
1
路网数据预处理(拓扑检查非常重要)
一、路网数据预处理
利用arcgis 进行路网预处理,具体流程如下:
1.在路网相交处打断:Editor-->More Editing tool-->Advanced editing 弹出Advanced editing 工具条,选择palanirilize line 工具
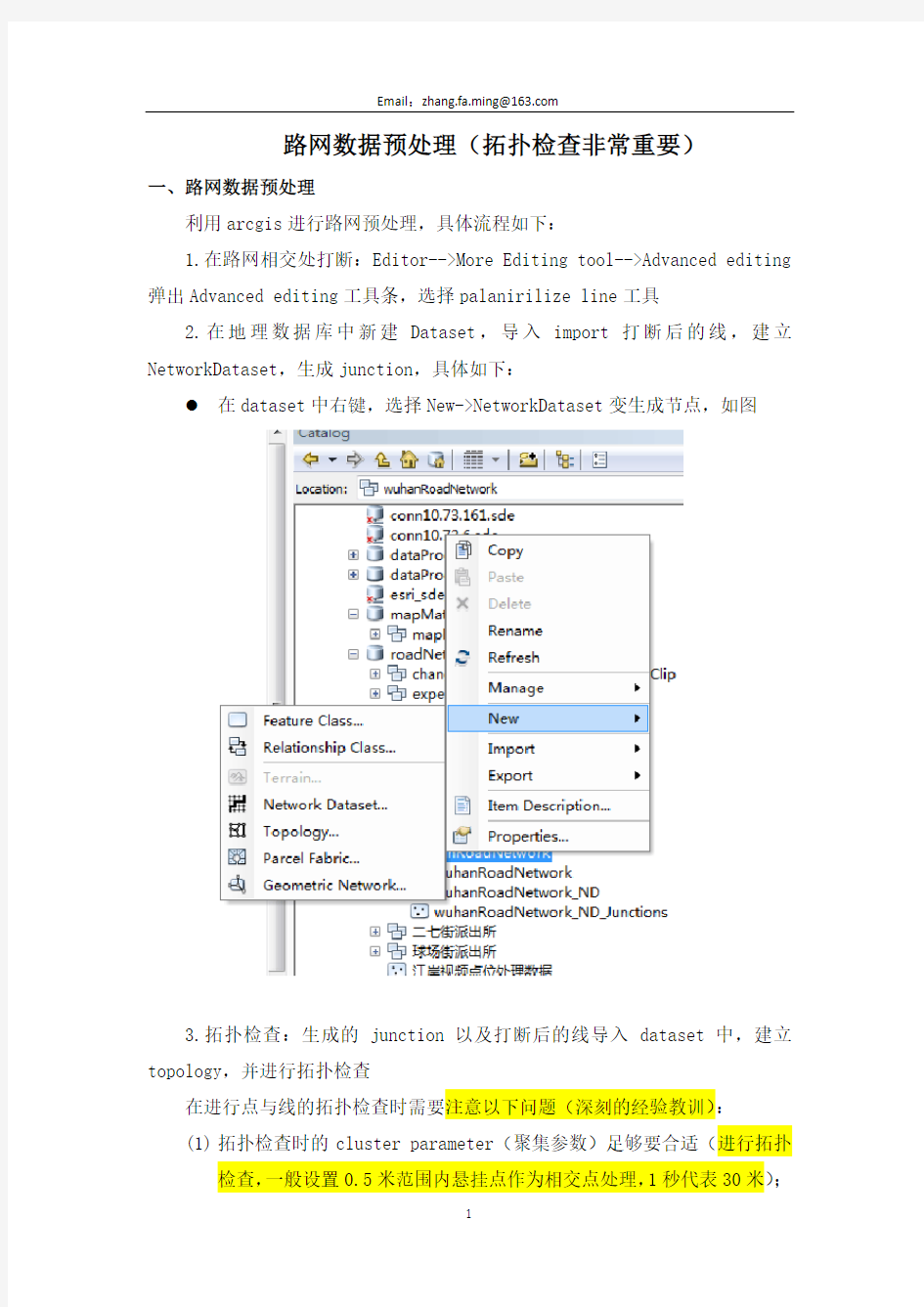
2.在地理数据库中新建Dataset ,导入import 打断后的线,建立NetworkDataset ,生成junction ,具体如下:
在dataset 中右键,选择New->NetworkDataset 变生成节点,如图
3.拓扑检查:生成的junction 以及打断后的线导入dataset 中,建立topology ,并进行拓扑检查
在进行点与线的拓扑检查时需要注意以下问题(深刻的经验教训):
(1) 拓扑检查时的cluster parameter (聚集参数)足够要合适(进行拓扑
检查,一般设置0.5米范围内悬挂点作为相交点处理,1秒代表30米)
;
2 cluster tolerance 设置为:一般设置为小数点后6位,即在原有数的基础上去掉两个零;
(2) 要进行点与线的多次拓扑检查:拓扑检查条件要设置严格,不仅点要被线的端点压盖,而且线的端点要被点压盖或者再设置其他拓扑条件(教训),至少要设置这两个条件;
拓扑规则设置窗口如下:
(3) 拓扑检查之后,原来不相交的线(两者由于手工操作原因,不相交,比
如相距1米,而此时进行拓扑检查后使其交于一点,但在此交点处线并没有打断)可能相交,需要再次将线打断处理,以构建正确拓扑(教训) 拓扑检查操作流程如下:
startEditing –error inspector 检查错误,error inspector 操作界面如下
4.如果线只是相交自动打断,即没有间隔,从表面上看是相连的一条(其实是两条),可以用
Arctoolbox 里的工具
DataManagement
Tools-Generalization-Dissolve工具来做融合,可以设置融合的参考字段,字段名称内容一致的自动融合成一条。融合后的图层保留参考字段属性,其他属性字段删除。在对路网进行融合时,设置融合的字段名为:Name and Property,通过此步骤,线段中间可能被打断成多条路段的情况合并成为一条路段;
5.重复1到3步骤,即可完成拓扑,步骤4一般不用,路网拓扑最终构建结
束;
二、路网数据序列化
序列化点文件与线文件
1.点文件中添加字段,NODEID,并编号;如图
2.线文件中添加字段,LINKID,并编号;
3.设置堆栈:-Xss100m -Xmx1024m -Xms256m
其他问题总结:
打断公路网络,使每个公路段都有明确的县级归属,操作:Arc toolbox -- analysis tool -- overlay -- intersect,出现对话框
3
如何对市场调研问卷的数据进行预处理 市场调研问卷数据的预处理是整个市场调研工作的重要环节,如果预处理做得不好,就会使有问题的问卷进入后面的数据分析环节,对最终结果产生严重影响。 一、信度检验 1.信度分析简介 信度,即信任度,是指问卷数据的可信任程度。信度是保证问卷质量的重要手段,严谨的问卷分析通常会采用信度分析筛选部分数据。 α值是信度分析中的一个重要指标,它代指0~1的某个数值,如果α值小于0.7,该批次问卷就应当剔除或是进行处理;如果大于0.9,则说明信度很高,可以用于数据分析;如果位于0.7~0.9,则要根据具体情况进行判定。如表1所示。 α值意义 >0.9信度非常好 >0.8信度可以接受 >0.7需要重大修订但是可以接受 <0.7放弃 2.信度分析示例 操作过程 下面介绍的是一个信度分析的案例,其操作过程为:首先打开信度分析文件,可以看到该文件的结构很简单,一共包含10个题目,问卷的份数是102份。然后进入SPSS的“分析”模块,找到“度量”下面的“可靠性分析”,将这十个题目都选进去。 在接下来的统计量中,首先看平均值、方差和协方差等,为了消除这些变量的扰动,可以选择要或者不要这些相关的量,另外ANOVA(单音数方差分析)是分析两个变量之间有无关系的重要指标,一般选择要,但在这里可以不要,其他一些生僻的量值一般不要。描述性在多数情况下需要保留,因为模型的输出结果会有一些描述,因此应当选中项、度量和描述性,然后“确定”,这时SPSS输出的结果就会比较清楚。 结果解读 案例处理汇总后,SPSS输出的结果如图1所示。
图1 信度分析结果 由图1可知,案例中调查问卷的有效数据是102,已排除数是0,说明数据都是有效的,在这里如果某个问卷有缺失值,就会被模型自动删除,然后显示出已排除的问卷数。在信度分析中,可以看到Alpha值是0.881,根据前文的判定标准,这一数值接近0.9,可以通过。在图右下方部分有均值、方差、相关性等多个项目,这主要看最后的“项已删除的Alpha值”,该项目表示的是删除相应项目后整个问卷数据信度的变动情况,可以看出题目1、题目2和题目6对应的数值高于0.881,表明删除这三个题目后整个问卷的Alpha值会上升,为了确保整个调查的严谨性,应当将这三个题目删除。 二、剔除废卷 删除废卷大致有三种方法:根据缺失值剔除、根据重复选项剔除、根据逻辑关系剔除。 1.根据缺失值剔除 缺失值的成因 在市场调查中,即使有非常严格的质量控制,在问卷回收后仍然会出现缺项、漏项,这种情况在涉及敏感性问题的调查中尤其突出,缺失值的占比甚至会达到10%以上。之所以会出现这种现象,主要有以下原因:一是受访者对于疾病、收入等隐私问题选择跳过不答,二是受访者由于粗心大意而漏掉某些题目等。 缺失值的处理 在处理缺失值时,有些人会选择在SPSS或Excel中将其所在的行直接删除。事实上,不能简单地删除缺失值所在的行,否则会影响整个问卷的质量。这是因为在该行中除了缺失的数据以外,其他数据仍旧是有效的,包含许多有用信息,将其全部删除就等于损失了这部分信息。 在实际操作中,缺失值的处理主要有以下方式,如图2所示。
