
第3章无失真信源编码
教学内容包括:信源编码概述、定长编码、变长编码常用的信源编码
3.1信源编码概述
讲课内容:
1、信源编码及分类
2、信源编码定义
3、信源编码基础
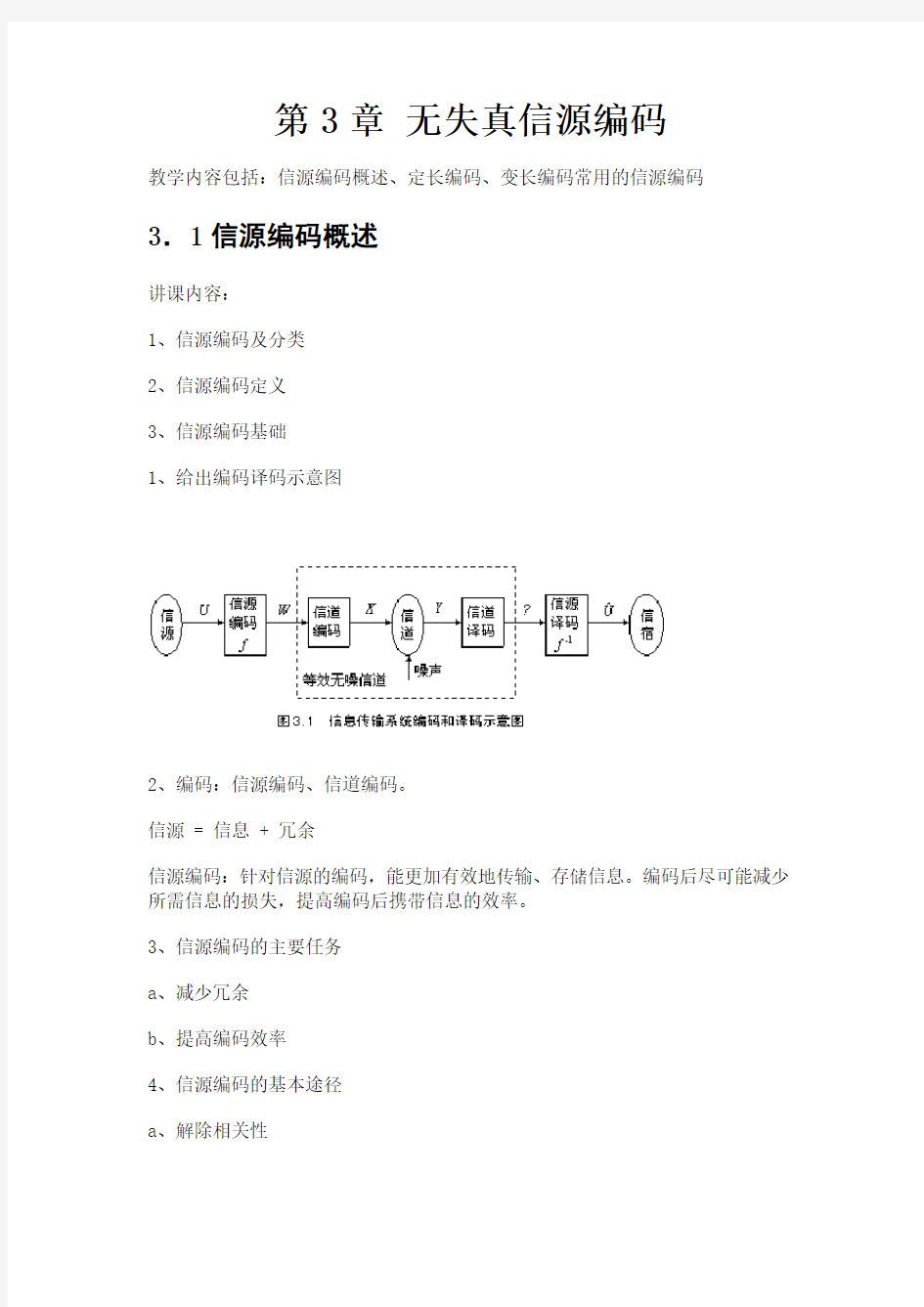
1、给出编码译码示意图
2、编码:信源编码、信道编码。
信源 = 信息 + 冗余
信源编码:针对信源的编码,能更加有效地传输、存储信息。编码后尽可能减少所需信息的损失,提高编码后携带信息的效率。
3、信源编码的主要任务
a、减少冗余
b、提高编码效率
4、信源编码的基本途径
a、解除相关性
b 、概率均匀化
4、信源编码的两个基本定理
a 、无失真编码定理(可逆编码的基础、只适用于离散信源)
b 、限失真编码定理(连续信源)
5、信源编码的分类
a 、冗余度压缩编码,可逆压缩,经编译码后可以无失真地恢复。
统计特性:Huffman 编码,算术编码Arithmetic Coding
b 、熵压缩编码,不可逆压缩
压缩超过一定限度,必然带来失真
允许的失真越大,压缩的比例越大
译码时能按一定的失真容许度恢复,保留尽可能多的信息
本章讨论离散信源无失真编码,包括定长、变长无失真编码定理和编码方法,以及几种实用的无失真信源编码,如香农编码、费诺编码、哈夫曼编码等。
6、信源编码的定义
首先给出信源编码的定义,
信源编码就是从信源符号到码符号的一种映射f ,它把信源输出的符号u i 变换成码元序列w i 。
f :u i ——>w i ,i =1,2,…,q
译码是从码符号到信源符号的映射。若要实现无失真编码,这种映射必须是一一对应的、可逆的。
给出马元、码字、马块、二元编码的概念
结合P34例3.1.1给出编码的分类如下:
给出平均码长的定义和公式。
结合P34例3.1.1进行二进制信源的简单编码,并计算平均码长。
3.2克拉夫特(Kraft)不等式
讲课内容:
1、变长码的码字分离技术
2、即时码的引入和码树表示方法
3、即时码与克拉夫特不等式
1、变长码的码字分离技术
a、同步信号
b、可分离码字
2、即时码和码树表示法
即时码是一种实时的惟一可译码,这类码无需另加同步信息,就能在接收端被分离出来。在信源编码和数据压缩中,这类编码无论在理论还是在实际中都有很大意义,对较简单的信源,可以很方便地用码树法直接且直观地构造出可以分离码(异前缀码)。
根据码树判定即时码:
3、即时码与克拉夫特不等式
但是当信源较复杂,直接画码树就比较复杂。针对这一问题,在数学上给出一个与码树等效的,表达码字可分离的充要条件,即著名的克拉夫特不等式。
【定理3.1.1】对于码长分别为l1,l2,…,l n的m元码,若此码为即时码,则必定满足
(3.1.4)
反之,若码长满足不等式(3.1.4),则一定存在具有这样码长的即时码。
给出该定理的理论意义与证明过程
【定理3.1.2】对于任意r进制惟一可译码,各码字的码长l i,i=1,2,…,n,必须满足Kraft不等式
,
反过来,若上式成立,就一定能构造一个r进制惟一可译码。
给出该定理的理论意义与证明过程
3.3定长编码
讲课内容:
1、定长编码定理
2、定长编码方法
3、定长编码的编码效率与差错率
1、定长编码定理
a、引入离散无记忆信源进行编码的最小平均码长问题
前面讨论编码时,都是对信源输出的单个符号进行编码,现在考虑更一般的情况,即对信源输出的符号序列进行编码。假设离散无记忆信源为[U,P U]=[u i,P(u
