
第四章回归分析
回归分析是根据统计资料建立经验公式的统计方法。回归分析可用于预测和控制,在自然科学,社会科学和应用技术中都有重要应用,它是统计学最重要的工具。回归分析方法和理论从Gauss提出最小二乘法开始,至今已近200年,目前仍在蓬勃发展,例如在回归诊断、维度缩减、半参数回归、非参数回归、LOGISTIC回归等方向不断有新的突破。本章介绍参数回归分析模型及其参数估计、检验、模型选择等理论和有关计算方法。参数回归分析主要分三类:线性回归、可以转化为线性回归的回归和非线性回归。本章依次介绍这三类模型。有关回归分析的一般理论可参见陈希儒(1984),方开泰(1988),Seber(1976),何晓群(1997),何晓群、刘文卿(2001)、Richard(2003)。Robert(1999)和王吉利(2004)提供了许多有趣的应用例子。
第一节多元线性回归模型
一、两个例子
例1 试验测定迟熟早籼广陆矮4号在某年5月5日至8月5日播种时(每隔10天播一期),播种至齐穗的天数(y)和播种至齐穗的总积温(x,日·度)的关系,数据列于下表,建立播种至齐穗的天数与总积温两者之间的关系。
y x
播种至齐穗的天数总积温(日·度)
70 1616.3
67 1610.9
55 1440.0
52 1400.7
51 1423.3
52 1471.3
51 1421.8
60 1547.1
64 1533.0
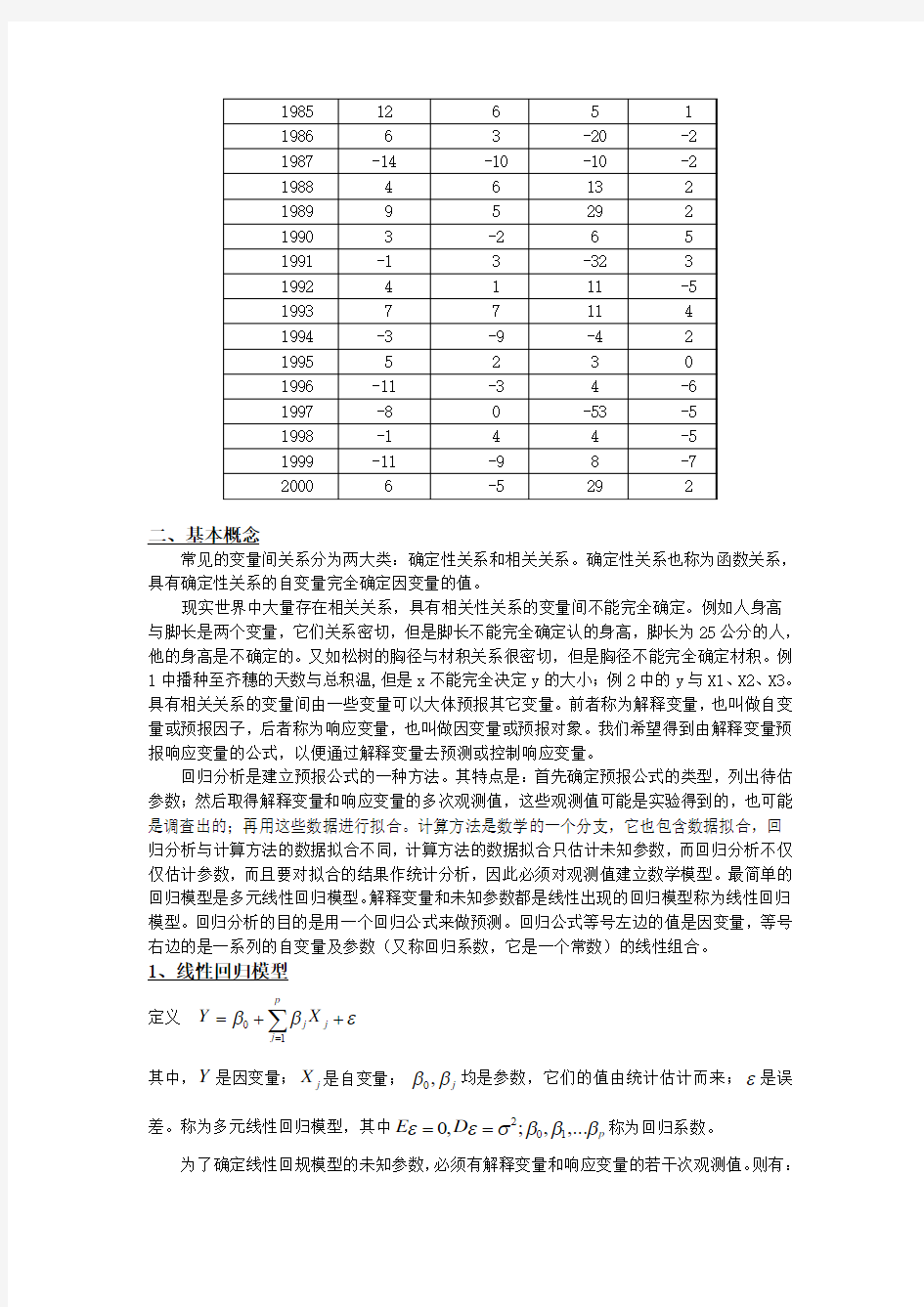
例2 某站为预报早稻播种育秧期间(下/3-下/4)的低温阴雨日数,通过相关普查和点聚图分析,最后选择了三个相关较好的预报因子:
X1--前一年9月份的阴雨日数距平;
X2--前一年10月份-当年1月份的阴雨日数距平和;
X3--当年1月份的阴雨日数距平.
y-- 历年早稻播种育秧期间的低温阴雨日数距平
试建立y与X1、X2、X3之间的关系。
二、基本概念
常见的变量间关系分为两大类:确定性关系和相关关系。确定性关系也称为函数关系,具有确定性关系的自变量完全确定因变量的值。
现实世界中大量存在相关关系,具有相关性关系的变量间不能完全确定。例如人身高 与脚长是两个变量,它们关系密切,但是脚长不能完全确定认的身高,脚长为25公分的人,他的身高是不确定的。又如松树的胸径与材积关系很密切,但是胸径不能完全确定材积。例1中播种至齐穗的天数与总积温,但是x 不能完全决定y 的大小;例2中的y 与X1、X2、X3。具有相关关系的变量间由一些变量可以大体预报其它变量。前者称为解释变量,也叫做自变量或预报因子,后者称为响应变量,也叫做因变量或预报对象。我们希望得到由解释变量预报响应变量的公式,以便通过解释变量去预测或控制响应变量。
回归分析是建立预报公式的一种方法。其特点是:首先确定预报公式的类型,列出待估参数;然后取得解释变量和响应变量的多次观测值,这些观测值可能是实验得到的,也可能是调查出的;再用这些数据进行拟合。计算方法是数学的一个分支,它也包含数据拟合,回归分析与计算方法的数据拟合不同,计算方法的数据拟合只估计未知参数,而回归分析不仅仅估计参数,而且要对拟合的结果作统计分析,因此必须对观测值建立数学模型。最简单的回归模型是多元线性回归模型。解释变量和未知参数都是线性出现的回归模型称为线性回归模型。回归分析的目的是用一个回归公式来做预测。回归公式等号左边的值是因变量,等号右边的是一系列的自变量及参数(又称回归系数,它是一个常数)的线性组合。
1、线性回归模型
定义 εββ++=
∑=p
j j j X Y 1
其中,Y 是因变量;j X 是自变量; j ββ,0均是参数,它们的值由统计估计而来;ε是误差。称为多元线性回归模型,其中p D E βββσεε,...,;,0102
==称为回归系数。
为了确定线性回规模型的未知参数,必须有解释变量和响应变量的若干次观测值。则有:
??
??
??
?++++=++++=n
np p n n p p x x y x x y εβββεβββ............1101111101 记??????? ??=?np n p p k
n x x x x x x X ...1.......1...11221111,??????? ??=?p k ββββ...101,??????? ??=?n n εεεε...211,??????? ??=?n n Y Y Y Y ...211 其中X 称为回归设计矩阵,通常简称为设计矩阵,一个线性回归模型可以用矩阵表示如下:
εβ+=X Y
2、线性回归的假设
线性回归的重要假设如下:
(1) 所有自变量是固定的,或由实验结果导出; (2) 回归模型是正确的; (3) 自变量的测量没有误差; (4) 误差的平均值是0;
(5) 误差的方差是常数,其值以2
σ表示;
(6) 误差之间不相关。
(7) 当我们要检验回归模型是否有效时(Significance ),我们附加另外一个假设,
误差服从正态分布
(1)--(6)可以表示为:
?