大数据处理常用技术简介 storm,Hbase,hive,sqoop, spark,flume,zookeeper如下 ?Apache Hadoop:是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。 ?Apache Hive:是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce 统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 ?Apache Pig:是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。 ?Apache HBase:是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。 ?Apache Sqoop:是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 ?Apache Zookeeper:是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务?Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。 ?Apache Cassandra:是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身 ?Apache Avro:是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制 ?Apache Ambari:是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。 ?Apache Chukwa:是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合Hadoop 处理的文件保存在HDFS 中供Hadoop 进行各种MapReduce 操作。 ?Apache Hama:是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架, Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
高速公路网络中的交通流 Peter Bickel[1],Chao Chen[2],Jaimyoung Kwon[1],John Rice[1],Pravin Varaiya[2],Erik van Zwet[1] 1.1 引言 交通拥堵已成为现代生活中令人烦恼的事实。虽然很难准确定量化,但拥挤已让加利福尼亚州人花费了数百万美元。由于更广泛的高速公路建设是不可能实现的,所以信息技术正越来越多地应用于改良中,它通过提供资料使现有高速公路更有效地使用。在这样的努力中,统计占有重要作用。 一个由教师、博士后、研究生以及加州大学伯克利分校的本科生组成的大型跨学科团队已致力于许多此类问题的研究工作。其研究人员来自计算机科学、电子工程、统计学和运输工程。 本文给出一些我们活动的概况,着重于收集洛杉矶高速公路交通网络流量统计及关于此网络出行时间的预测。本文内容安排如下:在洛杉矶高速公路系统,配备了密集部署的阵列感应器和线圈检测器,这是我们将在下一节要描述的。及时获得来自这些传感器的信息,正如1.3节所描述的,由高速公路性能测试系统显示并存档。在第1.4节中,我们简要地描述了在交通流极具吸引力的时空领域内使演化模型全球化的目的。然而,归根结底,我们最好要使用简单、直接的方法,而非试图去适应和更新这种综合模型。这些内容在第1.5节旅行时间预测的目的给予描述。第1.6节中包含最后的结语。 图1.1 双环检测器的设置 1.2 线圈检测器 感应线圈检测器是一个监测高速公路状况的基本传感器,是由埋在道路底下的电线组成的。交变电流产生一个电磁场,当发动机经过表面时,会引起电感的变化。这样的线圈非常密集地位于许多高速公路系统中,其每个车道里每半英里左右就有一束线圈(with loops in each lane located in banks every half mile or so)。图1.1显示了双环检测器。线圈里的数据通常按30秒到5分范围内的采样率获得的。 能从线圈推导出的基本变量是流量(每秒的车辆数)和占用量(车辆在环内的时间百分比),后者本质上是车辆密度。利用车辆平均长度的假设,这些测量