)|i=1,2,…,q],现要对U发出的N长符号序列进行编码。对信源U的N i
长符号序列进行r进制编码,实质上就是对扩展信源U N的单个符号进行编码,
既可定长编码,也可变长编码。若用代表对U N编码所得的平均码长,则我们
追求的是最小的码,这就引出了一个理论问题,平均码长可小到什么程度呢?对此问题,定长无失真编码定理和变长无失真编码定理都给予了明确的回答。只要可用的码字数不少于U N的符号数,即
就可做到惟一译码。将上式整理一下得
U的一个符号所需用去的码元数目/N以U的最大r进制熵为
下界,再小就不能惟一可译了。
b、给出解决方法----定长编码定理
【定理3.2.1(定长编码定理)】用r元符号表对离散无记忆信源U的N长符号序列进行定长编码,N长符号序列对应的码长为,若对于任意小ε>0,δ>0,只要满足
(3.2.3) 就几乎能实现无失真编码,且随着N的增大,译码错误率小于δ。反之,若
(3.2.4)
时,不可能实现无失真编码,且随着N的增大,译码错误概率近似等于1,几乎必定出错。
c、给出该定理的理论意义并分析定理的结论。
d、给出定长编码的效率
给出公式分析:
为使编码真正有效,必须增大信源序列的分组长度N,这就会使编、译码的延时增大,同时也会使编、译码器的复杂程度增加,因此,定长编码在冗余度压缩编码中的理论意义远大于其实用价值。
2、定长编码方法(P82例3.2.1)
a、计算平均码长
b、计算信源熵
c、计算编码效率
3、定长编码的失真与差错率
当 有望使更小。根据切比雪夫不等式可推得, () 当ζ2(U)和ε2均为定值时,只要N足够大,就可以使P e小于任意一正数δ,即,也就是当信源序列长度N满足 (3.2.12) 时,就能达到差错率要求。 定长编码在引入失真的前提下,还需要取很长的信源序列进行编码,才能达到较高的编码效率。既要不失真,又要很高的编码效率,只能采用变长编码。 结合【例 3.2.2】分析上述结论。 3.4变长编码 讲课内容: 变长编码定理(香农第一定理) 变长编码方法 变长编码的编码效率 1、变长编码定理 变长编码不要求所有码字长度相同,但希望平均码长最小,信源无失真变长编码定理给出了在无失真编码的前提下平均码长的界限。 【定理3.3.1(无失真变长编码定理)】用r元符号表对离散无记忆信源U的N长符号序列进行变长编码,记N长符号序列对应的平均码长为,那么,要做到无失真编码,平均码长必须满足 另一方面,一定存在惟一可译码,其平均码长满足 结合Kraft不等式和概率完备性质给出定理两个结论的证明过程。 2、变长编码方法 目标: 变长编码采用即时码,力求平均码长最小,此时编码效率最高,信源的冗余得到最大程度的压缩。对给定的信源,使平均码长达到最小的编码方法称为最佳编码,编出的码称为最佳码。将概率大的信息符号编以短的码字,概率小的符号编以长的码字,使得平均码字长度最短。 证明变长编码定理的过程中给出的构造方法即香农编码。但香农编码不能使平均码长达到最小,因此不是最佳编码。只有哈夫曼编码是真正意义上的最佳编码,对给定的信源,用哈夫曼编码方法编出的码,平均码长达到最小。 变长编码的基本思路: 针对不同编码平均码长的计算方法。 平均码长定义为 式中,是所对应的码字的长度。 结合【例3.3.1】给出构造方法并计算平均码长。 