??==I Var E 2
)(0
σεε 三、参数的估计
如何利用观测值估计模型中的参数p βββ,...,10?通常用最小二乘法,即选择适当β使
离差平方和
)()'()...()(21
110ββββββX y X y x x y S jp n
j p j j --=----=∑=
最小。早在1809年Gauss 就提出称为最小二乘法。
β的最小二乘估计是
Y X X X T T 1)(-∧
=β。
jp p j j x x y ∧
∧
∧
∧
+++=βββ...110称为j y 的拟合值(回归值),拟合向量记为
∧∧∧∧=?????
???????=βX y y y n (1)
jp p j j j x x y ∧
∧∧∧----=βββε...110称为第j 次纪录观测的残差。残差向量
∧
∧∧∧-=?????
?
??????=βεεεX Y n ...1。
残差平方和:2
∧
-=β
X
Y SSE ∑=∧
∧∧----=n
i ip p i i x x y 12110)...(βββ
回归平方和:∑=-=
n
i i
Y X SSR 12
)
?(β
总平方和: ∑=-=
n
i i
Y Y SST 1
2
)
(
误差方差2
σ的估计为均方误差MSE ,即
)
1/()1/(2
--=--==∧
∧m n SSE p n SSE MSE σσ
定理 2
,σβ的估计具有如下性质
(1) ββ=∧)(E (∧
β是β无偏估计)。
12)()(-∧
=X X Var T σβ。
(2) 2
2
)(σσ=∧
E ,(∧2
σ是2
σ的无偏估计)。
(3) ∧
β是的线性无偏最小方差估计(在β的线性无偏估计中,∧
β方差最小)。即通常
所称Gauss-Markov 定理。
(4) 正态性:若),,0(~2
I N σε则))(,(~1
2-∧
X X N T σββ;若观测个数n 很大,即
使ε不服从正态分布,仍近似地有))(,(~1
2
-∧
X X N T
σββ。
(5) 单个参数的分布:令?????
?
????????=∧∧∧∧p ββββ...10,若),,0(~2
σεN 则∧β的第i+1个分量
))(,(~11,12-++∧
i i T i i X X N σββ,其中11,1)(-++i i T X X 是 1
)(-X X T 对角线上第
1+i 个元素。从而可用11,12
)
()(-++∧
∧
=i i T
i X X STDERR σβ估计i ∧
β 的标准差。
(6) 若),,0(~2I N σε则有SST=SSR+SSE 。若再有p i i ,...2,10
==β,则
)1,(~)
1/()
/(----p n p F p n SSE p SSR 。
(7) 若),,0(~2
I N σε则SSE 与∧
β独立。从而:
)1(~)(/)(---∧
∧p n t STDERR i i i βββ。
(8) 若),,0(~2I N σε则β的极大似然估计与最小二乘估计相同。
四、假设检验
存在两个问题:(1)y 与p x x ,...,1是否有较好的线性关系?即回归模型是否有意义?如果真正的模型中p i i ,...2,1,0==β ,或i β的绝对值都很小,则p x x ,...,1的值 对y 影响都很小,不能起预报作用,我们认为y 与p x x ,...,1没有较好的线性关系,回归模型没有意义。(2)回归模型能否简化,即m x x ,...,1中是否存在某个自变量,它与y 无关或它能被其它自变量代替,因而回归模型中可以删去这个自变量?为此可以做如下两类检验。
1、线性关系显著性F 检验
即要检验
p i H i ,...2,1,0:0==β。
定理指出SST=SSR+SSE ,其中总方差SST 反映响应变量的发散程度;回归平方和SSR 反映由回归引起的分散性,SSE 反映误差变量的分散性。若0H 成立,SSR/SSE 应当很小,若SSR/SSE 很大,则否定0H 。为此取统计量SSR/SSE 。 定理
若0...:210====p H βββ成立,则
)1,(~)
1/(/----=
p n p F p n SSE p
SSR F
当F 很大时(超过临界值)(1,α--p n p F ),则回归效果显著。
因此,只需计算F 的值,并做F 检验即可,若F 很大,则否定0H 。 回归模型线性关系显著性也有其他检验方法:复相关系数平方
SST SSE R /12-=,
修正的复相关系数平方
)/()1)(1(12m n R n ADJRSQ ----=。
由于
1)1();1/(122-+=+=-R F F F R
复相关系数平方和修正的复相关系数平方越大,线性关系越显著。由于复相关系数和修正的复相关系数的分位数表不易查到,我们不介绍用这两个统计量做检验的方法。
2、单个解释变量显著性t 检验。
常常要考虑第i 个解释变量i x 是否在模型中有作用。一个好的模型,所有变量都应起作用。如果i x 的系数i β为零或绝对值很小,i x 无作用。为此对每个i 要检验
0:0=i i H β,
定理
当0:0=i i H β 成立时,有
i t =)1(~)(/)(---∧
∧
p n t STDERR i i i βββ。
若i t 绝对值很大,则应当否定i H 0。当)1(2
-->p n t t i α时拒绝原假设,认为y x i 对起作
用。
五、预报
做预报是回归分析的重要目的。
对回归问题,当β?得到后, p p x x y ∧
∧
∧
+++=βββ (110)
称为经验回归方程。
有了经验回归方程,若再给定解释变量的值)', (1)
p o
x x u =,就可得到预报值
o
p p o x x y ∧
∧
∧∧
+++=βββ (1)
100
但是,y 的真值满足εβββ++++=o
p p o
x x y ...1100,存在预报误差
εββββββ+-++-+-=-∧
∧
∧∧o
p p p o x x y y )(...)()(1
11000
由此可见,预报误差由两部分组成可得预报误差是零均值的。
预报值的置信区间理论比较复杂。可以如下计算:设解释变量的值为)', (1)
m o x x u =,令),...,1(10'=o m o x x X ,010)'('X X X X v -=,则概率为α-1的预报区间端点为
预测值的标准误差 2νσ
预测误差的标准差 2]1[σν+
预测值的置信区间
2/12
2/0
))1()(1(v m n t y +--±∧
σα
六、计算结果
例1(续)
data han; input y x@@; cards;
70 1616.3 67 1610.9 55 1440.0 52 1400.7 51 1423.3 52 1471.3 51 1421.8 60 1547.1 64 1533.0 ;
PROC REG; Model y=x; run;
运算结果:
Analysis of Variance Sum of Mean
Source DF Squares Square F Value Pr > F
Model 1 402.75088 402.75088 68.35 <.0001 Error 7 41.24912 5.89273 Corrected Total 8 444.00000
Root MSE 2.42749 R-Square 0.9071 Dependent Mean 58.00000 Adj R-Sq 0.8938 Coeff Var 4.18534
Parameter Estimates
Parameter Standard
Variable DF Estimate Error t Value Pr > |t| Intercept 1 -69.70404 15.46820 -4.51 0.0028 x 1 0.08536 0.01033 8.27 <.0001
y=-69.70404+ 0.08536x
data han;
input y x@@;
cards;
70 1616.3 67 1610.9 55 1440.0 52 1400.7 51 1423.3
52 1471.3 51 1421.8 60 1547.1 64 1533.0 . 1600
;
PROC REG;
Model y=x/P CLI;
run;
Dependent Variable: y
Output Statistics
Dependent Predicted Std Error
Obs Variable Value Mean Predict 95% CL Predict Residual
1 70.0000 68.2651 1.4821 61.5398 74.9905 1.7349
2 67.0000 67.8042 1.4357 61.135
3 74.4731 -0.8042
3 55.0000 53.2160 0.9948 47.0126 59.419
4 1.7840
4 52.0000 49.8613 1.2743 43.3783 56.3443 2.1387
5 51.0000 51.7905 1.1040 45.484
6 58.0963 -0.7905
6 52.0000 55.8878 0.8485 49.8071 61.9685 -3.8878
7 51.0000 51.6624 1.1146 45.3461 57.9787 -0.6624
8 60.0000 62.3582 0.9657 56.1805 68.5358 -2.3582
9 64.0000 61.1546 0.8946 55.0371 67.2721 2.8454
10 . 66.8738 1.3442 60.3124 73.4352 .