1)Volume(大体量):即可从数百TB到数十数百PB、 甚至EB的规模。 2)Variety(多样性):即大数据包括各种格式和形态的数据。 3)Velocity(时效性):即很多大数据需要在一定的时间限度下得到及时处理。 4)Veracity(准确性):即处理的结果要保证一定的准确性。 5)Value(大价值):即大数据包含很多深度的价值,大数据分析挖掘和利用将带来巨大的商业价值。 传统的数据库系统主要面向结构化数据的存储和处理,但现实世界中的大数据具有各种不同的格式和形态,据统计现实世界中80%以上的数据都是文本和媒体等非结构化数据;同时,大数据还具有很多不同的计算特征。我们可以从多个角度分类大数据的类型和计算特征。 1)从数据结构特征角度看,大数据可分为结构化与非结构化/半结构化数据。 2)从数据获取处理方式看,大数据可分为批处理与流式计算方式。 3)从数据处理类型看,大数据处理可分为传统的查询分析计算和复杂数据挖掘计算。 4)从大数据处理响应性能看,大数据处理可分为实时/准实时与非实时计算,或者是联机计算与线下计算。前述的流式计算通常属于实时计算,此外查询分析类计算通常也要求具有高响应性能,因而也可以归为实时或准实时计算。而批处理计算和复杂数据挖掘计算通常属于非实时或线下计算。 5)从数据关系角度看,大数据可分为简单关系数据(如Web日志)和复杂关系数据(如社会网络等具有复杂数据关系的图计算)。
6)从迭代计算角度看,现实世界的数据处理中有很多计算问题需要大量的迭代计算,诸如一些机器学习等复杂的计算任务会需要大量的迭代计算,为此需要提供具有高效的迭代计算能力的大数据处理和计算方法。 7)从并行计算体系结构特征角度看,由于需要支持大规模数据的存储和计算,因此目前绝大多数禧金信息大数据处理都使用基于集群的分布式存储与并行计算体系结构和硬件平台。
数据分析一定少不了数据预处理,预处理的好坏决定了后续的模型效果,今天我们就来看看预处理有哪些方法呢? 记录实战过程中在数据预处理环节用到的方法~ 主要从以下几个方面介绍: ?常用方法 ?N umpy部分 ?P andas部分 ?S klearn 部分 ?处理文本数据 一、常用方法 1、生成随机数序列 randIndex = random.sample(range(trainSize, len(trainData_copy)), 5*tra inSize) 2、计算某个值出现的次数 titleSet = set(titleData) for i in titleSet: count = titleData.count(i)
用文本出现的次数替换非空的地方。词袋模型 Word Count titleData = allData['title'] titleSet = set(list(titleData)) title_counts = titleData.value_counts() for i in titleSet: if isNaN(i): continue count = title_counts[i] titleData.replace(i, count, axis=0, inplace=True) title = pd.DataFrame(titleData) allData['title'] = title 3、判断值是否为NaN def isNaN(num): return num != num 4、 Matplotlib在jupyter中显示图像 %matplotlib inline 5、处理日期 birth = trainData['birth_date'] birthDate = pd.to_datetime(birth) end = pd.datetime(2020, 3, 5) # 计算天数birthDay = end - birthDate birthDay.astype('timedelta64[D]') # timedelta64 转到 int64 trainData['birth_date'] = birthDay.dt.days
XI`AN TECHNOLOGICAL UNIVERSITY 实验报告 实验课程名称数据集成、变换、归约和离散化 专业:数学与应用数学 班级: 姓名: 学号: 实验学时: 指导教师:刘建伟 成绩: 2016年5月5 日
西安工业大学实验报告 专业数学与应用数学班级131003 姓名学号实验课程数据挖掘指导教师刘建伟实验日期2016-5-5 同实验者实验项目数据集成、变换、归约和离散化 实验设备 计算机一台 及器材 一实验目的 掌握数据集成、变换、归约和离散化 二实验分析 从初始数据源出发,总结了目前数据预处理的常规流程方法,提出应把源数据的获取作为数据预处理的一个步骤,并且创新性地把数据融合的方法引入到数据预处理的过程中,提出了数据的循环预处理模式,为提高数据质量提供了更好的分析方法,保证了预测结果的质量,为进一步研究挖掘提供了较好的参考模式。三实验步骤 1数据分析任务多半涉及数据集成。数据集成是指将多个数据源中的数据合并并存放到一个一致的数据存储(如数据仓库)中。这些数据源可能包括多个数据库、数据立方体或一般文件。在数据集成时,有许多问题需要考虑。模式集成和对象匹配可能需要技巧。 2数据变换是指将数据转换或统一成适合于挖掘的形式。 (1)数据泛化:使用概念分层,用高层概念替换低层或“原始”数据。例如,分类的属性,如街道,可以泛化为较高层的概念,如城市或国家。类似地,数值属性如年龄,可以映射到较高层概念如青年、中年和老年。 (2)规范化:将属性数据按比例缩放,使之落入一个小的特定区间。大致可分三种:最小最大规范化、z-score规范化和按小数定标规范化。 (3)属性构造:可以构造新的属性并添加到属性集中,以帮助挖掘过程。例如,可能希望根据属性height和width添加属性area。通过属性构造可以发现关于数据属性间联系的丢失信息,这对知识发现是有用的。 3数据经过去噪处理后,需根据相关要求对数据的属性进行相应处理.数据规约就是在减少数据存储空间的同时尽可能保证数据的完整性,获得比原始数据小得