结合【例3.3.2】给出编码效率的计算方法,并对变长编码和定长编码的编码效率进行分析,将达到同样编码效率两种方法所需要付出的代价进行比较。 3.5香农编码 a、原理: 按照变长编码定理来决定码长,再用合适的方法构造码字,这就是香农编码。 b、编码步骤 设有离散无记忆信源,。二进制香农码的编码步骤如下: (1) 将信源符号按概率从大到小的顺序排列,为方便起见,令p(x1)≥p(x2)≥…≥p(x n); (2) 按下式求i个信源符号对应的码长l i,并取整; –log P(u i) ≤l i <–log P(u i) + 1 (3.4.1) (3) 按下式求i个信源符号的累加概率P i; (4) 将累加概率P i转换成二进制数; (5) 取P i二进制数小数点后l i个二进制数字作为第i个信源符号的码字。 结合【例3.4.1】给出具体编码方法。并计算其平均码长和编码效率。3.6费诺(Fano)编码 a、原理: 它是通过构造一个码树,编出的码是即时码,但不一定是最佳码。 b、编码步骤 (1) 将信源符号按概率从大到小的顺序排列,不失一般性,令p(x1)≥p(x2)≥…≥p(x n) 。 (2) 按编码进制数将概率分组,使每组概率尽可能接近或相等。如编二进制码就分成两组,编m进制码就分成m组。 (3) 给每组分配一位码元。如编二进制码,则给两组信源符号分别赋码元“0”和“1”。 (4) 将每一分组再按同样原则划分,重复步骤2和3,直到每一小组只含一个信源符号为止。 (5) 由此即可构造一个码树,所有终端节点上的码字组成费诺码。 c、结合【例3.4.2】给出具体编码方法。并计算其平均码长和编码效率。 d、总结费诺编码的基本特点: (1) 费诺编码在构造码树时,是从树根开始到终端节点结束,这与哈夫曼编码相反; (2) 由于赋码元时的任意性,因此费诺编码编出的码字不惟一; (3) 费诺编码虽属于概率匹配范畴,但并未严格遵守匹配规则,即不全是按“概率大码长小、概率小码长大”来决定码长,有时会出现概率小码长反而小的情况,如表3.4.2中符号u4对应的码字就是如此,因此平均码长一般不会最小。 3.7哈夫曼编码 哈夫曼编码是一种效率比较高的变长无失真信源编码方法,它的平均码长最短,因此是最佳编码。下面主要介绍二进制哈夫曼编码。 a、原理:构造一个码树。 b、编码步骤: (1) 将信源符号按概率从大到小的顺序排列,为方便起见,令p(x1)≥p(x2)≥…≥p(x n) 。 (2) 对概率最小的两个信源符号求其概率之和,同时给两个符号分别赋予码元“0”和“1”。将“概率之和”当作一个新符号的概率,与剩下符号的概率一起,形成一个缩减信源,结果得到一个只包含(n-1)个信源符号的新信源,称为信源的第一次缩减信源,用S1表示。 (3) 将缩减信源S1的符号仍按概率从大到小的顺序排列,重复步骤2,得到只含(n-2)个符号的缩减信源S2。 (4) 重复上述步骤,直至缩减信源只剩下两个符号为止,此时所剩两个符号的概率之和必为1。 (5) 按上述步骤实际上构造了一个码树,从树根到端点经过的树枝即为码字。 c、结合【例3.4.4】给出具体编码方法。并计算其平均码长和编码效率。 d、总结哈夫曼编码的基本特点: 第一,哈夫曼编码实际上构造了一个码树,码树从最上层的端点开始构造,直到树根结束,最后得到一个横放的码树,因此,编出的码是即时码。 