Sum of Residuals 0
Sum of Squared Residuals 41.24912
Predicted Residual SS (PRESS) 62.49600
例2(续)程序如下:
DATA DEF;
INPUT Y X1-X3 @@;
CARDS;
-8 0 -6 2
4 2 20 3
7 -1 19 4
-7 -5 -16 -2
12 6 5 1
6 3 -20 -2
-14 -10 -10 -2
4 6 13 2
9 5 29 2
3 -2 6 5
-1 3 -32 3
4 1 11 -5
7 7 11 4
-3 -9 -4 2
5 2 3 0
-11 -3 4 -6
-8 0 -53 -5
-1 4 4 -5
-11 -9 8 -7
6 -5 29 2
;
PROC REG;
MODEL Y=X1-X3;
RUN;
运算结果
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 3 790.89946 263.63315 13.53 0.0001
Error 16 311.65054 19.47816
Corrected Total 19 1102.55000
Root MSE 4.41341 R-Square 0.7173
Dependent Mean 0.15000 Adj R-Sq 0.6643
Coeff Var 2942.27112
Parameter Estimates
Parameter Standard
Variable DF Estimate Error t Value Pr > |t|
Intercept 1 0.34059 0.99172 0.34 0.7357
X1 1 0.82384 0.20358 4.05 0.0009
X2 1 0.12874 0.05317 2.42 0.0277
X3 1 0.59901 0.29557 2.03 0.0597
由上面可知:
回归方程为:Y=0.34059+0.82384X1+0.12874X2+0.59901X3
可知早稻育秧期间的低温阴雨日数与头年9月份的阴雨日数距平关系最密切。从上面也可以看出回归方程的线性关系是显著的。但实际上除X1外,其余回归系数都不显著。
1、建立了青海省海北地区土壤湿度与旬降水、旬平均气温之间的回归关系
分析:在模式的建立过程中,采用了青海省海北牧业气象试验站3月18日至10月28日23旬的土壤湿度、旬降水、旬平均气温的资料,用多元统计回归建立了方程。方差分析表中,给出Sr =6647.21656 ,Se= 16148 ,自由度为2和20, F = 3323.60828 /807.38700= 4.12,
还给出服从自由度(2,20)的F 分布随机变量大于 4.12的概率为0.0318<0.05,所以回归是
显著的。在参数估计中,截距、降水、气温三者的T检验都达到0.05的显著水平,所以认为回归系数是显著的。最后得出回归方程为:
y = 244.94+1.02*rain-0.34*temp
y :土壤湿度;rain : 旬降水 ;temp :旬平均气温
青海省海北地区土壤湿度与旬平均降水、气温的关系
09:14 Saturday, June 12, 2004 1
Obs v1 v2 v3
1 241 4.5 17
2 265 8.7 16
3 309 20.9 19
4 232 6.1 61
5 205 21.1 111
6 22
7 34.1 97
7 281 33.6 50
8 225 38.0 106
9 191 26.1 116
10 212 36.4 124
11 220 13.2 128
12 222 12.2 131
13 218 55.5 140
14 295 65.8 148
15 297 47.9 146
16 269 39.5 131
17 225 9.5 117
18 261 23.8 95
19 271 49.8 94
20 248 63.3 83
21 209 3.7 66
22 231 26.7 37
23 236 2.3 5
青海省土壤湿度与旬平均降水、气温的关系
09:14 Saturday, June 12, 2004 2
The REG Procedure
Model: MODEL1
Dependent Variable: v1 土壤湿度
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 2 6647.21656 3323.60828 4.12 0.0318 Error 20 16148 807.38700
Corrected Total 22 22795
Root MSE 28.41456 R-Square 0.2916
Dependent Mean 243.04348 Adj R-Sq 0.2208
Coeff Var 11.69114
Parameter Estimates
Parameter Standard
Variable Label DF Estimate Error t Value Pr > |t|
Intercept Intercept 1 244.93781 13.45982 18.20 <.0001
v2 降水 1 1.01582 0.37025 2.74 0.0125
v3 气温 1 -0.34172 0.15681 -2.18
第二节一般回归统计分析:PROC REG
PROC REG用最小二乘估计拟合线性回归模型。有多种模型选择方法来确定最优自变量子集来预测因变量。PROC REG 是一种一般的回归程序,而其它的回归程序有专门的应用。PROC REG 提供了九种模型选择方法,
PROC REG有如下的功能:
(1)能同时考虑数个线性回归模型,并可以交互式执行回归分析;
(2)输入数据可以是相关系数或变量的Cross Product;
(3)可输出因变量的预测值、误差、标准化误差、置信区间等,这些统计量可被储存在一个输出文件内,或利用指令PLOT绘成点状图;
(4)输出各种影响力值;
(5)绘制偏回归图(Partial Regression Leverage Plots)
(6)由最小误差平方法估计系数;
(7)检验回归系数;
(8)检验多变量的假设;
(9)将自变量的向量积纳入输出文件;
(10)诊断自变量之间线性相关的程度;
(11)有九种不同的方法可简化模型;
(12)利用PAINT指令可特别强调数据种某个或某些观测个体。
PROC REG 格式:
PROC REG options;
label: MODEL dependents= regressors /
BY variable-list;
FREQ variable;
ID variable;
VAR variable-list;
ADD variable-list;
DELETE variable-list;
REWEIGHT
WEIGHT variable;
label: MTEST
OUTPUT OUT= SAS-data-set keyword= names ...;
PAINT
PLOT
PRINT
REFIT;
RESTRICT equation1, ... equationk;
label: TEST equation1, ... equationk / option;
其中,PROC REG 与MODEL两道指令是必须的,不可省略。
一个REG程序种可含多个MODEL指令。在每个MODEL指令之后,可有一个OUTPUT指令及多个RESTRICT,TEST,MTEST等指令。至于WEIGHT,FREQ,ID指令则可有可无,而且只需使用一次,其效力即可贯穿整个REG程序。
PROC REG options;
下列选项可被用于PROC REG语句中:
ALL ANNOTATE= SAS-data-set
CORR COVOUT
DATA= SAS-data-set GOUT= graphics-catalog
GRAPHICS NOPRINT
OUTEST= SAS-data-set OUTSEB
OUTSSCP= SAS-data-set OUTSTB
OUTVIF PCOMIT= values
PRESS RIDGE= values
SIMPLE SINGULAR= n
USSCP
(1)DATA=输入文件名称
(2)OUTTEST=输出文件名称
(3)COVOUT
(4)OUTSSCP=输出文件名称
(5)NOPRINT 所有分析结果皆不印出
(6)SIMPLE 印出所有参与分析的变量的简单描述性统计量
(7)USSCP
(8)ALL 要求印出所有的分析结果
(9)CORR 要求打印在MODEL指令或VAR指令中界定之变量间的相关系数矩阵
label: MODEL dependents= regressors /
下列选项可被用于MODEL语句中:
ACOV ADJRSQ AIC
ALL B BEST=
BIC CLI CLM
COLLIN COLLINOINT CORRB COVB CP DETAILS DW GMSEP GROUPNAMES= I INCLUDE= INFLUENCE JP MSE NOINT NOPRINT OUTSEB OUTSTB OUTVIF P PARTIAL PC PCOMIT= PCORR1 PCORR2 PRESS R RIDGE= RMSE SBC
SCORR1 SCORR2 SELECTION= SEQB SIGMA= SLENTRY= SLSTAY= SP SPEC SS1 SS2 SSE START= STB STOP= TOL VIF XPX
其后的选项可分为六类:
第一类选项 此处有三个选项与报表的打印有关;
(1) NOPRINT 不打印MODEL 指令所界定的分析结果 (2) ALL 打印MODEL 指令所有分析的结果 (3) NOINT 规定回归模型中不包含截距 第二类选项 控制计算过程的打印,有两个选项;
(1) XPX 印出回归模型的)('
X X
(2) I 印出上述矩阵的逆矩阵。
第三类选项 界定有关参数估计值的有关事宜,有十六个
SS1 SS2 STB TOL VIF COVB CORRB SEQB COLLIN COLLINNOINT ACOV SPEC PCOOR1 PCOOR2 SCORR1 SCORR2
第四类选项 此类选项有七个,均与预测值、预测误差有关;
(1)P 由输入数据及回归模型预测值因变量的值。这个选项将产生包含原数据、因变
量的实际值与预测值以及预测误差的报表 (2) R
(3) CLM 印出各个预测平均数的95%置信区间之上限与下限 (4) CLI (5) DW
(6) INFLUENCE (7) PARTIAL
第五类选项 界定回归模型的选择,有下列十个选项:
(1) SELECTION=FORWARD (或F )
SELECTION=BACKWARD (或B ) SELECTION=STEPWISE
SELECTION=MAXR 最大相关法
SELECTION=MINR 最小相关法
SELECTION=RSQUARE 复相关系数平方法
SELECTION=ADJRSQ 矫正后的复相关系数法
SELECTION=CP CP法
SELECTION=NONE 进行全型的回归分析
(2)DETAILS
(3)INCLUDE=正整数这个选项规定将MODEL指令的前几个变量纳入每个回归模型里;
(4)START=正整数规定分析的第一个回归模型内至少应包括的自变量之数目
(5)STOP=正整数这个指令指示REG程序搜寻出一个含STOP=个数的最佳回归模型后即停止
(6)SLENTRY
(7)SLSTAY
(8)BEST
(9)GROUPNAMES
(10) NOINT
第六类选项与SELECTION=RSQUARE,ADJRSQ,CP的设定有关,有十四个选项;
ADJRSQ AIC BIC CP GMSEP JP MSE
RMSE PC SBC SIGMA SP SSE B
BY variable-list;
REG程序依据此指令所列举的变量将文件分成几个小的文件,然后对没一个小的文件分别执行分析。当选用此指令时,文件内的数据必须先按照BY变量串的值做由小到大的重新排列,这个步骤可籍PROC SORT达成