第三章交通流的基本特性 第一节概述 道路上的行人或运行的车辆构成行人流或车流,人流和车流统称为交通流。一般交通工程学研究中,有特指时的交通流是针对机动车交通流而言的。 交通流的定性和定量特征,称为交通流特性。观测和研究发现,由于在交通过程中人、车、路、环境的相互联系和影响作用,道路交通流具有以下三个基本特性。 1.两重性 对道路上运行车辆的控制既取决于驾驶员,又取决于道路及交通控制系统。一方面,驾驶员为避免与其他车辆发生冲突,必然受到道路条件及交通控制系统的制约;另一方面,驾驶员又可以在一定的时空条件下,依据自己的意志自由地改变车速和与其他车辆的相对位置。 2.局限性 由于机动车和道路的物理尺寸所限,车辆运行中相互之间可能会相互妨碍。仅由于道路通行能力的限制和车辆间的相互制约,就有可能引起交通拥挤;另外,车速也是有限的,并因车辆和时空条件而异。 3.时空性 由于车速是随机变化的,机动车在时间上和空间上的状态都是不相同的,因此,交通流既是现有时间变化规律,又有其空间变化规律。道路交通流的以上三个特性进一步说明:道路交通是一个复杂的动态系统。由这三个特性出发,将道路上的交通流用交通量、速度、密度三个基本参数加以描述。观测、整理和研究这些参数的变化规律以及它们之问的相互关系,可以为分析道路上的运营状况、交通规则、路网布设、线形设计、运输调度与组织、运力投放与调控以及为现有道路交通综合治理提供起决定作用的论证数据。
第二节交通量的基本特性 交通量是指单位时间内,通过道路某一地点或某一断面的实际交通参与 者(含车辆、行人、自行车等)的数量,又称交通流量或称流量。如果不加说明时,通常是指单位时间内通过道路某一地点或某一断面往来两个方向的车辆数,亦称为车流量。 在交通量观测和统计分析及实际应用中,常见的交通量有以下几种: 1.平均交通量 交通量不是一个静止的量,它是随时间变化的,在表达方式上通常取某一时段内的平均值作为该时段的代表交通量。如年平均日交通量就是将一年内的交通量总数除以当年的总天数所得出的平均值。常用的有平均日交通量,还有月平均日交通量,周平均日交通量以及任意期间(依特定分析目的而定)的平均日交通量等。以上平均交通量可以概括成如下的表达式 平均日交通量 (ADT)=1/n{∑Q (3—1) 式中 Q i——计算期内各单位时间的交通量; n——计算期内的单位时间总数。 如果计算年平均日交通量(A A D T)时,n为365或366,则 年平均日交通量 (AADT)= (3—2) 由此类推:
数据分析处理需求分类 1 事务型处理 在我们实际生活中,事务型数据处理需求非常常见,例如:淘宝网站交易系统、12306网站火车票交易系统、超市POS系统等都属于事务型数据处理系统。这类系统数据处理特点包括以下几点: 一就是事务处理型操作都就是细粒度操作,每次事务处理涉及数据量都很小。 二就是计算相对简单,一般只有少数几步操作组成,比如修改某行得某列; 三就是事务型处理操作涉及数据得增、删、改、查,对事务完整性与数据一致性要求非常高。 四就是事务性操作都就是实时交互式操作,至少能在几秒内执行完成; 五就是基于以上特点,索引就是支撑事务型处理一个非常重要得技术. 在数据量与并发交易量不大情况下,一般依托单机版关系型数据库,例如ORACLE、MYSQL、SQLSERVER,再加数据复制(DataGurad、RMAN、MySQL数据复制等)等高可用措施即可满足业务需求。 在数据量与并发交易量增加情况下,一般可以采用ORALCERAC集群方式或者就是通过硬件升级(采用小型机、大型机等,如银行系统、运营商计费系统、证卷系统)来支撑. 事务型操作在淘宝、12306等互联网企业中,由于数据量大、访问并发量高,必然采用分布式技术来应对,这样就带来了分布式事务处理问题,而分布式事务处理很难做到高效,因此一般采用根据业务应用特点来开发专用得系统来解决本问题。
2数据统计分析 数据统计主要就是被各类企业通过分析自己得销售记录等企业日常得运营数据,以辅助企业管理层来进行运营决策。典型得使用场景有:周报表、月报表等固定时间提供给领导得各类统计报表;市场营销部门,通过各种维度组合进行统计分析,以制定相应得营销策略等. 数据统计分析特点包括以下几点: 一就是数据统计一般涉及大量数据得聚合运算,每次统计涉及数据量会比较大。二就是数据统计分析计算相对复杂,例如会涉及大量goupby、子查询、嵌套查询、窗口函数、聚合函数、排序等;有些复杂统计可能需要编写SQL脚本才能实现. 三就是数据统计分析实时性相对没有事务型操作要求高。但除固定报表外,目前越来越多得用户希望能做做到交互式实时统计; 传统得数据统计分析主要采用基于MPP并行数据库得数据仓库技术.主要采用维度模型,通过预计算等方法,把数据整理成适合统计分析得结构来实现高性能得数据统计分析,以支持可以通过下钻与上卷操作,实现各种维度组合以及各种粒度得统计分析。 另外目前在数据统计分析领域,为了满足交互式统计分析需求,基于内存计算得数据库仓库系统也成为一个发展趋势,例如SAP得HANA平台。 3 数据挖掘 数据挖掘主要就是根据商业目标,采用数据挖掘算法自动从海量数据中发现隐含在海量数据中得规律与知识。