第二,哈夫曼编码采用概率匹配方法来决定各码字的码长,概率大的符号对应于短码,概率小的符号对应于长码,从而使平均码长最小。 第三,每次对概率最小的两个符号求概率之和形成缩减信源时,就构造出两个树枝,由于给两个树枝赋码元时是任意的,因此编出的码字并不惟一。 e、优点: (1) 有效的信源编码可取得较好的冗余压缩效果。 (2) 有效的信源编码可使输出码元概率均匀化。 在哈夫曼编码过程中,对缩减信源符号按概率由大到小的顺序重新排列时,应使合并后的新符号尽可能排在靠前的位置,这样可使合并后的新符号重复编码次数减少,使短码得到充分利用。 3.8游程编码(介绍) 1、定义: 游程编码是哈夫曼编码的一种改进和应用,主要用于黑、白二值文件的传真。 以文本文件的传真为例,扫描分割后的文件用离散像素序列来表示。白纸黑字的二值文件采用二元码进行编码,即表示背景(白色)时像素为码元“0”,表示内容(黑字)时像素为码元“1”。则任意一个扫描行的像素序列均是由若干个连“0”像素序列及若干个连“1”像素序列组合而成,且同类像素连续出现的概率很大。 2、游程序列 用交替出现的“0”游程和“1”游程的长度来表示任意二元序列。这种序列称为游程长度序列,简称游程序列。它是一种一一对应的变换,也是可逆变换,称为游程变换。例如二元序列 000101110010001… 可变换成如下游程序列 31132131… 连“0”这一段称为“0”游程,连“1”这一段称为“1”游程。而重复出现的同类像素的长度则称为游程长度。它们的长度分别称为游程长度L(0)和L(1)。由于是二进制序列,“0”游程和“1”游程总是交替出现。 3、游程变换减弱了原序列符号间的相关性,并把二元序列变换成了多元序列,这样就适合于用其他方法,如哈夫曼编码,进一步压缩信源,提高通信效率。 3.9冗余位编码 在信源序列中,常有许多符号不携带信息,除了符号的数目或所占时长外,完全可以不传送。 1、语音通信中,讲话的间歇 2、图像的背景基本不变,并在图像中占相当大一部分 这些符号称为冗余位,它们所占的时长对正确表达信源是必须的,但是没有必要全部传送,如果能去掉一部分,将会提高通信效率。 001000000010000---- 15,2,3,11 有一种典型的分帧传送是由林绪(Lynch)和达维生(Davission)分别独立提出的,简称L-D编码。L-D编码是一种分帧传送冗余位序列的方法。即在冗余位序列中取N个符号作为一帧,编成一个码字,码字中含有信息位的数量和位置信息,在接收端依据这些信息进行译码。 编码: L-D编码中的每个码字传送两个数:Q和T。Q是本帧内信息位的数目,而T 则含有各信息位的位置信息,由下式计算 (3.4.18) 其中,n j是帧内第j个信息位的位置号,n1最小,n Q最大。 在编码时,需要多少比特来表达Q和T呢?因为Q可以取0到N的各种值,共有N+1种,所以表达Q值需要 bit。Q值确定后,各信息位的可能 位置共有种,所以确定T值需要 bit。以上的[X]表示不小于X的最小整数,所以共需 ( bit) 【例3.4.8】有一冗余序列:001000000010000,令N=15,对其编L-D码。 解:这里,Q=2,n1=3,n2=11。则 , ,[log105]=7,[log(15+1)]=4, 分别用4位和7位二进制自然码表示Q和T,即得L-D编码:00100101111。 