FREQ variable;
FREQ变量的值表示各观察值重复出现的次数
ID variable;
指明一个变量,其功用在于识别观察体
VAR variable-list;
此指令的功用是要求将那些在MODEL指令中未提到的数值变量也一起包括在向量内乘积矩阵里,此选项须与选项OUTSSCP=并用
ADD variable-list;
DELETE variable-list;
REWEIGHT
WEIGHT variable;
label: MTEST
OUTPUT OUT= SAS-data-set keyword= names ...;
OUT=输出文件名称,这个文件含原输入文件的所有变量,以及本指令中所提到的变量keyword=变量名称串;
下列是十六种关键字及其定义:
(1)PREDICTED(P)
(2)RESIDUAL(R)
(3)L95M
(4)U95M
(5)L95
(6)U95
(7)STDP
(8)STDR
(9)STDI
(10) STUDENT
(11) COOKED
(12) H
(13) PRESS
(14) RSTUDENT
(15) DFFITS
(16) COVRATIO
PAINT
PLOT
PRINT
REFIT;
RESTRICT equation1, ... equationk;
label: TEST equation1, ... equationk / option;
EXAMPLE1预测人体吸入氧气的效率
本资料的数据来自一群中年男子的健康资料。每一名男士提供七个数据,分别是:年龄(AGE),体重(WEIGHT),吸氧的效率(OXY),跑1。5英里所需的时间—以分钟计(RUNTIME),休息时的心跳(RSTPULSE),跑步时的心跳(RUNPULSE),和最高心跳率(MAXPULSE)。其中吸氧效率(OXY)是因变量,另外六个是自变量。
/* This data set contains 31 observations . */
data fitness;
input age weight oxy runtime rstpulse runpulse maxpulse@@;
cards;
44 89.47 44.609 11.37 62 178 182 51 69.63 40.836 10.95 57 168 172 40 75.07 45.313 10.07 62 185 185 51 77.91 46.672 10.00 48 162 168 44 85.84 54.297 8.65 45 156 168 48 91.63 46.774 10.25 48 162 164 42 68.15 59.571 8.17 40 166 172 49 73.37 50.388 10.08 67 168 168 38 89.02 49.874 9.22 55 178 180 57 73.37 39.407 12.63 58 174 176 47 77.45 44.811 11.63 58 176 176 54 79.38 46.080 11.17 62 156 165 40 75.98 45.681 11.95 70 176 180 56 76.32 45.441 9.63 48 164 166
43 81.19 49.091 10.85 64 162 170 50 70.87 54.625 8.92 48 146 155
44 81.42 39.442 13.08 63 174 176 51 67.25 45.118 11.08 48 172 172 38 81.87 60.055 8.63 48 170 186 54 91.63 39.203 12.88 44 168 172
44 73.03 50.541 10.13 45 168 168 51 73.71 45.790 10.47 59 186 188 45 87.66 37.388 14.03 56 186 192 57 59.08 50.545 9.93 49 148 155 45 66.45 44.754 11.12 51 176 176 49 76.32 48.673 9.40 56 186 188 47 79.15 47.273 10.60 47 162 164 48 61.24 47.920 11.50 52 170 176 54 83.42 51.855 10.33 50 166 170 52 82.78 47.467 10.50 53 170 172 49 81.42 49.156 8.95 44 180 185 ;
proc reg data=fitness outest=regout;
oxyhat: model oxy=age weight runtime runpulse maxpulse rstpulse
/selection=stepwise;
model oxy=age weight runtime runpulse maxpulse rstpulse /selection=maxr;
run;
Stepwise Selection: Step 4
Variable maxpulse Entered: R-Square = 0.8430 and C(p) = 4.9695 Analysis of Variance Sum of Mean
Source DF Squares Square F Value Pr > F Model 4 717.69550 179.42388 34.90 <.0001 Error 26 133.68604 5.14177 Corrected Total 30 851.38154
Parameter Standard
Variable Estimate Error Type II SS F Value Pr > F Intercept 100.07910 11.57739 384.21858 74.72 <.0001 age -0.21266 0.09099 28.08629 5.46 0.0274 runtime -2.76824 0.33138 358.80967 69.78 <.0001 runpulse -0.33957 0.11555 44.40268 8.64 0.0068 maxpulse 0.25535 0.13188 19.27645 3.75 0.0638
Summary of Stepwise Selection
Variable Variable Number Partial Model
Step Entered Removed Vars In R-Square R-Square C(p) F Value Pr > F 1 runtime 1 0.7434 0.7434 15.4416 84.01 <.0001 2 age 2 0.0268 0.7702 13.0075 3.27 0.0815 3 runpulse 3 0.0501 0.8203 6.7141 7.54 0.0106 4 maxpulse 4 0.0226 0.8430 4.9695 3.75 0.0638
Example2 土壤中可给态磷含量
研究某一地区土壤中含植物可给态磷的情况.设y 是35℃时土壤中可给态磷含量;1x 是土壤中所含无机盐浓度;2x 是土壤中溶于K 2C03溶液并受溴化物水解的有机磷;3x 是土壤中
溶于K 2C03溶液但不溶于溴化物的有机磷。经18次测量得表3.2。求用1x , 2x , 3x 预报 y 的线性回归方程。并求当1x =15,2x =50,3x =100时y 的预报值和95%置信区间。
表5.2 可给态磷含量表
SAS 程序:
data pcontent; input x1-x3 y; cards;
0.4 52 158 64 0.4 23 163 60 3.1 19 37 71 0.6 34 157 61 4.7 24 59 54 1.7 65 123 77 9.4 44 46 81 10.1 3l 117 93 11.6 29 173 93 12.6 58 112 51 10.9 37 11l 76 23.1 46 114 96 23.1 50 134 77 21.6 44 73 93 23.1 56 168 95
1.9 36 143 54 26.8 58 202 168 29.9 5l 124 99 15 50 100 . ;
proc reg;/*调用reg 过程,data=pcontent 省略*/ model y=x1-x3/cli;/*因变量y,自变量x1,x2,x3*/ run;
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Prob>F Model 3 6805.87146 2268.62382 5.688 0.0092 Error 14 5583.73965 398.83855 C Total 17 12389.61111
Root MSE 19.97094 R-square 0.5493
Dep Mean 81.27778 Adj R-sq 0.4527 C.V. 24.57122
Parameter Estimates
Parameter Standard T for H0:
Variable DF Estimate Error Parameter=0 Prob > |T|
INTERCEP 1 43.650072 18.05441597 2.418 0.0298 X1 1 1.785339 0.53976542 3.308 0.0052 X2 1 -0.083291 0.42037025 -0.198 0.8458 X3 1 0.161022 0.11157815 1.443 0.1710
所以回归方程是
321161.0083.0785.165.43x x x y +-+=
Output Statistics
Dep Var Predict Std Err Lower95% Upper95%
Obs Y Value Predict Predict Predict Residual
1 64.0000 65.4745 10.401 17.1803 113.8 -1.4745
2 60.0000 68.6951 10.98
3 19.8111 117.6 -8.6951 3 71.0000 53.5599 11.707 3.9100 103.2 17.4401
4 61.0000 67.1698 8.623 20.5138 113.8 -6.1698
5 54.0000 59.5425 9.427 12.176
6 106.9 -5.5425 6 77.0000 61.0769 13.912 8.8754 113.3 15.9231
7 81.0000 64.1744 10.165 16.1115 112.2 16.8256
8 93.0000 77.9395 6.26
9 33.0451 122.8 15.0605 9 93.0000 89.8013 9.982 41.9151 137.7 3.1987 10 51.0000 79.3489 8.438 32.8495 125.8 -28.3489 11 76.0000 77.9019 5.110 33.6885 122.1 -1.9019 12 96.0000 99.4165 7.364 53.7642 145.1 -3.4165 13 77.0000 102.3 7.120 56.8297 147.8 -25.3038 14 93.0000 90.3032 8.953 43.3627 137.2 2.6968 15 95.0000 107.3 8.343 60.8583 153.7 -12.2788 16 54.0000 67.0699 7.345 21.4312 112.7 -13.0699 17 168.0 119.2 11.277 70.0026 168.4 48.8073 18 99.0000 112.8 9.867 64.9748 160.5 -13.7506 19 . 82.3678 6.521 37.3090 127.4 .