012. 数据预处理(1)——剔除异常值及平滑处理测量数据在其采集与传输过程中,由于环境干扰或人为因素有可能造成个别数据不切合实际或丢失,这种数据称为异常值。为了恢复数据的客观真实性以便将来得到更好的分析结果,有必要先对原始数据(1)剔除异常值; 另外,无论是人工观测的数据还是由数据采集系统获取的数据,都不可避免叠加上“噪声”干扰(反映在曲线图形上就是一些“毛刺和尖峰”)。为了提高数据的质量,必须对数据进行(2)平滑处理(去噪声干扰); (一)剔除异常值。 注:若是有空缺值,或导入Matlab数据显示为“NaN”(非数),需要①忽略整条空缺值数据,或者②填上空缺值。 填空缺值的方法,通常有两种:A. 使用样本平均值填充;B. 使用判定树或贝叶斯分类等方法推导最可能的值填充(略)。 一、基本思想: 规定一个置信水平,确定一个置信限度,凡是超过该限度的误差,就认为它是异常值,从而予以剔除。
二、常用方法:拉依达方法、肖维勒方法、一阶差分法。 注意:这些方法都是假设数据依正态分布为前提的。 1. 拉依达方法(非等置信概率) 如果某测量值与平均值之差大于标准偏差的三倍,则予以剔除。 3x i x x S -> 其中,11 n i i x x n ==∑为样本均值,1 2 211()1n x i i S x x n =?? ??? =--∑为样本的标准偏差。 注:适合大样本数据,建议测量次数≥50次。 代码实例(略)。 2. 肖维勒方法(等置信概率) 在 n 次测量结果中,如果某误差可能出现的次数小于半次时,就予以剔除。 这实质上是规定了置信概率为1-1/2n ,根据这一置信概率,可计算出肖维勒系数,也可从表中查出,当要求不很严格时,还可按下列近似公式计算:
数据挖掘实验报告(一) 数据预处理 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1.学习均值平滑,中值平滑,边界值平滑的基本原理 2.掌握链表的使用方法 3.掌握文件读取的方法 二、实验设备 PC一台,dev-c++5.11 三、实验内容 数据平滑 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性): (a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。 (b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。 (c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。 四、实验原理 使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值 五、实验步骤 代码 #include
现如今,很多人都听说过大数据,这是一个新兴的技术,渐渐地改变了我们的生活,正是由 于这个原因,越来越多的人都开始关注大数据。在这篇文章中我们将会为大家介绍两种大数 据技术,分别是大数据采集技术和大数据预处理技术,有兴趣的小伙伴快快学起来吧。 首先我们给大家介绍一下大数据的采集技术,一般来说,数据是指通过RFID射频数据、传 感器数据、社交网络交互数据及移动互联网数据等方式获得的各种类型的结构化、半结构化 及非结构化的海量数据,是大数据知识服务模型的根本。重点突破高速数据解析、转换与装 载等大数据整合技术设计质量评估模型,开发数据质量技术。当然,还需要突破分布式高速 高可靠数据爬取或采集、高速数据全映像等大数据收集技术。这就是大数据采集的来源。 通常来说,大数据的采集一般分为两种,第一就是大数据智能感知层,在这一层中,主要包 括数据传感体系、网络通信体系、传感适配体系、智能识别体系及软硬件资源接入系统,实 现对结构化、半结构化、非结构化的海量数据的智能化识别、定位、跟踪、接入、传输、信 号转换、监控、初步处理和管理等。必须着重攻克针对大数据源的智能识别、感知、适配、 传输、接入等技术。第二就是基础支撑层。在这一层中提供大数据服务平台所需的虚拟服务器,结构化、半结构化及非结构化数据的数据库及物联网络资源等基础支撑环境。重点攻克 分布式虚拟存储技术,大数据获取、存储、组织、分析和决策操作的可视化接口技术,大数 据的网络传输与压缩技术,大数据隐私保护技术等。 下面我们给大家介绍一下大数据预处理技术。大数据预处理技术就是完成对已接收数据的辨析、抽取、清洗等操作。其中抽取就是因获取的数据可能具有多种结构和类型,数据抽取过 程可以帮助我们将这些复杂的数据转化为单一的或者便于处理的构型,以达到快速分析处理 的目的。而清洗则是由于对于大数并不全是有价值的,有些数据并不是我们所关心的内容, 而另一些数据则是完全错误的干扰项,因此要对数据通过过滤去除噪声从而提取出有效数据。在这篇文章中我们给大家介绍了关于大数据的采集技术和预处理技术,相信大家看了这篇文 章以后已经知道了大数据的相关知识,希望这篇文章能够更好地帮助大家。