译码: 收端收到Q和T后,按下列方法译码: 寻找某一K,若 , 则 (3.4.19) 再令 (3.4.20) 再找某一值L,若 , 则 (3.4.21) 依此类推,直至求出n1,从而确定所有信息位的位置。 译码时,已知N=15,故前4位必为Q值,即Q=2。那么后面的7位必然代表T,故知T=47。由式(3.4.19)和(3.4.21)计算出:n =11,n1=3。即完成译码,恢 2 复出原冗余位序列。 L-D编码适合于冗余位较多或较少的情况,当冗余位和信息位数量相当时,L-D编码非但不能压缩码率,反而使其有所扩展,不宜应用。 本节介绍的各种信源编码都是针对离散信源,而且都是变长编码。虽然变长编码可提高编码效率,但也有它的固有缺点:需要大量缓冲设备来存储这些变长码,然后再以恒定的码率进行传送。另外,在传输的过程中,如果出现了误码,容易引起错误扩散,所以要求有优质的信道。 很多情况下信源是连续的,那么离散信源编码方法就不适用,也不能做到无失真编码,需要采取另外的编码方法。有时为了得到较高的编码效率,先采用某种正交变换,解除或减弱信源符号间的相关性,然后再进行信源编码。有时则利用信源符号间的相关性直接编码。由于这些编码方法在有关通信和信号处理课程中都已介绍过,此处不再赘述。 第八章 限失真信源编码 8.1设信源X 的概率分布P(X):{p(α1), p(α2), …,p(αr ) },失真度为d (αi , βj )≥0,其中 (i=1,2,…,r;j=1,2,…,s).试证明: ∑==r i j i j i b a d a p D 1 min )},(min ){( 并写出取得min D 的试验信道的传输概率选取的原则,其中 ))}/(,),/(),/({min ),(min 21i S i i j j i j a b p a b p a b p b a d = (证明详见:p468-p470) 8.2设信源X 的概率分布P(X):{p(α1), p(α2), …,p(αr ) },失真度为d(αi , βj )≥0,其中 (i=1,2,…,r;j=1,2,…,s).试证明: }),()({min 1 max ∑==r i j i i j b a d a p D 并写出取得max D 的试验信道传递概率的选取原则. (证明详见:p477-p478) 8.5设二元信源X 的信源空间为: -1 )( 1 0X :][X ????ωωX P P 令ω≤1/2,设信道输出符号集Y:{0,1},并选定汉明失真度.试求: (1) D min ,R(D min ); (2) D max ,R(D max ); (3) 信源X 在汉明失真度下的信息率失真函数R(D),并画出R(D)的曲线; (4) 计算R(1/8). 解: {}{}{}{}0 )()(0);()1()}0();1({min )1,1()1()1,0()0(;)0,1()1()0,0()0(min ),()(min )2() ()()/()(min );(min )0()(0 )/(),2,1(1)/(0)/(100110][1 0 00 0)1(0)0(),(min )()1(max 21min max min min 2 1 min ==∴====++=? ?? ???=' ===-===∴====?? ?? ??===?+?