Sum of Residuals 0 Sum of Squared Residuals 5583.7397 Predicted Resid SS (Press) 10720.7292
上表是预报值表,第一列给出观测值的序号;第二列给出响应变量的观测值;第三列给出响应变量的预报值;第四列给出预报值的标准差;第五列给出预报值为95%置信下限,第六列给出预报值的95%置信上限。从上表可见18次观测也给出预报值和95%置信区间;对第19次观测给出预报值为82.3678,95%置信区间为(37.3090,127.4)。
第三节 多元线性回归模型的选择
有多个解释变量的方幂或交叉积当作预报因子,当用三次,四次多项式拟合时,随着多项式次数升高,预报因子个数急剧增加。例如地质学中的趋势面分析,自变量个数为2,多项式次数为4时,预报因子个数为1+2+3+4+5=15。在气象,经济等问题中,有时解释变量本身个数也非常多,例如解释变量是在印度洋20个地点,每个地点9个时段的温度,这时解释变量有180个。过多的自变量不仅使计算复杂,也不能抓住主要因素,还给计算带来麻烦(X ’X 不满秩或行列式近于零),从而降低精度。实际上,自变量间很可能存在相关关系,有的自变量可以用另几个自变量很好地线性表示,这样的自变量应当从模型中删去。所以我们应当从许多解释变量中选出一些解释变量,由它们组成的回归模型,既包含起显著作用的解释变量,同时又使解释变量个数尽可能少。选择解释变量过程称为模型选择。
怎样选择自变量个数少的回归模型呢?有时可以从实际意义上判定,例如某种植物产量的回归模型中温度和某些时期降水、温度和施肥量是主要的,其它自变量不重要,这是该种植物生长特性决定的。但更多的情况是要我们用数学计算来判定。有许多数学原则可以用来
选择自变量,从而确定回归模型,例如∧
2
σ(平均残差平方和)最小原则,复相关系数最大原则、修正复相关系数最大原则、p C 统计量最小原则、p JJ 统计量最小原则、p S 统计量、平均估计方差(AEV )、刀切法(PRESS)、AIC 、BIC 等等。由此产生许多选择模型法。本节主
要介绍向前选择法,向后选择法,逐步筛选法。这3个方法每步增减一个变量,选择增减的变量以F 检验为原则。先选择两个F 水平out in F F ,:
(1)从有k 个解释变量的模型
ε++++=k k x b x b b y (110)
选择剔除变量的原则是:k x x x ,...,21中剔除一个变量i x ,变成
ε+++++++=++--k k i i i i x b x b x b x b b y (1111110)
,计算剔除的F 统计量i F (计算方法见塞伯,线性回归分析), i=1,2,….k 。选择i x ,使剔除它的i F 最小,而且满足out i F F <。 (2)从有k 个解释变量的模型
ε++++=k k x b x b b y (110)
中增加一个变量i x (i=k+1,k+2…L ),变成
ε+++++=i i k k x b x b x b b y (110)
计算增加的F 统计量i F ,(i=k+1,k+2…L )(计算方法见塞伯,线性回归分析)。选择i x ,使增加它的i F 最大,而且满足in i F F >。
1、向前选择法的原理是:
(1) 选择1个F 水平in F 。
(2) 拟合仅有常数项,没有解释变量的模型ε+=0b y 。
(3) 若解释变量m m x x x ,,...11-中p p s s s x x x ,,...11-已被选入回归模型,
ε++++=p s p s x b x b b y ...110,
对每一个未被选入的变量计算将它选入的F 值i F 。
(4)若其中有的i F 大于in F ,则将i F 最大的变量选入模型,转(3);若其中所有的i F 小于in F ,则停止选择过程,输出计算结果。 于是得到若干个回归方程,从中选出最合意的一个。
2、 向后选择法的原理是:
##公司 事故事件统计分析报告 ##年##月
目录 1 目的 (1) 2 统计范围 (1) 3 统计部门与人员 (1) 4 统计分析内容 (1) 4.1事故事件原因和种类 (1) 4.2伤害发生的时间分布特性 (1) 4.3伤害发生的地点分布特性 (2) 4.4致害物 (2) 4.5受伤人员工龄或年龄结构 (3) 4.6事故事件频率分析 (3) 4.7职业卫生重要因素分析 (3) 4.8事故事件费用分析 (4) 4.9标准化系统元素分析 (4) 5 结论 (4)
事故事件统计分析报告 1 目的 为了寻找公司事故事件的发生规律,加强公司的安全管理,杜绝事故事件的重复发生,对公司本半年发生的事故、事件进行统计分析。 2 统计范围 统计范围:整个矿山开采过程中发生的事故事件; 时间范围:。 3 统计部门与人员 统计部门: 统计人: 4 统计分析内容 4.1 事故事件原因和种类 矿山在半年的安全生产过程中,共发生起事故事件。其中,起属违章未遂事件。详细见附表1。 表1 事故事件原因种类表 4.2伤害发生的时间分布特性
伤害发生的时间分布见表2. 表2 伤害发生的地点统计表 4.3 伤害发生的地点分布特性 伤害发生的地点见表3。 表3 伤害发生的地点统计表 4.4致害物 致害物见表4。 表4致害物统计表
4.5受伤人员工龄或年龄结构 受伤人员工龄或年龄结构伤害见表5。 表5受伤人员工龄或年龄结构统计表 4.6 事故事件频率分析 事故事件频率见表6。 表6事故事件频率统计表 4.7 职业卫生重要因素分析 职业卫生重要因素分析见表7。 表7 职业卫生重要因素分析
毕业论文 题目多元回归分析中的变量选取 ——SPSS的应用 院(系)数学与统计学院 专业年级 2010级统计学 指导教师职称副教授
多元回归分析中的变量选取——SPSS的应用 殷婷 摘要 本文不仅对于复杂的统计计算通过常用的计算机应用软件SPSS来实现,同时通过对两组数据的实证分析,来研究统计学中多元回归分析中的变量选取,让大家对统计中的多元回归数据的选取和操作方法有更深层次的了解。一组数据是对于淘宝交易额的未来发展趋势的研究,一组数据时对于我国财政收入的研究。本文通过两个实证从不同程度上对数据选取的研究运用通俗的语言和浅显的描述将SPSS在多元回归分析中的统计分析方法呈现在大家面前,让大家对多元回归分析以及SPSS软件都可以有更深一步的了解。通过SPSS软件对数据进行分析,对数据进行处理的方法进行总结,找出SPSS对于数据处理和分析的优缺点,最后得在对变量的选取和软件的操作提出建议。 关键词:统计学 SPSS 变量的选取多元回归分析 Abstract
In this paper, not only for complex statistical calculations done by the commonly used computer application software of SPSS, through the empirical analysis of the two groups of data at the same time, to study the statistics of the variables in the multivariate regression analysis, let everybody to select multiple regression in statistical data and operation methods this paper, through two empirical to select data from different extent research using a common language and plain the SPSS statistical analysis method in multiple regression analysis of present in front of everyone, let everyone to multiple regression analysis and SPSS software can of the selection of variables and software. Keywords: Statistical SPSS The selection of variables multiple regression analysis 目录 摘要 (1) 英文摘要 (1) 引言 (3) 第一章回归分析 (3) 1.1自变量的选择 (4) 1.2国内外研究现状 (5) 第二章案例分析一:淘宝交易额的研究 (6) 2.1数据的来源及变量的选取 (6) 2.2相关分析 (7) 2.2.1散点图 (7)
陕西科技大学实验报告 课 程: 数理金融 实验日期: 2014 年 5 月 22 日 班 级: 数学112 交报告日期: 2013 年 5 月 23 日 姓 名: 常海琴 报告退发: (订正、重做) 学 号: 201112010101 教 师: 刘利明 实验名称: 多元回归分析 一、实验预习: 1.多元回归模型。 2.多元回归模型参数的检验。 3.多元回归模型整体的检验。 二、实验的目的和要求: 通过案例分析掌握多元回归模型的建立方法和检验的标准;并掌握分析解决实际金融问题的能力。 三、实验过程:(实验步骤、原理和实验数据记录等) 软件:Eviews3.1 数据:给定美国机动车汽油消费量研究数据。 实验原理:最小二乘法拟合多元线性回归方程 数据记录: 实例中1950年到1987年机动汽车的消费量、汽车保有量、汽油价格、人口数、国民生产总值 图1各个量之间的关系