大数据处理常用技术有哪些? storm,hbase,hive,sqoop.spark,flume,zookeeper如下 ?Apache Hadoop:是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。 ?Apache Hive:是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce 统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 ?Apache Pig:是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。 ?Apache HBase:是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。 ?Apache Sqoop:是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 ?Apache Zookeeper:是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务?Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。 ?Apache Cassandra:是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身 ?Apache Avro:是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制 ?Apache Ambari:是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。 ?Apache Chukwa:是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合Hadoop 处理的文件保存在HDFS 中供Hadoop 进行各种MapReduce 操作。 ?Apache Hama:是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架, Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
数据分析中,需要先挖掘数据,然后对数据进行处理,而数据预处理的字面意思就是对于数据的预先处理,而数据预处理的作用是为了提高数据的质量以及使用数据分析软件,对于数据的预处理的具体步骤就是数据清洗、数据集成、数据变换、数据规范等工作,数据预处理是数据分析工作很重要的组成部分,所以大家一定要重视这个工作。 首先说一下数据清洗就是清理脏数据以及净化数据的环境,说到这里大家可能不知道什么是脏数据,一般来说,脏数据就是数据分析中数据存在乱码,无意义的字符,以及含有噪音的数据。脏数据具体表现在形式上和内容上的脏。就目前而言,脏数据在形式上就是缺失值和特殊符号,形式上的脏数据有缺失值、带有特殊符号的数据,内容上的脏数据上有异常值。 那么什么是缺失值呢?缺失值包括缺失值的识别和缺失值的处理。一般来说缺失值处理方法有删除、替换和插补。先来说说删除法吧。删除法根据删除的不同角度又可以分为删除观测样本和变量,删除观测样本,这就相当于减少样本量来换取信息的完整度,但当变量有较大缺失并且对研究目标影响不大时,可以直接删除。接着说一下替换法,所谓替换法就是将缺失值进行替换,根据变量的不同又有不同的替换规则,缺失值的所在变量是数值型用该变量下其他数的均值来替换缺失值;变量为非数值变量时则用该变量下其他观测值的中位数或众数替换。最后说说插补法,插补法分为回归插补和多重插补;回归插补指的是将插补的变量转变成替换法,然后根据替换法进行替换即可。
刚刚说到的缺失值,其实异常值也是需要处理的,那么什么是异常值呢?异常值跟缺失值一样,包括异常值的识别和异常值的处理。对于异常值的处理我们一般使用单变量散点图或箱形图来处理,在图形中,把远离正常范围的点当作异常值。异常值的的处理有删除含有异常值的观测、当作缺失值、平均值修正、不处理。在进行异常值处理时要先复习异常值出现的可能原因,再判断异常值是否应该舍弃。 大家在进行清洗数据的时候需要注意缺失数据的填补以及对异常数值的修正,这样才能够做好数据分析工作,由于篇幅的关系,如何做好数据预处理工作就给大家介绍到这里了,希望这篇文章能够给大家带来帮助。
脑电数据预处理步骤
1)脑电预览。首先要观察被试脑电基本特征,然后剔除原始信号中一些典型的干扰噪声、肌肉运动等所产生的十分明显的波形漂移数据。 2)眼电去除。使用伪迹校正(correction)的方法,即从采集的 EEG 信号中减去受眼电(EOG)伪迹影响的部分。首先寻找眼电的最大绝对值,用最大值的百分数来定义 EOG 伪迹。接着构建平均伪迹,将超过 EOG 最大值某个百分比(如10%)的眼电导联电位识别为 EOG 脉冲,对识别的 EOG 脉冲进行平均,由协方差估计公式(2-1)计算平均 EOG 脉冲和其它电极之间的 EEG 的传递系数 b: b=cov(EOG, EEG)/var(EOG) (2-1) 其中 cov 表示协方差(covariance),var 表示方差(variance)。 最后根据公式(2-2)对受眼动影响的电极在产生眼动的时间段的波形进行校正,点对点地用 EEG 减去 EOG: corrected EEG=original EEG-b×EOG (2-2) 实验中设置最小眨眼次数为 20 次,眨眼持续时间 400ms。 3)事件提取与脑电分段。ERP 是基于事件(刺激)的诱发脑电,所以不同刺激诱发的 ERP 应该分别处理。在听觉认知实验中,多种类型的刺激会重复呈现,而把同种刺激诱发的脑电数据提取出来的过程叫做事件提取。这样,连续的脑电数据就会根据刺激事件为标准划分为若干段等长数据。以实验刺激出现的起始点为 0 时刻点,根据实验出现的事件对应的事件码,将脑电数据划分成许多个数据段,每段为刺激前 100ms 到刺激后 600ms。对每个试次(一个刺激以及相应的一段加工过程)提取一段同样长度的数据段。 4)基线校正。此步骤用于消除自发脑电活动导致的脑电噪声,以 0 时刻点前的数据作为基线,假设 0 时刻点前的脑电信号代表接收刺激时的自发脑电,用 0时刻点后的数据减去 0 时刻点前的各点数据的平均值,可以消除部分的自发脑
