)求出总体均数可信区间后,即可推断总体均数肯定会在此范围内
D )95%是指此范围包含总体均数在内的可能性是 95%,即估计错误的概率 是5% 试题来源:【2016公卫执业医师考试宝 典免 费下载】 小编教你如何快速通过公卫执业医师考 试 查看其他试题,请扫描二维码,立即获 得本 题库手机版详情咨询阪imo 7.总体率可信区间的估计符合下列 (C )情况时,可以借用正态近似法处理。 A )样本例数n 足够大时 B )样本率p 不太大时 C)np 和n(1-p)大于5时 D )p 接近1或0时 8.正太近似法估计总体率95%可信区间用(D ) B) p ±1.96(T C) p ±2.58(T 10. 关于假设检验,下列哪个是正确的 A )检验假设是对总体作的某种假设 A)p ±1.96s D)p ±1.96sp 9.统计推断的内容(C )。 A )用样本指标估计相应总体指标 B )假设检验 C )A 和B 答案均是 D )估计参考值范围
医师资格考试蓝宝书预防医学 欧阳家百(2021.03.07) 医学统计学方法 第一节基本概念和基本步骤(非常重要) 一、统计工作的基本步骤 设计(最关键、决定成败)、搜集资料、整理资料、分析资料。 总体:根据研究目的决定的同质研究对象的全体,确切地说,是性质相同的所有观察单位某一变量值的集合。总体的指标为参数。 实际工作中,经常是从总体中随机抽取一定数量的个体,作为样本,用样本信息来推断总体特征。样本的指标为统计量。 由于总体中存在个体变异,抽样研究中所抽取的样本,只包含总体中一部分个体,这种由抽样引起的差异称为抽样误差。抽样误差愈小,用样本推断总体的精确度愈高;反之,其精确度愈低。 某事件发生的可能性大小称为概率,用P表示,在0~1之间,0和1为肯定不发生和肯定发生,介于之间为偶然事件, <0.05或0.01为小概率事件。 二、变量的分类
变量:观察单位的特征,分数值变量和分类变量。 第二节数值变量数据的统计描述(重要考点) 一、描述计量资料的集中趋势的指标有 1.均数均数是算术均数的简称,适用于正态或近似正态分布。 2.几何均数适用于等比资料,尤其是对数正态分布的计量资料。对数正态分布即原始数据呈偏态分布,经对数变换后(用原始数据的对数值lgX代替X)服从正态分布,观察值不能为0,同时有正和负。 3.中位数一组按大小顺序排列的观察值中位次居中的数值。可用于描述任何分布,特别是偏态分布资料的集中位置,以及分布不明或分布末端无确定数据资料的中心位置。不能求均数和几何均数,但可求中位数。百分位数是个界值,将全部观察值分为两部分,有X%比小,剩下的比大,可用于计算正常值范围。 二、描述计量资料的离散趋势的指标 1.全距和四分位数间距。 2.方差和标准差最为常用,适于正态分布,既考虑了离均差(观察值和总体均数之差),又考虑了观察值个数,方差使原来的单位变成了平方,所以开方为标准差。均为数值越小,观察值 的变异度越小。 3.变异系数多组间单位不同或均数相差较大的情况。变异系数计算公式为:CV=s/×100%,公式中s为样本标准差,为样本均数。 三、标准差的应用