陕西科技大学理学院实验报告 - 2 - 1、录入数据 图2录入数据 2、回归分析 443322110X X X X Y βββββ++++= 图3运行结果 Y=24553723+1.418520x1-27995762x2-59.87480x3-30540.88x4 S (25079670) (0.266) (5027085) (198.5517) (9557.981) T (0.979) (5.314) (-5.568) (-0.301) (-3.195) 2R =0.966951 F=241.3764 - R =0.9629 dw=0.6265 四、实验总结:(实验数据处理和实验结果讨论等) 用残差和最小确定直线位置是一个途径。计算残差和有相互抵消的问题。用残差绝对值和最小确定直线位置也是一个途径绝对值计算起来比较麻烦。最小二乘法用绝对值平方和最小确定直线位置。0β、1β、2β、3β、4β具有线性特性,无偏特性,有效性。-R =0.9629基本上接近于1,拟合效果较好。
企业管理 对居民消费率影响因素的探究 ---以湖北省为例 改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。 本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。通常来说,影响居民消费率的因素是多方面的,如:居民总 收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。 1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。0-14岁人口比例与65岁及以上人口比例可由《湖北省统计年鉴》查得。
一、计量经济模型分析 (一)、数据搜集 根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。X1:居民总收入(亿元),X2:人口增长率(‰),X3:居民消费价格指数增长率,X4:少儿抚养系数,X5:老年抚养系数,X6:居民消费占收入比重(%)。 Y:消费率(%)X1:总收入 (亿元) X2:人口增 长率(‰) X3:居民消 费价格指 数增长率 X4:少儿抚 养系数 X5:老年抚 养系数 X6:居民消 费比重(%) 1995 1997 200039 2001 2002 2003 2004 2005 2006 2007 2008 2009
管理制度编号:YTO-FS-PD802 安全事故报告和统计分析制度通用版 In Order T o Standardize The Management Of Daily Behavior, The Activities And T asks Are Controlled By The Determined Terms, So As T o Achieve The Effect Of Safe Production And Reduce Hidden Dangers. 标准/ 权威/ 规范/ 实用 Authoritative And Practical Standards
安全事故报告和统计分析制度通用 版 使用提示:本管理制度文件可用于工作中为规范日常行为与作业运行过程的管理,通过对确定的条款对活动和任务实施控制,使活动和任务在受控状态,从而达到安全生产和减少隐患的效果。文件下载后可定制修改,请根据实际需要进行调整和使用。 一、安监室接到事故报告后,应立即按有关规定以书面形式(安全事故调度汇报卡)准确、完整地向镇安监站、镇人民政府上报事故情况,必要时可越级上报事故情况,紧急情况下可直接电话报告,在人员伤亡、财产损失发生变化时,应及时进行事故续报。 二、报告事故的主要内容为:事故发生单位概况,事故发生的时间、地点以及事故现场情况,事故的简要经过,事故已造成或者可能造成的伤亡人数,已经采取的措施和其他应当报告的情况。 三、在做好报告工作的同时,及时赶赴事故现场,协助事故救援,配合事故调查处理工作。 四、事故报表执行零报告制度,每月月底向镇安监站上报《伤亡事故情况报表》。 五、对本辖区内发生的安全生产事故每半年全面分析一次,做到事实叙述清楚,原因分析准确,防范措施得当。
使用Excel数据分析工具进行多元回归分析 使用Excel数据分析工具进行多元回归分析与简单的回归估算分析方法基本相同。但是由于有些电脑在安装办公软件时并未加载数据分析工具,所以从加载开始说起(以Excel2010版为例,其余版本都可以在相应界面找到)。 点击“文件”,如下图: 在弹出的菜单中选择“选项”,如下图所示: 在弹出的“选项”菜单中选择“加载项”,在“加载项”多行文本框中使用滚动条找到并选中“分析工具库”,然后点击最下方的“转到”,如下图所示:
在弹出的“加载宏”菜单中选择“分析工具库”,然后点击“确定”,如下图所示: 加载完毕,在“数据”工具栏中就出现“数据分析”工具库,如下图所示:
给出原始数据,自变量的值在A2:I21单元格区间中,因变量的值在J2:J21中,如下图所示: 假设回归估算表达式为: 试使用Excel数据分析工具库中的回归分析工具对其回归系数进行估算并进行回归分析:点击“数据”工具栏中中的“数据分析”工具库,如下图所示: 在弹出的“数据分析”-“分析工具”多行文本框中选择“回归”,然后点击“确定”,如下图所示:
弹出“回归”对话框并作如下图的选择: 上述选择的具体方法是: 在“Y值输入区域”,点击右侧折叠按钮,选取函数Y数据所在单元格区域J2:J21,选完后再单击折叠按钮返回;这过程也可以直接在“Y值输入区域”文本框中输入J2:J21; 在“X值输入区域”,点击右侧折叠按钮,选取自变量数据所在单元格区域A2:I21,选完后再单击折叠按钮返回;这过程也可以直接在“X值输入区域”文本框中输入A2:I21; 置信度可选默认的95%。 在“输出区域”如选“新工作表”,就将统计分析结果输出到在新表内。为了比较对照,我选本表内的空白区域,左上角起始单元格为K10.点击确定后,输出结果如下:
SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open;
2. Opening excel data source——OK. 第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise. 进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、
Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue. 3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.
管理制度编号:LX-FS-A48704 安全事故报告和统计分析制度标准 范本 In The Daily Work Environment, The Operation Standards Are Restricted, And Relevant Personnel Are Required To Abide By The Corresponding Procedures And Codes Of Conduct, So That The Overall Behavior Can Reach The Specified Standards 编写:_________________________ 审批:_________________________ 时间:________年_____月_____日 A4打印/ 新修订/ 完整/ 内容可编辑
安全事故报告和统计分析制度标准 范本 使用说明:本管理制度资料适用于日常工作环境中对既定操作标准、规范进行约束,并要求相关人员共同遵守对应的办事规程与行动准则,使整体行为或活动达到或超越规定的标准。资料内容可按真实状况进行条款调整,套用时请仔细阅读。 一、安监室接到事故报告后,应立即按有关规定以书面形式(安全事故调度汇报卡)准确、完整地向镇安监站、镇人民政府上报事故情况,必要时可越级上报事故情况,紧急情况下可直接电话报告,在人员伤亡、财产损失发生变化时,应及时进行事故续报。 二、报告事故的主要内容为:事故发生单位概况,事故发生的时间、地点以及事故现场情况,事故的简要经过,事故已造成或者可能造成的伤亡人数,已经采取的措施和其他应当报告的情况。
多元回归分析 在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型: 其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。 多元回归在病虫预报中的应用实例: 某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。分级别数值列成表2-1。 预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。 预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。 表2-1 x1 x2 x3 x4 y 年蛾量级别卵量级别降水量级别雨日级别幼虫密 度 级别 1960 1022 4 112 1 4.3 1 2 1 10 1 1961 300 1 440 3 0.1 1 1 1 4 1 1962 699 3 67 1 7.5 1 1 1 9 1 1963 1876 4 675 4 17.1 4 7 4 55 4 1965 43 1 80 1 1.9 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 11.8 2 3 2 28 3