数据预处理 一、实验原理 预处理方法基本方法 1、数据清洗 去掉噪声和无关数据 2、数据集成 将多个数据源中的数据结合起来存放在一个一致的数据存储中 3、数据变换 把原始数据转换成为适合数据挖掘的形式 4、数据归约 主要方法包括:数据立方体聚集,维归约,数据压缩,数值归约,离散化和概念分层等二、实验目的 掌握数据预处理的基本方法。 三、实验内容 1、R语言初步认识(掌握R程序运行环境) 2、实验数据预处理。(掌握R语言中数据预处理的使用) 对给定的测试用例数据集,进行以下操作。 1)、加载程序,熟悉各按钮的功能。 2)、熟悉各函数的功能,运行程序,并对程序进行分析。 对餐饮销量数据进统计量分析,求销量数据均值、中位数、极差、标准差,变异系数和四分位数间距。 对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。 3)数据预处理 缺省值的处理:用均值替换、回归查补和多重查补对缺省值进行处理 对连续属性离散化:用等频、等宽等方法对数据进行离散化处理 四、实验步骤 1、R语言运行环境的安装配置和简单使用 (1)安装R语言 R语言下载安装包,然后进行默认安装,然后安装RStudio 工具(2)R语言控制台的使用 1.2.1查看帮助文档
1.2.2 安装软件包 1.2.3 进行简单的数据操作 (3)RStudio 简单使用 1.3.1 RStudio 中进行简单的数据处理 1.3.2 RStudio 中进行简单的数据处理
2、R语言中数据预处理 (1)加载程序,熟悉各按钮的功能。 (2)熟悉各函数的功能,运行程序,并对程序进行分析 2.2.1 销量中位数、极差、标准差,变异系数和四分位数间距。 , 2.2.2对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。
大数据处理:技术与流程 文章来源:ECP大数据时间:2013/5/22 11:28:34发布者:ECP大数据(关注:848) 标签: “大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。特点是:数据量大(Volume)、数据种类多样(Variety)、要求实时性强(Velocity)。对它关注也是因为它蕴藏的商业价值大(Value)。也是大数据的4V特性。符合这些特性的,叫大数据。 大数据会更多的体现数据的价值。各行业的数据都越来越多,在大数据情况下,如何保障业务的顺畅,有效的管理分析数据,能让领导层做出最有利的决策。这是关注大数据的原因。也是大数据处理技术要解决的问题。 大数据处理技术 大数据时代的超大数据体量和占相当比例的半结构化和非结构化数据的存在,已经超越了传统数据库的管理能力,大数据技术将是IT领域新一代的技术与架构,它将帮助人们存储管理好大数据并从大体量、高复杂的数据中提取价值,相关的技术、产品将不断涌现,将有可能给IT行业开拓一个新的黄金时代。 大数据本质也是数据,其关键的技术依然逃不脱:1)大数据存储和管理;2)大数据检索使用(包括数据挖掘和智能分析)。围绕大数据,一批新兴的数据挖掘、数据存储、数据处理与分析技术将不断涌现,让我们处理海量数据更加容易、更加便宜和迅速,成为企业业务经营的好助手,甚至可以改变许多行业的经营方式。 大数据的商业模式与架构----云计算及其分布式结构是重要途径 1)大数据处理技术正在改变目前计算机的运行模式,正在改变着这个世界:它能处理几乎各种类型的海量数据,无论是微博、文章、电子邮件、文档、音频、视频,还是其它形态的数据;它工作的速度非常快速:实际上几乎实时;它具有普及性:因为它所用的都是最普通低成本的硬件,而云计算它将计算任务分布在大量计算机构成的资源池上,使用户能够按需获取计算力、存储空间和信息服务。云计算及其技术给了人们廉价获取巨量计算和存储的能力,云计算分布式架构能够很好地支持大数据存储和处理需求。这样的低成本硬件+低成本软件+低成本运维,更加经济和实用,使得大数据处理和利用成为可能。