==∑∑==ωω ωR D R Y X I p p p d p d p d p d p b a d a p D D H X H Y X H X H Y X I R D R Y X H i a b p a b p P D D p p b a d a p D j j i j i i j i j i j i j i j i 此时故此时或的信道矩阵 则满足保真度=最小允许失真度: 7.1 设输入符号集为}1 ,0{=X ,输出符号集为}1 ,0{=Y 。定义失真函数为 1 )0,1()1,0(0)1,1()0,0(====d d d d 试求失真矩阵D 。 解: 041 041041041),(min )(43 0411********),()(min min min max =?+?+?+?=== ?+?+?+?===∑∑i j i j i i j i i j j y x d x p D y x d x p D D 7.2 设输入符号集与输出符号集为}3 ,2 ,1 ,0{==Y X ,且输入信源的分布为 )3 ,2 ,1 ,0( 4 1 )(===i i X p 设失真矩阵为 []????? ???? ???=01 11 101111011110d 求D max 和D min 及R(D)。 解: 041 041041041),(min )(43 0411********),()(min min min max =?+?+?+?=== ?+?+?+?===∑∑i j i j i i j i i j j y x d x p D y x d x p D D 因为n 元等概信源率失真函数: ?? ? ??-??? ??-+-+=a D a D n a D a D n D R 1ln 11ln ln )( 其中a = 1, n = 4, 所以率失真函数为: ()()D D D D D R --++=1ln 13 ln 4ln )( 7.3 利用R(D)的性质,画出一般R(D)的曲线并说明其物理含义?试问为什么R(D)是非负且非增的? 解: 函数曲线: 第五章无失真信源编码定理与编码 5.1.1 信源编码和码的类型 1.信源编码 2.码的类型 若码符号集中符号数r=2称为二元码,r=3称为三元码,……,r元码。 若分组码中所有码字的码长都相同则称为等长码,否则称为变长码。 若分组码中所有码字都不相同则称为非奇异码,否则称为奇异码。 若每个码符号x i∈X的传输时间都相同则称为同价码,否则称为非同价码。 若分组码的任意一串有限长的码符号只能被唯一地译成所对应的信源符号序列则称为唯一可译码,否则称为非唯一可译码。 若分组码中,没有任何完整的码字是其他码字的前缀,则称为即时码(又称非延长码或前缀条件码),否则称为延长码。 本章主要研究的是同价唯一可译码。 5.1.2 即时码及其树图构造法 即时码(非延长码或前缀条件码)是唯一可译码的一类子码。 即时码可用树图法来构造。构造的要点是: (1)最上端为树根A,从根出发向下伸出树枝,树枝总数等于r,树枝的尽头 为节点。 (2)从每个节点再伸出r枝树枝,当某节点被安排为码字后,就不再伸枝,这节点为终端节点。一直继续进行,直至都不能伸枝为止。 (3)每个节点所伸出的树枝标上码符号,从根出发到终端节点所走路径对应的码符号序列则为终端节点的码字。 即时码可用树图法来进行编码和译码。 从树图可知,即时码可以即时进行译码。 当码字长度给定,即时码不是唯一的。 可以认为等长唯一可译码是即时码的一类子码。 