逐步回归分析的基本思想 在实际问题中, 人们总是希望从对因变量y有影响的诸多变量中选择一些变量作为自变量, 应用多元回归分析的方法建立“最优”回归方程以便对因变量y进行预报或控制。所谓“最优”回归方程, 主要是指希望在回归方程中包含所有对因变量y影响显著的自变量而不包含对影响不显著的自变量的回归方程。逐步回归分析正是根据这种原则提出来的一种回归分析方法。它的主要思路是在考虑的全部自变量中按其对y的作用大小, 显著程度大小或者说贡献大小, 由大到小地逐个引入回归方程, 而对那些对作用不显著的变量可能始终不被引人回归方程。另外, 己被引人回归方程的变量在引入新变量后也可能失去重要性, 而需要从回归方程中剔除出去。引人一个变量或者从回归方程中剔除一个变量都称为逐步回归的一步, 每一步都要进行F检验, 以保证在引人新变量前回归方程中只含有对y 影响显著的变量, 而不显著的变量已被剔除。 逐步回归分析的实施过程是每一步都要对已引入回归方程的变量计算其偏回归平方和(即贡献), 然后选一个偏回归平方和最小的变量, 在预先给定的水平下进行显著性检验, 如果显著则该变量不必从回归方程中剔除, 这时方程中其它的几个变量也都不需要剔除(因为其它的几个变量的偏回归平方和都大于最小的一个更不需要剔除)。相反, 如果不显著, 则该变量要剔除, 然后按偏回归平方和由小到大地依次对方程中其它变量进行检验。将对影响不显著的变量全部剔除, 保留的都是显著的。接着再对未引人回归方程中的变量分别计算其偏回归平方和, 并选其中偏回归平方和最大的一个变量, 同样在给定水平下作显著性检验, 如果显著则将该变量引入回归方程, 这一过程一直继续下去, 直到在回归方程中的变量都不能剔除而又无新变量可以引入时为止, 这时逐步回归过程结束。 在供选择的m个自变量中,依各自变量对因变量作用的大小,即偏回归平方和(partial regression sum of squares)的大小,由大到小把自变量依次逐个引入。每引入一个变量,就 ≤时,将该自变量引入回归方程。新变量引入回归方程后,对方对它进行假设检验。当Pα 程中原有的自变量也要进行假设检验,并把贡献最小且退化为不显著的自变量逐个剔出方程。因此逐步回归每一步(引入一个自变量或剔除一个自变量)前后都要进行假设检验,直至既没有自变量能够进入方程,也没有自变量从方程中剔除为止。回归结束,最后所得方程即为所求得的“最优”回归方程。 逐步回归分析的特点:双向筛选,即引入有意义的变量(前进法),剔除无意义变量(后退法) 多元线性回归的应用 1.影响因素分析 2.估计与预测用回归方程进行预测时,应选择 具有较高2 R值的方程。 3.统计控制指利用回归方程进行逆估计,即通 过控制自变量的值使得因变量Y为 给定的一个确切值或者一个波动范 围。此时,要求回归方程的2R值要 大,回归系数的标准误要小。 1.样本含量 应注意样本含量n与自变量个数m的比例。通常,
实验题目:多元线性回归、异方差、多重共线性 实验目的:掌握多元线性回归的最小二乘法,熟练运用Eviews软件的多元线性回归、异方差、多重共线性的操作,并能够对结果进行相应的分析。 实验内容:习题3.2,分析1994-2011年中国的出口货物总额(Y)、工业增加值(X2)、人民币汇率(X3),之间的相关性和差异性,并修正。 实验步骤: 1.建立出口货物总额计量经济模型: 错误!未找到引用源。(3.1) 1.1建立工作文件并录入数据,得到图1 图1 在“workfile"中按住”ctrl"键,点击“Y、X2、X3”,在双击菜单中点“open group”,出现数据 表。点”view/graph/line/ok”,形成线性图2。 图2 1.2对(3.1)采用OLS估计参数 在主界面命令框栏中输入ls y c x2 x3,然后回车,即可得到参数的估计结果,如图3所示。
图 3 根据图3中的数据,得到模型(3.1)的估计结果为 (8638.216)(0.012799)(9.776181) t=(-2.110573) (10.58454) (1.928512) 错误!未找到引用源。错误!未找到引用源。F=522.0976 从上回归结果可以看出,拟合优度很高,整体效果的F检验通过。但当错误!未找到引用源。=0.05时,错误!未找到引用源。=错误!未找到引用源。2.131.有重要变量X3的t检验不显著,可能存在严重的多重共线性。 2.多重共线性模型的识别 2.1计算解释变量x2、x3的简单相关系数矩阵。 点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x2、x3,点击OK,即可得出相关系数矩阵(同图4)。 相关系数矩阵 图4 由图4相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实解释变量之间存在多重共线性。 2.2多重共线性模型的修正
安全生产事故统计分析汇报 一、全省安全生产事故情况 2009年10月全省共发生各类生产安全事故779起,同比增加67起,上升9.41%;死亡205人,同比减少37人,下降15.29%。 发生一次死亡3-9人的较大事故2起,同比减少2起,下降50.00%;死亡8人,同比减少7人,下降46.67%。 2009年1-10月,全省共发生各类生产安全事故8351起,同比减少2079起,下降19.93%;死亡1591人,同比减少378人,下降19.20%。 发生一次死亡3-9人的较大事故28起,同比减少18起,下降39.13%;死亡102人,同比减少86人,下降45.74%。 较大事故分市区情况:西安6起,死亡20人;宝鸡2起,死亡10人;咸阳2起,死亡7人;铜川2起,死亡7人;渭南5起,死亡15人;榆林1起,死亡5人;汉中4起,死亡15人;安康6起,死亡23人。
较大事故分行业情况:道路交通事故23起,死亡84人;火灾事故1起,死亡3人;建筑施工事故2起,死亡8人;工矿商贸其他事故2起,死亡7人。 (一)工矿商贸企业 工矿商贸企业共发生生产安全事故106起,同比减少39起,下降26.90%;死亡134人,同比减少105人,下降43.93%。 1、煤矿企业发生伤亡事故24起,同比减少19起,下降44.19%;死亡26人,同比减少78人,下降75.00%。 2、金属与非金属矿企业发生伤亡事故27起,同比减少8起,下降22.86%;死亡29人,同比减少18人,下降38.30%。 3、建筑施工企业发生伤亡事故23起,同比减少8起,下降25.81%;死亡35人,同比减少18人,下降33.96%。 4、危险化学品企业未发生伤亡事故。 5、烟花爆竹企业发生伤亡事故1起,同比增加1起;死
一、什么是回归分析 回归分析(Regression Analysis)是研究变量之间作用关系的一 种统计分析方法,其基本组成是一个(或一组)自变量与一个(或一组)因变量。回归分析研究的目的是通过收集到的样本数据用一定的统计方法探讨自变量对因变量的影响关系,即原因对结果的影响程度。 回归分析是指对具有高度相关关系的现象,根据其相关的形态,建立一个适当的数学模型(函数式),来近似地反映变量之间关系的统计分析方法。利用这种方法建立的数学模型称为回归方程,它实际上是相关现象之间不确定、不规则的数量关系的一般化。 二、回归分析的种类 1.按涉及自变量的多少,可分为一元回归分析和多元回归分析一元回归分析是对一个因变量和一个自变量建立回归方程。多元回归分析是对一个因变量和两个或两个以上的自变量建立回归方程。 2.按回归方程的表现形式不同,可分为线性回归分析和非线性回归分析 若变量之间是线性相关关系,可通过建立直线方程来反映,这种分析叫线性回归分析。 若变量之间是非线性相关关系,可通过建立非线性回归方程来反映,这种分析叫非线性回归分析。
三、回归分析的主要内容 1.建立相关关系的数学表达式。依据现象之间的相关形态,建立适当的数学模型,通过数学模型来反映现象之间的相关关系,从数量上近似地反映变量之间变动的一般规律。 2.依据回归方程进行回归预测。由于回归方程反映了变量之间的一般性关系,因此当自变量发生变化时,可依据回归方程估计出因变量可能发生相应变化的数值。因变量的回归估计值,虽然不是一个必然的对应值(他可能和系统真值存在比较大的差距),但至少可以从一般性角度或平均意义角度反映因变量可能发生的数量变化。 3.计算估计标准误差。通过估计标准误差这一指标,可以分析回归估计值与实际值之间的差异程度以及估计值的准确性和代表性,还可利用估计标准误差对因变量估计值进行在一定把握程度条件下的区间估计。 四、一元线性回归分析 1.一元线性回归分析的特点 1)两个变量不是对等关系,必须明确自变量和因变量。 2)如果x和 y两个变量无明显因果关系,则存在着两个回归方程:一个是以x为自变量,y为因变量建立的回归方程;另一个是以
SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要就是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程 为: 毫无疑问,多元线性回归方程应该 为: 上图中的 x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差, 其中随机误差分为:可解释的误差与不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须就是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内, 将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,您也可以选择其它的方式,如果您选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果您选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该就是跟“因变量”关系最为密切,
SPSS 统计分析 欧阳歌谷(2021.02.01) 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2. Opening excel data source——OK. 第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise. 进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue. 3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue. 4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals (残差)选项组中的Unstandardized;点击Continue. 5.点击右侧Options,默认,点击Continue.