大数据处理技术ppt讲课稿 科信办刘伟 第一节Mapreduce编程模型: 1.技术背景: 分布式并行计算是大数据(pb)处理的有效方法,编写正确高效的大规模并行分布式程序是计算机工程领域的难题:分布式并行计算是大数据(pb)处理的有效方法,编写正确高效的大规模并行分布式程序是计算机工程领域的难题。并行计算的模型、计算任务分发、计算机结果合并、计算节点的通讯、计算节点的负载均衡、计算机节点容错处理、节点文件的管理等方面都要考虑。 谷歌的关于mapreduce论文里这么形容他们遇到的难题:由于输入的数据量巨大,因此要想在可接受的时间内完成运算,只有将这些计算分布在成百上千的主机上。如何处理并行计算、如何分发数据、如何处理错误?所有这些问题综合在一起,需要大量的代码处理,因此也使得原本简单的运算变得难以处理,普通程序员无法进行大数据处理。 为了解决上述复杂的问题,谷歌设计一个新的抽象模型,使用这个抽象模型,普通程序员只要表述他们想要执行的简单运算即可,而不必关心并行计算、容错、数据分布、负载均衡等复杂的细节,这些问题都被封装了,交个了后台程序来处理。这个模型就是mapreduce。 谷歌2004年公布的mapreduce编程模型,在工业、学术界产生巨大影响,以至于谈大数据必谈mapreduce。 学术界和工业界就此开始了漫漫的追赶之路。这期间,工业界试图做的事情就是要实现一个能够媲美或者比Google mapreduce更好的系统,多年的努力下来,Hadoop(开源)脱颖而出,成为外界实现MapReduce计算模型事实上的标准,围绕着Hadoop,已经形成了一个庞大的生态系统 2. mapreduce的概念: MapReduce是一个编程模型,一个处理和生成超大数据集的算法模型的相关实现。简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。 mapreduce成功的最大因素是它简单的编程模型。程序员只要按照这个框架的要求,设计map和reduce函数,剩下的工作,如分布式存储、节点调度、负载均衡、节点通讯、容错处理和故障恢复都由mapreduce框架(比如hadoop)自动完成,设计的程序有很高的扩展性。所以,站在计算的两端来看,与我们通常熟悉的串行计算没有任何差别,所有的复杂性都在中间隐藏了。它让那些没有多少并行计算和分布式处理经验的开发人员也可以开发并行应用,开发人员只需要实现map 和reduce 两个接口函数,即可完成TB级数据的计算,这也就是MapReduce的价值所在,通过简化编程模型,降低了开发并行应用的入门门槛,并行计算就可以得到更广泛的应用。 3.mapreduce的编程模型原理 开发人员用两个函数表达这个计算:Map和Reduce,首先创建一个Map函数处理一个基于key/value pair的数据集合,输出中间的基于key/value pair的数据集合,然后再创建一个Reduce函数用来合并所有的具有相同中间key值的中间value值,就完成了大数据的处理,剩下的工作由计算机集群自动完成。 即:(input)
实验一、数据预处理 学院计算机科学与软件学院 ?实验目的: (1)熟悉 VC++编程工具和完全数据立方体构建、联机分析处理算法。 (2)浏览拟被处理的的数据,发现各维属性可能的噪声、缺失值、不一致 性等,针对存在的问题拟出采用的数据清理、数据变换、数据集成的具体算法。(3)用 VC++编程工具编写程序,实现数据清理、数据变换、数据集成等功 能。 (4)调试整个程序获得清洁的、一致的、集成的数据,选择适于全局优化 的参数。 ?实验原理: 1 、数据预处理 现实世界中的数据库极易受噪音数据、遗漏数据和不一致性数据的侵扰,为 提高数据质量进而提高挖掘结果的质量,产生了大量数据预处理技术。数据预处理有多种方法:数据清理,数据集成,数据变换,数据归约等。这些数据处理技术在数据挖掘之前使用,大大提高了数据挖掘模式的质量,降低实际挖掘所需要的时间。 2 、数据清理 数据清理例程通过填写遗漏的值,平滑噪音数据,识别、删除离群点,并解 决不一致来“清理”数据。 3 、数据集成数据集成 数据集成将数据由多个源合并成一致的数据存储,如数据仓库或数据立方 体。 4 、数据变换 通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式。 5 、数据归约 使用数据归约可以得到数据集的压缩表示,它小得多,但能产生同样(或几 乎同样的)分析结果。常用的数据归约策略有数据聚集、维归约、数据压缩和数字归约等。 三、实验内容: 1 、主要代码及注释 头文件 #include
大数据处理数据时代理念的三大转变:要全体不要抽样,要效率不要绝对精确,要相关不要因果。具体的大数据处理方法其实有很多,但是根据长时间的实践,天互数据总结了一个基本的大数据处理流程,并且这个流程应该能够对大家理顺大数据的处理有所帮助。整个处理流程可以概括为四步,分别是采集、导入和预处理、统计和分析,以及挖掘。 采集 大数据的采集是指利用多个数据库来接收发自客户端的数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如,电商会使用传统的关系型数据库MySQL和Oracle等来存储每一笔事务数据,除此之外,Redis和MongoDB 这样的NoSQL数据库也常用于数据的采集。 在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间进行负载均衡和分片的确是需要深入的思考和设计。 统计/分析 统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL 的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。 导入/预处理 虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。也有一些用户会在导入时使用来自Twitter的Storm来对数据进行流式计算,来满足