5.1.3 唯一可译码存在的充要条件 (1)对含有q个信源符号的信源用含r个符号的码符号集进行编码,各码字的码长为l1,l2,…,l q的唯一可译码存在的充要条件是,满足Kraft不等式 5.1.4 唯一可译码的判断法 唯一可译码的判断步骤: 首先,观察是否是非奇异码。若是奇异码则一定不是唯一可译码。 其次,计算是否满足Kraft不等式。若不满足一定不是唯一可译码。 再次,将码画成一棵树图,观察是否满足即时码的树图的构造,若满足则是唯一可译码。 或用Sardinas和Patterson设计的判断方法:计算出分组码中所有可能的尾 第6章 限失真信源编码 一、例题: 【例6.1】 二元对称信源,信源{0,1}U =,接收变量{0,1}V =,在汉明失真定义下,失真函数为: (0,0)(1,1)0d d ==,(0,1)(1,0)1d d == 其失真矩阵为 011 0??=? ??? D 容易看出:对于离散对称信源,其汉明失真矩阵D 为一个方阵,且对角线上的元素为零,即: 011110111 1011 1 1 0?? ??????=???????? D 【例6.2】 信源U ={0,1,2},接收变量V ={0,1,2},失真函数为2 (,)()i j i j d u v u v =-,求失真矩阵。由失真定义得: d (0,0)=d (1,1)=d (2,2)=0 d (0,1)=d (1,0)=d (1,2)=d (2,1)=1 d (0,2)=d (2,0)=4 所以失真矩阵D 为 141 014 1 4?? ??=?????? D 【例 6.3】 离散无记忆信源输出二维随机序列12()U U =U ,其中(1,2)i U i =取自符号集 {0,1},通过信道传输到信宿,接收N 维随机序列12()V V =V ,其中(1,2)i V i =取自符号集 {0,1},定义失真函数 (0,0)(1,1)0(0,1)(1,0)1 d d d d ==== 求符号序列的失真矩阵。 解: 由N 维信源序列的失真函数的定义得 1 1(,)(,)(,) ,k k N N N i j i j k d d d u v N αβ=== ∈∈∑u v u U v V 所以 [][]1(00,00)(0,0)(0,0)0211(00,01)(0,0)(0,1)2 2 N N d d d d d d =+== += 类似计算其他元素值,得到信源序列的失真矩阵为 11012211012211102211102 2 N ??????????=? ?????????? ? D 【例6.4】 设信源符号有8种,而且等概率,即1()8 i P u = 。失真函数定义为 0(,)1i j i j d u v i j =?=?≠? 假如允许失真度12 D =,即只要求收到的符号平均有一半是正确的。我们可以设想这 样的方案: 方案一:对于1234,,,u u u u 这四个信源符号照原样发送,而对于5678,,,u u u u 都以4u 发送。如图6.1(a )所示。 方案二:对于1234,,,u u u u 这四个符号照原样发送,而对于5678,,,u u u u 分别以 1234,,,u u u u 发送。如图6.1(b )所示。第八章 限失真信源编码
第7章 限失真信源编码
信息论与编码[第五章无失真信源编码定理与编码]山东大学期末考试知识点复习
第6章 限失真信源编码
相关主题
文本预览