Logistic回归分析报告结果解读分析Logistic回归常用于分析二分类因变量(如存活和死亡、患病和未患病等)与多个自变量的关系。比较常用的情形是分析危险因素与是否发生某疾病相关联。例如,若探讨胃癌的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群有不同的临床表现和生活方式等,因变量就为有或无胃癌,即“是”或“否”,为二分类变量,自变量包括年龄、性别、饮食习惯、是否幽门螺杆菌感染等。自变量既可以是连续变量,也可以为分类变量。通过Logistic 回归分析,就可以大致了解胃癌的危险因素。 Logistic回归与多元线性回归有很多相同之处,但最大的区别就在于他们的因变量不同。多元线性回归的因变量为连续变量;Logistic回归的因变量为二分类变量或多分类变量,但二分类变量更常用,也更加容易解释。 回归的用法 一般而言,Logistic回归有两大用途,首先是寻找危险因素,如上文的例子,找出与胃癌相关的危险因素;其次是用于预测,我们可以根据建立的Logistic 回归模型,预测在不同的自变量情况下,发生某病或某种情况的概率(包括风险评分的建立)。 2.用Logistic回归估计危险度 所谓相对危险度(risk ratio,RR)是用来描述某一因素不同状态发生疾病(或其它结局)危险程度的 比值。Logistic回归给出的OR(odds ratio)值与相对危险度类似,常用来表示相对于某一人群,另一人群发生终点事件的风险超出或减少的程度。如不同性别的胃癌发生危险不同,通过Logistic回归可以求出危险度的具体数值,例如,这样就表示,男性发生胃癌的风险是女性的倍。这里要注意估计的方向问题,以女性作为参照,男性患胃癌的OR是。如果以男性作为参照,算出的OR将会是(1/,表示女性发生胃癌的风险是男性的倍,或者说,是男性的%。撇开了参照组,相对危险度就没有意义了。
1、稳健回归 其主要思路是将对异常值十分敏感的经典最小二乘回归中的目标函数进行修改。经典最小二乘回归以使误差平方和达到最小为其目标函数。因为方差为一不稳健统计量,故最小二乘 回归是一种不稳健的方法。为减少异常点的作用,对不同的点施加不同的权重,残差小的点权重大,残差大的店权重小。 2、变系数回归 地理位置加权 3、偏最小二乘回归 长期以来,模型式的方法和认识性的方法之间的界限分得十分清楚。而偏最小二乘法则把它 们有机的结合起来了,在一个算法下,可以同时实现回归建模(多元线性回归)、数据结构简化(主成分分析)以及两组变量之间的相关性分析(典型相关分析)。偏最小二乘法在统计应用 中的重要性体现在以下几个方面:偏最小二乘法是一种多因变量对多自变量的回归建模方法。偏最小二乘法可以较好的解决许多以往用普通多兀回归无法解决的问题。偏最小二乘法之所以被称为第二代回归方法,还由于它可以实现多种数据分析方法的综合应用。能够消除自变量选取时可能存在的多重共线性问题。普通最小二乘回归方法在自变量间存在严重的多 重共线性时会失效。自变量的样本数与自变量个数相比过少时仍可进行预测。 4、支持向量回归 能较好地解决小样本、非线性、高维数和局部极小点等实际问题。 传统的化学计量学算法处理回归建模问题在拟合训练样本时,要求残差平方和”最小,这样将有限样本数据中的误差也拟合进了数学模型,易产生过拟合”问题,针对传统方法这一不足之处,SVR采用“不敏感函数”来解决过拟合”问题,即f(x)用拟合目标值yk时,取:f(x) =E SVs( a a *i)K(xi,x) 上式中a和a许为支持向量对应的拉格朗日待定系数,K(xi,x)是采用的核函数[18],X为未 知样本的特征矢量,xi为支持向量(拟合函数周围的&管壁"上的特征矢量),SVs 为支持向量的数目?目标值yk拟合在yk-刀SVs(a-ia *i)K(xi,xk) 时?即认为进一步拟合是无意 义的。 5、核回归 核函数回归的最初始想法是用非参数方法来估计离散观测情况下的概率密度函数(pdf)。为了避免高维空间中的内积运算由Mercer条件,存在映射函数a和核函数K(?,?),使 得:
逐步回归分析 1、逐步回归分析的主要思路 在实际问题中, 人们总是希望从对因变量有影响的诸多变量中选择一些变量作为自变量, 应用多元回归分析的方法建立“最优”回归方程以便对因变量进行预报或控制。所谓“最优”回归方程, 主要是指希望在回归方程中包含所有对因变量影响显著的自变量而不包含对影响不显著的自变量的回归方程。逐步回归分析正是根据这种原则提出来的一种回归分析方法。它的主要思路是在考虑的全部自变量中按其对的作用大小, 显著程度大小或者说贡献大小, 由大到小地逐个引入回归方程, 而对那些对作用不显著的变量可能始终不被引人回归方程。另外, 己被引人回归方程的变量在引入新变量后也可能失去重要性, 而需要从回归方程中剔除出去。引人一个变量或者从回归方程中剔除一个变量都称为逐步回归的一步, 每一步都要进行检验, 以保证在引人新变量前回归方程中只含有对影响显著的变量, 而不显著的变量 已被剔除。 逐步回归分析的实施过程是每一步都要对已引入回归方程的变量计算其偏回归平方和(即贡献), 然后选一个偏回归平方和最小的变量, 在预先给定的水平下进行显著性检验, 如果显著则该变量不必从回 归方程中剔除, 这时方程中其它的几个变量也都不需要剔除(因为其它的几个变量的偏回归平方和都大于 最小的一个更不需要剔除)。相反, 如果不显著, 则该变量要剔除, 然后按偏回归平方和由小到大地依次对方程中其它变量进行检验。将对影响不显著的变量全部剔除, 保留的都是显著的。接着再对未引人回归方程中的变量分别计算其偏回归平方和, 并选其中偏回归平方和最大的一个变量, 同样在给定水平 下作显著性检验, 如果显著则将该变量引入回归方程, 这一过程一直继续下去, 直到在回归方程中的变量都不能剔除而又无新变量可以引入时为止, 这时逐步回归过程结束。 2、逐步回归分析的主要计算步骤 (1) 确定检验值 在进行逐步回归计算前要确定检验每个变量是否显若的检验水平, 以作为引人或剔除变量的标准。 检验水平要根据具体问题的实际情况来定。一般地, 为使最终的回归方程中包含较多的变量, 水平不宜取得过高, 即显著水平α不宜太小。水平还与自由度有关, 因为在逐步回归过程中, 回归方程中所含的变量的个数不断在变化, 因此方差分析中的剩余自由度也总在变化, 为方便起见常按计算自由度。为原始数据观测组数, 为估计可能选人回归方程的变量个数。例如, 估计可能有2~3个变量选入回归方程, 因此取自由度为15-3-1=11, 查分布表, 当α=0.1, 自由度, 时, 临界值, 并且在引入变量时, 自由度取, , 检验的临界值记, 在剔除
安全事故报告、统计与处理制度 1.制定依据 (1)《中华人民共和国安全生产法》 (2)《生产安全事故报告和调查处理条例》 2.适用范围 适用于对本公司发生的安全生产事故的报告、调查、统计和分析、处理、预防等过程。 3.实施主体及职责分工 (1)安全科负责组织事故调查处理工作,配合有关政府行政部门对事故事件进行调查和处理。 (2)安全生产领导小组在发生事故后,应立即组织相关人员到现场组织抢救,采取有效措施,防止事故扩大。 4.内容及要求 4.1 生产安全事故定义 生产安全事故是指在生产经营领域中发生的意外的突发事故,通常会造成人员伤亡或财产损失,使正常生产活动中断的事件。安全生产事故包括道路交通事故和停车场站事故,但不包括商务事故。 4.2 事故等级划分 根据生产安全事故造成的人员伤亡或者直接经济损失,安全生产事故一般分为四个等级: 5.2.1一般事故,是指造成3人以下死亡,或者10人以下重伤,或者1000万元以下直接经济损失的事故。
5.2.2 较大事故,是指造成3 人以上10 人以下死亡,或者10 人以上50人以下重伤,或者1000万元以上5000万元以下直接经济损失的事故; 5.2.3重大事故,是指造成10人以上30人以下死亡,或者50人以上100人以下重伤,或者5000万元以上1亿元以下直接经济损失的事故; 5.2.4特别重大事故,是指造成30人以上死亡,或者100人以上重伤(包括急性工业中毒,下同),或者1亿元以上直接经济损失的事故; 4.3 事故报告 (1)报告程序 1)发生生产安全事故,公司员工中首先发现者应立即报告安全科负责人,一般及以上等级事故必须报告总经理。对一般及以上等级事故,公司总经理接到报告后,在1小时内向当地人民政府有关部门报告。2)情况紧急时,事故现场有关人员可以直接向当地人民政府有关部门报告。 3)事故报告后出现新情况的,应当及时补报。自事故发生之日起30日内,事故造成的伤亡人数发生变化的,应当及时补报。道路交通事故、火灾事故自发生之日起7 日内,事故造成的伤亡人数发生变化的,应当及时补报。 (2)报告内容: 1) 事故发生单位名称及概况;
1. 对于多元共线性问题产生的根源,可以从两 个方面考虑: 1、由 变量性质引起 2、由数据问题引起 (情况一:样本含量过小 情况二: 出现强影响观测值 情况三: 时序变量) 1、 由变量性质引起 在进行多元统计分析时,作为自变量的某 些变量高度相关,比如身高、体重和胸 围,变量之间的相关 性是由变量自身的性 质决定的,此时不论数据以什么形式取 得,样本含量是大是小,都会出现自变量 的共线性问题。因 此,变量间自身的性质 是导致多元共线性的重要原因。 2、 情况一:样本含量过小 假设只有两个自变量X1与X2当n2时两 点 总能连成一条直线即使性质上原本并不存在 线性关系的 变量X1与X2由于样本含量问题产 生了共线性。样本含量较小 时,自变量容易 呈现线性关系。 如果研究的自变量个数大 于2设为X1X2,...,XP,虽然各自变量之间没有线性关系, 但如果样本含量n小于模型中自变量的个数,就可能导致多元 共线性问题。 情况二: 出现强影响观测值 进入20世纪80年代后期人们开始关注单个或几个样本点对多重共线性的影 响。研究表明存在两类这样的数据点 或点群:1导致或加剧多重共线性 2 掩盖存在着的多重共线性。a中因异常观测值的出现而掩盖了共线性b中因异常观测 值的出现而产生了共线性。这样的异常观测值称为多元共线性强 影响观测值。显然这种观测值会对设计矩阵的性态产生很大影响 从而影响参数估计。 情况三:时序变量 若建模所用的自变量是时序变量并且 是高阶单整时序变量这种时序变量之 间高度相关必然导致多重共线性。2.多元共线性的表现 (1)模型拟合效果很好,但偏回归系数几乎都 无统计学意义; (2)偏回归系数估计值的方差很大; (3)偏回归系数估计值不稳定,随着样本含量 的增减各偏回归系数发生较大变化或当一个自 变量被引入或剔除时其余变量偏回归系数有很 大变化; (4)偏回归系数估计值的大小与符号可 能与事先期望的不一致或与经验相悖,结 果难以解释。 3.多元共线性的诊断 常用的共线性诊断指标有以下几个: (1)方差膨胀因子 (2)特征根系统(system of eigenvalues) 主要包括条件指数和方差比。